Computación Cluster y Grid
Anuncio

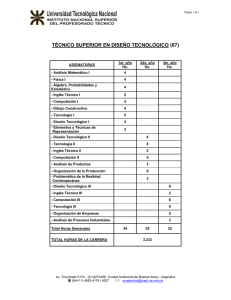
Computación Cluster y Grid Computación Cluster y Grid Gestión de Procesos 1 Gestión de Procesos Conceptos C t y taxonomías: t í Trabajos T b j y sistemas i t paralelos 2. Planificación Pl ifi ió estática: ái 1. Planificación de tareas dependientes Planificación Pl ifi ió d de tareas paralelas l l Planificación de múltiples tareas 3. Planificación dinámica: Equilibrado de carga Migración de procesos Migración de datos Equilibrado E ilib d d de conexiones i 2 Computación Cluster y Grid Escenario de Partida: Términos y Trabajos: T b j C j t d Conjuntos de ttareas ((procesos o hil hilos)) que demandan: (recursos x tiempo) y Recursos: R D t Datos, dispositivos, di iti CPU u otros t requisitos i it (finitos) necesarios para la realización de trabajos. y Tiempo: Periodo durante el cual los recursos están asignados (de forma exclusiva o no) a un determinado trabajo. j y Relación entre las tareas: Las tareas se deben ejecutar siguiendo unas restricciones en relación a los datos que generan o necesitan (dependientes y concurrentes) y Planificación: Asignación de trabajos a los nodos de proceso correspondientes. Puede implicar revisar, i auditar dit y corregir i esa asignación. i ió 3 Computación Cluster y Grid Escenario de Partida Recursos demandados Nodos (Procesadores) Tareas Trabajos OBJETIVO A i Asignación ió dde llos trabajos b j dde llos usuarios i a llos distintos procesadores, con el objetivo de mejorar prestaciones frente a la solución tradicional 4 Computación Cluster y Grid Características de un Sistema Distribuido y Sistemas Si t con memoria i compartida tid y Recursos de un proceso accesibles desde todos los p procesadores y Mapa de memoria y Recursos internos del SO (ficheros/dispositivos abiertos, puertos, etc.) y Reparto/equilibrio Reparto/eq ilibrio de carga (load sharing/balancing) automático a tomático y Si el procesador queda libre puede ejecutar cualquier proceso listo y Beneficios del reparto p de carga: g y Mejora uso de recursos y rendimiento en el sistema y Aplicación paralela usa automáticamente procesadores disponibles y Sistemas Si t distribuidos di t ib id y Proceso ligado a procesador durante toda su vida y Recursos de un proceso accesibles sólo desde procesador local y No sólo mapa de memoria; También recursos internos del SO y Reparto de carga requiere migración de procesos 5 Computación Cluster y Grid Escenario de Partida: Trabajos ¿Qué Q é se tiene ti que ejecutar? j t ? Tareas en las que se dividen los trabajos: y Tareas disjuntas y Procesos independientes y Pertenecientes a distintos usuarios y Tareas cooperantes y Interaccionan entre sí y Pertenecientes a una misma aplicación y Pueden presentar dependencias y O Pueden requerir ejecución en paralelo 6 Sistemas Operativos Distribuidos 6 Computación Cluster y Grid Tareas Cooperantes Dependencias D d i entre t tareas t y Modelizado por medio de un grafo dirigido acíclico (DAG). Tareas Ejecución Ej ió paralela l l y Implican un número de tareas concurrentes ejecutando simultáneamente: y De forma síncrona o Transferencia de datos y Ejemplo: Workflow asíncrona. y En base a una topología de conexión. y Siguiendo un modelo maestro/esclavo t / l o distribuido. y Con unas tasas de comunicación y un intercambio de mensajes. y Ejemplo: Código MPI 7 Sistemas Operativos Distribuidos 7 Computación Cluster y Grid Escenario de Partida: Objetivos ¿Qué Q é “mejoras “ j d de prestaciones” t i ” se espera conseguir? i? Tipología de sistemas: y Sistemas de alta disponibilidad y HAS: High Availability Systems y Que el servicio siempre esté operativo y Tolerancia a fallos y Sistemas de alto rendimiento y HPC: High Performance Computing y Que se alcance una potencia de cómputo mayor y Ejecución de trabajos pesados en menor tiempo y Sistemas de alto aprovechamiento y HTS: High Troughput Systems y Que el número de tareas servidas sea el máximo posible y Maximizar el uso de los recursos o servir a más clientes (puede no ser lo mismo). 