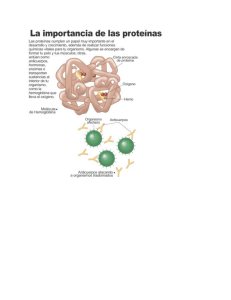
Agua MÓDULO II. BIOMOLÉCULAS
Anuncio

1 MÓDULO II. BIOMOLÉCULAS Agua El agua es el líquido mas común sobre la Tierra, las tres cuartas partes de la superficie terrestre están cubiertas de agua y si la superficie de la tierra fuera planta, estaría 2.5 Km. bajo el agua (1,2). Constituye del 70 a 85% del peso de muchas células y los fluidos extra celulares como la sangre, el liquido cefalorraquídeo, la savia, la orina y las lagrimas, están hechos a base de agua (2). El agua proporciona el medio para las reacciones metabólicas y como solvente biológico, regula las condiciones optimas de temperatura y pH para las células y el medio extracelular (2). Determina la estructura y el comportamiento de todas las biomoleculas (2), y su elevada capacidad calorífica permite que funcione como amortiguador de la temperatura al absorber mucha de la energía en forma de calor, generada por las reacciones bioquímicas. Además cumple una función como solvente al disolver muchas de las sustancias que regulan la concentración de iones hidrógeno (pH). Al ser la base de muchos de los fluidos biológicos, sirve para transportar nutrientes para el crecimiento de las células y para retirar los productos de desecho. En términos biológicos la estructura y propiedades del agua permiten entre otras cosas, la subida de la savia en los árboles, que el hielo flota en el agua y que no se acumule en el fondo de cuerpos de agua como sucedería si fuera mas denso y por ellos la vida ha podido evolucionar. El calor especifico del agua permite que los organismos que se desarrollan en los océanos o grandes cuerpos de agua vivan en un ambiente cuya temperatura es relativamente constante, de la misma forma, el gran contenido de agua de la plantas y animales terrestres les ayuda a mantener una temperatura interna relativamente invariable, y esta constancia de temperatura es crucial porque las reacciones químicas de importancia biológica porque tienen lugar en un estrecho limite de temperaturas (1,2). El gran calor de vaporización del agua permite la liberación de calor y con ello los organismos estabilizan su temperatura, la evaporación en la superficie de una planta o un animal terrestre es uno de los recursos principales de los organismos para descargar el exceso se calor (1,2). O por ejemplo, la capacidad disolvente del agua favorece la disolución de sustancia y con ello disminuye la temperatura a la cual esta se congela, fenómeno que se observan en plantas y animales resistentes al invierno. Como es evidente, el agua es una molécula indispensable para la vida, ya que los procesos metabólicos y de síntesis requieren que las moléculas puedan desplazarse, encontrarse e intercambiar parejas continuamente, un entorno liquido permite esta movilidad molecular y el agua esta admirablemente adecuado para este fin. A continuación se retoman los conceptos básicos del este tema, la información fue tomada de las siguiente fuente. 2 INFORMACIÓN ACTUALIZADA EN ESPAÑOL PARA LA ENSEÑANZA Y EL APRENDIZAJE DE ESTAS DISCIPLINAS CIENTÍFICAS. Comité asesor de publicaciones. Facultad de Medicina, UNAM Todos los derechos reservados Copyright © UNAM 2003 03-2002-121311275700-01 Instituto Nacional del Derecho de Autor de la Secretaría de Educación Pública del Gobierno de la República Mexicana. Esta página puede ser reproducida con fines no lucrativos, siempre y cuando no se mutile, se cite la fuente completa y su dirección electrónica: http://bq.unam.mx/~evazquez De otra forma requiere permiso previo por escrito de la institución o el autor. Preguntas/Comentarios Para recibir actualizaciones Última actualización: 15 de Octubre de 2003 Por alguna razón, esta página se ve mejor con internet explorer. 1) Mathews, C,K., K.E. van Holde y K.G. Ahern. 2002. Bioquímica. Addison Wesley. Madrid España. 1333 pag. 2) Boyer, R. 2000. conceptos de bioquímica. International Thomson Editores. México. D.F. 694 pag. La vida como sabemos transcurre en soluciones acuosas. La vida se originó en el agua de hecho, hasta hace muy poco tiempo los organismos acuáticos invadieron ambientes terrestres pero, aún así, cargan consigo su propio océano, pues la composición de sus fluidos intra y extracelulares son muy similares al agua de los mares. El agua es tan familiar para los seres vivos que nosotros los humanos generalmente la consideramos como un fluido muy simple, pero las 3 propiedades físicas y químicas del agua son de hecho muy exóticas y tienen profundos significados para la Biología, sus propiedades son muy importantes para el funcionamiento celular, de hecho están directamente relacionadas con las propiedades de las biomoléculas y, por tanto, con el metabolismo. Las estructuras de las macromoléculas que conforman a los seres vivos resultan de las interacciones con el medio acuoso que las contiene. La combinación de las propiedades del solvente responsables de las asociaciones intra e intermoleculares de estas substancias es peculiar del agua; ninguna otra substancia se asemeja al agua a este respecto. Por lo tanto no es de sorprenderse que el agua sea la sustancia más abundante en los sistemas biológicos, de hecho mas del 70% de los seres vivos está formado por agua. No olvidar que el agua aunque es un compuesto vital, por si misma carece de vida. El estudio de las propiedades del agua es central para la Bioquímica por las siguientes razones: A. A. Casi todas las biomoléculas asumen sus formas, y por tanto sus funciones en respuesta a las propiedades físicas y químicas del agua. B. B. El agua es el medio de la mayoría de las reacciones bioquímicas. Los productos y reactivos de las reacciones metabólicas, los nutrientes y los productos de desecho, dependen del agua para su transporte en el interior y exterior celular. C. C. El agua por si misma participa en muchas reacciones químicas que participan en la vida. Frecuentemente los componentes iónicos del agua, los iones H+ y OH-, son reactivos. De hecho la reactividad de muchos grupos funcionales de las biomoléculas, dependen de la concentración de estos iones en los alrededores. D. D. La oxidación del agua para producir oxígeno molecular, O 2, es la reacción fundamental de la fotosíntesis, en donde la energía del sol es almacenada químicamente para soportar la vida. La naturaleza inodora, incolora e insípida del agua es fundamental para los organismos vivos. 4 La molécula de H2O tiene una geometría doblada pues a pesar de ser simétrica, los enlaces que la forman, no se encuentran en línea recta. Lo anterior se debe a la naturaleza híbrida sp3, de los orbitales del oxígeno que se dirigen hacia las esquinas de un tetrahedro: Radio de van der Waals = 1.4 A° Enlace covalente O-H Radio de van der Waals 1.2 A° H O = 0.958 A° 104.5° H Envoltura de van der Waals Figura: representación de la molécula de agua. La gran diferencia en electronegatividad entre los átomos de Hidrógeno y Oxígeno confiere el 33 % del carácter iónico del enlace O-H como lo indica el momento dipolar del agua (1.85 debyes). El agua es claramente una molécula polar y esta característica tiene importantes implicaciones en los sistemas vivientes. El agua es una molécula polar, el átomo de Oxígeno con sus electrones no apareados (2s2px), posee una densidad de carga negativa (-), de –0.66e; en donde e es la carga de un electrón. Los átomos de Hidrógeno poseen una carga parcial positiva (+) de +0.33e: Configuración electrónica del Oxígeno O8 = 1s22s22px2py2pz Configuración electrónica del Hidrógeno 5 H1= 1s2 Figura: Representación de la configuración electrónica de los átomos de los elementos que forman a la molécula de agua. Al realizarse los enlaces con los dos átomos de Hidrógeno, el oxígeno adquiere la configuración del un gas noble o bien cumple con la regla del octeto de Lewis (2s22px2py2pz). Aún así en la última capa (L ó 2), el Oxígeno tiene dos electrones sin compartir, es precisamente con esos electrones con los que la otra molécula de agua se orienta para formar el puente de Hidrógeno: Las atracciones electrostáticas entre los dipolos de dos moléculas de agua tienden a orientarse de tal manera que el enlace O-H de una molécula de agua, apunta hacia el par de electrones no apareado del átomo de Oxígeno de la otra molécula de agua. Esto resulta en una asociación direccional intermolecular denominada puente de Hidrógeno El puente de Hidrógeno es una interacción que es crucial para las propiedades del agua y su papel como solvente. Su energía es muy débil (20 kJ mol-1), pero la suma de muchos de ellos hace a los compuestos que los presentan poseer características peculiares. En general un puente de Hidrógeno se representa como: D – H A en donde D-H es un ácido débil (donador) como N-H u O-H+ , a veces S-H+ ; y A es una base débil (aceptor), como N u O y ocasionalmente S. En el agua, los puentes de Hidrógeno tienen una distancia de aproximadamente 1.8 A°. Dadas las características explicadas anteriormente, debe quedar claro que cada molécula de agua puede establecer 4 puentes de Hidrógeno con otras moléculas de agua. Lo que hace una malla de moléculas ordenadas. 6 Los enlaces de hidrógeno entre las moléculas de agua proveen de las fuerzas cohesivas que hacen del agua un líquido a temperatura ambiente, de hecho favorecen también el orden extremo de las moléculas en el hielo que es agua sólida. El puente de hidrógeno es un enlace que se establece entre moléculas capaces de generar cargas parciales. El agua, es la sustancia en donde los puentes de hidrógeno son más efectivos, en su molécula, los electrones que intervienen en sus enlaces, están más cerca del oxígeno que de los hidrógenos y por esto se generan dos cargas parciales negativas en el extremo donde está el oxígeno y dos cargas parciales positivas en el extremo donde se encuentran los hidrógenos. La presencia de cargas parciales positivas y negativas hace que las moléculas de agua se comporten como imanes en los que las partes con carga parcial positiva atraen a las partes con cargas parciales negativas. De tal suerte que una sola molécula de agua puede unirse a otras 4 moléculas de agua a través de 4 puentes de hidrógeno. Esta característica es la que hace al agua un líquido muy especial. Los puentes de Hidrógeno, se forman por átomos de Hidrógeno localizados entre átomos electronegativos. Cuando un átomo de Hidrógeno está unido covalentemente, a una átomo electronegativo, ej. Oxígeno o Nitrógeno, asume una densidad () de carga positiva, debido a la elevada electronegatividad del átomo vecino. Esta deficiencia parcial en electrones, hace a los átomos de Hidrógeno susceptibles de atracción por los electrones no compartidos en los átomos de Oxígeno o Nitrógeno Obsérvese la configuración electrónica del Oxígeno: 8O 1s2 2s2 2px py pz de ahí que: + + - + + Figura: configuración electrónica del Oxígeno 7 el puente de Hidrógeno es relativamente débil entre -20 y -30 kJ mol-1, la fuerza de enlace aumenta al aumentar la electronegatividad y disminuye con el tamaño de los átomos participantes. Por tanto, el puente de Hidrógeno existe en numerosas moléculas no solo en el agua. Aquí solo se tratará lo referente al agua. La estructura del agua favorece las interacciones para formar puentes de Hidrógeno, el arreglo siempre es perpendicular entre las moléculas participantes, además, es favorecido por que cada protón unido a un Oxígeno muy electronegativo encuentra un electrón no compartido con el que interactúa uno a uno. De lo anterior se concluye que cada átomo d Oxígeno en el agua interacciona con 4 protones, dos de ellos unidos covalentemente y dos a través de puentes de Hidrógeno. colineales Figura: Información sobre los puentes de Hidrógeno Estudios de difracción de rayos X indican que la distancia entre los átomos de Oxígeno que intervienen en el puente de Hidrógeno, están separados por 0.28 nm lo que indica un arreglo tetraédrico de las moléculas de agua, además los puentes de Hidrógeno: TETRAHEDRO 8 Figura: representación de una molécula tetraédrica del agua. La colinealidad de los puentes es muy importante, un alejamiento de 10° ocasiona la que el puente se rompa. Linnus Pauling postuló a partir de observaciones de las transiciones moleculares (i.e. el movimiento de los átomos con respecto a aquellos a los que están unidos) de los átomos participantes en la molécula D2O (el deuterio forma parte de la pléyade de Hidrógeno), que el puente de Hidrógeno es la interacción más importante que juega un papel crítico no solo en la estructura del agua sino en la estructura y función de las macromoléculas biológicas. El agua tiene puntos de fusión y de ebullición así como calor de vaporización más elevados que otros solventes comunes Punto de fusión Punto de ebullición Calor de vaporización (°C) (°C) (J/g)* Agua 0 100 2,260 Metanol -98 65 1,100 Etanol -117 78 854 Propanol -127 97 687 Butanol -90 117 590 Acetona -95 56 523 Hexano -98 69 423 Benceno 6 80 394 -135 -0.5 381 -63 61 247 Butano Cloroformo 9 Tabla: Valores de punto de fusión, punto de ebullición y calor de vaporización para algunos líquidos. Estas propiedades inusuales son consecuencia de la atracción entre moléculas de agua adyacentes que le dan al agua líquida una gran cohesión interna. Un vistazo a la estructura electrónica de la molécula revela la causa de estas atracciones intramoleculares. Los puentes de Hidrógeno no son propios del agua, las moléculas polares como las sales, se disuelven en el agua porque reemplazan las interacciones agua-agua con interacciones agua-soluto que son energéticamente más favorables. Figura: Representación de los puentes de Hidrógeno más comunes en los sistemas biológicos 10 Figura: Puentes de Hidrógeno comunes en las biomoléculas Por el contrario, las moléculas no polares, como las grasas interfieren con las interacciones agua-agua, pero son incapaces de formar interacciones favorables agua-soluto, por lo tanto estas moléculas son poco solubles en agua. Los puentes de hidrógeno, las interacciones ionicas, hidrofóbicas (del griego terror al agua) y de van der Waals, son interacciones muy débiles por si mismas, pero colectivamente tienen una gran influencia en la estructura tridimensional de las macromoléculas biológicas. 11 Figura: Grupos polares y no polares en algunas biomoléculas. Todos los fenómenos bioquímicos están íntimamente relacionados con el agua debido a que las células son soluciones en donde el solvente es precisamente esa molécula. Por tanto, todas las características del agua, están directamente relacionadas con las propiedades estructura-función de las biomoléculas: Características del agua Constante dieléctrica Capacidad calorífica 12 Calor de vaporización Densidad Tensión superficial Constante de ionización El agua es el único compuesto cuyas propiedades físicas lo colocan a parte de cualquier otro líquido descrito a la fecha. Finalmente todas estas características están involucradas directamente con la formación de puentes de Hidrógeno, que son interacciones moleculares muy débiles, pero que en conjunto permiten formar estructuras moleculares muy complejas. La capacidad del agua para formar puentes de Hidrógeno, ha llevado a la generación de varias teorías para tratar de explicar al agua líquida. El agua tiene una de las constantes dieléctricas más elevadas. Constante dieléctrica para algunos compuestos Constante Compuesto dieléctrica () A 298 K H2O 78.5 Metanol 32.6 Etanol 24 H2S 9.3 C6H6 2.2 CCl4 2.2 CH4 1.7 Aire 1.00006 Mica 5.4 Poliestireno 2.5 Tabla: valor de la constante dieléctrica para algunos líquidos. El agua, por tanto, es uno de los solventes más polares que existen, esto se debe a la presencia de un átomo muy electronegativo, el Oxígeno, y dos muy poco electronegativos, los Hidrógenos en la molécula. La consecuencia de lo anterior, es que moléculas o partículas cargadas eléctricamente son fácilmente disociadas en presencia de agua. La ionización sucede por que las fuerzas coulómbicas entre las cargas opuestas son débiles y, por tanto, se rompen fácilmente. Estas fuerzas son proporcionales a q+q-/r2, en donde es la 13 constante dieléctrica, q+ y q- son la carga catiónica y aniónica respectivamente. Esta observación es muy importante para los sistemas biológicos pues la diferencia en los gradientes ionicos es la base energética y funcional de muchos procesos El agua posee una capacidad calorífica muy elevada, es necesaria una gran cantidad de calor para elevar su temperatura 1.0 °K. Para los sistemas biológicos esto es muy importante pues la temperatura celular se modifica muy poco como respuesta al metabolismo. De la misma forma, los organismos acuáticos, si el agua no poseyera esa cualidad, se verían muy afectados o no existirían. El agua tiene un elevado calor de vaporización, al igual que otros líquidos capaces de hacer puentes de Hidrógeno como el etanol o el ácido acético, pero a diferencia de otros líquidos como el hexano que no los hacen Compuesto H2O Ácido acético Etanol Hexano Calor de vaporización KJ mol-1 40.7 a 273 K 41.7 a 391 K 40.5 a 351 K 31.9 a 341 K Tabla: valor del calor de vaporización para algunos líquidos. Para los sistemas biológicos esta propiedad es muy importante pues gracias a ella es que se lleva a cabo eficientemente la respiración y sudoración. El agua líquida es más densa que el hielo a presión y temperatura estándar. Existe un cambio positivo en el volumen después del congelamiento, lo que ocasiona que el hielo flote. Si el hielo no flotara, la vida acuática en cuerpos de agua como lagos y en los polos terrestres, no existiría pues estos cuerpos de agua se congelarían desde el fondo hacia la superficie, de hecho, lo contrario, la capa de hielo que se forma sobre estos cuerpos de agua, resulta en un aislante térmico. 14 El agua tiene una tensión superficial elevada, esto hace que en los procesos biológicos, se utilicen moléculas tipo detergente (anfifílicas) para modificarla. Los surfactantes pulmonares por ejemplo, decrecen el trabajo necesario para abrir los espacios alveolares que permiten el intercambio gaseoso eficiente, la ausencia de estas substancias, ocasiona enfermedades severas y la muerte. Debido a su constante de ionización, el agua posee una conductividad elevada. La conductividad de hielo es elevada, pero 103 veces menor que en el estado líquido. Debido a esta característica el agua participa activamente en la conducción de señales eléctricas en el sistema nervioso. Muchas de las características que hacen al agua un líquido tan particular, se deben a su capacidad de hacer puentes de Hidrógeno. La solubilidad depende de las propiedades de un solvente que le permitan interaccionar con un soluto de manera más fuerte que como lo hacen las partículas del solvente unas con otras. Es de todos conocido que el agua es “el solvente universal”, pero esto no es del todo cierto; el agua ciertamente disuelve muchos tipos de substancias y en mayores cantidades que cualquier otro solvente. En particular, el carácter polar del agua la hace un excelente solvente para los solutos polares e iónicos, que se denominan hidrofílicos (del griego hydor, agua y philos, amante). Por otra parte, los compuestos no polares son virtualmente insolubles en agua (“el agua y el aceite no se mezclan”) y por lo tanto, son hidrofóbicos (del griego fobos, temer). Los compuestos apolares, son solubles en solventes no polares como el CCL4 (tetracloruro de Carbono) o el hexano. Lo anterior puede resumirse en: “lo semejante disuelve a lo semejante” ¿Porqué las sales se disuelven en el agua? Las sales, como el NaCl (cloruro de sodio) o el K2HPO4 (fosfato ácido de potasio), se mantienen unidas por fuerzas iónicas. Los iones de una sal, como lo hacen cargas cualesquiera, interactúan de acuerdo a la ley de Coulomb: 15 F kq 1 q 2 Dr 2 (1) en donde F es la fuerza entre las dos cargas eléctricas (q1 y q2), que están separadas por una distancia r. D es la constante dieléctrica del medio entre las cargas y k es una constante de proporcionalidad (8.99 x 109 J·m·C-2). A medida que la constante dieléctrica del medio crece, la fuerza entre las cargas decrece. La constante dieléctrica, es una medida de las propiedades de un solvente para mantener cargas opuestas separadas. En el vacío, D = 1 y en aire, es apenas un poco mayor. En la siguiente Tabla, se muestra la constante dieléctrica de algunos solventes comunes, así como sus momentos dipolares permanentes. Solvente Constante dieléctrica (D) Formamida 110.0 Agua 78.5 Dimetil sulfóxido 48.9 Metanol 32.6 Etanol 24.3 Acetona 20.7 Amoniaco 16.9 Coloroformo 4.8 Eter dietílico 4.3 Benceno 2.3 CCL4 2.2 Hexano 1.9 Momento dipolar (debye) 3.37 1.85 3.96 1.66 1.68 2.72 1.47 1.15 1.15 0.00 0.00 0.00 Tabla: Valores de constante dieléctrica y momento dipolar para algunos líquidos. La constante dieléctrica del agua es la más alta de un líquido puro, por el contrario, la de solventes no polares como los hidrocarburos, es relativamente pequeña. La fuerza entre dos iónes separados por una distancia dada en un líquido no polar como hexano o benceno, es 30 ó 40 veces mayor que en agua. Consecuentemente, en solventes no polares (con D baja), los iones de cargas opuestas, se atraen tan fuertemente que forman una sal, por el contrario, las fuerzas débiles que existen entre los iones en agua (D alta), permiten que cantidades significativas de iones permanezcan separadas. Un ion negativo inmerso en un solvente polar, atrae la parte positiva del dipolo del solvente y viceversa, por ejemplo, en el agua: 16 - anión H+ + H+ O + + cation Figura: representación de la orientación de aniones y cationes en solución acuosa El ion queda rodeado por capas concéntricas de moléculas de solvente. A este fenómeno se le denomina solvatación, en el caso específico del agua, hidratación. Este arreglo atenúa las fuerzas coulómbicas entre los iones, de ahí que los solventes polares tengan constantes dieléctricas tan elevadas. En el caso particular del agua, la constante dieléctrica es mayor que la de otros líquidos con momentos dipolares comparables, por que los puentes de hidrógeno entre las moléculas de agua permiten que los solutos se orienten de tal forma que las estructuras formadas resisten movimientos causados por el incremento en la temperatura, por lo cual, la distribución de cargas en mucho más efectiva. La solubilidad de las moléculas polares o iónicas en el agua, depende de los grupos funcionales que contengan para formar puentes de hidrógeno: hidroxilos (-OH), ceto (-C=O), carboxilo (-COOH) o amino (-NH2). Dentro de las biomoléculas solubles en agua se encuentran alguna proteínas, ácidos nucléicos y carbohidratos. 17 Carbohidratos Los sacáridos desempeñan una gran variedad de funciones en los organismos vivos, de hecho el principal ciclo energético de la biosfera depende en gran partes del metabolismo de los hidratos de carbono. Este proceso es la fotosíntesis y gran parte de los hidratos de carbono producidos por este proceso se almacenan en las plantas en forma de almidón o celulosa. Los animales obtienen los hidratos de carbono ingiriendo las plantas o los animales herbívoros. De esta forma, los hidratos de carbono sintetizados por las plantas pasan a ser en ultima instancia las principales fuentes de carbohidratos de todos los tejidos animales. Tanto la plantas como los animales realizan, a través del metabolismo oxidativo, una reacción que es esencialmente la inversa de la fotosíntesis, mediante la cual producen de nuevo CO2 y H2O. Esta oxidación de los hidratos de carbono es el principal procesos de generación de energía del metabolismo. El papel central que desempeñan los hidratos de carbono es evidente si tenemos en cuenta que el elemento básico de la alimentación de la mayor parte de los seres humanos es el almidón de los alimentos vegetales como el arroz, el trigo o las papas (1). Sin embargo, los carbohidratos tienen muchas otras funciones básicas en los organismos. Los carbohidratos mas simples son los monosacáridos y muchos azucares de importancia biológica son modificaciones o derivados de los de monosacáridos, por ejemplo, los esteres de fosfato (por ejemplo el DGliceraldehído 3 fosfato) son intermediarios importantes del metabolismo, y actúan como compuestos activados en la síntesis. (1,2). La glucosamina y la galactosamina son aminazúcares, otro tipo de derivados de los monosacáridos, muy extendidos en la naturaleza. La glucosamina y sus derivados son componentes estructurales de las paredes celulares de bacterias, mientras que la galactosamina es un componente de la quitina, un polímero que forma parte del exoesqueleto de los insectos y crustáceos, y del cartílago.