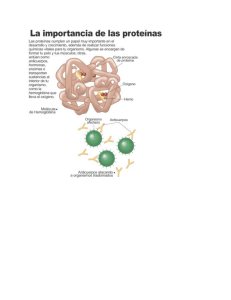
Proteínas. Funciones y estructura química. Aminoácidos y tipos
Anuncio

4 Proteínas. Profesor: José Manuel Cuezva; C−X 101. Sustituto José María Izquierdo. Introducción. Las proteínas son las moléculas que hacen el ser, entendido en el sentido de que son el fenotipo, que es lo que caracteriza externamente a un individuo. Estructuralmente son polímeros formados por la unión de los monómeros llamados aminoácidos, cada uno con una estructura como la que aparece a la izquierda, es decir, tienen una función ácida y una básica como su nombre indica. En estas moléculas, como en los azúcares, se puede apreciar un centro de asimetría en el carbono (el C2, después del carbono carboxílico), pero la diferencia es que en los aminoácidos la familia más numerosa es la L. Se cuentan veinte aminoácidos proteinogenéticos, cada uno de los cuales tiene una cadena lateral R distinta, y se unen entre sí formando péptidos mediante enlaces amida, por lo que el enlace se llama peptídico. Las proteínas son en realidad péptidos con un elevado número de restos (así se llama a cada monómero que forma parte de una cadena), y pueden actuar solas o combinadas para realizar la función propia de cada una de ellas, desde la visión (opsina) hasta la defensa del organismo (anticuerpos), pasando por la contracción muscular (miosina y actina), la formación de estructuras de soporte (citoesqueleto) y la catálisis a modo de enzimas como función más representativa (pero ya sabemos que hay moléculas de ARN capaces de catalizar determinadas reacciones, que son las ribozimas). Las vías de la información. Las proteínas son moléculas informativas porque son una copia codificada de la información contenida en el ADN. Si observamos el mecanismo de síntesis se una proteína desde que a la célula llega la primera señal correspondiente (una hormona u otra señal de cualquier tipo), ocurre que después de la cascada de segundos mensajeros y reacciones intermediarias, en el núcleo se activan uno o más genes mediante la acción de unos determinados factores de transcripción (recordar que si la hormona es esteroídica, el complejo receptor−hormona es ya un factor de transcripción). Estos factores se unen a los promotores y potenciadores de la expresión del gen en cuestión gracias a unas estructuras especiales en la doble hélice de ADN, y permiten que se sintetice una cadena de ARN mensajero tomando como molde una de las dos hebras del gen. Sin embargo, los genes en el ADN no son continuos, y hay espacios en los que no se dice nada con función estructural, así que el ARN recién formado tiene que eliminar esas secuencias, llamadas intrones, para dejar una sola hebra en la que se puedan leer los trozos de gen que tienen sentido estructural (los exones) sin saltos. Se utiliza la palabra leer porque es eso realmente lo que hacen los sistemas de transcripción, que es el proceso que se acaba de describir: Se comienza a sintetizar el ARN desde un extremo y nucleótido a nucleótido, reproduciendo fielmente lo que está en el ADN, como quien lee letras una detrás de la otra y las transcribe en un papel, sólo que aquí se tienen únicamente cuatro. El ARN recién sintetizado en el núcleo pasa al citoplasma rápidamente para ser traducido, es decir, hay que pasar la información contenida en una clave de cuatro letras, que son las bases púricas y pirimidínicas de los ácidos nucleicos, a una clave de veinte letras, que son los aminoácidos proteinogenéticos. La maquinaria enzimática encargada de la traducción, que es el nombre que se da al proceso, es el ribosoma. Éstos son unos enormes complejos nucleoproteicos (compuestos de ARN y proteínas) visibles al microscopio electrónico y con categoría de orgánulo, generalmente asociados al retículo endoplásmico rugoso o libres en el citoplasma. La traducción es algo necesariamente rápido porque el ARN es muy inestable, a diferencia del ADN, que es mucho más estable y además está protegido por su propia conformación de doble hélice (en el ARN sólo hay 1 una) y por las proteínas básicas presentes en el núcleo, con las que forma complejos. De este modo, ninguna proteína podría estar fabricándose de forma constante a partir de sólo una molécula de ARN, con lo que se asegura la reversibilidad del proceso. En la traducción el paso de una base cuatro a una base veinte se permite mediante un código denominado genético, en el que a cada aminoácido le corresponde un conjunto de tres nucleótidos. Es decir, el ARN se tiene que leer de tres en tres para poder traducir la información contenida en él. Además de códigos para cada aminoácido, también están codificadas en grupos de tres nucleótidos (tripletes) las secuencias de comienzo y final de la traducción, es decir, no todo el ARN se traduce porque se empieza y se acaba sin llegar a los extremos. Como a cada aminoácido le corresponde más de un triplete, se dice que el código es degenerado. Recientemente se ha descubierto que son veintiuno los aminoácidos proteinogenéticos, porque se ha incorporado la selenocisteína al grupo. Ésta se incorpora gracias a una modificación en un ARNt de serina. Forma y estructura. Después de tener el polímero de aminoácidos fabricado, todavía tiene que sufrir una serie de modificaciones, tanto espontáneas como catalizadas, para poder tomar su forma definitiva, llamada conformación nativa. Esta será la única forma en la que la proteína pueda realizar la función para la que ha sido diseñada, porque es esencial la distribución espacial de las distintas cadenas R de cada aminoácido para que se pueda formar un sitio en el que la catálisis sea posible (ver 1 Introducción). La forma definitiva de una proteína viene codificada en gran parte por la propia secuencia de aminoácidos, de tal modo que las interacciones débiles que se establecen entre los distintos radicales R (fuerzas de Van der Waals, puentes de hidrógeno, fuerzas iónicas e interacciones hidrofóbicas) son capaces de obligar a la cadena a formar determinadas estructuras en distintos órdenes de complejidad, llamadas estructuras secundarias, supersecundarias, dominios y estructuras terciarias (la estructura primaria es la propia secuencia de aminoácidos). Adquiriendo las distintas estructuras queda entonces la proteína como un esqueleto carbonado, que así se llama a la hilera de átomos implicados en los enlaces peptídicos (N−C−C−N−C−C...), del que sobresalen distintos grupos funcionales, que son los que llevan los diferentes grupos R. Con tal diversidad de funciones químicas de las que echar mano, no es de extrañar que las proteínas sean las moléculas catalíticas más importantes de la vida. Sin embargo el plegamiento no está totalmente determinado por la estructura primaria, sino que hay unas moléculas muy pequeñas, llamadas chaperoninas (del inglés chaperon: carabina, acompañante), que se unen al péptido en formación y le ayudan a alcanzar su conformación definitiva; es decir, el plegamiento en el medio celular está asistido. Algunas proteínas no tienen suficiente información para realizar por sí mismas la función para la que se han sintetizado, por lo que se unen a moléculas pequeñas, generalmente vitaminas, que realizan la función, generalmente oxidación y reducción reversibles, pero dirigidas y modificadas según la cadena polipeptídica en cuestión. Es decir, hay varias moléculas que están presentes como cofactores en muchas enzimas diferentes, pero que ven modificada su ación por la proteína a la que se unan, como si fueran instrumentos tontos que pueden hacer algo, pero que la proteína les dice dónde y cómo. Además la acción de las enzimas puede verse modificada por distintas transformaciones covalentes como la fosforilación, palmitoilación, DP−ribosilación o unión a una cadena terpénica para trasladarla a la membrana desde el citoplasma. Definición y características de las proteínas. El término proteína viene del griego proteios (ððððððð), que significa el primero, en la preeminencia. Se les dio ese nombre por la creencia generalizada de que tenía que haber sido la primero molécula viva sobre la Tierra, dado que su función principal y de la que depende toda la vida conocida es la de catalizar las reacciones celulares, incluida la replicación y la traducción. Esto en principio planteó la cuestión irresoluble de cómo había sido capaz el ADN de asumir las funciones de transferencia y conservación de la herencia, siendo una molécula tan monótona y simple comparada con las proteínas Cuando se descubrió la ribozima, la teoría vigente hasta la fecha que postulaba que las proteínas tenían que haber sido lo primero porque si no, no 2 habría replicación, se cambió por la teoría de el ARN antes, pero sin embargo el nombre de proteína ya estaba muy bien asentado. De hecho, sin las proteínas no se nos podría reconocer, porque son la expresión de la información genética, es decir, el fenotipo, y son tan importantes que representan el 50% del total del peso seco de una célula. Funciones de las proteínas. Como ya se ha dicho, la función más importante de las proteínas es la de ejercer como catalizadores biológicos de las reacciones que se llevan a cabo en la célula (recordar 1 Introducción). Su eficacia es tal que como media aumentan un millón de veces la velocidad de la reacción sin catalizar. Otra función muy importante es la de actuar como transporte y almacenamiento de iones, como la transferrina de la sangre y la ferritina del hígado. Además son el soporte y el mecanismo del movimiento coordinado, ya sea macroscópico, como la miosina del músculo, o microscópico, como los filamentos de actina en la locomoción por pseudópodos. También son el soporte para la acción de estos movimientos, tanto dentro como fuera de la célula: el colágeno de la matriz y los microfilamentos del citoesqueleto, respectivamente. Tienen una misión muy importante relacionada con las dos anteriores, que es el desplazamiento de los cromosomas a lo largo del huso acromático durante la mitosis y la meiosis. Otras funciones desarrolladas por proteínas son la transmisión del impulso nervioso (son los receptores de los neurotransmisores en la neurona postsináptica), la regulación y el control del crecimiento celular mediante receptores y la modulación de la expresión génica a cualquier nivel de síntesis o de degradación. La última función en esta lista, pero no la menos importante, es la defensa del organismo frente a infecciones, mediada tanto por los anticuerpos como por los receptores de las células T. Hay más funciones desarrolladas por proteínas; tantas como sean necesarias para llevar a cabo todas las funciones de un organismo vivo. Estructura química de las proteínas. Las proteínas son polímeros lineales formados por la condensación de veinte monómeros llamados aminoácidos mediante reacciones de condensación por deshidratación, como todas las polimerizaciones en la célula. Pueden estar compuestas sólo de aminoácidos (proteínas simples), o bien llevar unido algún grupo no proteico, llamado prostético, para dar numerosos tipos de proteínas conjugadas: nucleoproteínas con ácidos nucleicos (ribosoma, histonas), lipoproteínas con lípidos (LDL, HDL), fosfoproteínas con fósforo (caseína), metaloproteínas con átomos metálicos (citocromo oxidasa), glucoproteínas con oligosacáridos (−globulinas; ver 2 Glúcidos). En todos los casos es la proteína la que define la utilización de cada grupo prostético, que aunque es indispensable para la función que se tiene que llevar a cabo, sólo la parte proteica es capaz de utilizar el grupo prostético como mejor convenga, como si fuera una simple herramienta capaz de ser utilizada de distintos modos según la mano que la coja. De cualquier modo, todas las proteínas simples y las partes no prostéticas de las conjugadas muestran una composición media atómica de 50% C, 23% O, 16% N, 7% H y 3% S. Aminoácidos. Son los monómeros fundamentales de las proteínas. Se conocen veinte aminoácidos proteinogenéticos, cada uno de los cuales responde a la fórmula de la derecha y tienen una cadena lateral R distinta, que es la que define sus propiedades particulares, porque todos responden a la fórmula de ser ácidos 2−aminocarboxílicos, 3 aunque luego puedan tener otros grupos añadidos en su cadena lateral. Hay una excepción a l regla común, que es la prolina, porque éste es un iminoácido, en el que el átomo de nitrógeno forma dos enlaces con el esqueleto carbonado de la molécula, resultando un heterociclo de cinco átomos como el de la izquierda. A pH fisiológico todos los aminoácidos están ionizados tal y como se ha representado en los dibujos, aparte de cómo puedan estar los posibles grupos ionizables en las cadenas R. Esta disposición de las cargas en los aminoácidos los convierte en iones dipolares o zwitteriones, y por su composición química son capaces de actuar como ácidos o como bases, es decir, son anfóteros. Otra característica común a todos los aminoácidos es que son