ESTADISTICA DESCRIPTIVA 1. DEFINICION La estadística es una
Anuncio

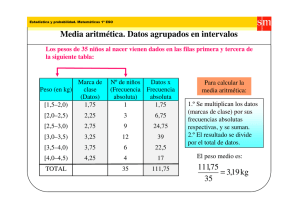
ESTADISTICA DESCRIPTIVA 1. DEFINICION La estadística es una ciencia que facilita la toma de decisiones: Mediante la presentación ordenada de los datos observados en tablas y gráficos estadísticos. Reduciendo los datos observados a un pequeño numero de medidas estadísticas que permitirán la comparación entre diferentes series de datos. Y estimando la probabilidad de éxito que tiene cada una de las decisiones posibles. 2. RAMAS DE LA ESTADISTICA ESTADISTICA DESCRIPTIVA: la cual se encarga de la recolección, clasificación y descripción de datos muéstrales o poblacionales, para su interpretación y análisis. ESTADISTICA MATEMATICA O INFERENCIAL: que desarrolla modelos teóricos que se ajusten a una determinada realidad con cierto grado de confianza. Basada en la Teoría de Probabilidades, también conocida como Estadística Deductiva o Inferencia Estadística. 3. CONCEPTOS BASICOS 3.1 POBLACION, COLECTIVO O UNIVERSO “cualquier conjunto de personas, objetos, ideas o acontecimientos que se someten a la observación estadística de una o varias características que comparten sus elementos y que permiten diferenciarlos”. Son poblaciones por ejemplo, los diferentes automóviles que se encuentran en un concesionario o las diferentes religiones de un país. 3.2 VARIABLE Las variables se clasifican en continuas o discretas, según admitan o no infinitos valores intermedios entre dos valores próximos respectivamente. En la practica, la distinción entre variable discreta y continua no es fácil, ya que todas las variables pueden ser consideradas discretas, porque los instrumentos de medida no permiten pasar de un cierto limite de precisión. 4. DISTRIBUCIÓN DE FRECUENCIAS 4.1 DISTRIBUCIÓN DE FRECUENCIAS SIMPLE 4.1.1 Frecuencia absoluta simple Es el número de veces que se presenta un determinado dato de un carácter en los diferentes elementos de una población. Se presenta por na . La frecuencia absoluta es, por tanto, el número de repeticiones de un determinado valor de la variable o una determinada modalidad del atributo. La frecuencia absoluta también representa el número de elementos de la población que tienen el mismo valor o modalidad. La suma total de todas las frecuencias absolutas es el tamaño de la población de elementos observados. Se representa por N. 4.1.2 Frecuencia relativa simple Se obtiene dividiendo la frecuencia absoluta de un determinado dato entre la suma de las frecuencias absolutas de todos los datos observados, es decir, entre el tamaño de la población. Se representa por fr = na / N La frecuencia relativa es, una proporción entre el número de veces que se repite un dato y el tamaño de la población. Las frecuencias relativas se suelen presentar en porcentaje (%fr) que se obtiene al multiplicar por 100 el valor correspondiente de la frecuencia relativa. En este caso, la suma total de todas las frecuencias relativas porcentuales será 100. 4.1.3 Frecuencia absoluta acumulada La frecuencia absoluta acumulada de un dato es igual a la frecuencia absoluta de este dato más la suma de las frecuencias absolutas de los datos anteriores. Se representa por Na. Esta frecuencia representa, cuando existe una relación de orden, el número de elementos de la población que quedan por encima o por debajo del elemento cuyo valor o modalidad se observa. 