(2). Los glucosidos, son ot grupo derivado de los monosacáridos, de estos destaca la ouabaína y la amigdalina por ser glucosidos tóxicos producidos por algunas plantas. (1) Cuando los monosacáridos se unen a otros monosacáridos se forman los ologosacáridos y los polisacáridos. Los oligosacáridos más sencillos y de mayor importancia biológica son los disacáridos, entre estos esta la lactosa (azúcar de la leche), la sacarosa (azúcar de mesa) y la trehalosa, constituyen reservas de energía soluble en las plantas y los animales. Dentro de los polisacáridos, la amilosa y la amilopectina (que forman el almidón de las plantas) y el glucógeno (que se almacena en las células animales y microbianas) destacan como sacáridos de almacenamiento. El almidón se encuentra almacenado en forma de gránulos en casi todos los tipos de células 18 vegetales, donde se produce por la acción de la energía fotosintética, es especialmente abundante en las papas, maíz y trigo. El glucógeno esta presente en forma de gránulos en las células del hígado y del músculo en los animales. (1,2) La celulosa, la quitina y los mucopolisacaridos, son polisacaridos sintetizados dentro de la célula y posteriormente expulsados fuera de ella para proveerla de una pared protectora o de una cubierta lubricante (2). La celulosa es el principal polisacárido de las plantas leñosa y fibrosas (como los árboles y las hierbas). Este homopolímero de glucosa es el mas abundante en la biosfera y constituye más del 50% de la materia orgánica. Forma en las paredes celulares redes fuertes y rígidas que le dan la resistencia característica, que al mismo tiempo permite la fabricación de ropa, papel, cartón y materiales para la construcción (1,2). Los animales no producen las enzimas que puedan romper la celulosa, los hongos de la madera putrefacta y algunas bacterias obtienen glucosa de la celulosa porque son capaces de sintetizar y secretar celulasa, una enzima que permite la fragmentación de la celulosa en unidades de glucosa. Los rumiantes, como las vacas pueden digerir la celulosa tan solo porque sus aparatos digestivos contiene bacterias simbióticas que producen celulasa. Las termitas albergan en su tracto digestivo microorganismos que producen celulasa y por ello pueden alimentase de tejidos leñosos. (1,2) El exoesqueleto protector de insectos, cangrejos y langostas, así como una pequeña proporción de la paredes celulares de levaduras, hongos y bacterias, se compone de quitina, los humanos no podemos tampoco digerirla. (1,2) Algunos polisacáridos estructurales se encuentran en el tejido conectivo (cartílagos y tendones) o en la matriz extra celular de los animales y plantas, y son conocidos como glucosaminoglucanos, anteriormende denominados mucopolisacaridos. Una función importante de estos polisacáridos es la formación de una matriz para mantener juntos los componentes proteicos de la piel y del tejido conjuntivo. El mas abundante de este tipo de moléculas es el ácido hialuronico, el cual se encuentra en el liquido sinovial de las articulaciones, en la matriz extracelular del tejido conectivo y en el humor vítreo del ojo, donde parece incrementar la viscosidad o funcionar como agente lubricante. (1,2) Mas de la mitad de todas las proteínas eucarionticas tienen cadenas de oligosacáridos o polisacáridos unidas a ellas por lo que se denominan glucoproteínas. Estas proteínas están implicadas en muchas funciones biológicas, como son la protección inmunitaria, el reconocimiento entre células, entre células y moléculas, la coagulación sanguínea y las interacciones entre patógenos y huéspedes. Un grupo importante de oligosacáridos es el de los antígenos de los grupos sanguíneos. (1) 19 Los oligosacáridos y polisacáridos tienen una función importante como marcadores celulares. Para que un oligosacárido o polisacárido actúe como señal de reconocimiento, debe haber proteínas que se unan a ellos de manera específica, una clase de proteínas de este tipo es el de las inmunoglobulinas. Otro grupo diferente de proteínas que une sacáridos es el de las lectinas. Las lectinas están presentes en células vegetales donde parecen desempeñar funciones defensivas y ayudar a la adhesión de las bacterias fijadoras de nitrógeno a las raíces. Recientemente se ha descubierto que también están extendidas en las células animales, donde interviene en las interacciones que se producen entre las células y las proteínas de la matriz intercelular y ayudan a mantener la estructura tisular y orgánica. (1). Todos los organismos obtienen energía de la degradación oxidativa de la glucosa y otros carbohidratos. Para algunos organismos esta es la principal o única fuente de energía. Los polisacáridos de almacenamiento tienen un diseño admirablemente adaptado a la función que realizan, y siempre que se necesite glucosa, puede obtenerse a partir de la degradación selectiva de los polímeros por enzimas especificas, estos procesos se conocen como glucólisis y glucogenólisis los cuales se tararan en la unidad seis. (1,2). A continuación se hace una análisis de la información básica de los carbohidratos, la información fue tomada de la siguiente fuente. INFORMACIÓN ACTUALIZADA EN ESPAÑOL PARA LA ENSEÑANZA Y EL APRENDIZAJE DE ESTAS DISCIPLINAS CIENTÍFICAS. Comité asesor de publicaciones. Facultad de Medicina, UNAM Todos los derechos reservados Copyright © UNAM 2003 03-2002-121311275700-01 Instituto Nacional del Derecho de Autor de la Secretaría de Educación Pública del Gobierno de la República Mexicana. Esta página puede ser reproducida con fines no lucrativos, siempre y cuando no se mutile, se cite la fuente completa y su dirección electrónica: http://bq.unam.mx/~evazquez De otra forma requiere permiso previo por escrito de la institución o el autor. Preguntas/Comentarios Para recibir actualizaciones Última actualización: 15 de Octubre de 2003 Por alguna razón, esta página se ve mejor con internet explorer. 20 3) Mathews, C,K., K.E. van Holde y K.G. Ahern. 2002. Bioquímica. Addison Wesley. Madrid España. 1333 pag. 4) Boyer, R. 2000. conceptos de bioquímica. International Thomson Editores. México. D.F. 694 pag. Los carbohidratos, conocidos también como hidratos de Carbono, glúcidos o azúcares (sakcharon, azúcar), son compuestos orgánicos formados en su mayoría por Carbono, Hidrógeno y Oxígeno, aunque en algunos, se encuentran también el azufre y nitrógeno. Los carbohidratos o azúcares, son compuestos formados por Carbono, hidrógeno y oxígeno que son sintetizados a partir de CO2 (bióxido de Carbono) y de H2O (agua) por los organismos fotosintéticos mediante el aprovechamiento de la energía de la luz solar (fotosíntesis), o bien por rutas sintéticas en los organismos heterótrofos, aunque el mayor aporte de los mismos para estos organismos esta dado por la dieta. El Carbono (C), es el elemento más abundante en las biomoléculas constituye alrededor del 50 % del peso seco de los seres vivos. El hidrógeno (H) es el elemento más pequeño. Su núcleo solamente contiene un protón y tiene solo un orbital en el cual gira solo un electrón. El oxígeno (O), elemento muy electronegativo, constituye entre el 25 y 30 % de las biomoléculas. Cabe señalar que el agua está formada por O e H en una proporción 1:2, y en los carbohidratos, la relación de átomos de C y moléculas de agua está en una proporción de 1:1, de ahí su nombre: hidratos de Carbono. La palabra carbohidratos deriva de la condición empírica de sus fórmulas moleculares: Cn(H2O)n 21 en donde n 3 porque en sus fórmulas moleculares, no todos los átomos de Carbono están "hidratados". En la siguiente Tabla se muestra la relación entre de algunas moléculas para un hombre adulto y sano. Molécula En el organismo Ingestión (%) en la dieta (gramos) proteínas lípidos carbohidratos ácidos nucleicos agua Otras substancias orgánicas (vitaminas, etc) Substancias inorgánicas 16.0 8.5 0.2 1.0 70.0 Calorías proporcionadas 80.0 0.3 380.0 1.0 2000.0 320 810 1520 insignificante - 0.2 trazas 5.0 10.0 - Tabla: relación entre de algunas moléculas para un hombre adulto y sano Nótese que: (i) la suma de la energía generada por la oxidación total de carbohidratos, lípidos y proteínas, genera alrededor de 2.65 Kcal, pero la mayoría son proporcionados por los carbohidratos; (i i ) aunque los carbohidratos son las biomoléculas con mayor consumo, forman una parte muy pequeña de la composición del organismo; los carbohidratos son utilizados rápidamente después de su ingestión. Los carbohidratos se clasifican según: - el número de unidades de azúcar que los componen en monosacáridos y polisacáridos. - la localización del grupo carbonilo en aldosas y cetosas. - el número de átomos de carbono en triosas, tetrosas, pentosas, hexosas, heptosas, etc. 22 Los grupos C-OH y C = O de los carbohidratos generan cargas parciales en las moléculas, lo que facilita la formación de puentes de hidrógeno. Los monosacáridos son muy solubles en el agua y en otros solventes polares En los grupos OH de los carbohidratos se generan cargas parciales con los que las moléculas de agua son capaces de establecer puentes de hidrógeno El puente de hidrógeno es un enlace que se establece entre moléculas capaces de generar cargas parciales. La molécula de agua está formada por dos átomos de hidrógeno y un átomo de oxígeno y es la sustancia que mejor hace los puentes de hidrógeno. En la molécula de agua, los electrones están más cerca del oxígeno que del hidrógeno y por esto se generan dos cargas parciales negativas en el extremo donde está el oxígeno y dos cargas parciales positivas en el extremo donde se encuentran los hidrógenos no y por esto se generan. La presencia de cargas parciales positivas y negativas hace que las moléculas de agua se comporten como imanes en los que las partes con carga parcial positiva atraen a las partes con cargas parciales negativas. Una molécula de agua puede unirse a otras cuatro moléculas de agua por medio de puentes de hidrógeno. Todos los carbohidratos excepto la dihidroxiacetona poseen uno o más átomos de carbono asimétricos, también conocidos como centros quirales. - Los isómeros son sustancias que tienen la misma composición pero diferente fórmula estructural. Los carbohidratos pueden aparecer en varias formas que difieren entre sí en la orientación de sus grupos -OH a los que se les llama estereoisómeros. - Los carbohidratos tienen carbonos asimétricos y el número de isómeros que un monosacárido puede tener sigue la relación 2n en donde n = número de carbonos asimétricos. - Los isómeros se clasifican de acuerdo a la orientación del -OH del carbono asimétrico más alejado del grupo carbonilo ( aldehido o cetona). Si el -OH se orienta a la derecha el carbohidrato pertenece a la serie D y si se orienta hacia la izquierda pertenece a la serie L. - Los monosacáridos tienen actividad óptica y desvían el plano de la luz polarizada hacia la derecha o hacia la izquierda. Los carbohidratos estructurales forman parte de las paredes celulares en los vegetales y les permiten soportar cambios en la presión osmótica entre los espacios intra y extracelulares. En las grandes plantas y en los árboles, la celulosa cumple la función de carga y soporte. La celulosa es de origen vegetal principalmente, sin embargo algunos invertebrados tienen celulosa en sus 23 cubiertas.El polisacárido estructural más abundante en los animales es la quitina. En los seres vivos las funciones de los carbohidratos se pueden generalizar en: a) energéticas (glucógeno en animales y almidón en vegetales, bacterias y hongos) La glucosa es un de los carbohidratos más sencillos comunes y abundantes; representa a la molécula combustible que satisface las demandas energéticas de la mayoría de los organismos. b) de reserva Los carbohidratos se almacenan en forma de almidón en los vegetales (gramineas, leguminosas y tubérculos) y de glucógeno en los animales. Ambos polisacáridos pueden ser degradados a glucosa. c) compuestos estructurales (como la celulosa en vegetales, bacterias y hongos y la quitina en artrópodos) Los carbohidratos estructurales forman parte de las paredes celulares en los vegetales y les permiten soportar cambios en la presión osmótica entre los espacios intra y extracelulares. Esta, es una de las sustancias naturales mas abundantes en el planeta. En las grandes plantas y en los árboles, la celulosa, estructura fibrosa construida de glucosa, cumple la doble función de carga y soporte. La celulosa es de origen vegetal principalmente, sin embargo algunos invertebrados tienen celulosa en sus cubiertas protectoras. El polisacárido estructural más abundante en los animales es la quitina. En los procariontes forma la pared celular construida de azúcares complejos como los péptidoglicanos y ácidos teicoicos. A las propiedades de esta estructura se le atribuyen muchas de las características de virulencia y antigenicidad. En algunos animales como los insectos los carbohidratos forman la quitina, el ácido condroitín sulfúrico y el ácido hialurónico, macromoléculas de sostén del aparato muscular. d) precursores Los carbohidratos son precursores de ciertos lípidos, proteínas y dos factores vitamínicos, el ácido ascórbico (vitamina C) y el inositol. e) señales de reconocimiento (como la matriz extracelular) Los carbohidratos intervienen en complejos procesos de reconocimiento celular, en la aglutinación, coagulación y reconocimiento de hormonas. 24 El número de unidades de azúcar que los componen a los carbohidratos los clasifican en monosacáridos y polisacáridos, Los disacáridos como la sacarosa, consisten en dos monosacáridos unidos covalentemente por un enlace O-glucosídico, que resulta cuando un hidroxilo en el azúcar reacciona con el Carbono anomérico de otra. Esta reacción representa la formación de un acetal a partir de un hemiacetal (glucopiranosa) y un alcohol. Para su formación, se necesita de la salida de una molécula de agua y para su ruptura, la hidrólisis de la misma. La manera en que los monosacáridos se unen para formar polisacáridos lleva a la formación de diferentes enlaces, el más común es el , en el cual los enlaces del átomo de O que participa en el enlace glucosídico, están en el mismo lado. El enlace es aquel en el cual los enlaces del átomo de O que participa en el enlace glucosídico, están en diferente lado i.e. arriba y abajo. Los átomos de Carbono que participan en el enlace glucosídico, pueden ser el 1 y 4, el 1y 1 o bien para ramificar el polisacárido el 1 y 6. 6 HOCH2 6 HOCH 2 HO 4 3 HO 1 CH2OH 5 5 O 1 OH 2 HO O 4 3 HO OH 1 2 OH O O CH2OH 6 5 2 3 HO 4 OH D-GLUCOSA (monosacárido) Glucosa Fructosa SACAROSA (polisacárido, disacárido) Figura: representación de un monosacárido y un disacárido. Los números en rojo indican la posición de los átomos de Carbono en la molécula. 25 Éstos últimos están formados por dos o más unidades de azúcar. Cuando la molécula está formada por pocas unidades se llama oligosacárido. Los oligosacáridos consisten de algunas unidades de monosacáridos, están a menudo asociados con proteínas (glicoproteínas) y lípidos (glicolípidos), en donde juegan papeles estructurales y regulatorios. Los polisacáridos consisten de muchas unidades de monosacáridos y tienen pesos moleculares cercanos a los millones de Daltones. Estas complejas moléculas pueden estar compuestas de las mismas unidades de monosacáridos (homopolisacáridos como la amilosa, amilopectina, quitina, glucógeno y celulosa) o de unidades diferentes (heteropolisacáridos como los peptidoglicanos, glicosaminoglicanos y proteoglicanos). 1. Triosas: gliceraldehído (aldotriosa) y dihidroxiacetona.(cetotriosa) 2. Tetrosas: eritrosa, treosa (tetraaldosas) y eritrulosa (tetracetosa) 3. Pentosas: ribosa, arabinosa, xilosa, lixosa (pentoaldosas), ribulosa y xilulosa (pentocetosas). 4. Hexosas: alosa, altrosa, glucosa, manosa, gulosa, idosa, galactosa, talosa (hexoaldosas), psicosa, fructosa, sorbosa y tagatosa (hexocetosas). 5. Heptosas, etc. Los nombres en negritas son los azúcares más abundantes en la naturaleza. Los carbohidratos son compuestos que tienen una fórmula condensada CnH2nOn, en donde n es el número de Carbonos, por ejemplo en la glucosa n=6, por tanto su fórmula molecular es: C6H12O6. Se pueden encontrar en forma lineal o bien cíclica. A ésta última corresponde también la fórmula molecular CnH2nOn. 26 Además de los grupos aldehído o cetona, los carbohidratos contienen también varios grupos hidroxilo (OH), todos ellos generan cargas parciales en la molécula, lo que facilita la formación de puentes de hidrógeno con el solvente que los contiene si este es polar como el agua, de ahí que los monosacáridos sean muy solubles en solventes polares. En los grupos OH de los carbohidratos se generan cargas parciales con los que las moléculas de agua son capaces de establecer puentes de hidrógeno. Todos los carbohidratos excepto la dihidroxiacetona poseen uno o más átomos de Carbono asimétricos, también conocidos como centros quirales. Una manera de reconocer la quiralidad, (aunque no la única), es buscar átomos de Carbono unidos a cuatro grupos o átomos diferentes (por ejemplo el Carbono 5 de la glucosa). Los azúcares modificados por los sistemas biológicos pueden tener asociados grupos amino o acetilo, oxidarse en sus grupos alcohol aldehído o cetona y formar ácidos, reducirse y formar desoxi-azúcares, o bien fosforilarse y formar monosacáridos mono o di fosforilados (como el gliceraldehído-3-fosfato o la glucosa-6-fosfato). La oxidación de una aldosa o de una cetosa da origen a los azúcares ácidos; estos pueden sufrir oxidaciones por la acción de alguna enzima o por medio de agentes oxidantes. A los azúcares capaces de oxidarse se les llama azúcares reductores. Los carbohidratos son derivados aldehídicos o cetónicos de alcoholes polihídricos (con varios hidroxilos), comprenden entonces, alcoholes cetónicos, alcoholes aldehídicos y sus derivados Figura: información sobre la nomenclatura utilizada para los grupos funcionales de los carbohidratos. 27 Cuando por hidrólisis es imposible fragmentar mas una molécula con función reductora (aldehído o cetona) y varias funciones alcohol, la molécula se denomina monosacárido o azúcar simple (terminación "osa"). Según el grupo carbonilo presente el monosacárido, se dividen en aldosas (si está en el extremo de la molécula) como la glucosa y cetosas (si está en medio de la molécula) como la ribulosa. Dependiendo del número de átomos de Carbono presentes en la molécula, pueden ser triosas, tetrosas, pentosas, etc. Los términos pueden ser combinados ej. La glucosa es una aldohexosa mientras que la ribulosa es una cetopentosa. La glucosa es la unica aldosa que aparece en forma libre en la naturaleza como monosacárido. A pesar de ello, existen muchos otros monosacáridos (Dgliceraldehído, D-Ribosa y D-Galactosa), que son importantes componentes de otras biomoléculas. Las azúcares L son mucho menos abundantes en la naturaleza que las D. Cuando una aldohexosa forma una estructura cíclica de 6 miembros se conoce como piranosa, cuando el ciclo es de 5 miembros (independientemente de que la molécula cuente con 6 Carbonos), se denomina furanosa. O Pirano O Furano Figura: representación de los monosacáridos en la forma cíclica de 5 y 6 miembros. Las configuraciones de los monosacáridos cíclicos son representadas por fórmulas de Haworth. Tanto las piranosas como las furanosas pueden tener isómeros a y b. Las piranosas pueden adquirir la configuración de bote o de silla, al igual que el ciclohexano. Las furanosas por el contrario, tienen una configuración planar en el espacio. 28 Cuando se forma la estructura cíclica, la molécula puede adquirir dos tipos de configuración diferentes: En el caso de las cetosas, el grupo carbonilo del Carbono 2, reacciona con el hidroxilo, del Carbono 5 dando origen a una estructura cíclica de 5 miembros (furanosa), al nuevo compuesto, se le denomina hemicetal. Una reacción en la cual el ciclo se hace por el ataque nucleofílico del OH del Carbono 5 al Carbono 1 de la hexosa, dará origen a un hemiacetal (piranosa). La formación de hemiacetales dentro de las moléculas de carbohidrato produce un Carbono asimétrico adicional que es el Carbono 1, al cual se le llama Carbono anomérico. El Carbono anomérico puede tener el OH orientado hacia abajo en cuyo caso se denominará por ejemplo -D-Glucopiranosa; cuando el OH se orienta hacia arriba, entonces se llamará -D-Glucopiranosa. Esto da origen a diasteroisómeros, y los dos isómeros resultantes se conocen como anómeros. Al formarse el anillo hemicetálico, el Carbono 2 se transforma en asimétrico dando origen a los isómeros alfa y beta, continuando con el ejemplo, a la -D-fructofuranosa y la -D- fructofuranosa. Cuando cuatro grupos diferentes están unidos a un átomo de Carbono [como el carbono de los aminoácidos (excepto uno)], resultan dos isómeros posibles, que son imágenes especulares no superponibles. Esta característica es indispensable para los sistemas biológicos. 29 Figura: representación de los isómeros ópticos de los aminoácidos. Estos isómeros se denominan enantiómeros y se dice que son quirales. La palabra quiral deriva de la palabra utilizada en griego para denominar a las manos, porque las imágenes especulares están relacionadas con la no superponibilidad, la mano derecha es imagen especular no superponible de la izquierda. Por razones históricas las imágenes especulares se denominan D (por dextro, derecha) y L (por levo, izquierda). Estos términos definen las posición en el espacio o configuración de los átomos unidos al Carbono y no definen la desviación del plano de la luz polarizada (rotación óptica) en una dirección específica, lo cual se designa también con d y l pero minúsculas. En los aminoácidos, bloques de construcción de las proteínas se encuentran en la forma L, aunque existen también aminoácidos en forma D. Al examinar la fórmula molecular de la glucosa se observa que dos de sus seis átomos de Carbono (C1 y C6), son centros quirales. Como cada átomo de Carbono en hibridación sp3 puede unir únicamente 4 sustituyentes, el número de estereoisómeros que puede haber en una molécula se calcula elevando el número de carbonos quirales a la cuarta potencia, de tal suerte que la glucosa, es uno de los 16 estereoisómeros posibles para las aldohexosas. En general aldosas con n átomos de Carbono, tienen 2n-2 estereoisómeros. En 1986 Emil Fisher elucidó estas configuraciones para las aldohexosas 30 Figura: la serie D de las aldosas. De acuerdo con la convención de Fisher, las D-azúcares tienen la misma configuración absoluta en el Carbono asimétrico más alejado del grupo carbonilo, como sucede en el D-gliceraldehído, de ahí que los azúcares L, son imágenes especulares de sus contrapartes D, como se muestra a continuación Figura: representación de la glucosa en sus formas D y L. Los azúcares que difieren en su configuración en un átomo de Carbono son epímeros entre ellos. La D-glucosa es epímero de la D-manosa con respecto al C2, mientras que es epímero de la D-Galactosa con respecto al C4. Por el contrario, la manosa y la galactosa no son epímeros pues difieren en la configuración de mas de un átomo de Carbono. 31 La posición del grupo carbonilo hace que las cetosas tengan un centro asimétrico menos que las aldosas (comparar D-Fructosa y D-glucosa). De ahí que el número de estereoisómeros para las primeras se calcula como 2n-3, en donde n también es el número de centros quirales. Las formas más comunes de las cetosas es con el carbonilo en el C2: 32 Figura: la serie D de las cetosas. Nótese que algunas de estas cetosas se nombran agregando ul antes del sufijo osa correspondiente de las aldosas; ej. D-Xilulosa es la cetosa correspondiente de la D-Xilosa. La dihidroxiacetona, D-Fructosa, D-Ribulosa y d-Xilulosa son las cetosas con actividades biológicas más importantes. Los isómeros son compuestos que tienen la misma composición atómica pero diferente fórmula estructural (por ejemplo, la serie de las cetoaldosas). En general una molécula con n centros quirales tiene 2n estereoisómeros. El gliceraldehído tiene 21=2; las aldohexosas con cuatro centros quirales, tienen 24=16 estereoisómeros. Los estereoisómeros de los monosacáridos pueden ser divididos en dos grupos, los cuales difieren en la configuración alrededor del centro quiral más lejano del carbono carbonílico (carbono de referencia). Tomemos como ejemplo al gliceraldehído (en fórmulas de proyección de Fisher): CHO CHO H C OH CH2OH D-glicerladehído HO C H CH2OH L-glicerladehído 33 Figura: representación de los isómeros D y L del gliceraldehído. Aquellos carbohidratos con la misma configuración en su carbono de referencia que el D-gliceraldehído, son designados como isómeros D (el OH del carbono de referencia está a la derecha), y aquellos con la configuración del Lgliceraldehído, son isómeros L (el OH del carbono de referencia está a la izquierda). Por ejemplo, de las 16 posibles aldohexosas, 8 de ellas son D y las 8 restantes L. Muchas de las hexosas que se encuentran en los organismos vivientes son isómeros tipo D, lo que indica inmediatamente, la estereoespecificidad de las enzimas que las utilizan como substrato. Los monosacáridos poseen actividad óptica y desvían el plano de la luz polarizada hacia la derecha o hacia la izquierda, esta propiedad puede ser cuantificada en un polarímetro. Si la luz gira en sentido de las manecillas de reloj, el compuesto es dextrorrotatorio (dextro: griego, derecha) y se designa con el signo +. Si por el contrario, la luz gira en sentido opuesto a las manecillas del reloj, es levorrotatorio (levo: griego, al contrario) y se designa con -. Los enantiómeros giran el plano de la luz polarizada en direcciones opuestas, pero con magnitudes iguales. Una mezcal con la misma cantidad de + y – se denomina racémica. A los metabolitos que ocupan lugares de intersección en el metabolismo se les denomina metabolitos de encrucijada. La glucosa-6-fosfato es uno de esos metabolitos de encrucijada. Una vez que el alimento ha sido digerido y los monosacáridos viajan por el torrente sanguíneo, deben ser transportados al interior de todas las células de todos los tejidos del cuerpo. Una vez que esto ha sucedido la mayoría de ellos serán transformados y fosforilados para producir glucosa-6-fosfato, que puede ser inmediatamente utilizada en la vía anaerobia de la glucólisis o bien una vez abastecida la demanda energética o los esqueletos de carbono para fabricar otras biomoléculas, la glucosa-6-fosfato puede ser utilizada para almacenar unidades de glucosa en el glucógeno que se almacena principalmente en el hígado y músculo esquelético. 