extremadamente solubles en agua, más que en ningún disolvente orgánico, y que forman cristales muy duros en solución pura, con puntos de fusión muy altos en torno a los 400 ºC, cosa que se explica únicamente gracias a interacciones más fuertes que las de Van der Waals, como pueden ser las electrostáticas proporcionadas por los grupos ionizables. Los aminoácidos se unen mediante una reacción de condensación entre el grupo carboxilo del primero y el grupo amino del siguiente, que en la célula está catalizada por el ribosoma durante la traducción. De este modo queda la estructura de la proteína como una sucesión de aminoácidos, empezando por el que tiene el grupo amino libre y acabando por el que tiene el grupo carboxilo libre, y cada uno de estos aminoácidos que forman parte de una proteína se llama residuo o resto. Una proteína, entendida como un polímero de aminoácidos, también puede llamarse péptido, polipéptido u oligopéptido, con lo que el enlace amida que se establece entre los residuos se llama generalmente peptídico. Las características de este enlace se verán más adelante. La estructura de las proteínas puede entonces verse como una hilera de átomos en la que se repite el motivo N−C−C, llamado esqueleto de la proteína, del que salen lateralmente las distintas cadenas R de cada residuo, y que van a ser las que den la funcionalidad a la molécula. Tipos de aminoácidos. Hay varios tipos de aminoácidos, según la naturaleza de su cadena lateral R. Aminoácidos no polares. Código de Código de Cadena lateral. tres letras. una letra. Alanina. Ala A Valina. Val V Leucina. Leu L Isoleucina. Ile I Metionina. Met M −CH3 −CH2−CH2−S−CH3 Observaciones. Puede encontrarse tanto en el interior como en el exterior de las proteínas, dado su pequeño tamaño. Es prácticamente inerte y es el aminoácido más abundante. Suelen encontrarse en el interior de las proteínas porque son más grandes que la alanina. Son inertes pero juegan un papel importante en el plegamiento porque generan interacciones hidrofóbicas. Igual que los anteriores, y además la sustitución asimétrica en C3 da estereoisómeros. Es el primero en el 4 ARNm. El azufre puede reaccionar con metales y formar enlaces de coordinación, aunque es bastante inactivo. Es un iminoácido. Su estructura rígida interfiere mucho en el plegamiento de las proteínas y obliga a la formación de los codos ð. No es reactivo. Sus anillos aromáticos son extremadamente apolares y están sepultados en el interior de las proteínas. Dado su tamaño, sobre todo el triptófano, se usan como espaciadores en la estructura proteica. Prolina. Pro P Fenilalanina. Phe F Triptófano. Trp W Aminoácidos polares. Código de Código de Cadena lateral. tres letras. una letra. Glicina. Gly G −H Serina. Ser S −CH2OH Treonina. Thr T −CHOH−CH3 Observaciones. Es el único que no tiene estereoisómeros. Está muy conservado y se puede encontrar en cualquier sitio porque permite todas las conformaciones normales y algunas muy raras. Aunque la cadena es apolar, la molécula entera sí es polar, por lo que se incluye aquí. Puede formar enlaces de hidrógeno y su fosforilación regula la actividad enzimática. El grupo hidroxilo es muy reactivo en ciertos centros activos, pero normalmente se encara al agua para permitir la solubilidad de la proteína. Como la anterior pero no tan reactivo y más hacia el interior. Tiene estereoisómeros 5 Asparagina o asparragina. Asn N −CH2−CO−NH2 Glutamina. Gln Q CH2−CH2−CO−NH2 Tirosina. Tyr Y Cisteína. Cys C −CH2−SH adicionales en C3. Aminas derivadas de aminoácidos ácidos. También forman enlaces de hidrógeno y aumentan la solubilidad. Débilmente ácido como el fenol (pKR = 10,46). Se encuentra en centros activos. Es el aminoácido más reactivo. Forma los puentes disulfuro para estabilizar la estructura de la proteína, dando un aminoácido doble llamado cistina. Puede ser ácido (pKR = 8,37). Observaciones. Aminoácidos cargados. Código de tres letras. Código de una letra. Lisina. Lys K Arginina. Arg R Histidina. His H Todos se encuentran siempre hacia el exterior de las proteínas, porque su carga les impide estar en Cadena lateral. otro sitio a no ser que se baje la constante dieléctrica del medio, como en los centros activos (1 Introducción). Forma las bases de Schiff −CH2−CH2−CH2−CH2−+NH3 (recordar el retinol en 3 Lípidos). El pKR es 10,54. La forma desprotonada es una base bastante fuerte (pKR = 12,48). La forma protonada se estabiliza por resonancia como se ve a la izquierda. Aminoácido raro que se suele encontrar en el centro activo de las enzimas. El anillo de imidazol protonado se estabiliza por resonancia entre las dos formas dibujadas a la izquierda. El 6 pKR es 6,0, con lo que a pH fisiológico y en solución acuosa hay 10 veces más forma desprotonada que protonada, pero en los centros activos puede estar en cualquier forma (ver 1 Introducción). Ácido aspártico. Asp D −CH2−COO− Ácido glutámico. Glu E −CH2−CH2−COO− Se encuentra en el centro activo de las enzimas ATPasas. También se encuentra en algún centro activo. Son las cadenas laterales las que definen las características físicoquímicas de los aminoácidos (polaridad, hidrofobicidad, aromaticidad, flexibilidad conformacional), pero sin embargo hay equivalencias a la hora de influir en el plegamiento de las proteínas, porque éste es algo más general y no depende estrictamente de cada uno de los aminoácidos de la secuencia, sino del equilibrio de fuerzas existente en el momento de realizarse el plegamiento. Se puede hacer una lista con los aminoácidos que son estructuralmente intercambiables: • Gly, Ala y Ser. • Ala y Val. • Val, Ile, Leu y Met. • Ile, Leu, Met, Phe, Tyr y Trp. • Arg, Lys e His. • Asp, Glu, Asn y Gln. • Ser, Thr, Asn y Gln. Cada una de estas equivalencias se puede dar en sitios determinados de cada proteína, no todas en el mismo sitio, porque entonces casi daría igual qué aminoácido hubiera. Aunque haya similitudes de tipo estructural, una mutación que conduzca a la sustitución de un aminoácido por otro equivalente, sólo será aceptada evolutivamente si permite mantener la función para la que está diseñada la proteína. Por este mecanismo de evitar la selección negativa de las mutaciones con analogías estructurales y funcionales, se ha llegado a la evolución proteica desde un solo precursor primitivo hasta las familias de moléculas con funciones iguales o parecidas, pero que no tienen todas la misma secuencia de aminoácidos. De este modo actualmente hay una gran diversidad de secuencias aminoacídicas con funciones y estructuras evolutivamente relacionadas, fruto del tiempo y la selección natural. Actividad óptica e isomería. Todos los aminoácidos naturales obtenidos de proteínas hidrolizadas, excepto la glicina, tienen actividad óptica. Esto significa que desvían un haz de luz polarizada porque tienen un átomo de carbono, el Cð, asimétricamente sustituido, es decir, tienen estereoisómeros que son imágenes especulares el uno del otro, lo 7 que no pasa con la glicina (recordar 2 Glúcidos). La rotación absoluta que se mide, llamada rotación específica, depende de la cadena lateral y del pH. Los aminoácidos, a diferencia de los glúcidos, son todos compuestos que estructuralmente en la proyección de Fischer tienen el grupo amino a la izquierda, es decir, son L−aminoácidos, aunque tampoco signifique que todos ellos sean levorrotatorios porque sólo se representa la configuración absoluta. También como en el caso de los azúcares, las enzimas son estereoespecíficas, no como la síntesis química que produce una mezcla equimolar de formas D y L sin actividad óptica, llamada racémica (racemato). Los aminoácidos naturales conservan su estereoespecificidad cuando se disuelven en agua, pero se pueden racemizar en presencia de bases muy fuertes, no de ácidos, o con cualquier reacción química en la que el carbono asimétrico tenga que pasar por un intermedio simétrico. La configuración en L se demostró a partir del estudio de cristalografía por rayos X en los años cuarenta. La treonina y la isoleucina tienen un carbono asimétrico más, el carbono Cð, con lo que tienen diastereoisómeros como los glúcidos. Los diastereoisómeros son todos los distintos isómeros de moléculas con uno o más carbonos asimétricos o quirales, y su número es 2n, donde n es el número de carbonos asimétricos o centros de asimetría. Ningún diastereoisómero se puede superponer a otro. Los epímeros son dos diastereoisómeros que difieren sólo en un carbono asimétrico. Los estereoisómeros o enantiómeros son dos diastereoisómeros que difieren en todos los carbonos asimétricos, de modo que son imágenes especulares el uno del otro. En la proyección de Fischer tanto de la L−isoleucina como de la L−treonina se sitúan los grupos hidroxilo y metilo a la derecha de la cadena, no en vano la isoleucina se sintetiza a partir de la treonina. Las especies de la serie L que los llevan a la izquierda forman la familia alo, con lo que hay cuatro tipos de cada aminoácido. Por ejemplo: • L−Thr. −NH3+ a la izquierda, −OH a la derecha. • L−alo−Thr. −NH3+ a la izquierda, −OH a la izquierda. • D−Thr. −NH3+ a la derecha, −OH a la izquierda. • D−alo−Thr. −NH3+ a la derecha, −OH a la derecha. Lo mismo ocurriría para la isoleucina. En condiciones normales de experimentación a pH 7, 20 ºC y con la franja D del sodio (ver 2 Glúcidos), los aminoácidos muestran el siguiente comportamiento óptico: • Levorrotatorios: Leu, Met, Pro, Phe, Trp, Gly, Ser, Thr, Asn, Gln, Tyr, Cys e His. • Dextrorrotatorios: Ala, Val, Ile, Lys, Arg, Asp y Glu. Absorción electromagnética. La mayoría de las sustancias orgánicas, incluyendo los aminoácidos, absorben luz de longitudes de onda inferiores a las del ultravioleta, aproximadamente por debajo de 220 nm. Sin embargo, el triptófano, la fenilalanina y la tirosina, todos con grupos bencénicos o derivados, absorben luz ultravioleta en el entorno de los 260 a 280 nm, lo que se puede utilizar para cuantificar de manera aproximada la cantidad de proteína de una muestra, porque siempre suelen formar parte de ellas. Además pueden servir para apreciar cambios conformacionales en proteínas que lleven estos aminoácidos. Características ácido−base. Todos los aminoácidos, cono ya se ha comentado, se encuentran cargados a pH fisiológico formando iones dipolares, híbridos o zwitteriones, con lo que tienen una muy buena solubilidad en agua y forman cristales a partir de disoluciones acuosas neutras de puntos de fusión muy altos (PF > 200 ºC), además de tener constantes dieléctricas y momentos dipolares muy grandes. El comportamiento particular de cada aminoácido 8 sirve para identificarlos en el laboratorio y eventualmente separarlos por cromatografía de intercambio iónico, lo que es un paso necesario para identificar la secuencia de una proteína. Por esta capacidad de presentar al menos dos grupos ionizables se pueden comportar como ácidos o como bases según las circunstancias, con lo que se son sustancias anfóteras según la teoría de los ácidos y bases de Brönsted y Lowry porque pueden tanto aceptar como donar protones. Al valorar un aminoácido con sosa, por ejemplo, se obtienen curvas de valoración en las que se establecen dos o tres equilibrios, según tenga el aminoácido una cadena lateral sin carga o ionizable, respectivamente. En cada caso se consideran como ácidos dibásicos o tribásicos, respectivamente. Cada uno de los equilibrios se caracteriza por una constante, cuyo logaritmo negativo es el pK correspondiente. En el entorno de pK ± 1, el aminoácido tiene capacidad tamponante y se puede aplicar la ecuación de Henderson−Hasselbalch . Otro parámetro característico de los aminoácidos es su punto isoeléctrico, que es el pH en el que todo él se encuentra sin carga neta, es decir, en forma de zwitterion. Este punto, representado por pI, se halla experimentalmente de la media de los dos equilibrios que dan origen al dicho ion dipolar y se encuentra en el punto de inflexión de la curva de valoración entre esos dos pK. Estas dos características se utilizan en el laboratorio para separar aminoácidos en cromatografías de intercambio iónico. En una proteína cada residuo que lleve un grupo ionizable mantiene su pK, con lo que la curva de valoración de la proteína se parecerá más a una pendiente, que variará su inclinación en función de la fuerza iónica, pero que siempre pasa por un mismo punto que es el pI de la proteína. Aminoácidos modificados. Después de la síntesis enzimática de la proteína, uniendo los aminoácidos correspondientes en el ribosoma, se pueden dar modificaciones puntuales de los residuos y producir aminoácidos modificados. • 4−hidroxiprolina: Es muy importante para estabilizar la estructura terciaria y cuaternaria del colágeno, que es la proteína mayoritaria de los mamíferos. La falta de vitamina C impide la hidroxilación y se produce la enfermedad llamada escorbuto, que se caracteriza por las hemorragias y pérdida de consistencia de los tejidos con caída de dientes y pelo. • 5−hidroxilisina: Como el anterior. • ð−N,N,N−trimetillisina y 3−metilhistidina: Se encuentran en las proteínas musculares. • ð−N−acetillisina, N−acetilserina, N,N,N−trimetilalanina y ð−N−metilarginina: Se encuentran en proteínas ribosómicas y en las histonas. • −carboxiglutamato: Interviene en el proceso de coagulación porque forma parte de la protrombina y su falta puede llagar a provocar hemorragias. • O−fosfoserina: La serina es el aminoácido que más se fosforila e interviene en el control de la transcripción. • N−formilmetionina: Es el primer aminoácido que se traduce en todos los ARNm procarióticos, donde además sirve de inicio de del proceso. Aminoácidos no proteinogenéticos. Se conocen unos 150 derivados de aminoácidos, mayoritariamente en plantas y hongos. Sus usos más importantes son como neurotransmisores, segundos mensajeros, hormonas y antibióticos. • Glicina, ácido −aminobitírico (GABA; descarboxilación en Cð de Glu), histamina (descarboxilación de His) y dopamina (un derivado de Tyr) son neurotransmisores. • Tiroxina (derivado de Tyr) es la hormona tiroidea T4. Se transporta asociada a albúmina y se desyoda mediante desyodasas para formar la hormona T3 más activa. Regula el metabolismo en general activando determinados genes como factores de trancripción y además en otras rutas específicas. 