4.1.4 Frecuencia relativa acumulada La frecuencia relativa acumulada de un dato es igual a la suma de las frecuencias relativas de todos los datos menores o iguales de dicho valor. Se representa por Fa. Al igual que las frecuencias relativas simples, se suelen presentar en porcentajes (%Fa). EJEMPLO: Se ha realizado un estudio del numero de empleados de 15 ferreterías de una zona de Madrid con los siguientes resultados: 4; 5; 4; 3; 3; 6; 4; 5; 3; 3; 4; 5; 3; 6. Construir la tabla estadística empleando frecuencias absolutas simples y acumuladas y, también, frecuencias relativas en porcentaje, simples y acumuladas. Solución: Nº empleados por tienda Frecuencia absoluta simple (n ) a Frecuencia absoluta acumulada (N ) Frecuencia relativa simple en % (%f ) r a Frecuencia relativa acumulada en % (%F ) a 3 5 5 5/ 15 = 0.33(x 100) = 33.3% 33,3 4 4 9 4/15 = 0.26 (x 100) = 26.6% 60 5 3 12 3/15 = 0.2 (x 100) = 20% 80 6 3 15 3/15 = 0.2 (x 100) = 20% 100 En primer lugar, se ordenan las tiendas de menor a mayor número de empleados, segunde detalla en la primera columna de la tabla inferior. En la segunda columna figuran las veces que se repite un mismo valor (la frecuencia absoluta). La suma de las frecuencias absolutas (15) es el número de elementos de la población. En la tercera columna aparecen las frecuencias absolutas acumuladas, cuyos valores se obtienen sumando al valor de la frecuencia absoluta correspondiente, la suma de todas las frecuencias absolutas anteriores. En la cuarta columna están las frecuencias relativas simples en porcentaje, obtenidas al dividir el valor de la frecuencia absoluta correspondiente entre el numero de elementos de la población, y multiplicadas por 100. En la quinta columna están las frecuencias relativas acumuladas en porcentaje, resultado de la suma del valor de la frecuencia relativa en porcentaje correspondiente mas, la suma de todas las frecuencias relativas en porcentaje anteriores. 4.2 DISTRIBUCIÓN DE FRECUENCIAS POR INTERVALOS O DATOS CONTINUOS Usualmente los valores de los datos no permiten un agrupamiento de ellos en una tabla de frecuencias simple, debido a que se encuentran distribuidos a través de todo el recorrido y el número de veces que se repite cada observación no es significativo en todos los casos, y en la mayoría de ellos su frecuencia es baja. 5. MEDIDAS DE TENDENCIA CENTRAL Las medidas de tendencia central, llamadas así porque tienden a localizarse en el centro de la información, son de gran importancia en el manejo de las técnicas estadísticas, sin embargo, su interpretación no debe hacerse aisladamente de las medidas de dispersión, ya que la representatividad de ellas está asociada con el grado de concentración de la información. Las principales medidas de tendencia central son: 5.1 MEDIA ARITMÉTICA Cotidiana e inconscientemente estamos utilizando la media aritmética. Cuando por ejemplo, decimos que un determinado fumador consume una cajetilla de cigarrillos diaria, no aseguramos que diariamente deba consumir exactamente los 20 cigarrillos que contiene un paquete sino que es el resultado de la observación, es decir, dicho sujeto puede consumir 18, un día; 19 otro; 20, 21, 22; pero según nuestro criterio, el número de unidades estará alrededor de 20. Matemáticamente, la media aritmética se define como la suma de los valores observados dividida entre el número de observaciones. Donde: ∑ : é : : ! " , $ % EJEMPLO Cantidad de cigarrillos consumidos por un fumador en una semana. Lunes: 18 Viernes: 20 Martes: 21 Sábado: 19 Miércoles: 22 Domingo: 19 Jueves: 21 Solución: Entonces la media aritmética es ∑ ∑& & ' ( ) ) ( & El fumador consume en promedio 20 cigarrillos diarios. Cuando la variable está agrupada en una distribución de frecuencias, la media aritmética se calcula por la fórmula: ∑+ * * * + *+ * Ejemplo: 1. Cantidad de cigarrillos consumidos por un fumador en una semana dada Cantidad 18 19 20 21 22 Frecuencia * 1 2 1 2 1 7 ∑+ ',- ),- (,- ,- , * ( & ( ./0112234 50 2. Calculo de La Media Aritmética. El Salario/día de 50 Operarias. MILES $/DIA Xi fi Xi fi 50 1 50 51 3 153 52 5 260 53 9 477 54 12 648 55 10 550 56 5 280 57 3 171 58 2 116 SUMAS O TOTAL 50 2705 ∑) * &(6 67. 