LECCIÓN 12 (β). APRENDIZAJE EN MÁQUINAS (II).
Anuncio
. APRENDIZAJE EN MÁQUINAS (II).")
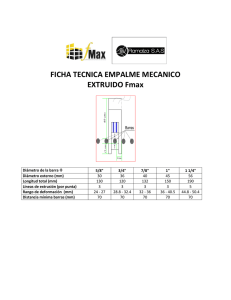
LECCIÓN 12 (β β). APRENDIZAJE EN MÁQUINAS (II). En esta lección abordaremos algunas de las limitaciones de los agentes aprendices de “conecta-4” desarrollados en la lección anterior. Esbozaremos la forma de construir redes neuronales capaces de evaluar tableros de “conecta-4” entrenándolas mediante aprendizaje con refuerzo. Concretamente, emplearemos una versión simplificada del método de diferencias temporales. Inteligencia Artificial e I.C.. 2004/2005 12.1 Dpto. Leng. C. Comp.(Universidad de Málaga) Inteligencia Artificial e I.C.. 2004/2005 12.2 Dpto. Leng. C. Comp.(Universidad de Málaga) R.12.1. Implementar un tipo de datos que represente una red neuronal multicapa, así como las funciones necesarias para calcular la salidad de la red y el algoritmo de aprendizaje mediante retropropagación. ************************** SOLUCION: El lector interesado puede encontrar una implementación LISP de libre disposición en la página Web del texto “Artificial Intelligence: a modern approach” de Stuart Russell y Peter Norvig (http://aima.cs.berkeley.edu). Las instrucciones de uso se encuentran en (http://aima.cs.berkeley.edu/lisp/doc/user.html#organization). Serán de especial interés para nosotros las siguientes funciones (aunque la implementación referida proporciona algunas otras): • • • • (make-connected-nn lista), que devuelve una red neuronal multicapa totalmente conectada con el número de unidades por capa indicadas en la lista. El primer elemento de la lista se refiere al número de entradas, y el último al número de salidas. (network-output lista-entrada nn), que devuelve la salida proporcionada por la red nn cuando recibe las entradas indicadas en la lista-entrada. (backprop-update nn lista-entrada lista-salida-actual lista-salida-deseada) que actualiza destructivamente los pesos de la red nn mediante el algoritmo de retropropagación ante la entrada lista-entrada, suponiendo que en ese momento la red produce la lista-salidaactual, cuando en realidad debería producir lista-salida-deseada. (print-nn nn) que muestra por pantalla de forma legible la estructura y pesos de la red neuronal nn. Por ejemplo, creemos una red con dos entradas, dos unidades en la capa oculta, y una salida, para aprender la función XOR de sus dos entradas. > (defvar *mi-nn*) *MI-NN* >(setf *mi-nn* (make-connected-nn '(2 2 1))) <red-neuronal-multicapa-27> > (dotimes (i 10000) ( backprop-update ( backprop-update ( backprop-update ( backprop-update NIL *mi-nn* *mi-nn* *mi-nn* *mi-nn* '(0 '(1 '(0 '(1 0) 0) 1) 1) (network-output (network-output (network-output (network-output '(0 '(1 '(0 '(1 0) 0) 1) 1) *mi-nn*) *mi-nn*) *mi-nn*) *mi-nn*) '(0)) '(1)) '(1)) '(0))) > (network-output '(0 0) *mi-nn*) (0.01755890776674844) > (network-output '(1 0) *mi-nn*) (0.9800031228551442) > (network-output '(0 1) *mi-nn*) (0.9835795152680812) > (network-output '(1 1) *mi-nn*) (0.015557196826686817) Inteligencia Artificial e I.C.. 2004/2005 12.3 Dpto. Leng. C. Comp.