9 • Citrulina y ornitina (Orn): Son intermediarios en la síntesis de arginina y urea, además de formar parte de algunos antibióticos. • Homocisteína (como Met sin el metilo final) es intermediario en la síntesis de cisteína. • S−adenosilmetionina: Se utiliza en los eucariotas para añadir las metilaciones en las bases del CAP del ARNm. • Azaserina y ð−cianoalanina son antibióticos derivados de la serina y la alanina. • Colina y etanolamina, que son derivados de la serina, y ella misma son segundos mensajeros (ver 3 Lípidos). Reacciones de los aminoácidos. Las reacciones típicas de los aminoácidos son todas las reacciones características de los grupos que tienen. Se utilizan para identificar los aminoácidos en los hidrolizados, hallar la secuencia de una determinada proteína, modificar determinados aminoácidos para detectar actividades enzimáticas y permitir su variación química y para la síntesis química de péptidos. Entre ellas se resaltan las más importantes. Reacciones del grupo carboxilo. Formación de amidas. Es la reacción típica de condensación enzimática por deshidratación, en la que el grupo carboxilo de un aminoácido se combina con el grupo amino del siguiente. Este enlace se llama también peptídico porque el polímero que se genera, es decir, la proteína, también puede llamarse polipéptido o péptido a secas. Formación de ésteres. Reacción utilizada en la síntesis química de proteínas para fijar y proteger el carboxilo del último aminoácido, con etanol o fenol, y evitar que reaccione. De esto se deduce que la síntesis química empieza al revés que la síntesis enzimática, es decir, se empieza a polimerizar por el extremo C−terminal en lugar de por el extremo N−terminal, que es lo que ocurre en el ribosoma. También se utiliza esta reacción para fijar una proteína a un soporte y luego proceder a su secuenciación según el método de la degradación de Edman. Formación de haluros de acilo. Reacción típica de grupos carboxilo en química orgánica, consiste en la sustitución del hidrógeno ácido por un átomo de un elemento halógeno. Reducción con LiBH4. Los carboxilos se reducen a alcohol primario en medio anhidro y en presencia de borohidruro de litio (LiBH4), que es un compuesto altamente reductor. Reacciones del grupo amino. Acilación con haluros o anhidros de ácidos. Se tratan los aminoácidos con haluros o anhidros de ácidos, por ejemplo clorocarbonato de bencilo, que genera un carbobenzoxiderivado del aminoácido correspondiente. Se utiliza en la protección el grupo amino en la síntesis química de proteínas. 10 Cuando la reacción se produce en condiciones suaves, como la anterior, se mantiene la estereoquímica del aminoácido, es decir, se mantiene el estereoisómero, pero si las condiciones son más drásticas, como por ejemplo con calor, se genera una mezcla racémica Valoración con ninhidrina. Esta reacción es la más utilizada para revelar aminoácidos o péptidos en las cromatografías en capa fina. La ninhidrina es el hidrato de tricetohidrindeno, y es un oxidante muy fuerte que provoca la descarboxilación oxidativa y desaminación del aminoácido, formando el aldehído correspondiente, CO2, amonio y una forma reducida de la ninhidrina llamada hidrindantina. En la segunda fase este derivado vuelve a reaccionar con una molécula de ninhidrina para condensarse en presencia de amoniaco y formar una sustancia coloreada llamada púrpura de Rueman, que absorbe a 570 nm. Con los iminoácidos esto no ocurre porque no tienen el grupo amino primario, y lo que se genera es una sustancia amarilla que absorbe a 440 nm. Es una reacción que se puede valorar en un colorímetro porque es proporcional a la cantidad de aminoácido. Formación de bases de Schiff. Puede ocurrir entre cualquier amino primario y cualquier grupo aldehído, pero en las proteínas, que es donde tiene una importancia relevante, sólo las aminas terminales de las cadenas laterales de la lisina son capaces de producirlas. Es una reacción de condensación en la que se genera un grupo imino, y que suele ser un intermediario en centros de reacción que contengan lisina y un substrato con un grupo aldehído. Reacción con cianato. Se produce la carbamilación de los aminoácidos al unirse un radical cianato al grupo amino (−CO−NH2). Se utiliza esta reacción para modificar la hemoglobina S, que es una mutación puntual de la hemoglobina normal en un solo aminoácido de la cadena ðð El cambio consiste en la sustitución de un ácido glutámico cargado y encarado al exterior por un valina apolar y que obliga a la proteína a cambiar de conformación para no quedar expuesta al agua. El cambio de conformación provoca automáticamente la falta de función, pero no es sólo eso, sino que la nueva conformación, que es inestable porque tiene un aminoácido apolar cerca del agua, se estabiliza mediante la polimerización de moléculas de hemoglobina S a través de la inclusión de esta nueva valina en un bolsillo hidrófobo de otra molécula. De este modo se generan largas cadenas de hemoglobina S que deforman el eritrocito y le obligan a adquirir forma de media luna o de hoz (de ahí el nombre) y los hacen inservibles. Sin embargo los eritrocitos falciformes son resistentes al paludismo, por lo que en los trópicos se han seleccionado las personas heterocigóticas que a pesar de tener una merma en la resistencia aeróbica, son capaces de convivir con el paludismo y no morir. Al carbamilar la hemoglobina falciforme se obliga a un nuevo cambio conformacional que restituye una forma parecida a la normal, y por lo tanto una función también casi normal. Identificación de los fragmentos N−terminales. Son reacciones de fijación y protección de varios tipos, enfocadas a identificar un fragmento proteico concreto en distintos procesos de secuenciación. Estas reacciones de secuenciación son los procesos de Sanger (con dinitrofluorobenceno), la dansilación con cloruro de dansilo y Edman (con fenilisotiocianato). Esta última es la más importante y la que utilizan los secuenciadores automáticos, porque degrada la cadena residuo a residuo sin tener que hidrolizarla entera. Reacciones de los grupos de la cadena lateral. 11 Suelen ser reacciones más cualitativas que cuantitativas. De las cadenas laterales capaces de reaccionar significativamente se encuentran el grupo hidroxifenilo de la tirosina, el grupo guanidino de la arginina y el grupo tiol de la cisteína, que merece una mención aparte porque es el más reactivo de todos y el más importante en el mantenimiento de la estructura proteica. En ese caso, las reacciones del grupo tiol son las siguientes. Formación de puentes disulfuro. Dos moléculas de cisteína cercanas oxidan los grupos tiol en presencia de ion ferroso (Fe2+) y oxígeno para formar un enlace disulfuro y un nuevo aminoácido que es la unión de dos cisteínas llamado L−cistina. En el medio celular esta reacción está catalizada por la proteín disulfuro isomerasa, que se encuentra en el retículo endoplásmico, del que es marcador, y une dos residuos de cisteína que han quedado cercanos debido al plegamiento de la proteína. Estos enlaces mantienen covalentemente la estructura de la proteína e impiden su fácil desnaturalización. Los puentes disulfuro se tienen que reducir en el laboratorio para realizar determinados ensayos en las proteínas como electroforesis en condiciones desnaturalizantes y secuenciación de proteínas, para lo que se utiliza ð−mercaptoetanol (que da dos cisteínas más una molécula de di−ð−dihidroxietildisulfuro), y también para mantener los residuos de cisteína reducidos en los centros activos de las enzimas, en donde se utiliza ditiotreitol. Formación de mercáptidos metálicos. La cisteína reacciona con metales pesados como el aluminio y el mercurio produciendo los mercáptidos correspondientes. Reacción de desplazamiento de Ellman. Es una reacción cuantificable que mide el número de cisteínas presentes en una muestra. El reactivo de Ellman es el ácido 5,5'−ditiobis(2−nitrobenzoico), que interacciona con el grupo tiol para dar ácido tionitrobenzoico en una reacción equimolar para cada residuo de cisteína. Péptidos. Un péptido es la unión de un número limitado de aminoácidos, hasta cincuenta, mediante la formación de enlaces amida entre los grupos amino y carboxilo unidos al carbono ð. Tal y como se sintetizan en la célula, se comienza por el extremo N−terminal y se acaba por el extremo C−terminal, nombrando todos los aminoácidos por orden cambiando la terminación −ina por −il, excepto la del último que queda invariable. Además por convención siempre se escriben de izquierda a derecha según se nombran y se sintetizan. En el momento que un aminoácido forma parte de una cadena pasa a llamarse resto o residuo, para resaltar el hecho de que está unido. Síntesis en la célula. La formación del enlace peptídico es muy cara energéticamente, pero sin embargo la evolución ha mantenido el sistema de síntesis proteica prácticamente invariable a lo largo de millones de años, con lo que debe suponer alguna ventaja añadida. Además es uno de los métodos universales que, junto con el código genético y las bases moleculares de la herencia, refuerzan la idea de que todos los seres vivos conocidos surgieron de un mismo antecesor común en el que ya se daban estos mecanismos, que tuvieron tanto éxito que automáticamente eliminaron todo lo que pudiera haber habido. El mecanismo de síntesis proteica sigue el dogma central de la Biología y constituye el último paso: la traducción. 12 En la célula se sintetizan los péptidos gracias a una compleja maquinaria bioquímica diseñada evolutivamente a tal efecto: el ribosoma. Éste es un complejo ribonucleoproteico (RNP) que incluye en su composición ARN especial llamado por esto ribosómico (ARNr). Este complejo se puede descomponer en dos subunidades, llamadas grande y pequeña, entre las que corre una cadena de ARNm con la información de la proteína que se va a sintetizar. Como se ha visto anteriormente, el ribosoma se desplaza físicamente a lo largo del ARNm a saltos de tres en tres bases, correspondiendo cada uno de esos tripletes o codones a un aminoácido, merced al código genético. En procariotas es siempre la formilmetionina (fMet) el primer aminoácido que se incorpora en un sitio especial de la subunidad grande, llamado sitio P o peptidilo, que está justamente sobre el codón de iniciación AUG. El siguiente codón está debajo de otro sitio en el ribosoma llamado sitio A o aminoacilo. Ni los aminoácidos ni el ribosoma son capaces de reconocer por sí solos dónde se tienen que incorporar, por lo que necesitan una molécula que haga las veces de código para que el ribosoma, que es el descodificador, pueda convertir el ARNm en proteína. Estas moléculas que son el código son los ARNt (transferentes, o también ARNs, solubles), y hay, evidentemente, al menos tantos como aminoácidos, a los que se unen específicamente gracias a enzimas al efecto que son las aminoacil−ARNt sintetasas, que también son específicas de aminoácido y de ARNt. Así que todos los aminoácidos se incorporan al ribosoma como aa−ARNt, pero por simplicidad se obviará en adelante. Una vez están la fMet y el siguiente aminoácido en los sitios del ribosoma, se produce un ataque nucleofílico por parte del grupo amino del segundo aminoácido al grupo carboxilo del primero (por el que se une al ARNt), con lo que se genera un dipéptido en el sitio A, y el sitio P se queda sólo con el fMet−ARNt. Esta reacción está catalizada por la peptidil transferasa, que es una de las proteínas de la subunidad grande del ribosoma. Después de esto, el ribosoma entero se tiene que mover exactamente tres nucleótidos a lo largo del ARNm, con lo que el péptido recién formado pasa al sitio P y se descubre de nuevo el sitio A con un nuevo codón libre al que se tiene que incorporar otro aminoácido. El ARNt del primer aminoácido pasa a otro sitio del ribosoma, llamado sitio E o de salida (del inglés exit), tras lo cual vuelve a disociarse y a flotar en el citoplasma para ser cargado de nuevo con su aminoácido específico. Otra vez se está en la situación de partida, en la que hay un péptido en el sitio P y el sitio A está vacío para que se incorpore el siguiente aminoácido. Por cada aminoácido incorporado se hidrolizan cuatro enlaces ricos en energía: • En la unión de aminoácido al ARNt. • En la incorporación del aminoácido al sitio A. • En la formación del enlace peptídico. • En la translocación del ribosoma al codón siguiente. Sin embargo, sólo se conservan cuatro en el enlace, por lo que toda la energía no utilizada sirve para mantener la fidelidad del proceso. 