8 Sistemas Operativos Distribuidos 8 Computación Cluster y Grid Sistemas de Cómputo y Dependen D d d de uso previsto i t d dell sistema: i t y Máquinas autónomas de usuarios independientes y Usuario U i cede d uso d de su máquina á i pero sólo ól cuando d está tá desocupada y ¿ ¿Qué ocurre cuando deja j de estarlo? y Migrar procesos externos a otros nodos inactivos y Continuar ejecutando procesos externos con prioridad baja yS Sistema dedicado sólo ó a ejecutar trabajos paralelos y Se puede hacer una estrategia de asignación a priori y O ajustar el comportamiento del sistema dinámicamente y Se intenta optimizar tiempo de ejecución de la aplicación o el aprovechamiento de los recursos y Sistema distribuido general (múltiples usuarios y aplicaciones) y Se S intenta i t t lograr l un reparto t de d carga adecuado d d 9 Sistemas Operativos Distribuidos 9 Computación Cluster y Grid Tipología de Clusters y High Hi h Performance P f Clusters Cl t y Beowulf; programas paralelos; MPI; dedicación a un problema y High Availability Clusters y ServiceGuard, Lifekeeper, Failsafe, heartbeat y High Throughput Clusters y Workload/resource managers; equilibrado de carga; instalaciones de supercomputación y Según servicio de aplicación: y Web-Service Clusters y LVS/Piranha; equilibrado de conexiones TCP; datos replicados y Storage Clusters y GFS; sistemas de ficheros paralelos; identica visión de los datos desde cada nodo y Database Clusters y Oracle Parallel Server; 10 Sistemas Operativos Distribuidos 10 Computación Cluster y Grid Planificación y La L planificación l ifi ió consiste i t en ell d despliegue li d de llas tareas de un trabajo sobre unos nodos del sistema: y Atendiendo a las necesidades de recursos y Atendiendo a las dependencias entre las tareas y El rendimiento final depende de diversos factores: y Concurrencia: Uso del mayor número de procesadores simultáneamente. y Grado de paralelismo: El grado más fino en el que se pueda descomponer la tarea. y Costes de comunicación: Diferentes entre procesadores dentro del mismo nodo y procesadores en diferentes nodos. y Recursos compartidos: Uso de recursos (como la memoria) comunes para varios procesadores dentro del mismo nodo nodo. 11 Computación Cluster y Grid Planificación y Dedicación D di ió d de llos procesadores: d y Exclusiva: Asignación de una tarea por procesador. y Tiempo compartido: En tareas de cómputo masivo con E/S reducida afecta dramáticamente en el rendimiento. Habitualmente no se hace. y La planificación de un trabajo puede hacerse de dos formas: y Planificación Pl ifi ió estática: táti I i i l Inicialmente t se d determina t i dónde y cuándo se va a ejecutar las tareas asociadas a un determinado trabajo. Se determina antes de que el trabajo entre en máquina. y Planificación dinámica: Una vez desplegado un t b j yd trabajo, de acuerdo d all comportamiento t i t d dell sistema, i t se puede revisar este despliegue inicial. Considera que el trabajo q j yya está en ejecución j en la máquina. q 12 Computación Cluster y Grid Gestión de Procesos Planificación Estática 13 Computación Cluster y Grid Planificación Estática y Generalmente G l t se aplica li antes t d de permitir iti lla ejecución del trabajo en el sistema. y El planificador (a menudo llamado resource manager) selecciona un trabajo de la cola (según política)) y si hay p y recursos disponibles p lo p pone en ejecución, si no espera. Cola de Trabajos Planificador Recursos? j Trabajos 14 no espera p síí Sistema Computación Cluster y Grid Descripción de los Trabajos y Para P poder d ttomar llas d decisiones i i correspondientes di t a la política del planificador, éste debe disponer de información sobre los trabajos: Número de tareas (ejecutables correspondientes) Prioridad Relación entre ellas (DAG) Estimación de consumo de recursos (procesadores, memoria, i di disco)) y Estimación del tiempo de ejecución (por tarea) y Otros parámetros de ejecución y Restricciones aplicables y y y y y Estas definiciones se incluyen en un fichero de descripción del trabajo, cuyo formato depende del planificador correspondiente. 