- Ninguna Categoria
En informática, el acrónimo RAID (del inglés Redundant Array of
Anuncio
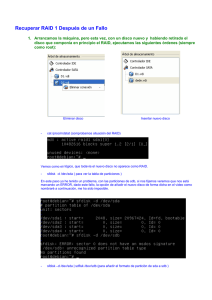
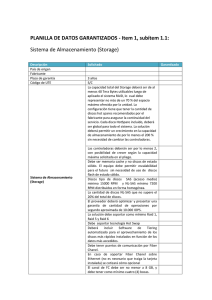
RAID En informática, el acrónimo RAID (del inglés Redundant Array of Independent Disks, originalmente Redundant Array Inexpensive Disks), traducido como «conjunto redundante de discos independientes», hace referencia a un sistema de almacenamiento de datos que usa múltiples unidades de almacenamiento de datos (discos duros o SSD) entre los que se distribuyen o replican los datos. Dependiendo de su configuración (a la que suele llamarse «nivel»), los beneficios de un RAID respecto a un único disco son uno o varios de los siguientes: mayor integridad, mayor tolerancia a fallos, mayor throughput (rendimiento) y mayor capacidad. En sus implementaciones originales, su ventaja clave era la habilidad de combinar varios dispositivos de bajo coste y tecnología más antigua en un conjunto que ofrecía mayor capacidad, fiabilidad, velocidad o una combinación de éstas que un solo dispositivo de última generación y coste más alto. En el nivel más simple, un RAID combina varios discos duros en una sola unidad lógica. Así, en lugar de ver varios discos duros diferentes, el sistema operativo ve uno solo. Los RAIDs suelen usarse en servidores y normalmente (aunque no es necesario) se implementan con unidades de disco de la misma capacidad. Debido al descenso en el precio de los discos duros y la mayor disponibilidad de las opciones RAID incluidas en los chipsets de las placas base, los RAIDs se encuentran también como opción en las computadoras personales más avanzadas. Esto es especialmente frecuente en las computadoras dedicadas a tareas intensivas y que requiera asegurar la integridad de los datos en caso de fallo del sistema. Esta característica no está obviamente disponible en los sistemas RAID por software, que suelen presentar por tanto el problema de reconstruir el conjunto de discos cuando el sistema es reiniciado tras un fallo para asegurar la integridad de los datos. Por el contrario, los sistemas basados en software son mucho más flexibles (permitiendo, por ejemplo, construir RAID de particiones en lugar de discos completos y agrupar en un mismo RAID discos conectados en varias controladoras) y los basados en hardware añaden un punto de fallo más al sistema (la controladora RAID). Todas las implementaciones pueden soportar el uso de uno o más discos de reserva (hot spare), unidades preinstaladas que pueden usarse inmediatamente (y casi siempre automáticamente) tras el fallo de un disco del RAID. Esto reduce el tiempo del período de reparación al acortar el tiempo de reconstrucción del RAID. Los niveles RAID más comúnmente usados son: RAID 0: Conjunto dividido RAID 1: Conjunto en espejo RAID 5: Conjunto dividido con paridad distribuida This is what you need for any of the RAID levels: A kernel with the appropriate md support either as modules or built-in. The mdadm tool The first two items are included as standard in most GNU/Linux distributions today. mdadm is now the standard software RAID management tool for Linux; using raidtools is deprecated (and the code does not appear to have been worked on since Jan 2003) and although it will still work for basic use, bugs have been reported where raidtools does not handle new features correctly. The main differences between mdadm and raidtools are: mdadm can diagnose, monitor and gather detailed information about your arrays mdadm is a single centralized program and not a collection of disperse programs, so there's a common syntax for every RAID management command mdadm can perform almost all of its functions without having a configuration file and does not use one by default Also, if a configuration file is needed, mdadm will help with management of its contents If your system has RAID support, you should have a file called /proc/mdstat. Remember it, that file is your friend. If you do not have that file, maybe your kernel does not have RAID support. Condicionales: --create: crear --verbose: para revisar que todo se hizo correctamente --level: especifica el raid --raid-devices: especifica cuantos dispositivos participaran en el raid --metadata: especifica el numero de superblock a utilizar --auto: especifica si se podrá particionar el raid --spare-devices: en caso de tener discos de repuesto aquí se especifica --fail: especificar cuando un disco se daña mdadm /dev/md0 --fail /dev/sda --add: agregar un disco al raid mdadm /dev/md0 --add /dev/sda --grow si cambiamos el raid a discos más grandes para que suba el storage ejecutamos esta condicional --size: especifica tamaño mdadm --grow /dev/md0 --size=max Arrays can be built on top of entire disks or on partitions. Un dispositivo RAID sólo se puede particionar si se ha creado con una opción - auto dado a la herramienta