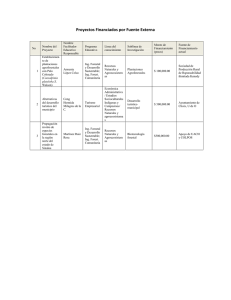
Document
Anuncio

los de ión ac alu ev la ra pa to es ien nal cim cio no na co les de ta ía res log fo to sos An ecur r Recreaciones para la estimación y la supervisión Steen Magnussen1 y David Reed2 EN ESTE CAPÍTULO, APRENDEREMOS LO SIGUIENTE: • Uso de modelos y agregación de datos en EFN e IFN • Cálculo y elaboración de modelos sobre contenidos de carbono y biomasa en ecosistemas forestales • Aspectos de las predicciones con modelos, calidad de los mismos, errores y sesgo • Problemas del cálculo y la elaboración de modelos sobre el cambio o evolución temporal de los atributos de IFN Resumen En muchas aplicaciones de inventarios forestales, deben calcularse varios atributos de interés utilizando una tabla de búsqueda o una ecuación (denominadas conjuntamente modelo). El tamaño del tronco, por ejemplo, es un atributo que en muy raras ocasiones se mide in situ. Al contrario, se calcula utilizando mediciones dimensionales como son el diámetro o la altura. Las observaciones individuales a menudo se valoran en conjunto con fines informativos y pueden agruparse durante la recopilación de datos de campo, como cuando los árboles se agrupan por categoría de diámetro o de altura. La valoración en conjunto simplifica la presentación de los datos; sin embargo, el contenido de la información es reducido. A menudo, variables como el volumen, la biomasa o el contenido de dióxido de carbono se calculan utilizando ecuaciones (modelos). A veces es difícil valorar cuando una determinada ecuación se puede aplicar a una situación concreta. Por lo tanto, es importante realizar una evaluación de la calidad de todas las ecuaciones (modelos) utilizadas en un inventario. La selección de una ecuación (modelo) determinada debería estar guiada por esta evaluación, así como por el objetivo y el contexto de la recreación. Algunos inventarios se centran en la evaluación del estado del recurso y otros, en los cambios que éste sufre a lo largo del tiempo. En el caso de otros objetivos, a menudo se prefiere realizar diferentes procedimientos de campo y diseños de muestreo. Llevar a cabo un muestreo con parcelas permanentes proporciona una estimación del estado y del cambio. Aquellos diseños que cuentan con un conjunto de parcelas permanentes más pequeñas (costoso) y con un conjunto de parcelas temporales más grandes (menos costoso) también pueden proporcionar buenas estimaciones acerca del estado y del cambio. Sin embargo, el análisis estadístico de estos diseños es bastante complejo, por lo que es necesario manejarlos con cuidado para asegurar la adecuada evaluación de su exactitud y precisión. 1 Científico sénior, Natural Resources Canada, Canadian Forest Service, West Burnside Road, Victoria BC V8Z 1M5, Canadá. Correo electrónico: [email protected] 2 Catedrático, School of Forest Resources and Environmental Science, Michigan Technological University, 1400 Townsend Ave., Houghton, MI 49931 EE. UU. Correo electrónico: [email protected] 1 1. Introducción Tanto en los inventarios forestales como en las aplicaciones de supervisión, muchos atributos forestales de interés no se miden de forma directa, ya que hacerlo resulta poco práctico o demasiado costoso. El mejor ejemplo conocido es el volumen del tronco, donde se miden los diámetros y las alturas de varios individuos y se emplea una tabla o ecuación (denominadas conjuntamente modelo) para calcular el volumen asociado (Köhl y otros, 2006, apartado 2.37). El volumen de detritus leñoso (coarse woody debris, CWD por sus siglas en inglés) constituye otro ejemplo (Köhl y otros, 2006, apartado 6.4.6; Woldendorp y otros, 2004). En la práctica, únicamente se mide un reducido número de pequeños segmentos de CWD para obtener el valor del volumen y la cantidad total (de CWD) en la zona de interés. Esto se calcula escalando las partes que se han medido, donde dicha escala dependerá del diseño de muestreo (Woldendorp y otros, 2004). Los avances en los procesos de detección remota (véase el capítulo ??) han favorecido el uso de mediciones fáciles de usar, así como de variables de fácil lectura (llamadas X) relacionadas con los atributos de interés (llamados Y). A continuación, se obtiene una estimación de Y para la zona o población de interés gracias a una pequeña muestra de Y y al conocimiento de las relaciones que existen entre X e Y (Köhl y otros, 2006, pág. 80). Más adelante se detallan los tipos de modelos disponibles para realizar estimaciones indirectas de cantidades como el volumen de madera, la biomasa y el contenido de dióxido de carbono; también se incluyen ejemplos. Del mismo modo, se describirán los problemas que es necesario tener en cuenta a la hora de elegir un modelo para una aplicación específica, así como los objetivos y contextos de la recreación. 2. Combinación La combinación es un proceso por el cual se agrupan datos u observaciones. Las combinaciones se crean para simplificar las 2 mediciones y el procesamiento de los datos (Stage y otros, 1993) o para resumir los datos y las observaciones en grupos y categorías de interés. Los datos de los atributos que se van a recopilar en un inventario se definen y ordenan según las necesidades de información que las partes interesadas tengan acerca del recurso forestal del cual se va a realizar el inventario (Dachang y Cossalter 2006, pág. 5). En un inventario de campo, es importante medir y registrar todos aquellos elementos de una parcela de muestra que cumplan con las definiciones o especificaciones del atributo deseado (para obtener más información véase el capítulo Diseños de muestreo). Los criterios y las definiciones de los datos se pueden basar en características demográficas. En el caso de los árboles, por ejemplo, podría tratarse del límite de tamaño mínimo, a menudo expresado como un diámetro mínimo, por ejemplo, 10 cm. Los criterios también pueden limitar las mediciones de las características de interés de determinadas especies o árboles. Es importante recordar que restringir los datos y las observaciones del inventario a aquellos elementos (árboles, arbustos, tocones, etc.) que cumplan con los criterios y definiciones establecidos, limita la inferencia y las estimaciones que se obtienen de estos datos a las unidades o partes de la población forestal que cumplan con dichas definiciones o criterios (véase el capítulo Observaciones y mediciones). Por ejemplo, si las estimaciones acerca del volumen de madera del tronco de los árboles vivos se realizan únicamente teniendo en cuenta aquellos árboles con un diámetro a la altura del pecho superior a 10 cm, no será posible calcular el volumen total o la biomasa del bosque de interés. En resumen, los resultados únicamente son aplicables a aquellos elementos de las poblaciones que tienen una probabilidad conocida positiva de ser incluidas en la muestra del inventario (Thompson 1992, pág. 21) (véase el apartado acerca del diseño de muestreo y la estimación). Los resúmenes de las unidades de muestreo no suelen incluir valores para todos los elementos que se han medido. Por ejemplo, a menudo los árboles se combinan en grupos en función de la especie, de aspectos demográficos como el diámetro y la altura o la condición social (apartado 2.2) la jerarquía, como el grupo funcional; (apartado 2.3) o la plantación total. La combinación puede ser unidimensional (p. ej.: volumen total por especie) o multidimensional (p. ej.: volumen por categoría de diámetro por especie), según proceda. La combinación de elementos de inventario también se puede realizar según el patrón de uso del terreno (p. ej.: rotación de cultivos) o según el uso futuro programado para un elemento del recurso (p. ej.: leña). Las consecuencias que cualquier combinación de elementos observados o medidos tienen en el análisis y la inferencia se deberán valorar con detenimiento (Clark y Avery 1976). Una vez que los datos se han combinado, suele ser complicado (o directamente imposible) recuperar los detalles subyacentes en una fase posterior si se desea(Ritchie y Hann 1997). Para conservar la exactitud y precisión de las estimaciones deseadas, en ocasiones es mejor dejar la combinación para la fase analítica que sigue a la finalización de la recopilación de datos de campo. Sin embargo, por motivos prácticos y de ahorro, la combinación suele tener lugar durante la observación de campo. En lugar de medir, por ejemplo, el diámetro de cada uno de los árboles de una parcela redondeando a 0,1 cm, en ocasiones y para más comodidad, se hace un recuento de aquellos cuya categoría de diámetro sea de 5, o incluso, de 10 cm. En este caso, los puntos medios de categoría se emplean con frecuencia en la fase analítica. Atención: una combinación siempre tiene la posibilidad potencial de introducir errores adicionales y, por lo tanto, hacer que la estimación resultante sea sesgada(Ducey 1999). Por supuesto, la combinación simplifica de forma significativa los procesos de campo y puede tener como resultado una mayor precisión general, si el ahorro que esta eficacia genera se emplea en la obtención de más datos de campo. Sin embargo, la compensación está lejos de ser algo sencillo, de ahí que hagamos hincapié en evitar las combinaciones carentes de sentido crítico. 2.1 Combinación por especies Las estimaciones de totales y por valores de área de unidad de una plantación, bosque o región, en ocasiones se combinan según las especies que cumplan determinadas definiciones o criterios relacionados con su tamaño o uso. Tal y como se ha mencionado anteriormente, aquellas especies que formen parte de la muestra del inventario, y que cumplan las definiciones o criterios, deben observarse y registrarse debidamente. De otro modo, las estimaciones serán sesgadas. Hay que tener que en cuenta que, cuando el personal de campo no puede identificar una especie, a esta deberá otorgársele un nombre que contenga elementos característicos que permitan su posterior identificación (por ejemplo, la forma o el tamaño de las hojas, cuerpos fructíferos, ramaje, corteza, etc.). La combinación de especies durante la recopilación de datos de campo puede hacerse de forma ordenada durante las investigaciones acerca de la biodiversidad y en aquellas orientadas al recuento de enfermedades o de los daños causados por insectos. De lo contrario, no se recomienda. Es frecuente que, en bosques templados, se realicen estimaciones de las características de las plantaciones por especie. En los bosques tropicales, esto puede resultar complicado, y probablemente sea más complicado de interpretar, debido a las complejas estructuras de las plantaciones o al gran número de especies existentes (Higgins y Ruokolainen 2004). En algunos casos, las especies se combinan por grupos ecológicos funcionales (como pueden ser aquellos con la copa más grande). Esto da como resultado un número manejable de grupos de especies, que son relativamente fáciles de interpretar en términos de la estructura del bosque (Gadow 1999). La utilidad comercial y la bioecología silvícola son aspectos que también se tienen 3 en consideración a la hora de realizar la combinación por especies. En los resúmenes a escala nacional o continental, los grupos de especies se pueden desarrollar con fines informativos debido al gran número de especies potenciales (Burns y Honkala 1990). Un grupo de especies denominado “Pino”, por ejemplo, puede incluir todas las especies Pinus que se encuentren en una determinada área geográfica de interés. 2.2 Combinación por tamaño Los árboles en ocasiones se combinan por demografía, lo que significa que aquellos árboles que tienen un tamaño y un estado social similar, se unen en grupos para los resúmenes de datos o para la recopilación de datos de campo. Las combinaciones por tamaño que se realizan con fines informativos o de análisis suelen ser bastante sencillas, salvo en los casos en los que las probabilidades de inclusión (como los factores de expansión) asociadas con los datos de inventario están vinculadas con el tamaño de los árboles (Köhl y otros, 2006, pág. 155). En el campo, el método de combinación más frecuente es, probablemente, una combinación de árboles por su diámetro (p. ej.: por categoría de 5 cm de diámetro). El número de árboles de cada categoría de diámetro se agrupa y los puntos medios de la categoría de diámetro se utilizan en los análisis posteriores para calcular variables como el volumen o la biomasa. Generalmente, en los protocolos de medición de campo se especifica el diámetro de árbol mínimo que se va a medir. Los umbrales de la inclusión o de la medición se definen según el objetivo del estudio y se suele emplear el diámetro comercial mínimo o una o dos categorías de diámetro por debajo de dicho umbral. Una estratificación de los esfuerzos de muestreo por tamaño es una limitación práctica inevitable cuando se realiza un muestreo de objetos de forma irregular, de gran variabilidad y dispersos. Un ejemplo es el muestreo de detritus leñoso (Roth y otros, 2003; Williams y otros, 2005). 