15 Computación Cluster y Grid Planificación de Tareas Dependientes y Considera C id llos siguientes i i t aspectos: t y Duración (estimada) de cada tarea. y Volumen V l d de d datos t ttransmitido itid all fifinalizar li lla ttarea ((e.g. fichero) y Precedencia entre tareas (una tarea requiere la finalización previa de otras). y Restricciones debidas a la necesidad de recursos especiales. Una opción consiste en transformar 2 2 11 1 1 2 7 2 1 3 4 16 1 1 todos los datos a las mismas unidades (tiempo): Tiempo de ejecución (tareas) Tiempo de transmisión (datos) 3 La Heterogeneidad complica estas 4 5 estimación: Ejecución dependiente de Representado por medio de un grafo acíclico dirigido procesador (DAG) Comunicación dependiente de conexión Computación Cluster y Grid Planificación de Tareas Dependientes y Planificación Pl ifi ió consiste i t en lla asignación i ió d de ttareas a procesadores en un instante determinado de tiempo: y Para un solo trabajo existen heurísticas eficientes: buscar camino crítico (camino más largo en grafo) y asignar tareas implicadas al mismo procesador. y Algoritmos con complejidad polinomial cuando sólo hay dos procesadores. y Es un p problema NP-completo p con N trabajos. j y El modelo teórico se denomina multiprocessor scheduling. 17 Computación Cluster y Grid Ejemplo de Tareas Dependientes 10 10 1 2 1 1 20 1 3 4 1 5 0 2 20 18 N2 1 10 Planificador 3 1 4 30 5 36 N1 N1 N2 5 El tiempo de comunicación entre procesos depende de su despliegue en el mismo nodo: Tiempo ~00 si están en el mismo nodo Tiempo n si están en diferentes nodos Computación Cluster y Grid Algoritmos de Clustering y Para P llos casos generales l se aplican li algoritmos l it d de clustering que consisten en: y Agrupar A llas ttareas en grupos (clusters). ( l t ) y Asignar cada cluster a un procesador. y La asignación óptima es NP NP-completa completa y Este modelo es aplicable a un solo trabajo o a varios en paralelo. paralelo y Los clusters se pueden construir con: y Métodos lineales y Métodos no-lineales y Búsqueda heurística/estocástica 19 Computación Cluster y Grid Planificación con Clustering A 2 2 1 C 2 B 4 3 3 1 D 2 G 3 E 2 F 2 1 5 3 1 3 2 I 20 1 H 2 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 A B C D E G F H I Computación Cluster y Grid Uso de la Replicación A 2 2 1 C 2 B 4 3 3 1 D 2 G 1 3 E 2 F 2 1 5 2 3 1 3 H 2 I Algunas tareas se ejecutan en varios nodos para ahorrar en la comunicación 21 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 A B C1 C2 D E G F H I Computación Cluster y Grid Migraciones con Procesos Dependientes y El uso d de estrategias t t i migratorias i t i permite it mejorar j ell aprovechamiento. y Se S pueden d d definir fi i en lla planificación l ifi ió estática. táti y Lo más habitual es que formen parte de las estrategias dinámicas. dinámicas 0 N1 1 2 N2 2 0 N2 2 Con migración 1 2 3 N1 3 2 3 4 22 Computación Cluster y Grid Planificación de Tareas Paralelas y Considera C id llos siguientes i i t aspectos: t y Las tareas requieren ejecutarse en paralelo y Intercambian I t bi mensajes j a llo llargo d de lla ejecución. j ió y Consumo de recursos locales (memoria o E/S) de cada tarea tarea. Modelo Centralizado (Maestro/Esclavo) M S1 S2 S3 S4 S5 Hipercubo Anillo Modelo distribuido 23 S6 Diferentes parámetros de comunicación: • Tasas de comunicación: Frecuencia, volumen de datos. • Topología de conexión: ¿Cómo intercambian l mensajes? los j ? • Modelo de comunicación: Síncrono (las tareas se bloquea a la espera de datos) o Asíncrono. Restricciones: • La propia topología física de la red de interconexión • Prestaciones P i d de la l red. d Computación Cluster y Grid Rendimiento de la Planificación y El rendimiento di i t d dell esquema d de planificación l ifi ió depende: y Condiciones C di i d de bl bloqueo ((equilibrado ilib d d de carga)) y Estado del sistema y Eficiencia de las com comunicaciones: nicaciones latencia y ancho de banda Envio no bloqueante Recepción bloqueante Barrera de sincronización Recepción no bloqueante 24 Envio bloqueante Ejecución Bloqueado Ocioso Computación Cluster y Grid Tareas Paralelas: No-regulares y En E algunos l casos llas ttopologías l í d de conexión ió no son regulares: y Modelado como grafo no dirigido donde: y Nodo representa un proceso con necesidades de CPU y memoria y Arcos incluye etiqueta que indica cantidad de datos que intercambian nodos implicados (tasa de comunicación) y El problema en su forma general es NP-completo y En el caso general se utilizan heurísticas: y P. ej. corte mínimo: Para P procesadores buscar P-1 cortes tal q que se minimice el flujo j entre cada p partición y Resultado: Cada partición (procesador) engloba a un conjunto de procesos “fuertemente acoplados” y No N ttan sencillo ill en llos modelos d l asíncronos í 25 Computación Cluster y Grid Tareas Paralelas: No-regulares N1 N2 N3 N1 3 2 3 3 2 2 1 8 5 6 4 3 4 2 4 1 5 2 Tráfico entre nodos: 13+17=30 N2 N3 2 3 2 1 8 5 6 4 3 4 4 1 5 2 Tráfico entre nodos: 13+15=28 Tanenbaum.