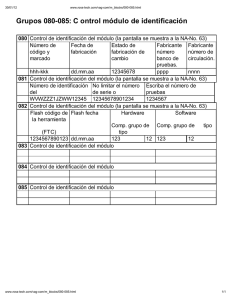
Paquete de Programas para el Análisis y Manejo de Datos
Anuncio

IDAMS Paquete de Programas para el Análisis y Manejo de Datos Desarrollado Internacionalmente Manual de Referencia de WinIDAMS (versión 1.3) Abril de 2008 c UNESCO 2001-2008 Copyright Publicado por UNESCO, Organización de las Naciones Unidas para la Educación, la Ciencia y la Cultura 7, Place de Fontenoy 75352 Paris 07 SP, Francia Tı́tulo de la obra original: WinIDAMS Reference Manual (release 1.3) c 2001-2008 by UNESCO Primera edición en inglés por la UNESCO en 1988 Traducción en español: Prof. Bernardo LIEVANO Profesor de Fisica y Matemáticas Escuela Colombiana de Ingenierı́a, Bogota, Colombia ISBN 92-3-102577-5 (UNESCO - versión en inglés) Prefacio Objetivos de IDAMS La idea en IDAMS, es poner a disposición de los Estados Miembros de UNESCO, exento de costo, un paquete de programas para el manejo y el análisis estadı́stico de datos. IDAMS utilizado en combinación con CDS/ISIS (programas de UNESCO para la administración y recuperación de datos de texto), entrega a los Estados Miembros de un paquete de programas integrado que permite el procesamiento de datos de texto y numéricos de una manera unificada para propósito cientı́fico y administrativo en universidades, institutos de investigación, administraciones nacionales, etc. El objetivo final es ayudar a los Estados Miembros a progresar en la racionalización del manejo de sus diversos sectores de actividad, objetivo crucial para el establecimiento de planes de desarrollo adecuados y las correspondientes monitorı́as de su ejecución. Origen y breve historia de IDAMS IDAMS proviene originalmente del paquete estadı́stico OSIRIS III.2 desarrollado al comienzo de la década de los años 70 en el Instituto para la Investigación Social de la Universidad de Michigan en los Estados Unidos de América. Ha sido y continua siendo enriquecido, modificado y puesto al dia por el Secretariado de la UNESCO con la cooperación de expertos de diferentes paises, a saber: especialistas Bélgas, Británicos, Colombianos, Eslovacos, Estadounidenses, Franceses, Húngaros, Poloneses, Rusos y Ucranianos; de ahı́ el nombre “Internationally Developed Data Analysis and Management Software Package”, en castellano “Paquete de software para el análisis y manejo de datos desarrollado internacionalmente”. Inicialmente, IDAMS se diseñó para computadores grandes de tipo IBM La primera versión (1.2) salió en 1988; tenı́a la mayorı́a de las facilidades de manaejo y análisis de datos. A pesar de que se tomó un número básico de rutinas y programas de OSIRIS III.2 éstos fueron substancialmente modificados y se adicionaron nuevos programas consistentes en ordenamiento de puntajes, análisis factorial, ordenamiento de alternativas y tipologı́a con clasificación ascendente. Se incorporaron recursos para manejo de nombres de códigos y de documentación de programas. Los programas estaban acompañados del Manual del Usuario, Listados de muestra y una Tarjeta de referencia rápida. La versión 2.0 salió en 1990 con mejoras técnicas en varios programas, se reagrupadon dos programas para calcular correlaciones de Pearson, por una parte, y otros dos programas para ordenamiento de alternativas por rangos, por la otra. La versión 3.0 salió en 1992; tenı́a mejoras significativas tales como: armonización de parámetros, palabras clave y sintáxis de proposiciones de control, posibilidad de verificar sin ejecución la sintáxis de las proposiciones de control, posibilidad de ejecutar programas con un número limitado de casos, armonización de los mensajes de error, posibilidad de reunir y listar las variables de Recode, recodificación alfabética y seis nuevas funciones aritméticas en la facilidad Recode. Se adicionaron dos nuevos programas para la verificación de consistencias y análisis discriminatorio. Se incluyó el anexo con fórmulas estadı́sticas al Manual. Nota: en 1993, después de la preparación de la versión 3.02 para los sistemas operacionales OS y VM/CMS, terminó el desarrollo de la versión para compuadores mainframe. Paralelamente, se adaptó IDAMS para microcomputadores bajo MS-DOS El desarrollo de la versión para microcomputadores comenzó en 1988 y avanzó en forma simultánea con el desarrollo de la versión para computadores grandes hasta la versión 3.0. II La primera versión (1.0) salió en 1989, con las mismas facilidades de la versión para computadores grandes. La versión 2.0 salió en 1990 y era totalmente compatible con la versión para OS. Es más, suministraba en la Interfaz del Usuario, facilidades para preparar el diccionario, entrada de datos, preparación y ejecución de archivos de setup e impresión de resultados. La versión 3.0 apareció en 1992 junto con la versión para OS. Sin embargo, la Interfaz del Usuario era mucho más amigable ya que tenı́a nuevos editores para el diccionario y los datos, ofrecı́a un acceso directo a prototipos de setup para todos los programas y se enriqueció con un módulo para exploración interactiva gráfica. Las dos versiones intermedias (3.02 y 3.04) que salieron en 1993 y 1994 respectivamente, incluı́an mejoras técnicas internas y la depuración de los programas. La versión 3.02 fué la última totalmente compatible con la versión de computadores grandes. La existencia independiente de micro IDAMS comenzó en 1993. Los programas se sometieron a pruebas completas y sistemáticas, especialmente en el área del manejo de errores del usuario y se hizo una depuración total. La versión 4.0 que apareció en 1996 (última versión para DOS) incluye una Interfaz del Usuario más amigable, posibilidad de ambiente personalizado, Manual del Usuario en linea, lenguaje de control simplificado, nuevas modalidades de presentación gráfica y capacidad de producir versiones en distintos idiomas. Dos nuevos programas aparecieron para dar al usuario técnicas de análisis de conglomerados y de búsqueda de estructura. Se reorganizó el Manual del Usuario para presentar los tópicos de una manera más concisa y más fácil de consultar. Inicialmente estaba sólo en inglés. Desde 1998, la versión 4 se desarrolló progresivamente en Español, Francés, Arabe y Ruso. 2000: primera versión de IDAMS para Windows y desarollo posterior La versión 1.0 de IDAMS para el sistema operativo gráfico Windows de 32 bits se puso a prueba en 2000 y su distribución se inició en 2001. Ofrece una moderna Interfaz del Usuario, nuevas caracterı́sticas para facilitar el uso y acceso en lı́nea al Manual de Referencia con la ayuda estándar de Windows. Nuevos componentes interactivos de análisis suministran herramientas para construcción de tablas multidimensionales, la exploración gráfica de datos y análisis de series de tiempo. La versión 1.1 salió en septiembre de 2002 con las siguientes mejoras: (1) externalización de textos para el uso de los programas en otros idiomas además del inglés; (2) concordancia de los textos en los resultados. Fue una primera versión para Windows que apareció en inglés, francés y español. La versión 1.2 salió en julio de 2004 en inglés, francés y español, y contiene nuevas funciones en tres programas, en la Interfaz del Usuario, y en los componentes interactivos para la exploración gráfica de datos y el análisis de series de tiempo. Ella salió en abril 2006 en portugués. La versión 1.3 salió igualmente en inglés, francés, español y portugués, y contiene un nuevo programa para análisis de variancia multivariado (MANOVA), cálculo de coeficiente de variabilidad en cuadro programas, mejorı́a de tratamiento de variables de Recode con decimales en SCAT y TABLES, y armonización completa de la longitud de registro de datos. Reconocimientos En primer lugar, se debe agradecer al profesor Frank-M. Andrews († 1994) del Instituto para la Investigación en Ciencias Sociales de la Universidad de Michigan, Estados Unidos de América, y a este Instituto el cual autorizó a UNESCO tomar el código fuente de OSIRIS III.2 para usarlo en el desarrollo del paquete de programas IDAMS. A partir de entonces, continuó el aporte de adiciones y mejoras sustanciales. En este aspecto, fueron particularmente importantes: el Dr. Jean-Paul Aimetti, Administrador de D.H.E. Conseil, Paris y profesor en el Conservatoire National des Arts et Métiers (CNAM), Parı́s (Francia); los profesores J.P. Benzécri y E.-R. Iagolnitzer, U.E.R. de Mathématiques, Université de Parı́s V (Francia); el ingeniero Tibor Diamant y el Dr. Zoltán Vas de la Universidad József Attila, Szeged (Hungrı́a); la profesora Anne-Marie Dussaix, Ecole Supérieure des Sciences Economiques et Commerciales (ESSEC), Cergy-Pontoise (Francia); el Dr. Igor S. Enyukov y el ingeniero Nicolaı̈ D. Vylegjanin, StatPoint, Moscú (Federación Rusa); el Dr III Péter Hunya, quién fué Director del Laboratorio Kalmár de Cibernética, Universidad József Attila, Szeged (Hungrı́a), y quien fué el Administrador del Programa IDAMS en UNESCO entre julio 1993 y febrero 2001; Jean Massol, EOLE, Parı́s (Francia); la profesora Anne Morin, Institut de Recherche en Informatique et Systèmes Aléatoires (IRISA), Rennes (Francia); Judith Rattenbury, ex-directora, Data Processing Division, World Fertility Survey, Londres y actualmente fundadora y cabeza de publicaciones SJ MUSIC, Cambridge (Reino Unido); J.M. Romeder y la Association pour le Développement et la Diffusion de l’Analyse des Données (ADDAD), Parı́s (Francia); el profesor Peter J. Rousseeuw, Universitaire Instelling Antwerpen, Amberes (Bélgica); el Dr. A.V. Skofenko, Academia de Ciencias, Kiev (Ucrania); el ingeniero Neal Van Eck, Philadelphia College of Textiles and Science, Philadelphia (EEUU); Nicole Visart quien lanzó el programa IDAMS y quien, en adición a sus contribuciones técnicas en todas las etapas, aseguró la coordinación y el monitoreo de todo el proyecto hasta su retiro en 1992. Es imposible dar el crédito a todas las personas, además de las mencionadas, quienes han contribuido con ideas y esfuerzo para IDAMS y para OSIRIS III.2 del cual se derivó IDAMS. Hasta ahora, IDAMS se desarrolla principalmente en UNESCO. A continuación se presenta una lista de los principales programas, componentes y facilidades incluidas en IDAMS, con los nombres de sus autores y programadores, y las instituciones en las cuales se llevó a cabo el trabajo. Interfaz del Usuario y facilidades básicas Recodificación de datos Ellen Grun Peter Solenberger Tibor Diamant Jean-Claude Dauphin ISR ISR UNESCO UNESCO Interfaz del Usuario Jean-Claude Dauphin UNESCO Acceso en lı́nea al Manual del Usuario Pawel Hoser Jean-Claude Dauphin Polish Academy of Sciences UNESCO Facilidades para el manejo de datos AGGREG BUILD CHECK CONCHECK CORRECT IMPEX LIST MERCHECK MERGE SORMER SUBSET TRANS Tina Bixby Jean-Claude Dauphin Carl Bixby Sylvia Barge Tibor Diamant Tina Bixby Jean-Claude Dauphin Neal Van Eck Tibor Diamant Péter Hunya Marianne Stover Sylvia Barge Jean-Claude Dauphin Karen Jensen Sylvia Barge Zoltán Vas Tina Bixby Nancy Barkman Jean-Claude Dauphin Carol Cassidy Jean-Claude Dauphin Judy Mattson Judith Rattenbury Jean-Claude Dauphin Jean-Claude Dauphin ISR UNESCO ISR ISR UNESCO ISR UNESCO Van Eck Computing Consulting UNESCO UNESCO ISR ISR UNESCO ISR ISR JATE ISR ISR UNESCO ISR UNESCO ISR ISR UNESCO UNESCO IV Facilidades para el análisis de datos CLUSFIND CONFIG DISCRAN FACTOR MANOVA MCA MDSCAL ONEWAY PEARSON POSCOR QUANTILE RANK REGRESSN SCAT SEARCH TABLES TYPOL Tablas multidimensionales GraphID TimeSID Leonard Kaufman Peter J. Rousseeuw Neal Van Eck Tibor Diamant Herbert Weisberg J.-M. Romeder and ADDAD Péter Hunya Tibor Diamand J.P. Benzécri, E.R. Iagolnitzer Péter Hunya Charles E. Hall Elliot M. Cramer Neal Van Eck Tibor Diamand Edwin Dean John Sonquist Tibor Diamant Joseph Kruskal Frank Carmone Lutz Erbring Spyros Magliveras Tibor Diamant John Sonquist Spyros Magliveras Neal Van Eck Ronald Nuttal Tibor Diamant Péter Hunya Robert Messenger Tibor Diamant Anne-Marie Dussaix Albert David Péter Hunya A.V. Skofenko M.A. Efroymson Bob Hsieh Neal Van Eck Peter Solenberger Judith Goldberg John Sonquist Elizabeth Lauch Baker James N. Morgan Neal Van Eck Tibor Diamant Neal Van Eck Tibor Diamant Jean-Paul Aimetti Jean Massol Péter Hunya Jean-Claude Dauphin Jean-Claude Dauphin Igor S. Enyukov Nicolaı̈ D. Vylegjanin Igor S. Enyukov Vrije Universiteit Brussel Vrije Universiteit Brussel Van Eck Computing Consulting UNESCO ISR ADDAD UNESCO UNESCO Université de Paris V Université de Paris V JATE George Washington University George Washington University ISR UNESCO ISR ISR UNESCO Bell Telephone Bell Telephone ISR ISR UNESCO ISR ISR ISR Boston College UNESCO JATE ISR UNESCO ESSEC ESSEC JATE Ukrainian Academy of Sciences ESSO Corporation ESSO Corporation ISR ISR ISR ISR ISR ISR Van Eck Computing Consulting UNESCO ISR and Van Eck Computing Consulting UNESCO CFRO CFRO JATE UNESCO UNESCO StatPoint StatPoint StatPoint V Con relación a la documentación, se debe agradecer a todas las personas que han aportado su colaboración, en particular a Judith Rattenbury quién redactó la primera versión del Manual en inglés (1988) ası́ como la revisión de las versiones posteriores hasta 1998; Jean-Paul Griset (UNESCO, Paris) quien concibió junto con Nicole Visart el diseño tipográfico utilizado para el Manual hasta 1998; Teresa Krukowska (grupo IDAMS, UNESCO, Paris) quién compiló los capı́tulos de las fórmulas estadı́sticas y a partir de 1998 mantiene al dı́a la versión original inglesa, hizo el nuevo diseño tipográfico y es responsable de la producción electrónica de las versiones en inglés, español, francés y portugués, y se hace cargo de la concordancia de los textos en inglés, español, francés y portugués hasta donde esto es posible. Reconocimientos a los autores de los documentos de OSIRIS de los cuales se tomó material para el Manual del Usuario de WinIDAMS, ası́: Volumen 1 del Manual del Usuario de OSIRIS III.2 (editado por Sylvia Barge y Gregory A. Marks) y el Volumen 5 (compilado por Laura Klem), Insituto para la Investigación Social, Universidad de Michigan, Estados Unidos de América. De la misma manera, se agradece la cooperación a los traductores de la documentación y del paquete de software en español, francés y portugués: Profesor José Raimundo Carvalho, CAEN Pós-graduação em Economia, UFC, Fortaleza, Brasil, por la traducción del Manual y de los textos que hacen parte integral de los programas en portugués. Profesor Bernardo Liévano, Escuela Colombiana de Ingenierı́a (ECI) Bogota, Colombia, por la traducción del Manual y de los textos que hacen parte integral de los programas en español. Profesora Anne Morin, Institut de Recherche en Informatique et Systèmes Aléatoires (IRISA), Rennes, Francia, por su contribución a la traducción de los textos que hacen parte integral de los programas en francés. Nicole Visart, Grez-Doiceau, Belgica, por la traducción del Manual en francés. Las siguientes instituciones se han encargado de las traducciones en arabe y en ruso del paquete y del Manual: ALECSO - Departmento de Documentación e Información, Túnez, Túnez, y Universidad Hidrometeorológica del Estado Ruso, Departmento de Telecomunicaciones, San Petersburgo, Federación Rusa. Solicitudes de WinIDAMS e información adicional Para información adicional sobre WinIDAMS referente a contenido, actualizaciones, entrenamiento y distribución, por favor escribir a: UNESCO Sector de la Comunicación y la Información División de la Sociedad de la Información CI/INF - IDAMS 1, rue Miollis 75732 PARIS CEDEX 15 Francia e-mail: [email protected] http://www.unesco.org/idams Índice general 1. Introducción 1.1. Interfaz del Usuario de WinIDAMS . . . . . . . 1.2. Facilidades para el manejo de datos . . . . . . . 1.3. Facilidades para el análisis de datos . . . . . . 1.4. Los datos en IDAMS . . . . . . . . . . . . . . . 1.5. Comandos de IDAMS y el archivo Setup . . . . 1.6. Caracterı́sticas estándar de IDAMS . . . . . . . 1.7. Importación y exportación de datos . . . . . . 1.8. Intercambio de datos entre CDS/ISIS e IDAMS 1.9. Estructura de este Manual . . . . . . . . . . . . I . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Nociones fundamentales 1 1 2 3 5 5 5 6 6 7 9 2. Los datos en IDAMS 2.1. El dataset IDAMS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.1.1. Descripción general . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.1.2. Método de almacenamiento y acceso . . . . . . . . . . . . . . . . . . . 2.2. Archivos Datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2.1. El arreglo de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2.2. Caracterı́sticas del archivo Datos . . . . . . . . . . . . . . . . . . . . . 2.2.3. Archivos jerárquicos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2.4. Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2.5. Códigos de datos faltantes . . . . . . . . . . . . . . . . . . . . . . . . . 2.2.6. Valores no numéricos o en blanco en variables numéricas - datos malos 2.2.7. Las reglas de edición de las variables en salida de programas IDAMS . 2.3. El diccionario IDAMS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.3.1. Descripción general . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.3.2. Ejemplo de un diccionario . . . . . . . . . . . . . . . . . . . . . . . . . 2.4. Matrices IDAMS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.4.1. La matriz cuadrada IDAMS . . . . . . . . . . . . . . . . . . . . . . . . 2.4.2. La matriz rectangular IDAMS . . . . . . . . . . . . . . . . . . . . . . 2.5. Uso de datos de otros paquetes . . . . . . . . . . . . . . . . . . . . . . . . . . 2.5.1. Datos primarios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.5.2. Matrices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 11 11 11 11 11 12 12 12 13 13 13 14 14 16 16 17 18 20 20 20 3. El archivo Setup de IDAMS 3.1. Contenido y propósito . . . . . . . . . . . . . . 3.2. Comandos de IDAMS . . . . . . . . . . . . . . 3.3. Especificación de archivos . . . . . . . . . . . . 3.4. Ejemplos de uso de comandos $ y especificación 3.5. Proposiciones de control de programa . . . . . 3.5.1. Descripción general . . . . . . . . . . . . 3.5.2. Reglas generales de codificación . . . . . 3.5.3. Filtros . . . . . . . . . . . . . . . . . . . 3.5.4. Tı́tulos . . . . . . . . . . . . . . . . . . 3.5.5. Parámetros . . . . . . . . . . . . . . . . 3.6. Proposiciones de Recode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 21 21 23 23 25 25 25 25 27 27 31 . . . . . . . . . . . . . . . . . . . . . de archivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ÍNDICE GENERAL VIII 4. Facilidad Recode 4.1. Reglas de codificación . . . . . . . . . . . . . . . . . . . . . . 4.2. Conjunto de muestra de proposiciones Recode . . . . . . . . . 4.3. Tratamiento de datos faltantes . . . . . . . . . . . . . . . . . 4.4. Como funciona Recode . . . . . . . . . . . . . . . . . . . . . . 4.5. Operandos básicos . . . . . . . . . . . . . . . . . . . . . . . . 4.6. Operadores básicos . . . . . . . . . . . . . . . . . . . . . . . . 4.7. Expresiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.8. Funciones aritméticas . . . . . . . . . . . . . . . . . . . . . . 4.9. Funciones lógicas . . . . . . . . . . . . . . . . . . . . . . . . . 4.10. Proposiciones de asignación . . . . . . . . . . . . . . . . . . . 4.11. Proposiciones especiales de asignación . . . . . . . . . . . . . 4.12. Proposiciones de control . . . . . . . . . . . . . . . . . . . . . 4.13. Proposiciones condicionales . . . . . . . . . . . . . . . . . . . 4.14. Proposiciones de definición/de asignación de valores iniciales 4.15. Ejemplos de uso de proposiciones de Recode . . . . . . . . . . 4.16. Restricciones . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.17. Nota . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 33 33 34 34 35 35 36 37 45 46 47 48 50 50 52 54 55 5. Manejo y análisis de datos 5.1. Validación de datos con IDAMS . . . . . . . . . . . . . 5.1.1. Visión general . . . . . . . . . . . . . . . . . . . 5.1.2. Verificación si los datos son completos . . . . . 5.1.3. Detección de valores no numéricos e inválidos . 5.1.4. Verificación de consistencia . . . . . . . . . . . 5.2. Manejo/transformación de datos . . . . . . . . . . . . 5.3. Análisis de datos . . . . . . . . . . . . . . . . . . . . . 5.4. Ejemplo de un pequeño trabajo a ejecutar con IDAMS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57 57 57 58 58 59 59 60 60 II . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . El trabajo con WinIDAMS 6. Instalación 6.1. Requisitos del sistema . . . . . . . . . 6.2. Procedimiento de instalación . . . . . 6.3. Prueba de la instalación . . . . . . . . 6.4. Archivos y carpetas creados durante la 6.4.1. Carpetas de WinIDAMS . . . . 6.4.2. Archivos instalados . . . . . . . 6.5. Desintalación . . . . . . . . . . . . . . 63 . . . . . . . . . . . . . . . . . . . . . instalación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65 65 65 65 66 66 66 67 7. Primeros pasos 7.1. Visión general de los etapas con WinIDAMS . . . . 7.2. Creación de un ambiente de aplicación . . . . . . . 7.3. Preparación del diccionario . . . . . . . . . . . . . 7.4. Captura de datos . . . . . . . . . . . . . . . . . . . 7.5. Preparación del setup . . . . . . . . . . . . . . . . 7.6. Ejecución del setup . . . . . . . . . . . . . . . . . . 7.7. Revisión de los resultados y modificación del setup 7.8. Impresión de los resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69 69 70 71 73 75 76 76 78 8. Archivos y carpetas 79 8.1. Archivos en WinIDAMS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79 8.2. Las carpetas en WinIDAMS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80 9. Interfaz del Usuario 9.1. Concepto general . . . . . . . . . . . . . . . . . . . . 9.2. Menús comunes a todas las ventanas de WinIDAMS 9.3. Personalización del ambiente para una aplicación . . 9.4. Crear/actualizar/mostrar archivos Diccionario . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81 81 82 83 85 ÍNDICE GENERAL IX 9.5. Crear/actualizar/mostrar archivos Datos . . . . . 9.6. Importación de archivos de datos . . . . . . . . . 9.7. Exportación de archivos Datos de IDAMS . . . . 9.8. Crear/actualizar/mostrar archivos Setup . . . . . 9.9. Ejecución de los setups de IDAMS . . . . . . . . 9.10. Manejo de los archivos Resultados . . . . . . . . 9.11. Creación/actualización de archivos en formato de III . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . texto y RTF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Facilidades para el manejo de datos 10.Agrupación de datos (AGGREG) 10.1. Descripción general . . . . . . . . . . . 10.2. Caracterı́sticas estándar de IDAMS . . 10.3. Resultados . . . . . . . . . . . . . . . . 10.4. Dataset de salida . . . . . . . . . . . . 10.5. Dataset de entrada . . . . . . . . . . . 10.6. Estructura del setup . . . . . . . . . . 10.7. Proposiciones de control del programa 10.8. Restricciones . . . . . . . . . . . . . . 10.9. Ejemplo . . . . . . . . . . . . . . . . . 87 89 90 91 92 92 94 95 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97 97 98 98 98 99 100 100 102 102 11.Construcción de un dataset IDAMS (BUILD) 11.1. Descripción general . . . . . . . . . . . . . . . . 11.2. Caracterı́sticas estándar de IDAMS . . . . . . . 11.3. Resultados . . . . . . . . . . . . . . . . . . . . . 11.4. Dataset de salida . . . . . . . . . . . . . . . . . 11.5. Diccionario de entrada . . . . . . . . . . . . . . 11.6. Datos de entrada . . . . . . . . . . . . . . . . . 11.7. Estructura del setup . . . . . . . . . . . . . . . 11.8. Proposiciones de control del programa . . . . . 11.9. Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103 103 104 104 105 105 106 106 106 107 12.Verificación de códigos (CHECK) 12.1. Descripción general . . . . . . . . . . . 12.2. Caracterı́sticas estándar de IDAMS . . 12.3. Resultados . . . . . . . . . . . . . . . . 12.4. Dataset de entrada . . . . . . . . . . . 12.5. Estructura del setup . . . . . . . . . . 12.6. Proposiciones de control del programa 12.7. Restricciones . . . . . . . . . . . . . . 12.8. Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109 109 109 109 110 110 110 112 112 13.Verificación de consistencia (CONCHECK) 13.1. Descripción general . . . . . . . . . . . . . . . 13.2. Caracterı́sticas estándar de IDAMS . . . . . . 13.3. Resultados . . . . . . . . . . . . . . . . . . . . 13.4. Dataset de entrada . . . . . . . . . . . . . . . 13.5. Estructura del setup . . . . . . . . . . . . . . 13.6. Proposiciones de control del programa . . . . 13.7. Restricciones . . . . . . . . . . . . . . . . . . 13.8. Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115 115 115 115 116 116 116 118 118 14.Verificación de intecalación de registros (MERCHECK) 14.1. Descripción general . . . . . . . . . . . . . . . . . . . . . . . 14.2. Caracterı́sticas estándar de IDAMS . . . . . . . . . . . . . . 14.3. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14.4. Datos de salida . . . . . . . . . . . . . . . . . . . . . . . . . 14.5. Datos de entrada . . . . . . . . . . . . . . . . . . . . . . . . 14.6. Estructura del setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121 121 123 123 123 124 124 . . . . . . . . . . . . . . . . . . . . . . . . ÍNDICE GENERAL X 14.7. Proposiciones de control del programa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124 14.8. Restricciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127 14.9. Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127 15.Corrección de datos (CORRECT) 15.1. Descripción general . . . . . . . . . . . 15.2. Caracterı́sticas estándar de IDAMS . . 15.3. Resultados . . . . . . . . . . . . . . . . 15.4. Dataset de salida . . . . . . . . . . . . 15.5. Dataset de entrada . . . . . . . . . . . 15.6. Estructura del setup . . . . . . . . . . 15.7. Proposiciones de control del programa 15.8. Restricción . . . . . . . . . . . . . . . 15.9. Ejemplo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129 129 129 130 130 130 130 131 132 132 16.Importación/exportación de datos (IMPEX) 16.1. Descripción general . . . . . . . . . . . . . . . 16.2. Caraterı́sticas estándar de IDAMS . . . . . . 16.3. Resultados . . . . . . . . . . . . . . . . . . . . 16.4. Archivos de salida . . . . . . . . . . . . . . . 16.5. Archivos de entrada . . . . . . . . . . . . . . 16.6. Estructura del setup . . . . . . . . . . . . . . 16.7. Proposiciones de control del programa . . . . 16.8. Restricciones . . . . . . . . . . . . . . . . . . 16.9. Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135 135 135 136 136 137 139 139 142 142 17.Listado de datasets (LIST) 17.1. Descripción general . . . . . . . . . . . 17.2. Caracterı́sticas estándar de IDAMS . . 17.3. Resultados . . . . . . . . . . . . . . . . 17.4. Dataset de entrada . . . . . . . . . . . 17.5. Estructura del setup . . . . . . . . . . 17.6. Proposiciones de control del programa 17.7. Restricción . . . . . . . . . . . . . . . 17.8. Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145 145 145 145 146 146 147 147 148 18.Intercalación de datasets (MERGE) 18.1. Descripción general . . . . . . . . . . . 18.2. Caracterı́sticas estándar de IDAMS . . 18.3. Resultados . . . . . . . . . . . . . . . . 18.4. Dataset de salida . . . . . . . . . . . . 18.5. Dataset de entrada . . . . . . . . . . . 18.6. Estructura del setup . . . . . . . . . . 18.7. Proposiciones de control del programa 18.8. Restricciones . . . . . . . . . . . . . . 18.9. Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149 149 149 150 150 152 152 153 155 155 19.Clasificación e intercalación de archivos (SORMER) 19.1. Descripción general . . . . . . . . . . . . . . . . . . . . 19.2. Caracterı́sticas estándar de IDAMS . . . . . . . . . . . 19.3. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . 19.4. Diccionario de salida . . . . . . . . . . . . . . . . . . . 19.5. Datos de salida . . . . . . . . . . . . . . . . . . . . . . 19.6. Diccionario de entrada . . . . . . . . . . . . . . . . . . 19.7. Datos de entrada . . . . . . . . . . . . . . . . . . . . . 19.8. Estructura del setup . . . . . . . . . . . . . . . . . . . 19.9. Proposiciones de control del programa . . . . . . . . . 19.10.Restricciones . . . . . . . . . . . . . . . . . . . . . . . 19.11.Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157 157 157 157 157 157 158 158 158 159 159 160 . . . . . . . . . . . . . . . . . . . . . . . . . . . ÍNDICE GENERAL XI 20.Subdivisión de datasets (SUBSET) 20.1. Descripción general . . . . . . . . . . . 20.2. Caracterı́sticas estándar de IDAMS . . 20.3. Resultados . . . . . . . . . . . . . . . . 20.4. Dataset de salida . . . . . . . . . . . . 20.5. Dataset de entrada . . . . . . . . . . . 20.6. Estructura del setup . . . . . . . . . . 20.7. Proposiciones de control del programa 20.8. Restricciones . . . . . . . . . . . . . . 20.9. Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161 161 161 161 162 162 162 163 164 164 21.Transformación de datos (TRANS) 21.1. Descripción general . . . . . . . . . . . 21.2. Caracterı́sticas estándar de IDAMS . . 21.3. Resultados . . . . . . . . . . . . . . . . 21.4. Dataset de salida . . . . . . . . . . . . 21.5. Dataset de entrada . . . . . . . . . . . 21.6. Estructura del setup . . . . . . . . . . 21.7. Proposiciones de control del programa 21.8. Restricciones . . . . . . . . . . . . . . 21.9. Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165 165 165 165 165 166 166 167 168 168 IV Facilidades para análisis de datos 171 22.Análisis de conglomerados (CLUSFIND) 22.1. Descripción general . . . . . . . . . . . . . 22.2. Caracterı́sticas estándar de IDAMS . . . . 22.3. Resultados . . . . . . . . . . . . . . . . . . 22.4. Dataset de entrada . . . . . . . . . . . . . 22.5. Matriz de entrada . . . . . . . . . . . . . 22.6. Estructura del setup . . . . . . . . . . . . 22.7. Proposiciones de control del programa . . 22.8. Restricciones . . . . . . . . . . . . . . . . 22.9. Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173 173 173 173 174 175 175 175 177 178 23.Análisis de configuración (CONFIG) 23.1. Descripción general . . . . . . . . . . . 23.2. Caracterı́sticas estándar de IDAMS . . 23.3. Resultados . . . . . . . . . . . . . . . . 23.4. Matriz de configuración de salida . . . 23.5. Matriz de distancias de salida . . . . . 23.6. Matriz de configuración de entrada . . 23.7. Estructura del setup . . . . . . . . . . 23.8. Proposiciones de control del programa 23.9. Restricción . . . . . . . . . . . . . . . 23.10.Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179 179 179 179 180 180 180 181 181 183 183 24.Análisis discriminatorio (DISCRAN) 24.1. Descripción general . . . . . . . . . . . 24.2. Caracterı́sticas estándar de IDAMS . . 24.3. Resultados . . . . . . . . . . . . . . . . 24.4. Dataset de salida . . . . . . . . . . . . 24.5. Dataset de entrada . . . . . . . . . . . 24.6. Estructura del setup . . . . . . . . . . 24.7. Proposiciones de control del programa 24.8. Restricciones . . . . . . . . . . . . . . 24.9. Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185 185 185 186 186 187 187 188 190 190 25.Funciones de distribución y de Lorenz (QUANTILE) 191 ÍNDICE GENERAL XII 25.1. Descripción general . . . . . . . . . . . 25.2. Caracterı́sticas estándar de IDAMS . . 25.3. Resultados . . . . . . . . . . . . . . . . 25.4. Dataset de entrada . . . . . . . . . . . 25.5. Estructura del setup . . . . . . . . . . 25.6. Proposiciones de control del programa 25.7. Restricciones . . . . . . . . . . . . . . 25.8. Ejemplo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191 191 191 192 192 192 194 194 26.Análisis factorial (FACTOR) 26.1. Descripción general . . . . . . . . . . . 26.2. Caracterı́sticas estándar de IDAMS . . 26.3. Resultados . . . . . . . . . . . . . . . . 26.4. Dataset(s) de salida . . . . . . . . . . 26.5. Dataset de entrada . . . . . . . . . . . 26.6. Estructura del setup . . . . . . . . . . 26.7. Proposiciones de control del programa 26.8. Restricciones . . . . . . . . . . . . . . 26.9. Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197 197 197 198 198 199 199 200 203 203 27.Regresión lineal (REGRESSN) 27.1. Descripción general . . . . . . . . . . . 27.2. Caracterı́sticas estándar de IDAMS . . 27.3. Resultados . . . . . . . . . . . . . . . . 27.4. Matriz de correlación de salida . . . . 27.5. Dataset de residuos de salida . . . . . 27.6. Dataset de entrada . . . . . . . . . . . 27.7. Matriz de correlación de entrada . . . 27.8. Estructura del setup . . . . . . . . . . 27.9. Proposiciones de control del programa 27.10.Restricciones . . . . . . . . . . . . . . 27.11.Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205 205 206 207 207 208 208 208 209 209 212 212 28.Escalamiento multidimensional (MDSCAL) 28.1. Descripción general . . . . . . . . . . . . . . . 28.2. Caracterı́sticas estándar de IDAMS . . . . . . 28.3. Resultados . . . . . . . . . . . . . . . . . . . . 28.4. Matriz de configuración de salida . . . . . . . 28.5. Matriz de datos de entrada . . . . . . . . . . 28.6. Matriz de ponderaciones de entrada . . . . . 28.7. Matriz de configuración de entrada . . . . . . 28.8. Estructura del setup . . . . . . . . . . . . . . 28.9. Proposiciones de control del programa . . . . 28.10.Restricciones . . . . . . . . . . . . . . . . . . 28.11.Ejemplo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 215 215 216 216 217 217 217 218 218 218 220 220 29.Análisis de clasificación múltiple (MCA) 29.1. Descripción general . . . . . . . . . . . . . 29.2. Caracterı́sticas estándar de IDAMS . . . . 29.3. Resultados . . . . . . . . . . . . . . . . . . 29.4. Dataset(s) de residuos de salida . . . . . . 29.5. Dataset de entrada . . . . . . . . . . . . . 29.6. Estructura del setup . . . . . . . . . . . . 29.7. Proposiciones de control del programa . . 29.8. Restricciones . . . . . . . . . . . . . . . . 29.9. Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221 221 222 222 224 224 225 225 227 227 . . . . . . . . . . . . . . . . . . 30.Análisis multivariado de variancia (MANOVA) 231 30.1. Descripción general . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231 30.2. Caracterı́sticas estándar de IDAMS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232 ÍNDICE GENERAL 30.3. Resultados . . . . . . . . . . 30.4. Dataset de entrada . . . . . 30.5. Estructura del setup . . . . 30.6. Proposiciones de control del 30.7. Restricciones . . . . . . . . 30.8. Ejemplos . . . . . . . . . . XIII . . . . . . . . . . . . . . . . . . programa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232 233 234 234 236 236 31.Análisis de variancia de una entrada (ONEWAY) 31.1. Descripción general . . . . . . . . . . . . . . . . . . 31.2. Caracterı́sticas estándar de IDAMS . . . . . . . . . 31.3. Resultados . . . . . . . . . . . . . . . . . . . . . . . 31.4. Dataset de entrada . . . . . . . . . . . . . . . . . . 31.5. Estructura del setup . . . . . . . . . . . . . . . . . 31.6. Proposiciones de control del programa . . . . . . . 31.7. Restricciones . . . . . . . . . . . . . . . . . . . . . 31.8. Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 239 239 239 239 240 241 241 242 243 32.Puntajes basados en el orden parcial de 32.1. Descripción general . . . . . . . . . . . . 32.2. Caracterı́sticas estándar de IDAMS . . . 32.3. Resultados . . . . . . . . . . . . . . . . . 32.4. Dataset de salida . . . . . . . . . . . . . 32.5. Dataset de entrada . . . . . . . . . . . . 32.6. Estructura del setup . . . . . . . . . . . 32.7. Proposiciones de control del programa . 32.8. Restricciones . . . . . . . . . . . . . . . 32.9. Ejemplos . . . . . . . . . . . . . . . . . casos (POSCOR) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 245 245 245 246 246 246 247 247 250 250 33.Correlación de Pearson (PEARSON) 33.1. Descripción general . . . . . . . . . . . 33.2. Caracterı́sticas estándar de IDAMS . . 33.3. Resultados . . . . . . . . . . . . . . . . 33.4. Matrices de salida . . . . . . . . . . . 33.5. Dataset de entrada . . . . . . . . . . . 33.6. Estructura del setup . . . . . . . . . . 33.7. Proposiciones de control del programa 33.8. Restricciones . . . . . . . . . . . . . . 33.9. Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253 253 253 254 255 255 255 256 257 257 34.Ordenamiento de alternativas (RANK) 34.1. Descripción general . . . . . . . . . . . . 34.2. Caracterı́sticas estándar de IDAMS . . . 34.3. Resultados . . . . . . . . . . . . . . . . . 34.4. Dataset de entrada . . . . . . . . . . . . 34.5. Estructuda del setup . . . . . . . . . . . 34.6. Proposiciones de control del programa . 34.7. Restricciones . . . . . . . . . . . . . . . 34.8. Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 259 259 260 260 261 262 263 264 265 35.Diagramas de dispersión (SCAT) 35.1. Descripción general . . . . . . . . . . . 35.2. Caracterı́sticas estándar de IDAMS . . 35.3. Resultados . . . . . . . . . . . . . . . . 35.4. Dataset de entrada . . . . . . . . . . . 35.5. Estructura del setup . . . . . . . . . . 35.6. Proposiciones de control del programa 35.7. Restricciones . . . . . . . . . . . . . . 35.8. Ejemplo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 267 267 267 268 268 269 269 270 271 36.Búsqueda de estructura (SEARCH) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273 ÍNDICE GENERAL XIV 36.1. Descripción general . . . . . . . . . . . 36.2. Caracterı́sticas estándar de IDAMS . . 36.3. Resultados . . . . . . . . . . . . . . . . 36.4. Dataset de residuos de salida . . . . . 36.5. Dataset de entrada . . . . . . . . . . . 36.6. Estructura del setup . . . . . . . . . . 36.7. Proposiciones de control del programa 36.8. Restricciones . . . . . . . . . . . . . . 36.9. Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273 273 274 274 275 275 275 278 278 37.Tablas univariadas y bivariadas (TABLES) 37.1. Descripción general . . . . . . . . . . . . . . 37.2. Caracterı́sticas estándar de IDAMS . . . . . 37.3. Resultados . . . . . . . . . . . . . . . . . . . 37.4. Tablas univariadas/bivariadas de salida . . 37.5. Matrices de estadı́sticas bivariadas de salida 37.6. Dataset de entrada . . . . . . . . . . . . . . 37.7. Estructura del setup . . . . . . . . . . . . . 37.8. Proposiciones de control del programa . . . 37.9. Restricciones . . . . . . . . . . . . . . . . . 37.10.Ejemplo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 281 281 282 282 284 284 284 285 285 290 291 38.Tipologı́a y clasificación ascendente (TYPOL) 38.1. Descripción general . . . . . . . . . . . . . . . . 38.2. Caracterı́sticas estándar de IDAMS . . . . . . . 38.3. Resultados . . . . . . . . . . . . . . . . . . . . . 38.4. Dataset de salida . . . . . . . . . . . . . . . . . 38.5. Matriz de configuración de salida . . . . . . . . 38.6. Dataset de entrada . . . . . . . . . . . . . . . . 38.7. Matriz de configuración de entrada . . . . . . . 38.8. Estructura del setup . . . . . . . . . . . . . . . 38.9. Proposiciones de control del programa . . . . . 38.10.Restricciones . . . . . . . . . . . . . . . . . . . 38.11.Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 293 293 293 294 295 295 295 296 296 296 299 299 V . . . . . . . . . . . . . . . . . . Análisis interactivo de datos 39.Tablas multidimensionales y su presentación gráfica 39.1. Visión general . . . . . . . . . . . . . . . . . . . . . . . 39.2. Preparación del análisis . . . . . . . . . . . . . . . . . 39.3. Ventana de tablas multidimensionales . . . . . . . . . 39.4. Presentación gráfica de tablas univariadas y bivariadas 39.5. Cómo hacer una tabla multidimensional . . . . . . . . 39.6. Cómo cambiar una tabla multidimensional . . . . . . . 301 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303 303 303 305 306 307 309 40.Exploración gráfica de datos 40.1. Visión general . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40.2. Preparación del análisis . . . . . . . . . . . . . . . . . . . . . . 40.3. Ventana principal de GraphID para análisis de un dataset . . . 40.3.1. Barra de menú y barra de herramientas . . . . . . . . . 40.3.2. Manipulación de la matriz de gráficos de dispersión . . . 40.3.3. Histogramas y densidades . . . . . . . . . . . . . . . . . 40.3.4. Lı́neas de regresión (Lı́neas suavizadas) . . . . . . . . . 40.3.5. Diagramas de caja y bigotes . . . . . . . . . . . . . . . . 40.3.6. Gráfico agrupado . . . . . . . . . . . . . . . . . . . . . . 40.3.7. Diagramas de dispersión tridimensionales y su rotación 40.4. Ventana de GraphID para análisis de una matriz . . . . . . . . 40.4.1. Barra de menú y barra de herramientas . . . . . . . . . 40.4.2. Manipulación de la matriz en pantalla . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313 313 313 313 314 316 318 318 319 320 320 321 321 322 . . . . . . . . . . . . . . . . . . . . . . . . ÍNDICE GENERAL XV 41.Análisis de series de tiempo 41.1. Visión general . . . . . . . . . . . . . . . . . . . 41.2. Preparación del análisis . . . . . . . . . . . . . 41.3. Ventana principal de TimeSID . . . . . . . . . 41.3.1. Barra de menú y barra de herramientas 41.3.2. Ventana de series de tiempo . . . . . . . 41.4. Transformación de series de tiempo . . . . . . . 41.5. Análisis de series de tiempo . . . . . . . . . . . VI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Fórmulas estadı́sticas y referencias bibliográficas 323 323 323 323 324 326 327 328 331 42.Análisis de conglomerados 42.1. Estadı́sticas univariadas . . . . . . . . . . . . . . . . . . . . . . . . . . 42.2. Medidas estandarizadas . . . . . . . . . . . . . . . . . . . . . . . . . . 42.3. Matriz de disimilitudes calculada a partir de un dataset de IDAMS . . 42.4. Matriz de disimilitudes calculada a partir de una matriz de similitudes 42.5. Matrix de disimilitudes calculada a partir de una matriz de correlación 42.6. Repartición alrededor de medoides (PAM) . . . . . . . . . . . . . . . . 42.7. Repartición para grandes datasets (CLARA) . . . . . . . . . . . . . . 42.8. Conglomeración difusa (FANNY) . . . . . . . . . . . . . . . . . . . . . 42.9. Conglomeración jerárquica acumulativa (AGNES) . . . . . . . . . . . 42.10.Conglomeración jerárquica divisiva (DIANA) . . . . . . . . . . . . . . 42.11.Conglomeración monotética (MONA) . . . . . . . . . . . . . . . . . . 42.12.Referencias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 333 333 333 334 334 334 334 336 336 337 338 339 339 43.Análisis de configuración 43.1. Configuratión centrada . . . . . . 43.2. Configuratión normalizada . . . . 43.3. Solución en ejes principales . . . 43.4. Matriz de productos escalares . . 43.5. Matriz de distancias entre puntos 43.6. Configuración rotada . . . . . . 43.7. Configuración transladada . . . . 43.8. Rotación varimax . . . . . . . . . 43.9. Configuración clasificada . . . . . 43.10.Referencias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 341 341 341 342 342 342 342 342 343 343 343 . . . . . . . . . . 2 grupos . . . . más de 2 grupos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 345 345 346 347 348 45.Funciones de distribución y de Lorenz 45.1. Formula para los puntos de separación . . . . . . . 45.2. Puntos de separación de la función de distribución 45.3. Puntos de separación de la función de Lorenz . . . 45.4. Curva de Lorenz . . . . . . . . . . . . . . . . . . . 45.5. El coeficiente de Gini . . . . . . . . . . . . . . . . . 45.6. Estadı́stica D de Kolmogorov-Smirnov . . . . . . . 45.7. Nota sobre los pesos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 349 349 349 350 350 350 350 351 46.Análisis factorial 46.1. Estadı́sticas univariadas . . . . . . . . . 46.2. Datos de entrada . . . . . . . . . . . . . 46.3. Matrices núcleo (matrices de relaciones) 46.4. Huella . . . . . . . . . . . . . . . . . . . 46.5. Valores y vectores propios . . . . . . . . 46.6. Tabla de valores propios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353 353 354 354 355 355 356 44.Análisis discriminatorio 44.1. Estadı́sticas univariadas . 44.2. Discriminación lineal entre 44.3. Discriminación lineal entre 44.4. Referencias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ÍNDICE GENERAL XVI 46.7. Tabla de factores de variables activas . 46.8. Tabla de factores de variables pasivas . 46.9. Tabla de factores de casos activos . . . 46.10.Tabla de factores de casos pasivos . . . 46.11.Factores rotados . . . . . . . . . . . . 46.12.Referencias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 356 358 358 360 360 360 47.Regresión lineal 47.1. Estadı́sticas univariadas . . . . . . . . . . . . . . . . . . . . . . 47.2. Matriz de sumas totales de cuadrados y productos cruzados . . 47.3. Matriz de sumas de cuadrados residuales y productos cruzados 47.4. Matriz de correlación total . . . . . . . . . . . . . . . . . . . . . 47.5. Matriz de correlación parcial . . . . . . . . . . . . . . . . . . . 47.6. Matriz inversa . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47.7. Estadı́sticas de resumen del análisis . . . . . . . . . . . . . . . . 47.8. Estadı́sticas de análisis para los predictores . . . . . . . . . . . 47.9. Residuos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47.10.Nota sobre la regresión por pasos . . . . . . . . . . . . . . . . . 47.11.Nota sobre la regresión descendente . . . . . . . . . . . . . . . . 47.12.Nota sobre la regresión con intercepto cero . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 361 361 361 362 362 362 362 363 364 365 365 366 366 48.Escalamiento multidimensional 48.1. Orden de los cálculos . . . . . . . . . . . . . . 48.2. Configuración inicial . . . . . . . . . . . . . . 48.3. Centrado y normalización de la configuración 48.4. Historia de los cálculos . . . . . . . . . . . . . 48.5. Esfuerzo para la configuración final . . . . . . 48.6. Configuración final . . . . . . . . . . . . . . . 48.7. Configuración clasificada . . . . . . . . . . . . 48.8. Resumen . . . . . . . . . . . . . . . . . . . . . 48.9. Nota sobre ataduras en los datos de entrada . 48.10.Nota sobre los pesos . . . . . . . . . . . . . . 48.11.References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 367 367 367 367 368 370 370 370 370 371 371 372 49.Análisis de clasificación múltiple 49.1. Estadı́sticas de la variable dependiente . . . . . . . . . . . . . . . . . . . 49.2. Estadı́sticas de los predictores para análisis de clasificación múltiple . . 49.3. Estadı́sticas del análisis para análisis de clasificación múltiple . . . . . . 49.4. Estadı́sticas de resumen de residuos . . . . . . . . . . . . . . . . . . . . 49.5. Estadı́sticas de categorı́a de los predictores, para análisis de variancia de 49.6. Estadı́sticas del análisis, para análisis de variancia de una entrada . . . 49.7. Referencias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . una entrada . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 373 373 374 376 376 377 377 377 50.Análisis multivariado de variancia 50.1. Estadı́sticas generales . . . . . . . . . . . . . . . . . . 50.2. Cálculos para una prueba en un análisis multivariado . 50.3. Análisis univariado . . . . . . . . . . . . . . . . . . . . 50.4. Análisis de covariancia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 379 379 381 384 384 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.Análisis de variancia de una entrada 385 51.1. Estadı́sticas descriptivas para cada categorı́a de la variable de control . . . . . . . . . . . . . . 385 51.2. Estadı́sticas del análisis de variancia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 386 52.Puntajes basados en el orden parcial 52.1. Terminologı́a especial y definiciones . 52.2. Cálculo de puntajes . . . . . . . . . 52.3. Referencias . . . . . . . . . . . . . . de . . . . . . casos 389 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 389 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 390 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 391 53.Correlación de Pearson 393 53.1. Estadı́sticas pareadas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393 53.2. Medias y desviaciones estándar no pareadas . . . . . . . . . . . . . . . . . . . . . . . . . . . . 394 ÍNDICE GENERAL XVII 53.3. Ecuación de regresión para puntajes primarios 53.4. Matriz de correlación . . . . . . . . . . . . . . . 53.5. Matriz de productos cruzados . . . . . . . . . . 53.6. Matriz de covariancia . . . . . . . . . . . . . . 54.Ordenamiento de alternativas 54.1. Manejo de los datos de entrada . . . . 54.2. Método basado en la lógica clásica . . 54.3. Métodos basados en la lógica difusa: la 54.4. Método difuso-1: capas no dominadas 54.5. Método difuso-2: rangos . . . . . . . . 54.6. Referencias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 394 394 394 394 . . . . . . . . . . . . . . . . . . . . . . . . relación de entrada . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 395 395 396 398 400 402 403 55.Diagramas de dispersión 405 55.1. Estadı́sticas univariadas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 405 55.2. Estadı́sticas univariadas por parejas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 405 55.3. Estadı́sticas bivariadas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 406 56.Búsqueda de estructura 56.1. Análisis de medias . . . 56.2. Análisis de regresión . . 56.3. Análisis de Ji-cuadrada 56.4. Referencias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 407 407 409 410 411 57.Tablas univariadas y bivariadas 413 57.1. Estadı́sticas univariadas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 413 57.2. Estadı́sticas bivariadas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 414 57.3. Nota sobre los pesos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 420 58.Tipologı́a y clasificación ascendente 58.1. Tipos de variables utilizadas . . . . . . . . . . . . . . . . . . . . 58.2. Perfil de caso . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58.3. Perfil de grupo . . . . . . . . . . . . . . . . . . . . . . . . . . . 58.4. Distancias utilizadas . . . . . . . . . . . . . . . . . . . . . . . . 58.5. Construcción de una tipologı́a inicial . . . . . . . . . . . . . . . 58.6. Caracterı́sticas de distancias por grupos . . . . . . . . . . . . . 58.7. Estadı́sticas de resumen . . . . . . . . . . . . . . . . . . . . . . 58.8. Descripción de la tipologı́a resultante . . . . . . . . . . . . . . . 58.9. Resumen de la cantidad de variancia explicada por la tipologı́a 58.10.Clasificación jerárquica ascendente . . . . . . . . . . . . . . . . 58.11.Referencias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 421 421 421 422 422 423 424 424 425 426 426 427 Apéndice: Mensajes de error de los programas de IDAMS. 429 Índice alfabético. 431 Capı́tulo 1 Introducción IDAMS es un paquete de programas para la validación, manejo y análisis estadı́stico de datos. Consiste en un grupo de programas y facilidades que usan el mismo ambiente de manera que un solo lenguaje permite el acceso a las diferentes funciones en todos los programas. Ejemplos del tipo de datos que se pueden procesar con IDAMS son: respuestas a las preguntas de una encuesta, información acerca de los libros en una biblioteca. caracterı́sticas personales y desempeño de los alumnos en una escuela, medidas de un experimento cientı́fico. La caracterı́stica que tienen en común estos datos es que consisten en valores de variables para cada una de las colecciones de objetos/casos (por ej. en una encuesta, las preguntas corresponden a las variables y los encuestados a los casos). Existen numerosos paquetes y programas que ayudan al análisis estadı́stico de tales datos. Una caracterı́stica especial de IDAMS es que también suministra facilidades para hacer una validación extensa de los datos (por ej. verificación de códigos y de consistencia) antes del análisis. En lo que concierne al análisis, IDAMS realiza técnicas clásicas tales como construcción de tablas, análisis de regresión, análisis de variancia de una entrada, análisis de discriminación y conglomerados y también algunas técnicas más avanzadas tales como análisis factorial de componentes principales, análisis factorial de correspondencias, cálculo de puntajes basados en el orden parcial de casos, ordenamiento de alternativas, segmentación y tipologı́a iterativa. Además, la versión de IDAMS para Windows (WinIDAMS) ofrece los componentes interactivos para construcción de tablas multidimensionales, exploración gráfica de datos y análisis de series de tiempo. 1.1. Interfaz del Usuario de WinIDAMS Es una interfaz de documento múltiple (MDI). Permite trabajar simultáneamente con diferentes tipos de documentos en ventanas separadas. Esta Interfaz suministra lo siguiente: la definición de las carpetas Datos, Trabajo y Temporal para una aplicación; la ventana Diccionario para crear/actualizar/mostrar archivos Diccionario; la ventana Datos para crear/actualizar/mostrar archivos Datos; la ventana Setup para preparar/mostrar archivos Setup (el editor de sintáxis en color); la ventana Resultados para mostrar, copiar e imprimir partes seleccionadas de los resultados; un editor general de texto; opción para ejecutar setups de IDAMS desde un archivo o desde la ventana activa Setup; facilidades interactivas de importar/exportar datos; acceso a los componentes de análisis interactivo de datos (Tablas multidimensionales, GraphID, TimeSID); acceso en lı́nea al Manual de Referencia. 2 1.2. Introducción Facilidades para el manejo de datos Agrupación de datos (AGGREG). Permite agrupar en un solo registro los registros que vienen de varios casos y produce a la salida un nuevo dataset con un registro por grupo, por ejemplo los miembros de una familia se reagrupan en un registro que representa la familia. Las variables en el nuevo registro son estadı́sticas de resumen de variables especı́ficas de los registros individuales, por ej. la suma, media, valor mı́nimo/máximo. Construcción de un dataset IDAMS (BUILD). Lee un archivo de datos primarios (que puede tener múltiples registros por caso) junto con un diccionario que describe las variables que se van a seleccionar. BUILD verifica la presencia de valores no numéricos en campos numéricos; los campos en blanco se pueden recodificar a valores numéricos especificados por el usuario y otros no numéricos se reportan y reemplazan con nueves. La salida es un dataset IDAMS que comprende un archivo Datos con un sólo registro por caso y un diccionario asociado que describe cada campo en los registros de datos. Verificación de códigos (CHECK). Reporta casos que tengan valores inválidos en las variables. Los códigos válidos para cada variable los especifica el usuario y se toman del diccionario. Verificación de consistencia (CONCHECK). Reporta casos con inconsistencias entre dos o más variables. Las proposiciones de Recode de IDAMS se utilizan para especificar las relaciones lógicas a verificar. Verificación de intercalación de registros (MERCHECK). Verifica que estén presentes los registros correctos para cada caso en un archivo de múltiples registros por caso. Produce un archivo de salida que tiene un número igual de registros por caso. Se pueden eliminar registros inválidos o duplicados y se pueden insertar registros faltantes con códigos de valores faltantes especificados por el usuario. Corrección de datos (CORRECT). Actualiza un archivo al aplicar correcciones a valores individuales de variables para casos especificados. El archivo Resultados contiene un informe escrito con la historia de las correcciones y estas se pueden archivar. Importación/exportación de datos (IMPEX). La importación tiene por objeto crear datasets o matrices de IDAMS a partir de archivos que vienen de otro programa. La exportación pretende hacer posible el uso de archivos Datos y Matrices, almacenados o creados por IDAMS, en otros paquetes. Se pueden importar/exportar archivos de texto en formato libre y en formato DIF. Listado de datasets (LIST). Se pueden listar los valores de variables seleccionadas (originales o recodificadas) y casos seleccionados en formato de columnas. Intercalación de datasets (MERGE). Se pueden intercalar dos datasets emparejando casos de acuerdo con un conjunto común de variables llamadas variables de emparejamiento. Hay cuatro opciones para seleccionar casos en el dataset de salida: (1) sólo casos presentes en ambos archivos (intersección); (2) cada caso en ambos archivos (unión); (3) cada caso en el primer archivo; (4) cada caso en el segundo archivo. El usuario especifica cuales variables de cada uno de los dos archivos de entrada van a la salida. Existe una opción para encajar un caso de un archivo con más de un caso del segundo archivo, por ej. para añadir datos de hogares de un archivo al registro de cada individuo en un segundo archivo. Clasificación e intercalación de archivos (SORMER). Es un utilitario de uso general para clasificar datos en forma ascendente o descendente hasta por 12 campos de clasificación. Se pueden intercalar hasta 16 archivos. Subdivisión de datasets (SUBSET). Produce un nuevo dataset (archivos Datos y Diccionario) con casos y variables seleccionados del dataset de entrada. Tiene una opción para verificar casos duplicados. Transformación de datos (TRANS). Este programa se usa para guardar las variables creadas por la facilidad Recode de IDAMS en un dataset permanente. 1.3 Facilidades para el análisis de datos 1.3. 3 Facilidades para el análisis de datos Análisis de conglomerados (CLUSFIND). Ejecuta análisis de conglomerados dividiendo un conjunto de objetos (casos o variables) en un conjunto de conglomerados determinado por uno de 6 algoritmos, 2 basados en la división alrededor de medoides, 1 basado en la lógica difusa y los otros 3 basados en una conglomeración jerárquica. Análisis de configuración (CONFIG). Ejecuta análisis sobre una configuración de entrada, creada por ejemplo con el programa MDSCAL. Tiene la capacidad de centrar, normalizar, rotar, trasladar dimensiones, calcular distancias entre puntos y productos escalares. Se puede graficar la configuración después de cada transformación. Análisis discriminatorio (DISCRAN). Busca la mejor función lineal de discriminación de un conjunto de variables que produce, hasta donde sea posible, una agrupación a priori de los casos. Utiliza un procedimiento por pasos, es decir, en cada paso entra la variable más poderosa. El programa distingue tres muestras de casos: la muestra básica sobre la cual se hacen los análisis discriminatorios principales, muestra de prueba sobre la cual se verifica la potencia de la función de discriminación y muestra anónima que se usa sólo para clasificar los casos. Se pueden guardar en un dataset la última asignación de grupos a los casos y valores de los dos primeros factores discriminatorios (para análisis con más de 2 grupos). Funciones de distribución y de Lorenz (QUANTILE). Funciones de distribución con 2 a 100 subintervalos, funciones de Lorenz, curva de Lorenz y coeficientes de Gini, y la prueba de Kolmogorov-Smirnov. Análisis factorial (FACTOR). Consiste en un conjunto de análisis factoriales de componentes principales (productos escalares, covariancias, correlaciones) y análisis factorial de correspondencias. Para cada análisis construye una matriz que representa las relaciones entre las variables y calcula sus valores propios y vectores propios. Calcula los factores para los casos y las variables dando para cada caso y cada variable su ordenada, su calidad de representación y su contribución a los factores. Estos factores se pueden guardar en el dataset y se puede obtener una representación gráfica de casos y variables en el espacio factorial. El programa distingue entre casos y variables activas y pasivas. Regresión lineal (REGRESSN). Suministra una capacidad general de regresión múltiple para análisis de regresión lineal estándar y por pasos. Se puede usar un dataset o una matriz de correlación como entrada. Se pueden imprimir residuos con la estadı́stica de Durbin-Watson para su correlación de primer orden, y también puede llevarse al archivo de salida, por ej. para análisis posteriores. Escalamiento multidimensional (MDSCAL). Este es un procedimiento de escalamiento multidimensional no métrico para el análisis de similitudes. Opera sobre una matriz de medidas de similitud o disimilitud y está diseñado para hallar la mejor representación geométrica de los datos. El usuario controla la dimensión de la configuración, la métrica usada y la manera de manejar las ataduras (valores iguales) en los datos de entrada. Análisis de clasificación múltiple (MCA). Examina las relaciones entre varias variables predictoras (control) y una sola variable dependiente y determina el efecto de cada predictor antes y después del ajuste de sus intercorrelaciones con otros predictores. Suministra información de las relaciones bivariadas y multivariadas entre predictores y la variable dependiente. Se pueden imprimir los residuos y llevarlos a un dataset. Análisis de variancia multivariado (MANOVA). Ejecuta análisis de variancia univariado y multivariado, y análisis de covariancia, usando un modelo general lineal. Se pueden usar hasta ocho factores (variables dependientes). Cuando hay más de una variable dependiente, se ejecutan ambos análisis univariado y multivariado. El programa aplica una solución exacta con un nombre igual o diferente de casos en las celdas. Análisis de variancia de una entrada (ONEWAY). Estadı́sticas descriptivas dentro de las categorı́as de la variable de control y estadı́sticas de análisis de variancia de una entrada tales como: suma total de cuadrados, suma de cuadrados entre medias, suma de cuadrados dentro grupos, eta y eta cuadrada (no ajustada y ajustada) y el valor de la prueba F. Puntajes basados en el orden parcial de casos (POSCOR). Calcula puntajes de escala ordinales a partir de variables de intervalos u ordinales. Se calculan los puntajes para cada caso involucrado en el análisis y miden la posición relativa del caso dentro del conjunto de los mismos. Los puntajes, opcionalmente con otras variables especificadas por el usuario, salen en la forma de un dataset IDAMS. 4 Introducción Correlación de Pearson (PEARSON). Calcula los coeficientes r de correlación de Pearson, covariancias y coeficientes de regresión. Se puede solicitar eliminación de datos faltantes por parejas o por casos. Las matrices de correlación y de covariancias de salida se pueden guardar en un archivo. Ordenamiento de alternativas (RANK). Determina un orden de alternativas por rangos usando datos preferenciales y tres procedimientos diferentes de asignación de rangos, uno basado en la lógica clásica y otros dos basados en la lógica difusa. Los datos preferenciales pueden representar una selección o un rango de alternativas. Se pueden especificar dos tipos de relaciones individuales preferenciales: débil y estricta. Con la asignación difusa de rangos, los datos determinan completamente los resultados obtenidos mientras que con la asignación clásica el usuario tiene la posibilidad de controlar los cálculos. Diagramas de dispersión (SCAT). Diagramas de dispersión, estadı́sticas univariadas (media, desviación estándar y N), estadı́sticas bivariadas (r de Pearson y estadı́sticas de regresión: coeficiente B y constante A). Búsqueda de estructura (SEARCH). Un procedimiento de segmentación binaria para desarrollar modelos predictivos. La pregunta “qué dicotomı́a y en que variable predictora se obtendrá el máximo aprovechamiento de la capacidad para predecir valores de la variable dependiente” dentro de un esquema iterativo, es la base del algoritmo usado. Tablas univariadas y bivariadas (TABLES). Las opciones incluyen: (1) distributiones de frecuencia univariadas simples y acumulativas y de porcentajes; (2) estadı́sticas univariadas: media, mediana, moda, variancia, desviación estándar, asimetrı́a, kurtosis, mı́nimo y máximo; (3) tablas de frecuencias bivariadas con porcentajes por fila, columna y total; (4) tablas de valores medios de una variable adicional; (5) estadı́sticas bivariadas: pruebas-t de medias entre pares de filas, Ji-cuadrada, coeficiente de contingencia, V de Cramer, Tau a, b, c de Kendall, Gama, Lambda, Ro de Spearman, estadı́sticas para la medicina basada en evidencia, y tres pruebas no parámetricas: Wilcoxon, Mann-Whitney y Fisher. Tipologı́a y clasificación ascendente (TYPOL). Crea una variable de clasificación como el resumen de un gran número de variables cuantitativas y cualitativas. El usuario escoge el número inicial y final de grupos, el tipo de distancia usada y la manera de comenzar la tipologı́a inicial. Los grupos de la tipologı́a inicial se estabilizan con un procedimiento iterativo. El número de grupos se puede reducir con un algoritmo de clasificación jerárquica ascendente. El programa distingue entre variables activas que participan en la construcción de la tipologı́a y variables pasivas para las cuales se calculan las estadı́sticas principales dentro de los grupos de la tipologı́a. Tablas interactivas multidimensionales. El componente “Tablas multidimensionales” permite visualizar y personalizar tablas con frecuencias, porcentajes de fila, de columna y totales, estadı́sticas univariadas (suma, conteo, media, máximo, mı́nimo, variancia, desviación estádar) de variables adicionales y estadı́sticas bivariadas. Se pueden anidar hasta siete variables en filas y columnas. Se puede repetir la construcción de tablas para cada valor hasta tres variables de “página”. También se pueden imprimir las tablas o exportarlas en formato libre (coma o carácter de tabulación como delimitador) o en formato HTML. Exploración gráfica interactiva de los datos. Un componente separado, GraphID, está disponible en WinIDAMS para explorar datos a través de despliegues gráficos. El despliegue básico se encuentra en la forma de gráficos de dispersión múltiple para diferentes pares de variables. Se puede graficar información adicional tal como histogramas y lı́neas de regresión. Los gráficos se pueden manejar de varias maneras. Por ejemplo, se pueden marcar en un gráfico casos seleccionados y luego resaltarlos en todos los otros gráficos. Se pueden aumentar partes del gráfico (“zoom”). Las matrices de IDAMS se muestran como gráficos de tres dimensiones en los cuales se representan las variables/los códigos en dos de los ejes y la tercera dimensión se usa para mostrar el tamaño de la estadı́sitica en la matriz (por ej. coeficiente de correlación) para cada par de variables. Análisis interactivo de series de tiempo. Otro componente separado, TimeSID, suministra la posibilidad de análisis interactivo de series de tiempo. Contiene análisis de tendencias, correlaciones auto y cruzadas, análisis gráfico y estadı́stico de los valores de las series de tiempo, pruebas de aleatoriedad y tendencia, predicción a corto plazo, periodogramas y estimación de densidades espectrales. Las series se pueden transformar calculando promedios, composiciones aritméticas, diferencias secuenciales, razones de cambio, se pueden suavizar con promedios móviles y se pueden descomponer usando filtros de frecuancia. 1.4 Los datos en IDAMS 1.4. 5 Los datos en IDAMS Dataset IDAMS - el archivo Datos. El archivo de entrada a IDAMS puede ser cualquier archivo de caracteres (ASCII) de formato fijo, es decir, los valores de una variable ocupan la misma posición en el registro para cada caso. Las caracerı́sticas del archivo Datos son: 1-50 registros por caso; cada caso puede contener hasta 4096 caracteres; número de casos limitado para la capacidad de disco y la representación numérica interna; las variables pueden ser numéricas (hasta 9 caracteres) o alfabéticas (hasta 255 caracteres). Dataset IDAMS - el archivo Diccionario. El diccionario se usa para describir los datos: puede contener hasta 1000 variables identificadas con un número único entre 1 y 9999; para cada variable, contiene como mı́nimo el número de la variable, su tipo (numérica o alfabética), su localización en el registro de datos; para cada variable se puede especificar también un nombre de variable, dos códigos de datos faltantes, el número de cifras decimales y número de referencia; para variables cualitativas se pueden incluir sus códigos y nombres correspondientes. El conjunto de los dos archivos Diccionario y Datos se conoce como dataset IDAMS. Matrices IDAMS. Algunos programas de análisis utilizan como entrada una matriz de valores rectangular o cuadrada en lugar de un archivo de datos primarios. La matriz cuadrada se usa para arreglos simétricos de estadı́sticas bivariadas con una constante en la diagonal. Solamente se guarda la esquina superior derecha de la matriz, sin la diagonal. La matriz rectangular es para arreglos no simétricos. El significado de filas y columnas varı́a según el programa de IDAMS. 1.5. Comandos de IDAMS y el archivo Setup Excepto los componentes interactivos de WinIDAMS, la ejecución de un programa de IDAMS comienza con un archivo Setup. Contiene información tal como especificación de archivos, proposiciones de control de programa, instrucciones de recodificación de variables, etc. separadas por comandos de IDAMS (comienzan con un signo $) los cuales identifican la clase de información que se especifica. El primer comando de IDAMS en el archivo Setup identifica siempre el primer programa que se va a ejecutar, por ej. $RUN TABLES $FILES DICTIN = nombre del archivo Diccionario DATAIN = nombre del archivo Datos $SETUP proposiciones de control para el programa TABLES $RECODE proposiciones de transformación de variables 1.6. Caracterı́sticas estándar de IDAMS Selección de casos. Por defecto, en una ejecución de un programa de IDAMS se procesan todos los casos de un archivo Datos. Para escoger un subconjunto, se incluye una proposición de filtro en el setup, por ej. INCLUDE V3=1 (incluir sólo aquellos casos para los cuales la variable 3 es igual a 1). 6 Introducción Selección de variables. Las variables son referidas por sus números de variable asignados en el diccionario. Se especifica un conjunto de variables en una lista de variables que sigue a continuación de palabras clave tales como VARS, CONVARS, OUTVARS. Tales listas de variables también pueden incluir variables R construidas con la facilidad Recode de IDAMS (ver más adelante) por ej. VARS=(V3-V6,V129,R100,R101). Transformación/recodificación de datos. Es una poderosa herramienta de recodificación que permite asignar nuevos códigos y construir nuevas variables. Las instrucciones de recodificación las escribe el usuario en el lenguaje Recode de IDAMS. Incluye la posibilidad de hacer cálculos aritméticos ası́ como también el uso de varias funciones especiales para operaciones tales como agrupamiento de variables, creación de variables “ficticias”, etc. También se permiten proposiciones condicionales. Los siguientes son ejemplos de proposiciones de Recode para construir tres nuevas variables R100, R101, R102: R100=V4+V5 R101=BRAC(V10,0-15=1,16-60=2,60-98=3,99=9) IF (MDATA(V3,V4) OR V4 EQ 0) THEN R102=99 ELSE R102=V3*100/V4 Las variables R ası́ construidas para cada caso se pueden usar temporalmente en el programa que se está ejecutando o se pueden guardar en un dataset con el programa TRANS. Ponderación de datos. Cuando se usan procedimentos complejos de muestreo durante la recolección de datos, puede ser necesario usar diferentes ponderaciones de los casos durante el análisis. Tales ponderaciones se guardan como una variable en el archivo Datos. Se utiliza entonces el parámetro WEIGHT para invocar la ponderación en las proposiciones de control del programa, por ej. WEIGHT=V5. Tratamiento de datos faltantes y datos “malos” . Se pueden identificar valores especiales como códigos de datos faltantes para cada variable numérica y guardarlos en el diccionario. Durante el procesamiento de los datos, el manejo de datos faltantes se hace con dos parámetros: MDVALUES (especifica cuales de los códigos de datos faltantes se usarán para verificar datos faltantes en las variables numéricas); MDHANDLING (especifica qué hacer cuando se encuentren datos faltantes). Normalmente se supone que los datos se han depurado antes del análisis. Si no es éste el caso entonces se dispone del parámetro BADDATA para omitir casos con valores no numéricos o con valores en blanco en campos numéricos o para tratar esos valores como datos faltantes. 1.7. Importación y exportación de datos IDAMS no utiliza formatos internos especiales para almacenar los datos. Cualquier archivo de caracteres ASCII de formato fijo puede ser descrito con un diccionario IDAMS y luego ser leı́do por IDAMS. Por el contrario, los datos en formato libre separados con Tab, coma o punto y coma se pueden importar a través de la Interfaz del Usuario de WinIDAMS. Aun más, el programa IMPEX permite crear datos de IDAMS de formato fijo a partir de un archivo de texto en cualquier formato libre o en formato DIF. Los datos creados por IDAMS son siempre archivos de caracteres de formato fijo. Los archivos pueden entrar directamente a otro programa junto con la información descriptiva apropiada para dicho programa. Los datos en formato libre separados con Tab, coma o punto y coma se pueden obtener a través de la Interfaz del Usuario de WinIDAMS. Aun más, el programa IMPEX permite a exportar un archivo IDAMS de formato fijo como archivo de texto en formato libre o formato DIF. Las matrices IDAMS se guardan en un formato especı́fico de IDAMS (descrito en el capı́tulo “Los datos en IDAMS”). Se puede usar el programa IMPEX para importar/exportar matrices con formato libre. 1.8. Intercambio de datos entre CDS/ISIS e IDAMS Hay un programa separado, WinIDIS, el cual prepara la descripción de los datos y hace la transferencia de los mismos entre IDAMS y CDS/ISIS (programas de UNESCO para el manejo de bases de datos y recuperación de información). La transferencia es controlada por los archivos de descripción de datos de IDAMS e ISIS 1.9 Estructura de este Manual 7 (el diccionario IDAMS y la tabla de definición de campos de CDS/ISIS). Para ir de ISIS a IDAMS siempre se construyen nuevos archivos de diccionario y de datos y se pueden intercalar con otros datos usando las facilidades de manejo de datos de IDAMS. Para ir de IDAMS a ISIS, hay tres posibilidades: (1) se puede construir una base de datos completamente nueva, (2) se pueden añadir los registros transferidos a una base de datos existente como nuevos registros de la base de datos, (3) se pueden actualizar los registros de una base de datos existente con los datos transferidos. 1.9. Estructura de este Manual Todas las caracterı́sticas generales de IDAMS, incluida la facilidad Recode, se describen en la Parte 1 de este Manual. La Parte 2 incluye las instrucciones de instalación, la descripción de archivos y carpetas usadas en WinIDAMS, una sección titulada “Primeros pasos” la cual lleva al usuario a través de los pasos requeridos para hacer una ejecución de IDAMS y la descripción de la Interfaz del Usuario de WinIDAMS. En las Partes 3 y 4 se dan descripciones detalladas de cada programa IDAMS. Estas documentaciones contiene las secciones siguientes: Descripción general. Una descripción del propósito principal del programa. Caracterı́sticas estándar de IDAMS. Descripción de las posibilidades de selección de casos y de variables, transformación de datos, capacidad de ponderación y manejo de datos faltantes. Resultados. Detalles de los resultados destinados a ser impresos (o revisados en pantalla). Descripción de archivos de salida y entrada. Una sección para cada dataset de IDAMS, cada matriz y cualquier otro archivo de entrada o salida diferente, que proporciona una descripción de su contenido. Estructura del setup. Una designación de las definiciones de archivos, comandos de IDAMS y proposiciones de control necesarias para ejecutar el programa. Proposiciones de control del programa. Los parámetros y formatos de cada una de las proposiciones de control del programa con un ejemplo para cada tipo. Restricciones. Un resumen de las limitaciones del programa. Ejemplos. Ejemplos de conjuntos completos de proposiciones de control para ejecutar el programa. La Parte 5 suministra una descripción de los componentes interactivos de IDAMS para la construcción de tablas multidimensionales, para la exploración gráfica de los datos y para el análisis de series de tiempo. En la Parte 6 se pueden encontrar detalles de técnicas estadı́sticas, fórmulas y referencias bibliográficas de los programas de análisis. Finalmente, los errores generados por los programas de IDAMS se resumen en el Apéndice. Parte I Nociones fundamentales Capı́tulo 2 Los datos en IDAMS 2.1. 2.1.1. El dataset IDAMS Descripción general El dataset consiste en dos archivos distintos y asociados: un archivo Datos y un archivo Diccionario que describe algunos o todos los campos (variables) en los registros de datos. Todos los archivos Diccionario/Datos que salen de un programa IDAMS son datasets de IDAMS. 2.1.2. Método de almacenamiento y acceso Los archivos Diccionario y Datos se leen y se escriben secuencialmente. De esta manera, se pueden guardar en cualquier medio de almacenamiento. No hay un archivo especial interno del “sistema” de IDAMS como en otros paquetes. Los archivos se encuentran en formato de texto/carácter (ASCII) y se pueden procesar en cualquier momento con utilitarios generales o editores o pueden entrar directamente a otros paquetes estadı́sticos. 2.2. 2.2.1. Archivos Datos El arreglo de datos Sin importar el formato que tengan los datos en el archivo, éstos pueden visualizarse como un arreglo rectangular de valores de variables, en donde el elemento xij es el valor de la variable representada por la columna j-ésima para el caso representado por la fila i-ésima. Por ejemplo, los datos de una encuesta se pueden mostrar de la manera siguiente: Casos Variables identificación educación sexo edad ... ___________________________________________________________________ caso 1 caso 2 . . 1300 1301 1302 . 6 2 3 . 2 1 1 . 31 25 55 . ... ... ... ... ... En el ejemplo, cada fila representa una persona que responde a una encuesta y cada columna representa una pregunta del cuestionario. 12 Los datos en IDAMS 2.2.2. Caracterı́sticas del archivo Datos Este archivo contiene normalmente, pero no necesariamente, registros de longitud fija, ya que el final del registro se reconoce con caracteres de alimentación de retorno. Sin embargo, la longitud del registro más largo debe suministrarse en la especificación de archivo (ver comando $FILES). No hay lı́mite para el número de registros del archivo Datos. La longitud máxima de registro es 4096 caracteres. Cada “caso” puede tener más de un registro (hasta un máximo de 50). Si en una ejecución particular de un programa, se accede a las variables desde más de un tipo de registro, entonces debe haber exactamente el mismo número de registros para cada caso. El programa MERCHECK puede usarse para crear archivos que cumplan esta condición. Nótese que cualquier archivo Datos de salida de un programa IDAMS siempre se reestructura para tener un sólo registro por caso. Si un archivo de datos primarios tiene tipos de registro diferentes y el tipo de registro está codificado y no tiene exactamente el mismo número de registros por caso, los programas de IDAMS se pueden ejecutar usando variables de un tipo de registro a la vez, mediante la selección de ese tipo de registro al comienzo. 2.2.3. Archivos jerárquicos IDAMS sólo procesa archivos “rectangulares” como se indicó anteriormente. Los archivos jerárquicos se pueden manejar al almacenar registros de los diferentes niveles en diferentes archivos y después se usan los programas AGGREG y MERGE para producir registros compuestos que tengan las variables de los diferentes niveles. Alternativamente, el archivo jerárquico completo de datos se puede procesar de a un nivel a la vez mediante el “filtrado” de registros para ese nivel (siempre que los tipos de registros estén codificados). 2.2.4. Variables Referencia a variables. Las variables en el archivo Datos se identifican con un número único entre 1 y 9999. Este número, precedido de una V (por ej. V3) se usa para referirse a una variable en particular en las instrucciones de control de programa. El número de variable se usa para asignar un ı́ndice a un registro descriptor de variable en el diccionario que suministra el resto de información necesaria acerca de la variable tal como el nombre y su ubicación dentro del registro de datos. Tipos de variable. Las variables pueden ser de tipo numérico o alfabético, ambas almacenadas en modo de caracteres. Variables numéricas. Estas pueden ser positivas o negativas con las siguientes caracterı́sticas: Un valor se puede componer de los caracteres numéricos 0-9, un punto decimal y un signo (+,-). Se permiten blancos a la izquierda. Los valores deben estar justificados a la derecha dentro del campo (es decir, sin blancos a la derecha) a menos que aparezca un punto decimal. El ancho máximo de campo es 9 pero sólo hasta 7 dı́gitos significativos (tomando enteros y decimales) se retienen en el procesamiento. Los valores de variable pueden ser enteros (por ej. una variable de edad o una variable categórica como sexo) o pueden tener decimales (por ej. una variable con valores de porcentajes). El número de decimales (NDEC) se guarda en el registro descriptor de la variable en el diccionario. Normalmente el punto decimal está “implı́cito” y no aparece en los datos. En este caso NDEC indica el número de dı́gitos del valor de la variable que se van a tratar como cifras decimales. Si se codifica un punto decimal “explı́cito” en los datos, entonces NDEC se utiliza para determinar el número de dı́gitos a retener a la derecha del punto decimal, con el redondeo necesario del valor, por ej. valores codificados 4.54 y 4.55 con NDEC=1 se usarán como 4.5 y 4.6 respectivamente. Un signo (si aparece) debe ser el primer carácter, por ej. “-0123”. Los campos en blanco se consideran no numéricos y se tratan cómo datos “malos”. Ver más adelante cómo tratar los blancos en los datos que indican datos inaplicables y faltantes. 2.2 Archivos Datos 13 Con excepción de BUILD, todos los programas de IDAMS aceptan valores en notación exponencial, por ej. el valor codificado como .215E02 se userá como 21.5. Variables alfabéticas. Se pueden guardar variables alfabéticas en los archivos Datos y pueden tener hasta 255 caracteres de longitud. Pueden usarse en los programas de manejo de datos. Las variables alfabéticas de 1-4 caracteres pueden usarse también en filtros. Para usarlas en los programas de análisis deben ser recodificadas a valores numéricos. Esto se puede hacer con la función BRAC de Recode. 2.2.5. Códigos de datos faltantes El valor de una variable para un caso en particular puede ser desconocido por muchas razones, por ejemplo una pregunta puede ser inaplicable a ciertos encuestados o uno de ellos puede rehusarse a contestar la pregunta. Se pueden establecer códigos especiales para datos faltantes en cada variable numérica y se pueden codificar en los datos cuando se necesiten. Se permiten dos códigos de datos faltantes: MD1 y MD2. En caso de usarlos, cualquier valor en los datos igual a MD1 se considerará dato faltante; cualquier valor mayor o igual que MD2 (si MD2 es positivo o cero) o menor o igual que MD2 (si MD2 es negativo) también se considerará dato faltante. Estos códigos de datos faltantes se guardan en el registro de diccionario de la variable. Igual que para valores de datos, pueden ser enteros o decimales con punto decimal implı́cito o explı́cito. Si se especifica MD1 o MD2 con punto decimal implı́cito, NDEC da el número de dı́gitos a tratar como cifras decimales. Si se ha codificado un punto decimal en MD1 o MD2, entonces NDEC determina el número de dı́gitos a la derecha del punto decimal que deben retenerse, y el valor se redondea apropiadamente. Cuando los códigos MD1 y MD2 de una variable están en blanco en el diccionario, significa que no hay códigos especiales numéricos de datos faltantes. Durante una ejecución de un programa IDAMS, los códigos MD1 y MD2 del diccionario que estén en blanco se convierten a códigos de datos faltantes por defecto con valores de 1,5 × 109 y 1,6 × 109 respectivamente. Como los códigos de datos faltantes están limitados a un máximo de 7 dı́gitos (o 6 dı́gitos y un signo negativo), pueden presentar problemas para variables de 8 y 9 dı́gitos. El usuario debe considerar el uso de un primer código negativo de datos faltantes en este caso. 2.2.6. Valores no numéricos o en blanco en variables numéricas - datos malos En los programas de manejo de datos de IDAMS, éstos simplemente se copian de un lado a otro y no se lleva a cabo una conversión a modo computacional (binario); en este caso no se verifica si las variables numéricas tienen valores numéricos. Sin embargo, cuando las variables se usan para análisis o en operaciones de Recode, entonces sus valores se convierten a modo binario y los valores con caracteres no numéricos causarán problemas. Normalmente, se deben limpiar esos caracteres de los datos antes del análisis. Además, valores en blanco en variables numéricas no se tratan automáticamente como datos faltantes; se consideran también como no numéricos o datos “malos”. Para permitir el análisis de datos con limpieza incompleta y para el manejo de campos en blanco no recodificados, se puede usar el parámetro BADDATA para tratar los blancos y otros valores no numéricos como faltantes y de esta manera tener la posibilidad de eliminarlos del análisis. La especificación del parámetro BADDATA=MD1 o BADDATA=MD2 resulta en la conversión de valores “malos” a los códigos MD1 o MD2 de la variable. Si los códigos MD1 o MD2 están en blanco, entonces los valores malos se convierten a los códigos de datos faltantes correspondientes por defecto (ver arriba) y entonces se tratan como valores faltantes (ver también la descripción del parámetro BADDATA en el capı́tulo “El archivo Setup de IDAMS”). 2.2.7. Las reglas de edición de las variables en salida de programas IDAMS Los programas IDAMS crean siempre un archivo Datos y un diccionario correspondiente, es decir un dataset IDAMS. El archivo Datos contiene un registro para cada caso. La longitud del registro es la suma de los anchos de campo de todas las variables de salida y es determinada por el programa. 14 Los datos en IDAMS Los valores de las variables numéricas se editan de acuerdo con una forma estándar que se describe a continuación. Si la totalidad del campo contiene unicamente los caracteres numéricos 0-9, éstos se envı́an a la salida tal como aparecen en el archivo de entrada. Si el campo contiene un número precedido por blancos (por ej. “ 5”), los blancos se convierten a ceros antes de la salida de los datos. Los campos con los blancos a la derecha (por ej. “04 ” en un campo numérico de tres dı́gitos), los blancos entre digitos (por ej. “0 4”) y sólo los blancos, se tratan según la especificación de BADDATA. Si el campo contiene un valor positivo o negativo con los caracteres “+” y “-” dados explı́citamente, el signo positivo se elimina y el signo negativo se pone antes del primer dı́gito numérico significativo. Si el campo contiene un número con un punto decimal explı́cito, se elimina el punto decimal y se produce un valor con el mismo tamaño del campo de entrada y n cifras decimales tal como se hayan definido en el campo NDEC de la descripción de la variable. Los blancos a la izquierda en el campo se convierten a ceros. Si en el campo de entrada se encuentran más de n dı́gitos después del punto decimal, el valor se redondea a n cifras decimales y se envı́a a la salida (por ej. si n=2 el valor de salida de 2.146 será 215; si n=0, el valor de salida para 1.5 será 002). Los blancos a la derecha no causan condición de error. Si se encuentran menos de n dı́gitos, se insertan ceros a la derecha en los lugares de los decimales faltantes. Los valores demasiado grandes para entrar en el campo asignado son tratados según la especificación de BADDATA. Los valores de las variables alfabéticas no se editan y son los mismos en la entrada y en la salida. 2.3. 2.3.1. El diccionario IDAMS Descripción general El diccionario se usa para describir las variables en los datos. Para cada variable, éste debe contener como mı́nimo el número de la variable, su tipo y su localización dentro del registro de datos. Adicionalmente se puede suministrar un nombre de variable, dos códigos de datos faltantes, el número de cifras decimales y un número o nombre de referencia. La información se guarda en registros descriptores de variables conocidos a veces como registros T. Registros opcionales C para variables categóricas dan nombres a los diferentes códigos posibles. El primer registro del diccionario, el registro descriptor del diccionario, identifica el tipo de diccionario, da los números de la primera y de la última variable usados en el diccionario y especifica el número de registros de datos que hacen un “caso”. El diccionario original lo prepara el usuario para describir los datos primarios. Los programas de IDAMS que construyen datasets siempre producen nuevos diccionarios que reflejan el nuevo formato de los datos. Los registros del diccionario se guardan como registros de formato fijo de longitud de 80 caracteres. A continuación se ofrece una descripción detallada de cada tipo de registro de diccionario. Registro descriptor de diccionario. Es siempre el primer registro del diccionario. Columnas Contenido 4 5-8 9-12 13-16 20 3 (indica el tipo de diccionario). Número de la primera variable (justificado a la derecha). Número de la última variable (justificado a la derecha). Número de registros por caso (justificado a la derecha). Forma en la cual se ha especificado la localización de variables (columnas 32-39) en los registros descriptores de variable. Blanco Número de registro y columnas inicial y final. La longitud de registro debe ser 80 para usar este formato si el número de registros por caso es > 1. 1 Posición inicial y ancho de campo. 2.3 El diccionario IDAMS 15 Registros descriptores de variables (registros T). El diccionario tiene un registro de éstos por cada variable. Estos registros están arreglados en orden ascendente por número de variable. Los números de variables no necesitan ser contiguos. El número máximo de variables es 1000. Columnas Contenido 1 2-5 7-30 32-39 40 41 45-51 52-58 59-62 73-75 T Número de variable. Nombre de variable. Localización; de acuerdo con la columna 20 del registro descriptor de diccionario. o bién 32-33 Número secuencial de registro con la columna inicial de la variable. 34-35 Número de columna inicial. 36-37 Número secuencial de registro con la columna final de la variable. 38-39 Número de columna final. o 32-35 Posición inicial de la variable dentro del caso. 36-39 Ancho de campo (1-9 para las variables numéricas y 1-255 para las variables alfabéticas). Número de cifras decimales (sólo variables numéricas). Blanco implica que no hay cifras decimales. Tipo de variable. Blanco Numérica. 1 Alfabética. Primer código de datos faltantes para variables numéricas (o blancos si no hay primer código de datos faltantes). Justificado a la derecha. Segundo código de datos faltantes para variables numéricas (o blancos si no hay segundo código de datos faltantes). Justificado a la derecha. Número de referencia (opcional - se puede usar para alguna referencia alfanumérica inmodificable para la variable, por ej. el número original de la variable o una referencia a la pregunta). Identificador de estudio (opcional - se puede usar para identificar el estudio al cual pertenece este diccionario). Nota 1: cuando se usan número de registro y de columna para identificar la localización de la variable, los listados de registros de diccionario no muestran el número de registro y de columna tal como aparecen en el registro del diccionario. En cambio, la localización de la variable se traslada y se imprime en el formato de posición inicial/ancho. Por ejemplo, para una variable en las columnas 22-24 del tercer registro de un archivo de registros múltiples por caso (longitud de registro 80), la posición inicial será 182 (2 * 80 + 22) y el ancho 3. Nota 2: si hay más de un registro por caso y la longitud de registro no es 80, entonces la notación de posición inicial y ancho de campo debe usarse en los registros T. La posición inicial se cuenta a partir del comienzo del primer registro. Por ejemplo, para registros de longitud 121, la posición inicial de un campo en la posición 11 del segundo registro de un caso serı́a 132. Registros de nombres de códigos (registros C). El diccionario puede contener estos registros opcionalmente para cualquiera de las variables. Van inmediatamente a continuación del registro T para la variable a la cual aplican y suministran códigos y nombres para diferentes valores posibles de la variable. Los usan programas tales como TABLES para imprimir nombre de filas y columnas junto con los códigos correspondientes. También pueden usarse como la especificación de códigos válidos para una variable durante la entrada de datos con la Interfaz del Usuario de WinIDAMS y para la validación de datos con el programa CHECK. 16 Los datos en IDAMS Columnas Contenido 1 2-5 6-9 C Número de variable. Número de referencia (opcional - se puede usar para alguna referencia inmodificable para la variable, por ej. el número original de la variable o una referencia a la pregunta). Valor del código justificado a la izquierda. Nombre para este código. (Nota: los programas de análisis sólo usan los primeros 8 caracteres e imprimen nombres de códigos aunque el nombre completo aparecerá en el listado del diccionario). Identificador de estudio (opcional). 15-19 22-72 73-75 2.3.2. Ejemplo de un diccionario Columnas: 1 2 3 4 5 6... 123456789012345678901234567890123456789012345678901234567890... T T T C C T C C C C T T 3 1 2 3 3 3 11 11 11 11 11 12 20 1 20 1 1 Identificación Edad Sexo 1 Mujer 2 Hombre Región 1 Norte 2 Sur 3 Este 4 Oeste Calificación promedio Nombre 1 6 8 5 2 1 16 1 17 31 31 30 1 99 000 900 Este es un diccionario que describe 6 campos en un registro de datos como se ven esquemáticamente a continuación. 1-5 V1 6-7 V2 8 V3 16 V11 17-19 V12 31-60 V20 ID Edad Sexo Región Calif. Nombre Las localizaciones de variables se expresan en términos de posición inicial y ancho de campo (1 en la columna 20 del registro descriptor de diccionario) y hay un registro por caso (1 en la columna 16). Hay una cifra decimal implı́cita en la variable de calificación promedio (V12). La variable edad tiene código 99 para datos faltantes. Para la calificación promedio, los ceros significan datos faltantes ası́ como todos los valores mayores o iguales a 90.0. El nombre de cada encuestado (V20) se graba como una variable de tipo alfabético (tipo 1) de 30 caracteres. Nótese que los números de variable no necesitan ser contiguos y que no se requiere describir todos los campos en los datos. 2.4. Matrices IDAMS Hay dos tipos de matrices IDAMS: cuadradas y rectangulares. Ambos tipos se describen por sı́ mismos, pero contrariamente al dataset IDAMS, el “diccionario” se guarda en el mismo archivo de los valores del arreglo. En general, estas matrices se crean con un programa IDAMS para ser usadas como entrada a otro programa y el usuario no tiene que estar familiarizado con el formato. Sin embargo, si es necesario preparar una matriz de correlación, una matriz de configuración, etc. a mano, entonces se deben observar los formatos descritos más adelante. Sin importar el tipo, todos los registros son de longitud fija de 80 caracteres. 2.4 Matrices IDAMS 2.4.1. 17 La matriz cuadrada IDAMS La matriz cuadrada se puede usar solamente para un arreglo cuadrado y simétrico. Sólo se guardan los valores del triángulo superior derecho, sin la diagonal. Un arreglo para una correlación de Pearson se guarda satisfactoriamente en esta forma. Programas que leen/producen matrices cuadradas. PEARSON produce matrices cuadradas de correlación y covariancia; REGRESSN produce matrices de correlación cuadradas; TABLES produce matrices cuadradas de medidas de asociación bivariadas. Estas matrices son la entrada apropiada para otros programas, por ej. la matriz de correlación que sale de PEARSON puede entrar a REGRESSN y a CLUSFIND. Adamás, CLUSFIND y MDSCAL leen las matrices cuadradas de similitudes o disimilitudes. Ejemplo. Columnas: Descriptor de matriz Formatos Identificación de variables Arreglo de valores Medias y desviaciones estándar 111111111122222222223... 123456789012345678901234567890... | | | | | | | | | | | 2 4 #F (12F6.3) #F (6E12.5) #T 1 EDAD #T 3 EDUCACION #T 9 RELIGION #T 10 SEXO -.011 -.174 -.033 .131 -.105 -.133 0.33350E 01 0.54950E 01 0.50251E 01 0.40960E 01 0.20010E 01 0.19856E 01 0.15000E 01 0.12345E 01 Formato. La matriz cuadrada contiene lo siguiente: 1. Un registro descriptor de la matriz. Este, el primer registro, da el tipo de matriz y las dimensiones del arreglo de valores. Columnas Contenido 4 5-8 2 (indica matriz cuadrada). Número de variables (justificado a la derecha). 2. Una proposición de formato Fortran que describe cada fila del arreglo de valores. La proposición de formato describe el número de campos por registros de 80 caracteres y el formato de cada uno. Por ejemplo, un formato de (12F6.3) indica que cada fila del arreglo se graba hasta con 12 valores por registro, cada valor ocupa 6 columnas 3 de las cuales son decimales. Si una fila contiene más de 12 valores, el valor 13 quedará en el siguiente registro, etc. Cada nueva fila del arreglo siempre comienza en un nuevo registro. Columnas Contenido 1-2 3-80 #F Proposición de formato, entre paréntesis. 3. Una proposición de formato Fortran que describe los vectores de medias y desviaciones estándar de variables. La proposición de formato describe el número de valores por registro y el formato de cada uno. Columnas Contenido 1-2 3-80 #F Proposición de formato, entre paréntesis. 4. Registros de identificación de variables. Son n registros, donde n es el número de variables especificadas en el registro descriptor de matriz. El orden de estos registros corresponde al orden de las variables que asignan ı́ndices a las filas (y columnas) del arreglo de valores. Cuando una matriz es creada por un programa IDAMS, los números de variable y los nombres de las mismas se retienen del dataset IDAMS del cual se generaron las estadı́sticas. 18 Los datos en IDAMS Columnas Contenido 1-2 3-6 8-31 #T or #R (indica identificación de variable para una fila de la matriz). Número de variable (justificado a la derecha). Nombre de variable. Las cuatro secciones anteriores de la matriz se llaman el “diccionario” de la matriz. En seguida del diccionario de la matriz está el arreglo de valores. 5. El arreglo de valores. Como el arreglo es simétrico y tiene celdas diagonales que contienen una constante (por. ej. una correlación de 1.0 para una variable correlacionada consigo misma), sólo se guarda el ángulo superior derecho sin la diagonal. Nótese que para una matriz de covariancia los elementos de la diagonal pueden calcularse utilizando las desviaciones estándar que están incluı́das en el archivo de la matriz (ver sección 7 más adelante). En el ejemplo anterior de la matriz de 4 variables, el arreglo total (antes de entrar en el formato de matriz cuadrada) serı́a ası́: vars 1 3 9 10 1 1.000 -.011 -.174 -.033 3 -.011 1.000 .131 -.105 9 -.174 .131 1.000 -.133 10 -.033 -.105 -.133 1.000 9 -.174 .131 10 -.033 -.105 -.133 La porción del arreglo que se guarda es: vars 1 3 9 10 1 3 -.011 Cada fila de este arreglo reducido da comienzo a un nuevo registro y se escribe de acuerdo con el formato especificado en el diccionario de la matriz (ver arriba). 6. Un vector de medias de variables. Los n valores se graban de acuerdo con la proposición de formato en el diccionario de la matriz. 7. Un vector de desviaciones estándar de variables. Los n valores se graban de acuerdo con la proposición de formato en el diccionario de la matriz. 2.4.2. La matriz rectangular IDAMS La matriz rectangular difiere de la matriz cuadrada en que el arreglo de valores puede ser cuadrado (y no simétrico) o rectangular. Más aún, como las variables no asignan ı́ndices a las filas de algunos arreglos, por ej. una tabla de frecuencias, la matriz rectangular puede o no puede contener registros de identificación de variables; la matriz rectangular no contiene ni medias ni desviaciones estándar de variables. Programas que leen/producen matrices rectangulares. Estas matrices son creadas por los programas CONFIG, MDSCAL, TABLES y TYPOL. Son apropiadas para como entrada a CONFIG, MDSCAL, TYPOL. 2.4 Matrices IDAMS 19 Ejemplo. Columnas: Descriptor de matriz Formatos Identificación de variables Arreglo de valores 111111111122222222223... 123456789012345678901234567890... | | | | | | | | 3 4 3 #F (l6F5.0) #T 2 CI #T 5 EDUCACION #T 8 MOVILIDAD #T 12 RIVALIDAD ENTRE HERMANOS 59 20 10 37 15 2 50 40 7 8 26 31 Formato. La matriz rectangular continene lo siguiente: 1. Un registro descriptor de la matriz. Columnas Contenido 4 5-8 9-12 16 20 21-40 41-60 61-80 3 (indica matriz rectangular) El número de filas (justificado a la derecha). El número de columnas (justificado a la derecha). Número de registros de proposiciones de formato (#F). (Blanco implica 1). Presencia de nombres de filas y columnas: blanco/0 Sólo hay nombres de fila (registros #R o #T). 1 Sólo hay nombres de columna (registros #C). 2 Hay nombres de filas y columnas (registros #R o #T, y #C). 3 No hay nombres de filas ni de columnas. Nombre de variable de fila (opcional). Nombre de variable de columna (opcional). Descripción de contenido de la matriz (opcional): Frequencies/weighted (frecuencias/ponderadas) Frequencies/unwtd (frecuencias/sin ponderar) Percentages/row (porcentajes de fila) Percentages/column (porcentajes de columna) Percentages/total (porcentajes de total de la tabla) Nombre de la variable par la cual las medias están incluı́das en la matriz. 2. Una proposición de formato Fortran que describe cada fila del arreglo de valores. El formato describe un registro de 80 caracteres. Por ejemplo, un formato de (16F5.0) indica que cada fila del arreglo se graba hasta con 16 valores por registro y cada valor ocupa 5 columnas sin ninguna cifra decimal. Columnas Contenido 1-2 3-80 #F La proposición de formato, entre paréntesis. 3. Registros de identificación de variables. El orden de estos registros corresponde al orden de las variables/los códigos que asignan ı́ndeces a las filas y columnas de la matriz. Cuando un programa de IDAMS crea una matriz rectangular, los números y nombres de las variables/los códigos se retienen del dataset o matriz de entrada del cual o de la cual se derivó el arreglo de valores. Columnas Contenido 1-2 3-6 8-31 #T o #R para nombres de filas, #C para nombres de columnas. Número de variable o valor de código (justificado a la derecha). Los códigos con longitud mayor que 4, se reemplazan con ****. Nombre de variable o nombre de código. Las tres secciones anteriores de la matriz se llaman el “diccionario” de la matriz. A continuación del diccionario de la matriz está el arreglo de valores. 4. El arreglo de valores. Se guarda todo el arreglo. Cada fila del arreglo da comienzo a un nuevo registro y se escribe de acuerdo con el formato especificado en el diccionario de la matriz. 20 2.5. 2.5.1. Los datos en IDAMS Uso de datos de otros paquetes Datos primarios Cada archivo en la forma de registros de formato fijo en modo de caracteres (ASCII) puede usarse directamente para los programas de IDAMS. Casi todos los paquetes de bases de datos y estadı́sticos tienen una función de “exportar” o “convertir” para producir archivos de datos de caracteres en formato fijo. Debe prepararse entonces un diccionario IDAMS para describir los campos requeridos en los datos. Un archivo de formato libre con Tab, coma o punto y coma como delimitador se puede importar directamente utilizando la Interfaz del Usuario de WinIDAMS. Ver el capı́tulo “Interfaz del Usuario” para más detalles. Los archivos de texto en formato libre (se puede utilizar para separar cualquier caracter, incluso blancos) y en formato DIF se pueden importar usando el programa IMPEX. Los datos almacenados en una base de datos CDS/ISIS se pueden importar con un programa WinIDIS. 2.5.2. Matrices Se puede usar el programa IMPEX para importar matrices en formato libre. Además, las matrices producidas fuera de IDAMS, por ejemplo una matriz en una publicación, pueden entrar de acuerdo con el formato descrito en la sección “Matrices IDAMS”. Capı́tulo 3 El archivo Setup de IDAMS 3.1. Contenido y propósito Para ejecutar los programas IDAMS el usuario prepara un archivo especial llamado archivo “Setup”, el cual controla la ejecución de los programas. El archivo Setup contiene comandos de IDAMS e instrucciones que especifican lo que se requiere, tales como qué programa se va a ejecutar, nombres de archivos, opciones a escoger del programa e instrucciones de transformación de variables; por. ej. $RUN nombre de programa $FILES especificación de archivos $SETUP proposiciones de control del programa $RECODE proposiciones de Recode 3.2. Comandos de IDAMS Estos comandos, los cuales comienzan con “$”, separan las diferentes clases de información que se suminsitran a una ejecución de un programa de IDAMS. Los comandos disponibles son: $RUN programa $FILES [RESET] $RECODE $SETUP $DICT $DATA $MATRIX $PRINT $COMMENT [texto] $CHECK [n] (nombre del programa a ejecutar) (señala el comienzo de especificación de archivos) (señala el comienzo de las proposiciones de Recode) (señala el comienzo de las proposiciones de control de programa) (señala el comienzo del diccionario) (señala el comienzo de los datos) (señala el comienzo de una matriz) (activa/desactiva el interruptor de impresión) (comentarios) (verifica si el paso previo terminó satisfactoriamente). La primera lı́nea en un archivo Setup debe ser siempre un comando $RUN que identifica el programa IDAMS a ejecutar. Otros comandos relacionados con la ejecución de este programa (seguidos de las proposiciones de control asociadas o de datos) se pueden colocar en cualquier orden. Estos se siguen con un comando $RUN para ejecutar el siguiente programa (si lo hay) y ası́ sucesivamente. Los comandos individuales de IDAMS se describen a continuación en orden alfabético. $CHECK [n]. Cuando este comando está presente, el programa no se ejecutará si el programa inmediatamente precedente terminó con un código de condición mayor que n. Si el comando está presente pero no se ha suministrado ningún valor, n toma 1 por defecto. 22 El archivo Setup de IDAMS Todos los programas de IDAMS terminan con un código de condición de 16 si se encuentran errores de setup. Por ejemplo, si TABLES se va a ejecutar inmediatamente después de TRANS pero el usuario no quiere ejecutar TABLES si se presenta un error en la ejecución de TRANS, un comando $CHECK después del comando $RUN TABLES va a impedir la ejecución de TABLES. El comando $CHECK puede aparecer en cualquier parte dentro del setup del programa pero por lo general se coloca inmediatamente después del comando $RUN. $COMMENT texto. El “texto” en este comando se imprime en el listado del setup. Este comando no tiene efecto en la ejecución del programa. $DATA. El comando $DATA señala que vienen los datos. No se puede usar si el programa genera un archivo Datos de salida y no se ha especificado el archivo DATAOUT, es decir que los datos de salida van a un archivo temporal por defecto. No se puede usar si se usa el comando $MATRIX. La longitud del registro de los datos en el setup no puede exceder de 80 caracteres. Si entran registros, o lı́neas más largas, sólo se usarán los primeros 80 caracteres. El comando $DATA desactiva el interruptor de impresión. Ası́, a menos de que un comando $PRINT venga inmediatamente después del comando $DATA, los datos no se imprimen. $DICT. El comando $DICT señala que viene un diccionario IDAMS. No se puede usar si el programa genera un archivo Diccionario de salida y no se ha especificado el archivo DICTOUT, es decir si el diccionario sale a un archivo temporal por defecto. El comando $DICT desactiva el interruptor de impresión. Ası́, a menos de que un comando $PRINT venga inmediatamente después del comando $DICT, el diccionario no se imprime. $FILES [RESET]. Señala el comienzo de especificación de archivos. Al comienzo de la ejecución de los programas de IDAMS se colocan nombres por defecto a cada archivo, con el uso de un archivo especial “idams.def”. Cualquiera de estos nombres por defecto, se puede cambiar con proposiciones de especificación de archivo introducidas después del comando $FILES (ver “Especificación de archivos” más adelante). Para obtener nuevamente los nombres por defecto para archivos Fortran FT (excepto FT06 y FT50), use el comando “FILES RESET”. $MATRIX. El comando $MATRIX señala que viene una matriz o una serie de matrices. No se puede usar si se usa $DATA. El comando $MATRIX desactiva el interruptor de impresión. Ası́, a menos que un comando $PRINT venga inmediatamente después del comando $MATRIX, la matriz no se imprime. $PRINT. Se invierte el interruptor de impresión; si estaba activado, $PRINT lo desactiva; si estaba desactivado, $PRINT lo activa. Si la impresión estaba activada, las lı́neas del archvo Setup se imprimen como una parte de los resultados. Cuando se encuentra un comando $RUN, el interruptor de impresión siempre se activa. Los comandos $DICT, $DATA y $MATRIX desactivan automáticamente el interruptor de impresión. $RECODE. La presencia de este comando señala que se va a usar la facilidad Recode de IDAMS. La facilidad Recode de IDAMS se describe en el capı́tulo “La facilidad Recode” de este manual. Las proposiciones de Recode normalmente siguen a continuación del comando $RECODE. Si un nuevo comando de IDAMS sigue inmediatamente después de un comando $RECODE, se usan las proposiciones Recode del setup del programa precedente. 3.3 Especificación de archivos 23 $RUN programa. $RUN especifica el programa que se va a ejecutar y siempre es la primera proposición en el setup. “programa” es el nombre del programa de 1-8 caracteres. Todos los comandos y proposiciones que van a continuación del comando $RUN y van hasta el siguiente comando $RUN se aplican al programa nombrado. El interruptor de impresión se activa cuando se encuentra un comando $RUN. Ver la descripción de $PRINT. $SETUP. El comando $SETUP señala el comienzo de las proposiciones de control del programa, es decir el filtro, tı́tulo, proposición de parámetros, etc. (ver más adelante). Se requiere el comando $SETUP aun cuando haya proposiciones de control de programa imediatamente después del comando $RUN. 3.3. Especificación de archivos Los nombres de los archivos a usar se dan después del comando $FILES y toman el formato siguiente: ddname=nombre de archivo [RECL=longitud máxima de registro] donde: ddname es el nombre de la referencia de archivo usado interiormente para los programas, por ej. DICTIN. Los archivos requeridos y los correspondientes ddnames para un programa en particular se dan en la documentación del programa en la sección titulada “Estructura del setup”. nombre de archivo es el nombre del archivo fı́sico. Encierre el nombre entre comillas sencillas si éste tiene blancos. Ver la sección “Carpetas en WinIDAMS” para explicaciones adicionales. RECL debe usarse si el primer registro del archivo Datos no es el más largo. Si no se ha especificado RECL la longitud de registro se toma como la longitud del primer registro. Si un registro posterior es más largo, se presenta un error de entrada. Ejemplos: DATAIN PRINT FT02 DICTIN = = = = A:ECON.DAT RECL=92 RSLTS.LST ECON.MAT \\nec0102\commondata\econ.dic Referirse a la sección “Personalización del ambiente para una aplicación” en el capı́tulo “Interfaz del Usuario” para una descripción adicional. 3.4. Ejemplos de uso de comandos $ y especificación de archivos Ejemplo A. Hacer múltiples ejecuciones de un programa de análisis, por ej. ONEWAY con los mismos datos pero, por ejemplo, con filtros diferentes. $RUN ONEWAY $FILES DICTIN = CHEESE.DIC DATAIN = CHEESE.DAT $RUN ONEWAY $SETUP 24 El archivo Setup de IDAMS Filtro 1 Otras proposiciones de control para ONEWAY $RUN ONEWAY $SETUP Filtro 2 Otras proposiciones de control para ONEWAY Ejemplo B. Ejecutar TABLES y ONEWAY usando el mismo diccionario y los mismos datos para cada programa y con el mismo Recode; no imprimir las proposiciones de Recode. $RUN TABLES $FILES DICTIN = ABC.DIC DATAIN = ABC.DAT RECL=232 $SETUP Proposiciones de control para TABLES $RECODE $PRINT Proposiciones de Recode $RUN ONEWAY $SETUP Proposiciones de control para ONEWAY $RECODE $COMMENT EL RECODE DE ENTRADA PARA TABLES SE USARA EN ONEWAY Ejemplo C. Ejecutar TABLES usando Recode de IDAMS, diccionario en el setup, datos en disco. Imprimir el diccionario de entrada. $RUN TABLES $FILES DATAIN = A:MYDATA.DAT $RECODE Proposiciones de Recode $SETUP Proposiciones de control para TABLES $DICT $PRINT Diccionario Ejemplo D. Usar los datos de salida de un programa de manejo de datos como entrada a los programas de análisis sin retener el archivo de salida, por ej. ejecutar TRANS seguido de TABLES usando los datos de salida de TRANS mediante la especificación del parámetro INFILE=OUT. TABLES no se ejecuta si TRANS tiene errores en las proposiciones de control. $RUN TRANS $FILES DICTIN = MY.DIC DATAIN = MY.DAT $SETUP Proposiciones de control para TRANS $RECODE Proposiciones de Recode $RUN TABLES $CHECK $SETUP Proposiones de control para TABLES, incluı́do el parámetro INFILE=OUT 3.5 Proposiciones de control de programa 3.5. 25 Proposiciones de control de programa 3.5.1. Descripción general Las proposiciones de control de la ejecución de programa (van a continuación del comando $SETUP), se usan para especificar los parámetros del programa a ejecutar. Hay tres proposiciones de control estándar que usan todos los programas: 1. la proposición opcional de filtro para seleccionar los casos a usar del archivo de datos, 2. la proposición mandatoria de tı́tulo que asigna un tı́tulo a la ejecución, 3. una proposición mandatoria de parámetros que selecciona las opciones para el programa; algunas opciones de programa son estándar en muchos programas, otras son especı́ficas de cada uno. Proposiciones de control adicionales requeridas en programas individuales se describen en la documentación del programa. 3.5.2. Reglas generales de codificación Las proposiciones de control entran en lı́neas de hasta 255 caracteres de longitud. Las lı́neas se pueden continuar si se coloca un guión al final de la lı́nea y se sigue en la siguiente. La longitud máxima de la información que puede entrar en una proposición de control es 1024 caracteres, excluı́dos los caracteres de continuación. Las letras minúsculas, con excepción de las que se encuentren en cadenas entre comillas sencillas, se convierten a letras mayúsculas. Si se incluyen cadenas de caracteres entre comillas sencillas en una proposición de control, éstas deben continuar en una lı́nea. 3.5.3. Filtros Propósito. Una proposición de filtro se usa para seleccionar un subconjunto de casos. Una proposición de filtro se expresa en términos de variables y de los valores tomados por esas variables. Por ejemplo, si la variable V5 indica “sexo del encuestado” en una encuesta y el código 1 representa mujer, entonces “INCLUDE V5=1” es una proposición de filtro que especifica encuestados femeninos como el subconjunto deseado de casos. El filtro principal selecciona casos de un archivo Datos de entrada y se aplica en toda la ejecución de un programa. Estos filtros están disponibles en todos los programas de IDAMS que cargan un diccionario (excepto BUILD y SORMER). Algunos programas permiten subdivisión adicional. Tales filtros “locales” se aplican solamente a una acción especı́fica del programa, por ej. una tabla de frecuencias. Ejemplos. 