13 El enlace peptídico. En la década de los treinta, Linus Pauling y descubrieron en ensayos acerca de los cambios conformacionales de las proteínas que el enlace peptídico tiene unas características que lo hacen especial. La distancia del enlace Cð − O es la mitad entre la que correspondería a un enlace doble (que es lo previsible en una amida) y un enlace simple, y otro tanto ocurre ene el caso del enlace con el nitrógeno del resto siguiente. Estos datos hacían suponer que el enlace era un híbrido de resonancia de dos formas extremas como las que se representan en la figura de la izquierda. Esto hace que el enlace peptídico sea polar, por la mayor densidad de carga electrónica alrededor del oxígeno, y además tiene características de doble enlace, con lo que es plano y puede presentar isomería cis−trans. De hecho, todos los restos que se van incorporando a una cadena polipeptídica en elongación siempre forman enlaces en trans, nunca en cis, debido a la menor repulsión estérica de las cadenas laterales R y al mayor alejamiento de los Cð: 4,04 Å en el trans frente a 2,8 Å en el cis. Sólo la prolina aparece unida mediante enlaces en cis gracias a una modificación posttraduccional producida por la peptidil prolil cis−trans isomerasa, y de hecho aunque esta configuración del enlace es 2 Kcal/mol más energética que la trans, la diferencia es inapreciable porque la cadena lateral de la prolina está ciclada con el grupo amino (imino), con lo que no hay diferencia sustancial en tanto a repulsiones estéricas se refiere porque siempre so muy altas. La prolina se incorpora en determinados sitios de la cadena polipeptídica que necesitan un cambio brusco de dirección, porque la rigidez de este aminoácido, unida a la configuración en cis y luego generalmente una glicina, que permite giros cerrados forman los llamados giros o acodalamientos ð. Ángulos de enlace. Como el enlace peptídico es plano y rígido, los únicos enlaces del esqueleto proteico que pueden girar sobre su eje son los que unen el Cð con sus respectivos grupos amino y carboxilo (excepto la prolina, claro). Los ángulos que pueden tomar desde un cero teórico en el que los dos enlaces peptídicos que flanquean un mismo carbono asimétrico se superponen en un mismo plano, están limitados por las repulsiones estéricas que podrían establecerse entre los diferentes grupos cercanos. El investigador hindú Ramachandran dedujo los límites mínimos y extremos entre los que se mueve el diámetro de cada átomo y observó que sólo había una diferencia de 0,1 Å, por lo que la diferencia entre los radios mínimo y extremo de Van der Waals (la zona de influencia de cada átomo) es de 0,05 Å. Sabiendo que el ángulo ð es el que puede tomar el enlace Cð − N alrededor de su eje, y el ángulo ð es el que toma el enlace Cð − CO alrededor del suyo, ambos contados en el sentido de las agujas del reloj si se observan los enlaces desde el Cð, Ramachandran representó todos los pares de valores teóricos teniendo en cuenta los impedimentos estéricos en un cuadro bidimensional ð/ð. De esta representación se dedujo que sólo un 15% de todos los posibles valores están permitidos en las proteínas, siendo todos los demás imposibles porque los grupos se estorbarían unos a otros. Mediante ensayos de laboratorio se ha comprobado la exactitud de las representaciones de Ramachandran y su utilidad para calcular ángulos de enlace de estructuras teóricas. Además se ha comprobado cómo la glicina puede formar casi cualquier ángulo de enlace saliéndose de ese 15%, dado el pequeño tamaño de su cadena lateral, y que la prolina restringe sus ángulos de enlace a un puñado de pares muy cercanos unos a otros. Importancia de los isómeros en el enlace. Ramachandran fue capaz de hacer la representación de los ángulos de enlace porque sólo hay dos, es decir, porque sólo hay ð−aminoácidos en las proteínas. Si en lugar de ð−aminoácidos fueran todos ð−aminoácidos, habría tres enlaces alrededor de los cuales se podrían hacer giros, cada uno con sus propias limitaciones estéricas, pero que en principio harían un número al cubo de posibles conformaciones, en lugar de un número al cuadrado. La conclusión teórica a la que se llega es que, como en las proteínas sólo hay ð−aminoácidos, los ð−aminoácidos han tenido que sufrir un proceso de selección contraria por el simple hecho de que permiten tal cantidad de conformaciones, al alejar tanto los grupos grandes, que sería imposible llegar en un tiempo 14 biológicamente lógico (unas horas) a una conformación mínimamente estable en una proteína. Esto llevaría a la imposibilidad de realizar la función correctamente, porque además cabrían varias conformaciones estables a las que se podría llegar por caminos diferentes según cómo les haya dado por colocarse a los enlaces. La existencia de ð−aminoácidos responde a la necesidad de limitar el número de mínimos energéticos disponibles para una cadena polipeptídica porque desde un principio tienen limitado sus ángulos de giro y, por tanto, los caminos por los que puede irse plegando la proteína. Todas las proteínas están además compuestas de L−aminoácidos, y las vías principales de síntesis y degradación utilizan estos estereoisómeros y no otros, salvo posteriores modificaciones. No se sabe por qué esta selección, pero sí se ha podido comprobar que los polímeros hechos de una mezcla de D− y L−aminoácidos son inestables, así que ahora la pregunta es por qué se escogió la familia L. Realmente se cree que fue por puro azar la primera que se utilizó y así siguió. Propiedades ópticas. Todos los péptidos tienen propiedades ópticas porque están hechos de monómeros ópticamente activos. Cuando son cortos y la estructura es abierta, es decir, sin plegamientos, la actividad óptica del péptido es la suma de las actividades de cada aminoácido, pero cuando la cadena se alarga y aparecen estructuras de orden superior, la actividad óptica deja de tener una relación con la secuencia de aminoácidos. Propiedades químicas de los péptidos. Los péptidos muestran básicamente la unión de todas las propiedades químicas de los aminoácidos que los componen, con la salvedad de que los grupos amino y carboxilo unidos a los Cð no pueden reaccionar porque están formando parte del enlace peptídico excepto los de los extremos N− y C−terminales. Propiedades ácido−base. Los péptidos tienen al menos los grupos ionizables de los extremos de la cadena, más los de las cadenas laterales, por lo que también pueden forman cristales de elevado punto de fusión, y además se pueden valorar como si fueran aminoácidos. Hay que resaltar que los pKa de los grupos ð−amino y ð−carboxilo libres, es decir, los de los extremos de la cadena, se van suavizando respecto a los de los aminoácidos libres a medida que la longitud aumenta porque la mayor distancia evita los efectos electrostáticos y de inducción que se dan entre esos grupos de carga opuesta cuando están cerca. Sin embargo esto no ocurre con los grupos ionizables de las cadenas laterales, que mantienen los pK muy cerca de los valores del aminoácido libre. Se puede determinar el pI de un péptido del mismo modo que el de un aminoácido, sólo que ahora es más difícil porque la curva de valoración ya no presenta escalones tan marcados, sino que se van suavizando hasta parecer una pendiente. En este caso es recomendable valorar el péptido a distintas temperaturas, y en el sitio donde se crucen las distintas curvas estará el pI. Reacciones de identificación. Como las anteriores, son iguales o muy parecidas a las de los aminoácidos. También se revelan los péptidos con ninhidrina después de una electroforesis o de una cromatografía, pero una reacción que es típica de péptidos y que con aminoácidos no se da es la reacción del biuret, porque se necesita la interacción con el enlace peptídico. Se basa en el establecimiento de enlaces de coordinación entre cuatro enlaces peptídicos consecutivos dos a dos en dos cadenas (o dos partes de la misma) que se encuentren paralelas, todo esto en medio básico con sosa. Una técnica parecida es la técnica de Lowry, que utiliza el reactivo de Folin (tungstato y molibdato de sodio en ácido fosfórico y clorhídrico), pero es diez veces más sensible: 0,1 a 1 mg de proteína/ml frente a 1 a 10 mg/ml. En ambos casos se forma el mismo complejo que es coloreado y absorbe a 640 nm. 15 Péptidos no proteinogenéticos. Glutatión. La fórmula es −Glu−Cys−Gly, con lo que el enlace peptídico entre el glutámico y la cisteína se realiza mediante el grupo carboxilo en y no con el que sería corriente. Está presente en grandes cantidades en las células de animales superiores (5 mM) y forma parte del sistema de transporte de aminoácidos al interior celular, catalizado por la −glutamil transferasa, que además actúa como reductor de centros activos, activador de enzimas y como protector en la oxidación de lípidos. Carnosina. Es la ð−Ala−His. El residuo de alanina es un ð−aminoácido. Es frecuente en el músculo. Tirocidina A. Es un péptido cíclico y con algunos aminoácidos en la forma D. Lo sintetiza una especie de Bacillus y es bastante tóxico porque es un sistema de protección contra las peptidasas, que las bloquea. Hormonas. • Factor regulador del hipotálamo. • Hormonas de la hipófisis posterior: Oxitocina y vasopresina. • Bradiquinina, que es un nonapéptido existente en el plasma sanguíneo. Antibióticos. • Valimonicina, cíclico. • Gramicidina. Determinación de la secuencia de aminoácidos. Actualmente se sigue el protocolo de Sanger establecido en 1953, aunque sólo parcialmente y adaptado a cada caso concreto. Sin embargo el descubrimiento del código genético y la capacidad que se tiene hoy día para construir fragmentos de ADNc ha limitado esta técnica al papel de una comprobación, más que un resultado en sí misma, de la secuencia deducida a partir de los fragmentos de material genético que se conservan en genotecas. Esto se debe a que la técnica no permite secuenciar fielmente péptidos de más de 50 ó 60 aminoácidos, a pesar de que el método se ha automatizado totalmente y ya no se hace eterno, pero sigue teniendo algunas limitaciones como se verá más adelante, y que son los pasos que no se realizan hoy día. Actualmente, al purificar una proteína, directamente se corta en péptidos que se separan en HPLC y se secuencian automáticamente, pero tampoco del todo. Si no se conoce la proteína, se fabrica una sonda degenerada (con inosina en el lugar de la base del tambaleo) que localiza el ARNm del que se fabrica luego el ADNc, que se amplifica mediante una PCR. Con el ADNc parcial se busca en una genoteca de ADNc el fragmento completo para determinar si la proteína se corresponde o por el contrario es nueva, porque sabiendo la secuencia del ADNc se sabe también la de la proteína que codifica. El protocolo se divide en los siguientes pasos: • Separar las subunidades. Se suele saber cuántas hay por el número de extremos N−terminales. • Reducir los puentes o enlaces disulfuro con ð−mercaptoetanol y posterior alquilación con yodoacetato para que no se oxiden con el oxígeno y vuelvan a formar puentes disulfuro. También se pueden someter a la 16 reacción de Ellman para su cuantificación. • Hidrólisis total del péptido y determinación de la composición de aminoácidos. Aquí es donde el método tiene su principal punto débil, que se obvia en la investigación actual. • Identificar los extremos N− y C−terminales. • Hidrólisis parcial del péptido, ya sea química o enzimática. • Secuenciación de cada uno de los péptidos mediante la reacción, degradación o recurrencia de Edman (el nombre es lo de menos). • Otra hidrólisis parcial distinta a la anterior que proporcione péptidos distintos que al secuenciarse puedan ser comparados a los anteriores. • Superposición de los grupos de péptidos obtenidos en las dos hidrólisis anteriores para poder llegar a una secuencia coherente común a los dos métodos de hidrólisis parcial. Puede que se necesite otra