“Sistemas Operativos Distribuidos” © Prentice Hall 1996 26 Computación Cluster y Grid Planificación de Múltiples Trabajos y Cuando C d se d deben b planificar l ifi varios i ttrabajos b j ell planificador debe: y Seleccionar S l i ell siguiente i i t ttrabajo b j a mandar d a máquina. á i y Determinar si hay recursos (procesadores y de otro tipo) para poder lanzarlo. lanzarlo y De no ser así, esperar hasta que se liberen recursos. Cola de Trabajos Planificador Recursos? j Trabajos 27 no espera p síí Sistema Computación Cluster y Grid Planificación de Múltiples Trabajos y ¿Cómo Có se selecciona l i ell siguiente i i t ttrabajo b j a iintentar t t ejecutar?: j t ? y Política FCFS (first-come-first-serve): Se respeta el orden de remisión de trabajos. j y Política SJF (shortest-job-first): El trabajo más pequeño en primer lugar, medido en: y Recursos, Recursos número de procesadores procesadores, o y Tiempo solicitado (estimación del usuario). y Política LJF (longest-job-first): Ídem pero en el caso inverso. y Basadas en prioridades: Administrativamente se define unos criterios de prioridad, que pueden contemplar: y Facturación del coste de recursos recursos. y Número de trabajos enviados. y Deadlines de finalización de trabajos. (EDF – Earliest-deadline-first) 28 Computación Cluster y Grid Backfilling y Backfilling B kfilli es una modificación aplicable a cualquiera de las políticas anteriores: y Si el trabajo seleccionado por la política no tiene recursos para entrar entonces,, p y Se busca otro proceso en la cola que demande menos recursos y pueda entrar. y Permite aprovechar mejor el sistema i t 29 Se buscan trabajos que demanden menos procesadores Planificador Recursos? sí no Backfilling Computación Cluster y Grid Backfilling con Reservas y Las L reservas consisten i t en: y Determinar cuándo se podría ejecutar la tarea inicialmente seleccionada, en base a las estimaciones de tiempos (deadline) y Se dejan j entrar trabajos j q que demandan menos recursos (backfilling) siempre y cuando fi li finalicen antes t d dell deadline. d dli y Aumenta el aprovechamiento del sistema, sistema pero no retrasa indefinidamente a los trabajos grandes. g 30 La técnica de Backfilling puede hacer que trabajos que demanden muchos recursos nunca se ejecuten Planificador Recursos? sí no Backfilling Computación Cluster y Grid Gestión de Procesos Planificación Dinámica 31 Computación Cluster y Grid Planificación Dinámica y La L planificación l ifi ió estática táti d decide id sii un proceso se ejecuta en el sistema o no, pero una vez lanzado no se realiza seguimiento de él él. y La planificación dinámica: y Evalúa el estado del sistema y toma acciones correctivas. y Resuelve problemas debidos a la paralelización del problema bl (desequilibrio (d ilib i entre t llas ttareas). ) y Reacciona ante fallos en nodos del sistema (caídas o falos parciales). parciales) y Permite un uso no dedicado o exclusivo del sistema. y Requiere una monitorización del sistema ((políticas de gestión de trabajos): y En la planificación estática se contabilizan los recursos comprometidos. 32 Computación Cluster y Grid Load Balancing vs. Load Sharing y Load L d Sh Sharing: i y Que el estado de los procesadores no sea diferente y Un procesador ocioso y Una tarea esperando a ser servida en otro procesador Asignación y Load Balancing: y Que la carga g de los p procesadores sea igual. g y La carga varía durante la ejecución de un trabajo y ¿Cómo se mide la carga? y Son conceptos muy similares, gran parte de las estrategias usadas para LS vale para LB (considerando objetivos relativamente diferentes). LB tiene unas matizaciones particulares. 