1. INCLUDE V2=1-5 AND V7=23,27,35 AND V8=1,2,3,6 2. EXCLUDE V10=2-3,6,8-9 AND V30=<5 OR V91=25 3. INCLUDE V50=’FRAN’,’UK’,’MORO’,’INDI’ Colocación. Si se usa un filtro principal, es siempre la primera proposición de control de programa. La documentación de cada programa indica si se pueden usar filtros “locales” también. Reglas de codificación. La proposición de filtro comienza con las palabras INCLUDE o EXCLUDE. Según la palabra usada, la proposición de filtro define el subconjunto de casos a usar (INCLUDE) o ignorar (EXCLUDE) por el programa. 26 El archivo Setup de IDAMS Una proposición puede contener un máximo de 15 expresiones. Una expresión consiste en un número de variable, un signo igual y una lista de posibles valores. Esta lista puede tener valores individuales y/o rangos de los mismos separados con comas, por ej. V2=1,5-9. Los rangos con extremos abiertos se indican con < o >, por ej. INCLUDE V1=0,3-5,>10; sin embargo la variable siempre debe estar seguida de un signo = para comenzar, por ej. V1>0 debe expresarse como V1=>0 y V1<0 como V1=<0. Las expresiones se conectan con las conjunciones AND y OR. • AND indica que debe hallarse un valor de cada una de las series de expresiones conectadas con AND. • OR indica que debe hallarse un valor por lo menos de una de las series de expresiones conectadas con OR. Las expresiones conectadas con AND se evalúan antes de las expresiones conectadas con OR. Por ejemplo, “expresión-1 OR expresión-2 AND expresión-3” se interpreta como “expresión-1 OR (expresión-2 AND expresión-3)”. Ası́, para que un caso esté en el subconjunto definido por estas expresiones, debe presentarse un valor de expresión-1 o valores de expresión-2 y expresión-3 o bién debe presentarse un valor de cada una de las tres expresiones. No se pueden usar paréntesis en la proposición de filtro para indicar precedencia de evaluación de expresiones. Las variables pueden aparecer en cualquier orden y en más de una expresión. Sin embargo, nótese que “V1=1 OR V1=2” es equivalente a la expresión sencilla “V1=1,2”. Nótese también que “V1=1 AND V1=2” es una condición imposible ya que un caso no puede tener ambos valores “1” y “2” para la variable V1. Una proposición de filtro puede terminar opcionalmente con un asterisco. Las variables en un filtro. • Se pueden usar variables de caracteres de tipo numérico y alfabético. • No se permiten variables R en filtros principales. Se permiten en filtros especificos de análisis o en filtros locales. Nótese que la proposición REJECT de Recode se puede usar para utilizar las variables R para filtrar casos. Los valores en un filtro para variables numéricas. • Los valores numéricos pueden ser enteros o decimales, positivos o negativos, por ej. 1, 2.4, -10. • Los valores se expresan en forma sencilla o en rangos y se separan con comas, por ej. 1-5, 8, 12-13. • Para variables numéricas de filtro, los valores en el archivo de datos se convierten primero a modo binario real con el número correcto de cifras decimales del diccionario y después se hace la comparación numéricamente con el valor en el filtro. Nótese que ésto significa que para una variable con decimales, los valores de filtro se deben suministrar con el punto decimal en el lugar correcto, por ej. V2=2.5-2.8. • Los casos con valores no numéricos en una variable de filtro siempre se excluyen de la ejecución. Los valores en un filtro para variables alfabéticas. • Valores de 1-4 caracteres se expresan como cadenas de caracteres entre comillas sencillas, por ej. ’F’. No se requiere entrar los blancos a la derecha, es decir que se añaden los blancos a la derecha. • Si la variable tiene un ancho de campo mayor que 4, entonces se usan sólo los primeros cuatro caracteres de los datos para comparar con la variable de filtro. • No se pueden usar rangos de cadenas de caracteres; sólo se permiten valores individuales separados con comas. Nota. La primera proposición después del comando $SETUP se reconoce como filtro principal si comienza con INCLUDE o EXCLUDE. Si los primeros caracteres que no estén en blanco son cualquier otra cosa, se supone que la proposición es un tı́ltulo. 3.5 Proposiciones de control de programa 3.5.4. 27 Tı́tulos Propósito. Una proposición de tı́tulo se usa para titular los resultados que produce un programa. Algunos programas de IDAMS imprimen este tı́tulo una vez al comienzo del listado mientras que otros lo utilizan para titular cada página del mismo. Ejemplos. 1. TABLAS DE LOS DATOS DE LAS ELECCIONES - JULIO, 2000 2. LISTADO DE DATOS DE ENCUESTA CORREGIDOS A34 Colocación. Todos los programas de IDAMS requieren una proposición de tı́tulo. El tı́tulo es la primera proposición de control de programa o (si se usa filtro) la segunda. Si no se desea tı́tulo en especial, es necesario de todas maneras incluir una lı́nea en blanco. Reglas de codificación. La proposición puede ser cualquier cadena de caracteres de los cuales se usan los primeros 80, es decir, si entra un tı́tulo con más de 80 caracteres, se trunca a los primeros 80. Si el tı́tulo no esta encerrado entre comillas sencillas, las minúsculas se convierten a mayúsculas y los blancos se reducen a un solo blanco. El tı́tulo no puede empezar con las palabras “INCLUDE” o “EXCLUDE”. 3.5.5. Parámetros Propósito. Todos los programas de IDAMS se han diseñado de una manera más o menos general de forma tal que permitan al usuario seleccionar varias opciones. Estas opciones y valores se llaman “parámetros” y se suministran en las proposiciones de control del programa, tales como “parámetros”, “especificaciones de regresión”, “especificaciones de tablas”, etc. El usuario especifica los parámetros en formato de palabra clave estándar con una palabra inglesa o su abreviación para identificar una opción. Ejemplos. 1. WRITE=CORR WEIGHT=V3, PRINT=(DICT, PAIR) (parámetros de PEARSON) 2. DEPV=V5 METHOD=STEP VARS=(R3-R9,V30) WRITE=RESID (parámetros de regresión de REGRESSN) 3. ROWV=(V3,V9,V10) COLV=(V4,V11,V19) CELLS=(FREQ,ROWPCT) STATS=(CHI,TAUA) (descripción de tabla de TABLES) Colocación. Todos los programas de IDAMS requieren la proposición principal de parámetros y debe seguir después de la proposición de tı́tulo. Si se escogen todos los valores por defecto, debe suministrarse una lı́nea con un asterisco. Cada documentación de programa indica el tipo y contenido de cualesquiera otras listas de parámetros que se requieran e indica su posición relativa a otras proposiciones de control del programa. Presentación de parámetros en formato de palabra clave en la documentación de programas. Toda la documentación tiene una notación estándar en las secciones que describen los parámetros de los que se dispone. La notación básica es la siguiente: Una diagonal indica que se puede escoger sólo uno de los términos mutuamente excluyentes, por ej. SAMPLE/POPULATION o PRINT=CDICT/DICT. Una coma indica que se pueden escoger todos, algunos o niguno de los ı́tems, por ej. STATS=(TAUA, TAUB, GAMMA). Cuando se combinan comas y diagonales, se puede escoger sólo uno (o ninguno) de los ı́tems dentro de cada grupo separados por comas y conectados con diagonales, por ej. PRINT= (CDICT/DICT, LONG/SHORT). 28 El archivo Setup de IDAMS Valores por defecto, si los hay, están en negrilla, por ej. METHOD=STANDARD/STEPWISE/ DESCENDING. Un valor por defecto es un valor que el programa asume para el parámetro, si no hay una selcción explı́cita hecha por el usuario. Si el uso de un parámetro es obligatorio pero no tiene valores por defecto se usan las palabras “Sin valor por defecto”. Las palabras en mayúsculas son palabras clave. Palabras o frases en minúsculas indican que el usuario debe reemplazar la palabra o la frase con un valor apropiado, por ej. MAXCASES=n, VARS=(lista de variables). Tipos de palabras clave. Hay 5 tipos de palabras clave para especificar parámetros. 1. Una palabra clave seguida de una cadena de caracteres. Este tipo de palabra clave identifica un parámetro que consiste en una cadena de caracteres, por ej. INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. El usuario puede especificar: INFILE=IN2 (los ddnames serian DICTIN2 y DATAIN2) 2. Una palabra clave seguida de uno o más números de variables, por ej. WEIGHT=número de variable El número de la variable de ponderación, si se van a ponderar los datos. VARS=(lista de variables) Usar sólo las variables en la lista; los números se pueden listar en cualquier orden con notación V o sin ella, es decir VARS=(V1-V3) o VARS=(1-3). Nótese que la documentación de los programas indica si se pueden usar variables V y R o sólo variables tipo V. El usuario puede especificar: WEIGHT=V39 (la variable de ponderación es V39) VARS=(32,1,10) (sólo se usan las variables especificadas) 3. Una palabra clave seguida de uno o más valores numéricos, por ej. MAXCASES=n Sólo se procesarán los primeros n casos. IDLOC=(i1,f1,i2,f2, ...) Columnas inicial y final para 1-5 campos de identificación de caso. El usuario puede especificar: MAXCASES=100 (sólo se procesarán los primeros 100 casos) IDLOC=(1,3,7,9) (la identificación de caso se halla en las columnas 1-3 y 7-9) 4. Una palabra clave seguida de uno o más valores de palabras clave. Los valores de palabra clave pueden ser una mezcla de opciones mutuamente excluyentes (separadas con diagonales) y opciones independientes (separadas con comas). Por ejemplo: PRINT=(OUTDICT/OUTCDICT/NOOUTDICT,DATA) OUTD Imprimir diccionario de salida sin registros C. OUTC Imprimir diccionario de salida con registros C si los hay. NOOU No imprimir diccionario de salida. DATA Imprimir los valores de las variables de salida. El usuario puede especificar: PRINT=(OUTC,DATA) (se imprime todo el diccionario de salida y se imprimen los datos) 3.5 Proposiciones de control de programa 29 PRINT=NOOUTDICT (no se imprime el diccionario de salida ni los datos) 5. Un conjunto de palabras clave mutuamente excluyentes. De un conjunto de opciones sólo se puede seleccionar una de ellas, por ej. SAMPLE/POPULATION SAMP Calcule la variancia y/o desviación estándar con la ecuación de la muestra. POPU Usar la ecuación de la población. Todas las palabras clave con excepción del último tipo van seguidas de un signo igual (=). Los valores de caracteres, numéricos y palabras clave que siguen al signo igual se llaman “valores asociados”. Reglas de codificación. Reglas para especificar palabras clave Sólo se requiere suministrar las primeras 4 letras de una palabra clave o una palabra clave asociada, aunque se puede suministrar toda la palabra clave. Ası́, “TRAN” es una abreviación apropiada para de la palabra clave “TRANSVARS”. No hay abreviación para palabras clave de 4 letras o menos. Reglas para especificar valores asociados El valor asociado es una lista de ı́tems. • Los ı́tems en la lista se separan con comas. • Si hay dos o más ı́tems, la lista debe estar entre paréntesis. • Rangos de valores enteros numéricos o de variables se indican con un guión. • No se permiten rangos de valores numéricos con decimales. Por ejemplo: R=(V2,3,5) PRIN=(DICT,DATA,STAT) MAXC=5 TRAN=(V5,V10-V25,V32) IDLOC=(1,3,7,8) El valor asociado es una cadena de caracteres. • La cadena debe encerrarse entre comillas sencillas si contiene caracteres no-alfanuméricos, por ej. FNAME=’EDUCACION:ONDA 1’. Nótese que los blancos, el punto y la coma son caracteres no-alfanuméricos. Cuando haya duda, use comillas sencillas. • Dos comillas sencillas consecutivas (no el carácter de comilla doble) se deben usar para representar una comilla sencilla, por ej. ANAME=’KEVIN”S’ (la comilla sencilla extra se elimina una vez que se ha leı́do la cadena). • Es mejor no separar una cadena entre lı́neas. Reglas para especificar listas de palabras clave Las palabras clave (con o sin valores asociados) se separan unas de otras con comas o con uno o más blancos, por ej. FNAME=’FRED’, TRAN=3 KAISER Una lista de palabras clave puede continuar en tantas lı́neas como sea necesario pero un guión es necesario al final de cada lı́nea para indicar la continuación, por ej. FNAME=’FRED’ TRAN=3 KAISER 30 El archivo Setup de IDAMS Las palabras clave se pueden suministrar en cualquier orden. Si una palabra clave aparece más de una vez en la lista, entonces se utiliza el último valor encontrado. Una palabra clave no puede separarse entre dos lı́neas. Cada lista de palabras clave puede terminar opcionalmente con un asterisco. Si se escogen todas las opciones por defecto, debe suministrarse una lı́nea con un asterisco. Detalles de parámetros más comunes y no descritos totalmente en la documentación de cada programa. 1. BADDATA. Tratamiento de datos no numéricos. BADDATA=STOP/SKIP/MD1/MD2 Cuando se encuentran caracteres no numéricos (incluidos blancos intercalados y campos totalmente en blanco) en variables numéricas, el programa debe: STOP Terminar la ejecución. SKIP Saltar el caso. MD1 Reemplazar los valores no numéricos por el primer código de datos faltantes (o por 1,5 × 109 si el primer código de datos faltantes no está specificado). MD2 Reemplazar los valores no numéricos por el segundo código de datos faltantes (o por 1,6 × 109 si el segundo código de datos faltantes no está specificado). Para SKIP, MD1 y MD2 se imprime un mensaje acerca del número de casos ası́ tratados. 2. MAXCASES. Número máximo de casos a procesar. MAXCASES=n El valor dado es el máximo número de casos que se van a procesar. Si n=0, no se leen casos; esta opción se puede usar para probar setups sin leer datos. Si no se especifica el parámetro, se procesan todos los casos. 3. MDVALUES. Especifica cuales de los códigos de datos faltantes (MD1,MD2) del diccionario o de las especificaciones de MDCODES en el Recode, si los hay, se van a usar para verificar datos faltantes en los valores de las variables. Nótese que algunos programas tienen adicionalmente un parámetro MDHANDLING para especificar cómo se van a manejar los valores faltantes en los datos. MDVALUES=BOTH/MD1/MD2/NONE BOTH Los valores de las variables se verificarán contra los códigos MD1 y los rangos de los códigos definidos par MD2. MD1 Los valores de las variables se verificarán contra los códigos MD1 solamente. MD2 Los valores de las variables se verificarán contra los rangos de los códigos definidos par MD2 solamente. NONE No se usarán códigos MD. Se consideran válidos todos los valores de los datos. Por defecto siempre se usan ambos códigos MD. 4. INFILE, OUTFILE. Especifican los ddnames con los cuales se definen los archivos Diccionario y Datos de entrada y salida. INFILE=IN/xxxx OUTFILE=OUT/yyyy Los archivos Diccionario y Datos de entrada y de salida para los programas de IDAMS se definen con ddnames DICTxxxx, DATAxxxx, DICTyyyy, DATAyyyy. Normalmente tienen los valores por defecto DICTIN, DATAIN. DICTOUT, DATAOUT. Si se usan varios programas de IDAMS en el setup, por ejemplo programas que utilizan diferentes datasets como entrada o cuando se usa la salida de un programa como entrada directa a otro programa (encadenamiento), entonces es necesario algunas veces cambiar estos valores por defecto. 5. WEIGHT. Este parámetro especifica la variable cuyos valores se usarán para ponderar los datos en los casos. WEIGHT=número de variable La variable especificada puede ser tipo V o tipo R, entera o decimal. Los casos con valores de ponderación faltantes, ceros, negativos y no numéricos, siempre se saltan y se imprime un mensaje acerca del total de casos ası́ tratados. Si no se especifica el parámetro WEIGHT, no se hace ponderación. 3.6 Proposiciones de Recode 31 6. VARS. Este parámetro y otros similares como ROWVARS, OUTVARS, CONVARS, etc. se usan para especificar una lista de variables. VARS=(lista de variables) Si se especifica más de una variable, la lista debe estar entre paréntesis. Reglas para especificar listas de variables Las variables se especifican con un “número” de variable precedido de una V o una R. Una V denota una variable de un dataset o de una matriz de IDAMS. Una R denota una variable que resulta de una operación de Recode. Nótese que internamente en el programa y en los resultados del mismo, las variables tipo V y tipo R se distinguen con el signo del número de variable; los números positivos denotan variables tipo V y los números negativos denotan variables tipo R. Para especificar un conjunto de variables numeradas en forma contigua, tales como V3, V4, V5, V6, conecte dos números con un guión, cada número precedido de una V (por ej. V3-V6 es válido; V3-6 es inválido). Use los rangos con precaución si el dataset que contiene las variables tiene vacı́os en la numeración de las mismas, ya que todas las variables dentro del rango deben aparecer en el dataset o en la matriz, es decir V6-V8 implica V6,V7,V8. Si V7 no está en el diccionario entonces aparecerá un mensaje de error. Las variables tipo V y tipo R no pueden estar mezcladas en un rango, es decir V2-R5 es inválido. Los números de variables individuales o rangos de números de variables se separan con comas. En general, para los programas de manejo de datos, las variables se pueden listar más de una vez mientras que para los programas de análisis de datos especificar una variable más de una vez es inapropiado y causará la terminación. Ver la documentación del programa para los detalles. Se pueden insertar blancos en cualquier parte de la lista. En general, las variables se pueden especificar en cualquier orden, Sin embargo, el orden de las variables puede tener significación especial para algunos programas, verificar la documentación del programa para los detalles. Ejemplos: VARS=(V1-V6, V9, V16, V20-V102, V18, V11, V209) OUTVARS=(R104, V7, V10-V12, R100-R103, V16, V1) CONVARS=V10 3.6. Proposiciones de Recode La facilidad Recode de IDAMS permite recodificar temporalmente los datos durante la ejecución de programas de IDAMS. Los resultados de esas operaciones de recodificación junto con las variables transferidas del archivo de entrada se pueden guardar también en archivos permanentes con el programa TRANS. La recodificación se invoca con el comando $RECODE. Este comando y las proposiciones asociadas de recodificación se colocan después del comando $RUN para el programa con el cual se va a usar la facilidad Recode. Por ejemplo: $RUN programa $FILES Definición de archivos $RECODE Proposiciones de Recode $SETUP Proposiciones de control de programa $RUN ONEWAY $FILES DICTIN=MYDIC DATAIN=MYDAT $RECODE R10 = BRAC(V3,0-10=1,11-20=2) R11 = SUM(V7,V8) NAME R10 ’NIVEL EDUC.’, R11’ING. TOT’ $SETUP INGRESO POR EDUC, SEXO BADDATA=SKIP CONVARS=(R10,V2) DEPVAR=R11 Una descripción completa de la facilidad Recode se encuentra en el capı́tulo “Facilidad Recode”. Capı́tulo 4 Facilidad Recode 4.1. Reglas de codificación Las proposiciones de Recode, tienen la forma: eti proposición donde eti es una etiqueta opcional de 1-4 caracteres que comienza en la posición 1 de la lı́nea y está seguido, por lo menos, de un espacio en blanco. Las proposiciones sin etiqueta deben comenzar en la posición 2 o más allá. La etiqueta permite que proposiciones de control tales como GO TO, se refieran a una proposición en particular, por ej. GO TO ST1. No puede haber etiquetas en las proposiciones de iniciación (CARRY, MDCODES, NAME). Para continuar una proposición en otra lı́nea, coloque un guión al final de la lı́nea y continúe en la lı́nea siguiente en cualquier posición. La longitud máxima de lı́nea es de 255 caracteres y el número total máximo de caracteres por cada proposición es de 1024, excluidos los guiones de continuación y los blancos después de cada guión. 4.2. Conjunto de muestra de proposiciones Recode Para dar alguna idea de como encajan los elementos del lenguaje de Recode, se ofrece a continuación una muestra de proposiciones Recode. $RECODE IF V5 LT 8 THEN REJECT (excluir casos donde V5 < 8) IF NOT MDATA(V6) THEN R51=TRUNC(V6/4) ELSE R51=0 R52=BRAC(V10,0-24=1,25-49=2,50-74=3, (agrupar valores de V10) 74-99=4,TAB=1) R53=BRAC(V11,TAB=1) (agrupar V11 igual que V10) IF V26 INLIST(1-10) THEN R54=1 AND R55=1 ELSE R54=2 IF R54 EQ 1 THEN GO TO L1 R55=99 R56=V15 + V35 GO TO L2 L1 R56=99 L2 R57=COUNT(1,V20-V27,V29) (cuantas de las variables tienen el valor 1) NAME R52 ’EDAD AGRUPADA’, R53 ’EDAD AGRUPADA EN MATRIM’ MDCODES R55(99),R56(99) 34 4.3. Facilidad Recode Tratamiento de datos faltantes Recode no verifica automáticamente los datos faltantes en las variables con excepción de las funciones especiales MAX, MEAN, MIN, STD, SUM, VAR. Por lo tanto el usuario debe controlar especı́ficamente los datos faltantes antes de hacer cálculos con las variables. Para este propósito está la función MDATA, por ej. IF MDATA (V5,V6) THEN R1=999 ELSE R1=V5+V6 Hay dos funciones adicionales, MD1 y MD2, las cuales devuelven el primero o segundo código de datos faltantes para una variable, por ej. R2=MD1(V6) asigna a R2 el valor del primer código de datos faltantes de V6. Finalmente, se pueden asignar códigos de datos faltantes a variables R o V con la proposición de definición MDCODES, por ej. MDCODES R3(8,9) asigna 8 y 9 como primero y segundo código de datos faltantes de R3. Algunas veces un conjunto de proposiciones de Recode no asigna un valor a una variable de resultado para un registro de datos en particular. La variable R tomará entonces el valor MD1 por defecto 1,5 × 109 el cual le fue asignado como valor inicial. Para cambiarla a un valor más aceptable, debemos ensayar si el valor es grande y si es ası́, asignar el valor de datos faltantes apropiado, por ej. IF R100 GT 1000000 THEN R100=99 MDCODES R100(99) 4.4. Como funciona Recode Verificación de sintaxis e interpretación. Las proposiciones de Recode se leen y se analizan para detectar errores antes de ser interpretadas por otras proposiciones de control de programa de IDAMS y antes de la ejecución del programa. Si se encuentran errores, se imprimen mensajes de diagnóstico y termina la ejecución del programa en curso. Resultados. Recode imprime las proposiciones de Recode que fueron suministradas por el usuario junto con los errores de sintaxis detectados, si los hubo. Esto se presenta antes de ejecutar el programa, es decir antes de imprimir la interpretación de las proposiciones de control del programa. Iniciación antes de comenzar a procesar un archivo de datos. Las tablas, códigos de datos faltantes, nombres, etc. se inician (de acuerdo con las proposiciones de iniciación/definición proporcionadas por el usuario) antes de comenzar la lectura de los datos, siempre que no haya errores de sintaxis. Las variables R en las proposiciones CARRY se inician con cero. Iniciación antes de procesar cada caso. Al comenzar el procesamiento de cada caso y antes de la ejecución de las proposiciones de Recode para ese caso, todas las variables R con excepción de aquellas listadas en proposiciones CARRY, se inician con los valores internos por defecto de IDAMS para datos faltantes (1,5 × 109 ). Ejecución de proposiciones de Recode. La recodificación propiamente dicha tiene lugar después de haber leı́do los datos para un caso y después de haber aplicado el filtro principal. Los casos que no pasan el filtro no van a las rutinas de Recode. Por lo tanto, no se pueden usar variables de Recode en filtros principales. El uso de las proposiciones de Recode es secuencial (es decir, la primera proposición se usa primero, después la segunda, la tercera, etc.) excepto cuando se modifican con las proposiciones GO TO, BRANCH, RETURN, REJECT, ENDFILE, ERROR (proposiciones de control). Cuando se han usado todas las proposiciones, el caso se pasa al programa IDAMS que se ejecuta. Cuando el programa ha terminado de usar el caso, se procesa el siguiente caso que haya pasado el filtro, la variables R se re-inician (excepto las variables en CARRY) con los códigos de datos faltanes y se ejecutan las proposiciones de Recode para ese caso y ası́ sucesivamente hasta llegar al final del archivo de datos. 4.5 Operandos básicos 35 Prueba de proposiciones Recode. Se pueden presentar errores de lógica que no son detectables por la facilidad Recode. Para verificar los resultados buscados contra los generados por Recode, las proposiciones de Recode deben probarse sobre unos pocos registros con el programa LIST y el parámetro MAXCASES iniciado por ejemplo a 10. Se pueden inspeccionar entonces los valores de las variables de entrada y de las correspondientes variables de resultados. Archivos usados por Recode. Cuando se encuentra un comando $RECODE en el archivo Setup, las lı́neas subsiguientes se copian a un archivo de trabajo en la unidad FT46. El programa RECODE lee las proposiciones Recode de este archivo y las analiza para buscar errores antes de pasar a la interpretación de otras proposiciones de control y antes de la ejecución cualquier programa IDAMS. Si hay errores, se imprimen los mensajes de diagnóstico y se termina la ejecución de ese programa de IDAMS. Las proposiciones interpretadas se escriben en forma de tablas en un archivo de trabajo en la unidad FT49 en la cual las lee el programa IDAMS que se ejecuta. Los mensajes acerca de las proposiciones de Recode se escriben en la unidad FT06 junto con los resultados del programa que se ejecuta. 4.5. Operandos básicos Variables. Las variables de Recode se refieren a variables de entrada (variables V) o variables de resultado (variables R). Se definen ası́: Variables de entrada (Vn). “V” seguida de un número. Estas son variables que siguen la definición del diccionario de entrada. Sus valores se pueden cambiar con Recode (por ej. V10=V10+V11). Normalmente deben ser numéricas, pero se pueden usar variables alfabéticas que no tengan más de cuatro (4) caracteres y en particular se pueden recodificar a valores numéricos. Variables de resultado (Rn). “R” seguida de un número (1 a 9999). Estas son variables creadas por el usuario. Las variables R, (excepto aquellas listadas en proposiciones CARRY - ver más adelante) se incian con el valor de datos faltantes por defecto 1,5 × 109 antes de procesar cada caso. Para usar una variable R en un programa, se especifica una R (en lugar de V) en la lista de variables correspondiente a un parámetro de palabra clave (por ej. WEIGHT=R50 o VARS=(R10R20)). Cuando los programas las escriben, se puede identificar un número de variables de resultado con un signo negativo. Ası́, la variable “10” es V10 y la variable “-10” es R10. Es menos confuso usar números diferentes para las variables de resultado a los números de las variables de entrada. Las variables R siempre son numéricas. Constantes numéricas. Las constantes pueden ser enteras o decimales, positivas o negativas, por ej. (3, 5.5, -50, -0.5). Constantes de caracteres. Las constantes de caracteres se encierran entre comillas sencillas (por ej. ’ABCXYZ’, ’M’). Una comilla sencilla dentro de una constante de caracteres se debe representar por dos comillas sencillas adyacentes (por ej. DON’TS se escribirı́a: ’DON”TS’). Se usan constantes de caracteres en la proposición NAME para asignar nombres a nuevas variables. También pueden usarse en expresiones lógicas para verificar valores de variables alfabéticas (por ej. IF V10 EQ ’M’); para estas comparaciones, sólo se usan los cuatro primeros caracteres y los valores de las variables/constantes con longitud inferior a cuatro (4) caracteres, se llenan de espacios en blanco a la derecha. Las constantes de caracteres no se pueden usar en funciones aritméticas (a excepción de BRAC). 4.6. Operadores básicos Operadores aritméticos. Los operadores aritméticos se usan dentro de los operandos aritméticos. Los operadores aritméticos en orden de precedencia, son: 36 Facilidad Recode EXP x * / + - (negación) (exponenciación a la potencia x, donde -181 < x < 175) (multiplicación) (división) (adición) (sustracción) Operadores relacionales. Los operadores relacionales se usan para determinar si existe o no alguna relación particular entre dos valores aritméticos. Los operadores relacionales son: LT LE GT GE EQ NE (menor que) (menor o igual que) (mayor que) (mayor o igual que) (igual) (no igual) Operadores lógicos. Los operadores lógicos se usan entre operandos lógicos. Los operandos lógicos toman solamente los valores “verdadero” o “falso”. Los operadores lógicos son: NOT AND OR 4.7. (ambos) (uno u otro) Expresiones Una expresión es una representación de un valor. Una constante sola, una variable o una referencia de una función son expresiones. Las combinaciones de constantes, variables, funciones y otras expresiones con operadores, son también expresiones. Recode puede evaluar expresiones aritméticas y expresiones lógicas. Nótese que se pueden usar paréntesis en cualquier parte dentro de una expresión para clarificar el orden de evaluación deseado. Expresiones aritméticas. Las expresiones aritméticas se construyen con operadores aritméticos y variables, constantes y funciones aritméticas. Las expresiones aritméticas producen un valor numérico. Ejemplos: V732 44 R67/V807 + 25 LOG(R10) (el (la (25 (el valor de V732) constante 44) más el valor de R67 dividido por el valor de V807) logaritmo del valor de R10) Expresiones lógicas. Las expresiones lógicas se evalúan para obtener un valor de “verdadero” o “falso”. No existen variables lógicas en el lenguaje Recode, de manera que el resultado de la evaluación de expresiones lógicas no se puede asignar a una variable. Las expresiones lógicas se pueden usar solamente con proposiciones IF. Ejemplos: R5 EQ V33 Verdadera, si el valor de R5 es igual al valor de V333, falsa si no lo es. (V62 GT 10) OR (R5 EQ V333) Verdadera, si alguna de las dos expresiones lógicas resulta verdadera, falsa si ambas expresiones lógicas resultan falsas. MDATA(V10,R20) AND V9 GT 2 Verdadera, si el valor de V10 o el valor de R20 corresponden a un código de datos faltantes y si el valor de V9 es mayor que 2, falsa, si lo anterior no se cumple. 4.8 Funciones aritméticas 4.8. 37 Funciones aritméticas Todas las funciones aritméticas devuelven un solo valor numérico. Las listas de argumentos para las funciones aritméticas pueden ser listas simples encerradas entre paréntesis o listas altamente estructuradas que involucren elementos de palabras clave y elementos en posiciones especı́ficas dentro de la lista. Las funciones disponibles son: Functión Ejemplo Propósito ABS BRAC ABS(R3) BRAC(V5,TAB=1,ELSE=9, 1-10=1,11-20=2) BRAC(V10,’F’=1,’M’=2) COMBINE V1(2), V42(3) COUNT(1,V20-V25) Valor absoluto Agrupamiento univariado COMBINE COUNT LOG MAX MD1,MD2 MEAN MIN NMISS NVALID RAND RECODE SELECT LOG(V2) MAX(V10-V20) MD1(V3) MEAN(V5-V8,MIN=2) MIN(V10-V20) NMISS(V3-V6) NVALID(V3-V6) RAND(0) RECODE V7,V8,(1/1)(1/2)=1, (2-3/3)=2, ELSE=0 SELECT (BY=V10,FROM=R1-R5,9) SQRT STD SUM TABLE TRUNC VAR SQRT(V2) STD(V20-V25,MIN=4) SUM(V6,V8,V9-V12,MIN=3) TABLE(V5,V3,TAB=2,ELSE=9) TRUNC(V26/3) VAR(V6,R5-R10,MIN=7) Recodificación alfabética Combinación de 2 variables Conteo de ocurrencias de un valor a través de un conjunto de variables Logaritmo de base 10 Valor máximo Valor de código de datos faltantes Valor medio Valor mı́nimo Nr. de valores de datos faltantes Nr. de valores de datos no faltantes Número aleatorio Recodificación multivariada Selección del valor de una variable dentro de un conjunto de variables según una variable ı́ndice Raı́z cuadrada Desviación estándar Suma de valores Recodificación bivariada Parte entera del valor del argumento Variancia A continuación se muestra la sintaxis exacta para cada función. ABS. La función ABS devuelve un valor que corresponde al valor absoluto del argumento entregado a la función. Prototipo: ABS(arg) Donde arg es cualquier expresión aritmética para la cual se tomará el valor absoluto. Ejemplo: R5=ABS(V5-V6) BRAC. La función BRAC devuelve un valor que es el resultado de operaciones especı́ficas (reglas) ejecutadas sobre una sola variable. Prototipo: BRAC(var [,TAB=i] [,ELSE=valor] [,regla1,...,regla n] ) Donde: var es cualquier variable tipo V o tipo R cuyos valores se van a probar. TAB=i numera el conjunto de reglas y la cláusula ELSE asociada en este uso de BRAC (opcional) o bien, se refiere a un conjunto de reglas establecidas en una utilización previa de BRAC. Nota: la cláusula ELSE se considera parte del conjunto de reglas de recodificación. ELSE=valor se usa cuando el valor de var no se puede encontrar dentro de las reglas dadas. Si ELSE=valor se omite, entonces se asume por defecto ELSE=99, ésto significa entonces que BRAC siempre recodifica. 38 Facilidad Recode regla 1, regla 2, ..., regla n es el conjunto de reglas que definen los valores que BRAC debe devolver, según el valor de var. Las reglas se expresan en la forma: x=c, en donde x define uno o más códigos y c es el valor a devolver cuando el valor de var sea igual al código o códigos definidos por x. Las posibles reglas (m es cualquier constante numérica o de caracteres) son: >m=c (si el valor de var es mayor que m, devuelva c) <m=c (si el valor de var es menor que m, devuelva c) m=c (si el valor de var es igual a m, devuelva c) m1-m2=c (si el valor de var está dentro del rango de m1 a m2, es decir m1<=var<=m2, devuelva c). Se pueden dar tantas reglas como sean necesarias. Se evalúan de izquierda a derecha y se usa la primera que se satisfaga. Nótese que se usan los sı́mbolos “>” y “<” a cambio de los operadores lógicos GT y LT. ELSE, TAB y las reglas se pueden especificar en cualquier orden. No se permiten rangos de valores de variables alfabéticas, por ej. ’A’-’B’ no estan permitidos. Ejemplos: R1=BRAC(V10,TAB=1,ELSE=9,1-10=1,11-20=2,<0=0) El valor de R1 será 1 si la variable V10 está dentro del rango de 1 a 10, será 2 si la variable V10 está dentro del rango 11 a 20 y será cero (0) cuando el valor de V10 sea menor que cero (0). Si V10 tiene cualquier otro valor, por ej. -3, 10.5, 25, 0, entonces se aplica la cláusula ELSE y R1 toma el valor de 9. Estas reglas de agrupamiento entre paréntesis se denominan tabla 1, de manera que pueden usarse posteriormente, por ej. R2=V1 + BRAC(V2, TAB=1) * 3 En este ejemplo, para la variable V2 se aplicarı́an las mismas reglas que a la variable V10 de agrupamiento entre paréntesis del ejemplo previo. El valor asignado a la variable R2 serı́a igual al de la variable V1 + (resultado del agrupamiento multiplicado por 3). R100=BRAC(V10,’F’=1,’M’=2,ELSE=9) Este es un ejemplo de recodificación de una variable alfabética, la cual tiene los valores ’F’ o ’M’ recodificados a los valores numéricos 1 y 2. COMBINE. La función COMBINE devuelve un valor único para cada combinación de valores de las variables que se usan como argumentos. Esta función se utiliza normalmente con variables categóricas. Prototipo: COMBINE var1 (n1), var2 (n2),...,varm(nm) Donde: var1 a varm son las variables tipo V o tipo R que se van a combinar. n1 a nm son los códigos máximos +1 de las respectivas variables. La lista de argumentos para la función COMBINE, no va entre paréntesis. Cada variable debe tener solamente valores no-negativos y enteros. Los valores devueltos se calculan con la siguiente fórmula: V1 + (n1 * V2) + (n1 * n2 * V3) + (n1 * n2 * n3 * V4) etc. El usuario, sin embargo, determina normalmente el resultado de la función al listar las combinaciones de valores en una tabla, como se ve en el primer ejemplo que sigue a continuación. Ejemplos: R1=COMBINE V6(2), R330(3) 4.8 Funciones aritméticas 39 Suponga que V6 tiene dos códigos (0,1) que representan hombres y mujeres respectivamente y R330 tiene tres códigos que representan jóvenes, personas con edad media y viejos, la proposición combinará los códigos de V6 y R330 para devolver una sola variable R1 ası́: V6 V330 R1 0 1 0 1 0 1 0 0 1 1 2 2 0 1 2 3 4 5 Hombres Mujeres Hombres Mujeres Hombres Mujeres jóvenes jóvenes con edad media con edad media viejos viejas Como V6 tiene dos códigos y R330 tiene tres, R1 tendrá seis. En el ejemplo anterior, si V6 tuviera códigos 1 y 2 en vez de 0 y 1, el valor máximo se deberı́a establecer como “3”. Esto permitirı́a los valores 0, 1 y 2, aunque el código 0 nunca aparecerı́a. Para evitar estos códigos “extra”, el usuario debe primero agrupar aquellas variables que produzcan un conjunto continuo de códigos que comiencen desde 0, es decir BRAC(V6,1=0,2=1). Restricciones: Puede tener un máximo de 13 variables. La función COMBINE no se puede usar con otras funciones dentro de la misma proposición de asignación. Se debe tener especial cuidado en especificar con los códigos máximos cuándo se usa la función COMBINE, de lo contrario, se generarán valores no-únicos. Por ejemplo, con “COMBINE V1(2), V2(4)” la función devolverá un valor de 7 para el par de valores, V1=1 y V2=3, y también devolverá un valor de 7 para el par de valores V1=3 y V2=2. Si los valores de 3 pueden existir para V1, entonces n1 se debe especificar como 4 (1 + código máximo). COUNT. La función COUNT devuelve un valor que es igual al número de veces que se presenta un valor de una variable o de una constante como el valor de una de las variables en la lista “varlist”. Prototipo: COUNT(val,varlist) Donde: val es normalmente una constante pero también puede ser una variable tipo V o tipo R. varlist especifica las variables V y/o las variables R, cuyos valores se verificaran contra val. Ejemplos: R3=COUNT(1,V20-V25) R3 se le asignará un valor igual al número de veces que se repita el valor 1 dentro de las seis variables V20-V25. Esto se podrı́a usar, por ejemplo, para contar el número de respuestas “SI” en un conjunto de preguntas hechas a un encuestado. R5=COUNT(V1,V8-V10) R5 se le asignará un valor igual al número de veces que se repita el valor de V1 dentro de las variables V8-V10. LOG. La función LOG devuelve un valor de punto flotante que es el logaritmo con base 10 del argumento entregado a la función. Prototipo: LOG(arg) Donde arg es cualquier expresión aritmética para la cual se quiere calcular su logaritmo con base 10. Ejemplos: R10=LOG(V30) 40 Facilidad Recode Nota: el logaritmo de cualquier número X en otra base B, se puede calcular fácilmente a partir de la siguiente transformación: R1=LOG(X)/LOG(B) Para el logaritmo natural (base e), serı́a: R1=2.302585 * LOG(X). Ası́ R1=2.302585 * LOG(V30) asignará a R1 el logaritmo natural de la variable V30. MAX. La functión MAX devuelve el valor máximo de un conjunto de variables. Se excluyen datos faltantes. El argumento MIN se puede usar para especificar el mı́nimo número de valores válidos a partir del cual se devolverá el valor máximo. En caso contrario, se devuelve el valor 1,5 × 109 asignado por defecto para datos faltantes. Prototipo: MAX(varlist [,MIN=n] ) Donde: varlist es una lista de variables tipo V y tipo R, y constantes. n es el número mı́nimo de valores válidos, para los cuales se calcula el valor máximo. El valor por defecto para n es 1. Ejemplo: R12=MAX(V20-V25) MD1, MD2. La función MD1 (o MD2) devuelve un valor que es el primero (o segundo) código de datos faltantes de la variable suministrada en el argumento. Prototipo: MD1(var) o MD2(var) Donde var es cualquier variable de entrada (variable V) o cualquier variable de resultado previamente definida (variable R). Ejemplo: R12=MD2(V20) Para cada caso procesado, R12 tendrá asignado el segundo código de datos faltantes para la variable de entrada V20. MEAN. La función MEAN devuelve el valor de la media de un conjunto de variables. Se excluyen valores de datos faltantes. El argumento MIN se usa para especificar el número mı́nimo de valores válidos para calcular la media. En caso contrario, el sistema devuelve el valor por defecto 1,5 × 109 para datos faltantes. Prototipo: MEAN(varlist [,MIN=n] ) Donde: varlist es una lista de variables tipo V y tipo R, y constantes. n es el número mı́nimo de datos válidos, para los cuales se calcula el valor de la media. El valor por defecto para n es 1. Ejemplo: R15=MEAN(R2-R4,V22,V5,MIN=2) El resultado será el valor de la media de las variables especificadas, si por lo menos dos de las variables tienen valores no-faltantes. En caso contrario, el resultado será 1,5 × 109 . MIN. La función MIN devuelve el valor mı́nimo de un conjunto de variables. Se excluyen valores de datos faltantes. El argumento MIN se puede usar para especificar el mı́nimo número de valores válidos, a partir del cual se calculará el valor mı́nimo. En caso contrario, se devuelve el valor 1,5 × 109 asignado por defecto para datos faltantes. Prototipo: MIN(varlist [,MIN=n] ) 4.8 Funciones aritméticas 41 Donde: varlist es una lista de variables tipo V y tipo R, y constantes. n es el número mı́nimo de valores válidos, para los cuales se calcula el valor mı́nimo. El valor por defecto para n es 1. Ejemplo: R10=MIN(V5,V7,V9,R2) NMISS. La función NMISS devuelve el número de valores faltantes en un conjunto de variables. Prototipo: NMISS(varlist) Donde varlist es una lista de variables tipo V y tipo R. Ejemplo: R22=NMISS(R6-R10) El valor que se devuelve, depende de cuantas de las variables R6-R10 tienen valores faltantes. El valor máximo es de 5 para un caso, en el cual todas las cinco variables tengan datos faltantes. NVALID. La función NVALID devuelve el número de valores válidos (no faltantes) dentro de un conjunto de variables. Prototipo: NVALID(varlist) Donde varlist es una lista de variables tipo V o tipo R. Ejemplo: R2=NVALID(V20,V22,V24) El valor que se devuelve, depende de cuántas variables tienen valores válidos. Se obtendrá un máximo valor de 3, si todas las variables tienen todos los valores válidos. Se devuelve cero cuando faltan datos para todas las tres variables. RAND. La función RAND devuelve un valor que corresponde a un número aleatorio uniformemente distribuido, basado en los argumentos “comienzo” y “lı́mite” que se describen a continuación. Prototipo: RAND(comienzo [,lı́mite] ) Donde: comienzo es una constante entera que se usa para iniciar la secuencia aleatoria. Si comienzo es cero, entonces se usa el tiempo ordinario del reloj. lı́mite es un argumento opcional. Es una constante entera que se usa para especificar el rango (3 significa un rango de 1 a 3). El valor asumido por defecto es 10, es decir que el rango por defecto es de 1 a 10. Ejemplos: R1=RAND(0) IF RAND(0) NE 1 THEN REJECT Para cada caso procesado, R1 tendrá asignado un número aleatorio, uniformemente distribuido de 1 a 10. La secuencia se inicia con el tiempo del reloj al ejecutar RAND por primera vez. Nótese que RAND puede usarse con la proposición REJECT para seleccionar una muestra aleatoria de casos. En el segundo ejemplo, el resultado será la inclusión de una muestra aleatoria de 1/10 de casos. RECODE. La función RECODE se usa para devolver un valor basado en los valores concurrentes de m variables. Prototipo: RECODE var1,var2,...,varm [,TAB=i] [,ELSE=valor] [,regla1,regla2,...,regla n] 42 Facilidad Recode Donde: var1,var2,...,varm es una lista de hasta 12 variables tipo V y tipo R que se van a probar. TAB=i numera el conjunto de reglas de recodificación establecidas en este uso de RECODE (opcional) o bien, se refiere a un conjunto de reglas establecidas en una utilización previa de RECODE. Nota: la cláusula ELSE no se considera parte del conjunto de reglas de recodificación. ELSE=valor (opcional), indica el valor a devolver cuando ninguna de las listas de códigos coincide con los valores de las variables. Aunque normalmente es una constante, también puede ser una expresión aritmética. Si ELSE se omite y ninguna de las listas de códigos coincide con los valores de las variables, la función no devuelve ningún valor, es decir que su valor permanece sin modificarse. Cuando es la primera proposición de asignación para una variable, entonces su valor será el dato de entrada para una variable tipo V o datos faltantes para una variable tipo R. regla1, regla2, ..., regla n, es el conjunto de reglas que definen los valores a devolver, según los valores de var1, var2,..., varm. Cada regla es de la forma “(lista de códigos 1)(lista de códigos 2) ... (lista de códigos p)=c”. Cada lista de códigos es de la forma “(a1/a2/.../am)” donde a1 es el código que se compara con var1, a2 es el código que se compara con var2, etc. El valor c corresponde al número que se devuelve cuando var1, var2,...,varm coinciden con los códigos definidos en cualquiera de las listas de códigos. El prototipo para una regla es: (a1/a2/.../am)(b1/b2/.../bm)...(x1/x2/.../xm)=c Cada lista de códigos contiene una lista y/o un rango de valores para cada variable, por ej. con dos variables, (3/2)(6-9/4)(0/1,3,5)=1. Los códigos en una lista de códigos pueden separarse por una diagonal (indica “AND”) o por una barra vertical (indica “OR”), aunque sólo una o la otra pueden usarse en una lista de códigos dada. Por ejemplo: (a1/a2/a3)=c (la función devolverá c si var1=a1 y var2=a2 y var3=a3) (a1|a2|a3)=c (la función devolverá c si var1=a1 o var2=a2 o var3=a3) Las reglas se examinan de izquierda a derecha. La primera lista de códigos que coincida con los valores de la lista de variables, determina el valor a devolver. La lista de argumentos para la función RECODE no va entre paréntesis. TAB, ELSE y las reglas pueden estar en cualquier orden. Ejemplos: R7=RECODE V1,V2,(3/5)(7/8)=1,(6-9/1-6)=2 A R7 se le asignará un valor basado en los valores de V1 y V2. En este ejemplo, R7 será 1 si V1=3 y V2=5, o si V1=7 y V2=8. R7 será 2 si V1=6-9 y V2=1-6. En los demás casos, R7 permanecerá sin cambios (ver atrás). R7=RECODE V1,V2,TAB=1,ELSE=MD1(R7),(3/5)(7/8)=1,(6-9/1-6)=2 A R7 se le asignará un valor igual al del ejemplo anterior, excepto que a R7 se le asignará su propio valor de MD1 cuando no se cumplan las reglas. TAB=1 permitirá usar estas mismas reglas en otra llamada a la función RECODE. Restricción: Cuando se use la función RECODE, ésta debe ser el único operando al lado derecho del signo igual. SELECT. La función SELECT devuelve el valor de la constante o variable en la lista que se define en FROM y el cual se encuentra en la misma posición definida por el valor de la variable en BY. (Advertencia: si el valor de la variable en BY es menor que 1 o mayor que el número de variables en la lista de FROM, 4.8 Funciones aritméticas 43 resulta un error fatal). Puede haber hasta 50 elementos en la lista de FROM, por lo tanto el valor máximo para la variable en BY es 50. Una función SELECT puede combinarse con otras funciones, operaciones y variables y formar ası́ expresiones complejas. Nota: la función SELECT selecciona el valor de una sóla variable de un conjunto de variables; la proposición SELECT selecciona la variable que se va a usar para el resultado. (Ver la sección “Proposiciones especiales de asignación” para una descripción de la proposición SELECT). Prototipo: SELECT (FROM=lista de variables y/o constantes, BY=variable) Ejemplo: R10=SELECT (FROM=R1-R3,9,BY=V2) R10 tendrá asignado el valor de R1, R2, R3 o 9 para los valores 1, 2, 3 y 4 de la variable V2 respectivamente. SQRT. La función SQRT devuelve un valor que es la raı́z cuadrada del argumento entregado a la función. Prototipo: SQRT(arg) Donde arg es cualquier expresión aritmética. Ejemplo: R5=SQRT(V5) STD. La función STD devuelve la desviación estándar de los valores de un conjunto de variables. Se excluyen valores de datos faltantes. El argumento MIN se usa para especificar el número mı́nimo de valores válidos para los cuales se va a calcular la desviación estándar. En caso contrario el sistema asume el valor para datos faltantes de 1,5 × 109 . Prototipo: STD(varlist [,MIN=n] ) Donde: varlist es una lista de variables tipo V y tipo R, y constantes. n es el número mı́nimo de valores válidos, para los cuales se calcula la desviación estándar. El valor por defecto para n es 1. Ejemplo: R5=STD(V20-V24,R56-R58,MIN=3) SUM. La función SUM devuelve la suma de los valores de un conjunto de variables. Se excluyen valores faltantes. El argumento MIN especifica el número mı́nimo de valores válidos de un caso, para calcular la suma. En caso contrario se asume el valor para datos faltantes por defecto 1,5 × 109 . Prototipo: SUM(varlist [,MIN=n] ) Donde: varlist es una lista de variables tipo V y tipo R, y constantes. n es el número mı́nimo de valores válidos, para los cuales se calcula la suma. El valor por defecto para n es 1. Ejemplo: R8=SUM(V20,V22,V24,V26,MIN=3) Si tres o más variables, tienen valores válidos, se devuelve la suma de estas variables, de lo contrario, se devuelve el valor 1,5 × 109 . TABLE. La función TABLE devuelve un valor basado en los valores concurrentes de dos variables. Prototipo: TABLE (r, c, [TAB=i,] [ELSE=valor,] [PAD=valor,] COLS c1,c2,...,cm, ROWS r1(vals fila r1),r2(vals fila r2),...,rn(vals fila rn)) 44 Facilidad Recode Donde: r es una variable o constante que se usará como “ı́ndice de fila” de una tabla. c es una variable o constante que se usará como “ı́ndice de columna” de una tabla. TAB=i numera la tabla definida en este uso de TABLE (opcional) o bien, se refiere a una tabla definida en una utilización previa de TABLE. ELSE=valor da un valor para usar con pares de valores que no están definidos en la tabla. Este valor puede ser una expresión aritmética. El valor de ELSE usa 99 por defecto cuando no se especifica, o sea que TABLE siempre devuelve un valor. PAD=valor da un valor para insertar en cualquier celda definida por la especificación COLS, pero no definida por la especificación ROWS. TAB, ELSE y PAD pueden estar en cualquier orden. c1,c2,...,cm son las columnas de la tabla. Se pueden usar rangos en la definición de columnas. r1,r2,...,rn son las filas de la tabla. El tamaño total de la tabla será m por n, donde m es el número de columnas y n es el número de filas. (vals fila r1), (vals fila r2),...,(vals fila rn) son los valores retornados dependiendo de los valores de r y c. Los valores se dan en el mismo orden de la especificación de columnas; el primer valor corresponde en c1, el segundo en c2, etc. Se pueden usar rangos en la definición de los valores de las filas. Ejemplos: suponga la siguiente tabla: Fil: Col: 1 2 3 4 5 6 2 3 5 6 8 1 1 1 3 9 1 2 2 3 9 2 2 2 3 9 2 2 2 3 9 3 3 3 3 9 4 4 4 4 9 R1=TABLE (V6, V4, TAB=1, ELSE=0, PAD=9, COLS 1-6, ROWS 2(1,1,2,2,3,4), 3(1,2,2,2,3,4),5(1,2,2,2,3,4),6(3,3,3,3,3,4),8(9)) Si V6 es igual a 5 y V4 es igual a 3, entonces a R1 se le asigna el valor 2 (la intersección de la fila 5 y la columna 3). Si V6 es igual a 2 y V4 es igual a 6, entonces a R1 se le asigna el valor 4 (la intersección de la fila 2 y la columna 6). Si V6 es igual a 4 y V4 es igual a 2, entonces a R1 se le asigna el valor 0 (la fila 4 no está definida; se usa el valor de la cláusula ELSE). R5=TABLE (3, V8, TAB=7, ELSE=TABLE(V1,V8,TAB=1) ) Este ejemplo usará la tabla llamada “7” con 3 como ı́ndice de fila y el valor de V8 como ı́ndice de columna. Si un valor de V8 no está en la tabla 7, entonces se usará la tabla denominada “1”, con ı́ndice de fila la variable V1 e ı́ndice de columna la variable V8. TRUNC. La función TRUNC devuelve el valor entero de un argumento. Prototipo: TRUNC(arg) Donde arg es cualquier expresión aritmética de la cual se va a tomar la parte entera. Ejemplo: R5=TRUNC(V5) R5 se le asignará el valor de la variable de entrada V5 truncada a un entero. 4.9 Funciones lógicas 45 VAR. La función VAR devuelve la variancia de los valores de un conjunto de variables, excluyendo los datos faltantes. El argumento MIN se usa para especificar el número mı́nimo de valores válidos, para los cuales se va a calcular la variancia. En caso contrario el sistema asume el valor para datos faltantes de 1,5 × 109 . Prototipo: VAR(varlist [,MIN=n] ) Donde: varlist es una lista de variables tipo V y tipo R, y constantes. n es el número mı́nimo de valores válidos, para los cuales se calcula la variancia para el caso. El valor por defecto para n es 1. Ejemplo: R9=VAR(V5-V10) 4.9. Funciones lógicas Cuando se evalúan funciones lógicas, éstas devuelven un valor “verdadero” o “falso”. No se pueden usar como operandos aritméticos. Se usan funciones lógicas en expresiones lógicas y las expresiones lógicas comprenden la porción de prueba de la proposición condicional “IF prueba THEN ...”. Las funciones disponibles son: Función Exjemplo Propósito EOF INLIST IF EOF THEN GO TO NEXT IF V5 INLIST(2,4,6) THEN R100=1 ELSE R100=0 IF MDATA(V5,V6) THEN R101=99 Verifica el final del archivo de datos Busca una lista de valores MDATA Verifica datos faltantes EOF. La función EOF se usa para agrupar valores a través de los casos. Ver el ejemplo 10 dado en la sección “Ejemplo de uso de proposiciones de Recode”. La presencia de la función EOF hace que las proposiciones de Recode se ejecuten una vez más después de encontrar el fin de archivo. El valor de la función EOF es “verdadero” durante de esta pasada de las proposiciones de Recode, y es “falso” todas las otras veces. Para la pasada final a través de las proposiciones de Recode, las variables tipo V tendrán el valor que tenı́an después de haber procesado totalmente el último caso. Las variables tipo R (excepto aquellas listadas en proposiciones CARRY), tendrán asignado el valor 1,5 × 109 . Las variables tipo R de CARRY permanecerán sin modificación. El usuario debe tener cuidado de establecer un camino correcto a seguir a través de las proposiciones de Recode cuando se haya llegado al fin de archivo. Prototipo: EOF Ejemplo: IF R1 NE V1 OR EOF THEN GO TO L1 INLIST. La función INLIST (abreviada IN) devuelve un valor “verdadero” si el resultado de una expresión aritmética es uno de los valores de un conjunto especificado de valores. Si la expresión es igual a un valor por fuera del conjunto de valores, la función devuelve el valor “falso”. Prototipo: expr INLIST(valores) o expr IN(valores) Donde: expr es cualquier expresión aritmética o una variable individual. valores es una lista de valores. Pueden ser discretos y/o un rango de valores. Ejemplos: IF R12 INLIST(1-5,9,10) THEN V5=0 46 Facilidad Recode Si R12 tiene un valor de 1,2,3,4,5,9 o 10, la función INLIST devuelve un valor “verdadero” y a la variable de entrada V5 se le asigna el valor cero. En caso contrario, la función INLIST devuelve un valor “falso” y la variable de entrada V5 mantiene su valor original. IF (V3 + V7) IN(2,4,5,6) THEN R1=1 ELSE R1=9 Si la suma de las variables de entrada V3 y V7 resulta en el valor 2,4,5 o 6, entonces INLIST devuelve un valor “verdadero” y la variable de resultado R1 contendrá el valor 1. En caso contrario, INLIST devolverá el valor “falso” y a la variable R1 se le asignará el valor 9. MDATA. La función MDATA devuelve un valor “verdadero” cuando cualquiera de las variables que se han pasado a la función tienen valores de datos faltantes; en caso contrario, la función devuelve el valor “falso”. Esta función se usa ampliamente ya que los valores de datos faltantes no se verifican automáticamente en la evaluación de expresiones, con excepción de las funciones MAX, MEAN, MIN, STD, SUM y VAR. Prototipo: MDATA(varlist) Donde varlist es una lista de variables de tipo V y tipo R. Puede haber un máximo de 50 variables en esta lista. Ejemplo: IF MDATA(V1,V5-V6) THEN R1=MD1(R1) ELSE R1=V1+V5+V6 Si alguna variable de la lista V1, V5, V6 tiene un valor igual a su código MD1 de datos faltantes, o está en el rango especificado por su código MD2, la función MDATA devuelve un valor “verdadero” y a la variable de resultado R1 se le asigna el valor de su primer código de datos faltantes. En caso contrario, la función MDATA devuelve el valor “falso” y a la variable R1 se le asigna el resultado de la suma de V1, V5 y V6. 4.10. Proposiciones de asignación Estas son las unidades estructurales principales del lenguaje Recode. Se usan para asignar un valor a un resultado. Se puede usar cualquier número entre 1 y 9999 para una variable R, pero se evita confusión si los números R son distintos de los números V de las variables en el diccionario, por ej. si hay 22 variables en el diccionario entonces comience la numeración de las variables R desde R30. También se pueden usar para asignar un valor nuevo a una variable de entrada. En este caso se pierde el valor original de la variable de entrada durante la ejecución del programa de IDAMS. Prototipo: variable=expresión Donde: variable es cualquier variable de entrada (Vn) o de resultado (Rn). expresión es cualquier expresión aritmética que use opcionalmente funciones aritméticas de Recode. Nótese que para las variables usadas en la expresión, no se verifican automáticamente los datos faltantes con excepción de las funciones especiales MAX, MEAN, MIN, STD, SUM, VAR. En todos los demás casos, se deben introducir proposiciones especificas para la verificación de datos faltantes en donde sea necesario. Para un ejemplo, ver “Proposiciones condicionales” más adelante. Ejemplos: R10=5 A R10 se le asigna el valor constante 5. R5=2*V10 + (V11 + V12)/2 Se puede usar cualquier expresión aritmética y los paréntesis se utilizan para cambiar la precedencia normal de los operadores aritméticos. V20=SQRT(V20) El valor en V20 se reemplaza por el valor de su raı́z cuadrada al usar la función SQRT. 4.11 Proposiciones especiales de asignación 47 R20=BRAC(V6,0-15=1,16-25=2,26-35=3,36-90=4,ELSE=9) A R20 se le asigna el valor 1, 2, 3, 4 o 9 de acuerdo con el grupo dentro del cual esté el valor de la variable V6. R10=MD1(V10) A R10 se le asigna un valor igual al primer código de datos faltantes de V10. 4.11. Proposiciones especiales de asignación DUMMY. La proposición DUMMY produce una serie de “variables ficticias”, codificadas 0 o 1, a partir de una sola variable. Prototipo: DUMMY var1,...,varn USING var(val1)(val2)...(valn) [ELSE expresión] Donde: var1, var2,...,varn es una lista de las variables ficticias cuyos valores están definidos por esta proposición. Pueden ser variables tipo V o tipo R, pueden listarse individualmente o en rangos y deben estar separadas por comas (por ej. R1-R3, R10, R7-R9, V20). El orden especificado se mantiene. Las referencias dobles (R1, R3, R1) son válidas. var es cualquier variable tipo V o tipo R. El valor de esta variable es probado contra las listas de valores (val1)(val2) etc. para asignar el valor apropiado a las variables ficticias. (val1)(val2)...(valn) son listas de valores que se usan para asignar el valor de las variables ficticias. Debe haber el mismo número de listas como variables ficticias haya (var1, var2, ..., varn). Las listas de valores pueden tener constantes solas o rangos o ambos. expresión es cualquier expresión aritmética que se usa como valor para todas las variables ficticias cuando el valor de la variable var no se encuentra en una de las listas de valores. El valor por defecto para expresión es la constante 0. El valor de la variable var se prueba contra las listas de valores (el número de listas de valores debe ser igual al número de variables ficticias); si var tiene un valor en la primera lista de valores, la primera variable ficticia toma el valor 1 y las otras 0; si el valor de var se presenta en la segunda lista de valores, la segunda variable ficticia toma el valor 1 y las demás 0, etc. Si el valor de var no se presenta en ninguna de las listas de valores, todas las variables ficticias toman el valor especificado después de la cláusula ELSE (valor por defecto 0). Ejemplo: DUMMY R1-R3 USING V8(1-4)(5,7,9)(0,8) ELSE 99 La tabla siguiente muestra los valores de R1, R2 y R3, basados en valores diferentes de V8: V8: R1: R2: R3: 1 1 0 0 2 1 0 0 3 1 0 0 4 1 0 0 5 0 1 0 7 0 1 0 8 0 0 1 9 0 1 0 0 0 0 1 OTROS 99 99 99 SELECT. La proposición SELECT hace que la variable en la lista de FROM que tiene una posición igual al valor de la variable BY, tome el valor de la expresión a la derecha del signo igual, es decir, selecciona a cual variable se le va a asignar un valor. Si el valor de la variable en BY es menor que 1 o mayor que el número de variables en la lista de FROM, resulta un error fatal. El número máximo de variables en la lista de FROM es de 50, por lo tanto, el máximo valor de la variable en BY es 50. Prototipo: SELECT (FROM=lista de variables, BY=variable)=expresión Ejemplos: SELECT (FROM=R1, V3-V10, BY=R99)=1 SELECT (BY=V1, FROM=V8, R2, R5)=R7*5 48 Facilidad Recode En el primer ejemplo, R1 tomará el valor de 1 si R99 es igual a 1; V3 tomará el valor de 1 si R99 toma el valor de 2,...; y V10 tomará el valor de 1 si R99 toma el valor de 9. Si R99 es mayor que 9 o menor que 1, se presentará un error fatal. Los valores de las ocho variables no referidas no se alterarán. SELECT se puede usar para un bucle ası́: L1 R99=1 SELECT (BY=R99, FROM=R1, V3-V10)=0 IF R99 LT 9 THEN R99=R99+1 AND GO TO L1 Las nueve variables R1, V3-V10, tomarán el valor cero una después de la otra, en tanto que R99 se incrementa de 1 a 9. El bucle se completa cuando R99 es igual a 9 y a todas las variables se han asignado valores iniciales. 4.12. Proposiciones de control Las proposiciones de Recode se ejecutan normalmente sobre cada caso en orden desde el primero hasta el último. El orden se puede cambiar con una de las proposiciones de control: Proposición Ejemplo Propósito BRANCH CONTINUE ENDFILE ERROR GO TO REJECT RELEASE BRANCH (V16,L1,L2) CONTINUE ENDFILE ERROR GO TO TOWN REJECT RELEASE RETURN RETURN Ramificar según el valor de una variable Continuar con la siguiente proposición No procesar más casos después de éste Terminar la ejecución completamente Ramificar incondicionalmente Rechazar el caso Entregar el caso al programa para ser procesado y asumir la ejecución de las proposiciones Recode nuevamente después, sin leer otro caso Usar el caso para análisis, sin recodificación adicional BRANCH. La proposición BRANCH cambia la secuencia en la cual se ejecutan las proposiciones, según el valor de la variable. Prototipo: BRANCH(var, etiquetas) Donde: var es una variable tipo V o tipo R. etiquetas es una lista de una o más etiquetas de proposiciones de 1-4 caracteres. Ejemplo: BRANCH(R99,LAB1,LAB2,LAB3) La transferencia se hace a LAB1, LAB2 o LAB3, según el valor de R99 sea 1, 2 o 3. CONTINUE. CONTINUE es una proposición simple que no ejecuta ninguna operación. Se usa como un punto conveniente al cual se hace la transferencia. Prototipo: CONTINUE Ejemplo: AT THAT IF V17 EQ 10 THEN GO TO AT R10=V11 GO TO THAT R20=V11*100 CONTINUE ENDFILE. La proposición ENDFILE hace que Recode cierre el dataset de entrada, exactamente como si hubiera encontrado un fin de archivo. Si se ha especificado la función EOF, la función EOF tomará un valor 4.12 Proposiciones de control 49 “verdadero” para una pasada final a través de las proposiciones de Recode desde el principio, después de haber ejecutado ENDFILE. Prototipo: ENDFILE Ejemplo: IF V1 EQ 100 THEN ENDFILE Esta proposición se puede usar para probar un conjunto de proposiciones Recode o un setup de IDAMS con los primeros n casos de un dataset. ERROR. La proposición ERROR hace que Recode termine con un mensaje de error que indica el número del caso y el número de la proposición de Recode en donde se presentó el error. Prototipo: ERROR Ejemplo: B IF R6 EQ 2 THEN GO TO B ERROR CONTINUE GO TO. La proposición GO TO se usa para cambiar la secuencia en la cual se ejecutan las proposiciones. Cuando no hay un GO TO o un BRANCH, cada proposición se ejecuta secuencialmente. Prototipo: GO TO etiqueta Donde etiqueta es una etiqueta de proposición de 1 a 4 caracteres. La proposición identificada por la etiqueta puede estar antes o después de GO TO. (Advertencia: tenga cuidado al referir una proposición antes de GO TO ya que pueden formarse bucles infinitos). Ejemplo: TOWN 1 GO TO TOWN . . R10=R5 GO TO 1 R10=R5+V11 R11=... REJECT. La proposición REJECT hace que Recode rechace el caso presente y obtenga otro caso. El nuevo caso se procesa desde el comienzo de las proposiciones de Recode. De esta manera, REJECT se puede usar como un filtro con variables tipo R. Prototipo: REJECT Ejemplo: IF MDATA (V8,V12-V13) THEN REJECT RELEASE. La proposición RELEASE hace que Recode entregue el caso al programa para procesarlo y tome nuevamente el control después de ese procesamiento sin leer otro caso. Después de tomar el control nuevamente, Recode continúa con la primera proposición de Recode. RELEASE se puede usar para separar un registro individual en varios casos para análisis. Nota: cuando se utiliza la proposición RELEASE tenga cuidado de no crear bucles infinitos. Prototipo: RELEASE Ejemplo: CARRY (R1) R1=R1+1 IF R1 LT V1 THEN RELEASE ELSE R1=0 RETURN. La proposición RETURN hace que Recode regrese el control al programa de IDAMS. No se ejecutan más proposiciones Recode para el caso en cuestión. 50 Facilidad Recode Prototipo: RETURN Ejemplo: A 4.13. IF V8 LT 12 THEN GO TO A RETURN R10=V8 Proposiciones condicionales La proposición IF permite la asignación condicional y/o control condicional. Es una proposición compuesta con varias proposiciones simples conectadas por las palabras clave THEN, AND y ELSE. Prototipo: IF prueba THEN prop1 [AND prop2 AND...prop n] [ELSE eprop1] [AND eprop2 AND...eprop n] Donde: prueba puede ser cualquier combinación de expresiones lógicas (incluidas funciones lógicas) conectadas con AND u OR y opcionalmente precedidas de NOT. Puede estar entre paréntesis, pero ésto no es necesario. prop1,...,prop n,eprop1,...,eprop n puede ser cualquier proposición de asignación o proposición de control (excepto CONTINUE). La(s) proposición(es) entre THEN y ELSE se ejecutan si el resultado de la prueba es “verdadero”. La(s) proposición(es) después de ELSE se ejecutan si el resultado de la prueba es “falso”. Si no hay cláusula ELSE, se ejecuta la siguiente proposición. Las palabras clave THEN y ELSE pueden estar seguidas cada una por cualquier número de proposiciones, conectadas cada una con la palabra clave AND. Ejemplos: IF V5 EQ V6 THEN R1=1 ELSE R1=2 Asigne el valor 1 a la variable R1 si V5 es igual a V6; si no lo es, entonces asigne a R1 el valor 2. IF MDATA(V7,V10-V12) THEN R6=MD1(V7) AND R10=99 ELSE R6=V7+V10+V11 AND R10=V12*V7 Asigne a la variable R6, el primer código de datos faltantes de la variable V7 cuando cualquiera de las variables V7, V10, V11, V12 sean iguales a sus códigos de datos faltantes; si esta condición no se cumple, entonces haga R6 igual a la suma de V7, V10 y V11 y haga también R10 igual al producto de las variables V12 y V7. IF (V5 NE 7 AND R8 EQ 9) THEN V3=1 ELSE V3=0 Haga V3 igual a 1 cuando V5 no sea igual a V7 y R8 sea igual a 9 (debe cumplir ambas condiciones), en caso contrario haga V3 igual a 0. (Nota: los paréntesis no son necesarios). IF MDATA(V6) OR V10 LT 0 THEN GO TO X Si falta el valor de V6 o si V10 es menor que cero, vaya a la proposición etiquetada X; de lo contrario, continue con la siguiente proposición. 4.14. Proposiciones de definición/de asignación de valores iniciales Estas proposiciones se ejecutan una sola vez, antes de comenzar el procesamiento de los datos, para asignar de valores iniciales que se van a utilizar durante la ejecución de proposiciones de Recode. No se pueden usar dentro de expresiones y no pueden tener etiquetas. 4.14 Proposiciones de definición/de asignación de valores iniciales 51 CARRY. La proposición CARRY hace que los valores de las variables listadas sean llevados de caso en caso. Las variables de CARRY son asignadas los valores iniciales con ceros sólo una vez (antes de comenzar a leer los datos). Las variables de CARRY se pueden usar como contadores o acumuladores para agrupamiento. Prototipo: CARRY(varlist) Donde varlist es una lista de variables tipo R. Ejemplo: CARRY(R1,R5-R10,R12) MDCODES. La proposición MDCODES cambia los códigos de datos faltantes del diccionario para las variables de entrada o asigna códigos de datos faltantes a variables de resultado. Los valores por defecto que usa Recode para variables tipo R y tipo V que no tengan especificación de datos faltantes en el diccionario y que no tengan especificación en MDCODES son MD1=1,5 × 109 y MD2=1,6 × 109 . Prototipo: MDCODES (varlist1)(md1,md2),(varlist2)(md1,md2), ..., (varlistn)(md1,md2) Donde: varlist1, varlist2, ..., varlistn son listas de variables individuales y de rangos de variables. md1 y md2 son respectivamente, el primero y segundo códigos de datos faltantes para todas variables listadas. Los códigos de datos faltantes que tengan decimales deben especificarse con el punto decimal explı́cito. Advertencia: sólo se retienen 2 cifras decimales para variables R y se redondean los valores apropiadamente, por ej. md1 especificado como 9.999 se trata como 10.00 . Se puede omitir cualquiera de los dos códigos md1 o md2. Si se omite md1, se debe colocar una coma que preceda al valor de md2. Ejemplos: MDCODES V5(8,9) El primer código de datos faltantes para V5 será 8; el segundo será 9. MDCODES (R9-R11)(,99), V7(8,9), V6(9) Para R9, R10 y R11, el primer código de datos faltantes será 1,5 × 109 y el segundo será 99. Para V7, el primer código de datos faltantes será 8 y el segundo será 9. Para V6, el primer código de datos faltantes será 9 y el segundo será 1,6 × 109 . NAME. La proposición NAME asigna nombres a variables tipo R o reasigna nombres a variables tipo V. Prototipo: NAME var1 ’nombre1’, var2 ’nombre2’, ..., varn ’nombre n’ Donde: var1,var2,...,varn son variables tipo V o tipo R. nombre1, nombre2, ..., nombre n son los nombres a asignar a estas variables. El número máximo de caracteres por nombre es 24; si es más largo, el nombre se trunca a 24 caracteres. El valor por defecto del nombre para una variable tipo R es ’RECODED VARIABLE Rn’. Para incluir un apóstrofo en un nombre (por ej. PERSON’S), usar dos comillas sencillas (por ej. PERSON”S). Ejemplo: NAME R1 ’V5 + V6’, V1 ’PERSON’’S STATUS’ 52 Facilidad Recode 4.15. Ejemplos de uso de proposiciones de Recode Supongamos que existe un archivo de datos con las siguientes variables: V1 V2 V4 V5 Identificador de ciudad Sexo Edad Nivel educativo V8 V9 V10 V21 V22 V31 V32 V33 V34 V35 V41 V42 V43 V44 V45 Ingreso del primer empleo Ingreso del segundo empleo Ingreso del compañero(a) Peso en Kg (un decimal) Altura en metros (dos decimales) ¿Posée automóvil? ¿Posée TV? ¿Posée estéreo? ¿Posée refrigerador? ¿Posée microcomputador? Número de hijos Edad primer hijo Edad segundo hijo Edad tercer hijo Edad cuarto hijo 1=hombre, 2=mujer 21-98, 99=sin definir 1=primaria, 2=secundaria, 3=universitaria, 9=sin definir 1=si, 2=no, 9=sin definir A continuación se muestra someramente la construcción de algunas variables de análisis posibles a partir de estos datos. 1. Ingreso total. Si faltan los ingresos del primero y del segundo empleos, entonces faltará el ingreso total. Si falta sólo uno de ellos entonces úselo como ingreso total. END o IF NVALID(V8,V9) EQ 0 THEN R101=-1 AND GO TO END IF NVALID(V8,V9) EQ 2 THEN R101=V8+V9 AND GO TO END IF MDATA(V8) THEN R101=V9 ELSE R101=V8 CONTINUE MDCODES R101(-1) R101=SUM(V8,V9,MIN=1) IF R101 EQ 1.5 * 10 EXP 9 THEN R101=-1 MDCODES R101(-1) 2. No usar el caso si el ingreso total es cero o falta. IF MDATA(R101) OR R101 EQ 0 THEN REJECT 3. Componer el ingreso con 3/4 del ingreso propio más 1/4 del ingreso del compañero(a). Si falta el ingreso del compañero(a) supóngalo como cero. IF MDATA(V10) THEN V10=0 IF MDATA(R101) THEN R102=MD1(R102) ELSE R102=R101 * .75 + V10 * .25 NAME R102’Ingreso compuesto’ MDCODES R102(99999) 4. Peso del encuestado agrupado en liviano (30-50), medio (51-70), y pesado (70+). R103=BRAC(V21,30-50=1,50-70=2,70-200=3,ELSE=9) Nótese que V21 está grabada con un decimal. Para asegurarase de que valores tales como 50.2 tengan una asignación a una categorı́a, los rangos dentro de la proposición BRAC deben traslaparse. Recode trabaja de izquierda a derecha y asigna el código al primer rango en el cual se presente el caso. De esta manera, un valor de 50.0 se ubicará en la categorı́a 1 pero un valor de 50.1 se ubicará en la categorı́a 2. Para colocar valores de 50.0 en la categorı́a 2, usar 4.15 Ejemplos de uso de proposiciones de Recode 53 R103=BRAC(V21, <50=1, <70=2, <200=3, ELSE=9) Un valor de 49 caerı́a en todas las tres categorı́as pero Recode usará el primer rango válido que encuentre (código 1). Un valor de 50 no satisfará al primer rango y se asignará el código 2. 5. Indice de alfluencia con valores de 0-5 de acuerdo con el número de bienes poseı́dos. R104=COUNT(1,V31-V35) Si todos los ı́tems se codifican 1 (sı́), el ı́ndice, R104, tomará el valor 5. Si todos se codifican 2 (no) o faltan, entonces el ı́ndice será cero. 6. Crear tres variables ficticias (codificadas 0/1) a partir de la variable educación. DUMMY R105-R107 USING V5(1)(2)(3) Las tres variables de resultado tomarán los valores siguientes: V5=1 V5=2 V5=3 V5 no es ni 1 ni 2 ni 3 R105=1, R105=0, R105=0, R105=0, R106=0, R106=1, R106=0, R106=0, R107=0 R107=0 R107=1 R107=0 (valor por defecto si no hay valor para ELSE) 7. Edad del hijo menor. Las edades de los últimos 4 hijos se guardan en las variables 42 a 45, el mayor está en V42. Si alguien tiene 3 hijos, entonces el valor de V44 da la edad del menor de los hijos; si alguien tiene 4 o más hijos entonces queremos V45. En este caso, V41 (número de hijos) se puede usar como un ı́ndice para seleccionar la variable correcta con la función SELECT. IF V41 GT 4 THEN V41=4 IF V41 EQ 0 OR MDATA(V41) THEN R109=99 ELSE R109=SELECT (FROM=V42-V45, BY=V41) NAME R109’Edad ultimo hijo’ MDCODES R109(99) 8. Relación peso/edad como un decimal redondeado al entero próximo. IF MDATA (V21,V22) OR V22 EQ 0 THEN R111=99 AND R112=99 ELSE R111=V21/V22 AND R112=TRUNC ((V21/V22) + .5) NAME R111’relación peso/edad dec’, R112 ’P/E REDONDEADO’ MDCODES (R111,R112)(99) 9. Crear una variable sencilla combinando sexo y nivel educacional en cuatro grupos ası́: Mujeres, sólo educación primaria Mujeres, educación+ secundaria Hombres, sólo educación primaria Hombres, educación+ secundaria Método a. Primero se reducen los códigos para sexo y educación a códigos contiguos que comienzan desde 0, se guardan los resultados temporalmente en las variables R901, R902. R901=BRAC (V5,1=0,2=1,ELSE=9) R902=BRAC (V6,1=0,2=1,3=1,ELSE=9) Ahora se usa la función COMBINE asegurándose primero de que los casos con codigos falsos se coloquen en una categorı́a de datos faltantes. IF R901 GT 1 OR R902 GT 1 THEN R110=9 ELSE R110=COMBINE R901(2),R902(2) 54 Facilidad Recode Método b. Usar IFs, colocando un valor por defecto de 9 al comienzo. R110=9 IF V5 EQ IF V5 EQ IF V5 EQ IF V5 EQ 1 1 2 2 AND AND AND AND V6 V6 V6 V6 EQ 1 THEN R110=1 INLIST (2,3) THEN R110=2 EQ 1 THEN R110=3 INLIST (2,3) THEN R110=4 Método c. Usar la función RECODE. R110=RECODE V5,V6(1/1)=1,(1/2-3)=2,(2/1)=4,(2/2-3)=5,ELSE=9 10. Agrupación de casos con Recode. Supongamos que queremos analizar los datos (que consisten en registros de nivel individual) a nivel ciudad, por ejemplo producir una tabla que muestre la distribución de ciudades por ingreso (V8,V9) y el % de gente con automovil propio en la ciudad (V31). Podrı́amos hacerlo con AGGREG para agrupar los datos a nivel de ciudad y después ejecutar TABLES. Alternativamente, podemos usar las proposiciones CARRY, EOF, y REJECT del lenguaje Recode y usar TABLES directamente. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 VIL CARRY (R901,R902,R903,R904) IF (R901 EQ 0) THEN R901=V1 IF (R901 NE V1) THEN GO TO VIL IF EOF THEN GO TO VIL R902=R902+1 R903=R903+V8+V9 IF (V31 EQ 1) THEN R904=R904+1 REJECT R101=(R904*100)/R902 R101=BRAC(R101,<25=1,<50=2,<75=3,<101=4) R102=R903/R902 R102=BRAC(R102,<1000=1,<2000=2,<5000=3,ELSE=4) R901=V1 R902=1 R903=V8+V9 IF (V31 EQ 1) THEN R904=1 ELSE R904=0 NAME R102’ingr. promedio’, R101’% con automóvil’ R901 es una variable de trabajo usada para para retener el identificador de la ciudad; cuando se lee el primer caso (R901=0), a R901 se le asigna el valor del identificador de ciudad (V1); R902 a R904 son variables de trabajo para el número de personas en la ciudad, el ingreso total de las personas en la ciudad y el número de personas con automóvil en la ciudad respectivamente. Mientras que el identificador de ciudad se mantiene igual, se acumulan los datos en las variables R902 a R904 (cuyos valores se “llevan” a medida que se lean nuevos casos). Entonces el caso se rechaza (no pasa al análisis) y se lee el nuevo caso. Cuando aparece un cambio en el identificador de ciudad, se ejecutan las instrucciones en la etiqueta VIL: los contenidos que tienen las variables R9902, R903 y R904 en ese momento se usan para calcular las variables requeridas (media agrupada del ingreso y % agrupado de propietarios de automóviles) y entonces se pasan estas variables al análisis después de colocar primero en las variables de trabajo los valores para el último caso leı́do (el primer caso de la siguiente ciudad). Cuando se llega al final del archivo, necesitamos estar seguros de que se usarán los datos de la última ciudad. La proposición 4 hace ésto. 4.16. Restricciones 1. El máximo número de variables R es 200. 2. El máximo número de tablas numeradas (BRAC, RECODE, TABLE) es 20. 3. El máximo número de caracteres en una proposición de Recode, excluidos los guiones de continuación es 1024. 4.17 Nota 55 4. El número máximo de etiquetas de proposiciones es aproximadamente 60. 5. El máximo número de constantes, incluidas las de todas las tablas es aproximadamente 1500. 6. El máximo número de nombres que se pueden definir en proposiciones NAME es 70. 7. El máximo número de valores de datos faltantes que se pueden definir en proposiciones MDCODES es 100 y sólo se retienen 2 cifras decimales para variables R. 8. El número máximo de anidamientos con paréntesis dentro de una proposición (es decir, paréntesis dentro de paréntesis) es 20. 9. El máximo número de operadores aritméticos es aproximadamente 400. 10. El máximo número de variables en proposición SELECT es 50. 11. El máximo número de proposiciones IF es aproximadamente 100. 12. El máximo número de anidamientos de funciones (es decir, referencias a función como argumentos de función) es 25. 13. El máximo número de proposiciones es aproximadamente 200. 14. El máximo número de etiquetas en una proposición BRANCH es 20. 15. El máximo número de variables de CARRY es 100. 16. El “máximo número de variables” dado en la sección de “restricciones” de cada documentación de programa de análisis, incluye variables R y variables V usadas en el análisis y variables V usadas en Recode pero no en el análisis. Ası́, si un programa tiene un máximo de 40 variables y se usan 40 variables de entrada en el análisis, no se pueden usar más variables de entrada que las 40 en las proposiciones de Recode. Las variables R definidas en las proposiciones de Recode y que no se usan en el análisis, no se necesita tenerlas en cuenta para el “máximo número de variables”. 17. El filtrado se hace antes de la recodificación, de manera que a las variables de resultado no se les pueda hacer referencia en filtros principales. 4.17. Nota Recodificación univariada/bivariada se puede hacer con los métodos de TABLE, IF y RECODE. Más adelante hay una breve comparación de estos métodos teniendo en cuenta dos aspectos de ejecución. Totalidad TABLE ... hace una recodificación completa. Se produce un valor de resultado, aún cuando el valor de entrada esté por fuera de la tabla (por que ELSE asume 99 por defecto). RECODE permite recodificación parcial. Si ninguna prueba es verdadera y no hay valor especificado para ELSE, no hay recodificación. Tamaño de tabla Las recodificaciones bivariadas y univariadas completas de gran tamaño tienen mayor eficiencia si usa TABLE e IF... Para una recodificación grande, uno a uno, univariada, con una lı́nea de una tabla rectangular, TABLE es mejor que IF... Capı́tulo 5 Manejo y análisis de datos 5.1. 5.1.1. Validación de datos con IDAMS Visión general Antes de iniciar un análisis de datos con cualquier programa, los datos necesitan, normalmente, validarse. Esta validación comprende tı́picamente tres etapas: 1. Verificar si los datos son completos, es decir verificar que todos los casos esperados están presentes en el archivo de datos y verificar que existan los registros correctos para cada caso cuando hay registros multiples per caso. 2. Verificar que las variables numéricas sólo tienen valores numéricos y verificar que los valores son válidos. 3. Verificar la consistencia entre las variables. Como muchos otros programas estadı́sticos, IDAMS exija que debe haber la misma cantidad de datos para cada caso. Si los datos para un caso abarcan varios registros, entonces cada caso debe abarcar exactamente el mismo conjunto de registros. Si algunas variables no se aplican a algunos casos, entonces se deben asignar valores “faltantes”. La capacidad de IDAMS de verificación de intercalación de registros, permite chequear que cada caso de datos tenga el conjunto correcto de registros. Esto se hace con el programa MERCHECK el cual produce un archivo de salida “rectangular” en el cual se han eliminado los registros extra/duplicados y los casos con registros faltantes se han rellenado o bién se les han asignado registros ficticios. La verificación de valores no numéricos en variables numéricas y la conversión opcional de campos en blanco a valores numéricos especificados por el usuario la hace el programa BUILD. La verificación de otros códigos inválidos la hace el programa CHECK en donde los que son códigos válidos se definen en proposiciones especiales de control o bién se toman de registros C en el diccionario que describe los datos. Si los datos se introducen con la Interfaz del Usuario de WinIDAMS, no se permiten caracteres no numéricos (excepto campos en blanco) en campos numéricos. Más aun, existe la posibilidad de verificación de códigos durante la introducción de datos y de una verificación general de códigos inválidos en todo el archivo de datos. Los registros C del diccionario, se usan para este propósito. Las verificaciones de consistencia se pueden expresar en el lenguaje Recode de IDAMS y se usan con el programa CONCHECK para listar casos con incosistencias. Los errores hallados en cualquiera de estos pasos se pueden corregir o bién con la Interfaz del Usuario o con el programa CORRECT. Una secuencia tı́pica de pasos para la detección y corrección de errores con IDAMS se describe con más detalle a continuación. 58 5.1.2. Paso 1 Manejo y análisis de datos Verificación si los datos son completos Producir tablas de resumen que muestren la distribución de los casos dentro de las unidades de muestreo, zonas geográficas, etc. para obtener una verificación contra los totales esperados. Esto es particularmente útil en una encuesta por muestreo. Por ejemplo, supongamos que se va a hacer una encuesta de hogares. Se toma una muestra seleccionando primero unidades primarias de muestreo (UPM), después, hasta cinco (5) áreas dentro de cada UPM y luego se entrevistan los hogares ubicados dentro de esas áreas. La distribución que tienen en los datos los hogares por UPM y área se puede obtener con la preparación de un pequeño diccionario que contenga solamente las dos variables: UPM y área. La tabla tendrá el siguiente aspecto: V2 AREA V1 UPM 01 02 03 . . 01 02 03 04 05 3 10 6 4 2 2 8 5 Esta tabla puede compararse con la bitácora de registro de los entrevistadores para verificar si en el archivo existen los datos de todas las entrevistas tomadas. Pasos 2, 3 y 4 son necesarios sólo cuando hay más que un registro por caso. Paso 2 Paso 3 Paso 4 Los registros de datos primarios se clasifican en orden de identificación de casos/identificación de registros con SORMER. Los datos primarios ya clasificados, se verifican con MERCHECK para ver si se tiene el grupo correcto de registros para cada caso. El archivo de salida contiene solamente casos “buenos”, es decir, aquellos con registros correctos. Los registros que sobren y los duplicados se eliminan. Los casos con registros faltantes se eliminan o se completan. Se imprimen todos los casos que tengan errores de intercalación. A continuación se hacen las correcciones de los errores detectados por MERCHECK. Esto se pueden hacer de varias maneras: Recapturar casos “malos” e intercalarlos con el archivo de salida de MERCHECK usando SORMER. Editar los datos primarios originales con un editor del sistema y repetir los pasos 2 y 3. Recapturar los casos “malos”, hacer los pasos 2 y 3 con estos datos y después intercalar el archivo de salida de esta ejecución del paso 3 con el archivo de salida original del paso 3. Con cualquier método que se escoja, el programa MERCHECK debe ejecutarse nuevamente con el archivo corregido para cerciorarse de que no hay errores. 5.1.3. Paso 5 Paso 6 Paso 7 Detección de valores no numéricos e inválidos Preparar un diccionario para todas las variables, con las proposiciones apropiadas para el manejo de campos en blanco. Ejecutar BUILD. La salida es un dataset IDAMS (archivos Datos y Diccionario). Todos los valores no numéricos inesperados se convierten en nueves (9) y se indican en los resultados. Con TABLES imprimir distribuciones de frecuencias de todas las variables cualitativas y los valores máximos, mı́nimos y medios de las variables cuantitativas. Esto da una idea inicial del contenido de los datos y muestra cuales variables tienen códigos inválidos (variables cualitativas) o valores muy grandes o muy pequeños (variables cuantitativas). También pueden compararse posteriormente con un listado similar producido después de la limpieza para observar cómo la validación afectó los datos. Preparar proposiciones de control que especifiquen los códigos válidos o los rangos de valores para cada variable. Estas proposiciones se pueden preparar con anterioridad para todas las 5.2 Manejo/transformación de datos Paso 8 59 variables, o bién, después del paso 6, solamente para aquellas variables de las cuales se sabe que tienen códigos inválidos. Usar el dataset de salida del paso 5 como entrada al programa CHECK para obtener un listado que muestre los casos que tienen valores inválidos. Téngase en cuenta que la especificación de códigos válidos para las variables también se puede tomar de los registros C del diccionario, si éstos se introdujeron en el paso 5. Preparar la corrección de errores en variables detectados en los pasos 5 y 7. Usar el programa CORRECT para actualizar el dataset IDAMS creado en el paso 5. Téngase en cuenta que las correcciones también se podrı́an hacer con la Interfaz del Usuario si el número de casos no es muy grande. Sin embargo, el uso de CORRECT es un método menos propenso a los errores. Ejecute nuevamente los pasos 7 y 8 hasta que no se encuentren errores. 5.1.4. Paso 9 Verificación de consistencia Preparar proposiciones lógicas de las verificaciones de consistencia que se van a hacer, por ej. PREGNANT (V32) = no aplicable si y sólo si SEX (V6) = masculino. Asignar un número de “resultado” a cada verificación de consistencia y traducir la lógica a proposiciones de RECODE en donde el resultado se pone en uno (1) para una inconsistencia, por ej. IF V6 EQ 1 AND V32 NE 9 THEN R1001=1 IF V6 NE 1 AND V32 EQ 9 THEN R1001=1 ELSE R1001=0 Paso 10 Usar el conjunto de proposiciones de Recode con CONCHECK para imprimir los casos con errores. Corregir los casos con errores como en el paso 8. Ejecute nuevamente los pasos 9 y 10 hasta que no se encuentren errores. Entonces los datos de salida de la última ejecución de CORRECT estarán listos para analizarlos. 5.2. Manejo/transformación de datos IDAMS posée un extenso conjunto de ayudas para generar ı́ndices, medidas derivadas, agrupamientos y otras transformaciones de los datos, incluida la recodificación alfabética. Las capacidades utilizadas más frecuentemente las provée la facilidad Recode, la cual puede llevar a cabo operaciones temporales en todos los programas de análisis que usan como entrada un dataset IDAMS. Los resultados de la recodificación se pueden guardar como variables permanentes con el programa TRANS. Estas facilidades operan en las variables que forman un caso y permiten recodificar los valores de una o más variables, generar nuevas variables mediante la combinación de las mismas, controlar la secuencia de estas operaciones mediante la ejecución de proposiciones lógicas y ejecutar un número de proposiciones y funciones especializadas adicionales. La nueva información del diccionario, necesaria para describir los resultados de las operaciones realizadas, se produce automáticamente. Para agrupaciones entre diferentes casos se dispone del programa AGGREG. AGGREG suministra sumas aritméticas y medidas relacionadas, rangos y conteos de valores de datos válidos dentro de grupos de casos. Las ejecuciones tı́picas de AGGREG involucran el uso previo del programa SORMER para clasificar el archivo Datos en los grupos deseados. Hay un número de circunstancias en las cuales es necesario combinar los registros de dos archivos diferentes, por ejemplo, datos recolectados en puntos diferentes en el tiempo. En la medida en que se reciben nuevos grupos de datos para las variables, el objetivo es añadirlos al registro que contenı́a los datos previos para el mismo caso o el mismo encuestado. El programa MERGE se encarga de esta labor, incluido el relleno apropiado con datos faltantes cuando no se encuentren entrevistados en el nuevo grupo. Ejemplos similares se presentan cuando en un programa de análisis se generan residuos o algún tipo de puntajes de escala para cada caso y se necesita incluirlos en los datos originales. Un proceso de combinación algo diferente se presenta cuando se van a combinar datos obtenidos de diferentes 60 Manejo y análisis de datos niveles de análisis. Una ilustración de ésto es la adición de datos de hogares a los registros individuales de los encuestados. Cuando se ordena un dataset de tal manera que todos los encuestados de un mismo hogar queden juntos, MERGE hace la intercalación necesaria de los registros duplicados. Se presenta una situación similar cuando se van a adicionar resúmenes de grupo obtenidos con AGGREG a los registros de cada caso en el grupo respectivo. Otro proceso de combinación de datasets, a menudo también llamado intercalación, se presenta cuando se desea añadir casos adicionales a un dataset. Los nuevos registros deben ser descritos por el mismo diccionario del dataset original. Este tipo de intercalación puede lograrse con el programa SORMER. La mayorı́a de los programas de IDAMS disponen como operaciones temporales, de funciones para la subdivisión de los datos (usando un “filtro”), con el objeto de seleccionar casos particulares para procesar. También es posible crear archivos permanentes que contengan subconjuntos de los datasets IDAMS (un subconjunto de variables o un subconjunto de casos, o ambos). Los programas TRANS y SUBSET son los más adecuados para esta clase de tareas, aunque otros programas que producen un dataset IDAMS como salida, tales como MERGE, también pueden usarse. La selección de casos puede hacerse sobre la base de que sólo ciertos casos tienen un interés lógico (por ejemplo sólo los encuestados de sexo femenino), o también puede hacerse al azar, con la función RAND de Recode en el programa TRANS. Muchas veces es de gran ayuda para el usuario poder obtener una imagen de los valores almacenados en el dataset IDAMS, con el objeto de verificar los resultados de los pasos de modificación de los datos y ciertamente en cualesquiera otras etapas. El programa LIST es el adecuado para este propósito y permite obtener listados completos de diferentes selecciones de variables y casos especı́ficos. El filtrado o la selección de los casos que se van a mostrar se puede lograr mediante la combinación de varias variables dentro de expresiones lógicas; un ejemplo serı́a una selección de sólo aquellos registros de mujeres solteras entre los 21 y los 25 años de edad. Tanto las variables numéricas y alfabéticas de un dataset como las variables construidas con proposiciones de Recode se pueden incluir en la salida impresa. La Interfaz del Usuario también tiene una opción para imprimir el contenido de un archivo de datos en formato de tabla. 5.3. Análisis de datos La consideración fundamental del usuario con respecto a la escogencia de un programa de análisis es si éste posée las funciones estadı́sticas apropiadas. Una guı́a en esta materia está fuera del alcance de este manual. En la Introducción se puede hallar un resumen de la función de cada programa de análisis de IDAMS. Se dan más detalles en la documentación individual de cada programa. Las fórmulas usadas en cada programa para calcular las estadı́sticas, y referencias se encuentran en la parte “Fórmulas estadı́sticas y referencias bibliográficas”. 5.4. Ejemplo de un pequeño trabajo a ejecutar con IDAMS Supongamos que un dataset IDAMS contiene las respuestas al cuestionario de una encuesta e incluye las siguientes variables: V11 representa el sexo del encuestado según la codificación siguiente: 1. Hombre 2. Mujer 9. Sin información V12 representa el ingreso del encuestado en dólares (99999 = sin información). V13 a V16 representan medidas de actitud ante diferentes situaciones. Las variables se codifican cada una para reflejar los sentimientos del encuestado ası́: 1. Muy positivo 2. Positivo 3. Neutro 4. Negativo 5. Muy negativo 8. No sabe 9. Sin información 0. La pregunta es irrelevante para el encuestado Supongamos que sólo se necesita un agrupamiento o recodificación de niveles de ingreso ası́: 5.4 Ejemplo de un pequeño trabajo a ejecutar con IDAMS Código nuevo 1 2 3 9 61 Significado Ingreso en el rango $0 a $9999 Ingreso en el rango $10,000 a $29,999 Ingreso de $30,000 o mayor Rechazado, sin información, no sabe Los cruces deseados son entre la versión nuevamente codificada de la variable de ingreso, V12, y cada una de las variables de actitud V13 a V16. Para este análisis sólo se seleccionarán encuestados femeninos. A continuación se muestra un “setup” de IDAMS con las proposiciones de control necesarias para hacer este trabajo. Los números entre paréntesis a la izquierda identifican cada proposición de control y la relacionan a la explicación subsiguiente. (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) $RUN TABLES $FILES DICTIN = ECON.DIC DATAIN = ECON.DAT $RECODE R101=BRAC(V12,0-9999=1,10000-29999=2,30000-99998=3, ELSE=9) NAME R101’Ingreso agrupado’ $SETUP INCLUDE V11=2 EJEMPLO DE TABLES USANDO DATOS ECONOMICOS * TABLES ROWVARS=(R101,V13-V16) ROWVAR=R101 COLVARS=(V13-V16) CELLS=(FREQS,ROWPCT) STATS=CHI En pocas palabras, lo siguiente es lo que hace cada proposición: (1) (2) (3)&(4) (5) (6)(7) (8) (9) (10) (11) (12) (13) (14) (15) “$RUN TABLES” es un comando de IDAMS, en el cual se le informa que se va a utilizar el programa TABLES. Esta proposición señala el comienzo de especificación de archivos para este trabajo. El dataset IDAMS se almacena en dos archivos separados. Uno contiene el diccionario y el otro los datos. Esta proposición indica que se requieren transformaciones de los datos. Las proposiciones que siguen a continuación se refieren especı́ficamente a los comandos de Recode. Estas dos lı́neas (una original y una de continuación) forman una proposición de Recode que indica que el agrupamiento entre corchetes deseado para la variable de ingreso V12, sigue el esquema indicado atrás. El resultado de la función BRAC se almacena en la variable de resultado R101. Esta proposición asigna un nombre a la variable R101. “$SETUP” es un comando que indica el fin de las proposiciones de Recode y el comienzo de las proposiciones de control del programa TABLES. Este es un “filtro” que indica que los únicos casos que se van a usar son aquellos en los cuales la variable V11 tenga el código 2, para las mujeres. Este es un tı́tulo que contiene el texto que se va a utilizar como encabezamiento de los listados. Esta lı́nea especifica los parámetros principales. Como sólo se ha dado un asterisco, para esta ejecución se escogen las opciones por defecto para todos los parámetros. La palabra TABLES se introduce en este punto para separar la información global precedente, válida para toda la ejecución, de las especificaciones de las tablas individuales que siguen. Esta proposición solicita distribuciones de frecuencia univariadas para 5 variables. Ahora se solicitan tablas bivariadas. Las celdas van a contener los conteos (frecuencias) y los porcentajes de fila; para cada tabla se imprimirá la estadı́stica Ji-cuadrada. Las dos listas de variables que siguen a las palabras clave ROWVAR y COLVARS especifican aquellas variables que se utilizarán, para las filas y las columnas de las tablas, respectivamente. De esta manera se producirán sucesivamente cuatro tablas: R101 (ingreso agrupado) por V13, V14, V15 y V16. Parte II El trabajo con WinIDAMS Capı́tulo 6 Instalación 6.1. Requisitos del sistema El paquete de programas WinIDAMS está disponible para versiones del sistema operacional Windows de 32 bits (Windows 95, 98, NT 4.0, 2000 y XP). Se recomienda un procesador Pentium II o un procesador más veloz y memoria RAM de 64 megabytes. En todos los sistemas se deben tener cerca de 11 megabytes de espacio libre en disco antes de instalar el programa WinIDAMS en cada versión lingüı́stica. 6.2. Procedimiento de instalación La versión 1.3 de WinIDAMS se almacena en CD de distribución en archivo de autoextracción WinIDAMS\English\Install\WIDAMSR13E.EXE WinIDAMS\French\Install\WIDAMSR13F.EXE WinIDAMS\Portuguese\Install\WIDAMSR13P.EXE WinIDAMS\Spanish\Install\WIDAMSR13S.EXE : : : : la la la la versión versión versión versión en en en en inglés francés portugués espa~ nol o en un archivo telecargado equivalente. Para instalar la versión en español: 1. Seleccione WIDAMSR13S.EXE con el explorador Windows. 2. Haga doble click en este archivo y siga las instrucciones de pantalla. 3. Al final del proceso de instalación aparece una caja de diálogo con la pregunta “Do you wish to install HTML Help 1.3 update now?” (Desea instalar la actualización de ayuda 1.3 de HTML ahora?). Se recomienda responder “YES” (SÍ). El procedimiento de instalación crea dos elementos en el Administrador de programas/menú Inicio, uno para ejecutar WinIDAMS y uno para desinstalar WinIDAMS. También crea un ı́cono que es un vı́nculo/atajo de WinIDAMS. 6.3. Prueba de la instalación Un archivo Setup con las proposiciones para ejecutar 4 programas de manejo de datos (CHECK, CONCHECK, TRANS y AGGREG) y 6 programas de análisis (TABLES, REGRESSN, MCA, SEARCH, TYPOL y RANK) se copia en la carpeta Trabajo durante la instalación. Para ejecutarlo: Active WinIDAMS con un doble click en su ı́cono. 66 Instalación Aparece la ventana principal de WinIDAMS con una aplicación por defecto desplegada en el panel izquierdo. Abra la carpeta Setup. Hay allı́ el archivo demo.set con las proposiciones para ejecutar los 10 programas Con un doble click este archivo se abre en la ventana Setup. Ejecútelo desde adentro de esta ventana. Los resultados se escriben en el archivo idams.lst que se abre automáticamente en la ventana Resultados. El archivo demo.lst con la versión distribuida de los resultados se encuentra en la carpeta Results. Compare las dos versiones de resultados. 6.4. 6.4.1. Archivos y carpetas creados durante la instalación Carpetas de WinIDAMS El nombre completo de la carpeta del sistema WinIDAMS se da en “Seleccione la Carpeta Destino” del instalador y se crean las siguientes carpetas (ver el capı́tulo “Carpetas y archivos” para una descripción más detallada) durante la instalación: de la versión en inglés de la versión en francés <WinIDAMS13-EN>\appl <WinIDAMS13-EN>\data <WinIDAMS13-EN>\temp <WinIDAMS13-EN>\trans <WinIDAMS13-EN>\work <WinIDAMS13-FR>\appl <WinIDAMS13-FR>\data <WinIDAMS13-FR>\temp <WinIDAMS13-FR>\trans <WinIDAMS13-FR>\work de la versión en portugués de la versión en espa~ nol <WinIDAMS13-PT>\appl <WinIDAMS13-PT>\data <WinIDAMS13-PT>\temp <WinIDAMS13-PT>\trans <WinIDAMS13-PT>\work <WinIDAMS13-SP>\appl <WinIDAMS13-SP>\data <WinIDAMS13-SP>\temp <WinIDAMS13-SP>\trans <WinIDAMS13-SP>\work 6.4.2. Archivos instalados Archivos del sistema en la carpeta Sistema (\WinIDAMS13-EN, \WinIDAMS13-FR, \WinIDAMS13-PT, \WinIDAMS13-SP) WinIDAMS.exe Ter32.dll Hts.dll unesys.exe Idame.mst Idame.xrf idams.def Graph32.exe graphid.ini Idtml32.exe Idaddto32.dll IDAMSC_DLL.dll Idams.chm <pgname>.pro Archivo principal ejecutable de la Interfaz del Usuario de WinIDAMS | | Dlls usados por la Interfaz del Usuario de WinIDAMS Archivo ejecutable usado para la ejecución de setups Archivo maestro de base de datos de texto para los programas de IDAMS Archivo de referencias cruzadas para la base de datos de texto Definición del mapeo entre ddnames y nombres de archivo Archivo ejecutable GraphID Archivo .ini usado por GraphID para almacenar colores, fuentes y coordenadas Archivo ejecutable TimeSID Dll usado por GraphID y TimeSID Dll usado por TimeSID Archivo de ayuda (Manual de referencias del usuario) de WinIDAMS Prototipos para programas de IDAMS 6.5 Desintalación 67 Archivos de diccionario y de datos usados como ejemplos, guardados en la carpeta Datos (\WinIDAMS13-EN\data, \WinIDAMS13-FR\data, \WinIDAMS13-PT\data, \WinIDAMS13-SP\data) educ.dic educ.dat rucm.dic rucm.dat watertim.dic watertim.dat data.csv tab.mat Archivos de setup y de resultados de demostración, guardados en la carpeta Trabajo (\WinIDAMS13-EN\work, \WinIDAMS13-FR\work, \WinIDAMS13-PT\work, \WinIDAMS13-SP\work) demo.set demo.lst 6.5. Desintalación Durante el procedimiento de instalación, se crea un programa desinstalador. El usuario puede ejecutar el desinstalador bien haciendo clic en WinIDAMS/Uninstall WinIDAMS en el Administrador de programas/menú Inicio o bien suprimiendo la entrada “WinIDAMS versión 1.3 en español, Julio de 2006” en Agregar/Quitar programas del Panel de control. Este desinstalador borra el contenido del carpeta de WinIDAMS usada en el proceso de instalación. No borra carpetas que no estén vacı́as. Capı́tulo 7 Primeros pasos 7.1. Visión general de los etapas con WinIDAMS En este ejemplo, se prepara un diccionario IDAMS para la descripción de los datos recogidos en un cuestionario y se toman los datos de algunos encuestados. Luego se prepara un conjunto de instrucciones (un “setup”) y se usa para obtener distribuciones de frecuencias de Edad, Sexo, y Educación (número de años agrupado en 4 grupos). Se procede como sigue: 1. Cree un ambiente de la aplicación. 2. Prepare y almacene un diccionario IDAMS que describa las variables en los datos. 3. Capture los datos (este paso sobra si los datos se capturaran fuera de WinIDAMS). 4. Haga y almacene un “setup” de instrucciones que especifique qué se va a hacer con los datos. 5. Ejecute el programa de IDAMS según el setup. 6. Revise los resultados y modifique el setup si es necesario; después repita a partir del paso 4. 7. Imprima los resultados. Para comenzar, primero active WinIDAMS. Verá la ventana principal de WinIDAMS 70 Primeros pasos 7.2. Creación de un ambiente de aplicación El ambiente de la aplicación le permite definir rutas para tres carpetas. Todos los archivos de entrada/salida se abrirán/crearán por defecto en una de estas carpetas. Esto le evita tener que escoger o suministrar siempre la ruta completa de la carpeta. Los archivos Diccionario y Datos: en la carpeta Datos. Los archivos Setup y Resultados: en la carpeta Trabajo. Los archivos temporales: en la carpeta Temporal. Haga clic en Aplicación en la barra de menú y después en Nuevo. Ahora ve el siguiente diálogo: Crearemos una nueva aplicación con el nombre “MyAppl” y con las carpetas de aplicación C:\MyAppl\data, C:\MyAppl\work y C:\MyAppl\temp suministrando estos nombres en los correspondientes cuadros de texto. 7.3 Preparación del diccionario 71 Para cada carpeta de aplicación creada que no exista, se verá un diálogo como el sigue a continuación: Haga clic en Yes (Si) para cada carpeta nueva y luego haga clic en OK. Ahora se ve la ventana principal WinIDAMS nuevamente. 7.3. Preparación del diccionario Crearemos un diccionario para describir los registros de datos para las siguientes variables: Número 1 2 3 4 Nombre Identificación Edad Sexo 1 Hombre 2 Mujer 9 MD Educación Ancho 3 2 1 Código de datos faltantes (MD) 9 2 Teclée Ctrl/N o haga clic en Archivo/Nuevo. Estos comandos abren el diálogo del Nuevo documento: El diálogo muestra la lista de tipos de documentos usados en WinIDAMS. Debe escoger “IDAMS Dictionary file” (archivo Diccionario), ya seleccionado por defecto. Haga clic en el campo de Nombre de archivo y suministre el nombre “demog”. Haga clic en OK. Nótese que automáticamente se añade la extensión .dic al nombre del archivo. 72 Primeros pasos Ahora se ve: • la ventana Aplicación; • una ventana con dos paneles para entrar la descripción de las variables y los códigos y nombres de códigos opcionales asociados. Aparece el nombre completo del archivo Diccionario “demog.dic”. Haga clic en la primera celda de la fila en el panel de variables e introduzca el número de la primera variable. Tan pronto como comience a introducir los datos de la fila marcada con un asterisco, se crea una nueva fila inmediatamente después y en la fila que está editando, aparece un lápiz en el encabezador de fila. Con Intro o Tab se puede mover al campo siguiente. Ahora introduzca nombre y ancho. Salte sobre los campos siguientes con Intro o con Tab y capture la descripción con Intro o Tab en el último campo. Nótese que WinIDAMS adopta la localización por defecto cuando se ha aceptado la fila de descripción. Cuando se teclea Intro o Tab en el último campo, el lápiz desaparece, lo cual significa que la fila ha sido capturada después de una verificación rudimentaria de campos. Ahora el campo es el primero de la fila siguiente (marcada con un asterisco) y puede introducir la descripción de la segunda variable, Edad. Haga lo mismo para la variable 3, Sexo, pero suministre para esta variable un código MD1 de datos faltantes con valor 9 (código para ausencia de respuesta). Después de aceptar la descripción de la variable 3, el primer campo (número de variable) de la fila con un asterisco, se convierte en el siguiente campo para recibir datos. Haga clic en cualquier campo de la fila que se acaba de introducir (variable 3, Sexo) para activarla. Cámbiese al panel de códigos haciendo clic en el campo de código de la primera fila. Nótese que este panel está sincronizado con la variable para la cual se están suministrando los datos en el panel de variables. Teclée 1 en el campo de código. Nuevamente, tan pronto como se comienza a introducir la información de los nombres de códigos, se crea una nueva fila inmediatamente después y la fila que se está editando muestra un lápiz. Oprima Intro para moverse al siguiente campo, introduzca Hombre en el campo de nombre. Oprima Intro. El campo actual es ahora el campo de código de la fila siguiente y puede entrar 2 con nombre Mujer y similarmente para el código 9. 7.4 Captura de datos 73 Regrese al panel de variables haciendo clic en el campo del número de variable en la fila con asterisco. Introduzca las informaciones para la variable 4. Para suprimir filas, haga clic al lado de la fila y escoja Cortar del menú Edición. Guarde el diccionario haciendo clic en Archivo/Guardar como y aceptando el nombre del archivo “demog.dic”. 7.4. Captura de datos Oprima Ctrl/N o haga clic en Archivo/Nuevo. Aparece el mismo diálogo de documento que ya se vió para el diccionario. Seleccione la lı́nea “IDAMS Data file” (archivo Datos) de la lista e introduzca el nombre del archivo Datos. Por convención, es mejor usar el mismo nombre para el archivo Datos y el archivo Diccionario correspondiente. Sólo cambia la extensión de archivo, “dic” para el archivo Diccionario y “dat” para el archivo Datos. El diccionario y los datos forman un dataset de IDAMS. Introduzca “demog” como nombre de archivo y haga clic en OK. Un diálogo Abrir archivo muestra ahora los diccionarios que existen para la aplicación actual y solicita escoger el diccionario que describe los datos. Escoja “demog.dic” y haga clic en Abrir. 74 Primeros pasos Aparece ahora una ventana de entrada de datos con tres paneles. Los datos son introducidos sólo en el panel del fondo. Los otros dos paneles están sincronizados para mostrar la descripción de la variable para la cual están entrando los datos y los nombres de códigos si los hay. Se muestra el nombre completo del archivo Datos “demog.dat” (la extensión .dat se añade automáticamente). Nótese que en las imagenes que siguen, la ventana Aplicación está cerrada. Haga clic en el primer campo de la fila con un asterisco y teclée la primera lı́nea de datos como se ve a continuación, oprima la tecla Intro después de cada dato. Tan pronto como se empiezan a entrar los datos, aparece una nueva fila y aparece un lápiz en el encabezador de la fila a la cual están entrando los datos, lo cual indica que se está editando esta fila. Después de entrar el valor de la última variable V4 y oprimir Intro, el primer campo de la fila siguiente se habilita para recibir datos. Introduzca los datos de los cinco casos que se dan a continuación. 7.5 Preparación del setup 75 Haga clic en Archivo/Guardar para guardar los datos en el archivo “demog.dat”. 7.5. Preparación del setup Oprima Ctrl/N o haga clic en Archivo/Nuevo. Seleccione la lı́nea “IDAMS Setup file” (archivo Setup) de la lista e introduzca un nombre, por ejemplo, “demog1” para el archivo Setup. Haga clic en OK. Nótese que la extensión .set se añade automáticamente al nombre del archivo y se muestra el nombre completo del archivo “demog1.set”. Se ve ahora una ventana vacı́a de setup. Introduzca lo siguiente: 76 Primeros pasos $RUN identifica el programa de IDAMS deseado; después del comando $FILES, se especifica el archivo Datos y el archivo Diccionario correspondiente; en seguida, las proposiciones de Recode aparecen precedidas de la lı́nea $RECODE (aquı́ se usa Recode para reunir años de educación en 4 grupos); finalmente, se dan los parámetros (de acuerdo con las reglas del programa TABLES) para la tarea (en este caso se solicitan distribuciones de frecuencia univariadas), precedidas del comando $SETUP. Haga clic en Archivo/Guardar y guarde el setup en el archivo “demog1.set”. 7.6. Ejecución del setup Desde adentro de la ventana Setup, haga clic en Ejecutar/Setup actual. Se guarda el setup en un archivo temporal y se ejecuta. Aparece un diálogo durante la ejecución y desaparece si la ejecución tuvo éxito. Los resultados se escriben, por defecto, en el archivo “idams.lst”. Para cambiar esta acción por defecto, se puede añadir debajo de $FILES una lı́nea PRINT con el nombre del archivo requerido, por ejemplo, “print=a:demog1.lst” para guardar los resultados en un diskette. 7.7. Revisión de los resultados y modificación del setup El archivo de los resultados se carga automáticamente cuando se termina la ejecución. 7.7 Revisión de los resultados y modificación del setup 77 La tabla de contenido de los resultados que hay en el panel izquierdo permite localizar rápidamente partes diferentes. Ábrala haciendo clic en “idams.lst” y oprima el botón con un asterisco en el teclado numérico, ahora haga clic en el elemento que desea ver. Si desea cambiar algo en el setup mientras revisa los resultados, entonces haga clic en el TAB “demog1.set” y haga las modificaciones requeridas. Oprima Ctrl/E para ejecutar. 78 Primeros pasos 7.8. Impresión de los resultados Seleccione Archivo/Imprimir. Seleccione las páginas que desea imprimir y haga clic en OK. Capı́tulo 8 Archivos y carpetas 8.1. Archivos en WinIDAMS Archivos del usuario Estos archivos los crea el usuario con la ayuda de las herramientas suministradas por la Interfaz del Usuario de WinIDAMS, o bien, se producen por IDAMS como un resultado final o como una salida para ser procesada posteriormente. Todos son archivos estándar de texto ASCII. Se permiten caracteres de tabulación; se convierten automáticamente al número correcto de blancos. Las extensiones unificadas las usa la Interfaz del Usuario para reconocer el tipo del archivo. Archivo Datos (*.dat). Cualquier archivo de datos puede entrar a los programas de IDAMS teniendo en cuenta que cada caso contenga un número igual de registros de formato fijo. Sin embargo, si la Interfaz del Usuario usa un archivo Datos, sólo puede haber un registro por caso. Puede haber registros de longitud variable con un máximo de 4096 caracteres por caso. Si el primer registro del archivo no es más largo, entonces la longitud máxima de registro (RECL) debe especificarse en la proposición de especificación de archivo correspondiente. Los archivos producidos por los programas de IDAMS tienen registros de longitud fija sin caracteres de tabulación. En general, no hay lı́mite para el número de casos que pueden entrar a un programa de IDAMS. Archivo Diccionario (*.dic). Se usa para describir las variables en los datos. Como mı́nimo, debe describir solamente las variables usadas en una ejecución particular de un programa, pero puede describir todas las variables en cada registro de datos. La longitud de registro es variable, pero tiene un máximo de 80. Si un programa IDAMS produce un diccionario, entonces la longitud del registro es fija (80 caracteres) sin caracteres de tabulación. El diccionario se puede preparar sin conocer su formato interno, en la ventana Diccionario de la Interfaz del Usuario. Alternativamente, se puede preparar con el Editor General y siguiendo el formato dado en el capı́tulo ”Los datos en IDAMS”. Archivo Matriz (*.mat). Las matrices de IDAMS (para guardar varias estadı́sticas) tienen registros de longitud fija (80 caracteres) sin caracteres de tabulación. Archivo Setup (*.set). Este archivo se usa para guardar comandos de IDAMS, especificaciones de archivos, proposiciones de control del programa y proposiciones de Recode (si las hay). Se puede preparar en la ventana Setup de la Interfaz del Usuario. La longitud de registro es variable aunque el máximo es de 255 caracteres. Archivo Resultados (*.lst). Normalmente IDAMS escribe los resultados en un archivo. El contenido de este archivo puede entonces revisarse antes de producir la salida al papel. Nota: para facilitar el trabajo con WinIDAMS, se aconseja utilizar el mismo nombre para los archivos Diccionario y Datos, y el mismo nombre para los archivos Setup y Resultados. Los archivos del usuario se especifican a continuación del comando $FILES en el archivo Setup (ver el capı́tulo “El archivo Setup de IDAMS”). 