hidrólisis parcial diferente, si el péptido es muy repetitivo, aunque en tal caso se hace realmente difícil. • Determinar el número y las posiciones de los distintos enlaces o puentes disulfuro, generalmente por cromatografía diagonal o bidimensional y la posterior secuenciación del péptido que lo contiene. Una vez llegamos a una proteína o péptido purificado por algún método de los de Santarén (centrifugación, precipitación selectiva con sulfato de amonio, diferentes cromatografías de intercambio iónico, afinidad o filtración molecular y determinación de la actividad), hay que separarlo en sus subunidades (si tiene) y reducir los enlaces disulfuro. Como todo esto no se sabe a priori, se somete la proteína a una cromatografía en condiciones desnaturalizantes para separarla en bandas, si es que tiene subunidades, o bien para tenerla almacenada en papel y poder luego trabajar con ella. Los extremos tiol libres se tiene que alquilar formando los S−carboxiderivados correspondientes porque si no volverán a oxidarse y no se podrán separar. La proteína o subunidad aislada se somete luego a una hidrólisis total ácida con HCl 6 N en condiciones de vacío y a 100 ó 120 ºC durante 10 a 24 horas. Con esto se consigue separar totalmente los aminoácidos sin producir racemización, pero el triptófano y, en mucha menor medida, la serina y la treonina, son destruidos y desaparecen como tales. Además los enlaces amida de la glutamina y la asparagina también se hidrolizan y pasan a ser glutamato y aspartato, respectivamente, y además se produce amonio que comienza a subir en pH. A veces se hace una segunda hidrólisis básica con NaOH, con la que se destruye la cisteína, la cistina (si no se ha reducido antes), la serina y la treonina, además de producirse racemización de los aminoácidos, pero se conserva el triptófano, por lo que sólo se utiliza para saber dónde está. Esta eliminación de aminoácidos es lo que supone un obstáculo a la hora de realizar este protocolo. Después de la hidrólisis total, los aminoácidos se separan en una cromatografía de intercambio iónico, de la que se pueden eluir con variaciones tanto de pH como de fuerza iónica. Para identificar los extremos N− y C−terminales se puede recurrir a tres métodos: • Reacción de Sanger: Consiste en la formación de derivados del aminoácido N−terminal. Esto se consigue con el 2,4−dinitrofluorobenceno, que en medio ligeramente básico provoca la condensación con el grupo amino libre, que en esas condiciones no está protonado, para formar un 2,4−dinitrofenilderivado y una molécula de ácido fluorhídrico. Después se somete la proteína a hidrólisis total y se realiza una cromatografía para detectar el aminoácido que estaba en primer lugar, es decir, el extremo N−terminal. Tiene el problema de que si ese aminoácido es de los que se eliminan o modifican en la hidrólisis, no se podrá detectar a menos que se tenga un patrón cromatográfico de los aminoácidos a los que se modifican en la hidrólisis y además se les ha unido un radical 2,4−dinitrofenilo. Además también se podría unir el reactivo al grupo amino de la asparagina y la glutamina. • Dansilación: Básicamente igual que la anterior, pero se utiliza el cloruro de dansilo (cloruro de 1−dimetilaminonaftaleno−5−sulfonilo), que al combinarse con el aminoácido correspondiente en las mismas condiciones que la reacción de Sanger forma un dansilderivado que es fluorescente y se detecta en un colorímetro de manera mucho más fiable y precisa (pmol). Tiene los mismos problemas de detección que el anterior. 17 • Degradación, secuencia o recurrencia de Edman. Actualmente es la única reacción de secuenciación que se utiliza, y además es un proceso totalmente automatizado. Tiene la enorme ventaja de que no hace falta hidrolizar toda la proteína, y de que es un método secuencial y recurrente, en el que se van hidrolizando los aminoácidos uno a uno empezando por el extremo N−terminal, con lo que se conserva la direccionalidad N!C de la síntesis biológica. El reactivo es el fenilisotiocianato (PITC), que en medio básico con trimetilamina sufre en su carbono del grupo ciano un ataque nucleofílico por parte del amino terminal desprotonado, como si fuera una reacción de elongación en el ribosoma. La disposición de la estructura electrónica de los enlaces del feniltiocarbamilderivado (PTC) es muy energética, y cambiando a condiciones ácidas con ácido trifluoroetanoico al 100% se produce la rotura del enlace peptídico entre los dos primeros aminoácidos porque el grupo tioamida que se forma realiza un ataque nucleofílico sobre el carbono carboxílico del primer aminoácido, es decir, el azufre se une al carbono carboxílico y lo separa del amino del siguiente aminoácido, liberando una molécula de anilinotiazolinona del aminoácido correspondiente (aa−ATZ) y dejando el péptido con un resto menos y un nuevo extremo amino libre. Luego se pasa a condiciones de ácido trifluoroetanoico al 25%, en las que se altera la estructura del aa−ATZ y se forma un feniltiohidantoínderivado (PTH−aa) que es lo que se detecta mediante HPLC. Cuando el extremo N−terminal se encuentra bloqueado o combinado con algo, como una acetilación, que es producto de separar las proteínas en electroforesis en geles de poliacrilamida, se tiene que fabricar un extremo N−terminal nuevo y para ello se recurre a la hidrólisis parcial química o enzimática con peptidasas. De este modo tenemos una colección de fragmentos susceptibles de ser secuenciados y conocidos. El carboxilo terminal se detecta haciéndolo reaccionar con borohidruro de litio para formar un alcohol primario, y luego realizando una hidrólisis total para detectarlo en una cromatografía. También se puede recurrir a una hidracinolisis, en la que la hidracina (NH2−NH2) rompe los enlaces peptídicos formando un aminoacilhidracida de todos los aminoácidos excepto del último (C−terminal), porque éste no formaba parte de ningún enlace peptídico. Éste también se detecta en una cromatografía. Otro modo de detectar el extremo C−terminal es utilizar las enzimas carboxipeptidasas, que eliminan secuencialmente los restos de uno en uno comenzando por ese extremo. El último paso del protocolo, pero que es el primero que se realiza actualmente, es la digestión o hidrólisis parcial de la proteína con unas enzimas llamadas proteasas o peptidasas, que son capaces de reconocer enlaces peptídicos en los que interviene un aminoácido concreto, y cortar exactamente en ese punto la cadena polipeptídica. Estas enzimas se dividen en dos grandes categorías según corten enlaces internos o terminales en endopeptidasas y exopeptidasas, respectivamente. • Endopeptidasas: • Dependen del primer aminoácido del enlace, es decir, que cortan el enlace aa1−C−N−aa2 según cómo sea aa1. Se dice que cortan detrás de: • Tripsina: Corta detrás de Lys y Arg, es decir de aminoácidos básicos con carga, y siempre que detrás no haya un prolina. Es altamente específica y la imposibilidad de cortar antes de prolina se debe a la cadena lateral ciclada. Se encuentra en el estómago y es especialmente activa a pH 2. • Quimiotripsina: Corta detrás de Phe, Tyr, Trp y Leu, es decir aminoácidos aromáticos o muy hidrófobos. Tampoco puede haber prolina detrás. • Clostripaína: Corta siempre detrás de arginina. • Dependen del segundo aminoácido del enlace, es decir, cortan el enlace aa1−C−N−aa2 según cómo sea aa2. Se dice que cortan delante de: • Pepsina: Corta delante de aminoácidos aromáticos o muy hidrófobos y también de aminoácidos ácidos: Phe, Tyr, Trp, Leu, Asp y Glu; y siempre que el aminoácido anterior no sea la prolina. Sustituye a la tripsina en el intestino y es activa a pH 7. • Termolisina: Corta delante de aminoácidos aromáticos y alifáticos (con cadena lateral de hidrocarburo simple) siempre que sean ramificados: Phe, Tyr, Trp, Leu, Ile y Val. Tampoco puede haber una prolina antes. 18 • Exopeptidasas: Sólo se enumeran dos carboxipeptidasas, pero hay muchas más: • Carboxipeptidasa A: Corta todos los extremos C−terminales excepto si son residuos de aminoácidos básicos con carga a pH fisiológico o prolina, es decir, corta los extremos que no sean Arg, Lys o Pro. Aunque la histidina también es un aminoácido básico, la forma mayoritaria está desprotonada y sin carga a pH fisiológico, lo que unido a su rareza la excluyen de la lista antes mencionada. Además de esto, no cortará ningún extremo si el resto anterior es uno de prolina. • Carboxipeptidasa B: Corta todos los extremos excepto los que sean de aminoácidos básicos con carga (otra vez sin His) o de cisteína, es decir, corta los extremos que no sean Arg, Lys o Cys, y tampoco cortará si hay un resto de prolina anterior. Los métodos de rotura parcial química se pueden resumir en los siguientes: • Bromuro de cianógeno (BrCN): Es altamente específico y corta siempre por el lado carboxilo de metionina, es decir, corta detrás de metionina. • Hidracinolisis: Es una hidrólisis total si se utiliza en exceso. Si no se rompe al azar. • Degradación de Edman: Es la hidrólisis selectiva del extremo N−terminal. • Ácido fórmico: hidroliza los enlaces Asp−Pro. • N−clorosuccinimida: Hidroliza en posiciones de triptófano. Los distintos péptidos generados en la hidrólisis parcial se tienen que separar por cromatografía de intercambio iónico, papel o filtración molecular o por electroforesis en geles de poliacrilamida con un tamaño de poro pequeño (15% a 20%), pero lo mejor para separar dos muestras procedentes de distintos tipos de hidrólisis parcial es realizar un mapa peptídico o experimento de huella, que consiste en realizar una primera dimensión cromatográfica y una segunda dimensión electroforética. Con esto se consigue una separación aceptable de los distintos fragmentos, de los que a continuación se obtiene su secuencia siguiendo el método de la degradación de Edman. Con todos los datos obtenidas de la secuenciación se tiene que poder llegar a dos sucesiones iguales de aminoácidos, cada una con la misma secuencia, pero formadas por los fragmentos procedentes de un solo método de hidrólisis parcial. Este proceso equivale al de encajar un rompecabezas. Si los resultados de la secuenciación no son concluyentes, puede ser necesaria una tercera hidrólisis parcial siguiendo otro método diferente a los anteriores. La localización de los puentes disulfuro se lleva a cabo mediante una electroforesis diagonal de los distintos péptidos producidos por una hidrólisis parcial cualquiera, en la que la primera dimensión se mantienen los enlaces disulfuro, pero que al cargar la segunda dimensión se reducen con ácido perfórmico, con lo que donde aparezca un punto desdoblado es que había un enlace. Estos fragmentos se recortan y secuencian para determinar las cisteínas responsables de los enlaces disulfuro, tomando como patrón la proteína entera previamente sintetizada. Síntesis química de péptidos. Los péptidos se sintetizan químicamente para obtener anticuerpos, hormonas y vacunas sintéticas, así como para determinar la función de segmentos de proteínas nuevas o purificadas. Como los aminoácidos tienen al menos dos grupos reactivos, hay que ir protegiendo los que convenga en cada una de las etapas de la síntesis. Actualmente se sigue el procedimiento de Merrifield, por el que ganó un premio Nobel, aunque el trabajo lo realizan máquinas automáticas. Con este método se sintetizan los péptidos al revés de cómo se realiza en las células, es decir, se comienza por el extremo C−terminal y se van uniendo de cada vez los aminoácidos que están antes en la secuencia. Primero se tiene que unir el último aminoácido mediante su extremo C−terminal a una resina de poliestireno, 19 con lo que queda anclado a ella (esto fue lo que dio el premio a Merrifield) y, además, se protege su grupo carboxilo. Previamente su grupo amino se ha protegido con cloruro de terbutiloxicarbonilo (TBOC) para que no reaccione con la resina, pero ahora interesa dejarlo al descubierto, con lo que se lava el aminoácido unido a la resina con ácido tricloroetanoico para liberar el extremo amino. Este proceso se lleva a cabo sobre un filtro porque la resina no puede pasar a su través, con lo que es mucho más cómodo que una síntesis en fase líquida. Al lavar la resina se libera el TBOC como CO2 y metilbutano. Una vez se tiene el aminoácido fijado con su extremo amino libre, hay que ponerlo en contacto con el otro aminoácido. Éste también viene con su extremo N−terminal protegido con TBOC, pero su extremo C−terminal está activado con diciclohexilcarbodiimida, que al condensarse con el amino del aminoácido unido se libera en forma de diciclohexilurea. De este modo se consigue un dipéptido unido a la resina por su extremo C−terminal y con el extremo N−terminal protegido con TBOC. Para continuar la síntesis se vuelve a lavar la resina con ácido tricloroetanoico y a repetir los pasos anteriores. Este método permite buenos rendimientos si no se sobrepasan los veinte aminoácidos