33 Computación Cluster y Grid Medición de la Carga y ¿Qué Q é es un nodo d iinactivo? ti ? y Estación de trabajo: “lleva varios minutos sin recibir entrada del teclado o ratón y no está ejecutando j p procesos interactivos” y Nodo de proceso: “no ha ejecutado ningún proceso de usuario en un rango de tiempo”. y Planifiación Pl ifi ió estática: táti ““no se lle h ha asignado i d ninguna i ttarea”. ” y ¿Qué ocurre cuando deja de estar inactivo? y No hacer nada → El nuevo proceso notará mal rendimiento rendimiento. y Migrar el proceso a otro nodo inactivo (costoso) y Continuar ejecutando el proceso con prioridad baja. y Si en lugar de considerar el estado (LS) se necesita conocer la carga (LB) hacen falta métricas específicas. 34 Computación Cluster y Grid Políticas de Gestión de Trabajos Toda T d la l gestión tió d de ttrabajos b j se b basa en una serie i d de decisiones (políticas) que hay que definir para una serie de casos: y Política P líti de d información: i f ió cuándo á d propagar la l información necesaria para la toma de decisiones. y Política P líti de d transferencia: t f i decide d id cuándo á d ttransferir. f i y Política de selección: decide qué proceso t transferir. f i y Política de ubicación: decide a qué nodo transferir. 35 Computación Cluster y Grid Política de Información C á d se ttransmite Cuándo it iinformación f ió sobre b ell nodo: d y Bajo demanda: únicamente cuando desea realizar una transferencia. transferencia y Periódicas: se recoge información periódicamente, la información está disponible en el momento de realizar la transferencia (puede estar obsoleta). y Bajo cambio de estado: cada vez que un nodo cambia de estado. Ámbito de información: y Completa: todos los conocen toda la información del sistema. y Parcial: cada nodo sólo conoce el estado de parte de los nodos del sistema. 36 Computación Cluster y Grid Política de Información ¿Qué Q é iinformación f ió se ttransmite?: it ? y La carga del nodoÆ ¿qué es la carga? Diferentes medidas: y %CPU en un instante de tiempo y Número de procesos listos para ejecutar (esperando) y Números Nú d de ffallos ll d de página á i / swaping i y Consideración de varios factores. y Se pueden considerar casos de nodos h t heterogéneos é ((con dif diferentes t capacidades). id d ) 37 Computación Cluster y Grid Política de Transferencia y Generalmente, G l t basada b d en umbral: b l y Si en nodo S carga > T unidades, S emisor de tareas y Si en nodo d S carga < T unidades, id d S receptor t de d tareas t y Tipos de transferencias: y Expulsivas: se pueden transferir tareas ejecutadas parcialmente. y Supone: transferir el estado del proceso asociado a la tarea (migración) o reiniciar su ejecución ejecución. y No expulsivas: las tareas ya en ejecución no pueden ser transferidas. 38 Computación Cluster y Grid Política de Selección y Elegir El i llos procesos d de ttareas nuevas (t (transferencia f i no expulsiva). y Seleccionar S l i llos procesos con un tiempo i d de transferencia mínimo (poco estado, mínimo uso de los recursos locales) locales). y Seleccionar un proceso si su tiempo de finalización en un nodo d remoto t es menor que ell titiempo d de finalización local. y El tiempo de finalización remoto debe considerar el tiempo necesario para su migración. y El tiempo de finalización puede venir indicado en la descripción del trabajo (estimación del usuario). y De no ser así,, el sistema debe estimarlo por p sí mismo. 39 Computación Cluster y Grid Política de Ubicación y Muestreo: M t consulta lt de d otros t nodos d para encontrar t adecuado. y Alternativas: y y y y y y Sin muestreo (se manda a uno aleatoriamente). Muestreo secuencial o paralelo. Selección aleatoria. Nodos más próximos. Enviar un mensaje al resto de nodos (broadcast). Basada en información recogida anteriormente. y Tres tipos de políticas: y Iniciadas por el emisor (Push) → emisor busca receptores y Iniciadas por el receptor (Pull) → receptor solicita procesos p y Simétrica → iniciada por el emisor y/o por el receptor. 