80 Archivos y carpetas Archivos del sistema El usuario no tiene acceso directo a los archivos del sistema. Estos se crean durante el proceso de instalación (archivos permanentes del sistema), durante la personalización del ambiente para una aplicación (archivos Aplicación) o durante la ejecución de procedimientos de WinIDAMS (archivos temporales de trabajo). Archivos permanentes del sistema. Incluyen los archivos ejecutables de programas, archivos dll, archivos de parámetros del sistema, archivo del Manual en pantalla (en formato HTML Help) y archivos de prototipos de setup. Archivos de controle del sistema. • Idams.def : definiciones de archivos por defecto que suministran conexión entre nombres lógicos y nombres fı́sicos de los archivos de usuario y los archivos temporales de trabajo. • <application nombre>.app : un archivo por aplicación que contiene los nombres de las carpetas Datos, Trabajo y Temporal. • lastapp.ini : archivo que contiene el nombre de la última aplicación usada. • graphid.ini : los parámetros de configuración para el componente GraphID . • tml.ini : los parámetros de configuración para el componente TimeSID . Archivos temporales de trabajo. No conciernen al usuario ya que se definen y se eliminan automáticamente. Tienen extensión de archivo .tmp y .tra. 8.2. Las carpetas en WinIDAMS Los archivos que usa WinIDAMS se guardan en las siguientes carpetas: archivos permanentes del systema en la carpeta Sistema, archivos Aplicación en la carpeta Aplicación, archivos Datos, Diccionario y Matriz en la carpeta Datos, archivos Setup y Resultados en la carpeta Trabajo, archivos temporales de trabajo en la carpeta Temporal y la carpeta Transpuesta. Las cinco carpetas obligatorias para la aplicación por defecto deben siempre estar presentes bajo la carpeta <system dir>. Se definen y se crean por la primera vez durante el proceso de instalación. Después, cuando WinIDAMS se ejecuta y falta alguna de las carpetas, ésta se crea nuevamente de manera automática. carpeta carpeta carpeta carpeta carpeta Aplicación Datos Temporal Transpuesta Trabajo <system <system <system <system <system dir>\appl dir>\data dir>\temp dir>\trans dir>\work donde <system dir> es el nombre de la carpeta Sistema dado durante el proceso de instalación. Referirse a la sección “Personalización del ambiente para una aplicación” del capı́tulo “Interfaz del Usuario” para una descripción más detallada de como las rutas definidas en la aplicación se usan en los programas de IDAMS. Capı́tulo 9 Interfaz del Usuario 9.1. Concepto general La Interfaz del Usuario de WinIDAMS es una interfaz de documentos múltiples. Puede mostrar y trabajar simultáneamente diferentes tipos de documentos tales como Diccionario, Datos, Setup, Resultados y documentos Texto en ventanas separadas. Más aun, suministra el acceso a la ejecución de los setups de IDAMS y de los componentes para el análisis interactivo de datos, a saber: Tablas multidimensionales, Exploración gráfica de los datos y Análisis de series de tiempo desde cualquier ventana del documento. La ventana principal de WinIDAMS contiene: la barra de menú para abrir menús desplegables con opciones o comandos de WinIDAMS, la barra de herramientas para escoger comandos rápidamente, la barra de estado para mostrar información acerca del documento activo o de la opción o comando resaltado, la ventana Aplicación, ubicada en el lado izquierdo, para mostrar el nombre de la aplicación, carpetas y documentos para la aplicación activa, las ventanas de documentos para mostrar los diferentes documentos de WinIDAMS. 82 Interfaz del Usuario La barra de menú y la barra de herramientas tienen contenidos fijos y dependiente de documentos. Los menús comunes a todos los tipos de documento se describen a continuación y los menús que dependen del tipo de documento se describen en las secciones relevantes. 9.2. Menús comunes a todas las ventanas de WinIDAMS La barra de menú principal contiene siempre los siguientes siete menús: Archivo, Edición, Ver, Ejecutar, Interactivo, Ventana y Ayuda. Archivo Nuevo Llama al cuadro de diálogo para seleccionar el tipo de documento a crear y suministrar su nombre y localización. Abrir Después de escoger el tipo de documento, llama al cuadra de diálogo para seleccionar el documento a abrir. Cerrar Guardar Cierra la ventana activa. Guarda el documento mostrado en la ventana activa. Guardar como Llama al cuadro de diálogo para guardar el documento que está en la ventana activa. Llama al cuadro de diálogo para cambiar las optiones de impresión y de la impresora. Muestra el documento activo tal como se verá cuan lo se imprima. Configurar impresora Vista preliminar Imprimir Llama al cuadro de impresión para imprimir el conenido del documento mostrado en la ventana activa o en el panel activo. Nótese que las partes ocultas del documento no se imprimen. Salir Termina la sesión de WinIDAMS. El menú puede contener también la lista hasta de 7 documentos abiertos recientemente, es decir, documentos usados en sesiones anteriores de WinIDAMS. Edición La disponibilidad y algunas veces el tı́tulo de algunos comandos en este menú puede ser diferente en diferentes ventanas. Deshacer Reversa la última acción. Rehacer Cortar Hace nuevamente la última acción cancelada. Mueve la selección al portapapeles. Copiar Pegar Copia la selección al portapapeles. Copia el contenido del portapapeles al sitio donde está ubicado el cursor. Buscar Reemplazar Da comienzo al mecanismo de búsqueda de Windows. Da comienzo al mecanismo de reemplazo de Windows. Buscar siguiente Busca la siguiente ocurrencia de la cadena de caracteres activa en el cuadro de diálogo de Buscar. Nótese que en las ventanas Resultados y Texto, las acciones de buscar/reemplazar se activan con los comandos Buscar, Buscar adelante, Buscar atrás, y Reemplazar. 9.3 Personalización del ambiente para una aplicación 83 Ver Barra de herramientas Muestra/oculta la barra de herramientas. Barra de estado Muestra/oculta la barra de estado. Aplicación Pantalla completa Muestra/oculta la ventana Aplicación. Muestra la ventana activa en pantalla completa. Haga clic en el ı́cono “Cerrar la pantalla completa” en la esquina superior izquierda o teclée Esc para regresar a la ventana anterior. Ejecutar Con excepción de la ventana Setup, el menú sólo tiene un comando, Seleccionar setup, para seleccionar un archivo con el setup a ejecutar. Interactivo Con este menú, se puede acceder a tres componentes de análisis interactivo, a saber: Tablas multidimensionales Exploración gráfica de los datos Análisis de series de tiempo Ver los capı́tulos correspondientes para una descripción detallada de cada componente. Ventana El menú contiene la lista de ventanas abiertas y de comandos estándar de Windows para organizarlos. Ayuda Manual de WinIDAMS Acerca de WinIDAMS 9.3. Da acceso al Manual de Referencia de WinIDAMS. Muestra información de la versión y el copyright de WinIDAMS y un vı́nculo para acceder a la página web de IDAMS en la sede principal de UNESCO. Personalización del ambiente para una aplicación El usuario puede definir y guardar los nombres de carpetas Datos, Tarbajo y Temporal en los archivos Aplicación con el nombre de la aplicación como nombre del archivo. El nombre de la última aplicación usada es guardado por el sistema y las caracterı́sticas que definen esta aplicación se cargan al comienzo de la siguiente sesión. Estas caracterı́sticas se pueden cambiar en cualquier momento durante la sesión de trabajo mediante la selección/creación y activación de otra aplicación. Como es necesario, por lo menos, un archivo Aplicación para usar WinIDAMS, se suministra una aplicación estándar llamada “Default” y se activa cuando se usa WinIDAMS por primera vez después de la instalación. Las caracterı́sticas de definición por defecto son: Carpeta Datos Carpeta Trabajo Carpeta Temporal <system dir>\data <system dir>\work <system dir>\temp donde <system dir> es el nombre de la carpeta Sistema fijado durante la instalación. Esta aplicación (guardada en el archivo Default.app) nunca debe suprimirse o modificarse. El usuario puede crear, modificar, o suprimir los archivos Aplicación (excepto el archivo Default.app) con el menú Aplicación de la barra de menú de la ventana principal de WinIDAMS. Contiene los siguientes comandos: 84 Interfaz del Usuario Nueva Llama al cuadro de diálogo para crear una aplicación nueva. Abrir Llama al cuadro de diálogo para escoger un archivo con los detalles de la aplicación que se va a abrir. Mostrar Cerrar Llama al cuadro de dialogo para escoger el archivo Aplicación y muestra las caracterı́sticas de la aplicación. Cierra la aplicación activa y abre la aplicación “Default”. Actualizar Crea nuevamente el arbol de la aplicación en uso. Creación de una nueva aplicación. La selección del comando Nueva de menú Aplicación suministra un cuadro de diálolgo para introducir el nombre de una nueva aplicación y los nombres de las carpetas Datos, Trabajo y Temporal. Con excepción del campo para el nombre de la aplicación, el cual está libre, todos los otros campos tienen valores tomados de la aplicación por defecto, que se pueden modificar. Puede introducir el nombre de la ruta o escogerlo, moviendo el resaltador al nombre requerido en el árbol de las carpetas. Oprima el botón de OK para guardar la aplicación. Con Cancelar, cancela la creación de una nueva aplicación y regresa a la ventana principal de WinIDAMS con las caracterı́sticas mostradas previamente. Abrir una aplicación. El comando Abrir de menú Aplicación llama al cuadro de diálogo para escoger un archivo de aplicación para abrir y suministra una lista de aplicaciones existentes en la carpeta Aplicación. Haciendo clic en el nombre requerido, se activan las caracterı́sticas de esta aplicación. Modificar una aplicación. Primero ábrala y luego cambie los valores de la misma manera que para crear una aplicación. Mostrar las caracterı́sticas de una aplicación. Use el comando Mostrar de menú Aplicación para llamar al cuadro de diálogo y haga clic en el nombre deseado. Para mostrar las caracterı́sticas de una aplicación activa, haga doble clic en el nombre en la ventana Aplicación. Suprimir una aplicación. Se puede retirar una aplicación existente si se suprime el archivo correspondiente. Use el comando Abrir de menú Aplicación para obtener una lista de archivos Aplicación, escoja el archivo para suprimir y use el botón derecho para acceder al comando de supresión de Windows. No se debe suprimir el archivo Default.app. Restaurar las caracterı́sticas de WinIDAMS por defecto. Se puede hacer de dos maneras: con el comando Cerrar de menú Aplicación, o bien para escoger y abrir el archivo Default.app. Cerrar una aplicación activa. Use el comando Cerrar de menú Aplicación. Se activa la aplicación por defecto. Las rutas definidas en la aplicación las usan los programas de IDAMS para prefijar el nombre de cualquier archivo que no comience con “<unidad>:\...” o con “\...”. 9.4 Crear/actualizar/mostrar archivos Diccionario 85 La ruta de la carpeta Datos : en las proposiciones con ddnames DICT..., DATA..., o FTnn referido a matrices. La ruta de la carpeta Trabajo : en las proposiciones con ddnames PRINT o FT06. La ruta de la carpeta Temporal : los nombres de archivos temporales. Ejemplo: Carpeta Datos: c:\MyStudy\students\data Especificación en el setup: dictin=students2004.dic Nombre completo del archivo diccionario: c:\MyStudy\students\data\students2004.dic 9.4. Crear/actualizar/mostrar archivos Diccionario La ventana Diccionario para crear, actualizar o mostrar un diccionario de IDAMS, se llama cuando: usted crea un nuevo archivo Diccionario (el comando Nuevo/“IDAMS Dictionary file” (archivo Diccionario) de menú Archivo o el botón Nuevo de la barra de herramientas), usted abre un archivo Diccionario (con la extensión .dic) mostrado en la ventana Aplicación (haga doble clic en el nombre del archivo requerido de la lista de “Datasets”), usted abre un archivo Diccionario (con cualquier extensión) que no está en la ventana Aplicación (el comando Abrir/Diccionario de menú Archivo o el botón Abrir de la barra de herramientas). Esta ventana suministra dos paneles: uno para la definición de variables (panel Variables) y otro para los códigos y los nombres de códigos de la variable en cuestión (panel Códigos). Una lı́nea azul en la parte superior del panel, indica el panel activo. Los encabezamientos de columna en el panel Variables tiene el siguiente significado: Número Número de variable. Nombre Loc, Ancho Nombre de variable. Posición inicial y ancho del campo de la variable en el archivo Datos. Dec Número de cifras decimales; un blanco implica que no hay decimales. 86 Interfaz del Usuario Tipo Tipo de variable (N=numérica, A=alfabética). Md1 Md2 Primer código de datos faltantes para variables numéricas. Segundo código de datos faltantes para variables numéricas. Refe IdEs Número de referencia. Identificador del estudio. Para mayor detalle, ver la sección “El diccionario IDAMS” en el capı́tulo “Los datos en IDAMS”. Nótese que con la ventana Diccionario, sólo se pueden crear, actualizar, mostrar diccionarios de descripción de datos que tengan un registro por caso. Cambiar la apariencia de los paneles. La apariencia de cada panel se puede cambiar separadamente y los cambios se aplican exclusivamente al panel activo. En cada panel hay las siguientes posibilidades de modificación: Aumentar el tamaño de la fuente - use el botón Aumentar de la barra de herramientas. Disminuir el tamaño de la fuente - use el botón Reducir de la barra de herramientas. Restaurar el tamaño de la fuente por defecto - use el botón 100 % de la barra de herramientas. Aumentar/Disminuir el ancho de columna - coloque el cursor del ratón sobre la lı́nea que separa dos columnas en el encabezado de columna hasta que le cursor se haya convertido en una barra horizontal con dos flechas y muévalo a derecha/izquierda teniendo apretado el botón izquierdo del ratón. El panel Variables puede modificarse aun más asi: Aumentar/Disminuir el alto de filas - coloque el cursor del ratón sobre la lı́nea que separa dos filas en el encabezado de fila hasta que el cursor se haya convertido en una barra horizontal con dos flechas y muévalo arriba/abajo manteniendo apretado el botón izquierdo del ratón. Definir una variable. Coloque el cursor en el panel Variables, llene el número de variable (por lo menos uno es obligatorio, las siguientes variables se numerarán añadiendo el valor 1), nombre (opcional), localización (si no se suministra, se asigna 1 a la primera variable y para las variables siguientes, se calcula la localización sumando el ancho de la variable precedente) y ancho (obligatorio). Otros campos tienen valores por defecto (que usted puede aceptar o modificar) o son opcionales y se pueden dejar en blanco. Oprima Intro o Tab para aceptar un valor en un campo y moverse al siguiente, o Mayúsculas/Tab para moverse al campo anterior. Nótese que mientras aparezca un lápiz pequeño en el encabezado de fila, ésta no se habrá guardado. Oprima Intro para aceptar la definición completa de variables. Un asterisco en el encabezado de fila indica que ésta es la fila siguiente y puede introducir una nueva definición de variable. Definir los códigos y sus nombres para una variable. Cámbiese al panel Códigos y llene los campos de códigos y nombres de códigos. Llene el valor del código, luego oprima Intro o Tab y llene el nombre del código, luego Intro o Tab para aceptar la fila y moverse a la siguiente. Una vez que se hayan definido los códigos y sus nombres, regrese al panel de Variables para la definición de una nueva variable. Modificar un campo bien en panel Variables o panel Códigos. Haga clic en el campo e introduzca el nuevo valor (al entrar el primer carácter del nuevo valor se borra el campo). Si se hace doble clic en el campo su valor se puede modificar parcialmente. Se puede usar la tecla Esc para recuperar el valor previo. Las operaciones de edición se pueden hacer en una fila o en un bloque de filas. Para marcar una fila, haga clic en cualquier campo de la misma. Aparece un triángulo en el encabezado de fila y la fila se colorea con azul oscuro. Para marcar un bloque de filas, coloque el cursor en el encabezado de fila en donde se desea iniciar la marcación y haga clic sobre le botón izquierdo del ratón. La fila se vuelve amarilla, indicando que está activa. Ahora mueva el cursor arriba o abajo hasta la fila en la que desea terminar la marcación y haga clic en el botón izquierdo del ratón mientra oprime la tecla de mayúsculas. Las filas marcadas se colorean con azul oscuro y el color amarillo marca la fila activa. Puede Cortar, Copiar y Pegar filas marcadas usando los comandos de Edición, botones equivalentes de la barra de herramientas o las teclas de acceso rápido Ctrl/X, Ctrl/C y Ctrl/V respectivamente. Con el botón derecho del ratón usted puede Insertar antes, Insertar después, Suprimir o Borrar la fila activa (aun cuando se haya marcado un bloque de filas). 9.5 Crear/actualizar/mostrar archivos Datos 87 Detectar errores en un diccionario. Utilize el comando Validez de menú Verificar. Están señalados uno a uno y se pueden corregir una vez se hayan mostrado todos. Más aun la Interfaz trata de prevenir que se guarden diccionarios con errores. También, cuando se abre un diccionario con errores, se advierte su existencia antes de abrir el mismo. 9.5. Crear/actualizar/mostrar archivos Datos La ventana Datos se usa para crear, actualizar o mostrar un archivo Datos de IDAMS. Nótese que debe haberse construido un diccionario de IDAMS que corresponda al archivo Datos y que con la ventana Datos sólo se pueden crear, actualizar o mostrar archivos Datos con un registro por caso. Esta ventana se llama cuando: usted crea un nuevo archivo Datos (el comando Nuevo/“IDAMS Data file” (archivo Datos) de menú Archivo o el botón Nuevo de la barra de herramientas), usted abre un archivo Datos (con la extensión .dat) mostrado en la ventana Aplicación (haga doble clic en el nombre del archivo requerido de la lista de “Datasets”), usted abre un archivo Datos (con cualquier extensión) que no está en la ventana Aplicación (el comando Abrir/Datos de menú Archivo o el botón Abrir de la barra de herramientas). La ventana se divide en tres paneles: uno muestra los códigos y sus nombres de la variable señalada (panel Códigos), el segundo muestra la definición de las variables (panel Variables) y el tercero provee lugar para introducción/modificación de datos (panel Datos). Sólo se puede editar el panel Datos. Los otros dos paneles sólo muestran la información relevante. Una lı́nea azul en la parte superior de cada panel indica cual panel está activa. Los paneles están sincronizados, es decir, la selección de un campo de variable en el panel Datos hace resaltar su correspondiente descripción y la selección de un campo en el panel Variables muestra el valor correspondiente a la variable en el caso señalado. Para la variable seleccionada, siempre se muestran los códigos y sus nombres, si los hay. Cambiar la apariencia de los paneles. La apariencia de cada panel se puede cambiar separadamente y los cambios se aplican exclusivamente al panel activo. En cada panel hay las siguientes posibilidades de modificación: 88 Interfaz del Usuario Aumentar el tamaño de la fuente - use el comando Aumentar de menú Ver o el botón Aumentar de la barra de herramientas. Disminuir el tamaño de la fuente - use el comando Reducir de menú Ver o el botón Reducir de la barra de herramientas. Restaurar el tamaño de la fuente por defecto - use el comando 100 % de menú Ver o el botón 100 % de la barra de herramientas. Aumentar/Disminuir el ancho de columna - coloque el cursor del ratón sobre la lı́nea que separa dos columnas en el encabezado de columna hasta que le cursor se haya convertido en una barra horizontal con dos flechas y muévalo a derecha/izquierda teniendo apretado el botón izquierdo del ratón. El panel Datos puede modificarse aun más ası́: Aumentar/Disminuir el alto de filas - coloque el cursor del ratón sobre la lı́nea que separa dos filas en el encabezado de fila hasta que el cursor se haya convertido en una barra horizontal con dos flechas y muévalo arriba/abajo manteniendo apretado el botón izquierdo del ratón. Colocar columna(s) al comienzo - marque la(s) columna(s) requerida(s) y use el comando Inmovilizar columnas de menú Ver (use el comando Liberar de menú Ver para regresarlas). Mostrar datos en un panel múltiple - use el comando Dividir de menú Ventana. Se suministra una cruz para determinar el tamaño de los cuatro paneles. El tamaño se puede cambiar después usando la técnica estandar de Windows. Se muestran todos los datos cuatro veces. La división horizontal se puede quitar haciendo doble clic en la lı́nea horizontal, la división vertical se puede quitar haciendo doble clic en la lı́nea vertical y toda la división se puede quitar haciendo doble clic en el centro de la división. Introducir un nuevo caso. Haga clic en el primer campo de una fila vacı́a y comience a teclear los datos. Oprima Intro o Tab para aceptar un dato para la variable y muévase a la variable siguiente, o Mayúsculas/Tab para moverse a la variable anterior. Nótese que mientras aparezca un pequeño lápiz en el encabezado de fila, el caso no se guarda. Oprimir Intro en la última variable guarda el caso y mueve el cursor al comienzo de la fila siguiente. Se puede insertar una fila nueva antes o después de la fila resaltada (haga clic en el botón derecho del ratón), o puede adicionarse la final del archivo (fila con un asterisco en el encabezado de fila). La entrada de datos se puede facilitar tomando ventaja de dos opciones dadas en el menú Opciones: Verifica códigos verifica valores de datos durante la entrada de los mismos contra códigos definidos en el diccionario, los solos dados por válidos. Salto automático mueve el cursor automáticamente al siguiente campo cuando haya un número suficiente de dı́gitos para llenar el campo. Si no se selecciona, debe oprimir Intro o Tab para moverse al campo siguiente. Modificar el valor de una variable. Haga clic en el campo de la variable y entre el nuevo valor (la entrada del primer carácter del nuevo valor, borra el campo). Se puede usar doble clic en el campo de una variable para modificar parte del valor. Se puede usar la tecla Esc para recuperar el valor previo. Copiar el valor de una variable a otro campo. Haga clic en el campo de la variable y copie su contenido al portapapeles (el comando Copiar de menú Edición, Ctrl/C o Copiar de la barra de herramientas). Después, haga clic en otro campo y peque el valor (el comando Pegar de menú Edición, Ctrl/V o Pegar de la barra de herramientas). El comando Deshacer caso de menú Edición se puede usar para recuperar el valor previo. Las operaciones de edición se pueden hacer sobre una fila o un bloque de filas de la misma manera que en la ventana del Diccionario. Para marcar una fila, haga clic en cualquier campo de esta fila. Aparece un triángulo en el encabezado de la fila y la fila se colorea en azul oscuro. Para marcar un bloque de filas, colque le cursor en el encabezado de la fila en donde quiere comenzar a marcar y haga clic en el botón izquierdo del ratón para encenderlo. La fila se torna amarilla, para indicar que está activa. Mueva ahora el cursor hacia arriba o hacia abajo hasta la fila en la cual desea terminar la marcación y haga clic en el botón izquierdo del ratón mientras oprime la tecla de mayúsculas. Las filas marcadas se colorean con azul oscuro y el color amarillo muestra la fila que está activa. 9.6 Importación de archivos de datos 89 Las filas marcadas se pueden cortar, copiar o pegar con los comandos bajo Edición, con los botones equivalentes de la barra de herramientas o con las teclas de acceso rápido Ctrl/X, Ctrl/C y Ctrl/V respectivamente. Con el botón derecho del ratón se puede Insertar antes, Insertar después, Suprimir o Borrar la fila activa (aun si está marcado un bloque de filas). Dos comandos para manejo de datos en el menú Gestión de datos permiten verificación de los datos después de la entrada de los mismos o bién de los datos venidos del exterior, y clasificación de los datos: Verificar códigos verifica valores de datos de todos los casos en el archivo Datos contra los códigos definidos en el diccionario, los solos dados por válidos. Al final de la verificación, aparece un mensaje que muestra el número de errores encontrados y se ofrece la posibilidad de corregirlos uno a uno con el cuadro de diálogo para corrección de datos. Este cuadro suministra el número secuencial de caso, número y nombre de variable, valor de código inválido, y una lista de códigos válidos como están definidos en el diccionario. Clasificar llama al cuadro de diálogo de la clasificación para especificar hasta tres variables de clasificación y su correspondiente orden de clasificación de cada una de ellas. Después de hacer clic en OK, aparece el archivo clasificado en el panel Datos. También se pueden clasificar los datos sobre una variable (una columna) con doble clic en el número de la variable del encabezado del panel de datos. Un doble clic clasifica los casos en orden ascendente. Para obtener la clasificación en orden descendiente, repita el doble clic. Se proponen dos tipos de gráfico para una variable en el menú Gráficos. Gráfico de barras suministra un gráfico de barras basado en frecuencias o porcentajes de las categorı́as de una variable cualitativa. Para variables cuantitativas, el usuario define el número de barras (NB) en dos lados de la media (M) y un coeficiente (C) para calcular el ancho de las barras (clases). El ancho de las barras (BW) es igual al valor de la desviación estándar (STD) multiplicado para el coeficiente (BW=C*STD). Las barras se construyen usando los valores M-NB*BW, ..., M-2BW, M-BW, M, M+BW, M+2BW, ..., M+NB*BW. El alto de un ectángulo= (frecuencia relativa de la clase)/(ancho de la clase). Además, para variables cuantitativas se puede obtener una curva de la distribución normal con la media y desviación estándar calculadas. Histograma, orientado a variables cuantitativas, suministra un histograma basado en frecuencias o porcentajes con el número de barras especificado por el usuario. Los gráficos para variables cuantitativas contienen también estadı́sticas univariadas para la variable trazada tales como: media, desviación estándar, variancia, asimetrı́a y kurtosis. Las variables con puntos decimales se multiplican por un factor de escala para obtener valores enteros. En este caso, se debe ajustar en consecuencia los valores de la media, de la desviación estándar y de la variancia. 9.6. Importación de archivos de datos WinIDAMS suministra una herramienta para importar archivos de datos directamente a IDAMS a través de la Interfaz del Usuario. Se puede acceder a esta herramienta en la ventana principal de WinIDAMS, en la ventana Datos y en la ventana Tablas multidimensionales. Se pueden importar tres tipos de archivos de formato libre: archivos .txt delimitados con Tab, archivos .csv separados con punto y coma, archivos .csv separados con coma. La información dada en la primera fila se considera como etiquetas de columnas y se usa como nombres de variables durante el proceso de construcción del diccionario. Entonces, la presencia de etiquetas de columnas es obligatoria en la primera fila de los archivos de entrada. 90 Interfaz del Usuario Además, el carácter usado para separar campos se detecta en la primera fila y el carácter usado en la notación decimal se detecta en la secunda fila del archivo. Entonces, si una variable tiene valores decimale, la presencia de estos valores es obligatoria en la secunda fila del archivo. Durante el proceso de importación, el contenido de las variables alfabéticas importadas se puede cambiar a códigos numéricos, manteniendo los valores alfabéticos como nombres de códigos en el diccionario de IDAMS creado. Comas usadas como separador decimal para variables numéricas se convierten en puntos. La operación de importación de datos se activa con el comando Importar de menú Archivo, seguido de la selección del archivo requerido en el cuadro de diálogo estándar Abrir de archivos. Se muestran juntos con los valores de todos los campos para los tres primeros casos. Entonces, se puede verificar la lectura de los datos antes de proceder a la importación. Después aparecen dos ventanas llamadas Datos externos y Definición de variables, ambas son ventanas de tipo hoja de cálculo. La ventana de Datos externos sólo muestra el contenido del archivo a importar. No se permiten operaciones de edición con excepción de copiar una selección al portapapeles. La ventana de Definición de variables sirve para preparar descripción de variables de IDAMS. Su contenido inicial viene dado por defecto y sobre la base de los datos importados, pero hay libertad de cambiarlo y completarlo si es necesario. Las columnas tienen la siguiente información: Descripción Nombre de variable Tipo AnchMáx Tipo de variable (numérica por defecto). Es el tipo de variable de entrada. Si una variable de entrada es alfabética y debe salir como numérica, solicite recodificación (ver más adelante). Ancho máximo de la variable. NDec Md1 Número de cifras decimales; blanco implica que no hay cifras decimales. Primer código de datos faltantes para variables numéricas. Md2 Recodificación Segundo código de datos faltantes para variables numéricas. Solicitud para recodificar una variable alfabética a valores numéricos. Para modificar la definición de variables, coloque el cursor dentro de la ventana y despés use las teclas de navegación o el ratón para moverse al campo requerido y cambiar su contenido. Use el comando Dataset de menú Construir para crear el archivo Diccionario de IDAMS y el archivo Datos. Ambos estarán en la carpeta Datos de la aplicación activa. 9.7. Exportación de archivos Datos de IDAMS WinIDAMS tiene también una herramienta para exportar datos directamente a través de la Interfaz del Usuario. Esto se puede hacer desde la ventana Datos con el comando Exportar de menú Archivo. El archivo Datos de IDAMS que aparece en la ventana en que se está trabajando, se puede guardar en uno de los tres tipos de archivos de formato libre: archivos .txt delimitados por Tab, archivos .csv separados con punto y coma. archivos .csv separados con coma. En la primera fila de los datos exportados, los nombres de variables del diccionario correspondiente, aparecen como nombres de columnas. Si existen nombres de códigos para una variable, los valores numéricos de códigos se pueden sustituir opcionalmente por sus correspondientes nombres en el archivo de datos en salida. Además, las variables numéricas pueden salir con coma usada como separador decimal. 9.8 Crear/actualizar/mostrar archivos Setup 9.8. 91 Crear/actualizar/mostrar archivos Setup La ventana Setup para preparar o mostrar un archivo Setup de IDAMS se llama cuando: usted crea un nuevo archivo Setup (el comando Nuevo/“IDAMS Setup file” (archivo Setup) de menú Archivo o el botón Nuevo de la barra de herramientas), usted abre un archivo Setup (con extensión .set) mostrado en la ventana Aplicación (haga doble clic en el nombre del archivo requerido en la lista de “Setups”), usted abre un archivo Setup (con cualquier extensión) que no esté en la ventana Aplicación (el comando Abrir/Setup de menú Archivo o el botón Abrir de la barra de herramientas. La ventana suministra dos paneles: el de arriba es para preparar el archivo mismo de setup (panel Setup) y el de abajo para mostrar los mensajes de error cuando se verifican proposiciones de filtro y Recode (panel Mensajes). Sólo se puede editar el panel Setup. Nótese que se muestran los comandos de IDAMS en negrilla y los nombres de programas en rosado si se han escrito correctamente. Los textos colocados en un comando $comment se muestran en verde. Para preparar un nuevo setup usted puede teclear todas las proposiciones o puede usar el prototipo de setup del programa requerido y modificarlo según sea necesario. Se suministran prototipos de setup para todos los programas. Se puede acceder a ellos seleccionando el nombre del programa en la lista bajo el botón Prototipos de la barra de herramientas. Para copiar el prototipo al panel Setup, haga clic en el nombre del programa requerido. Para los detalles acerca de cómo preparar archivos Setup, vea el capı́tulo “El archivo Setup de IDAMS” y la descripción del programa correspondiente. Se pueden hacer operaciones de edición igual que con cualquier editor de textos ASCII, es decir, usted puede Cortar, Copiar, y Pegar cualquier selección usando los comandos de Edición, los botones equivalentes de la barra de herramientas o las teclas de acceso rápido Ctrl/X, Ctrl/C y Ctrl/V respectivamente. Dos comandos de verificación de setup en el menú Verificar permiten la verificación de conjuntos de proposiciones de filtro y de Recode. Sintaxis de Recode activa la verificación de la sintaxis en las proposiciones de Recode incluidas en el setup. Todos los errores que se encuentren se reportan en el panel Mensajes con el número del conjunto de Recode, la lı́nea con error y el carácter o caracteres que causan el problema de sintaxis. Haciendo doble clic sobre la lı́nea errónea o en el mensaje de error en el panel Mensajes muestra esta lı́nea en 92 Interfaz del Usuario el panel Setup con una flecha amarilla. Puede corregir los errores y repetir la verificación de sintaxis, antes de pasar a la ejecución del setup. Sintaxis de filtros activa la verificación de la sintaxis en las proposiciones de filtro incluidas en el setup. Todos los errores que se encuentren se reportan en el panel Mensajes con el número de la proposición de filtro, la lı́nea de la proposición y el carácter o caracteres que causan el problema de sintaxis. Haciendo doble clic sobre la lı́nea errónea o en el mensaje de error en el panel Mensajes muestra esta lı́nea en el panel Setup con una flecha amarilla. Nótese que aunque la mayorı́a de los errores de sintaxis en las proposiciones de filtro y de Recode se pueden detectar y corregir aquı́, IDAMS lleva a cabo otra verificación sistemática de sintaxis durante la ejecución del setup. También se reportan en los resultados, los errores de ejecución que no se pueden detectar aquı́. 9.9. Ejecución de los setups de IDAMS Para ejecutar los programas de IDAMS (para los que se han preparado instrucciones y se han guardado en un archivo Setup), use el comando Seleccionar setup de menú Ejecutar en cualquier ventana de documento de WinIDAMS. En el cuadro de diálogo estándar de Windows, se pide escoger el archivo del cual se deben tomar las instrucciones para la ejecución. Si usted está preparando sus instrucciones en la ventana Setup, puede ejecutar los programas del setup activo usando el comando Setup actual de menú Ejecutar. El programa o los programas se ejecutarán y los resultados se escribirán en el archivo especificado para PRINT bajo $FILES (por defecto IDAMS.LST en la carpeta Trabajo que esté activa). Al final de la ejecución, se abrirá el archivo de resultados en la ventana Resultados. 9.10. Manejo de los archivos Resultados La ventana Resultados para acceder, mostrar e imprimir partes seleccionadas de resultados se llama cuando: usted abre un archivo Resultados (con extensión .lst) mostrado en la ventana Aplicación (haga doble clic en el nombre del archivo requerido en la lista de “Results”), usted abre un archivo Resultados (con cualquier extensión) que no está en la ventana Aplicación (el comando Abrir/Resultados de menú Archivo o el botón Abrir de la barra de herramientas), usted ejecuta el setup de IDAMS; se muestra automáticamente el contenido del archivo Resultados. La tabla de contenido del archivo Resultados, facilita una navegación rápida por los resultados. Puede acceder al comienzo del resultado de un programa en particular o aun, a una sección en particular. Es más, el menú Edición suministra acceso a una facilidad de búsqueda. 9.10 Manejo de los archivos Resultados 93 La ventana está dividida en tres paneles: uno muestra la tabla de contenido de resultados (TDC) como una estructura de árbol, el segundo muestra el contenido de resultados y el tercero muestra mensajes de errores y de advertencias incluidos en los resultados. Por defecto, se retiene la división en las páginas del contenido de resultados hecha por los programas (la opción Modo de página en el menú Ver ésta activa). Para hacer más compacto el contenido de resultados, desactive esta opción. Las lı́neas en blanco al final de las páginas se retiran de todas las páginas y los saltos de página insertados por los programas se reemplazan con la lı́nea de texto “Page break”. Para abrir/cerrar rápidamente el árbol TDC se dispone de tres botones en el teclado numérico: * + abre todos los niveles del árbol bajo el nodo seleccionado cierra todos los niveles del árbol bajo el nodo seleccionado abre un nivel bajo el nodo seleccionado. Para ver una sección en particular, haga doble clic sobre su tı́tulo en el árbol TDC. Para localizar un mensaje de error o de advertencia, haga doble clic sobre el texto del mismo. No se permite modificación del contenido de resultados. Sin embargo, partes seleccionadas (resaltadas o marcadas en cuadros de selección en el árbol TDC) o todos los resultados, se pueden copiar al portapapeles (el comando Copiar de menú Edición, Ctrl/C o botón de Copiar en la barra de herramientas) y pegadas a cualquier documento con las técnicas estándar de Windows. Se puede imprimir todo el contenido o páginas seleccionadas de un archivo Resultados con el comando Imprimir de menú Archivo o con el botón Imprimir de la barra de herramientas. Nótese que la impresión se hace con orientación horizontal y esta orientación no se puede cambiar. El contenido del archivo Resultados tal como se muestra, se puede guardar en formato RTF o en formato de texto con el comando Guardar como de menú Archivo. Las lı́neas en blanco al final se eliminan siempre. Los saltos de página se manejan de acuerdo con la opción Modo de página. 94 Interfaz del Usuario 9.11. Creación/actualización de archivos en formato de texto y RTF WinIDAMS tiene un Editor General que le permite abrir y modificar cualquier tipo de documento en formato de caracteres. Sin embargo, su función básica es suministrar una facilidad para editar archivos Texto y ofrecer aspectos sofisticados de formato y edición. Se debe evitar la manipulación de archivos Diccionario, Datos o Setup y la manipulación de archivos Matriz debe hacerse cuidadosamente. La ventana Texto se llama cuando: usted crea un nuevo archivo Texto (el comando Nuevo/“Text file” (archivo Texto) o “RTF file” (archivo RTF) de menú Archivo, o el botón Nuevo de la barra de herramientas), usted abre un archivo Matriz (con extensión .mat) mostrado en la ventana Aplicación (haga doble clic en el nombre del archivo requerido en la lista de “Matrices”), usted abre cualquier archivo de caracteres que no esté en la ventana Aplicación (el comando Abrir/Con el Editor General de menú Archivo o el botón Abrir de la barra de herramientas). El Editor General suministra un número de comandos estándar de edición que son conocidos por los usuarios de Windows. Se escriben a continuación pero no se describen en detalle. Insertar suministra comandos para insertar salto de página y de sección, pintura, objeto OLE (vinculación e incrustación de objetos), marco y objeto de dibujo. Los comandos de la Fuente le permiten cambiar la fuente y el color del texto seleccionado y el color del fondo. Los comados del Párrafo le permiten alinear párrafos diferentemente, sangrı́arlos, mostrarlos en doble espacio, dibujar un borde alrededor y sombrear el fondo. Tabla permite el acceso a un número de comandos para insertar y manipular tablas. Ver contiene tres comandos adicionales para mostrar el documento activo en modo de página, mostrar la regla y el marcador de parágrafo. La barra de herramientas de formato le permite escoger rápidamente los comandos de formato usados con más frecuencia. Parte III Facilidades para el manejo de datos Capı́tulo 10 Agrupación de datos (AGGREG) 10.1. Descripción general AGGREG reune registros individuales (casos) en grupos definidos por el usuario y calcula las estadı́sticas descriptivas de resumen para variables especificadas en cada grupo. Las estadı́sticas incluyen sumas, medias, variancias, desviaciones estándar, ası́ como valores máximos y mı́nimos y el conteo de datos no faltantes. Se crea un dataset IDAMS como salida, es decir, el archivo de datos agrupado (agregado) y descrito por un diccionario IDAMS; el archivo de datos agrupados, contiene un registro (caso) por grupo con variables que son el resumen a nivel de grupo de cada una de las variables de entrada seleccionadas. En el capı́tulo “Tablas univariadas y bivariadas” de la parte “Fórmulas estadı́sticas y referencias bibliográficas” se pueden encontrar fórmulas para calular media, variancia y desviación estándar. Sin embargo, deben ajustarse ya que los casos no están ponderados y el coeficiente N/(N-1) no se usa en el cálculo de la variancia y desviación estándar de la muestra. Nótese que las estadı́sticas se seleccionan para el conjunto total de variables agrupadas. De esta manera, si hay 2 variables agrupadas y tres estadı́sticas seleccionadas, entonces habrá 6 variables calculadas. AGGREG le permite al usuario cambiar el nivel de agrupación de datos, por ejemplo, de miembros de una familia a nivel de hogares o de distrito a nivel regional, etc. Por ejemplo, supongamos que un archivo de datos contiene registros de cada individuo de un hogar y queremos analizar estos datos a nivel de hogares. AGGREG nos permite agrupar valores de las variables de registros individuales de cada hogar para crear un archivo de registros a nivel de hogares para análisis posteriores. Para ser más especı́ficos, si el archivo de datos a nivel de individuos tiene una variable que nos da el ingreso personal, AGGREG podrı́a crear registros a nivel de hogares con una variable que describa el ingreso total por hogar. Agrupamiento de datos. El usuario especifica hasta 20 variables de definición de grupos (variables de identificación) que determinan el nivel de agrupamiento del archivo de salida. Por ejemplo, si se quieren agrupar datos a nivel de miembros de una familia a nivel de hogares, entonces una variable que identifique el hogar serı́a la variable de definición de grupo. Cada vez que AGGREG lee un registro de entrada, busca cambios en cualquiera de las variables de identificación. Cuando se encuentra un cambio, se produce un registro de salida que contiene estadı́sticas de resumen, calculadas con las variables agrupadas especificadas para el grupo de registros que se acaban de procesar. Inserción de constantes dentro de los registros de grupo. Se pueden insertar constantes dentro de cada registro de grupo con los parámetros PAD1, ... , PAD5, los cuales especifican las llamadas variables pad. El valor de una variable pad es una constante. Transferencia de variables. Se pueden transferir variables a los registros de salida. Nótese que solamente los valores del primer caso dentro del grupo son transferidos. 98 10.2. Agrupación de datos (AGGREG) Caracterı́sticas estándar de IDAMS Selección de casos y variables. El filtro estándar está disponible para escoger un subconjunto de casos a partir de los datos de entrada. Con los parámetros, se especifican las variables de identificación que definen los grupos y las variables a ser agrupadas. Las variables de identificación se incluyen automáticamente en el dataset de salida. Transformación de datos. Se pueden usar las proposiciones de Recode. Tratamiento de datos faltantes. El valor de cada variable agrupada se compara con ambos códigos de datos faltantes y si se detecta que se trata de un valor faltante, se excluye automáticamente de los cálculos. Un porcentaje suministrado por el usuario, el “punto de corte” (ver el parámetro CUTOFF), determina el número de datos faltantes permitido antes de producir el valor de resumen como un código de datos faltantes. Por ejemplo, supongamos que se quiere calcular la media de una variable agrupada dentro de un grupo y éste contiene 12 registros, 6 de los cuales tienen datos faltantes, es decir, el 50 %. Si el valor de CUTOFF es 75 %, se calcula la media de los 6 datos no faltantes y ésta es la salida para el grupo. Si el valor de CUTOFF es de 25 %, entonces no se calcula la media y se produce como salida el primer código de datos faltantes. 10.3. Resultados Resumen de datos faltantes. (Opcional: ver el parámetro PRINT). Para cada variable en cada grupo, se imprime: el número de la variable de entrada, el número de la variable de salida, el número de registros con datos no faltantes y el porcentaje de registros con datos faltantes. Resumen de grupos. (Opcional: ver el parámetro PRINT). El número de registros de entrada para cada grupo. Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variables y registros C si los hay, sólo para las variables usadas en la ejecución. Diccionario de salida. (Opcional: ver el parámetro PRINT). Estadı́sticas generadas. (Opcional: ver el parámetro PRINT). Se pueden imprimir todas las variables calculadas para cada registro agrupado. También se dan el número de variable de la correspondiente variable agrupada y las variables de identificación. 10.4. Dataset de salida El dataset de los datos agrupados en la salida es un archivo Datos descrito por un diccionario IDAMS. Cada registro contiene valores de las variables de identificación, de las variables calculadas, de las variables transferidas y de las constantes pad; se produce un registro para cada grupo. Orden y numeración de variables. Las variables de salida se encuentran en el mismo orden relativo de las variables de entrada a partir de las cuales fueron derivadas, sin importar si la variable de entrada se usó como variable de identificación, variable a ser agrupada o variable a ser transferida. De esta manera, si se utiliza la primera variable de entrada, la variable o variables que se deriven de ella, serán la primera o primeras variables de salida. Cada variable de entrada que se use como variable de identificación o variable a ser transferida, corresponde a una variable de salida; cada variable agrupada corresponde a 1-7 variables de salida, según el número de estadı́sticas de resumen solicitadas (estas variables salen en el orden relativo: suma, media, variancia, desviación estándar, conteo, mı́nimo, máximo). Las variables de salida son siempre renumeradas, a partir del número suministrado en el parámetro VSTART. Las constantes pad siempre van al final. Nombres de variable. Las variables de salida tienen los mismos nombres de las variables de entrada de las cuales se derivaron, con la excepción de que para las variables agrupadas se codifican los caracteres 23 y 24 del campo del nombre: 10.5 Dataset de entrada S M V D CT MN MX = = = = = = = 99 suma media variancia desviación estándar conteo mı́nimo máximo. Las constantes pad, tienen los nombres de variable “Pad variable 1”, “Pad variable 2”, etc. Tipo de variable. Las variables de identificación y las variables transferidas salen con el mismo tipo de variable que la de entrada. Las variables calculadas son siempre numéricas. Ancho de campo y número de decimales. El ancho de campo de las variables agrupadas de salida depende de las estadı́sticas, el ancho de campo de entrada (FW), el número de cifras decimales de entrada (ND) y las cifras decimales extra, solicitadas por el usuario en el parámetro DEC. Los anchos de campo y el número de cifras decimales, se asignan de la manera mostrada a continuación, donde FW=ancho del campo de entrada y ND=número de cifras decimales de entrada para las variables de entrada, y FW=6 y ND=0 para las variables que vienen de Recode. Estadı́stica Ancho de campo Cifras decimales SUMA MEDIA VARIANCIA DESVIACION ESTÁNDAR MÍNIMO MÁXIMO COUNTEO FW FW FW FW FW FW 4 ND ND + DEC *** ND + DEC *** ND + DEC *** ND ND 0 * ** *** + + + + 3* DEC ** DEC ** DEC ** Si el ancho de campo pasa de 9, se reduce a 9. Si el ancho de campo pasa de 9, entonces el número de decimales extra se reduce igualmente. Si el número de decimales pasa de 9, entonces DEC se reduce de la misma manera. Códigos de datos faltantes. Los códigos de datos faltantes para las variables de identificación y para las variables transferidas se toman del diccionario de entrada. El segundo código de datos faltantes (MD2) es siempre blancos para variables calculadas. El valor del primer código de datos faltantes (MD1) se asigna de la siguiente manera: Variable de salida FW de salida <= 7 FW de salida > 7 variable CONTEO MD1 de salida 9’s -999999 9999 Números de referencia. Las variables calculadas reciben un número de referencia igual al de su variable de base. Registros C. Los registros C del diccionario de entrada se transfieren al diccionario de salida para las variables de identificación y para las variables transferidas. Nota acerca del cálculo de las estadı́sticas. Antes de producir la salida, los valores calculados se redondean al ancho de campo y al número de cifras decimales calculadas. Si el valor calculado excede a 999999999 o es inferior a -99999999, entonces sale como 999999999. 10.5. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. Las variables de definición de grupo (identificadoras) y las variables a ser transferidas pueden ser numéricas o alfabéticas, aunque las variables numéricas se tratan como cadenas de caracteres, es decir, un valor de ’044’ es diferente de ’ 44’. No pueden ser variables recodificadas. Las variables a ser agrupadas deben ser numéricas y pueden ser variables recodificadas. 100 Agrupación de datos (AGGREG) El archivo se procesa secuencialmente y se reunen los registros contiguos que tengan el mismo valor para las variables identificadoras. De esta manera, el archivo de entrada debe clasificarse con las variables identificadoras como llave de clasificación antes de usar AGGREG. Notar que AGGREG no verifica el orden de clasificación de los registros del archivo de entrada. 10.6. Estructura del setup $RUN AGGREG $FILES Epecificación de archivos $RECODE (opcional) Proposiciones de Recode $SETUP 1. Filtro (opcional) 2. Tı́tulo 3. Parámetros $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx DICTyyyy DATAyyyy PRINT 10.7. diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) diccionario de salida datos de salida resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-3, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: INCLUDE V1=10,20,30,50 OR V10=90-300 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: REUNION DE DATOS PROFESOR/ESTUDIANTE 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: IDVARS=(V1,V2) STATS=(SUM,VARI) DEC=3 AGGV=(V5-V10,V50-V75) PAD1=80 INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de datos no numéricos. Ver el capı́tulo “El archivo Setup de IDAMS”. 10.7 Proposiciones de control del programa 101 MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. IDVARS=(lista de variables) Hasta 20 números de variable para definir los grupos. No se permiten variables R. Sin valor por defecto. AGGV=(lista de variables) Variables V o R para ser agrupadas. Sin valor por defecto. STATS=(SUM, MEAN, VARIANCE, SD, COUNT, MIN, MAX) Parámetros para escoger las estadı́sticas solicitadas (se debe seleccionar al menos una de: SUM, MEAN, VARIANCE, SD). Salen para cada grupo y para cada variable AGGV. SUM La suma. MEAN La media. VARI La variancia. SD La desviación estándar. COUN El número de casos válidos. MIN El valor mı́nimo. MAX El valor máximo. SAMPLE/POPULATION SAMP Calcular la variancia y/o la desviación estándar con la ecuación de muestra. POPU Usar la ecuación de población. OUTFILE=OUT/yyyy Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de salida. Por defecto: DICTOUT, DATAOUT. VSTART=1/n Número de variable para la primera variable en el dataset de salida. CUTOFF=100/n Porcentaje de casos con códigos MD permitidos antes de producir la salida de un código MD. Un valor entero. DEC=2/n Para las variables calculadas que involucren media, variancia o desviación estándar: número de cifras decimales adicionales a aquellas de las correspondientes variables de entrada (ver restricción 7). TRANSVARS=(lista de variables) Las variables cuyos valores, tal como aparezcan en el primer caso de cada grupo, se van a transferir al archivo de salida. No se permiten variables R. PAD1=constante PAD2=constante PAD3=constante PAD4=constante PAD5=constante Se pueden añadir hasta 5 constantes al dataset de salida. El número de caracteres dado, determina el ancho del campo de la constante PAD. 102 Agrupación de datos (AGGREG) PRINT=(MDTABLES, GROUPS, DATA, CDICT/DICT, OUTDICT/OUTCDICT/NOOUTDICT) MDTA Imprimir una tabla que suministre el porcentaje de datos faltantes encontrado para cada variable agrupada en cada grupo. GROU Imprimir el número de casos por grupo. DATA Imprimir los valores de cada variable calculada en cada registro de grupo. CDIC Imprimir el diccionario de entrada para las variables accedidas con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. OUTD Imprimir el diccionario de salida sin registros C. OUTC Imprimir el diccionario de salida con registros C, si los hay. NOOU No imprimir el diccionario de salida. 10.8. Restricciones 1. Máximo número de variables a ser agrupadas es 400. 2. Máximo número de variables de identificación es 20. 3. Máximo número de caracteres en las variables de identificación es 180. 4. Máximo número de variables a ser transferidas es 100. 5. No se permiten variables recodificadas como IDVARS o TRANSVARS. 6. La misma variable no pueden aparecer en dos listas de variables. 10.9. Ejemplo Producir un dataset de salida que contenga un caso agrupado para cada valor único de V5 y V7; las variables en cada caso van a ser la suma, la media y la desviación estándar de 4 variables de entrada y 1 variable recodificada, agrupadas en los casos que forman el grupo (es decir, con los mismos valores de V5 y V7); los valores de V10 y de V11 para el primer caso de cada grupo van a transferirse a los registros de salida; se requiere un listado de los valores producidos para cada caso; en el archivo de salida, las variables se numerarán a partir del número 1001. $RUN AGGREG $FILES PRINT = AGGR.LST DICTIN = IND.DIC archivo Diccionario de entrada DATAIN = IND.DAT archivo Datos de entrada DICTOUT = AGGR.DIC archivo Diccionario de salida DATAOUT = AGGR.DAT archivo Datos de salida $RECODE R100=COUNT(1,V20-V29) NAME R100’INDICE DE SALUD’ $SETUP REUNION DE 4 VARIABLES DE ENTRADA Y UNA VARIABLE RECODIFICADA IDVARS=(V5,V7) AGGV=(V31,V41-V43,R100) STATS=(SUM, MEAN, SD) VSTART=1001 PRINT=DATA TRANS=(V10,V11) - Capı́tulo 11 Construcción de un dataset IDAMS (BUILD) 11.1. Descripción general BUILD toma un archivo de datos “primarios”, que puede contener varios registros por caso, junto con un diccionario que describe las variables requeridas y crea un archivo Datos nuevo con un solo registro por caso que contiene valores solamente para las variables especificadas. Al mismo tiempo, produce un diccionario IDAMS de salida que describe el archivo Datos con nuevo formato, en otras palabras se crea un dataset IDAMS. Además de la reconstrucción de los datos, BUILD también verifica valores no numéricos en variables numéricas. ¿Por que usar BUILD? Cualquier programa IDAMS se puede usar sin tener que utilizar BUILD, al preparar por separado un diccionario IDAMS. Sin embargo, se recomienda usar BUILD como un paso preliminar ya que: - verifica la correcta preparación del diccionario, - asegura que haya una correspondencia exacta entre el diccionario y los datos, - asegura que no haya caracteres no numéricos inesperados en los datos, - reduce los datos a la forma de un solo registro compacto por caso, - recodifica los espacios en blanco con valores especificados por el usuario. Procesamiento de las variables numéricas. Cuando BUILD procesa un campo como si tuviera una variable numérica, verifica que el campo contenga un número reconocible o contenga solamente blancos. Si se presenta un valor diferente de los anteriores, por ej. “3J”, “3-”, “++2”, etc. se imprime la posición secuencial del caso, el número de variable asociado con el campo y el caso de entrada y se usa una cadena de nueves como el valor de salida. Las reglas de procesamiento son las siguientes: Si un campo contiene un número reconocible, el número se edita a una forma estándar antes de enviarlo a la salida (ver el capı́tulo “Los datos en IDAMS” para una descripción más detallada). Si un campo contiene sólo blancos, BUILD recodificará el valor asignándole el primero o segundo códigos de datos faltantes, nueves o ceros en el campo de salida o, si no se especificó recodificación, indicará un error y el campo de salida estará en blanco. La columna 64 de los registros T se puede usar para especificar la recodificación correspondiente a la variable (ver la sección “Diccionario de entrada”). Si un campo contiene los blancos a la derecha, por ej. “04 ” en un campo numérico de tres dı́gitos o los blancos entre digitos, por ej. “0 4”, se reportará como un error y el valor se llenará con dı́gitos 9. Si un campo contiene un valor positivo o negativo con el carácter “+” o “-” mal colocado, por ej. “1-23”, se reportará como un error y el valor se llenará con dı́gitos 9. 104 Construcción de un dataset IDAMS (BUILD) Si un código de datos faltantes para una variable tiene un dı́gito más que el campo de entrada, el campo de salida será un dı́gito mayor que el campo de entrada. Se puede usar cuando es necesario aumentar el ancho del campo de salida sin cambiar el ancho del campo de entrada; por ejemplo, si se han definido los códigos 0-9 y blanco para una variable que ocupa una sola columna, el campo blanco no se podrı́a recodificar con un valor numérico único sin disponer de un código de salida de 2 dı́gitos. Tabla que muestra ejemplos de ediciones hechas con BUILD y el contenido del campo de salida para un campo de entrada numérico de 3 dı́gitos ____________________________________________________________________________________ Valor Nr. MD1 de dec. entrada ______ ___ ____ 032 32 3 2 32 -03 -3 - 3 3.2 32 .32 3.2 .32 .35 -.3 -.3 -03 A32 3-2 11.2. 0 0 0 0 0 0 0 0 1 1 1 2 1 0 1 1 - 9999 8888 Recodif. especif. ________ 1 0 Ninguna - Valor de salida ______ 0032 032 999 999 -03 -03 -03 003 032 003 032 032 004 -00 -03 -03 8888 000 999 999 Ancho del campo de salida ________ 4 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 4 3 3 3 3 Mensaje de error _______________ blancos intercalados en var... blancos intercalados en var... (sólo si PRINT=RECO) (sólo si PRINT=RECO) blancos en var ... caracteres malos en var... caracteres malos en var... Caracterı́sticas estándar de IDAMS Selección de casos y variables. Este programa no tiene provisión para la selección de casos a partir del archivo de datos de entrada. El filtro estándar no está disponible. Por medio de la descripción de variables, se puede seleccionar para los datos de salida cualquier subconjunto de los campos dentro de un caso. Transformación de datos. Las proposiciones de Recode no se pueden usar. Tratamiento de datos faltantes. BUILD no hace distinción entre datos verdaderos y valores de datos faltantes. Sin embargo, los campos en blanco se pueden recodificar a códigos de datos faltantes, ceros o nueves. 11.3. Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). La columna “Brule” del listado del diccionario contiene reglas para la recodificación de campos en blanco, tal como se especifica en la columna 64 del diccionario de entrada. Tener en cuenta que los posibles mensajes de error producidos para las descripciones de las variables, están mezclados con el listado del diccionario y no contienen un número de variable. Si no se imprime el diccionario de entrada, puede ser muy difı́cil la identificación de errores. 11.4 Dataset de salida 105 Diccionario de salida. (Opcional: ver el parámetro PRINT). Los registros descriptores de variables (registros T) se imprimen con o sin registros C, si los hay. Caracterı́sticas del archivo Datos de salida. Longitud del registro de datos de salida. Mensajes de la edición de datos. Para cada caso que contenga errores se imprime el caso de entrada (hasta 100 caracteres por lı́nea) y un registro de los errores en el orden del número de variable. Mensajes de la recodificación de campos en blanco. (Opcional: ver el parámetro PRINT). Para cada caso que contenga campos en blanco recodificados, se imprime un mensaje de la recodificación junto con el caso de entrada. Este listado está integrado con la impresión de los mensajes de errores en los datos, si se presentan errores para el caso. 11.4. Dataset de salida BUILD crea un archivo Datos y el diccionario IDAMS correspondiente, es decir un dataset IDAMS. Téngase en cuenta que los registros T producidos por BUILD siempre definen la ubicación de las variables en términos de la posición inicial y el ancho del campo. El archivo Datos contiene un registro para cada caso o unidad de análisis. La longitud del registro es la suma de los anchos de campo de todas las variables de salida y es determinada por el programa BUILD. Valores de variables numéricas. Los valores de las variables numéricas se editan de acuerdo con una forma estándar que se describe en el párrafo “Procesamiento de las variables numéricas” arriba. Valores de variables alfabéticas. Los valores de las variables alfabéticas no se editan y son los mismos en la entrada y en la salida. Ancho de campo. BUILD normalmente asigna como ancho de una variable el número de caracteres del campo de la variable de entrada correspondiente. Sin embargo, cuando un código de datos faltantes para una variable tiene un dı́gito más que el campo de entrada, el campo de salida será un dı́gito mayor que el campo de entrada. Localización de variable. BUILD asigna los campos de salida según el orden de los números de las variables. De acuerdo con ésto, si las dos primeras variables tienen anchos de salida de 5 y 3, se asignan las posiciones 1-5 para la primera variable y 6-8 para la segunda variable, etc. Número de referencia e identificador de estudio. El número de referencia, si no es blanco, e identificador de estudio son los mismos que sus valores de entrada. Si el campo del número de referencia de un registro T o un registro C es blanco, se llena con el número de la variable. 11.5. Diccionario de entrada Describe las variables que se van a seleccionar para la salida. El formato está descrito en el capı́tulo “Los datos en IDAMS”, la columna 64 del registro T se usa para especificar una regla de recodificación de campos en blanco en una variable de la manera siguiente: blanco 0 1 2 9 - no hay recodificación de campos en blanco, recodifique campos en blanco a ceros, recodifique campos en blanco al primer código de datos faltantes de la variable, recodifique campos en blanco al segundo código de datos faltantes de la variable, recodifique campos en blanco a nueves. Nota. La ventana Diccionario de la Interfaz del Usuario no permite acceso a la columna 64; entonces, use el Editor General de WinIDAMS (Archivo/Nuevo/Archivo usando Editor General) o cualquier otro editor de texto para llenar esta columna. 106 Construcción de un dataset IDAMS (BUILD) 11.6. Datos de entrada Los datos pueden ser cualquier archivo de registros de longitud fija, con uno o más registros por caso, siempre que se tenga exactamente el mismo número de registros para cada caso. El archivo debe estar clasificado por tipo de registro dentro de cada ID de caso. Los valores para cualquier variable deben localizarse en las mismas columnas del mismo registro para cada caso. Si los datos de entrada tienen más de un registro por caso, debe usarse siempre MERCHECK antes que BUILD para garantizar que los datos tengan los mismos registros para cada caso. Nótese que BUILD no acepta notación exponencial en los datos. 11.7. Estructura del setup $RUN BUILD $FILES Especificación de archivos $SETUP 1. Tı́tulo 2. Parámetros $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx DICTyyyy DATAyyyy PRINT 11.8. diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) diccionario de salida datos de salida resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-2, a continuación. 1. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: ESTUDIO DE CONSTRUCCION DE ARCHIVO A35 2. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: MAXERROR=50 INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. 11.9 Ejemplos 107 LRECL=80/n Longitud de cada registro de los datos de entrada. (Se usa para verificar si las posiciones de comienzo de las variables en los registros T son válidas). MAXCASES=n Número máximo de casos a usar del archivo de entrada. Por defecto: se usan todos los casos. VNUM=CONTIGUOUS/NONCONTIGUOUS CONT Verifica que las variables estén numeradas en orden ascendente y consecutivo en el diccionario de entrada. NONC Verifica solamente que las variables estén numeradas en orden ascendente. MAXERR=10/n Número máximo de casos con errores antes de terminar la ejecución de BUILD. OUTFILE=OUT/yyyy Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de salida. Por defecto: DICTOUT, DATAOUT. PRINT=(RECODES, CDICT/DICT, OUTDICT/OUTCDICT/NOOUTDICT) RECO Imprimir los casos de entrada que tengan uno o más campos, todos en blanco, que hayan sido recodificados. CDIC Imprimir el diccionario de entrada para todas las variables con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. OUTD Imprimir el diccionario de salida sin registros C. OUTC Imprimir el diccionario de salida con registros C, si los hay. NOOU No imprimir el diccionario de salida. 11.9. Ejemplos Ejemplo 1. Construir un dataset IDAMS (archivos Diccionario y Datos); los registros de datos de entrada tienen una longitud de registro de 80 con 3 registros por caso; las variables tienen una numeración no contigua en el diccionario de entrada; la variable 2 es el identificador completo (columnas 5-10) mientras que las variables V3 y V4 contienen las dos partes del identificador (columnas 5-8, 9-10 respectivamente); los campos en blanco se reemplazarán por el primer código de datos faltantes de las variables V101, V122, V168, y con ceros para la variable V169; los blancos en la variable V123 (edad) se tratarán como errores. $RUN BUILD $FILES DATAIN = ABCDATA.DAT RECL=80 archivo Datos de entrada DICTOUT = ABC.DIC archivo Diccionario de salida DATAOUT = ABC.DAT archivo Datos de salida $SETUP CONSTRUCCION DE UN DATASET IDAMS VNUM=NONC MAXERR=200 $DICT 3 1 169 3 T 1 CODIGO CIUDAD 1 1 1 3 T 2 IDENTIFICADOR DEL ENCUE 5 10 T 3 NUMERO DEL HOGAR 5 8 T 4 NUMERO DEL ENCUESTADO 9 10 T 101 POS. DEL ENCUE EN FAMIL 13 0 9 1 T 122 SEXO 225 9 1 T 123 EDAD 48 49 T 168 OCUPACION 358 59 99 98 1 T 169 INGRESO 61 65 99998 0 ID ID ID ID QS1 QS2 QS2 QS3 QS3 108 Construcción de un dataset IDAMS (BUILD) Ejemplo 2. Verificar la presencia de caracteres no numéricos en 4 campos numéricos; el archivo Datos de entrada tiene un registro por caso; los registros se identifican con un campo alfabético; las 5 variables no se numeran en forma contigua; como no se necesitan los archivos de salida que BUILD produce normalmente, se definen como archivos temporales (extensión TMP) que IDAMS borra automáticamente al final de la ejecución. $RUN BUILD $FILES DATAIN = NEWDATA.DAT RECL=256 archivo Datos de entrada DICTOUT = DIC.TMP archivo temporal Diccionario de salida DATAOUT = DAT.TMP archivo temporal Datos de salida $SETUP VERIFICACION DE CARACTERES NO NUMERICOS Y CAMPOS EN BLANCO VNUM=NONC LRECL=256 PRINT=NOOU MAXERR=200 $DICT 3 1 35 1 1 T 1 NOMBRE ENCUESTADO 1 20 1 T 21 EDAD 21 2 T 22 INGRESO 29 6 T 25 NR. SITIOS DE TRABAJO 129 1 T 35 TITULO SCI. 201 1 Capı́tulo 12 Verificación de códigos (CHECK) 12.1. Descripción general CHECK verifica si las variables tienen datos válidos y produce un listado con todos los códigos inválidos por identificador de caso y número de variable. Especificación de códigos. Hay dos maneras de especificar los códigos de las variables a verificar. Primera, las proposiciones de control del programa incluyen un conjunto de “especificaciones de códigos” en el cual se definen las variables y sus códigos válidos. Segunda, el usuario puede suministrar una lista de variables de la cual se van a tomar códigos válidos de los registros C en el diccionario. En cualquier ejecución de CHECK, el usuario puede aplicar el primer método para unas variables y el segundo para otras. Las especificaciones de código para variables en el setup tienen prioridad sobre las especificaciones del diccionario. Método usado para verificar valores de los datos. Los valores de los datos para variables numéricas y alfabéticas se verifican carácter por cáracter contra los códigos válidos especificados. Ası́, si se da una especificación de códigos válidos de “V2=02,03”, un valor de “ 2” en los datos será inválido; un blanco a la izquierda en los datos no se considera igual a cero. Si se especifican valores de códigos con menos dı́gitos que el ancho de campo de la variable, se suponen ceros a la izquierda. Ası́, si se da la especificación “V2=2,3”, donde V2 es una variable de 2 dı́gitos, los valores válidos para la comparación de los datos serán 02,03. De manera similar, si se suministran “-3” y “1” como códigos válidos para una variable de 3 dı́gitos, CHECK editará los códigos con “-03” y “001” antes de efectuar cualquier comparación de datos con estos valores. Nota. Si se encuentra un error de sintaxis en una especificación de códigos, se verifica el resto de las especificaciones de códigos pero no se procesan los datos. 12.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. El filtro estándar está disponible para seleccionar un subconjunto de casos del dataset de entrada. El usuario escoge las variables a verificar, especificándolas en una “lista de variables” y/o en las “especificaciones de códigos”. Transformación de datos. Las proposiciones de Recode no se pueden usar. Tratamiento de datos faltantes. CHECK no hace distinción entre datos sustantivos y valores de datos faltantes; todos los datos reciben el mismo tratamiento. 12.3. Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Se imprimen los registros del diccionario para todas las variables, no solamente para aquellas variables que se van a verificar. 110 Verificación de códigos (CHECK) Documentación de códigos inválidos. Para cada caso en el que se encuentre una variable con un código inválido, CHECK imprime el valor o los valores de la(s) variable(s) de identificación, las variables con error y sus valores. 12.4. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. CHECK puede verificar datos válidos en variables numéricas y alfabéticas. Si el diccionario contiene registros C, éstos pueden usarse para definir códigos válidos de las variables. Para los valores de las variables numéricas se supone que se encuentran en la forma que tendrı́an después de haber pasado por el programa BUILD. Esta suposición implica que no hay blancos a la izquierda (fueron reemplazados por ceros), que un signo negativo, si lo hay, aparece en el extremo izquierdo del campo y que no aparecen puntos decimales explı́citos. 12.5. Estructura del setup $RUN CHECK $FILES Especificación de archivos $SETUP 1. 2. 3. 4. Filtro (opcional) Tı́tulo Parámetros Especificaciones de códigos (tantas como sean necesarias) $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx PRINT 12.6. diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-3, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: INCLUDE V10=3 AND V20=1-9 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: DATOS: DATOS DE TESIS, VERSION 1 12.6 Proposiciones de control del programa 111 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: IDVA=(V1-V4) VARS=(V22-V26,V101-V102) INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. START=1/n Número secuencial del primer caso a ser verificado. VARS=(lista de variables) Variables para las cuales se van a tomar codigos válidos de los registros C en el diccionario. MAXERR=100/n Máximo número de casos permitidos con códigos inválidos; si se excede este número, se termina la ejecución del programa. IDVARS=(lista de variables) Hasta 20 variables cuyos valores se imprimen cuando se encuentra un código inválido. Estas consistirán normalmente como mı́nimo, de las variables que identifican un caso pero pueden incluir otras variables que suministren información adicional al usuario. Las variables pueden ser alfabéticas o numéricas. Sin valor por defecto. PRINT=CDICT/DICT CDIC Imprimir el diccionario de entrada para todas las variables con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. 4. Especificaciones de códigos (opcional). Estas especificaciones definen las variables a verificar y sus valores de código válidos o inválidos. Ejemplos: V3=1,3,5-9 (Los datos para la variable 3 pueden tener los códigos 1,3,5-9. Cualquier otro código será inválido y será documentado). V7,V9,V12-V14= 2,50-75,100 (Los datos para las variables 7,9 y 12 a 14 pueden tener sólo los valores 2, 50-75, 100). V50 <> 75 (Los datos para la variable 50 pueden tener cualquier valor excepto 75). Formato general lista de variables = lista de valores de código o lista de variables <> lista de valores de código Reglas de codificación Cada especificación de códigos debe comenzar en una lı́nea nueva. Para continuar en otra lı́nea, interrumpa después de una coma y coloque un guión. Se pueden usar todas las lı́neas de continuación que sean necesarias. Pueden aparecer blancos en cualquier lugar de las especificaciones. 112 Verificación de códigos (CHECK) Lista de variables Cada número de variable debe estar precedido por una letra V. Las variables se pueden expresar una por una (separadas con una coma), por rangos (separadas con un guión) o una combinación de ambos (V1,V2,V10-V20). Las variables se pueden definir en cualquier orden. Todas las variables agrupadas en una expresión deben tener el mismo ancho de campo (por ej. para “V2,V3=10-20” V2 y V3 deben tener ambas el mismo ancho de campo definido en el diccionario). Las variables a verificar pueden ser numéricas o alfabéticas. Válido (=) o inválido (<>) Un signo = indica que los valores de código que siguen son los códigos válidos para las variables especificadas. Todos los demás códigos se documentarán como errores. <> (no igual) indica que los códigos que siguen son inválidos. Todos los casos que tengan estos códigos para las variables especificadas se documentarán como errores. Lista de valores de código Los códigos se pueden expresar uno por uno (separados con una coma), por rangos (separados con un guión) o una combinación de ambos. Para variables numéricas, no es necesario suministrar ceros a la izquierda (por ej. V1=1-10), pero recuerde que si se verifican varias variables para códigos comunes, todas deben tener definido en el diccionario el mismo ancho de campo. Para datos con cifras decimales, no coloque el punto decimal en el valor, pero suministre el valor de manera que refleje exactamente las cifras decimales implicadas, por ej. el número 2 con un decimal debe ser dado como “20”. Para valores alfabéticos, no es necesario colocar blancos a la derecha, éstos son añadidos por el programa de manera que completen la longitud del ancho de campo de la variable. Para definir un blanco o para especificar un valor con blancos intercalados, encierre el valor entre comillas sencillas. (por ej. V10=’NEW YORK’,’WASHINGTON’,’ ’). Los valores de código se pueden definir en cualquier orden. Notas. 1) Si se dan dos especificaciones diferentes para la misma variable, sólo se utilizará la última de ellas. 2) Las especificaciones de códigos para una variable reemplazan el uso de registros de nombres de códigos del diccionario para las variables especificadas con el parámetro VARS. 12.7. Restricciones 1. El máximo número de variables de identificación es 20. 2. El máximo número de códigos distintos que se pueden suministrar en las especificaciones de código es 4000. Esta restricción se puede obviar con rangos de códigos ya que un rango de códigos se cuenta sólo como 2 códigos. 12.8. Ejemplos Ejemplo 1. Busqueda de códigos ilegales en variables cualitativas y valores fuera de rango en variables cuantitativas; los únicos códigos válidos para las variables V10, V12 y V21 a V25 son 1 a 5 y 9; el código 9998 es ilegal para la variable V35; los códigos 0 y 8 son ilegales para las variables V41, V44 y V46; las variables V71 a V77 deben tener valores dentro del rango de 0 a 100 o 999; los casos se identifican con las variables V1, V2 y V4; no se usan los valores de códigos del diccionario. 12.8 Ejemplos 113 $RUN CHECK $FILES PRINT = CHECK1.LST DICTIN = STUDY1.DIC archivo Diccionario de entrada DATAIN = STUDY1.DAT archivo Datos de entrada $SETUP BUSQUEDA DE CODIGOS ILEGALES Y VALORES FUERA DE RANGO IDVARS=(V1,V2,V4) V10,V12,V21-V25=1-5,9 V35<>9998 V41,V44,V46<>0,8 V71-V77=0-100,999 Ejemplo 2. Verificación de la validez del código unicamente para un subconjunto de casos (cuando la variable V21 es igual a 2 o igual a 3 y la variable V25 es igual a 1); los códigos válidos para algunas variables se toman de los registros C del diccionario; adicionalmente, se da una especificación válida para la variable V48; los casos se identifican con la variable V1. $RUN CHECK $FILES DICTIN = STUDY2.DIC archivo Diccionario de entrada DATAIN = STUDY2.DAT archivo Datos de entrada PRINT = CHECK.PRT $SETUP INCLUDE V21=2,3 AND V25=1 BUSQUEDA DE CODIGOS ILEGALES IDVARS=V1 VARS=(V18-V28,V36-V41) V48=15-45,99 Capı́tulo 13 Verificación de consistencia (CONCHECK) 13.1. Descripción general El uso de CONCHECK junto con las proposiciones de Recode de IDAMS ofrece la capacidad de verificación de consistencia la cual permite probar relaciones ilegales entre valores de diferentes variables. Las proposiciones condicionales incluidas en el setup de CONCHECK se usan para denominar cada una de las verificaciones e indicar qué variables se deben listar ante un error. La verificación de consistencia se define por medio de Recode al probar una relación lógica y después asignar el valor 1 a una variable R si la condición no se satisface, por ej. si V3 no puede tomar lógicamente el valor de 9 cuando V2 toma el valor de 3, se puede usar la siguiente proposición de Recode: IF V2 EQ 3 AND V3 EQ 9 THEN R100=1 ELSE R100=0 Cuando se detecta una inconsistencia en un caso, se imprimen los identificadores del caso (ID). Además se imprimen también los valores de un conjunto de variables definidas con el parámetro VARS. Este conjunto de variables se usa para tener una visión general del caso, de manera que se pueda detectar más fácilmente la razón de la inconsistencia y asegurar que la corrección de una inconsistencia no va a producir otra. Para cada condición de consistencia que falle se puede imprimir un conjunto separado de variables con el número y nombre de la condición; este conjunto consiste normalmente de las variables que se verifican. 13.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. El filtro estándar está disponible para escoger un subconjunto de casos a verificar. Las variables a imprimir cuando se presenten inconsistencias se especifican con el parámetro VARS (para el caso) o CVARS (para una condición individual). Transformación de datos. Las proposiciones de Recode se usan para indicar las validaciones de consistencia requeridas. Tratamiento de datos faltantes. CONCHECK no hace distinción entre datos sustantivos y valores de datos faltantes; todos los datos reciben el mismo tratamiento. 13.3. Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variables y registros C, si los hay, sólo para las variables usadas en la ejecución. 116 Verificación de consistencia (CONCHECK) Inconsistencias. Para cada caso que presente una inconsistencia se imprime una lı́nea de identificación con el número de secuencia del caso y opcionalmente los valores de los identificadores de caso. A continuación se imprimen los valores de las variables especificadas en el parámetro VARS. Para cada inconsistencia individual detectada en un caso, se imprimen el número y nombre de la condición correspondiente y los valores de las variables especificadas en la proposición de condición. Estadı́sticas de error. Al final de la ejecución se imprime una tabla de resumen con el número de casos procesados, el número de casos que tienen por lo menos una inconsistencia y, para cada condición de consistencia, su número y nombre y el número de casos que no pasaron la prueba. 13.4. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. Se pueden usar variables numéricas o alfabéticas. 13.5. Estructura del setup $RUN CONCHECK $FILES Especificación de archivos $RECODE (opcional) Proposiciones de Recode que indican las inconsistencias $SETUP 1. 2. 3. 4. Filtro (opcional) Tı́tulo Parámetros Proposiciones de condición $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx PRINT 13.6. diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al capı́tulo ”El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-4, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: INCLUDE V1=1 13.6 Proposiciones de control del programa 117 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: PRUEBA DE INCONSISTENCIAS PARA LA REGION NORTE 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: IDVARS=(V1,V3-V4) MAXERR=50 INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos. Ver el capı́tulo ”El archivo Setup de IDAMS”. MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. MAXERR=999/n Número máximo de inconsistencias a imprimir antes de detener la ejecución de CONCHECK. IDVARS=(lista de variables) Hasta 5 variables cuyos valores se imprimirán para identificar casos con inconsistencias. Por defecto: se imprime el número secuencial de caso. VARS=(lista de variables) Variables a imprimir para cualquier caso que tenga por lo menos un error. FILLCHAR=’cadena de caracteres’ Hasta 8 caracteres usados para separar variables cuando se imprimen las inconsistencias. Por defecto: 2 espacios. PRINT=(CDICT/DICT, VNAMES) CDIC Imprimir el diccionario de entrada para las variables accedidas con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. VNAM Cuando se imprimen variables para casos inconsistentes, imprimir los primeros 6 caracteres del nombre en vez de los números de las variables. 4. Proposiciones de condición (se debe dar por lo menos una). Se suministra una proposición de condición para cada consistencia a verificar con una referencia a las correspondientes proposiciones de Recode, un nombre para la prueba y las variables cuyos valores se deben imprimir cuando falle la prueba. Las reglas de codificación son las mismas de los parámetros. Cada proposición condicional debe comenzar en una nueva lı́nea. Ejemplo: TEST=R3 CVARS=(V34,V36,V52) CNAME=’EDAD, SEXO, ESTADO DE EMBARAZO’ TEST=número de variable Una variable para la cual un valor no igual a cero, indica que una verificación de consistencia ha fallado. Sin valor por defecto. 118 Verificación de consistencia (CONCHECK) CVARS=(lista de variables) Lista de variables cuyos valores se deben imprimir cuando se presente esta inconsistencia. Por defecto: sólo se imprimen las variables especificadas en IDVARS y VARS. CNUM=n Número de condición. Por defecto: número secuencial de la condición. CNAME=’cadena de caracteres’ Nombre para esta condición, hasta 40 caracteres. Por defecto: no asigna nombre. 13.7. Restricciones 1. Sólo se imprimen los primeros 4 caracteres de las variables alfabéticas. 2. Los nombres de condición no pueden tener más de 40 caracteres de longitud. 3. El número máximo de variables de identificación es 5. 4. El número máximo de variables a imprimir para cada caso con errores es 20 (lista de variables en VARS). 5. El número máximo de variables a imprimir para cada condición es 20 (lista de variables en CVARS). 13.8. Ejemplos Ejemplo 1. Verificar la relación entre V6 y V7 y entre V20 y V21; para cada caso con errores se imprimirán las variables de identificación V2 y V3 junto con los valores de las variables claves V8-V10; se imprimirán los nombres de las variables. $RUN CONCHECK $FILES PRINT = CONCH1.LST DICTIN = MY.DIC archivo Diccionario de entrada DATAIN = MY.DAT archivo Datos de entrada $RECODE R1=0 R2=0 IF V5 INLIST(1-5,8) AND V7 EQ 2 THEN R1=1 IF V20 LE 3 AND V21 EQ 5 OR V20 EQ 8 AND V21 EQ 7 OR V20 EQ V21 THEN R2=1 $SETUP PRUEBA PARA 2 INCONSISTENCIAS PRINT=VNAMES IDVARS=(V2,V3) VARS=(V8-V10) TEST=R1 CNAME=’primera inconsistencia’ CVARS=(V5,V7) TEST=R2 CNAME=’segunda inconsistencia’ CVARS=(V20,V21) Ejemplo 2. Verificar 5 condiciones en la parte 2 de un cuestionario; las pruebas se van a numerar a partir de 201; se van a listar todas las variables de la parte 2 para cada cuestionario con errores, junto con las variables claves de la parte uno (V5-V10); además, se van a imprimir nuevamente ciertas variables usadas en las pruebas para cada prueba que falle. Tenga en cuenta el uso de la función SELECT de Recode para iniciar con ceros las correspondientes variables de resultados. 13.8 Ejemplos $RUN CONCHECK $FILES DICTIN = MY.DIC archivo Diccionario de entrada DATAIN = MY.DAT archivo Datos de entrada $SETUP PARTE 2 DE LA VERIFICACION DE CONSISTENCIA MAXERR=400 IDVARS=(V1,V3) VARS=(V5-V10,V200-V231) TEST=R1 CNUM=201 CVARS=(V203-V205) TEST=R2 CNUM=202 CVARS=(V203,V210-V212) TEST=R3 CNUM=203 CVARS=(V214,V215) TEST=R4 CNUM=204 CVARS=(V222-V226) TEST=R5 CNUM=205 CVARS=(V229,V230) $RECODE R900=1 A SELECT (FROM=(R1-R5), BY R900) = 0 IF R900 LT 5 THEN R900=R900+1 AND GO TO A IF V203 IN(1-5,17,20-25) AND V204 EQ 3 OR V205 EQ ’M’ THEN R1=1 IF V203 GT 6 AND MDATA(V210,V211,V212) THEN R2=1 IF 2*TRUNC(V214/2) EQ V214 OR V215 EQ 0 THEN R3=1 IF COUNT(1,V222-V226) LT 2 THEN R4=1 IF MDATA(V229) AND NOT MDATA(V230) THEN R5=1 119 Capı́tulo 14 Verificación de intecalación de registros (MERCHECK) 14.1. Descripción general El programa MERCHECK detecta y corrige los errores de intercalación de registros (registros faltantes, duplicación de registros y registros inválidos) en un archivo con registros múltiples por caso. La salida es un archivo con igual número de registros por caso, rellena los registros faltantes y elimina los registros duplicados y los registros inválidos. Aunque la concepción original de este programa se hizo para imagen de tarjeta, se pueden tener registros hasta de 128 caracteres de longitud. Como los demás programas IDAMS suponen que cada caso en un archivo de datos tiene exactamente el mismo número de registros, el uso de MERCHECK es un paso esencial de verificación inicial para todos los archivos que tengan más de un registro por caso. Operación del programa. El usuario suministra un conjunto de Descripciones de registros que definen los tipos de registro permitidos. En el momento de procesar los datos, el programa carga en un área de trabajo todos los registros de datos consecutivos de entrada que tengan un mismo identificador de caso. Los registros se comparan, uno a uno, con los tipos de registro definidos y se construye un caso de salida. Los registros se rellenan, se eliminan, se reordenan, etc. según las necesidades. El caso se lleva al archivo de salida y el programa regresa para leer el conjunto de registros de entrada para el siguiente caso. Los resultados muestran las correcciones hechas por el programa a los datos de entrada. Identificación de casos y de registros. MERCHECK requiere que el identificador de caso esté en la misma posición para todos los registros. Los campos del identificador de casos pueden estar ubicados entre columnas no contiguas y puede estar compuesto por cualquier tipo de caracteres. Los tipos de registro se identifican por un solo campo identificador de registro (de 1-5 columnas) que puede tener cualquier tipo de carácter excepto blancos. A continuación se muestra el bosquejo de un archivo de datos con dos tipos de registros. Los puntos hacen referencia a campos de datos o campos en blanco. ...SE23..........01...............10...... ...SE23..........01...............12...... ...SE23..........02...............10...... ...SE23..........02...............12...... ...SE24..........01...............10...... ...SE24..........01...............12...... primer campo identificador de caso segundo campo identificador de caso campo identificador de registro En este ejemplo hay dos tipos de registro para cada caso, que se identifican con los números 10 o 12 en las columnas 35 y 36. El identificador de caso (ID de caso) está compuesto por dos campos no consecutivos en las columnas 4-7 y 18-19. Ası́ “SE2301”, es un identificador de caso, “SE2302” es otro y “SE2401” es otro. 122 Verificación de intecalación de registros (MERCHECK) Eliminación de registros inválidos. Se imprime de manera opcional pero no se transmite al archivo de salida, un registro de datos de entrada conocido como registro “extra”, el cual contiene un identificador de registro no definido en las Descripciones de registros. Adicionalmente, hay dos opciones para eliminar otros tipos de registros inválidos. Los registros que no tengan una constante especı́fica, se rechazan. (Ver los parámetros CONSTANT, CLOCATION, y MAXNOCONSTANT). El usuario puede especificar el valor del identificador del primer caso válido. Todos los casos con un identificador cuyo valor sea menor que el valor especificado, se rechazan. (Ver el parámetro BEGINID). Opciones para el manejo de casos con registros faltantes. El usuario debe escoger, con el parámetro DELETE, una de las tres formas posibles para el manejo de los casos incompletos. 1. DELETE=ANYMISSING. No se produce caso de salida cuando faltan uno o más tipos de registro. 2. DELETE=ALLMISSING. Un caso no sale si no se encuentra por lo menos un identificador válido de registro. 3. DELETE=NEVER. El programa nunca excluye ningún caso que tenga uno o más registros faltantes. En esta alternativa, el programa construye un registro para cada tipo de registro faltante y lo llena con blancos o con valores suministrados por el usuario. Ver el parámetro PADCH y el parámetro PAD de las Descripciones de registros. La complementación tiene lugar en columnas diferentes de las de identificación de campos de caso y de campos de registro. El programa siempre inserta los identificadores apropiados para casos y registros. Opciones para el manejo de casos con registros duplicados. Un registro duplicado es aquel que tiene los mismos identificadores de caso y de registro que otro, sin interesar el contenido de ambos registros. El usuario especifica cual duplicado debe mantenerse si hay más de un registro de entrada con los mismos identificadores de caso y de registro. Por ejemplo, la opción DUPKEEP=1 hace que el programa guarde el primer registro y descarte los otros. El caso no se transfiere al archivo de salida si se encuentra un número de duplicados menor que n (donde DUPKEPP=n), es decir, que para borrar casos con registros duplicados, se especifica un valor grande para n. Precaución: puede suceder que registros con identificadores duplicados no contengan los mismos datos. Corresponde al usuario decidir la conveniencia de retener o no un determinado registro. Opciones para el manejo de registros eliminados. Los registros de datos de entrada que se han eliminado, es decir, aquellos que no van al archivo de salida, se pueden colocar en otro archivo (ver el parámetro WRITE). Selección de tipos de registro. MERCHECK le permite al usuario subdividir tipos de registros, seleccionados a partir de un archivo de entrada más amplio. Incluya simplemente sólo los identificadores requeridos en las Descripciones de registros y escoja una opción apropiada para la impresión de errores (EXTRAS=n o PRINT=ERRORS, por ejemplo) y un valor razonable para MAXERR. Es esencial minimizar la impresión de casos con errores ya que casi siempre cada caso con identificadores faltantes en el archivo de entrada, será impreso como error debido a registros con identificación inválida (es decir, aquellos que no se han especificado en las Descripciones de registros). Capacidad de comenzar nuevamente. El parámetro BEGINID se usa para volver a comenzar el programa MERCHECK cuando la ejecución anterior terminó antes de haber procesado todos los datos de entrada. El usuario debe determinar el identificador del último caso procesado y asignar al parámetro BEGINID ese valor +1. (Si el programa termina porque se excedió el valor del parámetro MAXERR, en el listado de salida aparecerá el último registro leido y el valor asignado al parámetro BEGINID deberá ser el identificador de caso de ese registro). Nota. MERCHECK tiene por objeto la verificación de archivos de datos con múltiples registros por caso y debe haber un identificador de registro en cada registro. Teóricamente, MERCHECK se podrı́a usar para eliminar registros duplicados y registros sin alguna constante especı́fica para archivos con casos de un solo registro por caso. Sin embargo, ésto sólo puede hacerse si los registros contienen alguna constante cuyo valor se pueda asimilar a un identificador de registro. Este tipo de operación se realiza mejor con el programa SUBSET al usar un filtro que excluya los registros que carezcan de una constante y con la opción DUPLICATE=DELETE para eliminar los duplicados. (Ver la documentación de SUBSET). 14.2 Caracterı́sticas estándar de IDAMS 14.2. 123 Caracterı́sticas estándar de IDAMS Selección de casos y variables. Con excepción de las definiciones anteriores, esta opción no se encuentra en este programa. Transformación de datos y datos faltantes. Estas opciones no se aplican en MERCHECK. 14.3. Resultados Casos con errores. El listado completo de la documentación de cada caso con errores tiene tres partes: un resumen de los errores, registros no transferidos al archivo de salida (registros malos) y los casos transferidos al archivo de salida (casos buenos) tal como aparecen en este archivo de salida. Ver más adelante para mayor información sobre estos componentes. Para datos con un gran número de tipos de registros y muchos casos con errores, el listado de los casos errados puede ser costoso y para algunos jobs innecesario. La cantidad de listado requerido depende del mayor o menor conocimiento que el usuario tenga acerca de los datos y de su habilidad para corregir o re-corregir los errores. Por ejemplo, si un usuario espera que se presenten muchos rellenos (padding), pero ninguna o casi ninguna duplicación de registros o registros inválidos, es suficiente tener en el papel sólo el resumen de los errores y especificar que se almacenen los casos con errores (si los hay) (ver la opción WRITE=BADRECS) y listarlos posteriormente. Se pueden aplicar varios controles a la cantidad de listado obtenido con los parámetros PRINT, EXTRAS, DUPS y PADS. Casos con errores: resumen de errores. El resumen de errores consiste en una identificación del caso con errores (conteo de caso o ID de caso) y uno de tres tipos de mensaje referentes a los errores que se presentaron. El conteo secuencial de los casos no considera los registros o casos eliminados porque ellos aparecen antes del comienzo del identificador o les falta la constante requerida. El identificador del caso se toma de los identificadores del campo tal como se haya especificado en el parámetro IDLOC. Se reportan tres tipos de errores, a saber: 1. tipo de registro inválido, 2. casos con registros faltantes, 3. casos con registros duplicados. Casos con errores: registros malos. Se presentan los registros inválidos y los registros duplicados, ası́ como también todos los registros de casos que se han rechazado por carencia de registros. Se imprimen en el orden en que se encuentran en el archivo de entrada. Casos con errores: registros buenos. Cuando se guarda un caso, después de haber detectado un error, los registros que pasan al archivo de salida, incluidos aquellos que se han rellenado, se imprimen. Registros anteriores a BEGINID. Su impresión es opcional. Ver parámetro PRINT=LOWID. Registros sin clasificar. Normalmente se imprimen, sin embargo el listado puede suprimirse. Ver parámetro PRINT=NOSORT. Registros sin constante especificada. Se imprime cualquier registro que carezca de la constante especificada por el usuario en las columnas adecuadas. Este listado se puede suprimir. Ver parámetro PRINT=NOCONSTANT. Estadı́sticas de ejecución. Al final de resultados, se imprimen los totales de registros faltantes, registros inválidos y registros duplicados asi como también, el número total de casos leı́dos, casos escritos, casos eliminados y casos con errores. 14.4. Datos de salida Los datos de salida van a un archivo con longitud de registro igual a la de los registros de entrada y con el mismo número de registros por caso. Cada caso tiene cada uno de los tipos de registro especificados en las descripciones de registros. 124 Verificación de intecalación de registros (MERCHECK) 14.5. Datos de entrada Los datos de entrada consisten en un archivo con registros de longitud fija, clasificado normalmente por el ID del caso y dentro de éste, por el identificador de registro. La longitud del registro no puede exceder de 128 caracteres. 14.6. Estructura del setup $RUN MERCHECK $FILES Especificación de archivos $SETUP 1. Tı́tulo 2. Parámetros 3. Descripciones de registros (tantas como se requieran) $DATA (condicional) Datos Archivos: FT02 DATAxxxx DATAyyyy PRINT 14.7. registros rechazados (registros de casos malos) cuando se ha especificado WRITE=BADRECS datos de entrada (omitir si se usa $DATA) datos de salida (casos buenos) resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-3, a continuación. 1. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: MERCHECK DE MIS DATOS ESTUDIO 308 SAM 7/18/48 2. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: MAXE=25 RECORDS=8 IDLOC=(1,5) INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para el archivo Datos de entrada. Por defecto: DATAIN. MAXCASES=n Número máximo de casos a usar del archivo de entrada. Por defecto: se usan todos los casos. MAXERR=10/n Número máximo de casos con errores. Cuando hay casos que tengan (n + 1) errores, termina la ejecución del programa. Los casos que están antes del parámetro BEGINID, los casos sin clasificar y los registros sin constante, no se cuentan como casos con errores. Se consideran casos con error los que contienen registros inválidos, duplicados o faltantes. 14.7 Proposiciones de control del programa 125 OUTFILE=OUT/yyyy Un sufijo de ddname de 1-4 caracteres para el archivo Datos de salida. Por defecto: DATAOUT. RECORDS=2/n Número de registros por caso (tal como se hayan definido en las Descripciones de registros). IDLOC=(i1,f1, i2,f2, ...) Columnas inicial y final para identificación de 1-5 campos de identificación de caso. Debe suministrarse por lo menos una columna. Si hay más de un campo de identificación de caso, entonces deben especificarse en el orden en el cual los datos están clasificados. Sin valor por defecto. BEGINID=’ID del caso’ El caso con el identificador más bajo a partir del cual el programa comienza el proceso: de 1-40 caracteres encerrados entre comillas sencillas si contiene caracteres no alfanuméricos. Si se usan casos con identificadores de campos múltiples, el valor debe ser el resultado de la concatenación de los identificadores individuales de cada campo clasificados. Por defecto: blancos. NOSORT=0/n Número máximo de casos sin clasificar tolerado por el programa. Cuando se presenta un número de casos sin clasificar igual o mayor que (n+1), la ejecución del programa termina. DELETE=NEVER/ANYMISSING/ALLMISSING Especifica bajo que condiciones referentes a registros faltantes, se borra o no se borra un caso. NEVE Nunca rechaza un caso por registros faltantes. Si falta uno o todos los registros, el programa rellena (con blancos o con valores especificados por el usuario), todos los registros que falten y rechaza cualquier registro con identificador inválido, antes de la salida del caso. ANYM No sale ningún caso para el cual falten uno o más registros, es decir que no se graban casos incompletos. ALLM No sale ningún caso para el cual no haya registros válidos, es decir, cuando todos los registros para un caso tienen valores inválidos de los ID de registro. PADCH=x Caracter para usar cuando se rellenan los registros. Los caracteres no alfanuméricos deben estar entre comillas sencillas. Ver también Descripciones de registros para mayores detalles sobre la acción de relleno (padding) de registros. Por defecto: blancos. DUPKEEP=1/n Especifica (para registros duplicados) que se debe guardar el n-ésimo duplicado. Si se encuentran menos duplicados que n, el caso en el cual éstos se presentan se elimina (aún si se especifica DELETE=NEVER). WRITE=BADRECS Crear un archivo de los registros rechazados (casos malos). CONSTANT=valor Valor de una constante. Debe ir entre comillas sencillas si contiene caracteres no alfanuméricos. Cualquier registro de datos de entrada sin la constante, se rechaza. La localización de la constante debe ser la misma en todos los registros de entrada, sin importar el tipo de registro. 126 Verificación de intecalación de registros (MERCHECK) CLOCATION=(i, f) (Se suministra sólo cuando se usa CONSTANT). Localización del campo de la constante. i Columna inicial para el campo de la constante en cada registro. f Columna final para el campo de la constante en cada registro. MAXNOCONSTANT=0/n (Se suministra sólo cuando se usa CONSTANT). Número máximo de registros sin la constante que son tolerados por el programa. Cuando se encuentran n + 1 registros sin constante, MERCHECK termina la ejecución. PRINT=(CONSTANT/NOCONSTANT, SORT/NOSORT, ERRORS/NOERRORS, LOWID, BADRECS, GOODRECS) CONS Imprimir registros sin constante especificada. NOCO No imprimir registros sin constante especificada. SORT Imprimir mensaje de tres lı́neas para los casos por fuera del orden de clasificación. NOSO No imprimir casos por fuera del orden de clasificación. LOWI Imprimir todos los registros que tengan un identificador de caso menor de BEGINID. Las siguientes opciones de impresión, se refieren a los listados de casos con errores (es decir, registros faltantes, duplicaciones e inválidos). ERRO Imprimir resumen de errores para cada caso con un error. NOER No imprimir resumen de errores para casos con errores. BADR Imprimir registros rechazados (malos) para casos con errores. GOOD Imprimir registros aceptados (buenos) para casos con errores. EXTRAS=0/n DUPS=0/n PADS=0/n Si un caso tiene un número de registros inválidos (extra/duplicados/con relleno) inferior a n y no otros errores, no se imprime. Ası́, un caso que tenga solamente 2 registros inválidos y no le falten registros o no tenga registros duplicados, no se imprime si se asigna EXTRAS=3; pero, por otra parte, se imprime de acuerdo con la especificación en PRINT si le falta 1 registro. Por defecto: se imprimen todos los casos con errores, de acuerdo con las especificaciones de PRINT. 3. Descripciones de registros (obligatoria: una por cada tipo de registro que se seleccione como salida). Las reglas de codificación son las mismas de los parámetros. Cada descripción de registro debe comenzar en una nueva lı́nea. Ejemplo: RECID=21 RIDLOC=1 RECID=3 RIDLOC=2 PAD=’43599999998889999999881119’ RECID=xxxxx Un código de tipo de registro, de 1-5 caracteres no blancos. Debe encerrarse entre comillas sencillas si contiene caracteres en minúsculas. Sin valor por defecto. RIDLOC=i Columna inicial para el identificador de campo. Sin valor por defecto. PAD=’xxx....’ Valores a usar cuando se rellena un registro de este tipo. La cadena de valores debe estar entre comillas sencillas cuando contenga caracteres no alfanuméricos. El primer carácter se colocará en la columna 1 del registro rellenado de salida, etc. Para pasar a la lı́nea siguiente, coloque un guión. Si la longitud de la cadena es menor que la longitud de registro, entonces el resto se rellena hacia la derecha con el PADCH especificado en la proposición del parámetro. Por defecto: se usa PADCH para toda la cadena. Nota: los valores correctos de los identificadores de caso y registro, se insertan automáticamente en las posiciones correctas, en el registro que se ha rellenado. 14.8 Restricciones 14.8. 127 Restricciones 1. La longitud máxima del registro de entrada es 128. 2. El número máximo de registros de salida por caso es 50. 3. El programa reserva un espacio de trabajo para un máximo de 60 registros con valor igual del identificador de caso. En esta cuenta se incluyen los registros válidos, duplicados, inválidos y registros rellenados por el programa. MERCHECK termina la ejecución cuando en el area de trabajo hay más de 60 registros con un identificador de caso igual. 4. La longitud máxima combinada de los identificadores de campo dentro de un caso en particular, es de 40 caracteres. 5. La longitud máxima de un campo identificador de registro es de 5 caracteres consecutivos no blancos. 6. La longitud máxima de una constante para verificación es de 12 caracteres. 7. El número máximo de campos identificadores de caso es 5. 14.9. Ejemplos Ejemplo 1. Verificar la intercalación de tres registros por caso, los cuales tienen tipos de registro 1, 2 y 3 respectivamente; los registros faltantes se rellenan: registros 1 y 2 se rellenan con blancos y el registro 3 se rellena con una copia de los valores dados en el parámetro PAD; los casos con registros no válidos (cuando todos los registros de un caso tienen tipos de registro inválidos), se escriben en el archivo BAD; los registros que presenten un máximo de cuatro registros duplicados, también se escriben en el archivo BAD (si un caso tiene 5 o más duplicados de un tipo de registro en particular, entonces se guarda como un caso bueno usando el quinto duplicado y eliminando los otros). $RUN MERCHECK $FILES PRINT = MERCH1.LST FT02 = \DEMO\BAD.DAT archivo de registros malos de salida DATAIN = \DEMO\DATA1.DAT archivo Datos de entrada DATAOUT = \DEMO\DATA2.DAT archivo Datos de salida (sólo con casos buenos) $SETUP VERIFICACION DE INTERCALACION DE DATOS IDLO=(1,3,5,6,10,10) RECO=3 DELE=ALLM DUPK=5 WRITE=BADRECS MAXE=200 RECID=1 RIDLOC=12 RECID=2 RIDLOC=12 RECID=3 RIDLOC=12 PAD=’99999999999399999999999999999999999999999999999999999999999999999999999999999999’ Ejemplo 2. Verificar los datos, borrando casos con registros faltantes y eliminando casos que no pertenecen al estudio; el archivo Datos contiene dos registros por caso; se guardan los casos con registros duplicados (se desechan todos, excepto el primero de una serie de registros duplicados); hay un tipo de registro TT en las columnas 4 y 5 de un registro y un tipo AB en las columnas 7 y 8 del otro registro; el identificador del estudio, HST, debe aparecer en las columnas 124-126 de cada registro. 128 Verificación de intecalación de registros (MERCHECK) $RUN MERCHECK $FILES FT02 = BAD.DAT archivo de registros malos de salida DATAIN = DATA.DAT RECL=126 archivo Datos de entrada DATAOUT = GOOD.DAT archivo Datos de salida (sólo con casos buenos) $SETUP VERIFICACION DE INTERCALACION DE DATOS IDLO=(1,3) RECO=2 WRITE=BADRECS MAXE=20 CONS=HST CLOC=(124,126) RECID=TT RIDLOC=4 RECID=AB RIDLOC=7 Capı́tulo 15 Corrección de datos (CORRECT) 15.1. Descripción general CORRECT ofrece la facilidad de corregir la información contenida en un dataset IDAMS. Se pueden corregir valores de las variables individuales en casos especificados o eliminar casos en forma total. CORRECT sirve para corregir errores en variables individuales de casos especı́ficos que hayan sido detectados por BUILD, CHECK o CONCHECK. La preparación de instrucciones de actualización es fácil. Las verificaciones se llevan a cabo de manera que exista compatibilidad entre los datos y la corrección y se imprime una buena documentación en la cual se describen todas las correcciones hechas. Operación del programa. CORRECT lee primero el diccionario y almacena la información acerca de todas las variables del dataset. A continuación se procesan las instrucciones de corrección. Después de leer una instrucción, CORRECT lee el archivo Datos y copia los casos hasta identificar el caso especificado en la instrucción. CORRECT ejecuta la instrucción, bién sea, imprimiendo el caso o revisando los valores de las variables seleccionadas y llevando el caso al archivo de salida o eliminándolo del mismo, según lo apropiado. Cuando se han agotado todas las instrucciones, los casos restantes, si los hay, se copian al archivo de salida y la ejecución termina en forma normal. Si hay errores en el orden de clasificación de las instrucciones de corrección o en el orden de clasificación de los casos, y también, si hay errores de sintaxis en las instrucciones de corrección, CORRECT informa de la situación en el listado de salida y pasa a la instrucción siguiente. Corrección de variables. El usuario especifica la identificación del caso seguida de los números de variables que se van a corregir, junto con sus nuevos valores. Se pueden corregir las variables numéricas (enteras o decimales) y alfabéticas. Corrección de variables de identificación de casos. Si se va a corregir un campo de identificación, se afectará, normalmente, el orden de clasificación y por lo tanto debe usarse el parámetro CKSORT=NO. Si la variable de identificación contiene caracteres no-numéricos erróneos, entonces se encierra su valor entre comillas sencillas en la instrucción de corrección. Eliminación de casos. El usuario puede eliminar un caso del archivo Datos mediante la especificación de la información de identificación del caso y la palabra “DELETE”. Listado de casos. El usuario puede escoger un caso en particular para imprimirlo con la especificación de la identificación del caso y la palabra “LIST”. 15.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. Se puede escoger un subconjunto de casos para procesar y llevar a la salida mediante la inclusión de un filtro estándar. La selección de variables es inapropiada. Transformación de datos. Las proposiciones de Recode no se pueden usar. 130 Corrección de datos (CORRECT) Tratamiento de datos faltantes. CORRECT no hace distinción entre datos verdaderos y valores de datos faltantes; el concepto no aplica a la operación del programa. 15.3. Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Se imprimen los registros del diccionario para todas las variables, no solamente aquellos que corresponden a las que se van a corregir. Listado de las instrucciones de corrección. Siempre se imprimen las instrucciones de corrección. El programa también imprime, en forma opcional, con cada corrección: (1) registros de datos de entrada, (2) registros eliminados, o (3) registros corregidos (ver el parámetro PRINT). 15.4. Dataset de salida Siempre sale una copia del diccionario. Si no se necesita, la definición de archivo DICTOUT puede omitirse. Los datos se copian siempre al archivo de salida, aún si no hay correcciones o eliminaciones. 15.5. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario de IDAMS. Normalmente, CORRECT espera que los casos vengan clasificados en orden ascendente por las variables de identificación de caso. Sin embargo, el usuario puede indicar (con el parámetro CKSORT) que los casos no se encuentran en orden ascendente. Esta opción debe usarse con precaución: el orden de las instrucciones de corrección debe ser exactamente el mismo orden de los datos en el archivo. 15.6. Estructura del setup $RUN CORRECT $FILES Especificación de archivos $SETUP 1. 2. 3. 4. Filtro (opcional) Tı́tulo Parámetros Instrucciones de corrección (tantas como sean necesarias) $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx DICTyyyy DATAyyyy PRINT diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) diccionario de salida datos de salida resultados (por defecto IDAMS.LST) 15.7 Proposiciones de control del programa 15.7. 131 Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-3, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: INCLUDE V1=10,20,30 AND V12=1,3,7 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: CORRECCION DE CODIGOS ALFA EN LA ELECCION DE 2001 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: PRINT=CORRECTIONS, IDVARS=V4 INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Si MAXC=0, en todas las instrucciones de corrección se verifican los errores de sintáxis pero no se procesan los datos. Por defecto: se usan todos los casos. IDVARS=(lista de variables) Hasta 5 números de variable para los campos de identificación de caso. Si se especifica más de un identificador de campo, los números de variables deben suministrarse en orden de clasificación de mayor a menor. Sin valor por defecto. CKSORT=YES/NO Indica si se debe verificar la clasificación del orden ascendente secuencial de los campos de identificación. La ejecución termina si se detecta un caso fuera de orden. OUTFILE=OUT/yyyy Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de salida. Por defecto: DICTOUT, DATAOUT. PRINT=(DELETIONS, CORRECTIONS, CDICT/DICT) DELE Listar los casos para los cuales se especificó una instrucción de eliminación en las instrucciones de correción. CORR Listar los casos corregidos. CDIC Imprimir el diccionario de entrada para todas las variables con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. 4. Instrucciones de corrección. Estas proposiciones indican cual de las opciones de listar, eliminar o corregir se van a aplicar y para cuales casos. Ejemplos: ID=1026,V5=9,V6=22 ID=’PEDRO PEREZ’,DELETE ID=091,3,LIST ID=023,16,V8=’DON_T’,V9=’TEACH|RES’ (Para el caso con identificador "1026", cambie el valor de V5 a 9 y el valor de V6 a 22). (Elimine el caso con identificador "PEDRO PEREZ" del archivo de salida). (Listar el caso con identificador "091", "3"). (Cambiar el valor de V8 a DON’T y de V9 a TEACH,RES). 132 Corrección de datos (CORRECT) Reglas de codificación Cada instrucción de corrección debe comenzar en una lı́nea nueva. Para seguir a otra lı́nea, interrumpa después de la coma al final de una corrección completa de variable y coloque un guión. Se pueden usar tantas lı́neas de continuación como sean necesarias. Pueden aparecer blancos en cualquier lugar de las instrucciones. Los casos y las instrucciones de corrección deben estar clasificados exactamente en el mismo orden relativo según los identificadores. Valores de identificación de caso El caso a corregir se identifica con la palabra clave “ID=” seguida del valor o valores de la variable o variables de identificación. La lista de valores en la instrucción no va entre paréntesis. Cada valor, incluido el último, debe estar seguido de una coma y el orden de los valores debe corresponder al orden de las variables en la lista de variables de identificación especificadas con el parámetro IDVARS. El número de dı́gitos o de caracteres en un valor debe ser igual al ancho de la variable como se haya establecido en el diccionario, es decir, puede ser necesario incluir los ceros a la izquierda. Valores que contengan caracteres no numéricos deben encerrarse entre comillas sencillas, por ej. ID=9, ’PAM’. Tipo de instrucción La identificación de caso está seguida de la palabra “LIST”, de la palabra “DELETE” o de una cadena de corrección de variables. Correcciones de variables Una corrección de variable consiste en un número de variable precedido de una “V” y seguido de un “=” y del valor correcto, por ej. V3=4. Correcciones de variable para diferentes variables en el mismo caso se separan con comas. Valores de corrección para variables numéricas pueden especificarse sin ceros a la izquierda. Si la variable incluye cifras decimales, se puede colocar el punto decimal pero éste no se escribe en el archivo de salida. Los dı́gitos se alinean de acuerdo con el número de cifras decimales indicado en el diccionario y se redondean los dı́gitos decimales en exceso. Si el valor contiene caracteres no numéricos, éste debe encerrarse entre comillas sencillas. Una coma intercalada debe representarse como una barra vertical y una comilla sencilla intercalada debe representarse como un guión de subrayado; el programa convertirá la barra vertical y el subrayado a la coma y a la comilla sencilla respectivamente, por ej. v8=’Don t’). Los valores de corrección para valores alfabéticos deben encajar con el ancho de la variable. Si el valor de corrección contiene blancos o caracteres en minúsculas, éste debe encerrarse entre comillas sencilas. 15.8. Restricción El número máximo de variables identificadoras de caso es 5. 15.9. Ejemplo Corrección de un archivo Datos; se van a corregir variables numéricas y alfabéticas y se van a eliminar dos casos; los casos se identifican con las variables V1, V2 y V5; no se cambia el diccionario y por lo tanto, no se requiere diccionario de salida. 