34 La mayoría de los carbohidratos en los mamíferos se obtienen de la dieta, entre estos se encuentran polisacáridos como el almidón, la celulosa y dextrinas (productos de la hidrólisis incompleta del almidón que con yodo se tiñen rojo, el almidón por el contrario, azul) y disácaridos como la sacarosa (fructofuranósido de glucopiranósido o simplemente azúcar de mesa) que esta formada por una molécula de glucosa (una piranosa) y otra de fructosa (una furanosa). La función más importante de la saliva es humedecer y lubricar el bolo alimenticio, desde el punto de vista digestivo es importante por contener a la amilasa salival o ptialina, enzima que hidroliza diversos tipos de polisacáridos. El pH de la saliva es cercano a la neutralidad, por lo que en el estómago esta enzima se inactiva totalmente, de tal suerte que los carbohidratos no sufren modificaciones de importancia en este órgano. Es hasta el intestino donde los disacáridos y los polisacáridos deben ser hidrolizados en sus unidades monoméricas para poder atravesar la pared intestinal y tomar así el torrente sanguíneo para llegar a las células e ingresar al interior para ser utilizados en cualquiera de las funciones en que participan (energética, de reconocimiento, estructural o como precursor de otras moléculas). En el duodeno se vierte el jugo pancréatico que contiene entre otros muchos elementos, amilasa pancreática (Su pH óptimo es de 7.1 y rompe al azar los enlaces alfa,1-4 del almidón), diastasa o amilopsina, esta última muy parecida a la enzima salival. En la digestión de los carbohidratos intervienen diferentes enzimas que desempeñan cada una funciones diferentes y que por tanto, tienen especificidades diferentes. Para romper las ramificaciones se necesita a la amilo1-6-glucosidasa. La reacción de hidrólisis, consiste en el rompimiento de uniones covalentes por medio de una molécula de agua. La hidrólisis de un enlace glucosídico se lleva a cabo mediante la disociación de una molécula de agua. El hidrógeno del agua se une al oxígeno del extremo de una de las moléculas de azúcar; el OH se une al carbono libre del otro residuo de azúcar. El resultado de esta reacción, es la liberación de un monosacárido, dos si la molécula hidrolizada fue un disacárido o bien el polisacáridon-1, dependiendo de la molécula original. Los carbohidratos son las biomoléculas más abundantes en la tierra. Por ejemplo, cada año la fotosíntesis transforma más de 100 x 109 toneladas de CO2 y H2O en celulosa y otros derivados. Algunos carbohidratos como el azúcar común y el almidón, son parte de la dieta en muchas partes del mundo y su oxidación es un proceso central a partir del cual deriva mucha energía en células de organismos no fotosintéticos. Los carbohidratos poliméricos insolubles en agua funcionan como elementos de protección y estructura de la 35 pared celular de plantas y bacterias y de los tejidos conectivos de los animales. Otros polímeros de carbohidratos lubrican las articulaciones del esqueleto de los vertebrados y participan en el reconocimiento y adhesión de las células. Otros polímeros de carbohidratos más complicados se encuentran unidos de manera covalente a lípidos y proteínas actuando como señales que determinan la localización intracelular o el destino metabólico de estas biomoléculas híbridas denominadas genéricamente como glicoconjugados. Dentro de los procesos económico-industriales de interés humano sobre los carbohidratos, se encuentra el proceso de la fermentación. En este proceso que incluye todos los pasos de la glucólisis, aunque el producto final –piruvatoes degradado a etanol y CO2. La fermentación es un proceso que se lleva a cabo en ausencia de oxígeno por levaduras y otros microorganismos, que son utilizados en la industria para fermentar los carbohidratos derivados de múltiples fuentes. Es así como se obtienen múltiples productos como cerveza, vino y tequila. Glucogenólisis Enzimas: glucosa fosforilasa, desramificante y fosfoglucomutasa. fosforolisis del glucógeno para dar glucosa-1-fosfato La glucosa-1-fosfato se isomeriza a glucosa-6-fosfato La glucosa-6-fosfato puede ser utilizada en la glucólisis, la vía de las pentosas fosfato o para mantener la glicemia (concentración fisiológica de glucosa en sangre) En el proceso se lleva a cabo una cascada de fosforilaciones generada por la síntesis de cAMP. La unión alfa,1-6 detiene a la fosforilasa, en ese momento actúa una enzima con doble actividad, por una parte es transferasa, desprende las tres unidades de glucosa terminales de la rama y las transfiere a otra rama de glucógeno, posteriormente utiliza su actividad de amilo-1,6-glucosidasa hidrolizando el residuo en posición 1,6 con el cual trabaja la fosforilasa. Glucógeno: El glucógeno es el polisacárido principal de reserva en las células animales, es equivalente al almidón de los vegetales. Abunda en el hígado, aproximadamente es el 10 % de su peso, en el músculo es de entre 1 y 2 % en 36 los hepatocitos, hay gránulos que son agrupaciones de moleéculas simples muy ramificadas. A semejanza de la amilopectina resta formado por D-glucosa con enlaces alfa,1-4, pero esta mas ramificado y es mas compacto. Las ramificaciones están formadas por entre 8 y 12 residuos en posiciones alfa, 1-6. Esta macromolécula puede aislarse de los tejidos con soluciones calientes de KOH. El glucógeno se forma a partir de la unión de una unidad de glucosa a una proteína, la glucogenina que ayuda a estabilizar a la primera molécula de glucógeno para que se pueda dar el primer enlace alfa,1-4. Glucólisis: La glucólisis fue la primera vía metabólica que se describió, Eduard Buchner en 1897 estudio la fermentación de la glucosa en extractos de levaduras. En 1941 Fritz Lipmann y Herman Kalkar describieron las funcioness de los compuestos de alta energía como el ATP en el metabolismo. Con la purificación de enzimas y experimentos en bacterias y levaduras se describieron las reacciones de esta vía metabólica. Las funciones de los cofactores como el NAD+ y de las moléculas fosforiladas, se describieron por primera vez en la glucólisis. Fermentación: Es el proceso de aprovechamiento de la glucosa en ausencia de O 2, el objetivo final de este proceso es la formación de ATP para realizar trabajo. La vida se originó en ausencia de O2 por lo que esta vía esta considerada como la mas primitiva y esta presente en todos los organismos. Para que la vida de los mamíferos pueda llevarse a cabo adecuadamente, es necesario un aporte constante de glucosa al torrente sanguíneo. La glucosa es la fuente de energía preferida por el cerebro y por células que carecen de mitocondrias o tienen muy pocas como los eritrocitos maduros. La glucosa es 37 también esencial como fuente de energía para el músculo en ejercicio en donde es el sustrato de la glucólisis en el citoplasma anaerobio. La glucosa sanguínea puede ser obtenida a través de tres fuentes: la dieta, la degradación del glucógeno y la síntesis de novo de la misma (gluconeogénesis): Glucosa Utilizada 40 - Glucosa de la dieta (gramos/hora) 20 Glucógeno Gluconeogénesis 10 - 0 40 8 horas 16 24 2 20 Días Figura: fuentes de abastecimiento de la glucosa. La ingesta de la glucosa y de sus precursores como el almidón, monosacáridos (fructosa) y disacáridos (lactosa, manosa y sacarosa), es esporádica y no siempre es un aporte directo de glucosa a la sangre (piénsese por ejemplo en la intolerancia a la lactosa). Por el contraste, la gluconeogénesis puede proveer una síntesis continua de glucosa, pero tiende a ser lenta en la respuesta a la falta de glucosa sanguínea. Este problema se ha resuelto al almacenar grandes cantidades de glucosa que pueden ser mobilizadas de manera muy rápida, a partir del glucógeno. La ausencia de glucosa en la dieta provoca la rápida liberación a partir del glucógeno previamente almacenado en el hígado. De manera similar el glucógeno almacenado en el músculo es degradado durante el ejercicio. Cuando disminuye la reserva de glucógeno, algunos tejidoss sintetizan glucosa de novo utilizando los esqueletos de los aminoácidos de las proteínas como fuente de Carbono para hacer glucosa. Estructura y función del glucógeno. Los almacenes principales de glucógeno en el cuerpo de los mamíferos son el músculo esquelético y el hígado; en muchas otras células se almacena en muy bajas cantidades. La misión del glucógeno en el músculo es proveer de la fuente necesaria para producir ATP durante la contracción muscular. Por el 38 contrario el glucógeno hepático se utiliza para mantener los niveles de glucosa sanguínea en los eventos tempranos del ayuno. Cantidades de glucógeno en hígado y músculo. Aproximadamente 1 ó 2 % del peso húmedo del músculo en reposo de un adulto bien alimentado, unos 400 g, son glucógeno; por el contrario, en el hígado, unos 100 g son glucógeno, entre el 6 y 8 % de su peso húmedo. No se sabe la razón metabólica para estas cantidades, pero en algunas enfermedades del almacenamiento de glucosa, la cantidad en hígado y músculo puede ser significativamente mayor. Estructura del glucógeno Una molécula de glucógeno puede llegar a tener una masa molecular de Da. Estas moléculas están almacenadas en gránulos citoplásmicos que contienen la mayoría de las enzimas necesarias para su síntesis y degradación. El glucógeno es una cadena ramificada de exclusivamente alfa-D-glucosa. 108 Los enlaces glucosídicos principales son alfa-1,4, cada intervalo de entre 8 y 10 residuos enlazados en esta forma, hay uno enlazado en posición alfa-1,6, a esto se le conoce como una ramificación. 39 Figura: representación de la estructura del glucógeno. Fluctuaciones de las reservas de glucógeno. El glucógeno del hígado se incrementa durante el estado de buena alimentación y es disminuido durante el ayuno. El glucógeno muscular no es afectado por periodos pequeños de ayuno (algunos días) y es solo moderadamente disminuido en periodos de ayuno prolongados (semanas). El glucógeno del músculo es regenerado como respuesta a periodos de consumo de energía elevados, por ejemplo después del ejercicio. La síntesis y degradación del glucógeno son procesos concomitantes, las diferencias entre las velocidades de estos procesos determina los niveles de glucógeno almacenado durante situaciones metabólicas específicas. 40 Lípidos Los lípidos son un grupo de sustancias heterogéneo que no se disuelven en el agua o en disolventes polares, pero si en no polares como el cloroformo, eter o benceno, esta característica le confiere muchas de sus propiedades y permite la multiplicidad de sus funciones, las cuales van desde el metabolismo energético hasta las funciones estructurales. Los componentes mas abundantes de los lípidos son los ácidos grasos, y su papel biológico principal es servir como combustible metabólico para la célula. Los ácidos grasos se ingieren y se almacenan en forma de triacilgliceroles para servir como deposito de energía. Cuando hay una demanda de energía, se liberan y circulan en la sangre por todo el organismo. En los tejidos animales se denominan grasas y son sólidos a temperatura ambiente (como la mantequilla) porque en ellos predominan ácidos grasos saturados. En las semillas de las plantas son los aceites (por ejemplo aceite de oliva o de maíz) y contienen principalmente ácidos grasos insaturados y por ellos son líquidos a temperatura ambiente. (1) Los triacilgliceroles desempeñan tres funciones biológicas principales; la producción de energía, la producción de calor y el aislamiento. Se almacenen en forma de gotas oleosas en el citoplasma de las células vegetales y animales. Los adipositos son un ejemplo de células animales especializadas en el almacenamiento de grasas (1). Las ceras son otro ejemplo de lípidos no polares, forman la cubierta protectora de las hojas de las plantas, lubrican la piel y sirven de repelente al agua en las plumas de las aves. (2). La cera de abeja y la lanolina obtenida de la lana de cordero y utilizada como suavizante de la piel y en preparados de cosméticos, son ejemplos de ceras comercialmente importantes. (2) Los lípidos polares tienen una función biológica distinta, ya que combinados con proteínas sirven para construir las membranas biológicas. (2). Los glicerofosfolípidos, también nombrados fosfoglicéridos son constituyentes importantes de las membranas en los reinos monera, vegetal y animal.(1) Los esfingolípidos son otro grupo de lípidos polares presentes en las membranas, entre estos destacan las ceramidas, las esfingomielinas (presente en la membrana y característico de la vaina de mielina de los axones nerviosos) y los glucoesfíngolípidos (frecuentes en las membranas del cerebro y de las células nerviosas, y participantes en el reconocimiento de las superficies celulares, la especificidad de la asociación celular en los tejidos y la transmisión de impulsos nerviosos). (2). Los glucoglicerolípidos son lípidos estructurales de las membranas animales, están muy extendidos en las membranas vegetales, principalmente en las cloroplásticas en donde forma mas del 50% de los lípidos 41 que la componen, también son abundantes en las membranas de las arqueobacterias.(1) Otro grupo de lípidos que presentan importantes funciones en la células son los esteroides, el colesterol es el mejor esteroide conocido, es precursor de la síntesis de muchas hormonas esteroideas (como el estradiol, la testosterona y el cortisol), así como de ácidos biliares. (2). Los eicosanoides comprenden a las prostaglandinas, los tromboxanos y los leucotrienos son una clase de lípidos que se caracterizan por ejercer una acción local de tipo hormonal y por su baja concentración. Influyen en las funciones de la reproducción, regulan la coagulación y la presión sanguínea, participan en la generación de inflamación, fiebre y dolor asociados a lesiones y enfermedades, regulan la temperatura y el ciclo sueño- vigilia en los humanos y otros animales. (2). En las plantas, los terpenos constituyen un grupo abundante de aceites vegetales, son los responsables de los aromas y sabores específicos de las plantas. (2). Algunos lípidos especiales tambien funcionan como vitaminas, feromonas y transportadoras de electrones (ubiquinona o coenzima Q, plastoquinona y menaquinona). (2). A continuación se hace una análisis de la información básica de los lípidos, la información fue tomada de la siguiente fuente. INFORMACIÓN ACTUALIZADA EN ESPAÑOL PARA LA ENSEÑANZA Y EL APRENDIZAJE DE ESTAS DISCIPLINAS CIENTÍFICAS. Comité asesor de publicaciones. Facultad de Medicina, UNAM Todos los derechos reservados Copyright © UNAM 2003 03-2002-121311275700-01 Instituto Nacional del Derecho de Autor de la Secretaría de Educación Pública del Gobierno de la República Mexicana. Esta página puede ser reproducida con fines no lucrativos, siempre y cuando no se mutile, se cite la fuente completa y su dirección electrónica: http://bq.unam.mx/~evazquez De otra forma requiere permiso previo por escrito de la institución o el autor. Preguntas/Comentarios Para recibir actualizaciones 42 Última actualización: 15 de Octubre de 2003 Por alguna razón, esta página se ve mejor con internet explorer. 5) Mathews, C,K., K.E. van Holde y K.G. Ahern. 2002. Bioquímica. Addison Wesley. Madrid España. 1333 pag. 6) Boyer, R. 2000. conceptos de bioquímica. International Thomson Editores. México. D.F. 694 pag. Los lípidos, son un grupo de compuestos químicamente diversos, solubles en solventes orgánicos (como cloroformo, metanol o benceno), y casi insolubles en agua. La mayoría de los organismos, los utilizan como reservorios de moléculas fácilmente utilizables para producir energía (aceites y grasas). Los mamíferos, los acumulamos como grasas, y los peces como ceras; en las plantas se almacenan en forma de aceites protectores con aromas y sabores característicos. Los fosfolípidos y esteroles constituyen alrededor de la mitad de la masa de las membranas biológicas. Entre los lípidos también se encuentran cofactores de enzimas, acarreadores de electrones, pigmentos que absorben luz, agentes emulsificantes, algunas vitaminas y hormonas, mensajeros intracelulares y todos los componentes no proteícos de las membranas celulares. Los lípidos, pueden ser separados fácilmente de otras biomoléculas por extracción con solventes orgánicos y pueden ser separados por técnicas experimentales como la cromatografía de adsorción, cromatografía de placa fina y cromatografía de fase reversa. La función biológica más importante de losa lípidos es la de formar a las membranas celulares, que en mayor o menor grado, contienen lípidos en su estructura. En ciertas membranas, la presencia de lípidos específicos permiten realizar funciones especializadas, como en las células nerviosas de los mamíferos. La mayoría de las funciones de los lípidos, se deben a sus propiedades de autoagregación , que permite también su interacción con otras biomoléculas. De hecho, los lípidos casi nunca se encuentran en estado libre, generalmente están unidos a otros compuestos como carbohidratos (formando glucolípidos) o a proteínas (formando lipoproteínas). Estas importantes biomoléculas se clasifican generalmente en: Lípidos saponificables Estas moléculas se hidrolizan en soluciones alcalinas produciendo ésteres de ácidos grasos. Saponificación deriva del método antiguo para la producción de 43 jabón, que es una sal sódica o potásica de un ácido carboxílico de cadena larga (R=C13-C19): Figura: reacción de saponificación. A este grupo esfingolípidos y ceras. pertenecen los acilgliceroles, fosfoacilgliceroles, Lípidos no saponificables. Estos lípidos, no sufren hidrólisis alcalina como en le caso de aquellos que si son saponificables. A este grupo pertenecen los terpenos, esteroides y prostaglandinas y todos los compuestos relacionados. Además de los anteriores, existen lípidos anfipáticos en cuya molécula existe una región polar opuesta a otra apolar. Estos lípidos forman las bicapas lipídicas de las membranas celulares y estabilizan las emulsiones (liquido disperso en un líquido). Los ácidos grasos de importancia biológica, son ácidos monocarboxílicos (ej. Ác laurico: CH3(CH2)10COOH) de cadenas alifáticas de diverso tamaño y que pueden contener o no insaturaciones: Los ácidos grasos naturales insaturados (líquidos a temperatura ambiente), son isómeros geométricos cis que pueden ser monoinsaturados (ej. Ácido oleíco (ácido 9-octadecenoíco) CH3(CH2)7CH=CH(CH2)7COOH) o poliinsaturados (ej. Ácido araquidónico (ácido 5,8,11,14-eicosatetraenoico) CH3(CH2)4(CH=CHCH2)4(CH2)2COOH). 44 Figura: representación del ácido oleico. Los ácidos grasos poliinsaturados, desde el punto de vista nutricional se consideran como esenciales pues no son sintetizados por los mamíferos; fisiológicamente, se encuentran formando sales o jabones (formando micelas). Los ácidos grasos de cadena larga, insolubles en agua, forman ésteres con alcoholes y tioésteres con la coenzima A. Compuestos de importancia biológica como las prostaglandinas, tromboxanos y leucotrienos, son derivados de ácidos grasos poliinsaturados de 20 carbonos como el ácido araquidónico. En los acilgliceroles (o acilglicéridos), uno o más de los grupos hidroxilo (OH) de la molécula de glicerol, están esterificados de ahí que se dividan en monoacil, diacil y triacilgliceroles; en estos últimos, todos los hidroxilos del glicerol (3), están esterificados con ácidos grasos. Estos ácidos grasos pueden ser iguales entre ellos o diferentes y dependiendo de la longitud de las cadenas que esterifican al glicerol y de su grado de insaturación, los triacilgliceroles (triacilglicéridos), se dividen en grasas (sólidas) o aceites (líquidos). Estas moléculas, son hidrofóbicas y no forman micelas. Cadenas hidrocarbonadas que varían en su longitud: (CH3(CH2)nCOOH; n: 14 16 18 20 22 24 12 ácido laurico; dodecanoico ácido miristico; tetradecanoico ácido palmitico; hexadecanoico ácido estearico; octadecanoico ácido araquidico; eicosanoico ácido behenico; docosanoico ácido lignocerico; tetracosanoico 45 Los ácidos grasos también varían de acuerdo a su grado de instauración, sus propiedades físicas varían con esta propiedad. CH3(CH2)nCH=CH(CH2)nCOOH n: 16:1 18:1 18:2 18:3 ácido palmitoleico; 9-hexadecenoico ácido oleico; 9-octadecenoico ácido linoleico; 9,12-octadecadienoico ( ó ) ácido alfa-linolenico; 9,12,15- octadecatrienoico ó ácido gama-linolenico; 6,9,12- octadecatrienoico 20:4 araquidónico; 5,8,11,14-eicosatetraenoico 20:5 EPA; ácido 5,8,11,14,17-eicosapentanoico 24:1 ácido nervonico; 15-tetracosenoico; octadecatrienoico Estos lípidos consisten de una molécula de glicerol que está triesterificada; su principal función es la reserva energética. Figura: representación de las moléculas de glicerol y triacilgicérido Los grupos R son ácidos grasos. Los triacilglicéridos (TAG) (triacilgliceroles o grasas), son la reserva principal de energía metabólica en animales y el 90 % de la ingesta de lípidos. O CH2 O C O 16 46 Figura: representación de un TAG Al igual que la glucosa, son metabólicamente oxidados a CO 2 y agua, muchos de sus átomos tienen estados de oxidación más bajos que los de la glucosa, su metabolismo oxidativo rinde el doble de la energía que una cantidad igual de carbohidratos o proteínas en peso seco. H (kcal/g peso seco) Carbohidratos 66.994 Grasas 154.808 Proteínas 71.128 Las grasas se almacenan en ambientes anhidros. El glucógeno se almacena en forma hidratada, la cual contiene aproximadamente el doble de su peso seco, por lo tanto las grasas proveen más de seis veces la energía metabólica que el mismo peso de glucógeno hidratado. Las enzimas digestivas de los TAGs son hidrosolubles, su digestión se lleva a cabo en interfases lípido-agua. La velocidad de este proceso, depende entonces del área superficial de la interfase, la cual se incrementa por los movimientos peristálticos del intestino combinados con la emulsificación de los ácidos biliares (detergentes digestivos sintetizados en el hígado y llevadas al intestino delgado en donde la digestión y absorción lipídica se lleva a cabo). La lipasa pancreática (TAG lipasa; estructura tridimensional resuelta), hidroliza a los TAG en posición 1 y 3 formando secuencialmente 1,2diacilglicerol y 2-acilglicerol y las sales de Na+ y K+ de los ácidos grasos (jabones que ayudan a la emulsificación). 47 La TAG lipasa presenta activación superficial i.e. su actividad se incrementa al entrar en contacto con la interfase lípido-agua, no se une a la interfase, está en contacto con la colipasa (1:1). El sitio catalítico de la enzima, residuos 1-336 (tiene 449) contiene una triada parecida a la que se encuentra en la serin proteasas (Ser, His y Asp) y la enzima sufre un cambio conformacional para realizar su catálisis. Los fosfolípidos son degradados por la fosfolipasa pancreática A2 (estructura tridimensional resuelta en veneno de cobra y de abeja), la cual por hidrólisis corta en la posición 2 del glicerol para dar el lisofosfolípido correspondiente, el cual es también un detergente. De hecho la lecitina (fosfatidilcolina) es secretada en la bilis presumiblemente para ayudar a la digestión de lípidos. La reacción se lleva preferencialmente en interfases al igual que la TAG lipasa, pero ésta no lleva a cabo un cambio conformacional en la catálisis, contiene un poro o canal, por medio del cual el substrato llega al sitio catalítico. En vez de triada catalítica, contiene una diada (His y Asp) junto con una molécula de agua - Fosfolipasa A1 O O O CH2 O C R1 R2 C O CH O CH2 O P O X Fosfolipasa C H2O R2 C OH Fosfolipasa A2 O CH2 O C R1 HO CH O CH2 O P O X Fosfolipasa D LISOFOSFOLÍPIDO FOSFOLIPÍDO Figura: Sitios de acción de las fosfolipasas. Los productos de la digestión de los lípidos, son absorbidos por las células de la mucosa intestinal (en el intestino delgado) el proceso es facilitado por los ácidos biliares que ayudan a formar micelas. Organismos con los conductos biliares obstruidos absorben muy poca cantidad del total de la dieta lipídica, pero eliminan formas hidrolizadas de éstos en las heces (a este trastorno se le conoce como ESTEATORREA). Los ácidos biliares son esenciales para el transporte de los productos de la digestión de los lípidos, no sólo para su degradación, así mismo son necesarios para el transporte de vitaminas liposolubles (A,D,E y K). 