Computer - Oscar Plata
Anuncio

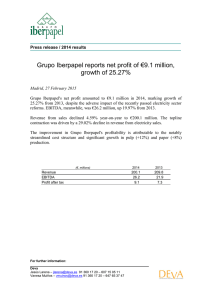
Red SyeC – Primer Workshop 26-27 enero 2016 Aceleración de Aplicaciones Intensivas en Datos Grupo de Arquitectura de Computadores Universidad de Málaga 1 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Red SyeC – Primer Workshop, 26-27 enero 2016 Aceleración de Aplicaciones Intensivas en Datos Application/Architecture Context • Data-intensive, big-data applications § Large amount of “random” memory accesses across “large” memory regions (“low” spatial, temporal memory locality) § “Small” amount of computation per data item (“small” arithmetic intensity) § “Large” amount of exploitable parallelism 2 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Red SyeC – Primer Workshop, 26-27 enero 2016 Aceleración de Aplicaciones Intensivas en Datos Application/Architecture Context • Data-intensive, big-data applications § Large amount of “random” memory accesses across “large” memory regions (“low” spatial, temporal memory locality) § “Small” amount of computation per data item (“small” arithmetic intensity) § “Large” amount of exploitable parallelism • How to efficiently process such workloads? § Storage perspective: Big-data processing is based mostly on secondary storage § However, improvements in capacity/cost of main memory allows to have a large amount of data in main memory 3 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Red SyeC – Primer Workshop, 26-27 enero 2016 Aceleración de Aplicaciones Intensivas en Datos Application/Architecture Context • Data-intensive, big-data applications § Large amount of “random” memory accesses across “large” memory regions (“low” spatial, temporal data locality) § “Small” amount of computation per data item (“small” arithmetic intensity) § “Large” amount of exploitable parallelism • How to efficiently process such workloads? § Storage perspective: Big-data processing is based mostly on secondary storage § However, improvements in capacity/cost of main memory allows to have a large amount of data in main memory • Multi-core, many-core architectures § Compute-centric paradigm § “Large” amount of parallel computational power § “Many” cores partially sharing a complex, large, “deep” on-chip cache hierarchy § “Limited” off-chip main memory bandwidth (pin count limitation) Oscar Plata 4 Grupo de Arquitectura de Computadores, Universidad de Málaga Aceleración de Aplicaciones Intensivas en Datos Red SyeC – Primer Workshop, 26-27 enero 2016 Application/Architecture Context • Challenging to scale up such workloads on such architectures § “Low” data locality leads to “limited” cache efficiency 5 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Aceleración de Aplicaciones Intensivas en Datos Red SyeC – Primer Workshop, 26-27 enero 2016 Application/Architecture Context • Challenging to scale up such workloads on such architectures § “Low” locality leads to “limited” cache efficiency § “Random” memory accesses leads to “limited” data prefetching efficiency 6 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Aceleración de Aplicaciones Intensivas en Datos Red SyeC – Primer Workshop, 26-27 enero 2016 Application/Architecture Context • Challenging to scale up such workloads on such architectures § “Low” locality leads to “limited” cache efficiency § “Random” memory accesses leads to “limited” data prefetching efficiency § “Small” arithmetic intensity leads to “limited” ability to hide memory latency 7 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Aceleración de Aplicaciones Intensivas en Datos Red SyeC – Primer Workshop, 26-27 enero 2016 Application/Architecture Context • Challenging to scale up such workloads on such architectures § § § § “Low” locality leads to “limited” cache efficiency “Random” memory accesses leads to “limited” data prefetching efficiency “Small” arithmetic intensity leads to “limited” ability to hide memory latency “Large” amount of parallelism allows to hide memory latency by “fast” multithreading but at the cost of “high“ requirements of memory bandwidth 8 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Red SyeC – Primer Workshop, 26-27 enero 2016 Aceleración de Aplicaciones Intensivas en Datos Application/Architecture Context • Challenging to scale up such workloads on such architectures § § § § “Low” locality leads to “limited” cache efficiency “Random” memory accesses leads to “limited” data prefetching efficiency “Small” arithmetic intensity leads to “limited” ability to hide memory latency “Large” amount of parallelism allows to hide memory latency by “fast” multithreading but at the cost of “high“ requirements of memory bandwidth • Performance/energy challenges § Memory bandwidth § Frequent data transfers across the memory hierarchy § Moving data around consumes a lot of energy 35 30 25 20 15 10 5 0 16b carry-select 16b multiplier 8x128x16 SRAM (R) 8x128x16 SRAM (W) External IO access