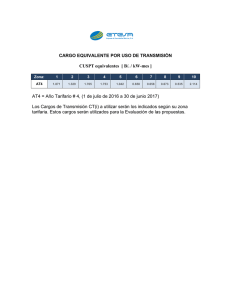
Bucket Sort - upcAnalisisAlgoritmos
Anuncio

Bucket Sort
Algoritmos de ordenamiento
es un algoritmo de ordenación que funciona
dividiendo un vector en un número finito de
recipientes. Cada recipiente es entonces
ordenado individualmente
Andrés Felipe Serna Caicedo
07/10/2010
Bucket Sort
El ordenamiento por casilleros (bucket sort en inglés) es un algoritmo de
ordenamiento que distribuye todos los elementos a ordenar entre un número finito de
casilleros. Cada casillero sólo puede contener los elementos que cumplan unas
determinadas condiciones. En el ejemplo esas condiciones son intervalos de números.
Las condiciones deben ser excluyentes entre sí, para evitar que un elemento pueda ser
clasificado en dos casilleros distintos. Después cada uno de esos casilleros se ordena
individualmente con otro algoritmo de ordenación (que podría ser distinto según el
casillero), o se aplica recursivamente este algoritmo para obtener casilleros con menos
elementos. Se trata de una generalización del algoritmo Pigeonhole sort. Cuando los
elementos a ordenar están uniformemente distribuidos la complejidad computacional de
este algoritmo es de O(n).
El algoritmo contiene los siguientes pasos:
1. Crear una colección de casilleros vacíos
2. Colocar cada elemento a ordenar en un único casillero
3. Ordenar individualmente cada casillero
4. devolver los elementos de cada casillero concatenados por orden
5.
Historia
Herman Hollerith (feb. 29, 1860 hasta nov. 17, 1929) es el primero conocido por haber
generado un algoritmo similar a la Base de ordenación.
Era hijo de inmigrantes alemanes, nació en Buffalo, Nueva York y fue un Estadístico del
Censo. Él desarrolló una perforadora de tarjetas Tabulating Machine.
máquina de Hollerith incluyó ponche, tabulador y clasificador, y se utilizó para generar el
censo de población oficial de 1890. El censo tomó seis meses, y en otros dos años, todos
los datos del censo se completó y se define.
Hollerith formó la empresa Tabulating Machine en 1896. La compañía se fusionó con
International Time Recording Company y Computing Scale Company para formar equipo
Tabulating Recording Company (CTR) en 1911. CTR fue el predecesor de IBM. CTR
cambió su nombre a International Business Machines Corporation en 1924.
Hollerith se desempeñó como ingeniero de consultoría con el CTR hasta su retiro en
1921.
Hay referencias a Harold H. Seward, un científico de la computación, como el
desarrollador de Radix sort en 1954 en el MIT. También desarrolló el tipo de recuento.
Análisis del Algoritmo
1. Correctitud
Inicio
1. count=bucket
bucket: arreglo donde se van a ingresar los números de forma ordenada pues es
aquí donde el método guardara sus datos para mostrarlos y ubicarlos en su orden
de menor a mayor
2. arr:= a;
este es el arreglo de números que le entra al bucket para ser organizado por el
algoritmo
3. i := 0;
i: este es el máximo valor que encontraremos en el arreglo podríamos de cir que
es la forma en que delimitamos al algoritmo para el mejor y el pero caso
Mantenimiento
1. i<tamaño de a; i:= i+1 la posición de I incrementa debido al tamaño del a
que es el arreglo de datos que tenemos de eso depende el incremento de I en este
caso hasta que la función no se cumpla deja de incrementar su valor del orden n+1
2. bucket [a[i]]:=bucket[a[i]] +1; el bucket en la posición a[i]que sería el numero de la
posición a[i] incrementa en el orden n+1 hasta que el ciclo termine o mientras I es
menor que el tamaño del arreglo de a.