(Universidad de Málaga) R.12.2. Diferencias temporales: redes neuronales a) Diseñar una red neuronal para evaluar estados del juego del conecta-k en un tablero n x m, y una función adecuada para codificar la entrada. b) Definir las funciones necesarias para entrenar una red neuronal como las definidas en R.11.1, empleando una variante sencilla del método de diferencias temprorales: a. b. c. d. (nn-estado-ganador estado nn). (nn-estado-perdedor estado nn). (nn-estado-empate estado nn). (nn-actualiza-dt estado sucesor nn) ************************** SOLUCION: a) Una posibilidad es la siguiente, codificaremos cada posición del tablero mediante dos entradas a la red neuronal. La primera será 1 si hay una ficha de MAX en la posición, y 0 en caso contrario. La segunda será 1 si hay una ficha de MIN en la posición, y 0 en caso contrario. De este modo, para un tablero de n x m necesitaremos 2 x n x m entradas en la red neuronal. En cuanto a la evaluación una posibilidad es disponer de dos salidas en la red. La primera (pa) se interpretará como la probabilidad de que la posición sea ganadora para MAX, y la segunda (pi) como la probabilidad de que la posición sea ganadora para MIN. El resultado de la evaluación será pa – pi. La función de codificación puede ser la siguiente: (defun estado-codifica-nn (e fmax fmin) "Estado del conecta-k en tablero fxc → entrada codificada para la red neuronal" (let ((tab (estado-tablero e)) (entrada-nn nil)) (dotimes (f (tablero-nfilas tab) entrada-nn) (dotimes (c (tablero-ncolumnas tab)) (push (if (equalp (tablero-contenido tab f c) fmax) 1 0) entrada-nn) (push (if (equalp (tablero-contenido tab f c) fmin) 1 0) entrada-nn))))) b) El método para entrenar una red neuronal multicapa mediante aprendizaje por refuerzo es un algoritmo conocido como TD(λ) (véase el libo de Sutton y Barto, 1998). De momento nos conformaremos con emplear el algoritmo de retropropagación, entrenando la red del siguiente modo: cuando una posición del juego sea final, la entrenaremos con la salida correcta (posición ganadora, perdedora, o de empate para MAX); cuando la posición no sea final, entrenaremos la red para que su evaluación sea parecida a la de la siguiente posición en la secuencia de entrenamiento. (defun nn-estado-perdedor (e nn fmax fmin) "modifica destructivamente nn entrenándola con e es como estado perdedor" (let ((entrada (estado-codifica-nn e fmax fmin))) (backprop-update nn entrada (network-output entrada nn) ;salida actual '(0 1)))) ;salida deseada (defun nn-estado-empate (e nn fmax fmin) "modifica destructivamente nn entrenándola con e como estado perdedor" (let ((entrada (estado-codifica-nn e fmax fmin))) (backprop-update nn entrada (network-output entrada nn) ;salida actual '(0 0)))) ;salida deseada Inteligencia Artificial e I.C.. 2004/2005 12.4 Dpto. Leng. C. Comp.(Universidad de Málaga) (defun nn-estado-ganador (e nn fmax fmin) "modifica destructivamente nn entrenándola con e como estado perdedor" (let ((entrada (estado-codifica-nn e fmax fmin))) (backprop-update nn entrada (network-output entrada nn) ;salida actual '(1 0)))) ;salida deseada (defun nn-actualiza-dt (e e2 nn fmax fmin) "nn entrena destructivamente nn suponiendo predicción para e2" que e debería converger a (let ((entrada (estado-codifica-nn e fmax fmin)) (entrada2 (estado-codifica-nn e2 fmax fmin))) (backprop-update nn entrada (network-output entrada nn) ;salida actual (network-output entrada2 nn)))) ;salida deseada ¡dif. temp.! Inteligencia Artificial e I.C.. 2004/2005 12.5 Dpto. Leng. C. Comp.