4 Nota: si los árboles se seleccionan con una probabilidad proporcional a su tamaño, la utilización de categorías de diámetro puede resultar problemática (Ducey 2000). Puesto que los datos de los inventarios forestales a menudo se vuelven a utilizar para otros objetivos, es preferible mantenerlos en el mismo formato en el que fueron recopilados. Por ejemplo, para un usuario que quiere diseñar la distribución por diámetro (Cao 2004; Gove y Patil 1998) los datos no agregados le resultarán más interesantes. Los árboles también se pueden combinar por categoría de altura, la cual puede influir en el resultado de los productos madereros derivados (Köhl y otros, 2006, pág. 36). La categoría de altura también puede emplearse para combinar árboles según la disponibilidad de zonas para pastoreo o la estructura del hábitat de la vida salvaje (Spetich y Parker 1998). La combinación por altura es probablemente más común en los estudios ecológicos o de pastoreo que en aquellos que se centran en la evaluación de las oportunidades de la utilización de fibra comercial. Por último, los árboles se pueden agrupar según su posición en la cubierta forestal, como pueden ser aquellos con la copa más grande (Gargaglione y otros, 2010; Nigh y Love 2004). Este tipo de clasificación es más útil en los estudios ecológicos que en aquellos que intentan realizar un inventario del material comercial. La clasificación estructural puede tener una gran importancia a la hora de evaluar el potencial del pasto o de otros materiales comerciales que no contengan fibra. 2.3 Combinación por jerarquía Los árboles se pueden combinar en varios sistemas jerárquicos con el fin de llevar a cabo su análisis o simplemente a título informativo (Mairota y otros, 2002). Los árboles se pueden combinar por jerarquía biológica (árboles individuales → especies → grupo ecológico funcional → plantación) o por jerarquía de utilización (árboles individuales → categoría de diámetro → categoría de producto → especies → plantación). El informe puede incluir resúmenes de varios o de todos los niveles de la jerarquía. La combinación también tiene lugar a nivel espacial (p. ej.: Wolf 2005). La unidad espacial puede ser una plantación o una unidad más pequeña (como un píxel en una imagen de detección remota). La combinación se realiza en todas las unidades que cumplan determinados criterios relacionados con sus atributos o valores de datos forestales. El objetivo de la combinación espacial podría ser informar y analizar o mejorar la eficacia del muestreo a través de la estratificación (Köhl y otros, 2006, pág. 105). En el análisis de los datos agregados de forma espacial, es obligatorio recuperar toda la información relevante, remontándose hasta el origen de los datos (observados, basados en muestreo, basados en modelo, previstos, imputados, interpolados, etc.), así como cualquier estimación disponible acerca de la precisión y sesgo. La covarianza espacial entre los tipos de datos de recursos forestales agregados puede complicar en gran medida el análisis estadístico de estos datos (Mairota y otros, 2002; Rossi y otros, 2009; Schwab y Maness 2010; Waser y Schwarz 2006). En las combinaciones espaciales, las unidades espaciales se pueden combinar por tipo de bosque (p. ej.: tropical húmedo) o por región geográfica para llevar a cabo su análisis a nivel nacional o local. La región geográfica se puede basar en limitaciones políticas (p. ej.: fronteras provinciales o estatales) o zonas ecológicas, como las zonas de vida Holdridge (p. ej.: Ni y otros, 2005). La combinación a nivel de plantación puede realizarse tras la estimación (previsión) de las variables de interés de cada unidad de muestra en una plantación. La metodología apropiada para la combinación se determina según el diseño de muestreo y los objetivos del estudio. La combinación se puede integrar en el diseño de muestreo gracias a la utilización del muestreo estratificado (De Vries 1986, pág. 31). 2.4 Estimación de la categoría agregada En el caso de los árboles medidos en parcelas de área fija, las estimaciones de los valores por hectárea se obtienen dividiendo las características de los respectivos árboles individuales por el tamaño de la parcela de la cual se realiza el muestreo: Yij = A −1 nij ∑X k ijk Yij = cantidad calculada por hectárea de variable ith medida para la unidad de muestreo jth y la categoría de combinación nij con observaciones de X; Xijk = valor de la variable medida para el árbol kth en la unidad de muestreo ith y la categoría de combinación jth; A = tamaño, en hectáreas, de la unidad de muestreo individual. Para los árboles medidos con unidades de muestreo de radio variable, (véase Observaciones y mediciones para más información) se obtienen estimaciones de los valores por hectárea al dividir las características respectivas de cada árbol individual por el área basal del árbol medido y multiplicando por el factor de expansión del área basal: Yij = cantidad estimada por hectárea de la variable medida para la unidad de muestreo ith y la categoría de combinación jth con observaciones nij de X; BAF = factor de área basal, equivalente al área basal por hectárea representada por cada árbol medido; Xijk = valor de la variable medida para el árbol kth en la unidad de muestreo ith y la categoría de combinación jth; Bijk = área basal en m2 del árbol medido kth en la unidad de muestreo ith y la categoría de combinación jth 5 (Yˆ ) La estimación del total o de la Yˆ media de un parámetro de población, obtenido gracias a un diseño de muestreo de probabilidad, sigue los principios básicos del estimador Horwitz-Thomson (Overton y Stehman 1995): () Yˆ = ∑ Yi × π i−1 , Yˆ = Yˆ × N −1 i∈s donde la suma de las unidades (i) de la muestra (s) π i es la probabilidad de inclusión de la muestra de la unidad muestreada ith (véase el apartado acerca del muestreo). En una población de N unidades, la estimación a menudo se realiza con una mezcla de n observaciones a nivel de unidad basadas en muestras y de N-n estimaciones derivadas a partir de modelos o introducidas de otra forma (McRoberts 2006; McRoberts y otros 2002). En este caso, cada estimador del total es simplemente la suma de todos los valores N a nivel de unidad (observaciones y estimaciones). El estimador de precisión asociado puede deducirse directamente de la teoría estadística (Overton y Stehman 1995). En casos más complicados, es necesario emplear el método delta (Davison 2003, pág. 33-35). La estimación de parámetros de poblaciones a partir de unidades de observación se realiza de forma rutinaria en los inventarios forestales (véase el capítulo sobre diseño de muestreos). Existen dos unidades de muestreo básicas que se utilizan con frecuencia en las aplicaciones de inventario forestal: 1) parcelas de área fija y 2) parcelas de radio variable (p. ej.: Corona y otros, 2010). El muestreo transecto es un caso especial de parcelas de área fija y puede emplearse de forma similar en diferentes aplicaciones (Hedley y Buckland 2004). En la mayoría de los casos, se obtienen las estimaciones de las variables de interés para cada una de las unidades de la muestra y, a continuación, se combinan para obtener las estimaciones de mayores áreas (agregadas) de interés. El método de combinación de 6 estimaciones a partir de unidades individuales de la muestra y los métodos para calcular su precisión asociada dependen del diseño de muestreo. 2.5 Efectos de la combinación en la estimación y la recreación La combinación, durante la fase de recopilación de datos de campo, simplifica esta recopilación y puede mejorar la precisión relativa. Ya hemos descrito algunos de los problemas estadísticos relacionados con la combinación de datos. A continuación se ofrece un resumen. El inconveniente potencial de la combinación de datos durante la fase de su recopilación es la posible introducción de sesgo y la más que probable reducción de la precisión y exactitud de las estimaciones resultantes, todo ello a consecuencia de la introducción de errores (Clark y Avery 1976). Por ejemplo, combinar todos los árboles en una categoría de especie podría provocar la pérdida de información acerca del tamaño de los árboles individuales. Puesto que los datos de los inventarios forestales se pueden emplear para diferentes propósitos y en multitud de combinaciones, es recomendable limitar la combinación a la fase de informe o de análisis de un inventario. Las decisiones acerca de la combinación que se realiza durante la fase de recopilación de datos afectan a su utilización futura. Los nuevos y emergentes problemas importantes a los que el sector forestal se debe enfrentar pueden requerir detalles que se perdieron en su momento debido a la presión económica. No es posible, por ejemplo, analizar los diversos aspectos de la biodiversidad si las especies se han combinado durante la recopilación de datos de campo. El aumento de las técnicas de detección remota en los inventarios forestales (Tomppo y otros, 2008) se puede considerar como un proceso de combinación (in extremis). Desagregar los datos agregados únicamente es posible si se está dispuesto a realizar suposiciones acerca de la distribución de la frecuencia de los posibles valores de datos que se han combinado en uno solo (Papalia 2010). Únicamente en raras ocasiones se pueden justificar dichas suposiciones. 3. Estimación del volumen El volumen es la medida de la cantidad de madera más utilizada. Por lo general se calcula para evaluar el valor económico o el potencial de utilización comercial. El volumen de madera puede referirse tanto a una porción o parte específica de un árbol, como al árbol en su totalidad. El volumen de madera total de un árbol incluye los volúmenes de tronco, ramaje, tocón y raíces. En el caso de los árboles en pie, la producción de volumen por encima del suelo se basa en el volumen de madera de la corteza de las coníferas; sin embargo, en las especies arbóreas de hoja caduca puede incluir el volumen del ramaje. En función del objetivo de la medición y de las tradiciones locales, las mediciones o predicciones del volumen cúbico de madera pueden hacer referencia, por ejemplo, al volumen de corteza total, al volumen total del árbol (corteza y ramas) o al volumen de las partes de un árbol que se van a utilizar para un fin específico (Köhl y otros, 2006, pág. 47). Las estimaciones de volumen pueden incluir o no la corteza y, en las estimaciones por encima del suelo, el tocón. El volumen es siempre una medida cúbica y se suele expresar en metros cúbicos. El volumen comercializable a veces se expresa en otras unidades, siempre relacionadas con el uso comercial (Skovsgaard 2004). En el campo, el volumen de los árboles en pie se calcula, generalmente, a partir de mediciones como el diámetro o el diámetro más alguna altura de interés (p. ej.: la altura comercializable, la altura total o la altura para un límite de diámetro definido por el uso). La utilización posterior de las ecuaciones de volumen apropiadas, ecuaciones cónicas o una regla de registro proporcionará la estimación de volumen deseado (Lynch 1988; 1995; Tesfaye 2005; Tomé y otros, 2007; Yamamoto 1994a; 1994b). El volumen se puede medir directamente a partir de árboles caídos o de registros; sin embargo, a menudo se calcula a partir de dimensiones como el diámetro mínimo o la longitud de la pieza (Husch y otros, 1972). La medición directa del volumen en ocasiones se realiza dividiendo un árbol en partes más pequeñas, las cuales se consideran cilindros (Köhl y otros, 2006, pág. 50). El volumen de los postes de registro o de los productos procesados puede calcularse midiendo sus dimensiones. El conocimiento local es necesario para transformar en estimación el volumen de madera sólida. Con el avance de la tecnología de teledetección, especialmente de LiDAR (véase el capítulo dedicado a la teledetección), ahora es posible combinar los cálculos y estimaciones de campo referentes al volumen de una unidad espacial (parcela) con un conjunto de variables auxiliares para obtener pronósticos basados en modelos del volumen de área por unidad o estimaciones por árbol del volumen para árboles lo suficientemente grandes y distintos como para ser identificados con un alto grado de seguridad (Maltamo y otros 2004a; Maltamo y otros, 2004b; Parker y Evans 2004; Popescu y otros, 2003). 