48 Dentro de las células intestinales, los ácidos grasos forman un complejo con la proteína intestinal que une ácidos grasos (I-FABP; estructura tridimensional resuelta) incrementa la solubilidad de éstas moléculas y protege contra la acción detergente de las mismas. Los productos de la digestión de los lípidos que son absorbidos por la mucosa intestinal, son transformados en TAG y empacados en partículas de lipoproteínas llamadas QUILOMICRONES o bien en lipoproteínas de muy baja densidad (VLDL) en el hígado. Estas partículas se liberan al torrente sanguíneo vía el sistema linfático para llegar a todos los tejidos. Los componentes de los quilomicrones y las VLDL son hidrolizados a ácidos grasos libres y glicerol en los capilares del tejido adiposo y músculo esquelético por la acción de la lipoproteína lipasa, entonces los ácidos grasos libres pueden ser utilizados y/o almacenados, mientras que el glicerol es transportado al hígado o riñón en donde es transformado en DHAP por la reacción secuencial de la glicerol cinasa y la glicerol-3-fosfato deshidrogenasa. H OH H HO H H H H O H Glicerol cinasa H OH Glicerol ATP ADP H OH NADH + H + H H 2O PO 3 Glicerol-3-fosfato G3P NAD + H H Glicerol fosfato deshidrogenasa OH O TPI PO32DHAP H O H OH PO32GAP Figura: destino del glicerol de los TAG´s hidrolizados La mobilización de los TAG almacenados en el tejido adiposo necesita de su hidrólisis para generar glicerol y ácidos grasos libres, esta reacción es catalizada por la TAG lipasa sensible a hormonas. Los ácidos grasos libres son liberados al torrente sanguíneo en donde se unen a la ALBÚMINA (monómero 65 kD que representa la mitad de la proteína sérica). En ausencia de esta proteína, la solubilidad de los ácidos grasos libres es del orden de 10 -6 M, por arriba de esta concentración, forman micelas y son detergentes (pueden destruir la estructura de las membranas celulares). En complejo con albúmina, su solubilidad es de 2 mM. Hay organismos que presentan muy poca albúmina en sangre (ANALBUMINEMIA), no presentan graves síntomas, sus ácidos grasos son evidentemente transportados por otras proteínas séricas. 49 Componentes principales de las membranas, consisten de un glicerol-3fosfato esterificado en C1 y C2 por ácidos grasos y en el grupo fosforil con un grupo X polar que es generalmente un derivado de un alcohol (X= agua: ácido fosfatídico; X= etanolamina: fosfatidiletanolamina; X= colina: fosfatidilcolina (lecitina); X= serina: fosfatidilserina; X= myo-inositol: fosfatidilinositol; X= glicerol: fosfatidilglicerol y X= fosfatidilglicerol: difosfatidilglicerol (cardiolipina)). Figura: representación del glicerol-3-fosfato y glicerofosfolípido. El grupo X polar derivado de un alcohol puede ser igual a: X= agua: ácido fosfatídico; X= etanolamina: fosfatidiletanolamina; X= colina: fosfatidilcolina (lecitina); X= serina: fosfatidilserina; X= myo-inositol: fosfatidilinositol; X= glicerol: fosfatidilglicerol y X= fosfatidilglicerol: difosfatidilglicerol (cardiolipina)). Los plasmalógenos son fosfoglicéridos en los que el glicerol fosfato tiene unido en el C1, mediante un enlace tipo éter, un alcohol de cadena larga. Comúnmente, la parte polar de los plasmalógenos es etanolamina, colina o serina. 50 Figura: un plasmalógeno. Los esfingolípidos, son componentes importantes de las membranas, derivados del aminoalcohol insaturado esfingosina o dihidroesfingosina (C18). Figura: la esfingosina Este alcohol, se une a un ácido graso de cadena larga por medio de un enlace amina para formar una ceramida. Las ceramidas, se encuentran en pequeñas cantidades en los tejidos de plantas y animales, pero dan origen a los esfingolípidos más abundantes: 51 Figura: una ceramida. Las esfingomielinas, son los esfingolípidos más comunes; son ceramidas esterificadas con fosforilcolina o fosforiletanolamina. Aunque las esfingomielinas difieren químicamente de la fosfatidilcolina y la fosfatidiletanolamina, sus conformaciones y distribuciones de carga son muy similares. La mielina que rodea y aísla eléctricamente a muchos axones en las neuronas del tejido nervioso, es particularmente rica en esfingomielinas. Figura: la esfingomielina Cuando las ceramidas se combinan con un azúcar forman a los glucoesfingolípidos, que se dividen en: cerebrósidos (o glucoesfingolípidos), son los esfingolípidos más simples, su cabeza polar consiste de una unidad de azúcar. Los galactocerebrósidos, que se encuentran en las membranas celulares neuronales del cerebro, tienen una cabeza polar de -D galactosa. 52 Figura: un galactocerebrósido Los glucocerebósidos, que también tienen un residuo de -D galactosa se encuentran en membranas celulares de otros tejidos. A diferencia de los fosfolípidos, los cerebrósidos carecen de grupos fosfato y por lo tanto, son frecuentemente compuestos no ionicos. Los residuos de algunos galactocerebrósidos están sulfatados en la posición 3 formando compuestos conocidos como sulfátidos. Los gangliósidos son el grupo más complejo de los esfingolípidos. Son oligosacáridos de ceramidas que incluyen entre sus residuos de azúcar al menos un residuo de ácido siálico (ácido N–acetilneuramínico (NAM) y sus derivados). Los gangliósidos son componentes primarios de la superficie de las membranas celulares y constituyen una fracción significativa (aproximadamente 6%) de los lípidos del cerebro, en otros tejidos, están presentes en cantidades mucho menores. Figura: ácido siálico. 53 Las ceras son lípidos completamente insolubles en agua; se encuentran en la superficie de plantas y animales, donde funcionan como impermeabilizante, están constituidas por ácidos grasos esterificados (generalmente con número par de átomos de carbono) a alcoholes de cadena larga (de 10 a 30 carbonos). Los ácidos grasos que forman parte de estos lípidos, pueden ser ramificados, insaturados o formar anillos. Se encuentran en la mayoría de los organismos, pero constituyen el grupo más abundante de los aceites vegetales, de hecho son los responsables de los aromas y sabores específicos de las plantas, mientras mayor sea la cantidad de oxígeno en la molécula, mayor será su aroma. Estos compuestos, se forman a partir del ispreno (unidad de 5 átomos de carbono); pueden contener desde una hasta ocho unidades. Las unidades pueden arreglarse linealmente (como en el escualeno) o cíclicamente (como en la limonina). Dentro de los terpenos se clasifica a los carotenoides que son tetraterpenos muy importantes en los mamíferos, especialmente el -caroteno que es precursor de la vitamina A (11cis-retinal). También las vitaminas liposolubles D (colecalciferol) y K son consideradas como terpenos. Los esteroides, son lípidos simples no saponificables, en su mayoría de origen eucarionte, derivados del ciclopentanoperhidrofenantreno Figura: la molécula del ciclopentanoperhidrofenantreno 54 El colesterol es el esteroide más abundante en los animales, se clasifica como un esterol por la presencia de un hidroxilo (OH) en el C3 y su cadena lateral alifática de 8 a 10 átomos de carbono. Figura: la molécula del colesterol El colesterol, es un componente mayoritario de las membranas plasmáticas animales y se encuentra en menor cantidad en las membranas de los organelos. El grupo OH en la molécula, le da un débil carácter anfífilo y el núcleo esteroide, es una estructura no polar, rígida y planar. Por lo tanto, es un determinante importante de las propiedades de la membrana. Este esteroide, es abundante también en lipoproteínas del plasma sanguíneo, en donde aproximadamente el 70% de este es esterificado por ácidos grasos de cadena larga para formar ésteres de colesterol. EL colesterol es el precursor metabólico de las hormonas esteroides, que son substancias que regulan una gran variedad de funciones fisiológicas, que incluyen el desarrollo sexual y el metabolismo de los carbohidratos. El papel del colesterol en enfermedades cardiovasculares (link hormonas esteroides). Las plantas contienen muy poco colesterol. Entre los esteroles que se encuentran comúnmente en sus membranas se encuentran el estigmasterol y el -sitosterol, que difieren del colesterol solo en las cadenas alifáticas. Las levaduras y hongos contienen otros esteroles en sus membranas como el ergosterol que tiene un doble enlace (C7-C8). Los procariontes no contienen en sus membranas ningún esterol, excepto los micoplasmas. Los derivados del colesterol son: los ácidos biliares, las hormonas esteroides –estrógenos, progestágenos, glucocorticoides, mineralocorticoides y andrógenos- y la vitamina D, que deriva del colesterol aunque propiamente no es un esteroide.(link) 55 Dentro de las estructuras que pueden formar los lípidos, se encuentran las MONOCAPAS, BICAPAS, LIPOSOMAS Y MICELAS. Además de las membranas celulares. Muchas biomoléculas, contienen tanto grupos polares (o cargados iónicamente) como regiones apolares, por lo tanto son simultáneamente hidrofílicas e hidrofóbicas. Estas moléculas, como los iones de ácidos grasos (ej. Palmitato: C15H31COO-) se conocen como anfifílicas (anfífilos o anfipáticos) del griego amphi, ambos + pathos, pasión. ¿Cómo interactúan los anfifílos con un solvente acuoso? El agua tiende a hidratar la porción hidrofílica del anfífilo, pero simultáneamente tiende a excluir a la porción hidrofóbica. Por lo tanto, los anfifílos tienden a formar agregados dispersos ordenados estructuralmente. Dentro de las estructuras que pueden formar los lípidos, se encuentran las MONOCAPAS, BICAPAS, LIPOSOMAS Y MICELAS. Además de las membranas celulares. En soluciones acuosas, las moléculas anfifílicas como los detergentes y los jabones, forman micelas, que son agregados globulares de miles de moléculas de anfifílos cuyos grupos hidrocarbonados están que lejos del contacto del agua y la parte polar en contacto directo con las moléculas de agua a través de puentes de hidrógeno. Este arreglo molecular elimina los contactos desfavorables entre el agua y las partes hidrofóbicas de los anfífilos permitiendo la solvatación de los grupos polares. La formación de micelas, es un proceso cooperativo, pocas moléculas de anfífilo no pueden alejar sus colas hidrofóbicas del agua, consecuentemente, soluciones diluidas de anfífilos, no pueden formar micelas. Hasta que la concentración de anfífilo sobrepase la concentración micelar crítica (cmc) sucede la formación de micelas. El valor de la cmc depende del anfífilo y de las condiciones de la solución que lo contiene. Los lípidos de cadenas hidrocarbonadas sencillas tienden a formar micelas. Los gliceofosfolípidos y los esfingolípidos tienden a formar bicapas, las formas de estos lipidos es aproximadamente rectangular, esta propiedad hace que se agreguen en micelas discoidales, llamadas bicapas lipídicas. Una suspención de fosfolípidos en agua forma vesículas multilamelares con un arreglo parecido al de la cebolla, que están formadas por bicapas lipidicas. Después de sonicar (agitación por vibraciones ultrasónicas), estas estructuras se rearreglan formando liposomas, que son vesículas selladas, llenas de solvente que está rodeado por una sola bicapa. Con estos arreglos, se puede, experimentalmente, preparar membranas biológicas, en estas membranas, se 56 pueden introducir proteínas para el estudio aislado del resto de los componentes celulares de un solo sistema. A este arreglo se le llama entonces proteoliposoma. Figura: proteoliposomas. Tomada de Edgar Vázquez-Contreras, Marietta Tuena de Gómez-Puyou, and Georges Dreyfus. (1996). PROTEIN EXPRESSION AND PURIFICATION 7, 155–159 La barra corresponde a 100 nm Las interacciones que estabilizan a las micelas o bicapas se conocen como fuerzas hidrofóbicas o interacciones hidrofóbicas, para indicar que resultan de la tendencia del agua a escluir a los grupos hidrofóbicos. A diferencia de los puentes de hidrógeno, las interacciones hidrofóbicas son relativamente débiles y carecen de orientación. De cualquier forma, las interacciones hidrofóbicas son de suma importancia en los fenómenos biológicos, pues son responsables de la integridad de las biomoléculas, así como de los agregados supramoleculares como las membranas. 57 Proteínas Las proteínas, como grupo de biomoléculas desempeñan una gran variedad de funciones; unas transportan y almacenan moléculas pequeñas; otras constituyen gran parte de la organización estructural de las células y los tejidos. La contracción muscular, la respuesta inmunitaria y la coagulación de la sangre se producen mediante proteínas, quizás las mas importantes de todas las proteínas sean las enzimas, los catalizadores que facilitan la enorme variedad de reacciones que canalizan el metabolismo en rutas esenciales. Para cumplir esta diversidad de funciones cada tipo de célula en cada organismo posee varios miles de clases de proteínas.(1) La proteínas son extremadamente complejas, todas presentan características comunes, están constituidas de aminoácidos, pero cada una tiene una estructura funcional lógica y propia. (1) Los aminoácidos se seleccionan de una reserva de 20 moléculas diferentes, cada una con una estructura química distinta. Cada tipo de proteína tiene una estructura particular definida por la secuencia de sus aminoácidos, la cual esta determinada genéticamente. La información necesaria para incorporar los aminoácidos en la proporción y el orden adecuado reside en la secuencia de bases de nucleótidos de un gen (una región de ADN). La composición y secuencia de aminoácidos característicos de cada proteína es lo que permite el plegamiento tridimensional de las proteínas, para que se lleve a cabo la función para la cual fue diseñada. Y por la enorme posibilidad de combinaciones en la composición y secuencia de aminoácidos las proteinas pueden llevar a cabo funciones tan diversas como las citadas previamente.(2) Las diferentes proteínas se caracterizan por su peso molecular, secuencia de aminoácidos y propiedades físicas particulares. Su estructura molecular puede dividirse en primaria, que define la secuencia de aminoácidos; secundaria que define los elementos estructurales repetidos regularmente; la estructura terciaria que define la ordenación tridimensional completa y la cuaternaria que define la asociación de dos o mas polipéptidos (2) La secuenciación de aminoácidos de una proteína permite predecir su estructura secundaria, terciaria y cuaternaria, y de los datos de la secuenciación se obtiene información sobre el desarrollo evolutivo de la proteína, mutaciones etc. A continuación se hace una análisis de la información básica de los aminoácidos y las proteínas, la información fue tomada de la siguiente fuente. INFORMACIÓN ACTUALIZADA EN ESPAÑOL PARA LA ENSEÑANZA Y EL APRENDIZAJE DE ESTAS DISCIPLINAS CIENTÍFICAS. Comité asesor de publicaciones. Facultad de Medicina, UNAM 58 Todos los derechos reservados Copyright © UNAM 2003 03-2002-121311275700-01 Instituto Nacional del Derecho de Autor de la Secretaría de Educación Pública del Gobierno de la República Mexicana. Esta página puede ser reproducida con fines no lucrativos, siempre y cuando no se mutile, se cite la fuente completa y su dirección electrónica: http://bq.unam.mx/~evazquez De otra forma requiere permiso previo por escrito de la institución o el autor. Preguntas/Comentarios Para recibir actualizaciones Última actualización: 15 de Octubre de 2003 Por alguna razón, esta página se ve mejor con internet explorer. 7) Mathews, C,K., K.E. van Holde y K.G. Ahern. 2002. Bioquímica. Addison Wesley. Madrid España. 1333 pag. 8) Boyer, R. 2000. conceptos de bioquímica. International Thomson Editores. México. D.F. 694 pag. Cuando los científicos pusieron atención a los eventos relacionados con la nutrición, a principios del siglo XIX, rápidamente descubrieron que los productos naturales contenían Nitrógeno, eran esenciales para la sobrevivencia de los animales. En 1839, G.J. Mulder, un químico alemán, acuñó el término proteína (del griego proteios, que quiere decir primario). Los avances científicos y tecnológicos de ese entonces, no permitieron conocer la composición de las proteínas en sus monómeros, los aminoácidos, aunque el primer aminoácido fue aislado de un ser vivo en 1930. Durante mucho tiempo se pensó que las substancias que formaban a las plantas, incluyendo a las proteínas, se incorporaban del todo en el cuerpo de los animales. Este malentendido se aclaró cuando el procesos de la digestión quedó claro. Antes de determinar que en este 59 proceso las proteínas son degradadas en aminoácidos, los científicos volcaron su atención a las propiedades nutricionales de esta biomoléculas. Los experimentos con la dieta de los animales demostraron que el contenido de aminoácidos de una proteína particular determina su contenido nutricional. Por ejemplo algunas proteínas de cereales son deficientes en el aminoácido Lisina, y los animales que se alimentan únicamente con estos cereales presentan trastornos metabólicos. Para 1925, todas las estructuras de los aminoácidos habían sido determinadas y su importancia en las proteínas estaba ampliamente documentada. Los estudios modernos de proteínas y aminoácidos nos han demostrado la importancia de los aminoácidos en el metabolismo del Nitrógeno, esencial para la vida. Los experimentos de Stanley Miller y Harold Urey en 1953, en donde una mezcla de H2O, CH4, NH3 y H2 se bombardeó durante una semana con rayos UV y descargas eléctricas, todo esto en condiciones anoxigénicas, dio origen a la generación de algunas moléculas solubles en agua, las cuales se muestran en la siguiente Tabla Compuesto Ácido fórmico Glicina Ácido glicólico Alanina Ácido láctico -alanina ácido propiónico ácido acético ácido iminodiacético ácido -amino-n-butírico ácido -hidroxibutírico ácido succinico sarcosina ácido iminoaceticopropiónico N-Metilalanina Ácido glutámico N-metilurea Urea Ácido aspártico Ácido -aminoisobutírico Rendimiento (%) 4.0 2.1 1.9 1.7 1.6 0.76 0.66 0.51 0.37 0.34 0.34 0.27 0.25 0.1|3 0.07 0.051 0.051 0.34 0.24 0.007 0.007 60 Tabla: moléculas encontradas después de realizar el experimento de Miller y Urey Las moléculas resaltadas en verde, son constituyentes de las proteínas Las proteínas son las moléculas más abundantes y diversas en cuanto a función en los sistemas biológicos. Virtualmente, cada proceso de la vida depende de esta clase de biomoléculas. Por ejemplo, las enzimas y hormonas polipeptídicas dirigen y regulan el metabolismo, por el contrario las proteínas contráctiles permiten el movimiento de los músculos. En el tejido óseo, la proteína colágena permite que se impregnen cristales de fosfato de Calcio en los huesos, lo cual es similar al esqueleto de metal que tiene una casa y el cual se recubre con concreto; algo similar ocurre con el cristalino del ojo. En la sangre está presente la albúmina que transporta a las grasas impidiendo su acumulación en los canales por los cuales transita y también las inmunoglobulinas o anticuerpos que ayudan a la detección y posterior destrucción de agentes patógenos. La generación de energía en el cuerpo a partir de las moléculas nutritivas contenidas en los alimentos, es extraída y transformada por una serie de proteínas esenciales. A pesar de la inmensa gama de funciones que estas macromoléculas biológicas pueden tener, en realidad sólo son polímeros lineales de aminoácidos que comparten características estructurales al adoptar una estructura tridimensional y es precisamente la composición de aminoácidos la que permite que exista esta diversidad. A partir de lo anterior debe quedar claro el papel vital que juegan las propiedades de los aminoácidos para los sistemas vivientes. Estructura de los aminoácidos. Aunque se han encontrado mas de 300 diferentes aminoácidos en la naturaleza, el análisis de un gran número de proteínas muestra que todas ellas están formadas por 20 tipos de aminoácidos estándar (mencionados más adelante). Estas moléculas poseen la siguiente composición: 61 Figura: características estructurales de los aminoácidos. Se muestra la forma totalmente protonada. Cada uno de los 20 aminoácidos (excepto la prolina), posee un grupo carboxilo, uno amino y una cadena lateral, además de un átomo de Hidrógeno todos ellos unidos a un átomo de Carbono central denominado (alfa). Por ello, estos compuestos orgánicos se conocen como -aminoácidos porque con excepción de la prolina (que contiene un grupo amino secundario), los 19 restantes tienen un grupo amino primario, un substituyente ácido carboxílico además de un hidrógeno y un substituyente diferente en el mismo átomo de carbono. Los aminoácidos pueden actuar como ácidos o bases, son anfolitos. Las moléculas que contienen grupos de polaridad opuestas se conocen como zwiteriones o iones dipolares. De acuerdo con su composición, los aminoácidos son muy solubles en agua y muy insolubles en solventes orgánicos. Alrededor de pH 7.0, que es el valor fisiológico para la mayoría de los seres vivos, el grupo carboxilo está disociado, formando al anión carboxilato (COO-) y el grupo amino está protonado (NH3+): Figura: equilibrio ácido-base en un aminoácido 62 En las proteínas, casi todos los grupos carboxilo y amino de los aminoácidos que las componen, están combinados formando el enlace peptídico y, por tanto, no están disponibles para participar en esta reacción de disociación, solo participan en la estructura, formando puentes de Hidrógeno. De acuerdo con lo anterior, es la naturaleza de las cadenas laterales la que al final determina el papel que un aminoácido juega en una proteína. De ahí que generalmente se clasifique a los aminoácidos de acuerdo a la naturaleza de su cadena lateral. Los carbonos son centros ópticamente activos o quirales (de mano), tienen cuatro substituyentes diferentes (este fenómeno no sucede en la glicina cuyo grupo R es un átomo de Hidrógeno), que pueden ocupar dos diferentes arreglos espaciales que son imágenes especulares (de espejo) no superponibles: Figura: Imágenes especulares de la alanina Cada una de estas estructuras se denominan isómeros ópticos, enantiómeros o bien estereoisómeros y son ópticamente activas (pueden rotar el 63 plano de la luz polarizada en diferente dirección dependiendo del estereoisómero que se trate). Aquellos estereoisómeros que rotan el plano de la luz polarizada hacia la izquierda se denominan levorrotatorios o L (de levo: izquierda), los que lo hacen hacia la derecha se denominan dextrorrotatorios o D (dextro: derecha). D-aminoácido L-aminoácido D-aminoácido + L-aminoácido polarímetro polarímetro polarímetro Figura X. Representación de la observación de isómeros ópticos en el polarímetro. El polarímetro es el aparato que ordena el plano de la luz en un solo plano. Una muestra con igual cantidad del enantiómero L y D, no modifica el plano de la luz polarizada y se denomina mezcla racémica (ejemplo del extremo derecho en la Figura X). 