Tutorial_I
Anuncio

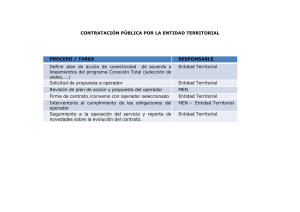
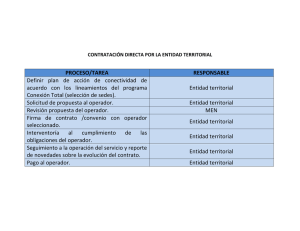
Tutorial: Uso básico de RapidMiner Introducción En el mundo de la minería de datos (Data Mining) es imprescindible contar con software especializado que permita trabajar los datos para alcanzar los objetivos propuestos. En este contexto, este tutorial pretende acercar al lector al uso de RapidMiner, un sistema Open Source para Data Mining. Este texto está basado en la versión 5.1 de RapidMiner, edición para Windows 64. Sin embargo, no debería haber mayores diferencias con las ediciones para otros sistemas operativos. Por otro lado, se asume que el lector ya posee una copia instalada del software (puede descargarse gratis de http://rapid-i.com/content/view/26/84/lang,en/), que tiene un conocimiento básico de Excel y que entiende nociones estadísticas y de algunos modelos predictivos. Parte I: Predicción de variables reales Una de las mejores formas de familiarizarse con un programa computacional es usándolo, por lo que en esta primera parte se busca aplicarlo en un ejemplo con datos reales. Contexto El Ministerio de Educación de Chile provee públicamente bases de datos con información de establecimientos educacionales. En particular, en este ejemplo se trabajará con la base de datos de Rendimiento, la cual contiene la cantidad de alumnos aprobados, reprobados y retirados, por colegio, nivel de enseñanza, grado y sexo. Para este ejemplo, se usará la base de datos correspondiente al año 2009, la cual puede descargarse de: http://ded.mineduc.cl/DedPublico/archivos_de_datos Análisis Propuesto En la base de datos descargada (Ren2009.xls), se puede observar que cada fila contiene una serie de datos acerca de los establecimientos educacionales, tales como rol identificador, código de enseñanza, comuna en la que se ubica, región, tipo de dependencia, etc. Si se quiere obtener más información acerca de qué significa cada campo, se recomienda leer el documento adjunto con la base de datos REN2009.doc. Ahora bien, entre los datos se encuentra la cantidad de alumnos reprobados, aprobados y retirados por curso, para cada establecimiento. Lo que se propone analizar es el porcentaje de aprobación de los alumnos de enseñanza básica de los establecimientos registrados. Cabe notar, que porcentaje de aprobación se entenderá como la razón entre el número total de alumnos aprobados en la enseñanza básica y el número total de alumnos de enseñanza básica de un mismo establecimiento. Este porcentaje se puede obtener fácilmente de la planilla de datos descargada, así como también se debe eliminar los establecimientos que no corresponden a enseñanza básica (cod_ense distinto de 110). Junto a este documento se adjunta una planilla con todas las modificaciones necesarias (Ren2009_mod.xls). A partir de estos datos se pretende construir un modelo que permita predecir con un cierto nivel de certeza cuál será el porcentaje de aprobación (variable real) en un establecimiento de enseñanza básica en función de algunas variables conocidas (como región comuna, dependencia, etc). Trabajo con RapidMiner Para llevar a cabo el objetivo propuesto se deben seguir los siguientes pasos. 1. Abrir RapidMiner. Si es la primera vez que se ejecuta el programa, seguir los siguientes pasos, de lo contrario saltar al paso 7. 2. RapidMiner mostrará una alerta indicando que no se tiene un repositorio creado, se debe pulsar en Ok. 3. En la pantalla siguiente, seleccionar New local repository y hacer clic en Next. 4. En el campo Alias seleccionar un nombre para el repositorio, por ejemplo LocalRepository. 5. En el campo Root Directory, seleccionar una carpeta del disco en la que se quiera ubicar el repositorio. 6. Hacer clic en Finish. La ventana de bienvenida debería aparecer, mostrando íconos para las opciones New, Open Recent, Open, Open Template y Online Tutorial. 