3.1 Ecuaciones de volumen El volumen de la corteza (V) se suele expresar de forma cuantitativa como una función del diámetro (D), el diámetro y la altura (H) o la altura comercializable. A veces, otras variables, como por ejemplo la longitud del tronco limpio, se utilizan para calcular el volumen (Husch y otros, 1972). Una consideración importante a tener en cuenta es que cualquier variable que sea necesaria para calcular el volumen debe observarse durante la fase de recopilación de datos de campo. Los dos siguientes modelos “clásicos” se utilizan con frecuencia (Köhl y otros, 2006, pág. 50) : V = α + β × D 2 × H o V = ω × Dς × H ψ y, en ambos casos, α, β e γ son coeficientes que se van a determinar a través de muestras (pequeñas) específicas, en las que los volúmenes de los árboles se determinan cuidadosamente 7 o se conocen gracias a estudios anteriores, esto es, el conocimiento previo. Cuando la altura del árbol se puede expresar como una función del diámetro (Begin y Raulier 1995; Huang y Titus 1992; Jayaraman y Lappi 2001; Moore y otros, 1996; Nanos y otros, 2004; Zhou y McTague 1996) la relación se puede integrar en la predicción del volumen basada únicamente en el diámetro. Las tablas de búsqueda de volumen de tronco tabuladas para determinadas especies, ubicaciones y diámetro del tronco se denominan tarifas volumétricas (Fonweban y Houllier 1997; Magnussen 1998; Paine y McCadden 1988). La elección del modelo puede depender del objetivo y de los datos de la recreación (Skovsgaard 2004). Las ecuaciones que se han enumerado suponen, de forma implícita, la forma de árbol de tronco único y pueden necesitar ser modificadas o sustituidas por especies con una forma más compleja. En ocasiones, la ecuación del volumen puede ajustarse más fácilmente después de una transformación logarítmica, ya que dicha transformación lleva el modelo a otra forma lineal. Sin embargo, se introduce un sesgo negativo cuando el logaritmo de V esperado se convierte de nuevo a unidades aritméticas (Baskerville 1972; Bi y otros, 2001; Lee 1982; Wiant y Harner 1979). El sesgo es aproximadamente el orden de la magnitud de la mitad de la varianza residual de la ecuación, al menos cuando se puede justificar la suposición de una distribución normal de los residuos del modelo. En ausencia de ecuaciones de volumen local de confianza, es posible hacer uso de las relaciones geométricas para obtener un valor aproximado. El volumen de un cilindro es simplemente el área de la base por la altura, y el volumen de un cono es la tercera parte del volumen de un cilindro con la misma área de base y altura. Los árboles no son ni conos ni cilindros, pero análisis empíricos a menudo indican que el volumen de aquellos árboles que sólo tienen un tronco está entre el de un cono y el de un cilindro, con un volumen de árbol con frecuencia entre 0,40 8 y 0,45 veces el de un cilindro equivalente. Al emplear un valor de, por ejemplo, 0,42, obtendremos V ≈ 0.42 × B × H donde B es el área basal del árbol a la altura del pecho y H es la altura comercializable del árbol. Esta ecuación a menudo sobrestima el volumen de los árboles que han crecido al aire libre con una forma más cónica, subestima el volumen de los árboles con una forma más cilíndrica y puede necesitar modificarse para aquellas especies que tienen una forma más compleja. Sin embargo, proporciona una primera aproximación que, posteriormente, se podrá modificar en función de la experiencia local. Aquellas ecuaciones de volumen que derivan de los indicadores de detección remota a menudo son lineales (posiblemente tras una transformación logarítmica) con una forma de modelo que depende del tipo de sensor, la resolución de los datos y la escala (Biggs 1991; Magnusson y otros, 2007; McRoberts y otros, 2007; Straub y otros, 2010; Yu y otros, 2008). La aplicación de cualquier modelo implica que las estimaciones posteriores no sean exactas. Las estimaciones obtenidas a partir de modelos pueden sesgarse debido a las limitaciones del modelo, y en todos los casos, son predicciones del valor esperado teniendo en cuenta el valor de los indicadores (Kangas 1996). Por ejemplo, si se calcula un valor de tronco a partir de D y H utilizando una ecuación de volumen local, el valor estimado de V debería interpretarse como el valor medio de todos los árboles existentes en la población que tienen los mismos valores de D y de H. El árbol real en cuestión puede tener un volumen superior o inferior al del valor esperado (Gregoire y Williams 1992). Si un modelo proporciona estimaciones con un nivel de sesgo inaceptable, podría ser necesario o bien diseñar un modelo mejorado o bien calibrar el ya existente (Erdle y MacLean 1999; Kangas y Maltamo 2000; Lappi 1991). 4. Estimación de la biomasa La biomasa se define como la masa total de materia orgánica vegetal viva expresada en toneladas secas o en toneladas secas por unidad de superficie. Las estimaciones de la biomasa se pueden limitar a la porción de vegetación, árboles o componentes de los árboles (como el follaje o la madera) que se encuentran por encima del suelo (Gschwantner y otros 2009). La biomasa de una plantación forestal (compartimento) es a menudo proporcional al volumen y área basal de ésta. Por el contrario, la biomasa de un árbol individual es, por lo general, proporcional a su diámetro y altura (Teobaldelli y otros, 2009). La asignación de la biomasa en función de diferentes componentes funcionales está relacionada con las especies, las condiciones de crecimiento y los requisitos de agua, nutrientes y energía tanto de las plantas individuales como de las plantaciones (Gargaglione y otros, 2010; Zhang y Borders 2004). El contenido de dióxido de carbono de la vegetación está directamente relacionado con la biomasa, tal y como se describe en el siguiente apartado. La estimación directa de la biomasa forestal es una propuesta que requiere mucho trabajo y que, además, resulta costosa. El muestreo estratificado de la estimación basada en el campo de la biomasa por área de unidad es el único enfoque realista (Loaiza Usuga y otros, 2010). Los estratos se suelen definir según los componentes claramente identificables de las plantas vivas (como fungi, musgo, hierbas, pastos, arbustos, plántulas, brinzales, árboles, epífitas). La biomasa en cada una de las unidades de muestreo se determina según el peso después del secado siguiendo los protocolos estándar (Gabriëls y Berg 1993). Aquellos elementos del muestreo (por ejemplo, los árboles) que son demasiado grandes para un manejo práctico y rentable, se dividen en partes más pequeñas y son éstas las que se tienen en cuenta en la estimación de la biomasa. Es muy importante que tanto el plan de disección como el de muestreo aseguren un estimador no sesgado de la biomasa de los elementos de gran tamaño (Ahmed y otros, 1983; Cancino y Saborowski 2005; Good y otros, 2001; Gregoire y otros, 1995). 4.1 Componentes de la biomasa La biomasa se puede calcular en total para plantaciones o partes de ésta, según se ha indicado; sin embargo, a menudo es necesaria la información acerca de su distribución por componente de la planta. Los componentes de la biomasa se pueden dividir según sea necesario en función de una aplicación determinada pero, a menudo, incluyen categorías como la madera del tronco, la madera del ramaje, el follaje, la corteza, las raíces, etc. con más o menos subdivisiones, según sea necesario. Una limitación frecuente es que la suma de las estimaciones de los componentes de la biomasa debe ser igual a la biomasa total de las plantaciones, o partes de éstas de interés. En muchas aplicaciones, únicamente se emplea la biomasa superficial. Obviamente, existen componentes de la biomasa que se encuentran en el subsuelo, como las raíces gruesas y finas; sin embargo, los estudios que cuantifican estos valores son difíciles de llevar a cabo y únicamente se pueden realizar para un pequeño número de especies y ecosistemas. Además, por lo general, la exactitud de sus datos es mayor (Lukac y Godbold 2010; Macinnis-Ng y otros, 2010; Niiyama y otros, 2010; Pramod y Mohapatra 2010; Zhang y otros, 2010a). A nivel de plantación, se puede calcular la biomasa del follaje, de los arbustos, de las hierbas, de los líquenes, del musgo, etc. En escenarios forestales, la que predomina suele ser la biomasa del follaje. Se dan casos en los que la copa de un árbol es pequeña y su follaje o su biomasa también lo son, en comparación con otros componentes del ecosistema. La decisión acerca de qué componentes de la biomasa son necesarios tener en cuenta depende de los ecosistemas que se van a estudiar, así como del uso que se le va a dar a la información obtenida. Cannell (1982) presenta un compendio de datos de biomasa a nivel mundial a partir de secciones transversales de los ecosistemas. Este compendio incluye los ratios de los diferentes 9 componentes de la biomasa para muchos tipos de bosque. En 2011, este compendio sigue considerándose la compilación más relevante en cuanto a cifras de biomasa de referencia. En una reciente reevaluación de la biomasa forestal y del almacenamiento de dióxido de carbono, se puede encontrar un conjunto más pequeño de estimaciones de biomasa (Keith y otros, 2009). 4.2 Ecuaciones de la biomasa Las ecuaciones de la biomasa se emplean para pronosticar la biomasa a partir aquellas variables auxiliares disponibles de forma inmediata (X). Las ecuaciones pueden pronosticar la biomasa de un árbol individual o la biomasa arbórea de una determinada superficie forestal. Las ecuaciones a nivel de árbol expresan la biomasa como una función de las dimensiones del árbol (diámetro y altura). Las ecuaciones para los pronósticos de la biomasa a nivel de superficie pueden variar en función de las variables auxiliares (X). Las ecuaciones generadas por variables X relacionadas con el campo, que generalmente aplican atributos a nivel de plantación como el área basal, hacen referencia al tamaño del árbol (altura y diámetro) o agregados de atributos a nivel de árbol similares. Las ecuaciones generadas por variables X obtenidas a partir de datos derivados de la detección remota (Gallaun y otros, 2010; Wijaya y otros, 2010; Zhao y otros, 2009) varían en función del tipo de sensor y de la resolución de dichas variables (X). En muchos casos, la biomasa utilizada en estas ecuaciones como variable independiente (Y) en raras ocasiones se considera una estimación directa de la biomasa, sino una estimación obtenida a través de otro conjunto de modelos que “amplía” las estimaciones de inventario disponibles de los atributos de árbol y plantación a los componentes de la biomasa deseados (Albaugh y otros, 2009; Gallaun y otros, 2010; Jalkanen y otros, 2005; Lehtonen y otros, 2004; Levy y otros, 2004; Schroeder y otros, 1997; Somogyi y otros, 2008; Teobaldelli y otros, 2009; Wijaya y otros, 2010; Zhao y otros, 2009). 