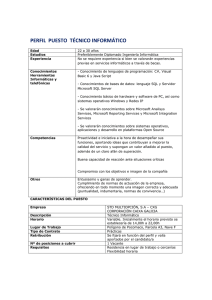
Autenticación y autorización en - Tecnología, Tips y Programación
Anuncio

www.dotnetmania.com nº 55 enero 2009 6,50 € Visual Basic • C# • ASP.NET • ADO.NET • AJAX • Silverlight • .NET Framework dotNetManía dedicada a los profesionales de la plataforma .NET Autenticación y autorización en Servicios Web entrevista Michael Howard y Adam Shostack Senior Security Program Managers Microsoft Corp. SQL Server Agregando inteligencia a mis aplicaciones mediante SQL Server Data Mining ALManía Personalizando nuestras builds Isla VB Visual Basic ¿lenguaje dinámico? TodotNet@QA Un vistazo a Entity Framework Aplicación del patrón de diseño Acción. Definición de componentes en ASP.NET • HttpHandlers y HttpModules para SharePoint 2007 • Silverlight 2.0 Toolkit. Controles, visualización de datos y mucho más (I) editorial dotNetManía Dedicada a los profesionales de la plataforma .NET Vol. III •Número 55 • Enero 2009 Precio: 6,50 € Cumplimos 5 años Editor Paco Marín ([email protected]) Redactor jefe Marino Posadas ([email protected]) Redacción Dino Esposito, Guillermo 'Guille' Som, Luis Fraile, Luis Miguel Blanco y Miguel Katrib (Grupo Weboo) Empresas colaboradoras Alhambra-Eidos Krasis Plain Concepts Raona Solid Quality Mentors Además colaboran en este número Enric Forn, Francisco González, Gustavo Vélez, Jeffrey Álvarez, Juan Luis Ceada y Magda Teruel. Diseño y maquetación Silvia Gil (Letra Norte) Atención al suscriptor Pilar Pérez ([email protected]) Edición, suscripciones y publicidad .netalia c/ Robledal, 135 28522 - Rivas Vaciamadrid (Madrid) www.dotnetmania.com Tf. (34) 91 666 74 77 Fax (34) 91 499 13 64 Imprime Gráficas MARTE ISSN 1698-5451 Depósito Legal M-3.075-2004 Bienvenido al número 55, de enero de 2009, de dotNetManía. Con el ejemplar que tiene ahora en sus manos, terminamos nuestro quinto año de publicación. Estamos orgullosos de esto, pero también somos conscientes de que la única forma de mantenerse —caso de que la haya— es seguir trabajando duro, manteniendo la tensión y esforzándonos en dar lo mejor de nosotros mismos, en definitiva, con el mayor respeto a los lectores y patrocinadores de esta revista. Cada mes debemos empezar de nuevo con la ilusión del primer número, pero con la experiencia de estos cinco años. En esta ocasión, hemos tenido la suerte de poder entrevistar a Michael Howard y Adam Shostack, Senior Security Program Managers en Microsoft Corp. Michael y Adam conversaron con nosotros acerca de la seguridad del código que se desarrolla con las herramientas de Microsoft hoy en día y del que desarrollaremos en el futuro también. Jeffrey Álvarez Massón y Miguel Katrib nos muestran las ventajas que el uso del patrón de diseño Acción ofrece para el desarrollo de componentes ASP.NET en el artículo “Aplicación del patrón de diseño Acción. Definición de componentes en ASP.NET”. Tenemos nuestra dosis de SharePoint con Gustavo Vélez, que en su artículo “HttpHandlers y HttpModules para SharePoint 2007” describe las posibilidades de los manejadores y módulos HTTP, hasta el momento no demasiado explotados por los desarrolladores. Aprovecho la ocasión para recomendarle la revista online totalmente gratuita que Gustavo ha creado y que publica junto con otras personas en http://www.gavd.net/servers/compartimoss/compartimoss_main.aspx. El artículo de portada de este mes, “Autenticación y autorización en servicios Web con cabeceras y extensiones SOAP”, de Juan Luis Ceada, nos muestra cómo interceptar las llamadas a nuestros servicios Web para tener control sobre los accesos a ellos y mejorar no solo la seguridad, sino también la calidad del servicio. Así podremos decidir quién, a dónde y cuántas veces puede acceder a nuestros servicios. Marino Posadas complementa la información publicada en su libro “Programación en Silverlight 2.0” con su artículo “Silverlight 2.0 Toolkit. Controles, visualización de datos y mucho más (I)”, primero de una serie de dos, que describe el nuevo paquete de herramientas y controles que complementa a las ya incluidas en el SDK del producto, y que se distribuyen bajo licencia pública de Microsoft (Ms-PL), código fuente incluido, en CodePlex. Además, encontrará nuestras secciones habituales SQL Server, ALManía e Isla VB. Espero que todo esto sea de su agrado. Paco Marín sumario 55 Entrevista a Michael Howard y Adam Shostack 10-12 Michael Howard y Adam Shostack, reconocidos expertos en temas relacionados con la seguridad, pasaron por Barcelona con motivo del reciente Tech-Ed 2008, que tuvo lugar a mediados de noviembre. Además de impartir algunas sesiones, tuvieron un rato para entrevistarse con dotNetManía y hablarnos sobre ese aspecto tan importante para el software de hoy. Aplicación del patrón de diseño Acción. Definición de componentes en ASP.NET 14-19 En este artículo se propone un nuevo enfoque para la representación de acciones como componentes en aplicaciones visuales, y se muestran las múltiples ventajas que este enfoque proporciona a través de su aplicación práctica al desarrollo de formularios Web ASP.NET. HttpHandlers y HttpModules para SharePoint 2007 20-24 Este artículo describe las posibilidades que ofrecen los manejadores HTTP (HttpHandlers) y los módulos HTTP (HttpModules) de ASP.NET, y cómo pueden utilizarse estos mecanismos para implementar funcionalidades avanzadas en sitios de SharePoint 2007. Autenticación y autorización en servicios Web con cabeceras y extensiones SOAP 26-35 En ocasiones es necesario tener un control exhaustivo de los accesos que se producen a nuestros servicios Web (quién accede, a dónde y cuántas veces), tanto por seguridad como para mantener la calidad del servicio. En este artículo veremos cómo podemos cumplir estos requisitos interceptando las llamadas realizadas por los clientes a nuestra plataforma de servicios Web. Silverlight 2.0 Toolkit. Controles, visualización de datos y mucho más (I) 36-39 En paralelo con la presentación de la versión final de Silverlight 2.0, se anunciaba en las webs “oficiales” de la plataforma la intención de mejorar el desarrollo mediante la publicación paulatina de nuevos controles y herramientas que potencien las posibilidades de creación de aplicaciones RIA con Silverlight, al tiempo que se anticipaban algunas características de la versión 3.0, que según Scott Guthrie estará disponible a finales de 2009. Vamos a revisar aquí algunas de las posibilidades que ofrece el último paquete de herramientas, publicado a primeros del pasado mes de diciembre. Agregando inteligencia a mis aplicaciones mediante SQL Server Data Mining 40-43 La minería de datos se puede utilizar para analizar información y realizar predicciones. En este artículo voy a ilustrar el uso de la minería de datos en una aplicación Web. Vamos a tomar los datos de venta de un portal Web y cierta información de nuestros clientes para analizar qué productos ofrecer a determinados perfiles de clientes, realizar campañas publicitarias u ofrecer productos que sean comprados conjuntamente cuando un cliente agrega un producto a la cesta de la compra. Personalizando nuestras builds 44-48 En muchas ocasiones, en el momento en que generamos la versión de nuestra aplicación nos dejamos el último ensamblado añadido, la modificación del fichero de configuración, o los PDB generados se encuentran en modo Debug. Team Foundation Build nos ayuda a simplificar estas tareas, mejorando el versionado de nuestros proyectos. Visual Basic ¿lenguaje dinámico? 50-53 En la próxima versión de .NET Framework (la 4.0) se incluirá lo que se conoce como DLR (Dynamic Language Runtime), que viene a ser el motor de ejecución de los lenguajes dinámicos de .NET. De esa forma, se permitirá al CLR (y por extensión a los lenguajes como VB y C#) el acceso de forma dinámica a los miembros de los objetos que haya en memoria, algo parecido a lo que siempre se ha conocido como late binding... o casi... dnm.todotnet.qa 54-56 Un vistazo a Entity Framework dnm.biblioteca 57 ADO.NET Entity Framework. Aplicaciones y servicios centrados en datos Application Architecture Guide 2.0: Designing Applications on the .NET Platform dnm.desvan 58 <<dotNetManía noticias noticias noticias noticias noticias 6 Microsoft da pasos concretos hacia la interoperabilidad La empresa promueve la transparencia publicando las notas de implementación de ODF y Open XML Para promover una mayor interoperabilidad entre las aplicaciones de productividad, Microsoft publicó este 16 de diciembre la documentación que detalla su implementación del soporte para OASIS Open Document Format (ODF) versión 1.1 en Microsoft Office 2007 SP2, actualmente en fase beta y prevista para su liberación el próximo año. Notas similares relativas a la implementación de Open XML (Ecma 376 Edición 1) en Office aparecerán en las próximas semanas. Esta información se seguirá actualizando en la medida en que los productos cambien a lo largo del tiempo y a partir de las sugerencias de los usuarios. Estas notas de implementación ofrecen una guía completa de cómo Microsoft está implementando ODF y Open XML dentro de la suite Office. Las notas, disponibles gratuitamente en el sitio Web de la Document Interoperability Initiative (DII), en http://www.documentinteropinitiative.org, serán de suma utilidad a los desarrolladores que busquen mejorar la interoperabilidad de sus soluciones con los productos de Microsoft, e igualmente constituirán un interesante recurso de aprendizaje. Las notas contienen: •Detalles sobre decisiones de implementación. Al implementar un estándar, el implementador puede encontrar el texto ambiguo o más permisivo de lo que sería apropiado para una implementación particular. En tales casos, el implementador debe tomar la decisión que mejor satisfaga sus necesidades. Este tipo de información permite a los desarrolladores ver qué dirección está siguiendo un fabricante y tomar decisiones informadas sobre sus propios esfuerzos de interoperabilidad. •Detalles sobre datos adicionales incorporados a los ficheros. Los estándares de formatos de ficheros típicamente permiten almacenar en los ficheros información adicional específica de las aplicaciones (por ejemplo, ciertas personalizaciones). Suministrando esta información, los fabricantes permiten a los desarrolladores interpretar correctamente esos datos adicionales. •Detalles sobre las desviaciones en la implementación. En cualquier aplicación se pueden presentar casos en que un implementador no puede seguir exactamente el estándar por una u otra razón. En tales casos, es importante que los fabricantes documenten exhaustivamente su enfoque, de manera que otros fabricantes puedan tomar decisiones informadas sobre cómo enfocarán su implementación. La estandarización es un primer paso importante hacia la interoperabilidad, pero se necesita más trabajo adicional por parte de los fabricantes para alcanzar ese objetivo: •Seguimiento compartido de la evolución de los estándares por parte de los cuerpos correspondientes. Microsoft tiene el compromiso de participar activamente en la evolución de los estándares ODF, Open XML, XPS y PDF; ha contribuido a ODF en OASIS y colabora en el mantenimiento de Open XML en ISO/IEC. •Transparencia. Los fabricantes deben ser transparentes al implementar estándares en sus propios productos. Publicando estas notas de implementación, Microsoft está ayudando a otros desarrolladores y fabricantes a tomar decisiones informadas a la hora de crear sus productos. •Colaboración. Los fabricantes deben colaborar con otros fabricantes para identificar y resolver las "colisiones del mundo real" que surjan entre implementaciones, y crear herramientas y soluciones para mejorar la interoperabilidad a lo largo del tiempo. Microsoft llevará a cabo alrededor del mundo sesiones de trabajo de DII y otras actividades para promover la colaboración entre fabricantes y, en definitiva, el intercambio efectivo de datos entre implementaciones de estándares de formatos de datos. Concurso “Inspire al mundo con solo 10K” Con el objetivo último de promover el desarrollo de aplicaciones basadas en las últimas tecnologías de interfaz de usuario de Microsoft, los organizadores del conocido evento MIX han creado un concurso bajo el lema “Inspire al mundo con solo 10K”. Se trata de desarrollar una aplicación Silverlight o WPF para navegador cuyo código fuente y recursos embebidos no sobrepasen en total los 10 KB. El ganador obtendrá un pase gratuito para el evento MIX ’09 que se celebrará en Las Vegas entre el 18 y el 20 de marzo, además de tres noches de hotel y una tarjeta Visa con 1.500 dólares. Para más información y las bases del concurso, visite http://2009.visitmix.com/MIXtify/TenKGallery.aspx. << dnm.directo.noticias Se libera conjuntamente con módulos destinados a simplificar los despliegues RFID Hace unos días, Microsoft liberó una beta pública de BizTalk Server 2009, conjuntamente con módulos destinados a simplificar los despliegues RFID. Se trata de la primera versión pública para pruebas de la plataforma de integración basada en Arquitecturas orientadas a servicios (SOA) de Microsoft. Se espera que la versión definitiva sea lanzada durante la primera mitad de 2009, según Burley Kawasaki, Director de la División de Sistemas Conectados de Microsoft. "Es una versión completa en lo que respecta a características", dijo Kawasaki. "Estamos buscando recibir mucho más feedback sobre el producto como parte de su terminación". La beta está disponible para su descarga para los clientes actuales de BizTalk suscritos al programa Software Assurance. BizTalk Server 2009 soporta los productos más recientes de la plataforma Microsoft, principalmente la versión de Windows Communications Foundation (WCF) incluida en .NET Framework 3.5 SP1, además del soporte completo para Visual Studio 2008 SP1 y las ediciones más recientes de SQL Server y Windows Server. Además, soporta nativamente HyperV y ofrece clustering mejorado, mejoras en la tolerancia a fallos y adaptadores e interfaces de integración con host adicionales. Igualmente se brinda soporte para un nuevo registro basado en las especificaciones de UDDI 3.0. Para las organizaciones dedicadas al desarrollo, BizTalk Server 2009 ofrece nuevas posibilidades para la gestión del Ciclo de vida de las aplicaciones mediante el soporte para Team Foundation Server, que permitirá a los equipos de programadores aprovechar la gestión de código, seguimiento de fallos e integración de builds que éste ofrece. Los desarrolladores que lleven a cabos desarrollos a medida basados en .NET podrán conectarse a BizTalk y mapear cualquiera de los artefactos que BizTalk gestiona en sus aplicaciones, como si de código fuente se tratara. Como parte de la versión liberada hoy, Microsoft también ha liberado BizTalk RFID Standards Pack y RFID Mobile. El primero es un módulo de servidor de BizTalk que soporta los principales estándares RFID, incluyendo Rag Data Translation (TDT) y Low Level Reader Protocol (LLRP). El segundo funciona bajo Windows Mobile y dispositivos basados en Windows CE. RFID Mobile ofrece una API común para todos los dispositivos que ejecuten Microsoft .NET Compact Framework y para la gestión remota de esos dispositivos. Finalmente, Microsoft ha liberado también una CTP de la versión actualizada de Enterprise Service Bus Guidance 2.0, que incluye nueva documentación y prácticas recomendadas para el desarrollo de aplicaciones basadas en SOA. "Estamos aprovechando algunas de las nuevas posibilidades de Visual Studio y añadiendo nuevas herramientas visuales que permitan definir y actualizar topologías de bus de servicios dentro de Visual Studio", dijo Kawasaki. También ha entrado en funcionamiento un nuevo portal Web "que permite a los desarrolladores agregar publicadores o suscriptores al bus sin necesidad alguna de desarrollo personalizado. Es un modelo de autoservicio". Disponible actualización para .NET 3.5 SP1 El pasado día 20 fue puesta a disposición del público una actualización para .NET Framework 3.5 SP1. Esta actualización corrige problemas detectados en .NET 2.0 SP2, .NET 3.0 SP2 y .NET 3.5 SP1 desde su aparición. Puede descargar e instalar los paquetes correspondientes (específicos para las distintas combinaciones de procesador y sistema operativo) desde http://support.microsoft.com/kb/959209. Nuevo portal sobre capacitación tecnológica de Alhambra-Eidos Como parte de la línea de continuo reforzamiento de su área de Formación, Alhambra Eidos pone en marcha su nuevo portal temático sobre capacitación tecnológica en las líneas tecnológicas que son de su especialidad: desarrollo de software, sistemas avanzados, comunicaciones y telefonía, así como sobre los distintos aspectos de seguridad comunes a todas ellas. El acceso a dicho portal puede realizarse a través de www.formaciontic.com. En él se podrá encontrar datos relativos a la oferta de formación de la compañía, información sobre novedades tecnológicas y anuncios de interés para aquellos que deseen mantener al día sus capacidades técnicas. Entre las primeras informaciones relevantes que pueden consultarse se encuentran las relativas a los nuevos cursos y seminarios de alta especialización sobre desarrollo seguro, experiencia de usuario, Visual Studio 2008, virtualización, etc. Los interesados también encontrarán allí todo lo relativo al plan de formación subvencionada para partners de Microsoft, ya que Alhambra Eidos ha sido una de las compañías seleccionadas para impartir dicho plan durante el curso 2008-2009. <<dotNetManía Microsoft libera primera beta de BizTalk Server 2009 7 << dnm.directo.noticias Disponible SP3 de SQL Server 2005 Desde el pasado 16 de diciembre está disponible el Service Pack 3 (SP3) de SQL Server 2005, así como la Actualización acumulativa (Cumulative Update) 11 para SQL Server 2005 SP2. Según la compañía, el SP3 incluye mejoras en el motor de bases de datos, así como en los servicios de replicación, Notification Services y Reporting Services; adicionalmente, contiene todas las actualizaciones de seguridad y corrección de errores aparecidas anteriormente. Para aquellos clientes que opten por no aprovechar las nuevas posibilidades, la Actualización acumulativa contiene únicamente los hot fixes. La versión más general del SP3 de SQL Server 2005, aplicable a las ediciones Enterprise, Developer, Standard y Workgroup, puede descargarse desde: http://www.microsoft.com/downloads/details.aspx?FamilyID=ae7387c3348c-4faa-8ae5-949fdfbe59c4. Por otra parte, SQL Server 2005 SP3 Express está disponible aquí: http://www.microsoft.com/downloads/detai ls.aspx?familyid=3181842A-4090-4431ACDD-9A1C832E65A6. Y SQL Server 2005 SP3 Express with Advanced Services aquí: http://www.microsoft.com/downloads/detai ls.aspx?familyid=B448B0D0-EE7948F6-B50A-7C4F028C2E3D. Al mismo tiempo, Microsoft ha liberado versiones actualizadas al nivel SP3 de las extensiones opcionales que forman parte del Feature Pack para SQL Server 2005. Puede descargar esas extensiones aquí: http://www.microsoft.com/downloads/details.aspx?FamilyID=536fd7d5-013f-49bc-9fc777dede4bb075. <<dotNetManía Microsoft libera Oxite para los desarrolladores 8 A principios de diciembre, el equipo que se encarga de los sitios para desarrolladores Channel 8, 9 y 10 liberó el motor de blogs y gestión de contenidos conocido como Oxite, que puede obtenerse en el sitio de CodePlex http://www.codeplex.com/oxite. Oxite fue desarrollado originalmente para el sitio Web del evento MIX (http://www.visitmix.com) y se apoya, como cabría esperar, en ASP.NET MVC y SQL Server. Esta herramienta viene a suplir, según sus creadores, la ausencia hasta el momento de ejemplos de gran calado basados en ASP.NET MVC, y se suministra con código fuente bajo el modelo de licencia Ms-PL, ofreciendo así a los desa- rrolladores el derecho a incorporar Oxite en sus propios productos. El proyecto, deliberadamente, no está orientado a usuarios finales, sino a desarrolladores. Aunque Oxite ofrece todas las características que un sistema de blogs debe soportar (feeds RSS, moderación de comentarios, pingbacks, etc.) carece de las características de instalación y configuración sencillas que requiere el software para usuarios finales, utilizando en vez de eso Visual Studio Web Developer Express para esas tareas. La idea de Microsoft es que los desarrolladores se basen en Oxite para crear sus propias aplicaciones de blogs o CMS. Se trata, sin embargo, de un proyecto de la comunidad, por lo que si ésta lo convierte en un producto más orientado a los consumidores, Microsoft no interferirá. Liberado IronPython 2.0 A principios de diciembre, Jason Zander anunció la disponibilidad de IronPython 2.0, una implementación del lenguaje Python diseñada para ejecutarse sobre la plataforma .NET, poniendo todas las librerías de .NET a disposición de los programadores Python y manteniendo al mismo tiempo compatibilidad total con la versión estándar del lenguaje. La novedad esencial incorporada en esta versión es que IronPython funciona ahora sobre el Dynamic Language Runtime (DLR), un motor de ejecución genérico para lenguajes dinámicos que se ejecuta sobre el CLR y hace posible la interoperabilidad de múltiples lenguajes dinámicos a nivel del sistema de tipos. Para más información y descargas (incluyendo el código fuente), visite http://www.codeplex.com/IronPython. Presentada Galería de diseños de ASP.NET MVC Hace unos días, Microsoft publicó una nueva galería de diseños para aplicaciones basadas en la arquitectura ASP.NET Model-ViewController. Esta galería aloja plantillas de diseños de sitios Web que el usuario puede descargar y utilizar en sus desarrollos. Cada plantilla de diseño incluye un fichero Site.master , una hoja de estilos CSS y, opcionalmente, un conjunto de recursos y código de soporte. Cualquiera puede “subir” nuevos diseños a la galería, que funciona bajo licencia bajo licencia Creative Commons. Visítela en http://www.asp.net/mvc/gallery/ default.aspx. entrevista Magda Teruel y Luis Fraile entrevista a Michael Howard y Adam Shostack Senior Security Program Managers en Microsoft Corp. Magda Teruel es Team Leader de Raona. Magda es MCPD Windows Developer. http://www.magda.es. Luis Fraile es MVP de Team System y colabora activamente en MAD.NUG (Grupo de usuarios de .NET de Madrid). Actualmente es director técnico en Multidomo Networks. Puede consultar su blog en www.lfraile.net. Michael Howard y Adam Shostack, reconocidos expertos en temas relacionados con la seguridad, pasaron por Barcelona con motivo del reciente Tech-Ed 2008, que tuvo lugar a mediados de noviembre.Además de impartir algunas sesiones, tuvieron un rato para entrevistarse con dotNetManía y hablarnos sobre ese aspecto tan importante para el software de hoy. ¿Qué opináis del panorama actual del software que se hace actualmente? ¿Es suficientemente seguro? Michael Howard: En lo que respecta a Microsoft, y