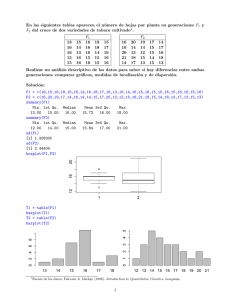
Test chi-cuadrado y del cociente de verosimilitudes
5 de junio de 2008
Vamos a aplicar los tests X 2 y G2 .
>
+
>
+
+
>
>
religion.counts <- c(178, 138, 108, 570, 648, 442, 138, 252,
252)
table.3.2 = cbind(expand.grid(list(Religious.Beliefs = c("Fund",
"Mod", "Lib"), Highest.Degree = c("<HS", "HS or JH", "Bachelor or Grad"))),
count = religion.counts)
table.3.2.array = tapply(table.3.2$count, table.3.2[, 1:2], sum)
(res = chisq.test(table.3.2.array))
Pearson's Chi-squared test
data: table.3.2.array
X-squared = 69.1568, df = 4, p-value = 3.42e-14
Los conteos esperados los obtenemos con
> res$expected
Highest.Degree
Religious.Beliefs
<HS HS or JH Bachelor or Grad
Fund 137.8078 539.5304
208.6618
Mod 161.4497 632.0910
244.4593
Lib 124.7425 488.3786
188.8789
Los tests y frecuencias esperadas pueden obtenerse con el paquete vcd.
> library(vcd)
> assocstats(table.3.2.array)
X^2 df
P(> X^2)
Likelihood Ratio 69.812 4 2.4869e-14
Pearson
69.157 4 3.4195e-14
Phi-Coefficient
: 0.159
Contingency Coeff.: 0.157
Cramer's V
: 0.113
La función chisq.test lleva test de Montecarlo.
> chisq.test(table.3.2.array, sim = T, B = 2000)
Pearson's Chi-squared test with simulated p-value (based on 2000
replicates)
data: table.3.2.array
X-squared = 69.1568, df = NA, p-value = 0.0004998
1
El test del cociente de verosimilitud G2 se obtiene como
> fit.glm = glm(count ~ Religious.Beliefs + Highest.Degree, data = table.3.2,
+
family = poisson)
> fit.glm$deviance
[1] 69.81162
> temp <- predict(fit.glm, type = "response")
> matrix(temp, nc = 3, byrow = T, dimnames = list(c("<HS", "HS or JH",
+
"Bachelor or\nGrad"), c("Fund", "Mod", "Lib")))
Fund
Mod
Lib
<HS
137.8078 161.4497 124.7425
HS or JH
539.5304 632.0910 488.3786
Bachelor or\nGrad 208.6618 244.4593 188.8789
2
 0
0