15.9 Ejemplo $RUN CORRECT $FILES PRINT = CORRECT1.LST DICTIN = DATA1.DIC archivo Diccionario de entrada DATAIN = DATA1.DAT archivo Datos de entrada DICTOUT = DATA2.DIC archivo Diccionario de salida (igual a entrada) DATAOUT = DATA2.DAT archivo Datos de salida (corregido) $SETUP CORRECCION DE UN ARCHIVO DE DATOS IDVARS=(V1,V2,V5) ID=311,01,21,V12=’JUAN MOLINA’ ID=311,05,41,DELETE ID=557,11,32,V58=199,V76=2,V90=155 ID=559,11,35,V12=’AGATA CHRISTI’,V13=’F’ ID=657,31,11,V58=100,V77=4,V90=105,V36=999999,V37=999999,V38=999999, V41=98,V44=99 ID=711,15,11,DELETE 133 Capı́tulo 16 Importación/exportación de datos (IMPEX) 16.1. Descripción general El programa IMPEX hace importación y exportación de datos en formato libre o formato DIF, e importación y exportación de matrices en formato libre. En un archivo de formato libre los campos pueden separarse con un carácter de tabulación, un blanco, la coma, punto y coma o con otro carácter dado por el usuario. El carácter usado en notación decimal puede ser el punto o la coma. Un archivo Datos importado/exportado puede contener números y nombres de variable como nombrestas de columnas. Un archivo Matriz importado/exportado puede contener números de variable/valores de código y nombres de variable/nombres de código como nombres de columnas/filas. Importación de datos. El programa crea un nuevo dataset de IDAMS a partir de un archivo de datos ASCII existente en formato libre o formato DIF (un formato para intercambio de datos desarrollado por Software Art ProductsCorp.) y a partir de un diccionario IDAMS. El diccionario de entrada es para definir cómo se van a transferir los campos del archivo Datos de entrada al dataset IDAMS de salida. Exportación de datos. El programa crea un nuevo archivo de datos ASCII que contiene variables de un dataset existente de IDAMS y variables nuevas definidas con proposiciones Recode de IDAMS. El archivo exportado puede ser de formato libre o formato DIF. Importación de matrices. El programa crea un archivo Matriz de IDAMS a partir de un archivo ASCII en formato libre que contenga un triangulo inferior de una matriz cuadrada o una matriz rectangular. Exportación de matrices. El programa crea un archivo ASCII que contiene todas las matrices almacenadas en un archivo Matriz de IDAMS. Para exportar matrices sólo se dispone del formato libre. 16.2. Caraterı́sticas estándar de IDAMS Selección de casos y variables. El filtro estándar está disponible para seleccionar un subconjunto de casos de los datos de entrada cuando se solicita exportar datos. También en exportación de datos, la selección de variables se hace con el paramétro OUTVARS. Transformación de datos. Si se exportan datos, se pueden usar las proposiciones de Recode. Tratamiento de datos faltantes. No se verifican datos faltantes a excepción de la verificación que se hace con Recode en la exportación datos. En la importación de datos, los campos vacı́os (campos vacios entre delimitadores consecutivos) se reemplazan con el primer código de datos faltantes o con un campo de nueves si no se ha definido el primer código de datos faltantes. 136 16.3. Importación/exportación de datos (IMPEX) Resultados Importación de datos Diccionario de entrada. (Opcional: ver el parámetro PRINT). Los registros descriptores de variable y registros C, si los hay, para todas las variables incluidas en el diccionario de entrada. Nombres y códigos de columnas de entrada. (Opcional: ver los parámetros PRINT y EXPORT/IMPORT). Se imprimen los nombres y los códigos de columnas (sin formato) tal como se leen del archivo de entrada. Datos de entrada. (Opcional: ver el parámetro PRINT). Se imprimen sin formato para todos los casos las lı́neas de datos de entrada, tal como se leen del archivo de entrada. Diccionario de salida. (Opcional: ver el parámetro PRINT). Datos de salida. (Opcional: ver el parámetro PRINT). Se dan los valores para todos los casos y todas las variables, 10 valores por lı́nea, en el mismo orden de las lı́neas de datos de entrada. Exportación de datos Diccionario de entrada. (Opcional: ver el parámetro PRINT). Los registros descriptores de variable y registros C, si los hay, sólo para variables usadas en la ejecución. Datos de salida. (Opcional: ver el parámetro PRINT). Se dan los valores de las variables V o R para todos los casos, 10 valores por lı́nea. Para variables alfabéticas sólo se imprimen los primeros 10 caracteres. Importación de matrices Matriz de entrada. (Opcional: ver el parámetro PRINT). Se imprime la matriz que se encuentra en el archivo ASCII de entrada, con o sin nombres y códigos de columnas. Exportación de matrices Matrices de entrada. (Opcional: ver el parámetro PRINT). Se imprimen las matrices que se encuentran en el archivo Matriz de IDAMS de entrada, con o sin registros descriptores de variable o de nombres de código. 16.4. Archivos de salida Importación La salida es un dataset IDAMS o una matriz IDAMS segun se haya solicitado una importación de datos o de matriz. En el caso de un dataset IDAMS, los valores de las variables numéricas se editan de acuerdo con las reglas de IDAMS (ver el capı́tulo “Los datos en IDAMS”). Campos numéricos vacı́os (es decir, cadenas vacı́as entre caracteres delimitadores) en un formato libre se reemplazan con el primer código de datos faltantes o con nueves si el primer código de datos faltantes no está definido. Exportación La salida es un archivo ASCII cuyo contenido varı́a de acuerdo con los requerimientos de exportación. Datos en formato DIF. Este es un archivo con secciones “Header” (encabezamiento) y “Data” (datos). Los VECTORS corresponden a variables IDAMS y los TUPLES a los casos. Adicionalmente a los ı́tems requeridos de encabezamiento, se usa LABEL (un ı́tem estándar opcional) para exportar nombres de variables. En la sección DATA, el indicador de valor “V” se usa siempre para valores numéricos. Se usa punto decimal o coma en la notación decimal cuando el número de decimales definido en el diccionario es mayor que cero. Datos en formato libre. Este es un archivo en el cual los valores de variables se separan con un delimitador (ver los parámetros WITH y DELCHAR) y los casos se separan, adicionalmente, con retornos de carro más caracteres de alimentación de lı́nea. Para valores numéricos, se incluye un punto decimal o una coma (ver el parámetro DECIMALS) si el número de decimales definido en el diccionario es mayor que cero. Los valores 16.5 Archivos de entrada 137 de variables alfabéticas pueden estar entre comillas sencillas o comillas dobles, o sin encerrar entre caracteres especiales (ver el parámetro STRINGS). Matriz en formato libre. El formato de las matrices producidas por IMPEX es el mismo que el formato requerido para matrices importadas (ver “Importación de matrices” en la sección “Archivos de entrada” más atrás). La única diferencia es que se insertan caracteres adicionales de separación para asegurar la posición correcta de los nombre de filas y columnas en un paquete de hoja electrónica. 16.5. Archivos de entrada Importación de datos Para importar datos, la entrada es: un archivo ASCII con un arreglo de datos en formato libre en el cual los campos están separados con un delimitador y un diccionario IDAMS el cual define como transferir datos a un dataset IDAMS (deben describirse todos los campos en el diccionario de entrada); un archivo de datos en formato DIF, y también un diccionario IDAMS. Los archivos de entrada también pueden tener información de diccionario. Para archivos de formato libre ésto significa que los nombres y códigos de columna (los cuales corresponden a nombres de variable y números de variable) se suministran con el arreglo de datos como primeras filas del arreglo. Los nombres y códigos son ambos opcionales. Si se suministran, los nombres de columna reemplazan a los nombres de variable del diccionario de entrada y se insertan en el diccionario de salida. Pueden encerrarse entre caracteres especiales (ver el parámetro STRINGS). Los códigos de columna sólo se usan para verificar contra los números de variable del diccionario de entrada. Para archivos de formato DIF, los nombres de columna aparecen como ı́tems LABEL en la sección de “Header” (encabezamiento). Los códigos de columna pueden estar presentes como primera fila en el arreglo de datos. Importación de matrices Para importación de matrices, la entrada es siempre un archivo ASCII en formato libre en el cual los valores numéricos/cadenas de caracteres se separan con un delimitador. Campos vacı́os (es decir, cadenas vacı́as entre caracteres delimitadores) se saltan. Cada archivo puede tener una sóla matriz para importar. El archivo Matriz de entrada puede opcionalmente suministrar información del diccionario consistente en una serie de cadenas para nombrar columnas/filas de la matriz y los valores correspondientes de código. Si se suministran, deben seguir la sintáxis dada más adelante (la cual es diferente para matrices rectangulares y cuadradas). Matriz rectangular Esta es un archivo ASCII que contiene un arreglo rectangular de valores en formato libre; puede incluir información del diccionario. Ejemplo. Salario promedio; Grupo de edad; Sexo; Hombre; Mujer; 1;2; 20 - 30;1;600;530; 31 - 40;2;650;564; 41 - 60;3;723;618; Formato. 1. Las primeras tres cadenas contienen: (1) una descripción del contenido de la matriz, (2) el tı́tulo de fila (“nombre de variable de fila”) y (3) el tı́tulo de columna (“nombre de variable de columna”). (Opcional). 2. Nombres de columna. (Opcional: un nombre para una columna de valores en el arreglo). 138 Importación/exportación de datos (IMPEX) 3. Códigos de columna (Opcional: un código para una columna de valores en el arreglo). 4. El arreglo de valores. (Puede contenir opcionalmente un nombre y un código de fila antes de cada fila de valores). Nota. Si los nombres de fila y columna, y códigos no están presentes, se generan automáticamente para la matriz IDAMS de salida (nombres como R-#0001, R-#0002, ... C-#0001, C-#0002, ... y códigos desde 1 hasta el número de filas y columnas respectivamente). Matriz cuadrada Esta es un archivo ASCII que contiene un triángulo inferior izquierdo de una matriz triangular inferior (sin los elementos de la diagonal) y opcionalmente vectores de medias y desviaciones estándar después de la matriz como una serie de datos en formato libre. Ejemplo. ;;Paris;Londres;Bruselas;Madrid; ... ;;1;2;3;4; ... Paris;1; Londres;2;0.55; Bruselas;3;0.45;0.35; Madrid;4;1.45;2.35;1.15; . . . Formato. 1. Nombres de columna (“nombres de variable”). (Opcional: tantos nombres como columnas/filas de valores en el arreglo). 2. Códigos de columna (“números de variable”). (Opcional: tantos códigos como columnas/filas de valores en el arreglo). 3. El arreglo de valores. (Puede contenir opcionalmente un nombre y código de fila antes de cada fila de valores). 4. Un vector de medias. (Opcional). 5. Un vector de desviaciones estándar. (Opcional). Nota. Si los nombres o códigos no están presentes, se generan automáticamente para la matriz IDAMS de salida (nombres como V-#0001, V-#0002, ... y códigos desde 1 hasta el número de filas/columnas respectivamente). Exportación de datos y matrices Según se vaya a exportar datos o una matriz, la entrada es un archivo Datos descrito por un diccionario IDAMS (se pueden usar variables numéricas y alfabéticas) o un archivo Matriz IDAMS cuadrada o rectangular. 16.6 Estructura del setup 16.6. 139 Estructura del setup $RUN IMPEX $FILES Especificación de archivos $RECODE (opcional con exportación de datos; no disponible otramente) Proposiciones de Recode $SETUP 1. Filtro (opcional) 2. Tı́tulo 3. Parámetros $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx DICTyyyy DATAyyyy PRINT 16.7. diccionario de entrada para exportar/importar datos (omitir si se usa $DICT) datos/matriz de entrada (omitir si se usa $DATA) diccionario de salida para importar datos datos/matriz de salida resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-3, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución si se ha especificado exportación de datos. Ejemplo: EXCLUDE V19=2-3 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: EXPORTACION DE INDICADORES DE DESARROLLO SOCIAL 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: EXPORT=(DATA,NAMES) FORMAT=DELIMITED WITH=SPACE IMPORT=(DATA/MATRIX, NAMES, CODES) DATA Se solicita importar datos. MATR Se solicita importar matriz. NAME Se incluyen nombres de variable en el archivo Datos a importar. Se incluyen nombres de variable/de código en el archivo Matriz a importar. CODE Se incluyen números de variable en el archivo Datos a importar. Se incluyen números de variable/valores de código en el archivo Matriz a importar. 140 Importación/exportación de datos (IMPEX) EXPORT=(DATA/MATRIX, NAMES, CODES) DATA Se solicita exportar datos. MATR Se solicita exportar matriz. NAME Se exportan nombres de variable en el archivo Datos de salida. Se exportan nombres de variable/de código en el archivo Matriz de salida. CODE Se exportan números de variable en el archivo Datos de salida. Se exportan números de variable/valores de código en el archivo Matriz de salida. Nota. Sin valor por defecto. Se debe especificar IMPORT o EXPORT (no ambos). INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para el(los) archivo(s) de entrada: archivo Datos o Matriz para importar (ddname por defecto: DATAIN), archivos Diccionario y Datos para exportar (ddnames por defecto: DICTIN, DATAIN), archivo Matriz IDAMS para exportar (ddname por defecto: DATAIN). BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos a exportar o importar y los valores con “amplitud insuficiente de campo” en salida. Ver el capı́tulo “El archivo Setup de IDAMS”. MAXCASES=n Sólo se aplica si se ha especificado importación/exportación de datos. Número máximo de casos (después de filtrar) a usar del archivo Datos de entrada. Por defecto: se usan todos los casos. MAXERR=0/n Número máximo de errores “amplitud insuficiente de campo” permitido antes de detener la ejecución. Estos errores se presentan cuando el valor de una variable es muy grande para caber en el campo asignado, por ej. un valor de 250 cuando se ha especificado un ancho de campo de 2. OUTFILE=OUT/yyyy Un sufijo de ddname de 1-4 caracteres para el(los) archivo(s) de salida: archivos Diccionario y Datos obtenidos por importación (ddnames por defecto: DICTOUT, DATAOUT), archivo Matriz IDAMS obtenido por importación (ddname por defecto: DATAOUT), archivo Datos o archivo Matriz exportado (ddname por defecto: DATAOUT). OUTVARS=(lista de variables) Se aplica sólo si se ha especificado exportación de datos. Las variables V y R que se van a exportar. El orden de las variables en la lista no es significativo ya que salen en orden numérico ascendente. Todos los números de las variables V y R deben ser únicos. Sin valor por defecto. MATSIZE=(n,m) Se aplica sólo si se ha especificado importación de matriz. Número de filas y columnas de la matriz a importar. El programa supone una matriz rectangular si han especificado ambos y una matriz cuadrada simétrica si uno de ellos se ha omitido. n Número de filas. m Número de columnas. Sin valor por defecto. 16.7 Proposiciones de control del programa 141 FORMAT=DELIMITED/DIF Especifica el formato de los datos/la matriz de entrada para importación o el formato de los datos/la(s) matriz(ces) de salida para exportación. DELI Los datos/la(s) matriz(ces) se esperan en formato libre, en el cual los campos están separados por un delimitador (ver adelante). DIF Los datos se esperan en formato DIF. Nota: el formato DIF está disponible sólo para exportar o importar datos. WITH=SPACE/TABULATOR/COMMA/SEMICOLON/USER (Condicional: ver FORMAT=DELIMITED). Especifica el carácter delimitador para separar campos de archivos en formato libre. SPAC Un carácter en blanco (código ASCII: 32). TABU Un carácter de tabulación (código ASCII: 9). COMM La coma “,” (código ASCII: 44). SEMI El punto y coma “;” (código ASCII: 59). USER Un carácter especificado por el usuario (ver el parámetro DELCHAR más adelante). Nota: cuando se importan/exportan archivos DIF, siempre se usa COMMA como carácter delimitador, independientemente del que se haya seleccionado. DELCHAR=’x’ (Condicional: ver el parámetro WITH=USER atrás). Define el carácter usado para separar campos de archivos en formato libre. Valor por defecto: blancos. DECIMALS=POINT/COMMA Define el carácter usado en notación decimal. POIN El punto “.” (código ASCII: 46). COMM La coma “,” (código ASCII: 44). STRINGS=PRIME/QUOTE/NONE Define el carácter para encerrar cadenas de caracteres. PRIM Comillas sencillas. QUOT Comillas dobles. NONE No se usa un carácter especial. Nota: en importación/exportación de archivos DIF, siempre se usa QUOTE, independientemente de lo que se haya seleccionado. NDEC=2/n Número de cifras decimales a retener en exportación. PRINT=(DICT/CDICT/NODICT, DATA) DICT Imprimir diccionario sin registros C. CDIC Imprimir diccionario con registros C, si los hay. DATA Imprimir los datos/la(s) matriz(ces). Nota: a) Las opciones de impresión del diccionario controlan la impresión del diccionario de salida y de entrada. b) La opción de impresión de datos controla la impresión de datos de salida si se está exportando un archivo Datos; controla la impresión de datos la salida y la entrada si se está importando un archivo Datos (nunca se imprime la entrada si se importa un archivo de formato DIF). c) Para matrices, la matriz de entrada se imprime si se ha especificado imprimir datos. 142 Importación/exportación de datos (IMPEX) 16.8. Restricciones 1. El número máximo de variables R que se pueden exportar es 250. 2. El número máximo de variables que se pueden usar en una ejecución (incluidas las variables usadas solamente en proposiciones de Recode) es 500. 3. El número máximo de filas de matriz es 100. 4. El número máximo de columnas de matriz es 100. 5. El número máximo de casillas de matriz es 1000. 16.9. Ejemplos Ejemplo 1. Variables escogidas del dataset de entrada se transfieren al archivo de salida junto con las dos nuevas variables; los datos salen en formato libre y sus valores se separan con punto y coma; se usa coma en la notación decimal y los valores alfabéticos se encierran entre comillas dobles; los nombres y números de variable se incluyen en el archivo de salida. $RUN IMPEX $FILES PRINT = EXPDAT.LST DICTIN = OLD.DIC archivo Diccionario de entrada DATAIN = OLD.DAT archivo Datos de entrada DATAOUT = EXPORTED.DAT archivo Datos exportado $SETUP EXPORTACION DE DATOS IDAMS DE FORMATO FIJO A DATOS DE FORMATO LIBRE EXPORT=(DATA,NAMES,CODES) BADD=MD1 MAXERR=20 OUTVARS=(V1-V20,V33,V45-V50,R105,R122) FORMAT=DELIM WITH=SEMI DECIM=COMMA STRINGS=QUOTE $RECODE R105=BRAC(V5,15-25=1,<36=2,<46=3,<56=4,<66=5,<90=6,ELSE=9) MDCODES R105(9) NAME R105’GRUPOS DE EDAD’ IF MDATA(V22) THEN R122=99.9 ELSE R122=V22/3 MDCODES R122(99.9) NAME R122’ARTICULOS POR A~ NO’ Ejemplo 2. Se importan datos en formato DIF a IDAMS; nombres y códigos de columna se incluyen en el archivo de entrada y se usa la coma para notación decimal. $RUN IMPEX $FILES PRINT = IMPDAT.LST DICTIN = IDA.DIC archivo Diccionario que describe los datos a importar archivo Datos a importar archivo Diccionario de salida archivo Datos de salida DATAIN = IMPORTED.DAT DICTOUT = IDAFORM.DIC DATAOUT = IDAFORM.DAT $SETUP IMPORTACION DE DATOS EN FORMATO DIF A DATASET IDAMS DE FORMATO FIJO IMPORT=(DATA,NAMES,CODES) BADD=MD1 MAXERR=20 FORMAT=DIF DECIM=COMMA 16.9 Ejemplos 143 Ejemplo 3. Se exporta un conjunto de matrices rectangulares creadas con el programa TABLES; los campos se separan con punto y coma y la coma se usa para notación decimal; los nombres y códigos de fila y columna se incluyen en el archivo de la matriz de salida; se imprimen las matrices de entrada. $RUN IMPEX $FILES PRINT = EXPMAT.LST DATAIN = TABLES.MAT archivo con las matrices rectangulares DATAOUT = EXPORTED.MAT archivo con las matrices exportadas $SETUP EXPORTACION DE MAT RECTANG DE IDAMS EN FORMATO FIJO A MAT DE FORMATO LIBRE EXPORT=(MATRIX,NAMES,CODES) PRINT=DATA FORMAT=DELIM WITH=SEMI DECIM=COMMA STRINGS=QUOTE Ejemplo 4. Importación de una matriz cuadrada que contiene medidas de distancia para 10 objetos numerados de 1 a 10; sólo se incluyen valores enteros y se separan con el signo % ; los codigos de fila/columna ası́ como los vectores de medias y desviaciones estándar se incluyen en el archivo de la matriz. $RUN IMPEX $FILES PRINT = IMPMAT.LST DATAOUT = IMPORTED.MAT archivo con la matriz importada $SETUP IMPORTACION DE UNA MAT EN FORMATO LIBRE A MAT CUADRADA IDAMS DE FORMATO FIJO IMPORT=(MATRIX,CODES) MATSIZE=10 FORMAT=DELIM WITH=USER DELCH=’%’ $DATA $PRINT % 1% 2% 3% 4% 5% 6% 7% 8% 9% 10% 1% 2%38% 3%72%25% 4%24%53%17% 5%64%26%76%18% 6%48%25%63%15%61% 7%12%50%7%42%8%8% 8%19%7%13%4%14%1%15% 9%29%37%34%21%24%35%3%5% 10%32%57%29%45%26%28%74%24%61% %46%15%7%7119%74%38%9%19%34%256% %9%11%84%8971%23%28%12%20%35%843% Capı́tulo 17 Listado de datasets (LIST) 17.1. Descripción general LIST se usa para imprimir los datos de un archivo, las variables recodificadas e información del diccionario IDAMS asociado. Se pueden seleccionar variables especı́ficas para ser impresas o se pueden listar todos los datos y/o el diccionario. Cada registro de un archivo Datos es una flujo continuo de valores. Cuando se imprime tal como es, resulta difı́cil distinguir los valores de variables adyacentes. LIST elimina esta inconveniencia porque ofrece un formato de impresión de datos que separa los valores de las variables. Se puede imprimir un diccionario IDAMS sin su correspondiente archivo Datos mediante el suministro de un archivo ficticio (es decir, un archivo vacı́o o nulo), al definir el archivo Datos. 17.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. Los casos se pueden seleccionar con un filtro o con la opción de saltar casos (SKIP). La opción de saltar, si se usa, especifica que se imprime el primer caso y después cada n-ésimo caso. Si se especifica un filtro, la opción de saltar se aplica a los casos que han pasado por el filtro. De los casos seleccionados, se imprimen los valores de los datos para todas las variables descritas en el diccionario o para un subconjunto si se ha especificado el parámetro VARS. Transformación de datos. Se pueden usar las proposiciones de Recode. Tratamiento de datos faltantes. Los valores de datos faltantes se imprimen tal como se presentan, sin causar acción especial. 17.3. Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variable y registros C, si los hay, solamente para variables utilizadas en la ejecución. Si se escogen para imprimir todas las variables, entonces se imprime el diccionario completo en orden secuencial. Datos. Las variables numéricas se imprimen con el punto decimal explı́cito, si lo hay, y sin ceros a la izquierda. Si un valor desborda el ancho de campo, éste se imprime como una cadena de asteriscos. Los datos malos reemplazados por códigos de datos faltantes por defecto se imprimen como blancos. Se imprimen los valores de una variable en una columna que se extiende con el número de páginas necesarias para abarcar todos los casos escogidos para imprimir. El siguiente es un bosquejo en bloque del formato de impresión: 146 Listado de datasets (LIST) v v v v xxx xxx xxx xxx . . xxxx xxxx xxxx xxxx . . x x x x . . xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx . . Los encabezamientos v de las columnas representan los números de las variables y las x representan los valores de las variables. Si el usuario pide más variables de las que caben en una fila (127 caracteres), LIST hará un número de pasadas al archivo de datos e imprimirá tantas variables como pueda cada vez. Por ejemplo, si se van a imprimir 50 variables, LIST lee los datos, escribe todos los valores, digamos para las primeras 10 variables. Después lee nuevamente los datos y escribe, digamos para las siguientes 12 variables y ası́ sucesivamente. El número de variables impresas en cada pasada, depende de los anchos de campo de las variables que se van a imprimir y es calculado automáticamente por LIST. Secuencia e identificación de casos. Existen opciones para imprimir un número secuencial de caso y/o de los valores de las variables de identificación en cada caso (ver parámetros PRINT e IDVARS). Se imprimen como las primeras columnas. Variables de Recode. Se imprimen con 11 dı́gitos incluidos un punto decimal explı́cito y dos cifras decimales. 17.4. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. Si sólo se necesita un listado del diccionario, el archivo Datos se especifica como NUL. 17.5. Estructura del setup $RUN LIST $FILES Especificación de archivos $RECODE (opcional) Proposiciones de Recode $SETUP 1. Filtro (opcional) 2. Tı́tulo 3. Parámetros $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx PRINT diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) resultados (por defecto IDAMS.LST) 17.6 Proposiciones de control del programa 17.6. 147 Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-3, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: INCLUDE V5=100-199 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: LISTADO DEL ESTUDIO: 113A 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: VARS=(V3,V10-V25) IDVARS=V1 INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos. Ver el capı́tulo “El archivo Setup de IDAMS”. MAXCASES=n Número máximo de casos a imprimir. Por defecto: se imprimen todos los casos. SKIP=n Se imprime cada caso n-ésimo (o cada caso n-ésimo que pase por el filtro), comenzando por el primer caso. El último caso siempre se imprime a no ser que la opción MAXCASES lo prohiba. Por defecto: se imprimen todos los casos (o todos los casos que pasen por el filtro). VARS=(lista de variables) Imprimir los datos de las variables especificadas. Los valores de variables se imprimen en el orden en que aparecen en esta lista. Por defecto: se imprimen todas las variables del diccionario. IDVARS=(lista de variables) Se imprimen los valores de la(s) variable(s) especificada(s) para identificar cada caso. SPACE=3/n Número de espacios entre columnas. El valor máximo es SPACE=8. PRINT=(CDICT/DICT, SEQNUM, LONG/SHORT, SINGLE/DOUBLE) CDIC Imprimir el diccionario de entrada para todas las variables con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. SEQN Imprimir un número secuencial para cada caso que se imprima. Nótese que los casos se numeran después de pasar por el filtro. LONG Asume 127 caracteres por lı́nea de impresión. SHOR Asume 70 caracteres por lı́nea de impresión. SING Espacio sencillo entre lı́neas. DOUB Doble espacio entre lı́neas. 17.7. Restricción La suma de los anchos de campo de las variables que se van a imprimir, incluidos las variables identificadoras de caso, debe ser menor o igual a 10,000 caracteres. 148 Listado de datasets (LIST) 17.8. Ejemplos Ejemplo 1. Listar 50 variables, incluida una variable de recodificación; todos los casos se imprimirán con sus variables de identificación (V1, V2 y V4); se imprimirá el diccionario pero sin registros C. $RUN LIST $FILES PRINT = LIST1.LST DICTIN = STUDY.DIC archivo Diccionario de entrada DATAIN = STUDY.DAT archivo Datos de entrada $RECODE R6=BRAC(V6,0-50=1,51-99=2) $SETUP LISTADO DE 50 VARIABLES CON 3 VARIABLES ID CON CADA GRUPO IDVA=(V1,V2,V4) VARS=(V3-V49,V59,V52,R6) PRIN=DICT Ejemplo 2. Imprimir un diccionario completo con registros C, sin imprimir los datos. $RUN LIST $FILES DICTIN = STUDY.DIC archivo Diccionario de entrada DATAIN = NUL $SETUP LISTADO COMPLETO DE UN DICCIONARIO PRIN=CDICT Ejemplo 3. Verificación de una recodificación mediante el listado de valores de variables de entrada y de variables recodificadas para 10 casos. $RUN LIST $FILES DICTIN = A.DIC archivo Diccionario de entrada DATAIN = A.DAT archivo Datos de entrada $RECODE R101=COUNT(1,V40-V49) IF MDATA(V9,V10) THEN R102=99 ELSE R102=V9+V10 R103=BRAC(V16,15-24=1,25-34=2,35-54=3,ELSE=9) $SETUP VERIFICACION DE LOS VALORES DE TRES VARIABLES RECODIFICADAS MAXCASES=10 SKIP=10 SPACE=1 VARS=(V40-V49,R101,V9,V10,R102,V16,R103) Capı́tulo 18 Intercalación de datasets (MERGE) 18.1. Descripción general MERGE intercala variables que vienen de casos en un dataset IDAMS, con variables que vienen de un segundo dataset, emparejando los casos con una(s) variable(s) comun(es) de emparejamiento. Los casos en los dos datasets no tienen que ser idénticos; esto es, todos los casos presentes en un dataset, no tienen que estar en el otro. El archivo Datos de salida está compuesto de registros que tienen variables especificadas por el usuario de cada uno de los dos datasets de entrada, junto con su correspondiente diccionario IDAMS. Con el objeto de distinguir los dos datasets de entrada, uno se llama “dataset A” y el otro “dataset B” en la documentación del programa. Combinación de datasets con colecciones idénticas de casos. Un ejemplo de uso del programa es la combinación de los datos de la primera y subsiguiente series de entrevistas con la misma colección de encuestados. Combinación de datasets con recolecciones diferentes de casos. Cuando hay más de una serie de entrevistas en una encuesta, algunos encuestados pueden retirarse y otros incluirse. El programa permite estas discrepancias entre datasets y se le puede solicitar, por ejemplo, que produzca registros de salida para todos los encuestados, incluidos aquellos entrevistados en una sola serie. En este ejemplo, los valores de las variables para una serie en la cual un encuestado no fue entrevistado, saldrán como datos faltantes. Combinación de datasets con diferentes niveles de datos. También se usa MERGE para combinar dos datasets diferentes, uno de los cuales contiene datos más agregados que el otro. Por ejemplo, los datos de hogares se pueden añadir a registros individuales de miembros de familia. 18.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. Se puede especificar un filtro para uno o para los dos datasets de entrada. La única diferencia en el formato del filtro es que debe estar precedido de una “A:” o de una “B:” en las columnas 1-2, para indicar el dataset al cual se aplica el filtro. Las variables de salida seleccionadas o todas las variables de salida de cada dataset de entrada se pueden incluir en el dataset de salida. Estas variables de salida se especifican en una lista de variables que tiene el formato usual, excepto que las variables se denotan con una “A” o una “B” (en vez de “V”) para indicar el dataset de entrada en el cual se encuentran. Por ejemplo, “A1, B5, A3-A45” selecciona las variables V1, V3-V45 del dataset A y la variable V5 del dataset B. Ver la descripción de variables de salida en la sección “Proposiciones de control del programa”. Transformación de datos. Las proposiciones de Recode no se pueden usar. Tratamiento de datos faltantes. Para las opciones de salida MATCH=UNION, MATCH=A y MATCH=B, se usan los códigos de datos faltantes como valores para las variables de salida que no están disponibles para un caso particular. Ver el parágrafo “Manejo de casos que aparecen en un dataset de entrada solamente” en la sección que describe el dataset de salida más adelante. Los códigos de datos faltantes se obtienen de los 150 Intercalación de datasets (MERGE) diccionarios de los datasets A y B. El usuario indica para cada dataset si se usa el primero o segundo código de datos faltantes, y ésto para todas las variables de este dataset (ver los parámetros APAD y BPAD). Si una variable no tiene un código de datos faltantes apropiado en el diccionario, se usan espacios en blanco en el dataset de salida. Los datos faltantes nunca salen como el valor de una variable de salida que sea también una variable de emparejamiento, por que una variable de emparejamiento siempre está disponible en el dataset que contiene el caso. Por ejemplo, si se selecciona MATCH=UNION, supongamos que las variables A1 y B3 se han seleccionado como las variables de emparejamiento y que sólo A1 se imprimió como variable de salida (A1 y B3 no se imprimen ambas ya que presumiblemente, tienen el mismo valor): entonces, si faltó un caso en el dataset A, el valor de la variable de salida A1 será el valor de la variable B3. 18.3. Resultados Números de variable anteriores (de entrada) versus números de variable nuevos (de salida). (Opcional: ver el parámetro PRINT). Una carta que contiene los números de las variables de entrada y los números de referencia y los números correspondientes de las variables de salida y números de referencia. Diccionario de salida. (Opcional: ver el parámetro PRINT). Documentación de casos sin emparejar en cualquiera de los datasets A o B. Hay varias maneras de documentar los casos sin emparejar, es decir, casos que aparecen sólo en un dataset (ver el parámetro PRINT). Se pueden imprimir los valores de las variables de emparejamiento: - cuando las variables de salida de cualquiera de los datasets se rellenan con datos faltantes, - cuando se eliminan casos del dataset A, - cuando se eliminan casos del dataset B. Se pueden imprimir los valores de las variables del dataset A cuando un caso del dataset A no encaja con ningún caso del dataset B. Las variables se imprimen en el orden especificado para el dataset en la lista de variables de salida, seguida de la lista de variables de emparejamiento que tampoco son variables de salida. Se pueden imprimir los valores de las variables del dataset B cuando un caso del dataset B no encaja con ningún caso del dataset A. Las variables se imprimen en el orden especificado para el dataset en la lista de variables de salida, seguida de la lista de variables de emparejamiento que tampoco son variables de salida. Conteo de casos. El programa imprime el número de casos existentes en los datasets A y B, el número de casos en el dataset A y que no están en el dataset B, el número de casos en el dataset B y que no están en el dataset A y el número total de casos escritos en la salida. 18.4. Dataset de salida La salida es un nuevo archivo Datos y un diccionario IDAMS correspondiente. Cada registro de datos contiene el valor de las variables de salida para emparejar casos de los datasets A y B. Nótese que una variable de emparejamiento no se produce automáticamente: el usuario debe incluir la(s) variable(s) de emparejamiento a partir de uno de los datasets en la lista de variables de salida para asignar al registro de salida un identificador de caso. Manejo de casos que aparecen solamente en un solo dataset de entrada. Hay cuatro acciones posibles: 1. MATCH=INTERSECTION. Los casos que aparecen en un solo dataset de entrada no se incluyen en el dataset de salida. (Si los datasets A y B se consideran como conjuntos de casos, la salida es la intersección de los conjuntos A y B). 18.4 Dataset de salida 151 2. MATCH=UNION. Cualquier caso que aparezca en cualquiera de los datasets de entrada se incluye en el dataset de salida. A las variables del dataset de entrada que no contengan el caso se les asignan valores de datos faltantes en el dataset de salida. (La salida es la unión de los conjuntos A y B). 3. MATCH=A. Cualquier caso que aparezca en el dataset A, se incluye en el dataset de salida, mientras que un caso que sólo aparece en el dataset B, no se incluye. Si un caso sólo se encuentra en el dataset A, a las variables del dataset B se les asignan valores de datos faltantes en el dataset de salida para ese caso. (La salida es el conjunto A). 4. MATCH=B. Tiene la misma acción que la opción 3, pero el dataset B define cuales casos se incluyen en el dataset de salida. (La salida es el conjunto B). Manejo de casos duplicados. Cuando uno de los dos datasets de entrada contiene más de un caso con el mismo valor en la variable o variables de emparejamiento, se dice que el dataset contiene casos duplicados. Normalmente (es decir, cuando no se especifica el parámetro DUPBFILE) el programa imprime un mensaje que señala la presencia de duplicados y luego los trata cada uno como un caso diferente. Los casos escritos en el dataset de salida dependerán de la opción escogida en MATCH. El cuadro siguiente muestra cómo funciona esto. Intercalación de archivos con duplicados (sin especificar DUPBFILE) Entrada A ID 01 01 02 | | N1 | | EVA | ANA | CORA | | Salida B | | ID N2 | | 01 ADAN | 02 PEDRO | 03 JORGE | | MATCH = UNION | | ID N1 N2 | | 01 EVA ADAN | 01 ANA ____ | 02 CORA PEDRO | 03 ____ JORGE | MATCH = A ID 01 01 02 | | N1 N2 | | EVA ADAN | ANA ____ | CORA PEDRO | | MATCH = B ID 01 02 03 | | N1 N2 | | EVA ADAN | CORA PEDRO | ____ JORGE | | MATCH =INTER ID N1 N2 01 EVA ADAN 02 CORA PEDRO Sin embargo, los duplicados se pueden interpretar y manejar de una manera diferente cuando uno de los dos datasets contiene casos en un nivel de análisis más bajo que el otro. Por ejemplo, un dataset contiene datos de hogares y el segundo contiene datos de miembros de hogares. En este caso, las variables de emparejamiento especificadas para cada dataset serı́an la identificación de los hogares. Ası́, naturalmente se presentarán duplicados en el dataset de “miembros de hogares”, ya que la mayorı́a de hogares tienen más de un miembro. Al especificar el parámetro DUPBFILE, no se imprime mensaje de presencia de duplicados y se construyen casos para cada caso “duplicado” en el dataset B con las variables del caso de emparejamiento del dataset A, copiadas en cada caso construido. El siguiente cuadro muestra un ejemplo de este procedimiento. Intercalación de archivos a diferentes niveles (se especificó DUPBFILE) Entrada A | | ID N1 | | 01 ALVA | 03 MORA | 04 RIZO | | | | | B | | ID N2 | | 01 ANA | 01 EVA | 01 PEDRO | 02 CORA | 02 ADAN | 03 JORGE | | Salida MATCH = UNION | | ID N1 N2 | | 01 ALVA ANA | 01 ALVA EVA | 01 ALVA PEDRO | 02 ____ CORA | 02 ____ ADAN | 03 MORA JORGE | 04 RIZO _____ | MATCH = A | | ID N1 N2 | | 01 ALVA ANA | 01 ALVA EVA | 01 ALVA PEDRO | 03 MORA JORGE | 04 RIZO ____ | | | MATCH = B | | ID N1 N2 | | 01 ALVA ANA | 01 ALVA EVA | 01 ALVA PEDRO | 02 ____ CORA | 02 ____ ADAN | 03 MORA JORGE | | MATCH = INTER ID N1 N2 01 01 01 03 ANA EVA PEDRO JORGE ALVA ALVA ALVA MORA Orden y numeración de variables. La salida de variables se lleva acabo en el orden en el que aparecen en la lista de variables de salida y siempre se renumeran a partir del valor dado en el parámetro VSTART. 152 Intercalación de datasets (MERGE) Ası́, una lista de variables de salida tal como “A1-A5, B6, A7-A25,B100” crea un dataset con variables de V1 a V26 si VSTART=1. Los números de referencia de variables, si los hay, se transfieren sin modificar al diccionario de salida. Localización de variables. MERGE asigna la localización de variables a partir de la primera variable de salida y luego continúa en orden a través de la lista de variables de salida. 18.5. Dataset de entrada MERGE necesita dos archivos de datos de entrada, cada uno de ellos descrito por un diccionario IDAMS. Las variables de emparejamiento pueden ser alfabéticas o numéricas. Las variables de emparejamiento correspondientes que vienen de los datasets A y B, deben tener el mismo ancho de campo. Las variables de salida pueden ser alfabéticas o numéricas. Cada archivo de datos de entrada debe estar clasificado en orden ascendente por las variables de emparejamiento, antes de usar MERGE. 18.6. Estructura del setup $RUN MERGE $FILES Especificación de archivos $SETUP 1. 2. 3. 4. 5. Filtro(s) (opcional) Tı́tulo Parámetros Especificación de variables de emparejamiento Variables de salida $DICT (condicional) Diccionario (ver Nota más adelante) $DATA (condicional) Datos (ver Nota más adelante) Archivos: DICTxxxx DATAxxxx DICTyyyy DATAyyyy DICTzzzz DATAzzzz PRINT diccionario de entrada del dataset A (omitir datos de entrada del dataset A (omitir si se diccionario de entrada del dataset B (omitir datos de entrada del dataset B (omitir si se diccionario de salida datos de salida resultados (por defecto IDAMS.LST) si se usa $DICT) usa $DATA) si se usa $DICT) usa $DATA) Nota. En el setup, se puede introducir uno de los datasets de entrada A o B, pero no ambos. Sin embargo, los registros que siguen a continuación de $DICT y $DATA se copian en los archivos definidos por DICTIN y DATAIN respectivamente. Entonces, si el dataset A se coloca en el setup, el dataset A estará definido por DICTIN y DATAIN y se debe especificar el parámetro INAFILE=IN. De la misma manera, si el dataset B va en el setup, se debe especificar el parámetro INBFILE=IN. 18.7 Proposiciones de control del programa 18.7. 153 Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-3, a continuación. 1. Filtro(s) (opcional). Selecciona un subconjunto de casos de los datasets A y/o B para usar en la ejecución. Nótese que cada proposición de filtro debe estar precedida por “A:” o “B:” en las columnas 1 y 2 para indicar a cual dataset se va a aplicar el filtro. Ejemplo: A: INCLUDE V1=10,20,30 B: INCLUDE V1=10,20,30 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: INTERCALACION DE DATOS DE MAESTROS Y ESTUDIANTES 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: MATCH=INTE PRINT=(A,B) INAFILE=INA/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos A de entrada. Por defecto: DICTINA, DATAINA. INBFILE=INB/yyyy Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos B de entrada. Por defecto: DICTINB, DATAINB. MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo A de entrada. Por defecto: se usan todos los casos. MATCH=INTERSECTION/UNION/A/B INTE Llevar a la salida sólo los casos que aparezcan en ambos datasets A y B. UNIO Llevar a la salida los casos que aparezcan en uno de los dos o en ambos datasets A y B, rellenando las variables con datos faltantes cuando sea necesario. A Llevar a la salida sólo los casos que aparezcan en el dataset A, rellenando las variables que vienen del dataset B con datos faltantes cuando sea necesario. B Llevar a la salida sólo los casos que aparezcan en el dataset B, rellenando las variables que vienen del dataset A con datos faltantes cuando sea necesario. Sin valor por defecto. DUPBFILE Un caso en el dataset A puede emparejarse con uno o más casos (es decir, duplicados) del dataset B. Para cada emparejamiento, se crea un registro de salida, dependiendo del parámetro MATCH. Nota: el dataset con los duplicados esperados debe definirse como el dataset B. Por defecto: los casos duplicados en cualquiera de los datasets serán anotados en los resultados y entonces serán tratados como casos diferentes según la especificación en el parámetro MATCH. OUTFILE=OUT/zzzz Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de salida. Por defecto: DICTOUT, DATAOUT. VSTART=1/n Número de variable para la primera variable en el dataset de salida. 154 Intercalación de datasets (MERGE) APAD=MD1/MD2 Cuando se rellenan las variables de A con datos faltantes: MD1 Llevar a la salida el primer código de datos faltantes. MD2 Llevar a la salida el segundo código de datos faltantes. BPAD=MD1/MD2 Cuando se rellenan las variables de B con datos faltantes: MD1 Llevar a la salida el primer código de datos faltantes. MD2 Llevar a la salida el segundo código de datos faltantes. PRINT=(PAD/NOPAD, ADELETE/NOADELETE, BDELETE/NOBDELETE, VARNOS, A, B, OUTDICT/OUTCDICT/NOOUTDICT) PAD Imprimir los valores de las variables de emparejamiento cuando se rellenen cualesquiera variables de los datasets A o B con códigos de datos faltantes. ADEL Imprimir los valores de la variable de emparejamiento para el dataset A cada vez que no se incluya un caso del dataset A en el archivo de datos de salida. BDEL Imprimir los valores de la variable de emparejamiento para el dataset B cada vez que no se incluya un caso del dataset B en el archivo de datos de salida. VARN Imprimir un listado con los números de las variables de los datasets de entrada y sus correspondientes números de variable en el dataset de salida. A Imprimir todos los valores de las variables de emparejamiento y de salida para los casos que aparezcan solamente en el dataset A, estén o no estén incluidas en el dataset de salida. B Imprimir todos los valores de las variables de emparejamiento y de salida para los casos que aparezcan solamente en el dataset B, estén o no estén incluidas en el dataset de salida. OUTD Imprimir el diccionario de salida sin registros C. OUTC Imprimir el diccionario de salida con registros C, si los hay. NOOU No imprimir el diccionario de salida. 4. Especificación de variables de emparejamiento (mandatorio). Esta proposición define las variables de los datasets A y B que se van a comparar para emparejar los casos. Nótese que cada archivo Datos de entrada debe estar clasificado, con la(s) variable(s) de emparejamiento como llaves de clasificación antes de usar MERGE. Ejemplo: A1=B3, A5=B1 Lo cual significa que para emparejar un caso del dataset A con un caso del dataset B, el valor de la variable V1 del dataset A, debe ser igual al valor de la variable V3 del dataset B y similarmente para las variables V5 y V1. Formato general An=Bm, Aq=Br, ... Reglas de codificación El ancho de campo de las dos variables que se van a comparar debe ser idéntico. La comparación se hace carácter por carácter, no numéricamente. Ası́, “0.9” no es equivalente a “009”, ni “ 9” es igual a “09”. Si el ancho de campo no es el mismo, use el programa TRANS para cambiar el ancho de una de las variables antes de usar MERGE. Cada par de variables de emparejamiento está separado con una coma. Puede haber blancos en cualquier parte de la proposición. Para continuar en otra lı́nea, termine la información en una coma y coloque un guión para indicar continuación. 5. Variables de salida (mandatorio). Definen cuales variables de cada uno de los datasets de entrada se van a transferir a la salida y cual es su orden de salida. 18.8 Restricciones Ejemplo: 155 A1, B2, A5-A10, B5, B7-B10 Lo que significa que el dataset de salida contendrá la variable V1 del dataset A, seguida por la variable V2 del dataset B, seguida por las variables V5 hasta V10 del dataset A, etc. en ese orden. Reglas de codificación Las reglas de codificación son las mismas que las de la especificación de variables con el parámetro VARS, excepto que se usan las letras A y B en vez de la letra V. Cada número de variable del dataset A está precedido de una “A” y cada número de variable del dataset B está precedido de una “B”. Las variables duplicadas en la lista, se cuentan como variables separadas. 18.8. Restricciones 1. El número máximo de variables de emparejamiento de cada dataset es 20. 2. Las variables de emparejamiento deben ser del mismo tipo y ancho de campo en cada dataset. 3. La longitud total máxima del conjunto de variables de emparejamiento de cada dataset es 200 caracteres. 18.9. Ejemplos Ejemplo 1. Combinación de registros de dos datasets con el mismo número de casos; en ambos datasets, los casos se identifican con las variables 1 y 3; todas las variables se seleccionan de cada uno de los datasets de entrada. $RUN MERGE $FILES DICTOUT = AB.DIC archivo Diccionario de salida DATAOUT = AB.DAT archivo Datos de salida DICTINA = A.DIC archivo Diccionario de entrada del dataset A DATAINA = A.DAT archivo Datos de entrada del dataset A DICTINB = B.DIC archivo Diccionario de entrada del dataset B DATAINB = B.DAT archivo Datos de entrada del dataset B $SETUP COMBINACION DE REGISTROS DE 2 DATASETS CON EL MISMO NUMERO DE CASOS MATCH=UNION A1=B1,A3=B3 A1-A112,B201-B401 Ejemplo 2. Combinación de datasets con número de casos diferentes; sólo los casos con registros en ambos datasets se llevan a la salida; los casos se identifican con las variables 2 y 4 en el primer dataset y con las variables 105 y 107 respectivamente en el segundo dataset; las variables en el dataset de salida serán renumeradas a partir del número 201 y se pide un listado de referencias; sólo se tomarán las variables seleccionadas de cada dataset de entrada. $RUN MERGE $FILES los mismos del ejemplo 1 $SETUP COMBINACION DE REGISTROS DE 2 DATASETS CON DIFERENTE NUMERO DE CASOS MATCH=INTE VSTA=201 PRIN=VARNOS A2=B105,A4=B107 B105,B107,A36-A42,B120,B131 156 Intercalación de datasets (MERGE) Ejemplo 3. Combinación de datasets con datos de niveles diferentes; los casos del dataset A se combinan con un subconjunto de casos del dataset B; un caso del dataset A puede aparearse con uno o más casos del dataset B; los casos del dataset A que no se emparejen con un caso del subconjunto del dataset B se descartan y no se imprimen. $RUN MERGE $FILES los mismos del ejemplo 1 $SETUP B: INCLUDE V18=2 AND V21=3 COMBINACION DE 2 DATASETS CON DIFERENTES NIVELES DE DATOS MATCH=B DUPB A1=B15 B15,A2,A6-A12,B20-B31,B40 Ejemplo 4. Se va a calcular el ingreso por hogar a partir de un dataset de miembros de hogares y luego intercalarlo con los registros individuales de los miembros; se usa primero AGGREG para sumar los ingresos (V6) de los individuos en los hogares; V3 es la variable que identifica cada hogar; el dataset de salida de AGGREG (definido por DICTAGG y DATAAGG) contendrá 2 variables, el identificador de hogar (V1) y el ingreso por hogar (V2); este dataset se usa en seguida como el dataset “A” de MERGE para sumar el ingreso por hogar apropiado (variable A2) al registro original de cada individuo (variables B1-B46). $RUN AGGREG $FILES PRINT = MERGE4.LST DICTIN = INDIV.DIC archivo Diccionario de entrada DATAIN = INDIV.DAT archivo Datos de entrada DICTAGG = AGGDIC.TMP archivo temporal Diccionario de salida de AGGREG DATAAGG = AGGDAT.TMP archivo temporal Datos de salida de AGGREG DICTOUT = INDIV2.DIC archivo Diccionario de salida de MERGE DATAOUT = INDIV2.DAT archivo Datos de salida de MERGE $SETUP SUMA DE LOS INGRESOS IDVARS=V3 AGGV=V6 STATS=SUM OUTF=AGG $RUN MERGE $SETUP FUSION DEL INGRESO POR HOGAR CON LOS REGISTROS INDIVIDUALES INAFILE=AGG INBFILE=IN DUPB MATCH=B A1=B3 B1-B46,A2 Nótese que una vez que se han hecho las asignaciones de datasets bajo $FILES, no es necesario repetirlas si se vuelven a usar en pasos siguientes. Capı́tulo 19 Clasificación e intercalación de archivos (SORMER) 19.1. Descripción general SORMER le permite al usuario ejecutar Clasificar/Intercalar de una manera más conveniente ya que permite, mediante el uso de los formatos de los parámetros de IDAMS, especificar la información de los campos de control para clasificación o intercalación. Si el archivo Datos está descrito por un diccionario IDAMS, entonces se puede enviar a la salida una copia del diccionario correspondiente a los datos clasificados y los campos de clasificación se especifican con las variables apropiadas; en caso contrario, se especifican a través de su localización. Orden de clasificación. El usuario debe especificar si los datos se van a clasificar/intercalar en orden ascendente o descendente. 19.2. Caracterı́sticas estándar de IDAMS SORMER es un programa utilitario y no contiene ninguna de las caracterı́sticas estándar de IDAMS. 19.3. Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variables y registros C, si los hay, para las variables claves de classificacción. Resultados de Clasificar/Intercalar. Número de registros clasificados/intercalados. 19.4. Diccionario de salida Una copia del diccionario de entrada que corresponde al archivo Datos de salida. 19.5. Datos de salida La salida es un archivo con los mismos atributos del archivo o archivos de entrada cuyos registros están clasificados según el orden solicitado. 158 Clasificación e intercalación de archivos (SORMER) 19.6. Diccionario de entrada Si los campos de clasificación se especifican con números de variable, entonces se debe entrar un diccionario IDAMS con registros T, como mı́nimo para estas variables. Sólo se permiten diccionarios que describan un registro por caso. 19.7. Datos de entrada Para clasificar, se lee un solo archivo Datos el cual contiene uno o más campos (o variables) cuyos valores definen el orden de clasificación deseado. Para intercalar, la entrada consiste de 2-16 archivos Datos, cada uno con el mismo formato de registro, es decir, la misma longitud de registro y los campos que definen el orden de clasificación en las mismas posiciones. Cada archivo debe haberse clasificado previamente con los campos de control de intercalación, antes de pasar a intercalar los archivos. 19.8. Estructura del setup $RUN SORMER $FILES Especificación de archivos $SETUP 1. Tı́tulo 2. Parámetros $DICT (condicional) Diccionario para las variables de los campos de clasificación/intercalación Archivos para clasificar: DICTxxxx diccionario IDAMS para las variables de los campos de clasificación (omitir si se usa $DICT) SORTIN datos de entrada DICTyyyy diccionario de salida SORTOUT datos de salida Archivos para intercalar: DICTxxxx diccionario IDAMS para las variables de los campos de intercalación (omitir si se usa $DICT) SORTIN01 1er archivo de datos SORTIN02 2do archivo de datos . . DICTyyyy diccionario de salida SORTOUT datos de salida PRINT resultados (por defecto IDAMS.LST) Nota. Cuando se solicita la ejecución de SORMER más de una vez en un archivo Setup, las definiciones para el archivo de entrada en la ejecución subsiguiente, solamente modifican pero no reemplazan las definiciones del archivo de entrada especificadas previamente, por ej. si SORTIN01, SORTIN02 y SORTIN03 se especifican para la primera ejecución y SORTIN01 y SORTIN02 se especifican para la segunda ejecución en el mismo setup, los “nuevos” SORTIN01 y SORTIN02, ası́ como el “antiguo” SORTIN03 se tomarán para la intercalación. 19.9 Proposiciones de control del programa 19.9. 159 Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-2, a continuación. 1. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: CLASIFICACION ONDA UNO 2. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: KEYVARS=(V2,V3) INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para el archivo Diccionario de entrada. Por defecto: DICTIN. OUTFILE=yyyy Un sufijo de ddname de 1-4 caracteres para el archivo Diccionario de salida. Debe especificarse para obtener en la salida una copia del diccionario de entrada. SORT/MERGE SORT Se clasifican los datos de entrada. MERG Se intercalan dos o más archivos de datos. ORDER=A/D A Clasificación ascendente sobre los campos de clasificación. D Clasificación descendente. KEYVARS=(lista de variables) Lista de las variables que se van a usar como campos de clasificación (se debe suministrar el diccionario IDAMS). Nota: el archivo Datos debe tener sólo un registro por caso para seleccionar esta opción. Si hay más de un registro por caso, usar KEYLOC. KEYLOC=(I1,F1, I2,F2, ...) In Localización del comienzo del n-ésimo campo de clasificación. Fn Localización del final del n-ésimo campo de clasificación. Debe especificarse aún si tiene el mismo valor de la posición de comienzo de campo. Nota. Sin valor por defecto. Se debe especificar uno de los dos parámetros KEYVARS o bién KEYLOC, pero no ambos. PRINT=CDICT/DICT CDIC Imprimir el diccionario de entrada para las variables de clasificación con registros C, si los hay. DICT Imprimir el diccionario de entrada sin los registros C. 19.10. Restricciones 1. Se pueden intercalar hasta 16 archivos como máximo. 2. Se puede especificar un máximo de 12 campos de control o variables para clasificar/intercalar. 3. El número máximo de registros depende del espacio de disco disponible para el archivo de salida y para los archivos de trabajo SORTWK01, 02, 03, 04, 05. Estos archivos de trabajo pueden asignarse a un disco diferente al disco por defecto si es necesario. 160 Clasificación e intercalación de archivos (SORMER) 19.11. Ejemplos Ejemplo 1. Intercalar tres archivos con igual formato, clasificados previamente; cada archivo está descrito por el mismo diccionario IDAMS; los casos se clasifican en orden ascendente sobre tres variables: V1, V2 y V4. $RUN SORMER $FILES PRINT = SORT1.LST DICTIN = \SURV\DICT.DIC archivo SORTIN01 = DATA1.DAT archivo SORTIN02 = DATA2.DAT archivo SORTIN03 = DATA3.DAT archivo DICTOUT = \SURV\DATA123.DIC archivo SORTOUT = \SURV\DATA123.DAT archivo $SETUP INTERCALAR DE TRES ARCHIVOS DE DATOS: DATA1 MERG KEYVARS=(V1,V2,V4) OUTF=OUT Diccionario de entrada Datos 1 de entrada Datos 2 de entrada Datos 3 de entrada Diccionario de salida Datos de salida DATA2 Y DATA3 Ejemplo 2. Clasificar un archivo de datos en orden descendente sobre dos campos: el primer campo tiene 4 caracteres de longitud y comienza en la columna 12; el segundo campo tiene una longitud de 2 caracteres y comienza en la columna 3; no se usa diccionario. $RUN SORMER $FILES SORTIN = RAW.DAT archivo Datos de entrada SORTOUT = SORT.DAT archivo Datos de salida $SETUP CLASIFICACION DE UN ARCHIVO DE DATOS SIN USAR DICCIONARIO KEYLOC=(12,15,3,4) ORDER=D Capı́tulo 20 Subdivisión de datasets (SUBSET) 20.1. Descripción general SUBSET divide en subconjuntos un archivo Datos y su diccionario IDAMS correspondiente por caso y/o variable, o copia los archivos completos. Verificación del orden de clasificación. El programa tiene una opción para verificar que los casos se encuentren clasificados en orden ascendente, basado en una lista de variables de clasificación (ver el parámetro SORTVARS). Los casos adyacentes con identificación duplicada no se consideran fuera de orden. Sin embargo hay una opción para eliminar las duplicaciones de cualquier caso. 20.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. La subdivisión de un caso en subconjuntos se lleva a cabo con un filtro que selecciona un conjunto particular de casos del dataset de entrada. La selección de variables se hace al definir un conjunto de variables de entrada que se van a transferir al dataset de salida. Las variables pueden salir en cualquier orden y pueden ser transferidas más de una vez, si los números de variable de salida son renumerados. Transformación de datos. Las proposiciones de Recode no se pueden usar. Tratamiento de datos faltantes. SUBSET no hace distinción entre datos sustantivos y valores de datos faltantes; todos los datos reciben el mismo tratamiento. 20.3. Resultados Diccionario de salida. (Opcional: ver el parámetro PRINT). Estadı́sticas de subdivisión. La longitud del registro de salida, el número de registros del diccionario de salida y el número de registros de datos de salida. Números de variable anteriores (de entrada) versus números de variable nuevos (de salida). (Opcional: ver el parámetro PRINT). Se imprime una cartilla que contiene los números de variable de entrada y números de referencia y los correspondientes números de variable de salida y números de referencia. Notificación de casos duplicados. (Condicional: si se verifica el orden de clasificación del archivo, todos los casos duplicados se documentan, no importa si se ha especificado el parámetro DUPL=DELE). Para cada identificación de caso que aparezca más de una vez en los datos, se imprime el número de duplicados, el número secuencial y la identificación del caso. Además, el programa imprime el número de registros de datos de entrada y el número de registros de datos de entrada eliminados. 162 Subdivisión de datasets (SUBSET) 20.4. Dataset de salida El archivo Datos de salida y su diccionario IDAMS correspondiente se construyen a partir del subconjunto de casos y/o variables, especificado por el usuario a partir del archivo de entrada. Cuando se copian todas las variables, es decir, cuando no se ha especificado OUTVARS, la estructura de los registros de salida es idéntica a la de los registros de entrada y el diccionario de salida será una copia exacta del diccionario de entrada. De lo contrario, la información del diccionario para las variables en el archivo de salida se asigna de la manera siguiente: Orden y numeración de variables. Si se ha especificado VSTART, la salida de variables se lleva acabo en el orden en el que aparecen en la lista OUTVARS y siempre se renumeran a partir del valor dado en el parámetro VSTART. Si no se ha especificado VSTART, el programa no cambia los números de variable y las variables salen en orden ascendente de los números. Localización de variables. La localización de variables se asigna de forma contigua de acuerdo con el orden de las variables en la lista OUTVARS (si se ha especificado VSTART) o en el orden de los números de variable después de clasificar (si no se ha especificado VSTART). Tipo de variable, ancho y número de decimales son los mismos que sus valores de entrada. Número de referencia. Los mismos que sus valores de entrada o modificados de acuerdo con el parámetro REFNO. Registros C. Los registros C del diccionario de entrada se transfieren al diccionario de salida. 20.5. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. Se pueden usar variables numéricas o alfabéticas. 20.6. Estructura del setup $RUN SUBSET $FILES Especificación de archivos $SETUP 1. Filtro (opcional) 2. Tı́tulo 3. Parámetros $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx DICTyyyy DATAyyyy PRINT diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) diccionario de salida datos de salida resultados (por defecto IDAMS.LST) 20.7 Proposiciones de control del programa 20.7. 163 Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-3, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: INCLUDE V1=10,20,30 AND V2=1,5,7 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: SUBDIVISION DE LA ELECCION DE 1968, V1-V50 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: SORT=(V1,V2), DUPLICATE=DELETE INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. SORTVARS=(lista de variables) Si se va a verificar el orden de clasificación del archivo, se especifican hasta 20 variables que definen la secuencia de clasificación en orden de mayor a menor. Los duplicados se consideran en orden ascendente. DUPLICATE=KEEP/DELETE Eliminación de casos duplicados (sólo se aplica cuando se especifica SORT). KEEP Lleva a la salida todos casos duplicados que se presenten. DELE Lleva a la salida sólo el primer caso de los casos duplicados y escribe mensaje para los duplicados. OUTVARS=(lista de variables) Suministre esta lista sólo si va a salir un subconjunto de variables del dataset de entrada. Si no se ha seleccionado VSTART, la lista de variables no puede contener duplicados. De lo contrario, las variables pueden estar en cualquier orden y repetirse según se necesite. Por defecto: se llevan a la salida todas las variables. OUTFILE=OUT/yyyy Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de salida. Por defecto: DICTOUT, DATAOUT. VSTART=n Las variables se numerarán secuencialmente a partir de n en el dataset de salida. Por defecto: se retienen los números de variable de entrada. REFNO=OLDREF/VARNO OLDR Retiene los números de referencia en los registros T y C tal como están en el dataset de entrada. VARN Actualiza el campo del número de referencia en los registros C y T para que encaje con el número de variable de salida. 164 Subdivisión de datasets (SUBSET) PRINT=(OUTDICT/OUTCDICT/NOOUTDICT, VARNOS) OUTD Imprimir el diccionario de salida sin registros C. OUTC Imprimir el diccionario de salida con registros C, si los hay. VARN Imprimir una lista con los números de variables anteriores y nuevos y con los números de referencia. 20.8. Restricciones 1. El máximo número de variables de clasificación es 20. 2. El ancho de los campos combinados de las variables usadas para la clasificación, no puede exceder de 200 caracteres. 20.9. Ejemplos Ejemplo 1. Construcción de un subconjunto de casos para variables seleccionadas; las variables se renumerarán a partir de 1 y se imprimirá una tabla que muestre la numeración anterior de las variables y la nueva numeración asignada. $RUN SUBSET $FILES PRINT = SUBS1.LST DICTIN = ABC.DIC archivo DATAIN = ABC.DAT archivo DICTOUT = SUBS.DIC archivo DATAOUT = SUBS.DAT archivo $SETUP INCLUDE V5=2,4,5 AND V6=2301 SUBDIVISION DE CASOS Y VARIABLES PRINT=VARNOS VSTART=1 OUTVARS=(V1-V5,V18,V43-V57,V114,V116) Diccionario de entrada Datos de entrada Diccionario de salida Datos de salida Ejemplo 2. Uso del programa SUBSET para verificar casos duplicados; los casos se identifican con las variables de las columnas 1-3 y 7-8; hay un registro por caso; no se necesita dataset de salida y no se guarda. $RUN SUBSET $FILES DATAIN = DEMOG.DAT $SETUP CHEQUEO DE CASOS DUPLICADOS SORT=(V2,V4) PRIN=NOOUTDICT $DICT $PRINT 3 2 4 1 1 T 2 PRIMERA VAR ID DE CASO T 4 SEGUNDA VAR ID DE CASO archivo Datos de entrada 1 7 3 2 Capı́tulo 21 Transformación de datos (TRANS) 21.1. Descripción general El programa TRANS crea un nuevo dataset IDAMS que contiene variables de un dataset existente y nuevas variables definidas por las proposiciones de Recode. Es la manera de “salvar” variables recodificadas. TRANS tiene una opción de impresión y ası́ puede usarse para probar proposiciones de Recode sobre un número pequeño de casos antes de ejecutar un programa de análisis o antes de guardar el archivo completo. 21.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. El filtro estándar está disponible para seleccionar un subconjunto de los casos del archivo Datos de entrada. La selección de variables se lleva a cabo con el parámetro OUTVARS. Transformación de datos. Se pueden usar las proposiciones de Recode. Tratamiento de datos faltantes. Los códigos de datos faltantes apropiados se escriben en el diccionario de salida; éstos se copian normalmente del diccionario de entrada pero pueden también ser obviados o suministrados para variables de salida a través de la proposición Recode MDCODES. No se hace verificación de datos faltantes sobre valores de datos, excepto a través del uso de proposiciones de Recode. 21.3. Resultados Diccionario de salida. (Opcional: ver el parámetro PRINT). Datos de salida. (Opcional: ver el parámetro PRINT). Se dan los valores de todos los casos para cada variable V o R, 10 variables por lı́nea. Para variables alfabéticas sólo se imprimen los primeros 10 caracteres. 21.4. Dataset de salida La salida es un dataset IDAMS que contiene sólo aquellas variables (V y R) especificadas en el parámetro OUTVARS. La información del diccionario para las variables en el archivo de salida se asigna de la manera siguiente: Orden y numeración de variables. Si se ha especificado VSTART, la salida de variables se lleva acabo en el orden en el que aparecen en la lista OUTVARS y siempre se renumeran a partir del valor dado en el parámetro VSTART. Si no se ha especificado VSTART, el programa no cambia los números de variable y las variables salen en orden ascendente de los números. 166 Transformación de datos (TRANS) Nombre de variable y códigos de datos faltantes. Se toman del diccionario de entrada (sólo variables V) o de las proposiciones de Recode NAME y MDCODES, si las hay. Localización de variable. La localización de variables se asigna de forma contigua de acuerdo con el orden de las variables en la lista OUTVARS (si se ha especificado VSTART) o en el orden de los números de variable después de clasificar (si no se ha especificado VSTART). Tipo de variable, ancho y número de decimales. Variables V: tipo, ancho de campo y número de decimales son los mismos que sus valores de entrada. Variables R: el tipo para variables R es siempre numérico; el ancho y número de decimales se asignan de acuerdo con los valores especificados para los parámetros WIDTH (por defecto 9) y DEC (por defecto 0), o de acuerdo con los valores especificados para variables individuales con las especificaciones de diccionario. Número de referencia e identificador de estudio. El número de referencia y el identificador de estudio para una variable V son sus mismos valores de entrada. Para las variables R el identificador de estudio es siempre REC. Registros C. No se pueden crear registros C para variables R. Los registros C (si los hay) para todas las variables V se copian al diccionario de salida. Nótese que si una variable V es codificada nuevamente durante una ejecución de TRANS, los registros C que salen no se pueden aplicar más a la nueva versión de la variable. 21.5. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. Se pueden usar variables numéricas o alfabéticas. 21.6. Estructura del setup $RUN TRANS $FILES Especificación de archivos $RECODE (opcional) Proposiciones de Recode $SETUP 1. 2. 3. 4. Filtro (opcional) Tı́tulo Parámetros Especificaciones de diccionario (opcional) $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx DICTyyyy DATAyyyy PRINT diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) diccionario de salida datos de salida resultados (por defecto IDAMS.LST) 21.7 Proposiciones de control del programa 21.7. 167 Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-4, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: EXCLUDE V19=2-3 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: CONSTRUCCION DE INDICADORES DE VIOLENCIA 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: VSTART=1, WIDTH=2, OUTVARS=(V2-V5,R7) INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos en entrada y los valores con “amplitud insuficiente de campo” en salida. Ver el capı́tulo “El archivo Setup de IDAMS”. MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. MAXERR=0/n Máximo número de errores “insufficient-field width” (amplitud insuficiente de campo) permitido antes de detener la ejecución. Estos errores se presentan cuando el valor de una variable es demasiado grande para caber dentro del campo asignado, por ej. un valor de 250 cuando se ha especificado WIDTH=2. Ver el capı́tulo “Los datos en IDAMS”. OUTFILE=OUT/yyyy Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de salida. Por defecto: DICTOUT, DATAOUT. OUTVARS=(lista de variables) Las variables V o R que irán a la salida. El orden de las variables en la lista es siginificativo sólo si se ha especificado el parámetro VSTART. Si no se especifica VSTART todos los números de variables V o R deben ser únicos. Sin valor por defecto. VSTART=n Las variables se numerarán secuencialmente a partir de n en el dataset de salida. Por defecto: se retienen los números de variable de entrada. WIDTH=9/n Valor por defecto del ancho de campo de la variable de salida a usar para las variables R. Este valor por defecto se puede reemplazar para variables especı́ficas con la especificación de diccionario WIDTH. Para cambiar el ancho de campo de una variable numérica V, se crea una variable R equivalente (ver Ejemplo 1). DEC=0/n Número de cifras decimales a retener para variables R. 168 Transformación de datos (TRANS) PRINT=(OUTDICT/OUTCDICT/NOOUTDICT, DATA) OUTD Imprimir el diccionario de salida sin registros C. OUTC Imprimir el diccionario de salida con registros C, si los hay. DATA Imprimir los valores de las variables de salida. 4. Especificaciones de diccionario (opcional). Para cualquier conjunto particular de variables, se puede especificar el ancho de campo y el número de cifras decimales. Estas especificaciones obviarán los valores colocados por los parámetros principales WIDTH y DEC. Nótese que los códigos de datos faltantes y los nombres de variables se asignan con las proposiciones de Recode MDCODES y NAME respectivamente. Advertencia: la proposición MDCODES retiene sólo 2 cifras decimales para variables R y redondea los valores apropiadamente. Las reglas de codificación son las mismas de los parámetros. Cada especificación de diccionario debe comenzar en una lı́nea nueva. Ejemplos: VARS=R4, WIDTH=4, DEC=1 VARS=R8, WIDTH=2 VARS=(R100-R109), WIDTH=1 VARS=(lista de variables) La lista de variables a la cual aplican los parámetros WIDTH y DEC. WIDTH=n Ancho de campo para las variables de salida. Por defecto: valor dado para el parámetro WIDTH. DEC=n Número de cifras decimales. Por defecto: valor dado para el parámetro DEC. 21.8. Restricciones 1. El máximo número de variables R que puede salir es 250. 2. El máximo número de variables que pueden ser usadas en la ejecución (incluidas las variables usadas sólo en las proposiciones Recode) es 500. 3. El máximo número de especificaciones de diccionario es 200. 21.9. Ejemplos Ejemplo 1. Las variables seleccionadas del dataset de entrada se transfieren al archivo de salida junto con las dos nuevas variables; no se cambian los números de variable; el ancho de campo de la variable de entrada V20 se cambia a 4. $RUN TRANS $FILES PRINT = TRANS1.LST DICTIN = OLD.DIC archivo Diccionario de entrada DATAIN = OLD.DAT archivo Datos de entrada DICTOUT = NEW.DIC archivo Diccionario de salida DATAOUT = NEW.DAT archivo Datos de salida $SETUP CONSTRUCCION DE DOS NUEVAS VARIABLES PRINT=NOOUTDICT OUTVARS=(V1-V19,R20,V33,V45-V50,R105,R122) VARS=R105,WIDTH=1 VARS=R122,WIDTH=3,DEC=1 21.9 Ejemplos 169 VARS=R20,WIDTH=4 $RECODE R20=V20 NAME R20’VARIABLE 20’ R105=BRAC(V5,15-25=1,<36=2,<46=3,<56=4,<66=5,<90=6,ELSE=9) MDCODES R105(9) NAME R105’GRUPOS DE EDAD’ IF MDATA(V22) THEN R122=99.9 ELSE R122=V22/3 MDCODES R122(99.9) NAME R122’NR. ARTICULOS POR ANO’ Ejemplo 2. Este ejemplo ilustra el uso de TRANS para verificar proposiciones de Recode; se listan los valores de los datos para las variables identificadoras (V1, V2), las variables usadas en Recode y las variables de resultado para los primeros 30 casos; no se requiere el dataset de salida y no se define. $RUN TRANS $FILES PRINT = TRANS2.LST DICTIN = STUDY.DIC archivo Diccionario de entrada DATAIN = STUDY.DAT archivo Datos de entrada $SETUP VERIFICACION DE RECODE WIDTH=2 PRINT=(DATA,NOOUTDICT) MAXCASES=30 OUTVARS=(V1-V2,V71-V74,V118,V12,V13,R901-R903) $RECODE R901=BRAC(V118,1-16=2,17=1,18-23=3,24=1,25-35=3,36=1,37=2,ELSE=9) IF NOT MDATA(V12,V13) THEN R902=TRUNC(V12/V13) ELSE R902=99 R903=COUNT(1,V71-V74) Ejemplo 3. Creación de un archivo de prueba con una muestra aleatoria de 1/20 del archivo Datos; no se necesita salvar el diccionario de salida ya que será idéntico al de entrada. $RUN TRANS $FILES DICTIN = STUDY.DIC archivo Diccionario de entrada DATAIN = STUDY.DAT archivo Datos de entrada DATAOUT = TESTDATA archivo Datos de salida $SETUP CREA ARCHIVO PRUEBA CON TODAS VARIABLES MUESTRA DE CASOS 1/20 PRINT=NOOUTDICT OUTVARS=(V1-V505) $RECODE IF RAND(0,20) NE 1 THEN REJECT Parte IV Facilidades para análisis de datos Capı́tulo 22 Análisis de conglomerados (CLUSFIND) 22.1. Descripción general CLUSFIND hace análisis de conglomerados mediante la separatión de un conjunto de objetos (casos o variables) en un conjunto de conglomerados según se determina por uno de seis algoritmos: dos algoritmos basados en repartición alrededor de medoides, uno basado en conglomeración difusa y tres basados en conglomeración jerárquica. 22.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. Si entran datos primarios, se puede utilizar el filtro estándar para escoger un subconjunto de casos de los datos de entrada. Las variables para análisis se espcifican en el parámetro VARS. Transformación de datos. Si entran datos primarios, se pueden usar las proposiciones de Recode. Ponderación de datos. No se aplica el uso de variables de ponderación. Tratamiento de datos faltantes. Si entran datos primarios, el parámetro MDVALUES está disponible para indicar cuales valores de datos faltantes, si los hay, se usarán para verificar datos faltantes. Los casos en los cuales hay datos faltantes para todas las variables se eliminan automáticamente. Si no, datos faltantes se eliminan por pares. Si los datos están estandarizados, el promedio y la desviación media absoluta se calculan usando sólo valores válidos. Cuando se calculan las distancias, sólo se consideran en la suma aquellas variables para las cuales hay valores válidos presentes para ambos objetos. Si entra una matriz, el parámetro MDMATRIX está disponible para indicar qué valor se va a usar para verificar elementos inválidos en la matriz. 22.3. Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variables y registros C, si los hay, solamente para variables utilizadas en la ejecución. Datos de entrada después de la estandarización. (Opcional: ver el parámetro PRINT). Los valores estandarizados para todos los casos para cada variable V o R usada en el análisis, precedidos de el promedio y la desviación absoluta media para estas variables. Matriz de disimilitudes. (Opcional: ver el parámetro PRINT). El triángulo inferior izquierdo de la matriz, tal como se leyó o fué calculado por el programa. 174 Análisis de conglomerados (CLUSFIND) Resultados del análisis PAM. Para cada número de conglomerados en turno (desde CMIN a CMAX) se imprime lo siguiente: número de objetos representativos (conglomerados) y la distancia final promedio, para cada conglomerado: identificador del objeto representativo, número de objetos y la lista de objetos que pertenecen a ese conglomerado, coordenandas de los medoides (valores de la variables de análisis para cada objeto repersentativo; sólo para el dataset de entrada), vector de conglomeración (un vector de números que corresponde a los objetos e indica a qué conglomerado pertenece cada objeto) y caracteristicas de conglomeración, representación gráfica de los resultados, es decir, un gráfico de silueta para cada conglomerado (opcional - ver el parámetro PRINT). Resultados del análisis FANNY. Para cada número de conglomerados en turno (desde CMIN a CMAX) se imprime lo siguiente: número de conglomerados, valor de la función objetivo en cada iteración, para cada objeto, su identificador y el coeficiente de pertenencia para cada conglomerado, coeficiente de partición de Dunn y su versión normalizada, conglomeración dura más cercana, es decir, número de objetos y la lista de objetos que pertenecen a cada conglomerado, vector de conglomeración, representación gráfica de los resultados, es decir, un gráfico de silueta para cada conglomerado (opcional - ver el parámetro PRINT). Resultados del análisis CLARA. Para el número de conglomerados ensayados se imprime lo siguiente: lista de objetos seleccionados en la muestra retenida, vector de conglomeración, para cada conglomerado: identificador del objeto representativo, número de objetos y la lista de objetos que pertenecen a ese conglomerado, distancia promedio y distancia máxima a cada medoide, representación gráfica de los resultados, es decir, un gráfico de silueta para cada conglomerado (opcional - ver el parámetro PRINT). Resultados del análisis AGNES contiene lo siguiente: ordenamiento final de los objetos (identificados por su identificador) y disimilitudes entre ellos, representación gráfica de los resultados, es decir, un gráfico de “bandera” de disimilitudes (opcional ver el parámetro PRINT). Resultados del análisis DIANA contiene lo siguiente: ordenamiento final de los objetos (identificados por su identificador) y diámetros de los conglomerados, representación gráfica de los resultados, es decir, un gráfico de “bandera” de disimilitudes (opcional ver el parámetro PRINT). Resultados del análisis MONA contiene lo siguiente: huella de las separaciones (opcional - ver el parámetro PRINT) para cada paso, con el conglomerado a separar, la lista de objetos (identificados por su valor de la variable identificadora) en cada uno de los dos subconjuntos y la variable usada para la separación, el ordenamiento final de objetos, representación gráfica de los resultados, es decir, un gráfico de separación con la lista de objetos en cada conglomerado y la variable usada para la separación (opcional - ver el parámetro PRINT). 22.4. Dataset de entrada El dataset de entrada es un archivo Datos descrito por un diccionario IDAMS. Todas las variables usadas para análisis deben ser numéricas; pueden ser enteras o con cifras decimales. La variable identificadora de caso puede ser alfabética. Las variables usadas en los análisis PAM, CLARA, FANNY, AGNES o DIANA deben tener escala de intervalo. Las variables usadas en el análisis MONA deben ser binarias (con valores 0 o 1). Nótese que CLUSFIND usa como máximo 8 caracteres del nombre de la variable como se suministra en el diccionario. 22.5 Matriz de entrada 22.5. 175 Matriz de entrada Esta es una matriz cuadrada de IDAMS. Ver el capı́tulo “Los datos en IDAMS”. Puede contener medidas de similitudes, disimilitudes o coeficientes de correlación. Nótese que CLUSFIND usa máximo 8 caracteres del nombre del objeto como se suministra en los registros de identificación de variables. 22.6. Estructura del setup $RUN CLUSFIND $FILES Especificación de archivos $RECODE (opcional con entrada de datos primarios; no disponible con entrada matricial) Proposiciones de Recode $SETUP 1. Filtro (opcional, sólo para entrada de datos primarios) 2. Tı́tulo 3. Parámetros $DICT (condicional) Diccionario para la entrada de datos primarios $DATA (condicional) Datos para la entrada de datos primarios $MATRIX (condicional) Matriz para la entrada de la matriz Archivos: FT09 DICTxxxx DATAxxxx PRINT 22.7. matriz de entrada (si no se usa $MATRIX y se usa entrada matricial) diccionario de entrada (si $DICT no se usa y INPUT=RAWDATA) datos de entrada (si $DATA no se usa y INPUT=RAWDATA) resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-3, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Disponible solamente con datos primarios de entrada. Ejemplo: INCLUDE V8=5-10 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: PARTICION CON CONGLOMERACION DIFUSA 176 Análisis de conglomerados (CLUSFIND) 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: ANALYSIS=PAM VARS=(V7-V12) INPUT=RAWDATA/SIMILARITIES/DISSIMILARITIES/CORRELATIONS RAWD En entrada: un archivo Datos descrito por un diccionario IDAMS. SIMI En entrada: medidas de similitudes en la forma de una matriz cuadrada IDAMS. DISS En entrada: medidas de disimilitudes en la forma de una matriz cuadrada IDAMS. CORR En entrada: coeficientes de correlación en la forma de una matriz cuadrada IDAMS. Parámetros sólo para entrada de datos primarios INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos. Ver el capı́tulo “El archivo Setup de IDAMS”. MAXCASES=100/n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Su valor depende de la memoria disponible. n=0 No ejecuta, sólo verifica los parámetros. 0<n<=100 Ejecución normal. n>100 Sólo permite ANALYSIS=CLARA. MDVALUES=BOTH/MD1/MD2/NONE Cuales valores de datos faltantes se van a usar para las variables accedidas en esta ejecución. Ver el capı́tulo “El archivo Setup de IDAMS”. STANDARDIZE Estandarizar las variables antes de calcular las disimilitudes. DTYPE=EUCLIDEAN/CITY Tipo de distancia utilizado para calcular las disimilitudes. EUCL Distancia euclideana. CITY Distancia en cuadra urbana (“city block”). IDVAR=número de variable Variable que se imprime como identificadora de caso. Sólo se usan tres caracteres en el listado. Ası́, las variables enteras deben tener valores menores que 1000. Sólo se imprimen los tres primeros caracteres de una variable alfabética. Sin valor por defecto. PRINT=(CDICT/DICT, STAND) CDIC Imprimir el diccionario de entrada para las variables accedidas con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. STAN Imprimir los datos de entrada después de la estandarización. Parámetros sólo para entrada matricial DISSIMILARITIES=ABSOLUTE/SIGN Para INPUT=CORR, especifica cómo se debe calcular la matriz de disimilitudes. ABSO Considerar valores absolutos de coeficientes de correlación como medida de similitud. SIGN Usar coeficientes de correlación con sus signos. 22.8 Restricciones 177 MDMATRIX=n Tratar los elementos de la matriz iguales a n como datos faltantes. Por defecto: todos los valores son válidos. PRINT=MATRIX Imprimir la martiz de entrada. Parámetros para ambos tipos de entrada VARS=(lista de variables) Variables a usar en este análisis. Sin valor por defecto. ANALYSIS=PAM/FANNY/CLARA/AGNES/DIANA/MONA Especifica el tipo de análisis a hacer. PAM Repartición alrededor de medoides. FANN Conglomeración difusa. CLAR Repartición alrededor de medoides (igual a PAM), pero para datasets de al menos 100 casos. CLUSFIND hará un muestreo de los casos y escogerá la mejor muestra representativa. Se extraen cinco muestras de 40+2*CMAX casos (ver el parámetro CMAX más adelante). Sólo para entrada de datos primarios. AGNE Conglomeratión jerárquica acumulativa. DIAN Conglomeratión jerárquica divisiva. MONA Conglomeración monotética de datos con variables binarias. Requiere al menos tres variables. Sólo para entrada de datos primarios. Sin valor por defecto. CMIN=2/n Para PAM y FANNY. Número mı́nimo de conglomerados a ensayar. CMAX=n Para PAM y FANNY, número máximo de conglomerados a ensayar. Para CLARA, número exacto de conglomerados ensayar. Por defecto: el mayor de 20 y el valor especificado en CMIN. PRINT=(DISSIMILARITIES, GRAPH, TRACE, VNAMES) DISS Imprimir la matriz de disimilitudes. GRAP Imprimir la representación gráfica de los resultados. TRAC Imprimir cada paso de la separación binaria cuando se especifica MONA. VNAM Para entrada matricial, imprimir los primeros 3 o 8 caracteres de nombres en vez de los números de las variables como identificador del objecto. 22.8. Restricciones 1. El número máximo de casos que se pueden usar en un análisis (excepto CLARA) es 100. 2. El número mı́nimo de casos requerido para análisis CLARA) es 100. 3. El número máximo de objetos en una matriz de entrada es 100. 4. Sólo los tres caracteres de una variable alfabética se usan en el listado. 178 Análisis de conglomerados (CLUSFIND) 22.9. Ejemplos Ejemplo 1. Conglomerar los primeros 100 casos en 5 grupos usando 6 variables cuantitativas V11-V16; se estandarizan los valores de las variables y se usa la distancia euclideana en los cálculos; la conglomeración se hace con la repartición alrededor de los medoides; se solicita imprimir gráficos; los casos se identifican con la variable V2. $RUN CLUSFIND $FILES PRINT = CLUS1.LST DICTIN = MY.DIC archivo Diccionario de entrada DATAIN = MY.DAT archivo Datos de entrada $SETUP ANALISIS PAM CON DATOS PRIMARIOS COMO ENTRADA BADD=MD1 VARS=(V11-V16) STAND IDVAR=V2 CMIN=5 CMAX=5 PRINT=GRAP Ejemplo 2. Conglomerado jerárquico aglomerativo de 30 pueblos; la matriz de entrada contiene distancias entre los pueblos y los pueblos se numeran de 1 a 30; se solicita imprimir gráficos; los nombres de pueblo se usan en el listado. $RUN CLUSFIND $FILES PRINT = CLUS2.LST FT09 = TOWNS.MAT archivo Matriz de entrada $SETUP ANALISIS AGNES CON LA MATRIZ DE DISTANCIAS COMO ENTRADA $COMMENT LAS DISTANCIAS ACTUALES SE DIVIDIERON POR 10.000 PARA $COMMENT ESTAR EN EL INTERVALO 0-1 INPUT=DISS VARS=(V1-V30) ANAL=AGNES PRINT=(GRAP,VNAMES) Capı́tulo 23 Análisis de configuración (CONFIG) 23.1. Descripción general CONFIG hace análisis de configuración espacial sencilla, sobre datos de entrada en la forma de una matriz rectangular de IDAMS (tal como se produce, por ejemplo en MDSCAL). Tiene la capacidad de centrar, normalizar, rotar, trasladar dimensiones, calcular distancias entre puntos y calcular productos escalares. Cada fila de una matriz de configuración suministra las coordenadas de un punto de la configuración. Ası́, el número de filas es igual al número de puntos (variables), mientras que el número de columnas es igual al número de dimensiones. CONFIG puede proveer resultados que le permiten al usuario comparar de manera más fácil, configuraciones las cuales originalmente tenı́an orientaciones disı́miles. Puede también usarse para hacer análisis adicionales sobre una configuración. La rotación, por ejemplo, puede hacer una configuración más fácilmente interpretada. 23.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. No se aplica la selección de un subconjunto de casos y no hay filtro disponible. Tampoco hay una opción de CONFIG que permita subdividir la configuración de entrada. Existe en CONFIG una opción para seleccionar una matriz de un archivo que tenga múltiples matrices (ver el parámetro DSEQ). Transformación de datos. No se aplica el uso de las proposiciones de Recode con CONFIG. Ponderación de datos. No se aplica el uso de variables de ponderación. Tratamiento de datos faltantes. CONFIG no reconoce datos faltantes en la configuración de entrada. Normalmente, ésto no presenta ningún problema, ya que las configuraciones se presentan usualmente completas. 23.3. Resultados Diccionario de la matriz de entrada. (Condicional: sólo si la matriz de entrada tenı́a diccionario. Ver parámetro MATRIX). Los registros de variables del diccionario de entrada con los números correspondientes usados en los gráficos (etiquetas de gráficos). Configuración de entrada. Una copia impresa de la configuración de entrada. Configuración centrada. (Opcional: ver el parámetro PRINT). Si se especifica PRINT=ALL o PRINT=CENT y la configuración de entrada ya está centrada, se imprime el mensaje “Configuración de entrada está centrada”. 180 Análisis de configuración (CONFIG) Configuración normalizada. (Opcional: ver el parámetro PRINT). Si se especifica PRINT=ALL o PRINT=NORM y la configuración de entrada ya está normalizada, se imprime el mensaje “Configuración de entrada está normalizada”. Solución en ejes principales. (Opcional: ver el parámetro PRINT). Las filas de la matriz son los puntos y las columnas son los ejes principales. Los elementos de la matriz son las proyecciones de los puntos sobre los ejes. Productos escalares. (Opcional: ver el parámetro PRINT). Se imprime la mitad inferior izquierda de la matriz simétrica. Cada elemento de la matriz es el producto escalar de un par de puntos (variables). Distancias entre puntos. (Opcional: ver el parámetro PRINT). Se imprime la mitad inferior izquierda de la matriz simétrica. Cada elemento de la matriz es la distancia entre un par de puntos (variables). La diagonal, siempre en ceros, se imprime. Configuración(es) transformada(s). (Opcional: ver el parámetro de especificación de transformación PRINT). La configuración transformada se imprime después de la rotación/traslación. Gráfico de la(s) configuración(es) transformada(s). (Opcional: ver el parámetro de especificación de transformación PRINT). Se dibuja la configuración transformada en dos ejes a la vez después de la rotación/traslación. Se numeran los puntos. Historia de la rotación varimax. (Opcional: ver el parámetro PRINT). Se imprime un vector que contiene la variancia de la matriz de configuración antes de cada ciclo de iteración. En seguida se imprime la matriz de configuración después de la rotación para maximizar el criterio normal de varimax. Tendrá el mismo número de filas y columnas de la matriz de configuración de entrada. Configuración clasificada. (Opcional: ver el parámetro PRINT). Se imprime horizontalmente a través de la página cada columna de la matriz de configuración, después de haber sido clasificada. Gráficos de vectores. (Opcional: ver el parámetro PRINT). Se dibuja la configuración final en dos ejes a la vez. Los puntos se numeran con las etiquetas de los gráficos de las variables tal como se imprimió con el diccionario de la configuración de entrada. 23.4. Matriz de configuración de salida La configuración final se puede escribir en un archivo (ver el parámetro WRITE). Sale como una matriz rectangular de IDAMS. Ver el capı́tulo “Los datos en IDAMS” para una descripción de las matrices de IDAMS. Los registros de identificación de variables se imprimen sólo si tales registros se han incluido en el archivo de la configuración de entrada (ver el parámetro MATRIX). El formato de los elementos de la matriz es 10F7.3. Los registros que contienen los elementos de la matriz se identifican con CFG en las columnas 73-75 y un número secuencial en las columnas 76-80. Las dimensiones de la matriz son las mismas de la matriz de entrada. 23.5. Matriz de distancias de salida La matriz de distancias entre puntos se puede escribir en un archivo (ver el parámetro WRITE). Sale en la forma de una matriz cuadrada de IDAMS, con registros ficticios suministrados para la media y la desviación estándar esperadas en este tipo de matriz. Los registros de identificación de variables se producen sólo si éstos se incluyeron en el archivo de la configuración de entrada (ver el parámetro MATRIX). El formato de los elementos de la matriz es 10F7.3. Los registros que contienen los elementos de la matriz se identifican con CFG en las columnas 73-75 y un número secuencial en las columnas 76-80. 23.6. Matriz de configuración de entrada La matriz de entrada debe estar en la forma de una matriz rectangular de IDAMS, con o sin registros de identificación de variables (ver el parámetro MATRIX). Ver el capı́tulo “Los datos en IDAMS” para una descripción del formato. 23.7 Estructura del setup 181 Las matrices de configuración obtenidas con el programa MDSCAL, pueden entrar directamente a CONFIG. La matriz de entrada de n(filas) por m(columnas), debe tener las coordenadas de n puntos para m dimensiones. No puede haber datos faltantes en la matriz de entrada. En un archivo leido por CONFIG, puede haber más de una configuración. La configuración a analizar se escoge con el parámetro DSEQ. 23.7. Estructura del setup $RUN CONFIG $FILES Especificación de archivos $SETUP 1. Tı́tulo 2. Parámetros 3. Especificaciones de transformación (opcionales) $MATRIX (condicional) Matriz Archivos: FT02 FT09 PRINT 23.8. configuración de salida y/o matriz de distancias configuración de entrada (omitir si se usa $MATRIX) resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-3, a continuación. 1. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: EJECUCION DE CONFIG DESPUES DE MDSCAL 2. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: PRINT=(CENT,SORT,DIST) TRANS MATRIX=STANDARD/NONSTANDARD STAN Se incluyen los registros de identificación de variables en la matriz de entrada. NONS No se incluyen los registros de identificación de variables en la matriz de entrada. DSEQ=1/n El número secuencial en el archivo de entrada de la configuración que se analiza. WRITE=(CONFIG,DISTANCES) CONF Llevar la configuración final a un archivo. DIST Llevar a un archivo la matriz de distancias entre puntos. 182 Análisis de configuración (CONFIG) TRANSFORM Se suministrarán especificaciones de transformación. PRINT=(CENTER, NORMALIZE, PRINAXIS, SCALARS, DISTANCES, VARIMAX, SORTED, PLOT, ALL) CENT Mover el origen al centroide del espacio. NORM Alterar el tamaño del espacio de manera que al sumar las cargas al cuadrado, esta suma sea igual al número de variables. PRIN Búsqueda de solución en ejes principales. SCAL Matriz de productos escalares. DIST Matriz de distancias entre puntos. VARI Rotación (después de transformación, si la hay) ortogonal (varimax). SORT Configuración clasificada (después de transformación, si la hay). PLOT Graficar la configuración final. ALL Imprimir CENT, NORM, PRIN, SCAL, DIST, VARI, SORT, PLOT. Por defecto: la configuración de entrada se imprime. Nota. Las opciones de análisis se llevan a cabo sobre los datos de la configuración de entrada en la secuencia especificada arriba, sin importar el orden en el cual se hayan especificado con el parámetro PRINT. Transformaciones, si las hay, se llevan a cabo antes de la rotación ortogonal de la configuración. Después de cada operación, se imprimen los resultados. Los efectos de las opciones de análisis son acumulativos. Si la configuración final se grafica y/o se almacena, ésto se hace después de haber hecho todos los análisis. 3. Especificaciones de transformación. (Condicional: si se ha especificado TRANSFORM, usar los parámetros como se explica a continuación). Se pueden especificar tantas transformaciones como se desée; cada una debe comenzar en una nueva lı́nea. Si el usuario especifica el ángulo de rotación (DEGREES) y dos dimensiones (DIMENSION), entonces se hace una rotación. Si se especifica una constante (ADD) y una dimensión (DIMENSION), se hace una traslación. Ejemplo: DEGR=45, DIME=(5,8) PRINT=PLOT PRINT=(CONFIG, PLOT) CONF Imprimir la configuración rotada o trasladada (automático para configuraciones con 2 dimensiones y para la configuración final). PLOT Graficar la configuración rotada o trasladada. Nota: no habrán resultados para la transformación si no se especifica PRINT. Debe especificarse para cada transformación. Parámetros de rotación DIMENSION=(n, m) Las dos dimensiones a rotar (sólo rotación pareada). DEGREES=n Angulo de rotación en grados (sólo rotación ortogonal). Parámetros de traslación DIMENSION=n La dimensión a trasladar. ADD=n Valor a sumar a cada coordenada en la dimensión especificada (puede ser negativo y tener cifras decimales). 23.9 Restricción 23.9. 183 Restricción El tamaño máximo de la matriz de configuración de entrada es de 60 filas por 10 columnas. 23.10. Ejemplos Ejemplo 1. Rotación y transformación de una matriz de configuración creada previamente por el programa MDSCAL; la configuración final se escribe en un archivo y se grafica; se rotan las dimensiones 1 y 2 por un ángulo de 60 grados; la dimensión 1 se transformará sumando 6. $RUN CONFIG $FILES PRINT = CONF1.LST FT02 = CONFIG.MAT archivo para la matriz de configuración de salida FT09 = MDS.MAT matriz de configuración de entrada $SETUP ANALISIS DE CONFIGURACION PRINT=(PLOT,VARI) TRAN WRITE=CONF DEGR=60 DIME=(1,2) PRINT=PLOT ADD=6 DIME=1 PRINT=PLOT Ejemplo 2. Cálculo de la matriz de productos escalares y la matriz de distancias entre puntos para la cuarta configuración en el archivo de entrada; no se requieren gráficos. $RUN CONFIG $FILES PRINT = CONF2.LST FT02 = SCAL.MAT FT09 = MDS.MAT $SETUP ANALISIS DE CONFIGURACION PRINT=(SCAL,DIST) DSEQ=4 archivo de salida para la matriz de productos escalares y la matriz de distancias entre puntos matriz de configuración de entrada Capı́tulo 24 Análisis discriminatorio (DISCRAN) 24.1. Descripción general La tarea del análisis discriminatorio es hallar la mejor o las mejores funciones de discriminación lineal de un conjunto de variables que reproduzca o reproduzcan, hasta donde sea posible, un agrupamiento “a priori” de los casos considerados. En este programa se usa un procedimiento por pasos, es decir, en cada paso la variable más poderosa entra a la función discriminatoria. La función criterio para la selección de la variable siguiente, depende del número de grupos especificados (el número de grupos varı́a entre 2 y 20). En el caso de dos grupos se usa la distancia de Mahalanobis. Cuando el número de grupos es mayor que dos, entonces el criterio para la selección de variables es la huella de un producto entre la matriz de covariancia de las variables involucradas y la matriz de covariancia interclase en una paso en particular. Esto es una generalización de la distancia de Mahalanobis definida para dos grupos. Además de ejecutar los pasos principales de análisis discriminatorio sobre una muestra básica, hay dos posibilidades opcionales: verificación del poder de la función o funciones discriminatorias con la ayuda de una muestra de prueba, para la cual se conoce la asignación de casos a grupos (como en la muestra básica) pero los cuales no se usaron en el análisis, y clasificación de los casos con la ayuda de funcion(es) discriminatoria(s) suministrada(s) por el análisis en una muestra anónima en la cual se desconoce, o por lo menos no se usa la asignación de casos a grupos. 24.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. El filtro estándar está disponible para escoger un subconjunto de casos de los datos de entrada. Es posible hacer una subdivisión adicional con el uso de las variables de muestra y de grupo. Las variables de análisis se escogen con el parámetro VARS. Transformación de datos. Se pueden usar las proposiciones de Recode. Ponderación de datos. Se puede usar una variable para ponderar los datos de entrada; esta variable de ponderación puede tener cifras enteras o decimales. Cuando el valor de la variable de ponderación para un caso es cero, negativo, dato faltante o no numérico, entonces el caso siempre se omite; se imprime el número de casos ası́ tratados. Tratamiento de datos faltantes. El parámetro MDVALUES está disponible para indicar cuales valores de datos faltantes, si los hay, se usarán para verificar los datos faltantes. Los casos con datos faltantes en la variable de muestra, la variable de grupo y/o las variables de análisis, se pueden excluir del análisis de manera opcional. 186 Análisis discriminatorio (DISCRAN) 24.3. Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variables y registros C, si los hay, sólo para las variables usadas en la ejecución. Número de casos en las muestras. El número de casos en las muestras básica, de prueba y anónima de acuerdo con los parámetros de definición de la muestra. Número revisado de casos en las muestras. El número de casos en las muestras básica, de prueba y anónima de acuerdo con los parámetros de definición de la muestra y del grupo. Nótese que las cifras revisadas pueden ser menores que las no revisadas para la muestra básica y la muestra de prueba si los grupos definidos no cubren completamente las muestras. Muestra básica. (Opcional: ver el parámetro PRINT). Se imprimen por grupos, las variables de identificación y de análisis de los casos en la muestra básica, los grupos se separan unos de otros con una lı́nea de asteriscos. Muestra de prueba. Igual a la muestra básica. Muestra anónima. Igual a la muestra básica pero no hay grupos. Estadı́sticas univariadas. El programa imprime las medias y desviaciones estándar grupales, ası́ como la media total para cada variable usada en el análisis. Resultados del procedimiento por pasos (para cada paso) Número del paso. El número secuencial del paso. Variables ingresadas. La lista de variables retenidas en este paso. Función discriminatoria lineal. (Condicional: sólo si se especifican 2 grupos). El término constante y los coeficientes de la función discriminatoria lineal correspondientes a las variables que ya han entrado. Tabla de clasificación para la muestra básica. Una tabla bivariada de frecuencias que muestra la redistribución de casos entre los grupos originales y los grupos en los cuales se los ha colocado según la función discriminatoria, seguida del porcentaje de casos clasificados correctamente. Tabla de clasificación para la muestra de prueba. Igual a la muestra básica. Lista de asignación de casos. (Opcional: ver el parámetro PRINT). Se imprimen los casos de las tres muestras con identificación de caso, colocación de caso y valor de la función discriminatoria (para 2 grupos) o distancias a cada grupo (para más de 2 grupos). Resultados del análisis factorial discriminatorio. (Condicional: sólo si se han especificado más de 2 grupos). Poder discriminatorio general y poder discriminatorio de los primeros tres factores, seguidos de los valores de los factores discriminatorios para las medias de grupos. Adicionalmente, se suministra una representación gráfica de casos y medias en el espacio de los dos primeros factores. 24.4. Dataset de salida Se puede pedir un dataset para la última asignación de grupos a los casos. Sale en la forma de un archivo Datos descrito por un diccionario IDAMS (ver el parámetro WRITE y el capı́tulo “Los datos en IDAMS”). Contiene en orden siguiente: - las variables transferidas, el código del grupo original renumerado por DISCRAN (“Original group”), el código del grupo asignado a los casos al final (“Assigned group”), el tipo de la muestra (“Sample type” - 1=muestra básica, 2=muestra de prueba, 3=muestra anónima) y, para análisis con más de 2 grupos, valores de los dos primeros factores discriminatorios (“Factor-1”, “Factor-2”). Las variables se numeran desde uno. El código del grupo original contiene el primer código de datos faltantes (999.9999) para los casos en la 24.5 Dataset de entrada 187 muestra anónima; los factores contienen el primer código de datos faltantes (999.9999) para los casos en la muestra de prueba y la muestra anónima. Nota: la variable especificada en IDVAR no sale de manera automátia y entonces debe ser incluida en la lista de variables para ser transferidas. 24.5. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. Se pueden especificar tres tipos de muestra en el archivo de entrada: - muestra básica, - muestra de prueba, - muestra anónima. El análisis se basa en la muestra básica. La muestra de prueba se usa para probar la(s) función(es) discriminatoria(s), los casos en la muestra anónima simplemente se clasifican con las funciones discriminatorias. Las muestras se definen con una “variable de muestra”. La muestra básica no debe estar vacı́a. Los grupos que se van a separar con la función discriminatoria deben definirse con una “variable de grupo”. Esta variable define una clasificación a priori de la muestra básica y de la muestra de prueba de los casos. Todas las variables usadas para análisis deben ser numéricas; pueden tener cifras enteras o decimales. La variable identificadora del caso y las variables para ser transferidas pueden ser alfabéticas. 24.6. Estructura del setup $RUN DISCRAN $FILES Especificación de archivos $RECODE (opcional) Proposiciones de Recode $SETUP 1. Filtro (opcional) 2. Tı́tulo 3. Parámetros $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx DICTyyyy DATAyyyy PRINT diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) diccionario de salida si se especifica WRITE=DATA datos de salida si se especifica WRITE=DATA resultados (por defecto IDAMS.LST) 188 Análisis discriminatorio (DISCRAN) 24.7. Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-3, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: INCLUDE V3=6 OR V11=99 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: ANALISIS DISCRIMINATORIO DE UNA ENCUESTA AGRICOLA 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: MDHA=SAMPVAR IDVAR=V4 VARS=(V12-V15) SAVAR=R5 BASA=(1,5) - INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos. Ver el capı́tulo “El archivo Setup de IDAMS”. MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. VARS=(lista de variables) Lista de las variables V o R a usar en el análisis. Sin valor por defecto. MDVALUES=BOTH/MD1/MD2/NONE Cuales valores de datos faltantes se van a usar para las variables accedidas en esta ejecución. Ver el capı́tulo “El archivo Setup de IDAMS”. MDHANDLING=(SAMPVAR, GROUPVAR, ANALVARS) Selección del tratamiento de datos faltantes. SAMP Se excluyen del análisis los casos que tengan datos faltantes en la variable de muestra. GROU Se excluyen del análisis los casos que tengan datos faltantes en la variable de grupo de las muestras básica y de prueba. ANAL Se excluyen del análisis los casos con datos faltantes en las variables de análisis. Por defecto: se incluyen los casos con datos faltantes. WEIGHT=número de variable Número de la variable de ponderación si se van a ponderar los datos. IDVAR=número de variable Variable de identificación de caso para el listado de datos y/o de asiganción de casos. Por defecto: se utiliza “DISC” como un identificador para todos los casos. STEPMAX=n Máximo número de pasos a ejecutar. Debe ser menor o igual al número de variables de análisis. Por defecto: número de variables de análisis. 24.7 Proposiciones de control del programa 189 MEMORY=20000/n Memoria necesaria para ejecución del programa. WRITE=DATA Crear un dataset IDAMS que contenga las variables transferidas, las variables de asignación de grupo, el tipo de muestra y los valores de factores discriminatorios, si los hay. OUTFILE=OUT/yyyy Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de salida. Por defecto: DICTOUT, DATAOUT. TRANSVARS=(variable list) Variables (hasta 99) para ser transferidas al dataset de salida. PRINT=(CDICT/DICT, OUTCDICT/OUTDICT, DATA, GROUP) CDIC Imprimir el diccionario de entrada para las variables accedidas con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. OUTC Imprimir el diccionario de salida con registros C si los hay. OUTD Imprimir el diccionario de salida sin registros C. DATA Imprimir los datos con asignación original de casos por grupos. GROU Imprimir para cada caso, la asignación de grupo basada en la función discriminatoria. Especificación de muestra Estos parámetros son opcionales. Si no se especifican, se toman todos los casos del archivo de entrada como muestra básica. Las muestras de prueba y anónima, si existen, se deben definir siempre en forma explı́cita. La intersección pareada de las muestras debe estar vacı́a. Sin embargo, las muestras no necesitan cubrir todo el archivo de entrada. Se puede usar un sólo valor o un rango de valores para escoger los casos que pertenecen a la muestra correspondiente: m1 = valor de la variable de muestra o m1 <= valor de la variable de muestra < m2 donde m1 y m2 pueden ser valores enteros o decimales. SAVAR=número de variable La variable usada para la definición de la muestra. Se pueden usar variables V o variables R. BASA=(m1, m2) Condicional: define la muestra básica. Se debe suministrar si se especifica SAVAR. TESA=(m1, m2) Condicional y opcional: si se especifica SAVAR. Define la muestra de prueba. ANSA=(m1, m2) Condicional y opcional: si se especifica SAVAR. Define la muestra anónima. Clasificación de la muestra básica Estos parámetros definen los grupos a priori usados en el procedimiento de análisis discriminatorio. Todos los grupos se deben definir explı́citamente y su intersección pareada debe estar vacı́a. Sin embargo, no necesitan cubrir toda la muestra básica. GRVAR=número de variable La variable usada para la definición de grupos. Se pueden usar variables V o R. Sin valor por defecto. 190 Análisis discriminatorio (DISCRAN) GR01=(m1, m2) Define el primer grupo en la muestra básica. GR02=(m1, m2) Define el segundo grupo en la muestra básica. GRnn=(m1, m2) Define el n-ésimo grupo en la muestra básica (nn <= 20). Nota. Por lo menos, se deben especificar dos grupos. 24.8. Restricciones 1. Número máximo de grupos a priori es 20. 2. La misma variable no se puede usar dos veces. 3. El tamaño máximo de campo para la variable identificadora de caso es 4. 4. Número máximo de variables a ser transferidas as 99. 5. No se pueden transferir variables R. 6. Si una variable a ser transferida es alfabética con ancho > 4, sólo se usan los primeros cuatro caracteres. 24.9. Ejemplos Ejemplo 1. Análisis discriminatorio de todos los casos juntos; los casos se identifican con la variable V1; se solicitan 5 pasos de análisis; los grupos a priori se definen con la variable V111 que incluye las categorı́as 1-6. $RUN DISCRAN $FILES PRINT = DISC1.LST DICTIN = MY.DIC archivo Diccionario de entrada DATAIN = MY.DAT archivo Datos de entrada $SETUP ANALISIS CANONICO DE DISCRIMINACION LINEAL PRINT=(DATA,GROUP) IDVAR=V1 STEP=5 VARS=(V101-V105) GVAR=V111 GR01=(1,3) GR02=(3,5) GR03=(5,7) Ejemplo 2. Repetir el análisis descrito en el Ejemplo 1, con el subconjunto de encuestados que tienen el valor 1 en la variable V5 y probar los resultados con los encuestados que tienen valor 2 en la variable V5. $RUN DISCRAN $FILES los mismos del ejemplo 1 $SETUP ANALISIS DE DISCRIMINACION LINEAL USANDO MUESTRAS BASICA Y DE PRUEBA PRINT=(DATA,GROUP) IDVAR=V1 STEP=5 VARS=(V101-V105) SAVAR=V5 BASA=1 TESA=2 GVAR=V111 GR01=(1,3) GR02=(3,5) GR03=(5,7) Capı́tulo 25 Funciones de distribución y de Lorenz (QUANTILE) 25.1. Descripción general QUANTILE genera funciones de distribución, funciones de Lorenz y coeficientes de Gini para variables individuales y hace la prueba de Kolmogorov-Smirnov entre dos variables o entre dos muestras. 25.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. Se puede usar el filtro estándar para escoger un subconjunto de casos de los datos de entrada. Además, se puede hacer cada análisis sobre un conjunto adicional mediante el uso de un parámetro de filtro. Las variables a analizar se especifican con el parámetro VAR. Transformación de datos. Se pueden usar las proposiciones de Recode. Ponderación de datos. Se puede usar una variable de ponderación para ponderar los datos; esta variable de ponderación puede tener valores enteros hasta el valor máximo asignable de 32,767. Nótese que los valores decimales se redondean al entero más próximo. Cuando el valor de una variable de ponderación para un caso es cero, negativo, faltante, no numérico o excede el máximo, entonces el caso se omite; se imprime el número de casos ası́ tratados. Tratamiento de datos faltantes. El parámetro MDVALUES está disponible para indicar cuales valores de datos faltantes, si los hay, se usarán para verificar los datos faltantes. Los casos con un dato faltante en una variable de análisis se eliminan de ese análisis. 25.3. Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variables y registros C, si los hay, solamente para variables utilizadas en la ejecución. Resultados para cada análisis. Función de distribución: mı́nimo, máximo, puntos de separación en el subintervalo. Función de Lorenz (opcional): mı́nimo, máximo, puntos de separación en el subintervalo y coeficiente de Gini. Curva de Lorenz (opcional): dibujada por deciles. Estadı́sticas de prueba de Kolmogorov-Smirnov (opcional). 192 Funciones de distribución y de Lorenz (QUANTILE) 25.4. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. Todas las variables referidas (excepto del filtro principal) deben ser numéricas; pueden tener valores enteros o decimales. 25.5. Estructura del setup $RUN QUANTILE $FILES Especificación de archivos $RECODE (opcional) Proposiciones de Recode $SETUP 1. 2. 3. 4. 5. 6. Filtro (opcional) Tı́tulo Parámetros Especificaciones de subconjuntos (opcional) QUANTILE Especificaciones de análisis (tantas como sean necesarias) $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx PRINT 25.6. diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-3 y 6 a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: INCLUDE V5=1 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: CONSTRUCCION DE DECILES 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: MDVAL=MD1, PRINT=DICT INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. 25.6 Proposiciones de control del programa 193 BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos. Ver el capı́tulo “El archivo Setup de IDAMS”. MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. MDVALUES=BOTH/MD1/MD2/NONE Cuales valores de datos faltantes se van a usar para las variables accedidas en esta ejecución. Ver el capı́tulo “El archivo Setup de IDAMS”. Los casos con datos faltantes se eliminan del análisis. PRINT=CDICT/DICT CDIC Imprimir el diccionario de entrada para las variables accedidas con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. 4. Especificaciones de subconjuntos (opcional). Estas proposiciones permiten escoger un subconjunto de casos para un análisis en particular. Ejemplo: MUJERES INCLUDE V6=2 Reglas de codificación Prototipo: nombre proposición nombre Nombre del subconjunto. 1-8 caracteres alfanuméricos comenzando con una letra. Este nombre debe coincidir exactamente con el nombre usado en las especificaciones de análisis subsecuentes. Blancos intercalados no se permiten. Se recomienda que todos los nombres se justifiquen a la izquierda. proposición Definición del subconjunto que siga la sintáxis del filtro estándar de IDAMS. 5. QUANTILE. La palabra QUANTILE en esta lı́nea, señala que siguen especificaciones de análisis. Debe incluirse (con el objeto de separar las especificaciones de subconjunto de las especificaciones de análisis) y sólo debe aparecer una vez. 6. Especificaciones de análisis. Las reglas de codificación son las mismas de los parámetros. Cada especificación de análisis debe comenzar en una nueva lı́nea. Ejemplos: VAR=R10 VAR=V25 VAR=V25 N=5 N=10 N=10 PRINT=CLORENZ FILTER=MALE FILTER=FEMALE ANALID=M KS=M VAR=número de variable Variable a ser analizada. Sin valor por defecto. WEIGHT=número de variable El número de la variable de ponderación, si se van a ponderar los datos. En la prueba de Kolmogorov-Smirnov no se pueden ponderar los datos. N=20/n Número de subintervalos. Si n<2 o n>100, se imprime un mensaje de advertencia y se usa 20 como valor por defecto. 