con la incorporación de SDL (Secure Development Lifecycle), sí. A través de SDL, tenemos desde 2004 procesos estrictos de seguridad, para todos y cada uno de los productos expuestos a Internet o bien productos destinados a empresas. De todas maneras, ahora es más fácil aplicar prácticas de seguridad y privacidad a nuevos productos porque no hay que preocuparse de dar un soporte heredado. En mi opinión, y respondiendo a vuestra pregunta, los nuevos productos de Microsoft son mucho más seguros que los antiguos. ¿Y a nivel de la industria? Michael: La industria tiene un gran camino por recorrer. Hoy en día el foco de ataques está en los productos de terceros, y estos ataques provocan grandes pérdidas a las empresas. Para ayudar en esto, estamos externalizando nuestro modelo de automatización. SDL nos ha servido a nosotros en nuestros productos (SQL Server, Office, Windows), por lo que lo ofrecemos a la industria como herramienta para que sus productos sean también más seguros. En cuanto a los productos de Microsoft que requieren desarrollo por parte de los partners (BizTalk, SharePoint), ¿cuál es la estrategia? Michael: La postura es clara: Microsoft y Bill Gates nos dicen “Lo haremos, no importa cuánto cueste”, pero no sabremos lo que harán los partners. Para ponérselo más fácil, externalizamos nuestras buenas prácticas, recomendaciones y las lecciones que hemos aprendido. Y además les damos una herramienta para hacerlo. Recientemente se está haciendo mucho hincapié en campos como la UX. ¿No estamos olvidándonos de la seguridad? Adam Shostack: No. Estamos empezando a aprender todos. Antes, la seguridad era cosa de especialistas solamente. Obviamente, la experiencia de usuario es importante, si la gente no quiere usar nuestro software, tenemos un problema. Pero poco a poco la seguridad (en unos dos años) empezará a tener un papel relevante, y se hablará de seguridad como se habla ahora de interfaces de usuario. ¿Y qué está haciendo Microsoft para popularizar la seguridad? Michael: Ciertamente, hoy por hoy la seguridad es una materia de expertos, pero no debería serlo, tiene que formar parte del proceso. Ahora que subimos a la nube, y todo el mundo pone su software al alcance de todos, es importante introducir la seguridad como parte importante de la metodología. ¿Qué hay del software en la nube? Sin duda, lanza nuevos retos en cuanto a seguridad. Michael: Sí, son numerosos y distintos los retos que, por ejemplo, Windows Azure debe afrontar respecto a Windows 7. Cada uno de ellos ha pasado por SDL, pero tenemos requisitos específicos confeccionados para cada producto, así como elementos comunes como el modelado de amenazas (threat modeling), aplicables tanto a Windows Azure como a Windows 7. ¿Y hay algo en concreto que haya recibido una especial atención? Adam: Sí, sin duda. Desde 2006, SDL ha incluido requerimientos específicos de seguridad y privacidad para los servicios online. De hecho, los requerimientos de seguridad de SDL comprenden y se expanden a lo largo de múltiples fases del desarrollo, y están diseñados para mitigar problemas comunes de las aplicaciones Web, como por ejemplo la inyección de SQL o las vulnerabilidades XSS. Michael: También el modelado de amenazas se considera absolutamente crítico en tecnologías como Windows Azure y Live Mesh. Ahora con VS2010 tenemos nuevas herramientas de testing, como Camano, que nos facilitan las tareas relacionadas con las pruebas (fallos no reproducibles, etc.). ¿Se está pensando en herramientas que permitan realizar pruebas de seguridad relacionadas con la inyección de SQL u otros ataques? Michael: No, de momento solo se dispone de herramientas de terceros. Las pruebas son importantes, pero son solo una parte de la solución. Hemos hecho grandes progresos para construir algún tipo de herramienta de pruebas de aspectos de seguridad, como fuzz testing (un tipo de prueba que consiste en proveer el sistema con datos aleatorios), y hemos publicado código fuente para que los desarrolladores puedan generar este tipo de pruebas. Algunas partes del testeo de seguridad pueden ser automatizadas, pero hoy en día el estado del arte es todavía muy inmaduro. Hay mucho movimiento respecto a ALM (metodologías, buenas prácticas, etc.). ¿Cómo veis la integración de SDL en este contexto? Michael: Es completamente necesario que los fabricantes de software traten las amenazas de seguridad y privacidad convenientemente. Construir y preservar una mayor confianza en el mundo de la informática significa que todos los fabricantes de software deben incorporar requisitos de seguridad y privacidad en sus productos para mitigar las amenazas. Adam: Para la industria del software, las buenas prácticas y la formación ayudan, pero la clave para mejorar la seguridad y la privacidad es implementar procesos repetibles que aporten avances medibles. Se necesitan procesos así para minimizar el número de vulnerabilidades de seguridad en diseño, código y documentación, y para detectar y eliminar esas vulnerabilidades tan temprano en el ciclo de vida como sea posible. Y la necesidad es mayor para el software de empresa o consumo que procesa datos recibidos de Internet, para controlar sistemas críticos con peligro de ser atacados o para procesar información personal identificable. Michael: En Microsoft, es muy importante que añadamos herramientas de seguridad y prácticas a los métodos actuales de desarrollo, y éste es el foco de nuestro grupo. Pero todavía estamos en un proceso temprano, y necesitamos invertir más tiempo y esfuerzo. Falta madurez en el proceso, entonces. Adam: Mejorar la seguridad de las aplicaciones implica muchos componentes, desde comprender las amenazas, requerimientos de diseño, herramientas de desarrollo, herramientas de pruebas y reducir la superficie de ataque. No hay una fórmula mágica. Para cumplir con todos estos requisitos, Microsoft forma a todos sus desarrolladores, testers, y program managers en el desarrollo de código más seguro, y siempre trata de mantener el número de vulnerabilidades de seguridad al mínimo a través del proceso de SDL. <<dotNetManía << dnm.directo.entrevista 11 << dnm.directo.entrevista Michael Howard <<dotNetManía Michael: Cuando preguntan cuántos expertos en seguridad tenemos en Microsoft, la respuesta es 6.500. Es decir, cada ingeniero posee los conocimientos y habilidades necesarios para la seguridad, y esto va en aumento: cada vez nuestro conocimiento es mayor. Adam: Y aunque cada vez sabemos más, es importante poder prescindir del rol de experto en seguridad, y que cada ingeniero sea capaz de tener una madurez mínima en cuanto a seguridad. ¿Entonces vamos a integrar SDL con el resto de herramientas de desarrollo? Michael: De momento no, quién sabe si en un futuro… Por ahora, y como primer paso, vamos a proporcionar herramientas cómodas que faciliten la integración de la seguridad. Para ello hemos creado la herramienta Threat Modeling Tool (http://msdn.microsoft.com/enus/security/dd206731.aspx). 12 Siempre está cuestionada la seguridad de los productos de Microsoft. Como parte del equipo de seguridad, ¿cuál es vuestra percepción? Michael: ¡Estoy de acuerdo! Hemos hecho increíbles progresos en los últimos años, y ahora estamos compartiendo nuestra experiencia para que todo el mundo pueda aplicar nuestras prácticas. Si se mira una gráfica temporal, el número de vulnerabilidades va disminuyendo sustancialmente en cada versión. ¿Entonces en unos años no habrá vulnerabilidades? (risas) Michael: Para ser honestos, la cota de cero vulnerabilidades es inalcanzable. Pero la tendencia es a la baja, sin duda. Por ejemplo, las vulnerabilidades de red están ahí, y están para todos los sistemas, pero hemos conseguido transformarlas de críticas a solamente importantes. SDL pretende reducir el número de vulnerabilidades en nuestro software, y está demostrado que introducir la seguridad y la privacidad en el código desde los inicios nos ha permitido mejorar notablemente nuestro software. Es algo de lo que estamos muy orgullosos. Adam Shostack Al menos, hay que agradecer que el tiempo de reacción sea corto. Michael: Sí, aunque hay que mirar la foto completa. Es muy fácil detectar un bug y alarmarse. Siempre hay el dedo que señala. Adam: Sí, y queremos evitar los dedos acusadores. En Microsoft se ha apostado por hacer una inversión real en seguridad. De hecho, la gran mayoría de los anuncios recientes están orientados a informar de que se presta gran atención a resolver los problemas de seguridad. Para finalizar, habladnos del futuro de SDL. Michael: Últimamente me preguntan esto a menudo. Yo soy un eterno optimista. Y esto es crítico cuando trabajas en seguridad para Microsoft (risas). El último informe de Security Intelligence (http://www.microsoft.com/security/portal/sir.aspx) indica que hay que dar un paso más, que la industria debe cambiar su forma de pensar. Cada vez lo hacemos mejor, sacamos más y más versiones y aunque no son perfectas, son cada vez más buenas. Si me hubieran preguntado hace cinco años, no hubiera pensado que íbamos a hacer el progreso que hemos hecho, y creo que vendrán todavía más mejoras en los próximos cinco años. ¿Hacia dónde va la tendencia? Michael: Vamos a ver un mayor movimiento destinado a proveer más soporte específico para la Web. Ya hemos hecho mucho con respecto a esto, pero es un panorama bastante incierto, y vamos a poner más recursos en esta área. También van a aparecer muchas más herramientas. Y si tuviera que desear una sola cosa, me encantaría ver la seguridad como parte habitual de la entrega de software en todos los proveedores. En esta misma línea, me gustaría ver que fuera de Microsoft los equipos empiezan a implementar SDL en sus organizaciones. Con los ataques dirigiéndose hacia la capa de aplicación, es incluso más crítico que los desarrolladores de software protejan a sus clientes embebiendo seguridad y privacidad en sus productos. Hablando con clientes y partners, hay un interés bastante significativo en adoptar SDL. Algunas compañías ya han implementado procesos alineados con los de SDL, y con nuestro esfuerzo para compartir nuestras herramientas con la industria, confío en que cada vez más se irán añadiendo. plataforma.net Jeffrey Álvarez Massón Miguel Katrib Aplicación del patrón de diseño Acción Definición de componentes en ASP.NET En este artículo se propone un nuevo enfoque para la representación de acciones como componentes en aplicaciones visuales, y se muestran las múltiples ventajas que este enfoque proporciona a través de su aplicación práctica al desarrollo de formularios Web ASP.NET. Reducir al mínimo el código fuente Miguel Katrib es doctor y profesor jefe de programación del departamento de Ciencia de la Computación de la Universidad de La Habana. Miguel es líder del grupo WEBOO, dedicado a la orientación a objetos y la programación en la Web. Es redactor de dotNetManía y asesor de la empresa DATYS Tecnología y Sistemas. Jeffrey Álvarez Massón es estudiante de la Maestría en Ciencia de la Computación de la Universidad de la Habana y colaborador del grupo WEBOO. Es desarrollador .NET de la empresa DATYS Tecnología y Sistemas. Hasta el momento, las tecnologías de componentes se han dirigido a la implementación de funcionalidades generales que no dependen de las reglas de un negocio en particular. Una vez que el programador entiende cómo utilizar un componente, establece un “contrato” con él y debe ser capaz de adaptarlo a sus necesidades propias. Este artículo se centra en el desarrollo de un tipo de componentes para ASP.NET que interactúan con otros ya existentes para darles un significado semántico. Esto se hace a partir del patrón de diseño Acción o Comando. El primer ejemplo en el que se utiliza el patrón de diseño Comando (Command), también común- mente llamado Acción (Action), apareció en un artículo de Lieberman en 1985. MacApp, ET++, InterViews y Unidraw definen clases que siguen este patrón; para más detalles, ver [1]. Chris Lasater explica el patrón y ofrece una implementación en C# [2], y Alex Homer [3] lo usa en ASP.NET, aunque no desde el enfoque de componentes. Este patrón (figura 1) consiste en encapsular como un objeto la solicitud de ejecutar cierta funcionalidad, permitiendo parametrizar a los clientes con peticiones diferentes, poner en cola las peticiones y soportar operaciones de deshacer [1]. La principal utilidad de este patrón consiste en que muchas veces es necesario realizar una operación cuya implementación, invocador y receptor pue- Figura 1: Diagrama del patrón Acción o Comando. Tomado de [1]. << dnm.plataforma.net Acciones contra manejadores de eventos Teniendo en cuenta este patrón y las ventajas que ofrece para el desarrollo de componentes la tecnología ASP.NET [4], en el presente trabajo se considerará la implementación de una acción como un componente visual que tendrá asociado una funcionalidad específica (una petición) cuya ejecución se desembocará a través de un evento. Por ejemplo: en una página Web, se desea hacer una pregunta de sí o no al usuario a través de que éste haga clic en un determinado botón. Si el usuario responde sí, se le redirecciona a otra página. Si la respuesta es no, permanece en la página actual. Una implementación típica incluiría una función script en la página Web y una invocación de la función. Si tenemos que hacer muchas preguntas de esta naturaleza, habrá que incluir la función, modificar parámetros y adicionar manejadores de eventos cada vez. Sin embargo, si se cuenta con un control de ASP.NET que se encargue de ello mediante la generación automática de JavaScript en el cliente, previa configuración de propiedades, se acelera considerablemente el trabajo. La acción no debe considerarse un control de usuario (user control). Su objetivo no es personalizar una interfaz de usuario, sino asociar operaciones a los eventos de controles que ya tienen una interfaz definida; se deja a cargo del programador de la acción definir a qué evento(s) se asociará la ejecución de la acción; por ejemplo, al evento Click de algún botón. El proceso de adicionar una acción en el diseñador Web de Visual Studio o de cualquier otro ambiente de desarrollo debe ser el siguiente: 1. Se busca en las acciones existentes en las bibliotecas de acciones para comprobar si existe alguna con la funcionalidad deseada. En caso afirmativo, la acción encontrada se arrastra del cuadro de herramientas hacia el área de diseño donde se encuentran los demás componentes. 2. Se establecen —siempre en tiempo de diseño— las propiedades de la acción necesarias para que ésta funcione correctamente. 3. Se garantiza que la acción sea ejecutada en algún evento de la aplicación (inicio de sesión, ocurrencia de un error), de un control (clic en un botón, cambio de selección en un combo), de la página (Load, Init), etc. 4. Se colocan en orden las acciones en la página, ya que si se asignaran dos o más acciones al evento Click del mismo botón, podría ser importante tener en cuenta que la acción que aparece antes en la página se ejecutará primero. Al convertir el patrón Acción en un componente para ASP.NET, se crea una entidad declarativa, visiblemente semejante a un caso de uso. A través de ella, se pueden relacionar actores, operaciones y receptores, tanto en tiempo de diseño como en ejecución. Esto ofrece mayor flexibilidad para cambiarlos en el momento necesario. Implementación del patrón Acción Se llamará A ctionBase (listado 1) a la clase base de todas las acciones, que consta de los siguientes miembros: • Método público Execute. Como su nombre indica, ejecuta la petición, operación o lógica programada en la acción. • Método público virtual Undo. Deshace la operación realizada. Si no es posible deshacer, se lanza una excepción NotSupportedException (éste es el comportamiento predeterminado). using System; using System.ComponentModel; namespace Weboo.Web.UI.WebControls { public abstract class A ctionBase : Control { public A ctionBase() : base() { } public sealed void Execute() { CancelEventHandler be = BeforeExecute; if (be != null) { CancelEventA rgs args = new CancelEventA rgs(); be(this, args); if (args.Cancel) return; } InternalExecute(); if (A fterExecute != null) { A fterExecute(this, new EventA rgs()); } public virtual void Undo() { throw new NotSupportedException(); } protected abstract void InternalExecute(); public event CancelEventHandler BeforeExecute; public event EventHandler A fterExecute; } } Listado 1: La clase ActionBase <<dotNetManía den cambiar en tiempo de ejecución. Por ejemplo, se tiene una tabla con datos producidos por una consulta SQL y se desea ocultar columnas u ordenar por una de ellas. El invocador puede ser el manejador de un evento de botón o de casilla de verificación, el receptor es la columna de la tabla que se desea ocultar o por la que se va a ordenar, y la acción puede ser ocultar u ordenar. 15 << dnm.plataforma.net • Método protegido y abstracto InternalExecute. Debe ser implementado por las clases herederas para proveer al control de su funcionalidad correspondiente. • Evento BeforeExecute. Se dispara antes de ejecutar la acción. A través de este evento, el programador puede cancelar la ejecución de la acción en caso de que ello sea conveniente. • Evento A fterExecute. Se dispara después de ejecutar la acción. Mediante este evento se puede hacer algún tratamiento posterior a la ejecución de la acción, como deshacer o incorporar lógica adicional. using using using using using namespace Weboo.Web.UI.WebControls { public abstract class ButtonA ction : A ctionBase { public ButtonA ction() : base() {} [Description("ID del botón que ejecutará la acción."), DefaultValue(""), TypeConverter(typeof(WebControlIDConverter)), WebControlIDFilter(typeof(IButtonControl))] public string ButtonID { get { string o = ViewState["ButtonID"] as string; return (o == null) ? String.Empty : o; } set { ViewState["ButtonID"] = value; } Las acciones que hereden de A ctionBase no pueden reemplazar al método Execute. El implementador de una acción concreta lo que debe es heredar de A ctionBase y redefinir el método abstracto InternalExecute, que como es protected no puede ser llamado directamente por un cliente, sino solo a través de Execute. Aunque un código cliente de un tipo derivado de A ctionBase podrá invocar explícitamente al método Execute, esto no es lo que se pretende. Una vez que se han establecido correctamente las propiedades de una acción en tiempo de diseño, ésta debe ser capaz de registrar sus propios métodos en un evento de cualquier control, ya sea un clic de un botón, un cambio de selección en un control de lista, etc. Es el código manejador del evento el que debe llamar entonces a Execute. } protected void SetClientClick(WebControl button) { if (!(button is IButtonControl)) throw new A rgumentException("El control con ID = '" + ButtonID + "' no implementa la interfaz IButtonControl."); Type buttonType = button.GetType(); PropertyInfo propClientClick = buttonType.GetProperty("OnClientClick"); string functionCode = "javascript:" + GetClientEventScript() + ((!this.ContainsServerCode) ? "; return false;" : ""); try { if (propClientClick== null) button.A ttributes["onclick"] = functionCode; else propClientClick.SetValue(button, functionCode.ToString(), new object[] { }); } catch (Exception ex) { throw new InvalidOperationException( "La propiedad OnClientClick del control " + ButtonID + " no se pudo cambiar. ", ex); } } protected virtual string GetClientEventScript() { return null; } <<dotNetManía Eventos en el cliente y en el servidor 16 En el desarrollo de componentes Web ASP.NET, una de las características más importantes a tener en cuenta es que tenemos dos tipos de eventos: los de cliente (navegador) y los de servidor. Por un lado, los scripts o segmentos de código interpretado (JavaScript, VBScript, etc.) son los encargados del funcionamiento de los controles en el navegador sin provocar llamadas al servidor; y por el otro, a través de envíos de infor- System; System.ComponentModel; System.Web.UI.WebControls; System.Web.UI; System.Reflection; protected void SetServerClick(WebControl button) { if (!(button is IButtonControl)) throw new A rgumentException("El control con ID = '" + ButtonID + "' no implementa la interfaz IButtonControl."); IButtonControl ib = (IButtonControl) button; ib.Click += new EventHandler(HandleClick); } protected virtual void HandleClick(object sender, EventA rgs e) { this.Execute(); } } } Listado 2: Implementación en C# de una acción asignable a un botón de ASP.NET << dnm.plataforma.net mación convenientemente oculta en la página, se reportan vía HTTP como eventos al servidor [5]. El código del listado 2 muestra una implementación para una acción asignable a un botón de una página Web ASP.NET (note que la acción es a su vez abstracta, porque no se ha dado ninguna implementación particular al método InternalExecute). Para mayor brevedad, las implementaciones del convertidor de tipo (type converter) WebControlIDConverter y del atributo WebControlIDFilterA ttribute han sido omitidas. Un convertidor de tipo, en pocas palabras, permite convertir un objeto de tipo X en una representación de tipo Y. Por ejemplo, existen convertidores para transformar números a cadenas y viceversa. Asociando un convertidor de tipo a través del atributo TypeConverterA ttribute a una propiedad de un control (Windows Forms o ASP.NET) se pueden obtener valores posibles para asignar a la propiedad cuando ésta se configura en la rejilla de propiedades de Visual Studio. En el paso 3 de la figura 2, puede notarse cómo el usuario ha elegido “Button1” de una lista de valores posibles de la propiedad ButtonID. WebControlIDConverter permite obtener una lista de los ID de controles presentes en la página Web, mientras que WebControlIDFilterA ttribute le indica al converti- Figura 2: Pasos para adicionar y configurar la acción Limpiar en Visual Studio .NET Una acción para borrar el contenido de formularios Web Como ejemplo de aplicación de la propuesta de este artículo, presentaremos una acción real para limpiar (poner en blanco el contenido de cuadros de texto y anular la selección en los controles de selección como DropDownList, ListBox, etc.) un formulario Web. Como se muestra en la figura 2, tal acción se arrastra desde el cuadro de herramientas al área de diseño de la página, y se le asocia un botón para ejecutarla; en este caso, habrá también que asociarle el control contenedor (por ejemplo, un panel) cuyo contenido se quiere limpiar (vaciando los controles que éste contiene). Por último, se decide si la acción se ejecutará en el cliente o en el servidor (propiedad ServerSide). Como se puede observar, en este caso es en el método OnLoad donde se llama a los métodos encargados de registrar la acción en el evento Click del <<dotNetManía La posibilidad de ejecutar la acción tanto en el cliente como en el servidor y el registro automático en los eventos del objeto invocador son ventajas de esta implementación dor de qué tipos deben ser los controles para ser incluidos en dicha lista. El método SetClientClick permite incluir en el elemento HTML del botón que se usará para ejecutar la acción el atributo onclick cuyo valor será la llamada a la función JavaScript (obtenida mediante GetClientEventScript), que deberá ser implementada en una cadena con el código de la función y registrada a través del método Page.Client Script.RegisterClientScriptBlock por los herederos de esta clase. Por su parte, el método SetServerClick, según la forma tradicional en C# para registrarse a eventos, incluye una llamada a Execute en el evento Click del botón. Como se puede apreciar, algunas de las ventajas de esta implementación son la posibilidad de ejecutar la acción tanto en el cliente como en el servidor y el registro automático de los métodos de la acción en los eventos del objeto invocador. 