10 Las ecuaciones que se aplican a los datos de los inventarios forestales se desarrollan para especies o grupos de especies determinados y se pueden desarrollar con los datos recopilados a partir de áreas geográficas limitadas. Existen algunos ejemplos, descritos más adelante, en los que ecuaciones más ampliamente aplicables se han desarrollado a partir de la síntesis de estudios publicados. Cannell (1984) propuso, para un amplio abanico de plantaciones de zonas templadas y tropicales, ecuaciones para calcular la biomasa leñosa a nivel de plantación a partir de su área basal y de la altura de los árboles; la mayoría de estas ecuaciones se emplean en tipos de bosques templados de coníferas. La aplicación de estas ecuaciones es sencilla, ya que emplean variables que, por norma general, se obtienen durante la recopilación de datos de campo. La aplicación se hace, como norma, para la estimación a nivel de plantación (parcela) más que para la estimación a nivel de árbol. A nivel de árbol individual, Jenkins y otros (2003) proponen ecuaciones compuestas aplicables a especies de frondosas templadas en América del Norte. Teobaldelli y otros ofrecen un conjunto de ecuaciones generalizadas parecido para cinco grupos de especies en Europa. Estas ecuaciones podrían aplicarse, con la cualificación apropiada, a otros tipos de bosques templados. Ofreceremos un ejemplo de una ecuación generalizada utilizada por Jenkins y otros . Más concretamente, la ecuación de Schumacher, donde la biomasa total por encima del suelo de los árboles individuales se calcula en función de la relación alométrica con el (b0 +b1 ln( D)) diámetro a la altura del pecho: B = e donde B es la biomasa total por encima del suelo (kg) de aquellos árboles cuyo diámetro a la altura del pecho sea de 2,5 cm o superior (D). Los coeficientes se ofrecen tanto para los grupos de especies de hoja caduca como para los de hoja perenne en todas las zonas de los Estados Unidos. También se utilizan grupos de especies más amplios (como Pino y Pícea, con un total de cinco grupos de especies de hoja caduca y cuatro de hoja perenne). Teobaldelli y otros proponen ecuaciones para el factor de ampliación (BEF) necesario para convertir una estimación de la masa arbórea en crecimiento (X) en una estimación de la biomasa (B). Una ecuación de ampliación utilizada con frecuencia tiene la forma de −b BEF = b0 + b1 × X 2 donde X es una medición de la masa arbórea en crecimiento. Brown (1997) presenta ecuaciones para árboles individuales en bosques tropicales. En el caso de las especies frondosas, se presentan dos ecuaciones para los bosques tropicales secos, dos para los bosques tropicales húmedos y una para los bosques tropicales lluviosos. Además, se presenta otra ecuación para las palmeras y otra para bosques tropicales de coníferas. Todas estas ecuaciones expresan la biomasa de árboles individuales como una función del diámetro y la altura, aunque varias formas de la ecuación se utilizan en diferentes aplicaciones. La biomasa de los diferentes componentes de la biomasa se suele calcular a partir de los modelos de la distribución (asignación) de la biomasa y la biomasa forestal por encima del suelo para componentes específicos (tronco, corteza, tocón, ramaje, follaje, fruto o semilla). Siguiendo con el ejemplo de Jenkins y otros , la proporción de la biomasa total en el componente de la biomasa ith de un árbol se puede calcular a partir de, digamos, el diámetro del árbol a la altura del pecho como b0 +b1×D−1 r = e i en Nota: la “conversión” de la masa arbórea en crecimiento en biomasa utilizando un conjunto de ecuaciones generalizadas y a partir de uno o más atributos de inventario fácilmente disponibles, y, a continuación, en componentes de la biomasa parece muy fácil en principio. Existen muchos factores y circunstancias que pueden poner en duda una estimación de biomasa obtenida a partir de ecuaciones generalizadas (Albaugh y otros, 2009; Jalkanen y otros, 2005; Lehtonen y otros, 2004; Retzlaff y otros, 2001). Es, por lo tanto, responsabilidad del analista elegir cuidadosamente tanto el modelo como la aplicación que se busca. En ocasiones, la limitación y la estructura de error de muchos modelos generalizados y fórmulas de asignación de biomasa alométricas no está bien documentada. 5. Estimación del contenido de dióxido de carbono Las estimaciones a nivel regional y nacional del contenido de dióxido de carbono de los ecosistemas y el cambio que éste sufre con el tiempo, son componentes importantes para evaluar el ciclo global del dióxido de carbono y su impacto en el clima y en los gases de efecto invernadero (Birdsey 2006; Cairns y Lasserre 2006; Waterworth y Richards 2008; Watson 2009). Los acuerdos internacionales deben mejorar su capacidad de evaluar las existencias de dióxido de carbono forestal y su cambio (Dutschke y Pistorius 2008; Kägi y Schmidtke 2005; Zhang y otros, 2009). En este contexto, cuantificar el contenido de dióxido de carbono existente en los bosques y en los ecosistemas forestales, y su contribución al ciclo del dióxido de carbono, son elementos cada vez más importantes. Los inventarios forestales realizan importantes contribuciones a la estimación del dióxido de carbono de los ecosistemas forestales ya que es relativamente sencillo evaluar los componentes vegetales capturados por un inventario (Dupouey y otros, 2010; Nabuurs 2010; Rodeghiero y otros, 2010; Tupek y otros, 2010). En muchos casos, el dióxido de carbono que se encuentra en la vegetación se emplea como un sustituto del dióxido de carbono total del ecosistema, ya que su derivación a partir de la información existente o de los continuos esfuerzos del inventario es bastante sencilla. El contenido de dióxido de carbono total de un ecosistema, que incluye componentes inorgánicos como el suelo, es mucho más difícil de evaluar, en especial si se debe cuantificar la precisión de 11 las estimaciones (Baritz y otros, 2010; Loaiza Usuga y otros, 2010). Las costosas estimaciones acerca del dióxido de carbono generalmente se derivan de unas pocas parcelas estudiadas de forma intensiva, cada una considerada como representativa de una gran área con suelo, vegetación y clima similar. Hoy en día, muchas estimaciones acerca del área de unidad del contenido de dióxido de carbono presente en la vegetación forestal se obtienen a partir de un conjunto de variables explicativas (regresores) obtenidas de diferentes sensores satélite o aéreos (Maselli y otros, 2010; Sánchez-Azofeifa y otros, 2009; Tagesson y otros, 2009). De forma invariable, estas estimaciones están basadas en la relación modelada que existe entre las estimaciones de la biomasa (dióxido de carbono) basadas en campo y una o más variables aéreas auxiliares. 5.1 El dióxido de carbono de la vegetación El contenido de dióxido de carbono de la vegetación es sorprendentemente constante en una amplia variedad de tipos de tejido y especies (Baritz y otros, 2010; Mäkelä y otros, 2008; Munishi y Shear 2004; Nogueira y otros, 2008; Rana y otros, 2010; Wauters y otros, 2008). Schlesinger (1991) apuntó que el contenido de C de la biomasa, en la mayoría de los casos, se encuentra entre el 45 y el 50% (por masa seca). En muchas aplicaciones, el contenido de dióxido de carbono (C) de la vegetación se puede calcular tomando una fracción de la estimación de biomasa seca (B), como en Ĉ = 0.475× B̂ . La precisión de una estimación de esta naturaleza no suele ser elevada debido a los errores en B̂ y se debe esperar que sea sesgada. En el caso de la materia muerta, el contenido de dióxido de carbono es una función del estado de descomposición (Boulanger y Sirois 2006; Garrett y otros, 2010; Mukhortova y Trefilova 2009; Vávrová y otros, 2009; Yang y otros, 2010). En el caso del material que aún se puede identificar, como la hojarasca fresca 12 o los árboles muertos en pie, la ecuación anterior se puede emplear para calcular el contenido de C si se puede calcular la masa del material, véase el apartado 5.2 que aparece a continuación. En el caso del material gravemente afectado por la descomposición, puede ser necesario determinar el contenido de C en las submuestras obtenidas a partir del material recopilado en el lugar y, a continuación, combinarlo con una estimación de la (bio) masa total de dicho tipo de material antes de poder calcular el contenido de C de los componentes vegetales. Incluso teniendo en cuenta los pequeños errores a consecuencia del muestreo, tanto la medición como el manejo del material pueden tener un gran impacto en la precisión de la estimación de un componente vegetal cuyo orden de magnitud sea mayor al de la muestra tomada (Woodall y otros, 2008). El contenido total de dióxido de carbono de la vegetación va más allá de los árboles. Incluye todas las partes y componentes de la comunidad vegetal, como hierbas, arbustos, musgo, etc. Las estimaciones de dióxido de carbono basadas en campo generalmente comienzan con una estimación de la biomasa (véase arriba) y sigue con una conversión, tal y como se ha detallado anteriormente. Para cumplir esta tarea, es necesario estratificar la comunidad y hacer un muestreo de cada estrato. Los estratos necesarios deben definirse en función de la composición, la estructura y la extensión de la comunidad en cuestión (Clark y otros, 2008; Friedel 1977; Kenow y otros, 2007). En algunos casos, puede tener sentido obtener estimaciones del contenido de C de formas de vida como las epifitas, mientras que en otros casos este dato puede ser irrelevante. El enfoque sigue los pasos descritos anteriormente para todos los tipos de vegetación: primero se calcula la biomasa de cada estrato (componente) utilizando los métodos de muestreo apropiados y, a continuación, se aplica el ratio para calcular el contenido de C. 5.2 Contenido de dióxido de carbono del ecosistema Además del contenido de dióxido de carbono de la vegetación, puede ser necesario calcular el contenido total que se encuentra en el ecosistema (Jia y Akiyama 2005; Wang y Sun 2008; Wise y otros, 2009). Esto incluye tanto las reservas de dióxido de carbono bióticas como las abióticas. La biomasa y el contenido de dióxido de carbono de aves (Pautasso y Gaston 2005) y mamíferos (Desbiez y otros, 2010; Plumptre y Harris 1995) se ignora con frecuencia ya que, en general, se trata de una pequeña fracción del contenido de dióxido de carbono total del ecosistema. Sin embargo, en ocasiones puede ser necesario calcular la biomasa y el contenido de dióxido de carbono de los artrópodos para obtener una correcta estimación de C del conjunto del ecosistema (Fisk y otros, 2010; Tovar-Sánchez 2009). Los insectos colonizadores pueden constituir una parte significativa de la biomasa total de algunos ecosistemas (Vasconcellos 2010; Yamada y otros, 2003) y los materiales abióticos que forman nidos y colonias pueden ser una parte importante del total de C. Un gran conjunto de dióxido de carbono abiótico es la materia orgánica del suelo (Chang y otros, 2010; Rovira y otros, 2010; Tipping y otros, 2010), la cual es particularmente importante a elevadas latitudes o altitudes. En algunos casos, este dato puede ser superior al nivel de dióxido de carbono vegetal. La materia vegetal muerta que se encuentra tanto en la superficie del suelo como en las capas superiores del suelo también puede tener un importante contenido de C que debería considerarse en cualquier estimación del contenido de C de un ecosistema (Fisk y otros, 2010; Gasparini y otros, 2010). McKenzie y otros, ofrecen un compendio de métodos para la recopilación de datos de campo relacionados con la estimación del dióxido de carbono en el suelo, hojarasca y detritus leñoso. Los datos cuantitativos acerca de la hojarasca forestal pueden ser escasos. Sin embargo, los países con alto riesgo de incendio forestal pueden contar con una información más amplia, puesto que llevan a cabo estudios acerca de los elementos de los bosques que aumentan de forma significativa el riesgo de incendio en periodos de sequía (Fernandes 2009; Kessell y otros, 1978). El contenido de dióxido de carbono de la hojarasca debería determinarse a partir de las muestras de campo diseñadas para ese objetivo específico. El contenido de dióxido de carbono de la hojarasca depende del estado de descomposición. Se puede aplicar un enfoque de ratio como el descrito para la vegetación, véase apartado 5.1, pero a menudo subestimará el contenido de C de la capa de hojarasca debido al escape de gases carbónicos durante el proceso de descomposición (Fioretto y otros, 2007; Hosseini y Azizi 2007; MacDicken 1997). Las estimaciones de C del terreno pueden obtenerse a partir del muestreo de campo y éste es el método más preciso y apropiado para calcular el contenido de dióxido de carbono de una ubicación concreta. La recopilación de datos de campo debería emplearse siempre que se necesitaran estimaciones precisas del C del terreno; sin embargo, es importante tener en cuenta la variación temporal que ocurre durante la estación de crecimiento y que, en el caso de estudios amplios, podrían necesitar de la ampliación del período de muestreo. Si existiera un mapa de clasificación de terreno del área en cuestión, podría incluir información acerca del contenido de dióxido de carbono de los diferentes suelos que hay en dicha área (Geissen y otros, 2009; Zhang y otros, 2010b). Un tipo de suelo determinado puede tener niveles de dióxido de carbono diferentes en función de la cubierta vegetal dominante y del uso del terreno; el suelo de un terreno de labranza puede tener un contenido de C muy diferente al de un terreno similar en un bosque maduro. Las estimaciones del contenido de C del suelo pueden estar disponibles o no para todas las condiciones en un área determinada. Batjes (2009) proporciona acceso a una amplia base de datos de propiedades físicas y químicas 13 globales del suelo, incluyendo información que se puede emplear en la estimación del contenido de C en el caso de que no exista información específica acerca del sitio. Estas estimaciones serán menos precisas que aquellas que se han realizado a partir del muestreo de campo, pero pueden resultar más económicas si no es necesario una estimación precisa acerca de una ubicación específica. En muchas aplicaciones, puede resultar más económico, e incluso ofrecer estimaciones finales de mayor precisión, utilizar un número más elevado de estimaciones del contenido de C de las unidades de muestra individuales, menos precisas, que medir con gran precisión el contenido de C de un subconjunto de unidades de muestra (MacDicken 1997). Las disyuntivas son una función del diseño de muestreo y el coste, y deben evaluarse en dicho contexto, véase el capítulo dedicado a los diseños de muestreo. Sin embargo, es necesario tener en cuenta que si el recurso es económico, las estimaciones de C son sesgadas, las oportunidades de una disyuntiva atractiva entre una muestra pequeña con observaciones costosas y una muestra mayor con observaciones económicas pueden verse gravemente reducidas (Köhl y otros, 2006, pág. 79). 