64 En 1843, al investigar el sedimento cristalino que se formaba en los barriles donde se fermenta el vino, Louis Pasteur encontró el fenómeno de actividad óptica. El sedimento investigado es en realidad el ácido paratartárico, también llamado ácido racémico por racemus, del latín racimo de uvas. Pasteur utilizó pinzas muy finas para separar dos tipos de cristales de forma idéntica, pero que claramente eran imágenes especulares. Ambos cristales poseían las características del ácido tartárico, pero uno de ellos desviaba el plano de la luz polarizada hacia la izquierda (levorrotatorio) y el otro hacia la derecha (dextrorrotatorio). Gracias al uso de la cristalografía de rayos X, ahora sabemos la configuración absoluta de ambas formas del ácido tartárico y muchas otras moléculas. A pesar de que en la naturaleza se encuentran tanto isómeros L como D, los aminoácidos que forman parte de las proteínas son en su inmensa mayoría L. Los aminoácidos D se encuentran solamente en pequeños péptidos de la pared celular bacteriana y en algunos antibióticos. La estereoespecificidad de algunas reacciones catalizadas por enzimas se debe precisamente a la asimetría de sus sitios activos, la cual está dada por las características quirales de los aminoácidos que las componen. La manera más común de clasificar a los aminoácidos es de acuerdo a la polaridad de sus cadenas laterales (grupos R). Lo anterior se debe a que las proteínas se pliegan en su conformación nativa en respuesta a la tendencia de remover las cadenas laterales de algunos de sus aminoácidos (residuos) del contacto con el agua y solvatar (hidratar), las cadenas laterales polares. Los 20 tipos de aminoácidos difieren considerablemente en sus propiedades fisicoquímicas así como en su polaridad, acidez, basicidad, aromaticidad, volumen, flexibilidad conformacional, en su habilidad para realizar entrecruzamientos y para formar puentes de Hidrógeno y reactividad química. Estas múltiples características, muchas de las cuales están 65 interrelacionadas, son las responsables de la gran variedad de funciones, estructuras y demás características de las proteínas. De acuerdo con este esquema de clasificación, hay tres grupos principales de aminoácidos: 1.- con cadenas laterales (grupos R) no polares; 2.con cadenas laterales polares no cargadas y 3.- 1.- con cadenas laterales polares cargadas y estas pueden ser ácidas o bien básicas. Cada uno de estos aminoácidos posee una cadena lateral no polar que no puede ceder o aceptar protones o participar en puentes de Hidrógeno o enlaces iónicos. La característica común de estas cadenas laterales es su naturaleza no soluble en agua, lo que promueve su participación en interacciones hidrofóbicas. Información para las abreviaturas de las figuras. b.- Las masas de los residuos están dadas para la forma neutra. Para la masa molecular de los aminoácidos parentales sume 18.0 D (masa molecular del agua), Para calcular la masa molecular de las cadenas laterales, reste 56.0 D (masa molecular de un grupo peptídico). c.- Calculada a partir de una base de datos de proteínas no redundantes que contiene 300,688 residuos. e.- Los símbolos de una y tres letras para la asparagina o ácido aspártico son Asx y B; para glutamina o ácido glutámico son Glx y Z respectivamente. El símbolo de una letra para un aminoácido no determinado o no estándar es X. Para todos los aminoácidos se presenta su nombre, el código de tres letras, así como su identificación por una sola letra. Una clasificación usual de los aminoácidos se refiere a si son esenciales o no para los organismos, en particular para los heterótrofos. Esencial se refiere a que la maquinaria enzimática que posee el organismo estudiado no es capaz de sintetizar a la molécula, de ahí que deba ser ingerida en la dieta. Los autótrofos, son los organismos fotosintéticos, que al no recibir aporte de energía externa más que en forma de luz, deben sintetizar todas sus biomoléculas y, por tanto, poseen toda la maquinaria metabólica para sintetizar a todos los aminoácidos. 66 Los aminoácidos esenciales son aquellos que deben ser ingeridos en la dieta, nuestro cuerpo no es capaz de sintetizarlos. GLICINA. Es un aminoácido no esencial. En 1820 se encontró que era un componente de la gelatina, fue el primer aminoácido identificado en proteínas hidrolizadas. Ayuda a disparar la liberación de Oxígeno para el proceso de fabricación celular que necesita de energía para llevarse a cabo; es muy importante en la manufactura de hormonas y es responsable del fortalecimiento del sistema inmune. Masa del residuo 57.0 D b; Ocurrencia promedio en proteínas 7.2 % c; pK1 -COOH 2.35; pK2 -NH+3 9.78. ALANINA. Es un aminoácido no esencial. Es una importante fuente de energía para músculo, cerebro y el sistema nervioso central; refuerza al sistema inmune en la producción de anticuerpos; ayuda en el metabolismo de azúcares y ácidos orgánicos. Masa del residuo 71.1 D b; Ocurrencia promedio en proteínas 7.8 % c; pK1 -COOH 2.35; pK2 -NH+3 9.87. VALINA. Es un aminoácido esencial. Promueve el vigor mental, la coordinación muscular y ayuda a calmar las emociones nerviosas. Masa del residuo 99.1 D b; Ocurrencia promedio en proteínas 6.6 % c; pK1 -COOH 2.29; pK2 -NH+3 9.74. 67 LEUCINA. Es un aminoácido esencial. Junto con la isoleucina provee de unidades para la fabricación de componentes bioquímicos esenciales, algunos de los cuales se utilizan para la producción de energía, estimulantes del cerebro superior y ayuda al organismo a estar alerta. Masa del residuo 113.2 D b; Ocurrencia promedio en proteínas 9.1 % c; pK1 -COOH 2.33; pK2 NH+3 9.74. ISOLEUCINA. Es un aminoácido esencial. Contiene un centro quiral extra, marcado con asterisco en la figura. Masa del residuo 113.2 D b; Ocurrencia promedio en proteínas 5.3 % c; pK1 -COOH 2.32; pK2 NH+3 9.76. METIONINA. Es un aminoácido esencial. Es el principal aporte de azufre, el cual previene desordenes en el pelo, la piel y las uñas; ayuda a 68 reducir los niveles de colesterol incrementando la producción en el hígado de lecitina un fosfolípido (fosfatidilcolina); reduce el contenido de grasa en el hígado y protege a los riñones; es un agente quelante natural de metales pesados; regula la formación de amonio y ayuda a la generación de orina libre de amonio, lo cual reduce la irritación de la vejiga. Promueve el crecimiento del pelo fortaleciendo los folículos pilosos. Masa del residuo 131.2 D b; Ocurrencia promedio en proteínas 2.2 % c; pK1 COOH 2.13; pK2 -NH+3 9.28. 69 PROLINA. Es un aminoácido no esencial. Es muy importante para el adecuado funcionamiento de articulaciones y tendones; ayuda a mantener y fortalecer el músculo cardiaco. Los números indican las posiciones en el ciclo. El grupo amino está unido a dos átomos de carbono: el Carbono y el Carbono de la cadena lateral; por tanto, a diferencia de los 19 aminoácidos restantes, la prolina posee un grupo amino secundario. Masa del residuo 97.1 D b; Ocurrencia promedio en proteínas 5.2 % c; pK1 COOH 1.95; pK2 -NH+3 10.64. FENILALANINA. Es un aminoácido esencial. Junto con tirosina y triptofano provee de la mayoría de la absorbencia UV y fluorescencia de las proteínas. En el cerebro se utiliza para producir norepinefrina, ayuda al organismo a estar alerta, reduce la ansiedad por hambre, funciona como un antidepresivo y ayuda a mantener la memoria. Está relacionado directamente con la fabricación de hormonas tiroideas. Masa del residuo 147.2 D b; Ocurrencia promedio en proteínas 3.9 % c; pK1 COOH 2.20; pK2 -NH+3 9.31. 70 TRIPTOFANO. Es un aminoácido esencial. Es un relajante muscular, ayuda a aliviar el insomnio induciendo el sueño normal; reduce la ansiedad y depresión; ayuda en el tratamiento de migrañas; ayuda en el sistema inmune; ayuda a reducir el riesgo de espasmos en arterias y corazón; trabaja junto con la lisina a reducir los niveles de colesterol. Los números indican las posiciones en el ciclo. Masa del residuo 186.2 D b; Ocurrencia promedio en proteínas 1.4 % c; pK1 -COOH 2.46; pK2 NH+3 9.41. Información para las abreviaturas de las figuras. b.- Las masas de los residuos están dadas para la forma neutra. Para la masa molecular de los aminoácidos parentales sume 18.0 D (masa molecular del agua), Para calcular la masa molecular de las cadenas laterales, reste 56.0 D (masa molecular de un grupo peptídico). c.- Calculada a partir de una base de datos de proteínas no redundantes que contiene 300,688 residuos. e.- Los símbolos de una y tres letras para la asparagina o ácido aspártico son Asx y B; para glutamina o ácido glutámico son Glx y Z respectivamente. El símbolo de una letra para un aminoácido no determinado o no estándar es X. Para todos los aminoácidos se presenta su nombre, el código de tres letras, así como su identificación por una sola letra. Una clasificación usual de los aminoácidos se refiere a si son esenciales o no para los organismos, en particular para los heterótrofos. Esencial se refiere a que la maquinaria enzimática que posee el organismo estudiado no es capaz de sintetizar a la molécula, de ahí que deba ser ingerida en la dieta. Los autótrofos, son los organismos fotosintéticos, que al no recibir aporte de energía externa más que en forma de luz, deben sintetizar todas sus biomoléculas y, por tanto, poseen toda la maquinaria metabólica para sintetizar a todos los aminoácidos. Los aminoácidos esenciales son aquellos que deben ser ingeridos en la dieta, nuestro cuerpo no es capaz de sintetizarlos. 71 Aminoácidos con cadenas laterales básicas. La cadena lateral de los aminoácidos básicos puede aceptar protones. A pH neutro la cadena lateral de la lisina y arginina está completamente ionizada y cargada positivamente. Por el contrario la histidina es básica muy débilmente y el aminoácido libre no tiene carga a pH neutro. Aún así cuando la histidina es incorporada en la proteína, su cadena lateral puede estar cargada positivamente o bien mantenerse neutra, dependiendo del ambiente ionico en donde se encuentre en la cadena polipeptídica. LISINA. Es un aminoácido esencial. Asegura la absorción adecuada de calcio; ayuda a la formación de colágena (que envuelve el cartílago y tejido conectivo); ayuda en la producción de anticuerpos, hormonas y enzimas. Estudios recientes señalan que este aminoácido puede ser efectivo contra el herpes mejorando el balance de nutrientes que reducen el crecimiento viral. Su deficiencia puede resultar en cansancio, inhabilidad para concentrarse, irritabilidad, ojos inyectados de sangre, retardo de crecimiento, pérdida del pelo, anemia y problemas reproductivos. Masa del residuo 128.2 D b; Ocurrencia promedio en proteínas 5.9 % c; pK1 COOH 2.16; pK2 -NH+3 9.06; pKR 10.54 (epsilon- NH+3). 72 ARGININA. Es un aminoácido no esencial y esencial. Lo anterior depende de la edad, es esencial para los jóvenes en crecimiento, pero no lo es para los adultos. Este aminoácido ayuda a la respuesta inmune a bacterias, virus y células tumorales; promueve la recuperación de heridas y la regeneración del hígado; causa la liberación de hormonas de crecimiento; se le considera crucial para el crecimiento muscular óptimo y la reparación de tejidos. Masa del residuo 156.2 D b; Ocurrencia promedio en proteínas 5.1 % c; pK1 -COOH 1.82; pK2 -NH+3 8.99; pKR 12.48 (guanidinio). HISTIDINA. Es un aminoácido esencial. Se encuentra abundantemente en la hemoglobina; se ha utilizado en el tratamiento de artritis reumatoide, enfermedades alérgicas, úlceras y anemia. Su deficiencia puede causar deficiencias en la audición. Masa del residuo 137.1 D b; Ocurrencia promedio en proteínas 2.3 % c; pK1 -COOH 1.80; pK2 NH+3 9.33; pKR 6.04 (imidazol). 73 Aminoácidos con cadenas laterales ácidas. Los aminoácidos aspártico y glutámico son donadores de protones. A pH neutro, la cadena lateral de estos aminoácidos está totalmente ionizada, conteniendo al grupo carboxilato con carga neta negativa (-COO-), de ahí que se les denomine frecuentemente como aspartato y glutamato para enfatizar esta propiedad. ÁCIDO ASPÁRTICO. Es un aminoácido no esencial. Ayuda en la expulsión de amonio perjudicial. Cuando el amonio ingresa al sistema circulatorio actúa como una substancia altamente tóxica que puede ser dañina para el sistema nervioso central. Estudios recientes señalan que el ácido aspártico puede incrementar la resistencia a la fatiga e incrementa la resistencia. Masa del residuo 115.1 D b; Ocurrencia promedio en proteínas 5.3 % c; pK1 -COOH 1.99; pK2 -NH+3 9.90; pKR 3.90 (-COOH). ÁCIDO GLUTÁMICO. Es un aminoácido no esencial. Se considera como “alimento del cerebro” mejora las capacidades mentales; ayuda rápidamente a la recuperación de la úlcera; ayuda a evitar la fatiga; ayuda en el control del alcoholismo, esquizofrenia y el ansia por el azúcar. Masa del residuo 129.1 D b; Ocurrencia promedio en proteínas 6.3 % c; pK1 -COOH 2.10; pK2 -NH+3 9.47; pKR 4.07 (-COOH). 74 Información para las abreviaturas de las figuras. b.- Las masas de los residuos están dadas para la forma neutra. Para la masa molecular de los aminoácidos parentales sume 18.0 D (masa molecular del agua), Para calcular la masa molecular de las cadenas laterales, reste 56.0 D (masa molecular de un grupo peptídico). c.- Calculada a partir de una base de datos de proteínas no redundantes que contiene 300,688 residuos. e.- Los símbolos de una y tres letras para la asparagina o ácido aspártico son Asx y B; para glutamina o ácido glutámico son Glx y Z respectivamente. El símbolo de una letra para un aminoácido no determinado o no estándar es X. Para todos los aminoácidos se presenta su nombre, el código de tres letras, así como su identificación por una sola letra. Una clasificación usual de los aminoácidos se refiere a si son esenciales o no para los organismos, en particular para los heterótrofos. Esencial se refiere a que la maquinaria enzimática que posee el organismo estudiado no es capaz de sintetizar a la molécula, de ahí que deba ser ingerida en la dieta. Los autótrofos, son los organismos fotosintéticos, que al no recibir aporte de energía externa más que en forma de luz, deben sintetizar todas sus biomoléculas y, por tanto, poseen toda la maquinaria metabólica para sintetizar a todos los aminoácidos. Los aminoácidos esenciales son aquellos que deben ser ingeridos en la dieta, nuestro cuerpo no es capaz de sintetizarlos. Estos aminoácidos tienen una carga igual a cero a pH neutro, de tal manera que la cadena lateral de la cisteina y tirosina pueden perder su protón a pH alcalino. La serina, treonina y tirosina contienen cada una un grupo hidroxilo que puede participar en la formación de puentes de Hidrógeno. La cadena lateral de la asparagina y glutamina contiene un grupo carbonilo y un amido, lo cuales pueden también participar en la formación de puentes de Hidrógeno. Puente disulfuro. 75 La cadena lateral de la cisteina contiene un grupo sulfidrilo (-SH), el cual es un componente importante del sitio activo de muchas enzimas. En las proteínas, el grupo –SH de dos residuos de cisteinas puede oxidarse para formar dímero, la cistina, que contiene un puente disulfuro (-S-S-). Cadenas laterales como sitios de unión para otros compuestos. La serina, treonina y raramente la tirosina, pueden participar con su grupo hidroxilo como sitio de unión para moléculas como el grupo fosfato (PO 4), la cadena lateral de la serina forma parte del sitio activo de muchas enzimas. Además el grupo amido de la asparagina, así como el hidroxilo de la serina y treonina, puede servir como un sitio de unión para cadenas de oligosacáridos en las glucoproteínas. SERINA. Es un aminoácido no esencial. Es la fuente para el almacenamiento de glucosa en hígado y músculo; ayuda al fortalecimiento del sistema inmune en la fabricación de anticuerpos. Sirve para sintetizar los ácidos grasos que rodean a las fibras nerviosas (mielina). Masa del residuo 87.1 D b; Ocurrencia promedio en proteínas 6.8 % c; pK1 -COOH 2.19; pK2 -NH+3 9.21. TREONINA. Es un aminoácido esencial. Es un constituyente importante de la colágena, elastina y proteínas del esmalte; ayuda a prevenir el exceso de grasa en el hígado; ayuda al aparato digestivo y tractos intestinales a funcionar suavemente. Al igual que la isoleucina, contiene un centro quiral extra, marcado con asterisco en la figura. 76 Masa del residuo 101.1 D b; Ocurrencia promedio en proteínas 5.9 % c; pK1 -COOH 2.09; pK2 -NH+3 9.10. ASPARAGINA. Es un aminoácido no esencial. Masa del residuo 114.1 D b; Ocurrencia promedio en proteínas 4.3 % c; pK1 -COOH 2.14; pK2 -NH+3 8.72. GLUTAMINA. Es un aminoácido no esencial. Masa del residuo 128.1 D b; Ocurrencia promedio en proteínas 4.3 % c; pK1 -COOH 2.17; pK2 NH+3 9.13. TIROSINA. Es un aminoácido no esencial. Transmite impulsos nerviosos en el cerebro; ayuda a vencer la depresión; mejora la memoria; promueve el alivio de funciones de la tiroides, glándulas adrenales y pituitaria. 77 Masa del residuo 163.2 D b; Ocurrencia promedio en proteínas 3.2 % c; pK1 COOH 2.20; pK2 -NH+3 9.21; pKR 10.46 (fenol). CISTEINA. Es un aminoácido no esencial. Su grupo tiol, único en los 20 aminoácidos puede formar puentes disulfuro con otro residuo de Cys, por medio de la oxidación de sus grupos tiol. Este compuesto dimérico es referido en la literatura bioquímica antigua como el aminoácido cistina. Este enlace disulfuro es muy importante para la estructura de las proteínas: puede unir polipéptidos separados o entrecruzar cisteinas en la misma cadena. La aparente confusión entre los nombres cistina y cisteina a llevado a referirlo como residuo media-cistina. Funciona como un antioxidante y es una poderosa ayuda para el cuerpo contra la radiación y polución; Puede ayudar a reducir el proceso de envejecimiento, desactiva radicales libres, neutraliza toxinas; es necesario para la formación de la piel, ayuda a la recuperación de quemaduras y operaciones quirúrgicas. El pelo y la piel están constituidos entre 10 y 14 % de cisteina. Masa del residuo 103.1 D b; Ocurrencia promedio en proteínas 1.9 % c; pK1 COOH 1.92; pK2 -NH+3 10.70; pKR 8.37 (sulfidrilo). Los aminoácidos poco comunes componentes de ciertas proteínas, todos son el resultado de modificaciones postraduccionales. Los que están modificados en el alfa-amino se encuentran en el amino terminal de la proteína. 4-hidroxiprolina epsilon-N,N,N-trimetillisina 3-metilhistidina 5-hidroxilisina o-fosfoserina gama-carboxyglutamato epsilon-N-acetillisina 78 omega-N-metilarginina N-acetilserina N,N,N-trimetilalanina N-formilmetionina Algunos derivados de los aminoácidos estándar y aminoácidos que no son componentes de las proteínas ácido gama amino butírico (GABA), histamina, dopamina, tiroxina, citrulina, ornitina, azaserina, Sadenosinmetionina. Los -aminoácidos además de ser las unidades monoméricas de las proteínas, son metabolitos energéticos y precursores de muchos compuestos nitrogenados como el hemo, las aminas fisiológicamente activas, glutatión, nucleotidos y enzimas nucleotidicas. Los aminoácidos están clasificados en esenciales y no esenciales. Los mamíferos pueden sintetizar los no esenciales, los esenciales deben adquirirlos de la dieta. El exceso de aminoácidos consumidos en la dieta, no puede ser almacenado para uso futuro, por el contrario, son transformados en intermediarios metabólicos comunes como el piruvato, oxaloacetato y alfacetoglutarato. Consecuentemente, los aminoácidos son precursores de glucosa, ácidos grasos y cuerpos cetónicos y por tanto son combustibles metabólicos. La ruptura de los aminoácidos se puede llevar por los siguientes eventos Desaminación Transaminación El ciclo glucosa-alanina transporta nitrógeno al hígado Desaminación oxidativa: Glutamato deshidrogenasa Otros mecanismos de desaminación 79 El catabolismo de la fenilalanina puede ser defectuoso genéticamente. Se han detectado muchos defectos genéticos en el metabolismo de los aminoácidos en humanos. La mayoría de estos defectos causan la acumulación de intermediarios específicos, esta condición causa defectos en el desarrollo neural y retardo mental. La primera enzima en el catabolismo de la fenilalanina, la fenilalanina hidroxilasa cataliza la hidroxilación de fenilalanina a tirosina. Un defecto genético en esta enzima es el responsable de la enfermedad FENILCETONURIA (PKU; primera enfermedad genética humana descubierta), esta enfermedad es la principal responsable de hiperfenilalaninemia. La fenilalanina hidroxilasa es una monooxigenasa. La enzima requiere de un cofactor para su catálisis la tetrahidrobiopterina, la cual transporta electrones del NADH al O2 en la hidroxilación de la fenilalanina. Durante este proceso, la coenzima es oxidada a hidrobiopterina; finalmente es reducida por la dihidrobiopterinareductasa en una reacción que requiere NADH. Figura: las reacciones de la fenilalanina hidroxilasa y la dihidrobiopterinareductasa 80 Papel de la tetrahidrobiopterina en la reacción catalizada por la fenilalanina hidroxilasa. Cuando la fenilalanina hidroxilasa es defectuosa genéticamente una segunda vía del metabolismo de la fenilalanina que normalmente se utiliza muy poco, entra en acción. En este proceso, la fenilalanina sufre de transaminación con el piruvato formando fenilpiruvato; tanto la fenilalanina como el fenilpiruvato se acumulan en sangre y otros tejidos y se excretan en la orina, de ahí el nombre de la enfermedad FENILCETONURIA. El fenilpiruvato puede ser descarboxilado formando fenilacetato o reducido formando fenillactato. El primero da un olor característico a la orina, lo cual es parte de la sintomatología. Caminos alternativos del catabolismo de la fenilalanina en los fenilcetonurios. El fenilpiruvato se acumula en los tejidos, sangre y orina. El fenilacetato y el fenillactato tambien se pueden encontrar el la orina. La acumulación de estos metabolitos en infantes tempranos produce desarrollo anormal del cerebro y causa retrazo mental, lo cual puede ser evitado con un estricto control de la dieta (evitando tirosina y fenilalanina). La tetrahidrobiopterina es necesaria para producir L-3,4-dihidroxifenilalanina (LDOPA) y 5-hidroxitriptofano (precursores esenciales para la síntesis de norepinefrina y serotonina respectivamente) se pueden agregar a la dieta. Existe otra variedad de defecto en la utilización de la fenilalanina, en la cual hay defectos en la enzima homogentisato dioxigenasa, esta enfermedad es mucho menos severa que la PKU. Estos pacientes que no tienen efectos serios excretan orina obscura por la oxidación del homogentisato. Esta enfermedad se denomina ALCAPTONURIA. Su descubridor, Archibald Garrod a principios del siglo XX fue el primero en hacer una conexión directa entre la falta de una enzima y un padecimiento. Condición Médica Incidencia aproximada(por cada 100,000 nacimientos) Albinismo Defecto enzima defectuosa síntomas y fenotipo 3 síntesis de melanina a partir de tirosina Tirosina 3monooxigenasa (tirosinasa) Falta de pigmentación; pelo blanco piel rosa Alcaptonuria 0.4 Degradación de tirosina homogenistato 1,2-dioxigenasa Pigmentación obscura de la orina; desarrollo tardío de artritis Argininemia 0.5 Síntesis de urea arginasa Retraso mental Acidemia arginosuccinica 1.5 Síntesis de urea Arginosuccinato liasa Vómito y convulsiones Deficiencia de 0.5 Síntesis de urea CPS I Letargo *, convulsiones, 81 muerte temprana la CPSI Homocistinuria 0.5 Degradación de metionina Cistation betasintasa Desarrollo defectuoso de huesos, retraso mental Enfermedad de orina de jarabe de maple+ 0.4 Isoleucina, leucina y valina Complejo deshidrogenasa de alfa-ceto ácidos de cadena ramificada Vómito, convulsiones, retraso mental, muerte temprana Acidemia metilmalonica 0.5 Conversión de propionil-CoA a succinil-CoA MetilmalonilCoA mutasa Vómito, convulsiones, retraso mental, muerte temprana fenilcetonuria 8 Conversión de fenilalanina a tirosina Fenilalanina hidroxilasa Vómito neonatal, retraso mental Tabla: Algunos desordenes genéticos humanos que afectan el catabolismo de los aminoácidos *Letargo (gr. lethe, olvido + argós, inactivo). Estado patológico de somnolencia profunda y prolongada de la cual es difícil despertar. + cetoaciduria de cadenas ramificadas Figura: localización metabólica de la enfermedad de “jarabe de maple” También se le conoce como cetoaciduria de cadenas ramificadas 82 Grupo Hemo aminas activas (epinefrina, norepinefrina, dopamina, serotonina (5hidroxitriptamina), GABA e histamina) glutatión (-glutamilcisteinglicina, tripéptido que actúa en la desintoxicación, transporte y procesos metabólicos como oxidaciones) cofactores tetrahidrofolato (en el metabolismo de unidades de un átomo de C). 