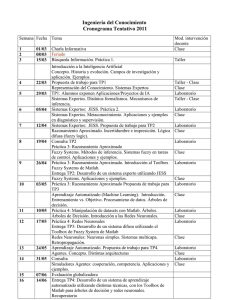
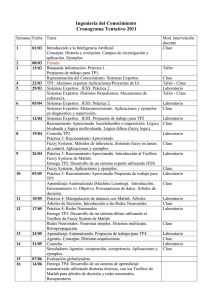
LA RED NEURONAL BACKPROPAGATION COMO INTERPOLADOR
Anuncio

LA RED NEURONAL BACKPROPAGATION COMO INTERPOLADOR al r/ Carlos Eduardo Castrill6n Velasquez ([email protected]), Jose Fernando Perlaza' Orduz, Aart Van Schoonhoven, Eduardo Owen ([email protected]), Roberto Segovia. ' . ;) I j ~ "1 Resumen: En el presente articulo se expone como aprovechar la caracteristica de generalizacion de la red neuronal BackPropagation para la interpolacion instantanea de datos en una y dos dimensiones, y como se puede realizar el entrenamiento de la misma durante el proceso (on line) para manejar datos que cambian dinamicamente. Ademas se muestra como rue esta h~cnica implementada sobre un instrumento de medicion climatologica para invernaderos, diseftado por los au to res. 1. INTRODUCCION Todo sistema interacrua permanentemente con olros, como resultado, el sistema en cuesti6n varia continuamente y en muchos casos sus variaciones se presentan de manera rapida y compleja. Este es el caso de los ecosistemas, y sistemas biol6gicos; ellos son complejos y su variaciones son practicamente impredecibles (9). En muchos procesos, (especialmente cuando se trata de investigacion) se requiere hacer un seguirniento preciso de muchas de las variables de estos sistemas, y se haee necesario el am1lisis y Iii interpretacion de estas variables de una manera casi continua 'e inmediata, donde la sola observaei6n humana no puede seguir la nipida evoluci6n y cambio de estos sistemas. l,C6mo podria realizarse este seguimiento, amilisis e interpretacion al mismo ritrno que la variac ion de las variables de mi sistema? Una opcion es interpolar una serie de puntos para encontrar la funcion de una curva que pasa por todos y cada uno de estos puntos (15). Las propiedades deseables en una interpolacion son entonces, tener una representaci6n parametrica, es decir que pueda representarse en funcion de ciertos parametros, obtener una curva suave, sin sobre oscilaciones entre los puntos y que el eambio en uno de los puntos no afecte a toda la eurva sino solo a un entomo reducido y faci! de calcular (15). Existen diversos metodos de interpolaci6n, entre los que se encuentran; mmlmos cuadrados, polinomios de interpolaci6n de Lagrange, polinomios de interpolacion de Newton, Splines, Interpolacion de Hermitte (16)(17). Segun los datos, su desviaci6n y distribuci6n, se escoge el metoda que puede lograr una mejor interpolaci6n. Estos metodos, son apropiados cuando el sistema es de dos dimensiones, pero para el caso de tres dimensiones la complejidad aumenta, sin mencionar el proceso de seleeci6n del metodo de interpolaci6n. Otra tecnica, es la propuesta en este articulo, usando la red neuronal backpropagation, la eual puede ajustar los parametros de interpolaci6n (que en este caso serian sus pesos) mediante un mecanismo de aprendizaje de los puntos conocidos, cuando se eonoce un nivel de error permitido en dicha interpolacion y ciertas condiciones de distribucion de los datos. La ventaja de esta tecnica esta en la facilidad para representar datos en tres dimensiones (0 mas), y en que el mecanismo de ajuste de pesos es automatico y oculto al programador, mediante el entrenarniento de la red neuronal. Este articulo pretende mostrar una estrategiade interpolaci6n de datos de una y dos dimensiones, para una variable, de manera nipida y precisa asi como su implementacion en sistemas de adquisicion de datos biologicos reales, basado en el principio· de funcionamiento y en la capacidad de generalizacion de la red neuronal Backpropagation (7). .. -', j] La red neuronal Backpropagation es capaz de generalizar un comportamiento a partir de un conjunto de muestras escogidas como patrones de entrenarniento. Asi como el cerebro humano, esta red necesita de una etapa de aprendizaje en la que se Ie presentan algunos ejcmplos, la red actualiza sus pesos mediante la presentacion repetida de estos ejemplos por medio de un mecanismo de· correcci6n de error hasta lIegar a obtener aciertos con estos patrones. En esc momenta se podra usar la red para encontrar cualquier otro valor difcrente. a los patrones de entrenamiento esperando una respuesta apropiada. En otras palabras esta red busca una funcion de comportamiento que se acople a los valores muestreados y al comportamiento del sistema con un valor minimo de error. La red backpropagation tiene cntonces una ctapa de entrenamiento y otra elapa de trabajo. . i::l i" ..:; .. J ,'~ "1 J ) '-' ,,'f'\: . ­ ",," \.~ '\ ...... '" ' ....~-.:.) ... SIll" ~) ~-' &:" LUi ~"'. V\.'~,",l \'IJ.f:.. Fig. 1. Estructura de una red neuronal Backpropagation Si se tiene un conjunto de puntos en un espacio tridimensional, cuya distribucion es conocida y se sabe quc la variacion entre un punto y otro, ocurre de manera suave,l,que mecanismo podria generar una interpolacion rapida de estos puntos y responder a la variacion ocurrida en alguna dimension de alguno(s) de los puntos? Supongamos que se tienen un conjunto de n puntos en un espacio tridimensional como 10 indica la figura 2. Cuando se trata de dos dimensiones, una red backpropagation hallana una curva, en el caso de tres dimensiones la red, aprende la superficie que pasa por dichos puntos, esto se aprecia en la figura 3. y % y P3t P1· • PS• . . , Fig. 3. Tnterpolaci6n en dos y tres dimensiones. ·P7 PS. P4. Aprovechando la capacidad de la RNA Backpropagation, de generalizar para todo el conjunto a partir de unos cuantos puntos, podemos disefiar una estrategia de interpolacion en tiempo real utilizando un objeto, la Red Neuronal Backpropagation. x ·Pn y Fig. 2. Puntos en 3 dimensiones. Ademas se conoce que la vanaClOn entre estos puntos se realiza de manera suave, sin oscilaciones entre elIos, y que puede variar su ubicaci6n con respecto a alguna de sus dimensiones, por tanto requerimos de una estructura que dinamicamente cambie los parametros de la curva que interpola estos puntos. La capacidad de generalizaci6n de la red neuronal Backpropagation mediante su mecanismo de aprendizaje iterativo de ciertos puntos logra una curva que pasa por cada uno de los puntos de entrenamiento con un error minimo especificado por el error de aprendizaje. En otras palabras, aprende dicha curva (7). Esta red esta compuesta por una capa de enjrada, capas ocultas y una capa de salida, cada neurona con sus salidas conectadas a todos los elementos dc la capa de adelante. Una red de m capas se puede vcr griificamente como en la figurn 1. 142 4 -" ..1 v\"l P2 2. MARCO TEORICO - W! /~., ~\ ... 3. PROBLEMA Y SOLUCION Una de las principales caracteristicas de las redes neuron ales Backpropagation, es su capacidad de generali:zacion(7), es decir que a partir del aprendizaje de una muestra de elementos de un conjunto presentados como patrones de entrenamiento, esta red, es capaz de generar una representacion de todo el conjunto durante'su operacion. ..... -' '............. Universidad del Valle, Centro Internacional de Agricultura Tropical (CIAT), SATEK Ltda.. 143 3. 1 Diagrama de j1ujo de estrategia de intelpolacioll Los puntos a interpolar son entonces los patrones de entrenamiento de la red neuronal, se definen tambien el error minimo con que se desea esta interpolacion y se establecen la estructura dc la red (numero de neuronas) de manera que esta pueda generar la curva que cubra todos los puntos sin sobre entrenamiento, que genere oscilaciones no deseadas, y el intervalo que se representara con la curva 0 superficie. Con estos val ores como entradas el diagrama de la estrategia de interpolacion seria el siguiente: Control de datos z M6dulo de entrenamiento de la ~ RNA Backpropagation Red ""enid. @ M6dulo de barrido instalacion con una diferencia entre punto y punto de I a 10 centimetros. Este barrido genera una matriz, cuadrada con los valores de la variable en cada cuadro de 10 x 10 CMS. Esta matriz es representada con gnificos de colorimetria como 10 muestra las figura 7. Errer C8US1Ido par ~fide --------- "-.,x~------""'" Superficie Patrones de Salida untos x,y de barrido dande e: es el error de entrenamiento. El segundo m6dulo se encarga de recibir una red neuronal con una estructUra que evite las oscilaciones entre puntos por algful sobre entrenamiento y el error minimo. con el que se desea obtener la interpolacion. Este bloque realiza un 'procedimiento de aprendizaje iterativo como el explicado anteriormente, hasta llegar al error minimo. Una vez terminado el aprendizaje de los puntos, este bloque entrega una RNA entrenada en cuyos pesos estan los panimetros que cara'cterizanla superficie que pasa por dichos puntos. Este valor puede dejarse fuo, 0 ser calibrado por el usuario entre ciertos limites impuestos por la capacidad de la red neuronal. Fig. 7. Datos interpol ados del microclima. Instrumento Microclimatics 2D. 4. APLICACI6N 5. PRUEBAS Y RESULTADOS Este mecanismo de interpolaci6n ha sido implementado en un instrumento de medici6n del microcIima de invernaderos y cuartos de crecimiento del Centro Internacional de . Agricultura· Tropical CIAT, el cual recibe el nombre de MicrocIimatics 2D. Este instrumento midelas variables, temperatura, humedad· Relativa, luminosidad y ventilaci6n para todo el area del invernadero. a partir de una red de sensores distribuida dentrl;> del mismo. Una· vez implementado calibrados los sensores y ajustado el mecanismo de interpolaci6n de manera que la red entrenada no presente oscilaciones no deseadas, observando que la variaci6n entre punto y punto se realice de manera suave. Se procedi6 a evaluar con un sensor de r~ferencia para cada variable, la precisi6n de la red comprobando que la medida obtenida en un punto cualquiera dentro de la instalaci6n corresponde a un valor con un error por debajo del deseado, en caso contrario, se variaba la estructura de la red neuronal, o se aumentaban las iteraciones de su entrenamiento hasta lograr un aprendizaje mas fino. Una solucion fue almacenar una red que estuviera cerca de los datos promedio, con 10 que su entrenamiento era mas rapido y preciso. El instrumento de medici6n esta compuesto por una red de sensores de humedad relativa, temperatura y luminosidad, distribuidos estratf!gicamente en el invernadero 0 instalaci6n en una matriz de 3 x 4 puntos, como 10 muestra la figura 6. En el,tercer mOdulo se realiza un barrido de un intervalo de la superflcie, simplemente entrando las posiciones x, y de varios puntos con una distancia Ax y /!"y pequeiia entre ellos que .depende de las necesidades del usuario 0 de la plataforma de visualizaci6n de los datos de salida. -.. . . . Este mecanismo es sensible daiios en la entrada, algUn dato que presente un valor extremo, producido por algful dano en la entrada, hace que la superficie aprendida se afecte notablemente, especialmente si es un valor cercano al limite del intervalo, como 10 muestra Ia figura 8. P.".l Hum>!lf",ado. ---' '--Vtntil.ldo:rtl 3.2 Error de interpolacion SuperflCle correct. • El error de entrenarniento de Ia red neuronal indica que los val ores real de cualquier punto puede ser el valor entregado mas 0 menos el valor de error, como 10 muestra la figura 5. -E;- ~:r: Fig. 5. Error de interpolacion Grupo de 4 sensotu Red de sen.mes Fig. 6. Red de sensores En esta aplicaci6n se conoce exactamente la posici6n de cada uno de los sensores, y estos son los patrones de entrada para la red neuronal. El valor medido por cada sensor corresponde a los patrones de salida. Los algoritmos de adquisici6n e interpolaci6n fueron realizados en lenguaje G, LabVIEW y siguen la estructura del diagrama de flujo explicado anteriormente, en un cicIo repetitivo. El error minimo establecido para estas redes es de 0.005 y el barrido de la red entrenada se realiza para toda la 144 con et bIoque de caito! de delo. Para esta aplicaci6n especifica de medici6n del microcIima, se pudo comprobar que los sensores percibian el minimo cambio para una distancia de separaci6n entre ellos maxima de 2,5 mts (I). a ,. Esta secuencia puede ser usada en un cicIo repetitivo, de esta manera la red neuronal estara permanentemente actualizando Ia superficie dado un cambio en sus patrones de entrenamiento. ~ La red presenta inmunidad a los daiiosen la entrada hasta para 3 puntos adyacentes entre si cuya separaci6n es inferior a 2,5 mts (I). Cuando los puntos defectuosos ascienden aun total de 4 se comienza a notar oscilaciones en esa zona y por tanto la superficie generada no representa la superficie real. Fig. 4. Diagrama de flujo de estrategia de interpolacion Este diagrama esta compuesto por tres bloques. El primero simplemente realiza una seleccion de los datos validos y trabaja a criterio del usuario de la estrategia ademas con este bloque se eliminan datos que en un sistema de adquisici6n previo hayan tenido errores. Los valores de las dimensiones X y Y corresponden a los patrones de entrada de la red, y la dimension Z equivale a la variable que se va a interpolar y corresponde a los patrones de salida. defecto en aIg\rlo de los pol,...... de _ode Fig. 9. Efecto entrada fuera de range eliminada. {(x I,y 1) ... (xn,yn)} RNA Error Mlnimo correct. Aunque los puntos de sensado estan distribuidos uniformemente sobre el espacio, es posible que para algunas otras aplicaciones sea necesario tener ciertas regiones mas densas, es decir, con mayor cantidad de puntos de sensado y con una separaci6n entre ellos mas pequeiia, si las variaciones en esa pequefia region son mas marcadas, pero este noes el caso para el microclima de. invemaderos y cuartos de crecimiento. . 6. CONCLUSIONES La red neuronal backpropagation, dada su capacidad de generalizaci6n, puede ser usada para realizar la interpolaci6n de datos, cuando se puede soportar cierto grado de error y se conoce ciertas caracteristicas con respecto a la variaci6n de la variable entre lospuntos para el intervalo de interpolaci6n. Se puede usar una secuencia de toma de patrones, entrenamiento de la red y barrido de la red entrenada, la cual al ser repetida ciclicamente logra que la interpolaci6n responda a alguna de entrada alcanzando una variaci6n en los datos interpolaci6n dinamica de datos. Por medio de esta estrategia de interpolaci6n se esta usando la red Backpropagation, que es una red neuronal con entrenamiento fuera de linea, en una operaci6n que requiere dicho aprendizaje EN LINEA. Error caus8do per defecto en eigIm de los --------­ ~ Fig. 8. Efecto de entrada fuera de rango. En otras palabras, un error grande en un patron de entrada se traduce en un error grande en gran parte de la red. Para evitar esto el primer bloque de la rutina de interpolaci6n elimina estos val ores que se salen de rango, afectando entonces solo de manera local al resultado de la interpolaci6n y no de manera general. Figura 9. Para realizaruna correcta interpolacion de los datos, se debe escoger el nfunero apropiado de neuronas de la capa intermedia, la cual se puede definir mediante una etapa de calibraci6n del interpolador. El exceso de. neuronas, puede provocar oscilaciones no deseadas y su deficiencia, puede dejar a la red con un error muy alto. El tiempo de procesamiento puede reducirse si se dispone de una red entrenada con valores. promedio 0 frecuentes, de los datos de interpolaci6n. Esto provoca que la red inicial quede mas cerca del error minimo. Tambien se puede recurrir a 145 almacenar la ultima' red entrenada y reutilizarla en el siguiente cicio. EI m6dulo de control de datos, que elimina los datos fuera de rango, hace que tared siempre se entrene con datos villidos, 10 que hace la tecnica de interpolacion inmune a danos en la entrada, afectando solamente una porcion local de la superficie interpolada. . EI interpolador con red Backpropagation se presenta entonces como una herramienta para trabajar con sistemas que requieran analisis e interpolacion de datos en tiempo de real de adquisici6n y para datos de mas de dos dimensiones que presentan complejidad para las tecnicas de interpolacion . convencionales. Este metodo tiene las siguientes caracteristicas: AnaIisis en tiempo real, representaci6n parametrica, generaci6n de una superflcie suave, inmune a dallos en las entradas, calibracion del error y de las oscilaciones no deseadas, adaptabilidad a las entradas, caIculo de parametros automatico y oculto al usuario. 14. Marrero Negron Pablo V.; Pagina web. Notas de an~1isis numerico, . . http://uprhmateOI.upr.clu.edul-pnmlnotas4061/index.htm IS. Pedro J. Pascual Broncano y Antonio Gutierrez, Pagina Web Escuela Tecnica Superior de Informaticadela Universidad Aut6noma de Madrid, 1998-2000 http://www.ii.uam.es/-pedro/graficos/teorialCurvaslntro/Curv asIntro.htm 16. Contenido de la materia Analisis Numerico y Programaci6n FORTRAN; Pagina Web, Universidad . Tecnol6gica de Panama; Facultad de Ingenieria Mecanica, http://ns.fim.utp.ac.palalfalanfortranlindex.html 17. DIAZ WLADIMIRO; Pagina Web; http://www.uv.es/-diazl 18. REDES NEURONALES ARTIFICIALES;pagina web http://www.gc.ssr.upm.es/inves/neurallann21anntUtorial.html 19. Eduardo Morales, Pagina Web, redes neuronales; http://w3.modtesm.mxl-emoraleslCursoslOptimizalnode68.h tml 20. Redes Neuronales Artificiales, Pagina web http://electronica:com.mxlneural 21. Redes Neuronales; Pagina web, CLASIFICACION DE FRASES DEL LENGUAJE NATURAL Sergio Roa Ovalle Luis Fernando Nino Departamento de Ingenieria de Sistemas Universidad Nacional de Colombia Bogotii, D.C. Resumen: En este articulo se considera la tarea de la c1asificacion de frases del lenguaje natural, utilizando una red neuronal recurrente. En este caso el resultado es la c1asificacion de las frases por su estado gramatical (gramaticalmente correctas 0 incorrectas). En este trabajo se logra en un . porcentaje aceptable esta c1asilicacion, utilizando como ejemplos para entrenar a la red neuronal recurrente, frases codificadas del lenguaje natural, b!lsandose .esta codification en la teoria lingiiistica de Reccion y Ligamiento. entrenamiento (algoritmo de retropropagaeion a traves del tiempo) utilizado ampliamente en redes neuronales recurrentes [5][6][10] y los resultados obtenidos a partir de la implementacion de la aplicaci6n que se realiz6. 2. EJEMPLOS DE ENTRENAMIENTO Los ejemplos de entrenamiento empleados se obtuvieron tomando frases codifieadas en este caso del lenguaje Ingles [6], basandose esta codificaei6n en la Teoria de RecCien y Ligamiento 0 de Principios y Parametros, la eual afirma que solo los parametros y el texico son adquiridos por un ser humano, los principios no son aprendidos [2]. Con el entrenamiento de la red neuronal, 10 que se busca es producir los mismos juieios que un hablante de lengua nativa sobre datos gramatical y no gramatiealmente correctos y en un futuro inferir del comportamiento de la red neuronal la gramatiea del lenguaje correspondiente sin tener mueho conocimiento de su estructura, en un intento por exhibir el mismo tipo de poder diseriminatorio que se ha obtenido por los lingiiistas con la Teoria de Recci6n y Ligamiento [6]. En [6] se describe el sistema empleado para clasificar las palabras en distintas categorias, como sustantivos, verbos, articulos, y tambien se obtiene una subeategorizacion de ellas, por ejemplo verbo transitivo. De esta codificaci6n se tomaron los respectivos ejemplos de entrenamiento. Algunos ejemplos usados en el entrenamierito, se muestran en la Tabla 1. Palahras clave: Redes neuronales recurrentes, procesamiento dellenguaje natural, teo ria de reccion y ligamiento, algoritmo de retropropagaclon a traves del tlempo. http://www.gc.ssr.upm.es/inves/neurallindex~html REFERENCIAS I. INTRODUCCION I. CASTRILLON C.E. y PERLAZA J.F., Caracterizacion del microclima en un invernadero y un cuarto de crecimiento (area de biotecnologia) en el CIAT, mediante teenicas de instrumentaci6n virtual. Tesis de grado, Universidad del Valle, Facultad de Ingenieria, Cali. 2000. 