17 << dnm.plataforma.net <<dotNetManía Hasta el momento, en ASP.NET las acciones se habían implementado como objetos a los que se hacían peticiones a través de un método como Execute 18 botón. Si además el evento se procesa en el cliente, se llama al método RegisterScriptCode para registrar el código JavaScript que garantizará la operación. En este caso InternalExecute solo se ejecutará si la propiedad ServerSide es true. Note que es este método quien invoca al método RecursiveClear para limpiar los controles. Se ha hecho también una redefinición (override) de GetClientEventScript para personalizar la llamada a la función script registrada con el ID del contenedor a limpiar. Por ejemplo, si FunctionName es igual a Clear y ContainerID es Panel1, este método devolverá Clear('Panel1'). Por último, tenga en cuenta que el método FindControl de la clase Control busca en el contenedor de nombres actual (naming container) un control con el ID especificado como parámetro [4]; sin embargo, en muchas ocasiones esto no es suficiente para encontrar un control, así que la clase Util (que no se ha incluido por motivos de espacio, pero puede descargarse del sitio Web de dotNetManía) incluye una versión estática de FindControl que si no encuentra el control en su naming container sube un nivel hacia arriba en la jerarquía de contenedores, repitiendo la búsqueda hasta llegar al nivel de la instancia de Page. Si a pesar de todo el control no se encuentra, el método devuelve null. using using using using using using System; System.Text; System.Web.UI; System.ComponentModel; System.Web.UI.WebControls; System.Drawing; namespace Weboo.Web.UI.WebControls { [DefaultProperty("ContainerID"), ToolboxBitmap(typeof(A ctionBase), "A ction.bmp")] public class A ctionClear : ButtonA ction { public A ctionClear() { ViewState["FunctionName"] = "Clear"; this.ServerSide = false; } [Description("Indica si los controles se limpian " + "actualizando sus propiedades en el servidor (true) " + "o en el cliente (false)."), DefaultValue(false)] public bool ServerSide { get { return (bool)ViewState["ServerSide"]; } set { ViewState["ServerSide"] = value; } } [Description("ID del control contenedor en el que se encuentran " + "los controles que se limpiarán."), DefaultValue(""), TypeConverter(typeof(A ssociatedControlConverter))] public string ContainerID { get { string o = ViewState["ContainerID"] as string; return (o == null) ? String.Empty : o; } set { ViewState["ContainerID"] = value; } } [Description("Nombre de la función script cliente " + "que ejecuta la acción de limpiar."), DefaultValue("Clear")] public string FunctionName { get { string o = ViewState["FunctionName"] as string; return (o == null) ? String.Empty : o; } set { ViewState["FunctionName"] = value; } } protected override void OnLoad(EventA rgs e) { base.OnLoad(e); Control button = Util.FindControl(this, this.ButtonID); if (button == null) return; if (ServerSide) SetServerClick(button); else { SetClientClick(button); RegisterScriptCode(); } } << dnm.plataforma.net protected override void InternalExecute() { Control control = Util.FindControl(this, ContainerID); if (control == null) throw new InvalidOperationException( String.Format( "Control con ID = {0} no encontrado.", ContainerID)); RecursiveClear(control); } private void RecursiveClear(Control control) { if (control is TextBox) ((TextBox)control).Text = String.Empty; else if (control is ListControl) ((ListControl)control).ClearSelection(); else foreach (Control current in control.Controls) RecursiveClear(current); } private void RegisterScriptCode() { Type pageType = Page.GetType(); if (!Page.ClientScript.IsClientScriptBlockRegistered( pageType, FunctionName)) { Page.ClientScript.RegisterClientScriptBlock(pageType, FunctionName, String.Concat( "<script language=\"javascript\">", "function ", FunctionName, "(id) {", " var c = document.getElementById(id);", " for (i = 0; i < c.all.length; i++)", " if ((c.all.item(i).tagName == \"INPUT\" &&", " c.all.item(i).type == \"text\") || ", " c.all.item(i).tagName == \"TEXTA REA \")", " c.all.item(i).value = \"\"; ", " else if (c.all.item(i).tagName == \"SELECT\" &&", " c.all.item(i).options.length > 0)", " c.all.item(i).options[0].selected = true; ", "}</script>") ); } } protected override string GetClientEventScript() { string idControl = this.ContainerID; if (ServerSide) { Control container = Util.FindControl(this, this.ContainerID); if (container == null) throw new A rgumentException("El control con ID = '" + ContainerID + "' no se encuentra."); idControl = container.ClientID; } return String.Format("{0}('{1}')", FunctionName, idControl); } } } Listado 3: Acción que limpia el contenido de un formulario Web. Conclusiones Hasta el momento, en ASP.NET las acciones se habían implementado como instancias de objetos a las que se hacían peticiones a través de un método como Execute. Los parámetros, como el receptor, se asignaban a propiedades desde el código. Con este nuevo enfoque de la acción en forma de componente de ASP.NET se obtienen las siguientes ventajas: • Solo hay que colocar el código imprescindible –es decir, el que es propio para cada página- en code behind. Todas las funcionalidades de la página se programan una sola vez en las acciones, lo cual conduce a una mayor facilidad de mantenimiento del código fuente. • El funcionamiento de la página puede definirse completamente en tiempo de diseño. • Mayor modularidad, reusabilidad y extensibilidad para incorporar nuevas funcionalidades a las páginas. • Facilidad para indicar que las acciones se ejecuten en el navegador, en el servidor o en ambos. • La creación de páginas Web ASP.NET desde Visual Studio puede realizarse sin muchos conocimientos de la tecnología. La aplicación de este enfoque a otros patrones de diseño, como Observador (Observer) o Publicación-Suscripción (Publish-Subscribe) [3], así como Fábrica Abstracta (Abstract Factory), Constructor (Builder) [1] y otros pueden aumentar las capacidades de desarrollo para definir y utilizar componentes en ASP.NET. Bibliografía [ 2] Lasater, Christopher G. CodeProject. Design Patterns: Command Pattern. Free source code and programming help. En http://www.codeproject.com/KB/books/DesignPatterns.aspx, 2006. [ 3] Homer, Alex. Design Patterns for ASP.NET Developers. Part 3: Advanced Patterns. En http://www.devx.com/dotnet/A rticle/34220/1763, 2007. [ 4] [ 5] Microsoft Developer Network for Visual Studio 2005. Microsoft, 2005. MacDonald, Matthew y Szpuszta, Mario. Pro ASP.NET 2.0 in C# 2005. Apress, 2005. págs. 67-69. <<dotNetManía [ 1 ] Gamma, Erich, et al. Design Patterns: Elements of Reusable Object-Oriented Software. Addison Wesley Longman, 1998. 19 Sharepoint Gustavo Vélez HttpHandlers y HttpModules para SharePoint 2007 Este artículo describe las posibilidades que ofrecen los manejadores HTTP (HttpHandlers) y los módulos HTTP (HttpModules) de ASP.NET, y cómo pueden utilizarse estos mecanismos para implementar funcionalidades avanzadas en sitios de SharePoint 2007. Gustavo Vélez es ingeniero mecánico y electrónico, especializado en el diseño, desarrollo e implementación de software (MCSD) basado en tecnologías de Microsoft, especialmente SharePoint. Es creador y webmaster de http://www.gavd.net/servers, y trabaja como senior developer en Winvision (http://www.winvision.nl) En el principio de los tiempos, solamente existía HTML. HyperText Markup Language (HTML) fue rápidamente aceptado, y constituye hoy en día la base de todo tipo de aplicaciones Web. Pero HTML solamente permite mostrar contenido estático, lo que rápidamente fue visto como una limitación seria para el desarrollo de tecnologías Web. Los desarrolladores necesitan mecanismos para que las aplicaciones Web sean dinámicas y permitan generar contenido a partir de bases de datos o siguiendo las preferencias de los usuarios. Por esta razón, los fabricantes de servidores Web comenzaron a crear tecnologías complementarias para garantizar el desarrollo dinámico en la Red: Microsoft creó la Internet Server API (ISAPI) para su Internet Information Services (IIS), que también fue adoptada por Apache, y Netscape desarrolló NSAPI (Netscape Server API) con el mismo objetivo. ISAPI consta de dos mecanismos principales: las extensiones y los filtros: • Las extensiones no son más que aplicaciones normales que se pueden hacer ejecutar mediante una solicitud Web. La parte más conocida de las extensiones ISAPI es la cadena de consulta (query string) que aparece al final de un URL en la forma de un signo de interrogación seguido de al menos una asociación parámetro-valor, éstos últimos separados entre sí mediante el símbolo “&” (por ejemplo, http://Servidor/default.aspx?param1=valor1& param2=valor2). • Los filtros son lo que la palabra indica: algo que destila y modifica la información entre la solicitud y la respuesta Web. Trabajar programáticamente con ISAPI nunca ha sido fácil por su complejidad: hay que utilizar directamente los compiladores de la familia Win32, y el desarrollo tradicionalmente solo ha sido posible con C/C++. Para aliviar este problema, ASP.NET ofrece los manejadores HTTP (HttpHandlers) y los módulos HTTP (HttpModules): • Los manejadores HTTP pueden ser vistos como un equivalente de las extensiones ISAPI, y a nivel de programación son componentes que implementan la interfaz System.Web.IHttpHandler. • De forma similar, los módulos HTTP pueden ser comparados con los filtros ISAPI, e implementan la interfaz System.Web.IHttpModule. El funcionamiento de SharePoint 2003 se basaba completamente en un filtro ISAPI especialmente diseñado para manejar el enrutamiento de las solicitudes Web. Esto producía algunos efectos colaterales, como por ejemplo que el servicio IIS estaba totalmente “secuestrado” por SharePoint, impidiendo el funcionamiento de << dnm.servidores.sharepoint HttpHandlers para SharePoint 2007 Para crear un manejador HTTP para SharePoint 2007, comience por crear un nuevo archivo con la extensión .ashx en el directorio C:\A rchivos de programa\A rchivos comunes\Microsoft Shared\Web server extensions\12\TEMPLA TE\LA YOUTS. El código de ejemplo que se presenta en el listado 1 (basado en una presentación de Ted Pattison) escribe en pantalla un texto establecido en el contexto de la página. Después de agregar una referencia al ensamblado de SharePoint y heredar de la interfaz IHttpHandler, se implementan la propiedad IsReusable y el método ProcessRequest de la interfaz. En éste último se crean objetos SPSite y SPWeb basados en el contexto para mostrar un texto informativo. El método IHtttpHandler.ProcessRequest recibe como parámetro el HttpContext de la página, de tal forma que la propiedad Response de éste pueda ser utilizado para escribir en la pantalla. Este es un ejemplo muy sencillo, pero útil para mostrar el funcionamiento de un manejador HTTP. El tipo MIME de la respuesta que se va a generar (ContentType) es “text/plain” en el ejemplo, pero podría utilizarse cualquier otro tipo, como XML, flujos binarios (por ejemplo para devolver imágenes), Adobe PDF o cualquier tipo de documento de Office. La extensión .ashx es reconocida por defecto por IIS como correspondiente a un manejador HTTP, pero se puede utilizar cualquier otra extensión que se desee, siempre que se la registre como tal en la sección httpHandlers de web.config o machine.config. <%@ WebHandler Language=”C#” Class=”HolaHttpHandler” %> <%@ A ssembly Name=”Microsoft.SharePoint, Version=12.0.0.0, Culture=neutral, PublicKeyToken=71e9bce111e9429c” %> using System; using System.Web; using Microsoft.SharePoint; public class HolaHttpHandler : IHttpHandler { public bool IsReusable { get { return false; } } public void ProcessRequest(HttpContext context) { SPWeb miSitio = SPContext.Current.Web; context.Response.ContentType = “text/plain”; context.Response.Write(“HolaHttpHandler desde el sitio “ + miSitio.Title + “ en “ + miSitio.Url); } } Listado 1 SharePoint se encarga de compilar el código en el momento de ser utilizado, por lo que no es necesario generar ni instalar DLL alguna. El archivo tampoco es guardado en memoria, por lo que tampoco es necesario ejecutar un IISRESET después de modificarlo. El ejemplo mostrado podría haber sido desarrollado prácticamente con el mismo código usando una página .aspx tradicional. La ventaja de un manejador HTTP reside en la posibilidad de hacer reconocer extensiones propias en IIS, y de interpretarlas y mostrarlas en pantalla utilizando un tipo específico de transformación (definido por la propiedad ContentType). De esta manera es posible, por ejemplo, enviar directamente al navegador documentos PDF o implementar algún tipo de contenido propio. HttpModules para SharePoint 2007 Los módulos HTTP permiten implementar una funcionalidad más general que la de los manejadores HTTP. La diferencia fundamental entre ellos dos radica en que los módulos se ejecutan para todas las solicitudes, sean del tipo que sean, sin importar la extensión concreta de la URL que se esté solicitando ni el manejador HTTP que será utilizado para satisfacerla. Esto abre las puertas a crear código que siempre realice alguna actividad en el sistema. Formalmente, la interfaz IHttpModule que deben implementar los módulos consta solamente de dos métodos, Init y Dispose. En Init se implementa la inicialización del módulo, y el método recibe como parámetro una referencia al contexto (objeto HttpA pplication) que representa a la aplicación Web en ejecución. Típicamente, en este método se “enganchan” manejadores para los eventos globales de la aplicación, como BeginRequest, EndRequest, A cquireRequestState, A uthenticateRequest o A uthorizeRequest. Normalmente, los eventos más interesantes son BeginRequest y EndRequest, que permiten actuar, respectivamente, sobre la solicitud del usuario antes de que SharePoint la pro- <<dotNetManía otras aplicaciones Web en el mismo servidor. En la versión 2007 de SharePoint, el filtro ISAPI ha sido sustituido por manejadores y módulos, garantizando de esta manera la compatibilidad con ASP.NET y liberando el servicio IIS. Otra gran ventaja es que ahora disfrutamos de un modelo abierto: el desarrollador puede crear sus propios módulos para implementar tareas específicas de un determinado portal utilizando C# o Visual Basic. 21 << dnm.servidores.sharepoint cese, y sobre la respuesta una vez que está lista para ser enviada de regreso. El ejemplo más sencillo de módulo HTTP que se puede pensar es uno que genere la misma respuesta para todas las solicitudes al sistema. Por supuesto que éste es un ejemplo bastante poco útil en la vida práctica, pero que podría utilizarse para, por ejemplo, presentar una página de aviso cuando el portal esté en mantenimiento. Recuerde que el módulo se ejecutará para todas las solicitudes, sin importar el tipo de URL que utilice cualquier usuario; la respuesta siempre será la página de mantenimiento. El código de este módulo se muestra en el listado 2. El ensamblado resultante de compilar este proyecto (de tipo “Class Library”) deberá ser firmado con un nombre seguro y copiado al directorio Bin de la aplicación Web respectiva en IIS (por ejemplo, C:\Inetpub\wwwroot\wss\VirtualDirectories\80\bin). En realidad, podría instalarse también en la GAC; pero para limitar el alcance de un ensamblado a una determinada aplicación Web es preferible situarlo en el directorio Bin. Para hacer que SharePoint reconozca el módulo, la línea que se muestra en el listado 3 (sustituyendo los valores adecuados para el nombre, tipo y clave pública) debe ser agregada al archivo web.config de la aplicación Web en IIS, bajo la sección HttpModules. using System; using System.Web; namespace HttpModulo_01 { public class Class1 : IHttpModule { public void Init(HttpA pplication context) { context.BeginRequest += new EventHandler(EmpezarSolicitud); } private void EmpezarSolicitud(object sender, EventA rgs e) { HttpContext.Current.Server.Transfer( “/_layouts/mantenimiento.html”, false); } public void Dispose() { } } } <<dotNetManía Listado 2 22 Como se puede observar, en el método de inicialización hemos añadido al evento BeginRequest del contexto del módulo un delegado asociado al método EmpezarSolicitud, que se deberá ejecutar cuando dicho evento se dispare. En el cuerpo de EmpezarSolicitud se transfiere la llamada a nuestra página de mantenimiento. El método Dispose, por supuesto, es indispensable de ser implementado, y deberá contener el código necesario para liberar cualesquiera recursos que pudieran haber sido adquiridos en Init. El orden de los elementos de la sección HttpModules de web.config es esencial para el correcto funcionamiento de SharePoint El orden en que se coloquen los elementos de esta sección es esencial para el funcionamiento de SharePoint (la autenticación tiene que ocurrir antes que la autorización, y ésta última antes de poder asignar roles), y debe ser mantenido, a riesgo de alterar el funcionamiento interno de SharePoint. Normalmente, un módulo propio se debe registrar al final de la sección, pero no es una regla obligatoria: en el caso de la página de mantenimiento, es posible que se decida que la autenticación y autorización no son necesarias, pues el sistema de todas formas no estará en funcionamiento, y por lo tanto el módulo HTTP se podría colocar al principio de la sección. Otra aplicación típica de los módulos es utilizar el evento A fterRequest para modificar la respuesta que SharePoint envía al usuario para mostrar cierta información en todas las páginas del portal (un pie de página o un texto mostrando las condiciones de uso), como se muestra en el listado 4. <add name=”HttpModulo_01” type=”HttpModulo_01.Class1, HttpModulo_01, Version=1.0.0.0, Culture=neutral, PublicKeyToken=97bc1af85e70ceb9” /> Listado 3 Como podrá observar, en la sección HttpModules del archivo web.config Sha- rePoint ya tiene configurados algunos módulos por defecto: caché, autenticación, autorización y manejo de roles. En este ejemplo, se está agregando un manejador al evento EndRequest del módulo para modificar el código HTML que SharePoint ya ha generado. El método TerminarSolicitud a su vez suministra, mediante HttpResponse.WriteSubstitution, un delegado asociado al método EscribirTexto, que es quien genera el texto necesario. El resultado se puede ver en la figura 1. Con respecto al funcionamiento del módulo, hay que señalar que el pie de página estará situado detrás de las etiquetas </BODY></HTML> del código HTML generado. Para el objetivo de using System; using System.Web; namespace HttpModulo_02 { public class Class1 : IHttpModule { public void Init(HttpA pplication context) { context.EndRequest += new EventHandler(TerminarSolicitud); } private void TerminarSolicitud(object sender, EventA rgs e) { HttpA pplication miHttp = (HttpA pplication) sender; miHttp.Context.Response.WriteSubstitution( new HttpResponseSubstitutionCallback(EscribirTexto)); } private static string EscribirTexto(HttpContext context) { return “Este es un pie de página”; } public void Dispose() { } } } Listado 4 Figura 1: Texto de pie de página en todas las páginas del portal un pie de página, el resultado es el esperado; pero aunque los navegadores modernos podrán mostrar el texto sin problemas, este código no es conforme a las especificaciones de w3.org. Probablemente la mejor solución sea obtener toda la respuesta HTML a través de un flujo, modificarla por medio de una concatenación o una expresión regular y enviar la respuesta modificada. El propósito del ejemplo es mostrar cómo utilizar un módulo en SharePoint; los detalles de implementación pueden ser especificados de acuerdo con las necesidades particulares. También hay que tener en cuenta que el texto del pie de página debería ser almacenado fuera del módulo, de manera de que cuando se desee modificar el texto no sea necesario recompilar el código. Aunque los eventos BeginRequest y EndRequest sean los más “populares”, hay otros eventos que pueden ser utilizados, y a veces es obligatorio usarlos. Es el caso de que se quiera cambiar dinámicamente la página maestra: en esta situación, es imprescindible utilizar el evento PreRequestHandlerExecute, que se dispara precisamente antes de que ASP.NET empiece a generar la página; si se utiliza otro evento, la página maestra ya habrá sido mezclada con el contenido y no será posible cambiarla. Un ejemplo de esto se presenta en el listado 5. Note que las posibilidades de este módulo son realmente extensas: en una instalación por defecto, SharePoint permite definir una sola página maestra por colección de sitios, y dicha página es configurada para todos los usuarios de la colección. Los temas son una forma de crear alguna personalización de páginas dentro de la colección, y permiten personalizar la configuración por cada usuario; pero los cambios que se pueden hacer con los temas están limitados a las modificaciones a realizar mediante estilos de CSS. Con un módulo HTTP de este tipo, se puede modificar radicalmente las páginas en base a grupos de usuarios o inclusive usuarios individuales, permitiendo que cada grupo tenga una interfaz completamente diferente, no solo visual, sino también funcionalmente. <<dotNetManía << dnm.servidores.sharepoint 23 << dnm.servidores.sharepoint using System; using System.Web; using System.Web.UI; namespace HttpModulo_03 { public class Class1 : IHttpModule { public void Init(HttpA pplication context) { context.PreRequestHandlerExecute += new EventHandler(CambiarSolicitud); } private void CambiarSolicitud(object sender, EventA rgs e) { Page Page miPagina = HttpContext.Current.CurrentHandler as Page; if (miPagina != null) miPagina.MasterPageFile = “~/Master1.master”; } public void Dispose() { } } } <<dotNetManía Listado 5 24 Continuando con los eventos que pueden ser utilizados, otro ejemplo de módulo HTTP que puede mejorar el funcionamiento