3. i < tamaño del bucket; i := i+1 la posición de I incrementa debido al tamaño del
bucket de eso depende el incremento de I en este caso hasta que la función no se
cumpla deja de incrementar su valor del orden n+1
4. bucket [i]>0;bucket[i]-- el bucket va a decrementar en cada cilco -1 para
acomodar el numero dentro de un grupo y hace la comparación hasta que el
bucket en la posición [i] sea menor o igual a cero hasta ese momento termina el
ese for
5. a[j++]:=i en la posición j del vector a se incorporara o se insertara el numero ya
organizado, j es una varia ble que esta en el for externo y esta definida que es el
numero del ciclo externo que va a ser la posición en el arreglo ya que ahí se
insertara el numero con su respectivo orden para después ser mostrado
Finalización
a[] con el arreglo completo ya organizado me menor a mayor, este es el
resultado final del algorimo.
1. Calcular el orden de complejidad
Es una generalización del tipo de recuento, y trabaja en el supuesto de que
claves para ser ordenados son uniformemente distribuidos en un área de
distribución conocida (por ejemplo de 1 a
m).
Es una especie estable, donde el orden relativo de cualquiera de los dos
elementos con la
misma clave se conserva.
Funciona de la siguiente manera:
configurar cubos m donde cada segmento es responsable de una porción igual de
la gama de llaves de la matriz.
coloque en cubos apropiados.
ordenar los elementos en cada segmento que no esté vacía mediante la
ordenación por inserción.
concatenar listas ordenadas de elementos de los cubos para conseguir el fin
último clasificado.
Análisis de tiempo de ejecución de la ordenación del cubo:
Cubos son creados sobre la base de la gama de elementos de la matriz. Esto es
una operación de tiempo lineal.
Cada elemento se coloca en su cubo correspondiente, que tiene lineales
tiempo.
tipo de inserción tarda cuadrática a correr.
La concatenación de listas ordenadas toma un tiempo lineal.
public static int[] bucketSort(int[] arr) {
int i, j;
1. int[] count = new int[arr.length];
2. Arrays.fill(count, 0);
3. for(i = 0; i < arr.length; i++ ) {
4. count[arr[i]]++;
}
5. for(i=0,j=0; i < count.length; i++) {
6. for(; count[i]>0; (count[i])--) {
7. arr[j++] = i;
}
}
return arr;
}
Orden de complejidad
1.
2.
3.
4.
5.
6.
7.
(ta)(tv)
ta
(ta)+(n-1)(ti+n)(tc)
2(tv)(ti)(n-1)
2(ta)+(n-1)(ti+n)(tc)
((n-1)(ti-n)(tc))(n-1)
(ta)(tv)(ti)(n-1)(n-1)
int[] count = new int[arr.length];
Algoritmo
Complejidad
(ta)(tv)
Arrays.fill(count, 0);
(ta)
for(i = 0; i < arr.length; i++ )
(ta)+(n-1)(ti+n)(tc)
count[arr[i]]++;
2(tv)(ti)(n-1)
for(i=0,j=0; i < count.length;
i++)
2(ta)+(n-1)(ti+n)(tc)
for(; count[i]>0; (count[i])--)
((n-1)(ti-n)(tc))(n-1)
arr[j++] = i;
(ta)(tv)(ti)(n-1)(n-1)
2. Calcular el orden del algoritmo
El tiempo de ejecución para la clasificación del cubo es
Ө (n) para todas las operaciones lineal O (n ^ 2) el tiempo necesario para ordenar la
inserción en cada segmento.
n-1
T (n) = Ө (n) +Σ O (n ^ 2)
i=0
Utilizando las soluciones matemáticas, el tiempo por encima de ejecución viene a ser
lineal.
Duración de tipo cubo se suele expresar como
T (n) = O (n+ m), donde
m es el rango de valores de entrada
n es el número de elementos de la matriz.