mdadm. Esta opción no está bien documentada, pero aquí es un ejemplo de trabajo que se traduciría en un dispositivo divisible hecho de dos discos sda y sdb: La emisión de este comando se traducirá en un dispositivo / dev/md_d0 que se pueden particionar con fdisk o parted. Las particiones estarán disponibles como / dev/md_d0p1, /dev/md_d0p2. Ahora si bien podemos ver entre las opciones que he puesto el (--metadata=1.2) en caso de que el bootloader vaya a estar dentro del raid, suponiendo que instalaremos dentro del raid, tendremos un problema debido a que LILO no soporta la version 1 de metadata para ello debemos especificarle la 0.90, otros bootloader como GRUB no presentan este inconveniente. En caso de que se dañase un disco donde reside el grub, al momento de incorporar uno nuevo debemos ejecutar el comando: grub-install (disco) Algunas limitantes a la hora de implementar metadata 0.90 son: La versión 0.90 superblock limita el número de dispositivos de componentes dentro de una matriz a 28, y limita cada componente dispositivo a un tamaño máximo de 2 TB en el kernel de la versión <3,1 y 4 TB de la versión del kernel> = 3.1. La versión 1 superblock es capaz de soportar las matrices con los dispositivos 384 + componentes, y soporta arrays con longitudes de sector de 64 bits. RAID 0 (Data Striping) Un RAID 0 (también llamado conjunto dividido, volumen dividido, volumen seccionado) distribuye los datos equitativamente entre dos o más discos sin información de paridad que proporcione redundancia. Es importante señalar que el RAID 0 no era uno de los niveles RAID originales y que no es redundante. El RAID 0 se usa normalmente para incrementar el rendimiento, aunque también puede utilizarse como forma de crear un pequeño número de grandes discos virtuales a partir de un gran número de pequeños discos físicos. Un RAID 0 puede ser creado con discos de diferentes tamaños, pero el espacio de almacenamiento añadido al conjunto estará limitado por el tamaño del disco más pequeño (por ejemplo, si un disco de 300GB se divide con uno de 100 GB, el tamaño del conjunto resultante será sólo de 200 GB, ya que cada disco aporta 100GB). Una buena implementación de un RAID 0 dividirá las operaciones de lectura y escritura en bloques de igual tamaño, por lo que distribuirá la información equitativamente entre los dos discos. También es posible crear un RAID 0 con más de dos discos, si bien, la fiabilidad del conjunto será igual a la fiabilidad media de cada disco entre el número de discos del conjunto; es decir, la fiabilidad total —medida como MTTF o MTBF— es (aproximadamente) inversamente proporcional al número de discos del conjunto (pues para que el conjunto falle es suficiente con que lo haga cualquiera de sus discos). Configuración: RAID-0 has no redundancy, so when a disk dies, the array goes with it. Having run mdadm you have initialised the superblocks and started the raid device. Have a look in /proc/mdstat to see what's going on. You should see that your device is now running./dev/md0 is now ready to be formatted, mounted, used and abused. RAID 1 (Mirroring) Un RAID 1 crea una copia exacta (o espejo) de un conjunto de datos en dos o más discos. Esto resulta útil cuando el rendimiento en lectura es más importante que la capacidad. Un conjunto RAID 1 sólo puede ser tan grande como el más pequeño de sus discos. Un RAID 1 clásico consiste en dos discos en espejo, lo que incrementa exponencialmente la fiabilidad respecto a un solo disco; es decir, la probabilidad de fallo del conjunto es igual al producto de las probabilidades de fallo de cada uno de los discos (pues para que el conjunto falle es necesario que lo hagan todos sus discos). Adicionalmente, dado que todos los datos están en dos o más discos, con hardware habitualmente independiente, el rendimiento de lectura se incrementa aproximadamente como múltiplo lineal del número del copias; es decir, un RAID 1 puede estar leyendo simultáneamente dos datos diferentes en dos discos diferentes, por lo que su rendimiento se duplica. Al escribir, el conjunto se comporta como un único disco, dado que los datos deben ser escritos en todos los discos del RAID 1. Por tanto, el rendimiento no mejora. Configuración: RAID 5 Un RAID 5 (también llamado distribuido con paridad) es una división de datos a nivel de bloques distribuyendo la información de paridad entre todos los discos miembros del conjunto. El RAID 5 ha logrado popularidad gracias a su bajo coste de redundancia. Generalmente, el RAID 5 se implementa con soporte hardware para el cálculo de la paridad. RAID 5 necesitará un mínimo de 3 discos para ser implementado. En el gráfico de ejemplo anterior, una petición de lectura del bloque «A1» sería servida por el disco 0. Una petición de lectura simultánea del bloque «B1» tendría que esperar, pero una petición de lectura de «B2» podría