7. Seleccionar New. La ventana de fondo cambiará y sobre ella aparecerá el explorador de repositorios (Repository Browser), en esta ventana: 8. Seleccionar el repositorio que se quiere usar (ejemplo: LocalRepository) 9. En el campo Name, introducir un nombre para este proyecto (ejemplo: Tutorial1). Si los pasos se han seguido correctamente, se estará observando la perspectiva de diseño de RapidMiner, que se compone básicamente de 3 paneles verticales (ver Screenshot 1). El de más a la izquierda sirve para tener acceso a los operadores y repositorios. El central (y el más grande por defecto), será el área en el que se diseñará el proceso y en el que se ubicarán los operadores que construyan el modelo. Por último, en el panel de la derecha se sitúa la pestaña de parámetros (Parameters), que permite configurar los operadores, y la pestaña de ayuda (Help). Screenshot 1: Pantalla inicial Ahora bien, el primer paso para comenzar a trabajar con los datos, es importar la planilla Excel al ambiente de trabajo de RapidMiner. Para esto, existen básicamente dos formas de hacerlo: mediante una importación directa al proyecto actual y mediante la inclusión de los datos al repositorio. En esta parte del tutorial, se usará la primera alternativa. 10. En la pestaña Operators, explorar las carpetas Import->Data. 11. Hacer clic en el operador Read Excel y arrastrarlo hacia el área de trabajo (Main Process). Hint: Para acceder rápidamente a un operador, sin tener que explorar las carpetas, se puede escribir su nombre en el campo [Filter]. Ahora bien, en la parte inferior del panel central, se encuentra la pestaña Problems y en ella han aparecido dos errores. Durante el diseño de un proceso, siempre se debe estar pendiente de esta pestaña, para ver si todo está correcto o si existe algún problema que se deba solucionar (ver Screenshot 2). Screenshot 2: Primeros errores En este caso, los errores se producen porque no se ha especificado ningún archivo que leer. Para solucionarlo, seguir los siguientes pasos. 12. Hacer clic en el cuadro Read Excel que ha aparecido en el área de diseño del proceso. 13. En la pestaña Parameters, pulsar el botón Import Configuration Wizard. Con esto, se abrirá el asistente de configuración que permitirá importar un archivo de manera fácil e intuitiva. 14. Explorar los archivos del computador, ubicar el archivo preparado Ren2009_mod.xls, seleccionarlo y pulsar en Next. 15. Tras unos instantes, aparecerá una vista previa del archivo y en él estarán todas las celdas marcadas. Se debe dejar así y pulsar en Next. A estas alturas se debería estar en el paso 3 de 4 (Step 3 of 4). En este paso, lo que se hace es especificar a RapidMiner si se tienen filas especiales en el archivo. En el caso de este ejemplo, la primera fila del archivo corresponde a los nombres de los campos y no a valores en sí. Normalmente RapidMiner debería detectar estas filas especiales y etiquetarlas como corresponde. 16. Asegurarse de que la primera fila tenga puesta la anotación Name, en la columna Annotation y pulsar en Next. En el último paso se deben definir los tipos de cada dato (integer, real, text, etc) y los roles de cada uno. Los roles que se usarán son básicamente tres: Id para el campo que identifica a cada fila (como por ejemplo rol, rut, etc), attribute para campos que contienen valores e información que debe ser considerada en el modelo y label para el campo que corresponde a la variable que se quiere predecir. 17. Dejar seleccionadas solo las siguientes columnas: rbd, reg_cod, pro_cod, com_cod, cod_depe, cod_area, apro. 18. Verificar que todas las columnas tengan el tipo integer (entero), a excepción de apro, que debe ser de tipo numeric. 19. Definir el rol de rbd como id y el de apro como label. 