Texto - Universidad Nacional Abierta
Anuncio

UNIVERSIDAD NACIONAL ABIERTA
VICERRECTORADO ACADEMICO
AREA DE INGENIERIA
CARRERA DE INGENIERIA DE SISTEMAS
PRONOSTICO DE MATRICULA DE ASIGNATURAS SIN PREREQUISITOS MEDIANTE MODELOS BASADOS EN SERIES DE TIEMPO
Autor: Mirna Liliana González González, C.I. V10.790.445
Tutor Académico: Ing. Edgar González, C.I. V-6.524.564
Asesor Empresarial: Lic. Celeste Longa, C.I. V-9.095.088
Caracas, Centro Local Metropolitano
Junio, 2005
UNIVERSIDAD NACIONAL ABIERTA
VICERRECTORADO ACADEMICO
AREA DE INGENIERIA
CARRERA DE INGENIERIA DE SISTEMAS
PRONOSTICO DE MATRICULA DE ASIGNATURAS SIN PREREQUISITOS MEDIANTE MODELOS BASADOS EN SERIES DE TIEMPO
Trabajo de grado presentado ante la
Universidad Nacional Abierta por
Mirna Liliana González González .
del Centro Local Metropolitano para
optar al título de Ingeniero de
Sistemas
Caracas, Junio de 2005
RESUMEN
El presente Trabajo de Grado se fundamenta en el pronóstico de la
matrícula de alumnos a inscribirse en las asignaturas sin pre-requisitos de
todas las carreras del Centro Local Metropolitano de la Universidad Nacional
Abierta, mediante la aplicación de algoritmos basados en series de tiempo.
La data utilizada en este pronóstico es la suministrada por la Unidad
de Computación del Centro Local Metropolitano, la cual posee un histórico
desde el primer semestre del año 1995 hasta la actualidad.
Una vez determinado los modelos a utilizar con base en nuestro
estudio, se hace uso de la tecnología web, y de programas de software libre
para desarrollar una aplicación computacional, donde de una manera sencilla
y eficiente se logre obtener el resultado de aplicar dichos modelos
matemáticos.
Con esto hemos garantizado, la adecuación y mantenimiento posterior
de la herramienta resultado del presente trabajo.
Palabras clave:
Pronóstico, series de tiempo, análisis clásico, modelos Arima.
ÍNDICE
Pág
Introducción…………………………………………………………………….. 1
Capítulo I: El Problema……………………………………………………….. 3
1.1Planteamiento del problema…………………………………………. 6
1.2 Formulación del problema…………………………………………… 6
1.3 Objetivos………………………………………………………………. 6
1.3.1 Objetivo General: ……………………………………………... 6
1.3.2 Objetivos específicos…………………………….…………… 6
1.4 Justificación de la Investigación……………………………………. 7
1.5 Limitaciones…………………………………………………………… 7
Capítulo II: Marco Teórico……………………………………………………. 8
2.1 Antecedentes de la Investigación…………………………………... 8
2.2 Bases Teóricas……………………………………………………….. 10
2.2.1 Definiciones Básicas………………………………………….. 10
2.2.2 Series temporales……………………………………………... 19
2.2.2.1 Análisis Clásico de series temporales…………………….. 24
2.2.2.2 Procesos de Box-Jenkins………………………………….. 50
2.2.2.3 Modelo Espectral……………………………………………. 55
2.2.2.4 Modelo UCARIMA…………………………………………... 58
2.2.2.5 Modelo ARCHI………………………………………………. 59
2.2.2.6 Modelo de Cointegración…………………………………… 59
2.2.2.7 Modelo AFRIMA…………………………………………….. 60
2.2.2.8 Modelo del Caos…………………………………………….. 60
2.3. Formulación del Modelo…………………………………………….. 61
Capitulo III marco metodológico……………………………………………... 65
3.1 Nivel de Investigación:……………………………………………….. 65
3.2 Diseño de la investigación:………………………………………….. 65
3.3 Población y Muestra:………………………………………………… 66
3.4 Técnicas e Instrumentos de Recolección de Datos:……………. 66
3.5 Técnicas de procesamiento de Datos …………………………… 67
3.6 Análisis de los Datos……………………………………………….. 71
Capítulo IV Resultados……………………………………………………….. 75
4.1 Software desarrollado……..……………………………………………… 75
4.1 Datos de entrada………………………………………………………….. 76
4.1 Salida de la simulación…………………………………………………… 77
Conclusiones…………………………………………………………………… 80
Recomendaciones…………………………………………………………….. 82
Bibliografía……………………………………………………………………… 83
Anexos………………………………………………………………………….. 84
A: Gráfica de todas las series
B: Instalación del EasyPHP
C: Manual de MySQL FRONT
D: Instalación de Promatric V1.0
E: Manual de usuario de Promatric V1.0
F: Datos suministrados por el Centro Local Metropolitano
G: Decreto 3390 Uso del Software Libre
INTRODUCCIÓN
Debido a lo cambiante de la realidad, siempre ha existido la
necesidad de hacer pronósticos. El ser humano, consciente y temeroso de la
incertidumbre, siempre ha buscado la forma de enfrentar el porvenir tomando
decisiones que condicionen y afecten su futuro propio y el de las
organizaciones donde se involucra.
Las técnicas de pronóstico han evolucionado considerablemente a lo
largo del tiempo, desde la intuición, pasando por las técnicas basadas en la
experiencia del pronosticador, hasta llegar a las más sofisticadas que utilizan
modelos matemáticos.