de SharePoint es uno que permita generar una página con mejor información para el usuario cuando ocurre un error en el sistema. SharePoint muestra por defecto una página que indica solamente que ha ocurrido un error, sin dar mayor información al respecto. Un módulo, por el hecho de ejecutarse en todas las consultas que pasan a través de IIS, está en capacidad de interceptar cualquier error que pueda ocurrir y actuar en consecuencia, como se muestra en el listado 6. En el manejador de eventos MiError del módulo se recorren una por una todas las excepciones que se han producido, creando entradas en el Visor de sucesos de Windows. Luego se eliminan los errores en el contexto y se redirige a una página especial. Esta página puede mostrar los mensajes de error, por ejemplo, e indicar que acción a realizar, si es necesario. Para el registro se generan aquí entradas muy sencillas, pero por supuesto en la vida real se debe incluir toda la información sobre el error para facilitar su repro- ducción y corrección. Igualmente, los errores se podrían almacenar en una base de datos u otro sistema de archivo (inclusive dentro de una lista de SharePoint), y se podría ejecutar otras acciones, como enviar un e-mail al administrador del sistema. Conclusión Los manejadores HTTP y los módulos HTTP nos permiten aumentar la flexibilidad y manejabilidad de SharePoint 2007. Desafortunadamente, hasta el presente han sido relativamente muy poco explotados, pero por su facilidad de programación y por la cantidad de situaciones en las que pueden ser aplicados, constituyen dos herramientas que siempre hay que tener en mente cuando se esté trabajando programáticamente con SharePoint. using System; using System.Diagnostics; using System.Web; namespace HttpModulo_04 { public class Class1 : IHttpModule { public void Init(HttpA pplication context) { context.Error += new EventHandler(MiError); } private void MiError(object sender, EventA rgs e) { Exception[] todosMisErrores = HttpContext.Current.A llErrors; foreach (Exception ex in todosMisErrores) { EventLog miLog = new EventLog (); miLog.Log = “A pplication”; miLog.Source = “Mi HttpModule”; miLog.WriteEntry(“Ha ocurrido un error: “ + ex.Message); } HttpContext.Current.Server.ClearError(); HttpContext.Current.Server.Transfer( “/_layouts/MiPaginaDeErrores.aspx”); } public void Dispose() { } } } Listado 6 plataforma.net Juan Luis Ceada Autenticación y autorización en servicios Web con cabeceras y extensiones SOAP En ocasiones es necesario tener un control exhaustivo de los accesos que se producen a nuestros servicios Web (quién accede, a dónde y cuántas veces), tanto por seguridad como para mantener la calidad del servicio. En este artículo veremos cómo podemos cumplir estos requisitos interceptando las llamadas realizadas por los clientes a nuestra plataforma de servicios Web. Juan Luis Ceada es Ingeniero en Informática. Actualmente trabaja en Arrakis Servicios y Comunicaciones (Grupo BT) como Jefe de proyectos y analista, estando a cargo de múltiples desarrollos y sistemas Web que usan tecnologías Microsoft. También es autor de múltiples artículos en revistas del sector. Un buen día llega uno de los comerciales de la empresa y te dice que uno de los nuevos clientes desea integrar sus sistemas con los nuestros. La idea del cliente es automatizar todos sus procesos, teniendo en cuenta que en parte de ellos intervendrá nuestra empresa como proveedora de algún tipo de servicio. En estos días, la solución más acertada para hacer frente a escenarios como éste pasaría por proveer de una capa de servicios Web, de tal forma que expongamos a nuestros clientes parte o todos los servicios de nuestra empresa. Pero claro, aquí empiezan nuestros dolores de cabeza y nos tenemos que plantear algunas cosas: ¿Cómo y con qué lo hago? ¿Cómo gestiono la seguridad de la capa de servicios Web (autenticación, autorización, confidencialidad, integridad)? ¿Cómo puedo dar mejor soporte al cliente? Algunas de estas preguntas tienen fácil y rápida respuesta. Por ejemplo, el “cómo y con qué lo hago”. Está claro, con ASP.NET. Con respecto a la confidencialidad y a la integridad de la información, podemos resolverlo utilizando SSL en nuestras comunicaciones (o haciendo uso del estándar WSSecurity), algo que hoy en día, tanto por coste como por facilidad de implementación, es aconsejable en todos los proyectos de este tipo. En las próximas líneas veremos cómo podemos resolver algunas de las otras cuestiones. ¿Qué vamos a desarrollar? El proyecto que vamos a llevar a cabo nos servirá como base para afrontar nuevos desarrollos de servicios Web. Nos permitirá: • Controlar los accesos: decidir quién puede acceder y desde dónde a nuestra plataforma de servicios Web, mediante el uso de login y password más validación de IP (sin depender del servidor IIS). • Controlar qué servicios Web y métodos pueden usar los clientes (autorización). • Controlar el número de accesos a nuestra plataforma: para evitar abusos, o simplemente para tener diferentes niveles de servicio en función de la importancia del cliente. • Tener la capacidad para decidir si las peticiones que recibamos son correctas o no, y denegar el acceso en caso de que no lo sean (para reducir la posibilidad de ciertos tipos de ataques). • Tener mecanismos de logging para poder dar mejor soporte a nuestros clientes en caso de que sea necesario. Y todo ello, sin necesidad de tener el control absoluto del servidor Web donde se alojen los servicios Web, puesto que nos basaremos únicamente en un modelo de datos gestionado por SQL Server para controlar todo lo anterior. << dnm.plataforma.net Como herramienta de desarrollo se ha optado por Visual Studio 2008 Web Developer Express Edition, y como base de datos, SQL Server 2005 Express Edition. No se utilizan las características novedosas de VS 2008, por lo que VS 20005 podría servir también. El modelo de datos Figura 1. Modelo de datos Además, en ws_metodoswebservice tenemos un campo llamado tamanomaximoxml. Este campo contendrá el tamaño aproximado en kilobytes del mensaje SOAP esperado para este método. El valor de este campo deberemos calcularlo en función de los parámetros que cada método pueda recibir. Por ejemplo, el mensaje SOAP de un método que reciba únicamente un entero como parámetro no debería superar el kilobyte de tamaño. Cualquier cosa que recibamos de más tamaño sin duda será una petición errónea como mínimo, pudiendo tratarse de un ataque de denegación de servicio (basado en el uso de un XML recursivo de gran tamaño, por ejemplo), que podremos parar o mitigar simplemente rechazando la petición antes de que sea procesada por el parser XML del servidor. En los casos de métodos para los que nos sea imposible prever el tamaño de los mensajes, podemos utilizar el valor 0 que equivale a “no verificar el tamaño” (cosa que deberíamos evitar siempre que sea posible). Las tablas ws_permisosusuario4webservice y ws_permisosusuario4metodo sirven para modificar los permisos por defecto de acceso a un servicio Web completo, o a métodos particulares de determinados servicios Web. Por ejemplo, podemos hacer que un supuesto método para enviar correos masivos (permiso denegado por defecto) del servicio clientes esté disponible para el usuario ws_admin. Para ello, bastará con añadir un registro en ws_permisosusuario4metodo con los valores ('ws_admin', 'clientes', 'mandarmailmasivo', 'P'), que se impondría al valor por defecto que se almacena en ws_metodoswebservice. La tabla ws_controlanchobanda nos ayudará a decidir cuándo un usuario está abusando del servicio, o simplemente si un usuario ha superado el límite de llamadas permitidas. En este caso, se ha decidido simplificar, de tal forma que podemos controlar únicamente cuántas llamadas a la plataforma se pueden hacen por unidad de tiempo. Valores válidos son “5 llamadas por segundo”, “20 al día” o “1000 al mes”. Aquí podríamos haber complicado aún más el esquema, haciéndolo más granular. Por ejemplo, “20 llamadas al día al servicio Web XXX”, “3 llamadas por segundo al método YYY del servicio Web XXX”, pero a efectos de este artículo es suficiente con algo más genérico. El campo unidaddetiempo debe contener dos caracteres, cuyos valores coinciden con los que admite la función dateadd de Transact-SQL (“dd” para días, “hh” para horas, etc.) <<dotNetManía Para poder llevar a cabo nuestro proyecto, tendremos que apoyarnos en un modelo de datos, cuyo diagrama podéis ver en la figura 1. Veamos para qué sirve cada tabla. En primer lugar, la tabla ws_usuarios almacena los logins y passwords de todos los usuarios que podrán acceder a nuestra plataforma de servicios Web. En la tabla ws_ipsautorizadas almacenaremos las direcciones IP desde donde podrán acceder dichos usuarios a la plataforma. Se admite el formato IP/máscara, con lo que con 192.168.0.0/255.255.0.0 (por ejemplo) estaríamos permitiendo el acceso desde cualquier máquina de la intranet a un usuario en particular. Las tablas ws_webservices y ws_metodoswebservice alojan, respectivamente, los nombres de cada uno de los servicios Web que vayamos a proporcionar a los clientes, junto con sus respectivos métodos. Todos y cada uno de los servicios Web que creemos, así como todos y cada uno de los métodos que estos posean, deberán estar registrados en estas tablas, o de lo contrario no seremos capaces de utilizarlos (ni siquiera nosotros: el sistema de seguridad nos lo impedirá). Ambas tablas contienen un campo llamado permisopordefecto que nos permitirá decidir si un servicio Web/método está disponible para todo el mundo (“P” de permitido) o para nadie (“D” de denegado) por defecto. Por ejemplo, un método para enviar un e-mail masivo a todos nuestros clientes puede estar desactivado por defecto por su “peligrosidad”, pero otro para consultar el nombre de un cliente a partir del NIF debería estar disponible por defecto, por ser algo “básico”. 27 << dnm.plataforma.net Evidentemente, para poder saber si un usuario supera el límite de llamadas, necesitamos un log donde registrar cuántas llamadas se han hecho. Para eso tenemos la tabla ws_estadisticas, donde almacenamos, entre otras cosas, la IP de origen, servicio Web y método accedido, así como la fecha y hora del acceso. Es importante recalcar que este modelo de datos va a ser accedido con muchísima frecuencia, por lo que conviene que sea supervisado por un administrador de bases de datos que pueda aportar su experiencia a la hora de optimizar el rendimiento del servidor. Procedimientos almacenados <<dotNetManía Para trabajar con el modelo de datos, usaremos procedimientos almacenados desarrollados en Transact-SQL. En concreto, dispondremos de cinco: • ws_validarusuario: valida las credenciales del usuario, a partir de login y password. 28 Figura 2. Procedimiento almacenado • ws_validartamanomensaje: comprueba si para un servicio Web y método en particular se está superando el tamaño de mensaje XML esperado. Al hilo de este artículo, me gustaría comentaros mi experiencia con la integración de nuestros clientes. Llevo ya algunos años ayudando a terceros a integrarse con nuestra plataforma, y he visto casi de todo: gente que no ha tenido el más mínimo problema, otros a los que les ha costado algo más, y algunos con los que durante algunos momentos he llegado a pensar en tirar la toalla. Pero al final todo han sido finales felices. Poder interceptar lo que los clientes envían (el XML en bruto), así como llevar un registro de las excepciones producidas ayuda (y no sabéis cuanto, sobre todo cuando aparecen los temidos problemas de interoperabilidad). Tener la mente abierta ayuda también: no os cerréis a dar soporte solo a la integración entre determinadas plataformas. Algunos clientes usarán .NET, y por tanto el soporte a la integración debería ser total. Otros usarán Java, que tampoco debería dar problemas. Pero otros usarán PHP, Ruby, C++ (o cualquier otra cosa), y a lo mejor no tenéis personal con el conocimiento necesario para dar soporte. En este caso, no os neguéis a ayudar. En todo caso, advertid que no es vuestro campo, pero siempre intentad ayudar (aunque tengáis que aprender sobre la marcha, siempre es más fácil para el “servidor” encontrar y depurar los problemas que para el “cliente”). Al final, habréis aprendido cosas nuevas, y tendréis una base de datos de ejemplos en diferentes lenguajes de programación que ayudarán a futuros nuevos clientes. Otra cosa: no os olvides nunca que una vez la integración se produce, ya no hay marcha atrás, y que cualquier problema repercutirá inmediatamente en los clientes. Por tanto la disponibilidad del servicio se vuelve importantísima, y habrá que prever con la antelación necesaria los cambios en la plataforma, manteniendo a los clientes informados, y realizando multitud de pruebas antes del paso a producción, siendo imprescindible en este caso contar con una plataforma de integración previa al paso a producción y distinta de la plataforma de desarrollo. Y un último consejo: la comunicación por e-mail está bien, pero de vez en cuando los clientes agradecen una llamada, aunque sólo sea para preguntar “¿cómo vais?”. • ws_validaracceso: comprueba si un usuario está autorizado para acceder a un determinado servicio Web/método, teniendo en cuenta los permisos del mismo y si ha superado el ancho de banda asignado o no. • ws_obteneripsusuarios: devuelve un conjunto de datos con todas las IP desde las que el usuario puede acceder a la plataforma. • ws_guardarestadistica: almacena los accesos que los usuarios van haciendo a la plataforma. De todos ellos, el que tiene mayor complejidad (nada del otro mundo) es ws_validaracceso, del que podéis ver una parte en la figura 2. Para poder utilizar estos procedimientos, hemos desarrollado un par de clases auxiliares (fichero WSA uxiliar.cs). La clase IPMask nos ayudará a la hora de comprobar si la IP desde la que accede el usuario coincide con alguna de las que tenemos almacenadas en la base de datos (teniendo en cuenta la máscara). Otra clase, llamada WSA uxiliar (dividida en capa de negocios y capa de acceso a datos) nos permitirá utilizar los procedimientos antes descritos. El único método que contiene algo de código adicional es ValidarA cceso, y solo porque además de llamar al pro- << dnm.plataforma.net cedimiento ws_ValidarA cceso también llama a ws_ObtenerIpsUsuario para obtener la lista de IP validadas y verificar si alguna coincide con la de origen (ver listado 1). credenciales de usuario. O las clases A uthExtension y A uthExtensionA ttribute, que son la base de todo el sistema. Pero vamos por partes. El servicio Web WSBase La propiedad Credenciales Una vez analizado el modelo de datos, pasemos a ver cómo lo utilizaremos en nuestra plataforma de servicios Web. En primer lugar, hemos creado un servicio Web que hereda directamente de System.Web.Services.WebService, y al que hemos llamado WSBase. Como su nombre indica, este servicio Web será la base de toda nuestra plataforma. Por tanto, todos y cada uno del resto de los servicios Web deberán descender de WSBase; esto es imprescindible para el correcto funcionamiento del sistema. Pero, ¿qué hace tan especial a WSBase? Pues varias cosas, en realidad. En primer lugar, en él se definen ciertas estructuras de datos que heredarán/utilizarán el resto de servicios Web. Por ejemplo, un objeto de la clase WSRequestHeader, que define el formato de las Como hemos comentado, todos los servicios Web, al descender de WSBase, heredan la propiedad Credenciales de tipo WSRequestHeader, que a su vez desciende de SoapHeader [1]. Al hacerla descender de SoapHeader, lo que estamos definiendo es una clase que usaremos como cabecera SOAP, y que será obligatorio proporcionar en todas y cada una de las llamadas a nuestra plataforma para poder realizar la validación del usuario. Afortunadamente, si se desarrolla la aplicación cliente también en .NET , bastará con asociar una única vez la cabecera SOAP en el código para que esta sea enviada en cada llamada automáticamente (en otros lenguajes es necesario pasar explícitamente dicha cabecera en cada una de las llamadas a métodos como un parámetro más). Frente a esta forma de proceder, en la que se comprueban las credenciales en cada petición, tenemos la posibilidad de validar las credenciales una única vez, de tal forma que no sea necesario pasar de nuevo por este proceso en sucesivas peticiones, ahorrándonos accesos a la base de datos. El problema es que esto nos obligaría a guardar cierta información en variables de sesión, y en el caso de que optemos por sesiones in-process esto significaría que el balanceo de carga (si existe) no sería tan eficiente, por tener que ligar cada sesión a un servidor particular. Y si se decide usar sesiones out-off-process, basadas en SQL Server, pues simplemente estaríamos trasladando los accesos a una base de datos distinta. La clase WSRequestHeader contiene solamente dos propiedades: login y password. Por tanto, en cada llamada a un método el cliente nos debe proporcionar estos datos dentro de la cabecera SOAP del mensaje. Una vez recibidos, buscaremos en la base de datos si dichos login/password están registrados public static void ValidarA cceso(string ip, string webservice, string metodo, string login) { System.Collections.Generic.List<IPMask> lipm = WSA uxiliarDA L.ObtenerIpsUsuario(login); bool encontradaip = false; if (lipm != null) { foreach (IPMask ipm in lipm) { if (!encontradaip) encontradaip = IPMask.ValidaIP(ip, ipm); } } if (!encontradaip) { throw new Exception(“No se puede acceder a la plataforma de WS desde la IP “ + ip); } Listado 1: Código del método WSAuxiliar.ValidarAcceso <<dotNetManía // una vez analizada la IP, vemos si le concedemos o no acceso al WS, teniendo // en cuenta factores como los permisos o las últimas estadísticas de acceso WSA uxiliarDA L.ValidarA cceso(webservice, metodo, login); 29 << dnm.plataforma.net El uso de cabeceras SOAP para la autenticación tiene ventajas frente al método tradicional, puesto que podemos “exigir” datos adicionales como números de licencia sin tener que complicar la interfaz de los métodos y son válidos. Como toda clase, WSRequestHeader podría admitir muchas más propiedades. Por ejemplo, podría incluir algún tipo de token pre-generado, número de licencia, o cualquier otro literal que sirva para garantizar la autenticación, y que los clientes nos deberán proporcionar. Pero, ¿cómo indicamos a las aplicaciones clientes de nuestro servicio Web que deben enviar una cabecera con credenciales al llamar a todos (o solo algunos) de los métodos existentes? Veamos el servicio Web Clientes (que, por supuesto, hereda de WSBase), implementado en Clientes.cs. Contiene dos métodos bastante simples: Consultar y Borrar. El código del método Consultar se presenta en el listado 2. información se incluye en el fichero WSDL, lo que permite a los entornos de desarrollo conocer las necesidades del servidor para poder generar el proxy cliente adecuado. Podríamos perfectamente tener varios tipos de cabeceras (unas más simples, otras más complejas), y hacer que cada una se asocie a un método distinto en función de nuestras necesidades. La clase AuthExtension La clase A uthExtension desciende de SoapExtension [2], y nos permitirá tener acceso a los mensajes SOAP que se intercambian entre cliente y servidor antes de que éstos lleguen a su destino final. Podremos analizarlos, y si es necesario, modificarlos. Y por supuesto, es posible recha- [WebMethod, A uthExtension(), SoapHeader(“Credenciales”)] public string Consultar(string dni) { return “Obtenidos los datos del cliente con dni “ + dni; <<dotNetManía Listado 2. El método Consultar del servicio Clientes 30 Como se puede apreciar, mediante atributos del método estamos indicando que éste se va a exponer a través de Web (WebMethod) y que va a llevar asociada una cabecera de nombre “Credenciales”. Esta zar peticiones si lo que estamos recibiendo desde el cliente “no nos gusta”. Esta clase, así como la clase A uthExtensionA ttribute que veremos a continuación, se han definido dentro de WSBase por sim- plificar, pero nada nos impide extraer este código a una DLL independiente que podríamos reutilizar en otros proyectos. Al heredar de SOA PExtension tenemos que sobrescribir cuatro métodos, aunque sólo el código de uno de ellos no es trivial: el del método ProcessMessage. Este método es llamado en cuatro ocasiones distintas por el framework ASP.NET: • Antes de deserializar el mensaje SOAP XML recibido en un objeto en el servidor (SoapMessageStage.BeforeDeserialize). • Después de deserializar el mensaje SOAP XML recibido en un objeto en el servidor (SoapMessageStage.A fterDeserialize). Para analizar las cabeceras hay que actuar en este punto. • Antes de serializar la respuesta en un mensaje XML SOAP para su envío al cliente (SoapMessageStage.BeforeSerialize). • Después de serializar la respuesta en un mensaje XML SOAP para su envío al cliente (SoapMessageStage.A fterSerialize). Como a nosotros en principio solo nos interesa analizar los mensajes que el cliente envía al servidor, nuestro código únicamente actuará en los dos primeros casos, tal y como se puede apreciar en el listado 3. Cada vez que el método ProcessMessage sea llamado, tenemos que comprobar el estado en el que se encuentra el mensaje. Cuando estemos en el paso BeforeDeserialize, que es el primero en producirse, poco podremos hacer, puesto que el mensaje por ahora no es más que un flujo de bytes. Pero en este momento podemos comprobar al menos a qué método y servicio Web se dirige la petición y, usando el método ValidarTamanoMensaje de la clase WSA uxiliar, validar el tamaño del mensaje que estamos recibiendo. Si es exagerado para lo que se esperaba, lanzaremos una excepción que abortará el resto del proceso, ahorrando así al servidor la tarea de deserializar el mensaje XML. << dnm.plataforma.net public override void ProcessMessage(SoapMessage message) { WSRequestHeader h; bool credencialesrecibidas = false; string loginrecibido = “”; // acciones que podemos realizar antes de deserializar el mensaje recibido if (message.Stage == SoapMessageStage.BeforeDeserialize) { // comprobamos que el tamaño en KBytes del mensaje recibido no supera // el máximo permitido para un método try { WSA uxiliar.ValidarTamanoMensaje(message.MethodInfo.DeclaringType.Name, message.MethodInfo.Name, message.Stream.Length / 1024); } catch (Exception ex) { WSA uxiliar.GuardarEstadistica(message.MethodInfo.DeclaringType.Name, message.MethodInfo.Name, “info no disponible”, ‘D’, HttpContext.Current.Request.ServerVariables[“REMOTE_A DDR”].ToString(), ex.Message); throw; } } <<dotNetManía // actuamos justo después de obtener el mensaje XML SOA P y deserializarlo // en un objeto,imprescindible para poder tratar la cabecera if (message.Stage == SoapMessageStage.A fterDeserialize) { foreach (SoapHeader header in message.Headers) { if (header is WSRequestHeader) { credencialesrecibidas = true; h = (WSRequestHeader)header; // validamos la petición try { loginrecibido = h.login; WSA uxiliar.ValidarUsuario(h.login, h.password); 32 // el usuario parece ok, vamos a comprobar si tiene acceso // al método y servicio Web deseado. WSA uxiliar.ValidarA cceso(HttpContext.Current.Request. ServerVariables[“REMOTE_A DDR”].ToString(), message.MethodInfo.DeclaringType.Name, message.MethodInfo.Name, h.login); // lo tiene, guardamos estadísticas WSA uxiliar.GuardarEstadistica(message.MethodInfo.DeclaringType.Name, message.MethodInfo.Name, h.login, ‘P’, HttpContext.Current.Request.ServerVariables[“REMOTE_A DDR”].ToString(),“”); } catch (Exception ex) { Además de lanzar la excepción, registraremos el acceso en la tabla de estadísticas. En este caso, como aún no se ha procesado el mensaje SOAP, no tendremos acceso al contenido de la cabecera, y por tanto no podremos saber qué usuario está realizando la petición, de ahí que se registre como login “info no disponible”. Cuando estemos en el paso A fterDeserialize (el segundo del proceso), lo primero que tendremos que hacer es recorrer todas las cabeceras del mensaje SOAP (podría haber más de una), buscando aquella que tenga el formato de nuestra clase WSRequestHeader. Si encontramos alguna, extraemos de ella tanto el login como la password del usuario, y procedemos a validarlos. En caso de que la validación no se lleve a cabo con éxito, o si no se han recibido las credenciales, se lanzará una excepción que abortará el tratamiento del resto de la petición, y se registrará el acceso “denegado” en el log. Una vez verificadas las credenciales, tendremos que ver si el usuario está autorizado para utilizar el método/servicio Web al que se está llamando (información que podemos obtener a través de la propiedad MethodInfo de la variable message que recibimos como parámetro). Además, también será necesario verificar si se supera el número de peticiones por unidad de tiempo contratadas. De todo eso se encarga el método ValidarA cceso de la clase WSA uxiliar, como vimos con anterioridad. Si todo es correcto, permitiremos el acceso, y anotaremos el acceso “permitido” en las estadísticas. La clase AuthExtensionAttribute Para poder hacer uso de la clase A uthExtension, tendremos que crear nuestro propio atributo de método, creando una nueva clase que herede de SoapExtensionA ttribute a la que llamaremos A uthExtensionA ttribute (ver listado 4). En << dnm.plataforma.net } } } if (!credencialesrecibidas) { string msg = “Toda llamada a método de servicio debe llevar las credenciales de usuario”; WSA uxiliar.GuardarEstadistica( message.MethodInfo.DeclaringType.Name, message.MethodInfo.Name, loginrecibido, ‘D’, HttpContext.Current.Request.ServerVariables[“REMOTE_A DDR”].ToString(), msg); throw new Exception(msg); } // aquí podríamos hacer otras cosas, como guardar el mensaje recibido // a modo de log para su futuro estudio } // antes de mandar el mensaje de vuelta al cliente if (message.Stage == SoapMessageStage.BeforeSerialize) { // aquí podríamos por ejemplo guardar en un log cualquier excepción // que haya ocurrido antes de devolvérsela al cliente, // útil para ayudar en el soporte } } Listado 3: Código del método ProcessMessage. [A ttributeUsage(A ttributeTargets.Method)] public class A uthExtensionA ttribute : SoapExtensionA ttribute { int _priority = 1; public override int Priority { get { return _priority; } set { _priority = value; } } public override Type ExtensionType { get { return typeof(A uthExtension); } } } Listado 4: Clase AuthExtensionAttribute ella solo tendremos que sobrescribir dos propiedades. La primera indica la prioridad de la “extensión”, y se utiliza cuando se usan simultáneamente varios atributos de tipo SoapExtensionA ttribute, para decidir con qué prioridad se procesan. La segunda simplemente hemos de modificarla para que devuelva el tipo de la clase que se encargará de procesar los mensajes SOAP, en nuestro caso A uthExtension. El servicio Web Clientes Como hemos comentado con anterioridad, se trata de un servicio Web desarrollado a modo de ejemplo para poder probar el mecanismo de control de acceso que hemos creado. Contiene dos métodos muy sencillos en su implementación. Por supuesto, ambos métodos, así como el servicio Web que los aloja, han sido dados de alta en la base de datos, que como hemos visto es el primer paso a afrontar a la hora de poder definir los controles de acceso. La única particularidad a destacar es que el método Borrar lo consideramos especialmente peligroso, y por eso por defecto todos los usuarios tienen el permiso de acceso a él denegado, siendo necesario establecer explícitamente que un usuario determinado tiene acceso al mismo. Como último señalamiento, volvamos a estudiar el método Consultar (ver listado 2). Como se puede apreciar, hay un tercer atributo en la definición del método que antes pasamos por alto: A uthExtension. Como habréis podido deducir, este atributo indica que toda llamada que se haga a dicho método va a ser "supervisada" por la clase A uthExtension, tal y como vimos con anterioridad. Si no se especificasen estos tres atributos, todo nuestro trabajo no serviría para nada. Por tanto, es muy importante no olvidar añadir a cada método de cada servicio Web los tres atributos (salvo que por algún motivo queramos que alguno de nuestros métodos no esté supervisado). <<dotNetManía // guardamos en log el acceso denegado al método/servicio WSA uxiliar.GuardarEstadistica(message.MethodInfo.DeclaringType.Name, message.MethodInfo.Name, h.login, ‘D’, HttpContext.Current.Request.ServerVariables[“REMOTE_A DDR”].ToString(), ex.Message); throw; 33 << dnm.plataforma.net Figura 3. Página de ejemplo Figura 4. Excepción por falta de permisos Consultar y otro al método Borrar , mientras que el tercero llamará al método Consultar, pero con una peculiaridad: construiremos a mano el mensaje XML, al que le meteremos mucha “morralla” y lo enviaremos mediante una petición HTTP POST, ignorando por tanto el proxy que Visual Studio ha generado a partir del WSDL. La idea es simular un supuesto ataque de un usuario malintencionado. El código que se ejecuta al pulsar sobre el primer botón se muestra en el listado 5. En él se aprecia en primer lugar como se crean sendos objetos que representan al proxy creado a partir del WSDL y a las credenciales de usuario. A continuación, rellenamos las credenciales, que son asignadas a la propiedad WSRequestHeaderValue del proxy. Y por último, llamamos al método Consultar. Puesto que las credenciales se asignan al proxy, esto significa que solo tenemos que proporcionarlas una vez, pudiendo hacer tantas llamadas a los métodos como queramos, ya que en todas y cada una de las peticiones se incluirá automáticamente la cabecera en los mensajes SOAP. El código que se ejecuta al pulsar el botón "Borrar" es análogo al del listado 5, mientras que el código del botón "Enviar mensaje XML gigante" es algo más complejo, pero tampoco nada del otro mundo. En la figura 4 se muestra la situación de error que se <<dotNetManía Las pruebas 34 Una vez presentados los principios generales del desarrollo, pasemos a realizar algunas pruebas. Para ello se incluye en el proyecto una página Web muy simple que hace uso del servicio Clientes. La interfaz de usuario es muy sencilla y tan solo contiene tres botones (ver figura 3). Uno de ellos servirá para invocar al método WSClientes.Clientes ws = new WSClientes.Clientes(); WSClientes.WSRequestHeader credenciales = new WSClientes.WSRequestHeader(); credenciales.login = “ejemplo”; credenciales.password = “ejemplo1”; ws.WSRequestHeaderValue = credenciales; Label1.Text = ws.Consultar(“12345678z”) Listado 5: Ejemplo de llamada al servicio Web << dnm.plataforma.net produce por falta de permisos. De forma similar, nuestro sistema reaccionará ante la falta de credenciales, un mensaje XML de tamaño excesivo o la superación del límite de 5 peticiones por hora que hemos establecido. Conclusión Figura 5. Excepción si no se introducen credenciales Figura 6. Excepción por tamaño máximo superado Con poco esfuerzo, hemos creado un sistema que nos permitirá tener mayor control sobre quién y cómo accede a nuestra plataforma de servicios Web. Además, como el sistema está basado únicamente en base de datos, no es necesario tener el control del servidor para poder utilizarlo, lo que puede venir muy bien de cara a instalaciones en hostings compartidos. Por supuesto, el sistema admite múltiples ampliaciones. Por ejemplo, podríamos guardar un log de todos los mensajes SOAP que nos llegan para poder ayudar a nuestros clientes con sus desarrollos (no todo el mundo usa herramientas avanzadas, y a veces es de gran ayuda ver qué datos estamos recibiendo en “bruto”). O podríamos almacenar en la base de datos todas las excepciones que se produzcan en la plataforma, junto con información adicional que nos permita depurar errores. En fin, que hay muchas posibilidades a explorar, para las que tan solo se necesita tener algo de tiempo y de imaginación. Bibliografía [ 1 ] http://msdn.microsoft.com/es- Figura 7. Excepción por ancho de banda [ 2] http://msdn.microsoft.com/enus/library/system.web.services.pro tocols.soapextension.aspx [ 3] Prosise, Jeff. “Build Secure Web Services With SOAP Headers and Extensions”, en http://www.developer.com/net/net/article.php/11087 _2192901_1. <<dotNetManía es/library/system.web.services.pro tocols.soapheader(VS.80).aspx 35 Silverlight Marino Posadas Silverlight 2.0 Toolkit Controles, visualización de datos y mucho más (I) En paralelo con la presentación de la versión final de Silverlight 2.0, se anunciaba en las webs “oficiales” de la plataforma la intención de mejorar el desarrollo mediante la publicación paulatina de nuevos controles y herramientas que potencien las posibilidades de creación de aplicaciones RIA con Silverlight, al tiempo que se anticipaban algunas características de la versión 3.0, que según Scott Guthrie estará disponible a finales de 2009.Vamos a revisar aquí algunas de las posibilidades que ofrece el último paquete de herramientas, publicado a primeros del pasado mes de diciembre. Marino Posadas es redactor jefe de dotNetMania y Software Arquitect de Alhambra-Eidos. Es MCP, MCSD, MCAD, MCT y MVP en Visual C#. Puede consultar su página Web en www.elavefenix.net El sitio oficial de descarga de los nuevos controles y herramientas para Silverlight es Codeplex (www.codeplex.com/silverlight), y es ahí donde el lector podrá encontrar el último paquete de herramientas y controles que complementa a las ya incluidas con el SDK del producto, y que se distribuyen bajo licencia pública de Microsoft (Ms-PL). Todo el código fuente está disponible en uno de los paquetes descargables, junto con ejemplos de cada elemento y característica soportada, y un ejemplo genérico “Sample Explorer”, que muestra en una sola página todos los elementos nuevos. En resumen, el paquete de diciembre de 2008 ofrece las siguientes novedades: • Controles: nuevos controles de IU que podemos dividir en dos clases, dependiendo de su grado de madurez: los que están considerados como estables (stable), y los que están a un paso de esa calificación (preview). o En el primer grupo se encuentran A utoCompleteBox, DockPanel, HeaderedContentControl, HeaderedItemsControl, Label, NumericUpDown, TreeView y WrapPanel. o Y en el segundo: Expander, ImplicitStyleManager y ViewBox. • Charting: control para la visualización gráfica de conjuntos de datos. Aunque se trata igualmente de un control, su complejidad y posibilidades hacen que merezca un estudio aparte. • Temas: soporte para temas (themes) al estilo de ASP.NET, donde se incluye media docena de temas de ejemplo. La clase ImplicitStyleManager se relaciona directamente con esta funcionalidad. • Automatización (Automation Peer): soporte para automatización de elementos de la interfaz de usuario. Especialmente interesante para la construcción de sitios accesibles. Desafortunadamente (en palabras del divulgador oficial de la tecnología, Jesse Liberty), la calidad del contenido de este kit de herramientas no corre pareja con los materiales didácticos que nos permitan aprender su funcionamiento e incorporarlo con rapidez a nuestras aplicaciones. Aparte del fichero .chm de ayuda del SDK, lo más interesante que se incorporó en esta versión fue la solución global con ejemplos que muestran todos los controles, junto a características de visualización de datos y soporte de temas en una sola aplicación, con acceso directo al código fuente en XAML/C#. << dnm.dnm.plataforma.net El propio Liberty, no obstante reconocer esta situación, ha publicado ya dos vídeos explicativos del kit y continuará con la labor de divulgación de estas novedades (ver el sitio http://silverlight.net/blogs/ La recomendación oficial es que no se utilicen más que los controles de categoría estable para labores de producción (y, según qué escenarios, habría que esperar a que alcanzaran la categoría de “maduros”). jesseliberty/archive/2008/12/08/a-complex-homefor-very-some-simple-toollkit-examples.aspx). Controles en estado preview Nosotros vamos a presentar los fundamentos del funcionamiento de este kit y sus herramientas asociadas, centrándonos solamente en el código fundamental de los elementos estables, y explicando las bases del charting y el uso de temas. Comenzamos presentando los controles actualmente en estado preview, citando simplemente su funcionalidad (sin ejemplos de código). Expander Controles Antes de nada, hay que decir que si el lector quiere probar este kit tal y como se hace con el resto de controles, desde Visual Studio, recuerde que deberá hacer referencia a la librería que los contiene ( Microsoft.Windows.Controls.dll), que encontrará en el directorio /binaries del paquete descargable, una vez descomprimido éste. Nótese la diferencia de nomenclatura de la DLL con respecto a la del paquete “estándar” (System.Windows.Controls). Además, la librería Microsoft.Windows.Controls.Input contiene el elemento NumericUpDown, así como clases base para la construcción de elementos similares. Una vez hecho esto, en el Cuadro de herramientas de Visual Studio 2008 aparecerán 10 elementos nuevos, tal y como se ve en la figura 1. Ya presente en Windows Presentation Foundation, es un control que muestra una cabecera con (o sin) un rótulo descriptivo, y un glifo que permite desplegar y colapsar una ventana en su parte inferior. Se debe tener cuidado en el diseño para controlar la superficie que se muestra respecto a otros controles de la interfaz. ViewBox Define un decorador de contenido, que puede cambiar el tamaño y escalar un único elemento interno hasta rellenar el espacio disponible. También está disponible en WPF. ImplicitStyleManager No es un control propiamente dicho, sino una clase sin interfaz de usuario propia que permite encapsular un comportamiento visual que propaga sus estilos a un conjunto de controles. Está vinculado con el funcionamiento de los temas, y una de sus enormes ventajas es la posibilidad de almacenar separadamente conjuntos de estilos (en una DLL, por ejemplo), y poder aplicarla después a distintos elementos de una interfaz dada. Hablaremos con detalle de su funcionamiento y programación en el próximo artículo, dedicado a los gráficos empresariales. En realidad, esto es solo una pequeña parte del paquete; un vistazo al Examinador de objetos nos mostrará que hay otros controles que no aparecen en la lista, bien porque sirven para la construcción de otros, bien porque no tienen una interfaz visual propia, debiendo ser ésta definida por el usuario (como ButtonSpinner). Controles (en estado stable) A utoCompleteBox Representa un control similar al ComboBox, pero que permite la búsqueda incremental en los elementos de la lista desplegable <<dotNetManía Figura 1 37 << dnm.plataforma.net según se van introduciendo datos en el control. La propiedad que activa/desactiva las características de búsqueda es IsTextCompletionEnabled, de tipo bool, activada de forma predeterminada. Para el ejemplo de la figura, el código sería el siguiente: XA ML <controls:A utoCompleteBox Width=”120” Height=”25” x:Name=”CajaA utoCompletar” /> C# CajaA utoCompletar.ItemsSource = new String[] { { “Pedro”, “Perico”, “Petronio”, “Patricio” }; XA ML <controls:HeaderedItemsControl x:Name=”CajaHeaderItems”> <controls:HeaderedItemsControl.Header> <Image Source=”Imagenes/s18.jpg” /> </controls:HeaderedItemsControl.Header> <controls:HeaderedItemsControl.ItemTemplate> <DataTemplate> <Border Background=”Beige” Width=”200” HorizontalA lignment=”Left”> <TextBlock Text=”{Binding}“ Margin=”10,0,0,0” /> </Border> </DataTemplate> </controls:HeaderedItemsControl.ItemTemplate> </controls:HeaderedItemsControl> HeaderedContentControl Representa la clase base para todos los controles que tienen una propiedad Content y una cabecera (contrapartida de HeaderedItemsControl, que veremos a continuación). Es muy sencillo de utilizar y programar. Para ver su esencia, basta con el siguiente código XAML, que produce por pantalla la imagen que acompaña estas líneas: XA ML <controls:HeaderedContentControl> <controls:HeaderedContentControl.Header> <Image Source=”Imagenes/s18.jpg” /> </controls:HeaderedContentControl.Header> <controls:HeaderedContentControl.Content> <TextBlock Text=”Figura 1: Tablero clásico” FontFamily=”A rial” FontSize=”18” /> </controls:HeaderedContentControl.Content> </controls:HeaderedContentControl> <<dotNetManía HeaderedItemsControl 38 Representa la clase base para todos los controles que tienen una propiedad ItemsControl y una cabecera. En este ejemplo, la propiedad utilizada para mostrar los contenidos simplemente define una plantilla para cada ítem de la lista (propiedad ItemTemplate). Esa plantilla va necesariamente dentro de un elemento <DataTemplate>, que admite cualquier conjunto válido de controles. La asociación de los datos a mostrar se realiza mediante databinding, como puede verse en el código adjunto: C# CajaHeaderItems.ItemsSource = new String[] {“1. d4, d6”,“2. Cf3, Cc6”, “3. A b5, A d2”, “4. ...”}; Label En principio, este control está pensado para completar las posibilidades de TextBlock, respecto a la inclusión de otros elementos. Podemos construir etiquetas de texto con bordes, fondos, figuras laterales o en background, etc. Muy útil para utilizar como ítem de otros elementos colectivos como cuadros combinados (combo boxes) y similares. Por ejemplo: <controls:Label BorderBrush=”Navy” BorderThickness=”5” Foreground=”Maroon” Background=”A quamarine” VerticalA lignment=”Center” Width=”150” HorizontalA lignment=”Center”> <StackPanel> <Image Source=”Imagenes/s18.jpg” /> <TextBlock Text=”Partidas famosas” /> </StackPanel> </controls:Label> NumericUpDown Es la versión de su homónimo de Windows Forms y WPF, solo que permite una gran cantidad de configuraciones visuales, y además soporta la confección de estilos personalizados a través de su atributo SpinnerStyle, al que se le puede asignar cualquier esti- << dnm.dnm.plataforma.net lo definido por el usuario. El código siguiente ejemplifica su utilización: <input:NumericUpDown BorderBrush=”Navy” BorderThickness=”3” Foreground=”Red” Height=”27” FontSize=”18” FontWeight=”Bold” Maximum=”12” Minimum=”1” DecimalPlaces=”1” UseLayoutRounding=”True“ Value=”3” /> TreeView los controles de Windows Forms) permite ubicar contenidos ligándolos a uno de los bordes (o todos) de su contenedor. El segundo va situando los contenidos en una secuencia mientras caben en pantalla, y continúa en filaso columnas sucesivas si el contenido no cabe en el contenedor. En el ejemplo de la siguiente figura, todos los elementos están contenidos en un DockPanel, pero el TreeView superior tiene asignada su propiedad adjunta de anclaje a Top, por lo que permanece en la parte superior. Por su parte, los tres Label de la parte inferior (el último, truncado en su salida) están incluidos dentro de un elemento WrapPanel con valores predeterminados de sus propiedades. Situación similar a la anterior, en cuanto a la funcionalidad, la capacidad de configuración visual y la posibilidad de persona lización del control. Admite innumerables niveles de anidación, y cada elemento TreeViewItem puede contener cualquier otro, con lo que es posible la personalización a cualquier nivel, modificando el atributo predeterminado ItemTemplate. Dispone igualmente de las propiedades de enlace a datos DataContext e ItemsSource. La figura adjunta se corresponde con el código siguiente: DockPanel y WrapPanel Se trata de los dos controles contenedores que faltaban con respecto a la oferta de WPF. El primero de ellos (recuérdese la propiedad con objetivo similar en El código significativo que produce esta salida es: <controls:DockPanel Width=”300” Height=”350” Background=”Blue”> <controls:TreeView controls:DockPanel.Dock=”Top” Background=”A ntiqueWhite” Width=”170” Height=”180” > <controls:TreeViewItem [...]> </controls:TreeViewItem> <controls:TreeViewItem [...]> </controls:TreeViewItem> <controls:TreeViewItem [...]> </controls:TreeViewItem> </controls:TreeView> <controls:WrapPanel> <controls:Label [...]> </controls:Label> <controls:Label [...]> </controls:Label> <controls:Label [...]