Ejercicios
Anuncio

Laboratorio de Paralelismo
Ejercicios tema 1
1. Se ha ejecutado una aplicación en un multiprocesador con 32 procesadores; un 10% del código se
ha ejecutado en los 32 procesadores, un 70% en 16 procesadores, y el resto en 4 procesadores.
Calcula el factor de aceleración (speed-up) y la eficiencia que se conseguirán (sin considerar otros
factores).
[ fa = 10,3; efic = 32% ]
2. Un programa se compone de dos partes, f1 y f2; dichas partes (funciones) se deben ejecutar una
después de la otra, y el tiempo de ejecución de ambas es similar. La primera parte se puede
ejecutar en paralelo utilizando cualquier número de procesadores, y no hay sobrecarga asociada
por ejecutarla en paralelo; con la segunda parte, en cambio, no se pueden utilizar más de 8
procesadores en su ejecución paralela. El sistema que se ha utilizado para ejecutar el programa
tiene P procesadores. Calcula:
a. el factor de aceleración en función de P, y el factor de aceleración máximo teórico.
b. el número de procesadores que se debe utilizar para conseguir una eficiencia de 0,5 y el
factor de aceleración que se conseguirá en ese caso.
[ a. fa_max = 16; b. P = 24; fa = 12 ]
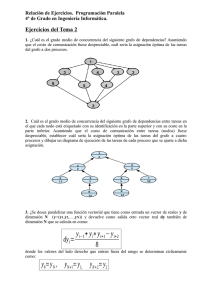
3. Se va a ejecutar en paralelo, en tres procesadores de una máquina SMP, una determinada
aplicación en la que se han identificado 14 tareas. El coste de cada tarea y las dependencias entre
ellas son las siguientes:
Tareas
A1
A2
A3
A4
A5
A6
A7
A8
A9
A10
A11
A12
A13
A14
Coste
2
8
2
4
5
1
3
2
2
1
2
1
3
2
Depende de
–
–
–
–
A1
–
A6
A3
A5
A9
A7
A1,A5
A7
A8
Indica cómo repartir esas tareas entre los tres procesadores para conseguir el factor de aceleración
más alto posible.
4. Se ejecuta una aplicación en paralelo en una máquina de P procesadores. Cuando se ejecuta en
paralelo, por cada segundo de ejecución en serie se debe realizar una operación de comunicación,
cuyo coste se puede modelar como 40 + 16×P1/2 milisegundos.
Sin tener en cuenta otros aspectos, calcula el factor de aceleración máximo que se puede
conseguir y el número de procesadores que se debe utilizar para conseguirlo. Dibuja el tiempo de
ejecución, el factor de aceleración y la eficiencia en función de P.
[ fa_max = 6,25; P = 25; ]
5. Un determinado sistema paralelo MPP de 256 procesadores utiliza como red de comunicación un
toro de dos dimensiones, 16 × 16 nodos, con enlaces de 10 Gbit/s. Se envía un paquete desde el
nodo P35 al nodo P212.
El tiempo de transmisión en la red se puede modelar como d × (10 + 1/B) + L/B ns (d = distancia;
L = tamaño del paquete en bytes; B = ancho de banda de los enlaces en byte/s). Además de ello,
hay que tener en cuenta una serie de overheads, debidos al tráfico —una media de 5 ns por cada
encaminador—, a los protocolos de generación y recogida de mensajes —200 + L ns—, y a la
cabecera y otros datos de control de los mensajes —8 bytes—.
Calcula el tiempo total de la comunicación y el ancho de banda efectivo obtenido en estos dos
casos: (a) se envían 8 bytes de datos; (b) se envían 256 bytes de datos (en ambos casos, un solo
paquete).
[ a. Tcom = 323,6 ns; AB = 0,19 Gb/s; b. Tcom = 780 ns; AB = 2.63 Gb/s; ]
6. Se ejecutan en paralelo, entre 4 procesadores, 100 iteraciones de un determinado bucle,
independientes entre sí. El tiempo de ejecución de cada iteración es de 1 s, salvo una de las
iteraciones, que tiene un tiempo de ejecución de 20 s.
Calcula el speed-up y la eficiencia que se consigue en los siguientes casos:
a. el reparto de iteraciones es estático consecutivo (trozos del mismo tamaño).
b. el reparto de iteraciones es estático entrelazado.
c. el reparto de iteraciones es dinámico, 1 a 1 (calcula el peor y el mejor caso); coste de una
operación de asignación de tareas, 50 ms.