Relative energy per operation 16b Memory transfer 9 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Red SyeC – Primer Workshop, 26-27 enero 2016 Aceleración de Aplicaciones Intensivas en Datos Data-Centric Computing • Change computing paradigm Compute-centric system ➠ Data-centric system § Distribute computation across the memory hierarchy 10 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Red SyeC – Primer Workshop, 26-27 enero 2016 Aceleración de Aplicaciones Intensivas en Datos Data-Centric Computing • Change computing paradigm Compute-centric system ➠ Data-centric system § Distribute computation across the memory hierarchy § Minimizes data motion § Reduces energy consumption NDP: Near Data Processing PNM: Processing Near Memory 11 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Red SyeC – Primer Workshop, 26-27 enero 2016 Aceleración de Aplicaciones Intensivas en Datos Data-Centric Computing • Change computing paradigm Compute-centric system ➠ Data-centric system § Distribute computation across the memory hierarchy § Minimizes data motion § Reduces energy consumption NDP: Near Data Processing PNM: Processing Near Memory PIM ⇒ 12 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Red SyeC – Primer Workshop, 26-27 enero 2016 Aceleración de Aplicaciones Intensivas en Datos Processing in Memory • Not a new idea § Smart memories in the 90’s § No interest in industry due to fabrication costs (focus on capacity/costs) 13 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Red SyeC – Primer Workshop, 26-27 enero 2016 Aceleración de Aplicaciones Intensivas en Datos Processing in Memory • Not a new idea § Smart memories in the 90’s § No interest in industry due to fabrication costs (focus on capacity/costs) • New memory technologies § Die stacked (3D) memory: 3D-DRAM 14 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Red SyeC – Primer Workshop, 26-27 enero 2016 Aceleración de Aplicaciones Intensivas en Datos Processing in Memory • Not a new idea § Smart memories in the 90’s § No interest in industry due to fabrication costs (focus on capacity/costs) • New memory technologies § Die stacked (3D) memory: 3D-DRAM § Hybrid Memory Cube (HMC): Micron § High Bandwidth Memory (HBM): AMD, Hynix (NVIDIA) 15 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Red SyeC – Primer Workshop, 26-27 enero 2016 Aceleración de Aplicaciones Intensivas en Datos Processing in Memory • Not a new idea § Smart memories in the 90’s § No interest in industry due to fabrication costs (focus on capacity/costs) • New memory technologies § Die stacked (3D) memory: 3D-DRAM § Hybrid Memory Cube (HMC): Micron § High Bandwidth Memory (HBM): AMD, Hynix (NVIDIA) • HMC Consortium § High performance memory architecture § Consortium: Micron, Altera, ARM, IBM, Samsung, Xilinx … 16 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Aceleración de Aplicaciones Intensivas en Datos Red SyeC – Primer Workshop, 26-27 enero 2016 HMC: Hybrid Memory Cube • What does this technology offer? § Better performance-power rate than conventional DRAM 17 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Aceleración de Aplicaciones Intensivas en Datos Red SyeC – Primer Workshop, 26-27 enero 2016 HMC: Hybrid Memory Cube • Architecture § Memory vaults instead of DRAM arrays + TSVs (Through-Silicon Vias) 18 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Aceleración de Aplicaciones Intensivas en Datos Red SyeC – Primer Workshop, 26-27 enero 2016 HMC: Hybrid Memory Cube • Architecture § Memory vaults instead of DRAM arrays + TSVs (Through-Silicon Vias) § Processor - Memory 19 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Red SyeC – Primer Workshop, 26-27 enero 2016 Aceleración de Aplicaciones Intensivas en Datos HMC: Hybrid Memory Cube • Processing in memory using HMC PIM ⇒ 20 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Red SyeC – Primer Workshop, 26-27 enero 2016 Aceleración de Aplicaciones Intensivas en Datos Processing in Memory • Memory accelerator • Design alternatives § General-purpose architecture § Specific-purpose architecture 21 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Red SyeC – Primer Workshop, 26-27 enero 2016 Aceleración de Aplicaciones Intensivas en Datos Processing in Memory • General-purpose architecture § IBM AMC (Active Memory Cube) [IBM J. Res.&Dev., 59, 2/3, March/May 2015] 22 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Red SyeC – Primer Workshop, 26-27 enero 2016 Aceleración de Aplicaciones Intensivas en Datos Processing in Memory • Specific-purpose architecture § Tesseract: Graph processing [ISCA 2015] 23 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga Aceleración de Aplicaciones Intensivas en Datos Red SyeC – Primer Workshop, 26-27 enero 2016 Accelerating Architectures • Memory accelerator vs GPU accelerator with stacked DRAM 24 Oscar Plata Grupo de Arquitectura de Computadores, Universidad de Málaga