> </controls:Label> </controls:WrapPanel> </controls:DockPanel> Conclusión Una vez presentados los controles, en la siguiente entrega de este repaso sobre Silverlight Toolkit revisaremos los controles de charting para la representación de gráficos empresariales, el funcionamiento de los temas y algunas peculiaridades de los procesos de depuración y automatización. <<dotNetManía <controls:TreeView Background=”A ntiqueWhite”> <controls:TreeViewItem IsExpanded=”True” Header=”A pertura española”> <controls:TreeViewItem IsExpanded=”True” Header=”Variante Ruy López”> <controls:TreeViewItem Header=”1. d4, d6” /> </controls:TreeViewItem> </controls:TreeViewItem> <controls:TreeViewItem IsExpanded=”False” Header=”Defensa siciliana”> <controls:TreeViewItem Header=”1. d4, Cf6” /> </controls:TreeViewItem> <controls:TreeViewItem IsExpanded=”True” Header=”Defensa Grünfeld”> <controls:TreeViewItem Header=”1. d4, Cf6” /> <controls:TreeViewItem Header=”1. c4, g6” Background=”Navy” Foreground=”Yellow” /> </controls:TreeViewItem> </controls:TreeView> 39 SQL Server dnm.servidores.sql Francisco González Agregando inteligencia a mis aplicaciones mediante SQL Server Data Mining La minería de datos se puede utilizar para analizar información y realizar predicciones. En este artículo voy a ilustrar el uso de la minería de datos en una aplicación Web.Vamos a tomar los datos de venta de un portal Web y cierta información de nuestros clientes para analizar qué productos ofrecer a determinados perfiles de clientes, realizar campañas publicitarias u ofrecer productos que sean comprados conjuntamente cuando un cliente agrega un producto a la cesta de la compra. Francisco González es es Data Platform Architect del área de Business Intelligence en Solid Quality Mentors. Francisco es ponente habitual en eventos como BI Conference o Tech-Ed USA y un enamorado de la minería de datos. La minería de datos es la ciencia de extraer información no trivial de conjuntos de datos; éstos pueden ocupar desde varios “megas” hasta varios “teras”. Dependiendo de la técnica que usemos, necesitaremos que el conjunto sea mayor o menor, aunque en muchos de los casos no es tan importante el tamaño como que los datos sean lo suficientemente representativos de lo que queremos analizar para poder más tarde realizar predicciones. Básicamente, cuando realizamos minería de datos lo primero que tenemos que hacer es limpiar los datos, para que éstos no tengan errores y no haya ambigüedades en códigos y demás. Una vez tenemos listos los datos, creamos una estructura donde elegimos el algoritmo de minería que vamos a utilizar, los atributos que seleccionamos para generar el modelo y los atributos que queremos predecir. Una vez construida la estructura, la procesamos junto con los datos, obteniendo un modelo. Un modelo es un conjunto de reglas que nos permiten realizar predicciones. Una vez que tenemos el modelo generado, podemos hacer consultas a dicho modelo mediante el lenguaje de consultas de minería de datos de SQL Server. Este lenguaje se denomina Data Mining Extensions (DMX). A través de ADODM (esto es, ADO para Minería de datos), podemos conectarnos al servidor de Analysis Services donde se encuentran alojados los modelos y ejecutar consultas expresadas en dicho lenguaje; normalmente, éstas las realizamos ya desde nuestras aplicaciones o portales Web, implementadas en código C# o Visual Basic. Figura 1. Proceso de minería de datos El hecho de que haya elegido un portal de una tienda en Internet no es casualidad. Tenemos que pensar que cuando utilizamos minería de datos estamos realizando predicciones, y éstas se basan en modelos estadísticos que en la mayoría de los casos darán resultados correctos, pero en otros no. Es decir, cuando hacemos predicciones estamos inven- << dnm.servidores.sql Minería en nuestra tienda on-line A través de una serie de ejemplos, vamos a explorar qué nos ofrece la minería de datos mediante SQL Server para mejorar las ventas de nuestro portal Web. Es conocido por todos que un buen diseño de una página Web hace que los clientes vuelvan una y otra vez; mediante minería, vamos a ser capaces de ofrecer a nuestros clientes esos productos que están predispuestos a comprar, o quizás justo al revés, esos productos que nunca buscarían y quizás si se los mostramos en un primer plano accedan a comprar, puesto que los productos que el cliente está predispuesto a comprar van a ser buscados por él inmediatamente. Minería para nuestros banners o anuncios Un banner es un medio publicitario dentro de nuestra Web que se ofrece al cliente en las propias páginas. ¿Cómo seleccionamos el banner a utilizar en cada página? Pues por lo general cambiamos los banners en el tiempo siguiendo reglas de marketing, o exponiendo los nuevos productos o los productos estrella de nuestra tienda. Ahora, gracias a la minería de datos, podemos ir más allá. Cuando un usuario se conecta a nuestra Web, en muchos casos se identifica; una vez que el usuario se ha registrado, ya sabemos quién es, pues quizás cuando se dio de alta nos facilitó datos como edad, sexo, ciudad, salario, número de hijos, número de coches, intereses, etc. Además, quizás haya comprado en nuestro portal anteriormente, con lo que ya tenemos suficiente información para ofrecer a nuestros clientes una campaña publicitaria eficiente. Podemos utilizar algoritmos como el de árboles de decisión para analizar qué productos son comprados por el perfil que acaba de entrar en la Web. De esta forma, si un tipo de cliente suele comprar ciertos productos, lo que hacemos es utilizar la información que tenemos del cliente para determinar qué productos ofrecer en nuestros banners. Así cuando el cliente se registra en el portal ya le aparecen banners con los pro- ductos que el modelo ha estimado que podría comprar. Además, podemos elegir que solo se le ofrezcan productos que no ha comprado todavía, gracias a que tenemos su historial de compras. Para ofrecer esta solución, realizaríamos los siguientes pasos: utilizaríamos los datos de compra de todos nuestros clientes para crear un modelo mediante el algoritmo de reglas de decisión que nos estime la probabilidad de compra, con respecto a los atributos del cliente y de los productos de nuestro catálogo. Una vez que tenemos el modelo generado, debemos realizar una consulta desde la página Web al modelo, para que nos ofrezca los productos con mayor probabilidad de compra para el cliente que está accediendo a nuestra Web. Descartamos los productos que ya han sido comprados por el cliente; en algunos casos es lógico que no vuelva a comprar un determinado producto que ya ha comprado anteriormente. Cuando sabemos el producto que queremos publicitar, accedemos a la base de datos de banners para obtener el banner y mostrarlo en pantalla. En la figura 2 se muestra la red de dependencia de los atributos de un modelo construido para predecir si un cliente es comprador de bicicletas o no. Este diagrama nos indica qué atributos son más determinantes a la hora de que un cliente compre una determinada bicicleta. Figura 2. Diagrama de dependencia de atributos <<dotNetManía tando, estamos tratando de deducir cuál va a ser la conducta de un usuario, o qué tipo de clientes compran determinados productos; esto significa que el resultado de una predicción puede ser erróneo. En un modelo de minería de datos, llamamos fiabilidad al grado de seguridad en que las predicciones van a ser correctas. Una de las técnicas que utilizamos para saber cuál es la fiabilidad de un modelo generado es probarlo con datos que no han sido utilizados para generar dicho modelo. Un ejemplo de esta técnica es el siguiente: utilizamos el 80% de los datos para generar el modelo; una vez generado éste, usamos el 20% restante para realizar predicciones y comprobamos si cada predicción ha sido realizada con éxito o no. Teniendo el número de veces que el modelo ha acertado y el número total de casos, podemos sacar un porcentaje; en este caso, hemos supuesto que los datos contienen el resultado del valor que vamos a predecir. Los datos para este ejemplo podrían haber sido el perfil de clientes y si compraron un determinado producto o no, de forma que, utilizando el modelo, podríamos predecir si el producto será comprado en base a atributos como edad, sexo, número de hijos, número de coches, sueldo, distancia al trabajo, localización, etc. 41 << dnm.servidores.sql El código del listado 1 ilustra el lenguaje DMX para realizar consultas a un modelo. Éste es el código que utilizaríamos para realizar una predicción cuando un determinado cliente se conecta a nuestra tienda online. La siguiente consulta nos devuelve una probabilidad ajustada acerca de si el cliente en particular, para el cual hemos introducido los datos en este ejemplo, compraría una bicicleta o no. una última pregunta que es si comprarían este nuevo producto. Nuestro objetivo, en este primer paso, es obtener una población representativa de todos nuestros tipos de clientes para ofrecerles la encuesta; para ello, utilizamos el algoritmo de clusters que nos define distintos grupos de clientes. De esta forma, elegimos clientes de cada grupo para realizar el sondeo, teniendo entonces clientes de cada uno de los SELECT [v Target Mail].[Bike Buyer], PredictA djustedProbability([v Target Mail].[Bike Buyer]) FROM [v Target Mail] NA TURA L PREDICTION JOIN (SELECT 25 A S [A ge], ‘02/02/1978 0:00:00’ A S [Birth Date], ‘2-5 Miles’ A S [Commute Distance], ‘High School’ A S [English Education], ‘S’ A S [Marital Status], 2 A S [Number Cars Owned], 3 A S [Number Children A t Home], 30000 A S [Yearly Income]) A S t Listado 1. Ejemplo de consulta DMX <<dotNetManía Minería para nuestra campaña de publicidad postal 42 Imaginemos ahora que acaba de entrar un producto nuevo en nuestro stock y disponemos de un presupuesto ajustado para realizar una campaña publicitaria, en la que vamos a enviar correo postal con información sobre dicho producto. En nuestra base de datos tenemos registrados 100.000 clientes, pero solo podemos enviar cartas a 25.000. ¿A cuáles de nuestros clientes enviamos las cartas publicitarias? Para contestar esta pregunta, vamos a utilizar minería de datos. Lo primero que vamos a hacer es preguntar a nuestros clientes acerca de si comprarían ese producto o no. Para ello, realizamos una encuesta donde básicamente obtenemos de nuevo la información que tenemos en el registro de clientes, más grupos de perfiles de nuestros clientes. En la figura 3 se muestra el diagrama de clusters que genera la ejecución del modelo. Una vez que hemos realizado la encuesta, tenemos una fuente de datos que nos sugiere qué clientes comprarían dicho producto. Estos datos los utilizamos para crear un nuevo modelo donde lo que hacemos es predecir si el producto va a ser comprado o no de acuerdo a los atributos del cliente; generado dicho modelo, podemos ejecutarlo para cada uno de nuestros clientes en la base de datos, seleccionando los 25.000 que tienen una probabilidad mayor de compra. De esta manera, enviamos nuestra publicidad a aquellos clientes con una mayor predisposición de compra, obteniendo quizás (pues no olvidemos que nos estamos basando en predicciones) un mayor retorno de la inversión. Minería para cesta conjunta Cuando un cliente inserta un producto en el carrito de la compra, podemos ofrecerle productos relacionados o que suelen comprarse conjuntamente con el ya elegido. Es muy probable que si compramos cuchillas de afeitar, compremos también espuma y bálsamo. Vamos a ilustrar aún más este ejemplo: una conocida cadena de productos alimenticios hizo un estudio, en el cual concluyó que en un alto porcentaje de casos cuando se compraban pañales también se compraba cerveza. Sin entrar en detalles de Figura 3. Diagrama de clusters << dnm.servidores.sql por qué esto sucede, lo que sí es cierto es que algunos productos se compran frecuentemente de manera conjunta, por lo que ofrecer al cliente, justo después de introducir un producto en la cesta de la compra, productos que suelen comprarse conjuntamente con éste, mejora la experiencia del comprador e incrementa las ventas de nuestro portal. Vamos a utilizar minería de datos para realizar dicha tarea. En primer lugar, disponemos del historial de compra de cada cliente cada vez que ha visitado nuestra tienda, por lo que disponemos de listas de productos que se han comprado a la vez. Ésta va a ser nuestra fuente de datos. Para obtener un modelo de estas características, utilizamos el algoritmo de reglas de asociación. Este algoritmo recibe como entrada una lista de productos y nos devuelve la probabilidad de cada uno de los productos que son comprados conjuntamente. De forma que, cuando un producto es añadido a la cesta de la compra, hacemos una consulta al modelo para que nos devuelva, por ejemplo, los dos productos que tienen una probabilidad mayor de ser comprados conjuntamente con ése, y se los ofrecemos al cliente. Cuando el cliente añade otro producto a la cesta, volvemos a consultar el modelo; pero esta vez le pasamos los dos productos que acaba de añadir, de manera que el modelo nos devuelva productos que se han comprado conjuntamente con respecto a la lista total de productos en el carrito de la compra. En la figura 4 podemos observar el conjunto de reglas que el algoritmo de reglas de asociación genera. Como vemos, las reglas contienen listas de pro- SQL Server nos provee una plataforma robusta para el desarrollo de aplicaciones inteligentes ductos que ya han sido añadidos a la cesta de la compra y la probabilidad de que un producto nuevo sea comprado conjuntamente con ellos. Ciclo de vida de un desarrollo de minería de datos Debido a que continuamente podemos estar agregando nuevos productos a la tienda y en nuestra Web se están procesando compras continuamente, nuestros modelos pueden fácilmente quedar desactualizados en poco tiempo. Por ello, es necesario que apliquemos una política de actualización de los modelos en el tiempo. Una de las formas más elegantes y productivas de realizar dicho proceso es mediante SQL Server Integration Services. Gracias a SSIS, podemos generar un proceso que reprocese los modelos cada cierto intervalo de tiempo. SSIS nos provee con tareas específicas de minería de datos. De esta forma, podemos planificar mediante el Agente de SQL Server la actualización de nuestros modelos en el tiempo, obteniendo así predicciones ajustadas a los datos actuales y no quedando nuestros modelos desfasados. Figura 4. Probabilidades de compra conjunta mediante el algoritmo de reglas de asociación Los portales Web son uno de los tipos de negocios que mejor están acogiendo la minería de datos. Esto es debido a que, por ejemplo, en la gestión “tradicional” de publicidad no había ninguna forma de elegir un mejor banner para un determinado cliente. Simplemente se elegía uno al azar de entre el conjunto de banners disponibles. Al utilizar minería de datos, podemos enfocar la publicidad al cliente; pero además, no incurrimos en riesgo alguno si nuestro modelo falla, pues lo que teníamos sin minería era una elección arbitraria. SQL Server nos provee una plataforma robusta para el desarrollo de aplicaciones inteligentes. <<dotNetManía Conclusión 43 ALManía Enric Forn Personalizando nuestras builds En muchas ocasiones, en el momento en que generamos la versión de nuestra aplicación nos dejamos el último ensamblado añadido, la modificación del fichero de configuración, o los PDB generados se encuentran en modo Debug. Team Foundation Build nos ayuda a simplificar estas tareas, mejorando el versionado de nuestros proyectos. Enric Forn es MCTS Team Foundation Server. Actualmente, Enric es consultor de Team System en Raona. A diferencia de otros productos, Microsoft Team Foundation Server (TFS) permite una amplia configuración para la personalización y adecuación a nuestro proceso de desarrollo. Este artículo nos lleva a las entrañas mismas de Team Foundation Build (puedes consultar información más detallada en http://tinyurl.com/66w39v). Team Foundation Build (a partir de ahora, TFB) es una extensión de TFS que se instala como un servicio. Se utiliza para la compilación de aplicaciones e infinidad de tareas relacionadas con la generación de una versión de una o varias soluciones. Algunas de las tareas que permite realizar son la generación de un informe de la compilación, la revisión del código, la publicación en servidores, entre otras. Supongo que ya habréis leído el buen artículo de Luis Fraile sobre TFB del ejemplar nº 50 de dotNetManía, y ya sabéis un poco como funciona. La base de TFB es el fichero TFSBuild.proj. Este fichero está en formato XML y contiene toda la información necesaria para realizar el proceso de generación (build). Por si alguien conoce el mundo del código abierto, viene a ser lo mismo que el fichero build.xml de ANT. TFB ejecuta MSBuild, que interpreta las tareas definidas en el fichero TFSBuild.proj. Microsoft Build Engine (MSBuild) es la plataforma que utiliza Visual Studio para generar las soluciones (más información en http://tin- yurl.com/6og6bo). Cuando TFB recibe una petición de build, descarga el código definido en el entorno de trabajo (o workspace) y también el script de build, para interpretarlo y ejecutar todas las tareas definidas. Figura 1. Edición del fichero TFSBuild.proj con Team Foundation Sidekicks << dnm.ALManía Estructura básica de TFSBuild.proj Como ya he dicho anteriormente, en el archivo TFSBuild.proj se recogen todas las tareas a realizar para la construcción de nuestra versión. Para conocerlo con más detalle, vamos a dividirlo en tres partes y comentar un poco las funciones de cada una de ellas: • Definición general del build. En esta sección encontramos la confi- guración global, es decir, los parámetros que afectan a la ejecución general del build: en qué agente se ejecuta (un agente es la máquina donde se encuentra instalado el servicio de TFB), los directorios de despliegue, si se ejecutan tests con su fichero de configuración, si se activa la ejecución de análisis de código, entre otros. Un ejemplo básico se presenta en el listado 1. bas funcionales, y una versión “Debug” específica para el desarrollo (listado 2). • Destinos (targets). En esta parte es donde se exprime realmente la potencia de TFB, pues se pueden realizar infinidad de tareas concretas para cubrir las necesidades de nuestra compilación o despliegue. MSBuild define un conjunto de targets que realizan un conjunto de <Import Project=”$(MSBuildExtensionsPath)\Microsoft\VisualStudio\TeamBuild\ Microsoft.TeamFoundation.Build.targets” /> <ProjectExtensions> <Description> </Description> <BuildMachine>TEA MBUILD</BuildMachine> </ProjectExtensions> <PropertyGroup> <TeamProject>Phoenix</TeamProject> <BuildDirectoryPath>D:\Deploy</BuildDirectoryPath> <DropLocation>\\TEA MBUILD\Deploy</DropLocation> <RunTest>true</RunTest> <RunCodeA nalysis>Never</RunCodeA nalysis> <UpdateA ssociatedWorkItems>false</UpdateA ssociatedWorkItem> <RunConfigFile>$(SolutionRoot)\Development\raona.teambuild.testrunconfig </RunConfigFile> </PropertyGroup> Listado 1. Definición general del build <ItemGroup> <SolutionToBuild Include=”$(SolutionRoot)\Raona\project1.sln” /> <SolutionToBuild Include=”$(SolutionRoot)\Raona\project2.sln” /> </ItemGroup> <ItemGroup> <ConfigurationToBuild Include=”Release|A ny CPU”> <FlavorToBuild>Release</FlavorToBuild> <PlatformToBuild>A ny CPU</PlatformToBuild> </ConfigurationToBuild> </ItemGroup> Listado 2. Configuración de la compilación • Configuración de la compilación. Aquí se definen cuáles son las soluciones que vamos a compilar y también las configuraciones. Se puede dar el caso de que queramos generar una versión “Release” para poder desplegarla y realizar sobre ella prue- tareas predefinidas (encontraréis más información sobre la biblioteca de tareas predefinidas en http://tinyurl.com/6acftf), y además podemos definir nuestros propios destinos. Un destino define el momento en que él se ejecuta, y <<dotNetManía Para modificar las tareas a ejecutar de una build, es necesario modificar el fichero TFSBuild.proj asociado a ella. En la versión 2005 de TFB, este fichero se encuentra ubicado en $/TeamBuildTypes dentro del repositorio de control de código. En la versión 2008, la ubicación de TFSBuild.proj puede ser cualquiera; por supuesto, siempre dentro del repositorio del control de código fuente. Antes de editar este fichero, es necesario desprotegerlo manualmente desde el Explorador de control de código fuente (lo que se conoce como check-out). Si editamos este fichero desde Visual Studio 2008 con SP1 instalado, el check-out es automático. Una vez hemos modificado y validado el script de build, es imprescindible proteger el fichero en el repositorio de control de código fuente (o lo que es lo mismo, hacer el check-in). Para facilitar la edición de este fichero, existen las Team Foundation Sidekicks (puedes descargarlas en http://tinyurl.com/623kf9). Son un conjunto de herramientas que, una vez instaladas, facilitan la administración de un servidor de TFS. Entre las herramientas hay una nueva opción de menú contextual, que aparece al hacer clic con el botón derecho sobre nuestra definición de build (figura 1). Como he comentado en el párrafo anterior, siempre que queráis realizar un cambio en el fichero TFSBuild.proj debéis subirlo al control de código fuente de nuestro repositorio (check-in). Esto hace que probar nuestras modificaciones sobre los scripts de build sea un poco lento. 45 << dnm.ALManía puede contener múltiples tareas. Todos los targets posibles se encuentran definidos en un fichero .targets ubicado en la máquina que hospeda el servicio de TFB. No es aconsejable modificar este fichero, ya que cualquier cambio afectaría a todos los scripts de build que tengamos implementados (a no ser que seamos usuarios muy experimentados). Para que podáis verlo de un modo más gráfico, se presenta un ejemplo en el listado 3. la ejecución del build: justo antes o después de descargar el código (BeforeGet y A fterGet), antes y después de compilar (BeforeCompile, A fterCompile). Los targets menos críticos para sobrescribir son Before* o A fter*, ya que no afectan a las tareas imprescindibles de ejecución de una build. En cambio, es más crítico sobrescribir destinos como tareas como CoreGet o CoreDropBuild, ya que puede afectar negativamente a la ejecución de nuestro build. Podéis consultar todos los targets disponibles en http://tinyurl.com/6kczfg. Un destino define el momento en el que él se ejecuta dentro del proceso de build y puede contener múltiples tareas <ItemGroup> <SourceFiles Include=”$(SolutionRoot)\Development\**” /> </ItemGroup> <Target Name=”A fterDropBuild”> <MakeDir Directories=”D:\TCompilacio\Development” /> <Copy SourceFiles=”@(SourceFiles)” DestinationFolder=”D:\TCompilacio\%(RecursiveDir)” /> <Exec Command=”NET USE T: \\TEA MBUILD\TCompilacio “ /> </Target> <<dotNetManía Listado 3. Destinos del build 46 En el fragmento que se muestra en el listado 3, extraído de un script de build, podemos ver que éste se está ejecutando en el destino A fterDropBuild, es decir, después de que TFB haya copiado todos los ficheros de la compilación en el directorio de destino. En este momento, se realizan tres tareas: la primera es la creación del directorio Development, mediante la tarea MakeDir. La segunda tarea copia los ficheros del destino definidos en el primer elemento y copia todo su contenido en el directorio de destino. Además, realiza una copia recursiva de todos los ficheros y subdirectorios contenidos en la raíz. Si eliminamos los “**” de la definición del directorio de origen y también la parte “%(RecursiveDir)” del directorio de destino, entonces solamente serían copiados los ficheros. Por último, en la tercera tarea se ejecuta un comando de consola. Esta tarea es muy interesante, ya que si no encontramos ninguna tarea predefinida con la que llevar a cabo la acción que nos interesa, seguramente encontraremos la forma de ejecutarlo a través de la línea de comandos. Existen muchos targets que permiten ejecutar tareas en cualquier momento de Se puede dar el caso de que queramos modificar las acciones predefinidas de un destino. Por ejemplo, es posible que queráis ejecutar un build con una versión concreta de código fuente. Una posibilidad de modificar un target sin modificar el fichero .targets de la máquina de build es poner el código en el propio script de build. En el caso de la descarga del código que acompaña a este artículo, se defi- ne el destino CoreGet (listado 4). Con este ejemplo, el build ejecutado no descarga la última versión de código, sino la versión etiquetada como “MiBuild_20080419.7”. Aún así, para realizar este tipo de modificaciones, en primer lugar, si podemos evitar sobrescribir targets nos evitaremos problemas. Pero si nuestras necesidades requieren hacerlo, es importante tener claro si ello afecta solamente a nuestro script de build o a todas las builds ejecutadas en el servidor donde modifiquemos el target. <Target Name=”CoreGet” Condition=” ‘$(IsDesktopBuild)’!