2. CARVAJAL, L.· Metodologia de la investigaci6n, Cali. 1990. 3. BUNGE, MARIO. La ciencia su metodo y su filosofia. p. 110. 4. BACHELARD, G. La formaci6n del espiritu cientifico. 5. COBO, H. Norinas Tecnicas. Octava edici6n. Impretec . Ltda. Guadalajara de Buga. 1998. p. 49.. 6. Natiorial Instruments,. LAB VIEW 5.1 Manual de programaci6n. 1999. 7. Hilera J. y Martinez V., Redes neuronales artificiales. Addison-Werley Iberoamericana. U.S.A. 1995. p. 390. 8. Kohonen T., An introduction to Neural Computing. 1988. 9. Jones, J.G.W. & Street, P.R.; System Theory Applied to Agriculture and The food chain. Elsevier Science Publishers Ltda. N.Y. U.S.A.; 1990. p. 365. 10. Robert, G.D. Steel & James H. Torria; Principles and procedures of statistics. McGraw Hill. N.Y. 1960. pA8I. 11. Adela Abad de Servin & Luis A. Servin Andrade; Introducci6n al muestreo. Editorial Limosa.. Mexico 1978. p.200. 12. Cardona, Jaiber; Desarrollo de mOdulos para redes neuronales backpropagation en ambientes de instrumentaci6n y. control implementados con LabVIEW. Universidad del Valle, Cali. Colombia 1998. 13. Duque Miriam Cristina; Estadista .biotecnologia y asesora del CIAT, Comuriicaci6n verbal, Palmira, 2000. Las redes neuronales han sido utilizadas ampliamente en tareas de clasificaei6n y, enpafticular, sonde mayor uso y difusi6h las redes multieapa con realimentacion. Sin embargo, en el caso de la clasificaci6n de frases dellenguaje natural se puede verificar' que las redes neuronales reeurrentes poseen una habilidad inherente para simular aut6matas de estado finito [5], por medio de los cuales se puede llegar a inferir la gramatica de un lenguaje regular [6]. En este caso, a partir del comportamiento de una red neuronal reeurrente como un sistema ctimimico [5] se puede lIegar a construir un automata finito deterministico [6] [4] [7] [8]. Sin embargo, se debe tener en cuenta que las gramaticas de los lenguajes naturales no pueden ser representadas en forma absoluta por modelos de estado finito, debido a la estructura jernrquica que poseen . estas gramaticas,. sin embargo, se ha demostrado que estas redes reeurrentes tienen el poder de representaci6n requerido para las soluciones jerarquicas [3J. TABLA 1 EJEMPLQS DE ENTRENAMfENTO CODIFICADOS Y SU CLASIFICACI6N Frase En el desarrollo de esta investigacion se utilizo entonees una red neuronal recurrente para la clasificaei6n de frases como gramaticalmente correctas 0 incorrectas. En este trabajo se eomprob6 la capacidad de una red neuronal denominada red neuronal de Elman, utilizada en trabajos previos con problemas de lenguaje natural [6], [3] [9]. Algunas otras redes neuronales recurrentes han sido propuestas pero la red neuronal de Elman ha. presentado resultados muy satisfactorios en cuanto al entrenamiento [6] .. En las siguientes secciones se hara una breve presentaei6n de los ejemplos codificados utilizados para el entrenamiento de la red, los cuales fueron tomados de [6] y cuya codifieaci6n se base. la teoria de Reccion y realiz6 teniendo como Ligamiento [2]. Posterionnerite se expondra la topologia de la red neuronal de Elman empleada, eI algoritmo de 146 Codificacion Estado gramatic al n4 v2 a2 c n4 v2 adv I I am eager for John to be here n4 v2 a2 c n4 pi v2 1 adv f-----­ n4 v2 a2 n4 .v2 adv 0 I am eager John n4 v2 a2 n4 pi v2 to be here 0 adv 1 I am eager to be n4.v2 a2 v2 adv here n4 v2 a2 21 v2 adv 1_ Como entradas a la red neuronal se presentanentonces las frases codificadas a traves de un analizador sintlictico y lexico. Esta clasificaci6n se codific6 de tal forma que la informaci6n se pueda presentar a la red neuronal. Por 147 ejemplo: ~".II P4Ml' Clase sustantivo No es de la clase = 0.0 Subcategoria 1 = 0.5 Subcategoria 2 = 0.666 Subcategoria 3 = 0.866 Subcategoria 4 = 1.0 WII donde no es la tasa inicial de aprendizaje (0.2), C, = 50,c} = 0.65, N = numero total de epocas de cntrenamiento (4000), 11 W _ _~~) u la epoca actual de entrenamiento. Este plan se usa para evitar que, el algoritmo conveJja a minimos locales no adecuados [6]. (Xlf''' --­ ~'y W III • • ~(n;l;{lJ WI! I' '\''\)1 ....~~1.''''''~.,~..-.'It.. '~ En [6] se describe la utilizaci6n de 9 clases de verbos (v), 4 de sustantivos (n), 4 de adjetivos (a) y 2 de preposiciones (P) y adicionalmente las clases marcador (mrkr) ,determinante (det), complemento (c) y adverbio (adv) que no tienen subcategorias, es decir se les da valor de 1.0. EI vidor que se Ie da a las subcategorias de sustantivos, verbos, adjetivos y preposiciones se establece a partir de un orden lineal de acuerdo a la similitud entre subcategorias [1]. Las salidas de la red neuronal son originalmente 0 (gramaticalmente incorrecto) y I (correcto), pero a la red se Ie' dieron como :salidas esperadas 0.1 y 0.9 para evitar que Ia funci6n de activacion para cada neurona se sature [6]. A la red neuronal se Ie presentaron 365 ejemplos de estc tipo repartidos equitativiunente entre ejemplos correctos e incorrectos para entrenarla y obtener como resultado la clasificaci6n de los distintos ejemplos en el estado gramatical correspondiente. '\ <l ·'>"'. .'.u,/·v ll 0 " , ,/'•.'t'fa I \JlIll ,7\l\WI~~_" rm / . "" ,," ..-_.---­ 'fICll1P!) Fig. 1. Utilizaci6n de la ventana En la Fig. I se muestra la red Neuronal de Elman. En la implementacion se determino usar 20 neuronas en la capa oculta ya que se presentaron los mejores resultados en la convergencia del algoritmo de entrenamiento. En la Fig. 1 no se muestran todas las conexiones. Para Ia capa de salida; las 2 neuronas se tomaron para la clasificacion de frases corrcctas e incorrectas. Si la frase es correcta la respuesta deseada para la primera neurona es 0.9, y parala segunda 0.1. Si la frase es incorrecta la respuesta deseada para la primera neurona es 0.1 y para la segunda 0.9, es deCir, Ia primera neurona clasificaria los ejemplos correctos y la segunda los incorrectos. ~, / -h \ -lO x.tl) 'W;l l't1{ll ''f:;; lu1\' ~; /'\Vf XlII} W;u' XilItl), I} * ! a lit & Fig. 2. Retropropagaci6n a traves del tiempo Sea U el conjunto de indices de neuronas quetienen salidas hacia otras neuronas, T(t) el conjurito de indices para los cuaies se tiene una respuesta deseada, e el error para cada neurona, E(t) el error en el tiempo t y E to /al (t',1) elerror total, desde un tiempo t' hasta t, se tiene que: e (/):::.(di(IJ-Yl (I) sikE T (I) A o elwlnu:aso E{t)=~ L .2 t~(l , [111 (t)r 1 3.TOPOLOGiA DE LA RED NEURONAL La red utilizada es una red neuronal recurrente, es decir que en general los estados anteriores de algunas 0 todas sus neuronas tambien se reciben como entrada a esas mismas neuronasy al resto [5]. En este caso se us6 Ii llamada Red Neuronal de Elman [3], en Ia cual existe retroalimentacion desde cada neurona en la capa oculta hacia el resto de neuronas en esa misma capa oculta. Para poder ingresar los ejemplos a la red neuronal se utiliza en la capa de entrada una ventana de tamaiio 2, en la que las frases se ingresan de a 2 palabras [6]. Cada ventana corresponde a 8 neuronas, correspondientes a las 8 categorias, es decir, en total, 16 neuronas, y el valor que se les ingresa es el correspondiente a la subcategoria 0 0 si la neurona no corresponde a esa categoria. Por ejemplo el ingreso de la frase codificada "nl v In corresponderia a 0.5 en la primera neurona, 0 en las oiias 7 de la respectiva ventana, 0 para la primera neurona de la 2a. ventana, 0.5 para la segunda neurona correspondiente a verbos y 0 para el resto. El uso de una ventana se debe al objetivo futuro de la investigacion, el cual es encontrar el automata correspondiente extrayendo esa informacion de los cambios en el estado de la red neuronal, esto debido ala caracterizacion de Ia red como un sistema dinamico [5]. Si se usara una vehtana tan grande como la frase con mayor cantidad de palabras el resultado de la red seria mejor pero no se estaria obserV'ando eleomportamiento que se busca [6]. El proceso se puede observar en la Fig. I. 0 4. ALGORITMO DE ENTRENAMIENTO ,. Se utilizo la actualizacion cstocastica, es decir, los ejemplos : son tomados en forma aleatoria paraevitar que dos ejemplos seguidos se tomen como de la misma clase y cada ejemplo es presentado e inmediatamente se hace la retropropagaci6n. Los pesos se inicializan aleatoriamente con valores desde -2 hasta 2, valores que presentaron un mejor rendimiento. C,..t.ff(t ',/)=.2: E(T) 5. RESULTADOS OBTENIDOS ' En el entrenamiento realizado el error total promedio dado por la surna de los errores cuadraticos de todos los ejemplos fue de 0.09 aprox. para un promedio de error por neuron a de 0.3. Debido a la complejidad computacional del problema, que para 11 neuronas es del orden O(nh) en espacio y O(1I 2h/h' para cada tiempo de entrenamiento, no se pudo realizar una gran cantidad de simulaciones. Para los 365 ejemplos cada simulacion duro 2h. 30m. en una maquina con procesador Pentium III.· En un principio los ejemplos iniciales que se Ie dieron fueron algo contmdictorios, porque algunas frases con codificaciones identicas tenian estados gramaticales diferentes. Estos ejemplos fueron eliminados y se logro mejorar el rendimiento de la red. , Se utilizo una version [10] del algoritmo de retropropagacion a traves del tiempo (BPTT) [5]. Este algoritmo seusa para el entrenamiento de redes neuronales recurrentes,' es una extension del algoritmo estandar. Se deriva de desplegar la operacion temporal de la red en una red con alimentacion hacia adelante, y su topologia crece en una capa' a cada paso de tiempo, manteniendose los pesos simlpticos. En la Fig. 2 se muestra una red recurrente sencilla con dog neuronas, mostrandose las conexiones entre elIas como primera instancia y en segundo lugar la red desplegada en el tiempo. EI algoritmo utilizado es una combinacion del BPTT por epocas (para cada epoca los ejemplos son mostrados en su totalidad y posteriormente se hace la retropropagacion) y el BPTT tnmcado 0 en tiempo real (los ejemplos se muestran e inmediatamente se realiza la retropropagaci6n para los It tiempos mas recientes) [5]. En este algoritmo solo hasta h' tiempos adicionales se hace la retropropagacion; en este caso h' se toma como el tiempo desde que ingresa laprimera palabra de una frase a la red neuronal hasta el tiempo de la ultima palabra. Para la implementaci6n, h se tomo con un valor de 20, que es aproximadamente el doble en promedio de h'. ' TABLA 2 Si ahora se define k 0 U, v como la respuesta neta y 0 como la funci6n de activaci6n (se utiliz6 la funcion Iogistica sigmoide) se tiene que el eaJculo de los gradientes locales pam la neurona k es el siguiente: "'·h·~{T)}e,ft) ' tp '(I'jh)} Respuesta Frase codificada Correcta~corr. deseada nl v2a2nl pi v21 adv nl v2 a4 nl v2 adv nl det nl v3 vO nl v2 nl vi nl v2 v6 nl v2 nl det nl v3 nl v2 v3 nl v2 a3 nl v2 a4 nl nl vO nl v3 nl n4 det nl v2 !rl T""'t n."'f }~ll/i' '(v1iTHl".(T)+ 'I ~______~RE=S~LT~DOSOB~NIDOS ,'··uililt + IU 2:. I .. ~' # r-/i'<T~t r O!M!'i,ll+Il~( J:A 1.' Se observa que solo se tienen en cuenta las respuestas deseadas para los ultimos h' tiempos. Una vez se ha hecho la retropropagacion hasta t-h+ 1 se realiza cl siguiente ajuste de pesos pam la neurona i: ' I L\ w~.=rl' L 6;lT)x,(T-l) t-J·oA~1 donde 0 es la tasa de aprendizaje, que se obtuvo de la siguiente manem: 1'11'1', Incorrecta 0.1352 Illcorrecta 0.8473 Correcta 0.0988 0.9012 Correcta Correeta Correcta Incorrecta Incorrecta . Incorre~ v2 a2 det nl v2 adv~631 0.9368 Incorre~1 .'~ (-Io,-:!" fif.f-/r' 0.031010.9~89 0.8765 0.7729 0.9459 0.0684 0.0083 __ 0.1234 -_"-C-0 ~} 0.0540 0.9315 0.9916 0 nl v3 v2 a 2 det nl 0.0:3'70 0.9629 Incorrecta I v 2 adv I det nl v2 v2 0.9369 0.0631' Correcta Se utilizaron otros 135 ejemplos para probar la red y, se estimo su clasificaci6n en un 70% aproximadamente. Algunos resultados obtenidos se muestran en la Tabla 2. 0 tJ, ...!!..­ \' I .~ ' ; ' } ~ J 6. CONCLUSIONES " , IIJIJ.l En este tmbajo se ha discutido aeerca de Ia clasificaci6n de frases del lenguaje natural y se ha encontrado que la 148 149 , INTERPOLADOR PARA CONTROLDIFUSO ADAPTATIVO clasificaci6n es relativamente satisfactoria, dada la capacidad inherente de las redes neuronales recurrentes para simular automatas de estadofinito deterministic os, y dado que las redes neuronales' recurrentes tambien son' una buena representacion para estructuras jenirquicas, en este caso la gramatica del lenguaje en estudio, se considera que estas redes pueden ser objeto de investigaciones posteriores ,en tareas de procesamiento dellenguajenatural y la obtencion de automatas y gramaticas que se puedan inferir de ellas. ·'7.AUTORES 12, no. I, pp. 126-140,2000. [7] C.W. Omlin y c.L. Giles, "Constructing Deterministic Finite-State Automata in Recurrent Neural Networks", J. ACM, voL 45, no. 6, p.937, 1996. [8] C.W. Omlin y C.L. Giles, "Extraction of Rules from Discrete-Time Recurrent Neural Networks," Neural Networks, vol. 9, no. 1, pp.41-52, 1996. [9] A. Stolcke, "Learning Feature-Based Semantics with Simple Recurrent Networks", Technical Report TR-90-015, Int'l Computer Science Inst., Berkeley, Calif., Abr. 1990 [lOJ R.I. Williams y 1. Peng, "An Efficient Gradient-Based Algorithm for On-Line Training of Recurrent Network Trajectories," Neural Computation, vol. 2, no. 4, pp. 490-501, 1990. Sergio Roa Ovalle es estudiante de ultimo semestre de pregrado en Ingenieria de Sistemas de la Universidad Nacional de Colombia sede Bogota. Sus areas de interes son procesamiento de Imagenes, ' VISIon computacional, procesamiento del lenguaje natural y de la voz" sistemas inteligentes, reconocimiento de patrones y computacion grafica. Betancur Betancur, Manuel; Pedraza Diaz, Marta Elena y Marin Arango, Diego Ignacio , GRIAL ':'Grupode Investigacion cn AutomaticaUniversidad Pontificia Bolivariana, Medellin, Colombia '[email protected] ReSumen:, Se presenta una idea para la optlmizacion de un proceso automatico de ada pta cion de uncontrolador FMRLC* slmulado. Dicha idea consiste e'n interpolar el valor de cada una de las reglas activadas conslderando el valor de las reglas vecinas segun su validez 0 certeza. La interpolation se realiza despues del mecanismo de inferencia y antes de la interfaz de concrecion (defuzzyfication). Esto se realiza para cada una de , las reglas activadas de forma tal que el valor final despues de la interfaz de concrecion es mejor que el obtenido con el FMRLC original. ' Abstract: An idea for the optimization of an automatic adaptation process in a simulated FMRLC* is presented. The Idea consists of interpolatillg the value or each one or the active rules using its neigbbors according to their certainty value. Interpolation follows the inference mechanism just before the defuzzyfication process. This is done for each one orthe active rules so that the final value after the defuzzyfication process is ' better than the one obtained with the original FMRLC. Luis Fernando Niiio es profesor de la Universidad Nacional de Colombia, Ingeniero de Sistemas Universidad Nacional de Colombia, Msc. en Matematicas, Universidad Nacional de Colombia, Mscen Matematicas con enfasis enCiencias dela Computacion, Universidad de Memphis, B.U., Ph.D., en Matematicas con enfasis en Ciencias de .la Computacion, Universidad de Memphis, ,E.U. Sus areas de interes son. Redes Neuronales y Sistemas' Bio-inspirados, Computacion Evolutiva, Sistemas lnmunologicos Artificiales, Procesamiento de lmagenes: y Computacion Griifica, Aplicacion de las Mateni~ticas' a las Ciencias de la Computac1on. ' Keywords: Interpolation, FMRLC*, IFMRLC+, Intelligent Fuzzy Control.' ' 1. INTRODUCCION Este trabajo es la segunda fase en la exploracion de una serie de ideas por parte del GRIAL tendientes, a mejorar el metodo FMRLC* para adaptacion y aprendizaje' autonomo en controladores difusos, usando ideas bio~nspiradas [5]. La importancia del trabajo radica en desarrollar un controlador difuso inteligente capaz de interpolar 10 que ha aprendido para algunas situaciones de modo que pueda aplicar ese conocimiento en situaciones similares pero menos conocidas. Esto es, que su comportamiento usani un ciertb grado de "sentido comtin" al enfrentar situaciones anormales 0 desconocidas. REFERENCIAS [I] E.B. Baum y F. Wilczek, "Supervised Learning of Probability Distributions by Neural Networks", Neural Information Processing Systems, pp. 52-61, New York: Am. Inst. Of Physics, 1988. [2] C.A. Black, "A step-by-step introduction to the Government and Binding theory of syntax," Summer Institute of Linguistics, 1999. [3] 1.L. Elman, "Distributed Representations, ,Simple Recurrent Networks, and Grammatical Structure," Machine Learning, vol. 7, nos. 2/3, pp. 195-226, 1991. New York: Springer Verlag, 1996. [4] C.L. Giles, C.B. Millcr, D. Chen, G.Z. Sun, H.H. Chen y Y.C. Lee, "Extracting and Learning an Unknown Grammar with Recurrent Neural Networks", Advances in Neural Information Processing Systems 4, pp. 317-324, San Mateo, Calif.: Morgan Kaufmann, 1990. [5] S. Haykin, Neural Networks, A Comprehensive Foundation. Second Edition. New Jersey: Prentice Hall, 1999. [6] S. Lawrence, G. Lee Giles, S. Fong, "Natural Language Grammatical Inference with Recurrent Neural Networks", IEEE Transactions on Knowledge and Data Engineering, vol. Esta investigacion muestra como usar cl conocimiento adquirido en las reglas ya aprendidas -teniendo como medida de su certeza 0 validez la cantidad de veces que estas hayan sido utilizadas- con el fill de mejorar el valor de reglas mcnos ciertas, y obtener asi un resultado que mejore la efectividad de la salida del controlador. 150 2. INSPlRACI6N DEL INTERPOLADOR Para ilustrar la idea basica suponga que un operario se enfrenta al problema dc guiar un bote usando el timon, pero recibe muy poca (0 ninguna) instruccion en cuanto a su funcionamiento. , Para unas, condiciones dadas de viento, oleaje y carga del bote; el timon tendra un cierto efecto en el rumbo del barco. Durante . este experimento mental dichas condiciones permaneceran constantes. Se realizarnn tres pruebas sobre este sistema hipotetico para asi llegar a la intuicion de la necesidad de un "interpolador" para lograr un resultado con , "sentido com un": En el primer escenario, al pedirle al novato "timonel" ,que gire el bote levemente, este aplicara una cierta fuerza al timon. Dependiendo de los resultados -que de seguro no seran'satisfactorios en un primer momento- el ajustara su conocimiento para ese caso particular. En 10 sucesivo ante solicitudes similares sera cada vez mas certera la accion a tomar, 'pues con la experiencia se adapta la accion de control, y con la memoria' se aprende. Esto implica que aplicara laaccion que fueexitosaen el pasado si se llegan a presentar las mismas condiciones' en el' futuro. Igual fundona el sistema para este caso cuando el "timonel" no es un humane sino el algoritrno FMRLC. En un segundo escenario, si en'vez de solicitar un giro leve, se solicita algototalmente diferente, por ejemplo un giro muy fuerte en sentido contrario, entonces las condiciones son otras. EI timonel (}(~ase controlador) debera realizar un proceso de aprendizaje similar al que se acaba de describir para el primer escenario. Este ensayo-error sucede tanto en el caso con el timonel humano como con el que usa el FMRLC. Lo interesante se aprecia en un tercer escenario posterior en el que se solicita realizar un giro con intensidad intermedia. Un timonel humane "intuitivamente" aplicani una "interpolaci6n" entre los dos escenarios que ya conoce y para los cuales confiaen las reglas aprendidas. Asi pues, aplicara una fuerza intermedia al ,timon (sin haberlo aprendido ni de terceros ni de su experiencia previa), y seguramente lograra resultados aceptables sin tener que seguir todo el proceso de aprendizaje para esc ca.so particular. Tomara un "atajo". Por supuesto, si las decisiones tomadas no resultasen adecuadas, sigue disponible su capacidad de adaptacion y aprendizaje para ajustar dicllo conocimiento a partir'de la experiencia. 