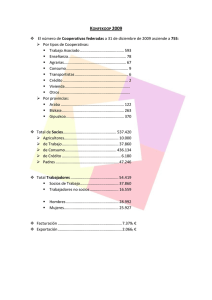
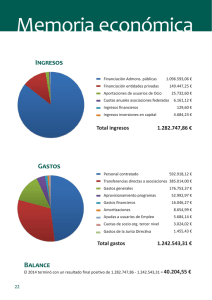
introduccion a los sistemas gestores de bases de datos
Anuncio

Bases de Datos Heterogéneas Autores: Sandra Navarro Carlos Castellano INTRODUCCION A LOS SISTEMAS GESTORES DE BASES DE DATOS El principal criterio que suele utilizarse para clasificar los SGBD es el modelo de datos en que se basa. Los modelos de datos empleados con mayor frecuencia en los SGBD comerciales actuales son el relacional, el de red y el jerárquico. Algunos SGBD recientes se basan en modelos orientados a objetos o conceptuales. Clasificaremos los SGBD como relacionales, de red, jerárquicos, orientados a objetos y otros. Un segundo criterio para clasificar los SGBD es el número de usuarios a los que da servicio el sistema. Los sistemas monousuario solo atiende a un usuario a la vez, y su principal uso se da en un computador personal. Los sistemas multiusuarios, entre los que se cuentan la mayor parte de los SGBD, atienden varios usuarios al mismo tiempo. Un tercer criterio es el numero de sitios en los que esta distribuida la base de datos. Casi todos los SGBD son centralizados, esto significa que los datos se almacenan en un solo computador. Los SGBD centralizados pueden atender a varios usuarios. Una tendencia reciente consiste en crear software para tener acceso a varias bases de datos autónomas preexistentes almacenadas en SGBD heterogéneos. SGBDF (SISTEMA GESTOR DE BASES DE DATOS FEDERADOS) Existe una idea que podría mejorar muchas cosas y entre otras se sugiere la integración de las bases de datos para crear una base de datos mundiales, con el fin de contar con información de todo tipo. Muestra de ello son lo enormes esfuerzos que realiza la comunidad económica europea para compartir información, idealmente esto es genial, pero en la practica surgen mucho problemas mas, por ejemplo no se puede compartir toda la información y menos la que tiene que ver con la seguridad nacional y la autonomía, por esta razón se han venido desarrollando en las ultimas décadas nuevos esquemas y a razón de esto surgen los manejadores de bases de datos federadas. Los sistemas de manejadores de bases de datos surgen en los 60 y en los 90 surgen los manejadores de base de datos federados. Aunque el concepto de bases de datos federadas viene de Hammer y McLeod en 1979 y luego retomado en 1985 por Heimbigner y McLeod y posteriormente en 1990 y 1991 por Sheth y Larson y luego por Saltor.En general los manejadores de bases de datos federados, tienen la funcione de compartir solo la información que quieran compartir las entidades participantes, además de que los usuarios locales podrán acceder de forma transparente los demás datos compartidos y ver los suyos, como si fuera una sola base de datos, esto sin embargo no es algo sencillo pero si embargo es algo muy útil. BASES DE DATOS FEDERADA Un sistema de bases de datos federadas es una colección de sistemas de bases de datos cooperativos y autónomos [Bhavani99]. En un sistema federado los usuarios tienen acceso a los datos, de los distintos sistemas, a través de una interfaz común sin embargo, no existe un esquema global que describa a todos los datos de las distintas bases de datos, en su lugar hay varios esquemas unificados, cada uno describiendo porciones de bases de datos y archivos para el uso de cierta clase de usuarios [Larson90]. Forma en que operan. Los componentes de un SBDF(Sistema de base de datos federadas) pueden efectuar operaciones locales o bien ejecutar consultas sobre los datos de la federación y pueden también ser usadas por otros componentes de la federación. La autonomía o la integración de los componentes la controla el administrador del sistema global en colaboración con los administradores de las bases de datos componente. Este nivel de integración se de de acuerdo a las necesidades propias de cada componente. Es posible también la agrupación en una federación o la misma desincorporación de la misma, y de igual forma es posible que entren o salgan componentes. Para poder lograr esto se establecen diferentes esquemas en el nivel federal. Se debe remarcar que una base de datos federada no es una base de datos única distribuida, mas bien son soluciones para acceder información depositada en diferentes bases de datos. 1. Integración manual, todo queda a cargo de unas pocas personas. Implica muchos cambios 2. Integración de datos. Se crea una nueva base de datos. 