20. Hacer clic en Finish (ver Screenshot 3) Screenshot 3: Configuración del asistente de importación de datos Con esto, RapidMiner ya será capaz de leer los datos de la planilla Excel y trabajar con ellos. Lo que resta a continuación es introducir los operadores necesarios para construir un modelo predictivo. En primera instancia, se construirá un modelo mediante una regresión lineal y se verá su rendimiento (se buscará medir su error en la predicción). 21. En la pestaña Operators, explorar las carpetas Evaluation->Validation, seleccionar el operador Split Validation y arrastrarlo al área de diseño, al lado derecho del operador Read Excel. Hint: Cuando se quiera obtener más información acerca de un operador, es posible seleccionarlo y presionar F1, lo cual desplegará una ventana con más información. El operador Split Validation es un operador compuesto (se puede ver que en la esquina inferior derecha del mismo aparecen dos cuadros azules), lo que significa que para su correcto funcionamiento, debe ser compuesto de otros operadores (ver Screenshot 4). Screenshot 4: Operador Split Validation Su funcionamiento consiste en tomar un conjunto de datos de entrada, tomar una cierta cantidad de ellos (configurable en la pestaña Parameters) y usarlos para entrenar un modelo predictivo. Luego, con el resto de los datos, validar el modelo recién creado y entregar estadísticas acerca de su rendimiento. Ahora bien, se puede observar que este operador posee una entrada (tra) para los datos de entrenamiento del modelo y 4 salidas (mod, para el modelo; tra, para los datos de entrenamiento; ave, para los datos de rendimiento del modelo). Para componer el operador adecuadamente, se deben seguir los siguientes pasos. 22. Hacer doble clic sobre el operador Split Validation, esto llevará al “interior” del mismo, que se compone de dos áreas: Training y Testing. 23. En la pestaña Operators, explorar las carpetas Modeling->Classification and Regression->Function Fitting, seleccionar el operador Linear Regression y arrastrarlo hasta el área de Training. 24. Conectar la entrada del operador con la entrada provista por Training y la salida mod, con la entrada mod. Hint: Para conectar fácilmente un operador a una entrada o salida de otro operador, se puede hacer clic con el botón derecho en la entrada/salida desconectada (debe estar marcada en rojo), seleccionar Quick Fixes y elegir la opción adecuada de conexión. 25. En la pestaña Operators explorar las carpetas Modeling->Model Aplication, seleccionar el operador Apply Model y arrastrarlo al área de testing. 26. En la pestaña Operators explorar las carpetas Evaluation->Performance Measurement, seleccionar el operador Performance y arrastrarlo a continuación del operador Apply Model. 27. Conectar la entrada mod de Apply Model, con mod de Testing y la unl con tes. 28. Conectar la salida lab de Apply Model con la entrada lab de Peformance. 29. Conectar la salida per de Performance, con la salida ave de Testing. 30. Hacer clic en la flecha azul que apunta hacia arriba en la parte superior (ver Screenshot 5). Screenshot 5: Interior del operador Split Validation Con esto, el operador Split Validation ha quedado correctamente conformado y hemos vuelto a la vista de diseño principal. Ahora solo resta hacer conexiones y el proceso estará listo. 31. Conectar la salida mod de Validation con la salida res del proceso. 32. Conectar la salida ave de Validation con otra salida res del proceso. Ahora bien, el proceso está finalmente construido. Los resultados que se esperan obtener son básicamente el modelo (mediante los coeficientes que definen la regresión lineal) y los datos acerca del rendimiento del modelo. Ejecutaremos el proceso para ver los resultados obtenidos. 33. Hacer clic en el botón triangular (forma de Play) de la barra superior (ver Screenshot 6). 34. Aceptar la advertencia sobre guardar el archivo actual. Screenshot 6: Proceso finalizado 35. Tras algunos instantes aparecerá un nuevo cuadro avisando que han aparecido nuevos resultados y preguntando si se quiere pasar a la perspectiva de resultados, aceptar. 