40 Computación Cluster y Grid Ejecución Remota de Procesos y ¿Cómo ejecutar un proceso de forma remota? y Crear el mismo entorno de trabajo: y Variables de entorno, entorno directorio act actual, al etc etc. y Redirigir ciertas llamadas al sistema a máquina origen: g y P. ej. interacción con el terminal y Migración (transferencia expulsiva) mucho más compleja: l j y “Congelar” el estado del proceso y Transferir a máquina destino y “Descongelar” el estado del proceso y Numerosos aspectos complejos: y Redirigir mensajes y señales y¿ ¿Copiar p espacio p de swap p o servir fallos de p pág. g desde origen? 41 Computación Cluster y Grid Migración de Procesos Diferentes Dif t modelos d l d de migración: i ió y Migración débil: y Restringida a determinadas aplicaciones (ejecutadas en máquinas virtuales) o en ciertos momentos. y Migración ó ffuerte: y Realizado a nivel de código nativo y una vez que la ttarea ha h iniciado i i i d su ejecución j ió ((en cualquier l i momento) t ) y De propósito general: Más flexible y más compleja y Migración Mi ió d de d datos: t y No se migran procesos sino sólo los datos sobre los que estaba trabajando. trabajando 42 Computación Cluster y Grid Migración: Recursos La migración L i ió d de recursos ttambién bié d depende d d de lla relación de éstos con las máquinas. y Unatachment resource. Ejemplo: un fichero de datos dell programa a migrar. d i y Fastened resource. Son recursos movibles, pero con un alto coste coste. Ejemplo: una base de datos datos, un sitio web. y Fixed resource. Están ligados estrechamente a una máquina y no se pueden mover. Ejemplo: dispositivos locales 43 Computación Cluster y Grid Migración: Datos de las Tareas y Los L d datos t que usa una ttarea también t bié d deben b migrarse: y Datos D t en disco: di E Existencia i t i d de un sistema i t d de fificheros h común. y Datos en memoria: Requiere “congelar” congelar todos los datos del proceso correspondiente (páginas de memoria y valores de registros). g ) Técnicas de checkpointing: y Las páginas de datos del proceso se guardan a disco. y Se puede ser más selectivo si las regiones que definen el estado están declaradas de alguna forma específica ((lenguajes/librerías g j especiales). p ) y Es necesario guardar también los mensajes enviados que potencialmente no hayan sido entregados. y Útiles también para casos en los que no hay migración: Fallos en el sistema. 44 Computación Cluster y Grid Migración Débil y La L migración i ió débil se puede d articular ti l d de lla siguiente i i t fforma: y Ejecución remota de un nuevo proceso/programa y En UNIX podría ser en FORK o en EXEC y Es más eficiente que nuevos procesos se ejecuten en nodo donde se crearon pero eso no permite reparto de carga y Hay que transferir cierta información de estado aunque no esté iniciado y Argumentos, entorno, ficheros abiertos que recibe el proceso, etc. y Ciertas librerías pueden permitir al programador establecer puntos en los cuales el estado del sistema de almacena/recupera y que q p pueden ser usados p para realizar la migración. g y En cualquier caso el código del ejecutable debe ser accesible en el nodo destino: y Sistema de ficheros común común. 45 Computación Cluster y Grid Migración Débil E lenguajes En l j ((como JJava): ) y Existe un mecanismo de serialización que permite transferir el estado de un objeto en forma de “serie de bytes”. y Se porporciona un mecanismo de carga bajo demanda de las clases de forma remota. serialización instancia A=3 Proceso.class Nodo 1 46 A=3 Solicitud de clase Proceso.class Cargador dinámico Nodo 2 Computación Cluster y Grid Migración Fuerte y Solución naïve: y Copiar el mapa de memoria: código, datos, pila, ... y Crear un nuevo BCP (con toda la información salvaguardada en el cambio de contexto). y Hay otros datos (almacenados por el núcleo) que son necesarios: i D Denominado i d estado t d externo t d dell proceso y Ficheros abiertos y Señales S ñ l pendientes di t y Sockets y Semáforos S áf y Regiones de memoria compartida y ..... 