151 a) Si en vez de un timonel humane dicho bote hubiese estado controlado por un FMRLC, para todos los escenarios' hubiese seguido el mismo algoritmo de aprendizaje. Por tal razon en el momento de hacer el primer giro de intensidad intermedia se hubiese desperdiciado el conocimiento previo adquirido para los giros leves y los giros fuertes. Es precisamente en este Ultimo tipo de escenarios donde resulta interesante y necesaria la capacidad de interpolacion para el FMRLC, emulando en alguna medida el comportamiento del timonel humano. b) 3. EL ALGORITMO FMRLC El metoda original FMRLC (Passino y Yurkovich [I]) que sirve de base para aplicar la idea del interpolador tiene un conjunto de llx II reglas en el control ad or, usando el error e(t) y.la derivada-del-error de(t) como entradas (Ver figura I). Dispone de un modelo de referencia de la planta para orientar la sintonia del controlador, de modo tal que la salida de dicho modelo de referencia Ym(t) se convierte en la salida deseada Y(t) de la planta real. Usando la desviacion Ye(t) & Yc(t) entre el modelo y la planta, se alimenta un modele inverso intuitivo de la planta para decidir las adaptaciones que deben hacerse a las reglas del controlador. Una matriz de certezas de 11 xll: Esta matriz cambiara dinamicamente durante la aplicacion del algoritmo asignandole un grade de certeza a cada una de las reglas' aprendidas, y su crecimiento dependera de una funei6n que converge ai, siendo este el valor maximo po sible de certeza, es decir,es equivalente a tener una seguridad del 100% de que esa'regla se ha adaptado muchas veces y que por 10 tanto debe ser correcta. Una matriz de mascara de 3x3: Esta matriz se utiliza para limitar el valor de ,Ia interpolacion a las reglas que mdean cada una de las reglas activadas, ya que el algoritmo toma solamente una regIa en cada iteracion y esto se repetini cuatro veces, una para cada regIa activada, teniendo en cuenta que el grade de importancia de las reglas vecinas esmenor que la de la regIa en juego. Esta matriz tiene unos' valores predeterminados los cuales' cambian dinamicamente dependiendo del b'fado de certeza dela regIa: en cuesti6ri, i.e. si la certeza de una'regIa determinada a la cual se Ie va a realizar el procesoes mayor a 0.8, la interpolaci6n solo ten<4U en cuenta la regia del. centro, es decir el valor del centro de la matriz de certt;!zas sera uno y todos los demas seran cero. ' ." El objetivo del. mecanismo de adaptacion es sintonizar el controlador difuso adaptando sus reglas de modo que el buque persiga la orientacion del modele de referencia. Por 10 general, el controlador difuso tiene 4 reglas activas, debido al traslape de las funcio!les de rnembresia de las (dos) entradas, el error e(t) y Ia derivada-del-error de(t). . Esas reglas son siempre vecinas, formando un "cuadrado'; que viaja por la matriz de reglas segun los valores de e(t) y de(t). Estas cuatro ieglas son las utilizadas para el calculo del valor de la accion de control en el momento de Ia concreci6n en cada cicIo de muestreo y control. . La planta 0 proceso simulado [3] es un. buque-tanque. La elltrada u(t) a la planta es el angul0 de "tim6n", y la salida Y(t) es la orientaci6n 0 rumbo de la nave. 152 Todas las simulaciones se realizaron para un buque-tanque. EI intervalo de tiempo fue lO.OOO segundos, con un paso de integraci6n de 1 segundo, y un periodo de muestreo de 10 segundos para eI controlador. [3]. EI codigo se encuentra disponible en [5]. c) Una valiable temporal: Esta variable es una matriz, de 11x11 ell donde se almacella el valor obtellido de la regIa despues del proceso de interpolaei6n, con el fin de no alterar el valor de las reglas adaptadas en la matriz de reglas original. Max.Error se define entonces como el maximo del valor absoluto de Ye(t) durante cada simulaci6n. 5.2. CECI "Criterio de error cuadratico integral" Este criterio res alta los errores grandes, y perdona los pequeiios segun una ley cuadratica. 5.3. CECIT "CECI temporal" Como el CECI, pero ademas perdona los errores iniciales, y castig~ los de estado estable. 5.4. CEAI "Criterio de error absoluto integral" Este criterio castiga con proporcionalidad' los errores grandes y pequeiios. 6. RESULTADOS Las Uicnicas empleadas por el interpolador conllevan a una notable mej~ria en el desempeno del sistema, las cuales pueden ser vistas cualitativamente cn las tablas I y 4 Y cuantitativamente en las tablas 2 y 3. En la tabla 1 se observa el resultado de la matriz de certezas para tres escenarios diferentes. Dicha matriz indica el grade de confiabilidad delaprendizaje para cada regIa difusa: Mejor Caso: Este es el primer caso que se presenta en la tabla 1. En este ejemplo, las presintonia inicial es la correcta, entonces solo son exploradas las reglas del centro, 10 cua( significa que hay una buena sintonia y que el control se realiza principalmente alrededor de esta zona. Caso Neutro: Es el segundo caso que se presenta en la tabla I. En este ejemplo la presintonia inicial la matriz de reglas se encuentra en cero, entonces se observa que algunas reglas alejadas del centro alcanzan a ser exploradas al cometer errores en las decisiones. Sin embargo, al final se logra que se exploren las reglas del centro que son las que deben predominar sobre el control. Peor Caso: Es el tercer caso que se presenta en la tabla I. En este ejemplo la presintonia inicial de la matriz de reglas tiene val ores totalmente opuestos a los correctos. Por 10 tanto en la grafica se observa como las reglas exploradas son las de los bordes (saturaciones) con una tendencia a explorar las del centro. Es decir, el sistema tiende a estabilizarse para futuras iteraciones. La segunda, "Neutral", supuso una condicion nula, sin sintonia, i.e. al controlador se Ie ensefio que no respondiera ante los errores, sino que dejara el timon centrado y quieto. Fig. 2 Proceso de Interpolaci6n calculado Ym(t) menos Rumbo real Y(t).Ye(t) es un indicador de la efectividad del proceso de adaptaeion: A medida que decrece, significa que la planta se esta comportando del modo propuesto en el, modele de referencia, 10 cual es el objetivo del mecanismo de adaptacion. 5.5. CEAIT "CEAI temporal" Como el CEAI, pero ademas perdona los errores iniciales, y castiga los de estado estable. . 5. SIMULACION En la primera familia se supuso un razonable "Mejor Caso" para el modelo del controlador, i.e. las reglas iniciales se presintonizaron usando conocimiento intuitivo de Ia planta, instruyendo aI controlador, para virar la nave y corregir adecuadamente la orientaci6n. 1--.-,---­ El metodode interpolacion IFMRLC propuesto aqui emplea los siguientes 3 elemen~os (Ver figura 2): Es posible establecer una analogia entre el metodo de interpolacion para eI control difuso adaptativo y el comportamiento de las personas aI enfrentar situaciones desconocidas. Estas suelen emplear herramientas similares a las usadas en situaciones parecidas vividas .anteriormente, pero de forma modificada puesto que no son iguales. Sin embargo, cuando se vive una situacion 0 experiencia completamente igual a una vivid a anteriormente, no es necesario modificar la forma en la cual se reacciona, sino que se confia en la experiencia previa. Una serle de 3 familias de pruebas se ejecutaron para los dos metodos (EI FMRLC "original" y el IFMRLC tlinterpolador"): 4. INTERPOLACION PARA EL FMRLC Fig. I. IFMRLC Una vez establecidos estos elementos, la interpolacion se realiza de la siguiente forma: se hace una multiplicaci6n entre la matriz de certezas y la de mascara obteniendo asi una nueva matriz la cual se normaliza. Luego se hace un producto punto entre esta matriz normalizada y la matriz de reglas. Finalmente este resuitado se lleva al lugar en donde iba a ser aplicada .' antes la regia enjuego. Vease Figura 2. La ultima, "Peor Caso ", supuso Ia peor condici6n posible, donde el diseiiador "erradamente" propone unas reglas iniciales que Ie ordenan al controlador aumentar el error girando la nave justo en el sentido equivocado. Esto equivale a enseiiar "mentiras" al timonel. Los criterios de desempeiio (benchmarks) us ados para todas las pruebas son los mismos y los resultados se muestran en la Tabla 2. Todos tienen valor ideal cero. Cada fila es un caso diferente. Las filas se agrupan por familias (condicion inicial). 5.1. Criterio Max.Error Sea el error-colltra-modelo-de-referencia Ye(t) el error que se presenta ante el mecanismo de aprendizaje, i.e. Rumbo 153 · TABLA 1: • COMPARACION DE LA MATRIZ DE CERTEZAS AL FINAL DE LAS SIMULACIONES "'.1t,,,,,!,_/111 __ ] .",?~,,1I' El interpolador tuvo solo una desmejora que se puede observar en la tabla 3, en el Mejor Caso, donde se tuvo una degradacion del 4% del maximo error obtenido para una referencia senoidal indicando un pequeno decremento en el maximo error absoluto, sin c.onsecuencias para los demas criterios de error los cuales tuvieron un buen comportamiento. § () ~ 1;:! 0 c.:!J "'u ~ .... ~ 0 t:.~ 3::E ~ N .t: 'ia 7. CONCLUSIONES ::E ....; I<f .... t.« <44'~--~n,.u , •• t_ .~~"'<>-"~1 "'" ~ ,,-,It..l 4. , _ ... ':;:11> l""".'. ".JII'"'' "~~ "'. r~~.,!, ~:::s () ~. g c.::; ~ 1'3z0 '" Como se puede observar, se logra una mejoria de hasta el 88% en el·peor caso que es justamente el mas critico e interesante. Los resultados esbozados en la tabla 2 muestran una mejora del 9% para el mejor caso, un 13% en el caso neutro y una mejoria del 88% para los casos peores y extremos -justo cuando mas se necesita la adaptaci6n inteligente­ con el nuevo metodo IFMRLC (interpolador). Por tanto, es justo decir que el interpolador aumenta la inteligencia del algoritmo FMRLC. (1) Tambienmejorola estabilidad en general y se suavizo el uso del actuador. REFERENCIAS ~ ()U (1) "0 .~ 'ia ::E ~.!r>~t,""'111f,*,,~,·j._\#',f ..H4~"-li N 1 ,q; ''1\ A.qu;i;li;;f_if... ,;:~\ "~1M"'" ''"'*''''',." w,U_'ttII: if_ ~ .._ " . , g ~ 0 c.~ ~u N .... ([) a t: (1) 3Q., ~ N .t: ~ ,...., Max-Error Seno Cuadrada ~iH",". ~-~"'-\t;;:. F//fol""t!' La tabla 2 presenta la medida de los criterios de desempeno para cada experimento, y la tabla 3. muestra la mejora comparativa en el desempeno del nuevo metodo interpolador contrastado con el original. [1.] PASSINO, K.M. y YURKOVICH, S., Fuzzy Control. Addison Wesley. USA. 1997. 475p [2.] OSORIO, M. y GONZALEZ, C.E., Ambiente interactivo para trabajo experimental en tiempo real usando Matlab, (9°:Cali:2000). En Memorias del IX Congreso Latinoamericano de Control Automatico, Cali, 2000, 1 CDROM [3.] Kevin M. Passino. Kevin M. Passino Home Page. Department of Electrical Engineering Ohio State. May 4,1999. Columbus Ohio. June 2 of 1999. <http://eewww.eng.ohio­ state.eduJ-passino/ic_code.htm> [Consulta: 14 Abril 2000]. [en linea]. [4.]BETANCUR, M. y ORTIZ, A., Fuzzy controller extrapolating adaptation methodology, (9°:Cali:2000). En Memorias del IX Congreso Latinoamericano· de Control Automatico, Cali, 2000, 1 CDROM [5.] Proyecto Fuzzy [en linea]. GRIAL, Mayo 2001. <http://www.upb.edu.co/griaVproyectos/fuzzy> [Consulta: 28 Mayo 200 I]. Cecit ,. CECI Seno Seno ' Cuadrada 2.Neutral 3.PeorCaso Original (x 103) lnterpolador Cuadrada Ceait Cuadrada 80067C 70829G 177680C I73380C 2 862500 138300 IS,S 1,85 TABLA 3 MEJORA EN EL DESEMPEflo DEL METODO DE INTERPOLACION Max-Error I.Mejor Caso Seno Cuadrada OO/! OO/! -4O/! 50/! Ceci Ceai Ceait Cecit Mejora Seno Cuadrada Seno Cuadrada Seno Cuadrada Scno Cuadrada Promedio 00/< Oo/! Oo/! Oo/! OO/! 00/< 00/< 0% Oo/! 50/! 160/< llo/< 17O/! 8o/! 12O/! 9% 3o/! 140/< 0% 13% 2.Neutral 0% 88% -­ 3.PeorCaso ..... 155 154 Ceai Seno I.Mejor Caso (1) t: (1) '" ....~ TABLA 2 RESULTADOS COMPARADOS PARA LOS METODOS ORIGINAL E INTERPOLADOR -~ ,t q ii II d TABLA 4 COMPARACI6N DE RESULTADOS DE SIMULACI6N PARA REGLAS INICIALIZADAS EN PEOR CASO ­ REFERENCIA CUADRADA Il Peor casu para reglas iniciales Consigna Cuadrada [\ !! I, ,I11 t: .~ IiII ~ II ~ 'I III » .s::: .~ ~ t" II » » » tl t: ~t: a I if II I La senal cuadrada de referencia es la misma en todos los casos. Se muestra gnificamente despues de filtrada por el modelo de referencia. La base de reglas se, presintonizo con el "Peor Caso". ( EI negado de "Mejor Caso". ) La ganancia del Modelo de Referenda es igual en todos los casos. , . Se grafican los 10000 segundos de simulacion. Rurtx>rea(S(jicl:Jlynnb>_(~)tEI""-l'VlotEl",",co,gr"""', II !I Erick Maldonado ([email protected]), Miguel Strefezza ([email protected]) .~ II I' MODELAJE Y CONTROL DE UNA ~LANTA PILOTO DE NEUTRALIZACION DE pH MEDIANTE UN CONTROLADOR HIBIUDO DIFUSO-PID .t;.J ~ -0'2' ~ - e."" ~ 'u c::r­ ·5 O\~ 0t<') ~O\ NN II lh o .g .~ u .5 :a ~.S ~~ ::Su ~ u.lu.l ~~ C> ._ ..... .~ § g g.... ... AA I .rnrrnJ[] - 1000 2000 3000 <4(lOO 5000 fiOOO 7000 8000 0000 , .t: ~'<t Vlu.l 1,.. .,_ .~ .~ .~ . . ___J .s 1i1o .:; S 'd .- -i:l .~ "" .~ ~ e.. ~ 00 ~l· '-I~ .' (l 1000 J 2000 J ' N 3QCO~. .;!;;-----'-;;"""~",",,,,,,~,-+';,ooo.'-l,;;: .. .... ;;!-l-;;;!;;;-.;:!. o.~ ::So gg Tlempo(s.c) 156 modelo se presentan en las secciones 2 y 3. El esquema de control propuesto y los resultados en la seccion 4, las conclusiones son dadas en la seccion 5. 2. EL PROCESO La planta piloto es la representacion a escala de un reactor continuo e isotermico tipotanque agitado CSTR (Colltinuos Stirred Tank Reactor). En el se lleva a cabo una neutralizacion entre un acido debil (Fa), acido acetico, y una base fuerte (Fb), el hidr6xido de sodio, ambos dentro de un medio acuoso obtenido por la introduccion de un flujo de agua destilada (Fw ), para facilitar las condiciones de operacion. Para mantener el volumen (V), 1,65 Its., dentro del reactor constante, se utiliza una tuberia de desagiie. Esto permite que el proceso pueda trabajar con un minimo de instrumentos:· una bomba dosificadora que sirve para manipular el flujo de base, un electrodo para medir el pH, dentro del tanque y una tuberia de desagfie. Otra bomba dosificadora, para variar la entrada del flujo de acido, que serviria para simular perturbaciones en el proceso. Los caudales son del orden de 5OmVmill. El esquema se muestra en la figura 1. Palabras Claves: Control de pH, Control Hibrido, Control Difuso. l. INTRODUCCI6N El control de pH es extremadamente necesario en las industrias de procesos quimicos e involucra plantas de alta complejidad. Estos sistemas no son lineales, son variantes con el tiempo, y no es £licit reproducirios. Los controladores chlsicos no pueden ajustarse a perturbaciones 0 a cambios de puntos de operacion. Como posible solucion de esto, controladores no lineales han sido propuestos [2][3J[IIJ. Bajo conocimiento preciso del proceso y de sus no linealidades, estos presentan un buen desempeno en ciertos rangos. 3. MODELO Los controladores difusos son disefiados con base a conocimientos de un experto 0 por extraccion de datos del proceso [10] y representados por reg las lingiiistioas del tipo Si-Entonces. Estos tambien han sido utilizados en procesos no lineales [l J[ 6]. Los controladores hibridos parten con el proposito de combinar diferentes h~cnicas de control, y asi aprovechar las ventajas de cada una de ellas[4] [8]. Donde no solo la' combinacion de tecnicas de inteligencia artificial son utilizados, sino tambien la de controladores clasicos con alguna de estas tecnicas[5J[7][9]. EI control clasico acrua en los rilomentos en el cual el proceso se encuentra trabajando en condiciones normales. El controlador difuso actua cuando se pr.esentan perturbaciones 0 no linealidades, mejorando la resimesta del sistema. Son simples de implementar, presentando buenos resultados. En este trabajo se presenta la aplicacion de un controlador hibrido difuso-PID para el control de pH en una reacci6n de neutralizacion. Adicionalmente a la salida de este controlador es afiadida una etapa integradora, esta produce que los tiempos de respuesta se reduzcan en forma significativa. EI sistema presenta buenos resultados y responde a diferentes puntos de operacion. La descripcion del proceso, asi como el u.lu.l AA Resumen: En este articulo se presenta el modelo de una planta piloto de neutralizacion de pH, entre un acido debH y una base fuerte, con el objetivo de diseiiar un controlador para esta reaccion. Una aproximaciiin del modelo y de la dlnamica del sistema es presentada. La valida cion es realizada con datos obtenidos experimentalmente de la planta. Para eL control de este proceso no lineal, se propone el uso de un controlador hibrido difuso-PID. Adicionalmente se introduce a la estrategia de control una etapa integradora, la cual reduce en forma slgnificativa tanto en el tlempo de respuesta como el de establecimiento. 10000 lInguo tEl til'lOO. SllIidatEI oa1raodtr dfuso (edrada tEl "'"'co), 9rad:lr!, '1WJJT~)'~·f"f"···)f~"."-"'"~'i" :! Dpto. Procesos y Sistemas, Universidad Simon Bolivar. Venezuela Para obtener el modelo de la planta, primero es necesario desan-ollar un modelo fenomenologico que describa la reaccion de neutralizacion en el reactor. Luego se procede a validar el modelo con datos reales. Fig. L Esquema general de la planta. 3.1 Modelo del Comportamiento Hidraulico y de la Instnllllelltacioll. Bajo condiciones de laboratorio, debido a la utilizacion de un mezclador magnetico y a las pequenas proporciones del 157 dimlmica del elemento· final de control debe ser. modelado como un sistema de primer orden, con' restricciones en la entrada y tiempo de retardo, con ganancia de la base =45, as! la funci6n de correcci6n de la base es: reactor, los efectos del mezcIado pueden ser despreciados. Por otro lado, estando eI medidor de pH localizado en las cercanfas del tubo de salida del recipiente, eI retardo por trans porte en la medida de la variable control ada tambien se puede despreciar. La dinamica del sensor de pH es tambien despredable, debido a que se posee una medida instantanea del pH. Tampoco el elemento final de control, la bomba de la base, posee una respuesta dimimica que afecte la validaci6n experimental. La HJ1. . 1.8 Bef "'I = (s + 0.001) a F~ ~~ ~II",""~I"'''' I,:;:., r ~f 1 a fb fb1 fb2 Flujo acido Fea Factor de correccion para el acido 1 bU3J1 rn n=I rn + +' phd3 e> ... feb _. ~ . .," operaci6n pH vs time .. ~. Zero-Pole planta Ph +CNA ...