6. Evaluación de la calidad del modelo Un modelo resume la relación conceptual que existe entre una o más variables dependientes (Y) y uno o más indicadores (X). El modelo puede definirse como una única ecuación (por ejemplo, Fehrmann y otros, 2008), un sistema de modelos relacionados (por ejemplo, Gertner y otros, 2002) o un modelo jerárquico (multinivel) (por ejemplo, Pedersen 1998). En la mayoría de los casos, los modelos se emplean en la predicción de nuevos valores de entidades no observadas a partir de los indicadores disponibles. Las ecuaciones de volumen, biomasa y dióxido de carbono que se han mencionado anteriormente, constituyen ejemplos de los tipos de modelo más básicos. 14 Un modelo se puede formular utilizando el conocimiento subjetivo (Curtin 1970) o el conocimiento extraído de otros estudios o sugerido por las tendencias aparentes de los datos observados. Las siguientes referencias proporcionan acceso a una amplia selección de modelos forestales (Amaro y otros, 2003; Dykstra y Monserud 2009; Schwab y Maness 2010; van Laar y Akça 2007). En los inventarios forestales y las ciencias biológicas, los datos muestran una gran cantidad de variaciones naturales y los modelos se limitan a pronosticar el valor esperado de las variables dependientes según los datos iniciales. La calidad de cualquier modelo se evalúa según su capacidad de proporcionar estimaciones no sesgadas (precisas) de estas expectativas, así como de la precisión de las predicciones de los modelos. Aquellos modelos con parámetros de modelo deterministas (fijos, invariables) generan una predicción única (el valor esperado) según un conjunto de valores de indicador. Los modelos estocásticos contienen uno o varios parámetros aleatorios (Biging y Gill 1997; Rennolls 1995). Por lo tanto, pueden generar tanto predicciones condicionales para una unidad aleatoria (un árbol, una parcela o una plantación forestal) como pronósticos para poblaciones medias (Schabenberger y Gregoire 1996). Cuando un modelo se ajusta a los datos, la comparación de los valores pronosticados por el modelo y los valores reales de la variable dependiente ofrece una evaluación inicial de la calidad del modelo. Por normal general, se recomienda que los modelos sean no sesgados, es decir que las desviaciones a partir de las predicciones de modelo (residuos) tengan un promedio de cero para cualquier dato, y precisas, lo que significa que los residuos se deben distribuir de forma estricta alrededor de los valores pronosticados. La calidad del modelo que se va a emplear en la predicción se evalúa mediante la comparación del pronóstico de una observación nueva no empleada en el desarrollo de un modelo, con el valor real de la nueva observación. Los criterios comunes para la evaluación de la calidad de un modelo incluyen, por ejemplo, una prueba t de la hipótesis de un error de predicción de modelo próximo a cero, la varianza de los errores de modelo, la magnitud de la desviación media absoluta (Venables y Ripley 1994), la prueba de los signos para probar las medias iguales de, digamos, los valores pronosticados y observados (Conover 1980, pág. 122). La prueba de Wald-Wolfowitz se puede emplear para probar la hipótesis de que los elementos de una secuencia de errores de modelo y el gradiante de los valores de indicador son independientes (Conover 1980, pág. 136). Las evaluaciones adicionales a menudo se orientan hacia la prueba de la suposición de una distribución normal de residuos de modelo (Brown y Hettmansperger 1996), un análisis de errores en modelos “curvos” (Ducharme y Fontez 2004; Huang 1997) y la homogeneidad de las varianzas de error en un intervalo de entrada (McKeown y Johnson 1996; O’Brien 1992; Shoemaker 2003). Reynolds (1984) ofrece un enfoque básico para evaluar la calidad de los modelos. Vanclay y Skovsgaard (1997) ofrecen una breve visión general y un marco operativo para evaluar la calidad de los modelos. Es frecuente ver una evaluación de modelo realizada mediante la exclusión de una parte de los datos durante la fase de ajuste del modelo o un marco de validación cruzada de exclusión a partir del cual el modelo se calcula de forma repetida dejando aparte una observación y, a continuación, comparando el valor real y pronosticado del dato retenido (Efron 2004). En nuestro caso, preferimos el último enfoque, ya que en pocas ocasiones es posible abarcar una gran parte de datos retenidos sin que esto afecte a las propiedades del modelo que se va a evaluar. Esto es, que con un número menor de observaciones, la recreación del modelo elegido pueda ser óptima. Cuando los tamaños de las muestras son pequeños, recomendados la creación de modelos basados en técnicas sólidas (Choi y otros, 2010; Lange y otros, 1989; Wang y Leng 2007). Cuando se aplica un modelo general, como las ecuaciones de volumen y de biomasa, o un modelo diseñado para unas especies determinadas en diferentes zonas geográficas, es importante tratar de evaluar la calidad del modelo antes de su aplicación. Esto puede requerir la recopilación de nuevos datos de campo o puede ser posible utilizar los ya existentes para este propósito. El hecho de no evaluar la calidad del modelo lleva al usuario a suponer que el modelo que se va a emplear es el adecuado para las especias y zona geográfica en la cual se va a aplicar, lo que puede ser cierto, o no. Los usuarios de los modelos deben tener siempre en cuenta que un modelo puede generar pronósticos inusuales. Las extrapolaciones, como la aplicación de los modelos con uno o más valores de pronóstico fuera del margen de los datos utilizados durante la adecuación del modelo, deberían evitarse siempre que sea posible puesto que el sesgo y la precisión podría no ser relevante para otros modelos correctamente fundamentados (Schreuder y Reich 1998) Gracias al avance de los modelos que confían en la utilización de datos obtenidos a través de detección remota, cada vez es más importante tener en cuenta (comprobar) si los indicadores son los mismos (p. ej.: con información idéntica acerca del contenido, datos recopilados a escalas espaciales idénticas y con estructuras de medición de error iguales) que los datos empleados durante el ajuste del modelo. En caso contrario, el impacto que los errores tienen en las variables también debería tenerse en cuenta (Carroll y otros, 1995; Fuller 1987). Los usuarios de los modelos ya existentes en muy raras ocasiones tienen potestad para realizar comprobaciones en ellos o validaciones. La información clave acerca de las propiedades estadísticas y los datos que sustentan el modelo a menudo no se encuentran o son difíciles de recuperar. En lugar de confiar al ciento por ciento en las predicciones de los modelos, una estrategia podría ser tomar una pequeña muestra de 15 probabilidad de las variables de interés y combinarla con los pronósticos obtenidos a partir de un modelo. La popularidad de este tipo de estimación asistida por modelo (Särndal y otros, 1992) ha aumentado. En la documentación estadística, el enfoque recibe el nombre de “Estimación de área pequeña” (Pfeffermann 2002; Tomppo 2006). Del mismo modo, los usuarios preocupados por la calidad de un modelo pueden adoptar el paradigma bayesiano, en el cual las distribuciones previas definidas por los usuarios y basadas en parámetros de modelos capturan tanto la incertidumbre del modelo como el posible sesgo e integran estas dudas en sus predicciones (Gertner y otros, 2002; Green y otros, 1999; Green y Strawderman 1996; Green y Valentine 1998). La validación de modelos complejos para aplicaciones a gran escala (p. ej.: predicciones del ecosistema acerca del contenido en dióxido de carbono) es posible en raras ocasiones. La validación de los componentes individuales del modelo puede que no garantice que las interacciones entre los componentes del modelo se capturen de forma adecuada. Siempre es responsabilidad del usuario comprobar las suposiciones del modelo, así como sus pronósticos. 7. Contribución del error de modelo al error total Los métodos para calcular la precisión de las estimaciones de inventario dependen del diseño de muestreo empleado en la recopilación de los datos. Sin embargo, estos métodos presuponen que las observaciones individuales se realizan libres de errores. En el caso de las estimaciones basadas en modelo, como el volumen, la biomasa y el dióxido de carbono, existen errores de modelo que es necesario tener en cuenta. Como consecuencia, podemos decir que hay tres fuentes de error principales: error de medición, error de modelo y error de muestreo. Por este motivo, se considera que las estimaciones de la precisión basadas en muestreo infravaloran 16 la varianza, o al revés, ya que implican intervalos de confianza demasiado estrechos, para aquellas variables como el volumen, la biomasa o el contenido de dióxido de carbono. De forma similar, los métodos para calcular los requisitos del muestreo con el objetivo de alcanzar el nivel de precisión deseado señalará un número menor de muestras que aquellas realmente necesarias, a menos que la consideración del error de modelo se tenga en cuenta además del error de muestreo. Para obtener más información véase el capítulo Diseños de muestreo. Los modelos de inventario nunca son perfectos. La discrepancia entre el valor (desconocido) real (YA) y el valor pronosticado a partir de un modelo (YP) se denomina error de modelo (εP). En formato ecuación YA = YP + ε P . La ecuación simple sería: (lineal) también implica que la varianza de una serie de valores pronosticados es menor o igual que la varianza de los valores reales. La igualdad únicamente se da en los modelos perfectos, en los que no existe varianza de error. Por ejemplo, si predecimos el volumen de los árboles en una parcela a partir de una ecuación de volumen adecuada, la varianza de las predicciones de volumen calculada será menor que la varianza real del volumen de los árboles de la parcela. Como consecuencia, el error estándar del volumen medio de una parcela pronosticado se verá sesgado a la baja. La varianza de los errores de predicción debe incluirse para obtener una estimación del error total no sesgada. En muchas aplicaciones debería considerarse el hecho de que los parámetros de los modelos que se emplean en un procedimiento de estimación no son más que cálculos con errores asociados. La decisión acerca de incluir también esta fuente de incertidumbre adicional en la estimación de los errores totales es personal. En el caso de los estudios de muestreo con muestras de gran tamaño, este tipo de error de modelo constituiría una gran parte del error total (varianza). La varianza de los errores de predicción puede ser mayor a la varianza residual obtenida durante el ajuste del modelo, en especial cuando la media y la covarianza de las variables de entrada varía de aquellas de los datos empleados en el ajuste del modelo. La aplicación del modelo más allá del dominio de aplicación recomendado podría aumentar el espectro de una grave inexactitud adicional del error. 