(Universidad de Málaga) la R.12.3.Redes neuronales para el juego del conecta-4. a) Definir una función crea-funcion-evaluacion-nn que reciba un objeto nn como los definidos en R12.2 y devuelva una función de evaluación de juegos considerando los valores de la red neuronal. b) Definir una función (aprende-nn-2 jug1 jug2 estr-rand &optional (pex 0.1)...), que reciba dos jugadores jug1, jug2, y aprenda una red neuronal que realice evaluaciones heurísticas para el jugador jug2. El jugador jug2 realizará movimientos de exploración aleatorios con probabilidad pex empleando una estrategia estr-rand. c) Definir una función (entrena-nn-2 ) análoga a la definida en R11.2 para tablas de utilidad. d) Apender una red neuronal empleando la función anteriror en 1000 partidas del juego del conecta-3 en un tablero 3x3. Crear un jugador-evaluar adecuado y comprobar su eficacia frente a jugadores aleatorios como los definidos en la lección 10. e) Considera el desarrollo de redes neuronales para problemas más complejos. ************************** SOLUCION: a) La definición es bastante sencilla, y muy similar a la empleada en R.11.2. Recordemos que la red neuronal que hemos diseñado en R12.2 tiene dos salidas, y debemos devolver la diferencia entre ellas: (defun crea-funcion-evaluacion-nn (nn &key fmax fmin) ;ficha de max #'(lambda (e) (let ((ganador (finalp e))) (cond ((eql ganador fmax) 1) ((eql ganador fmin) -1) (t (apply #'- (network-output (estado-codifica-nn e fmax fmin) nn))))))) b) La función aprende es igualmente similar a la definda en R11.2: (defun aprende-nn-2 (jug1 jug2 estr-rand nn &optional (fmax *jugador-2*) (fmin *jugador-1*) (pex 0.1) (e (hacer-estado-inicial))) "Aprende una red-neuronal para el jugador jug2" (cond ((or (agotado e) (finalp e)) nn) (t ;movimiento de jug1 (let ((e2 (elegir-suc-nth (jugador-elige-movimiento jug1 e) e))) ;jug1 (when (finalp e2) (nn-estado-perdedor e2 nn fmax fmin) (nn-actualiza-dt e e2 nn fmax fmin) (return-from aprende-nn-2 nn)) ;termina perdiendo (when (agotado e2) (nn-estado-empate e2 nn fmax fmin) (nn-actualiza-dt e e2 nn fmax fmin) (return-from aprende-nn-2 nn)) ;termina empatando el adversario ;movimiento de jug2 (let* ((explora? (< (random 1.0) pex)) ;cierto con prob. pex (e3 (elegir-suc-nth (if explora? (funcall estr-rand e2) (jugador-elige-movimiento jug2 e2)) e2))) (cond ((finalp e3) (nn-estado-ganador e3 nn fmax fmin)) ((agotado e3) (nn-estado-empate e3 nn fmax fmin))) (unless explora? (nn-actualiza-dt e e3 nn fmax fmin)) (aprende-nn-2 jug1 jug2 estr-rand nn fmax fmin pex e3)))))) Inteligencia Artificial e I.C.. 2004/2005 12.6 Dpto. Leng. C. Comp.(Universidad de Málaga) c) Nuevamente la solución es muy similar a la empleada en la lección 11: (defun entrena-nn-2 (npartidas &optional (nocultas 1) ;núm. unidades capa oculta (nfil *nfilas*) (ncol *ncolumnas*) (nn (make-connected-nn (list (* 2 nfil ncol) nocultas 2)))) (let* ((feval (crea-funcion-evaluacion-nn nn :fmax *jugador-2* :fmin *jugador-1*)) (j1 (make-jugador-aleatorio)) (j2 (make-jugador-evaluar :fmax *jugador-2* :fmin *jugador-1* :feval feval))) (dotimes (i npartidas nn) (aprende-nn-2 j1 j2 #'estrategia-random nn *jugador-2* *jugador-1*)))) d) Llegó el momento de la verdad... (setf *nfilas* 3) (setf *ncolumnas* 3) (setf *long-ganadora* 3) (setf *mi-nn* (entrena-nn-2 10000 1)) (conecta4 (make-jugador-humano) (make-jugador-evaluar :feval (crea-funcion-evaluacion-nn *mi-nn* :fmax *jugador-2* :fmin *jugador-1*)) t) …. Si disponemos de una función que muestre los efectos del entrenamiento, tal como la pedida en P11.3 (véase también el ejercicio propuesto P12.2), podremos observar cómo evoluciona el rendimiento de la red neuronal. A continuación se reproducen 3 secuencias de entrenamiento de tres redes diferentes (los pesos iniciales son aleatorios). Cada secuencia de entrenamiento consta de 2000 partidas, mostrándose cada 100 los resultados de 1000 partidas sin aprendizaje. En todos los casos hay una única capa oculta con una única unidad y se juega contra una estrategia aleatoria. Inteligencia Artificial e I.C.. 2004/2005 12.7 Dpto. Leng. C. Comp.