83 Los 20 aminoácidos que se encuentran comúnmente en las proteínas están unidos por enlaces peptídicos. La secuencia lineal de los aminoácidos unidos contiene la información necesaria para generar una molécula proteica con una estructura tridimensional particular. La complejidad de una estructura proteica se puede analizar de manera sencilla si se toman en cuenta cuatro niveles fundamentales de organización en las macromoléculas, que se denominan: estructura primaria, secundaria, terciaria y cuaternaria: Estructura primaria de la proteína aminoácidos Estructura secundaria de la proteína lámina Estructura terciaria De la proteína hélice hoja hélice Estructura cuaternaria 84 de la proteína + = Figura. los diferentes niveles de estructura que pueden existir en una proteína. La estructura cuaternaria corresponde a la triosafosfato isomerasa de la levadura Saccharomyces cerevisiae. El análisis de estos niveles estructurales revela que ciertos elementos estructurales se repiten en una gran variedad de proteínas, lo que sugiere que existen algunas “reglas” o “códigos” que gobiernan el proceso en el cual las proteínas se pliegan. La secuencia de aminoácidos que jamás es ramificada en una proteína, se denomina: secuencia primaria. Para conocer la secuencia de aminoácidos en la proteína se requiere la aplicación de muchas técnicas experimentales. Conocer la estructura primaria es muy importante porque muchas enfermedades genéticas residen en proteínas que poseen una secuencia de aminoácidos anormal. Si el cambio en la secuencia de aminoácidos es muy drástico entonces la estructura tridimensional de la proteína mutante (modificada), será diferente y, por tanto, su función no se llevará acabo de manera adecuada o bien, no se llevará a cabo. Si se conocen la estructura primaria de la proteína normal y la mutada, esta información puede ser utilizada para diagnosticar o bien estudiar a los diferentes padecimientos. Determinación de la secuencia primaria de una proteína o péptido por deducción de la secuencia de ADN. La secuencia de nucleótidos en una región codificante de ADN especifica la secuencia de aminoácidos en el polipéptido. De ahí que si puede ser determinada la primera, es posible deducir a la segunda utilizando una tabla de conversión denominada código genético, con la cual se pueden conocer las equivalencias entre los nucleótidos en el ADN y los aminoácidos en la proteína. Dependiendo de la fuente, la secuencia de aminoácidos puede ser deducida directamente, pero en algunos casos la secuencia primaria de la proteína es el resultado de cortes y/o modificaciones en la secuencia de nucleótidos una vez que el ADN ha sido transcrito a ARN, a estos cambios se les denomina modificaciones postranscripcionales. El transcrito (ARN) que está compuesto por nucleótidos, debe ser traducido a aminoácidos para formar a la proteína. Algunos de los aminoácidos pueden ser modificados covalentemente, 85 agregándoles carbohidratos, grupos modificaciones postraduccionales. fosfato o lípidos, estas son las En las proteínas, los aminoácidos están unidos uno seguido de otro, sin ramificaciones, por medio del enlace peptídico, que es un enlace amido entre el grupo -carboxilo de un aminoácido y el grupo -amino del siguiente. Este enlace se forma por la deshidratación de los aminoácidos en cuestión. Esta reacción es también una reacción de condensación, que es muy común en los sistemas vivientes: 86 Figura: reacción de condensación para la formación del enlace peptídico. Tres aminoácidos pueden ser unidos por dos enlaces peptídicos para formar un tripéptido, de manera similar se forman los tetrapéptidos, pentapéptidos y demás. Los enlaces peptídicos no se rompen con condiciones que afectan la estructura tridimensional de las proteínas como la variación en la temperatura, la presión, el pH o elevadas concentraciones de moléculas como el SDS (dodecil sulfato de sodio, un detergente), la urea o las sales de guanidinio. Los enlaces peptídicos pueden romperse de manera no enzimática, al someter simultáneamente a la proteína a elevadas temperaturas y condiciones ácidas extremas. Características del enlace peptídico. El enlace peptídico es plano y por tanto no existe rotación alrededor del enlace. El enlace peptídico posee un carácter de doble enlace, lo que significa que es mas corto que un enlace sencillo y, por tanto, es rígido y plano Esta característica previene la libre rotación alrededor del enlace entre el carbono carbonílico y el Nitrógeno del enlace peptídico. Aun así, los enlaces entre los carbonos y los aminos y carboxilo, pueden rotar libremente; su única limitación está dada por el tamaño del grupo R. Es precisamente esta capacidad de rotación la que le permite a las proteínas adoptar una inmensa gama de configuraciones. Configuración trans. Los enlaces peptídicos generalmente se encuentran en posición trans en lugar de cis y esto se debe en gran parte a la interferencia estérica (de tamaño) de los grupos R cuando se encuentran en posición cis. 87 Figura: Disposiciones del enlace peptídico en el espacio. Sin carga pero polar. Al igual que los enlaces amido, los grupos -C=O (carbonilo) y –NH (amino), de los enlaces peptídicos, son incapaces de recibir o donar protones en un amplio rango de valores de pH (entre 2 y 12). En las proteínas, los únicos grupos cargados son el N- y C-terminales y cualquier grupo ionizable presente en la cadena lateral de los residuos. Aún así, los grupos -C=O y –NH del enlace peptídico participan en la formación de puentes de Hidrógeno en las proteínas para dar origen a la estructura secundaria, particularmente -hélices y hojas y terciaria (ver mas adelante). El orden de los aminoácidos en la proteína. Por convención, el extremo amino terminal (NH3+) de la cadena polipeptídica denominado simplemente N-terminal, se escribe a la izquierda de la secuencia, por ende, el grupo carboxilo o C-terminal, se escribe a la derecha de la secuencia. Todas las secuencias se leen desde el N-terminal hasta el Cterminal. Esta convención se debe a que en el ribosoma, que es la enzima que hace los enlaces peptídicos en la naturaleza, la cadena crece agregando un nuevo aminoácido al carboxilo terminal, por lo tanto el extremo que emerge primero del ribosoma, es el N-terminal. En la siguiente figura el dipéptido se lee valina, alanina y no al revés Tomando en cuenta lo anterior, debe quedar claro una proteína o péptido tendrá diferentes características dependiendo de la cantidad y cualidad de los grupos ionizables presentes en la molécula. De manera que la proteína o péptido tendrá, al igual que los aminoácidos libres, curvas de titulación y pH isoeléctrico (pI) específicos, en los cuales el pH no sufre variaciones en un campo eléctrico. 88 Nombrando a los polipéptidos La unión de muchos aminoácidos a través de enlaces peptídicos se denomina poliéptido, que es una cadena sin ramificaciones de residuos de aminoácidos; así se denominan una vez que están unidos unos con otros. Al nombrar al polipéptido, los residuos que derivan de los aminoácidos terminados en -ina, como la glicina, los terminados en –ano, como triptofano y los terminados en ico, como aspártico, cambian estos sufijos por –il, con la excepción del carboxilo terminal. Así por ejemplo la valina y la alanina pueden formar al dipéptido valilalanina, a través de un enlace peptídico (ver figura), o el tripéptido compuesto por una valina en posición N-terminal, una glicina y en el C-terminal una leucina, se denomina valilglicilleucina: Figura: representación de la formación del dipéptido valilalanina. Los oligómeros son proteínas que están compuestas de mas de una cadena polipeptídica, es decir, poseen estructura cuaternaria y dependiendo de si las cadenas que los componen son iguales o diferentes, se denominan homooligómeros o heterooligómeros. El modelo mas sencillo de un 89 homooligómero es un homodímero (como la triosafosfato isomerasa mostrada en una figura anterior), el de un heteroologómero es un heterodímero, como la triptofano sintasa, que posee una subunidad y una . Existen oligómeros de mayor orden de agregación, por ejemplo en la ATPsinatasa existen en su forma mas simple (enzima bacteriana), 9 subunidades, en la enzima de mamífero existen alrededor de 15 subunidades. En ambos casos, no todas ellas se encuentran en una sola copia: Figura: Modelo de la ATPsintasa. Estructura de la ATPsintasa. En el esquema se presenta a la ATPsintasa más simple, la bacteriana. Esta enzima posee un complejo soluble denominado F1 de aproximadamente 380 kDa y una porción transmembranal F 0. al eliminar el Mg2+, en condiciones de fuerza iónica baja, estas estructuras pueden ser separadas. F1 consta de 5 subunidades con estequiometrías de 3:3:1:1:1 y F0 consta de tres subunidades con estequiometrías de 1:2:10-14. Si una proteína está compuesta por más de una cadena polipeptídica, antes de realizar el análisis de secuencia, se debe separar a los polipéptidos, es decir, eliminar la estructura cuaternaria. Las sales de guanidinio y la urea, perturban los enlaces no covalentes que participan en la estructura de la proteína y pueden servir para este propósito: A B H + H N H .. N H C .. .. O Cl .. N H H H .. N H C .. N H H 90 Figura: A.- clorhidrato de guanidinio; B.- urea Si las cadenas de aminoácidos están unidas por medio de puentes disulfuro, en el tratamiento deberá incluirse un agente reductor como el betamercapto etanol, el ditiotritol o el ácido perfórmico. Después de separar las cadenas, estas pueden ser aisladas, en caso de ser diferentes y someterse al análisis de secuencia de aminoácidos. No se pueden hacer generalizaciones sobre los tamaños o pesos moleculares de los péptidos y proteínas en relación con su función, pues pueden existir desde dos residuos (ver Figura X), hasta varios miles. Figura X: Aspartame o NutraSweet. De hecho muchas hormonas son pequeños péptidos: 91 HORMONA aminoácidos Oxitocina 9 glándula de secreción efecto pituitaria posterior contracciones urinarias Bradiquitina 9 inflamación Factor liberador de la tirotropina 3 inhibe la hipotálamo ocasiona la liberación de otra hormona, la tirotropina Tabla: algunas hormonas peptídicas de tamaño pequeño Muchos venenos secretados por hongos macromicetos como la amanitina y muchos antibióticos, son también pequeños péptidos. La insulina es una hormona pancreática que contiene dos cadenas de aminoácidos, una de 30 y la otra de 21 residuos; el glucagon, otra hormona pancreática posee 29 residuos y lleva a cabo la acción contraria a la insulina. La corticotropina es una hormona de 39 residuos, se secreta en la parte anterior de la glándula pituitaria y estimula la corteza adrenal. A continuación se muestran los datos moleculares de algunas proteínas (entre paréntesis se cita la fuente): Proteína Residuos peso molecular Cadenas (kDa) polipeptídicas Citocromo c 13.0 (H. sapiens) Ribonucleasa A 1 (páncreas bovino) Lisozima 1 (clara de huevo) 104 1 13.7 124 13.93 129 92 mioglobina 1 (corazón de caballo) Quimiotripsina 3 (páncreas de caballo) Quimiotripsinógeno 245 (bovino) Hemoglobina 4 (H. sapiens) Albúmina sérica 1 (H. sapiens) Hexocinasa 2 (levadura) ARN polimerasa 5 (E. coli) Apolipoproteína B 1 (H. sapiens) Glutamina sintetasa 12 (E. coli) 16.89 153 21.6 241 22.0 1 64.5 574 68.5 609 102.0 972 450 4,158 513 4,536 619 5,628 Tabla: datos moleculares de algunas proteínas El esqueleto polipeptídico no asume una estructura tridimensional al azar, de hecho está compuesto de arreglos regulares de aminoácidos que se encuentran en proximidad cerca dentro de la secuencia primaria. A estos arreglos regulares se les denomina estructura secundaria de la proteína. Las hélice- y las hojas y vueltas son ejemplos de estructura secundaria comúnmente encontrada en las proteínas. 93 Existen diferentes tipos de hélices en los polipéptidos, pero la hélice- es la más común. Esta estructura es una espiral que consiste de residuos de aminoácidos empaquetados formando un núcleo, en donde las cadenas laterales de los residuos se encuentran hacia fuera del eje central para evitar interferencias estéricas (de tamaño): PUENTES DE HIDRÓGENO INTRACATENARIOS CADENAS LATERALES POR FUERA DE LA HÉLICE Figura: representación del arreglo helicoidal en las proteínas. Un grupo muy diverso de proteínas contiene estructuras hélice-: las queratinas, que es un grupo de proteínas fibrosas poseen estructuras que están básicamente compuestas por ésta estructura secundaria. Estas proteínas son los componentes mayoritarios del pelo y la piel. La rigidez de estos tejidos depende de la presencia de puentes disulfuro en las proteínas. A diferencia de las 94 queratinas, la hemoglobina posee sólo el 80 % de hélice- y es una proteína globular y flexible. Puentes de hidrógeno. Una hélice- está estabilizada por puentes de hidrógeno entre los oxígenos de los grupos carbonilo del enlace peptídico y los hidrógenos de las amidas que son parte del esqueleto del polipéptido (ver figura anterior). Los puentes de hidrógeno se forman desde el grupo carbonilo de un enlace peptídico hasta el hidrógeno de la amida del cuarto enlace peptídico siguiente (o anterior en la parte media de la hélice), esto le da a la estructura su carácter helicoidal. De tal forma que todos los residuos que participan en la hélice están unidos por puentes de hidrógeno. Número de aminoácidos por vuelta de hélice. Cada vuelta de una hélice-alfa contiene 3.6 residuos; lo anterior indica que los residuos que están espaciados cada tres o cuatro residuos en la secuencia primaria, quedan estrechamente unidos por puentes de hidrógeno cuando se adquiere esta estructura secundaria. Algunos aminoácidos no permiten la formación de hélice-. La prolina no permite la formación de esta estructura secundaria porque su grupo amino no es geométricamente compatible con la espiral derecha de la hélice-alfa; por el contrario produce un cambio en la estructura que interrumpe la estructura helicoidal. Una gran número de aminoácidos cargados como glutamato, aspartato, histidina, lisina o arginina, pueden también interrumpir la estructura helicoidal al formar enlaces ionicos o al repelerse electrostáticamente. Finalmente, los aminoácidos con cadenas laterales voluminosas como el triptofano o aquellos que las tienen ramificadas en el carbono beta, es decir, el primer carbono del grupo R, como la valina o isoleucina pueden, dependiendo del número presente, interferir con la formación de la estructura secundaria. La hoja beta es otra forma de estructura secundaria en la cual todos los componentes del enlace peptídico están involucrados en la formación de puentes de hidrógeno: 95 Figura: representación del arreglo plano en las proteínas. Las superficies de las hojas beta aparecen plegadas y, por tanto, a menudo se les denomina como “hojas beta plegadas”. Cuando se realizan ilustraciones de esta estructura secundaria en la proteína, se representa con flechas anchas. Figura: representación de un segmento de hojas plegadas. A diferencia de las hélice-, las hojas , están compuestas por dos segmentos de la cadena polipeptídica. En esta estructura secundaria, los puentes de hidrógeno, que se forman, están perpendiculares al esqueleto del polipéptido. Si los segmentos, además, forman parte de cadenas polipeptídicas independientes, a la estructura secundaria formada se le denomina hebra . 96 Una hoja beta puede estar formada por dos o más cadenas o segmentos polipeptídicos, arreglados de manera paralela, es decir, con los grupos amino y carboxilo terminales de la estructura secundaria alineados hacia el mismo lado. El arreglo también puede ser antiparalelo, en donde los segmentos amino y carboxilo terminales están alternados: Hojas antiparalelas Hojas paralelas C-terminal N-terminal N-terminal C-terminal Figura: representación de hojas antiparalelas y paralelas Cuando se forman los puentes de hidrógeno entre cadenas polipeptídicas independientes, se denominan intercaterarios, los que se forman con una misma cadena son intracatenarios. En las proteínas globulares, las hojas beta siempre tienen un enrollamiento o torsión hacia la derecha. Generalmente estas estructuras se encuentran en los núcleos de las proteínas. Así como las hélice- y las hojas están presentes en las proteínas fibrosas y globulares, existe un número de enfermedades que resultan del almacenamiento anormal de proteínas fibrosas, que se denominan proteínas amieloides. Por ejemplo estas proteínas se generan en el cerebro de individuos con la enfermedad de Alzheimer, y están compuestas de fibrillas de hojas beta plegadas cuya estructura tridimensional es prácticamente idéntica a las fibrillas de la seda. 97 Las vueltas cambian la dirección de la cadena polipeptídica ayudando a formar la forma compacta y globular. Se encuentran a menudo en la superficie de las proteínas y generalmente posees residuos cargados. Estas vueltas poseen el nombre de reversas porque frecuentemente conectan hebras beta sucesivas que están formadas de hojas antiparalelas. Las vueltas están compuestas generalmente de cuatro aminoácidos uno de los cuales puede ser una prolina, el residuo que hace un rizo en la cadena polipeptídica. La glicina, que es el aminoácidos que tiene el grupo R mas pequeño, también se encuentra frecuentemente formando vueltas . Las vueltas se estabilizan por la formación de puentes de hidrógeno y enlaces ionicos. Aproximadamente la mitad de la estructura secundaria de una proteína globular promedio está formada por estructuras hélice- y/o hojas . El resto se describe como rizos, bucles o conformaciones enrolladas. Esta estructura secundaria no repetitiva no se encuentra al azar, simplemente posee un grado de regularidad menor que las descritas anteriormente. El término de conformación enrollada también se utiliza para describir a la proteína cuando ha sido desnaturalizada. Las proteínas globulares están construidas por la combinación de elementos de estructura secundaria (hélice-, hojas y estructuras no repetitivas). Esta estructura secundaria forma el núcleo de la proteína que es el interior de la molécula en su estructura tridimensional. La estructura secundaria está conectada en la superficie de la proteína por rizos o bucles (en algunos casos por vueltas beta). Las estructuras supersecundarias se producen al empaquetar las cadenas laterales de elementos de estructura secundaria adyacentes. Por ejemplo las hélice-alfa y hojas beta adyacentes en la secuencia de aminoácidos están también usualmente adyacentes en la estructura final plegada de la proteína. Algunos de los motivos más comunes se muestran a continuación: 98 UNIDAD -- hélice- representación lineal Hojas (paralelas) Clave o llave griega representaci ón lineal Meandro representación lineal 99 vuelta Figura: representación de algunos motivos estructurales comunes e las proteínas. La estructura primaria de una cadena polipeptídica determina su estructura terciaria. La estructura terciaria se refiere al plegamiento de dominios, que son las unidades básicas de estructura y función, y el arreglo final de los dominios en el polipéptido. La estructura de las proteínas globulares es solución acuosa es compacta, con una gran densidad (empaquetamiento) de los átomos en el núcleo de la molécula. Las cadenas hidrofóbicas se encuentran en el interior, por el contrario, los grupos hidrofílicos se encuentran generalmente en la superficie de la molécula. Todos los grupos hidrofílicos, incluyendo los que forman parte del enlace peptídico, están involucrados en la formación de puentes de hidrógeno o interacciones electrostáticas de otro tipo. De hecho, la función de la estructura secundaria (hélices- y hojas ), es proveer de la máxima posibilidad para hacer este tipo de interacciones en el interior de la proteína, evitando así que moléculas de agua queden atrapadas inespecíficamente en el interior de las proteínas, interrumpiendo su integridad. A continuación se muestran proteínas cuya estructura terciaria está compuesta en su mayoría de hélices-alfa, hojas beta o su combinación: Subunidad de la hemoglobina (principalmente hélices-), dominio VL de una inmunoglobulina (principalmente hojas ), triosafosfato isomerasa (hélices y hojas ) Los dominios son las unidades funcionales y tridimensionales de un polipéptido. Las cadenas polipeptídicas que son mayores a 200 aminoácidos en longitud consisten generalmente de dos o más dominios. El núcleo de un dominio está construido por combinaciones de estructura supersecundaria o motivos. El plegamiento de un dominio en una proteína generalmente es independiente de los otros dominios (si existen). De ahí que cada dominio 100 posea características que lo hacen plegarse independientemente del resto del polipéptido. La única estructura tridimensional de cada polipéptido está determinada por la secuencia de aminoácidos que lo componen. Las interacciones de las cadenas laterales de los residuos de la proteína guían al polipéptido para formar una estructura compacta. Cuatro tipos de interacciones cooperan para la estabilización de la estructura terciaria de las proteínas: Un puente disulfuro es un enlace covalente formado por dos grupos sulfidrilo (-SH), cada uno de ellos perteneciente a un residuo de cisteína, se unen de manera covalente para formar un residuo de cistína. Los dos residuos que forman al puente, pueden estar separados por muchos aminoácidos en la secuencia o bien pueden pertenecer a diferentes cadenas polipeptídicas; el plegamiento de la(s) cadena(s) polipeptídicas, lleva a los residuos de cisteína a estar muy próximos, lo que permite la formación del enlace disulfuro. La formación de este enlace estabiliza la estructura tridimensional de la proteína: 101 Figura: representación de la formación de un puente disulfuro. Los aminoácidos con cadenas laterales no polares tienden a localizarce en el interior de la proteína, en donde se asocian con otros aminoácidos con cadenas laterales no polares para alcanzar la máxima estabilidad posible. En general los aminoácidos polares tienden a encontrares en la superficie de las proteínas. Este arreglo general está invertido en algunas proteínas de membrana que forman poros o canales, en donde los aminoácidos con cadenas laterales no polares están en contacto con los lípidos componentes de la bicapa lipídica de la membrana y los aminoácidos polares están en el centro de la molécula formando el poro hidrofílico o canal. Dentro de estas internaciones se encuentran las fuerzas de van der Waals. 102 Figura: representación de la formación de una interacción hidrofóbica Los aminoácidos con cadenas laterales que contienen átomos de hidrógeno unidos a átomos de oxígeno o nitrógeno, como los grupos alcohol de la serina y treonina, pueden formar puentes de hidrógeno con átomos ricos en electrones, como el oxígeno del grupo carboxilo o bien el oxígeno del grupo carbonilo del enlace peptídico. La formación de los puentes de hidrógeno entre los grupos polares en la superficie de la proteína y el solvente acuoso que la contiene, incrementa su estabilidad. 103 Figura: representación de un puente de hidrógeno entre residuos de aminoácidos. Los grupos cargados negativamente que se encuentran en las cadenas laterales de algunos residuos de las proteínas como el grupo carboxilo (COO-) en la cadena lateral del aspartato o glutamato, pueden interactuar con cadenas laterales cargadas positivamente como el grupo epsilon amino de la lisina. 104 Figura: representación de un enlace ionico entre residuos de aminoácidos con cadenas laterales cargadas. Se acepta de manera general que la información necesaria para el plegamiento correcto de una proteína está contenido en la estructura primaria. Partiendo de esa premisa, es difícil explicar porqué algunas proteínas cuando carecen de estructura, es decir, cuando están desnaturalizadas o desplegadas, no alcanzan a formar su estructura biológicamente funcional, denominada nativa. Es claro que la estructura tridimensional debe empezar a formarse cuando el polipéptido empieza a emerger del ribosoma. En los casos en que durante la síntesis del polipéptido la estructura tridimensional no es completada de manera espontánea, existen proteínas llamadas chaperonas o chaperoninas que ayudan al polipéptido a llegar a su estructura nativa. Muchas proteínas consisten de una sola cadena polipeptídica, debido a esto se les denomina proteínas monoméricas o simplemente monómeros. 