8. Supervisión a lo largo del tiempo La supervisión a lo largo del tiempo permite la estimación de los cambios y las tendencias de los atributos forestales (Köhl y otros 2006, pág. 143). Los cambios y las tendencias se pueden calcular a partir de un conjunto de parcelas de muestra permanentes (véase el apartado 8.1), parcelas temporales (véase el apartado 8.2) o una combinación de ambas opciones (véanse los capítulos sobre diseño de muestreo y observaciones y mediciones). Las parcelas temporales se pueden utilizar para obtener estimaciones acerca del estado actual del bosque, mientras que las parcelas permanentes o una combinación de parcelas temporales y permanentes son requisitos previos para la obtención de una estimación del cambio a lo largo del tiempo (Picard y otros, 2010). La estimación del cambio es un reto complejo. En el sector forestal, existen tres tipos de cambios temporales importantes: 1) el cambio que se ajusta a la progresión esperada del material vivo y muerto de un bosque durante el período de interés (p. ej.: el incremento del volumen de árboles vivos), 2) las alteraciones abióticas y bióticas inesperadas (p. ej.: la mortalidad a causa de insectos, la nieve, el viento, el fuego, etc.) y 3) las actividades relacionadas con la gestión forestal (tala, explotación, plantación, siembra, etc.). Cada una de estas categorías funciona a diferentes escalas temporales y espaciales. Dada la multivariada naturaleza de los recursos forestales y el gran abanico de índices y modos de cambio, la eficacia de la mayoría de los diseños de muestreo dedicados a la estimación del cambio pueden resultar realmente eficaces para un atributo de cambio (por ejemplo, el incremento del volumen neto), pero ineficaces para capturar otros tipos de cambio (por ejemplo, índices de deforestación, volumen destruido por el fuego, mortalidad de insectos). Muy pocos diseños prácticos son eficaces a la hora de capturar el cambio en subpoblaciones sensibles pero pequeñas (como el número de ejemplares de especies raras o en posible peligro de extinción) (Christman 2000; Magnussen y otros, 2005). Para capturar de una forma adecuada los cambios relacionados con las alteraciones abióticas y bióticas y con las prácticas de gestión forestal, es frecuente realizar un censo de las variables auxiliares correlacionadas a través de la detección remota tanto al principio como al fin del periodo cubierto por las estimaciones de cambio (Coppin y otros, 2004; Stehman 2009; Tomppo y otros. 2008). En estas situaciones, las estimaciones de cambio se suelen evaluar según las expectativas o un conjunto de objetivos y aquellas que se centran en la precisión son importantes. Cuando el cambio se calcula a partir de una combinación de observaciones de campo y variables auxiliares obtenidas por detección remota, los estimadores de cambio y su precisión pueden ser complejos, por lo que la estimación real puede requerir la ayuda de un estadista (Stehman 2009). A menos que se pueda justificar por motivos estadísticos, el hecho de que una estimación de cambio sea no sesgada se debería identificar como un problema potencial. La ecuación de cambio más simple es aquella para una característica Y observada en un momento t y, de nuevo, en un momento Y = Yt + ΔYΔt donde futuro t + Δt. Tenemos t+Δt Yt es la medición inicial en un momento determinado t, Yt + Δt es la medición futura en un momento t + Δt, y ΔYΔt es el cambio de Y desde el momento t hasta el momento t + Δt. La varianza de la estimación de ΔYΔt, 17 depende del tipo de parcela (o mezcla de éstas) empleada en la recopilación de datos. Cualquier correlación entre mediciones en dos momentos del tiempo debe tenerse en cuenta a la hora de estimar la varianza de un cambio. Siguiendo con este sencillo ejemplo, la estimación del cambio es ΔYΔt = Yt+Δt −Yt . En este caso, la varianza de la estimación del cambio es igual a: ( ) ( ) ( ) ( ) ( ) ( var ΔYΔt = var Yt + var Yt+Δt − 2 ρ Yt ,Yt+Δt (Y ) − 2ρ (Y ,Y ) t+Δt t t+Δt var Yt var Yt+Δt ) donde var es la varianza, cov la covarianza y ρ, el coeficiente de correlación (entre las mediciones originales y futuras). Una fuerte correlación positiva reduce la varianza de la medición de cambio. Cuando una selección de muestreo se ha realizado con un diseño de muestreo de probabilidad desigual, el analista debe tener en cuenta que estas probabilidades pueden cambiar con el tiempo (Roesch y otros, 1993). Tal y como se ha explicado en el apartado 7, si la estimación de cambio referida anteriormente incluye el uso de cantidades que no son más que predicciones acerca de los valores esperados de uno o más modelos, será necesario justificar los errores “ocultos” en Yt y YΔt . Éste es el caso que se da en el sector forestal con más frecuencia. Lo que agrava el problema es el hecho de que los errores en Yt y YΔt en ocasiones tienden a estar correlacionados. Las complicaciones adicionales surgen cuando el método (protocolo o proceso) empleado para obtener Yt difiere del de Yt+Δt . . Se puede exigir la ayuda de un estadista profesional. 18 8.1 Estimación del cambio a partir de parcelas permanentes que se han vuelto a medir Las parcelas permanentes son ubicaciones forestales señalizadas, o identificadas de forma única, que se han medido en diferentes momentos (Köhl y otros, 2006, pág. 144). Desde un punto de vista estadístico y de análisis de datos, la mayor ventaja de las parcelas permanentes es la precisión mejorada de las estimaciones de cambio, gracias a una var Yt var Yt+Δt fuerte correlación de los errores de muestreo (véase la fórmula de la variabilidad de un cambio). Una mayor calidad de los datos también puede derivarse de una atención y control de calidad adicionales. Por último, las parcelas permanentes permiten sacar conclusiones acerca de la causa y el efecto (Augustin y otros, 2009). En los casos de las parcelas permanentes que se han medido sin interrupciones y con cuidado, la correlación que existe entre las mediciones siguientes tiende a ser positiva y relativamente fuerte, lo que, tal y como se ha indicado, reduce la varianza de una estimación de cambio. Sin embargo, la correlación con sucesivas mediciones puede deteriorarse rápidamente si transcurre mucho tiempo entre mediciones y también a causa de otros factores (como los incendios, el viento, la nieve, la sequía y las intervenciones de la gestión forestal). La gran calidad de los datos permite verificar los errores en los datos actuales y buscar anomalías en los anteriores. ( ) ( ) 8.2 Estimación del cambio a partir de parcelas temporales Las parcelas temporales ofrecen un grado máximo de flexibilidad: se pueden realizar diferentes estudios en diferentes momentos, midiendo las parcelas una única vez. Puesto que los estudios que se realizan en diferentes momentos se hacen en parcelas diferentes, la ventaja mencionada de la correlación positiva antes citada entre las observaciones específicas de una parcela en un momento t y t + Δt ya no existe (desaparece el emparejamiento natural de dos conjuntos de observaciones). Los árboles individuales de las parcelas temporales se miden más rápidamente y con menos precisión que aquellos que se encuentran en parcelas permanentes, lo que reduce la exactitud de las estimaciones, así como de la estimación de cambio resultante. Estas observaciones menos precisas también harán que sea más complicado detectar errores y anomalías en los datos (Cerioli 2010). Una menor exactitud de los datos puede compensarse, hasta cierto punto, con el uso de un mayor número de parcelas temporales. Sin embargo, la compensación final depende, de una forma complicada, de dónde y cómo ocurren los errores, así como del modelo utilizado en las observaciones (Carroll y otros, 1995). Referencias Ahmed J, Bonham CD, Laycock WA (1983) Comparison of techniques used for adjusting biomass estimates by double sampling. Journal of Range Management 36:217-221 Albaugh TJ, Bergh J, Lundmark T, Nilsson U, Stape JL, Allen HL, Linder S (2009) Do biological expansion factors adequately estimate stand-scale aboveground component biomass for Norway spruce? For Ecol Manage 258:2628-2637 Amaro A, Reed D, Soares P (2003) Modelling forest systems.In: Amaro A, Reed D, et al. (eds) Modelling forest systems. Lisbon p 432 Augustin NH, Musio M, von Wilpert K, Kublin E, Wood SN, Schumacher M (2009) Modeling spatiotemporal forest health monitoring data. J Am Stat Assoc 104:899-911 doi: 10.1198/jasa.2009.ap07058 Baritz R, Seufert G, Montanarella L, Ranst Ev (2010) Carbon concentrations and stocks in forest soils of Europe. For Ecol Manage 260:262-277 Baskerville GL (1972) Use of logarithmic regression in the estimation of plant biomass. Can J For Res 2:49-53 Batjes NH (2009) Harmonized soil profile data for applications at global and continental scales: updates to the WISE database. Soil Use and Management 25:124-127 Begin J, Raulier F (1995) Comparision de differentes approches modeles et tailles d’echantillons pour l’establissements de relations hauteur-diametre locales. Can J For Res 25:1303-1312 Bi H, Birk E, Turner J, Lambert M, Jurskis V (2001) Converting stem volume to biomass with additivity, bias correction, and confidence bands for two Australian tree species. New Zealand Journal of Forestry Science 31:298319 Biggs PH (1991) Aerial tree volume functions for eucalypts in western Australia. Can J For Res 21:1823-1828 Biging GS, Gill SJ (1997) Stochastic models for conifer tree crown profiles. For Sci 43:2534 Birdsey RA (2006) Carbon accounting rules and guidelines for the United States forest sector. Journal of Environmental Quality 35:1518-1524 Boulanger Y, Sirois L (2006) Postfire dynamics of black spruce coarse woody debris in northern boreal forest of Quebec. Can J For Res 36:1770-1780 Brown BM, Hettmansperger TP (1996) Normal scores, normal plots, and tests for normality. J Am Stat Assoc 91:1668-1675 Brown S (1997) Estimating biomass and biomass change of tropical forests: a primer. FAO Burns RM, Honkala BH (1990) Silvics of North America (Conifers and Hardwoods). Service UF Cairns RD, Lasserre P (2006) Implementing carbon credits for forests based on green accounting. Ecological Economics 56:610-621 19 Cancino J, Saborowski J (2005) Comparison of Randomized Branch Sampling with and without replacement at the first stage. Silv Fenn 39:201-216 Cannell MGR (1982) World forest biomass and primary production data. Academic Press, London UK Cannell MGR (1984) Woody biomass of forest stands. For Ecol Manage 8:299-312 Cao QV (2004) Predicting parameters of a Weibull function for modeling diameter distribution. For Sci 50:682-685 Carroll RJ, Ruppert D, Stefanski LA (1995) Measurement error in nonlinear models. Chapman & Hall, London Cerioli A (2010) Multivariate Outlier Detection With High-Breakdown Estimators. J Am Stat Assoc 105:147-156 doi: doi:10.1198/ jasa.2009.tm09147 Chang C, Wang C, Chou C, Duh C (2010) The importance of litter biomass in estimating soil organic carbon pools in natural forests of Taiwan. Taiwan Journal of Forest Science 25:171-180 Choi NH, Li W, Zhu J (2010) Variable Selection With the Strong Heredity Constraint and Its Oracle Property. J Am Stat Assoc 105:354-364 doi: doi:10.1198/jasa.2010.tm08281 Christman MC (2000) A review of quadratbased sampling of rare, geographically clustered populations. J Agric Biol Environ Stat 5:168-201 Clark PE, Hardegree SP, Moffet CA, Pierson FB (2008) Point sampling to stratify biomass variability in sagebrush steppe vegetation. Rangeland Ecology & Management 61:614622 Clark WAV, Avery KL (1976) The effects of data aggregation in statistical analysis. Geographical Analysis 8:428-438 Conover WJ (1980) Practical nonparametric statistics. Wiley, New York Coppin PR, Jonckheere I, Nackaerts K, 20 Muys B, Lambin EF (2004) Digital change detection methods in ecosystem monitoring: a review. Int J Remote Sens 25:1565-1596 Corona P, Blasi C, Chirici G, Facioni L, Fattorini L, Ferrari B (2010) Monitoring and assessing old-growth forest stands by plot sampling. Pl Biosys 144:171-179 Curtin RA (1970) Dynamics of tree and crown structure in Eucalyptus obliqua. For Sci 16:321-328 Dachang L, Cossalter C (2006) The assessment and monitoring of forest resources and forestry product statistics in China. CIFOR, Research CfIF, 36 Davison AC (2003) Statistical models. Cambridge University Press, Cambridge De Vries PG (1986) Sampling theory for forest inventory. A teach yourself course. Springer, Berlin Desbiez ALJ, Bodmer RE, Tomas WM (2010) Mammalian densities in a neotropical wetland subject to extreme climatic events. Biotropica 42:372-378 Ducey MJ (1999) What expansion factor should be used in binned probability proportional to size sampling? Can J For Res 29:1290-1294 Ducey MJ (2000) Prism cruising with diameter classes: theoretical consideations and practical recommendations. N J Appl For 17:110-115 Ducharme GR, Fontez B (2004) A smooth test of goodness-of-fit for growth curves and monotonic nonlinear regression models. Biometrics 60:977-986 Dupouey JL, Pignard G, Hamza N, Dhôte JF (2010) Estimating carbon stocks and fluxes in forest biomass: 2. Application to the French case based upon National Forest Inventory data. Forests, carbon cycle and climate change Dutschke M, Pistorius T (2008) Will the future be REDD? Consistent carbon accounting for land use. Int For Rev 10:476- 484 Wiley, New York Dykstra DP, Monserud RA (2009) Forest Growth and Timber Quality: Crown Models and Simulation Methods for Sustainable Forest Management: Proceedings of an International Conference.In: Dykstra DP, Monserud RA (eds) Portland OR p 276 Gabriëls PCJ, Berg JVvd (1993) Calibration of two