[ a/b. su = 2,7; efic = 68%; c. su = 2,6—3,8; efic = 66—96%; ]
7. Se quiere ejecutar en paralelo, en una máquina SMP de 8 procesadores, el bucle indicado. Escribe
el código que ejecutará cada procesador, en los siguientes casos:
a. se usan barreras como mecanismo de sincronización (planificación estática consecutiva).
b. se usan contadores como mecanismo de sincronización (planificación estática entrelazada).
c. si es posible, sin utilizar funciones de sincronización (planificación dinámica, tipo guided).
for (i=4; i<996; i++)
{
C[i] = B[i-1] + C[i];
A[i] = FUN1(B[i-4],C[i-2]);
B[i] = B[i] * 0,5;
}
8. Se quiere ejecutar en paralelo, en una máquina SMP de 4 procesadores, el siguiente bucle:
for (i=2; i<1000; i++)
for (j=0; j<1000; j++)
{
A[i][j] = A[i-2][j]
}
La matriz A está almacenada por filas, y en un bloque de cache caben 8 elementos de la matriz.
Escribe el código más eficiente posible para cada procesador de la máquina.
9. Se quiere ejecutar en paralelo, en una máquina SMP de 4 procesadores, el siguiente bucle:
for (i=3; i<1000; i++)
{
A[i] = A[i] * B[i-1];
B[i+1] = A[i-3] * 2 + 1;
}
Escribe código para cada uno de los threads independientes que se pueden generar para ejecutar
dicho bucle en paralelo.
10. Se desea ejecutar en paralelo, en un sistema de memoria compartida tipo SMP, el siguiente
código:
...
printf(“Introduce el valor de X”);
scanf (“%d”, &X);
for (i=1; i<N; i++)
A[i] = A[i-1] * X;
// entrada
// cálculo
for (i=0; i<N; i++)
B[i] = B[i] * A[i] + X;
min = MAXINT;
for (i=0; i<N; i++)
if (B[i] < min) min = B[i];
for (i=0; i<N; i++)
B[i] = B[i] – min;
for (i=0; i<N; i++)
printf(“%d \n”, B[i]);
...
// salida
Escribe el código (alto nivel, SPMD) que ejecutaría cada uno de los procesadores del sistema
paralelo. Utiliza las funciones de sincronización que consideres necesarias —locks,
barriers, wait... —. En el caso de ejecutar bucles en paralelo, la planificación debe ser
estática consecutiva. Cada proceso utiliza un variable local que le identifica, pid (de 0 a P–1).
Indica claramente qué variables son globales y cuáles son locales o privadas de cada proceso.
Análisis de rendimiento. Se ejecuta el código paralelo en una máquina de P procesadores. El
coste de cada instrucción de alto nivel es similar, por lo que podemos modelar el coste de
ejecución de un bucle de N iteraciones como N. Obtén una estimación del factor de aceleración
que se obtendrá, considerando que el coste de una operación de sincronización (cualquiera) es P.
No consideres las operaciones de entrada/salida, sino solamente el cálculo.
Dibuja el resultado en función de P, para el caso N = 1.024. Calcula el valor máximo. En
concreto, ¿cuál es el speed-up esperado para el caso de P = 4 procesadores? ¿Y para P = 32
procesadores? ¿Cómo pueden justificarse esos resultados?
[ fa(P=4) = 2,26; fa(P=32) = 3,2 ]
11. Se ejecuta 8 veces un determinado programa y se mide su tiempo de ejecución. Los resultados
obtenidos son (en ms): 23,256 / 24,128 / 23,872 / 24,190 / 25,876 / 144,637 / 22,987 / 23,386.
Haz una estimación del tiempo de ejecución del programa.
12. En un determinado experimento se ha medido el tiempo de ejecución de dos alternativas de un
programa en función del tamaño de los vectores procesados (y, en consecuencia, en función de la
carga de cálculo), y se han obtenidos los datos de la tabla.
Representa los datos en un gráfico de la manera más adecuada posible, y saca las conclusiones
pertinentes.
N (bytes)
T1 (ms)
T2 (ms)
1
2
5
100
1000
2000
3000
3200
3500
4000
20000
100000
0.081
0.162
0.405
8.104
81.062
162.010
242.013
259.197
283.518
323.998
1620.012
8099.996
20.020
20.053
20.215
22.167
39.893
59.756
80.176
83.830
89.875
99.568
421.532
2020.225
13. Las siguientes tablas muestran los tiempos de ejecución en microsegundos de dos programas
diferentes en función del parámetro N. Representa los datos y obtén una expresión matemática
que indique cómo varía T en función de N. A partir de ahí, calcula el tiempo de ejecución
esperado en cada caso para N = 100.
N
T1 (µs)
N
T2 (µs)
10
20
30
40
50
60
83
108
141
179
207
241
1
5
10
15
25
40
53
77
118
185
440
1611