3. Acceso integrado. DBMF(Data base manager federated) o SGBDF(Sistema gestor de bases datos federadas) o SMBDF(Sistema manejador de bases de datos federadas). Enfoque federado La forma en que cooperan se basa fundamentalmente en dos esquemas: El esquema de exportación. Denota las partes de la base de datos que va a compartir o que va a poner a disposición de los demás miembros de la federación. Así también es un subconjunto de un esquema componente ya que no todos lo datos deberán de ser disponibles para la federación El esquema de importación. Son vistas de la base de datos que proporcionan lo que desea el esquema de exportación. Arquitectura propuesta por (Sheth y Larson) Esquema local. Es el esquema conceptual de un sistema de bases de datos componente de la federación. Esquema componente. Este resulta al transformar un esquema local a un modelo canónico o común de datos del sistema manejador de bases de datos federadas. Esquema federado. Pueden existir varios esquemas federados en el sistema, dependiendo de cada tipo de usuarios dentro de la federación. Las clases de usuarios son los que tienen funciones similares, ejemplo ventas, justicia, compras, bibliotecas, etc.. Al esquema federado también se le conoce como empresarial o también de importación. AUTONOMÍA DE BASES DE DATOS. 1. Diseño: modelo, lenguaje, implementación. 2. Comunicación: como, cuando se responde a otros sistemas. 3. Ejecución: Criterio a seguir en la toma de decisiones. 4. Asociación: decisión de que datos se comparten y a quien. PROPIEDADES Este tipo de manejadores, tiene un manejo transparente para los usuarios. Se aprecia como una sola base de datos. A esto se le conoce como ínter operar y existen tres formas: Distribuidas, federadas o multibase. El sistema esta conformado por un conjunto de bases de datos heterogéneas. Esto significa que pueden o no tener diferentes sistemas operativos, diferente equipo de computo(hardware), diferentes manejadores de bases de datos, diferente modelo de datos(J, red, Relacional, orientada a objetos), diferente estructura de datos. Las bases de datos que participan en la BDF mantienen su autonomía. Esto quiere decir que cada elemento de la federación decide con quien, que y como compartir sus datos, además de que cada una cuenta con su respectivo diseño de acuerdo con las necesidades del usuario. El MBDF(Manejador de Bases de Datos Federadas) recibe una consulta sencilla y este a su vez la descompone en varia consultas parciales. El MBDF deberá tener un optimizador de recursos para aprovechar correctamente todos los componentes. Pueden ser físicamente distribuidas en diferentes lugares e incluso en lugares muy lejanos. NIVELES DE UN MBDF (Manejador de base de datos federada) Nivel componente. Bases de datos existentes. Nivel federado. Conjunto de bases de datos que ínter operan Se dice que las bases de datos se federan para dar lugar a un MBDF. Las federaciones se forman y desaparecen No existe un esquema conceptual único Un componente puede ser de varios sistemas federados Un componente puede ser otro sistema de bases de datos federados CLASIFICACIÓN. Débilmente acoplados Los usuarios deben de tratar explícitamente con las base de datos. Fuertemente acoplados Los administradores de la federación controlan el acceso y mantienen el sistema. Esquema federado único. SIRIUS-DELTA, DDTS. Múltiples esquemas federados: Mermaid, MULTIBASE. ARQUITECTURA. En el caso de las bases de datos federadas. Debemos identificar dos partes: 1. La parte de software 2. La parte de arquitectura de esquema. La segunda esta encargada de resolver las heterogeneidades sintácticas y semánticas de los distintos componentes de la base de datos. La heterogeneidad sintáctica se da por la autonomía de los componentes de la base de datos y con ello por sus diferencias en sus diseños. La heterogeneidad semántica se da por la diferente concepción que se tiene de los elementos por parte de las diferentes bases de datos. Para poder resolver esto se debe de contar con capas, aquí se conocen como capas de esquemas. Un sistema federado debe cumplir 3 aspectos. Autonomía. Heterogeneidad. Sistema distribuido. Arquitectura de 3 niveles (ANSI/SPARC) Físico (esquema interno). Lógico (Esquema conceptual) Externo (Esquema externo) Esta arquitectura es muy usada en el diseño