techniques for estimating herbage mass. Grass and Forage Science 48:329-335 Efron B (2004) The estimation of prediction error: Covariance penalties and crossvalidation. J Am Stat Assoc 99:619-631 Erdle TA, MacLean DA (1999) Stand growth model calibration for use in forest pest impact assessment. For Chron 75:141-152 Fehrmann L, Lehtonen A, Kleinn C, Tomppo E (2008) Comparison of linear and mixedeffect regression models and a k-nearest neighbour approach for estimation of singletree biomass. Can J For Res 38:1-9 Fernandes PM (2009) Combining forest structure data and fuel modelling to classify fire hazard in Portugal. Annals of Forest Science 66: doi: 10.1051/forest/2009013 Fioretto A, Papa S, Pellegrino A, Fuggi A (2007) Decomposition dynamics of Myrtus communis and Quercus ilex leaf litter: mass loss, microbial activity and quality change. Applied Soil Ecology 36:32-40 Fisk MC, Fahey TJ, Groffman PM (2010) Carbon resources, soil organisms, and nitrogen availability: landscape patterns in a northern hardwood forest. For Ecol Manage 260:1175-1183 Fonweban JN, Houllier F (1997) Volume equations and taper functions for Eucalyptus saligna in Cameroon. / Tarifs de cubage et fonctions de défilement pour Eucalyptus saligna au Cameroun. Annales des Sciences Forestières 54:513-528 Friedel MH (1977) The determination of an optimum sampling technique for biomass of herbaceous vegetation in a central Australian woodland. Australian Journal of Ecology 2:429-433 Fuller WA (1987) Measurement Error Models. Gadow KV (1999) Forest structure and diversity. Allg F Jagdztg 170:117-121 Gallaun H, Zanchi G, Nabuurs GJ, Hengeveld G, Schardt M, Verkerk PJ (2010) EU-wide maps of growing stock and aboveground biomass in forests based on remote sensing and field measurements. For Ecol Manage 260:252-261 Gargaglione V, Peri PL, Rubio G (2010) Allometric relations for biomass partitioning of Nothofagus antarctica trees of different crown classes over a site quality gradient. For Ecol Manage 259:1118-1126 Garrett LG, Kimberley MO, Oliver GR, Pearce SH, Paul TSH (2010) Decomposition of woody debris in managed Pinus radiata plantations in New Zealand. For Ecol Manage 260:1389-1398 Gasparini P, Gregori E, Pompei E, Rodeghiero M (2010) The Italian National forest inventory: survey methods for carbon pools assessment. / Inventario Forestale Nazionale: aspetti metodologici dell’indagine sui serbatoi di carbonio. Sherwood - Foreste ed Alberi Oggi 13-18 Geissen V, Sánchez-Hernández R, Kampichler C, Ramos-Reyes R, SepulvedaLozada A, Ochoa-Goana S, Jong BHJd, Huerta-Lwanga E, Hernández-Daumas S (2009) Effects of land-use change on some properties of tropical soils - an example from Southeast Mexico. Geoderma 151:87-97 Gertner GZ, Fang S, Skovsgaard JP (2002) A Bayesian approach for estimating the parameters of a forest process model based on long-term growth data. Ecol Model 119:249265 Good NM, Paterson M, Brack C, Mengersen K (2001) Estimating tree component biomass using variable probability sampling methods. 21 Journal of Agricultural, Biological, and Environmental Statistics 6:258-267 Gove JH, Patil GP (1998) Modeling the basal area-size distribution of forest stands: A compatible approach. For Sci 44:285-297 Green EJ, MacFarlane DW, Valentine HT, Strawderman WE (1999) Assessing uncertainty in a stand growth model by Bayesian synthesis. For Sci 45:528-538 Green EJ, Strawderman WE (1996) Predictive posterior distributions from a Bayesian version of a slash pine yield model. For Sci 42:456-464 Green EJ, Valentine HT (1998) Bayesian analysis of the linear model with heterogenous variance. For Sci 44:134-138 Gregoire TG, Valentine HT, Furnival GM (1995) Sampling methods to estimate foliage and other characteristics of individual trees. Ecology 76:1181-1194 Gregoire TG, Williams MS (1992) Identifying and evaluating the components of non-measurement error in the application of standard volume equations. The Statist 41:509-518 Gschwantner T, Schadauer K, Vidal C, Lanz A, Tomppo E, Cosmo Ld, Robert N, Duursma DE, Lawrence M (2009) Common tree definitions for National Forest Inventories in Europe. Silv Fenn 43:303-321 Halme M, Tomppo E (2001) Improving the accuracy of multisource forest inventory estimates by reducing plot location error - a multicriteria approach. Remote Sens Environ 78:321-327 Hedley SL, Buckland ST (2004) Spatial models for line transect sampling. J Agric Biol Environ Stat 9:181-199 Higgins MA, Ruokolainen K (2004) Rapid tropical forest inventory: a comparison of techniques based on inventory data from western Amazonia. Conserv Biol 18:799-811 Hosseini V, Azizi P (2007) Determination of 22 the rate of litter decomposition and dynamic of carbon, nitrogen and phosphorus of Fagus orientalis in Asalem and Vaz regions. Asian Journal of Chemistry 19:4341-4346 Huang LS (1997) Testing goodness-of-fit based on a roughness measure. J Am Stat Assoc 92:1399-1402 Huang S, Titus SJ (1992) Comparision of nonlinear height-diameter functions for major Alberta tree species. Can J For Res 22:1297-1304 Husch B, Miller CI, Beers TW (1972) Forest Mensuration. Ronald Press Jalkanen A, Mäkipää R, Ståhl G, Lehtonen A, Petersson H (2005) Estimation of the biomass stock of trees in Sweden: comparison of biomass equations and age-dependent biomass expansion factors. Annals of Forest Science 62:845-851 Jayaraman K, Lappi J (2001) Estimation of height-diameter curves through multilevel models with special reference to even-aged teak stands. For Ecol Manage 142:155-162 Jenkins JC, Chojnacky DC, Heath LS, Birdsey RA (2003) National-scale biomass estimators for United States tree species. For Sci 49:12-35 Jia S, Akiyama T (2005) A precise, unified method for estimating carbon storage in cool-temperate deciduous forest ecosystems. Agricultural and Forest Meteorology 134:7080 Kägi W, Schmidtke H (2005) Who gets the money? What do forest owners in developed countries expect from the Kyoto Protocol? Unasylva (English ed) 56:35-38 Kangas A (1996) On the bias and variance in tree volume predictions due to model and measurement errors. Scand J For Res 11:281290 Kangas A, Maltamo M (2000) Calibrating predicted diameter distribution with additional information. For Sci 46:390-396 Keith H, Mackey BG, Lindenmayer DB (2009) Re-evaluation of forest biomass carbon stocks and lessons from the world’s most carbon-dense forests. Proceedings of the National Academy of Sciences 106:1163511640 doi: 10.1073/pnas.0901970106 plants, soil and forest floor in different tropical forests. For Ecol Manage 260:1906-1913 Kenow KP, Lyon JE, Hines RK, Elfessi A (2007) Estimating biomass of submersed vegetation using a simple rake sampling technique. Hydrobiologia 575:447-454 Lynch TB (1988) Volume estimation from sample tree counts with certain individual tree volume equations. For Sci 34:677-697 Kessell SR, Potter MW, Bevins CD, Bradshaw L, Jeske BW (1978) Analysis and application of forest fuels data. Env Mgmt 2:347-363 doi: 10.1007/bf01866675 Köhl M, Magnussen S, Marchetti M (2006) Sampling methods, remote sensing and GIS multiresource forest inventory. Springer, Berlin Lange KL, Roderick J, Little A, Taylor MG (1989) Robust statistical modeling using the t distribution. J Am Stat Assoc 84:881-896 Lappi J (1991) Calibration of height and volume equations with random parameters. For Sci 37:781-801 Lee CY (1982) Comparison of two correction methods for the bias due to the logarithmic transformation in the estimation of biomass. Can J For Res 12:326-331 Lehtonen A, Mäkipää R, Heikkinen J, Sievänen R, Liski J (2004) Biomass expansion factors (BEFs) for Scots pine, Norway spruce and birch according to stand age for boreal forests. For Ecol Manage 188:211-224 Levy PE, Hale SE, Nicoll BC (2004) Biomass expansion factors and root:shoot ratios for coniferous tree species in Great Britain. Forestry (Oxford) 77:421-430 Lindgren O (1998) Quality control of measurements made on fixed-area sample plots.In: Integrated tools for natural resources inventories in the 21st century. Boise Idaho Loaiza Usuga JC, Rodríguez Toro JA, Ramírez Alzate MV, Lema Tapias ÁdJ (2010) Estimation of biomass and carbon stocks in Lukac M, Godbold DL (2010) Fine root biomass and turnover in southern taiga estimated by root inclusion nets. Plant and Soil 331:505-513 Lynch TB (1995) Use of a tree volume equation based on two lower-stem diameters to estimate forest volume from sample tree counts. Can J For Res 25:871-877 MacDicken KG (1997) A guide to monitoring carbon storage in forestry and agroforestry projects. A guide to monitoring carbon storage in forestry and agroforestry projects iv + 87-iv + 87 Macinnis-Ng CMO, Fuentes S, O’Grady AP, Palmer AR, Taylor D, Whitley RJ, Yunusa I, Zeppel MJB, Eamus D (2010) Root biomass distribution and soil properties of an open woodland on a duplex soil. Plant and Soil 327:377-388 Magnussen S (1998) Tree height tarifs and volume estimation errors in New Brunswick. N J Appl For 15:7-13 Magnussen S, Kurz.W, Leckie D, Paradine D (2005) Adaptive cluster sampling for estimation of deforestation rates. Eur J For Res 124:207-220 Magnusson M, Fransson JES, Holmgren J (2007) Effects on estimation accuracy of forest variables using different pulse density of laser data. For Sci 53:619-626 Mairota P, Florenzano GT, Piussi P (2002) Hypotheses on middle-long term effects of present forest management on biodiversity conservation. / Ipotesi sugli esiti a mediolungo termine della gestione forestale attuale sulla conservazione della biodiversità. Annali dell’Istituto Sperimentale per la Selvicoltura 33:207-236 Mäkelä A, Valentine HT, Helmisaari HS 23 (2008) Optimal co-allocation of carbon and nitrogen in a forest stand at steady state. New Phytologist 180:114-123 Maltamo M, Eerikainen K, Pitkanen J, Hyyppa J, Vehmas M (2004a) Estimation of timber volume and stem density based on scanning laser altimetry and expected tree size distribution functions. Remote Sens Environ 90:319-330 Maltamo M, Mustonen K, Hyyppa J, Pitkanen J, Yu X (2004b) The accuracy of estimating individual tree variables with airborne laser scanning in a boreal nature reserve. Canadian Journal of Forest ResearchRevue Canadienne De Recherche Forestiere 34:1791-1801 Maselli F, Chiesi M, Barbati A, Corona P (2010) Assessment of forest net primary production through the elaboration of multisource ground and remote sensing data. Journal of Environmental Monitoring 12:1082-1091 McKenzie N, Ryan P, Fogarty P, Wood J (2000) Sampling, measurement, and analytical protocols for carbon estimation in soil, litter, and coarse woody debris., Office AG, 14 McKeown SP, Johnson WD (1996) Testing for autocorrelation and equality of covariance matrices. Biometrics 52:1087-1095 McRoberts RE (2006) A model-based approach to estimating forest area. Remote Sens Environ 103:56-66 McRoberts RE, Nelson MD, Wendt DG (2002) Stratified estimation of forest area using satellite imagery, inventory data, and the k-Nearest Neighbors technique. Remote Sens Environ 82:457-468 McRoberts RE, Tomppo EO, Finley AO, Heikkinen J (2007) Estimating areal means and variances of forest attributes using the k-Nearest Neighbors technique and satellite imagery. Remote Sens Environ 111:466-480 Moore JA, Zhang L, Stuck D (1996) Heightdiameter equations for ten tree species in the 24 inland northwest. WJApplFor 11:132-137 Mukhortova LV, Trefilova OV (2009) Features of coarse woody debris decomposition in forest ecosystems of different natural zones of Central Siberia. Journal of Environmental Research and Development 4:321-333 Munishi PKT, Shear TH (2004) Carbon storage in afromontane rain forests of the Eastern Arc Mountains of Tanzania: their net contribution to atmospheric carbon. Journal of Tropical Forest Science 16:78-93 Nabuurs GJ (2010) Special section: European forest carbon balance as assessed with inventory based methods. For Ecol Manage 260:239-293 Nanos N, Calama R, Montero G, Gil L (2004) Geostatistical prediction of height/diameter models. For Ecol Manage 195:221-235 Ni Y, Ouyang Z, Wang X (2005) Application of Holdridge life-zone model based on the terrain factor in Xinjiang Automous Region. Journal of Environmental Sciences 17:10421046 Nigh GD, Love BA (2004) Predicting crown class in three western conifer species. Can J For Res 34:592-599 Niiyama K, Kajimoto T, Matsuura Y, Yamashita T, Matsuo N, Yashiro Y, Ripin A, Kassim AR, Noor NS (2010) Estimation of root biomass based on excavation of individual root systems in a primary dipterocarp forest in Pasoh Forest Reserve, Peninsular Malaysia. Journal of Tropical Ecology 26:271-284 Nogueira EM, Fearnside PM, Nelson BW (2008) Normalization of