194 Funciones de distribución y de Lorenz (QUANTILE) FILTER=xxxxxxxx Sólo se usan en este análisis los casos que satisfagan la condición definida en la especificación de subconjunto denominada xxxxxxxx. Si el nombre contiene caracteres no alfanuméricos, debe estar encerrado entre comillas sencillas. Se deben usar letras mayúsculas para hacer encajar el nombre del subconjunto el cual se convierte automáticamente a mayúsculas. ANALID=’nombre’ Un nombre para este análisis de manera que pueda ser referencia para una prueba de KolmogorovSmirnov. Si el nombre contiene caracteres no alfanuméricos, debe estar encerrado entre comillas sencillas. KS=’nombre’ Es el nombre asignado a un análisis anterior, con el parámetro ANALID y define la variable y/o la muestra con la cual se va a comparar este análisis usando la prueba de Kolmogorov-Smirnov. Si el nombre contiene caracteres no alfanuméricos, debe estar encerrado entre comillas sencillas. PRINT=(FLORENZ, CLORENZ) FLOR Imprimir la función de Lorenz y los coeficientes de Gini. CLOR Imprimir la curva de Lorenz, dibujada en deciles. (Se imprime la función de Lorenz también). Nota: si se ha especificado KS, se ignora el parámetro PRINT. 25.7. Restricciones 1. El número máximo de variables usadas (variables de análisis + la variable de ponderación + variables en filtros locales) es 50. 2. El número máximo de casos que se pueden analizar es 5000. 3. Número mı́nimo de subintervalos es 2; máximo es 100. 4. El número máximo de especificaciones de subconjuntos es 25. 5. Si se usa la prueba de Kolmogorov-Smirnov, el número máximo de casos que se pueden analizar es 2500. 6. La función de Lorenz y la prueba de Kolmogorov-Smirnov no se pueden solicitar para el mismo análisis. 7. Los valores de los puntos de separación siempre se imprimen con tres cifras decimales. Las variables con más de tres decimales se truncan a tres cuando se imprimen. 25.8. Ejemplo Generación de función de distribución, función de Lorenz y coeficientes de Gini para la variable V67; se hacen análisis separados en todos los datos y después en dos subconjuntos; se hace la prueba de Kolmogorov-Smirnov para probar la diferencia de distribuciones de la variable V67 en los dos subconjuntos de datos. $RUN QUANTILE $FILES PRINT = QUANT.LST DICTIN = MY.DIC archivo Diccionario de entrada DATAIN = MY.DAT archivo Datos de entrada $SETUP COMPARACION DE DISTRIBUCION DE EDADES PARA HOMBRES Y MUJERES * (valores por defecto para todos los parámetros) FEMALE INCLUDE V12=1 MALE INCLUDE V12=2 QUANTILE 25.8 Ejemplo VAR=V67 VAR=V67 VAR=V67 VAR=V67 195 N=15 N=15 N=15 N=15 PRINT=(FLOR,CLOR) PRINT=(FLOR,CLOR) FILT=FEMALE PRINT=(FLOR,CLOR) FILT=MALE FILT=MALE ANALID=F KS=F Capı́tulo 26 Análisis factorial (FACTOR) 26.1. Descripción general FACTOR cubre una serie de análisis factoriales de componentes principales y análisis de correspondencias que tengan especificaciones comunes. Da la posibilidad de ejecutar, con una sola lectura de datos, los análisis factoriales de correspondencias, de productos escalares, de productos escalares normados, de covariancias y de correlaciones. Para cada análisis, el programa construye una matriz que representa las relaciones entre las variables y calcula sus valores propios y sus vectores propios. Después calcula los factores de “caso” y “variable” que dan, para cada “caso” y “variable”, su ordenada, su calidad de representación y su contribución a los factores. También se puede imprimir una representación gráfica de los factores con opciones ordinarias o simplicio-factoriales. Los casos/variables activos (principales) son los casos/variables sobre cuya base se ejecuta el procedimiento de descomposición factorial, es decir, se usan en la computación de la matriz de relaciones. También se puede buscar una representación de otros casos/variables en el espacio factorial, que corresponde a las variables activas. Tales casos/variables (al no tener influencia en los factores) se llaman casos/variables pasivos (suplementarions). Se habla acerca de la representación ordinaria (de casos/variables) si los valores (puntajes de factores) que vienen directamente del análisis, se usan en la representación gráfica. Sin embargo, para una comprensión mejor de la relación entre casos y variables, es posible otra representación simultáneamente, la representación simplicio-factorial. 26.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. Se puede usar el filtro estándar para la selección de un subconjunto de casos de los datos de entrada. Las variables se escogen con los parámetros PVARS y SVARS. Transformación de datos. Se pueden usar las proposiciones de Recode. Ponderación de datos. Se puede usar una variable para ponderar los datos de entrada; esta variable de ponderación puede tener cifras enteras o decimales. Cuando el valor de la variable de ponderación para un caso es cero, negativo, dato faltante o no numérico, entonces el caso siempre se omite; se imprime el número de casos ası́ tratados. Tratamiento de datos faltantes. El parámetro MDVALUES está disponible para indicar cuales valores de datos faltantes, si los hay, se usarán para verificar los datos faltantes. Hay dos maneras de manipular los datos faltantes: se excluyen los casos con datos faltantes en las variables activas, en cambio, los datos faltantes en las variables pasivas se tratan como datos válidos, se excluyen del análisis, los casos con datos faltantes en variables activas y/o pasivas. 198 26.3. Análisis factorial (FACTOR) Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variables y registros C, si los hay, solamente para variables utilizadas en la ejecución. Estadı́sticas univariadas. (Opcional: ver el parámetro PRINT). Número de variable, nombre de variable, nuevo número de variable (renumerada a partir de 1), valores mı́nimos y máximos, media, desviación estándar, coeficiente de variación, suma, variancia, asimetrı́a, kurtosis y número ponderado de casos válidos para cada variable. Nótese que la desviación estándar y la variancia se estiman a partir de los datos ponderados. Datos de entrada. (Opcional: ver el parámetro PRINT). Grupos de 16 variables, que tienen en cada fila: el número correspondiente de casos, el total para variables activas y los valores de todas las variables, precedidos del total de las columnas (calculado solamente para los casos activos). Los valores se imprimen con el punto decimal explı́cito y con una cifra decimal. Si se requieren más de 7 caracteres para imprimir un valor, éste se reemplaza por asteriscos. Matriz de relaciones (matriz núcleo). (Opcional: ver el parámetro PRINT). La matriz (después de multiplicar por 10 a la n-ésima potencia como se indica en la lı́nea delente de la matriz), el valor de la huella y la tabla de valores propios y vectores propios. Histograma de valores propios. El histograma de porcentajes y porcentajes acumulativos de la contribución de cada valor propio a la inercia total. Los guiones en el histograma muestran el criterio de Kaiser para el análisis de correlación. Diccionarios de los archivos Datos de salida. (Opcional: ver el parámetro PRINT). El diccionario correspondiente a los factores de “caso” seguido del de los factores de “variable”. Tabla(s) de factores. Según la opción u opciones escogidas, se tiene: una tabla (para factores de “caso” o de “variable”), o dos tablas (para factores de “caso” y “variable”, en ese orden). Según la opción de impresión escogida, estas tablas sólo contienen los casos (variables) activos, solamente los casos (variables) pasivos, o ambos. Tabla de factores de “caso”. Suministra, lı́nea por lı́nea: valor del identificador de caso, información relevante a todos los factores juntos, es decir, la calidad de la representación del caso en el espacio definido por los factores, la ponderación del caso y la “inercia” del caso, información para cada factor a su turno, es decir, la ordenada del caso, el coseno cuadrado del ángulo entre el caso y el factor y la contribución del caso al factor. Tabla de factores de “variable”. Suministra, lı́nea por lı́nea, la misma información para las variables. Gráficos de puntos. (Opcional: ver el parámetro PLOTS). La primera lı́nea da el número del factor representado en el eje horizontal con su valor propio y su rango de valores mı́nimos-máximos. La segunda lı́nea da la misma información, concerniente al eje vertical. Junto con el tı́tulo de la ejecución, se da el número de casos/variables (es decir puntos) representados. A la derecha de cada gráfico se imprime: número de puntos que no se pueden imprimir para esa ordenada (puntos traslapados), número de puntos que no fue posible representar, número de página. Factores rotados. (Opcional: ver el parámetro ROTATION). Se imprime la variancia calculada para cada matriz de factores en cada iteración de la rotación (con el método VARIMAX), seguida de las comunalidades de las variables antes y después de la rotación, y se termina con la tabla de factores rotados. Mensaje de terminación. Al final de cada análisis, se imprime un mensaje de terminación con el tipo de análisis hecho. 26.4. Dataset(s) de salida Se pueden construir, opcionalmente, dos archivos Datos cada uno con su diccionario IDAMS asociado. En el dataset de factores de “caso”, los registros corresponden a los casos (activos y pasivos), las columnas corresponden a las variables (incluidos el identificador de casos y las variables transferidas) y a los factores. 26.5 Dataset de entrada 199 En el dataset de factores de “variable”, los registros corresponden a las variables de análisis y las columnas contienen las identificaciones de variables (números originales de variables) y factores. Las variables de salida se numeran secuencialmente a partir de 1 y tienen las caracterı́sticas siguientes: Variable identificadora de casos y variables transferidas: las variables V tienen las mismas caracterı́sticas que su equivalente de entrada, las variables de Recode salen con WIDTH=9 y DEC=2. Variables calculadas de factores: Nombre Ancho de campo Nr. de decimales MD1 et MD2 26.5. especificado por FNAME 7 5 9999999 Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. Todas las variables usadas para análisis deben ser numéricas; pueden tener valores enteros o decimales. Deben ser dicotomizadas o medidas en una escala de intervalo. La variable de identificación de caso y las variables a ser transferidas pueden ser alfabéticas. Hay dos clases de variables de análisis, activas y pasivas. Adicionalmente, debe existir una variable que identifique el caso. Se pueden escoger otras variables para ser transferidas al archivo de salida de factores de “caso”. Se pueden especificar uno o más casos al final del archivo de entrada como casos pasivos. Para análisis de correspondencias, son adecuados dos tipos de datos: a) variables dicotómicas de un archivo Datos primarios o b) una tabla de contingencia descrita por un diccionario y entrada como un dataset. 26.6. Estructura del setup $RUN FACTOR $FILES Especificación de archivos $RECODE (opcional) Proposiciones de Recode $SETUP 1. 2. 3. 4. Filtro (opcional) Tı́tulo Parámetros Especificaciones de gráficos definidos por el usuario (condicional) $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx DICTyyyy DATAyyyy DICTzzzz DATAzzzz PRINT diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) diccionario de salida para factores de caso datos de salida para factores de caso diccionario de salida para factores de variable datos de salida para factores de variable resultados (por defecto IDAMS.LST) 200 Análisis factorial (FACTOR) 26.7. Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-4, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: EXCLUDE V10=99 OR V11=99 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los listados. Ejemplo: ENCUESTA AGRICOLA 1984 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: ANAL=(CRSP,SSPRO) TRANS=(V16,V20) IDVAR=V1 PVARS=(V31-V35) INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos. Ver el capı́tulo “El archivo Setup de IDAMS”. MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. MDVALUES=BOTH/MD1/MD2/NONE Cuales valores de datos faltantes se van a usar para las variables accedidas en esta ejecución. Ver el capı́tulo “El archivo Setup de IDAMS”. MDHANDLING=PRINCIPAL/ALL PRIN Se excluyen del análisis, los casos con datos faltantes en las variables activas y se incluyen los casos pasivos que tengan datos faltantes. Los factores de variables pasivas se basan sólo en datos válidos. ALL Se excluyen todos los casos con datos faltantes. ANALYSIS=(CRSP/NOCRSP, SSPRO, NSSPRO, COVA, CORR) Selección del análisis. CRSP Análisis factorial de correspondencias. SSPR Análisis factorial de productos escalares. NSSP Análisis factorial de productos escalares normados. COVA Análisis factorial de covariancias. CORR Análisis factorial de correlaciones. PVARS=(lista de variables) Lista de variables V o R a usar como variables activas (principales). Sin valor por defecto. SVARS=(lista de variables) Lista de variables V o R a usar como variables pasivas (suplementarias). WEIGHT=número de variable Número de la variable de ponderación si se van a ponderar los datos. 26.7 Proposiciones de control del programa 201 NSCASES=0/n Número de casos pasivos. Nota: estos casos no se incluyen en el cálculo de las estadı́sticas, matriz y factores; son los últimos “n” del archivo Datos. IDVAR=número de variable Variable de identificación de caso usada para identificar puntos en los gráficos y para identificar casos en el archivo de salida. Sin valor por defecto. KAISER/NFACT=n/VMIN=n Criterio para determinar el número de factores. KAIS Criterio de Kaiser - número de raı́ces mayor de 1. NFAC Número de factores deseado. VMIN El porcentaje mı́nimo de variancia a ser explicado por los factores tomados todos juntos. No debe teclearse el decimal, por ej. “VMIN=95”. ROTATION=KAISER/UDEF/NOROTATION Especifica rotación VARIMAX de factores de “variable”. Sólo análisis de correlaciones. KAIS El número de factores a rotar se define de acuerdo con el criterio de KAISER. UDEF El numero de factores a rotar lo especifica el usuario (ver el parámetro NROT). NROT=1/n Número de factores a rotar (si se especifica ROTATION=UDEF). WRITE=(OBSERV, VARS) Controla la salida de archivos de factores de “caso” y “variable”. Si se solicita más de un análisis con el parámetro ANALYSIS, estos archivos serán para el primer análisis especificado. OBSE Crear un archivo que contenga factores de “caso”. VARS Crear un archivo que contenga factores de “variable”. OUTFILE=OUT/yyyy Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos para los factores de “caso”. Por defecto: DICTOUT, DATAOUT. OUTVFILE=OUTV/zzzz Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos para los factores de “variable”. Por defecto: DICTOUTV, DATAOUTV. TRANSVARS=(lista de variables) Variables a transferir (hasta 99) al archivo de salida de factores de “caso”. FNAME=uuuu Una cadena de 1-4 caracteres usada como prefijo para nombres de variables de factores en los diccionarios de salida. Debe encerrarse entre comillas sencillas si contiene caracteres no-alfanuméricos. Los factores tienen los nombres uuuuFACT0001, uuuuFACT0002, etc. Por defecto: espacio en blanco. PLOTS=STANDARD/USER/NOPLOTS Controla la representación gráfica de los resultados. STAN Se imprimen gráficos estándar para pares de factores 1-2, 1-3, 2-3 con las opciones PAGES=1, OVLP=LIST, NCHA=4, REPR=COOR, VARPL=(PRIN,SUPP). USER Se desean gráficos definidos por el usuario (ver parámetros de control para gráficos definidos por el usuario, más adelante). 202 Análisis factorial (FACTOR) PRINT=(CDICT/DICT, OUTCDICTS/OUTDICTS, STATS, DATA, MATRIX, VFPRINC/NOVFPRINC, VFSUPPL, OFPRINC, OFSUPPL) CDIC Imprimir el diccionario de entrada para las variables accedidas con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. OUTC Imprimir diccionarios de salida con registros C, si los hay. OUTD Imprimir diccionarios de salida sin registros C. STAT Imprimir las estadı́sticas de variables activas y pasivas. DATA Imprimir los datos de entrada. MATR Imprimir matriz de relaciones (núcleo) y vectores propios. VFPR Imprimir factores de “variable” para las variables activas. VFSU Imprimir factores de “variable” para variables pasivas. OFPR Imprimir factores de “caso” para los casos activos. OFSU Imprimir factores de “caso” para los casos pasivos. 4. Especificaciones de gráficos definidos por el usuario. (Condicional: si PLOT=USER se especifica como parámetro). Repetir para cada gráfico bi-dimensional a imprimir. Las reglas de codificación son las mismas de los parámetros. Cada especificación de gráfico debe comenzar en una lı́nea nueva. Ejemplo: X=3 Y=10 X=número de factor Número del factor a representar en el eje horizontal. Y=número de factor Número del factor a representar en el eje vertical (ver también el parámetro FORMAT=STANDARD). ANSP=ALL/CRSP/SSPRO/NSSPRO/COVA/CORR Especifica los análisis para los cuales se van a imprimir los gráficos. ALL Gráficos para todos los análisis especificados en el parámetro ANALYSIS. Para el resto, se imprime un gráfico para un sólo análisis (las palabras clave tienen el mismo significado que para el parámetro ANALYSIS). Estas opciones implican un sólo gráfico. OBSPLOT=(PRINCIPAL, SUPPL) Selección de casos a representar en el gráfico o gráficos. PRIN Representar casos activos. SUPP Representar casos pasivos. VARPLOT=(PRINCIPAL/NOPRINCIPAL, SUPPL) Selección de variables a representar en el gráfico o gráficos. PRIN Representar variables activas. SUPP Representar variables pasivas. REPRESENT=COORD/BASVEC/NORMBV Selección de representación simultánea de puntos (casos/variables). COOR Coordenadas como se indican en la tabla de factores. BASV Representar vectores básicos. NORM Representar vectores básicos con norma especial para la representación “simpliciofactorial”. OVLP=FIRST/LIST/DEN Opción concerniente a la representación de puntos traslapados. FIRS Imprimir el número de la variable/identificación de casos sólo del primer punto. LIST Dar una lista vertical de los puntos que tengan la misma abscisa en el gráfico, hasta hallar otro punto (entonces se pierden los números de variable y/o los identificadores de caso). 26.8 Restricciones DEN 203 Imprimir la densidad (número de puntos traslapados). Imprimir para un punto “.”, para dos puntos (traslapados) “:”, para tres puntos “3”, etc, para 9 puntos “9”, para más de 9 puntos “*”. Se debe especificar NCHAR=2 si se selecciona esta opción. NCHAR=4/n Número de dı́gitos/caracteres usados para la identificación de variables/casos en el gráfico o gráficos (1 a 4 caracteres). PAGES=1/n Número de páginas por gráfico. FORMAT=STANDARD/NONSTANDARD Define el tamaño del marco del gráfico. STAN Usar un marco de 21 x 30 centı́metros para el gráfico que muestra el factor con rango más amplio en el eje horizontal y usa diferentes escalas para los dos ejes. NONS El marco no se estandariza en el sentido indicado en la opción anterior. El tamaño del gráfico se define con PAGES=n y los ejes son X e Y. 26.8. Restricciones 1. Número máximo de variables de análisis es 80. 2. Se debe especificar una y sólo una variable de identificación. 3. Número máximo de variables a ser transferidas es 99. 4. Número máximo de variables de entrada incluidas aquellas usadas en proposiciones de filtro y de Recode es 100. 5. Número máximo de gráficos definidos por el usuario es 24. 6. Si la variable de identificación o una variable a ser transferida es alfabética con ancho > 4, sólo se usan los primeros cuatro caracteres. 7. Los parámetros deben cumplir las siguientes especificaciones: max(D1,D2,D3) < 5000 donde D1 = NPV * NPV + 10 * NV D2 = NV * (NF + 6) + NPV * NIF D3 = NV + NF + NIF + 3 * NP y NV, NPV, NF, NIF, NP denominan el número total de variables de análisis, número de variables activas, número de factores a calcular, número de factores a ignorar y número máximo de puntos a representar en gráficos, respectivamente. 26.9. Ejemplos Ejemplo 1. Análisis factorial de correlaciones; el análisis se basa en 20 variables y se solicitan 7 factores; el número de factores a rotar se define de acuerdo con el criterio de Kaiser; se imprimirán las estadı́sticas, matriz de correlación, los valores propios, seguidos de factores de variables y gráficos estándar; no se almacenarán los factores en un archivo. 204 Análisis factorial (FACTOR) $RUN FACTOR $FILES PRINT = FACT1.LST DICTIN = A.DIC archivo Diccionario de entrada DATAIN = A.DAT archivo Datos de entrada $SETUP ANALISIS FACTORIAL DE CORRELACIONES ANAL=(NOCR,CORR) ROTA=KAISER NFACT=7 IDVAR=V1 PRINT=(STATS,MATRIX) PVARS=(V12-V16,V101-V115) Ejemplo 2. Análisis factorial de productos escalares basado en 10 variables; se representarán en gráficos 2 variables pasivas V5 y V7; los gráficos serán definidos por el usuario ya que sólo se requiere el primero de los puntos traslapados; se utilizará el criterio de Kaiser para determinar el número de factores y el número de factores a rotar; los factores de caso y de variable se llevarán a archivos de salida. $RUN FACTOR $FILES DICTIN = A.DIC archivo Diccionario de entrada DATAIN = A.DAT archivo Datos de entrada DICTOUT = CASEF.DIC archivo Diccionario de factores de caso DATAOUT = CASEF.DAT archivo Datos de factores de caso DICTOUTV = VARF.DIC archivo Diccionario de factores de variable DATAOUTV = VARF.DAT archivo Datos de factores de variable $SETUP ANALISIS FACTORIAL DE PRODUCTOS ESCALARES ANAL=(NOCRSP,SSPR) IDVAR=V1 WRITE=(OBSERV,VARS) PRINT=STATS PLOT=USER PVARS=(V112-V116,V201-V205) SVARS=(V5,V7) X=1 Y=2 VARP=(PRINCIPAL,SUPPL) X=1 Y=3 VARP=(PRINCIPAL,SUPPL) X=2 Y=3 VARP=(PRINCIPAL,SUPPL) - Ejemplo 3. Análisis de correspondencias sobre una tabla de contingencia descrita por un diccionario y entrada como un dataset en un archivo Setup a ejecutar; el número de factores se define de acuerdo con el criterio de Kaiser; se imprimirán la matriz de relaciones seguida de factores de variables y de casos; los gráficos serán definidos por el usuario ya que se pide una projección de casos. $RUN FACTOR $FILES PRINT = FACT3.LST $SETUP ANALISIS DE CORRESPONDENCIAS SOBRE UNA TABLA DE CONTINGENCIA BADD=MD1 IDVAR=V8 PLOTS=USER PRINT=(MATRIX,OFPRINC) PVARS=(V31-V33) $DICT 3 8 33 1 1 T 8 Grado cientı́fico 1 20 C 8 81 Professor C 8 82 Ass.Prof. C 8 83 Doctor C 8 84 Ma^ ıtrise C 8 85 Licencia C 8 86 Otro T 31 Jefe 4 20 T 32 Cientı́fico 7 20 T 33 Técnico 10 20 $DATA 81 5 0 0 82 1 3 0 83 0 17 01 84 0 28 04 85 0 0 01 86 0 0 17 Capı́tulo 27 Regresión lineal (REGRESSN) 27.1. Descripción general REGRESSN suministra una capacidad general para regresión múltiple, diseñada para análisis de regresión lineal estándar o por pasos. Se pueden hacer varios análisis de regresión, con parámetros y variables diferentes en una misma ejecución. Término constante. Si los datos de entrada son datos primarios, el usuario puede solicitar que las ecuaciónes no tengan término constante (ver el parámetro de regresión CONSTANT=0). En este caso se analiza una matriz basada en la matriz de productos cruzados en vez de una matriz de correlación. Esto cambia la pendiente de la lı́nea ajustada y puede afectar sustancialmente los resultados. En la regresión por pasos, las variables pueden entrar a la ecuación en un orden diferente al que se hubiese requerido en caso de estimar un término constante. Si la entrada es una matriz de correlación, la ecuación de regresión contiene siempre un término constante. Uso de variables categóricas como variables independientes. Existe una opción para crear un conjunto de variables ficticias (dicotómicas) a partir de variables categóricas especı́ficadas (ver el parámetro CATE). Estas se pueden utilizar como variables independientes en el análisis de regresión. Cociente F para introducir una variable en la ecuación. En la regresión por pasos, se adicionan a su turno, variables a la ecuación de regresión hasta que la ecuación sea satisfactoria. En cada paso, se selecciona la variable que tenga la correlación parcial más alta con la variable dependiente. Se calcula entonces un valor parcial de la prueba F para la variable y este valor se compara con un valor crı́tico suministrado por el usuario. Tan pronto como la F parcial para la proxima variable que va entrar sea menor que el valor crı́tico, se termina el análisis. Cociente F para retirar una variable de la ecuación. Una variable que puede haber sido la mejor variable individual para entrar en una etapa inicial de un análisis de regresión por pasos, en una etapa posterior, puede no ser la mejor debido a la relación actual con otras variables en la regresión. Para detectar ésto, el valor parcial F de cada variable en la regresión en cada paso del cálculo, es calculado y comparado con un valor crı́tico suministrado por el usuario. Cualquier variable cuyo valor parcial F se presente por debajo del valor crı́tico, se retira del modelo. Regresión por pasos. Si se pide regresión por pasos, el programa determina qué variables o cuales conjuntos de variables ficticias dentro del conjunto especificado de variables independientes se van a usar en la regresión y en que orden se van a introducir, se comienza con las variables forzadas y se continúa con las demás variables y los conjuntos de variables ficticias, una a una. Después de cada paso, el algoritmo escoge entre las variable predictoras restantes, la variable o el conjunto de variables ficticias que produzcan la reducción más grande en la variancia residual (no explicada) de la variable dependiente, a menos de que su contribución al cociente F total para la regresión permanezca por debajo de un umbral especificado. Igualmente, el algoritmo evalúa después de cada paso, si la contribución de alguna variable o de algún conjunto de variables ficticias ya incluidas, se presentan o no se presentan por debajo de un umbral especificado, caso en el cual se elimina de la regresión. Regresión descendente por pasos. Igual que en la regresión por pasos, excepto que el algoritmo comienza con todas las variables independientes y luego elimina variables y conjuntos de variables ficticias por pasos. 206 Regresión lineal (REGRESSN) En cada paso el algoritmo selecciona a partir de las variables predictoras que quedan, la variable o el conjunto de variables ficticias que produzcan la reducción más baja en la variancia explicada de la variable dependiente, a menos que ésta exceda un umbral especificado. Igualmente, el algoritmo evalúa en cada paso si la contribución de alguna variable o conjunto de variables ficticias previamente suprimidas de la regresión, se ha elevado por encima de un umbral especificado, caso en el cual, se vuelve a incluir en la regresión. Generación de un dataset de residuos. Con datos primarios como entrada, se pueden calcular residuos y llevarlos como un archivo Datos de salida descrito por un diccionario IDAMS. Ver la sección “Datasets de residuos de salida” para detalles del contenido. Nótese que para cada ecuación, se genera un dataset de residuos separado. También, como REGRESSN no tiene la capacidad de transferir variables de interes especı́fico en un análisis de residuos a partir de los datos primarios de entrada al dataset de residuos, puede ser necesario usar el programa MERGE para crear el dataset que contenga todas las variables deseadas. Una variable de identificación de caso (ID) del dataset de entrada se lleva al dataset de residuos para hacer posible el encaje. Generación de una matriz de correlación. Si entran datos primarios, el programa calcula coeficientes de correlación que pueden salir en el formato de una matriz cuadrada de IDAMS y ser usados para análisis posteriores. Las correlaciones de REGRESSN incluyen todas las variables de todas las ecuaciones de regresión y se basan en casos con datos válidos en todas las variables de la matriz. De esta manera, las correlaciones serán generalmente diferentes de las correlaciones obtenidas con el programa PEARSON cuando se ejecuta con la opoción MDHANDLING=PAIR. Cuando la eliminación de datos faltantes en REGRESSN deja un tamaño de muestra aceptablemente grande, REGRESSN es una alternativa de PEARSON para generar matrices de correlación (ver parágrafo “Tratamiento de datos faltantes”). 27.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. Si entran datos primarios, se puede usar el filtro estándar para escoger un subconjunto de casos a partir de los datos de entrada. Si se utiliza una matriz de correlación como entrada al programa, no se puede usar la selección de casos. Las variables para la ecuación de regresión se especifican en los parámetros DEPVAR y VARS. Transformación de datos. Si entran datos primarios, se pueden usar las proposiciones de Recode. Ponderación de datos. Si entran datos primarios, se puede usar una variable para ponderar los datos de entrada; esta variable de ponderación puede tener cifras enteras o decimales. El programa forzará la suma de las ponderaciones para que sea igual al número de casos de entrada. Cuando el valor de la variable de ponderación para un caso es cero, negativo, dato faltante o no numérico, entonces el caso siempre se omite; se imprime el número de casos ası́ tratados. Tratamiento de datos faltantes. 1. Entrada. Si entran datos primarios, el parámetro MDVALUES está disponible para indicar cuales valores de datos faltantes, si los hay, se usarán para verificar los datos faltantes. Los casos en los cuales haya datos faltantes para cualquier variable de regresión en cualquier análisis se eliminan (eliminación de datos faltantes “por casos”). Una opción (ver parámetro MDHANDLING) permite al usuario especificar el máximo número de casos con datos faltantes que puede tolerarse antes de terminar la ejecución. Advertencia: si se llevan a cabo análisis múltiples en una ejecución de REGRESSN, se calcula una sola matriz de correlación para todas las variables utilizadas en los diferentes análisis. Por causa del método de eliminación de casos con datos faltantes “por casos”, el número de casos usado y por lo tanto las estadı́sticas de regresión producidas pueden ser diferentes si los análisis se llevan a cabo separadamente. Si entra una matriz, los casos con datos faltantes se han debido acomodar al crear la matriz. Si una celda de la matriz de entrada tiene un código de dato faltante (es decir, 99.999) cualquier análisis que involucre dicha celda, se omite. 2. Residuos de salida. Si se piden residuos, se calculan para todos los casos que pasen el filtro (opcional) valores predichos y residuos. Si un caso tiene datos faltantes en cualquiera de las variables requeridas para estos cálculos, se generan códigos de datos faltantes en la salida. 3. Matriz de correlación de salida. El algoritmo de REGRESSN para el manejo de datos faltantes en la entrada de datos primarios no puede resultar en valores de datos faltantes en la matriz de correlación. 27.3 Resultados 27.3. 207 Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variables y registros C, si los hay, solamente para variables utilizadas en la ejecución. Estadı́sticas univariadas. (Sólo datos primarios). Se imprime la suma, el promedio, la desviación estándar, el coeficiente de variación, el valor máximo y el valor mı́nimo para todas las variables dependientes e independientes utilizadas. Matriz de sumas totales de cuadrados y productos cruzados. (Sólo datos primarios. Opcional: ver el parámetro PRINT). Matriz de sumas de cuadrados residuales y productos cruzados. (Sólo datos primarios. Opcional: ver el parámetro PRINT). Matriz de correlación total. (Opcional: ver el parámetro PRINT). Matriz de correlación parcial. (Opcional para cada regresión: ver el parámetro de regresión PARTIALS). El elemento ij-ésimo es la correlación parcial entre la variable i y la variable j, manteniendo constantes las variables especificadas en la lista de variables de PARTIALS. Matriz inversa. (Opcional para cada regresión: ver el parámetro PRINT). Estadı́sticas de resumen del análisis. Las siguientes estadı́sticas se imprimen para cada regresión o para cada paso de un regresión por pasos: error estándar de estimación, cociente F, coeficiente de correlación múltiple (ajustado y no ajustado), fracción de variancia explicada (ajustada y no ajustada), determinante de la matriz de correlación, grados de libertad de residuos, término constante. Estadisticas de análisis para predictores. Las siguientes estadı́sticas se imprimen para cada regresión o para cada paso de un regresión por pasos: coeficiente B (coeficiente de regresión parcial no estandarizado), error estándar (sigma) de B, coeficiente beta (coeficiente de regresión parcial estandarizado), error estándar (sigma) de beta, R cuadrada parcial y marginal, cociente t, cociente de covariancia, valores de la R cuadrada marginal para todos los predictores y cocientes t para todos conjuntos de las variables ficticias (para la regresión por pasos). Diccionario de residuos de salida. (Para entrada de datos primarios solamente. Opcional: ver el parámetro de regresión WRITE). Datos de residuos de salida. (Para entrada de datos primarios solamente. Opcional: ver el parámetro de regresión PRINT). Si hay menos de 1000 casos, los valores calculados, los valores observados y los residuos (diferencias) se pueden listar en orden ascendente por el valor del residuo. Se puede listar cualquier número de casos en el orden secuencial de entrada de los mismos. La estadı́stica de Durbin-Watson para la asociación de residuos se imprime para los residuos impresos en el orden secuencial de los casos. 27.4. Matriz de correlación de salida Se puede producir la matriz de correlación calculada (ver el parámetro WRITE). Se escribe en la forma de una matriz cuadrada de IDAMS (ver el capı́tulo “Los datos en IDAMS”). El formato es 6F11.7 para las correlaciones y 4E15.7 para las medias y desviaciones estándar. Además, en las columnas 73-80 de los registros se escriben tı́tulos para la información ası́: 208 Regresión lineal (REGRESSN) registro descriptor de matriz registros de correlación registros de media registros de desviación estándar N=nnnnn REG xxx MEAN xxx SDEV xxx (nnnnn es el tamaño de la muestra de REGRESSN. Las xxx corresponden a un número secuencial que comienza con 1 para el primer registro de correlación y se incrementa de uno en uno para cada registro sucesivo hasta el último registro de desviación estándar). Los elementos de la matriz son r de Pearson. Estas r, ası́ como las medias y las desviaciones estándar se basan en casos que tienen datos válidos en todas las variables especificadas en cualquiera de las listas de variables de regresión. Las correlaciones son para todos los pares de variables de toda la lista de variables de análisis, tomadas a la vez. 27.5. Dataset de residuos de salida Se puede pedir un dataset de residuos para cada análisis (ver el parámetro de regresión WRITE). Este tiene la forma de un archivo Datos descrito por un diccionario IDAMS. Contiene cuatro o cinco variables por caso, según los datos sean o no sean ponderados: una variable de identificación (ID), una variable dependiente, una variable dependiente predicha (calculada), un residuo y una ponderación, si la hay. El archivo de salida de los residuos tiene el mismo orden de los casos de entrada. Las caracetrı́sticas del archivo son: Número de variable (identificador) (variable dependiente) (variable predicha) (residuo) (ponderación - si hay) * ** *** 1 2 3 4 5 Nombre igual a entrada igual a entrada Predicted value Residual igual a entrada Ancho de campo Número de decimales Código MD1 * * 7 7 * 0 ** *** *** ** igual a entrada igual a entrada 9999999 9999999 igual a entrada transferido del diccionario de entrada para variables V o 7 para variables R transferido del diccionario de entrada para variables V o 2 para variables R 6 + Nr. de decimales para la variable dependiente menos el ancho de la variable dependiente; si ésta es negativa, entonces este valor es cero. Si el valor calculado o el residuo exceden el ancho de campo asignado, se reemplazan por código MD1. 27.6. Dataset de entrada El dataset de entrada de datos primarios es un archivo Datos descrito por un diccionario IDAMS. Todas las variables usadas para análisis deben ser numéricas; pueden ser enteras o con decimales. La variable identificadora de casos puede ser alfabética. 27.7. Matriz de correlación de entrada Es una matriz cuadrada de IDAMS. Una matriz de correlación generada por PEARSON o por una ejecución anterior de REGRESSN resulta apta como matriz de entrada a REGRESSN. El diccionario de la matriz de entrada debe contener números y nombres de variables. La matriz debe contener correlaciones, medias y desviaciones estándar. Se usan ambas, las medias y las desviaciones estándar. 27.8 Estructura del setup 27.8. 209 Estructura del setup $RUN REGRESSN $FILES Especificación de archivos $RECODE (opcional con datos primarios como entrada; no se usa con entrada matricial) Proposiciones de Recode $SETUP 1. 2. 3. 4. 5. Filtro (opcional) Tı́tulo Parámetros Definición de variables ficticias (condicional) Especificaciones de regresión (tantas como sean necesarios) $DICT (condicional) Diccionario para entrada de datos primarios $DATA (condicional) Datos primarios de entrada $MATRIX (condicional) Matriz de correlación de entrada Archivos: FT02 FT09 DICTxxxx DATAxxxx DICTyyyy DATAyyyy PRINT 27.9. matriz de correlación de salida matriz de correlación de entrada (si no se usa $MATRIX e INPUT=MATRIX) diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) diccionario de residuos de salida ) un conjunto por cada datos de residuos de salida ) archivo de residuos resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-3 y 5, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Disponible sólo con datos primarios de entrada. Ejemplo: INCLUDE V3=5 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: ANALISIS DE REGRESION 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: IDVAR=V1 MDHANDLING=100 210 Regresión lineal (REGRESSN) INPUT=RAWDATA/MATRIX RAWD Los datos de entrada vienen en la forma de un archivo Datos descrito por un diccionario IDAMS. MATR Los datos de entrada son coeficientes de correlación en la forma de una matriz cuadrada de IDAMS. Parámetros sólo para datos primarios de entrada INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos. Ver el capı́tulo “El archivo Setup de IDAMS”. MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. MDVALUES=BOTH/MD1/MD2/NONE Cuales valores de datos faltantes se van a usar para las variables accedidas en esta ejecución. Ver el capı́tulo “El archivo Setup de IDAMS”. MDHANDLING=0/n Número de casos con datos faltantes admitido antes de terminar. Un caso se considera faltante si éste contene datos faltantes en cualquiera de las variables de las ecuaciones de regresión. WEIGHT=número de variable Número de la variable de ponderación, si se van a ponderar los datos. CATE Se especifica CATE si se suministra una definición de variables ficticias. IDVAR=número de variable Variable que se lleva a la salida o se imprime como identificadora de casos si se han solicitado dataset de residuos. La variable de identificación no se debe incluir en ninguna lista de variables. WRITE=MATRIX Escribir la matriz de correlación calculada a partir de los datos primarios de entrada en un archivo de salida. PRINT=(CDICT/DICT, XMOM, XPRODUCTS, MATRIX) CDIC Imprimir el diccionario de entrada para las variables accedidas con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. XMOM Imprimir la matriz de sumas residuales de cuadrados y productos cruzados. XPRO Imprimir la matriz de sumas totales de cuadrados y de productos cruzados. MATR Imprimir la matriz de correlación. Parámetros para entrada de la matriz de correlación CASES=n Haga CASES igual al número de casos usados para la creación de la matriz de entrada. Este número se utiliza en el cálculo del nivel F. No admite valor por defecto; debe suministrarse cuando entra la matriz de correlación. PRINT=MATRIX Imprimir la matriz de correlación. 27.9 Proposiciones de control del programa 211 4. Definición de variables ficticias (condicional: si se ha especificado CATE como un parámetro). El programa REGRESSN puede transformar una variable categórica en un conjunto de variables ficticias. Para tener un tratamiento de variables como categóricas, el usuario debe: a) incluir el parámetro CATE en la lista de parámetros y b) especificar cuales variables se van a considerar como categóricas y los códigos a usar. Cada variable categórica a transformar está seguida de los códigos a usar entre paréntesis cuadrados. Para cada variable, los códigos no listados se excluyen de la construcción. Nota: la lista de códigos no debe ser exahustiva, es decir, no se deben imprimir todos los códigos existentes o de lo contrario, resultará una matriz singular. Ejemplo: V100(5,6,1), V101(1-6) Los códigos 5, 6 y 1 de la variable 100 se representarán en la regresión como variables ficticias, ası́ como también los códigos 1 a 6 de la variable 101. Una variable especificada en la definición de variables ficticias, cuando se use en listas de variables predictoras (VARS), variables parciales (PARTIALS) o variables forzadas (FORCE) para regresión por pasos, se referirán al conjunto de variables ficticias creado a partir de esa variable. En regresiones por pasos, los códigos de esa variable entrarán o se excluirán ambos a la vez, las R cuadradas marginales y los cocientes-F se calculan para todos los códigos de las variables conjuntamente ası́ como para los códigos individualmente. Una variable usada en la definición de variables ficticias no se puede usar como variable dependiente. 5. Especificaciones de regresión. Las reglas de codificación son las mismas de los parámetros. Cada conjunto de parámetros de regresión debe comenzar en una nueva lı́nea. Ejemplo: DEPV=V5 METH=STEP FORCE=(V7) VARS=(V7,V16,V22,V37-V47,R14) METHOD=STANDARD/STEPWISE/DESCENDING STAN Se hace regresión estándar. STEP Se hace regresión por pasos. DESC Se hace una regresión descendente por pasos. DEPVAR=número de variable Número de la variable dependiente. Sin valor por defecto. VARS=(lista de variables) Las variables independientes que se van a usar en el análisis. Sin valor por defecto. PARTIALS=(lista de variables) Calcular e imprimir una matriz de correlación parcial con las variables eliminadas de la lista de variables independientes. Por defecto: no hay parciales. FORCE=(lista de variables) Forzar las variables listadas a entrar en la regresión por pasos (METHOD=STEP) o a permanecer en la regresión descendente por pasos (METHOD=DESC). Por defecto: no hay forzamiento. FINRATIO=.001/n El valor del cociente F por debajo del cual una variable no entra al procedimiento por pasos; este es el cociente F para entrar. Debe darse el punto decimal. FOUTRATIO=0.0/n El valor del cociente F por encima del cual una variable se debe mantener para permanecer en el procedimiento por pasos; este es el cociente F para retirar. Debe darse el punto decimal. 212 Regresión lineal (REGRESSN) CONSTANT=0 Sólo para la entrada de datos primarios. El término constante debe ser igual a cero y no se estimará término constante. Por defecto: se calcula un término constante. WRITE=RESIDUALS Los residuos se escriben en un dataset IDAMS. OUTFILE=OUT/yyyy Se aplica solamente cuando se ha especificado WRITE=RESI. Un sufijo de ddname de 1-4 caracteres para los archivos del diccionario y de los datos de residuos de salida. Si se llevan los residuos al archivo de salida para más de un análisis, el nombre por defecto OUT, sólo puede utilizarse una sola vez. PRINT=(STEP, RESIDUALS, ERESIDUALS, INVERSE) STEP Se aplica solamente a una regresión por pasos: imprimir R cuadradas marginales para todos los predictores en cada paso. RESI Imprimir los residuos en el orden de los casos de entrada y la estadı́stica de DurbinWatson. ERES Imprimir los residuos, excepto para datos faltantes, en orden de magnitud del error, siempre que haya menos de 1000 casos. INVE Imprimir la matriz de correlación inversa. 27.10. Restricciones 1. Con datos primarios como entrada, puede haber hasta 99 o 100 variables distintas, (dependiendo de si hay o no hay una variable de ponderación) para utilizar en una sóla ecuación de regresión; el número total de variables en todo el análisis, incluidas las variables de Recode, la variable de ponderación y la variable de identificación, no puede ser mayor de 200. 2. Cuando la entrada es una matriz, ésta puede ser de 200 x 200 y se pueden usar hasta 100 variables en una sóla ecuación de regresión. 3. FINRATIO debe ser mayor o igual a FOUTRATIO. 4. Los residuos se pueden listar en orden ascendente por valor de residuo si hay menos de 1000 casos. 5. Una variable especificada en la definición de variables ficticias, no puede usarse como variable dependiente. 6. Máximo se pueden definir 12 variables ficticias a partir de una variable categórica. 7. Si la variable de identificación es alfabética con ancho > 4, sólo se usan los primeros cuatro caracteres. 27.11. Ejemplos Ejemplo 1. Regresión estándar con cinco variables independientes con una matriz de correlación IDAMS como entrada. $RUN REGRESSN $FILES FT09 = A.MAT archivo Matriz de entrada SETUP REGRESION ESTANDAR - USA MATRIZ DE ENTRADA INPUT=MATR CASES=1460 DEPV=V116 VARS=(V18,V36,V55-V57) 27.11 Ejemplos 213 Ejemplo 2. Regresión estándar con seis variables independientes y dos variables cada una con 3 categorı́as transformadas a 6 variables ficticias; se usan datos primarios de entrada; se van a calcular residuos y se escriben en un dataset de salida (los casos se identifican con la variable V2). $RUN REGRESSN $FILES PRINT = REGR2.LST DICTIN = STUDY.DIC archivo Diccionario de entrada DATAIN = STUDY.DAT archivo Datos de entrada DICTOUT = RESID.DIC archivo Diccionario de los residuos DATAOUT = RESID.DAT archivo Datos para residuos $SETUP REGRESION ESTANDAR - USA DATOS PRIMARIOS DE ENTRADA Y ESCRIBE RESIDUOS MDHANDLING=50 IDVAR=V2 CATE V5(1,5,6),V6(1-3) DEPV=V116 WRITE=RESI VARS=(V5,V6,V8,V13,V75-V78) Ejemplo 3. Dos regresiones: una estándar y una por pasos con datos primarios como entrada. $RUN REGRESSN $FILES DICTIN = STUDY.DIC archivo Diccionario de entrada DATAIN = STUDY.DAT archivo Datos de entrada $SETUP DOS REGRESIONES PRINT=(XMOM,XPROD) DEPV=V10 VARS=(V101-V104,V35) PRINT=INVERSE DEPV=V11 METHOD=STEP PRINT=STEP VARS=(V1,V3,V15-V18,V23-V29) Ejemplo 4. Regresión en dos etapas; la primera usa las variables V2 - V6 para estimar los valores de la variable dependiente V122; en la segunda etapa, dos variables adicionales V12, V23 se usan para estimar los valores predichos de V122, es decir V122 sin los efectos de V2 - V6. En la primera regresión, los valores predichos para la variable dependiente (V122) se calculan y se escriben en el archivo de residuos (OUTB) como la variable V3. Después se usa el programa MERGE para intercalar esta variable con las variables del archivo original que se necesitan en la segunda etapa. El dataset de salida de MERGE (un archivo temporal y por lo tanto no es necesario definirlo) tendrá cinco variables de la lista de construcción, numeradas V1 a V5, donde A12 y A23 (para usar como predictores de la segunda etapa) se convierten en V2 y V3, A122, la variable dependiente original, se convierte en V4 y B3, la variable que da los valores predichos de V122, se convierte en V5. Este archivo de salida se utiliza entonces como entrada de la segunda etapa. $RUN REGRESSN $FILES PRINT = REGR4.LST DICTIN = STUDY.DIC archivo Diccionario de entrada DATAIN = STUDY.DAT archivo Datos de entrada DICTOUTB = RESID.DIC archivo Diccionario de los residuos DATAOUTB = RESID.DAT archivo Datos para residuos $SETUP REGRESION EN DOS ETAPAS - PRIMERA ETAPA MDHANDLING=100 IDVAR=V1 DEPV=V122 WRITE=RESI OUTF=OUTB VARS=(V2-V6) $RUN MERGE $SETUP INTERCALACION DE LOS VALORES PREDICHOS (V3 EN ARCH.DE RES.) EN ARCH DE DATOS MATCH=INTE INAF=IN INBF=OUTB A1=B1 A1,A12,A23,A122,B3 214 Regresión lineal (REGRESSN) $RUN REGRESSN $SETUP REGRESION EN ETAPAS - SEGUNDA ETAPA MDHANDLING=100 INFI=OUT DEPV=V5 VARS=(V2,V3) Capı́tulo 28 Escalamiento multidimensional (MDSCAL) 28.1. Descripción general MDSCAL es un programa del escalamiento multidimensional no métrico para el análisis de similitudes. El programa, el cual opera sobre una matriz de medidas de similitud o disimilitud, está diseñado para encontrar, en cada dimensión especificada, la mejor representación geométrica de los datos en el espacio. El uso del escalamiento multidimensional no métrico, es parecido al del análisis factorial: por ej. se pueden puntualizar conglomerados de variables, se puede descubrir el número de dimensiones de los datos y algunas veces se pueden interpretar las dimensiones. Se puede usar el programa CONFIG para hacer análisis sobre una configuración de salida de MDSCAL. Configuración de entrada. Para comenzar los cálculos, se usa normalmente, una configuración inicial creada internamente, en forma arbitraria. Sin embargo, el usuario puede suministrar una configuración inicial. Hay varias razones para suministrar una configuración inicial. El usuario puede tener motivos teóricos para comenzar con una cierta configuración; se puede desear hacer iteraciones adicionales sobre una configuración que no se encuentra suficientemente cerca a la mejor; o, para ahorrar tiempo de computación, se puede desear suministrar una configuración de dimensiones más elevadas como punto de partida para una configuración de más baja dimensión. Algoritmo de escalamiento. El programa comienza con una configuración inicial, generada arbitrariamente o suministrada por el usuario, e itera (usando un procedimiento del tipo “descenso más inclinado”) sobre sucesivas configuraciones de ensayo, cada vez compara el orden de rango de las diferencias entre puntos en la configuración de ensayo con el orden de rango de la medida correspondiente en los datos. Una medida de “calidad de ajuste” (coeficiente de esfuerzo) se calcula después de cada iteración y la configuración se arregla nuevamente para mejorar el ajuste a los datos, hasta que, idealmente, el orden de rango entre las distancias entre puntos es perfectamente monotónico con el orden de rango de disimilitudes dado por los datos; en este caso, el “esfuerzo” será cero. En la práctica, los cálculos de escalamiento (en cualquier número de dimensiones) se detienen porque el esfuerzo alcanzó un valor suficientemente pequeño (STRMIN), el factor de escala (magnitud) del gradiente, alcanzó un valor suficientemente pequeño (SRGFMN), el esfuerzo ha mejorado demasiado lentamente (SRATIO), o se alcanzó un número de iteraciones definido previamente (ITERATIONS). El programa se detiene con cualquiera de estas condiciones que se presente primero. El mismo procedimiento se repite para la dimensión más baja que sigue, utiliza como configuración inicial los resultados anteriores, hasta alcanzar un número mı́nimo de dimensiones especificado. Durante los cálculos, el coseno del ángulo entre gradientes sucesivos, juega un papel importante de varias maneras; opcionalmente, se pueden especificar dos parámetros internos de ponderación (ver parámetros COSAVW y ACSAVW). Número de dimensiones y métrica. Se pueden obtener soluciones en 2 a 10 dimensiones. El usuario controla el número de dimensiones de las configuraciones obtenidas, a partir de la especificación del número máximo y mı́nimo de dimensiones deseadas y la diferencia de dimensiones de las soluciones sucesivas producidas (ver parámetros DMAX, DMIN, y DDIF). El usuario también especifica, con el parámetro R, si la métrica de distancia debe ser euclideana (R=2), que es el caso usual, o alguna otra métrica r de Minkowski. 216 Escalamiento multidimensional (MDSCAL) Esfuerzo. El esfuerzo es una medida de la bondad del ajuste de la configuración a los datos. El usuario puede escoger entre dos fórmulas para calcular el coeficiente de esfuerzo: el esfuerzo se estandariza por la suma de las distancias cuadradas desde la media (SQDIST) o bien, el esfuerzo se estandariza por la suma de las desviaciones cuadradas desde la media (SQDEV). En muchas situaciones, las configuraciones obtenidas por las dos fórmulas no son sustancialmente diferentes. En la fórmula 2, se obtienen valores más altos del esfuerzo para el mismo grado de ajuste. Ataduras en los coeficientes de entrada. Hay dos métodos alternos para el manejo de ataduras entre los datos de entrada; las distancias correspondientes puede requerirse que sean iguales (TIES=EQUAL) o puede permitirse diferir (TIES=DIFFER). Cuando hay pocas ataduras, es muy poca la diferencia entre las dos alternativas. Cuando hay gran número de ataduras, hay diferencia y se hace necesario considerar el contexto para hacer la selección. 28.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. El filtrado de casos debe hacerse en el momento de creación de la matriz, no en MDSCAL. El parámetro VARS permite que los cálculos se hagan sobre subconjuntos de la matriz y no sobre toda la matriz. Transformación de datos. No se aplica el uso de las proposiciones de Recode con MDSCAL. La transformación de los datos debe hacerse al crear la matriz. Ponderación de datos. La ponderación en el sentido usual (ponderar casos para corregir diferentes tasas de muestreo o diferentes niveles de agregación) debe hacerse antes de usar MDSCAL; tales ponderaciones deben ser incorporadas como datos en la matriz de entrada. Hay una opción de ponderación de naturaleza muy diferente en MDSCAL (ver el parámetro INPUT=WEIGHTS). Se puede usar para asignar ponderación a las celdas de las matriz de entrada; el usuario suministra una matriz de valores que se van a usar como coeficientes de ponderación para los elementos correspondientes en la matriz de entrada. Tratamiento de datos faltantes. Los datos faltantes de casos individuales se deben tener en cuenta en el momento de formación de la matriz, no en MDSCAL. Si después de haber creado la matriz, falta una entrada de la misma, es decir, contiene un código de dato faltante, existe la posibilidad de procesarlo en MDSCAL. La opción de recorte de MDSCAL (ver el parámetro CUTOFF) se puede usar para excluir del análisis los valores de datos faltantes si éstos son menores que valores de datos válidos. MDSCAL no tiene la opción de reconocer códigos de datos faltantes que sean números grandes (tales como 99.999, que es el código de datos faltantes emitido por PEARSON). Si existen códigos de datos faltantes grandes, éstos deberán editarse a números pequeños. Si una variable en particular, tiene muchos valores faltantes de entrada, posiblemente deberá ser excluida del análisis. 28.3. Resultados Matriz de entrada. (Opcional: ver el parámetro PRINT). Ponderaciones de entrada. (Opcional: ver el parámetro PRINT). Configuración de entrada. Si se da una configuración inicial, ésta siempre se imprime. Historia de los cálculos. Para cada solución, el programa imprime una historia completa de los cálculos, reporta el esfuerzo y sus parámetros auxiliares para cada iteración: Iteración Stress SRAT SRATAV CAGRGL COSAV ACSAV SFGR STEP el número de la iteración el valor actual del esfuerzo el valor actual del cociente de esfuerzo el promedio actual del cociente de esfuerzo (es un promedio ponderado exponencial) el coseno del ángulo entre el gradiente actual y el gradiente previo el promedio del coseno del ángulo entre gradientes sucesivos (un promedio ponderado) el promedio del valor absoluto del coseno del ángulo entre gradientes sucesivos (un promedio ponderado) la longitud (más apropiadamente, el factor de escala) del gradiente el tamaño del paso. 28.4 Matriz de configuración de salida 217 Motivo para terminar. Cuando se termina el cálculo, se indican los motivos con uno de los siguientes mensajes: “Se logró el mı́nimo”, “Número máximo de iteraciones usado”, “Se alcanzó esfuerzo satisfactorio”, o “Se alcanzó esfuerzo cero”. Configuración final. Para cada solución, se imprimen las coordenadas cartesianas de la configuración final. Configuración clasificada. (Opcional: ver el parámetro PRINT). Para cada solución, las proyecciones de puntos de la configuración final se clasifican ascendentemente por separado en cada dimensión y se imprimen. Resumen. Para cada solución, los datos originales se ordenan y se imprimen junto con sus distancias finales correspondientes (DIST) y las distancias hipotéticas requeridas para un ajuste monotónico perfecto (DHAT). 28.4. Matriz de configuración de salida Cuando se ha calculado la configuración final para cada número de dimensiones, se puede obtener como una matriz rectangular IDAMS. La configuración es centrada y normalizada. Las filas representan variables y las columnas dimensiones. Los elementos de la matriz se escriben en formato 10F7.3. Se generan registros de diccionario. Esta matriz puede ser una configuración inicial para otra ejecución de MDSCAL, o también puede ser capturada por otro programa, tal como CONFIG, para otros análisis. 28.5. Matriz de datos de entrada La entrada usual a MDSCAL es una matriz cuadrada IDAMS (ver el capı́tulo “Los datos en IDAMS”). Esta matriz es la mitad superior derecha sin diagonal y se define con el parámetro INPUT=STANDARD. TABLES y PEARSON generan matrices que son aptas para entrar a MDSCAL. La media y la desviación estándar no se usan, pero se deben suministrar registros ficticios apropiados. MDSCAL acepta matrices en otros formatos adicionalmente al triángulo superior derecho sin diagonal. Sin embargo, tales matrices deben tener la porción del diccionario de una matriz cuadrada IDAMS y deben tener registros al final, que contengan la pseudo-media y la pseudo-desviación estándar. Los siguientes parámetros de entrada, indican el formato exacto de la matriz de entrada: STAN STAN, DIAG LOWER, DIAG LOWER SQUARE triángulo superior derecho, sin diagonal triángulo superior derecho, con diagonal triángulo inferior izquierdo, con diagonal triángulo inferior izquierdo, sin diagonal toda la matriz cuadrada con diagonal. Las medidas contenidas en la matriz de datos pueden ser de similitud (tales como correlaciones) o de disimilitud. Aunque la entrada a MDSCAL, es normalmente, una matriz de coeficientes de correlación (por ej. una matriz de gamas o una matriz de r de Pearson), la matriz de entrada puede contener cualquier medida que tenga sentido como medida de proximidad. Como el escalamiento no métrico hace uso solamente de la ordinalidad de los datos, no se requiere suponer nada acerca de las propiedades cuantitativas o numéricas de los mismos. Al final debe haber el doble de variables que dimensiones. 28.6. Matriz de ponderaciones de entrada Si se suministra una matriz de ponderaciones, debe tener exactamente el mismo formato de la matriz de datos. El parámetro INPUT=(STAN/LOWE/SQUA,DIAG) se aplica a la matriz de ponderaciones, tanto como a la matriz de datos. El diccionario para la matriz de ponderaciones debe ser el mismo de la matriz de datos. No se utilizan medias ni desviaciones estándar, pero se deben suministrar las lı́neas ficticias correspondientes. Esta matriz contiene valores en correspondencia uno a uno con la matriz de datos, los cuales se usarán como ponderaciones para los datos. Estos valores se usan conjuntamente con el valor del parámetro CUTOFF al aplicarlos a los datos. Si un dato es mayor que el valor correspondiente del parámetro CUTOFF, pero su ponderación correspondiente es menor o igual a cero, entonces se señala una condición de error. Similarmente, si el dato es menor o igual al valor del parámetro CUTOFF y su ponderación correspondiente es mayor de 218 Escalamiento multidimensional (MDSCAL) cero, se genera una condición de error. Si se presenta una de estas inconsistencias, la ejecución termina. 28.7. Matriz de configuración de entrada La configuración de entrada debe estar en el formato de una matriz rectangular de IDAMS. Ver el capı́tulo “Los datos en IDAMS”. Suministra una configuración inicial, a partir de la cual se llevan a cabo los cálculos. Las filas deben representar las variables y las columnas las dimensiones. Usualmente es producida por una ejecución previa de MDSCAL y se pueda continuar una ejecución anterior, en el punto en el cual ésta quedó. La matriz debe tener tantas dimensiones como hayan sido dadas para el parámetro DMAX. Nota: si se especifica una lista de variables (VARS), MDSCAL usa las primeras n filas de la configuración de entrada, donde n es el número de variables del subconjunto, sin verificar los numeros de variable. 28.8. Estructura del setup $RUN MDSCAL $FILES Especificación de archivos $SETUP 1. Tı́tulo 2. Parámetros $MATRIX (condicional) Matriz de datos Matriz de ponderaciones Matriz de configuración inicial (Nota: no es necesario incluir todas las matrices aquı́; sin embargo, si se incluyen más matrices, éstas deben estar en el orden arriba indicado). Archivos: FT02 FT03 FT05 FT08 PRINT 28.9. matriz de configuración de salida matriz de ponderaciones de entrada, si se ha especificado INPUT=WEIGHTS (omitir si se usa $MATRIX) configuración inicial de entrada, si se ha especificado INPUT=CONFIG (omitir se usa $MATRIX) matriz de datos de entrada (omitir si se usa $MATRIX) resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-2, a continuación. 1. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: CORRIDA DE MDSCAL CON EL ARCHIVO X4952 2. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: DMAX=5 ITER=75 WRITE=CONFIG 28.9 Proposiciones de control del programa 219 INPUT=(STANDARD/LOWER/SQUARE, DIAGONAL, WEIGHTS, CONFIG) STAN La entrada es una matriz cuadrada IDAMS, sin diagonal, mitad superior derecha. LOWE La matriz de entrada es la mitad inferior izquierda de la matriz. SQUA La matriz de entrada es una matriz cuadrada completa. DIAG La matriz de entrada tiene los elementos de la diagonal. WEIG Se suministra una matriz de ponderaciones. CONF Se suministra la matriz de configuración inicial. VARS=(lista de variables) Lista de variables de la matriz sobrer la cual se va a hacer el análisis. Por defecto: se usa toda la matriz de entrada. FILE=(DATA, WEIGHTS, CONFIG) DATA La matriz de datos de entrada está en un archivo. WEIG La matriz de ponderaciones está en un archivo. CONF La matriz de configuración de entrada está en un archivo. Por defecto: se supone que todas las matrices se encuentran después de un comando $MATRIX en el orden: datos, ponderaciones, configuración. COEFF=SIMILARITIES/DISSIMILARITIES SIMI Coeficientes grandes en la matriz de datos indican que los puntos son similares o están cerca unos de otros. DISS Coeficientes grandes indican que los puntos no son similares o están lejos unos de otros. DMAX=2/n El máximo de la dimensión: el escalamiento comienza con el espacio de máxima dimensión. DMIN=2/n El mı́nimo de la dimensión: el escalamiento continúa hasta que alcance o pase de la dimensión mı́nima. DDIF=1/n Diferencia de dimensión: el escalamiento se lleva a cabo desde la dimensión máxima hasta la mı́nima, con pasos del tamaño de la diferencia de dimensión. R=2.0/n Indica cual es la métrica r de Minkowski a usar. Se puede utilizar cualquier valor >= 1.0. R=1.0 Métrica de cuadra urbana (“city block”). R=2.0 Distancia euclideana ordinaria. CUTOFF=0.0/n Se descartan los valores de datos iguales o menores a n. Si los valores legı́timos de los coeficientes de entrada se encuentran en el rango -1.0 a 1.0, se debe usar CUTOFF=-1.01. TIES=DIFFER/EQUAL DIFF Las distancias desiguales que correspondan a valores iguales en los datos, no contribuyen al coeficiente de esfuerzo y no se intenta igualarlas. EQUA Las distancias desiguales que correspondan a valores iguales en los datos, sı́ contribuyen al coeficiente de esfuerzo y sı́ se hace el intento de igualarlas. ITERATIONS=50/n Número máximo de iteraciones a hacer para un número dado de dimensiones. Este máximo es una precaución de seguridad para controlar el tiempo de ejecución. STRMIN=.01/n Esfuerzo mı́nimo. El escalamiento se detiene cuando se alcanza el valor de esfuerzo mı́nimo. 220 Escalamiento multidimensional (MDSCAL) SFGRMN=0.0/n El valor mı́nimo de factor de escala de gradiente. El proceso de escalamiento se detiene cuando se alcanza el valor mı́nimo de la magnitud del gradiente. SRATIO=.999/n El cociente de esfuerzo. El proceso de escalamiento se detiene si el cociente de esfuerzo entre dos pasos consecutivos alcanza n. ACSAVW=.66/n El factor de ponderación para el promedio del valor absoluto del coseno del ángulo entre dos gradientes sucesivos. COSAVW=.66/n El factor de ponderación del promedio del coseno del ángulo entre dos gradientes sucesivos. STRESS=SQDIST/SQDEV SQDI Calcular el esfuerzo utilizando la estandarización por la suma de las distancias cuadradas. SQDE Calcular el esfuerzo utilizando la estandarización por la suma de las desviaciones cuadradas desde la media. WRITE=CONFIG Guardar en un archivo la configuración final de cada solución. PRINT=(MATRIX, SORTCONF, LONG/SHORT) MATR Imprimir la matriz de entrada y la matriz de ponderaciones, si la hay. SORT Clasificar cada dimensión de la configuración final e imprimirla. LONG Imprimir las matrices en lı́neas largas. SHOR Imprimir las matrices en lı́neas cortas. 28.10. Restricciones 1. La capacidad del programa es de 1800 puntos (por ej. 1800 elementos de la matriz de similitud o disimilitud). Esto es equivalente a una matriz triangular de 60x60 o a una matriz cuadrada de 42x42. 2. Las variables se pueden escalar hasta 10 dimensiones. 3. La matriz de configuración inicial puede tener un máximo de 60 filas y 10 columnas. 28.11. Ejemplo Generación de una matriz de configuración de salida; la matriz de entrada de datos es una matriz estándar de IDAMS en un archivo; no hay matriz de entrada de ponderaciones ni matriz de configuración de entrada; se solicitan 20 iteraciones; se hace el análisis sobre un subconjunto de variables. $RUN MDSCAL $FILES FT02 = MDS.MAT archivo Matriz de configuración de salida FT08 = ABC.COR archivo Matriz de datos de entrada $SETUP ESCALAMIENTO MULTIDIMENSIONAL ITER=20 WRITE=CONFIG FILE=DATA VARS=(V18-V36) Capı́tulo 29 Análisis de clasificación múltiple (MCA) 29.1. Descripción general MCA examina las relaciones entre varias variables de predicción y una sóla variable dependiente y determina los efectos de cada predictor antes y después de los ajustes para sus intercorrelaciones con otros predictores dentro del análisis. También produce información acerca de las relaciones bivariadas y multivariadas entre los predictores y la variable dependiente. La técnica MCA se puede considerar equivalente a un análisis de regresión múltiple con variables ficticias. Sin embargo, a menudo MCA resulta más conveniente para usar e interpretar. MCA tiene también la posibilidad de hacer análisis de variancia de una entrada. MCA asume que los efectos de los predictores son aditivos, es decir que no hay interacciones entre los predictores. Está diseñado para usar con variables predictoras las cuales se miden en escalas nominales, ordinales y de intervalos. Acepta un número desigual de casos en las celdas construidas por clasificación cruzada de los predictores. Como alternativa al uso de MCA, se tiene REGRESSN y ONEWAY. REGRESSN suministra una capacidad de tipo general de regresión múltiple. ONEWAY hace un análisis de variancia de una entrada. La ventaja de MCA sobre REGRESSN consiste en aceptar variables predictoras en una forma tan débil como escalas nominales y no supone una relación lineal en la regresión. Las ventajas sobre ONEWAY son que en MCA el código máximo para una variable de control en un análisis de una entrada es 2999 (en lugar de 99 en ONEWAY). Generación de un dataset de residuos. Se pueden calcular residuos y llevarlos como un archivo de datos de salida descrito por un diccionario IDAMS. Ver la sección “Dataset(s) de residuos de salida” para detalles del contenido. Esta opción no se puede usar cuando se tiene sólo un predictor. Procedimientos iterativos. MCA utiliza un algoritmo de iteración para aproximar los coeficientes que constituyen las soluciones del conjunto de ecuaciones normales. El algoritmo de iteración se detiene cuando los coeficientes generados tienen la exactitud suficiente. Esto involucra la definición de una tolerancia y la especificación de una prueba para determinar cuando se ha satisfecho esta tolerancia (ver parámetros de análisis CRITERION y TEST). Hay cuatro pruebas de convergencia. Si los coeficientes no convergen dentro de los lı́mites impuestos por el usuario, el programa imprime los resultados de la última iteración. El número de iteraciones útiles depende, en alguna forma, del número de predictores usados en el análisis y de la fracción especificada de tolerancia. Cuando hay menos de 10 predictores, se ha encontrado que resulta conveniente especificar 10 como el número de máximo de iteraciones. Detección y tratamiento de interacciones. El programa asume que el fenómeno que se va estudiar se puede entender en términos de un modelo aditivo. Si sobre bases a priori, se sospecha que algunas variables en particular presentan interacciones entre ellas, MCA se puede usar para determinar la extensión de estas interacciones ası́. Si se especifica un predictor, MCA hace análisis de variancia de una entrada. Este análisis puede ayudar a determinar y eliminar interacciones entre predictores. El procedimiento completo es el siguiente (ver también Ejemplo 3): 222 Análisis de clasificación múltiple (MCA) 1. Determinar un conjunto de predictores de los cuales se sospecha que tendrán interacciones. 2. Formar una sola “variable de combinación” con estos predictores y la proposición COMBINE de Recode. 3. Ejecutar un análisis de MCA con los predictores sospechosos para obtener una R cuadrada ajustada. 4. Ejecutar un análisis de MCA con la “variable de combinación” como control en un análisis de variancia de una entrada para obtener eta cuadrada ajustada, la cual será mayor o igual a la R cuadrada ajustada. 5. Use la diferencia, eta cuadrada ajustada menos R cuadrada ajustada (la fracción de la variancia explicada que se pierde debido a la suposición de aditividad), como guı́a para determinar si se justifica el uso de una variable de combinación a cambio de los predictores originales. La prueba para interacción debe basarse en la misma muestra de la ejecución normal de MCA. Si se detectan interacciones, entonces debe usarse la variable de combinación como variable de predicción en lugar de las variables individuales que interactúan. 29.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. Los casos se pueden excluir del análisis en la ejecución de MCA con una proposición de filtro estándar. En el análisis de clasificación múltiple, se excluyen casos por haber excedido el código máximo de predictor. (Nota: si en una ejecución, una variable de predicción tiene un código fuera del rango 0-31, el caso con este valor se elimina de todos los análisis). Para un análisis en particular, se pueden excluir casos adicionales, debido a las condiciones siguientes: Un caso (referido como excéntrico) tiene un valor de la variable dependiente que es mayor que un número especificado de desviaciones estándar de la media de la variable dependiente. Ver los parámetros de análisis OUTDISTANCE y OUTLIERS. Un caso tiene una variable dependiente que es mayor que un valor máximo especificado. Ver parámetro de análisis DEPVAR. Un caso tiene datos faltantes para la variable dependiente o la variable de ponderación. Ver “Tratamiento de datos faltantes” y “Ponderación de datos” más adelante. Transformación de datos. Se pueden usar las proposiciones de Recode. Ponderación de datos. Se puede usar una variable para ponderar los datos de entrada; esta variable de ponderación puede tener cifras enteras o decimales. Cuando el valor de la variable de ponderación para un caso es cero, negativo, dato faltante o no numérico, entonces el caso siempre se omite; se imprime el número de casos ası́ tratados. Cuando se usan datos ponderados, las pruebas de significación estadı́stica deben interpretarse con precaución. Tratamiento de datos faltantes. El parámetro MDVALUES está disponible para indicar cuales valores de datos faltantes, si los hay, se usarán para verificar los datos faltantes. Los casos con datos faltantes en la variable dependiente siempre se excluyen. Los casos con datos faltantes en las variables de predicción se pueden excluir de todos los análisis con un filtro. (El uso de filtro para excluir casos con datos faltantes de las variables predictoras en la clasificación múltiple, solamente se necesita si los códigos de datos faltantes se encuentran dentro del rango 0-31; si el valor de algún predictor está por fuera de este rango, un caso se excluye automáticamente de todos los análisis en la ejecución). 29.3. Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variables y registros C, si los hay, solamente para variables utilizadas en la ejecución. Tabla de frecuencias ponderadas. (Opcional: ver el parámetro PRINT). Se imprime una matriz N x M para cada par de predictores donde N=código máximo de predictor de fila y N=código máximo de predictor de columna. El número total de tablas es P(P-1)/2 donde P es el número de predictores. 29.3 Resultados 223 Coeficientes para cada iteración. (Opcional: ver el parámetro de analisis PRINT). Coeficientes para cada clase para cada predictor. Estadı́sticas de la variable dependiente. Para la variable dependiente (Y): gran media, desviación estándar y coeficiente de variación, suma de Y y suma de Y cuadrada, sumas de cuadrados total, explicada y residual, número de casos usados en el análisis y suma de ponderaciones. Estadı́sticas de predictores para análisis de clasificación múltiple. Para cada categorı́a de cada predictor: código de categorı́a (clase) y nombre, si existe en el diccionario, número de casos con datos válidos (en forma primaria, ponderada y porcentaje), media (no ajustada y ajustada), desviación estándar y coeficiente de variación de la variable dependiente, desviación no ajustada de la media de la categorı́a a partir de la gran media y coeficiente de ajuste. Para cada variable predictora: eta y eta cuadrada (no ajustada y ajustada), beta y beta cuadrada, sumas de cuadrados no ajustadas y ajustadas. Estadı́sticas de análisis para análisis de clasificación múltiple. Para todos los predictores combinados: R cuadrada múltiple (no ajustada y ajustada), coeficiente de ajuste para grados de libertad, R múltiple (ajustada), lista de betas en orden descendente de sus valores. Estadı́sticas de análisis de variancia de una entrada. Para cada categorı́a del predictor: código de categorı́a (clase) y nombre, si existe en el diccionario, número de casos con datos válidos (en forma primaria, ponderada y porcentaje), media, desviación estándar y coeficiente de variación de la variable dependiente, suma y porcentaje de valores de la variable dependiente, suma de valores cuadrados de la variable dependiente. Para la variable predictora: eta y eta cuadrada (no ajustada y ajustada), coeficiente de ajuste para grados de libertad, sumas de cuadrados total, entre medias y dentro de grupos, valor F (se imprimen grados de libertad). Residuos. (Opcional: ver el parámetro PRINT). Se imprimen para cada caso, en el orden del archivo de entrada: la variable de identificación, el valor observado, el valor predicho, el residuo y la variable de ponderación si se ha usado. Estadı́sticas de resumen para los residuos. Si se solicitan residuos, el programa imprime el número de casos, la suma de ponderaciones, media, variancia, asimetrı́a y kurtosis de la variable de residuo. 224 29.4. Análisis de clasificación múltiple (MCA) Dataset(s) de residuos de salida Para cada análisis se puede, opcionalmente, llevar los residuos a un archivo de salida, descrito por un diccionario IDAMS. (Ver el parámetro de análisis WRITE=RESIDUALS). Se graba un registro por cada caso que haya pasado por el filtro contenido una variable de identificación, un valor observado, un valor calculado, un residuo para la variable dependiente y la variable de ponderación si se ha usado. Las caracterı́sticas del dataset son las siguientes: Número de variable (identificador) (variable dependiente) (variable predicha) (residuo) (ponderación - si hay) * ** *** 1 2 3 4 5 Nombre igual a entrada igual a entrada Predicted value Residual igual a entrada Ancho de campo Número de decimales Códigos MD * * 7 7 * 0 ** *** *** ** igual a entrada igual a entrada 9999999 9999999 igual a entrada transferido del diccionario de entrada para variables V o 7 para variables R transferido del diccionario de entrada para variables V o 2 para variables R 6 + Nr. de decimales para la variable dependiente menos el ancho de la variable dependiente; si ésta es negativa, entonces este valor es cero. Si faltan el valor observado o el valor de la variable de ponderación, o si el caso se excluyó por la verificación de código máximo o por criterio de dato excéntico, se graba un registro residual de todas las variables con código MD1 (con excepción de la variable de identificación). 29.5. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. Todas las variables usadas para análisis deben ser numéricas; pueden tener valores enteros o decimales, excepto los predictores que deben tener valor entero, entre 0 y 31 para clasificación múltiple y hasta 2999 para el análisis de variancia de una entrada. La variable identificadora de caso puede ser alfabética. Para un análisis con MCA se requiere un gran número de casos; una regla práctica es que el número total de categorı́as (es decir la suma de categorı́as sobre todos los predictores) no debe exceder el 10 % del tamaño de la muestra). La variable dependiente debe medirse en una escala de intervalo o ser una dicotomı́a, y no debe presentar mala asimetrı́a. Las variables predictoras en MCA deben estar categorizadas, preferiblemente no más de 6 categorı́as. Aunque MCA está diseñado para manejar predictores correlacionados, no debe haber dos predictores tan fuertemente correlacionados que presenten una superposición perfecta entre cualesquiera de sus categorı́as. (Si hay una superposición perfecta, se hace necesaria una recodificación para combinar categorı́as o un filtrado para retirar casos viciados). 29.6 Estructura del setup 29.6. 225 Estructura del setup $RUN MCA $FILES Especificación de archivos $RECODE (opcional) Proposiciones de Recode $SETUP 1. 2. 3. 4. Filtro (opcional) Tı́tulo Parámetros Especificaciones de análisis (tantas como sean necesarias) $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx DICTyyyy DATAyyyy PRINT 29.7. diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) diccionario de residuos de salida ) un conjunto por cada datos de residuos de salida ) archivo de residuos requerido resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-4, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: INCLUDE V6=2-6 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: EJECUCION DE PRUEBA PARA MCA 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: * INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos. Ver el capı́tulo “El archivo Setup de IDAMS”. 226 Análisis de clasificación múltiple (MCA) MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. PRINT=CDICT/DICT CDIC Imprimir el diccionario de entrada para las variables accedidas con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. 4. Especificaciones de análisis. Las reglas de codificación son las mismas que las de los parámetros. Cada especificación de análisis debe comenzar en una lı́nea nueva. Ejemplo: PRINT=TABLES, DEPVAR=(V35,98), ITER=100, CONV=(V4-V8) DEPVAR=(número de variable, codmax) Número de variable y código máximo para la variable dependiente. Sin valor por defecto; siempre se debe especificar el número de variable. El valor por defecto para el máximo código es 9999999. CONVARS=(lista de variables) Variables que se van a usar como predictores. Si sólo se especifica una variable, entonces se ejecuta un análisis de variancia de una entrada. Sin valor por defecto. MDVALUES=BOTH/MD1/MD2/NONE Cuales valores de datos faltantes de la variable dependiente se van a verificar. Ver el capı́tulo “El archivo Setup de IDAMS”. Nota: nunca se verifican datos faltantes para las variables de predicción. WEIGHT=número de variable Número de la variable de ponderación, si se van a ponderar los datos. ITERATIONS=25/n Número máximo de iteraciones. Rango 1-99999. TEST=PCTMEAN/CUTOFF/PCTRATIO/NONE Prueba de convergencia deseada. PCTM Prueba si el cambio en los coeficientes de una iteración a otra, se encuentra por debajo de la fracción especificada de la gran media. CUTO Prueba si el cambio en los coeficientes de una iteración a otra, es menor que un valor especificado. PCTR Prueba si el cambio en los coeficientes de una iteración a otra, es menor que una fracción especificada de la relación de la desviación estándar de la variable dependiente a su media. NONE El programa itera hasta exceder el máximo número de iteraciones especificado. CRITERION=.005/n Dar un valor numérico que es la tolerancia de la convergencia de la prueba escogida. Rango 0.0 a 1.0 (se debe dar el punto decimal). OUTLIERS=INCLUDE/EXCLUDE INCL Se incluyen en el análisis y se contarán, los casos con valores excéntricos de la variable dependiente. EXCL Los casos con valores excéntricos de la variable dependiente, se excluyen del análisis. 29.8 Restricciones 227 OUTDISTANCE=5/n Número de desviaciones estándar, tomadas desde la gran media, para definir cuándo un valor de la variable dependiente se considera excéntrico. WRITE=RESIDUALS Escribir los residuos en un dataset IDAMS; aplicar el modelo MCA, sólo al subconjunto de los casos que pasan los criterios de datos faltantes, código máximo y valores excéntricos. Los casos a los cuales el modelo MCA no se aplica, se incluyen en el dataset de residuos con todos sus valores (excepto el valor de la variable de identificación) marcados MD1. No se pueden obtener residuos si sólo se ha especificado una variable de predicción. OUTFILE=OUT/yyyy Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de salida. Por defecto: DICTOUT, DATAOUT. Nota: si más de un análisis solicita llevar residuos al archivo, los ddnames por defecto DICTOUT y DATAOUT sólo se pueden usar para uno. IDVAR=número de variable Número de una variable de identificación para ser incluida en el dataset de residuos. Por defecto: se crea una variable cuyos valores son números que indican la posición secuencial del caso en el archivo de residuos. PRINT=(TABLES, HISTORY, RESIDUALS) TABL Imprimir la tabulación cruzada por pares de predictores. HIST Imprimir los coeficientes de todas las iteraciones. Si no se ha seleccionado la opción HIST y la iteración converge, sólo se imprimen los coeficientes finales; si la iteración no converge, se imprimen los coeficientes de las dos últimas iteraciones. RESI Imprimir los residuos en el mismo orden secuencial de los casos de entrada. 29.8. Restricciones 1. Número máximo de variables de entrada, incluidas las variables de proposiciones Recode es 200. 2. El número máximo de variables predictoras (de control) por análisis es 50. 3. No es posible usar el número máximo de predictores, cada uno de ellos con el número máximo de categorı́as en un análisis. Si un problema excede la capacidad de memoria, se imprime un mensaje de error y el programa pasa al siguiente análisis. 4. Máximo número de análisis por ejecución es 50. 5. Las variables predictoras para el análisis de clasificación múltiple deben estar categorizadas, preferiblemente con 6 o menos categorı́as. Las categorı́as deben tener códigos enteros en el rango 0-31. Los casos con cualquier otro valor serán excluidos del análisis. 6. La variable predictora en el análisis de variancia de una entrada debe estar codificada dentro del rango 0-2999. Los casos con otros valores, se excluyen del análisis. 7. Si una variable predictora tiene cifras decimales, sólo se usa la parte entera. 8. Si la variable de identificación es alfabética con ancho > 4, sólo se usan los primeros cuatro caracteres. 29.9. Ejemplos Ejemplo 1. Análisis de clasificación múltiple con cuatro variables de control (predictores): V7, V9, V12, V13 y la variable dependiente V100; se harán análisis separados en todo el dataset y en dos subconjuntos de casos. 228 Análisis de clasificación múltiple (MCA) $RUN MCA $FILES PRINT = MCA1.LST DICTIN = STUDY.DIC archivo Diccionario de entrada DATAIN = STUDY.DAT archivo Datos de entrada $SETUP TODOS LOS ENCUESTADOS JUNTOS * (valores por defecto para todos los parámetros) DEPV=V100 CONV=(V7,V9,V12-V13) $RUN MCA $SETUP INCLUDE V4=21,31-39 SOLO CIENTIFICOS * (valores por defecto para todos los parámetros) DEPV=V100 CONV=(V7,V9,V12-V13) $RUN MCA $SETUP INCLUDE V4=41-49 SOLO TECNICOS * (valores por defecto para todos los parámetros) DEPV=V100 CONV=(V7,V9,V12-V13) Ejemplo 2. Análisis de clasificación múltiple con la variable dependiente V201 y tres variables de predicción V101, V102, V107; los datos se van a ponderar con la variable V6; se producirá un dataset de residuos en el cual los casos se identificarán con la variable V2; se excluirán los casos con valores extremos de la variable dependiente (casos excéntricos que estén a más de cuatro desviaciones estándar desde la gran media). Los residuos para los primeros 20 casos se imprimirán con el programa LIST. $RUN MCA $FILES PRINT = MCA2.LST DICTIN = LAB.DIC archivo Diccionario de entrada DATAIN = LAB.DAT archivo Datos de entrada DICTOUT = LABRES.DIC archivo Diccionario de residuos DATAOUT = LABRES.DAT archivo Datos de residuos $SETUP ANALISIS DE CLASIFICACION MULTIPLE - RESIDUOS VAN A UN ARCHIVO DE SALIDA * (valores por defecto para todos los parámetros) DEPV=V201 OUTL=EXCL OUTD=4 IDVA=V2 WRITE=RESI CONV=(V101,V102,V107) WEIGHT=V6 $RUN LIST $SETUP LISTADO DEL PRINCIPIO DEL ARCHIVO DE RESIDUOS MAXCASES=20 INFILE=OUT Ejemplo 3. Para una variable dependiente V52, se van a verificar las interacciones entre tres variables (V7, V9, V12). V7 se codifica 1,2,9, V9 se codifica 1,3,5,9 y V12 se codifica 0,1,9 donde los dı́gitos 9 significan valores de datos faltantes. Se construye, con Recode, una sola variable de combinación. Esto implica la recodificación de cada variable a un conjunto de códigos contiguos que comienza desde cero y luego se usa la función COMBINE para producir un código único para cada combinación posible de códigos de las tres variables separadas. Se ejecuta MCA con las tres variables separadas como predictores y se lleva a cabo un análisis de variancia de una entrada, con la variable de combinación como variable de control. Se excluyen los casos con datos faltantes en los predictores. Los casos con valores mayores de 90000 en la variable dependiente, también se excluyen. 29.9 Ejemplos $RUN MCA $FILES DICTIN = CON.DIC archivo Diccionario de entrada DATAIN = CON.DAT archivo Datos de entrada $SETUP EXCLUDE V7=9 OR V9=9 OR V12=9 VERIFICACION DE INTERACCIONES BADD=SKIP DEPV=(V52,90000) CONVARS=(V7,V9,V12) DEPV=(V52,90000) CONVARS=R1 $RECODE R7=V7-1 R9=BRAC(V9,1=0,3=1,5=2) R1=COMBINE R7(2),R9(3),V12(2) 229 Capı́tulo 30 Análisis multivariado de variancia (MANOVA) 30.1. Descripción general MANOVA hace análisis de variancia y covariancia univariado y multivariado, usando un modelo lineal general. Se pueden usar hasta ocho factores (variables independientes). Si se especifica más de una variable dependiente, se hacen análisis univariados y multivariados. El programa acepta números iguales y desiguales de casos en las celdas. MANOVA es el único programa de IDAMS para análisis multivariado de variancia. Se recomienda ONEWAY para el análisis univariado de variancia. MCA maneja problemas univariados de múltiples factores. No tiene limitaciones con relación a celdas vacı́as, acepta más de ocho predictores y permite más de 80 celdas. Sin embargo, el modelo básico de análisis de MCA es diferente del de MANOVA. Una diferencia importante es que MCA no es sensible a los efectos de interacción. Modelo jerárquico de regresión. MANOVA usa aproximación de la regresión al análisis de variancia. De manera más particular, el programa emplea un modelo jerárquico. Hay una consecuencia importante para el usuario: si una ejecución de MANOVA involucra más de una variable de factor y hay un número desproporcionado de casos en las celdas construidas por la clasificación cruzada de los factores, entonces se debe considerar el orden en el cual están especificadas las variables de factores. La desproporción de los números de casos en las subclases confunde los efectos principales y el investigador debe escoger el orden en el cual se deben eliminar los efectos de confusión. Al usar MANOVA, esto se logra con el orden en el que se especifican las variables de factor: cuando se usa orden estándar, las primeras variables especificadas tienen los efectos de las variables retiradas más tarde, es decir, el primer efecto listado se probará con todos los otros efectos principales eliminados. La regla general es que cada prueba elimina los efectos listados antes en las especificaciones de nombre de prueba e ignora los efectos listados después. Para un análisis estándar de dos entradas, el término de interacción no se afecta con el orden de las variables de factor; de forma general, para un análisis estándar de n entradas, el término de la n-ésima interacción y sólo ese término, no es afectado. El problema existe para ambos análisis, unvariado y multivariado. Opción de contraste. Hay dos opciones disponibles para definir los contrastes (ver el parámetro de factor CONTRAST). Los contrastes nominales se generan por defecto; son las desviaciones acostumbradas de las medias de fila y columna de la gran media y la generalización de las mismas para los contrastes de interacción. El programa también puede generar contrastes de Helmert. Aumento de la suma de cuadrados dentro de las celdas. Es posible aumentar la suma de cuadrados dentro de las celdas (término de error) usando los estimativos ortogonales (ver el parámetro AUGMENT). Esto permite usar el programa para cuadrados Latinos y para reunir los términos de interacción con errores. Reordenamiento y/o reunión de estimativos ortogonales. El programa tiene un ordenamiento convencional de estimativos de efectos ortogonales para uso estándar (media, C, B, A, BxC, AxC, AxB, AxBxC en diseño con tres factores). Sin embargo los estimativos ortogonales se pueden disponer en otro orden (ver el parámetro REORDER). Más aún, es posible reunir varios estimativos ortogonales tales como términos de interacción para pruebas simultáneas o fragmentar el cúmulo de estimativos ortogonales para un efecto dado 232 Análisis multivariado de variancia (MANOVA) en varios cúmulos más pequeños para hacer pruebas por separado (ver el parámetro de nombre de prueba DEGFR). 30.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. El filtro estándar está disponible para escoger casos para ejecución. Las variables dependientes se escogen con el parámetro DEPVARS y las covariadas con el parámetro COVARS. Las variables de factor se especifican con proposiciones especiales de factor. Transformación de datos. Se pueden usar las proposiciones de Recode. Nótese que solamente se aceptan valores enteros (positivos y negativos) para las variables usadas como factor. Ponderación de datos. No se aplica el uso de variables de ponderación. Tratamiento de datos faltantes. El parámetro MDVALUES está disponible para indicar cuales valores de datos faltantes, si los hay, se usarán para verificar datos faltantes. Se excluyen los casos con códigos de datos faltantes en cualquiera de las variables de entrada (dependientes, covariadas, o de factor). Esto puede resultar en muchos casos excluidos y constituye un problema potencial que debe considerarse cuando se planee el análisis. 30.3. Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variables y registros C, si los hay, solamente para variables usadas en la ejecución. Medias de celda y enes (N). Para cada celda, se imprime N y la media para cada variable dependiente y cada variable covariada. Las medias no se ajustan para ninguna variable covariada. Las celdas se etiquetan consecutivamente comenzando con “1 1” (para un diseño con 2 factores) sin importar los códigos actuales de las variables de factor. Al indexar las celdas, los ı́ndices del último factor son los menores (de más rápido movimiento). Basa de diseño. Es la matriz de diseño generada por el programa. Las ecuaciones de efectos están en las columnas comenzando con el efecto de la media en la columna 1. Si se ha especificado REORDER, se imprime la matriz después del reordenamiento. Intercorrelaciones entre los coeficientes de las ecuaciones normales. Matriz de correlación de errores. En un análisis multivariado de variancia, el término de error es una matriz variancia-covariancia. Este es el término de error reducido a una matriz de correlación (antes de ajustar para las variables covariadas, si las hay). Componentes principales de la matriz de correlación de errores. Las componentes están en las columnas. Son las componentes del término de error del análisis (antes de ajustar para las variables covariadas, si las hay). Matriz de dispersión de errores y errores estándar de estimación. Es el término de error del análisis, una matriz de variancia-covariancia. La matriz se ajusta para variables covariadas, si las hay. Cada elemento de la diagonal de la matriz es exactamente el que aparecerı́a en una tabla de análisis convencional de variancia como el error interno cuadrático medio de la variable. Los grados de libertad se ajustan para aumento si se solicita. Los errores estándar de estimación corresponden a las raı́ces cuadradas de los elementos de la diagonal de la matriz. Para análisis con variables covariadas Matriz de dispersión de errores ajustada a las correlaciones. Es el término del error, una matriz de variancia-covariancia reducida a una matriz de correlación, después de ajustarla para variables covariadas. Resumen del análisis de regresión. Componentes principales de la matriz de correlación de errores después de ajustes de covariadas. Las componentes están en las columnas. Son las componentes del término de error del análisis después 30.4 Dataset de entrada 233 del ajuste para las variables covariadas. Para análisis univariado Una tabla anova. Grados de libertad, suma de cuadrados, medias cuadráticas y cocientes F. Para análisis multivariado Se imprimen los siguientes items para cada efecto. Se hacen ajustes para las variables covariadas, si las hay. El orden de los efectos es exactamente opuesto al orden de las especificaciones de nombre de prueba. Cociente F para el criterio de razón de semejanza. Se usa aproximación de Rao. Es una prueba multivariada del significado del efecto global para todas las variables dependientes simultáneamente. Variancias canónicas de las componentes principales de la hipótesis. Son las raı́ces o valores propios de la matriz de hipótesis. Coeficientes de las componentes principales de la hipótesis. Son las correlaciones entre las variables y las componentes de la matriz de hipótesis. El número de componentes diferentes de cero para cualquier efecto será el mı́nimo de los grados de libertad y del número de variables dependientes. Puntajes de contraste de componentes para efectos estimados. Son los puntajes de la hipótesis de contrastes usados en el diseño. Son análogos a las medias de columna en un análisis univariado de variancia y se pueden usar de la misma manera para ubicar variables y contrastes que producen desviaciones inusuales de la hipótesis nula. Pruebas acumulativas de Bartlett sobre las raı́ces. Es una prueba aproximada para las raı́ces restantes después de eliminar la primera, la segunda, la tercera, etc. Cocientes F para pruebas univariadas. Son exactamente los cocientes F que se obtendrı́an en un análisis convencional de variancia. 30.4. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. Todas las variables deben ser numéricas. Las variables dependientes y covariadas deben medirse en escala de intervalo o deben ser una dicotomı́a. Las variables de factor pueden ser nominales, ordinales o intervalos pero deben tener valores enteros; se usan para designar la celda apropiada del caso. 234 Análisis multivariado de variancia (MANOVA) 30.5. Estructura del setup $RUN MANOVA $FILES Especificación de archivos $RECODE (opcional) Proposiciones de Recode $SETUP 1. 2. 3. 4. Filtro (opcional) Tı́tulo Parámetros Especificaciones de factores (tantas como sean necesarias; al menos se debe suministrar un factor) 5. Especificaciones de nombre de prueba (tantas como sean necesarias; al menos se debe suministrar un nombre de prueba) $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx PRINT 30.6. diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-5, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: INCLUDE V2=1-4 AND V15=2 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: ANALISIS DE EDAD Y SALARIO CON SEXO Y PROFESION COMO FACTORES 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: DEPVARS=(V5,V8) COVA=(V101,V102) INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos. Ver el capı́tulo “El archivo Setup de IDAMS”. 30.6 Proposiciones de control del programa 235 MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. MDVALUES=BOTH/MD1/MD2/NONE Cuales valores de datos faltantes se van a usar para las variables accedidas en esta ejecución. Ver el capı́tulo “El archivo Setup de IDAMS”. DEPVARS=(lista de variables) Una lista de variables a usar como variables dependientes Sin valor por defecto. COVARS=(lista de variables) Una lista de variables para usar como covariadas. AUGMENT=(m,n) Para construir el término de error, la suma interna de cuadrados se aumentará por las columnas m, m+1, m+2,...,n de la matriz ortogonal de estimativos. Por defecto: la suma interna de cuadrados se usará como término de error. REORDER=(lista de valores) Reordena los estimativos ortogonales de acuerdo con la lista (ver parágrafo “Reordenamiento y/o reunión de estimativos ortogonales” atrás). Nótese que si se solicita el reordenamiento de estimativos, el orden de las especificaciones de nombre de prueba debe corresponder al nuevo orden. Ejemplo: el orden convencional de un diseño de tres factores se puede cambiar por el orden: media, A, B, C, AxB, AxC, BxC, AxBxC usando REORDER=(1,4,3,2,7,6,5,8). PRINT=CDICT/DICT CDIC Imprimir el diccionario de entrada para las variables accedidas con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. 4. Especificaciones de factores (al menos se debe suministrar un factor). Se pueden especificar hasta 8 factores. Las reglas de codificación son las mismas de los parámetros. Cada especificación de factor debe comenzar en una nueva lı́nea. Ejemplo: FACTOR=(V3,1,2) FACTOR=(número de variable, lista de valores de código) Variable a usar como factor, seguida por los valores de código que se deben usar para designar la celda apropiada para el caso. CONTRAST=NOMINAL/HELMERT Especifica el tipo de contraste a usar en los cálculos. NOMI Contrastes nominales. Medias de efectos desviadas de la gran media, i.e. M(1)-GM, M(2)-GM, etc. HELM Contrastes de Helmer. Media de efecto desviada de la suma de medias desde 1 hasta r, donde están involucrados r niveles. 5. Especificaciones de nombre de prueba (al menos se debe suministrar un nombre de prueba). Estas especificaciones identifican las pruebas que se deben realizar. Deben estar en el orden correcto. Ordinariamente, habrá una especificación para la gran media seguida de una especificación de nombre para cada efecto principal y una especificación de nombre para cada interacción posible. Si se reordenan los parámetros de diseño o se reagrupan los grados de libertad (ver los parámetros REORDER y DEGFR), las proposiciones de nombre de prueba deben hacerse de acuerdo con las modificaciones. Las 236 Análisis multivariado de variancia (MANOVA) reglas de codificación son las mismas de los parámetros. Cada especificación de nombre de prueba debe comenzar en una nueva lı́nea. Ejemplo: TESTNAME=’gran media’ TESTNAME=’nombre de la prueba’ Un nombre que tenga hasta 12 caracteres para la prueba que se va a realizar. Las comillas son mandatorias si el nombre tiene caracteres no alfanuméricos. DEGFR=n La agrupación natural de grados de libertad (o de ecuaciones de parámetros de hipótesis) se presenta cuando se usa el orden convencional de pruebas estadı́sticas. DEGFR se usa solamente para cambiar la agrupación; por ejemplo, cuando se quieren reunir varios términos de interacción y probarlos simultáneamente o para separar los grados de libertad de algún efecto en dos a más partes. Cuando se usa el parámetro DEGFR, asegúrese de usarlo en todos las proposiciones de nombre de prueba, incluido un grado de libertad para la gran media. Por defecto: se usa el agrupamiento natural de grados de libertad. 30.7. Restricciones 1. El máximo número de variables dependientes es 19. 2. El máximo número de covariadas es 20. 3. El máximo número de especificaciones de factor es 8. 4. El máximo número de valores de código en una especificación de factor es 10. 5. El máximo número de celdas es 80. 6. Celdas con cero frecuencias, o solamente con un caso o con múltiples casos idénticos a veces causan problemas; la ejecución puede terminar prematuramente o puede llegar hasta el final pero produce cocientes F y otras estadı́sticas inválidas. 30.8. Ejemplos Ejemplo 1. Análisis univariado de variancia (V10 es la variables dependiente) con dos factores representados con A con códigos 1,2,3 y B con códigos 21 y 31; se usarán contrastes normales en los cálculos y se harán pruebas en el orden convencional. $RUN MANOVA $FILES PRINT = MANOVA1.LST DICTIN = CM-NEW.DIC DATAIN = CM-NEW.DAT $SETUP ANALISIS UNIVARIADO DE VARIANCIA DEPVARS=v10 FACTOR=(V3,1,2,3) FACTOR=(V8,21,31) TESTNAME=’gran media’ TESTNAME=B TESTNAME=A TESTNAME=AB archivo Diccionario de entrada archivo Datos de entrada Ejemplo 2. Análisis multivariado de variancia (V11-V14 son variables dependientes) con dos factores (“sexo” codificado 1,2 y “edad” codificada 1,2,3); se usarán contrastes nominales en los cálculos y se harán pruebas en un orden convencional. 30.8 Ejemplos 237 $RUN MANOVA $FILES los mismos del ejemplo 1 $SETUP ANALISIS MULTIVARIADO DE VARIANCIA DEPVARS=(v11-v14) FACTOR=(V2,1,2) FACTOR=(V5,1,2,3) TESTNAME=’gran media’ TESTNAME=edad TESTNAME=sexo TESTNAME=’sexo & edad’ Ejemplo 3. Análisis multivariado de variancia (V11-V14 son variables dependientes) con tres factores (A codificado 1,2, B codificado 1,2,3, C codificado 1,2,3,4); se usarán contrastes nominales en los cálculos y se harán pruebas en orden modificado (media, A, B, AxB, C, AxC, BxC, AxBxC). $RUN MANOVA $FILES los mismos del ejemplo 1 $SETUP ANALISIS MULTIVARIADO DE VARIANCIA - PRUEBAS EN ORDEN MODIFICADO DEPVARS=(v11-v14) REORDER=(1,4,3,7,2,6,5,8) FACTOR=(V2,1,2) FACTOR=(V5,1,2,3) FACTOR=(V8,1,2,3,4) TESTNAME=media TESTNAME=A TESTNAME=B TESTNAME=AxB TESTNAME=C TESTNAME=AxC TESTNAME=BxC TESTNAME=AxBxC Capı́tulo 31 Análisis de variancia de una entrada (ONEWAY) 31.1. Descripción general ONEWAY es un programa para hacer análisis de variancia de una entrada. Se puede producir en una sola ejecución, un número ilimitado de tablas, con parejas de variables dependientes e independientes. Cada análisis puede hacerse con todos los casos o con un subconjunto de los mismos, tomado del archivo Datos; la selección de casos para un análisis, es independiente de la selección para otros análisis. El término “variable de control” usado en ONEWAY es equivalente al término “variable independiente”, “predictor”, o en la terminologı́a del análisis de variancia, “variable de tratamiento”. Una alternativa del programa ONEWAYE es el programa MCA cuando se ha especificado sólo un predictor. Este programa permite un código máximo de 2999 para la variable de control, mientras que ONEWAY está limitado a un máximo de 99. 31.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. Se puede utilizar el filtro estándar para escoger un subconjunto de casos del archivo de entrada. Este filtro afecta todos los análisis de una ejecución. Adicionalmente, hay dos filtros locales para una selección independiente de subconjuntos de casos de datos para cada análisis. Si se usan dos filtros locales, un caso debe satisfacerlos a los dos para ser incluido en el análisis. Las variables para cada análisis se seleccionan con los parámetros de tablas DEPVARS y CONVARS. Se produce una tabla por separado para cada variable de la lista DEPVARS con cada variable de la lista CONVARS. Transformación de datos. Se pueden usar las proposiciones de Recode. Ponderación de datos. Se puede usar una variable para ponderar los datos de entrada; esta variable de ponderación puede tener cifras enteras o decimales. Cuando el valor de la variable de ponderación para un caso es cero, negativo, dato faltante o no numérico, entonces el caso siempre se omite; se imprime el número de casos ası́ tratados. Tratamiento de datos faltantes. El parámetro MDVALUES está disponible para indicar cuales valores de datos faltantes, si los hay, se usarán para verificar los datos faltantes. Los casos con datos faltantes en la variable dependiente, siempre se excluyen del análisis. Los casos con datos faltantes en la variable de control, se pueden excluir opcionalmente (ver el parámetro de tabla MDHANDLING). 31.3. Resultados Especificaciones de tabla. Se imprime una lista de especificaciones de tabla con una tabla de contenido de los resultados. 240 Análisis de variancia de una entrada (ONEWAY) Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variables y registros C, si los hay, solamente para variables utilizadas en la ejecución. Estadı́sticas descriptivas dentro de las categorı́as de la variable de control. Se imprimen estadı́sticas intermedias en forma de tabla para cada código de la variable de control, con: número de casos válidos (N) y suma de ponderaciones (redondeadas al entero más cercano), suma de ponderaciones como porcentaje de la suma total, media, desviación estándar, coeficiente de variación, suma y suma de cuadrados de la variable dependiente, suma de la variable dependiente como un porcentaje de la suma total. Se imprime una fila de totales para la tabla, con las sumas de todas las categorı́as de la variable de control (excepto categorı́as con cero grados de libertad, las cuales se excluyen de los totales). Estadı́sticas del análisis de variancia. Las categorı́as de la variable de control que tengan cero grados de libertad, no se incluyen en el cálculo de estas estadı́sticas. Para cada tabla, se imprimen las siguientes estadı́sticas: suma total de cuadrados de la variable dependiente, eta y eta cuadrada (no ajustada y ajustada), la suma de cuadrados entre grupos (suma de cuadrados entre medias) y la suma de cuadrados dentro de grupos, el cociente F (sólo se imprime si los datos no son ponderados). 31.4. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. Todas las variables analizadas deben ser numéricas; pueden tener valores decimales o enteros. Una variable dependiente debe medirse en una escala de intervalos o debe ser una dicotomı́a. Una variable de control puede ser nominal, ordinal o de intervalo pero debe tener valores en el rango 0-99. Si, para cualquier caso, la variable de control para un análisis, tiene un valor que excede este rango, el caso se elimina del análisis; no se imprime ningún mensaje al respecto. Si el valor de la variable de control tiene decimales, sólo se usa la parte entera (por ej. 1.1 y 1.6 se colocan ambas en el grupo 1); no se imprime ningún mensaje al respecto. 31.5 Estructura del setup 31.5. 241 Estructura del setup $RUN ONEWAY $FILES Especificación de archivos $RECODE (opcional) Proposiciones de Recode $SETUP 1. 2. 3. 4. Filtro (opcional) Tı́tulo Parámetros Especificaciones de tablas (tantas como sean necesarias) $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx PRINT 31.6. diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-4, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: EXCLUDE V3=9 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: DATOS DE EFECTOS DE ENTRENAMIENTO SOBRE JUGADORES DE FUTBOL 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: * INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos. Ver el capı́tulo “El archivo Setup de IDAMS”. MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. 242 Análisis de variancia de una entrada (ONEWAY) PRINT=CDICT/DICT CDIC Imprimir el diccionario de entrada para las variables accedidas con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. 4. Especificaciones de tablas. Las reglas de codificación son las mismas de los parámetros. Cada especificación de tabla debe comenzar en una nueva lı́nea. Ejemplos: CONV=V6 DEPV=V26 WEIG=V3 F1=(V14,2,7) F2=(V13,1,1) CONV=V5 DEPV=(V27-V29,V80) DEPVARS=(lista de variables) Una lista de variables a usar como variables dependientes CONVARS=(lista de variables) Una lista de variables a usar como variables de control. WEIGHT=número de variable Número de la variable de ponderación, si se van a ponderar los datos. MDVALUES=BOTH/MD1/MD2/NONE Cuales valores de datos faltantes se van a usar para las variables accedidas en este conjunto de tablas. Ver el capı́tulo “El archivo Setup de IDAMS”. MDHANDLING=DELETE/KEEP DELE Eliminar casos con datos faltantes en la variable de control. KEEP Incluir casos con datos faltantes en la variable de control. Nota: los casos con datos faltantes en la variable dependiente, siempre se excluyen. F1=(número de variable, código mı́nimo válido, código máximo válido) F1 se refiere a la primera variable de filtro que se usa para crear un subconjunto de los datos. El número de variable debe ser el número de la variable de filtro; los casos para los cuales, el valor de esta variable se encuentre en el rango mı́nimo-máximo, entran en la tabla. El valor mı́nimo puede ser un entero negativo. El máximo debe ser menor que 99,999. Las cifras decimales deben entrar en donde sea necesario. F2=(número de variable, código mı́nimo válido, código máximo válido) F2 se refiere a la segunda variable de filtro. Si se especifica un segundo filtro, un caso debe satisfacer los requisitos de ambos filtros para entrar en la tabla. 31.7. Restricciones 1. El número máximo de variables de control es 99. El número máximo de variables dependientes es 99. El número total de variables a las cuales se puede acceder es 204, incluidas las variables usadas en Recode. 2. ONEWAY usa variables de control dentro del rango 0-99. Si para cualquier caso, la variable de control de un cierto análisis, se encuentra fuera de este rango, el caso se elimina de la tabla. 3. La máxima suma de ponderaciones es alrededor de 2,000,000,000. 4. El cociente F se imprime sólo para datos sin ponderación. 31.8 Ejemplos 31.8. 243 Ejemplos Ejemplo 1. Tres análisis de variancia de una entrada, con V201 como variable de control y V204 como variable dependiente; primero para todo el archivo, segundo para un subconjunto de casos con valores 1-3 para la variable V5 y tercero para un subconjunto de casos con valores 4-7 para la variable V5. $RUN ONEWAY $FILES PRINT = ONEW1.LST DICTIN = STUDY.DIC archivo Diccionario de entrada DATAIN = STUDY.DAT archivo Datos de entrada $SETUP ANALISIS DE VARIANCIA DE UNA ENTRADA DESCRITO SEPARADAMENTE * (valores por defecto para todos los parámetros) CONV=V201 DEPV=V204 CONV=V201 DEPV=V204 F1=(V5,1,3) CONV=V201 DEPV=V204 F1=(V5,4,7) Ejemplo 2. Generación de un análisis de variancia de una entrada, para todas las combinaciones de las variables de control V101, V102, V105 y V110, y las variables dependientes V17 a V21; los datos son ponderados con la variable V3. $RUN ONEWAY $FILES los mismos del ejemplo 1 $SETUP GENERACION MASIVA DE ANALISIS DE VARIANCIA DE UNA ENTRADA * (valores por defecto para todos los parámetros) CONV=(V101,V102,V105,V110) DEPV=(V17-V21) WEIGHT=V3 Capı́tulo 32 Puntajes basados en el orden parcial de casos (POSCOR) 32.1. Descripción general POSCOR calcula puntajes (escala ordinal), con un procedimiento basado en la posición jerárquica de los elementos de un conjunto parcialmente ordenado de acuerdo con un número de propiedades (o caracterı́sticas). Los puntajes, calculados separadamente para cada elemento del conjunto, se llevan a un archivo de salida descrito por un diccionario IDAMS. Este dataset se puede utilizar después, como entrada para otros programas. Al utilizar el parámetro ORDER, se pueden calcular : (1) cuatro tipos de puntajes donde los cálculos se basan en la proporción de casos dominados por el caso examinado, (2) los otros cuatro donde los cálculos se basan en la proporción de casos que dominan al caso examinado. El rango de los puntajes se determina con el parámetro SCALE. Sólo se pueden esperar puntajes con sentido, cuando el número de casos involucrados es mucho más grande que el número de variables especificadas. En aplicaciones con variables de importancia no uniforme, se puede definir una lista de prioridades con el parámetro de análisis LEVEL en el ordenamiento parcial. Si las variables con prioridad más alta determinan sin ambigüedad la relación entre dos casos, entonces no se consideran las variables con prioridades más bajas. En el caso especial en el cual sólo se utiliza una variable de análisis, los valores transformados corresponden a sus probabilidades (ver las opciones ORDER=ASEA/DEEA/ASCA/DESA). En un análisis, se puede examinar una serie de conjuntos mutuamente excluyentes con la facilidad de subconjunto. En esta oportunidad, se calculan las variables de puntaje dentro de cada subconjunto de casos. 32.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. Se puede utilizar el filtro estándar para la selección de casos en una ejecución. También existe la opción de obtener subconjuntos de casos en cada análisis. Las variables que se van a transferir al archivo de salida se escogen con el parámetro TRANSVARS. Las variables para cada análisis, se eligen con las especificaciones de análisis. Transformación de datos. Se pueden usar las proposiciones de Recode. Nótese que el programa sólo utiliza la parte entera de las variables recodificadas, es decir, las variables recodificadas se redondean al entero más próximo. Ponderación de datos. No se aplica el uso de variables de ponderación. Tratamiento de datos faltantes. El parámetro MDVALUES está disponible para indicar cuales valores de datos faltantes, si los hay, se usarán para verificar los datos faltantes. El parámetro MDHANDLING indica si variables o casos con datos faltantes se deben excluir de un análisis. 246 Puntajes basados en el orden parcial de casos (POSCOR) 32.3. Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variables y registros C, si los hay, solamente para variables utilizadas en la ejecución. Diccionario de salida. (Opcional: ver el parámetro PRINT). 32.4. Dataset de salida El archivo de salida contiene los puntajes calculados junto con las variables transferidas, y opcionalmente, las variables de análisis para cada caso usado en el análisis (es decir, todos los casos que pasan el filtro y no excluidos con el uso de la opción de datos faltantes. También se produce un diccionario asociado IDAMS de salida. Las variables de salida tienen las caracterı́sticas descritas abajo, se numeran secuencialmente a partir de 1 y en el orden siguiente: Variables de análisis y de subconjunto (condicional: sólo si AUTR=YES). Las variables V tienen las mismas caracterı́sticas que sus equivalentes de entrada. Las variables de Recode salen con WIDTH=7 y DEC=0. Variable identificadora de casos y variables transferidas. Las variables V tienen las mismas caracterı́sticas que su equivalente de entrada. Las variables de Recode salen con WIDTH=7 y DEC=0. Variables calculadas de puntajes. Para ORDER=ASEA/DEEA/ASCA/DESA, una variable para cada análisis con: nombre ancho de campo número de decimales MD1 MD2 especificado especificado 0 especificado especificado por ANAME por FSIZE (por defecto: blanco) (por defecto: 5) por OMD1 por OMD2 (por defecto: 99999) (por defecto: 99999) Para ORDER=ASER/DESR/ASCR/DEER, dos variables para cada análisis con nombres especificados por los parámetros ANAME y DNAME respectivamente y otras caracterı́sticas tales como las mencionadas anteriormente. Nota. Si un análisis se repite para varios subconjuntos de casos mutuamente excluyentes, la variable de puntaje se calcula para los casos en cada subconjunto a su vez. Si un caso no se encuentra en uno de los subconjuntos definidos para el análisis, entonces sus valores de la(s) variable(s) de puntaje se colocan en el valor del código MD1. 