105 Muchas otras proteínas están formadas por dos o más cadenas polipeptídicas que pueden ser iguales o diferentes, cada una de estas cadenas pueden plegarse antes, durante e incluso después de su asociación para formar el oligómero. Después de la asociación u oligomerización, de los monómeros se obtiene la estructura cuaternaria de la proteína en cuestión. Si en la proteína solo existen dos subunidades, entonces se denomina dímero y puede ser homodímero o heterodímero, dependiendo de si las cadenas de los monómeros son iguales o diferentes, en general también pueden denominarse proteínas multiméricas. Figura: estructura tridimensional de un oligómero Se muestra l estructura de la triosafosfato isomerasa Las subunidades pueden mantenerse juntas en el oligómero por interacciones no covalentes (interacciones hidrofóbicas, puentes de hidrógeno o enlaces iónicos), como en la triosafosfato isomerasa o bien unidas por enlaces covalentes generalmente enlaces disulfuro, como en la insulina. Las subuidades pueden trabajar independientemente como en la triptofano sintasa o de manera concertada como en la triosafosfato isomerasa o la hemoglobina. Por su permanencia en las células: constitutivas, se sintetizan en tasas casi constantes. Son las encargadas de las secciones robustas del metabolismo, aquellas 106 proteínas sin las cuales a los seres vivos nos cuesta mucho trabajo sobrevivir. Recuérdese la carencia de Insulina en la diabetes melitus en los mamíferos, o la fenilcetonuria en los humanos o el veneno neurotóxico de los crótalos o los arácnidos que les permite inmovilizar a sus presas. adaptativas o inducibles se sintetizan en tasas que varían según las necesidades celulares. Por ejemplo, las bacterias únicamente producirán las enzimas necesarias para incorporar un nutriente desde el exterior hasta el interior celulas, si éste está presente en el medio extracelular. O bien el número de transportadores de glucosa en el citoplasma de nuestras células en condiciones de inanición. Estructurales como la colágena, elastina y fibrinógeno que se encargas de dar soporte a diversas estructuras celulares, además encontramos en esta clasificación a las proteínas que forman al citoesqueleto, los cilios, los flagelos, los microtúbulos, etc. Enzimas proteínas globulares Muchas proteínas transmembranales o proteínas que son secretadas poseen una señal en el extremo N-terminal de 13-36 residuos predominantemente hidrofóbicos que es reconocida por una proteína denominada SRP (partícula de reconocimiento de señal). Esta proteína se une a una señal en el polipéptido para un receptor en la membrana (en el retículo endoplásmico rugoso en los eucariontes o en la membrana plasmática en procariontes). Las proteínas que poseen este péptido señal se denominan preproteínas o si también contienen propéptidos: preproproteínas. (como la papaina: proteasa de la semilla de la papaya que se utiliza como ablandador de carnes) a las cuales para ser activas hay que removerles el péptido señal y el propéptido: Prepropapaina ·········· propapaina péptido señal papaina propéptido 107 En el caso de las proteínas membranales, una vez que el péptido señal a atravesado la membrana, es cortado específicamente por peptidasas de señal. La insulina y la colágena son preproproteínas, que junto con otros polipéptidos, necesitan de los siguientes cortes proteolíticos secuenciales: 1.- remoción de la Met inicial; 2.- remoción de péptidos señal; y 3.- corte de los propéptidos. Existen las poliproteínas que son polipéptidos que contienen la secuencia para dos ó más proteínas, por ejemplo algunas hormonas, algunas proteínas de los virus polio y del SIDA además de la ubiquitina. En estos polipéptidos existen sitios de corte específicos para proteasas, las cuales dan origen al número de proteínas especificado en la poliproteína (existen también polipéptidos que contienen a dos enzima o cuando menos dos mecanismos catalíticos diferentes, por ejemplo la 3-fosfoglicerato-cinasa/triosafosfato isomerasa de Termotoga maritima. Como dato importante hay que mencionar que actualmente se hacen grandes esfuerzos para obtener un inhibidor especifico contra la actividad de la proteasa del VIH (que cataliza un paso esencial en el ciclo viral) como un mecanismo para curar esta terrible enfermedad. Tanto en proteínas farnesiladas o geranilgeraniladas, la proteína es sintetizada con la secuencia carboxilo terminal CaaX, en donde “C” es un residuo de cisteína, “a” en a menudo un aminoácido alifático y “X” es cualquier aminoácido. Después de que el grupo prenilo es añadido al enlace tioeter con el residuo de Cys, el tripéptido aaX es hidrolíticamente removido y el nuevo carboxilo terminal es esterificado con un grupo metil (rojo en la figura). Cuando X es Ala, Met, o Ser, la proteína es farnesilada (arriba en la figura), por el contrario, cuando es Leu es geranilgeranilada. 108 Figura: proteínas farnesiladas (arriba) o geranilgeraniladas (abajo) Las enzimas son proteínas que incrementan la velocidad de una reacción química y no se consumen durante la misma (algunos tipos de ARN pueden actuar como enzimas, usualmente rompen y sintetizan enlaces fosfodiester; a estas moléculas se les denomina “ribozimas” y se encuentran en muy baja proporción en la naturaleza). Las moléculas de enzimas contienen hendiduras o cavidades denominadas sitio activo. El sitio activo está formado por las cadenas laterales de residuos específicos, lo que ocasiona que tenga un arreglo tridimensional particular, diferente al resto de la proteína. Este sitio es afín por la estructura tridimensional del sustrato: enzima 109 + sustrato sitio activo vacío sitio activo ocupado Figura: representación de la formación del complejo enzima-sustrato. El sitio activo la enzima (E) une al substrato (S) formando un complejo enzima-substrato (ES). En el complejo ES, E transforma a S en él o los productos, formando el complejo enzima-producto (EP), finalmente la enzima libera del sitio activo a P, regenerándose. E + S ES E + P La mayoría de las reacciones catalizadas por enzimas son muy eficientes y transcurren desde 106 hasta 1014 veces más rápido que la misma reacción no catalizada. Típicamente, cada molécula de enzima es capaz de transformar cada segundo de 100 a 1000 moléculas de substrato en producto. El número de estas moléculas transformadas a producto por molécula de enzima en cada segundo, se conoce como el número de recambio. Enzima Anhidrasa carbónica Corismato mutasa Triosafosfato isomerasa Carboxipeptidasa A AMP nucleosidasa Nucleasa estafilococal Velocidad en ausencia de enzima Velocidad de reacción catalizada Rendimiento 1.3 X 10 –1 2.6 X 10 –5 4.3 X 10 –6 3.0 X 10 –9 1.0 X 10 –11 1.7 X 10 -13 1.0 X 106 50 4300 578 60 95 7.7 X 106 1.9 X 106 1.0 X 109 1.9X 1011 6.0 X 1012 5.6 X 1014 110 Tabla: Eficiencia de las reacciones catalizadas por algunas enzimas. Las enzimas son muy específicas por el substrato de la reacción que catalizan. Interactúan con una o muy pocas moléculas y catalizan únicamente un tipo de reacción, por lo que las moléculas con las que interactúan deben ser muy parecidas, tanto en composición, como en estructura tridimensional. Por ejemplo, en la siguiente figura, en el panel A, se muestra la reacción catalizada por la enzima triosafosfato isomerasa (enzima que cataliza el paso 5 de la glucólisis), en el panel B se muestran inhibidores de la catálisis: A Glu 165 Glu 165 Glu 165 H H H H OH H OH O O P O OH H His 95 DHAP P His 95 H O O P OH Enediol GAP H 3C H 3C B O H O H His 95 111 Figura: A.- Reacción catalizada por la triosafosfato isomerasa; B.- Inhibidores de su catálisis. Nótese el parecido con la estructura de los sustratos y del intermediario Algunas enzimas se asocian con moléculas de carácter no proteíco que son necesarias para el funcionamiento de la enzima, estas moléculas se denominan cofactores. Comúnmente, los factores encontrados en las enzimas incluyen iones metálicos como el Zn2+ o el Fe2+, también pueden ser moléculas orgánicas que se denomina coenzimas como el NAD+, FAD, la conezima A y la C, generalmente las coenzimas son derivados de las vitaminas. A la enzima en ausencia de su cofactor (cuando lo tiene), se le denomina apoenzima, en presencia de su cofactor (cuando lo tiene), se le denomina holoenzima. La apoenzima generalmente carece de actividad biológica. La diferencia entre un cofactor y un grupo prostético, como el grupo hemo, es que este último está unido de manera covalente a la enzima, mientras que el cofactor puede ser removido de la misma con relativa facilidad. Coenzima Reacción Fuente vitamínica Enfermedad Humana por deficiencia Biocitina Carboxilación Biotina * Coenzima A Transferencia de acilos Pantotenato * Coenzimas de Cobalamima Alquilación Cobalamina (B12) anemia perniciosa Coenzimas de flavina Oxidación-reducción Riboflavina (B2) * Acido lipóico Transferencia de acilos * Coenzimas de nicotinamida Oxidación-reducción Nicotinamida (niacina) Pelagra Fosfato de piridoxal Transferencia de grupo amino Piridoxina (B6) * Tetrahidrofolato Transferencia de un grupo de 1 Carbono Acido fólico anemia megaloblástica 112 Tiemina pirofosfato Transferencia de aldehído Tiamina (B1) beriberi Tabla: Relación entre algunas coenzimas y las vitaminas a partir de las cuales se producen. Enfermedades generadas por la deficiencia * no tiene un nombre específico, su aparición es muy rara. La actividad enzimática puede ser regulada, esto quiere decir que dependiendo de los requerimientos metabólicos, las enzimas son activadas o inhibidas, para acelerar o disminuir la velocidad con la que catalizan la reacción, respondiendo así a las diferentes necesidades de sus productos en la célula. La regulación más común es modificando la concentración de su(s) substrato(s). En los eucariontes, muchas enzimas se localizan en organelos específicos en la célula. Esta compartamentalización ayuda a aislar los substratos de la reacción o productos de la misma, de tal forma que no hay competencia de reacciones, de esta manera se provee un medio favorable para la reacción, de tal forma que es posible localizar diferentes partes del metabolismo en diferentes organelos, haciendo a la célula una entidad organizada en donde simultáneamente funcionan miles de enzimas. El mecanismo de acción de una enzima se puede entender desde dos perspectivas. La primera trata a la catálisis desde el punto de vista de los cambios en energía que ocurren durante la reacción; las enzimas proveen una vía alterna, energéticamente favorable que es diferente de la reacción no catalizada. La segunda describe cómo el sitio activo facilita químicamente la catálisis de la enzima. Cambios de energía que ocurren durante la reacción. Virtualmente todas las reacciones químicas tienen una barrera energética que separa a los reactivos, reactantes o substratos de los productos. Esta barrera se denomina energía libre de activación que es la diferencia en energía que existe entre los reactivos y los productos. El lugar donde la energía libre de 113 activación es máxima, se denomina estado de transición. En la siguiente figura se ejemplifica la transformación del reactivo A en el producto B a través del estado de transición T*: A T* B Figura: Representación del cambio en la energía libre de una reacción catalizada enzimáticamente (línea continua) y la misma no catalizada (línea punteada). Energía libre de activación. Este máximo de energía representa el estado de transición en el cual se forma el intermediario rico en energía durante la conversión de los reactivos en los productos. Debido a la gran energía de activación que separa a los reactivos de los productos, a menudo la misma reacción es más lenta si no es catalizada, que si la cataliza una enzima. Velocidad de reacción. Las moléculas que reaccionarán en un evento químico, deben contener suficiente energía para sobrepasar la energía de activación del estado de transición en su camino para transformase en los productos. En ausencia de la enzima, solo una pequeña porción de la población de estas moléculas posee la energía suficiente para realizar la transición hacia los productos. La velocidad 114 de la reacción estará determinada por el número de moléculas que se encuentren en ese estado energético particular. En general, al disminuir la energía de activación, la mayoría de las moléculas tienen energía suficiente para pasar sobre el estado de transición y por tanto aumenten la velocidad de la reacción. Vía de reacción alterna. Una enzima permite que una reacción se lleve a cabo rápidamente bajo las condiciones que reinan en la célula. Lo anterior se realiza al disminuir la energía de activación. La enzima no modifica la energía contenida en los reactivos o producto; de la misma forma, no altera el equilibrio de la reacción. Química del sitio activo. El sitio activo de las enzimas no es un receptáculo pasivo para la unión del substrato, por el contrario es una maquinaria molecular muy compleja que emplea una amplia diversidad de mecanismos químicos que facilitan la interconversión de los substratos y los productos. Dentro de los factores que están relacionados con la eficiencia catalítica de las enzimas están los siguientes: Estabilización del estado de transición. El sitio activo de la enzima a menudo actúa como un molde molecular flexible en donde el substrato se une de forma geométricamente adecuada para transformarse en el estado de transición de la molécula. Al estabilizar al substrato en el estado de transición, la enzima aumenta de manera considerable la concentración de este intermediario reactivo que puede ser transformado en el producto(s) y, por tanto, acelerar la reacción. Otros factores. El sitio activo posee grupos catalíticos que incrementan la probabilidad de que se forme el estado de transición. En algunas enzimas, estos grupos pueden participar en una catálisis tipo ácido-base en la cual algunos residuos de aminoácidos proveen o aceptan protones. En otras enzimas, la catálisis involucra la formación temporal de un complejo covalente enzima-substrato. 115 O visualización empírica de la transformación del reactivo en el producto a través del estado de transición. Las conversiones de reactivos catalizadas por enzimas pueden ser visualizadas de la siguiente forma: ¿Cómo quitarle la envoltura a un chocolate? En esta visualización, el chocolate envuelto es el substrato. Es claro que la envoltura no se retirará del chocolate de manera espontánea y que se necesita de energía externa aplicada de manera adecuada para que el proceso se lleve a cabo. En este caso las manos funcionarán como la enzima chocolatasa, cuyo papel específico en esta naturaleza ficticia es precisamente retirar la envoltura de los chocolates. Lo primero que sucederá es que las manos tomarán al chocolate envuelto, es decir, se formará ES. Los arreglos necesarios realizados por los dedos, que en este caso ejemplifican a los residuos de aminoácidos del sitio catalítico de la chocolatasa, llevan al substrato (chocolate envuelto) a un estado en el cual la envoltura se ha retirado parcialmente, pero no del todo. Este momento ejemplifica al estado de transición, que con un poco más de inversión de energía, logra convertirse en los productos que son el chocolate más la envoltura. 116 Por supuesto este proceso no termina en este lugar, no tiene sentido catalizar una reacción si el o los productos de ésta no se utilizan como substratos de otras reacciones. Para qué desenvolver al chocolate si no ha de ser comido, por tanto, existe otra enzima que es una utilizadora de chocolate y otra que es la desechadora, que se deshace de la envoltura. Nótese que el ejemplo lejos de representar la realidad, hace suponer la inmensa cantidad de reacciones que se pueden catalizar en los sistemas vivientes. Las enzimas pueden ser aisladas de las células u organismos, para estudiar sus propiedades in vitro es decir, en un tubo de ensayo. Las diferentes enzimas muestran diferentes respuestas a los cambios en la concentración de substrato, temperatura y pH. Velocidad máxima: la velocidad de una reacción (v) es el número de moléculas de substrato convertidas en producto por unidad de tiempo y usualmente se expresa en µmoles de producto formadas por minuto. La velocidad de una reacción catalizada por una enzima, aumenta conforme se incrementa la concentración de substrato hasta que se llega a una velocidad máxima (Vmax), a partir de la cual la velocidad de la reacción, es independiente de la cantidad de substrato. El que la velocidad no pueda seguirse incrementando, refleja la saturación del sitio activo con el substrato. Vmax 0 Substrato Figura: representación de una cinética típicamente michaeliana. Vmax = velocidad de saturación o máxima. 117 La mayoría de las enzimas muestran cinéticas del tipo hipérbola rectangular como describieron en 1913 por primera vez Leonor Michaelis y Maud Menten. Este trazo se obtiene al graficar la velocidad de la reacción enzimática vs. La concentración de Substrato; este comportamiento se describe por ejemplo para la disociación del Oxígeno de la mioglobina. Existen algunas enzimas que se denominan “alostéricas”, que frecuentemente poseen una curva tipo sigmoide (en forma de S), que es similar a la mostrada para la disociación del Oxígeno de la hemoglobina. Hiperbólica (comportamiento cinético michaeliano) Sigmoide alostérico) 0 (comportamiento cinético Substrato Figura: representación de una cinética michaeliana y una alostérica. Incremento de la velocidad con la temperatura: En general, la velocidad de la reacción se incrementa con la temperatura hasta que un punto máximo es alcanzado. Este incremento se debe a que aumenta el número de moléculas ricas en energía que pueden pasar la barrera energética de estado de transición, para formar a los productos. Decremento de la velocidad con la temperatura: la elevación excesiva de la temperatura del medio que contiene a las enzimas, resulta en un decremento de la velocidad como resultado de la desnaturalización, es decir, la pérdida de la estructura tridimensional de las enzimas. zona de reactivación 118 máximo de actividad Zona inactivación 0 de Temperatura Figura: dependencia de la actividad enzimática con la temperatura Efecto del pH en la ionización del sitio activo: la concentración de H+ afecta la velocidad de la reacción en muchas formas. Primero el proceso catalítico usualmente requiere de que la enzima y el substrato tengan grupos químicos en una forma ionica particular para poder interactuar. Por ejemplo la actividad catalítica puede necesitar a un grupo amino, por ejemplo de una lisina en estado protonado (-NH3+) o no (-NH2+), el pH modifica este estado y por tanto a la velocidad de la reacción. Efecto del pH para la desnaturalización de la enzima: pH extremos pueden ocasionar la desnaturalización de las enzimas, debido a que la estructura con estos cambios es posible modificar las interacciones ionicas que intervienen en la estabilidad de la enzima en su estado nativo: 100 pepsina 50 tripsina fosfatasa alcalina 0 0 1 2 3 4 5 6 7 8 9 10 11 pH Figura: efecto de la variación en el pH sobre la actividad enzimática. El pH óptimo varía para las diferentes enzimas: el pH al cual las enzimas adquieren su máxima actividad es diferente para cada una de ellas y 119 depende de la secuencia de aminoácidos que las conforman, por supuesto, también está relacionado con el microambiente celular en el cual desarrollan su catálisis. Por ejemplo la pepsina que es una enzima digestiva que actúa en el estómago, posee un pH óptimo de alrededor de 2 unidades, por el contrario otras enzimas que actúan a pH neutro, se desnaturalizan a pH alcalino o ácido. Las enzimas al igual que otras proteínas tienen pesos moleculares que van desde 12,000 hasta más de un millón de kD. Algunas requieren de grupos diferentes a los aminoácidos para realizar su catálisis. Otras requieren de un cofactor que puede ser uno o más iones inorgánicos. Otras enzimas requieren de una coenzima. Ver las siguientes Tablas ION EJEMPLO DE ENZIMA Fe2+ o Fe3+ citocromo oxidasa, catalasa, peroxidasa K+ piruvato cinasa Mg2+ hexoquinasa, glucosa-6-fosfatasa, piruvato cinasa Mn2+ arginasa, ribonucleótido reductasa Mo dinitrogenasa, Ni2+ ureasa Se glutatión peroxidasa Zn2+ pirofosfatasa 120 Tabla: ejemplos de enzimas que requieren de iones inorgánicos para la catálisis. Ejemplo deCoenzima grupos transferidos Precursor en la dieta de los mamíferos Tiamina pirofosfato aldehídos tiamina Flavín adenin dinucleótido FAD Nicoinamida adenin dinucleótido NAD niacina) Coenzima A electrones ion hidruro (:H-) grupos acilo (vitamina B1) riboflavina (vitamina B2) ácido nicotínico ácido pantoténico Fosfato de piridoxal grupos amino piridoxina (vitamina B6) 5´-desoxiadenosilcobalamina (conezima B12) Biocina átomos de H y grupos alquilo CO2 vitamina B12 Biotina Tabla: algunas coenzimas, sus grupos de transferencia y sus precursores. Otras coenzimas: NADP Coenzima Q Biotina Definiciones. Grupo prostético: coenzima o metal unido covalentemente a la enzima. De características no proteicas Holoenzima: es una enzima cuya actividad catalítica depende de tener unido de manera covalente a su grupo prostético. Esto quiere decir que bajo ciertas condiciones el grupo prostético puede ser removido de la enzima, por motivos regulatorios, o bien existen estados en los cuales la enzima carece de este grupo, por ejemplo recién sintetizada la cadena de aminoácidos; la presencia del grupo prostético es una modificación postraduccional. Al estado de la enzima que carece del grupo prostético se le denomina apoenzima. Las enzimas que contienen grupos prostéticos no son 121 ACIDOS NUCLEICOS Los ácidos nucleicos desempeñan una importante función en el almacenamiento, transferencia y expresión de la información genética de cada célula, tejido y organismo. Los planos para la construcción de un organismo están codificados en su ácido nucleico, gran parte del desarrollo físico de un organismo a lo largo de su vida, así como, las proteínas que elaborarán sus células y las funciones que realizarán están todas registradas en estas moléculas. Los ácidos nucleicos pueden considerarse polímeros de unidades monoméricas o nucleótidos, en ocasiones llegan a tener centenares de millones de unidades y por ello se les suele asignar la denominación genérica de polinucleótidos. Los polímeros pequeños, que contienen tan solo algunos residuos, se denominan oligonucleótidos. El esqueleto covalente del ADN (y ARN) esta formado por unidades desoxirribosa ( o ribosa) alternados con grupos fosfato, formando una región invariable y común a todos los ácidos nucleicos. Esta región del ADN presenta direccionalidad (un extremo de la cadena tiene un grupo 3´hidroxilo y el otro uno 5´hidroxilo) y permanece inalterada a lo largo de toda la molécula por lo que juega un papel estructural muy importante. Las bases heterocíclicas conectadas al esqueleto covalente por enlaces N-glucosídicos sobresalen de las cadenas laterales y forman la región variable del ADN y ARN ya que la secuencia de las bases (A,G,C y T en ADN y A,G.C. y U en ARN) sirve de molde para especificar un ordenamiento particular que puede variar de una molécula a otra. Los ácidos nucleicos son metaestables ya que tienen favorecida termodinámicamente su ruptura. 122 Un ácido nucleico consiste de una secuencia de subunidades unidas químicamente. Cada subunidad, contiene una base nitrogenada (anillo heterocíclico de átomos de carbono y nitrógeno), una azúcar pentosa (anillo de 5 carbonos) y un grupo fosfato: Figura: representación de una cadena de nucleótidos 123 Las pirimidinas que tienen un anillo de seis miembros Figura: las pirimidinas. Las purinas que tienen un anillo de 5 miembros fusionado a uno de 6: Figura: las purinas 124 Cada ácido nucleico contiene 4 tipos de bases. Las mismas dos purinas, adenina (A) y guanina (G) están presentes en el ADN y en el ARN. Las dos pirimidinas, en el ADN son citosina (C) y timina (T), en el ARN, la timina se cambia por el uracilo (U). La única diferencia entre el uracilo y la timina es la presencia de un substituyente metil en la posición C5. De tal manera que en el ADN solo existen A,G,C y T, mientras que en el ARN contiene A,G,C y U. La base nitrogenada esta unida a la posición 1 del anillo de la pentosa por medio de un enlace glucosídico a la posición N1 de las pirimidinas o a la N9 de las purinas. Para evitar ambigüedades entre la numeración de los heterociclos y el anillo del azúcar, las posiciones de la pentosa se numeran como primos (´). Una base unida a una azúcar se denomina nucleósido, cuando se une un fosfato, la base-azúcar-fosfato se denomina nucleotido: Base Nucleosido Nucleotido Abreviatura ARN ADN Adenina adenosina ácido adenílico AMP dAMP Guanina guanosina ácido guanilico GMP dGMP Citosina Timina Uracilo citidina timidina uridina ácido citidilico ácido timidilico ácido uridilico CMP dCMP dTMP UMP Tabla: los diferentes arreglos de los nucleótidos. Los nucleótidos son los bloques de construcción a partir de los cuales se construyen los ácidos nucleicos. Los nucleótidos están unidos en una cadena polinucleotídica con un esqueleto que consiste de series alternadas de residuos de azúcar y fosfato. La posición 5´ de un anillo de pentosa está conectada a la posición 3´ de la siguiente pentosa vía un grupo fosfato (ver Figura 1). Por lo tanto, se dice que el esqueleto de azúcar-fosfato consiste de un enlace fosfodiester en posición 5´-3´. Las bases nitrogenadas están por fuera del esqueleto. El nucleótido terminal en uno de los extremos de la cadena tiene el grupo 5´ libre; y al otro lado de la cadena tiene un grupo 3´ libre. Es una convención escribir las secuencias de ácidos nucleicos en la dirección 5´-3´, de tal forma que el extremo 5´ está a la izquierda y el 3´ a la derecha. Cuando el ADN o el ARN son rotos en sus nucleótidos constituyentes, la ruptura puede llevarse a cabo en cualquiera de los lados de los enlaces fosfodiester. Dependiendo de las circunstancias, los nucleótidos tienen su grupo fosfato unido a cualquiera de las posiciones 5´ ó 3´ de la pentosa: 125 Figura: posibilidades del acomodo de los grupos fosfato en las ribosas de los nucleótidos. Todos los nucleótidos pueden existir en una forma en la cual hay más de un grupo fosfato unido a la posición 5´ por ejemplo: Figura: diferentes estados de fosforilación de un nucleótido Todos los enlaces (, y ) son ricos en energía, la cual se utiliza como fuente para múltiples actividades celulares. Los nucleótidos 5´trifosfatados son los precursores de la síntesis de los ácidos nucleicos. 