~ Flujo base Fig. 2 Diagrama del sistema. La dinamica de la bomba de flujo de acido es representada con factor de ganancia del addo= 17 con un tiempo muerto, debido a retard os observados, de e­ 680" asf la correccion del acido resulta: Aef = 7.5· 7 6.5 . .4 * 0~9 (s + 0.025)(s + 0.028) 6508 + 1 6 pH 5.5 R j: Si e es Ai y de es!lj entonces dUj'''' eel +'deCz + C3 (I) Donde Cn sonconstantes y la salida del modelo es calcuhida por el promedio de los pesos de la contrlbuci6n decada regia. Las funciones' de perte.nencia del error (e) y de Ia variaci6n del error (de) se muestran en la figura 5. Una vez disejiado este controlador es necesario ver su desempeiio con la planta, de manera que se puedan obtener nuevos eonocimientos que permitan sintonizar el controlador PID. EI controlador PID esta descrito por: u=Kpe+Kde+Kdedt Cuando el error se hace pequeno el controlador difuso, para evitar sobrepicos, realiza una aeClOn de contrapeso evitando de esta forma que esto suceda 0 que sea 10 nuis pequeno posible. EI PID clasico por tener parte integral posee "memoria", por 10 que al acercarse al punto de operacion aun recuerda su estado anterior, esto se refleja en su salida de forma que esta por 10 general es mayor de 10 que se necesita, favoreciendo al sobrepaso, mientras que el controlador difuso por estar basado en reglas y comparaciones puede modificar mas rapidamente su salida, por 10 querealiza una flip ida acci6n compensatoria. Ademas presenta un· buen desempeiio cuando las no linealidades se presentan en el sistema. . FinaImente, al esquema de control hibrido, es agregada una etapa integradora, la cual hace novedosa la estrategia control del sistema. La funci6n de esta etapa es integrar el valor de la salida del controlador hibrido. Esto trae como consecuencia, que la respuesta del sistema se haga mas flIPida, produciendo una disminuci6n notoria en el tiempo de establecimiento, como se observa en la figura 7. Este tiempo se reduce en un 90% aproximadamente. Ademas esta etapa no produce alteraciones en la estabilidad del sistema, factor que 10 hace relevante dentro del esquema disefiado. (2) Se podria utilizar algUn metoda conocido de sintonizaci6n, como es el de Ziegler-Nichols, aunque con un mayor conocimiento' de la planta y de su interacci6n con el controlador difuso, resulta mucho truis 6ptimo haeer la seleccion de los parametros de una forma mas intuitiva, de manera que se complementen las acciones de ambos controladores. En la figura 6 se muestra la respuesta del sistema con un controlador PID, se puede notar que es muy lento. . ~~~ De esta forma en la salida del controlador se observan la contribuci6n de. fuertes efectos proporcionales, integrales, doblemente integrales. En forma mas abstracta y global se puede ver el controlador como el trabajo en paraIelo de un controlador "inteligente", que ejerce compensaci6n al controlador clasico, en paralelo a un controlador de la forma (PU 2). La presencia de efectos tipo integral, Iogra~" un error en estado estacionario nulo, al tiempo que permite que se alcance este estado muy nipidamente. 3.2 Validacioll y Resultados de la Simulaci6n. 3.5 LI 3 0 ---l~OOO--~rooo~~3000----~~~--5000~ 0000 Se desarrollo el modelo en SIMULINK®, figura 2. Se tierrpo (s) . realizaron varias simulaciones con este modelo, a Fig. 3. Cambios en el pH. continuaci6n se describe una de elias. Donde Fa,Fal ,fb,fb I Por medio de las simulaciones se observa la necesidad de Y fb2 son los val ores de acido y base utilizados para obtener introducir acciones de control del tipo integrativa, al la respuesta de la planta. . tiempo que el conocimiento adquirido de la planta se Al principio solamente ~I agua y el acido son mezcIados. . puede expresar con mayor facilidad a partir del error y la Inidalmente, un flujo de base en forma constante es variacion del error. Tomando estas como variables de afiadido. A los 2000 segundos, el flujo de la base es entrada para el control difuso. aumentado, produciendo un aumento del pH. Luego, a los i I 3000 segundos, el flujo de base es reducido, produciendo una caida del pH. Finalmente a los 4000 segundos, el flujo H de addo es reducido, produciendo un incremento en eI pH. p Los cambios en el pH son mostrados en la figura 3. ... -+ 4. CONTROL HIBRIDO DIFUSO-PID. Fig. 4. Esquema de Control Propuesto. EI sistema es muy lento, por 10 que una de las metas mas importantes que se tuvo en consideracion durante el proceso de disefio fue mejorar Ia velocidad del sistema, tanto en tiempo de alza, como en eI de establecimiento. Esto implica que el controlador difuso debe ser extremadamente rapido, por 10 que el tiempo de cruculo del mismo, debe ser pequeno, esto sugiere que se utilice el metodo de Takagi y Sugeno, al tiempo que el numero de reglas utilizadas sea pequeno. As! para este disefio se utilizan solamente cinco reglas que describan cl comportamiento del proceso, las cuales son de la forma: Aquf se describe el esquema de control hibrido propuesto, el cual combina las bondades del controlador PID y del difuso. Es simple de implementar, figura 4, donde las acciones de ambos controladores son sumadas. El controlador esta defillido por las regia." difusas del tipo Si-Entonces, obtenidas a partir de las simulaciones realizadas con eI modelo de la figura 2. 158 pH n..J,_"""" Fig. 5. Funciones ile Pettenencia ilel error (e) y de la variaci6n ilel error (ile). Si en el control hibrido se observan las acciones del control PID y del difuso en forma. independiente, se notara que en los instantes de error grande, los dos controladores actUan en forma aunada para alcanzar el punto de operacion en el menor tiempo de alza posible. II pH Tiempo (seg) Fig. 7. Respuesta de la PJanta con el esquema propuesto. 5. CONCLUSIONES 1 r-==­ pH CO.lfotador PD pH Rlfmncla En este articulo, se ha presentado un esquema de control hibrido,entre un control PID· y del control difuso y es simple de implantar. El control difuso esta descrito mediante cinco reglas y cada universo de discurso esta formado por tres particiones. Tiempo (seg) 1500 2000 2500 '000 3m 4000 Fig. 6. Respuesta con un Control PID, 159 Se introduce una etapa integradora, la cual es novedosa, que produce un efecto muy importante en la respuesta del sistema, reduce en forma significativa el tiempo de establecimiento y no influye en forma negativa en" la estabilidad del sistema. Los resultados presentados por la estrategia de control son positivos, ya que la planta puede ser controlada para difere,ntes puntos de operacion a pesar de los cambios sensibles que puede presentar el control de pH, abarcando toda la gama de pH posible. Al tiempo que se ha logrado obtener a partir de un sistema muy lento,' uno bastante nipido, cuyo tiempo de establecimiento es del orden de 50 seg. en todos los casos, presentando sobrepico nulo en muchos casos y pequeno en otros. Se presenta el modelo de una planta piloto de laboratorio y su validacion basada en datos experimentales, demostrando que esta depende de las condiciones de operacion, de la dimimica de los instrumentos, los cuales no son simples de ajustar. No. I, pp. II. Y.H. Wong, P. R. Krinhnaswamy, W.K. Teo, B.D. Kulkarni, and P.B., Deshpande. [1994]. "Experimental' application of robust nonlinear control law to pH contro!'.'.: Chern. Eng. Sci., N. 49, pp.199-20 ' CONTROL DE UNA SISTEMA DE TANQUE PILOTO MEDIANTE LA UN CONTROLADOR DIFUSO OPTIMIZADO Carlos Jimenez ([email protected] ), Miguel Strefezza ([email protected]) Dpto. de Procesos y Sistemas, Universidad Simon Bolivar, Venezuela Resumen: En este articulo se plantea el modelaje, diseiio y la implementacion de un control de un sistema de tanque mediante un control diruso. En este sistema de tanque, se propone el control del nivel del liquido, variable principal a controlar, ademas del control del caudal que entra a dicho tan que. Para el control de nivel de este sistema no, lineal, se propone realizar la implementacion de un control difuso con optimizacion de los panimetros de las conclusiones de las reglas difusas mediante el metodo del gradiente estocastico. Para el control de caudal se implanta un controlador PI. Se realizan tanto simulaciones como la implementacion en tiempo real del esquema de control propuesto en el sistema de tanque, obtenit\ndose buenos e interesantes resultados en la aplicacion de est a tecnica. 6.AtITORES Erick Maldonado actualmente' cursa el decimosegundo trimestre de Ingenieria Electronica. Miguel Strefezza es profesor del Departamento de Procesos y Sistemas. Doctorado y Maestria en aplicaciones de control difuso y neuronal. Fax: +58-212-9063303. Tel: +58-212­ 9063327. Palabras Claves: Identificacion. 1. Control Difuso, conclusiones de .las reglas difusas mediante el metodo del gradiente estocastico. El esquema de control es implantado y presenta buenos resultados. La seccion 2 se presenta la descripcion del modelo de la planta, luego en la seccion 3 se presenta el esquema de control planteado y sus resultados, finalmente en la seccion 4, lasconc1usiones. 2. El proceso que se presenta en la planta es sencillo, pero no lineal, la figura 1 muestra su esquema general. Consiste en un tanque con un caudal de entrada, Qenb controlado por una valvula. En el tanque se presenta un caudal de salida, Qsah controlado por otra valvula. Optimizacion, INTRODUCCION , ....1>. '.~~•..;:r. ~,-. (1.", I~.· ~.~ En la industria la presencia de diferentes sistemas no lineales hace que los sistemas se hagan complejos al momento de ser reproducidos y controlados. Controladores chisicos y tccnicas no lineales para el control de este tipo de sistemas han sido presentadas [3][7], el problema es que para su aplicacion se debe tener un conocimiento preCiso de las no linealidades del sistema para su implantacion y asi lograr su control. BIBLIOGRAFiA l. F. Alfaro y V. Salas [1997]. "Modelado y Control de un Reactor Quimico utilizando Logica Difusa". Tesis de pregrado.· 2. T .K. Gustfsson and K. V. Waller [1992]."Nonlinear and Adaptive Control of pH". Ind. Eng. Chern. Res., Vol 31, N. 12, pp. 2681-2693 3. M.A. Henson and D.E. Seborg. [1994]. " Adaptive Nonlinear Control of pH Neutralization Process", IEEE Trans. Control Systems Technology. Vol. 2, N. 3, pp 169­ 182. 4. J-S. Jang, C-T. Sun [an Mizutani, E.[1997]. "Neuro­ Fuzzy and Soft Computing, Prentice Hall. 5. C. Lin and Y. Sheu [1991]. "A Hybrid Control approach for Pendulum-Car Control", Proceedings of the IECON'91, Japan, pp. 461-465. 6. E. H. Mamdani and B. Sembi [1980]. "Process Control using Fuzzy Logic", in Fuzzy Sets, Wang, P.P. and Chang, S.K.(edts.), Plenum Press: New York, pp. 249-266. 7. N. Matsunaga, K. Syoji and S. Kawaji [1989]. "A Proposal of Fuzzy Hybrids Control Method", IEEE System Control, SC-89-17, pp. 1-10. 8. L. Pavel and M. Chelarau [1992]. "Neural Fuzzy Architecture for Adaptive Control", Proceedings of the IEEE International Conference on Fuzzy Systems, pp. 1115­ 1122. 9. Y. Saito and T. Ishida [1990]. "Fuzzy PIO Hybrid Control- An application to Burner Control", Proceedings of the International Conference on Fuzzy Logic and Neural Networks, IIZUKA, Japan, pp. 65-69. 10. Takagi and M. Sugeno [1985]. "Fuzzy Identification of Systems and its applications to Modeling Control". IEEE Transaction on System, man and Cybernetics, Vol. SMC-15, MODELO DE LA PLANTA PILOTO. "".·,,1 "'''"I Samba Los controladores difusos son diseiiados en base a la experiencia de un operador 0 a datos obtenidos en el sistema, implementados mediante reglas lingiiisticas[8]. Estos han sido aplicados a diferentes procesos no lineales[I][4]. Para mejorar el diseno de los sistemas de inferencia difusa, se plantea la utilizacion de diferentes metodos de optimizacion[2][5][6].La optimizacion se puede descomponer en dos problemas, optimizacion estructural y parametrica. La estructural, en la cual se optimizan el numero de reglas, el numero de subconjuntos difusos a utilizar. La optimizacion parametrica, en la cual se realiza un optimizacion las funciones de pertenencia de entrada y de salida, donde estas funciones se suponen conocidas[5]. En forma general estos se pueden dividir en metodos de optimizacion analitica, basado en el gradiente descendente, utilizados para optimizacion parametrica, metodos evolucionarios, basados en Ia utilizacion de algoritrnos geneticos utilizados tanto para optimizacion estructural como parametrica y los metodos de clasificacion, utilizados para la optimizacion estructural. En el presente. trabajo se presenta la aplicacion y la implantacion, en un sistema de tanque, de un control difuso optimizado para el control de nivel y del control del caudal con un control PI clasico. En este caso se plantea realizar una optimizacion paramctrica, en la cual solo se optimizan las 160 161 Fig. I Esquema de fa Pfanta. En la planta real se realizaron varias pruebas para obtener las respuestas del sistema y as! poder modelar matematicamente el comportamiento de la misma. Se caracterizo la dimlmica del nivel del tanque, manteniendo el caudal de entrada y el nivel constantes. La figura 2 muestra el modelo de la dimimica del nivel, en este diagrama se considera la dinamica de la valvula de salida como parte de la del tanque. Ademas seinc1uye un sumador, que anade caudal al nivel del tanque. Esto es 10 adecuado para completar el modelo, asi se reflejan los cambios de nivel por efecto del cambio del caudal de entrada, 10 cual puede considerarse como perturbaciones en este. Gil;.,,, o D:l33",.t-gflIto' '1j..,.. , Fig. 2 Dimimica del Nivel En la caracterizacion del caudal al igual que para el caso anterior se mantiene constante el caudal y luego se Ie hace un cambio. De esta manera se obtiene la respuesta de Ia valvula, y se tiene model ado el sistema completo. En la figura 3 se muestran el modelo modelo que simula la dinamica de la vaJvula del caudal de entrada. EI bloque llamado "Transport Delay", representa un pequeno retardo que es observado en la valvula realluego que se Ie acciona con una senal referencia. I Si e es P y si de es P entonces qaj es N Si e es N y si de es N entonces qaj es P Donde los bi son constantes y la salida viene calculada por el promedio de los. pesos de la contribucion de cada regia, ecuaci6n I. Donde: qaj es la variacion en la valvula del caudal, para ajustar mas 0 menor cantidad de Uquido en el tanque. En la figura 6, se muestra el esquema de control a implementar~ I N Lajb Fig. 3. ValVula de caudal. 3.2 Control PI Difuso con optimizacion de parametros.de la salida (conclllsiones de las reglas) (1) Laj ... .. j=1 ~~~l~ ~. W~::: 3. ESQUEMA DE CONfROL PROPUESTO. En este sistema se desea controlar tanto el nivel del tanque, que es considerada como nuestra variable principal, asi como el caudal que a este entra, evidentemente cada variable tendra un controlador asociado. En el caso del control de nivel, es donde se implantarn el controlador PI difuso optimizado, para el control del caudal, se utilizan\ un controlador c1asico. Ademas como parte de la estrafegia de control, la salida del controlador difuso tambien servin\ como una referenda adicional a la referenda del control de caudal. Como se observa en la figurn 4. ... ~ ~ ~ ~ &i = -11·, (y(x)-d(x))' (CXj/ .I;lXj) (2) j y = i=~ Finalmente, se incluye en ambos casos el bloque controlador que permite estabilizar adecuadamente las repuestas. conclusiones de las misnias. En este ca~o, se aplicarn la optimizacion de las conclusiones en el sistema. La ecuacion que derme la optimizacion de los parnmetros en" las conclusiones de las reglas es la siguiente: • ~ u ~ M M 1 1 Dentro de la teoria de control de'sistemas, se ofrecen muchos metodos para mejorar y optimizar las caracteristicas de un sistema de control dado. Ya sea desde el punto de vista estructural .0 parametrico, la optimizacion requiere de metodos matematicos que no lIeven a una sobrecarga del modelo a optimizar, por 10 que la comprension y seleccion del metodo mas adecuado es una tarea profunda y laboriosa. La aplicacion de esta variable de optimizacion, se realiza sumando justo despues del calculo de cada conclusion la variable que corresponde a esa salida. Es de acotar que la constante: 11 E [1,0] define en cierta forma la calidad de la optimizacion. La diferencia: (y(x)-d(x)), denota realmente el calculo del error entre el valor de inferencia difusa y la referencia, que en ese momento entia a la etapa de optimizacion. e ~;1~ ;~ 0,8 . . 0.8 . . 0.' 0.2 .• J.~5--:: .•'*.~.-"~~3~-:: ..-:! .•';"2~..~.•~,"";;:~.:-"''-::-•.'!",,:---:.:-:.•i':2-'::' •.'!".3:--:.:-:.•~'-~0.•5 de EI metodo que se presenta para optimizar los parnmetros de nuestro control PI Difusoes el .metodo del gradiente estocastico. ·Los parnmetros a los que se puede aplicar este metodo en nuestro sistema difuso pueden ser: 0 los pesos generados en los antecedentes de las reg las difusas oen las EI control de caudal se realiza con un controlador PI, el cual se obtiene sintonizando de forma heuristica, basado en la respuesta del sistema ante una entrada escalon. La figura 7 muestra las simulaciones con la senal Fig. 5. Funciones de Membrecia del error (e) y su Variaci6n (de) - ToWakspace v.!IwIacaulal Ptlse . =FB ----G Mont", mr SalIda ,4Just&C ~ r:;J ,"I. • I",""" ' .' r Well' 1n1: II - """ nivet riI\I lema Fig. 4. Esquema de Control Propuesto 3.1 Control PI DifilSO Fig. 6 Esquema de Control Implantado en la Planta Piloto TABLA I TABLA DE BUSQUEDA DEL CONTROLADOR. Como se senal6 anteriormente se utilizarn un controlador PI Difuso para el control del nivel, el diseno de este esta basado en la emulacion del control que realiza un PI chlsico sobre la respuesta de un sistema de primer orden ante una entrada escalon. EL control consiste en monitorear el error (e) y su variac ion (de) del sistema para generar cambios en la senal de control. N z NG Np z Np z p z Pp p utiIizada para optimizar el control difuso en el esquema de control, se puede observar la respuesta del sistema, sin y con optimizacion. Variado el nivel del tanque entre 30 y 50 cm. 5.5 Niv<l(anxIO) ~--- 5 M I I I, I ,I 4.5 PG 4 3.5 Luego de realizar las pruebas, las funciones de membrecia definidas para el error (e) y su variacion (de), se muestran en la figura 5. Para obtener la salida del control difuso, eI metodo de inferencia de Takagi-Sugeno es utilizado, las variables de salida son mostradas en la Tabla I. Donde, Positivo: P, Negativo: N; Cero: Z; grande: G, pequeno: p. Las reglas vienen dada de la forma: R i : Si e es Ai y de es Ci entonces dUi es bi EI indice: i, se refiere a I:i conclusion i-esima que se esta calculando. EI indice: j, refiere el calculo de la sumatoria de los pesos 0 antecedentes de cada regia. Asi queda definido el control PI Difuso a emplear para eI control del nivel, pero ya que se desea controlar del caudal de entrada para que el sistema pueda responder' mas rnpidamente ante las perturbaciones en el nivel, a continuacion se define otro control difuso que monitorea eI errory su variation para aumentar 0 disminuir el caudal de entrada cuando sea conveniente. Las reglas de este control son solo dos: 162 ~.~., 2.5 . /r­ I I I . ... 500 Finalmente, este esquema de control se implanta en el sistema de control de la planta real. Las respuestas del sistema ante la optimizacion tambien se hacen 1-1\ I \ I yT Ticrnpo(scg) 100 variaciones en los puntos de opera cion luego de haber finalizado la optimizacion del control difuso. u,.-.fl!!lr...."".. , ~...A--1 r- .. _• I J;:::':::, f · I 1000 !) Fig. 7. Resultado de las Simulaciones. Sin optimizar (linea cortada), optimizada (linea continua). -............... ojl) ~JJ '. .. '. . . ,,-'-.....,......,..­ nr: J.I ~~ ,$I) Fig: 8. Respuesta del sistema a diferentes puntos de operaci6n. Como puede observarse en esta figura 7, la optimizacion produce en este caso una senal para el nivel mas estable y con menos ruido que sin la optimizacion. Esto asegura que la respuesta del sistema ha sido mejorada. En la figura 8, se muestra la una simulacion de respuesta del sistema con patentes. En la figum 9 se observa la respuesta del sistema ante la senal utilizada para la implantation del control difuso optimizado en la planta piloto. Variado el nivel del tanque entre 20 y 30 cm . En la figura lOse muestra la respuesta de 163 la plarita' ante diferentes puntos de operacion y ante perturbaciones en el caudal (350-400 seg). 