32.5. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. Por las variables del análisis sólo se usan números enteros. Notar que los valores decimales se redondean al entero más próximo. La variable de identificación de casos y las variables a ser transferidas pueden ser alfabéticas. 32.6 Estructura del setup 32.6. 247 Estructura del setup $RUN POSCOR $FILES Especificación de archivos $RECODE (opcional) Proposiciones de Recode $SETUP 1. 2. 3. 4. 5. 6. Filtro (opcional) Tı́tulo Parámetros Especificaciones de subconjuntos (opcional) POSCOR Especificaciones de análisis (tantas como sean necesarias) $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx DICTyyyy DATAyyyy PRINT 32.7. diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) diccionario de salida datos de salida resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-3 y 6 a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: INCLUDE V2=1-4 AND V15=2 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: ESCALAMIENTO DE LAS VARIABLES RU DE ENTRADA 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: MDHAND=CASES TRAN=V5 IDVAR=R6 INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos. Ver el capı́tulo “El archivo Setup de IDAMS”. 248 Puntajes basados en el orden parcial de casos (POSCOR) MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. MDVALUES=BOTH/MD1/MD2/NONE Cuales valores de datos faltantes se van a usar para las variables accedidas en esta ejecución. Ver el capı́tulo “El archivo Setup de IDAMS”. MDHANDLING=VARS/CASES Tratamiento de datos faltantes. VARS Se excluyen de la comparación las variables con valores de datos faltantes. CASE Se excluyen del análisis los casos con valores de datos faltantes. OUTFILE=OUT/yyyy Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de salida. Por defecto: DICTOUT, DATAOUT. IDVAR=número de variable Variable a ser transferida al dataset de salida para la identificación de casos. Sin valor por defecto. TRANSVARS=(lista de variables) Se pueden transferir variables adicionales (hasta 99) al dataset de salida. Esta lista no puede incluir variables de análisis o variables utilizadas en las especificaciones de subconjuntos. Estas se transfieren automáticamente con el parámetro AUTR. AUTR=YES/NO YES Se transfieren al dataset de salida en forma automática, las variables de análisis y las variables utilizadas en la especificación de subconjuntos. NO No se transfieren las variables de análisis ni las de subconjuntos. FSIZE=5/n Ancho de campo de las variables (puntajes) calculadas. SCALE=100/n Valor (factor de escala) que especifica el rango (0 - n) de los puntajes calculados. OMD1=99999/n Valor del primer código de datos faltantes para las variables (puntajes) calculadas. OMD2=99999/n Valor del segundo código de datos faltantes para las variables (puntajes) calculadas. PRINT=(CDICT/DICT, OUTDICT/OUTCDICT/NOOUTDICT) CDIC Imprimir el diccionario de entrada para las variables accedidas con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. OUTD Imprimir el diccionario de salida sin registros C. OUTC Imprimir el diccionario de salida con registros C, si los hay. NOOU No imprimir el diccionario de salida. 4. Especificaciones de subconjuntos (opcional). Aquı́ se especifican subconjuntos de casos mutuamente excluyentes para un análisis en particular. Ejemplo: EDAD INCLUDE V5=15-20,21-45,46-64 32.7 Proposiciones de control del programa 249 Reglas de codificación Prototipo: nombre proposición nombre Nombre del subconjunto. 1-8 caracteres alfanuméricos comenzando con una letra. Este nombre debe coincidir exactamente con el nombre usado en las especificaciones de análisis subsecuentes. Blancos intercalados no se permiten. Se recomienda que todos los nombres se justifiquen a la izquierda. proposición Definición del subconjunto. Comenzar con la palabra INCLUDE. Especificar el número de variable (variable V o R) sobre la cual se basan los subconjuntos (no se permiten variables alfabéticas). Especificar valores y/o rangos de valores separados por comas. Cada valor o rango define un subconjunto. Las comas separan los subconjuntos. Los rangos negativos deben estar en secuencia numérica, por ej. -4 - -2 (para -4 a -2); -2 - 5 (para -2 a +5). Los subconjuntos deben ser mutuamente excluyentes (es decir, los mismos valores no pueden aparecer en dos rangos). En el ejemplo anterior, se definen 3 subconjuntos basados en el valor de V5 para la especificación del subconjunto EDAD. Colocar un guión al final de una lı́nea para continuar en la lı́nea siguiente. 5. POSCOR. La palabra POSCOR en esta lı́nea, indica que a continuación vienen especificaciones de análisis. Debe incluirse (para separar las especificaciones de subconjuntos de las de análisis) y sólo debe aparecer una vez. 6. Especificaciones de análisis. Las reglas de codificación son las mismas de los parámetros. Cada especificación de análisis debe comenzar en una nueva lı́nea. Ejemplo: ORDER=ASER ANAME=MSDCORE DNAME=DOWNSCORE VARS=(V3-V6) LEVELS=(1,1,2,2) VARS=(lista de variables) Las variable V y/o R a usar en el análisis. Sin valor por defecto. ORDER=ASEA/DEEA/ASCA/DESA/ASER/DESR/ASCR/DEER Especifica el tipo de puntaje a calcular. El puntaje se basa en: ASEA DEEA ASCA DESA ASER/DESR ASER DESR casos mejores o iguales/dominantes casos peores o iguales/dominados casos definitivamente mejores/dominantes definitivamente casos definitivamente peores/dominados definitivamente con relación al número total de casos casos mejores o iguales/dominantes casos definitivamente peores/dominados definitivamente con relación al número de casos comparables ASCR/DEER ASCR casos definitivamente mejores/dominantes definitivamente DEER casos peores o iguales/dominados con relación al número de casos comparables Nota. En los dos últimos casos, los puntajes se calculan con cualquier selección. La suma de ellos es igual al valor especificado en el parámetro SCALE. 250 Puntajes basados en el orden parcial de casos (POSCOR) SUBSET=xxxxxxxx Especifica el nombre de la especificación de subconjunto a usar, si lo hay. Si el nombre contiene caracteres no alfanuméricos, debe encerrarse entre comillas sencillas. Se deben usar letras mayúsculas para hacer encajar el nombre en la especificación de subconjuntos el cual se convierte automáticamente a mayúsculas. LEVELS=(1, 1,..., 1) / (N1,N2,N3,...,Nk) “k” es el número de variables utilizadas en la lista de variables de análisis. Ni define el orden de prioridad de la variable i-ésima de la lista de variables involucradas en el ordenamiento parcial. Un valor más alto implica una prioridad más baja. Los valores de prioridad deben especificarse en la misma secuencia de las correspondientes variables en la lista de variables de análisis. El valor de 1 por defecto, implica que todas las variables tienen la misma prioridad. ANAME=’nombre’ Un nombre del puntaje ascendente, que contenga hasta 24 caracteres. Las comillas sencillas son obligatorias si el nombre contiene caracteres no alfanuméricos. Por defecto: blancos. DNAME=’nombre’ Un nombre del puntaje descendente, que contenga hasta 24 caracteres. Las comillas sencillas son obligatorias si el nombre contiene caracteres no alfanuméricos. Por defecto: blancos. 32.8. Restricciones 1. El valor de las variables de análisis debe estar en el rango -32,767 a +32,767. 2. En el parámetro LEVEL, los componentes de la lista de prioridades deben ser enteros positivos dentro del rango 1 a 32,767. 3. Número máximo de análisis es 10. 4. Número máximo de variables a ser transferidas es 99. 5. Una variable se puede utilizar solamente una vez, ası́ sea una variable identificadora, en una lista de análisis o en una lista de transferencia. Si se necesita usar la misma variable dos veces, entonces debe recodificarse previamente para obtener una copia de la misma variable con un número diferente de variable (de resultado). 6. El número máximo de variables utilizadas en análisis, en las especificaciones de subconjuntos y en la lista de transferencia es 100 (incluye variables V y R). 7. El número máximo de especificaciones de subconjunto es 10. 8. Si la variable de identificación o una variable a ser transferida es alfabética con ancho > 4, sólo se usan los primeros cuatro caracteres. 9. Aunque no hay lı́mite para el número de casos procesados, nótese que el tiempo usado para ejecución crece como una función cuadrática del número de casos analizados. 32.9. Ejemplos Ejemplo 1. Cálculo de dos puntajes con las mismas variables V10, V12, V35 a V40; el primer puntaje se calculará para todo el archivo, el segundo puntaje será calculado separadamente para tres subconjuntos (para valores 1, 2 y 3 de la variable V7); los casos con datos faltantes se excluyen del análisis; ambos puntajes se basan en los casos dominados estrictamente con relación al número de casos comparables; los casos se identifican con las variables V2 y V4, las cuales se transferirán al archivo de salida. Nótese que Recode se utiliza para hacer una copia de las variables ya que una restricción del programa significa que una variable puede usarse una vez solamente. 32.9 Ejemplos 251 $RUN POSCOR $FILES PRINT = POSCOR1.LST DICTIN = PREF.DIC archivo Diccionario de entrada DATAIN = PREF.DAT archivo Datos de entrada DICTOUT = SCORES.DIC archivo Diccionario de salida DATAOUT = SCORES.DAT archivo Datos de salida $SETUP CALCULO DE DOS PUNTAJES MDHAND=CASES IDVAR=V2 TRANSVARS=V4 TYPE INCLUDE V7=1,2,3 POSCOR ORDER=DESR ANAME=’PUNTAJE CREC. GLOBAL’ DNAME=’PUNTAJE DECR. GLOBAL’ VARS=(V10,V12,V35-V40) ORDER=DESR ANAME=’PUNTAJE AJUSTADO CREC.’ DNAME=’PUNTAJE AJUSTADO DECR.’ SUBS=TYPE VARS=(R10,R12,R35-R40) $RECODE R10=V10 R12=V12 R35=V35 R36=V36 R37=V37 R38=V38 R39=V39 R40=V40 Ejemplo 2. Cálculo de tres puntajes basados en casos dominantes con relación al número total de casos; las variables de análisis no se transferirán al dataset de salida; las variables con datos faltantes se excluyen de la comparación; las variables para identificación de casos V1 y V5, se transfieren al dataset de salida. $RUN POSCOR $FILES los mismos del ejemplo 1 $SETUP CALCULO DE TRES PUNTAJES AUTR=NO IDVAR=V1 TRANSVARS=V5 POSCOR ORDER=ASEA ANAME=’PUNT.1 CREC’ ORDER=ASEA ANAME=’PUNT.2 CREC’ ORDER=ASEA ANAME=’PUNT.3 CREC’ VARS=(V11,V17,V55-V60) VARS=(V108-V110,V114,V116,V118,V120) VARS=(V22,V33,V101-V105) Capı́tulo 33 Correlación de Pearson (PEARSON) 33.1. Descripción general PEARSON calcula e imprime matrices de coeficientes de correlación r de Pearson y covariancias para todos los pares de variables en una lista (opción de matriz cuadrada) o para cada pareja de variables formada al tomar una variable de cada dos listas de variables (opción de matriz rectangular). Se puede especificar la eliminación de datos faltantes “por pares” o “por casos”. PEARSON se puede utilizar también para obtener una matriz de correlación, la cual puede ser posteriormente leida por los programas REGRESSN o MDSCAL. Aunque REGRESSN puede calcular su propia matriz de correlación, su opción de manejo de datos faltantes sólo puede eliminar “por casos”. En contraste, PEARSON puede generar una matriz con el uso de un algoritmo de eliminación “por pares” para datos faltantes. 33.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. Se puede utilizar el filtro estándar para la selección de un subconjunto de casos de los datos de entrada. Las variables para las cuales se desea la correlación se especifican con los parámetros ROWVARS y COLVARS. Transformación de datos. Se pueden usar las proposiciones de Recode. Ponderación de datos. Se puede usar una variable para ponderar los datos de entrada; esta variable de ponderación puede tener cifras enteras o decimales. Cuando el valor de la variable de ponderación para un caso es cero, negativo, dato faltante o no numérico, entonces el caso siempre se omite; se imprime el número de casos ası́ tratados. Tratamiento de datos faltantes. El parámetro MDVALUES está disponible para indicar cuales valores de datos faltantes, si los hay, se usarán para verificar los datos faltantes. Se calculan las estadı́sticas univariadas para cada variable a partir de los casos que tengan datos válidos (no faltantes) para la variable. Datos faltantes: eliminación por pares. Las estadı́sticas por pares y el coeficiente de correlación, se pueden calcular de los casos que tengan datos válidos para ambas variables (MDHANDLING=PAIR). Ası́, un caso se puede utilizar en los cálculos para algunos pares de variables y no usarse para otros. Este método de manejo de datos faltantes se llama algoritmo de eliminación “por pares”. Nota: si hay datos faltantes, se pueden calcular coeficientes de correlación individuales para diferentes subconjuntos de datos. Si hay muchos datos faltantes, se pueden presentar inconsistencias internas en la matriz de correlación, las cuales pueden causar dificultades en análisis multivariados posteriores. 254 Correlación de Pearson (PEARSON) Datos faltantes: eliminación por casos. El programa puede también recibir la instrucción (MDHANDLING=CASE) para calcular estadı́sticas pareadas y correlaciones a partir de los casos que tengan datos válidos en todas las variables de la lista de variables. De esta manera, un caso se usa en el cálculo para todos los pares de variables o no se usa. Este método de manejar los datos faltantes se llama algoritmo de eliminación “por casos” (también se encuentra en el programa REGRESSN) y sólo se aplica a la opción de matriz cuadrada. 33.3. Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variables y registros C, si los hay, solamente para variables utilizadas en la ejecución. Opción de matriz cuadrada Estadı́sticas pareadas. (Opcional: ver el parámetro PRINT). Para cada par de variables de la lista, se imprime la siguiente información: número de casos válidos (o suma ponderada de casos), media y desviación estándar de la variable X, media y desviación estándar de la variable Y, prueba T para el coeficiente de correlación, coeficiente de correlación. Estadı́sticas univariadas. Para cada variable de la lista, se imprime la siguiente información: número de casos válidos y suma de ponderaciones, suma de puntajes y suma de puntajes cuadrados, media y desviación estándar. Coeficientes de regresión para puntajes primarios. (Opcional: ver el parámetro PRINT). Para cada par de variables x, y se imprimen los coeficientes de regresión a y c y los términos constantes b y d de las ecuaciones de regresión x=ay+b y y=cx+d. Matriz de correlación. (Opcional: ver el parámetro PRINT). Se imprime el triángulo inferior izquierdo de la matriz. Matriz de productos cruzados. (Opcional: ver el parámetro PRINT). Se imprime el triángulo inferior izquierdo de la matriz. Matriz de covariancia. (Opcional: ver el parámetro PRINT). Se imprime el triángulo inferior izquierdo de la matriz con su diagonal. En cada una de las tablas anteriores, se imprime por página, un máximo de 11 columnas y 27 filas. Opción de matriz rectangular Tabla de frecuencias de variables. Número de casos válidos para cada par de variables. Tabla de valores de la media para las variables de columnas. Se calculan y se imprimen las medias para cada variable de columna en los casos que son válidos, a su turno, para cada variable de fila. Tabla de desviaciones estándar para variables de columnas. Igual que para las medias. Matriz de correlación. (Opcional: ver el parámetro PRINT). Coeficientes de correlación para todos los pares de variables. Matriz de covariancia. (Opcional: ver el parámetro PRINT). Covariancias para todos los pares de variables. En cada una de las tablas anteriores, se imprime por página, un máximo de 8 columnas y 50 filas. Nota: si un par de variables no tiene casos válidos, se escribe 0.0 para la media, desviación estándar, correlación y covariancia. 33.4 Matrices de salida 33.4. 255 Matrices de salida Matriz de correlación Cuando se especifica el parámetro WRITE=CORR, se produce la matriz de correlación, en la forma estándar de una matriz cuadrada IDAMS. El formato de las correlaciones es 8F9.6; el formato para la media y la desviación estándar es 5E14.7. Las columnas 73-80, se utilizan para identificar los registros. La matriz contiene correlaciones, medias y desviaciones estándar. Las medias y las desviaciones estándar están sin parear. Los registros de diccionario que produce PEARSON, tienen números y nombres de variable del diccionario de entrada y/o de proposiciones de Recode. El orden de las variables lo determina el orden de las mismas en la lista. PEARSON puede generar correlaciones iguales a 99.999901, y medias y desviaciones estándar iguales a 0.0 cuando los valores calculados carezcan de sentido. Razones tı́picas de ésto pueden ser por ejemplo, que se hayan eliminado todos los casos debido a datos faltantes o una de las variables tuvo un valor constante. Nótese que MDSCAL no acepta estos “valores faltantes” y REGRESSN sı́. Matriz de covariancia Cuando se especifica el parámetro WRITE=COVA, se produce la matriz de covariancia, sin la diagonal, en la forma de una matriz cuadrada estándar de IDAMS. 33.5. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. Todas las variables del análisis deben ser numéricas; pueden tener valores enteros o decimales. 33.6. Estructura del setup $RUN PEARSON $FILES Especificación de archivos $RECODE (opcional) Proposiciones de Recode $SETUP 1. Filtro (opcional) 2. Tı́tulo 3. Parámetros $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: FT02 DICTxxxx DATAxxxx PRINT matrices de salida si se especifica el parámetro WRITE diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) resultados (por defecto IDAMS.LST) 256 Correlación de Pearson (PEARSON) 33.7. Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-3, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: INCLUDE V2=11-15,60 OR V3=9 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: PRIMERA CORRIDA DE PEARSON - ABRIL 27 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: WRITE=CORR, PRINT=(CORR,COVA) ROWV=(V1,V3-V6,R47,V25) INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos. Ver el capı́tulo “El archivo Setup de IDAMS”. MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. MATRIX=SQUARE/RECTANGULAR SQUA Calcular coeficientes de correlación de Pearson para todos los pares de variables de la lista en ROWV. RECT Calcular los coeficientes de correlación de Pearson para cada par de variables formado al tomar una variable de cada una de las dos listas en ROWV y COLV. ROWVARS=(lista de variables) Una lista de variables V o R a correlacionar (MATRIX=SQUARE) o la lista de variables de fila (MATRIX=RECTANGULAR). Sin valor por defecto. COLVARS=(lista de variables) (Sólo MATRIX=RECTANGULAR). Una lista de variables V o R a usar como variables de columna. Se escriben 8 columnas por página; si las listas de variables de columna o de fila tienen menos de 8 variables, es preferible (para facilidad de lectura del listado) tener la lista corta como la lista de variables de columna. MDVALUES=BOTH/MD1/MD2/NONE Cuales valores de datos faltantes se van a usar para las variables accedidas en esta ejecución. Ver el capı́tulo “El archivo Setup de IDAMS”. MDHANDLING=PAIR/CASE Método para el manejo de datos faltantes. PAIR Eliminación por pares. CASE Eliminación por casos (no disponible con MATRIX=RECTANG). WEIGHT=número de variable Número de la variable de ponderación, si se van a ponderar los datos. 33.8 Restricciones 257 WRITE=(CORR, COVA) Sólo MATRIX=SQUARE. CORR Escribir en un archivo de salida, la matriz de correlación con medias y desviaciones estándar. COVA Escribir en un archivo de salida, la matriz de covariancia con medias y desviaciones estándar. PRINT=(CDICT/DICT, CORR/NOCORR, COVA, PAIR, REGR, XPRODUCTS) CDIC Imprimir el diccionario de entrada para las variables accedidas con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. CORR Imprimir la matriz de correlación. COVA Imprimir la matriz de covariancia. PAIR Imprimir estadı́sticas pareadas (sólo MATRIX=SQUARE). REGR Imprimir los coeficientes de regresión (sólo MATRIX=SQUARE). XPRO Imprimir la matriz de productos cruzados (sólo MATRIX=SQUARE). 33.8. Restricciones Cuando se especifica MATRIX=SQUARE 1. El número máximo de variables permitido en una ejecución es 200. Este lı́mite incluye todas las variables de análisis y variables usadas en proposiciones Recode. 2. Los números de las variables recodificadas no pueden exceder de 999 si se especifica el parámetro WRITE. (Salen como números negativos en la parte descriptiva de la matriz, la cual sólo tiene cuatro columnas reservadas para el número de variable, por ej. R862 saldrı́a como -862). Cuando se especifica MATRIX=RECTANGULAR 1. El número máximo de variables en la lista para filas o columnas es 100. 2. El máximo total variables de filas, columnas, variables usadas en Recode y variable de ponderación es 136. 33.9. Ejemplos Ejemplo 1. Cálculo de una matriz cuadrada de coeficientes de correlación de Pearson, con eliminación de casos con datos faltantes por pares; la matriz se escribirá en un archivo de salida y se imprimirá. $RUN PEARSON $FILES PRINT = PEARS1.LST FT02 = BIRDCOR.MAT archivo Matriz de salida DICTIN = BIRD.DIC archivo Diccionario de entrada DATAIN = BIRD.DAT archivo Datos de entrada $SETUP MATRIZ DE COEFICIENTES DE CORRELACION PRINT=(PAIR,REGR,CORR) WRITE=CORR ROWV=(V18-V21,V36,V55-V61) 258 Correlación de Pearson (PEARSON) Ejemplo 2. Cálculo de coeficientes de correlación de Pearson para las variables V10-V20, con las variables V5-V6. $RUN PEARSON $FILES DICTIN = BIRD.DIC archivo Diccionario de entrada DATAIN = BIRD.DAT archivo Datos de entrada $SETUP COEFICIENTES DE CORRELACION MATRIX=RECT ROWV=(V10-V20) COLV=(V5-V6) Capı́tulo 34 Ordenamiento de alternativas (RANK) 34.1. Descripción general RANK ofrece un ordenamiento razonable de alternativas, utilizando datos preferenciales como entrada y tres procedimientos de categorización, uno basado en la lógica clásica (el método ELECTRE) y otros dos basados en lógica difusa. Los dos métodos se diferencian esencialmente en la manera de construir las matrices relacionales. Con rangos difusos, los datos determinan completamente el resultado mientras que con el ordenamiento por el método clásico, el usuario, basado en los conceptos de la lógica clásica, tiene la posibilidad de controlar el cálculo de las relaciones que están por encima de las alternativas. El método ELECTRE (lógica clásica) implementado en RANK, en un primer paso, utiliza los datos preferenciales de entrada para calcular una matriz final que expresa la opinión total colectiva acerca de la “dominancia” entre las alternativas, la estructura de relación no corresponde necesariamente a un ordenamiento lineal o parcial. La relación de “dominancia” para cada par de alternativas se controla por las condiciones de “concordancia” y “discordancia” establecidas por el usuario. Se pueden obtener diferentes relaciones estructurales a partir de los mismos datos al cambiar los parámetros de análisis. En el segundo paso, el procedimiento busca una secuencia de capas (o núcleos) de alternativas no dominadas. El primer núcleo consiste en las alternativas de más alto rango en todo el conjunto considerado. Debe notarse que en ciertos casos puede que no existan más núcleos, debido a bucles dentro de la relación. Esto puede ser verdad aún en el nivel más alto. El primer método difuso (capas no dominadas) se desarrolló originalmente para resolver problemas de toma de decisiones con información difusa. Este método permite encontrar una secuencia de núcleos de alternativas no dominados dentro de una estructura de preferencia difusa, la cual no representa necesariamente un orden (total) lineal. Los núcleos subsiguientes son aquellos grupos de alternativas que tengan el rango más alto dentro las alternativas que no pertenezcan a los núcleos previos de nivel más alto. El primer núcleo comprende las alternativas de rango más alto dentro todo el conjunto considerado. El segundo método difuso (rangos) trata de encontar la credibilidad de frases como “la j-ésima alternativa está exactamente en la posición p-ésima dentro el orden por rangos”. Los resultados son claros en el caso de una relación lineal (total) en los datos; de lo contrario, se debe tener cuidado al interpretar los resultados. El proceso de optimización, desarrollado para manejar el caso general (normalizado o no-normalizado), permite al usuario decidir si debe normalizar o no la matriz relacional difusa antes del proceso de rangos (ver opción NORM). Después de la normalización se necesita un proceso cuidadoso de interpretación de los resultados. Usualmente datos incompletos resultan en una matriz relacional no-normalizada, especialmente cuando se usa DATA=RAWC y el número seleccionado de alternativas en respuestas individuales es más pequeño que el número de alternativas posibles. Aunque una matriz no-normalizada produce resultados en los cuales el nivel de incertidumbre es más alto, puede suministrar un cuadro más realista acerca de la relación latente que determina los datos; en verdad la normalización se puede interpretar como una clase de extrapolación. 260 Ordenamiento de alternativas (RANK) Se pueden especificar dos tipos de relación individual preferencial (estricta o débil), en caso de que los datos que representen una selección de alternativas y en caso de que los datos representen alternativas por rangos. 1. Datos que representan una selección de alternativas. Preferencia estricta: se considera que cada alternativa seleccionada tiene un único rango (diferente) y a las no seleccionadas se les asigna el mismo rango más bajo. Preferencia débil: se considera que todas las alternativas seleccionadas tienen un mismo rango común, el cual es más alto que el rango de las no seleccionadas. 2. Datos que representan una ordenación de alternativas por rango. Preferencia estricta: se considera que todas las alternativas con rangos tienen diferentes valores y las relaciones entre las alternativas del mismo rango se excluyen de los cálculos de la relación de preferencia global entre las alternativas. Preferencia débil: en los cálculos se tienen en cuenta las alternativas con el mismo rango. 34.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. Se puede usar el filtro estándar para escoger un subconjunto de casos de los datos de entrada y se usa el parámetro VARS para seleccionar las variables. Transformación de datos. Se pueden usar las proposiciones de Recode. Nótese que el programa sólo utiliza la parte entera de las variables recodificadas, es decir que estas variables se redondean al entero más próximo. Ponderación de datos. Los datos se pueden ponderar con valores enteros. Nótese que los valores ponderados se redondean al entero más próximo. Cuando el valor de la variable de ponderación para un caso es cero, negativo, dato faltante o no numérico, entonces el caso siempre se omite; se imprime el número de casos ası́ tratados. Tratamiento de datos faltantes. Se puede usar el parámetro MDVALUES para indicar cuales valores de datos faltantes se van a usar para la verificación de los datos faltantes. Para DATA=RAWC, las variables con datos faltantes se saltan; para DATA=RANKS, los valores faltantes se sustituyen con el rango más bajo. 34.3. Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variables y registros C, si los hay, solamente para variables utilizadas en la ejecución. Datos inválidos. Mensajes acerca de los datos incorrectos (rechazados). Métodos basados en la lógica difusa (METHOD=NOND/RANKS) Matriz de relaciones. Se imprime por filas una matriz cuadrada que representa la relación difusa. Si las filas tienen más de 10 elementos, se continúa en la(s) lı́nea(s) siguiente(s). Descripción de las relaciones. Después de imprimir el tipo de relación, se imprimen tres medidas que caracterizan de manera concisa la relación, a saber: ı́ndice de coherencia absoluta, ı́ndice de intensidad e ı́ndice de dominación absoluta. Resultados del análisis. Los resultados se presentan de manera diferente para cada método. Para METHOD=NOND los núcleos se imprimen secuencialmente a partir del rango más alto y para cada uno de ellos se suministra la siguiente información: su número secuencial con nivel de certeza, los códigos y los nombres de alternativas o los números y nombres de variables (hasta 8 caracteres), los valores de la función de pertenencia de las alternativas, indicando que tan fuertemente están ligadas al núcleo; los valores de pertenencia de alternativas que pertenecen a núcleos anteriores se sustituyen por asteriscos, 34.4 Dataset de entrada 261 lista de alternativas que pertenecen al núcleo con el valor de pertenencia más alto (alternativas con mayor credibilidad). Para METHOD=RANKS se imprime primero la matriz relacional normalizada si se solicitó antes la normalización. Después se imprimen los resultados, de dos maneras para una interepretación más fácil. 1. Se imprimen secuencialmente todas las alternativas con la siguiente información para cada una: código y nombre de la alternativa o número y nombre de variable, los valores de la función de pertenencia de la alternativa, indicando que tan fuertemente está conectada con cada rango, la lista del rango o de los rangos de mayor credibilidad para esta alternativa. 2. Se imprimen todos los rangos secuencialmente con la siguiente información para cada uno: número de rango, códigos y nombres de las alternativas o números y nombres de variables, los valores de la función de pertenencia de la alternativas, indicando que tan fuertemente están conectadas con ese rango, la lista de la(s) alternativa(s) de mayor credibilidad para ese rango. Método basado en la lógica clásica (METHOD=CLAS) Resultado del análisis. Se imprimen, para cada estructura relacional de “dominancia” final que resulta de un análisis, las diferencias de rangos y las proporciones mı́nimo/máximo de población especificadas por el usuario, seguidas de la lista de núcleos sucesivos no-dominados (identificados por su número secuencial) con las alternativas que les pertenecen. Nota. Las alternativas se titulan con los 8 primeros caracteres del nombre de la variable para DATA=RANKS o con los 8 caracteres del nombre de código (si hay registros C en el diccionario) para DATA=RAWC. 34.4. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. Todas las variables del análisis deben tener valores enteros positivos. Nótese que las variables con valores decimales, se redondean al entero más próximo. Las preferencias se pueden presentar de dos maneras en los datos. En la siguiente ilustración se muestra como hacerlo. Supongamos que se han recolectado datos acerca de las preferencias de los empleados sobre varios factores relacionados con su trabajo: Oficina individual Salario alto Vacaciones largas Supervisión mı́nima Compatibilidad entre colegas Las dos maneras de representar ésto en un cuestionario son: 1. DATA=RAWC En este caso, los factores se codifican (1 a 5) y se solicita al encuestado señalarlos en el orden de su preferencia. Las variables en los datos representarı́an los rangos: V6 Factor más importante V7 Segundo factor más importante . . V10 Factor menos importante 262 Ordenamiento de alternativas (RANK) y los códigos asignados a cada una de estas variables por un encuestado representarı́an los factores (1=oficina individual, 2=salario alto, etc.). No es necesario escoger todos los factores posibles, se podrian pedir por ejemplo, los tres más importantes, especificando sólo esas variables de la lista de variables: V6, V7, V8. El número de factores diferentes usados se especifica con el parámetro NALT. 2. DATA=RANKS Aquı́, cada factor aparece en el cuestionario como una variable: V13 Oficina individual V14 Salario alto . . V17 Compatibilidad entre colegas y al encuestado se le invita a asignar un rango a cada uno, en el cual 1 se da al factor más importante, 2 al siguiente, etc. Aquı́ las variables representan los factores y sus valores representan los rangos. A cada variable se le debe asignar un rango y todos los factores entran siempre al análisis. Los rangos deben codificarse de 1 a n donde n es el número de variables que se consideran. Notas 1. Si DATA=RANKS, el código 0 y todos los códigos mayores que n, en donde n es el número de variables (número de alternativas), se tratan como datos faltantes y se les asigna el rango más bajo. 2. Si DATA=RAWC, los primeros NALT codigos diferentes encontrados durante la lectura de los datos (excluido 0), se usan como códigos válidos. Otros códigos hallados posteriormente en los datos, se toman como códigos ilegales. El cero siempre se trata como un código ilegal. Si el número de alternativas escogidas por los encuestados es menor que NALT, entonces aparecen las alternativas no seleccionadas en el listado con valores de código cero y nombre de código vacı́o. 34.5. Estructuda del setup $RUN RANK $FILES Especificación de archivos $RECODE (opcional) Proposiciones de Recode $SETUP 1. 2. 3. 4. Filtro (opcional) Tı́tulo Parámetros Especificaciones de análisis (tantas como sean necesarias) (sólo para lógica clásica) $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx PRINT diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) resultados (por defecto IDAMS.LST) 34.6 Proposiciones de control del programa 34.6. 263 Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-4, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: INCLUDE V2=11 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: PRIMERA EJECUCION DE RANK 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: DATA=RANKS PREF=STRICT MDVALUES=NONE VARS=(V11-V13) INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos. Ver el capı́tulo “El archivo Setup de IDAMS”. MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. MDVALUES=BOTH/MD1/MD2/NONE Cuales valores de datos faltantes se van a usar para las variables accedidas en esta ejecución. Ver el capı́tulo “El archivo Setup de IDAMS”. Para DATA=RAWC, las variables con datos faltantes no se incluyen en el ordenamiento. Para DATA=RANKS, los datos faltantes se recodifican al rango más bajo. VARS=(lista de variables) Una lista de variables V y/o R a usar en el procedimento de rangos. Sin valor por defecto. WEIGHT=número de variable Número de la variable de ponderación, si se van a ponderar los datos. METHOD=(CLASSICAL/NOCLASSICAL, NONDOMINATED, RANKS) Especifica el método a usar en el análisis. CLAS Método de lógica clásica (ELECTRE). NOND Método difuso 1, llamado capas no dominadas. RANK Método difuso 2, llamado rangos. DATA=RAWC/RANKS Tipo de datos. RAWC Las variables corresponden a los rangos (la primera variable de la lista tiene el primero rango, la segunda el segundo, etc.), y su valor es el número del código de la alternativa seleccionada. RANK Las variables representan las alternativas, sus valores son los rangos de las alternativas correspondientes. 264 Ordenamiento de alternativas (RANK) PREF=STRICT/WEAK Determina el tipo de relación de preferencia a usar en el análisis. STRI Se usa una relación de preferencia estricta. WEAK Se usa una relación de preferencia débil. NALT=5/n (DATA=RAWC solamente). El número total de alternativas para ordenar. Nota: si DATA=RANKS, el número de alternativas se coloca automáticamente como el número de variables de análisis. NORMALIZE=NO/YES (METHOD=RANKS solamente). NO No normalizar. YES Se hace la normalización de la matriz relacional antes de calcular el valor de la función de pertenencia de las alternativas. PRINT=CDICT/DICT CDIC Imprimir el diccionario de entrada para las variables accedidas con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. 4. Especificaciones de análisis (condicional: sólo en el caso de la lógica clásica). Las reglas de codificación son las mismas de los parámetros. Cada especificación de análisis debe comenzar en una nueva lı́nea. Ejemplo: PCON=66 DDIS=4 PDIS=20 DCON=1/n Diferencia de rangos que controla la concordancia en opiniones individuales (casos). Debe ser un entero dentro del rango 0 a NALT-1. PCON=51/n Mı́nima proporción de concordancia individual expresada como un porcentaje y requerida en la opinión colectiva. Debe ser un entero dentro del rango 0 a 99. El valor por defecto significa que por lo menos, se necesita un acuerdo del 51 % para tener una concordancia colectiva. DDIS=2/n Diferencia de rangos que controla la discordancia en las opiniones individuales (casos). Debe ser un entero dentro del rango 0 a NALT-1. PDIS=10/n Máxima proporción de discordancia individual, expresada como un porcentaje, tolerada en la opinión colectiva. Debe ser un entero en el rango 0 a 100. El valor por defecto significa que no se tolera una discordancia individual mayor del 10 %. 34.7. Restricciones 1. El número máximo de variables permitidas en una ejecución es 200, incluidas las variables de Recode y las variables de ponderación. 2. El número máximo de variables de análisis es 60. 34.8 Ejemplos 34.8. 265 Ejemplos Ejemplo 1. Determinación de un ordenamiento de alternativas, usando datos recolectados en forma de rangos de alternativas; hay diez alternativas, se asume una relación de preferencia débil y se hará una análisis con el método de rangos. $RUN RANK $FILES PRINT = RANK1.LST DICTIN = PREF.DIC archivo Diccionario de entrada DATAIN = PREF.DAT archivo Datos de entrada $SETUP ORDENAMIENTO DE ALTERNATIVAS : METODO DE RANGOS DATA=RANKS PREF=WEAK METH=(NOCL,RANKS) VARS=(V21-V30) Ejemplo 2. Determinación de un ordenamiento de alternativas, con datos recolectados en forma de una selección por prioridades; se escogen tres alternativas entre 20 y el orden de las variables determina la prioridad de la selección; se supone preferencia estricta; se solicitan los dos métodos de análisis difuso. $RUN RANK $FILES los mismos del ejemplo 1 $SETUP ORDENAMIENTO DE ALTERNATIVAS POR RANGOS : DOS METODOS DIFUSOS NALT=20 METH=(NOCL,NOND,RANKS) VARS=(V101-V103) Ejemplo 3. Determinación de un ordenamiento de alternativas, usando datos recolectados en forma de una selección por prioridades; se escogen 4 alternativas entre 15 y el orden de las variables no determina la prioridad de la selección (preferencia débil); se harán cuatro análisis de lógica clásica manteniendo siempre igual a 1 las diferencias de rangos, pero aumentando la proporción de discordancia y disminuyendo la proporción de concordancia. $RUN RANK $FILES los mismos del ejemplo 1 $SETUP ORDENAMIENTO DE ALTERNATIVAS : LOGICA CLASICA PREF=WEAK NALT=15 METH=CLAS VARS=(V21,V23,V25,V27) PCON=75 DDIS=1 PDIS=5 PCON=66 DDIS=1 PDIS=10 PCON=51 DDIS=1 PDIS=15 PCON=40 DDIS=1 PDIS=20 Capı́tulo 35 Diagramas de dispersión (SCAT) 35.1. Descripción general SCAT es un programa de análisis bivariado que produce diagramas de dispersión, estadı́sticas univariadas y bivariadas. Los diagramas de dispersión se trazan en un sistema de coordenadas rectangulares; para cada combinación de valores coordenados que aparece en los datos, se muestra la frecuencia con la cual se presenta. SCAT es útil para mostrar relaciones bivariadas cuando el número de valores de diferentes variables es grande y el número de casos que contenga uno de estos valores es pequeño. Si una variable toma relativamente pocos valores dentro de un número grande de casos, el programa TABLES es más adecuado. Formato del gráfico. Cada gráfico se define separadamente con la especificación de las dos variables que se van a usar (llamadas variables X y Y). Las escalas de los ejes se ajustan separadamente para cada gráfico y ası́ permitir el trazado de variables que difieran radicalmente en escala sin pérdida de resolución gráfica. Normalmente, el programa dibuja la variable con el rango más amplio (antes de modificar la escala) en el eje horizontal. Sin embargo, el usuario puede solicitar que la variable X se dibuje siempre en el eje horizontal. Si las frecuencias son inferiores a 10, éstas se llevan al gráfico. Para frecuencias en el rango 10-65, se usan las letras del alfabeto. Si la frecuencia de un punto es mayor de 65, se coloca un asterisco en el diagrama. Este esquema de codificación, es parte de los resultados para facilidad de referencia. Estadı́sticas. Se imprimen para cada variable accedida, incluidos el filtro y la variable de ponderación, si los hay: la media, la desviación estándar, el valor máximo y el valor mı́nimo. Para cada gráfico el programa también imprime la media, desviación estándar, conteo de casos y rango de las dos variables, el coeficiente de correlación r de Pearson, la constante y el coeficiente no estandarizado de regresión para predecir Y a partir de X. 35.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. Se puede usar el filtro estándar para escoger un subconjunto de casos de los datos de entrada. Además, se puede especificar un rango de variables y una variable de filtro en el gráfico para restringir los casos incluidos en un gráfico en particular. Las variables para dibujar, se especifican por parejas con los parámetros de gráfico. Transformación de datos. Se pueden usar las proposiciones de Recode. Nótese que para las variables R el programa utiliza el número de cifras decimales dado en el parámetro NDEC. Ponderación de datos. Se puede especificar una variable de ponderación para cada gráfico. Las variables V y R con decimales se multiplican por un factor de escala para obtener valores enteros. Ver la sección “Dataset de entrada” abajo. Cuando el valor de la variable de ponderación para un caso es cero, negativo, dato faltante o no numérico, entonces el caso siempre se omite; se imprime el número de casos ası́ tratados. 268 Diagramas de dispersión (SCAT) Tratamiento de datos faltantes. El parámetro MDVALUES está disponible para indicar cuales valores de datos faltantes, si los hay, se usarán para verificar los datos faltantes. Las estadı́sticas univariadas que aparecen al comienzo de los resultados, inmediatamente después del diccionario, se basan en todos los casos que tienen datos válidos en cada variable considerada por separado. Para los gráficos en sı́, el programa elimina los casos que tengan datos faltantes en una o las dos variables en un gráfico dado. La eliminación por pares también afecta las estadı́sticas bivariadas que se imprimen en la parte superior de cada gráfico. 35.3. Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variables y registros C, si los hay, solamente para variables utilizadas en la ejecución. Estadı́sticas univariadas. Las siguientes estadı́sticas se imprimen para cada variable referida, incluidas las variables de filtro de gráfico y de ponderación: valores máximo y mı́nimo, media y desviación estándar, y número de casos con valores de datos válidos. Clave del esquema de codificación de gráficos. Una tabla que muestra la correspondencia entre las frecuencias actuales y los códigos usados en los gráficos. Gráficos y estadı́sticas. Para cada gráfico requerido, se imprime un diagrama de dispersión de 8 1/2” x 12”. En la parte superior del diagrama se imprimen los valores de las estadı́sticas univariadas (medias, desviaciones estándar) y bivariadas (r de Pearson, constante de regresión A y coeficiente de regresión no estandarizada B. 35.4. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. Todas las variables del análisis y del filtro de gráfico deben ser numéricas; enteras o decimales. Las variables con decimales se multiplican por un factor de escala para obtener valores enteros. Este factor se calcula como 10n donde n es el número de decimales del diccionario para las variables V y del parámetro NDEC para las variables R, y aparece en los resultados para cada variable. 35.5 Estructura del setup 35.5. 269 Estructura del setup $RUN SCAT $FILES Especificación de archivos $RECODE (opcional) Proposiciones de Recode $SETUP 1. 2. 3. 4. Filtro (opcional) Tı́tulo Parámetros Especificaciones de gráficos (tantas como sean necesarias) $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx PRINT 35.6. diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-4, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: INCLUDE V21=6 AND V37=5 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: ESTUDIO 600, JULIO 16, 1999, EDAD POR PESO POR SUBMUESTRA 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Los nuevos parámetros son precedidos por un asterisco. Ejemplo: BADD=MD2 INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos. Ver el capı́tulo “El archivo Setup de IDAMS”. MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. 270 Diagramas de dispersión (SCAT) MDVALUES=BOTH/MD1/MD2/NONE Cuales valores de datos faltantes se van a usar para las variables accedidas en esta ejecución. Ver el capı́tulo “El archivo Setup de IDAMS”. * NDEC=0/n Número de decimales (máximo 4) a conservar para las variables R. PRINT=CDICT/DICT CDIC Imprimir el diccionario de entrada para las variables accedidas con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. 4. Especificaciones de gráficos. Un conjunto para cada gráfico. Las reglas de codificación son las mismas de los parámetros. Cada especificación de gráfico debe empezar en una lı́nea nueva. Ejemplo: X=V3 Y=R17 FILTER=(V3,1,1) X=número de variable Número de la variable X. Y=número de variable Número de la variable Y. WEIGHT=número de variable Número de la variable de ponderación si se van a ponderar los datos. FILTER=(número de variable, código mı́nimo válido, código máximo válido) Filtro de gráfico. Sólo aquellos casos en los cuales el valor de la variable de filtro es mayor o igual al codigo mı́nimo y menor o igual al código máximo, se incluyen en el gráfico. Por ejemplo, para especificar que sólo los casos con códigos 0-40 en la variable 6 se van a incluir, se especifica: FILTER=(V6,0,40). HORIZAXIS=MAXRANGE/X MAXR Dibujar la variable con el rango más álto en el eje horizontal. X Dibujar siempre la variable X en el eje horizontal. 35.7. Restricciones 1. El número máximo de variables por ejecución es 50. Este máximo incluye todo: variables X y Y, variables de filtro de gráfico, variables de ponderación y variables usadas en proposiciones de Recode. 2. No hay lı́mite al número de gráficos pero SCAT produce sólo 5 gráficos por cada pasada de los datos de entrada. 35.8 Ejemplo 35.8. 271 Ejemplo Generación de dos gráficos (ponderados con la variable V100 y sin ponderar) repetidos para tres diferentes grupos de datos. $RUN SCAT $FILES PRINT = SCAT1.LST DICTIN = MY.DIC archivo Diccionario de entrada DATAIN = MY.DAT archivo Datos de entrada $SETUP GENERACION DE DOS DIAGRAMAS * (valores por defecto para todos los parámetros) X=V21 Y=V3 FILTER=(V5,1,2) X=V21 Y=V3 FILTER=(V5,1,2) WEIGHT=V100 X=V21 Y=V3 FILTER=(V5,3,3) X=V21 Y=V3 FILTER=(V5,3,3) WEIGHT=V100 X=V21 Y=V3 FILTER=(V5,4,7) X=V21 Y=V3 FILTER=(V5,4,7) WEIGHT=V100 Capı́tulo 36 Búsqueda de estructura (SEARCH) 36.1. Descripción general SEARCH es un procedimiento de segmentación binaria usado para desarrollar un modelo predictivo para la(s) variable(s) dependiente(s). Busca en un conjunto de variables predictoras aquellas que más aumenten la habilidad del investigador para explicar la variancia o la distribución de una variable dependiente. La pregunta: “¿cual separación dicotómica sobre la cual una variable individual de predicción nos dará una máxima mejora en nuestra habilidad para predecir valores de la variable dependiente?”, inmersa en un esquema iteractivo, es la base para el algoritmo de este programa. SEARCH divide la muestra, a través de una serie de separaciones binarias, en series de subgrupos mutuamente excluyentes. Los subgrupos escogen de manera que, en cada paso en el procedimiento, la separación en los dos nuevos subgrupos explica más de la variancia o de la distribución (reduce más el error predictivo) que la separación en otro par de subgrupos. SEARCH puede hacer las siguientes funciones: * * * * Maximizar diferencias en medias de grupo, lı́neas de regresión de grupo, o distribuciones (criterio de máxima similitud de Ji-cuadrada). Asignar rangos a los predictores para darles preferencia en la partición. Sacrificar poder explicativo por simetrı́a. Comenzar después haber generado de una estructura parcial especificada de árbol. Generación de un dataset de residuos. Se pueden calcular residuos y llevarlos a la salida como un archivo Datos descrito por un diccionario IDAMS. Ver “Dataset de residuos de salida” para los detalles. 36.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. Se puede utilizar el filtro estándar para escoger un subconjunto de casos de los datos de entrada. La(s) variable(s) dependiente(s) se especifica(n) en el parámetro DEPVAR y las predictoras se especifican en el parámetro VARS en las proposiciones de predictor. Transformación de datos. Se pueden usar las proposiciones de Recode. Ponderación de datos. Se puede usar una variable para ponderar los datos de entrada; esta variable de ponderación puede tener cifras enteras o decimales. Cuando el valor de la variable de ponderación para un caso es cero, negativo, dato faltante o no numérico, entonces el caso siempre se omite; se imprime el número de casos ası́ tratados. Tratamiento de datos faltantes. Casos con datos faltantes en una variable dependiente continua o en una covariada se eliminan automáticamente. Casos con datos faltantes en una variable dependiente categórica se pueden excluir con una proposición de filtro o al especificar códigos válidos con el parámetro DEPVAR. Casos con datos faltantes en las variables predictoras no se excluyen automáticamente. Sin embargo, la proposición de filtro y/o el parámetro CODES se pueden usar para este propósito. 274 36.3. Búsqueda de estructura (SEARCH) Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variables y registros C, si los hay, solamente para variables utilizadas en la ejecución. Casos excéntricos. (Opcional: ver el parámetro PRINT). Los casos excéntricos con los valores de la variable de identificación y de la variable dependiente. Huella. (Opcional: ver el parámetro PRINT, y opciones TRACE y FULLTRACE). La huella de separaciones para cada predictor en cada separación, contiene: los grupos candidatos para separar, el grupo escogido para separar, todas las separaciones elegibles para cada predictor, la mejor separación para cada predictor y el grupo separado. Resumen de análisis contiene el análisis de variancia o distribución, el resumen de separación, el resumen de grupos finales. Tablas de resumen de predictores. (Opcional: ver el parámetro PRINT, opciones TABLE, FIRST y FINAL). Las tablas del primer grupo (PRINT=FIRST), las tablas de grupos finales (PRINT=FINAL) o las tablas de todos los grupos (PRINT=TABLE), contiene el resumen de las mejores separaciones para cada predictor para cada grupo. Las tablas se imprimen en orden inverso de grupos, es decir, el último grupo al comienzo. Diagrama de árbol. (Opcional: ver el parámetro PRINT). Diagrama de árbol jerárquico. Cada nodo (caja) del árbol contiene: número de grupo, número de casos (N), número de separación, número de variable predictora, media de la variable dependiente (para análisis de medias), media de la variable dependiente y covariada y pendiente (para análisis de regresión). 36.4. Dataset de residuos de salida Los residuos se pueden llevar opcionalmente a la salida en la forma de un archivo Datos descrito por un diccionario IDAMS. (Ver el parámetro WRITE). Para análisis de medias y de regresión y para análisis de Ji-cuadrada con variables dependientes múltiples, cada registro contiene: una variable de identificación, la variable de grupo, variable(s) dependiente(s), una(s) variable(s) dependiente(s) predicha(s) (calculada), residuo(s) y una ponderación, si la hay. Para análisis de Ji-cuadrada con una variable dependiente categórica, contiene: una variable de identificación, la variable de grupo, la primera categorı́a de la variable dependiente, la primera categorı́a predicha (calculada) de la variable dependiente, el residuo para la primera categorı́a de la variable dependiente, la segunda categorı́a de la variable dependiente, la segunda categorı́a predicha (calculada) de la variable dependiente, el residuo para la segunda categorı́a de la variable dependiente, etc. y una ponderación, si la hay. Las caracterı́sticas de las variables de salida son las siguientes: Número de variable (identificador) (variable de grupo) (var dependiente 1) (var predicha 1) (residuo para var 1) (var dependiente 2) (var predicha 2) (residuo para var 2) ... (ponderación - si hay) * ** *** 1 2 3 4 5 6 7 8 . n Nombre igual a entrada Group variable igual a entrada igual a entrada igual a entrada igual a entrada igual a entrada igual a entrada ... igual a entrada cal res cal res Ancho de campo Número de decimales Código MD1 * 3 * 7 7 * 7 7 . * 0 0 ** *** *** ** *** *** ... ** igual a entrada 999 igual a entrada 9999999 9999999 igual a entrada 9999999 9999999 ... igual a entrada transferido del diccionario de entrada para variables V o 7 para variables R transferido del diccionario de entrada para variables V o 2 para variables R 6 + Nr. de decimales para la variable dependiente menos el ancho de la variable dependiente; si ésta es negativa, entonces este valor es cero. 36.5 Dataset de entrada 275 Si el valor calculado o el del residuo execeden el ancho de campo asignado, se reemplaza por el código MD1. 36.5. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. Todas las variables usadas para análisis deben ser numéricas; pueden tener valores decimales o enteros. La variable dependiente puede ser continua o categórica. Las variables predictoras pueden ser ordinales o categóricas. La variable de identificación de caso puede ser alfabética. 36.6. Estructura del setup $RUN SEARCH $FILES Especificación de archivos $RECODE (opcional) Proposiciones de Recode $SETUP 1. 2. 3. 4. 5. Filtro (opcional) Tı́tulo Parámetros Especificaciones de predictores Especificaciones de separaciones predefinidas (opcional) $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: DICTxxxx DATAxxxx DICTyyyy DATAyyyy PRINT 36.7. diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) diccionario de residuos de salida datos de residuos de salida resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-5, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: INCLUDE V3=5 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: BUSCANDO ESTRUCTURA 276 Búsqueda de estructura (SEARCH) 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: DEPV=V5 INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos. Ver el capı́tulo “El archivo Setup de IDAMS”. MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. ANALYSIS=MEAN/REGRESSION/CHI MEAN Análisis de medias. REGR Análisis de regresión. CHI Análisis de Ji-cuadrada. Con una sola variable dependiente, se usará la lista de códigos por defecto 0-9 y no se hará verificación de datos faltantes. DEPVAR=número de variable/(lista de variables) La variable o variables dependientes. Nótese que se puede suministrar una lista de variables solamente cuando se especifica ANALYSIS=CHI. Sin valor por defecto. CODES=(lista de códigos) Solamente se puede suministrar una lista de códigos para ANALYSIS=CHI y una variable dependiente. Nótese que en este caso no se hace verificación de datos faltantes para la variable dependiente y sólo se usan en el anáisis los casos con códigos listados. COVAR=número de variable El número de la variable covariada. Debe suministrase para ANALYSIS=REGR. WEIGHT=número de variable Número de la variable de ponderación, si se van a ponderar los datos. MINCASES=25/n Número mı́nimo de casos en un grupo. MAXPARTITIONS=25/n Número máximo de particiones. SYMMETRY=0/n La cantidad de poder explicativo que se quiere perder para obtener simetrı́a, expresado como un porcentaje. EXPL=0.8/n Incremento mı́nimo en el poder explicativo que se requiere para una separación, expresado como un porcentaje. 36.7 Proposiciones de control del programa 277 OUTDISTANCE=5/n Número de desviaciones estándar de la media del grupo al que pertenecen, que definen un caso excéntrico. Nótese que se reportan los casos excéntricos si se especifica PRINT=OUTL, pero no se excluyen del análisis. IDVAR=número de variable Variable que sale con los residuos y/o que se imprime con cada caso clasificado como caso excéntrico. WRITE=RESIDUALS/CALCULATED/BOTH Residuos y/o valores calculados que se escribirán como un dataset IDAMS. RESI Salen sólo valores de residuos. CALC Salen sólo valores calculados. BOTH Salen valores de residuos y valores calculados. OUTFILE=OUT/yyyy Sólo se aplica si se especifica WRITE. Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de residuos de salida Por defecto: DICTOUT, DATAOUT. PRINT=(CDICT/DICT, TRACE, FULLTRACE, TABLE, FIRST, FINAL, TREE, OUTLIERS) CDIC Imprimir el diccionario de entrada para las variables accedidas con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. TRAC Imprimir la huella de separaciones para cada predictor para cada separación. FULL Imprimir la huella completa de separaciones para cada predictor, incluidas las separaciones elegibles pero sub-óptimas. TABL Imprimir las tablas de resumen de predictores para todos los grupos. FIRS Imprimir las tablas de resumen de predictores para el primer grupo. FINA Imprimir las tablas de resumen de predictores para los grupos finales. TREE Imprimir el diagrama del árbol jerárquico. OUTL Imprimir los casos excéntricos con valores de variable identificadora y de variable dependiente. 4. Especificaciones de predictores (mandatorio). Suministrar un conjunto de parámetros para cada grupo de predictores que se pueda describir con los mismos valores de los parámetros. Las reglas de codificación son las mismas de los parámetros. Cada especificación de predictor debe comenzar en una nueva lı́nea. Ejemplo: VARS=(V8,V9) TYPE=F VARS=(lista de variables) Variables predictoras a las cuales se aplican los otros parámetros. Sin valor por defecto. TYPE=M/F/S La restricción del predictor. M Los predictores se consideran “monotónicos”, es decir, los códigos de predictores se van a mantener adyacentes durante el barrido de la partición. F Los códigos de predictores se consideran “libres”. S Los códigos de predictores se “selecionarán” y separarán de los códigos restantes al formar particiones de ensayo. CODES=(0-9)/máximo código/(lista de códigos) El valor de código más grande aceptable o una lista de códigos aceptables. Los códigos pueden estar en el rango de 0 a 31. Los casos con código fuera del rango 0 a 31 siempre se descartan. 278 Búsqueda de estructura (SEARCH) RANK=n Rango asignado. Si desean rangos, se asigan un rango predictor de 0 a 9. Un rango de cero indica que se van a calcular estadı́sticas para los predictores, pero no se van a usar al hacer las particiones. 5. Especificaciones de separaciones predefinidas (opcional). Si desean separaciones predefinidas, se suministra un conjunto de parámetros para cada separación predefinida. Las reglas de codificación son las mismas de los parámetros. Cada especificacióon de separación predefinida debe comenzar en una nueva lı́nea. Ejemplo: GNUM=1 VAR=V18 CODES=(1-3) GNUM=n El número del grupo a separar. Los grupos se especifican en orden ascendente, en donde la muestra entera original es el grupo 1. Cada conjunto de parámetros forma dos nuevos grupos. Sin valor por defecto. VAR=número de variable Variable predictora que se usa para hacer la separación. Sin valor por defecto. CODES=(lista de códigos) Lista de los códigos del predictor que definen el primer subgrupo. Todos los demás códigos pertenecerán al segundo subgrupo. Sin valor por defecto. 36.8. Restricciones 1. Número mı́nimo de casos requerido es 2 * MINCASES. 2. Número máximo de predictores es 100. 3. Valor máximo de predictor es 31. 4. Número máximo de códigos de variables categóricas es 400. 5. Número máximo de separaciones perdefinidas es 49. 6. Si la variable de identificación es alfabética con ancho > 4, sólo se usan los primeros cuatro caracteres. 36.9. Ejemplos Ejemplo 1. Análisis de medias con cinco variables predictoras; se solicita un mı́nimo de 10 casos por grupo; se reportan los casos excéntricos con más de 3 desviaciones estándar de la media del grupo; los casos se identifican con la variable V1. $RUN SEARCH $FILES PRINT = SEARCH1.LST DICTIN = STUDY.DIC archivo Diccionario de entrada DATAIN = STUDY.DAT archivo Datos de entrada $SETUP ANALISIS DE MEDIAS - CINCO VARIABLES PREDICTORAS DEPV=V4 MINC=10 OUTD=3 IDVAR=V1 PRINT=(TRACE,TREE,OUTL) VARS=(V3-V5,V12) VARS=V21 TYPE=F CODES=(1-4) Ejemplo 2. Análisis de regresión con seis variables predictoras; se van a computar residuos y valores calculados y se van a escribir en un dataset (los casos se identifican con la variable V2). 36.9 Ejemplos 279 $RUN SEARCH $FILES PRINT = SEARCH2.LST DICTIN = STUDY.DIC archivo Diccionario de entrada DATAIN = STUDY.DAT archivo Datos de entrada DICTOUT = RESID.DIC archivo Diccionario para residuos DATAOUT = RESID.DAT archivo Datos para residuos $SETUP ANALISIS DE REGRESION - SEIS VARIABLES PREDICTORAS ANAL=REGR DEPV=V12 COVAR=V7 MINC=10 IDVAR=V2 WRITE=BOTH PRINT=(TRACE,TABLE,TREE) VARS=(V3-V5,V18) VARS=V22 TYPE=F Ejemplo 3. Análisis de Ji-cuadrada con una variable dependiente categórica y códigos seleccionados; se predefinen las dos primeras separaciones. $RUN SEARCH $FILES DICTIN = STUDY.DIC archivo Diccionario de entrada DATAIN = STUDY.DAT archivo Datos de entrada $SETUP ANALISIS DE JI: VARIABLE DEPENDIENTE CATEGORICA, SEPARACIONES PREDEFINIDAS ANAL=CHI DEPV=V101 CODES=(1-5) MINC=5 PRINT=(FINAL,TREE) VARS=(V3,V8) TYPE=S GNUM=1 VAR=V8 CODES=3 GNUM=2 VAR=V3 CODES=(1,2) Capı́tulo 37 Tablas univariadas y bivariadas (TABLES) 37.1. Descripción general El uso principal de TABLES es obtener listados de tablas de frecuencias univariadas y bivariadas con la opción de mostrar porcentajes de fila, columna y esquina, y de manera opcional, estadı́sticas univariadas y bivariadas. También se pueden obtener tablas de valores medios de una variable. Ambos las tablas univariadas/bivariadas y estadı́sticas bivariadas se pueden bajar a un archivo de manera que se utilicen desde un programa generador de informes con un formato escogido por el mismo usuario, o puede entrar a GraphID u otros paquetes, tales como EXCEL, por despliegue gráfico. Tablas univariadas. Se pueden generar frecuencias univariadas y frecuencias univariadas acumulativas para cualquier número de variables de entrada y se pueden también expresar como porcentajes de la frecuencia total ponderada o sin ponderar. Adicionalmente se puede obtener la media de una variable de celda. Tablas bivariadas. Se puede generar cualquier número de tablas bivariadas. Adicionalmente a las frecuencias ponderadas y/o sin ponderar, una tabla puede tener frecuencias expresadas como porcentajes basados en los marginales por fila y columna o en el total de la tabla y la media de una variable de una celda. Todos estos ı́tems se pueden incluir en una sola tabla hasta con seis ı́tems por celda, o bién, se puede imprimir cada una individualmente como una tabla separada. Estadı́sticas univariadas. Para análisis univariado, se dispone de las siguientes estadı́sticas: media, moda, mediana, variancia (sin asimetrı́a), desviación estándar, coeficiente de variación, asimetrı́a y kurtosis. Existe también una opción de cuantiles (NTILE). Se puede solicitar una división desde tres partes hasta diez partes. Estadı́sticas bivariadas. Para el análisis bivariado, se pueden solicitar las siguientes estadı́sticas: - pruebas-t de medias (asume poblaciones independientes) entre pares de filas, Ji-cuadrada, coeficiente de contingencia y V de Cramer, Taus de Kendall, Gama, Lambdas, S (numerador de las estadı́sticas taus y gama), su desviación estándar y normal, y su variancia, ro de Spearman, estadı́sticas para medicina basada en evidencia (EBM), pruebas no paramétricas: Wilcoxon, Mann-Whitney y Fisher. Matrices de estadı́sticas. Con excepción de las pruebas, estadı́sticas EBM o estadı́sticas que involucren a S, se pueden imprimir o bajar a un archivo, matrices con todas las estadı́sticas bivariadas mencionadas. Se pueden producir las matrices correspondientes a n ponderadas o sin ponderar. Tablas de 3 y de 4 entradas. Estas tablas se pueden construir haciendo uso de las posibilidades de repetición y de división en subconjuntos. La variable de repetición se puede pensar como una variable de control o de panel. La posibilidad de dividir en subconjuntos puede usarse para escoger más casos para un grupo en particular de tablas. 282 Tablas univariadas y bivariadas (TABLES) Tablas de sumas. Se pueden producir tablas en las cuales las celdas contengan la suma de una variable dependiente si se especifica la variable dependiente como el factor de ponderación. Por ejemplo, WEIGHT=V208, donde V208 representa el ingreso de un encuestado, y se quiere obtener el ingreso total de todos los encuestados en una sola celda. Nota. Se tienen las siguientes opciones para controlar la presentación de los resultados: Se puede asignar un tı́tulo para cada conjunto de tablas. Se pueden imprimir porcentajes y las medias en tablas separadas si se desea. Se puede suprimir la malla de celdas. Se pueden imprimir las filas que no tengan entradas en una sección particular de una tabla de frecuencias grande; las tablas que tengan más de diez columnas se imprimen por secciones y el uso de la opción “zero rows (cero filas)” asegura que las diferentes secciones tengan el mismo número de filas (lo cual es importante si éstas se van a recortar y pegar posteriormente). 37.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. Se puede usar el filtro estándar para escoger un subconjunto de casos de los datos de entrada. Además, se pueden usar filtros locales y factores de repetición (llamados especificaciones de subconjunto) para escoger un subconjunto de casos para una tabla en particular. En tablas especificadas individualmente, la variable o variables a utilizar con la tabla se escogen con los parámetros de especificación de tabla R y C. Para conjuntos de tablas, las variables se seleccionan con los parámetros de especificación de tabla ROWVARS y COLVARS. Transformación de datos. Se pueden usar las proposiciones de Recode. Nótese que para las variables R el programa utiliza el número de cifras decimales dado en el parámetro NDEC. Ponderación de datos. Se puede especificar, de manera opcional, una variable de ponderación para cada conjunto de tablas. Las variables V y R con decimales se multiplican por un factor de escala para obtener valores enteros. Ver la sección “Dataset de entrada” abajo. Cuando el valor de la variable de ponderación para un caso es cero, negativo, dato faltante o no numérico, entonces el caso siempre se omite; se imprime el número de casos ası́ tratados. Tratamiento de datos faltantes. 1. El parámetro MDVALUES está disponible para indicar cuales valores de datos faltantes, si los hay, se usarán para verificar los datos faltantes. 2. Las frecuencias univariadas y bivariadas se imprimen siempre para todos los códigos en los datos sin importar si se trata de datos faltantes o no. Para retirar completamente de las tablas los datos faltantes, se puede especificar un filtro o un subconjunto de casos. Alternativamente, se pueden definir valores máximos y/o mı́nimos de las variables de fila y de columna. 3. Los casos con datos faltantes, se pueden opcionalmente incluir en los cálculos de porcentajes y de las estadı́sticas bivariadas. Esto se puede hacer con el parámetro de tabla MDHANDLING. 4. Los casos con datos faltantes en la variable de celda se excluyen siempre de las tablas univariadas y bivariadas. 5. Los casos con datos faltantes, se excluyen siempre de los cálculos de las estadı́sticas univariadas. 37.3. Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variables y registros C, si los hay, solamente para variables utilizadas en la ejecución. Una tabla de contenido del listado. El contenido indica cada tabla producida y da el número de página en el cual está localizada. Se suministra la información siguiente: 37.3 Resultados - 283 números de variables de fila y columna (0 si no hay) numero de variable para el valor de la media - variable de celda (0 si no hay) número de la variable de ponderación (0 si no hay) valores mı́nimo y máximo de fila (0 si no hay) valores mı́nimo y máximo de columna (0 si no hay) nombre de filtro y nombre del factor de repetición porcentajes: fila, columna y total (T=solicitado, F=no solicitado) RMD: datos faltantes para la variable de fila (T=eliminar, F=no eliminar) CMD: datos faltantes para la variable de columna (T=eliminar, F=no eliminar) CHI: Ji-cuadrada (T=solicitada, F=no solicitada) TAU: tau a, b o c (T=solicitada, F=no solicitada) GAM: gama (T=solicitada, F=no solicitada) TEE: pruebas t (T=solicitadas, F=no solicitadas) EXA: prueba no paramétrica de Fisher (T=solicitada, F=no solicitada) WIL: prueba no paramétrica de Wicoxon (T=solicitada, F=no solicitada) MW: prueba no paramétrica de Mann-Whitney (T=solicitada, F=no solicitada) SPM: ro de Spearman (T=solicitada, F=no solicitada) EBM: estadı́sticas para medicina basada en evidencia (T=solicitadas, F=no solicitadas). Las tablas que se solicitan con los parámetros de tabla PRINT=MATRIX o WRITE=MATRIX no se imprimen en el contenido y siempre se imprimen primero con números de página y de tabla negativos. Otras tablas se imprimen en el orden de las especificaciones de la tabla, excepto para aquellas en las cuales sólo se hayan solicitado las estadı́sticas univariadas; éstas siempre se agrupan juntas al final del listado. Tablas bivariadas. Cada tabla bivariada comienza en una página nueva; una tabla grande puede ocupar más de una página. Las tablas se imprimen con un máximo hasta de 10 columnas y 16 filas por página, según el número de ı́tems de cada celda. Las filas y columnas se imprimen sólo para los códigos que aparezcan en los datos. Los totales de filas y columnas y las frecuencias acumuladas marginales y porcentajes se imprimen, si ası́ se ha solicitado, alrededor de los bordes de la tabla. Una tabla grande se imprime por tiras verticales. Por ejemplo, una matriz con 40 filas de códigos y 40 columnas de codigos se imprimirı́a normalmente en 12 páginas tal como se muestra en el siguiente diagrama, en el cual los números en las celdas muestran el orden en el cual se imprimen las páginas: primeros 10 segundos 10 terceros 10 cuartos 10 primeros 16 códigos 1 4 7 10 segundos 16 codigos 2 5 8 11 últimos 8 códigos 3 6 9 12 códigos Estadı́sticas bivariadas. (Opcional: ver el parámetro de tabla STATS) Pruebas-t. (Opcional: ver el parámetro de tabla STATS). Si se solicitan pruebas-t, se imprimen éstas y las medias y las desviaciones estándar de la variable de columna para cada fila en una página separada. Matrices de estadı́sticas bivariadas. (Opcional: ver el parámetro de tabla PRINT). Se imprime la esquina inferior izquierda de la matriz. Se imprimen 8 columnas y 25 filas por página. Matriz de las N. (Opcional: ver el parámetro de tabla PRINT). Se imprime con el mismo formato de la matriz estadı́stica correspondiente. Tablas univariadas. (Opcional: ver el parámetro de tabla CELLS). Normalmente, cada tabla univariada se imprime al comienzo de una nueva página. Se imprimen las frecuencias, porcentajes y las medias de una variable, si se han solicitado, para diez códigos en una página. Estadı́sticas univariadas. (Opcional: ver el parámetro de tabla USTATS). Cuantiles. (Opcional: ver el parámetro de tabla NTILE). Se imprimen N-1 puntos, por ej. si se han solicitado cuartiles, el parámetro NTILE toma el valor 4 y se imprimen 3 puntos de separación. 284 Tablas univariadas y bivariadas (TABLES) Numeración de páginas. Es de la forma ttt.rr.ppp donde: ttt rr ppp 37.4. = = = número de la tabla número de repetición (00 si no se usa) número de página dentro de cada tabla. Tablas univariadas/bivariadas de salida Se pueden obtener en un archivo, tablas univariadas y bivariadas con las estadı́sticas solicitadas en el parámetro CELLS, si se especifica WRITE=TABLES. Las tablas están en el formato de matriz rectangular de IDAMS (ver el capı́tulo “Los datos en IDAMS”). Se produce una matriz para cada estadı́stica solicitada. Si se usa un factor de repetición, se produce una matriz para cada repetición. Las columnas 21-80 del registro descriptor de la matriz, contienen la siguiente descriptión adicional de la matriz: 21-40 41-60 61-80 Nombre de la variable de fila (para tablas bivariadas). Nombre de la variable de columna. Descripción de los valores en la matriz. Los registros de identificación de variable (#R and #C) contienen valores y nombres de código para las variables de fila y de columna respectivamente. Las estadı́sticas se escriben como registros de 80 caracteres de acuerdo con un formato Fortran 7F10.2. Las columnas 73-80 contienen un identificador de la manera siguiente: 73-76 77-80 Identificación de la estadı́stica: FREQ, UNFR, ROWP, COLP, TOTP o MEAN. Número de tabla. Nótese que los códigos de datos faltantes no se incluyen en la matriz. 37.5. Matrices de estadı́sticas bivariadas de salida Se pueden seleccionar estadı́sticas para bajarlas a un archivo. Por ejemplo, si se han seleccionado gamas y taus, entonces se generará una matriz de gamas y una matriz de taus separadamente. Las matrices de salida de estadı́sticas bivariadas se solicitan con las especificaciones WRITE=MATRIX o bién con los parámetros de tabla ROWVARS o ROWVARS y COLVARS. Si se usa un factor de repetición, se baja al archivo una matriz por cada repetición. Las matrices son de la forma matriz de IDAMS cuadrada o rectangular (ver el capı́tulo “Los datos en IDAMS”). Los valores en la matriz se escriben con el formato Fortran 6F11.5. Las columnas 73-80 contienen la siguiente identificación: 73-76 77-80 Identificación de la estadı́stica: TAUA, TAUB, TAUC, GAMM, LSYM, LRD, LCD, CHI, CRMV o RHO. Número de tabla. Nota. Si se suministra sólo ROWVARS, se escriben registros de medias y desviaciones estándar ficticias, 2 registros por 60 variables. El segundo registro de formato (#F) en el diccionario especifica un formato 60I1 para estos registros ficticios. Esto se hace de manera que la matriz se ajuste al formato de una matriz IDAMS cuadrada. 37.6. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. Excepto variables del filtro principal, todas otras variables referidas deben ser numéricas. En distribuciones y ponderaciones, las variables V y R con cifras decimales se multiplican por un factor de escala para obtener valores enteros. Este factor se calcula como 10n donde n es el número de decimales del 37.7 Estructura del setup 285 diccionario para las variables V y del parámetro NDEC para las variables R, y aparece en los resultados para cada variable. Estadı́sticas univariadas sin distribuciones se calculan usando el número de decimales del diccionario para las variables V y del parámetro NDEC para las variables R. Los campos con caracteres no-numéricos (incluidos campos en blanco) se pueden tabular con el parámetro BADDATA con MD1 o MD2. Ver el capı́tulo “El archivo Setup de IDAMS”. 37.7. Estructura del setup $RUN TABLES $FILES Especificación de archivos $RECODE (opcional) Proposiciones de Recode $SETUP 1. 2. 3. 4. 5. 6. Filtro (opcional) Tı́tulo Parámetros Especificaciones de subconjuntos (opcional) TABLES Especificaciones de tablas (tantas como sean necesarias) $DICT (condicional) Diccionario $DATA (condicional) Datos Archivos: FT02 DICTxxxx DATAxxxx PRINT 37.8. tablas/matrices de salida diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al el capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, 1-3 y 6 a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: INCLUDE V3=6 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: TABLAS DE FRECUENCIAS 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Los nuevos parámetros son precedidos por un asterisco. Ejemplo: BADDATA=SKIP 286 Tablas univariadas y bivariadas (TABLES) INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos. Ver el capı́tulo “El archivo Setup de IDAMS”. MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. MDVALUES=BOTH/MD1/MD2/NONE Cuales valores de datos faltantes se van a usar para las variables accedidas en esta ejecución. Ver el capı́tulo “El archivo Setup de IDAMS”. * NDEC=0/n Número de decimales (máximo 4) a conservar para las variables R. PRINT=(CDICT/DICT, TIME) CDIC Imprimir el diccionario de entrada para las variables accedidas con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. TIME Imprimir el tiempo después de cada tabla. 4. Especificaciones de subconjuntos (opcional). Estas proposiciones permiten escoger un subconjunto de casos para una tabla o un conjunto de tablas. Ejemplo: CLASS INCLUDE V8=1,2,3,-7,9 Hay dos clases de especificación de subconjunto: filtros locales y factores de repetición. Cada uno tiene una función diferente, pero sus formatos son muy similar. Una especificación se puede utilizar como filtro local para una o más tablas y como un factor de repetición para otras. Reglas de codificación Prototipo: nombre proposición nombre Nombre del subconjunto. 1-8 caracteres alfanuméricos comenzando con una letra. Este nombre debe coincidir exactamente con el nombre usado en las especificaciones de análisis subsecuentes. Blancos intercalados no se permiten. Se recomienda que todos los nombres se justifiquen a la izquierda. proposición Definición del subconjunto que siga la sintáxis del filtro estándar de IDAMS. Para los factores de repetición, sólo se puede especificar una variable en la expresión. A continuación se describe como trabajan los filtros locales y los factores de repetición. Filtros locales. Una especificación de subconjunto se identifica como un filtro local para una tabla o un conjunto de tablas, al especificar el nombre del subconjunto con el parámetro FILTER. El filtro local funciona de la misma manera que el filtro estándar excepto que se aplica solamente a las especificaciones de la tabla en la cual ha sido referido. Ejemplo: EDUCATN (nombre subconjunto) INCLUDE V4=0-4,9 AND V5=1 (expresión) En el ejemplo anterior, si EDUCATN se define como filtro local en las especificaciones de la tabla, la tabla se producirı́a con la inclusión de sólo aquellos casos con códigos 0,1,2,3,4 o 9 para V4 y 1 para V5. 37.8 Proposiciones de control del programa 287 Factores de repetición. Una especificación de subconjunto se identifica como un factor de repetición para una tabla o un conjunto de tablas, al especificar el nombre del subconjunto con el parámetro REPE. Sólo se debe dar una variable en una especificación de subconjunto para usarla como factor de repetición. Los factores de repetición permiten la generación de tablas de 3 entradas, en donde la variable utilizada en el factor de repetición, se puede considerar como una variable de control o de panel. Si se utiliza un factor de repetición y un filtro, se puede obtener una tabla de 4 entradas. Las expresiones INCLUDE, hacen que las tablas producidas incluyan los casos para cada valor o rango de valores de la variable de control utilizada en la expresión. Los valores o rangos se separan con comas. Ası́ si hay n comas en la expresión, se producirán n+1 tablas. Ejemplo: EDUCATN (nombre subconjunto) INCLUDE V4=0-4,9 (expresión) En el ejemplo anterior, si EDUCATN se designa como un factor de repetición, resultarán dos tablas: una que la incluye los casos codificados 0-4 para la variable 4, y otra que incluye los casos codificados 9 para la variable 4. EXCLUDE se puede usar para producir tablas con todos los valores excepto aquellos especificados. Ejemplo: EDUCATN (nombre subconjunto) EXCLUDE V1=1,4 (expresión) En el ejemplo anterior, si EDUCATN se designa como un factor de repetición, resultarán dos tablas: una con todos los valores excepto 1 y otra con todos los valores excepto 4. 5. TABLES. La palabra TABLES en esta lı́nea, señala que siguen especificaciones de tablas. Debe incluirse (con el objeto de separar las especificaciones de subconjuntos de las especificaciones de tablas) y sólo debe aparecer una vez. 6. Especificaciones de tablas. Las especificaciones de tablas se utilizan para describir las caracterı́sticas de las tablas que se van a producir. Las reglas de codificación son las mismas de los parámetros. Cada conjunto de especificaciones de tabla debe comenzar en una lı́nea nueva. Ejemplos: R=(V6,1,8) CELLS=FREQS R=(V6,1,8) C=(V9,0,4) REPE=SEX CELLS=(ROWP,FREQS) ROWV=(V5-V9) CELLS=FREQS USTA=MEAN ROWV=(V3,V5) COLV=(V21-V31) R=(0,1,8) C=(0,1,99) (una tabla univariada) (una tabla bivariada con factor de repetición, es decir tabla de 3 entradas) (conjunto de tablas univariadas) (conjunto de tablas bivariadas) ROWVARS=(lista de variables) Lista de variables para la cual se requieren tablas univariadas o lista de variables que se va a usar como filas en tablas bivariadas. COLVARS=(lista de variables) Lista de variables a usar como columnas para tablas bivariadas. R=(var, rmin, rmax) var Número de variable de fila o de variable univariada de una tabla individual. Para suministrar los valores máximos y mı́nimos de un conjunto de tablas, coloque el número de variable en ceros, por ej. R=(0,1,5); en este caso los códigos máximos y mı́nimos se aplican a todas las variables en el parámetro ROWVARS. rmin Código mı́nimo de la(s) variable(s) de fila para los cálculos estadı́sticos y de porcentajes. rmax Código máximo de la(s) variable(s) de fila para los cálculos estadı́sticos y de porcentajes. Si se especifica rmin o rmax, entonces se deben especificar ambos. Si sólo se especifica el número de variable, los valores máximos y mı́nimos no se aplican. 288 Tablas univariadas y bivariadas (TABLES) C=(var, cmin, cmax) var Número de variable de columna para una tabla bivariada individual. Para suministrar los valores máximos y mı́nimos de un conjunto de tablas, coloque el número de variable en ceros, por ej. C=(0,2,5); en este caso los códigos máximos y mı́nimos se aplican a todas las variables en el parámetro COLVARS. cmin Código mı́nimo de la(s) variable(s) de columna para los cálculos estadı́sticos y de porcentajes. cmax Código máximo de la(s) variable(s) de columna para los cálculos estadı́sticos y de porcentajes. Si se especifica cmin o cmax, entonces se deben especificar ambos. Si sólo se especifica el número de variable, los valores máximos y mı́nimos no se aplican. TITLE=’tı́tulo de la tabla’ Tı́tulo para imprimir en el encabezamiento de cada tabla en este conjunto. Por defecto: no imprime tı́tulo. CELLS=(ROWPCT, COLPCT, TOTPCT, FREQS/NOFREQS, UNWFREQS, MEAN) Contenido de las celdas de tablas cuando se ha especificado PRINT=TABLES o WRITE=TABLES. ROWP Porcentajes para tablas univariadas o porcentajes basados en totales de fila para tablas bivariadas. COLP Porcentajes basados en totales de columnas en tablas bivariadas. TOTP Porcentajes basados en el gran total en tablas bivariadas. FREQ Conteos de frecuencia ponderada (el mismo sin ponderar si no se especifica WEIGHT). UNWF Conteos de frecuencia sin ponderar. MEAN Media de la variable especificada por VARCELL. VARCELL=número de variable El número de la variable para la cual se va calcular la media en cada celda de la tabla. MDHANDLING=ALL/R/C/NONE Indica cuales valores de datos faltantes deben excluirse de los cálculos de porcentajes y estadı́sticas bivariadas. ALL Eliminar todos los valores de datos faltantes. R Eliminar los valores de datos faltantes para las variables de fila. C Eliminar los valores de datos faltantes para las variables de columna. NONE No eliminar valores de datos faltantes. Nota: los casos con datos faltantes siempre se excluyen de las estadı́sticas univaridas. WEIGHT=número de variable Número de la variable de ponderación, si se van a ponderar los datos. FILTER=xxxxxxxx El nombre de 1-8 caracteres de la especificación de subconjunto que se va a usar como filtro local. Debe estar encerrado entre comillas sencillas si tiene caracteres no-alfanuméricos. Si el nombre no coincide con alguno de los nombres de las especificaciones de subconjunto, se salta la tabla. Se deben usar letras mayúsculas con el objeto de hacer encajar el nombre en la especificación de subconjuntos el cual se convierte automáticamente a mayúsculas. REPE=xxxxxxxx El nombre de 1-8 caracteres de la especificación de subconjunto que se va a usar como factor de repetición. Debe estar encerrado entre comillas sencillas si tiene caracteres no-alfanuméricos. Si el nombre no coincide con alguno de los nombres de las especificaciones de subconujunto, se salta la tabla. Las tablas se repetirán para cada grupo de casos especificado. Se deben usar letras mayúsculas con el objeto de hacer encajar el nombre en la especificación de subconjuntos el cual se convierte automáticamente a mayúsculas. 37.8 Proposiciones de control del programa 289 USTATS=(MEANSD, MEDMOD) (Sólo tablas univariadas). MEAN Imprimir media, mı́nimo, máximo, variancia (sin asimetrı́a), desviación estándar, coeficiente de variación, asimetrı́a, kurtosis, total de casos ponderados y sin ponderar. MEDM Imprimir mediana y moda (si hay ataduras, se escoge el valor numérico más pequeño). NTILE=n (Sólo tablas univariadas). La n es el número de cuartiles que se van a calcular; debe estar en el rango 3-10. STATS=(CHI, CV, CC, LRD, LCD, LSYM, SPMR, GAMMA, TAUA, TAUB, TAUC, EBMSTAT, WILC, MW, FISHER, T) Si se va imprimir o producir como salida alguna de las estadı́sticas bivariadas, suministrar el parámetro STAT con cada una de las estadı́sticas deseadas. Tablas bivariadas y matrices de salida CHI Ji-cuadrada. (Si no se ha pedido MATRIX, la selección de CHI, CV o CC hará que se calculen las tres). CV V de Cramer. CC Coeficiente de contingencia. LRD Lambda, variable de fila es la variable dependiente. (Si no se ha pedido MATRIX, la selección de cualquiera de las lambdas hará que se calculen las tres). LCD Lambda, variable de columna es la variable dependiente. LSYM Lambda, simétrica. SPMR Estadı́stica Ro de Spearman. GAMM Estadı́stica Gama. TAUA Estadı́stica tau a. (Si no se ha pedido MATRIX, la selección de cualquiera de las taus hará que se calculen las tres). TAUB Estadı́stica tau b. TAUC Estadı́stica tau c. Tablas bivariadas solamente EBMS Estadı́sticas para medicina basada en evidencia. WILC Prueba de rangos con signo de Wilcoxon. MW Prueba de Mann-Whitney. FISH Prueba exacta de Fisher. T Pruebas-t entre todas las combinaciones de filas, hasta un lı́mite de 50 filas. DECPCT=2/n Número de decimales impresos para porcentajes, máximo cuatro. DECSTATS=2/n Número de decimales impresos para las estadı́sticas media, mediana, taus, gama, lambdas y Jicuadrada. Todas las demás estadı́sticas se imprimirán con 2+n decimales (es decir, por defecto 4). WRITE=MATRIX/TABLES Si se va a generar un archivo de salida, se debe suministrar el parámetro WRITE y el tipo de salida. MATR Bajar al archivo las matrices de estadı́sticas seleccionadas. Si el parámetro ROWVARS se especifica, se produce una matriz cuadrada para cada estadı́stica solicitada en el parámetro STATS con todos los apareamientos de las variables que aparecen en la lista. Si se especifican los parámetros ROWVARS y COLVARS, se produce una matriz rectangular para cada estadı́stica solicitada en el parámetro STATS con cada variable que aparezca en la lista de ROWVARS, apareada con cada variable que aparezca en la lista de COLVARS. 290 Tablas univariadas y bivariadas (TABLES) TABL Bajar al archivo las tablas de estadı́sticas solicitadas en el parámetro CELLS. PRINT=(TABLES/NOTABLES, SEPARATE, ZEROS, CUM, GRID/NOGRID, N, WTDN, MATRIX) Opciones que se refieren a tablas univariadas/bivariadas solamante. TABL Imprimir las tablas con ı́tems especificados por CELLS. SEPA Imprime cada ı́tem especificado en CELLS como una tabla separada. ZERO Mantener las filas con marginales cero en el listado. (Sólo aplica si la tabla tiene más de 10 columnas y por lo tanto ha de imprimirse por tiras). CUM Imprimir frecuencias y porcentajes acumulados y marginales por fila y columna. Si los datos son ponderados, las cifras se calculan sobre frecuencias ponderadas solamente. GRID Imprimir la malla alrededor de las celdas de tablas bivariadas. NOGR Suprimir la malla alrededor de las celdas de tablas bivariadas. Opciones N WTDN MATR 37.9. que se refieren a WRITE=MATRIX solamente. Imprimir la matriz de las n para las matrices de estadı́sticas solicitadas. Imprimir la matriz de las n ponderadas, para las matrices de estadı́sticas solicitadas. Imprimir las matrices de estadı́sticas especificadas con STATS. Restricciones 1. El número máximo de variables para frecuencias univariadas es 400. 2. La combinación de variables y especificaciones de subconjuntos está sujeta a la siguiente restricción: 5NV + 107NF < 8499 donde NF es el número de especificaciones de subconjuntos y NV es el número de variables. 3. Los valores de los códigos en tablas univariadas deben estar dentro del rango -2,147,483,648 a 2,147,483,647. 4. Los valores de los códigos para tablas bivariadas deben estar en el rango -32,768 a 32,768. Cualesquiera valores de código fuera de este rango, se recodifican inmediatamente a los valores de los puntos extremos del rango, por ej. -40,000 se recodificará a -32,768 y 40,000 se convertirá en 32,768. De esta manera, en las especificaciones de tablas bivariadas, 32,768 corresponde al máximo “valor máximo”. (Nótese que una variable de 5 dı́gitos con un código de datos faltantes de 99999 tendrá en el listado la fila de dato faltante con tı́tulo 32,768). 5. La frecuencia máxima acumulada, ponderada o sin ponderar para una tabla (y para cualquier celda, fila o columna) es 2,147,483,647. 6. Dimensiones máximas de la tabla. Bivariada: 500 códigos de fila, 500 códigos de columna, 3000 celdas con entidades diferentes de cero. Univariada: 3000 categorı́as cuando se hayan solicitado frecuencias, mediana/moda; de lo contrario, son ilimitadas. Nota: para una variable como ingreso, si hay más de 3000 valores únicos de ingreso, no se puede obtener una mediana o una moda sin antes haber agrupado la variable. 7. Los valores no enteros de las variables tipo V en distribuciones y ponderaciones se tratan como si no existiera el punto decimal; se imprime un factor de escala para cada variable. 8. Las pruebas-t de medias entre filas se llevan a cabo solamente en las primeras 50 filas de una tabla. 9. Para la salida de la matriz de estadı́sticas bivariadas, el máximo número de variables por fila o columna es de 95. 10. Si se van a producir archivos de salida para frecuencias bivariadas y matrices de estadı́sticas, todos van al mismo archivo fı́sico de salida. 11. Cuando se utilizan variables recodificadas, no se pueden titular las filas y las columnas de las tablas. 37.10 Ejemplo 37.10. 291 Ejemplo En el ejemplo a continuación, se piden las siguientes tablas: 1. Conteos de frecuencia para las variables V201-V220. 2. Estadı́sticas univariadas sin tablas de frecuencias para las variables V54-V62 y V64. Las medias tendrán un decimal y las demás estadı́sticas 3 decimales. 3. Conteos de frecuencias ponderadas y sin ponderar y porcentajes con frecuencias acumuladas y porcentajes para las variables V25-V30 y la versión agrupada de la variable V7. Los casos con datos faltantes no se excluirán de los porcentajes o de las estadı́sticas. Se solicitan la mediana y la moda. 4. Para las categorı́as de la variable individual V201, se piden conteos de frecuencias y la media de la variable V54. 5. 8 tablas bivariadas (con variables de fila V25-V28 y variables de columna V29, V30) repetidas por los valores 1 y 2 de la variable 10 (sexo), es decir que la variable sexo se utiliza como variable de panel (control). En cada celda habrá conteos, porcentajes por filas, por columnas y por totales. Se piden las estadı́sticas Ji-cuadrada y Taus. 6. Tablas de 3 entradas con la región (V3) agrupada en tres categorı́as como variable de panel. Las tablas se restringen a casos de hombres solamente (V10=1). En cada celda aparecerán conteos de frecuencias y media de la variable V54. 7. Una tabla de conteos de frecuencia ponderada individual, con exclusión de los casos en los cuales la variable de fila y/o de columna tomen el valor de 9. 8. Las matrices de las estadı́sticas Tau A y Gama se imprimirán y se bajarán a un archivo para todos los pares de variables V54-V62. También se imprimirá una matriz de conteo de casos válidos para cada par de variables. 1. 2. 3. 4. 5. 6. 7. 8. $RUN TABLES $FILES PRINT = TABLES.LST FT02 = TREE.MAT matrices de estadı́sticas DICTIN = TREE.DIC archivo Diccionario de entrada DATAIN = TREE.DAT archivo Datos de entrada $RECODE R7=BRAC(V7,0-15=1,16-25=2,26-35=3,36-45=4,46-98=5,99=9) NAME R7’V7 AGRUPADA’ $SETUP EJEMPLO DE TABLAS BADDATA=MD1 MALE INCLUDE V10=1 SEX INCLUDE V10=1,2 REGION INCLUDE V3=1-2,3-4,5 MD EXCLUDE V19=9 OR V52=9 TABLES ROWV=(V201-V220) TITLE=’Conteo de frecuencias’ ROWV=(V54-V62,V64) USTATS=MEANSD PRINT=NOTABLES DECSTAT=1 ROWV=(V25-V30,R7) USTATS=MEDMOD CELLS=(FREQS,UNWFREQS,ROWP) WEIGHT=V9 PRINT=CUM MDHAND=NONE R=(V201,1,3) CELLS=(FREQS,MEAN) VARCELL=V54 ROWV=(V25-V28) COLV=(V29-V30) CELLS=(FREQS,ROWP,COLP,TOTP) STATS=(CHI,TAUA) REPE=SEX ROWV=(V201-V203) COLV=V206 CELLS=(FREQS,MEAN) VARCELL=V54 REPE=REGION FILT=MALE R=V19 C=V52 WEIGHT=V9 FILT=MD ROWV=(V54-V62) STATS=(TAUA,GAMMA) PRINT=(MATRIX,N) WRITE=MATRIX Capı́tulo 38 Tipologı́a y clasificación ascendente (TYPOL) 38.1. Descripción general TYPOL crea una variable de clasificación que resume un gran número de variables. Se permite que el núcleo inicial de grupos esté constituido por el uso de una variable de clasificación inicial, definida “a priori” (variable clave), una muestra aleatoria de casos, o una muestra por pasos. Un proceso iterativo mejora los resultados mediante la estabilización de los núcleos. Los grupos finales constituyen las categorı́as de la variable de clasificación que se busca. El número de grupos de la tipologı́a se puede reducir si se utiliza un algoritmo de clasificación jerárquica ascendente. Las variables activas son aquellas sobres las cuales se hace el agrupamiento y reagrupamiento de los casos. También se pueden buscar las estadı́sticas principales de otras variables dentro de los grupos construidos de acuerdo con las variables activas. Tales variables (que no tienen influencia en la construcción de los grupos) se llaman variables pasivas. TYPOL acepta variables cuantitativas y cualitativas, estas últimas se tratan como cuantitativas depués de una dicotomización completa de sus respectivas categorı́as, lo cual resulta en la construcción de tantas variables dicotomizadas (1/0) como número de categorı́as haya de la variable cualitativa. También es posible estandarizar las variables activas (tanto cuantitativas como cualitativas después de la dicotomización). TYPOL opera en dos etapas: 1. Construcción de una tipologı́a inicial. El programa construye una tipologı́a de n grupos, como se haya solicitado por el usuario, a partir de los casos los cuales se caracterizan por un número dado de variables (consideradas como cuantitativas). El usuario puede escoger la manera de establecer una configuración inicial (ver el parámetro INITIAL), y también el tipo de distancia (ver el parámetro DTYPE) utilizado por el programa para calcular la distancia entre los casos y los grupos. 2. Clasificación ascendente adicional (opcional). Si el usuario desea una tipologia con menos grupos, el programa -mediante un algoritmo de clasificación jerárquica ascendente- reduce uno a uno, el número de grupos hasta llegar al número especificado por el usuario. 38.2. Caracterı́sticas estándar de IDAMS Selección de casos y variables. El filtro estándar está disponible para escoger un subconjunto de casos a partir de los datos de entrada. Las variables se especifican con parámetros. Transformación de datos. Se pueden usar las proposiciones de Recode. Ponderación de datos. Se puede usar una variable para ponderar los datos de entrada; esta variable de ponderación puede tener cifras enteras o decimales. Cuando el valor de la variable de ponderación para un 294 Tipologı́a y clasificación ascendente (TYPOL) caso es cero, negativo, dato faltante o no numérico, entonces el caso siempre se omite; se imprime el número de casos ası́ tratados. Tratamiento de datos faltantes. El parámetro MDVALUES está disponible para indicar cuales valores de datos faltantes, si los hay, se usarán para verificar los datos faltantes. Los casos con datos faltantes en las variables cuantitativas pueden ser excluidos del análisis (ver el parámetro MDHANDLING). 38.3. Resultados Diccionario de entrada. (Opcional: ver el parámetro PRINT). Registros descriptores de variables y registros C, si los hay, solamente para variables utilizadas en la ejecución. Tipologı́a inicial Construcción de una tipologı́a inicial. (Opcional: ver el parámetro PRINT). El reagrupamiento de grupos iniciales, seguido de una tabla de números de referencias cruzadas atribuidos a los grupos antes y después de la construcción de los grupos iniciales. Tabla(s) que muestra(n) la redistribución de casos entre una iteración y la siguiente y da el porcentaje del número total de casos agrupados correctamente. Evolución del porcentaje de variancia explicada de una iteración a la otra. Caracterı́sticas de distancias por grupos. El número de casos en cada grupo inicial de la tipologı́a, junto con el valor de la media y de la desviación estándar de las distancias. Tablas de las distancias. (Opcional: ver el parámetro PRINT). Tablas de distancias mostrando dentro de cada grupo, la distribución de casos a través de quince intervalos continuos siendo estos intervalos: diferentes para cada grupo (primera tabla), idénticos para todos los grupos (segunda tabla). Caracterı́sticas globales de distancias. El número total de casos, con la media y desviación estándar globales de las distancias. Estadı́sticas de resumen. La media, desviación estándar y el peso de la variable para las variables cuantitativas y para las categorı́as de las variables cualitativas activas. Descripción de la tipologı́a resultante. Para cada grupo de tipologı́a, se imprime primero su número y el porcentaje de casos que le pertenecen. Después se suministran las estadı́sticas, variable por variable, en el siguiente orden: (1) variables cuantitativas activas (2) variables cuantitativas pasivas (3) variables cualitativas activas (4) variables cualitativas pasivas. Para cada variable cuantitativa se da su monto de variancia explicada, su valor de media global y, dentro de cada grupo de la tipologı́a, su media y desviación estándar. Para cada categorı́a de la variable cualitativa, se da primero su monto de variancia explicada y el porcentaje de casos que le coresponden; luego dentro de cada grupo de la tipologı́a se imprime: verticalmente el porcentaje de casos a través de las categorı́as de la variable en la primera lı́nea y horizontalmente, el porcentaje de casos a través de los grupos de la tipologı́a (porcentajes por fila) en la segunda lı́nea (opcional: ver el parámetro PRINT). Resumen de la cantidad de variancia explicada por la tipologı́a. Se dan los siguientes porcentajes de variancia explicada: la variancia explicada por las variables más discriminatorias, es decir, aquellas que tomadas juntas son responsables por el 80 % de la variancia explicada, la media de la cantidad de variancia explicada por las variables activas, la media de la cantidad de variancia explicada por todas las variables juntas, la media de la cantidad de variancia explicada por las variables más discriminatorias junto con la proporción de estas variables. 38.4 Dataset de salida 295 Nota: cuando aparecen variables cualitativas en las tablas, se imprimen los primeros 12 carateres del nombre de la variable junto con el código que identifica la categorı́a. Cuando aparecen variables cuantitativas en las tablas, se imprimen todos los 24 caracteres del nombre de la variable. Clasificación jerárquica ascendente Tabla de raices cuadradas de desplazamientos y distancias, calculadas para cada par de grupos. (Opcional: ver el parámetro PRINT). Tabla de reagrupamiento Nr.1. Estadı́sticas de resumen para las variables cuantitativas activas y las categorı́as de variables cualitativas activas de los grupos implicados en el reagrupamiento. Descripción de la nueva tipologı́a resultante. (Opcional: ver el parámetro LEVELS). La misma información anterior. Resumen de la cantidad de variancia explicada por la nueva tipologı́a. La misma información anterior. Nótese aquı́ la media de la cantidad de variancia explicada por las variables más discriminatorias antes del reagrupamiento. El resumen de la clasificación jerárquica ascendente se imprime después de cada reagrupamiento hasta el número de grupos especificado por el usuario. Tres diagramas que muestran el porcentaje de variancia explicada como una función del número de grupos de las tipologı́as sucesivas, a su turno, para: todas las variables, las variables activas, las variables que explican el 80 % de la variancia antes de llevar a cabo el reagrupamiento. Perfiles para cada grupo de la tipologı́a. (Opcional: ver el parámetro PRINT). Estos perfiles se imprimen y se grafican para todos los grupos de la primera tipologı́a resultante y después para los grupos obtenidos en cada reagrupamiento. Arbol jerárquico se produce al final. 38.4. Dataset de salida Se puede pedir un dataset de “variable de clasificación” para la primera tipologı́a resultante y sale en la forma de un archivo Datos descrito por un diccionario IDAMS (ver el parámetro WRITE y el capı́tulo “Los datos en IDAMS”). Contiene la variable de identificación de caso, las variables transferidas, la variable de clasificación (“GROUP NUMBER”) y para cada caso, su distancia multiplicada por 1000 desde cada categorı́a de la variable de clasificación, llamadas “variables de distancia” (“n GROUP DISTANCE”). Las variables se numeran desde uno e incrementan de uno en uno en el orden siguiente: variable de identificación de caso, variables transferidas, variable de clasificación y variables de distancia. 38.5. Matriz de configuración de salida Se puede escribir opcionalmente una matriz de configuración de salida en la forma de una matriz rectangular de IDAMS (ver el parámetro WRITE). Ver el capı́tulo “Los datos en IDAMS” para una descripción del formato. Esta matriz suministra, lı́nea por lı́nea, para cada variable cuantitativa y para cada categorı́a de variables cualitativas activas, su valor medio a través de los grupos y su desviación estándar total para la tipologı́a inicial, es decir, antes de que los reagrupamientos tengan lugar. Los elementos de la matriz se escriben en formato 8F9.3. Se escriben registros de diccionario. 38.6. Dataset de entrada La entrada es un archivo Datos descrito por un diccionario IDAMS. Todas las variables usadas para análisis deben ser numéricas; pueden ser enteras o decimales. La variable identificadora de casos y las variables a ser transferidas pueden ser alfabéticas. 296 Tipologı́a y clasificación ascendente (TYPOL) 38.7. Matriz de configuración de entrada La matriz de configuración de entrada debe estar en la forma de una matriz rectangular IDAMS. Ver el capı́tulo “Los datos en IDAMS” para una descripcion del formato. La matriz es opcional y suministra una configuración inicial para usar en los cálculos. Las estadı́sticas incluidas deberı́an ser valores medios para las variables cuantitativas y proporciones (no porcentajes) para las categorı́as de variables cualitativas (por ej. .180 en vez de 18.0 %). Una matriz de configuración producida por el programa en una ejecución previa puede servir como configuración de entrada. 38.8. Estructura del setup $RUN TYPOL $FILES Especificación de archivos $RECODE (opcional) Proposiciones de Recode $SETUP 1. Filtro (opcional) 2. Tı́tulo 3. Parámetros $DICT (condicional) Diccionario $DATA (condicional) Datos $MATRIX (condicional) Matriz de configuración de entrada Archivos: FT02 FT09 DICTxxxx DATAxxxx DICTyyyy DATAyyyy PRINT 38.9. matriz de configuración de salida si se ha especificado WRITE=CONF matriz de configuración de entrada si se ha especificado INIT=CONF (omitir si se usa $MATRIX) diccionario de entrada (omitir si se usa $DICT) datos de entrada (omitir si se usa $DATA) diccionario de salida si se especifica WRITE=DATA datos de salida si se especifica WRITE=DATA resultados (por defecto IDAMS.LST) Proposiciones de control del programa Referirse al capı́tulo “El archivo Setup de IDAMS” para una descripción más detallada de las proposiciones de control del programa, ı́tems 1-3, a continuación. 1. Filtro (opcional). Selecciona un subconjunto de casos para usar en la ejecución. Ejemplo: INCLUDE V1=10-40,50 38.9 Proposiciones de control del programa 297 2. Tı́tulo (mandatorio). Una lı́nea que contenga hasta 80 caracteres para titular los resultados. Ejemplo: PRIMERA CONSTRUCCION DE VARIABLE DE CLASIFICACION 3. Parámetros (mandatorio). Para seleccionar opciones del programa. Ejemplo: MDHAND=ALL AQNTV=(V12-V18) DTYPE=EUCL PRINT=(GRAP,ROWP,DIST) INIG=5 FING=3 INFILE=IN/xxxx Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de entrada. Por defecto: DICTIN, DATAIN. BADDATA=STOP/SKIP/MD1/MD2 Tratamiento de los datos no numéricos. Ver el capı́tulo “El archivo Setup de IDAMS”. MAXCASES=n Número máximo de casos (después de filtrar) a usar del archivo de entrada. Por defecto: se usan todos los casos. AQNTVARS=(lista de variables) Una lista de variables que especifica las variables cuantitativas activas. PQNTVARS=(lista de variables) Una lista de variables que especifica las variables cuantitativas pasivas. AQLTVARS=(lista de variables) Una lista de variables que especifica las variables cualitativas activas. PQLTVARS=(lista de variables) Una lista de variables que especifica las variables cualitativas pasivas. MDVALUES=BOTH/MD1/MD2/NONE Cuales valores de datos faltantes se van a usar para las variables accedidas en esta ejecución. Ver el capı́tulo “El archivo Setup de IDAMS”. MDHANDLING=ALL/QUALITATIVE/QUANTITATIVE ALL Se saltan los casos con datos faltantes en variables cuantitativas y se excluyen del análisis los códigos de datos faltantes en variables cualitativas. QUAL Se excluyen del análisis los valores de datos faltantes en las variables cualitativas. QUAN Se saltan los casos con datos faltantes en las variables cuantitativas. REDUCE Estandarización de variables activas, cuantitativas y cualitativas. WEIGHT=número de variable Número de la variable de ponderación, si se van a ponderar los datos. DTYPE=CITY/EUCLIDEAN/CHI CITY Distancia en cuadra urbana (“city block”). EUCL Distancia euclideana. CHI Distancia de Ji-cuadrada. Nota: con referencia a la selección del tipo de distancia, se recomienda usar: la distancia en cuadra urbana cuando algunas variables activas son cualitativas y otras son cuantitativas, 298 Tipologı́a y clasificación ascendente (TYPOL) la distancia euclideana cuando las variables activas son todas cuantitativas (con estandarización cuando no se hayan medido todas con la misma escala), la distancia de Ji-cuadrada cuando las variables activas son todas cualitativas. INIGROUP=n Número de grupos iniciales. Si una variable clave va a servir como base para la tipologı́a y si el número de grupos iniciales especificado aquı́ es mayor que el valor máximo de la variable clave, el programa corrige ésto automáticamente. También, si hay ciertas categorı́as con cero casos, el número de grupos iniciales será el número de categorias no vacı́as que tengan casos. Sin valor por defecto. FINGROUP=1/n Número de grupos finales. INITIAL=STEPWISE/RANDOM/KEY/INCONF La manera como la configuración inicial es establecida. STEP Muestra por pasos. RAND Muestra aleatoria. KEY El perfil de los grupos iniciales es creado de acuerdo con una variable clave. INCO Se da un perfil “a priori” de grupos iniciales en un archivo de configuración de entrada. Nota: las variables incluidas en la configuración de entrada deben corresponder exactamente a las variables suministradas con los parámetros AQNTV y/o AQLTV. STEP=5/n Si se ha solicitado muestra de casos por pasos (INIT=STEP), n es la longitud del paso. NCASES=n Si se ha solicitado la muestra aleatoria de casos (INIT=RAND), n es el número de casos (sin ponderar) en el archivo de entrada, o una buena estimación siempre que no exceda el número de casos. Sin valor por defecto; debe especificarse si INIT=RAND. KEY=número de variable Si se ha usado una variable clave para construir grupos iniciales (INIT=KEY), éste es el número de la variable clave. Sin valor por defecto; debe especificarse si INIT=KEY. ITERATIONS=5/n Número máximo de iteraciones para convergencia del perfil de grupo. REGROUP=DISPLACEMENT/DISTANCE DISP El reagrupamiento se basa en el desplazamiento mı́nimo. DIST El reagrupamiento se basa en la distancia mı́nima. WRITE=(DATA, CONFIG) DATA Crear un dataset IDAMS que contenga la variable identificadora de casos, las variables transferidas, la variable de clasificación y las variables de distancia. CONF Bajar la matriz de configuración a un archivo. OUTFILE=OUT/yyyy Un sufijo de ddname de 1-4 caracteres para los archivos Diccionario y Datos de salida. Por defecto: DICTOUT, DATAOUT. IDVAR=número de variable La variable a ser transferida al dataset de salida para identificar los casos. Obligatorio si WRITE=DATA se ha especificado. 38.10 Restricciones 299 TRANSVARS=(lista de variables) Variables adicionales (hasta 99) para ser transferidas al dataset de salida. LEVELS=(n1, n2, ...) Imprimir la descripción de la tipologı́a resultante para el número de grupos especificado. Por defecto: se imprime la descripción después de cada reagrupamiento. PRINT=(CDICT/DICT, OUTCDICT/OUTDICT, INITIAL, TABLES, GRAPHIC, ROWPCT, DISTANCES) CDIC Imprimir el diccionario de entrada para las variables accedidas con registros C, si los hay. DICT Imprimir el diccionario de entrada sin registros C. OUTC Imprimir el diccionario de salida con registros C si los hay. OUTD Imprimir el diccionario de salida sin registros C. INIT Imprimir la historia de la construcción de la tipologı́a inicial. TABL Imprimir dos tablas con clasificación de distancias. GRAP Imprimir el gráfico de los perfiles. ROWP Imprimir porcentajes de fila para categorı́as de variables cualitativas. DIST Imprimir tabla de distancias y desplazamientos para cada reagrupamiento. 38.10. Restricciones 1. El número máximo de grupos iniciales es 30. 2. El número máximo total de variables es 500, incluidas variable de ponderación, variable clave, variables a ser transferidas, variables de análisis (variables cuantitativas + número de categorı́as para variables cualitativas) y variables usadas temporalmente en proposiciones de Recode. 3. Si la variable de identificación o una variable a ser transferida es alfabética con ancho > 4, sólo se usan los primeros cuatro caracteres. 4. No se pueden usar variables R como variable identificadora o como variables a ser transferidas. 38.11. Ejemplos Ejemplo 1. Creación de una variable de clasificación al reunir 5 variables cuantitativas y 4 variables cualitativas con uso de distancia en cuadra urbana; se establecerá una configuración inicial mediante selección aleatoria de casos; la clasificación comienza con 6 grupos y termina con 3; el reagrupamiento se basa en la distancia mı́nima; los datos faltantes se excluyen del análisis. $RUN TYPOL $FILES PRINT = TYPOL1.LST DICTIN = A.DIC archivo Diccionario de entrada DATAIN = A.DAT archivo Datos de entrada $SETUP BUSCA NUMERO DE CATEGORIAS EN UNA VARIABLE DE CLASIFICACION AQNTV=(V114,V116,V118,V120,V122) AQLTV=(V5-V7,V36) REDU INIG=6 FING=3 INIT=RAND NCAS=1200 REGR=DIST PRINT=(GRAP,ROWP,DIST) Ejemplo 2. Generación de una variable de clasificación a partir del Ejemplo 1 con 4 categorı́as; la variable se va escribir en un archivo; las variables V18 y V34 se usan como cuantitativas pasivas y las variables V12 y V14 como cualitativas pasivas. 300 Tipologı́a y clasificación ascendente (TYPOL) $RUN TYPOL $FILES PRINT = TYPOL2.LST DICTIN = A.DIC archivo Diccionario de entrada DATAIN = A.DAT archivo Datos de entrada DICTOUT = CLAS.DIC archivo Diccionario de salida DATAOUT = CLAS.DAT archivo Datos de salida $SETUP GENERACION DE UNA VARIABLE DE CLASIFICACION AQNTV=(V114,V116,V118,V120,V122) AQLTV=(V5-V7,V36) REDU PQNTV=(V18,V34) PQLTV=(V12,V14) INIG=6 FING=4 INIT=RAND NCAS=1200 REGR=DIST PRINT=(GRAP,ROWP) WRITE=DATA IDVAR=V1 Parte V Análisis interactivo de datos Capı́tulo 39 Tablas multidimensionales y su presentación gráfica 39.1. Visión general El componente interactivo “Tablas multidimensionales” de WinIDAMS le permite visualizar y personalizar tablas multidimensionales con frecuencias, porcentajes de fila, de columna y totales, estadı́sticas univariadas (suma, conteo, media, máximo, mı́nimo, variancia, desviación estándar) de variables adicionales y estadı́sticas bivariadas. Las variables de fila y/o columna se pueden colocar al mismo nivel o bien se pueden anidar hasta siete variables en filas y columnas. Se puede repetir la construcción de una tabla para cada valor de hasta tres variables de “página”. También se pueden imprimir o exportar cada página de la tabla en formato libre (con coma o carácter de tabulación como delimitadores) o en formato HTML. Los datasets de IDAMS usados como entrada deben tener el mismo nombre para los archivos Diccionario y Datos con extensiones .dic y .dat respectivamente. Sólo se puede usar un dataset por vez, es decir, si se abre un otro dataset, entonces se cierra automáticamente el dataset que está en uso. 39.2. Preparación del análisis Selección de los datos. Hay un dataset disponible para construir tablas multidimensionales hasta que se cambie al activar nuevamente el componente “Tablas multidimensionales”. El diálogo le permite escoger un archivo de datos, bien sea de una lista de archivos usados recientemente (Recientes) o de cualquier carpeta (Existentes). Por defecto se usa la carpeta Datos de la aplicación actual. Si se asigna “Archivos Datos (*.dat)” a “Archivos de tipo:” sólo se muestran archivos Datos de IDAMS. Selección de variables. Al seleccionar un dataset para análisis, se llama al cuadro de diálogo para definición de la tabla. Se presenta una lista de las variables disponibles y se presentan cuatro ventanas para especificar variables con diferentes propósitos. Use las técnicas arrastrar y colocar para mover las variables entre y/o dentro de las ventanas requeridas. Variables de página se usan para construir páginas separadas de la tabla para cada valor distinto de la variable a la vez y para todos los casos juntos (página Total). Los casos incluidos en una página en particular tienen todos el mismo valor en la variable de página. Las variables de página nunca se anidan. El orden en el cual se especifican las variables determina el orden en el cual se colocan las páginas. Variables de fila son aquellas cuyos valores se usan para definir filas de la tabla. Su orden determina la secuencia de uso de anidamiento. Variables de columna son aquellas cuyos valores se usan para definir columnas de la tabla. Su orden determina la secuencia de uso de anidamiento. 