36. Seleccionar la pestaña Linear Regression. En esta pestaña se puede observar el modelo generado en este proceso. En primer lugar, se muestra una tabla con los coeficientes de la regresión, así como también con otra información estadística. Si se selecciona la opción Text View, se muestra la función de regresión que permite calcular el porcentaje de aprobación en función de las otras variables (ver Screenshot 7). Por último, interesa ver cuán buena es la predicción realizada por este modelo, para ello: 37. Seleccionar la pestaña Performance Vector (Peformance). En esta parte, se muestran distintas medidas de error del modelo. En el caso del ejemplo, se obtiene un error cuadrático medio de 7.157 (ver Screenshot 8), lo cual es bastante alto considerando que el rango de valores válidos es de 0 a 100 (pues es un porcentaje). Screenshot 7: Resultados del modelo Screenshot 8: Resultados de rendimiento Hasta este punto, hemos concluido exitosamente la elaboración de un modelo predictivo en RapidMiner, usando datos reales y hemos medido su capacidad de predicción. Como último paso, se verá como cambiar el modelo que se genera de forma fácil y rápida. En particular, se probará crear un modelo usando Redes Neuronales. 38. Volver a la perspectiva de diseño (View->Perspectives->Design) 39. Entrar al operador Validation, haciendo doble clic en él. 40. Seleccionar el operador Linear Regression, hacer un clic con el botón derecho y seleccionar Replace Operator->Modeling->Classification and Regression->Neural Net Training->Neural Net. 41. Volver a la vista principal 42. Hacer correr el proceso Con esto, fácilmente se ha reemplazo el método de construcción del modelo, pasando de una simple regresión lineal a algo más complejo como lo es una red neuronal. Al analizar los resultados obtenidos, se puede observar que el error calculado es mayor que en el caso anterior. Este procedimiento de probar con otros operadores para entrenar el modelo puede repetirse y experimentar con distintos métodos, sin embargo, se debe tener en consideración que no todos los operadores trabajan con los mismos tipos de datos, por lo que se debe tener cuidado de elegir un operador capaz de predecir variables reales y que trabaje con variables numéricas. Conclusiones e ideas propuestas Ya finalizando este tutorial, debería haber quedado claro como se construye un modelo en RapidMiner, desde la etapa de importación de datos hasta la etapa de evaluación del modelo. Ahora bien, para seguir trabajando con este ejemplo y familiarizarse aún más con este software, puede ser interesante cargar otros datos (como por ejemplo el rendimiento del año 2010) y aplicar el modelo ya construido sobre esos datos, para comparar los valores obtenidos por el modelo versus los valores reales medidos. Cabe destacar que este ejemplo, si bien es bueno para entender el funcionamiento del programa, no es tan bueno desde el punto de vista del análisis, ya que predecir el porcentaje de alumnos aprobados dentro de un colegio puede ser una variable que no entregue mucha información (un colegio puede ser bueno o malo y aún así tener el mismo porcentaje de aprobación similar). Por otro lado, se observó que los modelos construidos son poco precisos, lo cual se explica por la baja cantidad de variables discriminativas entre establecimientos. Más aún, basta tener dos establecimientos en la misma comuna, bajo la misma dependencia (municipal, por ejemplo), para que el modelo ya prediga el mismo porcentaje de aprobación. Por último, dejo propuesto pensar en qué otras variables se podrían predecir usando la misma base de datos, o también, aplicar el mismo procedimiento para los establecimientos de enseñanza media. Como se puede ver, solo con lo expuesto en este tutorial las opciones ya son muchas. En la siguiente parte, se presentará un ejemplo para predecir variables categóricas en un contexto similar.