4. CONCLUSIONES ! i ,I I I :: ~ ; ,; ,I \ il ,i ~ :1 En este articulo, se ha presentado la implantacion de un control difuso optimizado para el control de nivel en una planta real, no presenta problemas de retardo 0 sobrecarga del proceso de calculo y ejecucion. Se pudo comprobar los resultados de la optimizacion en el modelo real con las simulaciones realizadas. Este control es combinado con un control chisico PI, para controlar el caudal. Los resultados muestran que este esquema de control son positivos~ mostrando su efectividad y posibilidad de implantar en un sistema no lineal. 3.51 Nivel (cmxlO) 3 2.5 'i 2 :t " :l ," ,J 1.5 :~ 1 I't " : ~ :1 .i;~ , ~ o.s,; 50 100 150 200 250 300 350 400 '50 500 REFERENCIAS [1]Alfaro, F. y Salas, V. [1997]. "Model ado y Control de un Reactor Quimico utilizando Logica Difusa". Tesis de pregrado. ' [2]Berenji, H.R.[1993]. "Q-Learning for Fuzzy Rules", Proc. of IJCAI' 93 ,Chambery. [3]Camacho, E. F.; Bordons, c.; [1992]. "Model Predictive Control in the Process Industry". Springer editions. Sevilla, Espafia. [4]Dote, Y. and Honma, M. [1987]. "Improved Fuzzy-Set Temperature Distribution Control for Electric Furnance". Proc. of the second IFSA, Tokyo, Japan, 1987. Y.[l999]. "Algorithmes [5]Glorennec, Pierre d'apprentissage pour systemes d'inference flou". Hermes Science Publications, Paris, 1999. [6]Jang, J-S, Sun, C-T and Mizutani, E.[1997]. ''Neuro­ Fuzzy and Soft Computing". Prentice Hall, Inc. 1997. [7]Palizban, H. O'Kelly, P. And Rees, N.[l995]. "Practical Optimal Predictive Control of Power Plant Coal Mills". Proc. IFAC Symp; Control of Power Plants and Power Systems, pp. 177-182. [8]Takagi, T. and Sugeno, M. [1985]. "Fuzzy Identification of Systems and its Applications to Modeling and· Control". IEEE Transaction on System, Man and Cybernetics, Vol. SMC-15, No. I, pp. 116-132. Fig. 9. Respuesta de la Planta Piloto. Nivel (arriba) y Caudal (abajo) I Ademas se presenta el modelo de la planta, obtenida a partir de datos experimentales y demostrando que este depende de los puntos de operacion y de la dimlmica de los instrumentos. <I .' un Ii :If I~ " ) 11 if II ~tt :~CM.rtl.l : n (~ J II ill, : t\ ~ ..ty '~"'n -::ref f-:.#\ ("I, ! . 1,,----1 ·'t'fl~ '--, • ;.)j -Jj .. >.' r~, !\Ir\_< [1 --"....",..1 jj,' .... ­ " ~,~ ~'-j itti r~"t):t~1 I: Fig. 10. Respuesta de la planta II AUTORES Carlos Jimenez actualmente cursa el decimoquinto trimestre de Ingenieria Electronica, esta realizando su tesis de grado en control difuso. Ha aplicado para realizar su postgrado en Japon. . Miguel Strefezza es profesor del Departamento de Procesos y Sistemas' con Doctorado y Maestria, en aplicaciones de control difuso y neuronal. Fax: +58-212-9063303. Tel: +58­ 212-9063327. ,I, ]1 '11 H. Alvarez ([email protected]) Facultad de Minas. Universidad Nacional de Colombia. Grupo de Automatica M. Pefia ([email protected]) . Instituto de Automatica, Universidad Nacional de San Juan, Argentina. Abstract: This work presents a possible structure for the fuzzy partition of input space during the identification of a Takagi-Sugeno Fuzzy Inference System (TS FIS). The proposal states the use of a Multi-Dimensional Fuzzy Set (MDFS) for each rule instead of various single fuzzy sets on individual discourse universes. It is demonstrated by examples how the MDFS reduces the identification complexity in spite of lack of linguistic interpretation. Additionally, the information contained in a MDFS, which is directly adjusted from data, results major than using fuzzy partitions on each individual discourse universes. Therefore, the precision of the FIS model is enhanced. Keywords: Fuzzy Inference Systems, Takagi-Sugeno, fuzzy sets, clustering. I. INTRODUCTION . The use of artificial intelligence tools for modeling emerged during the early nineties as a promising addition for controlling and optimizmg industrial, processes. A lot of works have used Artificial Neural Networks (ANN) and Fuzzy Inference Systems (FIS) for function approximation [Johansen, 1996; Bossley, 1997]. Several structural modification have been proposed over the initial ANN and FIS types in order to improve their capabilities for modeling dynamical processes. However, a lot of work must be done before taking at hand a modeling tool which be easier identified and gives high precision with small parameters and ~ow structural complexity. The aim of this paper is to propose a modified treating of fuzzy sets in. the rule antecedent, during a fuzzy model identification. The Takagi-Sugeno Fuzzy Inference System (TS FIS) is used here to identified a process model [Takagi and Sugeno, 1985].The novelty in the proposed identification procedure is the implicit definition ofa Multi-Dimensional Fuzzy Set (MDFS) over each rule antecedent. In this way, it is not necessary to perform an explicit fuzzy sets definition in the rule antecedent, i.e. triangular, trapezoidal, bell-shaped, etc. On the contrary, a simple MDFS characteristic point is determined and a distance measurement is stated from each spatial point to such a MDFS characteristic point. In this way, a few lines in the FIS operation algorithm allow calculate the membership values of any spatial point to each MDFS associated with the rule base. In spite of the lack of linguistic meaning, theMDFS uses all the information contained in the data set avoiding the information reduction that occurs when an explicit fuzzy set is obtained for each rule [Pefia et. aI., 1998; Espinosa, 200 I]. The paper is 'organized as follow. Firstly, the FIS are presented in general, but given especial attention to Takagi- i"~~~ : ~~ .~ IMPLICIT MULTIDIMENSIONAL FUZZY SETS IN TAKAGI-SUGENO FUZZZY MODELING 164 Sugeno type. Next, a detailed description of rule antecedent part and MDFS concept is given. In the fourth part, the steps for identified a TS FIS model using MDFS is stated. Finally, two applications are presented when a TS FIS model was found and tested as a process model. The conclusions part ends this paper with a brief mention of future works. II. TAKAGI-SUGENO FUZZY INFERENCE SYSTEM AS A MODELING TOOL A Fuzzy Inference System (FIS) is a linguistic tool that performs a mapping S:X c R n ~ Y c Rm. When this mapping is used as a )Ilodel, the FIS is called a Fuzzy Model (FM). In this tool, the. knowledge about the relationship between input domain X and output domain Y is encoded as a set of IF-THEN rules. Rule antecedent and consequent may contain linguistic terms linked by logical operators: And, Or, Not, etc. In order to conform the antecedent, any FIS defines a set of linguistic temis Ai at the domain of each input variable. This set of terms Ai={ AJ. A 2, ... ,As} is known as a fuzzy partition on the variable X. The number of linguistic terms in Ai (granularity) is strongly related to FIS precision when it is used as a model. The other rule component is the consequent, which is directly related to the output variable Y. The rule output may be a fuzzy set (Linguistic FIS, Relational FIS) ora numerical function (Takagi-Sugeno FIS). If the output is a fuzzy set it is necessary to perform a defuzzification procedure in order to get a numerical value (Linguistic and Relational FIS) .. The final element in FIS is the inference machine. This operates over the rules in order to map a set of input values to output values. This static mapping S:X c R n ~ Y c R m is augmented with the dynamic behavior of the system being modeled using external filters applied to the model input vector. These filters allow FIS to operate with a vector of model inputs (regressor) constituted by current and delayed values of the system inputs. The Takagi-Sugeno FIS Model uses as consequent a linear function ofthe·jnput variables. This model is able to represent a general class of static or dynamic nonlinear systems. In this model the rules are of the form: Ri: Then: If: x is B i (x) yi=J i (x) (I) where x=[xI, X2,oo.,XN] are the N inputs of the Fuzzy Model (regressor), Bi(X) is a N-dimensional fuzzy set and '/ is the output for the rule i defined by the function f(x). Generally, this function is expressed as an affine linear function of the input variables: 165 f ie x )­- ao + a\x\... + I j + a IMXM -- where aj are tunable scalars. Nonnalization procedures are commonly applied to the input and output variables in order to avoid scale differences. The consequent parameters are those being used by the function fi (x) The exponent m is currently taken equal 2.0 but other values can be used. This procedure generally produces convex input sets in the M-dimensional input space. Under some circumstances non-convex input sets may appear. To prevent this, a multi-center cluster defmition can be used. In this case the MDFS definition is based in two or more chamcteristic points fPena et. Vj.. (2) I + aTx ao and the antecedent pammeters are those that define the fuzzy partition of the problem space. The nonnalized model output, Yn' is B. The selection ofmodel inputs calculated as a weighted avemge of the contribution of each rule: Y /I = ~l W ; (~ )y ! / /I t w i (x n) To avoid using an excessive number of inputs in a FIS based model, it is necessary to apply an input selection method which can find those. inputs that greatly affect the system output. If x ={XI. X2•...•XN} is the set of model inputs, then the number of possible input sets is (2N-l), the number of subsets of x (excepting the void set). To select the inputs among all the possible input sets there are seveml methods: Regularity Criterion (RC), Lipzchitz Coefficients (LC), False Nearest Neighborhood (FNN) [Rhodes and Momri, 1996; Menold et. a1. 1996; Pefia et. al. 1998]. (3) f where wi (Xn) is the membership value of the nonnalized input vectorx n to the input fuzzy set of the rule i. 1 I ·1 j :~; Ii !l rJ I f III. MULTIDIMENSIONAL FUZZY SETS IN A TS FIS MODEL Usually, most of FIS operate with an explicit. antecedent partition, but it is possible to use an implicit partition. A Multi-Dimensional Fuzzy Set (MDFS) Aij is an implicit partition proposed in this paper. In this case, all the individual fuzzysetsin the antecedent of each rule are tmnsfonned into a single MDFS. This procedure implies to solve the logical opemtions indicated in the rule antecedent, if a set of individual fuzzy partitions were given. In spite of the lost of linguistic meaning that occurs during this procedure by using MDFS a more compact FIS model is attained. Additionally, it is not necessary to explicit the fonn of each fuzzy set' in the rule antecedent. Therefore" the tasks related to FlS model design and tuning (model identification) result easier. Additionally, a fuzzy clustering is perfonned over the data to obtain a first guess of the final number or rules. In this case the model design (or structure selection) is a direct step in model identification procedure. Input fuzzy sets can be obtained by various ways. Typically the procedure for obtaining fuzzy sets reduces the original membership values to standard fuzzy fonns function as bell­ shaped, trapezium, triangle, etc. The effects of such a reduction are showed in Figure l. In this case two clusters present similar center coordinates when they are projected on Xt, X2 axis (dashed lines). Therefore, only one explicit fuzzy set results for the two clusters. In order to avoid this infonnation lack, the following fonnulation for the M­ dimensional input fuzzy sets is stated. The fuzzy clustering procedure mentioned above establishes a center value for each identified fuzzy cluster. To calculate the membership grade of a particular input datum, the first M coordinates of the center are selected, corresponding to' the M input variables. Each membership is computed using: Il;k = 1I±(di~ Jm d j=1 for identification. If input-output identification data are genemted experimentally by injecting input sequences u(k) into an unknown system, then the question arises as to the proper choice of input sequences u(k) which will produce an unifonn identification set [Johansen, 1996]. If an' input x is constructed which systematically produces experimental data, and sufficiently covers the domain X, then it is possible to obtain a more accnmte process model. (4) Jk where Jllk is the membership value of datum x(k) to center Vi. di/c = IIx(k)-vII! is the distance from datum x(k) to center VI and for mathematical consistence, if ~k = 0, then Jlik=O because x(k) = C. Modelstructure identification IV. A TS FIS MODEL IDENTIFICATION PROCEDURE System identification is defined as the process of construing a model of a dynamic system with its experimental data. The Takagi-Sugeno FIS is governed by the pammeter set a. which takes all the required FIS pammeters from equation (2). The size of e is fixed by the number of inputs in the regressor x and the number offuzzy cluster (or rules)c. Upon detennining 9 and x, the model is identified. The TS FIS identification procedure can be' divided into four steps: acquisition of data for the identification; selection of model inputs; identification of model structure (model design) and identification ofmodel parameters. It should be noted here tImt, since the used fonnulation to calculate membership functions is detennined by a given distance function, the input fuzzy sets are stated over the concatenated antecedent with their center as the only defining parameter for each group (i.e. a MDFS defmition). Using MDFS the FIS model identification begins with a fuzzy C-mean clustering in order to detennine the appropriate partition of the combined input-output space. These clusters allow the calculation of the membership values for the training data set. This is done by measuring the Euclidian distance from each point x to the center of the Cluster using equation (4) with m=2. Next, a direct projection of the membership functions from this input-output space to the input space allows the identification of the MDFS through their characteristic points. Finally, a least square procedure is applied to find the consequent parameters in rules. A. The acquisition ofdata for the identification The previous step in the FIS based model building is '. the acquisition of an adequate set of identification data. The way these data are acquired should allow to, explore the process opemting zone, because the quality of the model will be determined by the characteristic of the exciting input selected 166 The last step, needed for completing the definition of FIS structure is to' find· the optimal number of rules. The fuzzy clustering technique is an appropriate tool for this task. The criterion used here is: n c S(c)=L L(Uik)m(I!Xk k:l -Vi If -llv; -xW) (5) i:l where n is the number of data to be clustered; c is the number of clusters (c::::: 2) ; Xl is kth data vector, x is the avemge of data x,•...•xn;; :Vi is the vector representing the center of the ith cluster; II . I is the nonn opemtor; Jlik is the gmde of kth data belonging to ith cluster, and m is an adjustable weight (usually m=1.5­ 3). The number of clusters, c, is determined so that S(c) reaches a minimum as c increases; it is supposed to be a typical local minimum. D. Model parameter identification Up to this point we have already found the FIS structure by inputs identification and rules elicitation using a fuzzy clustering over the input-output identification data. Both procedures gave two results: an (M+l)-dimensional input­ output space partition through c clusters and one center for each cluster, taken as its MDFS characteristic. However, since the output is unknown at the prediction moment, we should detennine an antecedent partition just over a reduced M­ dimensional space which contains only the M input variables (usually known). Then each rule antecedent is assigned a membership value obtained from the fuzzy clustering on the input-output space: Jl x di)...., x M (i) = Jl x di),..., X}.f (i), y(i) (6) Once the MDFS of input clusters are obtained, the FIS parameter identification is completed by tile known Takagi­ Sugeno method considering the output vector Y, the pammeter vector 0 and the weighted inputs X. Therefore, the problem is reduced to solving the following typical least square equation for obtaining 0: o =(XT Xrl X T y (7) In this way the pammeter vector 0 is found and the.FIS model is completed. V. TWO ILUSTRATIVE APPLICATIONS In this section two TS FIS model identified by means of the previously discussed procedure are presented. The use of MDFS is emphaSized in order to illustrate its utility. Firstly, a model for penneability reduction is presented. Finally, a model for the pH neutralization process is showed. Both examples use TS FIS model with MDFS in the rule antecedent. A. A model for permeability reduction by fines flow through porous media The transport of fine particles in fonnations followed by plugging is recognized as the major cause of fonnation damage in hydrocarbon wells. The TS FIS model presented here was identified for predicting the principal behavior of fonnation damage under known solution injection flow rate, medium porosity, salt concentration and initial medium penneability. For the laboratory experiments, suspensions of Calcium Carbonate (CaCOJ ) were injected into the porous media. The particle size distribution for. the CaCO J suspensions were measured with the Counter Coulter equipment and the mean particle size derived from the distributions was about 8 !lm. The porous media were constructed with clean sand which grain sizes were carefully selected for each experiment. The characteristics of the sandpacks and suspensions used in this study guarantee that no size exclusion mechanisms will be present during the displacements. In case of consolidated samples, particle size and pore size should be considered as input parameters. The data base experimentally obtained contains 42 penneability curves [Zuluaga et ai., 200 I]. Due to limited laboratory data, during the TS FIS model identification, the clustering method was bounded in the maximum number of clusters. It must be pointed out that the input variables; initial penneability (Ko), porosity (Por), concentration (C) and flow rate (Q) were normalized in the interval [-1,+1]. Pore volume (PV) and the relationship KlKo were nonnalized in the interval [0,+1]. During the sensitivity analysis, the exclusion of the input PV produced a static model response. Therefore, it was essential to include PV as a model input in order to provide dynamic behavior to the model. With these five input variables the number of consequent parameters would be Na=(5+l)*c, with c being the number of clusters. Additionally, for each pore volume injected there are 42 penneability reduction points and each fuzzy rule has six tunable parameters that must be adjusted with experimental data for each PV. Therefore, with 42 laboratory curves the maximum number of clusters (No) would be about Nol(5+1)=42/6=7. Then, the FIS model was attained maintaining the cotnpromisebetween the maximum number of clusters and the best perfonnance. After a sensitivity analysis it was found that 6 clusters yielded the 167 I Ii best results. Table I shows the centers of MDFS obtained for this model. The performance of a FIS model using MDFS and a FIS model using triangular fuzzy sets, both compared to real laboratory data is showed in Figure 2. 