sintetizados, pero baja drásticamente al aumentar el número, así como con la inclusión de lisina, porque tiene otro grupo amino sobre el que se podría añadir el aminoácido, en lugar de sobre el grupo amino normal. Plegamiento proteico. Causas del plegamiento. Las fuerzas que guían el plegamiento de una cadena polipeptídica son todas interacciones débiles debidas al reconocimiento intramolecular entre partes de la misma molécula. Para que este reconocimiento se produzca debe haber complementariedad espacial y una unión de fuerzas. El plegamiento se realiza en un entorno celular. Aunque la secuencia de aminoácidos determina en gran medida el plegamiento y, por tanto, la forma final de la proteína, no hay que olvidar que ésta se encuentra en un medio celular, en el que tiene algunas facilidades y limitaciones. Para empezar, en el citoplasma existen unas proteínas que ayudan a la cadena polipeptídica a comenzar su plegamiento y, en cierto modo, restringen el número posible de conformaciones para un segmento concreto de la proteína a unas cuantas que son rápidamente accesibles. Con esto se consigue una necesaria rapidez hasta llegar a la forma definitiva y, además, se procura que los elementos de los que luego se vaya a componer la proteína sean unos cuantos, y no todos los posibles. No podemos olvidar que el entorno de plegamiento es básicamente agua. En ella la constante dieléctrica es cercana a ochenta, con lo que todas las interacciones de los grupos R entre ellos y con el agua van a estar muy limitadas, si son iónicas. Por esto el principal motor del plegamiento proteico son las interacciones más débiles: fuerzas de Van der Waals, puentes de hidrógeno e interacciones hidrofóbicas. Fuerzas de naturaleza entrópica y entálpica. Ya se ha adelantado que el entorno acuoso es determinante a la hora de plegar una proteína. En este medio las fuerzas electrostáticas o de carácter eléctrico, como son las que se dan entre grupos cargados, con un dipolo, entre dipolos, fuerzas de Van der Waals y puentes de hidrógeno, ven muy limitado su rango de acción. Esta limitación es más fuerte cuanto mayor sea la fuerza que la genera. De este modo no se van a encontrar nunca restos cargados en el interior de las proteínas, donde el entorno es apolar, porque su interacción con el agua es muy fuerte; otro tanto ocurre con los aminoácidos polares. Sin embargo, los restos no hidrófilos que pueden interaccionar entre sí mediante fuerzas de Van der Waals sí lo hacen, y se apilan en el interior de las proteínas 20 porque interaccionan muy débilmente con el agua. Además de estas consideraciones cabe destacar el puente de hidrógeno, que es una especie de interacción dipolo−dipolo en la que un átomo de hidrógeno se une a otro muy electronegativo (O, N), con lo que se genera un momento dipolar muy fuerte capaz de interaccionar con otro átomo electronegativo para compartir el protón (H+). Es un enlace muy direccional y se da en todos los carbonilos y aminas del enlace peptídico, lo que en el interior de las moléculas ayuda a mantener la estructura dado su carácter aditivo y son los principales mantenedores de la forma después de que la proteína se haya plegado, dando elementos periódicos repetitivos que conforman la estructura secundaria. No rebajan significativamente la energía porque la propia estructura les impide llegar a su mínimo energético, que es −4 Kcal/mol, y se quedan en −3 Kcal/mol. Se ha dicho que en un entorno acuoso las fuerzas de naturaleza entálpica antes mencionadas quedan apantalladas por la gran constante dieléctrica del agua. Por eso son las fuerzas de naturaleza entrópica las que ejercen y guían en mayor medida el plegamiento. Estas fuerzas responden a la naturaleza misma del agua, y su efecto es lo que anteriormente se conocía como fuerzas hidrofóbicas o interacciones hidrofóbicas que no son tales, sino sólo la consecuencia. De todos los restos de una proteína, los polares desordenan las moléculas de agua al formar la capa II de solvatación (recordar 1 Introducción), pero los apolares obligan a las moléculas del agua a ordenarse a su alrededor para formar una caja de solvatación. Esto disminuye la entropía del sistema, con lo que espontáneamente los restos apolares se apilan para formar una caja de solvatación común con menos moléculas de agua ordenadas, dentro de la cual ya no se siente la gran constante dieléctrica, que puede bajar a niveles cercanos a 1. Esto refuerza la unión por fuerzas de Van der Waals o por puentes de hidrógeno y estabiliza esa parte de la proteína ya plegada. Balance energético del plegamiento. Los términos entrópico y entálpico de la proteína se tienen que sumar a los del agua. De esto se observa que la proteína disminuye bastante su entropía, pero el agua la aumenta enormemente porque el efecto hidrofóbico se une al desorden de la capa II de solvatación creada en torno a residuos polares. El balance energético es comparativamente menor que la ganancia de entropía, lo que da idea de la importancia de este término para juzgar la espontaneidad en el plegamiento proteico. Una manera de adivinar dónde van a quedar los aminoácidos una vez plegada la proteína es usando la relación que existe entre el tamaño y la superficie molecular accesible al agua, utilizando el radio de Van der Waals como referencia. Cuanto mayor sea esta superficie, mayor tendencia a estar en el interior tiene el aminoácido y por tanto mayor hidrofobicidad. Con éste y otros datos se pueden construir tablas de hidrofobicidad e hidrofilicidad y combinarlas para dar tablas de hidropatía, en las que los valores negativos y positivos indican el carácter apolar o polar del aminoácido en cuestión. De todo lo anterior se puede deducir si un resto va a quedar expuesto al agua o por el contrario va a quedar dentro de la proteína, así como la espontaneidad del plegamiento. Mantenimiento de la estructura. Las fuerzas que mantiene la integridad conformacional y, por tanto, funcional de la proteína, son cooperativas e intervienen en el interior de la proteína una vez que se ha plegado. Esto se comprueba en los diagramas de desnaturalización por calor, en los que se ve cómo al llegar a una temperatura crítica de fusión Tm (de melting, fusión en inglés), se provoca la rotura de algunos puentes de hidrógeno que hacen que el resto colapse como un castillo de naipes que estaba en equilibrio y le quitan una sola carta del medio. Puentes disulfuro. Si después de que una proteína se haya plegado se encuentran cerca dos residuos de cisteína, entonces cabe la 21 posibilidad de oxidar ambos átomos de azufre y unirlos covalentemente, entrecruzando la estructura proteica entre dos puntos cercanos en el espacio aunque distantes en la secuencia. La formación de este puente disulfuro está a cargo de la enzima proteín−disulfuro isomerasa, que es uno de los llamados catalizadores del plegamiento proteico y que se encuentra en el retículo endoplásmico, del que es un marcador. Esta unión transforma los dos residuos de cisteína en un residuo de cistina, que es el aminoácido doble que surge. Elementos de estructura proteica. Niveles estructurales en proteínas. • Estructura primaria: Secuencia de aminoácidos. • Estructura secundaria: Disposición regular del esqueleto polipeptídico en unidades definidas por una periodicidad en los ángulos de enlace ð y ð. • Estructura supersecundaria: También llamada motivos estructurales. Son agregados físicos preferenciales de varios elementos de estructura secundaria contiguos. • Dominios: Regiones globulares diferenciables en la estructura tridimensional de una proteína. Surgen de la unión de varios motivos, generalmente contiguos. • Estructura terciaria: Disposición espacial de dos o más dominios. • Estructura cuaternaria: También llamada agregados proteicos. Son la unión de varias cadenas polipeptídicas mediante fuerzas débiles o enlaces disulfuro para formar una entidad superior con funciones diferenciables de las de cada polipéptido de los que se compone. Estructura secundaria. Incluye grupos lineales helicoidales o planos, además de los acodamientos ð que cambian la dirección del esqueleto polipeptídico. Todos los grupos lineales, incluyendo los planos, se pueden definir según los parámetros de una hélice: • Número de aminoácidos necesarios para llegar a una situación en la que se repiten las características periódicas. Equivale a el número de aminoácidos por vuelta de hélice: n. • Incremento de altura que proporciona cada aminoácido al elemento lineal de estructura secundaria. Equivale a la proyección de la distancia longitudinal de cada aminoácido sobre el eje de una hélice: d. • Paso de rosca. Equivale a la distancia longitudinal que se tiene que recorrer sobre la hélice para encontrarse en la misma situación periódica: p = n · d. • Anchura del grupo lineal, tomando como referencia el esqueleto polipeptídico, no los grupos R. Equivale al diámetro que tendría la hélice y, por tanto, al doble del radio r. Hélices. Hay varios elementos de estructura secundaria que adquieren una forma real de hélice, de los que el más abundante es la hélice ð, hipotetizada por Pauling y posteriormente demostrada su existencia mediante Cristalografía. Es una varilla sólida, no hueca, con arrollamiento dextrógiro, en la que los átomos ocupan todo el centro y se exponen hacia fuera todos los grupos R. En ésta como en todas las hélices se establecen puentes de hidrógeno entre los átomos del esqueleto polipeptídico dentro de ella misma. En este caso se establecen entre el carbonilo del residuo i y el amino del residuo i + 4. La periodicidad comienza desde el carbonilo de uno de los aminoácidos y desde allí se mantiene cada 3,6 residuos por vuelta, con los ángulos ð = −45º y ð = −60º. El paso es de 0,56 nm. La mayoría de las hélices ð tienen 7 u 11 residuos, que se corresponden con 2 ó 3 vueltas. Además, las hélices ð tienen momento dipolar, ya que todos los puentes de hidrógeno están alineados hacia el extremo carboxilo de la hélice. Esta distribución de la densidad de carga a lo largo de la hélice permite la unión de ligandos aniónicos a los extremos N−terminales de una hélice ð de su receptor correspondiente, porque allí los puentes 22 de hidrógeno no tienen con qué enlazarse y están accesibles a una posible interacción. Esta capacidad de unir ligandos puede ser un mecanismo de regulación de la función proteica, y de hecho se observa en receptores de la superficie celular. Hay aminoácidos que tienen mayor probabilidad de aparecer en una hélice ð que otros, como son Glu, Met, Ala y Leu, y también hay otros que se consideran rompedores de hélices, como Pro por tener su ángulo ð bloqueado, y Ser y Thr porque sus grupos OH pueden establecer puentes de hidrógeno con el esqueleto polipeptídico y desestabilizar la estructura helicoidal; otro tanto podría decirse de los grupos cargados de Asn y Asp. Las representaciones en espiral permiten saber las interacciones y posibles localizaciones de las hélices en la estructura proteica, así como saber hacia dónde se encaran, si hacia dentro o al agua, según sean hidrófobas, hidrófilas o anfipáticas. Hay más tipos de hélice, en los que cambian los parámetros de ð y ð. Éstos son la hélice 310, la hélice ð levógira y la hélice ð. De estas tres sólo la primera es una estructura real. La segunda es una rarísima excepción y la tercera, aunque teóricamente posible, no existe. La razón de esto último reside en que para alojar más residuos por vuelta, que es lo que ocurre en una hélice ð, se necesita aumentar el radio de la hélice, con lo que los átomos se alejan y ya no es posible la estabilización de la estructura mediante interacciones de Van der Waals entre los átomos del esqueleto polipeptídico y a través del eje de la hélice, como ocurre en las hélices ð. La hélice 310 es una hélice dextrógira con tres residuos por vuelta en la que los puentes de hidrógeno se establecen entre el carbonilo i y el amino i + 3, con lo que no están exactamente alineados. Son hélices cortas que generalmente aparecen en los extremos de hélices ð, con pocos residuos que casi nunca pasan de la vuelta. Es bastante restringido el número de restos que caben en una hélice 310, porque la estructura apila los grupos R unos encima de los otros, y no al tresbolillo como en las hélices ð, con lo que si son muy voluminosos se distorsiona la hélice. Grupos lineales ð. La estructura se puede asimilar a una hélice muy estirada de sólo dos residuos por vuelta y de sólo 1 Å de radio. Con estos parámetros se consigue una estructura lineal en forma de línea quebrada en la que los grupos R se disponen alternativamente hacia arriba y hacia abajo del plano teórico que pasaría por el eje de la hélice. Evidentemente. Los puentes de hidrógeno ya no se pueden establecer entre átomos del mismo grupo lineal, sino que tienen que ser con grupos lineales ð adyacentes. Éstos se pueden disponer de manera paralela o antiparalela, siendo