wood density in biomass estimates of Amazon forests. For Ecol Manage 256:990-996 O’Brien PC (1992) Robust procedures for testing equality of covariance matrices. Biometrics 48:819-827 Overton WS, Stehman SV (1995) The Horwitz-Thompson theorem as a unifying perspective for probability sampling: with examples from natural resource sampling. Am Stat 49:261 Oxies J (1976) Permanent plots in forestry growth and yield research. Dept. For. Yield Res., 43 Paine DP, McCadden RJ (1988) Simplified forest inventory using large-scale 70-mm photography and tarif tables. Photogr Eng Rem Sens 54:1423-1427 Papalia RB (2010) Data disaggregation procedures within a maximum entropy framework. J Appl Stat 37:1947 - 1959 Parker RC, Evans DL (2004) An application of LiDAR in a double-sample forest inventory. W J Appl For 19:95-101 Pautasso M, Gaston KJ (2005) Resources and global avian assemblage structure in forests. Ecology Letters 8:282-289 Pedersen BS (1998) Modeling tree mortality in response to short- and long-term environmental stresses. Ecol Model 105:347351 Pfeffermann D (2002) Small area estimation - New developments and directions. Int Stat Rev 70:125-143 Picard JF, Magnussen S, Banak NL, Namkosserena S, Yalibanda Y (2010) Permanent sample plots for natural tropical forests: A rationale with special emphasis on Central Africa. Env Monit Assess 164:279-295 Rana R, Langenfeld-Heyser R, Finkeldey R, Polle A (2010) FTIR spectroscopy, chemical and histochemical characterisation of wood and lignin of five tropical timber wood species of the family of Dipterocarpaceae. Wood Science and Technology 44:225-242 Rennolls K (1995) Forest height growth modelling. For Ecol Manage 71:217-225 Retzlaff WA, Handest JA, O’Malley DM, McKeand SE, Topa MA (2001) Whole-tree biomass and carbon allocation of juvenile trees of loblolly pine (Pinus taeda): influence of genetics and fertilization. Can J For Res 31:960-970 Reynolds MRJ (1984) Estimating the error in model predictions. For Sci 30:454-469 Ritchie MW, Hann DW (1997) Implication of disaggregation in forest growth and yield modeling. For Sci 43:223-233 Rodeghiero M, Tonolli S, Vescovo L, Gianelle D, Cescatti A, Sottocornola M (2010) INFOCARB: a regional scale forest carbon inventory (Provincia Autonoma di Trento, Southern Italian Alps). For Ecol Manage 259:1093-1101 Roesch FA, Jr., Green EJ, Scott CT (1993) A test of alternative estimators for volume at time 1 from remeasured point samples. Can J For Res 23:598-604 Plumptre AJ, Harris S (1995) Estimating the biomass of large mammalian herbivores in a tropical montane forest: a method of faecal counting that avoids assuming a ‘steady state’ system. J Appl Ecol 32:111-120 Rossi JP, Samalens JC, Guyon D, Halder Iv, Jactel H, Menassieu P, Piou D (2009) Multiscale spatial variation of the bark beetle Ips sexdentatus damage in a pine plantation forest (Landes de Gascogne, Southwestern France). For Ecol Manage 257:1551-1557 Popescu SC, Wynne RH, Nelson RF (2003) Measuring individual tree crown diameter with lidar and assessing its influence on estimating forest volume and biomass. Can J Rem Sens 29:564-577 Roth A, Kennel E, Knoke T, Matthes U (2003) Line intersect sampling: An efficient method for sampling of coarse woody debris? Forstwissenschaftliches Centralblatt 122:318336 Pramod J, Mohapatra KP (2010) Leaf litterfall, fine root production and turnover in four major tree species of the semi-arid region of India. Plant and Soil 326:481-491 Rovira P, Jorba M, Romanyà J (2010) Active and passive organic matter fractions in Mediterranean forest soils. Biology and Fertility of Soils 46:355-369 25 Sánchez-Azofeifa GA, Castro-Esau KL, Kurz WA, Joyce A (2009) Monitoring carbon stocks in the tropics and the remote sensing operational limitations: from local to regional projects. Ecol Appl 19:480-494 Särndal CE, Swensson B, Wretman J (1992) Model assisted survey sampling. Springer, New York Schabenberger O, Gregoire TG (1996) Population-averaged and subject-specific approaches for clustered categorical data. Journal of Statistical Computation and Simulation 54:231-253 Schlesinger WH (1991) Biogeochemistry, an analysis of global change. Academic Press, New York Schreuder HT, Reich RM (1998) Data estimation and prediction for natural resource public data. USDA Forest Service, RMRSRN-2 Schroeder P, Brown S, Mo J, Birdsey R, Cieszewski C (1997) Biomass estimation for temperate broadleaf forests of the United States using inventory data. For Sci 43:424434 Schwab O, Maness TC (2010) Rebuilding spatial forest inventories from aggregated data. Journal of Forestry 108:274-281 Scott CT (1984) A new look at sampling with partial replacement. For Sci 30:157-166 Scott CT (1998) Sampling methods for estimating change in forest resources. Ecol Appl 8:228-233 Scott CT, Köhl M (1993) A method for comparing sampling design alternatives for extensive inventories. Eidgenössischen Forschungsanstalt für Wald, Schnee und Landschaft, 68 Shoemaker LH (2003) Fixing the F test for equal variances. Am Stat 57:105 - 114 Skovsgaard JP (2004) Forest measurements. Encyclopedia of Forest Sciences. Academic Press, New York 26 Somogyi Z, Teobaldelli M, Federici S, Matteucci G, Pagliari V, Grassi G, Seufert G (2008) Allometric biomass and carbon factors database. iForest 1:107-113 Spetich MA, Parker GR (1998) Distribution of biomass in an Indiana old-growth forest from 1926 to 1992. American Midland Naturalist 139:90-107 Stage AR, Crookston NI, Monserud RA (1993) An aggregation algorithm for increasing the efficiency of population models. For Ecol Manage 68:257-271 Stehman SV (2009) Model-assisted estimation as a unifying framework for estimating the area of land cover and land-cover change from remote sensing. Remote Sens Environ 113:2455-2462 Straub C, Weinacker H, Koch B (2010) A comparison of different methods for forest resource estimation using information from airborne laser scanning and CIR orthophotos. Eur J For Res 129:1069-1080 doi: 10.1007/ s10342-010-0391-2 Tagesson T, Smith B, Löfgren A, Rammig A, Eklundh L, Lindroth A (2009) Estimating net primary production of Swedish forest landscapes by combining mechanistic modeling and remote sensing. Ambio 38:316324 Teobaldelli M, Somogyi Z, Migliavacca M, Usoltsev VA (2009) Generalized functions of biomass expansion factors for conifers and broadleaved by stand age, growing stock and site index. For Ecol Manage 257:1004-1013 Tesfaye T (2005) A ratio method for predicting stem merchantable volume and associated taper equations for Cupressus lusitanica, Ethiopia. For Ecol Manage 204:171-179 Thompson SK (1992) Sampling. Wiley, New York Tipping E, Chamberlain PM, Bryant CL, Buckingham S (2010) Soil organic matter turnover in British deciduous woodlands, quantified with radiocarbon. Geoderma 155:10-18 Tomé M, Tomé J, Ribeiro F, Faias S (2007) Total volume, volume ratio and taper equation for Eucalyptus globulus Labill. in Portugal. / Equação de volume total, volume percentual e de perfil do tronco para Eucalyptus globulus Labill. em Portugal. Silva Lusitana 15:25-39 Wang HS, Leng CL (2007) Unified LASSO estimation by least squares approximation. J Am Stat Assoc 102:1039-1048 Wang X, Sun Y (2008) Review on research and estimation methods of carbon storage in forest ecosystem. World Forestry Research 21:24-29 Tomppo E (2006) The Finnish multi-source national forest inventory -- small area estimation and map production. In: Kangas A, Maltamo M (eds) Forest inventory methodology and applications. Springer, Dordrecht, NL, 195-224 Waser LT, Schwarz M (2006) Comparison of large-area land cover products with national forest inventories and CORINE land cover in the European Alps. International Journal of Applied Earth Observation and Geoinformation 8:196-207 Tomppo E, Olsson H, Stahl G, Nilsson M, Hagner O, Katila M (2008) Combining national forest inventory field plots and remote sensing data for forest databases. Remote Sens Environ 112:1982-1999 Waterworth RM, Richards GP (2008) Implementing Australian forest management practices into a full carbon accounting model. For Ecol Manage 255:2434-2443 Tovar-Sanchez E (2009) Canopy arthropods community within and among oak species in central Mexico. Acta Zoologica Sinica 55:e11119-e11119 Tupek B, Zanchi G, Verkerk PJ, Churkina G, Viovy N, Hughes JK, Lindner M (2010) A comparison of alternative modelling approaches to evaluate the European forest carbon fluxes. For Ecol Manage 260:241-251 van Laar A, Akça A mensuration. 2 ed (2007) Forest Vanclay JK, Skovsgaard JP (1997) Evaluating forest growth models. Ecol Model 98:1-12 Vasconcellos A (2010) Biomass and abundance of termites in three remnant areas of Atlantic Forest in northeastern Brazil. Revista Brasileira de Entomologia 54:455-461 Vávrová P, Penttilä T, Laiho R (2009) Decomposition of Scots pine fine woody debris in boreal conditions: implications for estimating carbon pools and fluxes. For Ecol Manage 257:401-412 Venables WN, Ripley BD (1994) Modern applied statistics with S-Plus. Springer-Verlag, New York Watson C (2009) Forest carbon accounting: overview and principles. (UNDP) UNDP, Wauters JB, Coudert S, Grallien E, Jonard M, Ponette Q (2008) Carbon stock in rubber tree plantations in Western Ghana and Mato Grosso (Brazil). For Ecol Manage 255:23472361 Wiant HV, Harner EJ (1979) Percent bias and standard error in logarithmic regression. For Sci 25:167-168 Wijaya A, Kusnadi S, Gloaguen R, Heilmeier H (2010) Improved strategy for estimating stem volume and forest biomass using moderate resolution remote sensing data and GIS. Journal of Forestry Research 21:1-12, i Williams MS, Ducey MJ, Gove JH (2005) Assessing surface area of coarse woody debris with line intersect and perpendicular distance sampling. Canadian Journal of Forest Research-Revue Canadienne de Recherche Forestiere 35:949-960 Wise RM, Maltitz GPv, Scholes RJ, Elphinstone C, Koen R (2009) Estimating carbon in savanna ecosystems: rational distribution of effort. Mitigation and Adaptation Strategies for Global Change 14:579-604 27 Woldendorp G, Keenan RJ, Barry S, Spencer RD (2004) Analysis of sampling methods for coarse woody debris. For Ecol Manage 198:133-148 Wolf A (2005) Fifty year record of change in tree spatial patterns within a mixed deciduous forest. For Ecol Manage 215:212-223 Woodall CW, Heath LS, Smith JE (2008) National inventories of down and dead woody material forest carbon stocks in the United States: challenges and opportunities. For Ecol Manage 256:221-228 Yamada A, Inoue T, Sugimoto A, Takematsu Y, Kumai T, Hyodo F, Fujita A, Tayasu I, Klangkaew C, Kirtibutr N, Kudo T, Abe T (2003) Abundance and biomass of termites (Insecta: Isoptera) in dead wood in a dry evergreen forest in Thailand. Sociobiology 42:569-571 Yamamoto K (1994a) Compatible stem form equations based on the relationship between stem volume and stem cross-sectional area. Journal of the Japanese Forestry Society 76:108-117 Yamamoto K (1994b) A simple volume estimation system and its application to three coniferous species. Can J For Res 24:12891294 Yang F, Li Y, Zhou G, Wenigmann KO, Zhang D, Wenigmann M, Liu S, Zhang Q (2010) Dynamics of coarse woody debris and decomposition rates in an old-growth forest in lower tropical China. For Ecol Manage 259:1666-1672 Yu X, Hyyppa J, Kaartinen H, Maltamo M, Hyyppa H (2008) Obtaining plotwise mean height and volume growth in boreal forests using multi-temporal laser surveys and various change detection techniques. Int J Remote Sens 29:1367-1386 Zhang X, Yin Y, Yu L, Yao L, Ying H, Zhang N (2010a) Influence of water and soil nutrients on biomass and productivity of fine tree roots: a review. Journal of Zhejiang Forestry College 27:606-613 28 Zhang X, Zhu J, Hou Z (2009) Carbon removals/sources of forests and forest conversion and applied carbon accounting methods and parameters in major developed countries. Forest Research, Beijing 22:285-293 Zhang YJ, Borders BE (2004) Using a system mixed-effects modeling method to estimate tree compartment biomass for intensively managed loblolly pines - an allometric approach. For Ecol Manage 194:145-157 Zhang Z, Yu D, Shi X, Warner E, Ren H, Sun W, Tan M, Wang H (2010b) Application of categorical information in the spatial prediction of soil organic carbon in the red soil area of China. Soil Science and Plant Nutrition 56:307-318 Zhao K, Popescu S, Nelson R (2009) Lidar remote sensing of forest biomass: A scaleinvariant estimation approach using airborne lasers. Remote Sens Environ 113:182-196 Zhou B, McTague JP (1996) Comparison and evaluation of five methods of estimation of the Johnson system parameters. Can J For Res 26:928-935