de bases de datos relacionales mas no así en diseño de bases de datos orientadas a objetos Existen muchas otras arquitecturas para el manejo de las bases de datos federadas, un ejemplo puede ser la arquitectura de 8 niveles o por ejemplo la de esquemas de data warehouse. PROBLEMÁTICA PARA LA IMPLEMENTACIÓN DE BASES DE DATOS FEDERADAS. Uno de los principales problemas es la incompatibilidad entre los sistemas de consulta entre los diferentes fabricantes, aunque existen estándares para el SQL por ejemplo el SQL 92, normalmente los fabricantes construyen dialectos, o finalmente una instrucción no es la misma es un manejador que en otro, o simplemente tipos de datos. Otro problema es la codificación por ejemplo unos usan ASCII otros ASCII extendido o el EBCDIC. Otro aspecto importante, son los códigos de error generados por los distintos fabricantes, que normalmente no son compatibles. Problemas en transacciones. ¾ Control de concurrencia. El SMBDF no conoce las transacciones a nivel de componentes y lo SMBD componentes no siempre pueden distinguir entre transacciones propias y externas. ¾ Heterogeneidad. Cada SMBD mantiene su autonomía. ¾ La autonomía total es incompatible con la atomicidad. Soluciones comerciales Existen varias opciones y varias instituciones y compañías que trabajan para solucionar estos problemas de interoperabilidad, mas sin embargo muy pocos trabajan para la administración global, algunas de las compañías que trabajan en soluciones son augsoft, Oracle, Sybase, y ha usado distintas opciones por ejemplo ODBC(open Data Base Connectivity) y JDBC el conector de Java, en general los grandes manejadores de bases de datos contienen alguna herramienta para poder hacer esto lo malo es que tienen un producto para conectarse con otros manejadores, pero cada uno se vende aparte además de que los costos son exorbitantes. ESTRATEGIA DE PROCESAMIENTO DE UN SISTEMA GESTOR DE BASE DE DATOS Diferentes Tipos de bases de datos (BD) se han desarrollado e implementado con el propósito de satisfacer las demandas de los usuarios, estas bases de datos pueden ser diseñadas en forma independiente por una organización. Como resultado, la heterogeneidad de las BD es necesaria cuando estas coexisten en una organización que requiere compartir datos entre ellas. Por lo cual se ha creado un enfoque de integración llamado Sistema de base de datos Federado (SBDF) para soportar la interoperabilidad de las BD heterogéneas. Cuando la Federación ha sido creada, se crea una nueva arquitectura diferente llamada Arquitectura de ejecución, en la cual se crean capas de software (módulos) que gestionan el flujo de datos y procesan la consulta global. Esto permite que subconsultas se procesen sobre las Bases de Datos Componentes (BDC) donde la información es extraída, combinándose resultados parciales para construir un único resultado final, como lo muestra la figura No.2. El buen desempeño del procesamiento de consultas en sistemas Federados depende de la optimización de planes de ejecución de la consulta global. Existen varias técnicas para la optimización de una consulta federada antes y después de la descomposición de la misma consulta como procesos algorítmicos. A continuación se describe una técnica de procesamiento, en la cual se diseñan e implementan los submódulos de Descomposición de consultas y Consolidación de resultados dentro del Gestor de consultas Federadas. El mecanismo de desarrollo establece la construcción de un árbol cuyos nodos se descomponen inicialmente en join explícitos y posteriormente en join implícitos. Hecho lo anterior, algoritmos son aplicados a las subconsultas intermedias sobre predicados y proyecciones. Una vez ejecutados los algoritmos que cubren el proceso de descomposición, entran en función diferentes técnicas de optimización afectando a los dos submódulos. Diferentes técnicas heurísticas se presentan para optimizar la optimización basada en una búsqueda exhaustiva de planes de ejecución apoyada por estadísticas de la BDC, las cuales se procesan con un modelo del costo. Finalmente, la consolidación de resultados parciales se lleva a cabo manteniendo la respuesta federada en el nodo raíz. Como función objetiva, se busca optimizar los recursos y el tiempo de respuesta, por lo tanto, se pretende buscar el mejor plan de ejecución con el mínimo costo de recursos y menor tiempo de respuestas.