este último el modo en que los puentes de hidrógeno son totalmente lineales. La unión de dos o más grupos lineales ð define una lámina ð, de la que alternativamente salen los grupos R arriba y abajo del plano quebrado que se forma. Los grupos lineales de los extremos de una lámina sólo pueden formar la mitad de puentes de hidrógeno, porque sólo tienen un grupo lineal a su lado. En ese caso se establecen puentes de hidrógeno con otra estructura se la misma proteína, con el agua o con la misma lámina ð cerrada sobre sí misma. Esto último puede ocurrir si se compone de al menos 8 grupos lineales. Dependiendo de la naturaleza de los residuos, puede haber láminas ð hidrofóbicas o anfipáticas, según cómo sea cada uno de los lados que se puede considerar. Cada grupo no suele tener más de siete residuos, y se pueden mezclar paralelos y antiparalelos en una misma lámina, aunque no es muy frecuente. Las explicaciones anteriores se refieren a grupos lineales ð y láminas ð totalmente extendidas y rectas, en los que los ángulos de ð y ð se sitúan en la misma línea que va desde el centro a la esquina superior izquierda de la representación de Ramachandran. Sin embargo, lao corriente es encontrarse con grupos lineales ð retorcidos, en los que se acumula una pequeña diferencia de giro entre el aminoácido n y el n + 1, por lo que los grupos lineales se tienen que asociar formando un ángulo de unos 25º para formar láminas, ya que si no, 23 no se pueden establecer puentes de hidrógeno entre ellos. Esta torsión genera que el plano de la lámina ð tenga concavidad y convexidad, y se pueda hablar de un arriba y un debajo del plano. Además, esta geometría de planos torcidos provoca que la conectividad entre dos grupos lineales paralelos siempre se haga a derechas y por encima del plano que definen. De estos grupos lineales no suele haber más de siete por lámina, y no más de siete residuos por grupo lineal, generalmente impares (3, 5 ó 7). Codos. Son elementos de estructura secundaria que rompen la linealidad de los otros dos elementos descritos anteriormente. Hay tres tipos de acodamientos, de los que el tipo III es un tramo de una hélice 310, y los de tipo I y II son una distorsión de aquélla. En todos los casos la estructura se estabiliza mediante un solo puente de hidrógeno entre el carbonilo i y en amino i + 3. La diferencia entre el tipo II y el tipo I es que el primero tiene el enlace entre n + 1 y n + 2 girado 180º, con lo que se provoca el acercamiento del carbonilo i + 1 al grupo R del aminoácido n + 2. Esto se soluciona colocando glicina en la posición n + 2, ya que su R es un átomo de hidrógeno, y generalmente n + 1 es prolina, que con su ángulo ð fijado permite este tipo de acodamientos. Viendo la secuencia de aminoácidos se puede detectar fácilmente un acodamiento si se lee PG, ya que es una combinación muy poco frecuente y que sólo aparece en este tipo de estructuras. La frecuencia relativa de aparición de cada tipo es: • I: 35%. • II: 15%. • III: 15%. • Otros giros no estructurados: 35%. Los centros activos de las enzimas suelen estar en los acodamientos y, además, suelen estar en el exterior estableciendo interacciones con el agua y suelen marcar los límites de los exones. Diagramas y representaciones estructurales. La estructura de un polipéptido o de una proteína se puede representar mediante las coordenadas atómicas, que da mucha información pero es extremadamente complicado de manejar a no ser que se busquen datos concretos. El extremo opuesto es la representación sólo del esqueleto polipeptídico, con lo que se pueden adivinar los huecos donde se pueden alojar los grupos prostéticos. Una representación intermedia consiste en plasmar el esqueleto polipeptídico como si fuera una cinta hecha a base de planos que contienen los enlaces peptídicos. Con esta representación se pueden ver y observar muy bien los elementos de estructura secundaria, pero no los de mayor entidad. La representación más utilizada y que mejor describe la estructura tridimensional de una proteína es la que representa las hélices ð por cilindros y los grupos lineales ð por flechas planas. Con esta representación se advierten todos los elementos estructurales salvo la estructura primaria. Los diagramas de topología muestran esquemáticamente las relaciones entre los grupos lineales ð, lo que permite comparar fácilmente estructuras que en principio no tienen parecido, y asimilar analogías estructurales con analogías funcionales y homologías evolutivas. Esto permite realizar taxonomía molecular a partir de los datos de la estructura. Estructura supersecundaria. También llamados motivos, aparecen en el plegamiento como una asociación de varios elementos de estructura secundaria que son consecutivos en la secuencia. 24 Motivo EF. Recibe ese nombre porque el primer sitio donde se describió fue en la parvalbúmina, cuyas hélices ð E y F se asocian de manera característica. También recibe el nombre de hélice−bucle−hélice (helix−loop−helix). La parvalbúmina es una proteína que liga calcio justo en el bucle, que es de unos doce restos. Como ella, otras proteínas que también ligan calcio, como la calmodulina y la troponina, también tienen este motivo y a él se une el calcio gracias a la gran cantidad de aminoácidos ácidos cargados negativamente y las interacciones dipolares con los carbonilos del enlace peptídico. En el centro del bucle tiene que haber una glicina totalmente conservada para permitir el giro. Además, el final de la hélice E y el comienzo de la F son anfipáticos, de modo que las regiones apolares se solapan y unen las dos hélices como si fueran los dedos de una mano. Los factores de transcripción de genes son un pequeño péptido que precisamente consta de dos hélices ð unidas mediante un bucle. Es decir, constan de un solo motivo que es éste, con la salvedad de que en ellos el bucle no es tan grande y no liga calcio. Estos factores de transcripción funcionan introduciendo una de las dos hélices en el surco mayor del ADN y leyéndolo hasta encontrar su sitio de unión. Existe una correlación entre motivos estructurales y la estructura primaria, de modo que se pueden detectar en la propia secuencia de aminoácidos. Por esta razón se llama motivos también a estos segmentos de la estructura primaria que luego generan la estructura supersecundaria, pero no hay que confundirlos. Espiral múltiple de hélices ð. Llamado coiled coil en inglés (enrollamiento enrollado), consiste en el enrollamiento levógiro de dos a cinco hélices ð, tanto paralelas como antiparalelas para generar una superhélice que en el caso de dos hélices paralelas tiene un paso de rosca de 140 Å. Aparece en proteína fibrosas como la ð−queratina y es el elemento de dimerización de factores de transcripción como fos y jun, donde este motivo se llama cremallera de leucina. La dimerización es posible porque las hélices son anfipáticas y aparece leucina cada siete aminoácidos, que es algo más de dos vueltas. Como no se colocan los restos de leucina exactamente uno sobre otro a lo largo del eje de la hélice, hace falta una torsión para permitir la dimerización y que las leucinas de ambas hélices ð encajen en los huecos que hay en la otra hélice cada cuatro restos. Los residuos que flanquean ese núcleo hidrófobo definido por las leucinas están cargados e interaccionan entre sí y con el agua para mantenerse unidos. En un superenrollamiento de hélices ð se pueden definir parámetros como el ángulo de cruce entre las dos hélices, y el de cada una de ellas con el eje de la superhélice (10 a 20º). Hay muchas proteínas que recurren a esta solución estructural, por ejemplo, la tropomiosina tiene dos hélices paralelas, la hamaglutinina tiene tres paralelas, la ADN polimerasa I tiene dos antiparalelas, el represor del operón de lactosa tiene cuatro antiparalelas. En el caso de las hélices antiparalelas los residuos de unión entre hélices se sitúan justamente intercalándose, y no al tresbolillo como en la unión de hélices paralelas. Unión de grupos lineales ð. La unión genérica es ððð, donde ð puede ser: • Un segmento sin estructura: ðcð. • Una hélice ð: ððð. • Un grupo lineal ð: Meandro ð. • Un codo: Horquilla ð. La unión entre los distintos elementos de estructura secundaria nunca se hace directamente, sino que siempre hay unos cuantos restos de unión sin conformación definida, y que justamente son los críticos para la 25 funcionalidad de la proteína. Los grupos ððð envuelven un espacio hidrófobo entre el plano de la lámina y la hélice, por lo que ésta tiene que ser anfipática. El carácter hidrófobo o anfipático de la lámina ð depende de lo que tenga por debajo de ella, ya que por encima al menos, la parte que se encara a la hélice ð sí tiene que ser hidrófoba. La sucesión modular de este motivo genera el desplazamiento de Rossmann, que apoya la teoría de la generación modular de las proteínas, a base de ir uniendo elementos estructurales en entidades cada vez mayores. La sucesión de grupos lineales ð en horquillas puede generar barriles ð, en los que la lámina es anfipática, o plegamientos más complejos como el de las inmunoglobulinas. La unión de grupos lineales ð paralelos mediante una hélice ð siempre se hace a derechas, quizás por la propia torsión del grupo ð. Además, siempre se hacen por encima del plano porque es la manera te liberar tensión del grupo lineal. Dos grupos lineales antiparalelos consecutivos siempre se unen mediante una horquilla. Los elementos próximos en la estructura primaria suelen estar también próximos en la estructura secundaria y supersecundaria, de la que surgen los dominios por agrupamiento. Dos horquillas adyacentes se pueden unir entre sí de doce modos diferentes, sin embargo, los más corrientes son la unión directa y la unión en greca, con frecuencias 50%, 25%, 25%. Algunos autores sugieren que la greca ha surgido como una torsión en una sola horquilla larga después de que se hubiera producido una inserción. Proteínas fibrosas. Suelen ser proteínas simples y repetitivas destinadas a misiones estructurales. ð−queratina. Son ubicuas en mamíferos. Se encuentran en el pelo, las uñas y la piel. Su estructura es una hélice ð típica, que luego se enrolla con otra para producir una protofibrilla que se asocia con otras y produce filamentos gruesos de queratina, que son el componente principal del pelo. La diferencia en la dureza del pelo y de las uñas depende del número de puentes disulfuro que se establezcan. ð−queratina. Aparece en la seda y en las plumas de aves y las escamas de los reptiles. Es una repetición de GSGAGA y forma láminas ð que se apilan unas sobre otras encarando los lados iguales, produciendo bandas estrechas y anchas. Colágeno. Es la proteína más abundante en los mamíferos, donde forma el tejido conjuntivo y la matriz extracelular. Está diseñada para resistir grandes tensiones. Estructuralmente es una repetición de GXY y contiene mucha prolina, alanina y aminoácidos modificados como hidroxiprolina (Hyp) e hidroxilisina (Hyl). Un solo polipéptido no tiene estructura secundaria, por lo que necesita asociarse a otros dos para adquirirla. De este modo una molécula de colágeno es un trímero en forma de hélice dextrógira, en que cada monómero es otra hélice levógira y muy estirada, de sólo 1,6 Å de radio, 2,9 Å de paso de rosca y 3,3 restos por vuelta. La estructura se mantiene estable gracias a que se conserva un resto de glicina cada tres aminoácidos, justo donde contactan los monómeros. Esto permite su acercamiento y el establecimiento de enlaces de hidrógeno entre cadenas, que atañen al amino de la glicina y al carbonilo del aminoácido X de otra cadena. 