304 Tablas multidimensionales y su presentación gráfica Variables de celda son aquellas cuyos valores se usan para calcular las estadı́sticas univariades (por ej. la media) en las celdas de la tabla. El orden en el cual se especifican determina su orden de aparición en la tabla. Puede haber hasta 10 variables de celda. Anidamiento. Si se especifica más de una variable de fila y/o columna, se anidan por defecto. Para usarlas en forma secuencial, en el mismo nivel, haga doble clic en la variable de la fila o columna de la lista de variables y marque la opción de tratamiento en el mismo nivel. Nota: esta opción no está disponible para la primera variable de una lista. Porcentajes. Se pueden obtener porcentajes en cada celda (de fila, de columna y totales) haciendo doble clic sobre la última variable de fila anidada en la ventana de definición de tabla escogiendo los tipos de porcentajes requeridos. Estadı́sticas univariadas. Se pueden obtener diferentes estadı́sticas (suma, conteo, media, máximo, mı́nimo, variancia, desviación estándar) para cada variable de celda haciendo doble clic sobre la variable en la ventana de definición de tabla y marcando la estadı́stica o estadı́sticas requeridas. Las fórmulas para calcular media, variancia y desviación estándar se pueden encontrar en la sección “Estadı́sticas univariadas” del capı́tulo “Tablas univariadas y bivariadas”. Sin embargo, deben ajustarse ya que los casos no se ponderan. Tratamiento de datos faltantes. El tratamiento de datos faltantes por defecto se aplica a la primera construcción de tabla. Después, se puede cambiar con el menú Cambiar. La opción Valores de datos faltantes se usa para indicar cuales valores de datos faltantes, si los hay, se usarán para verificar datos faltantes en los valores de las variables de fila y columna. Ambos Los valores de las variables se verificarán contra los códigos MD1 y los rangos de los códigos definidos por MD2. MD1 Los valores de las variables se verificarán contra los códigos MD1 solamente. MD2 Los valores de las variables se verificarán contra los rangos de los códigos definidos por MD2 solamente. Ninguno No se usarán códigos MD. Se consideran válidos todos los valores de los datos. Por defecto, se usan ambos códigos MD. La opción Manejo de datos faltantes se usa para indicar cuales valores de datos faltantes deben excluirse de los cálculos de porcentajes y estadı́sticas bivariadas. Todos Elimine todos los valores de datos faltantes. Fila Elimine los valores de datos faltantes para las variables de fila. 39.3 Ventana de tablas multidimensionales Columna Ninguno 305 Elimine los valores de datos faltantes para las variables de columna. No elimine valores de datos faltantes. Por defecto, se eliminan todos los valores de datos faltantes. Nota: los casos con datos falantes en variables de celda siempre se excluyen de los cálculos de estadı́sticas univariadas. Esta exclusión se hace por celda, separadamente para cada variable. De esta manera, el número de casos válidos puede no ser igual a la frecuencia de la celda. La estadı́stica “conteo” muestra el número de casos válidos. Cambiar la definición de la tabla. El comando Especificación de menú Cambiar llama al cuadro de diálogo con la definición de la tabla actual. Puede cambiar variables para análisis, su anidamiento ası́ como pedir porcentajes y estadı́sticas univariadas. Hacer clic en OK reemplaza la tabla actual por una nueva. 39.3. Ventana de tablas multidimensionales Después de seleccionar las variables y hacer clic en OK, aparece la ventana de Tablas multidimensionales en la ventana de documento de WinIDAMS. Por defecto, se muestran las frecuencias y las medias de todas las variables de celda. Si se especifican las variables de página, se muestran los nombres de códigos de estas variables en el tabulador en la parte inferior de la tabla. Se puede acceder a una página en particular con un clic en su nombre (o su código). Cambiar la presentación de la página. Se puede cambiar separadamente la presentación de cada página, los cambios se aplican exclusivamente a la página activa. Son posibles las siguientes modificaciones: Aumentar el tamaño de la fuente - use el comando Aumentar de menú Ver o el botón Aumentar de la barra de herramientas. Disminuir el tamaño de la fuente - use el comando Reducir de menú Ver o el botón Reducir de la barra de herramientas. Restaurar el tamaño de la fuente por defecto - use el comando 100 % de menú Ver o el botón 100 % de la barra de herramientas. 306 Tablas multidimensionales y su presentación gráfica Aumentar/Disminuir el ancho de columna - coloque el cursor del ratón sobre la lı́nea que separa dos columnas en el encabezado de columna hasta que el cursor se haya convertido en una barra vertical con dos flechas y muévalo a derecha/izquierda teniendo apretado el botón izquierdo del ratón. Minimizar el ancho de columnas - marque la columna o columnas requeridas y use el comando Cambiar tamaño de columnas de menú Formato. Aumentar/Disminuir el alto de fila - coloque el cursor del ratón sobre la lı́nea que separa dos filas en el encabezado de fila hasta que el cursor se haya convertido en una barra horizontal con dos flechas y muévalo arriba/abajo teniendo apretado el botón izquierdo del ratón. Minimizar el alto de filas - marque la fila o filas requeridas y use el comando Cambiar tamaño de filas de menú Formato. Ocultar columnas/filas - reduzca el ancho/alto de la columna/fila a cero. Para mostrar nuevamente una columna/fila ocultada, coloque el cursor sobre la lı́nea donde está ocultada hasta que aquel se convierta en una barra vertical/horizontal con dos flechas y haga doble clic en el botón izquierdo del ratón. Adicionalmente, el comando Formato/Estilo permite el acceso a un número de posibilidades de formato de tablas tales como: selección de fuentes, tamaño de fuentes, colores, etc. para la celda activa o para todas las celdas de una lı́nea activa. Estadı́sticas bivariadas. Se calculan estadı́sticas bivariadas para cada tabla o cada página (Ji-cuadrada, coeficiente fi, coeficiente de contingencia, V de Cramer, Taus, Gammas, Lambdas, y D de Sormer). Use el comando Estadı́sticas de menú Mostrar para mostrar las estadı́sticas al final de la tabla. Esta operación debe repetirse separadamente para cada página si es necesario. Las fórmulas para calcular las estadı́sticas bivariadas se pueden encontrar en la sección “Estadı́sticas bivariadas” del capı́tulo “ Tablas univariadas y bivariadas”. Nótese que las estadı́sticas se calculan solamente cuando hay una variable de fila y una variable de columna. Imprimir una página de tabla. Se puede imprimir todo el contenido o solamente partes deseadas de una página activa de tabla con el comando Imprimir de menú Archivo. Si quiere imprimir solamente algunas columnas y/o filas, oculte primero las otras filas/columnas. Se imprimen las columnas y filas mostradas. Exportar una página de tabla. Se puede exportar en formato libro (delimitadas con comma o carácter de tabulación) o en formato HTML, todo el contenido o solamente partes deseadas de una página activa de tabla. Use el comando Exportar de menú Archivo y escoja el formato deseado. Si quiere exportar solamente algunas columnas y/o filas, oculte primero las otras filas/columnas. Se exportan las columnas y filas mostradas. 39.4. Presentación gráfica de tablas univariadas y bivariadas Las frecuencias mostradas en una página de tablas univariadas o bivariadas se pueden presentar gráficamente con uno de los 24 estilos de gráficos que están a su disposición. Se inicia la construcción del gráfico con el comando Crear de menú Gráfico. Este comando llama al cuadro de diálogo para escoger el estilo de gráfico para la página activa. Adicionalmente, puede pedir el uso de transformación logarı́tmica de frecuencias y dar una leyenda para los colores y los sı́mbolos usados en el gráfico. Los gráficos proyectados no se pueden manipular. Sin embargo, se pueden guardar en uno de los dos formatos, a saber: formato JPEG de intercambio de archivos (.jpg) o formato Bitmap de Windows (.bmp) con los comandos relevantes en el menu de Archivo. Tambien se pueden copiar en el portapapeles (el comando Copiar de menú Edición, el botón Copiar de la barra de herramientas o teclas Ctrl/C) y pasar a cualquier editor de texto. Nótese aquı́ otra vez, que se usan para esta presentación, sólo las frecuencias de las filas y columnas mostradas, es decir, no de las filas y columnas que están ocultas. 39.5 Cómo hacer una tabla multidimensional 39.5. 307 Cómo hacer una tabla multidimensional Usaremos el dataset “rucm” (“rucm.dic” es el archivo Diccionario y “rucm.dat” es el archivo Datos) que es en la carpeta Datos por defecto y el cual está instalado con WinIDAMS. Construiremos una tabla de tres entradas con dos variables de fila anidadas (“SCIENTIFIC DEGREE” y “SEX”), una variable de columna (“CM POSITION IN UNIT”) y una variable de celda (“AGE”) para la cual pediremos la media, el máximo y el mı́nimo. Haga clic en Interactivo/Tablas multidimensionales. Este comando abre un diálogo para escoger un archivo Datos de IDAMS. Haga clic en rucm.dic y Abrir. Se ve ahora un diálogo para especificar las variables que desea usar en la tabla multidimensional. 308 Tablas multidimensionales y su presentación gráfica Escoja las variables “SCIENTIFIC DEGREE” y “SEX” como VARIABLES DE FILA, “CM POSITION IN UNIT” como VARIABLE DE COLUMNA y “AGE” como VARIABLE DE CELDA. Con el ratón, arrastre y coloque las variables (oprima el botón izquierdo del ratón sobre la variable que desea mover, mantenga oprimido el botón mientras mueva la variable y suéltela en la lista de variables a donde quiere llevarla). Se pueden escoger y mover varias variables simultáneamente de una lista a otra (oprima la tecla Ctrl cuando seleccione). El orden de las variables en las listas VARIABLES DE FILA y VARIABLES DE COLUMNA especifica implı́citamente el orden de anidamiento. La primera variable de la lista será la de más afuera. El orden de las variables en una lista se puede modificar arrastrando y colocando las variables en la misma lista. Después de escoger las variables, puede cambiar las opciones por defecto, haciendo doble clic sobre la variable. Un doble clic sobre la variable “AGE” en la lista VARIABLES DE CELDA abre el diálogo siguiente: La media aparece marcada por defecto. Marque Máx y Mı́n. Ahora haga clic sobre OK aquı́ y sobre OK en el diálogo de definición de tabla multidimensional. 39.6 Cómo cambiar una tabla multidimensional 39.6. 309 Cómo cambiar una tabla multidimensional Solicitar tablas separadas. Suponga que desea ver una tabla separada para hombres y mujeres. Haga clic sobre Cambiar/Especificación y obtiene nuevamente el diálogo con la selección previa de variables. Coja y mueva con el ratón la variable “SEX” de la lista VARIABLES DE FILA a la lista VARIABLES DE PAGINA y haga clic sobre OK. Se observa a primera vista que es total para todos los valores juntos (hombres y mujeres). En la parte inferior de la vista se ven tres etiquetas “Total”, “MALE”,“FEMALE”. “Total” es la etiqueta de la vista actual. 310 Tablas multidimensionales y su presentación gráfica Para ver la página de los hombres, haga clic en la etiqueta “MALE” Para ver la página de las mujeres, haga clic en la etiqueta “FEMALE” 39.6 Cómo cambiar una tabla multidimensional 311 Solicitar porcentajes. Ası́ como las frecuencias se muestran por defecto, los porcentajes deben pedirse explı́citamente. Haga clic sobre Cambiar/Especificación y obtiene nuevamente el diálogo de la selección previa de variables. Haga doble clic en la variable de fila “SCIENTIFIC DEGREE” y ve un diálogo con casillas para marcar frecuencia (marcada por defecto), % Fila, % Columna, y % Total. Marque todas las casillas de porcentajes ası́: Haga clic sobre OK para aceptar el cambio y haga clic sobre OK en el diálogo de definición de tablas multidimensonales. Ve la tabla multidimensional previa con todos los porcentajes. 312 Tablas multidimensionales y su presentación gráfica Capı́tulo 40 Exploración gráfica de datos 40.1. Visión general GraphID es un componente de WinIDAMS para la exploración interactiva de los datos a través de una visualización gráfica. Acepta dos clases de entrada: datasets de IDAMS en los cuales los archivos Diccionario y Datos tienen el mismo nombre con extensiones .dic y .dat respectivamente, archivos Matriz de IDAMS cuya extensión debe ser .mat. Sólo se puede usar un dataset o una matriz cada vez, es decir, la apertura de un otro archivo, cierra automáticamente el que se está usando. 40.2. Preparación del análisis Selección de datos. Para seleccionar datos, use el comando Abrir de menú Archivo o haga clic en el botón Abrir de la barra de herramientas. A continuación, en el cuadro de diálogo de Abrir, escoja su archivo. La asignación de “Archivos Datos (*.dat)” o “Archivos Matriz (*.mat)” a “Archivos de tipo:” permite filtrar los archivos mostrados. Selección de identificación de caso. Si ha escogido un dataset, se le pide especificar una identificación de caso la cual puede ser una variable o el número secuencial del caso. Se puede escoger una variable numérica o alfabética de una lista desplegable. Selección de variables. Si ha escogido un dataset, se le pide especificar las variables que quiera analizar. Las variables numéricas se pueden escoger de la “Lista de origen” de posibles variables y moverlas al área de “Vars seleccionadas”. Mover las variables entre las listas se puede hacer con clic en los botones >, < (mover sólo las variables resaltadas), >>, << (mover todas las variables). Nótese que las variables alfabéticas no están disponibles aquı́ y la variable identificadora del caso no debe escogerse para análisis. Tratamiento de datos faltantes. Se proponen dos posibilidades: (1) en la eliminación por casos, se usa un caso en análisis solamente si tiene datos válidos en todas las variables escogidas; (2) en la eliminación por pares, se usa un caso si tiene datos válidos en ambas variables de cada par de variables separadamente. 40.3. Ventana principal de GraphID para análisis de un dataset Después de hacer la selección de variables para el análisis y de un clic en OK, la ventana principal de GraphID muestra la matriz inicial de gráficos de dispersión con tres variables y propiedades por defecto de la matriz. Este gráfico se puede manipular con varias opciones y comandos en menús y/o con los ı́conos equivalentes de la barra de herramientas. 314 40.3.1. Exploración gráfica de datos Barra de menú y barra de herramientas Archivo Abrir Llama al cuadro de diálogo para escoger un nuevo dataset/matriz para análisis. Cerrar Guardar como Cierra todas las ventanas del análisis actual. Llama al cuadro de diálogo para guardar la imagen gráfica de la ventana activa en formato Bitmap (*.bmp) de Windows. Guardar casos enmascarados Guarda para utilización ulterior, el número secuencial de casos enmascarados en la sesión actual, la numeración sigue la secuencia de casos en el archivo Datos analizado. Imprimir Llama al cuadro de diálogo para imprimir el contenido de la ventana activa. Vista preliminar Configurar impresora Salir Muestra una visión previa de la impresión de la imagen gráfica de la ventana activa. Llama al cuadro de diálogo para modificar las opciones de la impresión y de la impresora. Termina la sesión de GraphID. El menú también puede contener la lista de los archivos abiertos recientemente, es decir, archivos usados en sesiones previas de GraphID. Edición El menú sólo tiene un comando, Copiar, para copiar la imagen gráfica de la ventana activa al portapapeles. Ver Configuración Llama al cuadro de diálogo para escoger sı́mbolos, colores, variables y número de columnas y filas visibles en la matriz. Escalas Barra de herramientas Muestra/oculta las escalas del gráfico en la ventana de aumento activa. Muestra/oculta la barra de herramientas. Barra de estado Muestra/oculta la barra de estado. 40.3 Ventana principal de GraphID para análisis de un dataset Info Info de celda Apariencia del pincel Fuente para escalas Fuente para nombres Colores básicos 315 Muestra una ventana con información relevante acerca del dataset: número de casos, número de variables, nombre del archivo Datos, etc. Muestra una ventana con información relevante del gráfico activo: nombres de variables, sus medias, desviaciones estándar, coeficientes de correlación y regresión. Llama al cuatro de diálogo para escoger el sı́mbolo y color de los casos dentro del rectángulo del pincel. Llama al cuadro de diálogo para escoger la fuente de escalas de la ventana de aumento activa. Guardar colores Llama al cuadro de diálogo para escoger la fuente de los nombres de variables. Llama al cuadro de diálogo para escoger colores de la ventana activa: color de margen, color de cuadrı́cula y color de fondo de la celda diagonal. Guarda la modificación de colores. Guardar fuentes Guarda la modificación de fuentes. Herramientas En este menú puede hallar herramientas para manipular la matriz de gráficos de dispersión y para llamar otros gráficos suministrados por GraphID. Pincel Activa/cancela el modo pincel. Aumento Agrupación Aumenta el gráfico activo o el contenido del pincel a toda la ventana. Llama al cuadro de diálogo para especificar la creación de grupos. Cancelar agrupación Histogramas Cancela el agrupación. Llama al cuadro de diálogo para especificar gráficos para mostrar en la celdas de la diagonal y sus propiedades. Llama al cuadro de diálogo para especificar tipos de lı́neas de regresión (lı́neas suavizadas) y sus propiedades. Lı́neas suavizadas Gráficos de 3D Llama al cuadro de diálogo para seleccionar variables para usar como ejes para la dispersión 3D y rotación. Modo dirigido Activa/cancela modo dirigido. Diagramas de caja y bigotes Llama al cuadro de diálogo para seleccionar variables y colores para mostrar diagramas de caja y bigotes. Titilado Hace titilar los casos proyectados. Enmascaramiento Enmascara los casos dentro del rectángulo del pincel. Desenmascaramiento Restaure paso por paso los casos enmascarados. Hacer enmascaramiento guardado Enmascara los casos enmascarados y guardados en la sesión previa. Gráfico agrupado Llama al cuadro de diálogo para seleccionar variables de fila y de columna de una tabla de dos dimensiones, y las variables X e Y para proyección de sus gráficos en las celdas de la tabla. Ventana El menú contiene la lista de ventanas abiertas y de comandos de Windows para organizarlos. Ayuda Manual de WinIDAMS Acerca de GraphID Da acceso al Manual de Referencia de WinIDAMS. Muestra información de la versión y el copyright de GraphID y un vı́nculo para acceder a la página web de IDAMS en la sede principal de UNESCO. 316 Exploración gráfica de datos Íconos de la barra de herramientas Hay 21 botones en la barra de herramientas que dan acceso directo a los mismos comandos/opciones como en los correspondientes menús. Se escriben a continuación tal como aparecen de derecha a izquierda. Abrir Guardar Copiar Imprimir Colores básicos Fuente para nombres Fuente para ecalas Pincel Aumento Agrupación Histogramas 40.3.2. Lı́neas suavizadas Diagramas de 3D Modo dirigido Diagramas de caja y bigotes Cancelar titilado Disminuir el nivel de titilado Aumentar el nivel de titilado Enmascarar los casos dentro del rectángulo del pincel Restaure paso por paso los casos enmascarados Información acerca de la versión de GraphID Manipulación de la matriz de gráficos de dispersión Configuración de la matriz de gráficos de dispersión. La matriz actual de gráficos de dispersión se puede cambiar con el comando Configuración de menú Ver. Visible: Aquı́ se puede definir el número de columnas y filas para mostrar en la pantalla (no necesitan ser iguales). Se pueden ver otras celdas desplazando la pantalla. Variables: El cuadro de diálogo tiene dos listas de variables: “Lista de origen” y “Vars seleccionadas”. Se pueden mover las variables de una lista a otra haciendo clic en los botones >, < (mover sólo variables resaltadas), >>, << (mover todas las variables). Sı́mbolos: En este cuadro de diálogo, puede seleccionar la forma y el color de los sı́mbolos que se van a usar para representar cada grupo de casos en los gráficos. Si no se especifican grupos, entonces todos los casos caen por defecto en un solo grupo y todos se representan con el mismo signo (por defecto es un rectángulo negro pequeño). Uno puede asignar un sı́mbolo a un grupo o bien colapsar grupos asignando el mismo sı́mbolo a dos o más grupos. La lista de grupos se suministra en el cuadro de la izquierda. Los otros dos cuadros, son cuadros de selección de sı́mbolos y colores. Para seleccionar un color o un sı́mbolo, simplemente haga clic sobre él. Aparece inmediatamente la imagen del sı́mbolo en el botón al lado del nombre del grupo resaltado. Modo dirigido. Esta opción es útil cuando el orden de los casos en algunas variables de columna tiene sentido, por ej. cuando los valores de una variable de columna indican intervalos de tiempo. Enlazando las imágenes de manera secuencial con lı́neas rectas, puede ayudar, por ejemplo, a buscar patrones cı́clicos. Para cambiar a gráficos dirigidos o regresar a gráficos de dispersión, pulse el botón Modo dirigido de la barra de herramientas o use el comando Modo dirigido de menú Herramientas. Enmascaramiento y desenmascaramiento de casos. Puede enmascarar casos proyectados en los gráficos de dispersión. Este aspecto puede ser útil, por ejemplo, para retirar del gráfico los casos extraviados. Enmascarar está disponible cuando el pincel está activo. Para enmascarar casos incluidos en el rectángulo del pincel, haga clic en el botón Enmascarar de la barra de herramientas. Los casos enmascarados se ocultan en todos los gráficos de dispersión. El enmascaramiento de casos se puede repetir varias veces. Todos o una parte de los casos enmascarados se puede desenmascarar haciendo clic en el botón Restaurar de la barra de herramientas. Guardar y utilizar de nuevo casos enmascarados. Se puede guardar el número secuencial de casos enmascarados en la sesión actual en el archivo correspondiente al dataset analizado con el comando Archivo/Guardar casos enmascarados. Estos casos se pueden enmascarar de nuevo en la(s) sesión(es) siguiente(s) con el comando Herramientas/Hacer enmascaramiento guardado. 40.3 Ventana principal de GraphID para análisis de un dataset 317 Agrupación de casos. Esta opción permite ver cómo una variable reúne los casos en grupos en todos los gráficos. La variable puede ser cualitativa o cuantitativa. Además de seleccionar la variable para crear grupos, el usuario controla la forma de hacerlo (por valores o por intervalos y el número de grupos). El cuadro de diálogo para crear grupos se activa haciendo clic en el botón Agrupación de la barra de herramientas o con el comando Agrupación de menú Herramientas. Exploración con el pincel. El pincel es un rectángulo que se puede mover, aumentar y cuyo tamaño se puede redefinir. Mientras se mueve sobre el gráfico de dispersión, los casos dentro del pincel se resaltan en el color y forma del pincel en todos los otros gráficos de dispersión. Una de las aplicaciones es determinar si una aglomeración de casos representa verdaderamente un cúmulo en un gráfico de dispersión en el espacio multidimensional o si es simplemente una propiedad de la proyección. Para este propósito, coloque el pincel sobre una aglomeración en un gráfico de dispersión y observe cómo estos casos se ubican en los otros gráficos. Si la misma aglomeración aparece en los otros gráficos entonces puede tratarse de un cúmulo real. Desde luego, los gráficos de dispersión deben escogerse de forma que las distancias entre casos sean del mismo orden en los diferentes gráficos. Otra aplicación del pincel es estudiar las distribuciones condicionales. Si las 4 esquinas del pincel se dan como xmin , xmax , ymin , ymax , entonces los casos dentro del pincel son los que satisfacen las condiciones: xmin < x < xmax and ymin < y < ymax y los casos que satisfacen estas condiciones se pueden estudiar en los otros gráficos. También puede usar Pincel para enmascarar y buscar casos. Para entrar o cancelar el modo Pincel, haga clic en el botón Pincel de la barra de herramientas o use el comando Pincel de menú Herramientas. Para colocar el pincel en el área deseada, ubique el cursor en el borde, pulse el botón izquierdo del ratón, arrastre y suelte en el otro borde. Para mover o cambiar el tamaño del pincel, coloque el cursor dentro del rectángulo del pincel o en el lado del mismo, pulse el botón izquierdo y arrastre. Nota: para mover rápidamente el pincel a otra celda, coloque el cursor en la celda deseada y pulse el botón izquierdo del ratón. Aumento. Crea una nueva ventana para agrandar la celda deseada o, en modo Pincel, agrandar el pincel. Esta nueva ventana aumentada tiene la mayorı́a de las propiedades de una matriz de gráficos de dispersión con una celda, por ejemplo, puede usar el pincel para identificar un nuevo conjunto de casos y luego agrandar nuevamente. Si la matriz madre de los gráficos de dispersión está en modo Pincel, la modificación del pincel se refleja inmediatamente en la ventana agrandada; de lo contrario, la ventana agrandada refleja las modificaciones introducidas en la celda escogida en la matriz madre. El comando Escalas de menú Ver le permite mostrar las escalas de valores de variable para la ventana activa agrandada. Titilado. Esta función es útil cuando hay variables discretas o cualitativas en los datos analizados. En este caso, es posible que las matrices usuales de los gráficos de dispersión no suministren suficiente información ya que una parte o todas las proyecciones 2D y 3D presenta cuadrı́culas en 2D o 3D y por lo tanto es imposible determinar visualmente cuantos casos coinciden en la misma posición de la cuadrı́cula y a cuales grupos pertenecen. El titileo es una transformación aleatoria de los datos. Los valores de los datos (x ) se modifican adicionando un “ruido” (a*U ) donde U es un valor aleatorio uniformemente distribuido del intervalo (-0.5, 0.5) y a es una factor para controlar el nivel del titilado. Para establecer el nivel deseado de titilado, use los botones Disminuir el nivel de titilado, Aumentar el nivel de titilado y Cancelar titilado de la barra de herramientas. Nótese que el titileo sólo se puede obtener en la ventana de la matriz de gráficos de dispersión. 318 Exploración gráfica de datos 40.3.3. Histogramas y densidades Se pueden mostrar histogramas, densidades normales, gráficos de puntos y tres estadı́sticas univariadas en las celdas diagonales de la matriz de gráficos de dispersión. Para obtenerlos, haga clic en el botón Histogramas de la barra de herramientas o use el comando Histogramas de menú Herramientas. En el cuadro de diálogo presentado puede seleccionar los gráficos deseados, el color y el número de barras de histogramas. Con la opción Estadı́sticas, se suministran las siguientes estadı́sticas: Asimetrı́a (Skew), Kurtosis (Kurt) y Desviación estándar (Std). 40.3.4. Lı́neas de regresión (Lı́neas suavizadas) Se pueden mostrar hasta 4 diferentes lı́neas de regresión en cada gráfico de dispersión: Regresión lineal MLE - Maximum Likelihood Estimation (regresión lineal usual) Regresión lineal local Media local Mediana local 40.3 Ventana principal de GraphID para análisis de un dataset 319 Nótese que estas son lı́neas de regresión de Y contra X, donde las variables X y Y se proyectan respectivamente en los ejes horizontal y vertical. Para obtener las lı́neas, haga clic en el botón Lı́neas suavizadas o use el comando Lı́neas suavizadas de menú Herramientas. Luego, en el cuadro de diálogo escoja las lı́neas deseadas, el color y el valor del parámetro de suavización. El parámetro de suavización es el número de “vecinos” (casos vecinos) y esta igual 7 por defecto. No puede exceder n/2 donde n es el número de casos. 40.3.5. Diagramas de caja y bigotes Este es un aspecto especialmente útil si los casos se han fraccionado en grupos (ver “Agrupación de casos” más atrás). Use el comando Diagrama de caja y bigotes de menú Herramientas o haga clic en el botón Diagrama de caja y bigotes para obtener un cuadro de diálogo que especifica el número de filas y columnas visibles ası́ como los colores para la ventana de las diagramas de caja y bigotes. Para cada variable escogida, se muestra un rectángulo dentro del cual se encuentran de cajas, cada caja corresponde a un grupo de casos. La base de la caja se puede obtener proporcional al número de casos en el grupo y las fronteras superior e inferior muestran los cuartiles superior e inferior respectivamente. Los extremos superior e inferior de las lı́neas verticales (bigotes) que emergen de la caja corresponden a los valores máximo y mı́nimo de la variable en el grupo. Las lı́neas dentro de la caja son la media (lı́nea verde) y la mediana (lı́nea punteada azul) de la variable en el grupo. La parte izquierda del rectángulo muestra la escala de la variable y el margen inferior del rectángulo muestra los números de grupo. Puede cambiar los colores y las fuentes de los gráficos con los botones apropiados de la barra de herramientas. Se puede registrar estos cambios como nuevos valores por defecto para las siguientes sesiones y ventanas. El botón Colores permite cambiar los colores de: Cajas Fondo Extensiones Lı́nea de mediana Lı́nea de media Márgenes Los botones Fuentes permiten cambiar las fuentes a escalas y nombres de variables. 320 Exploración gráfica de datos Se puede agrandar cualquier celda de un diagrama de caja y bigotes. Escoja la celda deseada y haga clic en el botón Aumento de la barra de herramientas. 40.3.6. Gráfico agrupado Permite la proyección de un gráfico de dispersión de dos dimensiones dentro de las celdas de una tabla de dos dimensiones, y ası́ un análisis en cuatro dimensiones. Use el comando Herramientas/Gráfico agrupado para obtener una ventana de diálogo en la cual se especifican variables de fila y de columna para la construcción de la tabla, y las variables X y Y para los gráficos de dispersión. También se pide escoger la forma de calcular el número de filas y de columnas. Hay dos posibilidades: pueden ser iguales al número de valores diferentes de variable o al número de intervalos especificados por el usuario. Los intervalos calculados son del mismo tamaño. 40.3.7. Diagramas de dispersión tridimensionales y su rotación Para obtener un diagrama de dispersión tridimensional, haga clic en el botón Diagramas de 3D de la barra de herramientas o use el comando Diagramas de 3D de menú Herramientas. El cuadro de diálogo le permite escoger tres variables para proyectarlas en los ejes OX, OY y OZ. Después de OK, se obtiene una nueva ventana con un diagrama de dispersión tridimensional de las variables escogidas. Si la ventana de la matriz madre está en modo pincel, los casos encerrados en el rectángulo del pincel también se resaltan en el color y forma del pincel en este diagrama. Puede usar los elementos de control del cuadro de diálogo en el panel izquierdo de la ventana para cambiar la imagen gráfica y rotarla. El botón en la esquina superior izquierda se puede usar para regresar el gráfico a la posición inicial. El botón en la esquina superior derecha se puede usar para colocar el centro de la nube de puntos: en el centro de gravedad o en cero. Los botones en el grupo Rotar se usan para mover el diagrama de dispersión alrededor de los ejes correspondientes y los del grupo Esparcir se usan para mover puntos desde y hacia el centro. El grupo Nombres permite mostrar u ocultar nombres de variables en los ejes correspondientes. 40.4 Ventana de GraphID para análisis de una matriz 321 Finalmente, el diagrama de dispersión 3D se puede proyectar como tres diagramas de dispersión 2D al solicitar la vista 2D. 40.4. Ventana de GraphID para análisis de una matriz Una vez escogido el archivo de matrices, puede hacer clic en Abrir o hacer doble clic sobre el nombre del archivo para mostrar un histograma 3D con una barra para cada celda de la primera matriz. La altura de la barra representa el valor de la estadı́stica, con la escala construida usando su rango, es decir, h = (sval − smin )/(smax − smin ). Por defecto, los valores negativos se muestran en azul y los positivos en rojo. Puede escoger colores para nombres y escalas, valores negativos y positivos, paredes, piso y fondo. Use la misma técnica de los diagramas de caja y bigotes. En la parte derecha de la ventana se le presenta una lista de matrices incluida en el archivo. Nótese que sólo se muestran los primeros 16 caracteres de la descripción del contenido de la matriz. Si no hay descripción, GraphID muestra “Untitled n”. Puede traer la matriz a la pantalla haciendo clic sobre la descripción del contenido. La matriz en pantalla se puede manipular con las opciones y comandos en los elementos de la barra de menú y con los ı́conos equivalentes de la barra de herramientas. 40.4.1. Barra de menú y barra de herramientas Archivo y Edición Se suministran los mismos comandos de los correspondientes menús en el análisis de datasets, excepto Cerrar. 322 Exploración gráfica de datos Ver Barra de herramientas Muestra/oculta la barra de herramientas. Barra de estado Muestra/oculta la barra de estado. Colores Fuente para escalas Llama al cuadro de diálogo para seleccionar los colores de la ventana activa: nombres de fila/columna y escalas, valores negativos y positivos, paredes, piso y fondo. Llama al cuadro de diálogo para escoger la fuente para las escalas. Fuente para nombres Llama al cuadro de diálogo para escoger la fuente para los nombres. Ventana y Ayuda Están disponibles los mismos comandos de los correspondientes menús en el análisis de datasets. Íconos de la barra de herramientas Hay botones disponibles en la barra de herramientas que suministran acceso directo a los mismos comandos/opciones que en los correspondientes menús. Se listan aquı́ tal como aparecen de izquierda a derecha. Abrir Guardar Copiar Imprimir Colores Fuente para nombres Fuente para escalas Información acerca de la versión de GraphID. 40.4.2. Manipulación de la matriz en pantalla Similar a la manipulación de los gráficos de dispersión 3D, puede usar los elementos de control del cuadro de diálogo en el panel izquierdo de la ventana para cambiar la imagen gráfica y para rotar la matriz en pantalla. El botón superior se puede usar para devolver el gráfico a la posición inicial. El botón Colores le permite cambiar los colores de: Barra (valores positivos) Pared Barra (valores negativos) Piso Fondo Nombres y escala. Las casillas del grupo Ocultar/Mostrar le permite mostrar u ocultar paredes, escala, nombres en los ejes correspondientes y la diagonal, si aplica. Los botones en el grupo Rotar se pueden usar para mover la matriz alrededor del eje vertical. Los botones en los grupos Columnas y Filas se pueden usar para cambiar el tamaño de columnas y filas respectivamente. Los botones en el grupo Centrar le permiten mover el gráfico a la izquierda, derecha, arriba y abajo. Capı́tulo 41 Análisis de series de tiempo 41.1. Visión general TimeSID es un componente de WinIDAMS para análisis de series de tiempo. Usa datasets de IDAMS como entrada cuyos archivos Diccionario y Datos deben tener el mismo nombre con extensiones .dic y .dat respectivamente. Sólo se puede usar un dataset a la vez, es decir que al abrir un otro dataset automáticamente se cierra el que se está usando. 41.2. Preparación del análisis Selección de datos. Para seleccionar un dataset, use el comando Abrir de menú Archivo o haga clic en el botón Abrir de la barra de herramientas. A continuación, en el cuadro de diálogo de Abrir, escoja su archivo. Al asignar “Archivos Datos (*.dat)” a “Archivos de tipo:” se muestran solo archivos Datos de IDAMS. Selección de series. También se pide especificar las series (variables) que quiere analizar. Las variables numéricas se pueden escoger de la lista “Series accesibles” de posibles variables y mover al área “Seleccionadas”. Mover las variables entre las listas se puede hacer con clic en los botones >, < (mover sólo las variables resaltadas), >>, << (mover todas las variables). Nótese que aquı́ no hay variables alfabéticas. Tratamiento de datos faltantes. Los valores “datos faltantes” se excluyen de las transformaciones de series; se excluyen también del cálculo de estadı́sticas y auto-correlaciones. En todos los otros análisis, los valores de datos faltantes se reemplazan por el promedio general. 41.3. Ventana principal de TimeSID Después de seleccionar las series y de un clic en OK, la ventana principal de TimeSID muestra el gráfico de la primer serie de la lista de series seleccionadas. Las series se pueden manipular y analizar con varias opciones y comandos en menús y/o con los ı́conos equivalentes de la barra de herramientas. 324 41.3.1. Análisis de series de tiempo Barra de menú y barra de herramientas Archivo Abrir Llama al cuadro de diálogo para escoger un nuevo dataset para análisis. Cerrar Guardar como Cierra todas las ventanas del análisis actual. Llama al cuadro de diálogo para guardar el contenido del panel activo o de la ventana activa. Las imagenes gráficas se guardan en formato Bitmap (*.bmp) de Windows. Las tablas de datos y de estadı́sticas se guardan en formato de texto. Imprimir Llama al cuadro de diálogo para imprimir el contenido del panel activo o de la ventana activa. Vista preliminar Muestra una visión previa de la impresión del contenido del panel activo o de la ventana activa. Configurar impresora Llama al cuadro de diálogo para modificar las opciones de la impresión y de la impresora. Termina la sesión de TimeSID. Salir El menú también puede contener la lista de los archivos abiertos recientemente, es decir, archivos usados en sesiones previas de TimeSID. Edición El menú sólo tiene un comando, Copiar, para copiar el contenido del panel activo o de la ventana activa al portapapeles. 41.3 Ventana principal de TimeSID 325 Ver Barra de herramientas Muestra/oculta la barra de herramientas. Barra de estado Muestra/oculta la barra de estado. Escala OX Fuente para escalas Muestra/oculta la escala OX para las series de tiempo. Llama al cuadro de diálogo para escoger la fuente de escalas. Colores básicos Llama al cuadro de diálogo para escoger colores de margen y de fondo. Ventana Tabla de datos Llama la ventana con la tabla de datos. Las columnas de la tabla de datos son las series de tiempo analizadas (incluidos los resultados de transformación). Además de Tabla de datos, el menú contiene la lista de ventanas abiertas y las opciones estándar de Windows para organizarlas. Ayuda Manual de WinIDAMS Acerca de TimeSID Da acceso al Manual de Referencia de WinIDAMS. Muestra información de la versión y el copyright de TimeSID y un vı́nculo para acceder a la página web de IDAMS en la sede principal de UNESCO. Los otros dos menús, Transformaciones y Análysis, se describen detalladamente en las secciones “Transformación de series de tiempo” y “Análisis de series de tiempo” más adelante. Íconos de la barra de herramientas Hay 9 botones activos en la barra de herramientas que dan acceso directo a los mismos comandos/opciones como en los correspondientes elementos de menú. Se listan aquı́ tal como aparecen de derecha a izquierda. Abrir Copiar Imprimir Colores básicos Fuente para escalas Histogramas, estadı́sticas Correlaciones auto y cruzadas Autoregresión Información acerca de TimeSID 326 Análisis de series de tiempo 41.3.2. Ventana de series de tiempo La ventana de series de tiempo se divide en tres paneles: el de la izquierda es para cambiar las propiedades de la ventana y para seleccionar series (variables), el de la derecha arriba es para mostrar varias series de tiempo y el de la derecha abajo es para mostrar la serie actual. Cambiar la apariencia de la ventana. Los dos paneles para mostrar series de tiempo están sincronizados y se pueden cambiar con los controles suministrados en el panel de la izquierda. Por defecto, el panel superior derecho está vacı́o y su tamaño está reducido. El panel derecho inferior muestra la serie actual dejando visibles la barra de desplazamiento y las escalas. El tamaño de cualquiero de los paneles se puede cambiar con el ratón y la escala OX se puede ocultar/mostrar con el comando “Escala OX” de menú Ver. Más aun, la presentación de gráficos se puede modificar de la manera siguiente: Regulación del grado de compresión de gráficos - use los botones bajo “Compresión de OX”. Colores para fondo y márgenes - use el botón Colores. Fuente para escalas - use el botón Fuente para escalas. Cambiar el nombre de la serie de tiempo. Escoja la serie de tiempo requerida, haga clic en el nombre con el botón derecho del ratón y escoja la opción Cambiar nombre. La ventana activa presenta el nombre para ser modificado. Nótese que estas modificaciones son temporales y se guardan solamente durante la sesión. Escoger la serie de tiempo para mostrarla en pantalla. En el panel izquierdo de la ventana se suministra una lista de series de tiempo. Al hacer doble clic sobre una variable de la lista, puede escoger la forma y el color de la lı́nea de proyección. Después de OK, se muestra el gráfico correspondiente en el panel superior de la ventana. Esta operación se puede repetir para diferentes variables y de esta forma, puede obtener varios gráficos mostrados simultáneamente en el panel superior de la pantalla. El panel inferior derecho siempre muestra la serie actual. Suprimir una serie del análisis. Escoja la serie de tiempo requerida, haga clic en el nombre con el botón derecho del ratón y escoja la opción Suprimir serie. 41.4 Transformación de series de tiempo 41.4. 327 Transformación de series de tiempo Los datos de series de tiempo se pueden transformar calculando diferencias, suavización, supresión de tendencias, transformación funcional, etc. El menú Transformaciones tiene comandos para crear nuevas series de tiempo basadas en valores de series seleccionadas. Nótese que las variables mostradas están renumeradas secuencialmente a partir de cero (0). Promedio crea una nueva serie de tiempo como promedio de las series especificadas. Las series tomadas para los cálculos se seleccionan en el cuadro de diálogo “Selección de series” (ver sección “Preparación del análisis”). Aritmética en parejas crea un conjunto de series de tiempo haciendo operaciones aritméticas en parejas de series de tiempo especificadas en el cuadro de diálogo (cada serie especificada en la primera lista de argumentos con el segundo argumento). Diferencias, MA, ROC crea un conjunto se series de tiempo basado en transformaciones (diferencias secuenciales, promedios movibles (MA) no centradas, razón de cambio (ROC)) de las series especificadas en el cuadro de diálogo. En el mismo cuadro se asignan los parámetros especificados para cada transformación ası́ como el tipo de transformación ROC. 328 41.5. Análisis de series de tiempo Análisis de series de tiempo Los aspectos del análisis se activan con comandos en el menú Análysis. Estadı́sticas crea una tabla con la media, la desviación estándar, los valores mı́nimo y máximo para la serie de tiempo seleccionada y una tabla con estadı́sticas para prueba de la hipótesis “aleatoriedad versus tendencia” . También muestra un histograma para esta serie. Correlaciones auto y cruzadas crea una nueva ventana con un conjunto de celdas que contienen gráficos de auto-correlaciones y correlaciones cruzadas para el conjunto especificado de las series de tiempo. Tendencia (paramétrica) crea una nueva serie de tiempo como la estimación de un modelo paramétrico de tendencia para la serie de tiempo especificada. El modelo de tendencia y la serie se seleccionan en un cuadro de diálogo. Autoregresión estima los parámetros de un modelo de autoregresión de predicción a corto plazo para la serie de tiempo especificada. Espectro (un análisis espectral) produce una tabla de valores del espectro (frecuencia, periodo, densidad), gráfico de estimación del espectro, y para el espectro de tipo DFT, gráfico de la desviación del espectro acumulativo a partir del espectro acumulativo de ruido blanco. Para la estimación de densidades espectrales, se puede utilizar el método de la transformada discreta rápida de Fourier (DFT) o el método de la entropı́a máxima (MENT). En el procedimiento DFT se utilizan dos ventanas para mejorar la estimación de estas densidades: la ventana de datos de Welch para el tiempo y suavizado polinomial para la frecuencia. Espectro cruzado analiza una pareja de series de tiempo estacionarias. Suministra las densidades coespectrales, el espectro de fase y los valores de coherencia ası́ como sus gráficos. La estimación de las densidades co-espectrales se hace con la ventana de suavizado de Parzen. Filtros de frecuencia es un procedimiento de descomposición de una serie de tiempo en componentes de frecuencia. Construye una serie nueva utilizando uno de los filtros siguientes: pasa-bajos, pasaaltos, pasa-banda o parada-banda. Para un filtro pasa-bajos o pasa-altos, su banda es igual al valor del parámetro Frecuencia. Para un filtro pasa-banda o parada-banda, las bandas de frecuencia están 41.5 Análisis de series de tiempo 329 definidas por el intervalo (Frecuencia - ancho de la ventana, Frecuencia + ancho de la ventana). Con una opción Eliminar tendencia se puede suprimir la tendencia de la serie antes filtración (después, el componente de tendencia se añade a los resultados de la filtración). Referencias Farnum, N.R., Stanton, L.W., Quantitative Forecasting Methods, PWS-KENT Publishing Company, Boston, 1989. Kendall, M.G., Stuart, A., The Advanced Theory of Statistics, Volume 3 - Design and Analysis, and time series, Second edition, Griffin, London, 1968. Marple Jr, S.L., Digital Spectral Analysis with Applications, Prentice-Hall, Inc., 1987. Parte VI Fórmulas estadı́sticas y referencias bibliográficas Capı́tulo 42 Análisis de conglomerados Notación x h, i, j, l f, g p c k Nj N 42.1. = valores de variables = subı́ndices para objetos = subı́ndices para variables = número de variables = subı́ndice para conglomerado = número de conglomerados = número de objetos en conglomerado j = número total de casos. Estadı́sticas univariadas Si la entrada es un dataset IDAMS, se calculan las siguientes estadı́sticas para todas las variables usadas en el análisis: a) Promedio. xf = X xif i N b) Desviación absoluta media. sf = 42.2. X i |xif − xf | N Medidas estandarizadas En la misma situación, el programa puede calcular medidas estandarizadas, también llamadas puntajes z, dados por: zif = xif − xf sf para cada caso i y cada variable f utilizando el valor promedio y la desviación absoluta media de la variable f (ver sección 1 más atrás). 334 Análisis de conglomerados 42.3. Matriz de disimilitudes calculada a partir de un dataset de IDAMS Los elementos dij de una matriz de disimilitudes miden el grado de disimilitud entre los casos i y j. Los dij se calculan directamente a partir de los datos primarios o a partir de los puntajes z si se solicita la estandarización de las variables. Se pueden escoger dos tipos de distancias: euclideana o en cuadra urbana (“city block”). a) Distancia euclideana. v uX u p dij = t (xif − xjf )2 f =1 b) Distancia en cuadra urbana (“city block”). dij = p X f =1 42.4. |xif − xjf | Matriz de disimilitudes calculada a partir de una matriz de similitudes Si la entrada es una matriz de similitudes con elementos sij , los elementos dij de la matriz de disimilitudes se calculan ası́: dij = 1 − sij 42.5. Matrix de disimilitudes calculada a partir de una matriz de correlación Si la entrada es una matriz de correlación con elementos rij , los elementos dij de la matriz de disimilitudes se calculan usando una de las dos fórmulas: SIGN o ABSOLUTE. Cuando se usa la fórmula SIGN, las variables con una correlación positiva alta reciben un coeficiente de disimilitud cercano a cero mientras que las variables con una correlación negativa fuerte se cosideran muy disı́miles. dij = (1 − rij )/2 Cuando se usa la fórmula ABSOLUTE, se asigna una disimilitud pequeña a las variables con alta correlación positiva o con fuerte correlación negativa. dij = 1 − |rij | 42.6. Repartición alrededor de medoides (PAM) El algoritmo busca k objetos representativos (medoides) que se encuentran centrados en los conglomerados que ellos definen. El medoide, objeto representativo del conglomerado, es aquel objeto para el cual la disimilitud promedio con todos los objetos en el conglomerado es mı́nima. En realidad, el algoritmo PAM minimiza la suma de disimilitudes en vez de la disimilitud promedio. La selección de k medoides se lleva a cabo en dos fases. En la primera, se obtiene un conglomerado inicial con la selección sucesiva de objetos representativos hasta hallar k objetos. El primer objeto es aquel para el cual la suma de las disimilitudes con todos los otros objetos es tan pequeña como sea posible. (Es una especie de “Mediana multivariada” de los N objetos, de allı́ el término “medoide”.) En cada paso, PAM 42.6 Repartición alrededor de medoides (PAM) 335 selecciona el objeto que hace decrecer la función objetivo (suma de disimilitudes) tanto como sea posible. En la segunda fase, se hace un intento de mejorar el conjunto de objetos representativos. Esto se hace al considerar todos los pares de objetos (i, h) para los cuales se ha escogido el objeto i y el objeto h no se ha escogido, verificando si la escogencia de h y desechando i reduce la función objetivo. En cada paso, se hace el intercambio más económico. a) Distancia (disimilitud) promedio final. Esta es la función objetivo de PAM que puede verse como una medida de la “bondad” del conglomerado final. Distancia promedio final = N X di,m(i) i=1 N donde m(i) es el objeto representativo (medoide) más cercano al objeto i. b) Conglomerados aislados. Hay dos tipos de conglomerados aislados: conglomerados L y conglomerados L∗ . El conglomerado C es un conglomerado L si para cada objeto i que pertenece a C máx dij < mı́n dih j∈C h6∈C El conglomerado C es un conglomerado L∗ si máx dij < mı́n dlh i,j∈C l∈C,h6∈C c) Diámetro de un conglomerado. Se define el diámetro del conglomerado C como la mayor disimilitud entre objetos que pertenecen a C: DiámetroC = máx dij i,j∈C d) Separación de un conglomerado. Se define la separación del conglomerado C como la menor disimilitud entre dos objetos, uno de los cuales pertenece a C y el otro no. SeparaciónC = mı́n dlh l∈C,h6∈C e) Distancia promedio a un medoide. Si j es el medoide del conglomerado C, la distancia promedio de todos los objetos de C a j se calcula ası́: Distancia promedioj = X dij i∈C Nj f ) Distancia máxima a un medoide. Si el objeto j es el medoide del conglomerado C, la distancia máxima de todos los objetos de C a j se calcula ası́: Distancia máximaj = máx dij i∈C g) Siluetas de los conglomerados. Cada conglomerado se representa con una silueta (Rousseeuw 1987), que muestra cuales objetos caen bien dentro del conglomerado y cuales simplemente tienen una posición intermedia. Para cada objeto se suministra la siguiente información: - número del conglomerado al cual pertenece (CLU), número del conglomerado vecino (NEIG), el valor si (denotado como S(I) en el listado), el identificador de tres caracteres del objeto i, una lı́nea cuya longitud es proporcional a si . 336 Análisis de conglomerados Para cada objeto i, el valor si se calcula ası́: si = b i − ai máx(ai , bi ) donde ai es la disimilitud promedio del objeto i con todos los demás objetos del conglomerado A al cual pertenece i y bi es la disimilitud promedio del objeto i con todos los objetos del conglomerado más cercano B (vecina del objeto i). Nótese que el conglomerado vecino es como la segunda mejor escogencia del objeto i. Cuando el conglomerado A tiene sólo un objeto i, si se coloca en cero (si = 0). h) Ancho promedio de la silueta de un conglomerado. Es el promedio de si para todos los objetos i de un conglomerado. i) Ancho promedio de silueta. Es el promedio de si para todos los objetos i en los datos, es decir el ancho promedio de silueta para k conglomerados. Se puede usar para seleccionar el “mejor” número de conglomerados a escoger el k que produzca el promedio más grande de si . Otro coeficiente, SC, llamado coeficiente de silueta, se puede calcular manualmente como el ancho promedio máximo de silueta sobre todos los k para los cuales se pueden construir las siluetas. Este coeficiente es una medida adimensional de la cantidad de estructura de conglomeración que se ha encontrado con el algoritmo de clasificación. SC = máx sk k Rousseew (1987) propuso la siguiente interpretación del coeficiente SC: 0,71 − 1,00 Se encontró una estructura fuerte. 0,51 − 0,70 Se encontró una estructura razonable. 0,26 − 0,50 La estructura es débil y podrı́a ser artificial; debe tratar métodos adicionales con estos datos. ≤ 0,25 No hay estructura substancial. 42.7. Repartición para grandes datasets (CLARA) Al igual que PAM, el método CLARA también se basa en la búsqueda de k objetos representativos, pero el algoritmo CLARA esta diseñado especialmente para analizar grandes conjuntos de datos. Consecuentemente, la entrada a CLARA ha de ser un dataset IDAMS. Internamente, CLARA tiene dos pasos. Primero se toma una muestra del conjunto de objetos (casos), y se divide en k conglomerados con el mismo algoritmo de PAM. A continuación, cada objeto que no pertenezca a la muestra se asigna al más cercano entre los k objetos representativos. La calidad de esta conglomerado se define como la distancia promedio entre cada objeto y su objeto representativo. Después se sacan cinco muestras, se aglomeran y se escoge la que tenga la distancia promedio más baja. Se analiza a continuación la aglomeración retenida de todos los datos. La distancia promedio final, las distancias promedio y máximas a cada medoide se calculan de la misma manera que en PAM (para todos los objetos y no sólo para aquellos en la muestra escogida). También se calculan siluetas y estadı́sticas relacionadas de la misma manera que en PAM, pero sólo para los objetos de la muestra escogida (ya que toda la silueta serı́a muy grande para imprimir). 42.8. Conglomeración difusa (FANNY) La conglomeración difusa es una generalización de la repartición, que se puede aplicar al mismo tipo de datos que el método PAM pero el algoritmo es de naturaleza diferente. En vez de asignar un objeto a un conglomerado en particular, FANNY da su grado de pertenencia (coeficiente de pertenencia) a cada conglomerado y ası́ suministra una información más detallada acerca de la estructura de los datos. 42.9 Conglomeración jerárquica acumulativa (AGNES) 337 a) Función objetivo. La técnica de conglomeración difusa usada en FANNY busca minimizar la función objetivo XX u2ic u2jc dij k X i j X Función objetivo = u2jc 2 c=1 j donde uic y ujc son funciones de pertenencia que están sujetas a las restricciones uic ≥ 0 para i = 1, 2, . . . , N ; c = 1, 2, . . . , k X para i = 1, 2, . . . , N uic = 1 c El algoritmo que minimiza esta función objetivo es iterativo y se detiene cuando la función converge. b) Conglomeración difusa (pertenencia). Son los valores de pertenencia (coeficientes de pertenencia uic ) que dan el valor más pequeño de la función objetivo. Indican para cada objeto i, que tan fuertemente pertenece al conglomerado c. Nótese que la suma de los coeficientes de pertenencia es igual a 1 para cada objeto. c) Coeficiente de partición de Dunn. Este coeficiente, Fk , mide que tan “dura” es una aglomeración difusa. Varı́a del mı́nimo de 1/k para una conglomeración completamente difusa (donde todos los uic = 1/k) hasta 1 para una conglomeración totalmente dura (donde todos los uic = 0 o 1). Fk = k N X X u2ic / N i=1 c=1 d) Coeficiente de Dunn de partición normalizado. La versión normalizada del coeficiente de Dunn siempre varı́a de 0 a 1, cualquiera que sea el valor escogido de k. Fk0 = Fk − (1/k) kFk − 1 = 1 − (1/k) k − 1 e) Conglomeración dura más cercana. Esta partición (= conglomeración “dura”) se obtiene asignando cada objeto al conglomerado en el cual tenga el más alto coeficiente de pertenencia. Se calculan siluetas y estadı́sticas relacionadas de la misma manera que en PAM. 42.9. Conglomeración jerárquica acumulativa (AGNES) Este método se puede aplicar al mismo tipo de datos que los métodos PAM y FANNY. Sin embargo, no es necesario especificar el número de conglomerados requeridos. El algoritmo construye una jerarquı́a en forma de árbol que contiene implı́citamente todos los valores de k, comenzando por N conglomerados y siguiendo con fusiones sucesivas hasta obtener un solo conglomerado con todos los objetos. En el primer paso, se unen los dos objetos más cercanos (es decir, con disimilitud entre objetos más pequeña) para formar un conglomerado de dos objetos, mientras que los demás conglomerados tienen un solo miembro. En cada paso siguiente se fusionan los dos conglomerados más cercanos (con disimilitud entre objetos más pequeña). a) Disimilitud entre dos conglomerados. En el algoritmo AGNES, se usa el método del promedio del grupo de Sokal y Michener (llamado algunas veces “método del promedio no ponderado de los grupos pareados”) para medir las disimilitudes entre conglomerados. Sean R y Q dos conglomerados y |R| y |Q| el número de objetos en cada uno de ellos. La disimilitud d(R, Q) entre los conglomerados R y Q se define como el promedio de todas las disimilitudes dij donde i es cualquier objeto de R y j es cualquier objeto de Q. d(R, Q) = 1 XX dij |R| |Q| i∈R j∈Q 338 Análisis de conglomerados b) Ordenamiento final de objetos y disimilitudes entre ellos. En la primera lı́nea, los objetos se imprimen en el orden en que aparecerán en la representación gráfica de los resultados. En la segunda lı́nea se imprimen las disimilitudes entre conglomerados de unión. Nótese que el número de disimilitudes impreso es uno menos que el número de objetos N porque hay N − 1 fusiones. c) Bandera de disimilitudes. Es una representación gráfica de los resultados. Una bandera consiste en tiras y estrellas. Las estrellas indican enlaces y las tiras son repeticioners de identificadores de objetos. Una bandera se lee siempre de izquierda a derecha. Cada lı́nea con estrellas comienza en la disimilitud de los conglomerados fusionados. Hay escalas fijas encima y debajo de la bandera que van de 0.00 (disimilitud 0) hasta 1.00 (la disimilitud más grande encontrada). La disimilitud más alta actual (correspondiente a 1.00 en la bandera) se encuentra justamente debajo de la bandera. d) Coeficiente aglomerativo. El ancho promedio de la bandera se llama coeficiente aglomerativo (AC). Describe la fuerza de la estructura de aglomeración encontrada. AC = 1X li N i donde li es la longitud de la lı́nea que contiene el identificador del objeto i. 42.10. Conglomeración jerárquica divisiva (DIANA) El método DIANA se puede usar para el mismo tipo de datos que el método AGNES. Aunque AGNES y DIANA producen salidas similares, DIANA construye su jerarquı́a en la dirección opuesta, comenzando con un gran conglomerado que contiene todos los objetos. En cada paso, divide un conglomerado en dos más pequeños, hasta que todos los conglomerados tengan un solo elemento. Esto significa que para N objetos, la jerarquı́a se construye en N − 1 pasos. En el primer paso, los datos se dividen en dos conglomerados haciendo uso de las disimilitudes. En cada uno de los pasos siguientes, se divide el conglomerado con diámetro más grande (ver 6.c atrás) de la misma manera. Después de N − 1 pasos divisorios, todos los objetos están aparte. a) Disimilitud promedio con todos los objetos. Sea A un conglomerado y |A| el número de objetos en él. La disimilitud promedio entre el objeto i y todos los demás objetos en el conglomerado A se define como en 6.g atrás. di = X 1 dij |A| − 1 j∈A,j6=i b) Ordenamiento final de objetos y diámetros de conglomerados. En la primera lı́nea, se imprimen los objetos en el orden en que aparecerán en la representación gráfica. Debajo se imprimen los diámetros de los conglomerados. Estas dos secuencias de números caracterizan juntas toda la jerarquı́a. El diámetro más rande indica el nivel de división de todos los datos. Los objetos a la izquierda de este valor constituyen un conglomerado y los objetos a la derecha constituyen otro. El segundo diámetro más grande indica la segunda división, etc. c) Bandera de disimilitudes. Igual que para el método AGNES, es una representación gráfica de los resultados. También consiste de lı́neas con estrellas y las tiras que repiten los identificadores de objetos. La bandera se lee de izquierda a derecha pero las escalas fijas encima y debajo ahora van de 1.00 (correspondiente al diámetro de todo el archivo de datos) a 0.00 (correspondiente al diámetros de las clases con un solo elemento). Cada lı́nea con estrellas termina en el diámetro en el que el conglomerado se divide. El diámetro actual de los datos (correspondiente a 1.00 en la bandera) se suministra debajo de la bandera. d) Coeficiente divisorio. El ancho promedio de la bandera se llama coeficiente divisorio (DC). Describe la fuerza de aglomeración de la estructura encontrada. DC = 1X li N i donde li , es la longitud de la lı́nea que contiene el identificador del objeto i. 42.11 Conglomeración monotética (MONA) 42.11. 339 Conglomeración monotética (MONA) El método MONA está orientado a datos que consisten exclusivamente de variables binarias (dicótomas, que toman sólo dos valores, de manera que xif = 0 o xif = 1). Aunque el algoritmo es del tipo jerárquico divisorio, no usa disimilitudes entre objetos y por lo tanto no se calcula una matriz de disimilitudes. La división en conglomerados utiliza directamente las variables. En cada paso, una de las variables (digamos, f ) se usa para dividir los datos mediante la separación de objetos i para los cuales xif = 1 de aquellos en los que xif = 0. En el paso siguiente, cada conglomerado obtenido en el paso anterior se divide aun más, usando valores (0 y 1) de una de las variables restantes (se pueden usar variables diferentes en conglomerados diferentes). El proceso continúa hasta que cada conglomerado contenga un objeto o bién, las variables restantes no puedan dividirlo. Para cada división, se escoge la variable más fuertemente asociada con las otras variables. a) Asociación entre dos variables. La medida de asociación entre dos variables f y g se define ası́: Af g = |af g df g − bf g cf g | donde af g es el número de objetos i con xif = xig = 0, df g es el número de objetos con xif = xig = 1, bf g es el número de objetos con xif = 0 y xig = 1, y cf g es el número de objetos con xif = 1 y xig = 0. La medida Af g expresa si las variables f y g dan divisiones similares del conjunto de objetos y se puede considerer como una clase de similitud entre variables. Para seleccionar la variable más fuertemente asociada con las otras variables, se calcula la medida total Af para cada variable ası́: Af = X Af g g6=f b) Orden final de objetos. Los objetos se imprimen en el orden en que aparecen en el gráfico de separación. Los pasos de separación y las variables usadas para la separación se imprimen debajo de los identificadores de objetos. c) Gráfico de separción (bandera). Esta representación gráfica es muy similar a la bandera que produce DIANA. La longitud de una fila de estrellas ahora es proporcional al número del paso en el cual se hizo la separación. Las filas de identificadores de objetos corresponden a objetos. Una fila de identificadores que continúa a la derecha de la bandera, señala un objeto que se convirtió en un conglomerado con un solo elemento en el paso correspondiente. Las filas de identificadores graficadas entre dos filas de estrellas indican objetos que pertenecen a un conglomerado que no se pudo separar. 42.12. Referencias Kaufman, L., and Rousseeuw, P.J., Finding Groups in Data: An Introduction to Cluster Analysis, John Wiley & Sons, Inc., New York, 1990. Rousseeuw, P.J., Silhouettes: a Graphical Aid to the Interpretation and Validation of Cluster Analysis, Journal of Computational and Applied Mathematics, 20, 1987. Capı́tulo 43 Análisis de configuración Notación Sea A(n,t) una matriz rectangular de n variables (filas) y t dimensiones (columnas). Una variable o punto a tiene t coordenadas, cada una correspondiente a una dimensión. ais i, j = elemento de la matriz A localizado en la iésima fila y la sésima columna = subı́ndices para variables (filas) n = número de variables s, l, m = subı́ndices para dimensiones (columnas) t 43.1. = número de dimensiones. Configuratión centrada Las variables se centran en cada dimensión restando la media de cada columna de cada elemento en la columna. X ais ais centrada = ais − i n Después de haber efectuado los cálculos con ésta formula, la media de las coordenadas de las n variables es cero para cada dimensión. 43.2. Configuratión normalizada La suma de cuadrados de todos los elementos de la matriz A dividida por el número de variables n, calcula la media del segundo momento de las variables. Cada elemento de la matriz queda normalizada por la raı́z cuadrada del este valor (ver el denominador abajo). ais ais normalizada = sX X a2is /n i s Después del esta normalización, la suma de cuadrados de los elementos ais es igual a n. 342 Análisis de configuración 43.3. Solución en ejes principales Se rota la configuración de forma que dimensiones sucesivas suministran la máxima variancia posible. Sea A la configuración a rotar y B la configuración en la forma de ejes principales. Cálculo de la matriz B: La matriz simétrica A0 A de dimensión (t, t) es calculada en primer lugar. Después los vectores propios, T , de A0 A se determinan con el método de diagonalización de Jacobi. La matriz A está transformada en la matriz B con elementos bis , tal que B = A T , B tiene n lı́neas y t columnas de la misma forma que la matriz A. 43.4. Matriz de productos escalares SPij = X ais ajs s La matriz SP es una matriz cuadrada y simétrica de dimensión (n, n) de productos escalares de variables. El producto escalar de una variable con ella misma, es su segundo momento. Si cada variable ha sido centrada y normalizada, (media igual a cero y desviación estándar igual a la unidad), la matriz SP se convierte en una matriz de correlaciones. 43.5. Matriz de distancias entre puntos DISTij = s X s (ais − ajs )2 DIST es una matriz cuadrada y simétrica de distancias euclideanas entre variables. 43.6. Configuración rotada La rotación puede ser llevada a cabo de dos en dos dimensiones cada vez. Corresponde al usuario seleccionar las dimensiones, por eg. 2 y 5 (columna 2 y columna 5) y el ángulo φ de la rotación en grados. Las nuevas coordenadas se calculan como sigue: a0il a0im = ail cos φ + aim sin φ = −ail sin φ + aim cos φ El cálculo se lleva a cabo para cada valor de i, y tantas veces como haya variables. En la matriz A, las columnas l y m, se transforman en los vectores de las nuevas coordenadas que han sido calculadas como se indicó arriba. 43.7. Configuración transladada La traslación puede ser llevada a cabo en una sola dimensión (una columna) cada vez. El usuario especifica la constante T a ser adicionada a cada elemento de la dimensión, y la columna l a la que se aplica. Para todas las coordenadas de l (n coordenadas ya que hay n variables): a0il = ail + T 43.8 Rotación varimax 43.8. 343 Rotación varimax (a) Los elementos ais de A están normalizados por la raı́z cuadrada de las comunalidades correspondientes a cada variable y definimos ais bis = rX a2is s (b) Después de construir B = (bis ), uno buscará el mejor eje de proyección para las variables, una vez se haya igualado su inercia. La maximización de la función Vc se lleva a cabo, a través de rotaciones sucesivas, de dos en dos dimensiones cada vez, hasta que se alcanza la convergencia. X 2 X bis b4is − n X i i Vc = n2 s La matriz resultante B con elementos bis , tiene el mismo número de filas y columnas que la matriz inicial A. 43.9. Configuración clasificada Es la configuración final impresa en formato diferente. Cada dimensión se imprime ahora como una fila, con los elementos en orden ascendente. 43.10. Referencias Greenstadt, J., The determination of the characteristic roots of a matrix by the Jacobi method, Mathematical Methods for Digital Computers, eds. A. Ralston and H.S. Wilf, Wiley, New York, 1960. Herman, H.H., Modern Factor Analysis, University of Chicago Press, Chicago, 1967. Kaiser, H.F., Computer program for varimax rotation in factor analysis, Educational and Psychological Measurement, 3, 1959. Capı́tulo 44 Análisis discriminatorio Notación x = k = i, j g = = valores de variables subı́ndice para el caso subı́ndices para variables superı́ndice para el grupo q = p = subı́ndice para el paso número de variables w = valor del peso xgk yqg = = vector de los elementos p correspondientes al caso k en el grupo g vector con los valores de la media de las variables seleccionadas g = en el paso q para el grupo g número de casos en el grupo g Wg Iq = = suma total de los pesos para el grupo g subconjunto de ı́ndices para las variables seleccionadas en el paso q. N 44.1. Estadı́sticas univariadas Estas estadı́sticas, ponderadas si ası́ se han especificado, se calculan para cada grupo y para cada variable de análisis, usando la muestra básica. Se calcula la también la media para toda la muestra básica (media total). a) Media. g xgi = N X wkg xgki k=1 Wg Nota: la media total se calcula con la fórmula analoga. b) Desviación estándar. sgi = v u Ng uX 2 u wg (xg ) u t k=1 k ki Wg 2 − (xgi ) 346 Análisis discriminatorio 44.2. Discriminación lineal entre 2 grupos El procedimiento se basa en la función discriminatoria lineal de Fisher y la matriz de covariancia total se usa para calcular los coeficientes de esta función. La clasificación de los casos se hace con los valores de esta función y no con las distancias. El criterio aplicado para escoger la siguiente variable es la D2 de Mahalanobis (distancia de Mahalanobis entre dos grupos). Después de cada paso, el programa produce la función discriminatoria, la tabla de clasificación y el porcentaje de casos clasificados correctamente para la muestra básica y para la muestra de prueba. a) Función discriminatoria lineal. Denominemos la función discriminatoria calculada en el paso q como fq (x) = X bqi xi + aq i∈Iq Los coeficientes bqi de esta función para las variables i incluidas en el paso q corresponden a los elementos del único vector propio de la matriz (yq1 − yq2 )0 Tq−1 y el término constante se calcula asi: 1 aq = − (yq1 − yq2 )0 Tq−1 (yq1 + yq2 ) 2 donde Tq es la matriz de covariancia total (calculada para casos extraidos de ambos grupos) de las variables incluidas en el paso q, con los elementos tij = X k wk (xki − xi )(xkj − xj ) W1 + W2 b) Tabla de clasificación para la muestra básica. Se asigna un caso: al grupo 1 si fq (x) > 0 , al grupo 2 si fq (x) < 0 . No se asigna un caso si fq (x) = 0 . Porcentaje de casos correctamente clasificados se calcula como el cociente entre el número de casos en la diagonal y el número total de casos en la tabla de clasificación. c) Tabla de clasificación para la muestra de prueba. Se construye de la misma manera que la tabla para la muestra básica (ver 2.b más atrás). d) Criterio de selección de la siguiente variable. Para este propósito se usa la distancia de Mahalanobis entre los dos grupos. La variable escogida en el paso q es la que maximiza el valor de Dq2 . Dq2 = (yq1 − yq2 )0 Tq−1 (yq1 − yq2 ) e) Asignación y valor de la función discriminatoria lineal para los casos. Se calculan y se imprimen para el último paso o cuando éste precede a un decrecimiento del porcentaje de casos clasificados correctamente. El valor de la función se calcula de acuerdo con la fórmula descrita anteriormente en el punto 2.a; en el cálculo se usan las variables retenidas en el paso. La asignación de casos a los grupos se hace según lo descrito el punto 2.b anteriormente. Se usan las mismas reglas de asignación y la misma formula para la muestra básica, las medias de grupos, la muestra de prueba y la muestra anónima. 44.3 Discriminación lineal entre más de 2 grupos 44.3. 347 Discriminación lineal entre más de 2 grupos El procedimiento de discriminación de 3 o más grupos no solamente utiliza la matriz de covariancia total sino también la matriz de covariancia entre grupos. El criterio para escoger la siguiente variable a usar aquı́ es la huella del producto de estas dos matrices (generalización de la distancia de Mahalanobis para dos grupos). Después de escoger la nueva variable a entrar, se ejecuta el análisis factorial discriminatorio lineal y el programa produce el poder discriminatorio total y el poder discriminatorio para los tres primeros factores. Los casos se clasifican de acuerdo con las distancias a los centros de los grupos. En cada paso, el programa calcula e imprime la tabla de clasificación y el porcentaje de casos clasificados correctamente para la muestra básica y para la muestra de prueba. a) Tabla de clasificación para la muestra básica. La distancia de un caso x al centro del grupo g en el paso q se define como la función lineal vyqg (x) = (yqg )0 Tq−1 (yqg − 2x) donde Tq , como se describio en 2.a anteriormente, es la matriz de covariancia total (calculada para los casos extraidos de todos los grupos) para las variables incluidas en el paso q, con los elementos tij = X k wk (xki − xi )(xkj − xj ) W Un caso se asigna al grupo para el cual vyqg (x) tenga el valor más pequeño (la distancia más pequeña). Porcentaje de casos correctamente clasificados se calcula como el cociente entre el número de casos en la diagonal y el número total de casos en la tabla de clasificación. b) Tabla de clasificación para la muestra de prueba. Se construye de la misma manera que para la muestra básica (ver 3.a más atrás). c) Criterio de selección de la siguiente variable. La variable escogida en el paso q es aquella que maximiza el valor de la huella de la matriz Tq−1 Bq , donde Tq es la matriz de covariancia total usada en el paso q (ver 3.a más atrás), y Bq es la matriz de covariancias entre grupos, con elementos bij = X g W g (yig − xi )(yjg − xj ) W La siguiente parte del análisis (puntos 3.d - 3.h a continuación) se lleva a cabo en una de las siguientes tres circunstancias: cuando el paso precede a un decrecimiento del porcentaje de casos clasificados correctamente, cuando el porcentaje de casos clasificados correctamente es igual a 100, cuando es el ultimo paso. d) Asignación y distancias de los casos en la muestra básica. Las distancias a cada grupo se calculan como se describió en el punto 3.a anteriormente; las variables usadas en los cálculos son aquellas retenidas en el paso. La asignación de casos a los grupos se lleva a cabo como se describió en el punto 3.a anteriormente. e) Análisis factorial discriminatorio. Se analiza la matriz Tq−1 Bq descrita en 3.c más atrás. Los dos primeros vectores propios correspondientes a los dos valores propios más grandes de esta matriz son los dos ejes factoriales discriminatorios. El poder discriminatorio de los factores se mide con los correspondientes valores propios. Como el programa suministra el poder discriminatorio para los tres primeros factores, la suma de los valores propios permite estimar el nivel de los valores propios restantes, es decir, de aquellos que no se imprimen. f ) Valores de factores discriminatorios para todos los casos y medias de grupos. Para un caso, el valor del factor discriminatorio se calcula como el producto escalar del vector del caso que contenga las variables retenidas en dicho paso con el vector propio correspondiente al factor. 348 Análisis discriminatorio Notese que estos valores no se imprimen sino que se utilizan en una representación gráfica de los casos en el espacio de los dos primeros factores. Para una media de grupo, se calcula el valor del factor discriminatorio de la misma manera, reemplazando el vector del caso por el vector de media de grupo. g) Asignación y distancias de los casos en la muestra de prueba. Las distancias a cada grupo se calculan de la misma manera y la asignación de casos a los grupos se hace siguiendo las mismas reglas que para la muestra básica (ver 3.d más atrás). h) Asignación y distancias de los casos en la muestra anónima. Las distancias a cada grupo se calculan de la misma manera y la asignación de casos a los grupos se hace siguiendo las mismas reglas que para la muestra básica (ver 3.d más atrás). 44.4. Referencias Romeder, J.M., Méthodes et programmes d’analyse discriminante, Dunod, Paris, 1973. Capı́tulo 45 Funciones de distribución y de Lorenz Notación pi i = valor del iésimo punto de separación = subı́ndice para el punto de separación s N = número de subintervalos = número total de casos. 45.1. Formula para los puntos de separación El número de puntos de separación es inferior en una unidad al número solicitado de subintervalos, por ej. la mediana implica dos subintervalos y un punto de separación. pi = V (α) + β [V (α + 1) − V (α)] donde V es un vector ordenado de datos, por ej. V (3) es el tercer componente en el vector, i(N + 1) α = entero s β= i(N + 1) −α s y entero(x) es el mayor entero que no exceda x. 45.2. Puntos de separación de la función de distribución Hay cuatro posibilidades: Si un punto de separación es idénticamente igual a un valor y éste no está atado a ningún otro valor, entonces el valor mismo es el punto de separación. Si un punto de separación se presenta entre dos valores y los dos valores no son iguales, entonces el punto de separación se determina utilizando la interpolación lineal ordinaria. Si un punto de separación es idénticamente igual a un valor y dicho valor está atado a uno o más valores, entonces el procedimiento involucra el cálculo de nuevos puntos medios. Sea k el valor, m la frecuencia con la que ocurre y d la distancia mı́nima entre los items en el vector V. El intervalo k ± mı́n(d, 1)/2 se divide en m partes y los puntos medios son calculados para éstos nuevos intervalos. El punto de separación adecuado es el punto medio. Si un punto de separación se presenta entre dos valores que son idénticos, el procedimiento involucra el cálculo de nuevos puntos medios e interpolación lineal ordinaria. Sea k el valor, m la frecuencia con 350 Funciones de distribución y de Lorenz la que el ocurre y d la distancia mı́nima entre los items en el vector V. El intervalo k ± mı́n(d, 1)/2 se divide en m partes y los puntos medios son calculados para éstos nuevos intervalos. Entonces la interpolación lineal se lleva a cabo entre dos nuevos puntos medios adecuados. 45.3. Puntos de separación de la función de Lorenz Para determinar los puntos de separación en la función de Lorenz, los componentes del vector ordenado de datos se suman y en cada paso el total acumulado se divide por el total general. Los puntos de separación se calculan de la misma forma que se describe arriba. 45.4. Curva de Lorenz La función de Lorenz trazada contra la proporción de la población ordenada, da la curva de Lorenz que siempre está contenida en el triángulo inferior del cuadrado unitario. El programa QUANTILE utiliza diez subintervalos para generar la curva de Lorenz. Note que los valores de la función de Lorenz son llamados “Fracción de riqueza” en la impresión efectuada por la computadora. 45.5. El coeficiente de Gini El coeficiente de Gini, representa el doble del área entre la función de Lorenz y la diagonal trazada en el cuadrado unitario. Toma valores entre cero y uno. Cero (0) indica “igualdad perfecta” - todos los valores de los datos son iguales. La unidad (1) indica “desigualdad perfecta” - hay un valor diferente de cero. El programa utiliza una aproximación: s−1 Coeficiente de Gini = 1 − 1 2X li − s s i=1 donde li es el iésimo punto de separación de la función de Lorenz. Esta aproximación es más precisa cuando el número de puntos de separación aumenta; se recomienda que al menos diez sean utilizados. 45.6. Estadı́stica D de Kolmogorov-Smirnov La prueba de Kolmogorov-Smirnov trata la similitud entre dos funciones acumulativas. Si dos distribuciones acumulativas para dos muestras están muy separadas en cualquier punto, ésto sugiere que las muestras provienen de poblaciones diferentes. La prueba se enfoca sobre la mayor diferencia entre las dos distribuciones. Sean V1 y V2 los vectores ordenados para la primera y la segunda variable respectivamente, y X el vector de códigos que aparecen en cualquiera de las dos distribuciones. El programa crea las dos funciones acumulativas F1 (x) y F2 (x) respectivamente. Entonces busca la diferencia absoluta mayor entre las distribuciones, D = máx(|F1 (x) − F2 (x)|) e imprime: x : el primer valor para la mayor diferencia en valor absoluto f1 f2 : el valor de F1 asociado con x : el valor de F2 asociado con x. Si las N para V1 y V2 son iguales e inferiores a 40, el programa imprime la estadı́stica K igual a la diferencia en frecuencias asociada a la mayor diferencia. Una tabla de valores crı́ticos de la estadı́stica K, denotada 45.7 Nota sobre los pesos 351 como KD , puede ser consultada para determinar la significación de la diferencia observada. Si las N para V1 y V2 no son iguales o superiores a 40, el programa imprime las estadı́sticas siguientes: Desviación no ajustada = D = |f1 − f2 | r N1 N2 Desviación ajustada = D N1 + N2 donde N1 y N2 son iguales al número de casos en V1 y V2 respectivamente. Ji-cuadrada aproximada = 4D2 N1 N2 N1 + N2 Nota: la significación de la desviación direccional máxima puede ser encontrada cuando se compara este valor de Ji-cuadrada a una distribución Ji-cuadrada con dos grados de libertad. 45.7. Nota sobre los pesos Para los puntos de separación de la función de distribución, los puntos de separación de la función de Lorenz y los coeficientes de Gini, los datos pueden ser ponderados con un entero. Si un peso es especificado, cada caso se cuenta implı́citamente como “w” casos, donde “w” es el valor del peso para el caso correspondiente. La prueba de Kolmogorov-Smirnov es siempre calculada para datos no ponderados. Capı́tulo 46 Análisis factorial Notación x = i = valores de variables subı́ndice para el caso j, j 0 = α = subı́ndices para variables subı́ndice para el factor m = I1 = número de factores determinados/deseados número de casos activos J1 = número de variables activas w W valor del peso suma total de los pesos para casos activos. 46.1. = = Estadı́sticas univariadas Estas estadı́sticas se calculan para todas las variables usadas en el análisis, es decir, variables activas y variables pasivas, si las hay. Nótese que las variables se numeran nuevamente a partir de 1 (columna RNK). Sólo los casos activos entran a los calculos. a) Media. xj = I1 X wi xij i=1 W b) Variancia (estimada). N N −1 2 sbj = !" W I1 X i=1 wi x2ij − I1 X W2 c) Desviación estándar (estimada). q sbj = sbj 2 d) Coeficiente de variación (C. Var.). Cj = sbj xj i=1 wi xij 2 # 354 Análisis factorial e) Total (suma de xj ). I1 X T otalj = wi xij i=1 f ) Asimetrı́a. g1j = g) Kurtosis. g2j = m3j q sb2j sb2j m4j −3 (b s2j )2 donde m3j = donde I1 X i=1 m4j = wi (xij − xj )3 I1 X i=1 W wi (xij − xj )4 W h) N ponderada. Número de casos activos si no se especifica ponderación, o número ponderado de casos activos (suma de ponderaciones). 46.2. Datos de entrada Se imprimen los datos tanto para casos activos como para casos pasivos. La primera columna de la tabla contiene los valores de la variable identificadora del caso (hasta 4 digitos). La segunda columna (Coef) contiene el valor de la ponderación asignada a cada caso (wi ). La tercera columna (PI) es igual a la suma ponderada de los valores de las variables activas para cada caso (totales ponderados de fila). Pi· = J1 X wi xij j=1 La primera lı́nea contiene los primeros 4 caracteres del nombre de cada variable. La segunda lı́nea (PJ) es igual a la suma ponderada de los valores de los casos activos para cada variable (totales ponderados de columna). P·j = I1 X wi xij i=1 Nótese que el valor de “Coef” al comienzo de esta lı́nea es igual al número ponderado de casos activos y el valor de “PI” es igual al total general (P ) de las variables activas para los casos activos. P = I1 X i=1 Pi· = J1 X j=1 P·j = I1 X J1 X wi xij i=1 j=1 El resto de la tabla de entrada de datos contiene los valores (con una cifra decimal) de las variables activas y pasivas. 46.3. Matrices núcleo (matrices de relaciones) Para cada tipo de análisis se calula y se imprime una matriz núcleo. Esta es una matriz de relaciones entre variables. Nótese que para los listados los valores en la matriz están multiplicados por un factor cuyo valor se imprime junto al tı́tulo de la matriz. Este factor es cero cuando algunos valores de la matriz exceden 5 caracteres (puede ser el caso de productos escalares o de matrices de covariancia). 46.4 Huella 355 Para el analisis de correspondencias, los elementos Cjj 0 de la matriz núcleo se calculan ası́: C jj 0 I1 X 1 (wi xij ) (wi xij 0 ) = p p Pi· P·j P·j 0 i=1 Para el analisis de productos escalares, los elementos SPjj 0 de la matriz núcleo se calculan ası́: SPjj 0 = I1 X wi xij xij 0 i=1 Para el analisis de productos escalares normados, los elementos N SPjj 0 de la matriz núcleo se calculan ası́: I1 X wi xij xij 0 i=1 N SPjj 0 = v u I1 I1 X u X t 2 wi x2ij 0 wi xij i=1 i=1 Para el analisis de covariancias, los elementos COVjj 0 de la matriz núcleo se calculan ası́: COVjj 0 = I1 X i=1 wi (xij − xj ) (xij 0 − xj 0 ) W Para el analisis de correlaciones, los elementos CORjj 0 de la matriz núcleo se calculan ası́: I1 X i=1 wi (xij − xj ) (xij 0 − xj 0 ) CORjj 0 = v u I1 I1 uX X t wi (xij − xj )2 wi (xij 0 − xj 0 )2 i=1 46.4. i=1 Huella La huella de la matriz núcleo se calcula como la suma de sus elementos en la diagonal. La huella también es igual al total de los valores propios (inercia total). Nótese que para el análisis de correlaciones y para el análisis de productos escalares normados la inercia total es igual al número de variables activas. Huella = J1 X λα α=1 46.5. Valores y vectores propios Se imprimen los valores propios y los vectores propios para los factores retenidos. Tiene el mismo significado para cada tipo de análisis pero son de poco interés para el usuario. Para el análisis de correspondencias, el programa imprime un valor propio y un vector propio más que el número de factores determinado/deseado. Primero se imprime el factor para el valor propio trivial (siempre igual a 1) y luego se ignora. Los factores restantes se numeran nuevamente (a partir de 1) en las tables de casos/variables activos/pasivos. 356 Análisis factorial 46.6. Tabla de valores propios La tabla contiene todos los valores propios, simbolizados aquı́ por λα , calculados por el programa. Nótese que en el análisis de correspondencias, el primer valor propio trivial (siempre 1) se imprime solamente en la tabla y su valor se resta de la huella cuando se calcula el porcentaje en el punto 6.d más adelante. a) NO. Número secuencial de valor propio, α, en orden ascendente. b) ITER. Número de iteraciones usadas para calcular los vectores propios correspondientes. El valor cero significa que el vector propio se obtuvo a la vez que el anterior (desde abajo). c) Valor propio. Esta columna muestra una secuencia de valores propios, lambdas, cada uno correspondiente al factor α. d) Porcentaje. Contribución del factor a la inercia total (en términos porcentuales). τα = λα × 100 Huella e) Cumul (porcentaje acumulativo). Contribución de los factores 1 a α a la inercia total (en términos porcentuales). Cumulα = τ1 + τ2 + · · · + τα f ) Histograma de valores propios. Cada valor propio se representa mediante una lı́nea de asteriscos en la cual la cantidad de asteriscos es proporcional al valor propio. El primer valor propio del histograma siempre se representa con 60 asteriscos. El histograma permite un análisis visual de la disminición relativa de valores propios para factores subsiguientes. 46.7. Tabla de factores de variables activas La tabla contiene las ordenadas de las variables activas en el espacio factorial, sus cosenos al cuadrado con cada factor y sus contribuciones a cada factor. Adicionalmente, contiene la calidad de estas variables, sus ponderaciones y sus inercias. a) JPR. Número de variable para las variables activas (principales). b) QLT. Se mide la calidad de representación de la variable en el espacio de m factores, para todo tipo de analisis, con la suma de cosenos cuadrados (ver 7.f más adelante). Los valores más cercanos a 1 indican un nivel más alto de representación de la variable por los factores. QLTj = m X COS2α j α=1 c) PESO. Valor de ponderación de la variable. Para todo tipo de analisis, se calcula como un cociente entre el total de la variable y el total general (ver sección 2 atrás), multiplicado por 1000. f·j = P·j × 1000 P Nótese que la ponderación (PESO) impresa en la última lı́nea de la tabla es igual a: - el total general para el análisis de correspondencias, - el número ponderado de casos para otros tipos de análisis. d) INR. Inercia correspondiente a la variable. Indica la parte de la inercia total relacionada con la variable en el espacio de factores. 46.7 Tabla de factores de variables activas 357 Para el analisis de correspondencias, se calcula como el cociente entre la inercia de la variable y la inercia total, multiplicado por 1000. Nótese que la inercia de la variable depende de la ponderación de ésta y que el valor de huella usado no incluye el valor trivial del valor propio. J1−1 X f·j Fα2 j α=1 IN Rj = Huella × 1000 donde Fα j es la ordenada de la variable j que corresponde al factor α (ver 7.e más adelante). Para el analisis de productos escalares y el analisis de covariancias, la inercia de la variable no depende de la ponderación de ésta. IN Rj = J1 X Fα2 j α=1 × 1000 Huella Para el analisis de productos escalares normados y el analisis of correlaciones, la inercia de la variable sólo depende del número de variables activas. IN Rj = 1 × 1000 J1 Nótese que la inercia (INR) impresa en la última lı́nea de la tabla es igual a 1000. Las siguientes tres columnas se repiten para cada factor. e) α#F . La ordenada de la variable en el espacio factorial, denominado aquı́ con Fα j . f ) COS2. Coseno cuadrado del ángulo entre la variable y el factor. Es una medida de la “distancia” entre la variable y el factor. Valores cercanos a 1 indican distancias más cortas al factor. Para el analisis de correspondencias, se calcula ası́: COS2α j = Fα2 j J1−1 X Fα2 j × 1000 α=1 Para el analisis de productos escalares y el analisis de covariancias, COS2α j = Fα2 j J1 X Fα2 j × 1000 α=1 Para el analisis de productos escalares normados y el analisis of correlaciones, COS2α j = Fα2 j × 1000 g) CPF. Contribución de la variable al factor. Para el analisis de correspondencias, CP Fα j = f·j Fα2 j × 1000 λα Para todos los otros tipos de analisis, CP Fα j = Fα2 j × 1000 λα Nótese que la contribución (CPF) impresa en la última lı́nea de la tabla es igual a 1000. 358 Análisis factorial 46.8. Tabla de factores de variables pasivas La tabla contiene la misma información descrita en el punto 7 más atrás, pero para variables pasivas. a) JSUP. Número de variable para las variables pasivas (suplementarias). b) QLT. Calidad de representación de la variable en el espacio de m factores (ver 7.b atrás). c) PESO. Valor de ponderación de la variable (ver 7.c atrás). d) INR. Inercia correspondiente a la variable. Nótese que las variables pasivas no contribuyen a la inercia total. De esta manera, la inercia aquı́ indica si la variable podrı́a jugar algún papel en el análisis si se utilizara como variable activa. Se calcula de la misma forma que las variables activas en los respectivos análisis (ver 7.d atrás). La inercia (INR) impresa en la última lı́nea de la tabla es igual a la INR total sobre todas las variables pasivas. Las siguientes tres columnas se repiten para cada factor. e) α#F . La ordenada de la variable en el espacio factorial, denominada aquı́ por Fα j . f ) COS2. Coseno cuadrado del ángulo entre la variable y el factor. Se calcula en la misma forma que para las variables activas en los análisis respectivos (ver 7.f atrás). g) CPF. Contribución de la variable al factor. Nótese que las variables pasivas no participan en la construcción del espacio factorial. Ası́, la contribución sólo indica si la variable podrı́a tener algún papel en el análisis si se utilizara como variable activa. CPF se calcula de la misma manera que para las variables activas en los análisis respectivos (ver 7.g atrás). La contribución (CPF) impresa en la última lı́nea de la tabla es igual al CPF total sobre todas las variables pasivas. 46.9. Tabla de factores de casos activos La tabla contiene las ordenadas de los casos activos en el espacio factorial, sus cosenos cuadrados con cada factor y sus contribuciones a cada factor. Además, contiene la calidad de la representación de estos casos, sus ponderaciones y sus inercias. a) IPR. Valor de identificador de caso para los casos activos (principales). b) QLT. Se mide la calidad de representación del caso en el espacio de m factores, para todos los tipos de analisis, con la suma de cosenos cuadrados (ver 9.f más adelante). Valores cercanos a 1 indican un nivel más alto de representación del caso por los factores. QLTi = m X COS2α i α=1 c) PESO. Valor de ponderación del caso. Para el analisis de correspondencias, se calcula como el cociente entre la suma (ponderada) de variables activas para este caso y el total general (ver sección 2 atrás), multiplicado por 1000. fi· = Pi· × 1000 P Nótese que la ponderación (PESO) que se imprime en la última lı́nea de la tabla es igual al total general. Para todos los otros tipos de analisis, fi· = wi × 1000 P Nótese que la ponderación (PESO) que se imprime en la última lı́nea de la tabla es igual al número ponderado de casos. 46.9 Tabla de factores de casos activos 359 d) INR. Inercia correspondiente al caso. Indica la parte de le inercia total relacionada con el caso en el espacio de factores. Para el analisis de correspondencias, se calcula como el cociente entre la inercia del caso y la inercia total, multiplicado por 1000. Nótese que la inercia del caso depende de la ponderación del caso y que el valor de huella usado aquı́ no incluye el valor trivial del valor propio. fi· J1−1 X Fα2 i α=1 IN Ri = Huella × 1000 Para todos los otros tipos de analisis, IN Ri = J1 X wi z2 W × Huella j=1 ij ! × 1000 donde zij = xij xij q PI1 i=1 2 para análisis de productos escalares para análisis de productos escalares normados wi xij / W xij − xj xij −xj sj para análisis de covariancias para análisis de correlaciones y sj es la desviación estándar de la muestra para la variable j. Nótese que la inercia (INR) que se imprime en la última lı́nea de la tabla es igual a 1000. Las siguientes tres columnas se repiten para cada factor. e) α#F . La ordenada del caso en el espacio factorial, denominada aquı́ por Fα i . f ) COS2. Coseno cuadrado del ángulo entre el caso y el factor. Es una medida de “distancia” entre caso y factor. Los valores más cercanos a 1 indican distancias más cortas al factor. Para el analisis de correspondencias, se calcula ası́: COS2α i = Fα2 i × 1000 J1−1 X Fα2 i α=1 Para todos los otros tipos de analisis, COS2α i = Fα2 i × 1000 J1 X 2 Fα i α=1 g) CPF. Contribución del caso al factor. Para el analisis de correspondencias, CP Fα i = fi· Fα2 i × 1000 λα Para todos los otros tipos de analisis, CP Fα i = wi Fα2 i × 1000 W λα Nótese que la contribución (CPF) que se imprime en la última lı́nea de la tabla es igual a 1000. 360 Análisis factorial 46.10. Tabla de factores de casos pasivos La tabla contiene la misma información que la descrita en el punto 9. más atrás, pero para los casos pasivos. a) ISUP. Valor de identificador de caso para los casos pasivos (suplementarios). b) QLT. Calidad de representación del caso en el espacio de m factores (ver 9.b atrás) c) PESO. Valor de ponderación del caso (ver 9.c atrás). d) INR. Inercia correspondiente al caso. Nótese que los casos pasivos no contribuyen a la inercia total. Ası́, la inercia aquı́ indica si el caso podrı́a tener algún papel en el análisis si se usara como caso activo. Se calcula de la misma manera que para los casos activos en los respectivos análisis (ver 9.d atrás). La inercia (INR) que se imprime en la última lı́nea de la tabla es igual a la INR total sobre todos los casos pasivos. Las siguientes tres columnas se repiten para cada factor. e) α#F . La ordenada del caso en el espacio factorial, denominada aquı́ por Fα i . f ) COS2. Coseno cuadrado del ángulo entre el caso y el factor. Se calcula de la misma manera que los casos activos en los respectivos análisis (ver 9.f atrás). g) CPF. Contribución del caso al factor. Nótese que los casos pasivos no participan en la construcción del espacio factorial. Ası́, la contribución indica solamante si el caso podrı́a tener algún papel en el análisis si se hubiera usado como caso activo. CPF se calcula de la misma manera que los casos activos en los análisis respectivos (ver 9.g atrás). La contribución (CFP) impresa en la última lı́nea de la tabla es igual al CPF total de todos los casos complementarios. 46.11. Factores rotados Sólo en análisis de correlaciones. Los factores de “variables” se pueden rotar cuando se haya terminado el análisis factorial. El procedimiento Varimax que se utiliza aquı́ es el mismo usado en el programa CONFIG. Nótese que los factores de “variables” para las variables activas se pueden tratar como una configuración de J1 objetos en un espacio dimensional α. 46.12. Referencias Benzécri, J.-P. and F., Pratique de l’analyse de données, tome 1: Analyse des correspondances, exposé élémentaire, Dunod, Paris, 1984. Iagolnitzer, E.R., Présentation des programmes MLIFxx d’analyses factorielles en composantes principales, Informatique et sciences humaines, 26, 1975. Capı́tulo 47 Regresión lineal Notación y x = valor de la variable dependiente = valor de una variable independiente i, j, l, m = subı́ndices para variables p = número de predictores k 47.1. = subı́ndice para el caso N w = número total de casos = valor del peso multiplicado por W = suma total de los pesos. N W Estadı́sticas univariadas Estas estadı́sticas ponderadas son calculadas para todas las variables utilizadas en el análisis, es desir, variables ficticias, variables independientes y la variable dependiente. a) Promedio. xi = X wk xik k N b) Desviación estándar (estimada). sbi = v X 2 u X 2 uN w x (w x ) − k ik k ik u t k k N (N − 1) c) Coeficiente de variación (C.var.). Ci = 47.2. 100 sbi xi Matriz de sumas totales de cuadrados y productos cruzados Es calculada para todas las variables utilizadas en el análisis como sigue: X t.s.s.c.p. ij = wk xik xjk k 362 Regresión lineal 47.3. Matriz de sumas de cuadrados residuales y productos cruzados Esta matriz, llamada matriz de cuadrados y productos cruzados de puntajes de desviación, es calculada para todas las variables utilizadas en el análisis como sigue: X X wk xik wk xjk X k k r.s.s.c.p. ij = wk xik xjk − N k 47.4. Matriz de correlación total Los elementos de esta matriz son calculados directamente a partir de la matriz de la suma de cuadrados residuales y productos cruzados. Note que si esta fórmula se escribe en todo detalle y si se multiplican por N numerador y denominador, se trata de la fórmula convencional de la r de Pearson. r.s.s.c.p. ij rij = √ √ r.s.s.c.p. ii r.s.s.c.p. jj 47.5. Matriz de correlación parcial El ij ésimo elemento de esta matriz es la correlación parcial entre la variable i y la variable j, manteniendo constantes ciertas variables especı́ficas. Las correlaciones parciales describen el grado de interrelación que puede existir entre dos variables si se controla la variación en una o más variables. También describen la correlación entre variables independientes que serı́an seleccionadas en una regresión por pasos. a) Correlación entre xi y xj manteniendo constante xl (parciales de primer orden). rij − ril rjl q rij· l = p 2 2 1 − ril 1 − rjl donde rij , ril , rjl son los coeficientes de orden cero (coeficientes r de Pearson). b) Correlación entre xi y xj manteniendo constantes xl y xm (parciales de segundo orden). rij· l − rim· l rjm· l q rij· lm = p 2 2 1 − rim· 1 − rjm· l l donde rij· l , rim· l , rjm· l son las parciales de primer orden. Nota: el programa calcula las correlaciones parciales aumentando paso a paso a partir de los coeficientes de orden cero pasando a los coeficientes de primer orden, después a los coeficientes de segundo orden, etc. 47.6. Matriz inversa En el caso de una regresión estándar, ésta es la inversa de la matriz de correlación de las variables independientes y de la variable dependiente. Para una regresión por pasos, ésta es la inversa de la matriz de correlaciones de las variables independientes en la ecuación final. El programa utiliza el método de eliminación de Gauss para invertir. 47.7 Estadı́sticas de resumen del análisis 47.7. 363 Estadı́sticas de resumen del análisis a) Error estándar de la estimación. Es la desviación estándar de los residuos. vX u u (yk − ybk )2 u t k Error estándar de estimación = gl donde ybk = gl = valor proyectado de la variable dependiente para el k ésimo caso grados de libertad del residuo (ver 7.f más abajo). b) Cociente F para la regresión. Es la estadı́stica F para determinar la significación estadı́stica del modelo considerado. Los grados de libertad son p y N − p − 1. F = R2 gl p (1 − R2 ) donde R2 es igual a la fracción de la variancia explicada (ver 7.d más abajo). c) Coeficiente de correlación múltiple. Es la correlación entre la variable dependiente y el valor proyectado. Indica la fortaleza de la relación entre el criterio y la función lineal de los predictores y es similar a un coeficiente simple de correlación de Pearson excepto que siempre es positivo. √ R = R2 R no es impresa si el término constante ha sido forzado a tomar el valor cero. d) Fracción de la variancia explicada. R2 puede ser interpretada como la proporción de la variación en la variable dependiente, explicada por las variables explicativas. Llamado algunas veces el coeficiente de determinación, es una medida de eficacia de la regresión lineal. Entre más grande sea, la ecuación ajustada explicará mejor la variación en los datos. X (yk − ybk )2 k R2 = 1 − X k 2 (yk − y) donde ybk y = = valor proyectado de la variable dependiente para el k ésimo caso media de la variable dependiente. Al igual que R, R2 no es impresa si el término constante es forzado a tomar el valor cero. e) Determinante de la matriz de correlación. Es el determinante de la matriz de correlación de las variables predictoras. El valor del determinante de esta matriz, varı́a de cero a uno y es obtenido mediante la suma de varios productos de sus elementos. Determinantes cuyos valores son cercanos a cero, indican que algunas o todas las variables explicativas tienen un alto grado de correlación. Un determinante igual a cero indica que se trata de una matriz singular que no tiene inverso. f ) Grados de libertad de residuos. Si la constante no está forzada a tomar el valor cero, gl = N − p − 1 Si la constante está forzada a tomar el valor cero, gl = N − p 364 Regresión lineal g) Término constante. X A=y − Bi xi i donde 47.8. y xi = = promedio de la variable dependiente (ver 1.a arriba) promedio de la iésima variable predictora (ver 1.a arriba) Bi = coeficiente B de la iésima variable predictora (ver 8.a abajo). Estadı́sticas de análisis para los predictores a) B. Son los coeficientes de regresión parcial no estandarizada que son los indicados (en vez de las betas) para utilizarse en una ecuación de proyección de valores primarios. Son sensibles a la escala de medida de la variable predictora ası́ como a la variancia de la variable predictora. Bi = βi donde sby sbi βi = ponderación beta para el predictor i (ver 8.c abajo) sby sbi = desviación estándar de la variable dependiente (ver 1.b arriba) = desviación estándar de la variable predictora i (ver 1.b arriba). b) Sigma B. Es el error estándar de B, una medida de fiabilidad del coeficiente. Sigma Bi = (error estándar de la estimación) r cii r.s.s.c.p. ii donde cii es el iésimo elemento de la diagonal de la inversa de la matriz de correlación de los predictores en la ecuación (ver sección 6 arriba). c) Beta. Coeficientes de regresión que se llaman también los “coeficientes estandarizados de regresión parcial” o “coeficientes estandarizados B”. Son independientes de la escala de medida. Las magnitudes de los cuadrados de las betas indican las contribuciones relativas de las variables a la proyección. −1 βi = R11 Ryi donde R11 Ryi = = matriz de correlación de los predictores en la ecuación vector columna de correlaciones de la variable dependiente y los predictores indicada por el predictor i. d) Sigma Beta. Es el error estándar del coeficiente beta, una medida de fiabilidad del coeficiente. Sigma βi = sigma Bi sbi sby e) r cuadrada parcial. Son las correlaciones parciales, al cuadrado, entre el predictor i y la variable dependiente, y, eliminada la influencia de otras variables en la ecuación de regresión. El coeficiente de correlación parcial al cuadrado, es una medida de que tanto la parte de variación en la variable dependiente que no está explicada por otros predictores, está explicada por el predictor i. 2 ryi· jl... = 2 2 Ry· ijl... − Ry· jl... 2 1 − Ry· jl... 47.9 Residuos 365 donde 2 Ry· ijl... = R cuadrada múltiple con el predictor i 2 Ry· jl... = R cuadrada múltiple sin el predictor i. f ) r cuadrada marginal. Es el incremento de la variancia explicada, al añadir el predictor i a los otros predictores ya incluidos en la ecuación de regresión. 2 2 ri2 marginal = Ry· ijl... − Ry· jl... g) Cociente t. Puede ser utilizado para probar si la hipótesis que β, o B, es igual a cero; es decir si el predictor i no tiene una influencia lineal en la variable dependiente. Su significancia se puede determinar de la tabla de t con N − p − 1 grados de libertad. βi Bi = t = sigma βi sigma Bi h) Coeficiente de covariancia. La tasa de covariancia de xi es el cuadrado del coeficiente de correlación múltiple, R2 , de xi con las otras p − 1 variables independientes en la ecuación. Es una medida de la intercorrelación de xi con los otros predictores. Coeficiente de covariancia i = 1 − 1 cii donde cii es el iésimo elemento de la diagonal del inverso de la matriz de correlación de los predictores en la ecuación (ver sección 6 arriba). 47.9. Residuos Los residuos son la diferencia entre los valores observados de la variable dependiente y los valores calculados por la ecuación de regresión. ek = yk − ybk La prueba para detectar la correlación serial, popularmente conocida como la estadı́stica d de Durbin-Watson para autocorrelación de primer orden de residuos, se calcula ası́: d= N X (ek − ek−1 )2 k=2 N X e2k k=1 47.10. Nota sobre la regresión por pasos La regresión por pasos incluye los predictores en el modelo paso a paso, comenzando con la variable independiente que está más correlacionada con y. Después del primer paso, el algoritmo selecciona a partir de las variables independientes restantes, aquella que disminuye al máximo la variancia restante (no explicada) de la variable dependiente, es decir, la variable cuya correlación parcial con y es más elevada. Entonces, el programa hace una prueba parcial de F de inclusión para ver si la variable absorbe una cantidad significativa de variación relativa, a aquella que ya ha sido absorbida por las variables que ya forman parte de la regresión. El usuario puede especificar un valor F mı́nimo, para incluir cualquier variable; el programa evalúa si el valor de F calculado en un paso dado, satisface el mı́nimo especificado y si lo satisface, incluye la variable en la regresión. En forma similar, el programa decide a cada paso si cada variable incluida previamente, continua a satisfacer el mı́nimo (también proporcionado por el usuario), y si no, la excluye. Valor parcial de F para la variable i = 2 2 (Ry· P i − Ry· P )(gl) 2 1 − Ry· Pi 366 Regresión lineal donde 2 Ry· Pi 2 Ry· P = R cuadrada múltiple para el conjunto (P ) de predictores = ya incluidos en la regresión, con el predictor i R cuadrada múltiple para el conjunto (P ) de predictores gl = ya incluidos en la regresión grados de libertad de los residuos. En cualquier paso del procedimiento, los resultados son los mismos que habrı́a en una regresión estándar utilizando el conjunto particular de variables; ası́, el último paso de una regresión por pasos muestra los mismos coeficientes de una pasada normal utilizando las variables que “sobrevivieron” el procedimiento de selección hecho paso a paso. 47.11. Nota sobre la regresión descendente La regresión descendente es similar a la regresión paso a paso, a excepción que el algoritmo comienza con la inclusión de todas las variables independientes y después quita o añade nuevamente las variables, en la forma de paso a paso. 47.12. Nota sobre la regresión con intercepto cero Cuando se utiliza el programa REGRESSN, es posible solicitar una intercepto cero, es decir, que la variable dependiente sea cero cuando todas las variables independientes son cero. Si una regresión a través del origen es especificada, todas las estadı́sticas a la excepción de aquellas citadas de 1 a 4 arriba, están basadas sobre una media cero. El coeficiente de correlación múltiple y la fracción de variancia explicada (artı́culos 7.c y 7.d) no son impresas. Las estadı́sticas que no están centradas con respecto a la media pueden ser muy diferentes de lo que podrı́an serlo, si hubieran sido centradas; ası́, en una solución por pasos, las variables pueden ser incluidas en la ecuación en un orden diferente del que ha sido hecho, si una constante hubiera sido estimada. En el programa REGRESSN una matriz con elementos X wk xik xjk aij = sX k X wk x2ik wk x2jk k k es analizada en vez de R, la matriz de correlación. Las B, los coeficientes de regresión parcial no estandarizados, se obtienen mediante sX X wk x2ik wk x2jk Bi = βi k k Capı́tulo 48 Escalamiento multidimensional Notación x = elemento de la configuración i, j, l, m = subı́ndices para variables 48.1. n s = número de variables = subı́ndice para dimensión t = número de dimensiones. Orden de los cálculos Para un número dado de dimensiones, t, MDSCAL calcula la configuración de mı́nimo esfuerzo (“stress”) utilizando un proceso iterativo. El programa comienza con una configuración inicial (suministrada por el usuario o por programa) y continúa modificándola hasta que converge hacia la configuración que tenga el mı́nimo esfuerzo. 48.2. Configuración inicial Si el usuario no proporciona una configuración de entrada, el programa genera una configuración arbitraria tomando los primeros n puntos a partir de la lista a continuación (cada expresión entre paréntesis representa un punto): (1, 0, 0, . . . , 0), (0, 2, 0, . . . , 0), (0, 0, 3, . . . , 0), .. . (0, 0, 0, . . . , t), (t + 1, 0, 0, . . . , 0), (0, t + 2, 0, . . . , 0), .. . 48.3. Centrado y normalización de la configuración Al principio de cada iteración, la configuración es centrada y normalizada. Si xis denota el elemento en la iésima lı́nea y sésima columna de la configuración, entonces 368 Escalamiento multidimensional xis centrada = xis − xs xis normalizada = donde xs = X xis − xs n.f. xis i n es la media de la dimensión s y v u n n.f. = u t X X x2 is i s es el factor de normalización. Note que el total de la suma de cuadrados de los elementos de la configuración centrada y normalizada es igual a n, el número de variables. 48.4. Historia de los cálculos Al término de cada iteración, las partidas de 4.a a 4.h abajo, son impresas. Esto crea un descriptivo secuencial que, en general, es de interés solamente cuando se teme que la convergencia no sea completa. Sin embargo, al final del descriptivo secuencial la razón para detenerse es impresa. Si el programa no se para porque un mı́nimo ha sido alcanzado, aun ası́ puede ser cierto, que la solución alcanzada sea prácticamente igual al mı́nimo que hubiera sido alcanzado después de unas cuantas iteraciones suplementarias - en particular, si el esfuerzo es muy pequeño, que es generalmente el caso. a) Stress (esfuerzo). La medida de esfuerzo tiene dos funciones. Primero, es una medida de que tan bien la configuración calculada, semeja los datos de entrada. Segundo, es utilizada para decidir cómo los puntos deberán ser desplazados en la nueva iteración. Hay dos fórmulas disponibles para calcular el esfuerzo: SQDIST y SQDEV. vXX u u (dij − dbij )2 u u i j XX Esfuerzo SQDIST = u t d2 ij i j vX X u u (dij − dbij )2 u u i j Esfuerzo SQDEV = u X X t (dij − d )2 i j donde dij dbij = = d = distancia entre las variables i y j en la configuración (ver 8.c abajo) los números que minimizan el esfuerzo, sujetos a la condición que las dij sean del mismo orden de rango que los datos de entrada (ver 8.d más abajo) media de las dij . b) SRAT. Coeficiente de esfuerzo. El usuario puede detener el procedimiento de escalamiento, especificando un coeficiente de esfuerzo a alcanzar. Para la primera iteración (iteración 0), su valor se fija a 0.800. SRAT = Esfuerzo actual Esfuerzo anterior 48.4 Historia de los cálculos 369 c) SRATAV. Promedio de coeficiente de esfuerzo. Para la primera iteración su valor es igual a 0.800. SRATAVactual = (SRATactual )0,33334 × (SRATAVanterior )0,66666 d) CAGRGL. Este es el coseno del ángulo entre el gradiente actual y el gradiente anterior. XX 00 gis gis CAGRGL = cos Θ = sX Xi i s 2 gis s sX X i 00 2 (gis ) s donde g g 00 = = gradiente actual gradiente anterior. El gradiente inicial está fijado de acuerdo con la constante: r 1 Inicial gis = t e) COSAV. Coseno promedio del ángulo entre los gradientes sucesivos. Este es una media ponderada. Para la primera iteración, su valor se fija a cero. COSAVactual = CAGRGLactual × COSAVW + COSAVanterior × (1,0 − COSAVW) donde COSAVW es un factor de ponderación controlado por el usuario. f ) ACSAV. Promedio del valor absoluto del coseno del ángulo entre gradientes sucesivos. Esta es una media ponderada. Para la primera iteración, su valor es fijado a cero. ACSAVactual = |CAGRGLactual | × ACSAVW + ACSAVanterior × (1,0 − ACSAVW) donde ACSAVW es un factor de ponderación controlado por el usuario. g) SFGR. Factor de escala del gradiente. Conforme los cálculos se llevan a cabo, el factor de escala de los gradientes sucesivos disminuye. Una forma de detener el proceso de escalamiento es alcanzando un factor de escala mı́nimo para el gradiente que ha sido proporcionado por el usuario. s 1XX 2 SFGR = g n i s is donde g es igual al gradiente actual. h) STEP. Tamaño del paso. En la formula de tamaño del paso, las dos determinantes principales del tamaño del paso siguiente, son el tamaño del paso inmediatamente anterior y el factor de ángulo. Los tamaños de pasos utilizados no afectan la solución final pero afectan el número de iteraciones necesarias para alcanzar una solución. STEPactual = STEPanterior × f de ángulo × f de relajamiento × f de buena suerte donde factor (f) de ángulo = 4,0COSAV 1,4 factor (f) de relajamiento = AB A = 1 + (mı́n(1, SRATAV))5 B = 1 + ACSAV − |COSAV| p mı́n(1, SRAT) factor (f) de buena suerte = El tamaño del primer paso se calcula como sigue: STEP = 50. × Esfuerzo × SFGR 370 Escalamiento multidimensional 48.5. Esfuerzo para la configuración final Esta es una iteración adicional utilizando el último valor de la columna del esfuerzo del descriptivo secuencial (ver 4.a arriba). El Esfuerzo es una medida de que tan bien la configuración iguala los datos de entrada. La interpretación del esfuerzo para la configuración final depende de la formula utilizada en los cálculos. Note que la utilización de esfuerzo SQDEV rinde valores de esfuerzo substancialmente mayores para el mismo grado de “bondad de ajuste”. Para la modalidad clásica de utilizar MDSCAL, Kruskal y Carmone proporcionan el cuadro a continuación, para un rango de valores de N (digamos de 10 a 30) y un rango de dimensión (digamos de 2 a 5): Esfuerzo SQDIST Pobre Aceptable Bueno Excelente “Perfecto” 48.6. Esfuerzo SQDEV 20.0 % 10.0 % 5.0 % 2.5 % 0.0 % 40.0 % 20.0 % 10.0 % 5.0 % 0.0 % Configuración final En cada iteración la configuración siguiente se forma comenzando a partir de la configuración precedente y desplazándose en dirección (negativa) del gradiente de esfuerzo, de una distancia igual al tamaño del paso. STEP (gradiente) SFGR Cada fila de la matriz de configuración final proporciona las coordenadas de una variable de la configuración. La orientación de los ejes de referencia es arbitraria y por ello uno debe buscar los ejes que hayan sido girados o inclusive ejes oblicuos que sean interpretados de inmediato. Si una distancia Euclideana ordinaria se utilizó, es posible girar la configuración tal que sus ejes principales coincidan con los ejes cardinales. El programa CONFIG puede ser utilizado para este propósito. Nueva configuración = configuración precedente + 48.7. Configuración clasificada Es la configuración final presentada con cada dimensión clasificada - las coordenadas han sido nuevamente ordenadas de pequeñas a grandes. 