6( 67. (( 9:434/50 3. Si la información está relacionada en una distribución de frecuencias por intervalos, se toman como valores de la variable las marcas de clase de los intervalos, entiéndase por marca de clase el punto medio entre los límites de cada clase o intervalo. Cálculo de La Media Aritmética de la Resistencia de 100 Baldosas ∑& * 77'(( 77' (( La resistencia promedio de las 100 baldosas es de 448 Kg/Cm². 5.2 LA MEDIANA No se basa en la magnitud de los datos, como la media aritmética, sino en la posición central que ocupa en el orden de su magnitud, dividiendo la información en dos partes iguales, dejando igual número de datos por encima y por debajo de ella. 5.2.1 La Mediana Cuando los datos no están Agrupados en Intervalos. Partiendo de la información bruta, ordenamos los datos ascendente o descendentemente: <= , <> , <? … … … . . <A … … … <B D:50 0 D: E F G, 4 :4 +901 ò E G , F- D:50 0 D: Ejemplo: C 4 :4 901 1. En el ejercicio de los cigarrillos, consumidos por un fumador tenemos lunes 18, martes 21, miércoles 22, jueves 21, viernes 20, sábado 19, y domingo 19. Ordenando ascendentemente: <= 18, <> 19, <? 19, <L 20, <O 21, <P 21, <Q 22 n, es impar, entonces D:50 0 D: E F G , &F 7 ( 2. Consumo mensual de agua, en m3, por la fábrica de confecciones “la hilacha” Enero= 10 Mayo= 14 Septiembre = 18 Febrero = 12 Junio= 19 Octubre = 22 Marzo= 15 Julio= 17 Noviembre = 15 Abril = 18 Agosto= 18 Diciembre = 13 <= 10, <> 12, <? 13, <L 14, <O 15, <P 15, <Q 17, <V 18, <W 18, <=X 18, <== 19, <=> 22 D:50 0 D: D: E G , F E G ,Y- & 6 & Y , F Como se puede observar, en este caso la mediana no es un dato perteneciente a la información, es un parámetro que divide la información dejando el 50% por encima y el 50% por debajo de ella. 5.2.2 La Mediana Cuando la Información se Encuentra Agrupada en Intervalos Si la información esta agrupada en intervalos iguales, entonces la mediana se calcula según la siguiente expresión: Z[ 2 \ C,A]=CA ^ Me: Mediana LI: Limite inferior del intervalo donde se encuentra la mediana (intervalo mediano), el cual se determina observando en que clase se encuentra la posición n/2. n: Numero de observaciones C,A]=- : _ CA : _ A: Amplitud del intervalo. EJEMPLO En la columna de frecuencia acumulada advertimos que la observación número 50 se halla en el cuarto intervalo 4. (( \ *0,]\ d6 b c D: (( 776. 76 e//f+ D: `a * d6 Se concluye que el 50% de las baldosas resiste menos de 445.45 Kg/Cm2 y el 50% resiste mas de 445.45 Kg/Cm2. 5.3 LA MODA La moda, como su nombre lo indica, es el valor más común (de mayor frecuencia dentro de una distribución. Una información puede tener una moda y se llama unimodal, dos modas y se llama bimodal, o varias modas y llamarse multimodal. Sin embargo puede ocurrir que la información no posea moda. 5.3.1 La Moda Cuando los datos no están Agrupados en Intervalos El valor que más veces se repite es 54 con una frecuencia de 12, entonces decimos que la moda es Mo = 54.000.00 pesos diarios. Los valores de mayor frecuencia corresponden a 19 y 21, por lo tanto se trata de una distribución bimodal con Mo1=19 y Mo2=21. 