11 Table I. Center coordinates of the Multidimensional Fuzzy Sets obtained 'for.EermeabilitJ:: m<?del. Ii Variable-+ Rule .J. KO Por C Q PV II·II 1 -0.4173 0.4097 0.2867 cO.6723 -0.5794 0.4317 0.0165 -0.5446 -0.2291 0.0075 -0.0763 0.0296 0.8322 0.0087 0.2193 0.0374 -0.7934 -0.7829 0.4182 0.5436 -0.6011 -0.6776 0.3508 -0.3681 0.3673 0.3753 0.3901 0.3904 0.3717 0.3866 11 Ii' 2 3 4 11 Ii 11 5 6 11 A model in space state was established avoiding observability problem of input-output process model. The structure of the final pH model is presented in Figure 3. As can be seen; two fuzzy models are necessary because of two process states are used (xl and Xl)' A description of such states was given in a benchmark stated in [Alvarez et a!., 2001]. In the present work only the model for state XI is showed, but the results were similar for the other state (Xl)' Xl i: 0.6 0.4 !~'A~-~ ~'g-;:-o -1r-~-""1!!I'--m~B:'_ "0. 0 "0_ -0- -<>0- -0- 0 _ 0.0 +-------,------~----___l 0.0 100.0 200.0 300.0 Pore Volume. Fig.. 2. Penneability reduction showing actual response (- -). Fuzzy model with MDFS response (-'"-) and Fuzzy model with triangular fuzzy sets response (-0-) for a validation curve (Ko=26200). • Ii I M j j The maximum mean squared error of the Fuzzy Model using MDFS was 0.04460. On the other hand, the maximum mean squared error of the Fuzzy Model using triangular fuzzy sets in input variables was 0.10 160. Additionally, the model using MDFS was easier identified that the model with triangular fuzzy sets. It is evident taken into account that in the first case it is not necessary to perform an input fuzzy sets identification. j B. A model for pH neutralization benchmark ~ In this model, the intention was to capture the relevant dynamic performance of a wastewater neutralization process, previously stated as a benchmark [Alvarez et aI., 2001]. A set of experimental data where taken from a process installed at Instituto de Automatica, Universidad Nacional de San Juan, Argentina. In brief, the assembly consists of three tanks and one Continuous Stirred Tank Reactor (CSTR). The tanks contain solutions of strong acid (HN0 3), strong base (NaOH) and an acid salt (NaHC03) which gives the buffer effect of the neutralization system. Such an assembly resembles the current conditions of industrial wastewater neutralization. Three dosage pumps with 4 to 20 m.a. command signal are used to reproduce operational conditions and control actions. One pH sensor with 4 to 20 m.a. transmitter is used on the CSTR output stream. The data set· used to identify and validate. the TS FIS model was attained applying several perturbation to the process. In this way, the normal operative region of the neutralization process was. covered with 3000 identification data ario 3000 validation date. A sampling time of 15 seconds was used. ~ ,~! II I I I I I lij I I II ~ I ~ I -3 ~ -5 equatio~ pH Fuzzy Model . -6 1 0 (l.p ­ \~~~ r~~~~~y I,.!'#tJ~i' 61 V"\ \[/1,. 1JtQ, III' ~~ J ~~,-' \j • 15000 Fig. 4. Real data (continuous MDFS ( .....) and Fuzzy Pena, M., diSciascio, F. and Carelli, R. (\ 998). Structure identification of a Takagi-Sugeno fuzzy model (in Spanish). Proc. VIII CLCA, 2. Rhodes and Morarl (1996). Determining the model order of nonlinear input/output systems. AIChe-Journal, vol. 44, pp 151-163. Takagi, T. and Sugeno, M. (1985). Fuzzy Identification of systems and its application to modeling an control, IEEE Trans. on Systems Man and Cybemetics, 15: 1. 116 -132. Zuluaga, E.; Alvarez, H. and Velasquez, J. (2001) Prediction of permeability reduction by external particle invasion using artificial neural networks and fuzzy models. Accepted to Canadian JOllmal ofPetrolewn Technology. • 30000 45000 . Time in seconds and Estimated XI using Fuzzy model withs with triangular fuzzy sets (~----). Fig. 3. Scheme of the proposed model 0.2 ,• -2 Output Xl 0 l.: o~ ....~ lil~ -1 Fuzzy 1.2 1.0 . x, -4 i, 0.8 3 X 10. CI~~-'---""'---'--- Table 2 shows the center coordinates of the multidimensional fuzzy sets obtained for the model of state XI. The model inputs (regressor) were five delayed state XI and two delayed control action u. Five clusters (rules) were found as the optimum number. All variables were normalized in the interval [0, I]. The performance of FIS model with MDFS and FIS model with triangular fuzzy sets regard real validation laboratory data is presented in Figure 4. The maximum mean squared error of the Fuzzy Model using MDFS was 0.002705. On the other hand, the maximum mean squared error of the Fuzzy Model using triangular fuzzy sets in input variables was 0.006163. As can be seen, in this case the performance of fuzzy model with MDFS is better than the performance of fuzzy model with triangUlar fuzzy sets, TABLE 2 CENfER COORDINATES OF THE MULTIDIMENSIONAL FUZZY SETS OBTAINED FOR TIlE MODEL OF STATE AI Rule ..... ~ Variable .J. 168 X,.(k-I) 0.49480 0.69272 0.90480 0.26938 . xl.(k-2) 0.49529 0.69163 0.90554 0.26800 X •.(k-3) 0.55162 0.26733 0.42466 0.20443 X,.(k-4) 0.55248 0.26190 0.42617 0.20072 XI.(k-5) 0.55178 0.26047 0.42658 0.19973 u.(k-l) 0.55206 0.26192 0.42623. 0.19790 u.(k-2) 0.55110 0.26757 0.42469 0.19913 0.2437 7 0.2451 I 0.6953 8 0.7043 4 0.7081 4 0.7051 5 0.6976 8 VI. CONCLUSIONS' In this work the use of Multi-Dimensional Fuzzy Sets (MDFS) in the. antecedent of Takagi-Sugeno Fuzzy Systems (TS FIS) was explored. Such a proposal reduce the lack of information occurred during typical fuzzy set. Additionally, the MDFS in the antecedent produces an easier method to identifying fuzzy models. Unfortunately, the MDFS reduces the linguistic interpretability of the obtained fuzzy systems. Looking for illustrate this facts, two applications of fuzzy identification using MDFS in the TS FIS antecedent were presented and compared with fuzzy model using triangular fuzzy sets in the antecedents. The performance of fuzzy . models with MDFS was better than that of fuzzy models with triangular fuzzy sets. A lot ofwork must be done in order to find the best distance measurement in a MDFS. In the present work only an Euclidian measurement was used. This measurement can result very simple when a high nonlinear process is being modeled. It is clear that a more complex distance measurement will allow a reduced number of clusters (rules) and a more compact cluster representation without lost of information. REFERENCES Alvarez, H.; Londono, C.; diSciascio, F. and Carelli, R. (200 I) pH Neutralization Process as a Benchmark for Testing Nonlinear Controllers. Indust. and Eng. Chemistry Research, May 2001. Bossley, K.M.(1997) Neurofuzzy modelling approaches in system identification. PhD thesis, University of Southampton, U.K. Espinosa, J. (2001). Fuzzy modeling and control PhD thesis. Katholieke Universiteit Leuven, Belgium. Johansen, T. (1996) Identification of nonlinear systems using . empirical data and prior knowledge. Alltomatica, 32, 99 589-606. Menold, P.; Allgower, F. and Pearson, R, (1996) Nonlinear structure identification or chemical processes. Technical Report AUT96-32. Insitut fur Automatik-Zurich. 169 APLICACION DE OPTIMIZACION MULTIOBJETIVO CON ALGORITMOS GENETICOS A UN PROBLEMA DE ELECTRIFICACIONRURAL Adriana Pulgarin ([email protected]), Ricardo Smith ([email protected]), Posgrado en Aprovechamiento de Recursos Hidniulicos. Facultad de Minas Universidad Nacional de Colombia Resumen: En este articulo se presenta una aplicacion de los Algoritmos Geneticos como herramienta de solution a un problema de optimization de las inversiones en electrification rural en el cual se considero apropiado optimizar simuItaneamente varios objetivos. Palabras Clave: Electrification Rural, Algoritmos Geneticos, Optimizacion Multiobjetivo l. INTRODUCCION La aplicad6n de los Algoritmos Geneticos para solucionar un problema de optimizaci6n con Multiples Objetivos acomete un problema trabajado en afios anteriores por el Posgrado en Aprovechamiento de los Recursos Hidnlulicos para la Corporaci6n Autonoma Regional del Rio Nare 'CORNARE' (Manjares, 1989), en la cual se adelant6 el estudio de los proyectos que se requerian para la electrificaci6n de toda el area bajo su jurisdiccion, dadas ciertas condiciones de disponibilidad de recursos y de condiciones politicas y nonnativas que rigen para la regi6n. El estudio considera 956 proyectos posibles, para realizar en un horizonte de tiempo de cinco afios y con unos recursos presupuestales provenientes de las transferencias de ley obligatoria que las entidades propietarias de plantas hidroelectricas de generaci6n hacen a la Corporaci6n. Para dar soluci6n a este problema, en este articulo se propone aprovechar el manejo paralelo de las soluciones que hacen los Algoritmos Geneticos y hacer uso de un metoda de optimizaci6n multiobjetivo con Algoritmos Geneticos, Suma de Radios Globales Ponderados (SWRG), propuesto por Bentley y Wakefield (1997), que pennite manejar simultaneamente todos los objetivos. Los resultados obtenidos se comparan con los obtenidos mediante un metodo tradicional de optimizaci6n con mUltiples objetivos: El Metodo de las Restricciones, que iterativamente optirniza el problema eligiendo un solo objetivo y trata los demas como restricciones. A traves de tin gran numero de ejecuciones del algoritmo, en cada una de las cuales los objetivos restringidos toman diferentes valores, se puede obtener una curva de intercambio entre pares de objetivos, pero este proceso es demasiado dispendioso en cuanto a su codificaci6n y tiempo de ejecuci6n. 2. OPTlM!ZACION MULTIOBJETIVO La optimizaci6n Multiobjetivo bl1sca optimizar un vector cuyos componeutes son cada uno de los objetivos. La soluci6n a un problema de este tipo no es un punto unico, sino una familia de puntos que definen una frontera (curva trade ­ off), conocida tambien como soluci6n paretiana (Bentley y Wakefield, 1997) 0 conjunto de soluciones no dorninadas. Una soluci6n no dominada es una solucion tal que dentro de la regi6n factible no existe otra soluci6n para la cual los , valores de los objetivos sean mejores 0 iguales a los de ella. De otra fonna, Una soluci6n X es dominada si existen una soluci6n factible y no peor que X para todos los objetivos F; , i = 1,... , k (Smith y otros, 2000): f(x) frY) maximizacion. V 1 :S i :S k para problemas de Por su naturaleza los problemas de optimizaci6n multiobjetivo requieren para su soluci6n tecnicas diferentes a las tecnicas estandar utilizad,as en optimizaci6n con un solo objetivo. En las iIltimas dos decadas se han desarrollado Algoritmos Geneticos para trabajar problemas de optimizaci6n multiobjetivo; algunos de enos, estan basados en metodos clasicos, como el metoda de las restricciones y el metoda de las ponderaciones, mientras que otros plantean nuevas estrategias de soluci6n. Los Algoritmos Geneticos trabajan con una poblaci6n de individuos que represent an soluciones potenciales del problema y que son modificados a traves de las diferentes generaciones (0 iteraciones). Debido a su estructura, los Algoritmos Geneticos pueden buscar aqueHas soluciones no dominadas en fonna paralela; convirtiendose en herramientas muy atractivas para resolver problemas multiobjetivo. 3. ALGORlTMOS GENETICOS Y OPTIMIZACION MULTlOBJETIVO Para haHar una soluci6n mediante Algoritmos Geneticos en un problema de optimizaci6n multiobjetivo existen, en forma general, dos fonnas de aproximaci6n: La primera de elias se basa en los metod os tradicionales de soluci6n a problemas multiobjetivo. como los son el Metodo de las Restricciones, en el cual el Algoritmo Genetico se codifica de tal manera que todos los objetivos, excepto uno, sean constantes (restringidos a un solo valor); el objetivo restante se toma como la funci6n de aptitud para el algoritmo genetico y el Metodo de la suma ponderada de los objetivos, en la cual se 170 requiere de al elecci6n inicial de el conjunto de pesos para los objetivos. La segunda fonna de aproximaci6n, la confonnan los metodos que tratan de considerar conjuntamente todos los objetivos y hallar de fonna simultanea el conjunto de soluciones no dominadas al problema. Algunas de estas aproximaciones penniten ademas, la posibilidad de guiar la evolucion del algoritmo para que conveIja a un pequeno sUbconjunto de soluciones no dominadas defmido por el usuario, esto para evitar el caso bastante comtin en problemas grandes, en el que se hallan muchas soluciones no dominadas, cuando en realidad, el conjunto de soluciones deseadas por el decisor es un subconjunto pequeno del conjunto de soluciones Paretianas., Esta segunda forma de aproximacion es la que se emplea en este trabajo para dar solucion al problema planteado. Los metodos "que consideran simultaneamente todos los objdivos se enfrentan dificultades adicionales a las que se presentan cuando se intenta optimizar un problema de un solo objetivo. Bentley y Wakefield (1997), sugieren que la mayor obstaculo denominado Problema de Clasijicacion, radica en que para los problemas multiobjetivo, cada solucion tiene varios val ores de aptitUd, uno por cada objetivo a considerar; 10 que representa un problema a la hora de juzgar la aptitud global de los individuos, por ejemplo en un problema puede existir un individuo en la poblaci6n con valores de aptitud muy altos con respecto a algunos objetivos y valores de aptitud baja para los objetivos restantes, a la vez que puede existir un individuo con valores de aptitud medios para todos los objetivos. Bentley y Wakefield, (1997) analizan y clasifican diversos metodos de optirnizacion multiobjetivo con Algoritmos Geneticos de' acuerdo a la forma en que estos resuelven el interrogante de como evaluar acertadamente los individuos en presencia de varias funciones objetivo (clasificacion jerarquica) de manera que el algoritmo lIegue a un conjunto de soluciones no dominadas que solucione el problema de una fonna eficiente. Para realizar esta clasificacion utilizan los conceptos de Independencia del Rango e Importancia. Luego de evaluar con problemas particulares,' algunos de los metodos discutidos, los autores obtienen buenos resultados con el metodo Suma de Radios Globales Ponderados (ver anexo 1). . 3.1 Manejo de Restricciolles Un aspecto importante de especial consideracion en la aplicaci6n de este tipo de algoritmoses el manejo de restricciones, ya que los Algoritmos Geneticos no las trabajan explicitamente, haciendo que los procesos de evaluacion de un individuo en una poblaci6n lleguen a ser bastante complejos, especialmente en la presencia de soluciones factibles y no factibles y que cada apJicacion requiera de un manejo de las restricciones que se adapte al problema que se esta implementando Michalewicz (1994b). . ' En' esta aplicacion se utiliz~ una fonna de penalizaci6n para problemas enteros (Bean y Hadj-Alouane, 1992) en la cual se 171 relajan las restricciones por una funci6n de penalizacion no lineal comunmente usada en programacion no lineal continua. Esta funcion de penalizaci6n consiste de la suma ponderada de las violaciones de las restricciones elevadas al cuadrado 4. PLANTEAMIENTO DEL PROBLEMA DE ELECTRIFICACION RURAL La Corporacion Autonoma Regional Rionegro-Nare 'CORNARE' es una entidad de caracter publico descentralizado, cIeado por ley y con jurisdiccion en 26 municipios que confonnan hi. region del Oriente del Departamento de, Antioquia, region de Colombia en Sudamerica, encargada de administrar, controlar y encauzar el uso y aprovechamiento de los recursos naturales renovables dentro del concepto del desarrollo humano sostenible. La region del Oriente Antioqueiio, esta compuesta por 26 municipios que ocupan un territorio de 809400 hectareas, el 13% del departamento. Con el objetivo de adelantar su programa de' electrificaci6n rural CORNARE identific6 956' proyectos posibles; cada proyecto se caracteriza por el niImero de viviendas rurales que favorece, por su costo economico, por su aporte a la cobertura del servicio electrico municipal, por la demanda de electricidad a las subestaciones asociadas a el, entre otros. Se considero importante 'el planteamiento de objetivos que ayuden a dirigir el plan de eIectrificaci6n de manera adecuada a las necesidades de la regi6n. Estos objetivos incluyen: La Eficiencia econ6mica en la asignaci6n de recursos, la Equidad en las coberturas municipales, el tratamiento preferencial a los municipios prioritarios y el asegurar presencia politica en todos los municipios de la zona. ' Adicionalmente, el problema esta sujeto a una serie de restricciones. La fonnulacion matematica del problema es la siguiente: ' 4.1 Funciones Objetivo EOdenda economica en la asignacion de recurs os Con este objetivo se busca maximizar los beneficios asociados a la construccion de los proyectos, representados por la cantidad de viviendas que se atienden con cada proyecto' particular. Este objetivo se representa matematicamente de la siguiente manera. T Max Z1 = N L L Ik,t*Nuviv K (=0 k=1 donde N es el numero de proyectos considerados, Nuvivk es el niImero de viviendas que se benefician con la implementacion del proyecto k, I k. I es una variable binaria (0,1) que indica la decisi6n de implementar 0 no eI proyecto k, en el periodo de tiempo t. Equidad en las coberturas municipales Con este objetivo se desea conseguir un nivel mmlD10 de cobertura en todos los municipios de laregi6n, ya que en 1989 existian grandes desequilibrios en coberturas municipales varian do entre un 8.1% y 93.2%' Este objetivo pueden escribirse de la sig~iente manem:' , . Restr;cciones de contilrgencia .' Utilizadas pam indicar que la 'construccion 'de un proyecto esta condicionada a la construccion previa de otro proyecto:' Se plantean as!: ' ", =Cobertura i,t-1 + n L I k,t * (Colltribuciollk,t) ~ Cobdes i,t k=1 kei i e municipios no prioritari OS donde Coberturai.l.l es el porcentaje cob.ertum del servicio en el municipio i al inicio del periodo .t, Contribuci6nk,/ es la contribucion del proyecto k al incremento en el porcentaje de cobertum del servicio en el municipio i en eI periodo t, Cobdest.1 es eI porcentaje de cobertum deseada pam el municipio i al fmal del periodo considemdo y n es el niunero de proyectos que pertenecen al municipio i. Tratamiento preferencial a los municipios prioritarios La leyestipl.!