atenderse concurrentemente ya que sería servida por el disco 1. Cada vez que un bloque de datos se escribe en un RAID 5, se genera un bloque de paridad dentro de la misma división (stripe). Un bloque se compone a menudo de muchos sectores consecutivos de disco. Una serie de bloques (un bloque de cada uno de los discos del conjunto) recibe el nombre colectivo de división (stripe). Si otro bloque, o alguna porción de un bloque, es escrita en esa misma división, el bloque de paridad (o una parte del mismo) es recalculada y vuelta a escribir. El disco utilizado por el bloque de paridad está escalonado de una división a la siguiente, de ahí el término «bloques de paridad distribuidos». Las escrituras en un RAID 5 son costosas en términos de operaciones de disco y tráfico entre los discos y la controladora. Los bloques de paridad no se leen en las operaciones de lectura de datos, ya que esto sería una sobrecarga innecesaria y disminuiría el rendimiento. Sin embargo, los bloques de paridad se leen cuando la lectura de un sector de datos provoca un error de CRC. En este caso, el sector en la misma posición relativa dentro de cada uno de los bloques de datos restantes en la división y dentro del bloque de paridad en la división se utilizan para reconstruir el sector erróneo. El error CRC se oculta así al resto del sistema. De la misma forma, si falla un disco del conjunto, los bloques de paridad de los restantes discos son combinados matemáticamente con los bloques de datos de los restantes discos para reconstruir los datos del disco que ha fallado «al vuelo». El fallo de un segundo disco provoca la pérdida completa de los datos. Configuración: Ahora, para ver como se reconstruye el raid 5 ejecutamos cat a /proc/mdstat, también lo podemos combinar con watch -n1 para verlo cada 1 segundo. Una vez que se configura un raid guardaremos la configuración en /etc/mdadm.conf Para ello utilizamos re direccionamiento. Para detener un RAID corriendo ejecutamos: Y para volverlo a encender simplemente reiniciamos la maquina, aunque esta opción es un poco extrema por eso solo ejecutamos uno de los siguientes comandos: Si antes habíamos creado con esto: pues solo ejecutamos esto: O este: Y pensaran, oye pero este es mucho mas fácil pero en caso de que tengan varios RAID parados, este los subirá a todos, como en la foto mas arriba. LVM LVM es el acrónimo de Logical volume managent, que en computación hace referencia a una forma de asignar espacio de forma más flexible que las formas tradicionales como el particionado. En particular un volume manager puede concatenar, dividir o combinar particiones (¡incluso de discos distintos!) en otras virtuales más grandes que los administradores pueden redimensionar o mover, potencialmente sin ni siquiera interrumpir su uso. También permite la administración de volúmenes definidos por grupos de usuarios, otorgándole al administrador del sistema lidiar con grupos de volúmenes con nombres más sensibles como “desarrollo” o “sistema” en vez de nombres de discos físicos que poco nos dicen como “sda” y “sdb”. Un LVM se descompone en tres partes: Volúmenes físicos (PV): Son las particiones del disco duro con sistema de archivos LVM. (raid's) Volúmenes lógicos (LV): es el equivalente a una partición en un sistema tradicional. El LV es visible como un dispositivo estándar de bloques, por lo que puede contener un sistema de archivos (por ejemplo /home) Grupos de volúmenes (VG): es la parte superior de la LVM. Es la "caja" en la que tenemos nuestros volúmenes lógicos (LV) y nuestros volúmenes físicos (PV). Se puede ver como una unidad administrativa en la que se engloban nuestros recursos. Hay que hacer notar que mientras un PV no se añada al VG, no podemos comenzar a usarlo. Tips: La partición /boot no debiera incluirse en el LV porque no todos los bootloaders saben utilizarlas, de forma que podríamos quedar con un sistema que no sea arrancable. Borrar tabla de particiones: dd if=/dev/zero of=/dev/(disco) bs=1k count=1 A continuación vamos a hacer las configuraciones: Creación de Physical Volume, comando: pvcreate Entre más opciones que hay podemos chequearlo con pvdisplay: Creación de un Volume Group, comando: vgcreate El volume group se puede hacer de 1 disco o más. Entre más opciones que hay podemos chequear con vgdisplay: Creacion de un Logical Volume, comando: lvcreate -L: especifica el tamaño del volumen -l 100%FREE: especifica todo el espacio restante -n: el nombre del volumen Entre más opciones que hay podemos chequearlo con lvdisplay:
 0
0
Anuncio




Descargar
Anuncio
Añadir este documento a la recogida (s)
Puede agregar este documento a su colección de estudio (s)
Iniciar sesión Disponible sólo para usuarios autorizadosAñadir a este documento guardado
Puede agregar este documento a su lista guardada
Iniciar sesión Disponible sólo para usuarios autorizados