48.8. Resumen a) IPOINT, JPOINT. Estos son subı́ndices de las variables, (i, j), indicando a que par de variables se refieren las tres estadı́sticas a continuación. b) DATA. Para cada pareja de variables, es el ı́ndice de igualdad o diferencia proporcionado por el usuario en la matriz de datos de entrada. c) DIST. Es la distancia entre puntos en la configuración final. Para la métrica - r de Minkowski, dij = " X s r |xis − xjs | #1/r En caso que r = 2, ésta se convierte en la distancia euclideana s X (xis − xjs )2 dij = s 48.9 Nota sobre ataduras en los datos de entrada 371 En caso que r = 1 ésta se convierte en la distancia de cuadra urbana (“city block”) X dij = |xis − xjs | s d) DHAT. D-hats son los números que minimizan el esfuerzo, sujeto a la restricción que las d-hats tengan el mismo rango de orden que los datos de entrada; son distancias “adecuadas”, estimadas a partir de los datos de entrada. Se obtienen a partir de: XX XX dij y dbij = i i j dbij ≥ dblm j si pij ≤ plm o pij ≥ plm (similitudes) (diferencias) donde dij dbij pij 48.9. = distancia en la configuración entre las variables i y j = una transformación monotónica de las pij = el ı́ndice de entrada de similitud o de diferencia entre las variables i y j. Nota sobre ataduras en los datos de entrada Las ataduras en los datos de entrada, es decir, los valores iguales en la matriz de datos de entrada, pueden ser tratados de dos maneras, el usuario indicará su elección. El primer enfoque, DIFFER, trata las ataduras en la matriz de entrada como una relación de orden indeterminado, que puede ser resuelta en forma arbitraria para disminuir la dimensión o el esfuerzo. El segundo enfoque, EQUAL, trata las ataduras como una implicación de una relación de equi-valencia, que (hasta donde es posible) es mantenida (inclusive si el esfuerzo es aumentado). Si hay pocas ataduras, el enfoque seleccionado no tendrá mucha diferencia. 48.10. Nota sobre los pesos El programa permite la ponderación, pero no es una ponderación en el sentido usual de IDAMS. La ponderación MDSCAL puede ser utilizada para asignar una importancia diferente a los diferentes valores de los datos, ésto es, asignar pesos a celdas de la matriz de datos de entrada. Este tipo de ponderación puede ser utilizado, por ejemplo, para acomodar la variabilidad en la medida de los datos. Si los pesos son utilizados, vXX u u wij (dij − dbij )2 u u i j XX Esfuerzo SQDIST = u t wij d2ij i j vX X u u wij (dij − dbij )2 u u i j Esfuerzo SQDEV = u X X t wij (dij − d )2 i donde d= XX i j wij dij j XX i wij j y wij designa el valor en la celda ij de la matriz de pesos. 372 48.11. Escalamiento multidimensional References Kruskal, J.B., Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis, Psychometrica, 3, 1964. Kruskal, J.B., Nonmetric multidimensional scaling: a numerical method, Psychometrica, 29, 1964. Capı́tulo 49 Análisis de clasificación múltiple Notación y w = = valor de la variable dependiente valor del peso k i = = subı́ndice para el caso subı́ndice para el predictor j = subı́ndice para categorı́a dentro del predictor p c = = número de predictores número de categorı́as que no están vacı́as para todos los predictores aij Nij = = desviación ajustada de la j ésima categorı́a del predictor i (ver 2.c más abajo) número de casos en la j ésima categorı́a del predictor i N W = = número total de casos suma total de los pesos el subı́ndice ijk indica que el caso k corresponde a la j ésima categorı́a del predictor i. 49.1. Estadı́sticas de la variable dependiente a) Media. Media general de y. y= X wk yk k W b) Desviación estándar de y (estimada). v u u u u sby = t N N −1 !" W c) Coeficiente de variación. Cy = 100 sby y d) Suma de y. Suma de y = X k wk yk X k wk yk2 − X W2 k wk yk 2 # 374 Análisis de clasificación múltiple e) Suma de y cuadrada. Suma de y 2 = X wk yk2 k f ) Suma de cuadrados total. TSS = X k wk (yk − y)2 g) Suma de cuadrados explicada. ESS = XX i aij j X wijk yijk k h) Suma de cuadrados residual. RSS = TSS − ESS 49.2. Estadı́sticas de los predictores para análisis de clasificación múltiple a) Media de clase. Media de la variable dependiente para casos en la j ésima categorı́a del predictor i. yij = X k wijk yijk X wijk k b) Desviación no ajustada de la media general. aij no ajustada = y ij − y c) Coeficiente. Desviación ajustada aij de la media general. Este es el coeficiente de regresión para cada categorı́a de cada predictor. yk proyectado = y + X aijk i Los valores de aij son obtenidos por medio de un proceso iterativo que se detiene cuando yk proyectado)2 alcanza el mı́nimo. P k (yk − d) Media ajustada de clase. Es una estimación de lo que la media habrı́a sido, si el grupo hubiera sido exactamente igual a la población total en su distribución sobre toda clasificación de los predictores. Si no hubiera correlación entre predictores, la media ajustada serı́a igual a la media de la clase. yij ajustada = y + aij e) Desviación estándar (estimada) de la variable dependiente para la j ésima categorı́a del predictor i. v uX X 2 X u 2 wijk yijk − wijk yijk / wijk u u k k k u X sbij = u X t wijk − wijk / Nij k k 49.2 Estadı́sticas de los predictores para análisis de clasificación múltiple 375 f ) Coeficiente de variación (C.var.). Cij = 100 sbij y ij g) Desviación de la SS (Sum of Squares) no ajustada. Es la suma de cuadrados de las desviaciones no ajustadas para el predictor i. Ui = X X j k wijk yij − y 2 donde y ij es igual a la media de y para la j ésima categorı́a del predictor i. h) Desviación ajustada de la SS. Esta es la suma de cuadrados de las desviaciones ajustadas para el predictor i. Di = X X j k wijk a2ij i) Eta cuadrada para el predictor i. Eta cuadrada puede interpretarse como el porcentaje de la variancia en la variable dependiente que puede ser explicada solamente por el predictor i. ηi2 = Ui TSS j) Eta para el predictor i. Indica la habilidad del predictor, utilizando las categorı́as dadas, para explicar la variación en la variable dependiente. q ηi = ηi2 k) Eta cuadrada para el predictor i, ajustada para los grados de libertad. ηi2 ajustada = 1 − A (1 − ηi2 ) donde A es el ajuste para los grados de libertad (ver 3.b más abajo). l) Eta para el predictor i, ajustada. ηi ajustada = q 1 − A (1 − ηi2 ) m) Beta cuadrada para el predictor i. Beta cuadrada es la suma de cuadrados atribuida al predictor, después de haber “mantenido otros predictores constantes”, relativa al total de la suma de cuadrados. Esta expresión no está descrita en términos de porcentaje de la variancia explicada. βi2 = Di TSS n) Beta para el predictor i. Beta proporciona una medida de la habilidad del predictor para explicar la variación en la variable dependiente después de haber la ajustado para la influencia de todos los demás predictores. Los coeficientes Beta indican la importancia relativa de los predictores (entre más alto sea el valor, mayor será la variación explicada por la beta correspondiente). βi = q βi2 376 Análisis de clasificación múltiple 49.3. Estadı́sticas del análisis para análisis de clasificación múltiple a) R cuadrada múltiple no ajustada. Este es el coeficiente de correlación múltiple al cuadrado. Indica la proporción actual de la variancia explicada por los predictores usados en el análisis. R2 = ESS TSS b) Ajuste por grados de libertad. N −1 N −p−c−1 A= c) R cuadrada múltiple ajustada. Proporciona una estimación de la correlación múltiple en la población, a partir de la cual una muestra fue extraı́da. Note que es una estimación de la correlación múltiple que serı́a obtenida si los mismos predictores, pero no necesariamente los mismos coeficientes, fueran utilizados para la población. R2 ajustada = 1 − A (1 − R2 ) d) R múltiple ajustada. Este es el coeficiente de correlación múltiple ajustado para los grados de libertad. Es una estimación de la R que serı́a obtenida si los mismos predictores fueran aplicados a la población. p R ajustada = 1 − A (1 − R2 ) 49.4. Estadı́sticas de resumen de residuos El residuo para un caso k es rk = yk − yk proyectado. a) Media. r= X wk rk k W b) Variancia (estimada). sb2r = N N −1 !" W X k wk rk2 − X W2 k wk rk 2 # c) Asimetrı́a. La asimetrı́a de una distribución de residuos está medida por ! ! m3 N p g1 = N −2 sb2r sb2r donde m3 = X k wk (rk − r)3 W d) Kurtosis. La kurtosis de la distribución de residuos está medida por ! ! N m4 g2 = −3 N −3 (b s2r )2 donde m4 = X k wk (rk − r)4 W 49.5 Estadı́sticas de categorı́a de los predictores, para análisis de variancia de una entrada377 49.5. Estadı́sticas de categorı́a de los predictores, para análisis de variancia de una entrada Para detalles, ver el capı́tulo “Análisis de variancia de una entrada”. 49.6. Estadı́sticas del análisis, para análisis de variancia de una entrada Para detalles, ver el capı́tulo “Análisis de variancia de una entrada”. Tenga en cuenta que el factor de ajuste A usado en MCA para el análisis de variancia de una entrada se calcula de manera diferente que en el programa ONEWAY, o sea: A= 49.7. N −1 N −c Referencias Andrews, F.M., Morgan, J.N., Sonquist, J.A., and Klem, L., Multiple Classification Analysis, 2nd ed., Institute for Social Research, The University of Michigan, Ann Arbor, 1973. Capı́tulo 50 Análisis multivariado de variancia Notación y i, j = valor de la variable dependiente o covariada = subı́ndices para categorı́as de predictores k p = subı́ndice para el caso = número de variables independientes dfh dfe = grados de libertad para la hipótesis = grados de libertad para el error. 50.1. Estadı́sticas generales a) Medias de celda. Sea yijk la representación del valor de una variable dependiente o covariada para el caso k en la subclase i, j de una clasificación de dos entradas. y ij = Nij X yijk k=1 Nij donde Nij es igual al número de casos en la clase i, j. b) Base del diseño. La matriz de diseño se genera primero para cada factor de una matriz de diseño de una entrada (una matriz Kf ) de acuerdo con el tipo de contraste especificado por el usuario para ese factor. La matriz general de diseño K se obtiene a partir de las matrices de una entrada Kf tomando el producto de Kronecker de las matrices. La matriz de diseño siempre se imprime con las ecuaciones de efectos en las columnas, comenzando con la matriz de efecto de la gran media en la primera columna. c) Intercorrelaciones entre los coeficientes de las ecuaciones normales. La base del diseño se pondera con los conteos de celda. El efecto de frecuencias desiguales es introducir correlaciones entre las columnas de la matriz de diseño. Estas son esas correlaciones. Si las frecuencias de celda son iguales, habrá unos (1) en la diagonal y ceros en el resto. d) Solución de las ecuaciones normales. Los parámetros se estiman con mı́nimos cuadrados en la forma LX = (K 0 DK)−1 K 0 DY donde L = la matriz de contraste que tiene como fila i los contrastes independientes en los parámetros a ser estimados y probados 380 Análisis multivariado de variancia X = parámetros a ser estimados K D = = la matriz de diseño una matriz diagonal con el número de casos en cada celda Y = una matriz de medias de celda con columnas correspondientes a las variables. Cuando se trata de un diseño ortogonal y de constrastes ortogonales, los contrastes tienen estimativos independientes. Para frecuencias desiguales de celda, sin embargo, la K apropiado para diseños ortogonales ya no es ortogonal. Se requiere transformar K a la ortogonalidad en la métrica D. Esto se hace poniendo T = SK 0 D1/2 con T T 0 = T 0 T = I = SK 0 DKS 0 asi K 0 D1/2 = S −1 T y (K 0 DK)−1 = S 0 S y sustituyendo en la primera ecuación de arriba, (S 0 )−1 LX = SK 0 DY Esta última ecuación define un conjunto nuevo de parámetros que son funciones lineales de los contrastes, con la matriz SK 0 reemplazando K 0 . Estos parámetros son ortogonales. S es la matriz producida con la ortogonalización de Gram-Schmidt de K en la métrica D y reduce las filas de esta a longitud unitaria. S, y ası́ (S 0 )−1 , es triangular. e) Partición de matrices. En un análisis univariado de variancia, cada caso tiene una variable independiente y; en análisis multivariado de variancia, cada caso tiene un vector y de variables dependientes. El análogo multivariado de y 2 es el producto de matrices y 0 y y el análogo multivariado de una suma de cuadrados es una suma de productos de matrices. En un análisis multivariado, hay una matriz que corresponde a cada suma de cuadrados de un diseño univariado. Las pruebas multivariadas dependen de particiones de la suma total de productos de matrices, ası́ como las pruebas univariadas dependen de particiones de la suma total de cuadrados. Las fórmulas para la suma total de productos, la suma de productos entre subclases y la suma de productos dentro (intra) de subclases son St = Y 0 Y Sb = Y.0 DY. Sw = Y 0 Y − Y.0 DY. donde Y = la matriz N × p de datos primeros (N casos, p variables dependientes) Y. = la matriz n × p de medias de celda (n celdas, p variables dependientes) D = una matriz diagonal con el número de casos en cada celda. La suma de productos entre subclases se particiona aún más de acuerdo con los efectos sobre el modelo. f ) Matriz de correlación de errores. En un análisis multivariado de variancia, el término del error es una matriz variancia-covariancia. Este es ese término de error reducido a una matriz de correlación. La matriz de correlación se calcula usando Sw , la suma de productos internos o error interno. −1 Re = s−1 e S w se 50.2 Cálculos para una prueba en un análisis multivariado 381 donde Sw s2e = = la suma de productos dentro de subclases las entradas diagonales de Sw . Re es la matriz de coeficientes de correlación entre las variadas que estiman los valores de población. Si el usuario ha especificado que la suma de cuadrados dentro de subclases se aumentó para formar el término de error, el aumento tiene lugar antes de reducir la matriz a correlaciones. g) Componentes principales de la matriz de correlación de errores. Este es un análisis estándar de componentes principales de la matriz Re . Indica la estructura de factores de variables, encontrada en la población bajo estudio. Los valores propios (o raı́ces) se imprimen debajo de las componentes. h) Matriz de dispersión de errores. Es el término de error, una matriz variancia-covariancia para el análisis. La matriz se ajusta para covariadas, si las hay. Cada elemento de la diagonal de la matriz es exactamente el que aparecerı́a en una tabla de análisis convencional de variancia como el error interno cuadrático medio de la variable. Me = Sw dfe donde Sw = la suma de productos dentro de subclases dfe = los grados de libertad del error, ajustados para aumento si eso se solicitó. Si no hay aumento, los grados de libertad del error son iguales al número de casos menos el número de celdas en el diseño. i) Errores estándar de estimación. Corresponden a las raı́ces cuadradas de los elementos de la diagonal de la matriz Me . 50.2. Cálculos para una prueba en un análisis multivariado Se repiten los cálculos para cada prueba solicitada por el usuario. No se imprimen los resultados de los cálculos internos descritos más adelante bajo los puntos a) hasta d). a) Matriz de suma de cuadrados debida a la hipótesis. La suma de cuadrados entre subclases se divide de acuerdo con los varios efectos del modelo. Para probar una hipótesis dada, el programa determina los estimativos ortogonales a probar y calcula la suma de cuadrados debidos a la hipótesis (Sh ). b) Sw e Sh reducidas a cuadrados medios y escaladas al espacio de correlación. La matriz de cuadrados medios para la hipótesis, Mh , se calcula análogamente a los cuadrados medios para el error. Mh = Sh dfh donde Sh = la matriz de suma de cuadrados debida a la hipótesis (ver atrás). Los grados de libertad para la hipótesis dependen de la prueba solitada; para una prueba de efecto principal A, donde el factor A tiene “a” niveles, los grados de libertad para la hipótesis deberı́an ser a − 1. 382 Análisis multivariado de variancia Mh es una matriz de los productos medios de las entre-subclases asociada con el efecto principal o la hipótesis de interacción. Ambas Me y Mh están escaladas al espacio de correlación: −1 Re = ∆−1 e Me ∆e −1 Ch = ∆−1 e Mh ∆e donde Re = la matriz de coeficientes de correlación entre las variables que estiman valores de población Ch = una matriz, la cual, aunque no es de correlación, presenta las variancias y covariancias para las variables como han sido afectadas por el tratamiento Me Mh = = cuadrados medios para el error cuadrados medios para la hipótesis ∆e = una matriz diagonal que contiene los errores estándar de estimación. La matriz Re se calcula dos veces, una vez como se describió en la sección “Matriz de correlación de errores” y otra como se describió aquı́. Si no se han especificado covariadas, los resultados son idénticos y no se imprime la matriz Re . Si se han especificado una o más covariadas, la segunda matriz Re incorpora ajustes para covariadas. c) Solución de la ecuación de determinante. El método usual de cálculo del criterio de la razón de similitud de Wilk es de la ecuación de determinante |Mh − λMe | = 0 La ecuación anterior se ha pre- e post-multiplicado por la matriz diagonal ∆−1 e −1 |∆−1 e Mh ∆e − λRe | = 0 Sea Re = F F 0 donde F = la matriz de coeficientes de componentes principales que satisface F 0 F = ω, la matriz diagonal de valores propios de Re . La segunda ecuación de detrimento se pre-multiplica por F −1 y se post-multiplica por su transpuesta para dar |(∆e F )−1 Mh ((∆e F )−1 )0 − λF −1 (F F 0 )(F −1 )0 | = 0 o |(∆e F )−1 Mh ((∆e F )−1 )0 − λI| = 0 La última ecuación se resuelve para los valores λ. d) Criterio de razón de similitud. Λ= −1 s Y dfh × λq 1+ dfe q=1 donde λq = valores que no son cero en la última ecuación de la sección previa. 50.2 Cálculos para una prueba en un análisis multivariado 383 e) Cociente F para el crieterio de razón de similitud. El programa usa la aproximación F a los puntos de porcentaje de la distribución nula de Λ. F = k(2dfe + dfh − p − 1) − p(dfh ) + 2 1 − Λ1/k × 1/k 2p(dfh ) Λ donde k= s p2 (dfh )2 − 4 p2 + (dfh )2 − 5 Esta es una prueba multivariada de significancia del efecto para todas las variables dependientes simultaneamente. f ) Grados de libertad para el cociente F. p(dfh ) y k(2dfe + dfh − p − 1) − p(dfh ) + 2 2 Si p = 1 o 2 y dfh = 1 o 2, k se pone a 1 en casos cuando p(dfh ) = 2. g) Variancias canónicas de las componentes principales de la hipótesis. Estas son las lambdas calculadas como se describió en la sección “Solución de la ecuación de determinante” atrás. Se ordenan por magnitud descendente. El número de lambdas diferentes de cero para una ecuación dada es igual a dfh (el número de grados de libertad asociado con Mh ), o p, el número de variables dependientes, el que sea menor. h) Coeficientes de las componentes principales de la hipótesis. La resolución de la ecuación |(∆e F )−1 Mh ((∆e F )−1 )0 − λI| = 0 produce T , para lo cual −1 −1 0 F −1 ∆−1 ) = T λ T0 e Mh ∆e (F Se puede escribir como −1 0 0 −1 )T =λ T 0 F −1 ∆−1 e Xh Xh ∆e (F La ecuación anterior se considera como ∗ T 0 F −1 ∆−1 e X h = Sh donde Sh∗ (Sh∗ )0 = λ y escrita en la forma habitual de la ecuación de factor, X = F S, es ∗ ∆−1 e X h = F T Sh El programa imprime los coeficientes F T de las componentes principales de la hipótesis. i) Puntaje de las componentes de contraste para efectos estimados. Las filas de Sh∗ son los conjuntos de puntajes de factor atribuibles a las hipótesis que tienen como variancias máximas las λi . 384 Análisis multivariado de variancia j) Pruebas acumulativas de Bartlett en las raı́ces. Las pruebas se pueden usar para determinar la dimensionalidad de la configuración. Las lambdas o las raı́ces se ordenan ascendentemente según la magnitud. En las pruebas de Bartlett, se prueban primero todas las raı́ces. Después todas menos la primera, después todas menos las dos primeras, y ası́ sucesivamente. La prueba de Ji cuadrada suministra una prueba de significancia de la variancia para las raı́ces n − k después de aceptar las primeras k raı́ces. Primero se escalan las lambdas λi normada = dfh × λi dfe y luego se calcula Ji cuadrada χ2k+1 dfh + p + 1 = dfe + dfh − 2 s X ! ln(λi normada + 1) i=k+1 donde k s = número de raı́ces aceptadas (k = 0, 1, ..., s − 1) = número de raı́ces. El número de grados de libertad es DF = (p − k)(g − k − 1) donde g es igual al número de niveles de la hipótesis. −1 k) Cocientes F para pruebas univariadas. Son los elementos de la diagonal de ∆−1 e Mh ∆e . El cociente F para la variable y es exactamente el cociente F que se obtendrı́a para el efecto dado si se hubiera hecho un análisis univariado con la variable y como la única variable dependiente. 50.3. Análisis univariado Si se ha especificado una sola variable dependiente, también se hacen los cálculos como se han descrito atrás. Sin embargo, se toma ventaje de la simplificaciónn, es decir, la componente principal de la “matriz” de correlación de errores se hace igual a uno y no se hace ningún cálculo. El resultado de un análisis univariado de variancia es una tabla convencional de ANOVA con pequeñas diferencias. Tiene una fila para la gran media pero no tiene una fila para el total. Generalmente, la gran media no es interpretable. Para obtener la suma total de cuadrados, suma todas las sumas de cuadrados excepto la suma de la gran media. 50.4. Análisis de covariancia Par la mayor parte, las fórmulas descritas no tienen en cuenta las covariadas. Si se han especificado una o más covariadas, es la suma de productos de las matrices, Se e Sh que se han ajustado. Si hay q covariadas, el programa comienza llevándolas con p variables dependientes. Hay una matriz (p × q)× (p × q) de suma de productos del error, Se , y una matriz (p × q)× (p × q) Sh para cada hipótesis. Se calcula la matriz total St . Se y Sh se parten en secciones correspondientes a las variables dependientes y covariadas. Se obtienen matrices totales y de errores reducidas (p × p) y luego se obtiene, por resta, una matriz reducida para hipótesis. Se calculan las matrices de correlación de errores y sus componentes principales después del ajuste a Se para covariadas. Capı́tulo 51 Análisis de variancia de una entrada Notación y w = valor de la variable dependiente = valor del peso k i = subı́ndice para el caso = subı́ndice para la categorı́a en la variable de control Ni Wi = número de casos en la categorı́a i = suma de los pesos para la categorı́a i N = número total de casos W c = suma total de los pesos = número de categorı́as de código de la variable de control con grados de libertad que no son cero. 51.1. Estadı́sticas descriptivas para cada categorı́a de la variable de control a) Media. yi = X wik yik k Wi b) Desviación estándar (estimada). v u u u u sbi = t Ni Ni − 1 !" Wi X k 2 wik yik − c) Coeficiente de variación (C.var.). Ci = 100 sbi yi d) Suma de y. Suma yi = X k wik yik Wi2 X k wik yik 2 # 386 Análisis de variancia de una entrada e) Porcentaje. Suma yi Porcentajei = X Suma yi i f ) Suma de y cuadrada. X Suma yi2 = 2 wik yik k g) Total. El renglón de totales da las estadı́sticas a) a e) arriba calculadas para todos los casos, excepto aquellas categorı́as codificadas con cero grados de libertad. h) Grados de libertad para la categorı́a i. gli = Wi (Ni − 1) / Ni Categorı́as con cero grados de libertad no están incluidas en los cálculos de las estadı́sticas de resumen. 51.2. Estadı́sticas del análisis de variancia a) Suma de cuadrados total. TSS = XX i k 2 wik yik − X X i wik yik k W 2 b) Suma de cuadrados entre medias. Esta es llamada a veces la suma de cuadrados entre grupos. BSS = X i " X k wik yik X wik 2 # − X X i wik yik k W 2 k c) Suma de cuadrados dentro de grupos. WSS = TSS − BSS d) Eta cuadrada (“Etasq”). Esta medida puede ser interpretada como el porcentaje de variancia en la variable dependiente que puede ser explicada por la variable de control. Varı́a de cero a uno. η2 = BSS TSS e) Eta. Es una medida de intensidad de la asociación entre la variable dependiente y la variable de control. Varı́a de cero a uno. r BSS η= TSS f ) Eta cuadrada ajustada. Eta cuadrada ajustada para los grados de libertad. η 2 ajustada = 1 − A (1 − η 2 ) con el factor de ajuste A= W −1 W −c 51.2 Estadı́sticas del análisis de variancia 387 g) Eta ajustada. η ajustada = p η 2 ajustada h) Valor de F. El cociente F puede ser referido a la distribución F con c−1 y N −c grados de libertad. Un cociente F significativo quiere decir que existen diferencias entre las medias, o probablemente efectos entre los grupos. F = BSS/(c − 1) WSS/(N − c) El cociente F no se calcula si una variable de peso fue especificada. Capı́tulo 52 Puntajes basados en el orden parcial de casos 52.1. Terminologı́a especial y definiciones Sea un conjunto de elementos denotado por V = {a, b, c, . . . , } y una relación binaria definida en V denotada por R. a) Relación binaria. Una relación binaria R en V es tal que para cualesquiera dos elementos a, b ∈ V aRb Para una relación R en V existe una relación conversa R+ en V tal que bR+ a b) Relación reflexiva y antirreflexiva. Una relación R es reflexiva cuando aRa para todo a ∈ V y R es antirreflexiva cuando no(aRa) para todo a ∈ V c) Relación simétrica y antisimétrica. Una relación R es simétrica cuando R = R+ , esto es cuando aRb ⇐⇒ bRa para todo a, b ∈ V y R es antisimétrica cuando no es simétrica para todo a 6= b. d) Relación transitiva. Una relación R es transitiva cuando aRb ∧ bRc =⇒ aRc para todos a, b, c ∈ V e) Relación de equivalencia. Una relación R definida en un conjunto de elementos V es una relación de equivalencia cuando es: reflexiva, simétrica, y transitiva. Note que la relación comúnmente utilizada de “igualdad”, (=), definida en el conjunto de los números reales es una relación de equivalencia. 390 Puntajes basados en el orden parcial de casos f ) Relación de orden parcial estricto. Una relación R es un orden parcial estricto cuando satisface las condiciones: aRb y bRa no pueden ser satisfechas simultáneamente, y R es transitiva. Una relación de orden parcial estricto será notada de ahora en adelante por ≺ . g) Conjunto parcialmente ordenado. Un conjunto V es un conjunto parcialmente ordenado si una relación de orden parcial estricta “≺” es definida en él. Las propiedades fundamentales de un conjunto parcialmente ordenado son: a ≺ b ∧ b ≺ c =⇒ a ≺ c para todos a, b, c ∈ V a ≺ b y b ≺ a no pueden ser satisfechas simultáneamente. h) Conjunto ordenado. Un conjunto V es un conjunto ordenado si hay dos relaciones “≈” y “≺” definidas en él y que satisfacen los axiomas de orden: para dos elementos cualquiera a, b ∈ V, una y sólo una de las relaciones a ≈ b, a ≺ b, b ≺ a es satisfecha, “≈” es una relación de equivalencia, y “≺” es una relación transitiva. En otras palabras, un conjunto ordenado es un conjunto parcialmente ordenado además de la relación de equivalencia definida en él, y donde las condiciones “ni a ≺ b ni b ≺ a” y “a ≈ b” son equivalentes. i) Subconjunto de elementos que dominan a un elemento a. n o G(a) = g | g ∈ V; a ≺ g j) Subconjunto de elementos dominados por un elemento a. n o L(a) = l | l ∈ V; l ≺ a k) Subconjunto de elementos comparables. C(a) = G(a) ∪ L(a) Note que G(a) ∩ L(a) = ∅. l) Dominación estricta. Un elemento b domina estrictamente un elemento a si a≺b y no(b ≺ a) También se puede decir que “b es estrictamente mejor que a”, o que “a es estrictamente peor que b”. 52.2. Cálculo de puntajes Sea la lista de variables para ser utilizadas en el análisis notada por {x1 , x2 , . . . , xi , . . . , xv } y una lista de prioridades asociada a ella por {p1 , p2 , . . . , pi , . . . , pv }. Una relación de orden parcial construida en la base de esta colección de variables, a ≺ b para cualquiera de los casos a y b es equivalente a la condición x1 (a) ≤ x1 (b), x2 (a) ≤ x2 (b), . . . , xv (a) ≤ xv (b) 52.3 Referencias 391 donde xi (a) y xi (b) indican el valor de la iésima variable para los casos a y b respectivamente. Cuando se comparan dos casos, las variables cuya prioridad es la más elevada (valor de LEVEL más bajo) se consideran primero. Si éstas determinan la relación de forma inequı́voca el procedimiento de comparación termina. En caso de igualdad, la comparación continúa utilizando variables del nivel de prioridad siguiente. Este procedimiento se repite hasta que la relación se determina en uno de los niveles de prioridad, o hasta el final de la lista de variables. Para cada caso a del conjunto analizado, el programa calcula: N (a) = número de casos que dominan estrictamente al caso a N (a) = N (a) = número de casos equivalentes al caso a número de casos estrictamente dominados por el caso a y después uno (o dos) de los puntajes a continuación: s1 (a) = S N (a) N (a) + N (a) + N (a) r1 (a) = S − s1 (a) s2 (a) = S N (a) + N (a) N (a) + N (a) + N (a) r2 (a) = S − s2 (a) s3 (a) = S N (a) N r3 (a) = S N (a) + N (a) N s4 (a) = S N (a) + N (a) N r4 (a) = S N (a) N donde N = número de casos en el conjunto analizado S = valor del factor de escala (ver el parámetro SCALE). El parámetro ORDER selecciona los puntaje(s) como sigue: ASEA : r3 (a) DEEA : s4 (a) ASCA : r4 (a) DESA ASER : s3 (a) : s1 (a), r1 (a) DESR ASCR : s1 (a), r1 (a) : s2 (a), r2 (a) DEER : s2 (a), r2 (a). 52.3. Referencias Debreu, G., Representation of a preference ordering by a numerical function, Decision Process, eds. R.M. Thrall, C.A. Coombs and R.L. Davis, New York, 1954. Hunya, P., A Ranking Procedure Based on Partially Ordered Sets, Internal paper, JATE, Szeged, 1976. Capı́tulo 53 Correlación de Pearson Notación x, y w = valores de variables = valor del peso k N = subı́ndice para el caso = número de casos válidos en x y y W = suma total de los pesos. 53.1. Estadı́sticas pareadas Están calculadas para las variables, tomadas por parejas (x, y) en el subconjunto de casos que tengan datos válidos en x y y. a) Suma ponderada ajustada. El número de casos, ponderados, con datos válidos en x y y. b) Media de x. X x= wk xk k W Nota: la fórmula para la media de y es semejante. c) Desviación estándar de x (estimada). v X 2 u X u !" W wk x2k − wk xk # u u N k k sbx = t N −1 W2 Nota: la fórmula para la desviación estándar de y es semejante. d) Coeficiente de correlación. Momento producto r de Pearson. X X X W wk xk yk − wk xk wk yk k k k rxy = v" #" # u X 2 X X X u 2 2 2 t W wk xk − W wk yk − wk xk wk yk k k k k e) Prueba t. Esta estadı́stica se utiliza para probar la hipótesis que el coeficiente de correlación de la población es cero. √ r N −2 t= √ 1 − r2 394 Correlación de Pearson 53.2. Medias y desviaciones estándar no pareadas Están calculadas variable por variable para todas las variables incluı́das en el análisis, utilizando las fórmulas dadas en 1.a, 1.b y 1.c respectivamente, la diferencia en los resultados se debe en particular a la diferencia de casos válidos. a) Suma ponderada ajustada. El número de casos, ponderado, con datos válidos para x. b) Media de x. Media de la variable x para todos los casos que tengan datos válidos para x. c) Desviación estándar de x (estimada). La desviación estándar de la variable x para todos los casos que tengan datos válidos para x. 53.3. Ecuación de regresión para puntajes primarios Calculada para todos los casos válidos para la pareja (x, y). a) Coeficiente de regresión. Es el coeficiente no estandarizado de la regresión de y (variable dependiente) sobre x (variable independiente). sby Byx = rxy sbx b) Término constante. A = y − Byx x; 53.4. ecuación de regresión: y = Byx x + A Matriz de correlación Los elementos de esta matriz están calculados con base en la formula dada en 1.d arriba. Tenga en cuenta que las desviaciones estándar que salen en la matriz de correlación, se calculan de acuerdo con la fórmula dada en 1.c atrás (desviaciones estándar estimadas). 53.5. Matriz de productos cruzados Es una matriz cuadrada con los elementos siguientes: X CPxy = wk xk yk k 53.6. Matriz de covariancia Es la matriz que contiene los elementos a continuación: COVxy = rxy sx sy donde sx = v u u W X w x2 − X w x 2 u k k k k t k k W2 y sy se calcula de acuerdo con la fórmula análoga. Nótese que la matriz de covariancia que produce PEARSON en un archivo no tiene elementos de la diagonal. Para permitir su cálculo, las desviaciones estándar que produce esta matriz se calculan de acuerdo con la fórmula anterior (desviaciones estándar no estimadas). Capı́tulo 54 Ordenamiento de alternativas Notación i, j, l m = = subı́ndices para alternativas número de alternativas k n = = ı́ndice para el caso número de casos w = valor del peso. 54.1. Manejo de los datos de entrada Sea un conjunto de alternativas, A = {a1 , a2 , . . . , ai , . . . , am } y el conjunto de fuentes de información (llamados de ahora en adelante evaluaciones) notado por E = {e1 , e2 , . . . , ek , . . . , en }. En la práctica, los datos que proporcionan la información primaria sobre las relaciones preferenciales, pueden presentarse de varias formas. El programa acepta, sin embargo, dos tipos básicos de datos: datos que representan una selección de alternativas y datos que representan una ordenación de alternativas. Todo otro tipo de datos deberán ser transformados por el usuario antes de la ejecución del programa RANK. a) Datos que representan una selección de alternativas. En este caso las evaluaciones representan la selección de las alternativas preferidas y opcionalmente su orden de preferencia. En otras palabras, todas las evaluaciones ek seleccionan un subconjunto Ak de A y opcionalmente ordenan sus elementos. Por esta razón, Ak es un subconjunto de alternativas (ordenado, o desordenado), y las Ak constituyen el dato individual primario: o n Ak = aki1 , aki2 , . . . , akipk donde p = número máximo de alternativas que podı́an ser seleccionadas en una evaluación pk = número de alternativas actualmente seleccionadas en la evaluación ek y pk ≤ p < m . b) Datos que representan una ordenación de alternativas por rangos. Las evaluaciones representan la ordenación de alternativas en todo el conjunto A ası́ como la atribución a cada una de ellas de su número de rango. Formalmente, todas las evaluaciones ek dan un número de rango ρk (ai ) = ρki para todas las alternativas. En este caso, los datos están proporcionados en la forma siguiente: Pk = {ρk (a1 ), ρk (a2 ), . . . , ρk (am )} 396 Ordenamiento de alternativas Note que una alternativa aki1 es “estrictamente preferida a” o “domina estrictamente” a otra alternativa aki2 de acuerdo con los datos que provienen de la evaluación ek , si la primera tiene un rango superior a la segunda. Igualmente, una alternativa aki1 “es preferida a” o “domina” otra alternativa aki2 de acuerdo con los datos que provienen de la evaluación ek , si el rango de aki1 es al menos tan elevado como el rango de aki2 . El valor “1” es considerado como el rango más elevado. Solamente los datos descritos en el párrafo b) están dados en una forma que no requieren procesamiento adicional. Los datos que figuran en párrafo a) son transformados a la forma de los del párrafo b). Esta transformación hace una diferencia entre una preferencia estricta y una preferencia débil. Cuando se trata de datos representando una selección de alternativas completamente ordenadas (preferencia estricta), la regla de transformación, es la siguiente: para ai ∈ Ak ρk (ai1 ) = 1, ρk (ai2 ) = 2, . . . , ρk (aipk ) = pk pk + 1 + m ρk (ai ) = 2 para ai 6∈ Ak Cuando se trata de datos que representan una selección desordenada de alternativas (preferencia débil), se supone que todas las alternativas seleccionadas se encuentran al mismo nivel de preferencia. De acuerdo con esta suposición, la regla de transformación es: pk + 1 2 pk + 1 + m ρk (ai ) = 2 para ai ∈ Ak ρk (ai ) = para ai 6∈ Ak Como resultado de las trasformaciones definidas arriba, los datos de preferencia, (o prioridad en la selección) toman para los pasos subsiguientes del análisis, la forma: ρ11 ρ12 · · · ρ1i · · · ρ1m ρ21 ρ22 · · · ρ2i · · · ρ2m .. .. .. .. . . . . P(n,m) = ρk1 ρk2 · · · ρki · · · ρkm . .. .. .. .. . . . ρn1 ρn2 · · · ρni · · · ρnm 54.2. Método basado en la lógica clásica En este método, la matriz P se utiliza como si sus elementos fueran los datos iniciales del análisis. En lo que se refiere al carácter estricto o débil de la relación de preferencia, debe notarse que la relación de preferencia juega un papel solamente en los pasos que nos llevan a la matriz P. En los pasos subsiguientes del análisis, el procedimiento está controlado por otros parámetros, tales como la diferencia de rangos para la concordancia y la diferencia de rangos para la discordancia (ver abajo). El procedimiento de ordenamiento basado en la lógica clásica, consiste de dos pasos mayores, a saber: a) construcción de relaciones, y b) identificación de núcleos. a) Construcción de relaciones. En este paso, dos relaciones “de trabajo” (la relación de concordancia y la relación de discordancia) se construyen en primer lugar. Después, son utilizadas para construir una relación final de dominación. i) Las relaciones de concordancia y de discordancia se construyen a partir de la matriz P(n,m) , y las reglas aplicadas en este proceso son esencialmente iguales para ambas relaciones. Relación de concordancia. Se utilizan dos parámetros para crear una relación que refleje la concordancia de la opinión colectiva que “ai es preferida a aj ”: dc = pc = la diferencia de rangos para la concordancia (0 ≤ dc ≤ m − 1) la proporción mı́nima de concordancia (0 ≤ pc < 1). 54.2 Método basado en la lógica clásica 397 La diferencia de rangos para concordancia, permite al usuario influir en la evaluación de datos cuando construye las matrices de preferencias individuales h i RCk (dc ) = rckij (dc ) donde i, j = 1, 2, . . . , m. Los elementos de RCk (dc ), miden la dominación de ai sobre aj de acuerdo con la evaluación k, y son definidos como sigue: 1 si ρkj − ρki ≥ dc rckij (dc ) = 0 de otra forma. La suma de estas matrices mide la dominación promedio de ai sobre aj y toma la forma de una relación difusa descrita por la matriz h i RC(dc ) = rcij (dc ) donde rcij (dc ) = X k wk rckij (dc ) X wk k Note que mayores valores de dc nos llevan a reglas de construcción más rigurosas, ya que d1c < d2c implica rckij (d1c ) ≥ rckij (d2c ) y rcij (d1c ) ≥ rcij (d2c ) Una proporción mı́nima de concordancia hace posible la transformación de una relación difusa RC(dc ) en una relación no-difusa, llamada relación de concordancia, descrita por la matriz h i RC(dc , pc ) = rcij (dc , pc ) los elementos de la cual están definidos como sigue: 1 si rcij (dc ) ≥ pc rcij (dc , pc ) = 0 de otra forma. La condición rcij (dc , pc ) = 1 significa que la opinión colectiva está de acuerdo con la expresión “ai es preferida a aj ” al nivel (dc , pc ). Nuevamente, es claro que al incrementar el valor de pc uno obtiene condiciones más estrictas de concordancia. Relación de discordancia. La construcción de la relación de discordancia sigue el mismo camino que el que fue explicado para la concordancia. Los dos parámetros que controlan su construcción son: dd = pd = la diferencia de rangos para la discordancia (0 ≤ dd ≤ m − 1) la proporción máxima de discordancia (0 ≤ pd ≤ 1). Las relaciones individuales de discordancia se determinan primero en las matrices h i RDk (dd ) = rdkij (dd ) donde i, j = 1, 2, . . . , m. Los elementos de RDk (dd ), que miden la dominación de aj sobre ai de acuerdo a la evaluación k, se definen como sigue: 1 si ρki − ρkj ≥ dd rdkij (dd ) = 0 de otra forma. La suma de éstas matrices mide la dominación promedio de aj sobre ai y tiene la forma de una relación difusa descrita por la matriz h i RD(dd ) = rdij (dd ) donde rdij (dd ) = X k wk rdkij (dd ) X k wk 398 Ordenamiento de alternativas En lo que se refiere a la concordancia, el segundo parámetro (proporción máxima de discordancia), permite al usuario transformar la relación difusa RD(dd ) en una relación no-difusa, llamada la relación de discordancia, y que está descrita por la matriz h i RD(dd , pd ) = rdij (dd , pd ) los elementos de la cual están definidos como sigue: 1 si rdij (dd ) > pd rdij (dd , pd ) = 0 de otra forma. La condición rdij (dd , pd ) = 1 significa que la opinión colectiva está en discordancia con la aserción “ai es preferido a aj ”, es decir, que apoya a la expresión opuesta “aj es preferida a ai ”, al nivel (dd , pd ). Esto puede ser interpretado como un “veto colectivo” contra la aserción “ai es preferida a aj ”. Note que mayores valores para dd y pd nos llevan a reglas de construcción menos rigurosas y por tanto a condiciones más débiles de discordancia. ii) La relación de dominación está compuesta de relaciones de concordancia y de discordancia. La idea básica es que la expresión “ai es preferido a aj ” puede ser aceptada si la opinión colectiva está en concordancia con ella, es decir, rcij (dc , pc ) = 1, y no está en discordancia con ella, es decir, rdij (dd , pd ) = 0; de otra forma esta expresión tiene que ser rechazada. Entonces, la relación de dominación, siendo una función de cuatro parámetros, está descrita por la matriz R de m × m dimensiones h i R = rij (dc , pc , dd , pd ) donde los elementos son obtenidos de acuerdo con la expresión rij (dc , pc , dd , pd ) = mı́n rcij (dc , pc ), 1 − rdij (dd , pd ) rij es una función monotónicamente decreciente en los dos primeros parámetros, y creciente monotónicamente en los dos últimos. Esto implica que: incrementando las dc , pc y/o disminuyendo dd , pd , uno puede disminuir le número de conexiones en la relación de dominación, y cambiando los parámetros en dirección opuesta uno puede crear más conexiones. b) Identificación de núcleos. Los núcleos son subconjuntos de A (conjunto de alternativas) cuyos elementos son alternativas no-dominadas. Una alternativa aj es no-dominada, sı́, y solo si rij = 0 para todo i = 1, 2, . . . , m. i) De acuerdo con este criterio, el núcleo del conjunto A (el núcleo de más alto nivel) es el subconjunto n o C(A) = aj | aj ∈ A; rij = 0, i = 1, 2, . . . , m Si C(A) = ∅ entonces todas las alternativas están dominadas. Si C(A) = A entonces todas las alternativas no están dominadas. ii) Para encontrar el núcleo siguiente, los elementos del núcleo precedente son eliminados primero de la relación de dominación. Esto quiere decir que las filas y las columnas correspondientes son eliminadas de la matriz relacional. La búsqueda de un nuevo núcleo se repite entonces en la estructura reducida. La aplicación sucesiva de i) e ii) crea una serie de núcleos Ac1 , Ac2 , . . . , Acq . Estos núcleos representan capas sucesivas de alternativas con rangos decrecientos en la estructura preferencial, mientras que las alternativas pertenecientes al mismo núcleo se supone que tienen el mismo rango. 54.3. Métodos basados en la lógica difusa: la relación de entrada En el método de ordenamiento basado en la lógica difusa, la matriz P(n,m) se utiliza para construir: a) relaciones preferenciales individuales, y b) relaciones de entrada (llamadas también “relaciones difusas”) sobre el conjunto de alternativas A. En este contexto, el carácter estricto y débil de la relación de preferencia juega un papel importante. 54.3 Métodos basados en la lógica difusa: la relación de entrada 399 a) Construcción de relaciones preferenciales individuales. Para cada evaluación ek una relación de preferencia individual, que está dada implı́citamente en P, es transformada en una matriz de dimensión m × m: h i k Rk = rij donde i, j = 1, 2, . . . , m en la cual k = rij 1 si la expresión “ai es preferido a aj en la evaluación ek ” es cierta; 0 si la expresión es falsa. Dependiendo del tipo de preferencia utilizado, la expresión “ai es preferido a aj en la evaluación ek ” es equivalente a la desigualdad ρki < ρkj ρki ≤ ρkj (preferencia estricta), o (preferencia débil). b) Construcción de la relación de entrada (relación difusa). La suma de las matrices de preferencia individual genera la matriz que representa una relación difusa en el conjunto de alternativas A: i h R = rij donde rij = X k wk rij k X wk k Cada elemento rij de R puede ser interpretado como la credibilidad de aserciones “ai es preferida a aj ” en un sentido global, y sin referirse a una evaluación. Ası́, la siguiente interpretación general es posible: rij = 1 “ai es preferida a aj ” en todas las evaluaciones, rij = 0 “ai es preferida a aj ” en ninguna de las evaluaciones, 0 < rij < 1 “ai es preferida a aj ” en una cierta porción de las evaluaciones. c) Caracterı́sticas de la relación de entrada. i) Difusion no difuso : difuso : si rij = 0 o rij = 1 para todo i, j = 1, 2, . . . , m; de otra forma. ii) Simetrı́a simétrico : si rij = rji para todo i, j = 1, 2, . . . , m; antisimétrico : si rij 6= 0 implica que rji = 0 para toda i 6= j; asimétrico : de otra forma. iii) Reflexividad reflexiva : si rii = 1 para todo i = 1, 2, . . . , m; antirreflexiva : si rii = 0 para todo i = 1, 2, . . . , m; irreflexiva : de otra forma. iv) Tricotomia tricótomo : si rij + rji = 1 para todo i, j = 1, 2, . . . , m e i 6= j; (normalizado) atricótomo : de otra forma. (no normalizado) 400 Ordenamiento de alternativas v) Índice de coherencia. Su valor, C, depende del orden de las filas y columnas en R, es decir, en el orden de las alternativas en A, y −1 ≤ C ≤ 1. X (rij − rji ) i<j C=X (rij + rji ) i<j El ı́ndice de coherencia absoluta es una modificación de C, independiente del orden. Su valor, Ca , es una frontera superior para C y 0 ≤ Ca ≤ 1. X |rij − rji | i<j Ca = X (rij + rji ) i<j Los ı́ndices C y Ca son indicadores de la unanimidad en los datos de preferencia. La coherencia completa se indica cuando C = 1, mientras que Ca = 0 indica una incoherencia total. El valor −1 para el ı́ndice C puede ser interpretado como un orden de alternativas opuesto al orden definido por la relación difusa. vi) Índice de intensidad. El ı́ndice I puede ser interpretado como un nivel de credibilidad promedio de las expresiones “ai es preferida a aj ” o “aj es preferida a ai ”. En general, toma valores en −1 ≤ I ≤ 2, mientras que en el caso de una preferencia estricta, toma valores en 0 ≤ I ≤ 1. En caso que I = 1, ésto implica una relación normalizada (ver 3.c abajo) y significa que en todos los datos de preferencia una de las expresiones arriba es válida para todas las parejas de alternativas. X (rij + rji ) i<j I= m(m − 1)/2 vii) Índice de dominación. Es también un ı́ndice que depende del orden, y toma valores en −1 ≤ D ≤ 1. X (rij − rji ) D= i<j m(m − 1)/2 Índice de dominación absoluta, en forma similar al ı́ndice de coherencia, se define como un ı́ndice de dominación independiente del orden. Su valor, Da , es una frontera superior para D y toma valores en 0 ≤ Da ≤ 1. X |rij − rji | Da = i<j m(m − 1)/2 Los ı́ndices D y Da indican la diferencia promedio entre la credibilidad de las expresiones “ai es preferida a aj ” y de sus expresiones opuestas “aj es preferida a ai ”. Note que C, I, D y Ca , I, Da no son independientes entre ellos, a saber: C ·I =D y Ca · I = Da d) Matriz normalizada. Una matriz normalizada se obtiene a partir de la matriz R utilizando la transformación siguiente: 0 rij 54.4. = ( rij rij + rji rij si i 6= j y rij + rji 6= 0 de otra forma. Método difuso-1: capas no dominadas El método de ordenamiento basado en la lógica difusa supone una relación de preferencia difusa con una función de pertenencia µ : A × A −→ [0, 1] en un conjunto dado A de alternativas. Esta función de pertenencia está representada por la matriz R (ver la sección 3 arriba). Los valores rij = µ(ai , aj ) deben de ser 54.4 Método difuso-1: capas no dominadas 401 interpretados como los grados en los cuales las preferencias expresadas por las aserciones “ai es preferida a aj ” son ciertas. Otra suposición es que: en el caso de una preferencia débil, µ es reflexiva, es decir, µ(ai , ai ) = rii = 1 para toda ai ∈ A en el caso de preferencia estricta, µ es antirreflexiva, es decir, µ(ai , ai ) = rii = 0 para toda ai ∈ A El procedimiento del método difuso-1 busca un conjunto de alternativas no dominadas (notadas como las alternativas ND), considerando dicho conjunto como el núcleo de alternativas de más alto nivel. La razón es que las alternativas ND son: o equivalentes entre ellas, o no son comparables entre ellas sobre la base de la relación de preferencia considerada, y no están dominadas en el sentido estricto por otras. Para determinar un conjunto ND de alternativas difusas, dos relaciones difusas correspondientes a la relación de preferencia R son definidas: una relación difusa de casi-equivalencia y una relación difusa de preferencia estricta. Formalmente, están definidas como sigue: relación difusa de casi-equivalencia Re : Re = R ∩ R−1 relación difusa de preferencia estricta Rs : Rs = R \ Re = R \ (R ∩ R−1 ) = R \ R−1 donde R−1 es la relación opuesta de la relación R. Todavı́a más, las funciones de pertenencia siguientes están definidas para Re y Rs respectivamente: µe (ai , aj ) = mı́n(rij , rji ) rij − rji cuando rij > rji µs (ai , aj ) = 0 de otra forma. Para una alternativa fija aj ∈ A, la función µs (aj , ai ) describe un conjunto difuso de alternativas que están estrictamente dominadas por aj . El complemento de éste conjunto difuso, descrito por la función de pertenencia 1 − µs (aj , ai ), es para una aj fija, el conjunto difuso de todas las alternativas que no están estrictamente dominadas por aj . Entonces, la intersección de todos los complementos de conjuntos difusos (sobre todas las aj ∈ A) representa el conjunto difuso de aquellas alternativas ai ∈ A que no están dominadas estrictamente por cualquiera de las alternativas del conjunto A. Este conjunto se llama el conjunto difuso µND de alternativas ND en el conjunto A. Ası́, de acuerdo con la definición de intersección µND (ai ) = mı́n (1 − µs (aj , ai )) = 1 − máx µs (aj , ai ) aj ∈A aj ∈A El valor µND (ai ) representa el grado hasta el cual la alternativa ai no está estrictamente dominada por cualquiera de las alternativas del conjunto A. El núcleo de nivel más elevado de alternativas contiene aquellas alternativas ai que tienen el grado más elevado de no-dominación o, en otras palabras, que dan un valor a µND (ai ) que es igual al valor: M ND = máx µND (ai ) ai ∈A El valor de M ND es llamado nivel de certeza correspondiente al núcleo definido por: o n C(A) = ai | ai ∈ A; µND (ai ) = M ND Los núcleos siguientes se construyen mediante una aplicación sucesiva del procedimiento descrito arriba. Los elementos del núcleo inmediatamente anterior, son excluidos de la relación difusa, es decir, las filas y las columnas correspondientes son excluidas de la matriz de relación difusa. Entonces, los cálculos se repiten en la nueva estructura reducida. 402 Ordenamiento de alternativas 54.5. Método difuso-2: rangos La relación de entrada a éste método es la misma que para el método difuso-1, a saber: la matriz R que tiene que ser reflexiva o antirreflexiva. Sin embargo la pregunta a la que tenemos que responder, es completamente diferente. El procedimiento del método difuso-2 busca los niveles de credibilidad, notados cjp , de las aserciones “aj está exactamente en el pésimo lugar en la secuencia ordenada de alternativas en A”, denotada Tjp . Los valores de las cjp forman una matriz M de dimensiones m × m que representan una función de pertenencia difusa, en la cual las filas corresponden a las alternativas y las columnas a las posibles posiciones en la secuencia 1, 2, . . . , m. Para poder hacer posibles los cálculos de las cjp , éstas deben estar desglosadas en niveles de credibilidad ya conocidos rij y por tanto las aserciones Tjp deben estar desglosadas en expresiones elementales con niveles de credibilidad conocidos rij . Para ésto, añadiremos notaciones suplementarias. Note que para que una alternativa aj se encuentre exactamente en el pésimo lugar significa que es preferida a m − p alternativas y que está precedida por las p − 1 alternativas restantes. Cuando el subconjunto de alternativas después de aj ha sido fijado, entonces Ajm−p Ajp−1 Aj = = = el subconjunto de aquellas alternativas sobre las cuales aj es preferida, el subconjunto de alternativas que son preferidas a aj , el subconjunto A \ {aj }. Obviamente, Ajp−1 ∪ Ajm−p = Aj Ajp−1 ∩ Ajm−p = ∅ y la expresión Tjp es equivalente a una secuencia de aserciones “aj es preferida a todos los elementos de Ajm−p , y todos los elementos de Ajp−1 son preferidos a aj ”, conectados por el operador disyuntivo de lógica. Todavı́a más, la aserción “aj es preferida a todos los elementos de Ajm−p ” es una conjunción de las expresiones ya conocidas “aj es preferida a al ” con un nivel de credibilidad igual a rjl , para todos los elementos al de Ajm−p . Igualmente, la expresión “todos los elementos de Ajp−1 son preferidos a aj ” es una conjunción de las aserciones ya conocidas “ai es preferida a aj ” con un nivel de credibilidad igual a rij , para todos los elementos al de Ajm−p . Si empleamos los operadores difusos correspondientes, los elementos de la matriz M pueden ser obtenidos como sigue: # " rjl , mı́n rij mı́n mı́n cjp = j máx j j Am−p ⊆ Aj al ∈Am−p ai ∈Ap−1 El cálculo de los valores cjp se hace utilizando un procedimiento de optimización que genera una serie de subconjuntos Ajm−p (manteniendo j y p fijos) incrementando monotónicamente en forma estricta los valores de la función que tiene que ser maximizada en pasos sucesivos. El programa proporciona dos formas de interpretar la matriz M. Conjuntos difusos de rangos por alternativas. Para cada alternativa aj , los valores de una función de pertenencia difusa muestran la credibilidad de tener esta alternativa en el pésimo lugar (p = 1, 2, . . . , m). También, los rangos (lugares) más plausibles para cada alternativa son listados. Subconjuntos difusos de alternativas por rangos. Para cada rango (lugar) p, los valores de una función difusa de pertenencia muestran la credibilidad de las alternativas aj (j = 1, 2, . . . , m) de estar en ese lugar. También las alternativas más plausibles, candidatas para ese puesto, son listadas. 54.6 Referencias 54.6. 403 Referencias Dussaix, A.-M., Deux méthodes de détermination de priorités ou de choix, Partie 1: Fondements mathématiques, Document UNESCO/NS/ROU/624, UNESCO, Paris, 1984. Jacquet-Lagrèze, E., Analyse d’opinions valuées et graphes de préférence, Mathématiques et sciences humaines, 33, 1971. Jacquet-Lagrèze, E., L’agrégation des opinions individuelles, Informatique et sciences humaines, 4, 1969. Kaufmann, A., Introduction à la théorie des sous-ensembles flous, Masson, Paris, 1975. Orlovski, S.A., Decision-making with a fuzzy preference relation, Fuzzy Sets and Systems, Vol. 1, No 3, 1978. Capı́tulo 55 Diagramas de dispersión Notación x y = valor de la variable que se va a trazar horizontalmente = valor de la variable que se va a trazar verticalmente w k = valor del peso = subı́ndice del caso N = número total de casos W = suma total de los pesos. 55.1. Estadı́sticas univariadas Estas estadı́sticas que no son ponderadas se calculan para todas las variables indicadas en la pasada. a) Media. x= X xk k N b) Desviación estándar. sx = 55.2. v uX u x2k u t k N − x2 Estadı́sticas univariadas por parejas Se calculan para el conjunto de casos que tienen datos válidos en x y y. Son estadı́sticas ponderadas si se especifica una variable de peso. a) Media. x= X wk xk k W Nota: la fórmula de la media de y es análoga. 406 Diagramas de dispersión b) Desviación estándar. sx = v uX u wk x2k u t k − x2 W Nota: la fórmula de la desviación estándar de y es análoga. c) N. El número de casos, ponderado, con datos válidos en x y y. 55.3. Estadı́sticas bivariadas Están calculadas en el conjunto de casos con datos válidos en x y y. a) Momento producto r de Pearson. W X wk xk yk − X wk xk X wk yk k k k rxy = v" #" # u X 2 X 2 X X u t W wk x2k − W wk yk2 − wk xk wk yk k k k k b) Estadı́sticas de regresión: constante A y coeficiente B. A= X k wk yk − X wk xk B k W donde B es el coeficiente de regresión no estandarizado. W B= X k wk xk yk − W X k X k wk x2k − wk xk X k X k wk xk 2 wk yk La constante A y el coeficiente B se utilizan en la ecuación de regresión y = Bx + A para proyectar y a partir de x. Capı́tulo 56 Búsqueda de estructura Notación y x = valor de la variable dependiente = frecuencia (ponderada) de la variable categórica dependiente z o valores (ponderados) de variables dependientes dicótomas = valor de la covariada w = valor del peso k j = subı́ndice para el caso = subı́ndice para código de categorı́as de la variable dependiente m o subı́ndice para variables dicótomas dependientes = número de códigos de la variable dependiente g o número de variables dicótomas dependientes = subı́ndice de grupo; g = 1 indica toda la muestra i t = subı́ndice de grupos finales = número de grupos finales Ng Wg = número de casos en el grupo g = suma de pesos en el grupo g Ni Wi = número de casos en el grupo final i = suma de pesos en el grupo final i N W = número total de casos = suma total de pesos. 56.1. Análisis de medias Este método se puede usar cuando se analiza una variable dependiente (por intervalos o dicótoma) y varios predictores. Busca crear grupos que permitan la mejor predicción de los valores de la variable dependiente a partir del promedio de grupo. En otras palabras, los grupos creados deben suministrar las diferencias más grandes entre medias de grupos. El criterio de división (variación explicada) se basa en las medias de grupos. a) Estadı́sticas de huella. Son las estadı́sticas calculadas sobre toda la muestra (para g = 1) y sobre divisiones tentativas de grupos padres ası́ como también para cada grupo que resulte de la mejor división. i) Suma (wt). Número de casos (Ng ) si no se ha especificado la variable de ponderación o número de casos ponderado (Wg ) en el grupo g. 408 Búsqueda de estructura ii) Med y. Valor medio de la variable dependiente y en el grupo g. yg = Ng X wk ygk k=1 Wg iii) Var y. Variancia de la variable dependiente y en el grupo g. σy2g = Ng X k=1 wk (ygk − yg )2 Wg − Wg Ng iv) Variación. Suma de cuadrados de la variable dependiente (como en el análisis de variancia de una entrada) en el grupo g. Vg = Ng X k=1 wk (ygk − yg )2 v) Var expl. La variación explicada se mide con la diferencia entre la variación en el grupo padre y la suma de la variación en los dos grupos hijos. Suministra, para cada predictor, la cantidad de variación explicada por la mejor división de este predictor, es decir, el valor más alto obtenido sobre todas las posibles divisiones de este predictor. Sean g1 y g2 dos subgrupos (grupos hijos) obtenidos en una división del grupo padre g, y Vg1 y Vg2 sus variaciones respectivas. La variación explicada por esa división del grupo g se calcula ası́: V Eg = Vg − (Vg1 + Vg2 ) Entonces, este valor se maximiza sobre todas las divisiones posibles del predictor. vi) Variación explicada. Es el porcentaje de la variación total explicada por los grupos finales. VE VT donde V E y V T son, respectivamente, la variación explicada por los grupos finales y la variación total (ver 1.b adelante). P orcentaje = 100 b) Análisis de una entrada de grupos finales. Son estadı́sticas de análisis de variancia de una entrada calculadas para los grupos finales. i) Variación explicada y GL. Es la cantidad de variación explicada por los grupos finales y los grados de libertad correspondientes. VE =VT −VN =VT − t X Vi i=1 GL = t − 1 ii) Variación total y GL. Variación total calculada para toda la muestra, es decir, para el grupo 1 y los correspondientes grados de libertad. V T = V1 GL = W − 1 iii) Error and GL. Es la cantidad de variancia no explicada y los correspondientes grados de libertad. VN = t X Vi i=1 GL = W − t c) Tabla de resumen de separación. La tabla suministra valor medio de grupo, variancia y variación de la variable dependiente en cada división ası́ como también la variación explicada por esa división (ver 1.a atrás). 56.2 Análisis de regresión 409 d) Tabla de resumen de grupos finales. Esta tabla suministra valor medio, variancia y variación de la variable dependiente para los grupos finales (ver 1.a atrás). e) Porcentaje de variación explicada. El porcentaje de la variación total explicada por la mejor división de cada grupo, se calcula ası́: P orcentajeg = 100 V Eg VT Nótese que este valor es igual a cero para los grupos finales (indicados con un asterisco). f ) Residuos. Los residuos son las diferencias entre el valor observado y el valor predicho de la variable dependiente. ek = yk − ybk Como valor predicho, se asigna a un caso el valor medio de la variable dependiente para el grupo al cual pertenece, es decir 56.2. ybik = y i Análisis de regresión Este método se puede usar cuando se analiza una variable dependiente (por intervalos o dicótoma) con una covariada y varios predictores. Busca crear grupos que permitan la mejor predicción de valores de la variable dependiente a partir de la ecuación de regresión del grupo y el valor covariado. En otras palabras, los grupos creados deben suministrar las diferencias más grandes en las lı́neas de regresión de grupo. El criterio de división (variación explicada) se basa en la regresión de la variable dependiente sobre la covariada. a) Estadı́sticas de huella. Son las estadı́sticas calculadas sobre toda la muestra (para g = 1) y sobre divisiones tentativas de grupos padres ası́ como también para cada grupo que resulte de la mejor división. i) Suma (wt). Número de casos (Ng ) si no se ha especificado la variable de ponderación o número de casos ponderados (Wg ) en el grupo g. ii) Med y,z. Valor medio de la variable dependiente y y de la covariada z en el grupo g (ver 1.a.ii atrás). iii) Var y,z. Variancia de la variable dependiente y y de la covariada z en el grupo g (ver 1.a.iii atrás). iv) Pendiente. Es la pendiente de la variable dependiente y sobre la covariada z en el grupo g. bg = Ng X k=1 wk (ygk − y g )(zgk − z g ) Ng X k=1 wk (zgk − z g )2 v) Variación. Es el error o la suma residual de cuadrados al estimar la variable y por su regresión sobre la covariada en el grupo g, es decir, una medida de la desviación alrededor de la lı́nea de regresión. Vg = Ng X k=1 wk (ygk − y g )2 − bg × Ng X k=1 wk (ygk − yg )(zgk − z g ) donde bg es la pendiente de la lı́nea de regresión en el grupo g. vi) Var expl. Variación explicada (VE). Ver 1.a.v atrás para información general y 2.a.v atrás para detalles acerca de la V (variación) usada en el análisis de regresión. vii) Variación explicada. Es el porcentaje de la variación total explicada por los grupos finales. Ver 1.a.vi atrás y 2.b adelante. 410 Búsqueda de estructura b) Análisis de una entrada de grupos finales. Son estadı́sticas resumen para los grupos finales. Ver 1.b. atrás para información general y 2.a.v y 2.a.vi atrás para detalles sobre las medidas de V y V E usadas en el análisis de regresión. c) Tabla de resumen de separación. La tabla suministra el valor medio de grupo, variancia y variación de la variable dependiente en cada división ası́ como también la variación explicada por esa división. También suministra el valor medio y variancia de la covariada. Ver 2.a atrás para fórmulas. Se calculan las siguientes estadı́sticas de regresión para cada división: i) Pendiente. Es la pendiente de la variable dependiente y sobre la covariada z en el grupo g (ver 2.a.iv atrás). ii) Intercepto. Es el término constante en la ecuación de regresión. ag = y g − b g z g donde bg es la pendiente en el grupo g. iii) Corr. Coeficiente r de la correlación de Pearson entre la variable dependiente y y la covariada z en el grupo g. rg = Ng X k=1 wk (ygk − yg ) (zgk − z g ) q σy2g σz2g d) Tabla de resumen de grupos finales. Esta tabla suministra la misma información (a excepción de la variación explicada) que la “Tabla de resumen de separación”, pero para los grupos finales. e) Porcentaje de variación explicada. El porcentaje de la variación total explicada por la mejor división para cada grupo (ver 1.e y 2.a.vi atrás). f ) Residuos. Los residuos son las diferencias entre el valor observado y el valor predicho de la variable dependiente. ek = yk − ybk Los valores predichos se calculan ası́: ybik = ai + bi zik donde ai y bi son coeficientes de regresión para el grupo final i. 56.3. Análisis de Ji-cuadrada Este método se puede usar cuando se analiza una variable dependiente (nominal u ordinal) o un conjunto de variables dependientes dicótomas con varios predictores. Busca crear grupos que permitan la mejor predicción de la categorı́a de la variable dependiente a partir de su distribución de grupo. En otras palabras, los grupos creados deben suministrar las diferencias más grandes en las distribuciones de la variable dependiente. El criterio de división (variación explicada) se calcula sobre la base de la distribución de frecuencias de la variable dependiente. Nótese que las variables dependientes dicótomas múltiples se tratan como categorı́as de una variable categórica. a) Estadı́sticas de huella. Son las estadı́sticas calculadas sobre toda la muestra (para g = 1) y sobre divisiones tentativas de grupos padres ası́ como también para cada grupo resultante de la mejor división. i) Suma (wt). Número de casos (Ng ) si no se ha especificado la variable de ponderación o número ponderado de casos (Wg ) en el grupo g. ii) Variación. Es la entropı́a del grupo g, es decir, una medida del desorden en la distribución de la variable dependiente. Vg = −2 m X j=1 xjg· × ln xjg· x·g· 56.4 Referencias 411 donde xjg· = Ng X xjgk k=1 x·g· = m X xjg· j=1 y xjgk es la “frecuencia” (codificada 0 o 1) del código j (o valor de la variable j) del caso k en grupo g. iii) Var expl. Variación explicada (VE). Ver 1.a.v atrás para información general y 3.a.ii atrás para detalles sobre la V (variación) usada en el análisis de Ji-cuadrada. iv) Variación explicada. Es el porcentaje de la variación total explicada por los grupos finales. Ver 1.a.vi atrás y 3.b adelante. b) Análisis de una entrada de grupos finales. Son estadı́sticas resumen para los grupos finales. Ver 1.b atrás para información general y 3.a.ii y 3.a.iii atrás para detalles sobre las medidas V y la V E usadas en el análisis de Ji-cuadrada. c) Tabla de resumen de separación. Esta tabla suministra la variación de la variable dependiente en cada división ası́ como también la variación explicada por esa división. Ver 3.a.ii y 3.a.iii atrás para las formulas. d) Tabla de resumen de grupos finales. Esta tabla suministra la variación de la variable dependiente para los grupos finales. e) Porcentaje de variación explicada. El porcentaje de la variación total explicada por la mejor división para cada grupo (ver 1.e atrás y 3.a.iii atrás). f ) Distribución de porcentajes. Una tabla bivariada que muestra la distribución de porcentajes de la variable dependiente para todos los grupos (Pjg ). g) Residuos. Los residuos son las diferencias entre el valor observado y el valor predicho de la variable dependiente. Para el análisis con una variable categórica dependiente, los residuos se calculan para cada categorı́a de la variable. Ası́, el número de residuos es igual al número de categorı́as. ejk = xjk − x bjik Los valores observados, xjk , se crean como una serie de “variables ficticias”, codificadas 0 o 1. Como valor predicho para la categorı́a j, se le asigna al caso un valor proporcional al número de casos que están en esta categorı́a para el grupo al cual pertenece el caso, es decir: x bjik = Pji /100 Para el análisis con varias variables dependientes dicótomas, los residuos se calculan para cada variable. Ası́, el número de residuos es igual al número de variables dependientes. ejk = x0jk − x bjik Los valores observados se caculan ası́: xjk x0jk = m X xjk j=1 Como valor predicho para la variable j, se le asigna al caso un valor proporcional al número de casos que tengan valor 1 para esta variable en el grupo al cual pertenece el caso, es decir: 56.4. x bjik = Pji /100 Referencias Morgan, J.N., Messenger, R.C., THAID A Sequential Analysis Program for the Analysis of Nominal Scale Dependent Variables, Institute for Social Research, The University of Michigan, Ann Arbor, 1973. Sonquist, J.A., Baker, E.L., Morgan, J.N., Searching for Structure, Revised ed., Institute for Social Research, The University of Michigan, Ann Arbor, 1974. Capı́tulo 57 Tablas univariadas y bivariadas Notación x = valor de la variable de fila en tablas bivariadas o valor de la variable en tablas univariadas y w = = valor de la variable de columna en tablas bivariadas valor del peso k = subı́ndice para el caso i = j = subı́ndice de la fila en tablas bivariadas subı́ndice de la columna en tablas bivariadas r c = = número de filas en tablas bivariadas número de columnas en tablas bivariadas fi· f·j = = frecuencia marginal de la fila i en una tabla bivariada frecuencia marginal en la columna j de una tabla bivariada N = número total de casos. 57.1. Estadı́sticas univariadas a) Wtnum. Número de la variable de ponderación, o cero si el peso no está especificado. b) Wtsum. Número de casos si la variable de ponderación no está especificada, o número ponderado de casos (suma de los pesos). c) Moda. La primera categorı́a que contiene la frecuencia máxima. d) Mediana. La mediana está calculada como un cuantil “n-tile” con dos subintervalos solicitados. Ver el capı́tulo “Funciones de distribución y de Lorenz” para detalles. e) Media. X wk xk k x= X wk k f ) Variancia. Es un estimador insesgado de la variancia de la población. sb2x = N N −1 ! X k wk (xk − x)2 X k wk 414 Tablas univariadas y bivariadas g) Desviación estándar. Note que sbx no es en sı́ mismo un estimador insesgado de la desviación estándar de la población. sbx = p sb2x h) Coeficiente de variación (C.var.). Cx = 100 sbx x i) Asimetrı́a. La asimetrı́a de la distribución de x está medida por g1 = N N −2 ! m3 p 2 sbx sb2x ! donde m3 = X k wk (xk − x)3 X wk k Esta cifra es una medida de asimetrı́a. Distribuciones que son asimétricas hacia la derecha, es decir, la cola se encuentra del lado derecho, tienen una medida de asimetrı́a positiva; distribuciones que tienen una asimetrı́a cargada hacia la izquierda, tienen una medida de asimetrı́a negativa; una distribución normal tiene asimetrı́a igual a cero. j) Kurtosis. La kurtosis de la distribución de x está medida por g2 = N N −3 ! m4 (b s2x )2 ! − 3 donde m4 = X k wk (xk − x)4 X wk k La kurtosis mide el grado de picudez de una distribución. Una distribución normal tiene kurtosis igual a cero. Una curva de punta aguda tiene una kurtosis positiva; las distribuciones de puntas menos agudas que las de una distribución normal tienen una kurtosis negativa. k) Cuantiles (n-tiles). Los puntos de separación de los n-tiles, se calculan de la misma forma que en el programa QUANTILE. 57.2. Estadı́sticas bivariadas a) Ji-cuadrada. Ji-cuadrada es adecuada para probar la significación de las diferencias de las distribuciones entre grupos independientes. χ2 = X X (fij − Eij )2 Eij i j donde fij = frecuencia observada en la celda ij Eij = frecuencia estimada (calculada) en la celda ij; es el producto de la frecuencia de la fila i multiplicada por la frecuencia en la columna j, dividida por el total N . Para tablas de dos por dos, la χ2 se calcula de acuerdo con la formula siguiente: χ2 = N (|ad − bc| − N/2)2 (a + b)(c + d)(a + c)(b + d) donde a, b, c, d representan las frecuencias en las cuatro celdas. 57.2 Estadı́sticas bivariadas 415 b) V de Cramer. La V de Cramer describe la fuerza de asociación en una muestra. Su valor se sitúa entre cero, que refleja una independencia completa, y la unidad, indicando una dependencia total en las cualidades. s χ2 V = N (L − 1) donde L = mı́n(r, c) . c) Coeficiente de contingencia. Al igual que la V de Cramer, el coeficiente de contingencia se utiliza para describir la fuerza de asociación en una muestra. Su lı́mite superior es una función del número de categorı́as. El ı́ndice no puede alcanzar la unidad. CC = s χ2 χ2 +N d) Grados de libertad. gl = (r − 1)(c − 1) e) N ajustada. Es la N utilizada en los cálculos estadı́sticos, es decir, el número de casos con códigos válidos. Será ponderada si una variable de peso ha sido especificada. f ) S. S es igual al número de acuerdos en el orden, menos el número de desacuerdos en el orden. Para una celda dada en una tabla, todos los casos en las celdas a la derecha y abajo están en acuerdo, todos los casos a la izquierda y abajo están en desacuerdo. S es el numerador de la estadı́sticas tau y gama. S= r−1 X c X i=1 j=1 fij r X c X h=i+1 l=j+1 fhl − j−1 r X X m=i+1 n=1 fmn donde fij , fhl y fmn son las frecuencias observadas en las celdas ij, hl y mn respectivamente. g) Variancia de S. Es la variancia de S cuando hay ataduras. (Una atadura se presenta en los datos si más de un caso aparece en una fila o en una columna dadas). σs2 N (N − 1)(2N + 5) − = + " X + " X j j X j f·j (f·j − 1)(2f·j + 5) − #" f·j (f·j − 1)(f·j − 2) 18 X i X i # fi· (fi· − 1)(2fi· + 5) + fi· (fi· − 1)(fi· − 2) 9N (N − 1)(N − 2) # #" X fi· (fi· − 1) f·j (f·j − 1) + i 2N (N − 1) h) Desviación estándar de S. σs = p σs2 i) Desviación normal de S. Proporciona una prueba de significación de muestra grande para valores de tau o gama con ataduras. El número menos uno en el numerador es una corrección para continuidad (si S es negativa, el número uno es añadido). El número puede ser comparado a una tabla de distribución normal. La prueba está condicionada por la distribución de ataduras. Z= S−1 σs 416 Tablas univariadas y bivariadas j) Tau a. Tau a supone que no hay ataduras entre los datos, o que las ataduras, si las hay, representan un “error de medida” que se refleja claramente a través de una disminución de intensidad de la relación misma. Tau a tiene un rango que va de menos uno a más uno. τa = S N (N − 1) 2 k) Tau b. Tau b es similar a tau-a, a excepción que las ataduras están permitidas, es decir, puede haber más de un caso en una fila o columna dadas en la tabla bivariada. Tau b puede alcanzar la unidad solamente cuando el número de filas es igual al número de columnas. τb = s S N (N − 1) − T1 2 N (N − 1) − T2 2 donde T1 = hX i T2 = hX j i fi· (fi· − 1) / 2 i f·j (f·j − 1) / 2 l) Tau c. Tau c es similar a Tau b exceptuando que si el número de filas no es igual al número de columnas, tau b no puede alcanzar los valores más o menos la unidad, mientras que tau c puede alcanzarlos. τc = S 1/2 N 2 [(L − 1)/L] donde L = mı́n(r, c). m) Gama. La γ de Goodman-Kruskal es otra medida de asociación ampliamente usada que está relacionada estrechamente con la τ de Kendall. Puede variar de menos uno a más uno y puede ser calculada aun cuando ataduras ocurren en los datos. γ= S S+ + S− donde S S+ S− = S+ − S− = número total de parejas en orden similar = número total de parejas en orden diferente. n) Ro de Spearman. Es el momento producto de correlación ordinaria de Pearson calculado sobre los rangos. Varı́a de menos uno a más uno. La ro de Spearman calculada por el programa TABLES incorpora una corrección para ataduras. El factor de corrección, T , para un solo grupo de casos atados es: T = t3 − t 12 donde t es igual al número de casos atados en un rango dado, es decir, el número de casos en una fila dada o en una columna dada. La ro de Spearman se calcula P 2 P 2 P 2 x + y − d pP ρs = P 2 y x2 2 57.2 Estadı́sticas bivariadas 417 donde X X X X x2 = y2 = d2 = N3 − N X − Tx 12 3 N −N X − Ty 12 X (Xk − Yk )2 k Tx = Ty = suma de las T para todas las columnas con más de un caso Xk Yk = = rango del caso k en la variable fila rango del caso k en la variable columna. X suma de las T para todas las filas con más de un caso Note que cuando más de un caso ocurre en una fila (o columna) dada, el valor de las Xk (o las Yk ) para casos atados, es el promedio de los rangos que hubieran sido asignados si no hubiera habido ataduras. Por ejemplo, si hay 15 casos en la primera fila de una tabla, entonces a ésos 15 casos se les habrı́a asignado un rango, es decir, valor de X de 8. ñ) Lambda simétrica. Es una medida simétrica del poder de predicción; es adecuada cuando ni las filas ni las columnas están especialmente designadas como las fuentes a partir de las cuales debe proyectarse o ser conocidos en primer lugar. Lambda tiene un rango de cero a uno. λsym = X máx fij + j i X j máx fij − máx f·j − máx fi· i j i 2N − máx f·j − máx fi· j i donde fij máx fij = frecuencia observada en la celda ij = frecuencia máxima en la fila i máx fij = frecuencia máxima en la columna j máx f·j = frecuencia marginal máxima entre las j columnas máx fi· = frecuencia marginal máxima entre las i filas. j i j i o) Lambda A, variable dependiente en fila. Esta lambda es adecuada cuando la variable de fila es la variable dependiente. Es una medida de reducción proporcional en la probabilidad de error, cuando se proyecta la variable fila, especificado por una categorı́a de columna. La lambda dependiente de fila tiene un rango de cero a uno. λrd = X j máx fij − máx fi· i i N − máx fi· i Vea más arriba la definición de los términos de esta fórmula. p) Lambda B, variable dependiente en columna. Esta lambda es adecuada cuando la variable de la columna es la variable dependiente. Toma valores en el intervalo cero a uno. λcd = X i máx fij − máx f·j j j N − máx f·j j Vea más arriba la definición de los términos de esta fórmula. 418 Tablas univariadas y bivariadas q) Estadı́sticas para medicina basada en evidencia (EBM). Se calculan para las tablas 2 x 2 donde la primera fila contiene las frecuencias de evento (a) y no-evento (b) para los casos en el grupo experimental y la secunda fila contiene las frecuencias de evento (c) y no-evento (d) para los casos en el grupo control. Son calculadas las estadı́sticas siguientes: Tasa de eventos en el grupo experimental T EE = a/(a + b) Tasa de eventos en el grupo control T EC = c/(c + d) Reducción absoluta del riesgo (Diferencia de riesgo) RAR = |T EC − T EE| Reducción relativa del riesgo RRR = RAR/T EC Número necesario a tratar N N T = 1/RAR Riesgo relativo (relación de riesgo) RR = T EE/T EC y su intervalo de confianza al 95 % h √ i ICRR = exp ln(RR estimado) ± 1,96 T donde la variancia estimada de ln(RR estimado) es T = d/c b/a + a+b c+d Razón de posibilidades (odds ratio) RP = ad/bc y su intervalo de confianza al 95 % h √ i ICRP = exp ln(RP estimado) ± 1,96 V donde la variancia estimada de ln(RP estimado) es V = 1 1 1 1 + + + a b c d r) Prueba exacta de Fisher. La prueba exacta de probabilidad de Fisher es una técnica no-paramétrica muy útil para analizar datos discretos (que sean nominales o ordinales) a partir de dos muestras independientes. Es utilizada cuando todos los casos de dos muestras aleatorias independientes caen en una o en otra de dos categorı́as mutuamente exclusivas. La prueba determina si los dos grupos difieren en la proporción en la cual se separan las dos clasificaciones. La probabilidad de un resultado observado se calcula como sigue: p= (a + b)! (c + d)! (a + c)! (b + d)! N ! a! b! c! d! donde a, b, c, d representan la frecuencia en las cuatro celdas. El programa TABLES calcula ambas probabilidades exactas relativas a una o dos colas, que son llamadas “probabilidad de ocurrencia igual o extrema a la que fué observada” y “probabilidad de ocurrencia extrema a la que fué observada en cualquier dirección” respectivamente. 57.2 Estadı́sticas bivariadas 419 s) Prueba de Mann-Whitney. La prueba U de Mann-Whitney puede ser utilizada para probar si dos grupos independientes han sido seleccionados a partir de la misma población. Es la mejor alternativa a la prueba paramétrica t cuando la medida es inferior al escalamiento por intervalos. En el programa TABLES se requiere que la variable por fila sea la variable de agrupamiento dicotómica. Sean n1 n2 = número de casos en el grupo más pequeño de casos en los dos grupos = número de casos en el segundo grupo R1 R2 = suma de ordenaciones asignada al grupo con número de casos n1 = suma de ordenaciones asignada al grupo con número de casos n2 . Entonces U 1 = n1 n2 + n1 (n1 + 1) − R1 2 U 2 = n1 n2 + n2 (n2 + 1) − R2 2 y U = mı́n(U1 , U2 ) Si hay más de 10 casos en cada grupo, el programa TABLES proporciona la aproximación Z (aproximación normal de U ) calculada como sigue: Z= r U − n1 n2 /2 n1 n2 (n1 + n2 + 1) 12 t) Prueba de rangos con signo de Wilcoxon. La prueba estadı́stica de Wilcoxon sirve para probar la relación entre dos muestras y utiliza ambas informaciones, sobre la dirección y la magnitud relativa de la diferencia entre parejas de variables. La suma de rangos positivos, T + , se obtiene como sigue: Las diferencias con signo dk = xk − yk se calculan para todos los casos. Las diferencias dk son ordenadas con respecto al rango e independientemente de su signo. Los casos en los cuales dk toma el valor cero son descartados. A las dk que están atadas, se les asigna el promedio de los rangos atados. A cada rango se le anexa el signo (+ o −) de la d que representan. N 0 es el número de dk cuyo valor no es cero. T + es la suma de las dk con signo positivo. Si N 0 > 15, el programa calcula la aproximación Z (aproximación normal de T + ) como sigue: Z= T + − µT + σT + donde µT + = N 0 (N 0 + 1) 4 g σT2 + 1X N 0 (N 0 + 1) (2N 0 + 1) − nt (nt − 1) (nt − 2) = 24 2 t=1 g nt = = y número de grupos de diferentes rangos atados número de rangos atados en el grupo t. Note que la aproximación Z también está ajustada para los rangos atados. El uso de ésta, sin embargo, no produce cambio alguno en la variancia cuando no hay ataduras. 420 Tablas univariadas y bivariadas u) Prueba-t. El cociente t es adecuado para probar la diferencia entre dos medias independientes, es decir, dos muestras independientes. La variancia está calculada en común. t = s yi − yh ni + nh + nh s2h ni + nh − 2 ni nh ni s2i donde yi yh = = media de la variable de columna para casos en la fila i media de la variable de columna para casos en la fila h s2i s2h = = variancia de la muestra para la variable de columna para casos en la fila i variancia de la muestra para la variable de columna para casos en la fila h. Si se requieren las pruebas t, las desviaciones estándar de la muestra son calculadas para los casos en cada fila como sigue: si = 57.3. sP y2 − y 2i ni Nota sobre los pesos Si se solicitan las estadı́sticas bivariadas y una variable de ponderación es especificada, se imprime una indicación al respecto y las estadı́sticas se calculan utilizando los valores ponderados: xk x2k = = wk xk wk x2k yk yk2 = = N = fij = wk yk wk y 2 X k wk k la frecuencia ponderada en la celda ij. Capı́tulo 58 Tipologı́a y clasificación ascendente Notación x k v g, i, j = subı́ndice para la variable = subı́ndices para grupos a = número de variables activas (cuantitativas y cualitativas dicotomizadas) p t = número de variables pasivas (cuantitativas y cualitativas dicotomizadas) = número inicial de grupos Ni Nj α w W 58.1. = valores de variables = subı́ndice para el caso = número de casos en el grupo i ponderado si el peso del caso está especificado) = número de casos en el grupo j (ponderado si el peso del caso está especificado) = valor del peso de la variable = valor del peso del caso = suma total de los pesos del caso. Tipos de variables utilizadas El programa acepta variables cuantitativas y cualitativas (categóricas), estas últimas serán tratadas como cuantitativas después de haber sido dicotomizadas en sus categorı́as respectivas, es decir, después de la construcción de tantas variables dicotómicas (cero/uno) igual al número de categorı́as. Las variables utilizadas por el programa pueden ser activas o pasivas. Las variables activas son aquellas sobre las cuales la tipologı́a es construida. Las variables pasivas no participan en la construcción de la tipologı́a, pero el programa imprime para estas las estadı́sticas principales dentro de los grupos de la tipologı́a. Un conjunto de variables activas se denota aquı́, como Xa , y un conjunto de variables pasivas como Xp . 58.2. Perfil de caso El perfil del caso k es un vector Pk tal que Pk = (xk1 , xk2 , . . . , xkv , . . . , xka ) = (xkv ) donde todas las xv ∈ Xa . Si se requiere que las variables activas sean estandarizadas, el perfil de caso k se convierte en x kv Pk = sv donde sv es la desviación estándar de la variable xv (ver 7.b más abajo). 422 Tipologı́a y clasificación ascendente 58.3. Perfil de grupo El perfil del grupo i, conocido también como el barycentro de grupo, es un vector Pi tal que Pi = (xi1 , xi2 , . . . , xiv , . . . , xia ) = (xiv ) y en caso de datos estandarizados se convierte en, x iv Pi = sv donde el numerador es la media de la variable xv de los casos que corresponden al grupo i y el denominador es la desviación estándar de ésta variable. 58.4. Distancias utilizadas Hay tres tipos básicos de distancias utilizadas en este programa, que son la distancia en cuadra urbana (“city block”), la distancia euclideana y la distancia Ji-cuadrada de Benzécri. Estas pueden ser utilizadas para calcular las distancias entre dos casos, entre un caso y un grupo de casos y entre dos grupos de casos. A continuación, estas distancias están definidas como distancias entre dos grupos (entre perfiles de dos grupos), pero las otras distancias pueden ser obtenidas adaptando las formulas respectivas. a) Distancia en cuadra urbana (“city block”). dij = d(Pi , Pj ) = a X v=1 αv |xiv − xjv | a X αv v=1 b) Distancia euclideana. v uX u a u αv (xiv − xjv )2 u u v=1 dij = d(Pi , Pj ) = u a u X t α v v=1 c) Distancia Ji-cuadrada. v u a uX 1 piv pjv 2 − dij = d(Pi , Pj ) = t p pi pj v=1 v donde pv = t X xgv , pi = g=1 piv = xiv t a XX a X xiv , pj = v=1 , xgv g=1 v=1 pjv = a X xjv v=1 xjv t a XX xgv g=1 v=1 Todavı́a más, el programa proporciona la posibilidad de utilizar distancias “ponderadas”, llamadas desplazamiento (displacement), que son definidas como sigue: Dij = D(Pi , Pj ) = 2Ni Nj dij Ni + Nj Note que el desplazamiento entre el perfil de dos casos es igual a su distancia ya que Ni = Nj = 1. 58.5 Construcción de una tipologı́a inicial 58.5. 423 Construcción de una tipologı́a inicial a) Selección de la configuración inicial. Antes de comenzar el proceso de agregación de los casos, el programa selecciona la configuración inicial, es decir, t perfiles iniciales de grupo, en una de las formas siguientes: los perfiles de casos de t casos escogidos al azar (con números aleatorios) constituyen la configuración de partida; para obtener la configuración inicial, los casos restantes se distribuyen en t grupos como se describe más adelante; los perfiles de casos de t casos escogidos por pasos constituyen la configuración de partida; para obtener la configuración inicial, los casos restantes se distribuyen en t grupos como se describe más adelante; la configuración inicial es un conjunto de perfiles calculados para los casos distribuidos a lo largo de las categorı́as de una variable clave; la configuración inicial es un conjunto de perfiles de grupo proporcionados “a priori” por el usuario. Cuando la construcción comienza a partir de t perfiles, el programa considera este conjunto de t vectores, como un conjunto de t “casos de partida” y distribuye los casos restantes de acuerdo a la distancia de cada uno de los casos de partida. Notemos el conjunto de los t casos de partida por o n Ppartida = Pk1 , Pk2 , . . . , Pkt y la distancia entre grupos y/o casos i y j por D(Pi , Pj ). Note que D(Pi , Pj ) puede ser cualquier distancia definida en sección 4 más arriba. Para cada caso i 6∈ Ppartida el programa calcula i h β = mı́n D(Pi , Pkj ) 1≤j≤t i h γ = mı́n D(Pk1 , Pk2 ), D(Pk1 , Pk3 ), . . . , D(Pkt−1 , Pkt ) Hay dos posibilidades: β ≤ γ : el caso i queda asignado al grupo más cercano Pkj y el perfil de este grupo es calculado nuevamente Pkj = Pkj + Pi /2 β > γ : el caso i construye un nuevo grupo que es añadido al conjunto Ppartida , y los dos perfiles más cercanos Pkj y Pkj0 se suman formando un nuevo grupo con el nuevo perfil Pkj = Pkj + Pkj0 /2 Al final de este procedimiento, la configuración inicial es un conjunto de t perfiles o n Pinicial = P1 , P2 , . . . , Pj , . . . , Pt donde Pj es el perfil medio de todos los casos correspondientes al grupo j. En esta etapa, el programa no toma en cuenta la ponderación de los casos, si ésta existe. b) Estabilización de la configuración inicial. La configuración inicial es estabilizada por medio de un proceso iterativo. En cada iteración, el programa redistribuye los casos entre los grupos iniciales tomando en cuenta sus distancias de cada perfil de grupo. Aquı́ también hay dos posibilidades: cuando el caso i ∈ Pj y h i D(Pi , Pj ) = mı́n D(Pi , Pg ) 1≤g≤t entonces el caso es mantenido en el grupo Pj ; 424 Tipologı́a y clasificación ascendente cuando el caso i ∈ Pj pero h i D(Pi , Pj 0 ) = mı́n D(Pi , Pg ) 1≤g≤t entonces el caso i es transferido del grupo Pj al grupo Pj 0 , y los perfiles de esos dos grupos son calculados nuevamente como sigue: Pj = (Nj Pj − Pi ) /(Nj − 1) Pj 0 = (Nj 0 Pj 0 + Pi ) /(Nj 0 + 1) Después de haber efectuado esta operación, el grupo Pj contiene Nj − 1 casos y el grupo Pj 0 contiene Nj 0 + 1 casos. Note que si los casos están ponderados, entonces: Nj = Nj − wi Nj 0 = Nj 0 + wi Pi = wi Pi en donde wi es igual al peso del caso i; Nj y Nj 0 son el número de casos ponderados en los grupos Pj and Pj 0 respectivamente. La estabilidad de los grupos está medida por el porcentaje de casos que quedan en el mismo grupo entre dos iteraciones sucesivas. El procedimiento se repite hasta que los grupos se estabilizan o hasta que el número de iteraciones indicada por el usuario son efectuadas. 58.6. Caracterı́sticas de distancias por grupos a) N. Número de casos en cada grupo de la tipologı́a inicial. b) Media. Distancia media para cada grupo, es decir, el promedio de las distancias del perfil de grupo sobre todos los casos que partenecen a este grupo. c) D.E. Desviación estándar de la distancia para cada grupo. d) Clasificación de distancias. Distribución de casos en términos de frecuencia y porcentaje, a través de 15 intervalos continuos que son diferentes para cada grupo. e) Conteo total. Número total de casos que participan en la construcción de la tipologı́a inicial. f ) Media. Distancia media total. g) D.E. Desviación estándar total de la distancia. h) Clasificación de distancias (lı́mites iguales para cada grupo). Igual que 6.d arriba, a la excepción que los 15 intervalos tienen el mismo espectro en todos los grupos. 58.7. Estadı́sticas de resumen Son calculadas para las variables cuantitativas y para las variables cualitativas activas. a) Media. Media de las xv cuantitativas, tales que xv ∈ (Xa ∪ Xp ). Para las categorı́as de variables cualitativas, es una proporción de casos en ésa categorı́a. xv = X wk xkv k W 58.8 Descripción de la tipologı́a resultante 425 b) D.E. Desviación estándar. sv = v 2 u u W X w x2 − X w x u k kv k kv t k k W2 c) Peso. El valor de la ponderación calculada para cada variable es como sigue: αv = 58.8. 0 1 √ para variables cuantitativas pasivas para variables cuantitativas activas (c+1)/3 c 1 para categorı́as de una variable cualitativa activa, donde c es igual al número de categorı́as con datos para ésta variable para categorı́as de una variable cualitativa activa si se usa la distancia Ji-cuadrada. Descripción de la tipologı́a resultante Al final de la construcción de la tipologı́a inicial, y también al final de cada paso de la clasificación ascendente, todas las variables, es decir, activas y pasivas son evaluadas por una cantidad de variancia explicada. Es una medida de poder discriminante de cada variable cuantitativa y de cada una de las categorı́as de las variables cualitativas. Le sigue una descripción individual de todos los grupos de la tipologı́a. a) Proporción de casos. Porcentaje multiplicado por 1000 de los casos que corresponden a cada grupo de la tipologı́a. b) Variancia explicada. tg X i=1 VE(xv ) = X k 2 Ni (xiv − xv ) wk (xkv − xv )2 × 1000 donde tg xiv xv = número de grupos en la tipologı́a = media de la variable v en el grupo i = media global de la variable v. c) Media global. Para variables cuantitativas, los valores medios como descrito en 7.a arriba. Para cada categorı́a de las variables cualitativas, porcentaje de casos en esta categorı́a. d) Estadı́sticas para cada grupo de la tipologı́a. Para variables cuantitativas: primera lı́nea: valores medios tal como están descritos en 7.a arriba; segunda lı́nea: desviaciones estándar como están descritas en 7.b arriba. Para cada categorı́a de las variables cualitativas: primera lı́nea: porcentaje de casos de columna; segunda lı́nea: porcentaje de casos de fila. 426 58.9. Tipologı́a y clasificación ascendente Resumen de la cantidad de variancia explicada por la tipologı́a En forma similar a la descripción de la tipologı́a resultante, una tabla de resumen se imprime al final de la construcción de la tipologı́a inicial y al final de cada paso de la clasificación ascendente. a) Variables que explican el 80 % de la variancia. Presenta las variables con mayor poder discriminante - que, tomadas todas juntas - son responsables de la explicación de al menos el 80 % de la variancia, junto con la cantidad de variancia explicada por cada una de ellas individualmente (ver 8.b arriba). b) Variancia explicada media por las variables activas. VEactivas = a X αv VE(xv ) v=1 a X αv v=1 c) Variancia explicada media por todas las variables. VEtodas = a+p X αv VE(xv ) v=1 a+p X αv v=1 d) Variancia explicada media por las variables que explican el 80 % de la variancia total. Después de cada agrupamiento, el programa busca las variables que explican al menos el 80 % de la variancia total e imprime la variancia media explicada por ésas variables antes y después del agrupamiento ası́ como el porcentaje de dichas variables. 58.10. Clasificación jerárquica ascendente Después de haber creado la tipologı́a inicial, el programa efectúa una serie de agrupamientos, reduciendo uno por uno el número inicial de grupos hasta el número especificado por el usuario. A cada agrupamiento, el programa selecciona los dos grupos más cercanos, es decir, dos grupos con la menor distancia o desplazamiento (ver sección 4 arriba), y calcula el perfil para éste nuevo grupo. a) Grupo i + j. Perfil del nuevo grupo, impreso hasta para 15 variables activas en orden descendiente de su desviación (ver 10.d más abajo). Note que si hay menos de 15 variables activas, o menos de 15 variables con casos válidos en grupos agregados, el programa completa la lista utilizando variables pasivas. b) Grupo i. Perfil del grupo i, impreso para las mismas variables que están indicadas arriba. c) Grupo j. Perfil del grupo j, impreso para las mismas variables que están indicadas arriba. d) Desv. Valor absoluto de la diferencia entre perfiles de los grupos i y j, impreso para las mismas variables que están indicadas arriba. Desv(xv ) = |xiv − xjv | e) Desviación ponderada. Desviación ponderada por el peso de la variable y por la desviación estándar, impresa para las mismas variables que están indicadas arriba. DesvP(xv ) = Desv(xv ) αv sv 58.11 Referencias 58.11. 427 Referencias Aimetti, J.P., SYSTIT: Programme de classification automatique, GSIE-CFRO, Paris, 1978. Diday, E., Optimisation en classification automatique, RAIRO, Vol. 3, 1972. Hall & Ball, A clustering technique for summerizing multivariate data, Behavioral Sciences, Vol. 12, No 2, 1967. Apéndice Mensajes de error de los programas de IDAMS Visión general Se ha echo un esfuerzo para que los mensajes de error se expliquen por sı́ mismos. Este Apéndice esencialmente describe el esquema de codificación utilizado para los mensajes de error. Errores y advertencias Los errores (E) siempre causan la terminación de la ejecución de programas de IDAMS; las advertencias (W) alertan al usuario acerca de posibles anormalidades en los datos y/o proposiciones de control ası́ como también, de una interpretación equivocada de los resultados. Los mensajes de error y de advertencia tienen el formato siguiente: ***E* aaannn texto del mensaje de error ***W* aaannn texto del mensaje de advertencia donde nnn es un número de tres dı́gitos, que empieza en 001 para las advertencias y en 101 para los errores; aaa indica de donde proviene el mensaje, según las reglas siguientes: Mensajes de los programas: la primera letra del nombre del programa seguida de las dos consonantes siguientes del nombre del programa. Mensajes de las subrutinas: SYN errores de sintaxis general; RCD errores y advertencias de sintaxis de Recode; DTM errores en datos y diccionario y advertencias acerca de los archivos de datos y diccionario; SYS errores y advertencias del Monitor; FLM errores y advertencias sobre el manejo de archivos. 430 Mensajes de error de los programas de IDAMS Mensajes de error de ejecución que provienen de Fortran Cuando se presentan errores durante la ejecución de un programa, Visual Fortran RTL arroja mensajes de diagnóstico. Estos mensajes tienen el siguiente formato: forrtl: severidad (número): texto forrtl severidad número texto identifica la fuente como Visual Fortran RTL. los niveles de severidad son: severo (debe corigirse), error (deberı́a corigirse), advertencia (deberı́a investigarse), o info (sólo información). es el número del mensaje, también el valor IOSTAT para proposiciones I/O (Entrada/Salida). explica la causa del error. Los mensajes de ejecución se explican por si mismo y por esta razón, no se listan aquı́. Índice alfabético agrupación de datos, 59, 97 análisis basado en ordenamiento parcial de puntajes, 245, 389 de clasificación, 173, 293, 333, 421 de configuración, 179, 341 de correspondencias, 197, 353 de preferencias, 259, 395 de proximidades, 215, 367 de regresión, 205, 221, 361, 373 de segmentación binaria, 273, 407 de series de tiempo, 4, 323, 328 de variancia, 221, 239, 373, 385 discriminatorio, 185, 345 en componentes principales, 197, 353 factorial, 197, 353 análisis de variancia multivariado, 231 análisis multivariado de variancia, 231 archivos clasificación, 157 Datos, 5, 79 de datos, 12 de diccionario, 14 de matrices, 5, 16 del sistema, 80 permanentes, 80 del usuario, 79 Diccionario, 5, 79 especificación de, 23 intercalación, 157 jerárquicos, 12 Matriz, 79 nombre, 79 rectangulares, creación de, 57 Resultados, 79 Setup, 79 usados en WinIDAMS, 79 asimetrı́a, 354, 414 blancos identificación, 112 recodificación por BUILD, 103 códigos incorrectos/inválidos, especificación, 109 nombre de, 16 verificación, 89, 109 carpetas en WinIDAMS, 80 por defecto, 80 casos activos, 358 duplicados eliminación con SUBSET, 163 tratamiento con MERGE, 151 eliminación, 129, 161, 165 excénticos tratamiento por MCA, 226 tratamiento por SEARCH, 277 faltantes, tratamiento con MERGE, 150 fijación de número a procesar, 30 identificación con MERCHECK, 121 listado, 129, 145, 165 ordenamiento parcial, 245 pasivos, 360 selección de, 25 centrado de configuraciones, 179, 341 clasificación de alternativas, 259, 395 basada en la lógica clásica, 259, 396 basada en la lógica difusa, 259, 400, 402 clasificación de archivos, 157 clasificación de casos basada en la lógica difusa, 174, 336 basada en repartición, 173, 174, 334, 336 jerárquica, 173, 174, 293, 337–339, 421 clasificación de objetos basada en la lógica difusa, 174, 336 basada en repartición, 173, 174, 334, 336 jerárquica, 173, 174, 337, 338 clasificación jerárquica ascendente, 174, 177, 293, 337, 421 basada en variables dicotómicas, 174, 177, 339 de casos, 293, 421 descendente, 174, 177, 338 por aglomeración, 174, 177, 337 por división, 174, 177, 338 cociente F, 223, 240, 387 coeficiente de Gini, 191, 350 coeficientes B, 207, 254, 267, 364, 394, 406 beta, 207, 223, 364, 375 de contingencia, 281, 415 de correlación múltiple, 207, 223, 363, 376 parcial, 207, 362 r de Pearson, 206, 253, 362, 393 de regresión, 207, 254, 267, 364, 394, 406 de variación, 361, 373, 375, 385, 414 eta, 223, 240, 375, 386 comandos de IDAMS 432 ÍNDICE ALFABÉTICO $CHECK, 21 listado, 60, 145 $COMMENT, 22 no numéricos, edición, 103 $DATA, 22 numéricos $DICT, 22 edición, 103 $FILES, 22 tratamiento de campos no numéricos, 13 $MATRIX, 22 reagrupamiento (ver agrupación), 97 $PRINT, 22 recodificación, 31, 59 $RECODE, 22 salvar datos recodificados, 165 $RUN, 23 transformación, 59, 165 $SETUP, 23 para recodificación, 31 comentario en el setup, 22 seguro con TRANS, 59 configuración validación, 57, 58 análisis, 179, 341 verificación centrado, 179, 341 de consistencia, 57, 59, 115 matriz de configuración, 179, 215, 295, 296, 341, de intercalación, 57, 58 367 de orden de clasificación, 121, 161, 163 en entrada de CONFIG, 180 de valores, 57, 58, 109 en entrada de MDSCALE, 218 datos faltantes en entrada de TYPOL, 296 asignación de códigos por Recode, 51 en salida de CONFIG, 180 códigos de, 13 en salida de MDSCALE, 217 declaración en el setup, 30 en salida de TYPOL, 295 definición, 13 normalización, 180, 341 eliminación por casos proyección, 182 en PEARSON, 254 rotación varimax, 180, 343 en REGRESSN, 206 transformación, 180, 342 eliminación por pares corrección en PEARSON, 253 de datos, 57, 59, 88, 129 especificación en el diccionario, 15 de identificador de casos, 129 tratamiento con Recode, 34 Cramer (V de), 281, 306, 415 datos preferenciales curva de Lorenz, 191, 350 selección de alternativas, 261 tipos de, 260 D de Sormer, 306 ddname, 23 dataset, definición en IDAMS, 11 modificación, 30 datasets nombre por defecto, 30 construcción, 103 densidades, 318 copia, 161 desviación estándar, 304, 345, 353, 361, 373, 374, 385, importación, 89 393, 394, 405, 406, 414, 425 intercalación, 59, 149 determinación de prioridades, 259, 395 de diferente nivel, 59, 149 diagramas de mismo nivel, 59, 149 agrupados, 320 preparación, 58 de caja y bigotes, 319 subdivisión, 60, 161 de dispersión, 198, 202, 267, 316 datos tridimensional, 320 actualización, 129 diccionario agrupación, 59, 97 archivos de, 5, 79 almacenamiento, 11 construcción, 86, 103 archivos de, 5, 79 correción, 86 conversión a modo binario, 13 descripción, 14 corrección, 57, 59, 88, 129 en el setup, 22 en el setup, 22 listado con LIST, 145 en IDAMS, 5 registros entrada, 88 de códigos y nombres de categorı́as, 15 exportación, 90, 135 de tipo C, 15 formato DIF, 136 de tipo T, 15 formato libre, 90, 136 descriptor de diccionario, 14 formato, 11 descriptores de variables, 15 importación, 20, 89, 135 verificación, 86 formato DIF, 137 distancia formato libre, 89, 137 ÍNDICE ALFABÉTICO cuadra urbana, 176, 219, 297, 334, 371, 422 de Mahalanobis, 185, 346 euclideana, 176, 219, 297, 334, 370, 422 Ji-cuadrada, 297, 422 Durbin-Watson (estadı́stica de), 207, 365 factor de repetición en TABLES, 287 filtro, 25 colocación, 25 local, 25 en ONEWAY, 242 en QUANTILE, 194 ELECTRE (método de clasificación de alternativas), en SCAT, 270 259, 396 en TABLES, 286 eliminación principal, 25 de casos reglas de codificación, 25 con CORRECT, 129 variables a usar, 26 con SUBSET, 161 variables alfabéticas., 26 con TRANS, 165 variables numéricas, 26 de casos duplicados con SUBSET, 163 variables R, 26 de variables Fisher con SUBSET, 161 prueba exacta de, 281, 418 con TRANS, 165 prueba F de, 207, 223, 240, 363, 387 esfuerzo en análisis de proximidades, 216, 368 frecuencias estadı́sticas, cálculo de bivariadas, 281, 305 bivariadas por TABLES, 281 univariadas, 281, 305 de residuos por MCA, 223 univariadas acumulativas, 281 para medicina basada en evidencia, 281 función univariadas, 318 de distribución, 191, 349 interactivo, 304 de Lorenz, 191, 350 por AGGREG, 97, 98 discriminatoria lineal, 185, 346 por FACTOR, 198 funciones de Recode por TABLES, 281 aritméticas, 37 exploración gráfica interactiva, 4, 313 lógicas, 45 exportación de datos, 90, 135 gamma (estadı́stica), 281, 306, 416 de matrices, 135 Gini (coeficiente de), 191, 350 de tablas multidimensionales, 306 histogramas, 318 facilidades de análisis análisis de componentes principales, 3, 197, 353 IDAMS caracterı́sticas estándar, 5 análisis de configuración, 3, 179, 341 comandos, 21 análisis de conglomerados, 3, 173, 333 dataset, 11, 103 análisis de correspondencias, 3, 197, 353 construcción, 103 análisis de regresión, 3, 221, 373 exportación, 90 análisis de variancia, 3, 221, 373 importación, 89 análisis de variancia de una entrada, 3, 239, 385 datos análisis discriminatorio, 3, 185, 345 exportación, 135 análisis factorial, 3, 197, 353 importación, 135 búsqueda de estructura, 4, 273, 407 diccionario, construcción, 103 clasificación jerárquica ascendente, 4, 293, 421 especificación de archivos, 23 correlación de Pearson, 4, 253, 393 GraphID, 4, 313 diagramas de dispersión, 4, 267, 405 matrices, 16 escalamiento multidimensional, 3, 215, 367 exportación, 135 exploración gráfica interactiva de datos, 4, 313 importación, 135 funciones de distribución y de Lorenz, 3, 191, 349 mensajes de error, 429 interactivo de series de tiempo, 4, 323 programas de, 2, 3 nubes de puntos, 4, 267, 405 proposiciones de control, 25, 61 ordenamiento de alternativas, 4, 259, 395 proposiciones de recodificación, 31, 61 puntajes basados en el orden parcial de casos, 3, 245, 389 setup, 21, 61 regresión lineal, 3, 205, 361 tablas multidimensionales, 4, 303 segmentación binaria, 4, 273, 407 TimeSID, 4, 323 tablas multidimensionales interactivas, 4, 303 identificador de caso tablas univariadas y bivariadas, 4, 281, 413 corrección, 129 tipologia iterativa, 4, 293, 421 en LIST, 146 433 434 en MERGE (variables de emparejamiento), 154 importación de datos, 20, 89, 135 de matrices, 135 impresión de resultados, 93 imprimir tablas, 306 interacciones construcción de una variable de combinación, 222 definición, 221 detección y tratamiento, 221 intercalación de archivos, 157 de datasets, 59, 60, 149 de diferente nivel, 149 de mismo nivel, 149 Ji-cuadrada (prueba), 281, 306, 414 Kaiser (criterio de), 201 Kendall (taus de), 281, 306, 416 Kolmogorov-Smirnov (prueba de), 191, 350 kurtosis, 354, 414 lógica difusa clasificación de alternativas, 259, 400, 402 clasificación de objetos, 174, 336 lambda (estadı́sticas), 281, 306, 417 lista de variables, reglas de codificación, 31 listado de casos con CORRECT, 129 con LIST, 145 con TRANS, 165 de datos con LIST, 60, 145 de diccionarios con LIST, 145 Lorenz curva de, 191, 350 función de, 191, 350 Mahalanobis (distancia de), 185, 346 Man-Whitney (prueba de), 281, 419 manejo de datos agrupación de datos, 2, 97 clasificación e intercalación de archivos, 2, 157 construcción de un dataset IDAMS, 2, 103 corrección de datos, 2, 129 importación o exportación de datos, 2, 135 intercalación de datasets, 2, 149 listado de datos, 2, 145 subdivisión de datasets, 2, 161 transformación de datos, 2, 165 verificación de códigos, 2, 109 verificación de consistencia, 2, 115 verificación de intercalación de datos, 2 verificación de intercalación de registros, 121 matriz archivos de, 5, 16, 79 cuadrada, 17 descriptor, 17 ÍNDICE ALFABÉTICO formato, 17 de configuración, 179, 215, 295, 296, 341, 367 en entrada de CONFIG, 180 en entrada de MDSCALE, 218 en entrada de TYPOL, 296 en salida de CONFIG, 180 en salida de MDSCALE, 217 en salida de TYPOL, 295 de correlación, 206, 254, 362, 394 en entrada de CLUSFIND, 175 en entrada de REGRESSN, 208 en salida de PEARSON, 255 en salida de REGRESSN, 207 de correlación parcial, 207, 362 de correlaciones, 355 de correspondencias, 355 de covariancia, 254, 394 en salida de PEARSON, 255 de covariancias, 355 de distancias, 180, 342 en salida de CONFIG, 180 de estadı́sticas, 281 de estadı́sticas bivariadas en salida de TABLES, 284 de medidas de similitud/disimilitud, 173, 215, 334 en entrada de CLUSFIND, 175 en entrada de MDSCALE, 217 de productos cruzados, 207, 254, 361, 394 de productos escalares, 180, 342, 355 de relaciones, 197, 198, 260, 354, 399 en el setup, 22 exportación, 135 formato libre, 137 importación, 20, 135 formato libre, 137 inversa, 207, 362 programas que leen, 17, 18 programas que producen, 17, 18 proyección, 321 rectangular, 18 descriptor, 19 formato, 19 media, 304, 345, 353, 373, 374, 379, 385, 393, 394, 405, 413, 424 mensajes de error, 429 nombre de códigos, 16 de variables, 15 normalización de configuraciones, 180, 341 de la matriz de relaciones, 264, 400 nubes de puntos, 198, 202, 267, 316 palabras clave estándar, 27 reglas de codificación, 29 tipos de, 28 parámetros ÍNDICE ALFABÉTICO colocación, 27 comunes, 30 BADDATA, 30 INFILE, 30 MAXCASES, 30 MDVALUES, 30 OUTFILE, 30 VARS, 31 WEIGHT, 30 formatos de especificación, 27 presentación en el Manual, 27 reglas de codificación, 29 valores por defecto, 28 Pearson (coeficiente r de), 206, 253, 362, 393 pesos, 30 ponderación de datos, 30 porcentajes basados en el gran total, 281, 304 basados en totales de columna, 281, 304 basados en totales de fila, 281, 304 predictores, 221, 239, 273 preferencia débil, 260 estricta, 260 programas de análisis de datos, 3 de manejo de datos, 2 ejemplo de setup, 60 promedio, 333, 361 proposiciones de control filtro, 25 parmetros, 27 reglas de codificación, 25 tı́tulo, 27 proposiciones de Recode, 31 asignación, 46 condicionales, 50 control, 48 definición/asignación, 50 verificación, 35, 165 proposiciones, ejemplo de setup, 60 proyección de casos, 198, 267, 316 de variables, 198 prueba de Durbin-Watson, 207, 365 de Kolmogorov-Smirnov, 191, 350 de Man-Whitney, 281, 419 de Wilcoxon, 281, 419 exacta de Fisher, 281, 418 F de Fisher, 223, 240, 387 Ji-cuadrada, 281, 306, 414 t de Student, 281, 420 puntajes calculados por FACTOR, 198 calculados por POSCOR, 246 quantiles, 193, 283, 349, 414 reagrupamiento de datos con AGGREG, 97 435 Recode constantes (tipos de), 35 expresiones, 36 aritméticas, 36 lógicas, 36 forma de proposiciones, 33 funciones aritméticas, 37 funciones lógicas, 45 iniciación de valores de variables, 34 lenguaje, elementos de, 35 operadores aritméticos, 35 lógicos, 36 relacionales, 36 operandos básicos, 35 proposiciones, 46, 48 reglas de codificación, 33 restricciones, 54 tratamiento de datos faltantes, 34 variables V y R, 35 Recode, funciones aritméticas ABS, 37 BRAC, 37 COMBINE, 38 COUNT, 39 LOG, 39 MAX, 40 MD1, MD2, 40 MEAN, 40 MIN, 40 NMISS, 41 NVALID, 41 RAND, 41 RECODE, 41 SELECT, 42 SQRT, 43 STD, 43 SUM, 43 TABLE, 43 TRUNC, 44 VAR, 45 Recode, funciones lógicas EOF, 45 INLIST, 45 MDATA, 46 Recode, proposiciones BRANCH, 48 CARRY, 51 CONTINUE, 48 DUMMY, 47 ENDFILE, 48 ERROR, 49 GO TO, 49 IF, 50 MDCODES, 51 NAME, 51 REJECT, 49 RELEASE, 49 RETURN, 49 436 SELECT, 47 recodificación de blancos con BUILD, 103 de datos, 31, 59 salvar variables recodificadas, 165 registros duplicados, identificación y corrección, 122 eliminados, tratamiento, 122 faltantes, detección y reemplazo, 122 identificación en MERCHECK, 121 inválidos, identificación y corrección, 122 regresión, 205, 361 con variables categóricas, 205, 221 con variables ficticias, 205, 221 lı́neas de, 318 lineal múltiple, 205, 361 por pasos, 205, 365 por pasos descendente, 205, 366 repartición alrededor de medoides, 174, 177, 334, 336 basada en la lógica difusa, 174, 177, 336 residuos, 206, 221, 273, 376, 409–411 en salida de MCA, 224 en salida de REGRESSN, 208 en salida de SEARCH, 274 ro de Spearman, 281, 416 rotación varimax de configuraciones, 180, 343 de factores, 198, 360 salvar datos recodificados, 165 variables recodificadas, 165 segmentación binaria, 273, 407 selección de casos, 25 de variables, 31 series de tiempo análisis, 323, 328 autoregresión, 328 correlaciones, 328 espectro, 328 espectro cruzado, 328 estadı́sticas, 328 filtros de frecuencia, 329 proyección, 326 transformación, 327 setup archivos de, 5, 79, 91 comentarios, 22 ejecución, 92 preparación, 91 Sormer (D de), 306 Spearman (ro de), 281, 416 Student (prueba t de), 207, 281, 365, 420 subdivisión de datasets, 60, 161 sumas de cuadrados, 207, 223, 240, 361, 374, 386 tı́tulo colocación, 27 ÍNDICE ALFABÉTICO reglas de codificación, 27 tablas bivariadas, 281, 305, 413 de 3 y 4 entradas, 281 de contingencia, 281, 413 de estadı́sticas en salida de TABLES, 284 de factores, 198, 356 de frecuencias bivariadas, 281 de frecuencias univariadas, 281 de frecuencias univariadas acumulativas, 281 multidimensionales, 305 univariadas, 281, 305, 413 tau (estadı́sticas), 281, 306, 416 tipologı́a iterativa, 293, 421 transformación de configuraciones, 180, 342 de datos, 59, 165 para recodificación, 31 seguro con TRANS, 59 de series de tiempo, 327 V de Cramer, 281, 306, 415 validación de datos, 57, 58 valores excéntricos tratamiento por MCA, 226 tratamiento por SEARCH, 277 valores no numéricos, tratamiento, 30 valores propios, 355, 356 valores residuales, 206, 221, 273, 376, 409–411 en salida de MCA, 224 en salida de REGRESSN, 208 en salida de SEARCH, 274 variable de clasificación producida por TYPOL, 295 de combinación, 222 de grupo, 187 de muestra, 187 variables activas, 197, 293, 356, 421 agrupadas, 97 alfabéticas, 13 categóricas en MCA, 221 en REGRESSN, 205, 211 nombres de códigos, 16 con decimales, 12 construidas por POSCOR, 246 cualitativas, nombres de códigos, 16 de control, 97, 221, 239 eliminación, 161, 165 ficticias en MCA, 221 en REGRESSN, 205, 211 lista de, 31 colocación, 31 reglas de codificación, 31 localización en los registros, 15 nombre de, 15 asignación por Recode, 51 numéricas, 12 ÍNDICE ALFABÉTICO corrección, 129 edición, 14, 103 tratamiento de campos no numéricos, 13 tratamiento por BUILD, reglas de, 103 pasivas, 197, 293, 358, 421 referencia a, 12 salvar variables recodificadas, 165 selección de, 31 suplementarias, 197 variancia, análisis de, 221, 239, 373, 385 varimax rotación de configuraciones, 180, 343 rotación de factores, 198, 360 vectores propios, 355 verificación de códigos con ayuda de registros C, 89, 109 de consistencia, 57, 59, 115 de intercalación de datos, 57, 58 de proposiciones Recode, 35, 91, 165 de valores de datos, 57, 58, 109 del orden de clasificación de datos, 121, 161, 163 Wilcoxon (prueba de), 281, 419 WinIDAMS archivos, 79 carpetas, 80 personalización del ambiente, 83 437