-Ia que las,inversiones se deben dirigir de forma prioritaria h:icia los municipios que se yen directamente afectados por la construccion de embalses. Entonces, para cada municipio prioritario al 'final del 'horizonte de planificaeion se ~esea satisfacer: Max Z3 , =Cober/ura l•I ./ n + LJ k.1 * ( Contribuciom,,j >i::obdesiP,1 k=/ kei i E' municipios prio'ritarios donde Cobdes ;p,1 es la eobertum deseada pam el municipio prioritario i, al final del periodo considerndo. AI tratarse de munieipios prioritarios la cobertura minima deseadaenestos municipios debe ser mayor que la cobertura minima deseada en los municipios no prioritarios. II Max Z4 =LJk,t ~1: donde j es un proyecto que requiere ser construido antes de construir ken el tiempo t' . Restr;ccioltes de 110 dtlplicidad Utilizadas pam indicar que cada proyecto se puede eonstruir maximo una vez. Se plantean asi: ' T L/k., ~1, 4.2 Restricciolles Este problema de electrificacion rural esta sujeto a las siguientes restricciones, para todo k = 1,..., Nproy Se utiliza el metodo de Algoritrnos Genetieos para problemas con multiples objetivos propuesto por Bentley y Wakefield (1997), Suma de Radios Globales Pondemdos (SWRG, por sus iniciales en Ingles). Los valores de parnmetros del Algoritrno Genetico fueron fijados a traves de experimentos con diferentes eonfigumciones. En la Tabla 1 se presentan los valores de estos parametros. TABLA 1 PARAMETROSDELALGORnnMOGENETICO 1",0 donde Nproy es el niunero total de proyectos. Restricciolles presupllestales Utilizadas pam indicar ellimite del presupuesto pam inversiones que puede ser ejecutado en cada ano. ,Estas restricciones se ' presentan de la forma: , de 2000 Numero Individuos Iteraciones Probabilidad Cruce Mutacion I 1000 10% 25% 10% En la Fig. I se presentan los niveles de cobertura a1canzada en cada uno de los 26 municipios. De igual forma en la Fig. 2 se muestm los niveles tot ales de cobertum e'n cada municipio al final del periodo como resultado del programa de electrificacion rural que se obtiene con la aplicacion del metodo multiobjetivo de Algoritmos Geneticos, Suma de Radios Globales Ponderados. En la Fig. 3 se presenta una compamcion entre los resultados obtenidos por Manjarres (1989) utilizando el metodo de las restricciones y los resultados obtenidos en este trabajo con Algoritrnos Geneticos. Tambien, en la Tabla 2 y en la Tabla 3 se muestm la distribueion anual de los recursos economicos con cada uno de estos metodos en relacion con el presupuesto disponible, y el numero de viviendas beneficiadas. Como puede observase en dichas tablas, se obtuvo un mayor numero de viviendas beneficiadas cuando se utilizo el metodo de las restricciones pero se presenta mayor equilibrio en las coberturas municipales con la utilizaci6n del metodo de Algoritmos Geneticos (ver Fig. 3), asi mismo se hace mejor uso del presupuesto cuando se utilizan el metodo de Algoritmos Genetieos ya que por este metodo se dejan de utilizar aproximadamente 31' millones de. pesos del presupuesto disponible mientras que por el metodo de las restricciones este valor es de 1000 millones aprox. Nproy / '2)",tCostq.t ~PresuH, ! '"'[" k-eO . para todo t 1,...;r Restr;ccion de capacidad dispolf;ble ell las subestaciones Cada proyecto de electrificacion rural esta asoeiado a una subestacion desde la cual se Ie abastecera de energia, por 10 tanto esta restricci6nindica' quela demanda exigida por los proyectos asociados':i una subestaeion no debe exceder la capacidad de la ~stacon en cada' periodo considerado. La demanda de cada proyecto se calcula como PCE* Nuvivk ,donde PCE es el promedio de consumo' de energia por vivienda en kilovatios por ano (kWa). .L/k'l * dem k ~ DisPI.t para todo t kell - - - - -- -- - - -- - - - - - - - - - - - - - - -- - - - '" +-------. -. -. . ­ i donde COStOk,1 representa el costo de cada proyecto en el ano t,y Presup, es el presupuesto disponible pam inversion en el ano t. 40.0 :g 30.0 .. i!., _ ... ... ... ... _ _ _ - - ..... ­ - - • - - 26.5 - - - - • - - • - ............ 20.0 14.0 11 .6 5,9 5.0 ..... - • _ .. _ ... ... ... ... ... 11.6 10.7 Wj~_ I-lJLUJtjlJL:::~~-P~::!ilUl}lLFL~"" Muridp'o :AI plantear el problema resultan 956 variables de decision binarias, para cada' periodo de tiempo t, el horizonte de planificacion es de 5 aiios y en total se tienen 4780 variables distrib~idas de la siguiente manera: 172 _ _ • - ---. 24.1 Fig. L Adicion de cobertura en cada municipio I k •t , y 2791 restricciones _ ~ ... 5. SOLUCI6N CON ALGORITMOS GENETICOS de decisi6~ binarias _ _ . - - . - -- -­ ­ ­ 5.1 0.0 _ _ _ _ ... 35.1 20.3 ~ 8 ... _ _ _ _ .. donde DISP/.tes· la disponibilidad de capacidad en las subestaci6n i-esima para satisfaper las demandas en el periodo t. La sumatoria se hace sobre todos los proyectos asociados a la subestacion I. k=1 kei Gamntizando que en cada municipio se construya por 10 menos un proyeeto. ~ '2:'/1,' t=O Asegurar presencia politic a en todos los municipios de la zona. Con este objetivo se pretende haeer presencia en todos los municipios realizando inversiones en cada uno de ellos, se plantea de la siguiente mariera: 140 I' l(k,l) Max Z 2 Restricciones de no duplicidad: 956 Restricciones de contingencia: 1690 Restricciones de presupuesto: 5 Restricciones de Capacidad en las subestaciones: 173 -~P-;I ( " ".­ ! 100 0 80.0 g., 90.4 -~ .. ­ .~ (5 CD ~ "'C -> c: -l'! .~ c: ~ CD '~~E .!! .... CO ._ « « U '(3 -a. •.;;. .... ~ co CD .'~' - ~ - co Ii - Q -,li "cp "c: -­ U (!). (!) (!) °og'uu. 0 c:. 1:! ..J ..J ::E .~ te: t z a.CD & r:x: '" "- .: CD a:; c: 0 0: I m ','.' Ol III Dadas co -.~. "10' c: c: :; "ECD ·E0 g - .U - 0 .W' - ~ ..Jr:x:r:x:>.9.a~ c: c: c: c: '" III'" III'" III'" III'" III'" III Muridpo c: 0 III ..,// Fig. 2. Cobertura final en los municipios funciones objetivo de un problema: Ii (x~, i = 1,2,... , n y un conjunto de vectores de soluci6n al problema: {S.. S2 ,""sm}' Un metodo de (definida por el metodo) cambia cuando el rango efectivo i 1,2,..n . cambia. Un metodo de de Anexo 1 - .... las n clasificaci6n jernrquica es rango dependiente si la cIasificaci6n jerarquica de la aptitud de {sl' S2,..., S m} c: CD c c coca III Teniendo en cuenta la definici6n de rango efectivo, se puede introducir el concepto de independencia del rango, como 10 fonnula Bentley (1996): La aplicaci6n de metodo multiobjetivo con Algoritmos Geneticos, Suma de Radios GIobales Ponderados, penniti6 atacar un problema muy grande (electrificaci6n rural) considerando simuItaneamente todos los objetivos, y presentando ventajas muy significativas, tanto en tiempos de ejecuci6n como en la calidad de las soluciones haIIadas, con respecto al metodo de las restricciones utilizado tradicionalmente para atacar este problema. -6:.0-r -66.4 _ _ •• _ _ .g .Q CONCLUSIONES 78.6 ·1' 61.4 __ _ _ -e-n;-~ j!:. 80 0g;.... ::::J:::J n;CO u:J-E rocoCO U 41 .6 .;::;: :e 28.7 6. 86.6 66.6 _ r· .. . . -l • - - 20.0 ~ • - 64.5 60.0 -l • - - 0.0 ;9.0 -6 - 7.1. :; 40.0 --:r8~ 93:5 - -rI ­ \ 100.0100 D 1 ."~. . .. -. r :·:'f."J··':T. ~ - - - - - - - 5 3• ~ -- 9.Jl.l~"~ 6 hex), En este anexo se presentan los conceptos fonnulados por Bentley y Wakefield (1997): la independencia del rango y . la importancia que emplean para describir. el metodo de optimizaci6n multiobjetivo con Algoritmos Geneticos, SWRG, propuesto por eIIos y que se describe mas adelante. = cIasificaci6n jerarquica de rango independiente si la cIasificaci6n jerarquica de la aptitud de {sl,s2""sm} , definida por el metodo no cambia cuando el rango efectivo de Ij(x), i 50 = 1,2,... , n cambia. Independencia del Rango 40 g 30 '" !I j 8 20 ~ 1\ i\ ------I-{ J \ - :~. 10 o ~~~~(, N M ~ ~ ~ ~ ~ ts~iY,~-:; _ _~~ ft{. ~ 2 ~ ~ ~ ~ ~ ~ ~ ~ ~ N ~ ~ ~ ~ I -+-AG-SWRG ~ Fig. 3. Comparaci6n de las adiciones de cobertura municipal obtenidas por 2 metodos diferentes. TABLA 2 DISTRIBUCION DE ANUAL DE COSTOS Y NUMERO DE VIVIENDAS BENEFICIADASHALLADOS CON EL METODO DE LAS RESTRICCIONES. Nuvjv Ano Costo Presupuesto Presupuesto restante 2 2.768 2.371 3 2.252 4 2.116 5 2.006 11.513 Total $ 1.170.417.126 $ 1.173.159.598 $ 1.172.077.488 $ 1.114.820.247 $ 1.066.590.514 $ 5.697.064.973 $ 1.168.338.432 $ 1.047.317.943 $ 925.433.878 $ 788.691.042 $ 701.700.057 $ 4.631.481.351 $ 2.078.694 $ 125.841.655 $ 246.643.610 $ 326.129.205 $ 364.890.457 $ 1.065.583.622 TABLA 3. DISTRIBUCION DE ANUAL DE COSTOS Y NUMERO DE VIVlENDAS BENEFICIADAS HALLADOS CON EL MULTlOBJETlVO CON ALGORITMOS GENETlCOS. Nuviv Ano Costo Presupuesto Presupuesto restante 1.153 Total 2 1.768 3 2.303 4 2.868 5 3.264 11.356 $ 1.168.604.200 $ 1.165.549.107 $ 1.158.399.004 $ 1.107.903.821 $ 1.065.296.652 $ 5.665.752.784 $ 1.170.417.126 $ 1.173.159.598 $ 1.172.077.488 $ 1.114.820.247 $ 1.066.590.514 $ 5.697.064.973 174 Los. metodos de clasificaci6n independientes del rango no requieren infonnaci6n de pesos ex6gena para c1asificar las soluciolles apropiadamente y caIcular su aptitud global. Esta es una ventaja significativa con respecto a los metodos dependientes del rango (Bentley, 1996),ya que penniten que un Algoritmo Genetico pueda ser usado para diferentes problemas. . ~ No. MLJicipo '·Uil' "-'el Restricciales Segun Bentley y Wakefield (1997), la unica fonna para garantizar que todos los objetivos en un problema muItiobjetivo sean tratados igualmente por el Algoritmo Genetico, es convertir los rangos efectivos para que sean comparables, luego usar un metodo dependiente del rango, o usar directamente un metodo de cIasificaci6n ·independiente del rango, 10 que asegura que los objetivos no se comparan directamente unos con otros. En la utilizaci6n de un Algoritmo Genetico para un problema multiobjetivo, cada funci6n objetivo 0 funci6n de aptitud toma valores dentro de un intervalo numerico finito conocido como rango efectivo. El rango efectivo de una funci6n depende de la funci6n en si misma y de los valores que toman las variables del problema dentro del Algoritmo Genetico. El rango efectivo de una funci6n de aptitudf(x), es el intervalo comprendido entre el valor minimo y el valor maximo que toma la funci6n en el Algoritmo Genetico. $ 1.812.926 $ 7.610.491 $ 13.678.484 $ 6.916.426 $ 1.293.862 $ 31.312.189 Es de esperar que las funciones objetivo dentro de un problema multiobjetivo tengan diferentes rangos efectivos entre si, es decir, los rangos efectivos de las funciones no sernn conmensurables (Schaffer, 1985). Esto implica que si se agregaran simplemente los val ores de aptitud de los individuos dentro de una poblaci6n para obtener un solo valor de aptitud para cada uno de eIIos, la funci6n de aptitud con el rango efectivo mas grande dominaria la selecci6n. Como se ve en la Fig. 4, un valor de aptitud pobre para la funci6n objetivo que tiene el rango efectivo mas grande tiene un efecto mas negativo sobre la aptitud global que un valor pobre para la funci6n objetivo con el rango mas pequeno. Importancia Segun Bentley y Wakefield (1997), la importancia es otra propiedad deseable en la cIasificaci6n jerarquica y consiste en la habilidad de incrementar la importancia de algunos objetivos con respecto a otros en la cIasificaci6n de las soluciones para pennitir que la bUsqueda sea dirigida a converger en soluciones aceptables, aceptables dentro de un subconjunto mas pequeno del conjunto 6ptimo Paretiano, favoreciendo aqueIIas soluciones mas cercanas al 6ptimo de las funciones con mayor importancia, y en proporci6n a esta. . rango efectivo 1 o c o :::> '"E Q) m o ~ o o c Q) :::> m Se deduce que los metodos con Algoritmos Geneticos mas atractivos para resolver problemas multiobjetivo, seran aqueIIos que cuenten con un metodo de clasificaci6n jerarquica independiente del rango y que ademas pennitan especificar la importancia de los objetivos de una manera practica (Bentley y Wakefield, 1997), los metodos de evaluaci6n de los illdividuos: Suma de Radios Ponderados 00 rango efectivo 2 '"E Fig. 4. Rangos efectivos para dos funciones objetivo 175 (SWR) Y Suma de Radios Globales Ponderados (SWRG), proPtlestos p,or dichos autores cumplen con esos requisitos. Computer Science. University of North Carolina Charlotte. Smith, R., Y otros (2000), Decisiones con multiples objetivos e incertidumbre. Universidad Nacional de Colombia. Medellin, Colombia. Suma de Radios Ponderados (SWR) Los valores de aptitud para cada objetivo son convertidos en radios, usando la mejor y la peor solucion de cada generacion con respecto al objetivo considerado, esto remueve la dependencia del rango de las soluciones y estas pueden ser ponderadas y sumadas para proveer un tmico valor de aptitud para cada individuo. CONTROL NEURONAL DINAMICO PARA SINCRONIZACION DE CAOS' Edgar N. Sanchez ([email protected]), Luis J. Ricalde CINVESTAV, Unidad Guadalajara, MEXICO Jose P. Perez CINVESTAV. Unidad Guadalajara y U~iversidad Autonoma De Nuevo Leon, Monterrey, Nuevo Leon, Mexico Guanrong Chen University of Houston, Houston, Texas, USA and City University of Honk Kong Suma de Radios Globales Ponderados (SWRG) Resumen: Este articulo presenta una nueva estructura de control adaptable, basada en redes neuronales dinamicas para seguimiento de trayectorias de plantas no lineales desconocidas. Los principales componentes de esta estructura incluyen un identificador neuronal y una ley de control, los cuales conjuntamente garantizan el seguimiento deseado., La estabilidad del 'error de seguimiento es analizada por mediode los metodos basad os en funciones de Lyapunov. La aplicabilidad de la estructura propuesta es probada mediante un ejemplo con sistemas dinamicos complejos: sincronizacion de caos. Este metodo es una variacion del anterior. En lugar de convertir en radios las aptitudes separadas de cada solucion para cada objetivo usando los mejores y peores valores de la poblacion actual, se usan los valores globalmente mejores y peores. En ambos metodos, la importancia de los objetivos individuales puede asignarse mediante pesos. Cada cierto mlmero de generaciones, los pesos de los objetivos pueden ser variados, asi el "ordenamiento de acuerdo a la , importancia de cada objetivo en la aptitud global varia, es decir, un objetivo que inicialmente tenia el mayor grado de importancia pasa' a tener un grado de importancia secundario. Usando el metodo del control optimo inverso, una ley de control, capaz de producir caos en una red neuronal dimimica, fue presentada en [12J. EI presente articulo extiende estos resultados al seguimiento de trayectorias caoticas en sistemas dinamicos desconocidos. EI. nuevo esquema de control adaptable esta compuesto de un' identificador neuronal dinamico, el cual construye en linea un modelo para la planta desconocida y una ley de control, la cual asegura que la planta desconocida siga la trayectoria de referencia satisfactoriainente. EI nuevo metodo es ilustradopor un ejemplo de sistemas dinamicos complicados: sincronizacion de caos. Palabras Clave: 'Redes neuronales, sincronizacion' de caos, control adaptable, funci6nde Lyapunov, estabilldad. 1. INTROnUCCION , 2. PRELIMINARES MAmMATIcos A partir de la publicacion [1], ha habido un continuo incremento en el interes por aplicar redes neuronales en identificacion y control de sistemas no lineales. La mayoria de estas 'apliCaciones' usan estriicturas estaticas [2, 3]. Se ha desarrollado mucho ultimamente el uso de redes neuronales dinamicas, 10 cual permite unmodelado mas eficaz de los sistemas dinamicos mencionados [4]. Dos Iibros recientes [5J, [6] revisan la aplicacion de redes neuronales dinamicas para identificacion y control. En [5]., en particular. se utiliza un aprendizaje fuera qe linea, mientras. que [6J ,analiza identificacion' adaptable y control poi-medio de'aprendizaje en linea; la estabilidad en lazo cerrado se establece basandose en metodos de funcion de Lyapunov. En [6] el problema de seguimiento de trayectorias ,es reducido a un problema de seguimiento lineal, con aplicacion a motoresDC. Por otro lado, los metodos de control aplicados a sistemas no' lineales en general han sido extensamente desarrollados desde principios de los 80's, por ejemplo, basandose enla teoria de geometria diferencial [7]. Recientemente, el enfoque de pasividad ha generado gran interes para el desarrollo de nuevas leyes de control de sistemas no lineales [8]. Un problema importante es como lograr control no lineal robusto en la presencia de dinamicas no modeladas y perturbaciones externas. En esta linea de investigacion,existe el llamado control no lint!al H [9, I OJ. Una de las mayores dificultades de este metodo, ademas de la posible inestabilidad estructural def sistema,· es el resolver el sistema de ecuaciones diferenciales parciales asociado. Con el proposito de reducir este problema computacional, el lIamado metodo del control optimo inverse,. fue recientemeIlte desarrollado con base en el concepto de estabilidadentrada~ estado [11]. REFERENCIAS Bean, lC., y Hadj-Alouane, A.B. (1992), A dual genetic algorithm for bounded integers programs. Departamento de ingenieria industrial y operaciones, Universidad de Michigan, Repo~eTecnico 92-53. Bentley, P. J. 1• YWakefield, P. (1997). Finding acceptable solutions in the Pareto-Optimal range using Multiobjective Genetic Algorithms. (1) Department of Computer Science, University College London, (2) Division of Computing and Control Systems, School of Enginee'ring, University of Huddersfield, London, UK. Holland, 1 (1975), Adaptation en Natural and Artificial Systems, MIT Press. Manjarres, J.F. (1989), Aproximacion al planeamiento regional usando la programacion entera mixta, Tesis de Maestria. Posgrado en Aprovechamiento, de Recursos Hidniulicos, Facultad de Minas, Universidad Nacional de Colombia, Medellin. Michalewicz Z (1994a), Genetic algorithms + data structures = evolution programs. Springer-Verlag, New York, 2 ed. Michalewicz Z. (1994b), Genetic algorithms, numerical optimization, and constraints, Department of 176 a ser P~ero present~mos' el identificador n~uronal utilizado. , A) Redes Neurollales Recurrentes de Alto Orden. En [13], las redes I1euronales recurrentes de alto orden son definidas' como .- L x, - -a/x, + ~ LJ W" ,bol nY j~l. J,(l) l ' • - I 1- ,... ,n donde Xi es el estado de la i-esima neurona, L es el numero de conexiones de alto orden, {hh .. .ln} es unacoleccion de subconjuntosno ordenados de {l,2, ... ,m+n}, ai>O, Wik s01110s pesos ajustables en .la red neUronal, .~(k) sonenteros no negativos. y Y es un vector definido por T' T Y=[YJ,"',YmYn+]'''',Yn+"J =[S(XI),...,S(X,J,S(UI),'" S(u"J} , con U=[UJ,U2,. ..,UnJT la entrada a 1a red neuronal, y S(-) una funcion suave dada por Sex) = I +e' Para 1a funcion l+exp(-flx) sigmoidal, p es una constante positiva y E es un ntlmero real positivo. Por 10 tanto, S(x)E[E,e+1j. Como puede observarse, permite la introduccion de terminos de alto orden. Definiendoun vector z(x,u)=[zI(x,u),...,zdx,u)t = [IT Y jaJ(I) JE I, , ..., IT Y al(L)] j JE I L ( I ) puede reescribirse como I, X, =-a,x, + X, L,-, W"Zl(x,u),i = 1,..., -a,x, + w, (x,u), i = 1•..., donde Wi =[W~b"·Wi./)' En este articulo, se consideran ternullos II II (2) del tipo y=b'J, ... ,YmYn+]'...,Yn+"JT=[S(x]),...,S(x,J,S(UI),.....S(unJJ (esto 177 significa que se utiliza el' mismo numero de entradas que de estados). Tambien se supone que la entrada a la red neuronal la afecta directamente, asi que (1) puede reescribirse como, x,=-a,x,+w;z,(x)+u" i=I,... ,n (3) Reescribiendo (2) en forma matricia], se obtiene x==Ax+WZ(X)+II, se obtiene e=Ae+(W' -U0rz(x)+uHfr(z(x)-Z(xJ-a,(t,W) (13) w=W' -W,ii=ll-a,(t,l¥) (14) r, >0 i =1,..•, L y sustituyendo (14) en (13), se obtiene e=Ae+Wrz(x) + ffT'(z(x)-z(x.»+ii • .1 V=-liell 2 donde xp,J;,eK', gpeRlUn, ueRn. Tomando en consideracion que tanto f como g son desconocidos, se trata de modelar (5) por medio de una red neuronal dinllinica en la forma de (4). Por 10 tanto el modelo de la planta se convierte en, .:i:p =x+w =Ax+Wrz(x)+w +11• (6) =Ax+ WTz(x) + w,... +11- [(x" II) (9) la cual se puede escribir elemento a elemento como tv¥ = e,!!(x,) , i =1,2,... n, j =I,...,L Sustituyendo (18) en (17) se llega a V=-.k'e+e'nf(z(x)..;.z(x.»+e'ii -a,(t,JV) =Ae+wrz(x) +u + (-[(X"II) + A~ + IITz(xJ W. + x-tx" ( 17) ii=-Jif'(z(x)-z(xJ)-ke con la que se obtiene 8 d="'j r=28 x,{O) = (1 1 con y A - [tanh(1a;)) (T(x)::: tanh(kx,) k = 0.5 Los resultados de la simulacion se muestran en las figuras I a3. (19) ­ .. Fig. 1. Evolucion en el tiempo del estado Xz (22) ~t'r1!'''! ~M: n;·M 'W1!H,rnl' ,...- Luego, se obtiene, una accion de control, tanto para la red neuronal como para la planta, dada por: 1/ = ii +a,(t,JV) - IITz(x,) ­ (A + I)(x ­ x,) II,) ­ Ax, ..- (23) Teorema 1. Para el sistema no lineal desconocido modelado por (6), la ley de aprendizaje en linea (19) y Ia accion de control (23), en conjunto, aseguran el seguimiento de la referencia no lineal (12). (10) 4. EJEMPLO DE APLICACI6N Con el proposito de mostrar la aplicabilidad del esquema de control propuesto,se prob6 el siguiente ejemplo. . 