47 Computación Cluster y Grid Migración Fuerte Existen diferentes aproximaciones a posibles implementaciones: y A nivel de kernel: y Versiones modificadas del núcleo y Dispone de toda la información del proceso y A nivel de usuario: y Librerias de checkpointing y Protocolos para desplazamiento de sockets y Intercepción de llamadas al sistema Otros aspectos: y PID único de sistema y Credenciales y aspectos de seguridad 48 Computación Cluster y Grid Migración Fuerte y Desde espacio de usuario: y Servicio remoto de solicitud de migración migración. y Interceptores de llamadas al sistema. y Auditoría (reconstruir) y Redirección y Tratamiento de fallo de páginas remoto. Proceso Original Intercepción K Kernel l 49 Servicio Nodo j Nodo i Servicio Proceso Migrado Intercepción K Kernel l Computación Cluster y Grid Migración Fuerte y Servicio de solicitud de migración: 1 Interactúa 1. I t tú con los l procesos (vía ( í biblioteca bibli t ptrace, t por ejemplo). j l ) 2. Suspende la ejecución del proceso original 3 Obtiene datos del proceso (valores de registros o mapa de 3. memoria) 4. Crea nuevo proceso destino 5. Modifica valores de los registros 6. Monitoriza, en términos generales, el estado de los procesos Servicio Servicio ptrace t Proceso Original 50 Proceso Migrado fork + ptrace Computación Cluster y Grid Migración Fuerte y Interceptores de llamadas al sistema: 1 Necesarios 1. N i para conocer ell estado t d externo t 2. Sobrescribir las funciones asociadas a las llamadas al sistema 3 Despliegue por medio de bibliotecas dinámicas (e 3. (e.g., g LD_PRELOAD) 4. Se conoce la secuencia de llamadas hechas ((se puede repetir)) 5. Se puede redirigir una llamada a otro sitio (vía el servicio). Servicio Proceso Original open(…) LD_PRELOAD=foo.so open( ) open(…) Intercepción open(…) Kernel 51 Computación Cluster y Grid Migración Fuerte y Tratamiento de fallo de página remoto: 1. Acceso A a páginas á i no cargadas d d da una señall SEGV SEGV. 2. El interceptor captura la señal 3. Solicita S li it lla petición ti ió remota t a lla página á i en ell nodo d original i i l 4. Copia la página Servicio Proceso Migrado SEGV pág Intercepción 52 Computación Cluster y Grid Migración Fuerte y Se debe intentar que proceso remoto se inicie cuanto antes y Copiar todo el espacio de direcciones al destino y Copiar C i sólo ól páginas á i modificadas difi d all d destino; ti resto t se pedirán di á como fallos de página desde nodo remoto servidas de swap de origen y No copiar nada al destino; las páginas se pedirán como fallos de página desde el nodo remoto y servidas de memoria de nodo origen si estaban modificadas y servidas de swap de nodo origen si no estaban modificadas y Volcar a swap de nodo origen páginas modificadas y no copiar nada al destino: todas las páginas se sirven de swap de origen y Precopia: Copia de páginas g mientras ejecuta j proceso en origen g y Páginas de código (sólo lectura) no hay que pedirlas: y Se sirven en nodo remoto usando SFD 53 Computación Cluster y Grid Migración Fuerte y Migración de conexiones: y Afecta a las conexiones entrantes y salientes. y Solución por medio de proxies: y En realidad todas las direcciones son de un único servidor que redirige al nodo donde está el proceso en cada momento momento. y El problema es que no es escalable. y Solución a nivel IP: y Se asigna una dirección IP por proceso del sistema (vía DHCP) y Paquetes “Gratuitous ARP” para informar de cambio de MAC al migrar i ell proceso. y El problema es el rango de direcciones disponibles (red privada virtual). ) 54 Computación Cluster y Grid Beneficios de la Migración de Procesos y Mejora M j rendimiento di i t d dell sistema i t por reparto t d de carga y Permite aprovechar proximidad de recursos y Proceso que usa mucho un recurso: migrarlo al nodo del mismo y Puede mejorar algunas aplicaciones cliente/servidor y Para minimizar transferencias si hay un gran volumen de datos: y Servidor envía código en vez de datos (p. ej. applets) y O cliente envía código a servidor (p. ej. cjto. de accesos a b. de datos)) y Tolerancia a fallos ante un fallo parcial en un nodo y Desarrollo de “aplicaciones p de red” y Aplicaciones conscientes de su ejecución en una red y Solicitan migración de forma explícita y Ejemplo: Sistemas de agentes móviles 55 Computación Cluster y Grid Migración de Datos Usando en aplicaciones de tipo maestro/esclavo. y Maestro: Distribuye el trabajo entre los trabajadores. y Esclavo: Trabajador (el mismo código pero con