5.3.2 Cálculo de la Moda Cuando la Información está Agrupada en Intervalos Cuando la información se encuentra agrupada en intervalos de igual tamaño la moda se calcula con la siguiente expresión. D3 `a *+ \ *,+]b *+ \ *,+]- \ *,+F- Donde: Mo: Moda LI: Limite inferior del intervalo modal *+ : Frecuencia de la clase modal *,+]-: Frecuencia de la clase premodal. *,+F-: Frecuencia de la clase posmodal. A: Amplitud de los intervalos. EJEMPLO D3 `a c D3 7(( *+ \ *,+]b *+ \ *,+]- \ *,+F- dd \ (( 777. 77 e//f+ ,dd- \ \ ' A pesar que el valor 444.44 no es un dato real de la información asumimos ese parámetro como el de mayor ocurrencia. 6. MEDIDAS DE DISPERSIÓN Para medir el grado de dispersión de una variable, se utilizan principalmente los siguientes indicadores: 6.1 RANGO O RECORRIDO Es la medida de dispersión mas sencilla ya que solo considera los dos valores extremos de una colección de datos, sin embargo, su mayor utilización está en el campo de la estadística no paramétrica. R = Xmax – Xmin Xmax, Xmin son el máximo y el mínimo valor de la variable X, respectivamente. En el ejemplo introductorio, vemos que el rango para la primera información es R1=95-5=90, mientras que R2=51-49=2, se hace pues manifiesta la gran dispersión de la primera información contra la homogeneidad de la segunda. 6.2 DESVIACIÓN MEDIA La desviación media, mide la distancia absoluta promedio entre cada uno de los datos, y el parámetro que caracteriza la información. Usualmente se considera la desviación media con respecto a la media aritmética: gD Donde, ∑+ | \ |* DM: Desviación media : Diferentes valores de la variable X * : Numero de veces que se repite la observación : Media aritmética de la información n: tamaño de la muestra m: Numero de agrupamientos o intervalos. EJEMPLO: gD ∑+ &( | \ |* . 7 6( 1.400.00 es el error promedio que se comete al remplazar los ingresos diarios de cada una de las 50 obreras por 54.100 pesos. 6.3 VARIANZA La varianza obvia los signos presentes en la desviación estándar elevando las diferencias al cuadrado, lo cual resulta ser más elegante, aparte de que es supremamente útil en el ajuste de modelos estadísticos que generalmente conllevan formas cuadráticas. Numéricamente definimos la varianza, como desviación cuadrática media de los datos con respecto a la media aritmética: i Donde, ∑+ - * ,j \ j i> : Varianza <A : valor de la variable x <k : Media aritmética de la información CA : Frecuencia absoluta de la observación <A n: Tamaño de la muestra m: Numero de agrupamiento o intervalos. EJEMPLO: 1) i ∑+ - * Y(. 6( ,j \ j d. 6( Como los datos están expresados en miles de pesos y la varianza se encuentra en forma cuadrática obtenemos una varianza de 3’210.000 pesos. Sin embargo para una mejor comprensión debemos recurrir a la desviación típica o estándar definida como la raíz cuadrada de la varianza: i li m ∑+ - * ,j \ j c i √d. . &) El error estándar es de 1.791 pesos/diarios. 2) En el ejemplo de las baldosas: ∑+,j \ j - * i li m c i √)6)Y 7( e//f+ 6.4 COEFICIENTE DE VARIABILIDAD El coeficiente de variabilidad tiene en cuenta el valor de la media aritmética, para establecer un número relativo, que hace comparable el grado de dispersión entre dos o mas variables, y se define como: fo i (( Comparemos la homogeneidad de las dos informaciones anteriores, las cuales tienen diferente unidad de medida. Ejemplo: 9:434 . &) 50 fo 9:434 (. (dd c fo d. d% 67. 50 1) para el salario: 2) para la resistencia 7( e//.+ fo (. d6 c fo d. 6% 77' e//.+ Concluimos que es mucho más dispersa la información correspondiente a la resistencia de las baldosas.