=’true’ “ DependsOnTargets=”$(CoreGetDependsOn)” > <Get Condition=” ‘$(SkipGet)’!=’true’ “ Workspace=”$(WorkspaceName)” Recursive=”$(RecursiveGet)” Force=”$(ForceGet)” Version=”$(VersionToGet)” /> </Target> <PropertyGroup> <VersionToGet>LMiBuild_20080419.7</VersionToGet> </PropertyGroup> Listado 4. Modificación de un target en el script de build << dnm.ALManía Pero si todavía no encontráis la forma de llevar a cabo la tarea que queréis realizar con las tareas predefinidas de MSBuild, es posible implementar vuestra propia tarea personalizada en .NET (podéis consultar MSDN en http://tinyurl.com/67d2yq). Vamos a crear una tarea personalizada que simplemente necesita un parámetro que es la ruta de un fichero plano. La tarea escribe un texto en el fichero y lo almacena. Tenemos dos opciones: • Implementar directamente la interfaz ITask sobre nuestra clase. ITask está implementada en Microsoft.Build.Framework.dll. • Derivar nuestra clase de la clase auxiliar Task (que encontraréis en Microsoft.Build.Utilities.dll). Esta clase implementa la interfaz anterior, y además proporciona implementaciones por defecto de algunos de los métodos de ITask. En el método Execute, que tendremos que sobrescribir, es donde se implementa el código que queremos ejecutar. Este método no necesita parámetros, y debe devolver true si la tarea se ejecuta correctamente, o false en caso contrario. En nuestro ejemplo (listado 5), y por comodidad, utilizamos la clase Task. Una vez hemos implementado el código, será necesario configurar nuestro script de build como se muestra en el listado 6, para que se realice correctamente la llamada. En la primera parte registramos la tarea de modo que el script de build sea capaz de encontrar la clase a ejecutar. Fijaros que no tie- using using using using Microsoft.Build.Framework; Microsoft.Build.Utilities; System.IO; System.Diagnostics; namespace CustomTasks { public class HelloWorldTask : Task { private StreamWriter sw; [Required] protected string filename; public string FileName { get { return filename; } set { filename = value; } } public override bool Execute() { sw = new StreamWriter(Path.Combine(filename), true); sw.WriteLine(“Hello World !!”); sw.Flush(); sw.Close(); return true; } } } Listado 5. Código de la tarea personalizada ne ruta; la razón es que la DLL compilada se encuentra en el control de código fuente de nuestro repositorio, justo en la misma carpeta donde se encuentra nuestro script de build. Si queréis probar este ejemplo, deberéis añadir la DLL y realizar el check-in en la carpeta donde se encuentra el fichero TFSBuild.proj. En la segunda parte, solamente nos queda llamar la tarea en el destino que nos interese, en este caso justo después de compilar las soluciones. Este destino tiene la particulari- <UsingTask TaskName=”CustomTasks.HelloWorkdTask” A ssemblyFile=”HelloWorldTask.dll” /> <Target Name=”A fterCompile”> <!—Deploy Phoenix Version—> <HelloWorldTask FileName=” $(BinariesRoot)\HelloWorldFile.txt” /> </Target> Listado 6. Llamada a la tarea personalizada dad de que solamente se ejecuta si la compilación de las soluciones se ha realizado satisfactoriamente. Una pequeña observación a hacer sobre la llamada a la tarea es el paso por parámetro de la ruta del fichero. En una tarea se pueden definir n parámetros, eso sí, siempre como cadenas de caracteres. También comentar que la ruta del fichero es relativa a la ubicación de los ficheros compilados, lo que indica la variable BinariesRoot. Además de esta variable, existen muchas otras que podéis encontrar en http://tinyurl.com/5l9947. Compilación de proyectos de Visual Basic 6.0 En algunos de nuestros proyectos conviven aplicaciones desarrolladas en distintos lenguajes. Es por esta razón que en el script de build implementado para nues- <<dotNetManía Crea tu propia tarea personalizada 47 << dnm.ALManía tro proyecto se compilan varios proyectos de lenguajes diferentes: C#, C++ y Visual Basic 6.0. Los proyectos de los dos primeros lenguajes no tienen ningún problema en ser compilados por TFB. Sin embargo, al intentar compilar Visual Basic 6.0, la compilación fallará. Es cierto que podríamos compilar el proyecto directamente mediante un elemento <Exec>: Ejecución de tests sin utilizar los ficheros .vsmdi Otra tarea muy importante es la ejecución de los tests unitarios para validar la compilación de nuestros proyectos. Solamente daremos como realizado satisfactoriamente el build si se ejecutan correctamente los tests uni- <Exec Command=”C:\Program Files\Microsoft Visual Studio\VB98\VB6.exe /MA KE &quot;C:\LogFile.vbp.log&quot; &quot;C:\Project.vbp&quot;” /> Otra tarea muy importante es la ejecución de los tests unitarios para validar la compilación de nuestros proyectos Listado 7 En mis scripts de build utilizo mucho el comando Exec. Lo utilizo para mapear unidades de red, registrar librerías DLL de COM, o ejecutar cualquier comando de la mítica plataforma MS-DOS. Otro método para compilar proyectos de Visual Basic 6.0 consiste en utilizar un target definido por FreeToDev (lo encontraréis en la URL http://tinyurl.com/5t57jm). Con este target se pueden agrupar todos los proyectos de VB 6.0 a compilar. También es posible asignar una ruta de destino de los nuevos ejecutables. Primero, es necesario instalar el target en la máquina que ejecuta TFB. A continuación, añadimos la importación del nuevo target, mediante el elemento <Import> (listado 8). Finalmente, es necesario indicar los proyectos de Visual Basic a compilar, definir el target Execute y ejecutarlo después de la compilación. <RunConfigFile>$(SolutionRoot)\Common\Teambuild.testrunconfig</RunConfigFile> <ItemGroup> <TestContainerInOutput Condition=”’$(SolutionToBuild)’==’Raona’ “ Include=”Raona.UnitTest.dll” /> <TestContainer Include=”$(BinariesRoot)\Release\Raona.UnitTest.dll” /> </ItemGroup> Listado 9. Ejecución de tests unitarios tarios. Una pequeña personalización que tenemos a nuestra disposición consisten en ejecutarlos prescindiendo de los engorrosos ficheros .vsmdi (más información en http://tinyurl.com/5uvgen). En la configuración de las propiedades de la build, es necesario indicar la ruta del fichero TestRunConfig (listado 9). Y para indicar cuál es la DLL que contiene los tests, es necesario indicarlo al final del script. <<dotNetManía <Import Project=”$(MSBuildExtensionsPath)\BuildVB6\FreeToDev.MSBuildTasks.tasks” /> <ItemGroup> <ProjectsToBuild Include=”$(SolutionRoot)\Core\DevelopmentCore\ComPhoenix\ComPhoenix.vbp”> <OutDir>$(BinariesRoot)\Release</OutDir> </ProjectsToBuild> </ItemGroup> 48 <Target Name=”Execute”> <BuildVB6 Projects=”@(ProjectsToBuild)” /> </Target> <Target Name=”A fterCompile”> <CallTarget Targets=”Execute” /> </Target> Listado 8. Compilación de VB6 con FreeToDev Si observáis con atención el código del listado 9, veréis que existe una condición, ya que si compilas múltiples soluciones en un mismo script, y cada solución tiene su DLL con sus respectivos tests, TFB ejecutará todos los tests para todas las DLL. De esta forma, conseguimos ejecutar los tests exactos para cada solución. Conclusión En definitiva, si conocemos bien la herramienta y tenemos claro cómo es nuestro proceso de despliegue de las aplicaciones, TFB nos ahorra tiempo tanto en la construcción del paquete de distribución de la aplicación, como también en la supervisión de la calidad del código, ya sea con la ejecución de test unitarios o el análisis de código. Cada vez más, la figura del gestor de la configuración toma mayor importancia en un equipo de desarrolladores, ayudando a aumentar la velocidad y fiabilidad de despliegue de las aplicaciones, y también mejorando la calidad del código desplegado. Isla VB Guillermo «Guille» Som Visual Basic ¿lenguaje dinámico? En la próxima versión de .NET Framework (la 4.0) se incluirá lo que se conoce como DLR (Dynamic Language Runtime), que viene a ser el motor de ejecución de los lenguajes dinámicos de .NET. De esa forma, se permitirá al CLR (y por extensión a los lenguajes como VB y C#) el acceso de forma dinámica a los miembros de los objetos que haya en memoria, algo parecido a lo que siempre se ha conocido como late binding... o casi... Isla solidaria Guillermo Som ingresará los derechos de autor de este artículo en la cuenta de Ayuda a Juanma a vivir. Desde aquí, invita a los lectores de esta isla solidaria para que hagan sus aportaciones o participen en las subastas que se realizan desde la Web de Juanma para recaudar fondos con el fin de ayudar en la investigación de una cura para la enfermedad de Alexander. http://www.ayudajuanma.es. Dinámico, estático, ¿cuál es la diferencia? Guillermo “Guille” Som Es Microsoft MVP de Visual Basic desde 1997. Es redactor de dotNetManía, mentor de Solid Quality Mentors, tutor de campusMVP, orador de Ineta Latam y autor de los libros “Manual Imprescindible de Visual Basic .NET”, “Visual Basic 2005”, "Novedades de Visual Basic 9.0" y “Aprenda C# 3.0 desde 0.0 - Parte 3, lo nuevo”. http://www.elguille.info. En el contexto de este artículo, dinámico y estático se puede aplicar de dos formas, uno haciendo referencia a los tipos de datos y otro a los lenguajes. Cuando se habla de dinámico y estático haciendo referencia a los tipos de datos, estático significa que los tipos de datos solo soportan los elementos que ellos definen; es decir, solamente podemos acceder a los métodos, propiedades, etc., que estén definidos en el tipo. Por otro lado, dinámico significa que sin necesidad de conocer de antemano el tipo de datos que estamos usando, podamos acceder a cualquiera de los miembros (métodos, propiedades, etc.) que ese tipo defina (no confundamos esto con el polimorfismo, que si bien se puede parecer no es exactamente lo mismo). Aunque otra interpretación puede ser que esos tipos dinámicos no son específicos, sino que un mismo tipo (que en realidad ni es un tipo) soporta cualquier valor, algo parecido al tipo Variant de COM (o de VB6). Y por último, si ese tipo dinámico es producido por un lenguaje orientado a objetos, posiblemente sea una referencia a un objeto de un tipo que se ha inferido según el valor asignado, algo parecido a lo que hacen VB.NET y C# con la inferencia de tipos; la diferencia estará que los lenguajes estáticos habrán definido esas variables con un tipo de datos, mientras que los lenguajes dinámicos no suelen tener la necesidad (ni la obligación) de definir las variables. Cuando dinámico y estático se aplican a los lenguajes (para simplificar), estático significa que el lenguaje utiliza tipos estáticos, es decir especificaciones concretas para cada tipo de datos, mientras que los lenguajes dinámicos no necesitan definir esos tipos de datos, ya que suelen inferirse y el intérprete (los lenguajes dinámicos suelen tratarse como los lenguajes de script, y éstos suelen ser interpretados en lugar de compilados) inferirá el tipo según el valor asignado. En el resto del artículo nos centraremos en los tipos de datos más que a los lenguajes. Visual Basic y los tipos dinámicos A los lectores que conozcan o hayan usado alguna versión de Visual Basic (da igual si es para .NET o no), todo lo comentado seguramente les sonará de algo. Simplificando, podríamos decir que el acceso dinámico a los miembros de un objeto es lo que llaman en << dnm.isla.vb El DLR (principalmente la forma de gestionar los tipos de los lenguajes dinámicos y los de los lenguajes estáticos) permitirá que los lenguajes “clásicos” (y estáticos) de .NET como VB.NET y C# puedan interactuar con otros lenguajes (los llamados dinámicos) como Python, Ruby (ambos nombrados con el prefijo Iron, al menos en las versiones implementadas por Microsoft) e incluso JavaScript (la versión dinámica), y precisamente la necesidad de permitir usar los tipos dinámicos está justificada por la dificultad (o complicación) que supone el uso de objetos creados con los lenguajes dinámicos desde lenguajes estáticos. inglés late binding (enlace tardío) y el acceso estático lo que se conoce como early binding (enlace temprano), algo que en Visual Basic siempre ha existido. El enlace estático (o temprano) solo permite acceder a los miembros “conocidos” del tipo, es decir, los miembros que esa clase (o tipo) defina; esto está bien y es lo que siempre nos han recomendado (cuando los que ahora lo recomendamos estábamos aprendiendo), entre otras cosas porque la ejecución es más rápida y sobre todo menos propensa a errores. Incluso hay lenguajes como C# que solo permiten esta forma de enlace, al menos hasta ahora, ya que su próxima versión (la 4.0) sí que soportará el enlace dinámico además del estático. Por otra parte, el enlace dinámico (o tardío) nos permite hacer referencia a miembros que no existen en el tipo de datos que estamos usando. Para que esto sea posible, el tipo debe ser de uso general (en .NET de tipo Object, ya que todos los tipos de .NET se derivan de ese tipo básico). Es decir, el compilador aceptará el acceso a ese miembro que no está definido en el tipo de datos y será en tiempo de ejecución cuando se compruebe si ese miembro está realmente definido; por eso lo de “enlace tardío”, ya que hasta que no se ejecute ese código no se podrá comprobar el tipo de datos que realmente tiene ese “objeto”. Aclarar que actualmente este tipo de enlace tardío en los lenguajes de .NET solo se permite en Visual Basic, pero no en C#, aunque esto cambiará en la próxima versión. En el listado 1 podemos ver cómo acceder a un método inexistente en la clase Object, pero que en realidad el objeto referenciado por la variable obj1 sí que define, y por tanto este código funcionará perfectamente. La salvedad es que si estamos usando Visual Basic 2008, además de usar Option Strict Off, también deberíamos desactivar la inferencia automática de tipos, con idea de que por defecto las cosas se hagan como se deben hacer (definiendo expresamente la variable del tipo de datos que va a contener); por tanto, lo mejor es definir expresamente la variable obj1 como de tipo Object. El método Mostrar usado desde la variable obj1 está definido en la clase MiClase, por tanto la llamada a ese método funcionará cuando se ejecute la aplicación. ] Dim obj1 A s Object ‘ A signamos a la variable un nuevo objeto ‘ del tipo MiClase obj1 = New MiClase With {.Nombre = “Mi clase 1”} ‘ El tipo MiClase define el método Mostrar ‘ por tanto es correcto hacer esta llamada obj1.Mostrar(“Esta es”) Listado 1. Debemos tener desactivado Option Strict para que este código funcione Si el lector piensa que lo correcto hubiera sido declarar la variable obj1 del tipo MiClase, decirle que estaría en lo cierto, pero aquí he usado esa clase para que la variable tuviera algo, ya que lo habitual es que ese valor se obtuviera de alguna forma en la que no tengamos forma de comprobar que en realidad tiene ese valor, como podría ser si esa variable se asignara mediante una llamada a CreateObject, tal como vemos en el listado 2. La desventaja de usar el enlace tardío radica en el hecho de que el compilador no hace ninguna comprobación de que ese miembro realmente esté definido en el tipo de datos, y por tanto es posible que el código falle en tiempo de ejecución, y ya sabemos que no hay nada peor que nuestra aplicación falle cuando esté ejecutándose en el equipo de nuestros clientes. Dim obj2 A s Object ‘ Creamos un objeto del tipo Word.A pplication obj2 = CreateObject(“Word.A pplication”) ‘ A ntes de acceder al objeto, ‘ debemos asegurarnos de que Word está disponible If obj2 IsNot Nothing Then Console.WriteLine(obj2.A ctivePrinter) ‘ Si llamamos a un método inexistente, ‘ dará error obj2.Mostrar(“Hola”) End If Listado 2. Ejemplo de enlace tardío usando CreateObject <<dotNetManía [ NOTA 51 << dnm.isla.vb Por otro lado, hay situaciones en las que puede ser útil usar ese enlace dinámico, normalmente cuando usamos otros objetos que no proceden del propio .NET Framework, por ejemplo si usamos objetos COM procedentes de aplicaciones como Office, tal como acabamos de ver en el listado 2. Visual Basic puede ser no estricto, pero no es dinámico Tal como están las cosas actualmente, y de forma predeterminada (algunos seguimos lamentando que esto sea así), Visual Basic no es estricto a la hora de hacer conversiones o de acceder a los miembros de un objeto; es decir, se puede utilizar el enlace tardío a la hora de acceder a los miembros que no estén definidos expresamente (estáticamente) en un tipo en particular. Pero esto no significa que Visual Basic sea dinámico en el aspecto de permitir acceder dinámicamente a los miembros de un objeto, sino que lo simula y a la larga se obtienen los mismos resultados. La única forma de permitir que Visual Basic simule ser un lenguaje dinámico (en lo referente a acceder dinámicamente a los miembros de un objeto) es desactivando Option Strict. El problema es que esto es algo que muchos no recomendamos que se haga, y esperemos que no se justifique el hacerlo por la necesidad de acceder dinámicamente a los miembros de un tipo del que no tenemos la información de los miembros que expone públicamente. Ámbitos de Option Strict Afortunadamente, Visual Basic nos permite usar <<dotNetManía Option Strict (ya sea activado o desactivado) a dos 52 niveles, y el nivel más bajo (o reducido) en el que se puede utilizar es a nivel de fichero de código; es decir, podemos restringir la comprobación no estricta solo en el código que esté definido dentro de un fichero de código. Esto, unido a que podemos definir clases parciales, nos permite definir en esos ficheros de código solo aquellas partes de nuestros tipos que necesiten que la comprobación estricta del código no esté activada, ya que es esa comprobación estricta que se hace al tener activado Option Strict la que no nos permite acceder a miembros de un objeto que no estén definidos en el tipo de ese objeto, o sea cuando usamos lo que ahora se llama acceso dinámico. El otro ámbito de Option Strict es a nivel de proyecto, ya que podemos indicar que, por ejemplo, cierto estado esté activado en todo el proyecto. De esta forma, si no indicamos expresamente el estado de esta opción de comprobación estricta, siempre estará activado o desactivado, dependiendo del valor que haya- El enlace dinámico puede ser útil cuando usamos objetos que no proceden del propio .NET Framework, como los objetos COM de Office mos dado en las opciones del proyecto. Tal y como hemos visto en el párrafo anterior, cuando necesitemos desactivar esa comprobación estricta lo podremos hacer a nivel de fichero de código; de esa forma, solamente en ese fichero se dejará de hacer las comprobaciones que el compilador hace cuando asignamos el valor On a Option Strict. Recapitulando sobre Option Strict A título de recordatorio (así valdrá para aquellos lectores que no suelen utilizar Visual Basic y por tanto puede que no sepan para qué sirve esta instrucción) activando Option Strict el compilador nos obligará a definir todas las variables con un tipo de datos adecuado; además, a la hora de asignar un valor a esas variables se comprobará que el tipo de datos asignado es el mismo que el de la variable que recibe el valor o se puede convertir de forma implícita (automáticamente). Y cuando estamos asignando valores entre variables de distintos tipos de datos, también se comprobará si se puede hacer de forma implícita o se necesita hacer una conversión explícita (cast); en este último caso, la presencia en el código de esa conversión explícita nos pondrá en alerta de que es posible que dicha conversión falle y por tanto tengamos cuidado con ese código, ya que según la Ley de Murphy, si algo puede fallar, seguro que fallará. Cuando instalamos Visual Studio (o Visual Basic Express) el valor predeterminado de Option Strict es Off, es decir, desactivado; por tanto, todas estas comprobaciones que he comentado antes no se hacen. De esa forma, podemos declarar variables sin necesidad de indicar de qué tipo son y asignarles valores de cualquier tipo. Esto es posible ya que esas variables en realidad son de tipo Object y este tipo de datos acepta cualquier valor; por tanto, podremos asignar cualquier valor a una variable que sea de tipo Object. << dnm.isla.vb Problema, lo que se dice problema, no hay ninguno. De hecho, mucha gente piensa que incluso es mejor tener desconectada esa opción, ya que así no tenemos que preocuparnos en hacer conversiones entre tipos ni tener que declarar las variables con un tipo de datos determinado. Pero no nos engañemos: está demostrado que una programación con tipos de datos concretos es más eficiente que una que utilice tipos de datos más generalizados (por no decir “genéricos”, que se podría confundir con los tipos generic), y todo el trabajo que nos dará tener que hacer las conversiones de forma explícita nos ayudará a saber qué es lo que estamos haciendo y (como dije antes) alertarnos de que algo puede ir mal al hacer la conversión. Y es que el compilador de Visual Basic a la hora de hacer las conversiones entre tipos diferentes de datos lo hará casi de la misma forma que lo haremos nosotros, pero será más difícil de saber que se puede producir un fallo al convertir entre esos dos valores si no vemos que ahí se está haciendo una conversión. Los tipos dinámicos en .NET Framework 4.0 Aunque aún está en una fase muy temprana de desarrollo (a la hora de escribir este artículo solo está disponible la primera CTP), .NET Framework 4.0 incluirá soporte para los tipos dinámicos, ya que también permite mediante el DLR la integración con lenguajes dinámicos y por tanto, se podrá intercambiar información entre esos lenguajes y los denominados estáticos. Para permitir la utilización de los tipos dinámicos en lenguajes como C# (que son muy estrictos), se ha tenido que hacer uso de una nueva forma de definir esos tipos dinámicos, ya que el compilador no debe comprobar si los miembros que se aplican a ese objeto están definidos o no; al menos, esa comprobación no se hará en tiempo de compilación, si no que será en tiempo de ejecución cuando se compruebe si realmente el objeto asignado a esa variable dinámica soporta ese método o propiedad que se está usando. En C# 4.0 se definirá un tipo dinámico con la palabra clave dynamic; en cuanto el compilador se encuentre con esa