(Universidad de Málaga) SECUENCIA 1: ----------------------------------------Num. % % % partidas gana J2 empate pierde J2 0 32.00 16.70 51.30 100 53.10 13.80 33.10 200 49.30 15.10 35.60 300 47.30 17.40 35.30 400 69.30 14.60 16.10 500 81.40 18.60 0.00 600 79.70 20.30 0.00 700 83.40 16.60 0.00 800 78.10 21.90 0.00 900 82.40 17.60 0.00 1000 83.00 17.00 0.00 1100 80.80 19.20 0.00 1200 86.00 11.60 2.40 1300 82.00 18.00 0.00 1400 82.20 17.80 0.00 1500 78.10 16.30 5.60 1600 82.80 13.90 3.30 1700 84.20 12.30 3.50 1800 82.60 14.60 2.80 1900 84.20 13.30 2.50 2000 81.00 19.00 0.00 SECUENCIA 3: ----------------------------------------Num. % % % partidas gana J2 empate pierde J2 0 20.40 29.80 49.80 100 18.90 31.10 50.00 200 33.80 28.90 37.30 300 77.20 18.80 4.00 400 75.50 20.70 3.80 500 75.90 20.70 3.40 600 78.90 21.10 0.00 700 83.20 16.80 0.00 800 81.50 18.50 0.00 900 81.50 18.50 0.00 1000 81.20 18.80 0.00 1100 81.20 18.80 0.00 1200 84.60 12.80 2.60 1300 82.60 17.40 0.00 1400 82.70 17.30 0.00 1500 81.60 18.40 0.00 1600 82.80 15.60 1.60 1700 84.50 12.70 2.80 1800 82.30 14.80 2.90 1900 79.30 12.70 8.00 2000 80.90 12.20 6.90 SECUENCIA 2: ----------------------------------------Num. % % % partidas gana J2 empate pierde J2 0 26.60 22.70 50.70 100 33.50 21.20 45.30 200 33.40 10.40 56.20 300 36.10 8.40 55.50 400 42.00 12.60 45.40 500 43.60 0.00 56.40 600 44.40 0.00 55.60 700 42.40 12.30 45.30 800 41.80 11.60 46.60 900 39.10 13.70 47.20 1000 43.10 10.40 46.50 1100 53.50 7.30 39.20 1200 79.00 21.00 0.00 1300 81.50 18.50 0.00 1400 85.80 11.40 2.80 1500 80.70 19.30 0.00 1600 81.10 18.90 0.00 1700 83.50 16.50 0.00 1800 84.30 12.60 3.10 1900 79.60 20.40 0.00 2000 82.50 17.50 0.00 Nótese que puede ser necesario un cierto grado de experimentación antes de dar con una red correctamente entrenada. Inteligencia Artificial e I.C.. 2004/2005 12.8 Dpto. Leng. C. Comp.(Universidad de Málaga) e) Dado este éxito inicial, podemos considerar la posibilidad de construir una red neuronal que aprenda a jugar al conecta-4 en un tablero 4x4 o, por qué no, en un tablero 6x7. Para abordar la tarea con conocimiento de causa es conveniente leer antes el siguiente consejo que Richard Sutton nos ofrece en sus FAQ sobre aprendizaje con refuerzo (el texto original completo puede encontrarse en http://www.cs.ualberta.ca/~sutton/RL-FAQ.html): “P:Estoy aplicando aprendizaje con refuerzo con una red neuronal con retropropagación y no funciona, ¿qué debo hacer? R: Es un error frecuente emplear una red neuronal con retropropagación como aproximador de funciones en nuestros primeros experimentos de arpendizaje con refuerzo, lo que casi siempre nos lleva al fracaso y la insatisfacción. El principal motivo de este fracaso es que el uso eficaz de la retropropagación es bastante espinoso, más aún en una aplicación en línea como el aprendizaje con refuerzo. Es cierto que Tesauro [un conocido investigador, creador de Tdgammon, el mejor programa jugador de Backgammon] empleó este enfoque en su aplicación extraordinariamente exitosa del backgammon, pero tengamos en cuenta que cuando realizó su trabajo con Tdgammon, Tesauro ya era un experto en la aplicación de redes con retropropagación al juego del backgammon. Ya había construido el mejor