126 En los ácidos nucleicos, se encuentran dos tipos de pentosas. Esta característica diferencia al ADN del ARN y les da el nombre a los dos tipos de ácidos nucleicos: Figura: diferencias entre un ribonucleótido y un desoxirribonucleótido En el ADN, la pentosa es la 2-desoxiribosa y en el ARN es la ribosa. La diferencia la hace la presencia o ausencia de un grupo hidroxilo en la posición 2 del anillo. La idea de que el material genético es un ácido nucléico surge con el experimento de transformación de Griffith en 1928. En los ratones, la bacteria Pneumococcus ocasiona la muerte por neumonía. La virulencia de la bacteria está determinada por la cápsula de polisacáridos que forma parte de la superficie celular y que le permite escapar de la destrucción por el hospedero. Los diferentes tipos de Pneumococcus (I, II y III), tienen diferentes cápsulas, lo cual lo hace tener una superficie lisa (L). 127 Cada tipo de Pneumococcus puede generar una variante incapaz de generar la cápsula. Estas bacterias, tienen una cubierta rugosa (R) y son avirulentas; al no tener la protección contra la destrucción contra la defensa del hospedero, no ocasionan la enfermedad del ratón. Cuando se mata a las bacterias L por medio de tratamiento térmico, pierden la capacidad de infectar al ratón. Pero, al combinarse estas últimas con bacterias R, se obtiene un resultado diferente. Cuando ambas bacterias, Lisas inactivas y Rugosas no virulentas, se inyectan juntas, el ratón muere por neumonía. Además, bacterias S, pueden ser recuperadas del animal muerto. Tipo de Pneumococcus 1.- Bacterias L vivas 2.- Bacterias L muertas por calor 3.- Bacterias R vivas 4.- Mezcla de 2 y 3 Efecto en el ratón (después de la inyección) muere vive vive muere Tabla: resultados obtenidos por Griffith. En el experimento original, las bacterias L muertas, eran del tipo III. Las bacterias R vivas derivaron del tipo II. La bacteria virulenta recuperada, presenta cápsula de tipo III. Por lo tanto, alguna propiedad de las bacterias L tipo III pueden transformar a las bacterias vivas R, de tal forma que estas últimas tienen cápsula de polisacáridos tipo III y por tanto son virulentas. El componente de las bacterias muertas, responsable de la transformación, se denominó “principio transformante”. Este material pudo ser aislado al desarrollar un sistema libre de células, en el cual el extracto de las bacterias L muertas pudo ser agregados a las bacterias R vivas antes de ser inyectadas al ratón. En 1944, Avery y colaboradores aislaron el principio transformante y demostraron que es ácido desoxiribonucleico (ADN). En ese entonces, no se tenía conocimiento de que el ADN era un componente de las células de Pneumococcus, pero décadas atrás se reconocía como parte principal de 128 los cromosomas eucariontes. Lo cual unificó que las bases de la herencia para procariontes y eucariontes. Al discutir los resultados de la transformación, Avery escribió: “Si estamos en lo correcto, esto significa que los ácidos nucléicos no son meramente importantes desde el punto de vista estructural, sino substancias funcionalmente que determinan las actividades bioquímicas y características especificas de las células, de tal forma que al conocer esta substancia química es posible inducir cambios predecibles en las células.” La observación de que las bases están presentes en diferentes cantidades en el ADN de diferentes especies llevó al concepto de que la secuencia de bases es la forma en la cual la información genética es transportada. Existen 3 evidencias que llevaron a Watson y Crick (en 1953) a la construcción del modelo de la doble hélice del ADN: 1.- La difracción de rayos X muestra que el ADN tiene una forma de hélice regular, teniendo una vuelta casa 34 Å (3.4 nm) con un diámetro de aproximadamente 20 Å (2 nm). De acuerdo a lo anterior, debe tener 10 nucleótidos por vuelta. 2.- La densidad del ADN sugiere que la hélice debe contener cadenas de polinucleótidos. El diámetro constante de la hélice puede ser explicado si las bases de cada cara de la cadena están hacia adentro y están restringidas de tal manera que las purinas están siempre opuestas a las pirimidinas, evitando así los pares purina-purina o pirimidina-pirimidina. 3.- La proporción de G es siempre la misma que la de C en el ADN y las proporciones de A son siempre las mismas que las de T. De tal forma que la composición de cualquier ADN puede ser descrita por la proporción de sus bases C+G la cual varia entre 26 y 74 % dependiendo de la especie. Watson y Crick propusieron que las dos cadenas de polinucléotidos en la doble hélice están asociadas por puentes de hidrógeno entre las bases nitrogenadas: La siguiente figura muestra que usualmente, G solo puede hacer puentes de hidrógeno con G, por el contrario, A solo puede unirse con T. Estas reacciones se describen como pares de bases y las bases apareadas (G con C y A con T) son complementarias. 129 Figura: complementariedad de los pares de bases de Watson y Crick. El modelo requiere las dos cadenas de polinucléotidos corriendo en direcciones (antiparalelas). Al observar la hélice, se aprecia que una hebra corre en dirección 5´3´, mientras que su hebra complementaria lo hace en dirección 3´ 5´. Esto se refiere al enlace que se forma entre el grupo fosfato en posición 3´ de un nucleótido y el grupo hidroxilo 5´ en el siguiente nucleótido, de tal forma que en los extremos se encuentra un grupo3’ libre de un lado y uno 5´ del otro. 130 Figura: las cadenas de ADN son antiparalelas. El esqueleto azúcar-fosfato está en el exterior de la hélice y lleva cargas negativas en los grupos fosfato. In vitro, el ADN en solución las cargas se neutralizan por la unión de iones metálicos, típicamente por Na+. In vivo, las cargas son neutralizadas por proteínas cargadas positivamente. Estas proteínas juegan un papel muy importante al determinar la organización del ADN en la célula. Las bases se encuentran en el interior, acomodadas por pares perpendiculares a lo largo del eje de la hélice. Los pares de bases contribuyen a la estabilidad termodinámica de la doble hélice de dos formas. La energía es liberada por la formación de los pares de bases y por las interacciones entre los pares de bases adyacentes: 131 10 pares de bases Figura: el esqueleto de la molécula de ADN. Los puentes de hidrógeno entre las bases en cada cadena libera la energía correspondiente a 3 puentes de hidrógeno por cada par C-G y de dos por cada par A-T. El acoplamiento de las bases es un proceso hidrofóbico que resulta de la interacción entre los sistemas de electrones de los pares de bases. Cada par de bases está involucrado en estas dos interacciones. Las fuerzas de Van der Waals también son importantes en la interacción de los pares de bases. Cada par de bases está girado aproximadamente 37° alrededor del eje de la hélice con relación al siguiente par de bases, de tal suerte que hay 10 pares de bases en cada vuelta completa de la hélice para completar 360°. El giro de las dos hebras alrededor una de la otra, forma a la doble hélice con un surco mayor (aproximadamente 12 Å) y un surco menor (aproximadamente 22 Å). 132 La doble hélice está enredada ala derecha, las vueltas corren en sentido de las manecillas del reloj a lo largo del eje de la hélice. Estas características representan el modelo aceptado para lo que se conoce como forma B del ADN. Surco Mayor Surco Menor Figura: la estructura del ADN. Después de que se demostró que el principio transformante era ADN, se tenía que demostrar que esta molécula provee del material genético en diferentes sistemas. El bacteriofago T2, es un virus que infecta a las células de la bacteria Escherichia coli. Cuando los virus T2 se ponen en contacto con las bacterias, les inyectan algunos materiales. Después de aproximadamente 20 minutos, las células explotan (se lisan) y liberan una gran cantidad de nuevos virus. Hershey y Chase (en 1952) marcaron radioactivamente a fagos T2 en sus componentes de ADN (con 32P) o en los componentes de sus proteínas (con 35S) 133 ADN Proteínas Bacteriofago T2 Figura: representación de la composición de un bacteriofago T2. Infectaron bacterias de Escherichia coli con los fagos marcados (1 en la siguiente Figura) y dejaron continuar el ciclo (2 en la siguiente Figura) 1.- 2.- Figura: representación del experimento de Hershey y Chase 1 Las células de las bacterias infectadas, se rompieron por agitación. La solución de células rotas se centrifugó y se obtuvieron dos fracciones. Una de ellas contenía la cubierta vacía de los fagos (cápside), que fue liberada de la membrana de las bacterias por la agitación. La otra fracción contenía a las bacterias infectadas. La mayoría de la radioactividad del 32P estaba presente el las bacterias infectadas. Los fagos producidos por la infección contenían aproximadamente el 30% de la marca original de 32P y menos del 1% de las proteínas contenidas en los fagos originales: 134 Figura: representación del experimento de Hershey y Chase 2 Este experimento mostró directamente que el ADN de los fagos originales (parentales) entra a la bacteria y se vuelve parte de los fagos resultantes de la infección (progenie), exactamente el patrón de herencia esperado del material genético. Un fago (virus) se reproduce al apoderarse de la maquinaria de la célula hospedera para manufacturar copias de él mismo. El fago procesa el material genético cuyas características son análogas a las de los genomas celulares: es completamente reproducido y está sujeto a las mismas reglas que gobiernan a la herencia. El caso de T2 refuerza la conclusión de que el material genético es el ADN, es parte del genoma de las células o virus. El material genético de todos los organismos y de muchos virus es ADN. Pero algunos virus utilizan un ácido nucleico alternativo, el ácido ribonucleico (ARN) como material genético. Aunque su fórmula química es muy poco diferente de la del ADN, en estas circunstancias juega el mismo papel. Ejemplos de estos virus, es el de la hepatitis, de la gripe o influenza y el de inmunodeficiencia humana. La conclusión es que independientemente de si es ADN o ARN, el material genético de los seres vivos y de los virus es siempre un ácido nucleico. Las proteínas responsables del empaquetamiento del ADN se denominan histonas. Estas proteínas forman parte del alrededor de la mitad de la masa de la cromatina. Hay 5 clases principales de histonas: H1, H2A, H2B, H3 y H4, todas ellas contienen una gran cantidad de residuos cargados positivamente ( Arg y Lys). 135 Histona H1 H2A H2B H3 H4 número de residuos 215 129 125 135 102 Masa %Arg %Lys (kD) UEP* (x10-6 años) 23.0 14.0 13.8 15.3 11.3 1 9 6 13 14 29 11 16 10 11 8 60 60 330 600 Tabla: características de las histonas. *Unidad de periodo evolutivo: es el tiempo en el que la secuencia de aminoácidos de una proteína cambia en 1% después de que dos especies divergieron. Las histonas, se unen ionicamente a los grupos fosfato del ADN cargados negativamente. In vitro, esta interacción, se puede romper con 0.5 M de NaCl. Las histonas están conservadas evolutivamente, su función es tan crítica que no soportan cambios. Las histonas son objeto de modificaciones postraduccionales como metilaciones, acetilaciones y fosforilaciones en residuo específicos (Arg, His, Lys, Ser y Thr). La mayoría son revertidos al alterarse la carga de la proteína, lo que se refleja en su unión con el ADN. Aunque están conservadas evolutivamente, las modificaciones son diferentes dependiendo el tejido o el estado del ciclo celular. Por ejemplo, el 10% de la H2A tiene unido en el grupo de la Lys 119 en el carboxilo terminal a la proteína ubiquitina. En general, esta señal en el citoplasma resulta en la degradación de la proteína. En las células eritroides de embriones de pollo, existe una variante de H1 llamada H5, cuya función es desconocida (los eritrocitos de pollo, a diferencia de los humanos, son nucleados). En 1974 Roger Kornberg, describió al nucleosoma que es el primer nivel de organización de la cromatina. Las evidencias que usó Kornberg para ello fueron: 1.- la cromatina contiene aproximadamente el mismo número de moléculas de histonas H2A, H2B, H3 y H4 y no más de la mitad de H1. 2.- La cristalografía de rayos X indica que e la cromatina existe una estructura regular que se repite cada 100 Å sobre la fibra. Este mismo patrón se observa cuando ADN purificado se mezcla con cantidades equimolares de histonas, excepto H1. 3.- Micrografías electrónicas de la cromatina revelan que consiste de partículas de aproximadamente 100 Å de diámetro conectadas a partir de ADN desnudo (como un collar de cuentas) y son aparentemente las responsables del patrón de rayos X. 136 ADN Desnudo 100 Å 4.- Controlando el tiempo de digestión de la cromatina con la nucleasa micrococal, (que rompe la doble hebra del ADN), se obtienen diferentes estructuras: Monómeros tetrámeros dímeros trímeros Mediante experimentos de electroforesis en gel indican que cada partícula contiene alrededor de 200 pares de bases. 5.- Experimentos de entrecruzamiento, indican que las histonas H3 y H4 se asocian paa formar el heterotetrámero (H3)2(H4)2. Las observaciones de Kornberg lo llevaron a concluir que el nucleosoma, está formado por el octámero (H2A)2(H2B)2(H3)2(H4)2, además de aproximadamente 200 pares de bases de ADN. La quinta histona H1, postuló que estaba asociada de alguna manera en el exterior del nucleosoma. El ADN, se enreda alrededor nucleosoma: Cromatina + nucleasa micrococal cromatosoma de un octámero de histonas para formar el + nucleasa núcleo del nucleosoma micrococal + H1 137 cromatosoma: nucleosoma + H1 núcleo del nucleosoma: 146pb asociados con el octámero El ADN removido por la digestión se denomina ADN de unión. Y varia de especie a especie y de tejido a tejido entre 8 y 114 pares de bases, pero generalmente es de aproximadamente 55pares de bases. Cuando el ADN se replica in vivo, las hebras hijas, inmediatamente son incorporadas en nucleosomas. Cuando el ADN se replica en presencia de cicloheximida (inhibidor de la síntesis de ADN), sólo una hebra hija tiene nucleosomas. A medida que se disminuye la concentración de NaCl en un experimento, hasta la concentración fisiológica, la estructura de zig-zag de la cromatina forma un filamento de 300 Å de grosor en el cual se observan los nucleosomas. La hipótesis más aceptada, dice que el filamento de 300 Å está formado por la suma de los nucleosomas en un solenoide con 6 nucleosomas por vuelta. El solenoide, está estabilizado por las histonas H1 de forma cabeza-cola. Los cromosomas de la metafase depletados de sus histonas presentan un “andamio” fibroso de proteína rodeado por un halo de ADN. Las hebras de ADN forman giros que entran y salen del andamio en aproximadamente el mismo sitio. La mayoría de estos giros, tienen una longitud de entre 15 y 30 µm (45-90 pares de bases), de tal forma que cuando se condensan para formar el filamento de 300 Å, miden 6 µm. De ahí que se prediga que el diámetro de los cromosomas en metafase sea de 1.0 µm. 1.0 µm giro 0.3µm andamio 0.4 µm giro 0.3 µm Figura: Simulación del corte transversal de un cromosoma humano en metafase 138 La hibridación del ADN es el proceso más común para detectar un gen particular o un segmento de un ácido nucleico. Existen muchas variaciones del método básico, el que mas se utiliza es el uso de fragmentos de ADN o ARN marcados radioactivamente conocidos como sondas. De hecho esta metodología es la base de la amplificación controlada de ADN conocida como PCR por sus siglas en inglés Polimerase Chain Reaction o reacción en cadena de la polimerasa que se utiliza para la clonación y secuenciación de ADN. A diferencia del ADN todos los tipos de ARN, son de una sola hebra, la cual que se sintetiza a partir de moldes de ADN. Aún así, los ARNs, tienen estructuras estables (regiones de doble hélice antiparalelas) que les permite tener estructuras tridimensionales. En los ARN los pares de bases son generalmente AU y GC aunque eventualmente existen pares GU. En algunos (tARN) existe complementariedad inteARN que hace que tengan estructuras específicas y estructura terciaria. Dos principios del plegamiento de las proteínas se aplican al ARN: 1.- La estructura está dada por la secuencia de los grupos funcionales de la cadena (aminoácidos en proteínas y nucleotidos en ARN) y 2.- la estructura se forma al sintetizarse la cadena; es importante mencionar que la estructura del ARN que se está sintetizando puede afectar la transcripción de lo que resta de la cadena. En las células el ARN tiene tamaños que van desde 50 hasta decenas de miles de nucleótidos (excepcionalmente puede haber ARNs circulares). La complementariedad de los pares de bases de W-C es cierta para los complejos ADN-ADN, ARN-ARN y ADN-ARN. La evidencia directa de lo anterior, se tuvo al descubrir a la enzima ARN polimerasa, que existe virtualmente en todos los organismos. En una célula de E. coli hay alrededor de 3X103 moléculas de esta enzima. La ARN polimerasa une ribonucleotidos catalizando la formación de un enlace fosfodiester en dirección 3´-5´. Esta reacción ocurre solamente en presencia de ADN. Es decir el ADN especifica a la ARN polimerasa qué nucleótido debe unir, como se puede observar en la siguiente Tabla. 139 A U G C Total X174 Composición Composición predicha observada 0.25 0.33(T) 0.24 0.18 1.0 0.33 0.25 0.18 0.24 1.0 0.32 0.25 0.2 0.23 1.0 Tabla: La composición de bases en el ARN enzimáticamente sintetizado usando como molde el ssDNA (ADN de una dola hebra) del virus X174 En este caso se forma una doble hebra híbrida (ADN-ARN). Cuando el proceso se lleva a cabo en una hebra ADN-ADN el producto de ARN sale rápidamente del templado y las hebras de ADN vuelven a unirse. En este momento el ARN está listo para unirse al ribosoma. El mecanismo de síntesis de ARN es fundamentalmente igual al de ADN, los precursores son ribonucleotidos trifosfato. La síntesis de ARN es un proceso apresurado y su precisión no se acerca a la del ADN Desnaturalización y renaturalización del ADN de doble hebra: Ejemplo: gen (ADN): 5´ AATTCGTATCGATTAGCTGCGTGCAGTACGTC 3´ 3´ TTAAGCATAGCTAATCGACGCACGTCATGCAG 5´ ARN: 5´ AAUUCGUAUCGAUUAGCUGCGUGCAGUACGUC 3´ PROTEÍNA 1 3´ UUAAGCAUAGCUAAUCGACGCACGUCAUGCAG 5´ PROTEÍNA 2 La ARN polimerasa reconoce una secuencia específica en la hebra que se va a copiar a esta región específica que únicamente está en una de las hebras se le denomina promotor. En algunos fagos (T/ y SP8), la información está en una de las hebras, en otras (T4 y ), ambas hebras son transcritas, en una se encuentra la información para unas proteínas y en la otra, para otras; lo anterior también sucede también en E. coli . La síntesis de ARN ocurre en una dirección fija: La molécula de 3´-desoxiadenosina, es un inhibidor metabólico análogo a la adenosina que carece del O en posición 3´. Esta molécula se utilizó para determinar que la transcripción no ocurre a partir de ambos extremos de la cadena. El experimento se puede resumir como sigue: E. coli + 3´-desoxiadenosina 3´-desoxiadenosina-trifosfato unida a la cadena en 3´ 140 Como la 3´-desoxiadenosina no tiene el O-3´ la transcripción se detiene, si la dirección de la síntesis del ARN fuera en la dirección contraria (3´-5´) el inhibidor no se uniría. El conocimiento de la función genética del ADN, permitió entender cómo las células traducen el lenguaje de la secuencia de bases en el lenguaje de los polipéptidos. Los ácidos nucleicos no unen específicamente aminoácidos, por lo cual, en 1955, Crick propuso la hipótesis de la molécula adaptadora, para explicar este proceso. Está hipótesis dice que la traducción ocurre a través de un adaptador, y postulaba que cada un de estos adaptadores cargaba un aminoácido y reconocía al codon correspondiente: Polipéptido aa 1 aa 2 aa 3 Adaptadores Acido nucleico Codon 1 Codon 2 Codon 3 aan: aminoácido Figura: representación del mecanismo en el que participa el adaptador Crick sugirió que los adaptadores contenían ARN porque el reconocimiento tendería a ser por pares de bases complementarios. Más o menos al mismo tiempo, Paul Zamecnik y Mahlon Hoagland describieron que en el curso de la síntesis de proteínas, aminoácidos marcados radiactivamente con 14C permanecían unidos durante un tiempo a una fracción de ARN de masa molecular pequeña. Investigaciones más profundas indicaron que este ARN, que fue llamado ARN soluble (sARN), es el tARN, y que equivale a la molécula adaptadora propuesta anteriormente por Crick. En 1965, después de 7 años de esfuerzo, Robert Holley reportó la primera secuencia de bases significativa de un ácido nucleico biológico. Esta secuencia fue el tARN para la alanina (AlatARN) Los obstáculos que Holley tuvo que enfrentar para esta determinación fueron los siguientes: 1.- Todos los organismos contienen muchas especies de tARN, al menos una para cada tipo de aminoácido (i.e. 20). Estas moléculas tienen propiedades casi idénticas y por 141 tanto no son separados fácilmente. Algunas técnicas preparativas tuvieron que ser desarrolladas para que Holley determinara la secuencia del AlatARN. 2.- Holley tuvo que inventar los métodos que fueron utilizados inicialmente para secuenciar el ARN. 3.- Diez de las 76 bases del AlatARN de levadura están modificadas, sus fórmulas estructurales tuvieron que ser elucidadas a pesar de que se encuentran en cantidades menores a un miligramo. La longitud de los tARN varía de especie a especie y en los eucariontes de organelo en organelo, y va desde 60 hasta 95 nucleótidos (18-28 kD), pero la mayoría tiene 76 nucleótidos. D C G G 3´ A - OH C C A 5´ p - G C G C G U C G G C U U G C G m1 G U A UGCG AGGCC U A A GCGC UCCGG G D m2G C T C A D C G GG U A C G C G C G U U m1I I C G Anticodon Figura: secuencia de bases del AlatARN de levadura dibujado en su forma de trébol. Las partes circulares (verde), representan no complementariedad entre las bases. Los símbolos en color representan a los nucleótidos modificados. 142 Casi todos los tARNs, como reconoció Holley, presentan una estructura de trébol. Empezando por el extremo 5´, los tARNs tienen las siguientes características comúnes: 1.- grupo fosfato en extremo 5´. 2.- Un brazo de 7 pares de bases que incluye al nucleótido 5´ y pueden contener pares de bases diferentes a los de Watson-Crick como G-U. A esta región se le denomina como brazo aceptor o brazo del aminoácido, porque el aminoácido es llevado (cargado) en el OH libre del extremo 3´ de esta región. 3.- Un brazo de 3 a 4 pares de bases que termina en un giro que frecuentemente contiene la base modificada dihidrouracilo (D en la Figura), por lo cual se denomina brazo D. 4.- Un brazo de 5 pares de bases que termina en un giro que contiene el anticodon, el triplete de bases que es complementario con el codon en el mARN. A esta región se le denomina brazo del anticodon. 5.- Un brazo de 5 pares de bases que termina en un giro que casi siempre contiene la secuencia TC (en donde representa pseudouridina), esta región es denominada brazo TC o simplemente T. 6.- Todos los tARNs terminan en una secuencia CCA con el OH del extremo 3´ libre 7.- Hay 15 posiciones invariables (siempre tienen la misma base) y 8 posiciones semiinvariantes (contienen sólo una purina o pirimidina) que se presentan en los giros. El sitio de mayor variabilidad en los tARNs se encuentra en el denominado brazo variable, que tiene de 3 a 21 nucleótidos y puede tener una región lineal de 7 o más pares de bases. Una de las características más peculiares de los tARNs es su gran proporción, mayor a 25 %, de modificaciones postranscripcionales o bases hipermodificadas. Casi 80 de esas bases que se encuentran en más de 60 posiciones diferentes, han sido caracterizadas 143 Figura: bases derivadas del uracilo Figura: bases derivadas de la citosina Figura: bases derivadas de la adenina 144 Figura: bases derivadas de la guanina Usualmente estas bases modificadas, son adyacentes a la posición 3´del anticodon. La baja polaridad que presentan, probablemente incrementa la fidelidad de la traducción. Un factor importante es que ninguna de estas bases modificadas es esencial para mantener la integridad estructural del tARN, ni para el reconocimiento por el ribosoma, ni para la reacción de unión con su aminoácido respectivo. La estructura tridimensional del tARN fue resuelta de manera independiente por Alexander Rich y Sung Hou Kim y en un cristal diferente por Aaron Klug en 1974, a través de estudios de cristalografía de rayos X del PhetARN de levadura. La molécula asume una conformación con forma de L, en la cual la longitud de la L está dada por los brazos T y aceptor formando una doble hélice. La parte restante de la L está formada por los brazos D y del codon.