diferentes datos). y Representa un algoritmo de distribución de trabajo (en este t caso datos) d t ) que: y Evite que un trabajador esté parado porque el maestro no transmite datos datos. y No asigne demasiado trabajo a un nodo (tiempo final del proceso es el del más lento) y Solución: Asignación de trabajos por bloques (más o menos p pequeños). q ) 56 Computación Cluster y Grid Migración de Datos y Mejoras de rendimiento: y Equilibrado de carga: y Solución: Definir muchos paquetes de trabajo e ir despachándolos bajo demanda (finalización del anterior). y Intentar lanzar rápido los trabajos iniciales: y Solución: Uso de broadcast en el envío de paquetes inicial. y Si todos los nodos son homogéneos g y realizan el mismo trabajo finalizarán casi a la vez: y Plantea un posible problema de saturación del maestro que deriva en un retraso t en despachar d h nuevos paquetes t de d ttrabajo. b j y Solución: Asignación inicial en distintos tamaños. 57 Computación Cluster y Grid Planificación Dinámica vs. Estática y Los sistemas pueden usar indistintamente una, otro o No o Dinám mica Diná ámica l d las dos. 58 Estática No Estática Planificación adaptativa: Se mantiene un control central sobre los trabajos lanzados al sistema, pero se dispone de los mecanismos necesarios ppara reaccionar a errores en las estimaciones o reaccionar ante problemas. Estrategias de equilibrado de carga: Los trabajos se arrancan libremente en los nodos del sistema y por detrás un servicio de equilibrado q de carga/estado g ajusta la distribución de tareas a los nodos. Gestor de recursos (con asignación batch): Los procesadores se asignan de forma exclusiva y el gestor de recursos mantiene información sobre los recursos comprometidos. Cluster de máquinas sin planificación alguna: Que sea lo que Dios quiera… Computación Cluster y Grid Ejemplo: OpenMOSIX Preemptive process migration De forma transparente, y en cualquier instante se puede migrar un proceso de usuario El proceso migrado se divide en dos partes: y Contexto de sistema (deputy) que no puede ser migrado del nodo original original. y Contexto ed usuario (remote) que puede ser migrado Nodo origen 59 Nodo destino Computación Cluster y Grid Ejemplo: OpenMOSIX Dynamic load balancing y Se inician los procesos de migración con la intención de equilibrar la carga de los nodos y Se ajusta de acuerdo a la variación de carga de los nodos, características de la ejecución y número y potencia de los nodos y Intenta en cada momento reducir la diferencia de carga de cada pareja de nodos y La L política líti es simétrica i ét i y d descentralizada t li d (t (todos d llos nodos d ejecutan j t ell mismo algoritmo) Memory sharing y De mayor prioridad. y Intenta equilibrar el uso de memoria entre los nodos del sistema y Evita, en la medida de lo posible, hacer swapping. y La toma de decisiones de qué proceso migrar y donde migrarlo se evalúa lú en b base a lla cantidad tid d d de memoria i di disponible. ibl 60 Computación Cluster y Grid Ejemplo: OpenMOSIX Probabilistic information dissemination algorithms y Proporciona a cada nodo (a su algoritmo) suficiente información sobre los recursos disponibles en otros nodos nodos. Sin hacer polling. polling y Mide la cantidad de recursos disponibles en cada nodo y La emisión de esta información se hace a intervalos regulares de tiempo a un subconjunto aleatorio de los nodos. y En el ejecución de una migración, cada asignación de un proceso iimplica li un periodo i d d durante t ell cuall ell nodo d d debe b ejecutarlo j t l ((no puede d migrarlo de nuevo). 61 Computación Cluster y Grid Referencias y BProc: Beowulf Distributed Process Space http://bproc.sourceforge.net/ y Scyld Computer Corporation • Open MOSIX htt // http://openmosix.sourceforge.net/ i f t/ • OpenSSI htt // http://www.openssi.org/ i / http://www.scyld.com/ • A Dynamic Load Balancing System for Parallel Cluster Computing p g ((1996)) B. J. Overeinder, P. M. A. Sloot, R. N. Heederik. Future Generation Computer Systems • Transparent Process Migration: Design Alternatives and the Sprite p Implementation p ((1991)) Fred Douglis, John Ousterhout. Software - Practice and Experience 62 Computación Cluster y Grid