26 Hay cinco tipos de colágeno según las combinaciones de dos tipos de cadena, que son producto de dos genes distintos: ð1 y ð2. Además, hay cinco alelos de ð1: I, II, III, IV y V, y dos de ð2: I y V. Hay muchas hidroxilaciones en el colágeno, además de otras modificaciones posttraduccionales como glucosilación o el entrecruzamiento covalente. La finalidad de las hidroxilaciones es aportar grupos capaces de formar enlaces de hidrógeno y, por tanto, estabilizar la estructura. La variación en la hidroxilación también influye en el tipo de colágeno, ya que el número de hidroxilaciones influye mucho en la dureza del tejido final. Después de la síntesis en el retículo endoplásmico rugoso, la prolina se hidroxila gracias a la prolil hidroxilasa, que incluye oxígeno molecular a la vez que oxida ð−KG a succinato. La reacción requiere vitamina C como cofactor. La lisina también se hidroxila de modo parecido con la lisil hidroxilasa. Los productos de ambas reacciones son 4−hidroxiprolina y 5−hidroxilisina. La falta de vitamina C provoca una falta de hidroxilación, con lo que el tejido conjuntivo se vuelve frágil y aparecen los síntomas del escorbuto: caída de pelo, encías sangrantes, dientes flojos. Por esto los marinos llevaban en los barcos frutas frescas que tienen vitamina C. La Hyl se glucosila en su paso por el Golgi, primero con ðGal con una galactosil transferasa, y luego con ðGlc mediante una glucosil transferasa. Con esto queda el oligosacárido ðGlc(1−2)ðGal−N−Lys. No se sabe muy bien por qué se hidroxila así la Hyl, pero el hecho de que ocurra en los extremos de las fibras de colágeno sugiere que tenga algo que ver con el empaquetamiento de estas fibrillas. Para aguantar la tensión los monómeros se entrecruzan covalentemente mediante puentes entre lisinas. Para esto la lisil oxidasa realiza una desaminación oxidativa sobre el ð−amino de un residuo de lisina para formar allisina, que es su aldehído derivado. Ésta forma una base de Schiff con otra lisina cercana, que luego se reduce y queda un puente de lisina equivalente a un puente disulfuro. Además, también se da entrecruzamiento entre allisina y el enol−derivado de la allisina mediante una condensación aldólica (recordar 2 Glúcidos). La falta de entrecruzamiento provoca una enfermedad llamada latiguismo, que se sufrió después de la Guerra Civil porque se comía harina de semilla de altramuz, que tiene ð−aminopropionitrilo que es un tóxico muy potente para la lisil oxidasa porque se une a su centro activo. La fibrilla de tropocolágeno, la triple hélice, sólo tiene el 60% de los aminoácidos codificados. Esto se explica porque se eliminan los cien primeros residuos N−terminales y los trescientos últimos C−terminales. Esto se entiende porque los primeros residuos llevan el péptido señal para dirigir la proteína a excreción, y no se necesitan en la proteína nativa, pero el caso de los últimos residuos es curioso, porque tiene muchos residuos de cisteína que establecen enlaces disulfuro entre las tres cadenas para favorecer el comienzo de la adquisición de la estructura típica del colágeno. Después de que la molécula ya está formada, el extremo C−terminal no sirve de nada y se elimina. En la matriz las moléculas de tropocolágeno se ensamblan en fibrillas en las que cada hueco entre moléculas está ligeramente desplazado de respecto al de la fibrilla de al lado. Esto origina un patrón de bandas claras y oscuras donde no haya o haya material denso al paso de electrones y, por tanto, huecos. El colágeno sigue la vía exocítica con transporte cotraduccional, y después de sintetizado se hidroxila y al pasar al retículo endoplásmico liso se glucosila, pasando a ser precolágeno. En el Golgi empiezan a unirse los monómeros y a entrecruzarse, y al ser secretado todavía tiene los extremos N− y C−terminales, con lo que es procolágeno. Después de que las peptidasas de la matriz lo hidrolicen se tiene tropocolágeno, o colágeno a secas. Es un ejemplo de transformaciones posttraduccionales. Elastina. Tiene un alto porcentaje de glicina (30%), aminoácidos hidrófobos como alanina y valina (30%) y también incorpora prolina. Tiene muchas modificaciones posttraduccionales. 27 Es la excepción a la regla de que las proteínas funcionan gracias a una estructura fija, ya que su función es no tener estructura. Tiene tal cantidad de glicina que no tiene una conformación estable, sino muchas y muy variadas porque nunca llega a un mínimo relativo de energía. Por esto todas las moléculas de elastina son distintas. En la matriz hay una sopa de moléculas de elastina que se entrecruzan cono el colágeno y, además, a través de residuos de desmosina, formados a partir de tres allisinas más una lisina. Esto unido a la falta de conformación de la elastina hace que se forme una malla tridimensional extensible en dos y tres direcciones. Se encuentra en los vasos sanguíneos y otros sitios donde se requiere estiramiento. La desmosina tiene un heterociclo que le da color amarillo. Dominios. Son cada una de las regiones globulares claramente diferenciadas en la estructura tridimensional de una proteína. Son regiones concretas que se distinguen en un mapa de difracción de rayos X. Es la unidad básica del plegamiento independiente. Es una zona del polipéptido que origina una región globular. Generalmente tienen una función característica, por lo que se pueden asimilar a una función biológica definida. La disposición en el espacio de los dominios de una proteína determina la estructura terciaria. Los dominios son elementos estructurales discretos y sencillos que parecen surgir de un origen común, sugiriendo un origen modular de las proteínas, cada uno con una función que aporta una solución estructural para un problema determinado y se unen para dar una proteína funcional y con el efecto deseado. Cada familia de proteínas con una misma función tiene siempre un mismo dominio común. La evolución fue diversificando las proteínas a nivel de recombinación y unión modular de dominios en el ADN, desde la solución estructural simple hasta la unión de varios dominios en una sola proteína. Los dominios se clasifican según los tipos y disposición de los elementos de estructura secundaria. También se pueden clasificar según el número de capas de proteína y, por tanto, del número de entornos hidrófobos que generan. Esta clasificación hace hincapié en la importancia de las interacciones hidrofóbicas en el plegamiento. Tipo I. Sólo tienen hélices ð, por lo que forzosamente son antiparalelas: • Arriba−abajo: Entramado con poco ángulo, es como si fueran horquillas ð. • En greca o de hélices cruzadas: El ángulo de cruce de las hélices es fuerte, en torno a 50 ó 60º. El primer subtipo acumula los residuos hidrófobos entre las dos hélices, dejando los que están expuestos como residuos hidrófilos. Por esto son hélices ð anfipáticas. Sin embargo, en el segundo subtipo las hélices ð no lo son tanto. En ambos casos es difícil saber dónde va a estar el centro activo de la enzima, aunque suele encontrarse entre las dos hélices. Tipo II. Surgen de la combinación de grupos lineales ð y hélices ð. Realmente se pueden considerar una repetición variada de motivos ððð, con lo que todos los grupos lineales ð son paralelos, así como todas las hélices ð, pero los unos con las otras son antiparalelos. Hay dos subtipos: • Barril ðð o arrollamiento sencillo: El plegamiento sigue siempre el mismo sentido. Los grupos ððð se unen consecutivamente. • Silla de montar o arrollamiento doble: El plegamiento no es constante. La unión de los grupos ððð se 28 realiza al menos una vez mediante un salto en la correlación con la secuencia. El resultado es que una lámina ð queda flanqueada por hélices ð a ambos lados. En el primer subtipo, los residuos del barril ð interior son hidrófobos, y los del barril ð exterior anfipáticos. El interior del barril está totalmente lleno de los grupos R que salen hacia dentro. Parece ser que el barril ðð es un caso de convergencia estructural, aunque no es seguro. El centro activo está formado por todos los bucles de conexión entre los grupos lineales ð y las hélices ð, y no al revés. Estos restos son el objeto de la ingeniería de proteínas, ya que si se mantienen los elementos estructurales, cambiando los segmentos sin estructura (bucles) se pueden conseguir distintas afinidades. El segundo subtipo difiere principalmente de los barriles ðð en que el centro activo se sitúa entre los bucles de los grupos ð a las hélices ð, pero sólo de los que están en el cambio de sentido del plegamiento. Esto se ve bien en los diagramas de topología. Tipo III. Formado sólo por grupos lineales ð, por lo que son necesariamente antiparalelos: • Arriba−abajo: Sólo horquillas. • Con grecas. Se encuentran en muchas proteínas distintas, principalmente de transporte de moléculas apolares. Realmente la mayoría de las veces son dos láminas ð que se unen en forma de barril o de bocadillo. El barril permite disponer moléculas dentro, por lo que los grupos lineales son anfipáticos para poder encararse al exterior. En este apartado hay que destacar la importancia de la relación entre forma y función. La proteína que une retinol (RBP: retinol binding protein, en inglés) y lo transporta en la sangre desde el hígado hasta donde haga falta, es un barril ð antiparalelo. La ð−lactoglobulina de la leche no se sabía qué hacía, pero tenía la misma estructura que la RBP, con lo que se supuso que servía para llevar retinol a los lactantes, y se vio que es así porque hay un receptor para ese complejo en el intestino, y después se comprobó en más estudios. El segundo subtipo también puede formar barriles, pero no están abiertos, sino que están tapados por los segmentos de conexión entre los distintos grupos lineales. Por esta razón no sirven para transporte. Una vez más el centro activo se encuentra en estos segmentos. Estructura terciaria. Cada dominio suele ser producto de una sección única de la cadena polipeptídica con plegamiento independiente, pero también se generan por secciones no consecutivas en la secuencia. El centro activo suele estar en la interfase entre dominios porque cada uno realiza una función definida. Si sólo hay un dominio hay identidad con la estructura terciaria. Estructura cuaternaria. Se da por la asociación de proteína de la que surgen funciones, regulaciones y características nuevas mediante el fenómeno del alosterismo, que es la modulación de la actividad del complejo entero por la variación en la actividad de uno de los monómeros al haber unido algún ligando o substrato, y que se transmite a los demás mediante las fuerzas de unión entre ellos. Las interfases entre polipéptidos suelen ser hidrófobas y se asocian mediante fuerzas de Van der Waals y una necesaria complementariedad espacial. La gran ventaja de agrupar proteínas es que se pueden tener las enzimas de una sola ruta todas juntas, y evitar que los substratos tengan que difundir. 29 Proteínas globulares. Mioglobina. Monómero formado en un 80% por hélice ð. Constituye un dominio tipo I en greca o de hélices cruzadas. Tiene ocho hélices ð (A a H) y siete tramos de conexión (AB a GH). Todo el interior tiene restos apolares y el interior restos polares. Hay dos excepciones en dos histidinas E7 y F8 cargadas y encaradas al interior, flaqueando al grupo prostético hemo (Fe2+−protoporfirina IX). Cuatro de las hélices se rompen por prolina y el resto porque el hidroxilo de serina o treonina establecen puentes de hidrógeno con el amino del esqueleto polipeptídico. Tiene tres exones, de los que el central es el mayor y parece el responsable de unir hemo. Tratando la proteína con clostripaína, que corta por las arginina, se obtiene una miniglobina que contiene casi todo el exón central y es capaz de unir hemo. EL hemo es el isómero IX de la protoporfirina al que se une un catión Fe2+ estableciendo enlaces de coordinación con los nitrógenos del ciclo. Destacan dos radicales propiónico que sirven para tapar el hueco una vez instalado en su sitio. El anillo plano de hemo se introduce en un bolsillo hidrófobo entre las hélices 7 y 8 de tal modo que el Fe2+ enlaza con la HisF8 (histidina proximal) mediante un quinto enlace de coordinación, y la HisE7 (histidina distal) está cerca de la sexta posición de coordinación pero sin enlazar con el hierro. El hueco que deja es el justo para que una molécula de oxígeno entre y enlace formando un ángulo de 121º con el plano del hemo y el hierro quede totalmente sustituido. En ese momento el átomo de desplaza y pasa de estar 0,3 Å por debajo a estar 0,2 Å por encima del plano, lo que provoca un cambio conformacional en la proteína. El bolsillo hidrófobo evita que el Fe2+ se oxide, ya que si lo hace no funciona como transporte de oxígeno, y los radicales propiónico tapizan por fuera el entorno hidrófilo de la mioglobina. La HisE7 evita que entre donde el oxígeno ninguna otra cosa distinta. Además, disminuye la afinidad del hemo por el CO de 25000 a sólo 200 veces más que la afinidad por el O2, porque obliga al CO a formar un ángulo de 120º, y no de 90º, donde la interacción sería mayor. Con esto se consigue que el 99% de las moléculas estén saturadas de oxígeno y que no unan el CO que se produce endógenamente. Hemoglobina. Es un tetrámero 2ð2ð, cada una de las subunidades con estructura idéntica a la de mioglobina. Hay varios genes de hemoglobina que cambian su expresión y combinación durante el desarrollo. La actividad del tetrámero se regula con otra molécula, el 2,3−bisfosfoglicerato y que aparece en la estructura cuaternaria como un elemento nuevo de regulación. Respecto a la mioglobina se conservan los residuos críticos, como las histidinas y los comienzos y finales de las hélices, por lo tanto son los que ayudan a realizar la misión. Hay restos invariados, conservados y variables. Se puede hacer taxonomía molecular, que consiste en fabricar árboles de evolución y filogenia tomando como referencia los cambios observados en la secuencia de aminoácidos. Cuanto más importante sea la proteína menos cambios acumulará a lo largo del tiempo y más fácilmente se podrá asimilar su estudio a una evolución específica. Cuanto mayor sea la diferencia, anterior tiene que haber sido la divergencia. 30 31