programa jugador de backgammon empleando redes con retropropagación. Ya había aprendido todos los trucos y ajustes de parámetros que deben afinarse para que hacer que una red con retropropagación aprenda bien. A menos que tengas una experiencia igualmente amplia a tus espaldas, es bastante probable que acabes muy frustrado utilizando una red con retropropagación como aproximador de funciones en aprendizaje con refuerzo. La solución es dar un paso atrás y aceptar que sólo se puede innovar en un área cada vez. En primer lugar asegúrate de que comprendes la ideas del AR [aprendizaje con refuerzo] en el caso de tablas, y los principios generales de la aproximación de funciones en AR. Entonces avanza a un aproximador de funciones que se comprenda mejor, como uno lineal [..] Decididamente, alguien nuevo en los campos del aprendizaje y los algoritmos de aprendizaje con refuerzo no debería comenzar con redes de retropropagación.” ¡Buena suerte! Inteligencia Artificial e I.C.. 2004/2005 12.9 Dpto. Leng. C. Comp.(Universidad de Málaga) EJERCICIOS PROPUESTOS. P.12.1 Implementar el algoritmo de entrenamiento TD(λ) descrito en (Sutton y Barto, 1998). P.12.2. Definir una función (ver-aprendizaje-nn npartidas cadam kpruebas) que realice un total de npartidas de entrenamiento para las variantes del juego del conecta4, y devuelva la red neuronal aprendida. Cada cadam partidas se hará una pausa en el entrenamiento, se jugarán kpruebas partidas contra una estrategia aleatoria, y se mostrará por pantalla una estadística de los resultados. Esto nos permitirá observar la velocidad con que el programa aprende su estrategia de juego, y la eficacia de la misma. Por ejemplo, para el juego del conecta-3 en un tablero 3x3 se debería obtener un resultado parecido al mostrado en R12.3.d. 12.3. a) Escribir una nueva version de la función ver-aprendizaje-nn (P.12.2) que devuelva una lista con los pesos de la mejor red encontrada en el proceso de aprendizaje. b) Escribir una función (entrena-redes n) que realice n llamada a ver-aprendizaje-nn, y devuelva una lista con los pesos de la mejor red encontrada. P.12.4. Empleando la función del ejercicio anterior, entrenar un jugador para el juego del conecta-3 en un tablero 4x4 y analizar los resultados. Experimentar con distintos números de unidades en la capa oculta de la red neuronal. Repetir el proceso para el juego del conecta-4 en un tablero 5x5. P.12.5 Escribe una función de codificación que tenga en cuenta características adicionales del tablero del conecta-4, como los de la función de evaluación heurística descrita en la lección 10. Entrena nuevas redes neuronales que tengan en cuenta, además de las posiciones del tablero, los valores de estas características. P12.6 Hasta ahora hemos entrenado redes neuronales para conecta-4 jugando contra un jugador aleatorio. Considera la posibilidad de entrenar una red neuronal jugando contra otra que aprende al mismo tiempo. P12.7 Emplear las redes neuronales aprendidas en los ejercicios anteriores para crear un jugador-minimax. ¿Mejora el rendimiento del jugador a medida que ampliamos la profundidad de la búsqueda? ¿Por qué? Compara los resultados con el jugador minimax desarrollado empleando una tabla de utilidades. __________________________________________________________________________________ Las erratas y comentarios sobre estos apuntes son bienvenidos en: [email protected] Inteligencia Artificial e I.C.. 2004/2005 12.10 Dpto. Leng. C. Comp.(Universidad de Málaga)