178 ~I <11 .,'i ,f'! Fig. 3. Plano de fase de la planta 5 CONCLUSIONES Se ha presentado una nueva estructura adaptable basada en redes neuronales dinllinicas para seguimiento de trayectorias de para sistemas no lineales, desconocidos. Esta estructura esta compuesta de un identificador neuronal y. una ley de control para seguimiento detrayectorias. La estabilidad de Ia dinamica del error ha side establecida por medio del metoda de la funcion de Lyapunov. La aplicabilidad de la estructura propuesta fue probada en simulacion, por medio de un ejemplo de un sistema complejo: sincronizacion de caos. Los resultados son motivantes. El trabajo futuro en esta linea busca simplificar la condicion de tener el mismo numero de entradas que de estados en el sistema de control Los autores agradecen eI apoyo del proyecto CONACYT, Mexico, 32059 A. El segundo autor agradece el apoyo de la Facultad de Ciencias Fisico­ Matematicas de la Universidad Autonoma de Nuevo Leon. . u::: -Wr(z(x)-z(x,» - ke+ [(X" '" Agradecimientos. (21) V=-(A+k~~' <0 V'e,JV;tO Por 10 tanto, tim e(t) ::: 0 . (26) tanh(kx,) (2() keir I) =-51 ,r =1501 Los resultados obtenidos se pueden resumir en el siguiente +x-x, + Ax-Ae+a,(t,W»-IITz(xJ es una estimacion de 5 0.5 En la simulacion, se utilizo Ia siguiente red neuronal dinamica X::: Ax + rW'(T(x) + U x(O)=(O 0 of Considerando (20), se propone la siguiente ley de control, e == Ax+ WTz(x) + u + (-[(x"II.) + Wrz(x.) TV [-10) '(18) trfVTW}= -eTIVrz(x) Ahora, sumando y restando al lade derecho de (9) los terminos Ifrrz(x),a,(t,Ip) y Ae y recordando que wper.'=x-xp, se obtiene donde /8::10 (16) 2 +trVVw} . Como en [6], usamos la siguiente ley de aprendizaje (8) e=i, -x' ,., I L­ -} +-tryVTW V=eTAe+eTiiirz(x) +eT»nz(x) - z(xJ) +eTii donde el termino wper representa el eITor de modelado, y W son los valores desconocidos de los pesos, los cuales minimizan el error de modelado. Luego, podemos definir wper:=x-xp. Su derivada con respecto al tiempo es: X,I(O») (x., (0) x,, (0) = y x,, ::: -fix" Su derivada con respecto al tiempo, a 10 largo de las trayectorias de (15) esta dada por ~ e:=x,-x, ': con (5) 3. ANALISIS DE SEGUIMIENTO DE TRAYECTORIA. El error de seguimiento de trayectoria se define como la diferencia entre la salida de la planta desconocida modelada por (6) y la trayectoria de referencia definida por: X, ,: I,(X"II.); x, e R' (7) Definamos el error de seguimiento como, El objetivo, es hacer que el atractor caotico de Chen siga la referencia dada por el atractor de Lorenz definido como X'I = (T(x" - X,I) (25) x,,:z = rx" ­ X,.2 - X,.lX"J (15) A) Estabilizacion del seguimiento de trayectorias Una vez que se obtuvo (15), se puede proceder a estudiar su estabilizacion. Notar que e = 0, .IV = 0 es un' punto de equilibrio. Con el objeto de realizar un amHisis de estabilidad, se considera la siguiente funcion de Lyapunov: '-mlU flUtHlitj;nu con a = 35 b = 3 c = 28 Definiendo xp = F;,(xp,u)= I,(x,) + gp(X,)1I -a,(t,W) • (12) e == Ae+Wrz(x)+II-Wrz(xJ-a,(t,W) (24) +CXP , Sumando y restando a (12) el terminoWrz(x) se tiene B) Modelado de la planta La planta no linea] desconocida se mode]a como +(A + 1)(x-xp)+a,(t,IV)-IITz(xJ pi Por 10 tanto, (l0) se reduce a, (4) ,0 0 0 rL Estos parametros,,( juegan e] mismo papel que el tamafio del paso en el algoritmo de gradiente descendie~te. ~ x,, =(c-a)x -X,IX" xp1 =X,IXp' -bX,l J:(x"u.) = Ax; +JWz(xJ+(A+I)(x-x,)+~(t,Jh (II) donde xeR",JVeRnxL,z(x)eRL,ueR n yA=-A! A>O Ahora, se considera ]a siguiente modificacion a la red de alto orden: X =: Ax + wrz(x) + II donde r es una matriz diagonal definida como rl 0 0 0 o r, 0 0 r=lo 0 0 0 o 0 r L-I 0 En este ejemplo, la planta desconocida considerada en el atractor caotico de Chen generado por X,I = a(x" - X,I) Ahora, suponiendo que - [(X"II,) +Ax; + JWz(xJ +(A +I)(x-xp) +a,(t,W) =0 ,~~ Fig. 2. Diagrama de fase de la referencia REFERENCIAS 1. K. S. Narendra y K. Parthasarathy, "Identification and control of dynamical systems using neural networks", IEEE Trans, 011 Neural Networks, vol. 1, no. I, pp 4·27, 1990. 2. M. M. Gupta and D. H. Rao (Eds.), Neuro-Control Systems, Theory and Applications, IEEE Press, Piscataway, N.J., USA, 1994. 3. K. Hunt, G. Irwin and K. Warwick (Eds.), Neural Networks Engineering in Dynamic COlltrol Systems, Springer Verlag, New York, USA, 1995. 4. A. S. Poznyak, W. Yu, E. N. Sanchez, and 1. P. Perez, tlNonlinear adaptive trajectory tracking using dynamic neural networks tl , IEEE TrailS. 011 Neural Networks, vol. 10, no 6, pp 1402-1411, Nov. 1999. 5. K. Suykens, L. Vandewalle and R. de Moor, Artificial Neural Networks Jor Modelling and Co1ltrol oJ Nonlinear Systems, Kluwer Academic Publishers, Boston, USA,1996. 6. G. A. Rovitahkis and M. A. Christodoulou, Adaptive Control with Recurrent High-Order Neural Networks, Springer Verlag, New York, USA, 2000. 7. A. Isidori, Nonlinear COlltrol Systems, 3rd Ed., Springer Verlag, New York, USA, 1995. 179 8. D. J. Hill and P. Moylan ,"The Stability of nonlinear dissipative systems", IEEE Trans. on Auto. Control, vol. 21, 708-711,1996. 9. H. W. Knobloch, A. Isidori and D. FlockelZi, Topics in Control Theory, Birkhauser, Boston, USA, 1993. 10. T. Basar and \ P. Bernhard, H-Infinity Optimal Control and Related Minimax Design. Problems, Birkhauser, Boston, USA,1995. II. M. Krstic and H. Deng, Stablization of Nonlinear Uncertain Systems, Springer Verlang, New York, USA, 1998. 12. E. N. Sanchez, J. P. Perez and G. Chen, "Using dynamic neural control to generate chaos: an inverse optimal control approach", Int. J. ofBifurcation and Chaos, to appear 200 I. 13. E. B. Kosmatopoulos et ai., "Dynamical neural networks that ensure exponential identification error convergence", Neural Networks, vol. 1, no. 2, pp 299-314, 1997. 14. H. Khalil, Nonlinear Systems, 2nd Ed., Prentice Hall, Upper Saddle River, NJ, USA, 1996. 15. E. N. Sanchez and 1 P. Perez, "Input-to-state stability analysis for dynamic neural networks", IEEE Trans. Circuits Syst. , vol. 46, pp 1395-1398, 1999. LA LOGISTICA DEL CONGRESO INTERNACIONAL EN INTELIGENCIA 'COMPUTACIONAL'(CIIC-2001) Giovanni Perez Ortega (gperez@perseus:unalmerl.edu.co) John Sebastian Montoya,Gomez, Natalia Pineda Betancur Escuela Ingenieria de la Organizacion Universidad Nacional de Colombia - Sede Medellin Por esto quisimos desde aqui, el ultimo articulo de las merilOrias del CnC-2001, rendir un sincero homenaje a todas las personas que dieron vida a este proyecto, q~e demuestra que la Universidad Nacional de Colombia, continua cumpliendo con su mision y compromiso con la Academia, la Investigaci6n y la Extension a 10 largo y ancho del territorio colombiano. Resumen. Este articulo hace un recorrido por las actividades que constituyeron la base para la realizadon del CUC-200t y sirve de referenda para el montaje de eventos similares. Ademas, se destacan las dilicultadesque al final lograron vencerse de tal forma que se garantizara el hito; Asi mismo se resaltan las personas que nos apoyaron incondicionalmente, por 10 que este se constituye en un sincero homenaje. Objetivos del evento. EI CnC-2001 es un foro intemacional para investigadores y profesionales en los diferentes campos de la Inteligencia Computacional y. los Sistemas Bioinspirados. Ademas,es un espacio para promover el intercambio y la discusi6n de. ideas y experiencias en diferentes disciplinas, entre participantes provenientes de ia academia, 'la industria y las empresas estatales. EI proposito principal del CnC-200t es difundir e impulsar el desarrollo de la Inteligencia Computacional con la presentacion de trabajos realizados ensus areas. EI CnC-2001 se origin6 en la Red Colombiana en Inteligencia Computacional y Sistemas Bioinspirados. Palabras Clave: Logistica, Evento, CnC-200l, Integracion, Personas, Organization. Realizar el Congreso Internacional en Inteligencia ComputacionalCIIC-2001, no fue una labor de dias ni tampoco de una sola persona, mas bien se podria decir que durante los dos afios anteriores a la fecha de su iniciaci6n ya se estaba pensando en 10 que hoy se. presenta. Gracias a esos esfuelZos de mas 35 personas entre los que se destacan: el Vicerrector de la Sede UN Medellin, el Decano y el Vicedecano de Investigaci6n de la Facultad de Minas, el Director General del evento, los comites cientificos . Internacional y Local y los cinco auxiliares del CnC-200l, se logr6 alcanzar los objetivos, utilizando la planeaci6n,' la organizaci6n, la direcci6n yel control, en un recorrido que dur6 600 dias. En la Inteligencia Computacional.y la Informatica Bio Inspirada se desarrollan sistemas con base en los comportamientos y mecanismos exitosos observados en la naturaleza, logrando soluciones con representaci6n numerica del conocimiento, adaptabilidad, tolerancia. a fallas, velocidad de procesamiento comparable a los procesadores cognitivos humanos, y optirnizaci6n de la rata de error. No olvidamos las Dependencias de la UN, incluyendo la Sede Bogota, quienes en todo . momento se pusieron a disposici6n de la Organizaci6n del CnC-2001, y que no decir de la Oficina deComunicaciones, el Centro de Procesamiento de Informacion y su servicio de servidoresInternet, y el Centro de Publicaciones, que expusieron todos sus atributos y utilizaron todas las herramientas para que el cnC-2001 fuera 10 que es hoy, una verdadera reaUdad. Definicion de los temas del evento: Se definieron como temas principaJes del CIIC-200J: Algoritmos Evolutivos, Redes . Neuronales, Sistemas Difusos, Inteligencia Colectiva, Computacion Molecular, Aprendizaje de Maquina, Sistemas Hfbridos, Embrionica, Automatas Celulares, Evoluci6n Simulada, Vida Artificial, Hardware Evolutivo. Logistica del Evento. Definir logistica es una tarea algo dificil, pues mucltas veces el termino Ita 181 180 sido relacionado con las organizaciones militares l y otras, se ha definido como una gesti6n de distribuci6n fisica que integra las funciones de planificaci6n, implementaci6n y control del flujo eficiente de materias primas, recursos de producci6n y productos finales desde el punto de origen hasta el consum0 2 • Sin embargo, para el CIIC-200 I se definini como todas aquellas actividades que tengan relaci6n con el exito del evento, desde su inicio hasta su fin, aplicando la eficiencia y la eficacia. • Lanz!lmiento oficial del evento utilizando la pagina web. Con base en estas macro actividades, se construyeron los cronogramas de las acciones a adelantar cada una con el responsable y las Dependencias tanto en el interior de la Universidad, como al exterior; que podian colaborar con el exito del evento. De estas acciones se destacan: • Definici6n de bases de datos en los que aparecen publico objetivo, empresas con probabilidad de vinculaci6n y conferencistas o ponentes de propuestas academicas. • Actualizaci6n y mtraci6n de las bases de datos. Permiten aproximar los datos a la eficiencia. • Divulgaci6n y publicidad del evento. Incluye las actividades de: desarrollo de la imagen, afiche, peglablesy pendones entre otras. • Procesos de inscripciones: Es' una de las actividades mas importantes del evento. Requiere una clara coordinaci6n con la asistencia administrativa de la Facultad 0 la entidad que maneje la reglamentaci6n financiera del Estado, ademas debe permitir que para el usuario sea 10 mas sencillo y natural posible. • Contabilidad del evento. Debe estar acorde con el flujo de efectivo presentado al inicio de la propuesta. • Recursos fisicos: Actividad que impIica la consecuci6n de' elementos que tiene la Universidad y muchas yes se desconocen por los organizadores de los eventos. Por· ella se requiere destreza, habilidad y muchos contactos. • Memorias: Es una actividad obligatoria para los organizadores de un evento, pues de estas, muchas veces depende que los conferencistas internacionales asistan al evento. Deben cumplir ciertas normas en cuanto a su publicaci6n y registro. Las actividades empresariales que forman parte de la logistica, varian de empresa a erilpresa dependiendo de las caracteristicas como la estructura organizativa de cada una, las diferentes opiniones de los directivos 0 directores acerca de cada actividad deniro del ambito de las operaciones de la fmna. Para nuestro caso, se definieron las siguientes macro actividades con base en el proceso administrativo definido por H. Fayol [Fayol, 1961] desde los primeros anos de 1900, las cuales se convirtieron en la base fundamental de la construcci6n del CIIC-2001, recordando que si se desea realizar un evento similar, pueden tomarlas como base pero son susceptibles de cambiar, de acuerdo con 10 arriba expresado Actividades de Planeacion • Definici6n de misi6n, VISIOn y Objetivos (incluye el desdoble de la planeaci6n en politicas, directrices, metas, programas y reglas). Actividades de Organizacion • Definici6n . de las unidades de apoyo, las cuales incluyen la' conformaci6n . de los comites organizadores y los cientificos tanto nacional como internacional. Actividades de Direccion y Control • Establecimiento de los canales de comunicaci6n y los tipos de integraci6n de las unidades, en las que se incluyeron las reuniones y periocidades para las reuniones. Las Acciones Adicionalmente se incluyeron algunas actividades que se enrnarcan tambien dentro de este mismo proceso, tales como: • Integrar las actividades para lograr el objetivo del evento, fue quizas una de las tare as mas dificiles del CIIC-2001, debido al sin niImero de compromisos de cada responsable (con la academia, investigaci6n y extension), a la dificultad que representan muchas de las reglas en las universidades Estatales y a muchas personas que no son capaces de flexibilizar las reglas, de acuerdo al contexto en que hoy se vive. Presentacion ante las directivas Universitarias del proyecto (incluye flujo de fondos). I The Random House College Dictionary. New York. Random House. 1972 2 Aetas de la reuni6n anual en 1979 del National Council of Physical Distribution Management. 182 • De todas formas, se realizaron todos los esfuerzos para permitir que las acciones se materializaran e hicieran parte del exito de este evento. AIcance de la logistica. Segun la definici6n de logistica para el caso, esta reune todas las actividades que se repiten muchas veces a 10 largo del canal a traves del cual las materias primas se convierten en productos finales. Por 10 anterior, las materias primas del evento estan constituidas por las ponencias, los ponentes, las memorias, refrigerios, almuerzos, escarapelas, diplomas, silIas, entre otras y el canal, senin los dos grupos que se constituyeron alrededor del evento, la Direccion Academica, relacionada con todo 10 que tiene que ver con los expositores, conferencistas, conferencias, poster, y articulos; y la Direccion Administrativa, responsable de todas las actividades que tienen que ver con la infraestructura, financiaci6n y el personal auxiliar entre otros. Lo que se muestra entonces, es que debe haber una integracion entre estos dos tipos de actividades, las academicas y las administrativas, puesto que a pesar de ser diferentes, apuntan hacia el mismo objetivo. Las Fortalezas Para la Direcci6n Admirtistrativa del CIIC-2001, las principales fortalezas que tuvo el evento esta representado en las personas, su dinamismo, ahinco y esfuerzo, por ella es de destacarse: La respuesta de la Vicerrectoria de Sede a la Organizacion del evento, que demuestra que esta Dependencia siempre esta abierta a los proyectos que planteen una ventaja competitiva (segun el modelo Porteriano) con relacion a los demas. • La Ofieina de Comunicaciones de la Sede, la respuesta de algunos estudiantes de Ingenieria Industrial y Administrativa, los esfuerzos del Director General del CIIC­ 200 I, profesor Jesus Antonio Hernandez R. y su asistente Rosalicia Arnngo G., quienes sin lugar a dudas, son las personas a quienes debemos hoy su realizacion, puesto que fueron ellos quienes se convencieron de que su reto era alcanzar el exito del CIIC-2001 y a fe que 10 lograron. • La idoneidad, la capacidad de trabajo y la paciencia de los miembros del Comite Cientifico, para realizar la evaluaci6n del sinnumero de artlculos que se les entregaron para su valoracion. • La Disposicion de los conferencistas nacionales e internacionales para enriquecer este evento y que no dudaron en enviarnos sus articulos de quizas, muchos anos de labor investigativa. Asi mismo a aquellos investigadores, que nos enviaron sus articulos para evaluacion y que por alguna razon no calificaron para hacer parte de los • Las dificuItades. En la realizacion de todo evento se presentan dificultades, las cuales dependen de ciertas variables, que como se expreso anteriormente estan en funci6n de la naturaleza misma de la empresa que se desee emprender. Obviamente, este grado de dificultad, es directamente proporcional a la satisfaccion que se logra una vez se venzan todo tipo de obstaculos, alimentando la jerarquia de las necesidades a partir del tercer nivel segun Maslow [Chiavenato, 1996]. Entre las dificultades mas import antes que se presentaron durante los dias previos al inicio del CIIC-2001, fueron: • La Inversion en el CIIC-2001: Fue muy dificil convencer a la empresa privada para que se hiciera presente en el evento en cualquiera de las modalidades que se facilitaron para ello, tales como asistencia de empleados, publicidad en pendones, memorias, refrigerios, almuerzos, escarapelas, entre otros. Se sigue notando una aplicaci6n de los recursos empresariales hacia aquellas actividades que Ie garanticen un retorno inmediato de la inversion, dejando a un lado las actividades que Ie pudieran generar ingresos en el largo plazo utilizando la investigacion y la capacitaci6n. Es reflejo de la problematic a econ6mica que vive nuestro pais, por ella el CIIC-2001, no es la excepci6n. Conseguir el capital semilla: Es una da gran des dificultades que afrontan los grupos organizadores de este tipo de eventos, pues en su gran mayoria, las Facultades, Departamentos 0 Escuelas de las Universidades no cuentan con suficiente dinero para iniciar el desarrollo de las actividades. Para nuestro caso solo despues de un ano se logr6 conseguir los primeros recursos que permitieran elaborar el afiche y construir la pagina web con los temas relacionados con el CIlC-2001. ,183 pocos que tuvieron la opci6n de hacer parte de las conferencias y p6sters del evento. • La Universidad Nacional de Colombia, que hoy mas que nunca demuestra su importancia como eje central de 1a investigaci6n en la regi6n. Conclusiones ./ Las actividades especificas que hacen parte de la logistica de un evento son en su gran mayoria variables, por ello se deben presentar a modo de ejemplo, puesto que todo depende del ambiente y de las fuerzas externas que influyen en este . ./ Es muy importante para alcanzar el exito de un evento, realizar una buena integraci6n de las actividades que hacen parte de la logistica de este. Por 10 tanto deben considerarse los canales de comunicaci6n, las reuniones y controles peri6dicos como mecanismos para lograrlo . ./ El exito de la logistic a, est a en contar con personas dispuestas y comprometidas con e1 objetivo. La Universidad Naciona1 de Colombia, Sede Medellin ha demostrado poseer este recurso . ./ La consecuci6n de los recursos econ6micos, sigue siendo la principal dificultad que debe enfrentar el grupo organizador de un even to, por 10 tanto se requiere ofrecer servicios 0 productos altamente diferenciados. I I 1 r Bibliografia BALLOU, H. Ronald. Logistica Empresarial control y planificaci6n. Ediciones Diaz de Santos S.A. Madrid. 1991 CHIAVENATO, Idalberto. Introducci6n a la Teoria General de la Administraci6n. Mc Graw HilL Bogota. 2000 FAYOLo Henri. Administraci6n industrial y Gene.ral. Editorial Herrero Hermanos. Buenos Aires. 1961. HILL y JONES. Administraci6n Estrategica, un enfoque integrado. Mc Graw Hill. 1996. Mexico. 184