declaración, sabrá que debe aplicar late binding a esa variable, y por tanto no hacer ningún tipo de comprobación hasta que se esté ejecutando el código. En el listado 3 vemos un ejemplo parecido al del listado 1, solo que en esta ocasión estamos usando código de C# 4.0 y particularmente de la instrucción dynamic y lo que el uso de esa instrucción supone: enlace tardío. ¿Será Visual Basic un lenguaje dinámico? Tal como están las cosas, la respuesta es no. Al menos en lo que se refiere a los tipos dinámicos, ya que la intención es que llegue a serlo, es decir, que vuelva a ser un lenguaje de script o casi, ya que ahora a ese tipo de lenguajes se les llama dinámicos. Pero todo esto lo comprobaremos más adelante, cuando la próxima versión de Visual Basic (y de .NET Framework) esté más madura. Mientras tanto, contentémonos con lo que tenemos y aprovechémoslo; en esta isla seguiré explicando cosas para aprovechar mejor este lenguaje. dynamic obj1; // A signamos a la variable un nuevo objeto del tipo MiClase obj1 = new MiClase { Nombre = “Mi clase 1” }; // El tipo MiClase define el método Mostrar // por tanto es seguro hacer esta llamada obj1.Mostrar(“Esta es”); Listado 3. Código equivalente del listado 1 para usar con C# 4.0 En Visual Basic no se ha añadido ninguna nueva instrucción para definir este tipo de variables dinámicas, ya que Visual Basic permite usar ese modo “retardado” de comprobación si se utiliza Option Strict Off. Pero no nos confundamos: eso no es un tratamiento dinámico de los tipos de datos, ya que en realidad, para permitir que todo esto sea posible, se ha agregado una nueva interfaz para definir estos tipos dinámicos; esa interfaz es IDynamicObject, que está definida en el espacio de nombres System.Scripting.Actions, y Visual Basic no utiliza esta interfaz, sino que simplemente hace lo que ha estado haciendo durante muchos años: esperar a que llegue el momento de la ejecución del código, y en ese preciso momento es cuando comprueba si el objeto define o no ese método (o cualquier otro miembro al que queramos acceder). Si lo define, bien; si no lo define, mal y de regalo una excepción. Conclusiones En este artículo hemos hablado sobre algo que en los próximos meses (o años) seguramente será algo más habitual: los tipos y lenguajes dinámicos. Pero como hay que estar en la realidad, también hemos visto (aprovechando la coyuntura del tema) cómo Visual Basic puede ser dinámico o lo que es lo mismo, menos estricto con los tipos de datos que utilizamos en nuestras aplicaciones. Confío en que el lector sepa con más certeza que esa forma de dinamismo no es la más recomendable, salvo que realmente sepamos qué es lo que estamos haciendo, y en que después de esta lectura el lector sabrá qué es lo que hace en cada momento, o al menos sabrá cómo ser estricto a la hora de escribir el código o no serlo, si así lo considera oportuno. <<dotNetManía ¿Qué problema hay al usar Option Strict Off? 53 todonet@qa [email protected] Dino Esposito Arquitecto en IDesign, Dino Esposito es una de las autoridades mundiales reconocidas en tecnologías Web y arquitectura de software. Sus libros más recientes son "Programming ASP.NET 3.5-Core Reference" e "Introducing Microsoft ASP.NET AJAX" (Microsoft Press). Es ponente regular en eventos de la industria de ámbito mundial, como Tech-Ed o DevConnections, y europeos, como DevWeek y Basta. Un vistazo a Entity Framework Este mes exploramos algunas características relacionadas con Entity Framework y el desarrollo con la primera versión de una herramienta que tiene todavía mucho que decir y hacer en el futuro. Entity Framework se ha lanzado en su versión 1.0 este pasado verano, junto al SP1 de .NET Framework 3.5. Como muchos otros productos de Microsoft en versión 1.0, no es perfecto, y, tal como se ha visto en el pasado PDC, mejorará de forma muy significativa en su próxima versión. En este artículo responderé a algunas preguntas que surgen frecuentemente tras un primer acercamiento a Entity Framework. He comenzado con Entity Framework, con la idea de que tenía que ser muy superior a LINQ to SQL y centrado en el modelado de domain spaces a través de entidades y relaciones. Sin embargo, me parece muy similar a LINQ to SQL, y muy centrado en datos. ¿En qué es diferente de LINQ to SQL? Personalmente, he estado un tanto remiso a empezar con Entity Framework, y he comenzado a estudiarlo sólo un poco antes de la salida de su versión 1.0. Por el contrario, he estado haciendo un montón de cosas con LINQ to SQL, a plena satisfacción, desde el comienzo. Hay que decir que cambié de opinión repetidamente respecto a LINQ to SQL. Al principio, me parecía como un ADO.NET, pero muy mejorado. Concretamente, me parecía una especie de ADO.NET capaz de trabajar con objetos fuertemente tipados en lugar de las clásicas colecciones de filas y columnas (débilmente tipadas). Según esto, comencé por abordar el trabajo con LINQ to SQL en la parte donde normalmente tratamos con los datos físicos. Simplemente, sustituí la persistencia de ADO.NET por la de LINQ to SQL. Inmediatamente, me di cuenta de que ambos no eran intercambiables sin más. Una capa de LINQ to SQL dialoga con su contrapartida utilizando su propio modelo de objetos. Para desconectar uno e insertar el otro necesitas un trabajo de adaptación entre los tipos de datos que se inter- cambian. Si la capa intermedia está basada en DataSets, hay que convertir los objetos LINQ to SQL a éstos últimos, lo que puede resultar sorprendente, ya que la maquinaria de LINQ to SQL carga a bajo nivel streams de ADO.NET directamente en el modelo de objetos. Por otra parte, no parece una buena idea cambiar toda la capa de datos de un sistema existente solo por que exista una nueva tecnología disponible. Si, en lugar de eso, evalúas LINQ to SQL para un nuevo proyecto, verás que -más bien- se parece mucho a una herramienta ORM (Object/Relational Mapper). LINQ to SQL suministra un modelo de objetos e implementa un número de patrones comunes en su contexto de datos, tales como la carga diferida, unidades de trabajo, mapas de identidades, bloqueo optimista, etc. y suministra una correspondencia de objetos para la persistencia de la información. Realmente, te da objetos de negocio con datos y comportamiento. Así pues, puede considerársele una herramienta ORM con todos los derechos. Así de simple. columna en la base de datos como discriminador para distinguirlos. El valor del discriminador se usa para especificar de qué tipo de registro se trata. En otras palabras, esto quiere decir que se necesita tener una columna ad-hoc si se quiere crear y mantener una jerarquía en el modelo de objetos. Entity Framework soporta otros tipos de correspondencias. En particular, el tipo Tabla por tipo concreto, que utiliza una tabla separada por cada tipo en la jerarquía, y el tipo Tabla por subclase, un tipo híbrido que usa una tabla compartida para la información común acerca del tipo base y tablas separadas para los tipos derivados. Entity Framework también soporta los tipos complejos, tipos que se anidan dentro de otros más grandes y que no han sido pensados para constituir una entidad. El ejemplo canónico es el tipo Direc- ción, que recoge las propiedades Calle, Ciudad, Provincia y País. LINQ to SQL no soporta los tipos complejos, pero he diseñado un sistema alternativo que funciona sin romper el diseñador. Puedes leer el artículo completo en: http://dotnetslackers.com/articles/csharp/ComplexTypes-in-LINQ-to-SQL-Reloaded.aspx. Curiosamente, aunque Entity Framework soporta totalmente los tipos complejos, el diseñador de Visual Studio 2008 no lo hace (ver figura 1). Esto significa que es necesario editar manualmente el código fuente del modelo de entidades para introducir tipos complejos. Sin embargo, si esto se hace, el modelo de datos no podrá ser vuelto a cargar en el diseñador. Esto se resolverá en la versión 2.0 de Entity Framework. Por último, podemos encontrar otras diferencias en la forma en que ambos soportan la carga diferida y los planes de consulta. Figura 1: El diseñador de Visual Studio 2008 no soporta tipos complejos en Entity Framework ¿Cómo puedo especificar un query fetch plan con Entity Framework? ¿Está habilitada por defecto la carga diferida como en LINQ to SQL? Respecto a la carga de datos, existen algunas diferencias entre LINQ to SQL y Entity Framework. Veamos los detalles. Lo primero, la carga perezosa (lazy loa- ding) y la carga diferida (deferred loading) son equivalentes y se refieren a la misma funcionalidad básica: la capacidad de cargar automáticamente objetos bajo demanda. La carga perezosa es el nombre asignado en los libros de patrones de diseño para denominar una forma de codificar: el código es perezoso en el sen- <<dotNetManía Entity Framework no parece realmente un producto muy distinto desde el punto de vista de su arquitectura. La similitud no es una leyenda urbana, pues hubo que escalar bastante alto en las estructuras del software de Microsoft para decidirla. Podría decirse que ambos son el mismo tipo de producto, aunque con implementaciones distintas de algunas características. Cada producto fue desarrollado por equipos independientes, que vivían desconectados del resto del universo. Hoy, el mismo equipo está a cargo de ambos productos, y no les va a resultar fácil averiguar cómo diferenciarlos. La solución más probable parece dejar LINQ to SQL tal como está y mejorar solamente Entity Framework. Sin embargo, no va a salir nada antes de la próxima actualización significativa de .NET Framework a finales de 2009, si no en 2010. Después de todo, creo que la diferencia más grande entre ambos es el conjunto de bases de datos soportadas. LINQ to SQL se limita a SQL Server, mientras que Entity Framework es independiente de la base de datos y soporta un modelo abierto y extensible para proveedores de bases de datos de terceros (aunque la mayor parte de ellos está todavía en desarrollo, lo que vincula Entity Framework casi de forma exclusiva a la plataforma SQL Server). La capacidad de relaciones entre entidades de LINQ to SQL está limitada esencialmente a las del tipo 1:1 entre clases y tablas de la base de datos. Además, LINQ to SQL solo soporta una manera de implementar la herencia, conocida como Tabla por jerarquía. Este modelo usa una única tabla para mantener todos los tipos de una jerarquía de herencia (por ej. ClienteBase, ClienteRegistrado y ClienteDesconocido), y utiliza una [email protected] [email protected] << dnm.todonet@qa 55 <<dotNetManía T o d o t N e t . q a @ d o t n e t m a n i a . c o m T o d o t N e t . q a @ d o t n e t m a n i a . c o m << dnm.todonet@qa 56 tido de que los objetos solo se cargan en memoria en el momento en que son requeridos explícitamente. Carga diferida es el término que utiliza Microsoft en LINQ to SQL para hacer mención a un comportamiento observable: la carga se difiere hasta que los datos resultan absolutamente imprescindibles. En LINQ to SQL, la carga diferida está soportada y habilitada por defecto, lo que significa que si se hace una consulta de un pedido y más tarde se trata de leer la información del cliente relacionado, se lanza una nueva consulta. En las aplicaciones modernas basadas en dominios, la carga perezosa es una característica imperativa. Preserva el modelo de objetos de procedimientos prescriptivos de carga de datos que de otra forma tendrían que ser insertados en cada lugar donde se requiriera el acceso a datos. Consecuentemente, la lógica de negocio de una aplicación basada en dominios se "contaminaría" con código propio del acceso a datos. La carga perezosa puede tener ciertos efectos indeseables en el código (por ejemplo, demasiadas peticiones a la base de datos) si no se comprende y gestiona adecuadamente por los desarrolladores. Probablemente por esta razón, Entity Framework no soporta la carga perezosa en absoluto. Por diseño. La política es que ninguna llamada a la base de datos suceda sin el consentimiento explícito del desarrollador. Eche un vistazo al siguiente código: var orders = from o in context.Orders where o.Status == “Completed” select o; foreach (Order o in orders) { // A cceso al cliente relacionado if (!o.Customer.IsLoaded) { o.Customer.Load(); } // Trabajo con datos del cliente } En Entity Framework, para forzar a una entidad relacionada a que se cargue en memoria se precisa una llamada explícita. En LINQ to SQL también se puede deshabilitar la carga diferida, pero si se hace esto, solo se podrán recuperar los datos que falten mediante otra llamada. No se suministra ninguna otra contrapartida al método Load. El query fetch plan es el mecanismo que se usa para decidir qué relaciones deben resolverse automáticamente. Aquí tiene un ejemplo del funcionamiento en Entity Framework: Order order = context.Orders.Include(“OrderDetails”). Include(“Product”).First(); El método Include indica a la entidad que se rellene con datos provenientes de una relación existente entre entidades. Por otra parte, en LINQ to SQL se utiliza el método LoadWith para especificar qué relaciones deben resolverse. Aquí va un ejemplo: DataLoadOptions options = new DataLoadOptions(); options.LoadWith<Customer>(c => c.Order); options.LoadWith<Order>(o => o.OrderDetails); context.LoadOptions = options; Como puede verse, aquí se hace evidente otra diferencia entre ambos sistemas: en Entity Framework, el fetch plan se especifica a nivel de consulta; en LINQ to SQL, se define a nivel de contexto. Tengo que crear una relación entre una entidad Cliente y una entidad País. Quiero que la relación sea unidireccional. En otras palabras, quiero una relación 1:1 del tipo Cliente->País. Parece que no se puede conseguir esto sin tener igualmente una relación 1:n inversa entre País y Cliente. Esto es correcto y, nuevamente, es así por diseño. Las relaciones son bidireccionales. Lo sorprendente es que se acabe obteniendo una relación bidireccional, dado que las relaciones se crean a partir de restric- ciones (constraints) de las bases de datos, basándose en las claves ajenas. No hay un camino alternativo en esta versión; es algo que se arreglará en la versión 2.0. Traducido al castellano por Marino Posadas biblioteca.net ADO.NET Entity Framework Aplicaciones y servicios centrados en datos Unai Zorrilla, Octavio Hernández y Eduardo Quintás Editorial: Krasis Press Páginas: 414 Publicado: octubre de 2008 ISBN: 978-8493548995 Idioma: castellano Es un placer comentar la última obra de tres colaboradores de dotNetManía sobradamente conocidos por los lectores. Entity Framework es el nuevo marco para acceso a datos propuesto por Microsoft, disponible desde la aparición del SP1 de Visual Studio 2008, y propone un modelo de acceso y manipulación de datos muy novedoso. Por eso, un libro de este tipo era fundamental plantearlo –como así se ha hecho- desde el punto de vista de un desarrollador que conoce los fundamentos de ADO.NET pero no ha manejado aún los recursos de LINQ con todas sus variantes. El libro avanza desde la introducción y los conceptos de modelado que propone el marco EF hasta la puesta en práctica de soluciones reales mediante esta tecnología, y con esto queremos decir soluciones que están funcionando en empresas españolas en este momento. Ese es otro de sus valores, aparte del indudable tono didáctico que los tres han sabido imprimir a esta obra. Si la pregunta es ¿pero esto funciona en aplicaciones del día a día?, la respuesta es que sí, y la forma de aprenderlo…ya saben. Application Architecture Guide 2.0: Designing Applications on the .NET Platform J.D. Meier, Alex Homer, David Hill, Jason Taylor, Prashant Bansode, Lonnie Wall, Rob Boucher Jr. y Akshay Bogawat Editorial: Microsoft Páginas: 381 Publicado: diciembre de 2008 Idioma: inglés Con prólogos de Soma Somasegar y Scott Guthrie comienza esta obra digital (probablemente se imprimirá en papel igualmente), gratuita y totalmente recomendable para cualquier desarrollador o jefe de proyecto que quiera estar al día en la arquitectura de aplicaciones .NET siguiendo las buenas prácticas aplicadas a todas las fases del ciclo de vida de las aplicaciones. El libro está disponible para descarga en formato PDF desde la dirección de CodePlex http://www.codeplex.com/AppArchGuide (y ha tenido 20.000 descargas en una semana). novedades Además, es una revisión de todos los conceptos nuevos que incorporan las nuevas tecnologías, como Entity Framework, aplicaciones R.I.A (Silverlight), aplicaciones móviles, OBA, SharePoint LOB, etc. Y no se queda en el mero diseño arquitectónico, sino que recorre casi todo lo que hay que tener en cuenta al planear y construir una aplicación con cualquier tecnología .NET hoy en día, con especial énfasis en la construcción de las capas o las recomendaciones de implantación y mantenimiento. Imprescindible. Professional ADO.NET 3.5 with LINQ and the Entity Framework Robert Jennings. Editorial: Wrox. Páginas: 672. ISBN: 978-0470182611. Fecha de publicación: febrero de 2009. Idioma: inglés. Pro SQL Server 2008 Entity Framework Jim Wightman. Editorial: APress. Páginas: 550. ISBN: 978-1590599907. Fecha de publicación: octubre de 2009. Idioma: inglés. TEXTO: MARINO POSADAS desván Marino Posadas Web 2.0,Web semántica y Web implícita El notable avance de la participación social en Internet ha desembocado en cotas de comunicación y creación de recursos compartidos que exceden las previsiones de los más optimistas. En 2004 nacía un nuevo concepto: la Web 2.0, definida como la tendencia que propicia el uso de la red como herramienta de colaboración, creatividad e información compartidas y nueva funcionalidad remota. No conlleva –en su inicio– ninguna nueva especificación técnica, sólo un nuevo uso de la web como herramienta social. Tim Berners-Lee, de hecho, la definía como “una revolución empresarial, basada en el uso de Internet como plataforma, que requiere –eso sí– comprender las reglas del éxito que esa plataforma implica”. En realidad, se trata de nuevas formas de usar la Web, en parte propiciadas por las –para la mayoría, más supuestas que reales– mejoras en las prestaciones de los servicios de conexión de banda ancha. ¿Y dónde quedan las promesas? ¿Para cuándo un sistema inteligente de búsquedas en la red? Casi nadie va más allá de las 3 primeras páginas de enlaces devueltas por los buscadores, y todavía son muchas las ocasiones en que nos quedamos con la duda de si lo que estamos buscando existe o no. No se trata de estar en la Web, se trata de que te puedan encontrar. Muchos protestaban por el “monopolio” de Microsoft, y han abrazado amorosamente el de Google como un mal necesario. Si no estás en Google, no estás. Ya, ya sé que podemos usar otros: Live Search, Yahoo, etc., y que algunos comenzamos a explorar otras posibilidades, pero los usuarios del pri- mero son legión. Y los motores de búsqueda se basan en algoritmos que pueden fallar o que no son perfectos. La solución prometida era es la de la Web semántica. Se basa (disculpe el lector que ya lo conozca) en la idea de añadir metadatos semánticos a las páginas, de forma que –al igual que hacen las etiquetas XML con sus datos contenidos– describan lo que hay allí, su significado y sus relaciones, y lo hagan de una manera formal, de tal suerte que sea posible más tarde procesar esos datos mediante un software y conseguir que los resultados de una búsqueda tengan ese “factor de inteligencia” del que ahora carecen. El propio Berners-Lee lo intentó desde el principio, pero no fue posible, según reconocía en una charla ante el MIT Technology Review Emerging Technologies (ver http://www.digitaldivide.net/articles/view.php?ArticleID=20). Pero se necesitaría que las nuevas páginas creadas (parece muy difícil revisar las existentes) utilizaran las tecnologías de descripción de los contenidos, como RDF y OWL. No obstante, se están haciendo esfuerzos en ese sentido, pero son más académicos que corporativos, y mucho menos, particulares. El equi- <<dotNetManía utilidades del mes 58 Microsoft Web Platform Installer. Más que interesante paquete que permite montar en un equipo mediante un proceso único todas las herramientas gratuitas necesarias para el desarrollo Web con tecnologías de la compañía: IIS, Visual Web Developer 2008 Express Edition, SQL Server 2008 Express Edition y .NET Framework 3.5, pudiendo seleccionar las que se desea si no se necesitan todas. Para información y descargas: http://www.microsoft.com/web/channel/products/WebPlatformInstaller.aspx. po de Carmen Costilla en la Universidad Politécnica de Madrid, o Pablo Castells en la Autónoma, son ejemplos de ello, junto a otras iniciativas similares en centros de Calaluña, Baleares, Andalucía, etc. Y también existen propuestas interesantes a nivel gubernamental, como la Red Temática de la Web Semántica, promocionada por el Ministerio de Educación y Ciencia (http://www.redwebsemantica.es/SemWeb/sewView/frames.jsp), pero no es menos cierto que la inmensa mayoría de los desarrolladores no incorporan estas características en sus trabajos. Y además, en 2007, apareció un nuevo término: la Web implícita, vocablo acuñado para designar las Web especializadas en la síntesis de información personal recopilada de Internet aportando una imagen coherente y lo más completa posible del individuo (o grupos de individuos). Hay empresas que ya han hecho de esto su objetivo primario (ver http://www.orch8.net), y pueden encontrarse explicaciones más detalladas de esta idea en http://blog.eturner.net/?p=14, http://blogs.zdnet.com/ web2explorer/?p=413 y http://www.avc.com/a_vc/ 2006/12/2007_the_implic.html. Esta información puede incluir vínculos visitados con más frecuencia, hábitos de navegación, prácticas de búsqueda de información o cualquier otro dato generado sin la intervención explícita del usuario, y la información así obtenida podría utilizarse en muchos contextos diversos. Sería un complemento a las visiones y usos prometidos por las dos anteriores como –quizá– un anticipo de la próxima versión (sí, ya se habla de la siguiente, la Web 3.0), que tendría como objetivo la descentralización del yo. Pero tiempo habrá de volver a este tema… documentos en la red ASP.NET Patterns every developer should know. Artículo publicado en Developer Fusion por el conocido divulgador de tecnologías de Microsoft, Alex Homer. El artículo va acompañado de un ejemplo descargable muy descriptivo. Accesible en la página: http://www.developerfusion.com/article/8307/aspnet-patterns-every-developer-should-know. YouTube API: Try before you buy es un artículo de John Musser publicado en ProgrammableWeb sobre una página expuesta por YouTube con el fin de que los desarrolladores puedan probar la API de desarrollo de YouTube sin necesidad de descargarse el SDK correspondiente. Puede verse la explicación y el enlace en: http://blog.programmableweb.com/ 2008/12/09/youtube-api-try-before-you-buy.