Si el rango es el fin de n, a continuación, ordenar cubo es lineal. Pero si el rango es
amplio, a continuación, ordenar puede ser peor que cuadrática.
Ejemplo del Bucket Sort.
El ejemplo se utiliza una matriz de entrada de 9 elementos. Los valores clave está en el
rango de 10 a 19. Se utiliza una matriz auxiliar de listas enlazadas que se utiliza como
cubos.
Los elementos se colocan en cubos apropiados y los vínculos se mantienen para que
apunte al siguiente elemento. Orden de las dos teclas con un valor de 15 se mantiene
después de su clasificación.
Pseudocodigo
Ventajas
Base y tipo cubo son estables, la preservación del orden existente de claves iguales.
Trabajan en un tiempo lineal, a diferencia de la mayoría de otros tipos. En otras palabras,
no atascar cuando un gran número de elementos que habrá que resolver. La mayoría de
las clases de ejecución en O (n log n) o O (n ^ 2) el tiempo.
El tiempo para ordenar por artículo es constante, ya que no las comparaciones entre
elementos se hacen. Con suerte, el tiempo para ordenar por tiempo aumenta con el
número de elementos.
Radix sort es particularmente eficaz cuando se tiene un gran número de registros para
ordenar con claves cortas.
Desventajas
clase Base y el cubo no funcionan bien cuando las claves son muy largos, como el tiempo
de clasificación total es proporcional a la longitud de la clave y el número de elementos a
ordenar.
Ellos no son "in situ", utilizando más memoria de trabajo de un tipo tradicional.
Orden del algoritmo
Algoritmo
int i, j;
1. int[] count = new int[arr.length];
2. Arrays.fill(count, 0);
3. for(i = 0; i < arr.length; i++ ) {
4. count[arr[i]]++;
5. for(i=0,j=0; i < count.length; i++) {
6. for(; count[i]>0; (count[i])--) {
7. arr[j++] = i;
n-1
T (n) = Ө (n) +Σ O(n^2)
i=0
Orden
1
1
1
O(n)
O(n)
O(n)
O(n^2)
O(n^2)
Representacion Grafica
n
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
T(n)
1
6
21
52
105
186
301
456
657
910
1221
1596
2041
2562
3165
3856
4641
5526
6517
7620
1200000
1000000
800000
600000
Series1
400000
200000
1
57
113
169
225
281
337
393
449
505
561
617
673
729
785
841
897
953
0
Tiempo de ejecución
En el tiempo de ejecución en la plataforma de java varia por la razón que los valores que
entran en el arreglo cambian y cambia su orden con el mismo tamaño y limite para el
valor máximo su tiempo de ejecución varía entre un lapso siempre grande ejemplo de 16 a
31 con los mismo valores se hizo un promedio y con valores reales es una aproximación
con milisegundos
n
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
T(n)
1
6
21
52
105
186
301
456
657
910
1221
1596
2041
2562
3165
3856
4641
5526
6517
7620
t
0,448861
0,501414
0,553966
0,606519
0,659072
0,711625
0,764178
0,81673
0,869283
0,921836
0,974389
1,026942
1,079494
1,132047
1,1846
1,237153
1,289706
1,342258
1,394811
1,447364
60
50
40
30
20
10
0
Series1
Bibliografia
1. Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction
to Algorithms, Second Edition. MIT Press and McGraw-Hill, 2001. ISBN 0-262-03293-7.
Section 8.4: Bucket sort, pp.174–177.
2. http://en.wikipedia.org/wiki/Bucket_sort#Comparison_with_other_sorting_algorithms
3. http://www.brpreiss.com/books/opus5/html/page76.html
4. http://www.personal.kent.edu/~rmuhamma/Algorithms/MyAlgorithms/Sorting/bucketSor
t.htm
5. http://www.cs.unb.ca/~bremner/teaching/java_examples/snippet/BucketSort.java/