Casi cualquier organización, grande o pequeña, pública o privada,
utiliza el pronóstico ya sea implícito o explicito, debido a la necesidad de
planear, en forma responsable, la forma de enfrentar las condiciones futuras
de las cuales se tiene un conocimiento imperfecto. Quienes tienen a su cargo
la responsabilidad de tomar las decisiones, lo harán mejor si tienen una base
que las soporte de manera adecuada. Además, la necesidad de hacer
pronósticos cruza todas las líneas funcionales al igual que todo tipo de
organizaciones.
Las herramientas modernas de pronóstico, junto con la capacidad de
la computadora se han hecho indispensables para las organizaciones que
operan en el mundo moderno, al punto de que muchas decisiones
importantes están soportadas por los resultados que arrojan estas
predicciones, incluso con mucho tiempo de anterioridad.
Una de las razones de más peso para justificar el pronóstico, es la
administración de recursos. Si se tuviera conocimiento previo de la
ocurrencia de ciertas situaciones, los recursos pudieran ser mejor
administrados, sin incurrir en deficiencias ni en excesos que pudieran afectar
la organización incluso a niveles caóticos. En función de la imposibilidad de
tener conocimiento exacto de lo que ocurrirá en el futuro, el pronóstico es la
única herramienta.
El propósito de este Trabajo de Grado es precisamente establecer un
pronóstico que permita a la Universidad Nacional Abierta, aunque sea en
forma parcial, enfrentar de manera mas eficiente la planificación de sus
recursos para el próximo semestre. Específicamente, este trabajo pretende
realizar el pronóstico de la matricula de alumnos a inscribirse en las
asignaturas sin pre-requisitos de ingreso del Centro Local Metropolitano,
utilizando algoritmos de análisis de series de tiempo.
El proyecto está integrado esencialmente por cuatro capítulos: en el
primero se establece y delimita claramente el problema a tratar, junto con los
objetivos que se persiguen y la justificación y limitaciones del proyecto. En el
segundo se detalla todo el marco teórico en el que se basa la solución del
mismo, así como los antecedentes y la definición de los términos básicos. El
capítulo tres ubica la investigación dentro del nivel y diseño correspondiente
y establece la forma de conseguir y adaptar los datos antes de comenzar su
manipulación. El capítulo cuatro muestra los resultados obtenidos después
de la simulación, con su consecuente información de pronóstico, que es el
objeto primordial de toda la investigación.
CAPITULO I
EL PROBLEMA
1.1 Planteamiento del problema
La Universidad Nacional Abierta (UNA), fundada en 1977, es pionera
en educación a distancia en Venezuela. En realidad es el único instituto
formal del país cuyo sistema educativo es completamente a distancia. El
objetivo de la Universidad es “llevar la educación superior a todos los
rincones del país”, bajo una metodología que se caracteriza por la separación
física entre los alumnos y los profesores y la construcción de conocimientos
relevantes, mediante la utilización de “medios instruccionales indirectos” que
facilitan el aprendizaje individual y estimulan la capacidad y la creatividad de
los alumnos, permitiéndoles adelantar estudios universitarios de alta calidad,
independientemente de su ubicación geográfica y sin apartarse de sus
obligaciones laborales y familiares.
Además del Nivel Central, donde se gerencian los aspectos
académicos, logísticos y administrativas de la Universidad, la UNA cuenta, a
todo lo largo del territorio nacional, con 67 ubicaciones, 22 de las cuales son
Centros Locales ubicados en capitales de estado y 45 son Unidades de
Apoyo ubicadas en poblaciones aledañas. Los Centros Locales han
transitado a lo largo de un importante proceso que les ha permitido
evolucionar operativamente hasta constituir verdaderos centros académicos,
de investigación y extensión que, manteniendo relaciones estrechas con el
Nivel Central, son capaces de planificar actividades académicas, gerenciar
aspectos administrativos y brindar atención y apoyo a los requerimientos de
los estudiantiles y de las comunidades.
Operativamente, el Nivel Central se encarga de todo el proceso
académico, administrativo y logístico a nivel global, mientras que los Centros
Locales y Unidades de Apoyo se encargan de la interacción con el
estudiante.
Al inicio de cada período de estudio (régimen semestral), el estudiante
se inscribe de acuerdo a las asignaturas que haya elegido y satisfaga los
requisitos, con lo cual es provisto de un material de auto instrucción y un
documento explicativo de la forma de evaluación de cada asignatura, los
objetivos a lograr y la forma de hacerlo, de acuerdo a la correspondencia
entre los objetivos y el contenido del material de auto instrucción; además de
un calendario donde se establecen las fechas de presentación de pruebas y
los objetivos evaluables. Oportunamente, la Universidad publica las
direcciones de los Centros donde se aplicarán las pruebas.
En la fecha prevista para cada prueba, la Universidad despliega toda
una logística destinada a la aplicación de la evaluación a nivel general en
todo el país a la misma hora. Para ello, contrata centros de estudio (colegios,
liceos) y distribuye los alumnos de acuerdo a su ubicación. Estudiantes que
por razones de cualquier tipo, se encuentren fuera de sus centros habituales,
pueden gestionar la presentación de su prueba en cualquier centro a nivel
nacional. Dada la cantidad de estudiantes que maneja la Universidad, se
contratan también Supervisores de Pruebas, los cuales se encargan de velar
por la correcta aplicación de las mismas.
Obviamente, para el éxito de sus actividades, la Universidad requiere,
durante el semestre en curso, la planificación objetiva de recursos para el
próximo semestre, estimando el volumen de una serie de actividades dentro
de las que se encuentran la reproducción del material de auto instrucción, la
contratación del personal para atender las pruebas, la tramitación de los
locales para la presentación de exámenes, etc. La estimación de todos estos
recursos tanto materiales como humanos, que serán empleados el próximo
semestre en atender la operatividad de la universidad, está muy ligada a la
cantidad de alumnos que se inscribirán en las diferentes asignaturas
ofertadas en las carreras que ofrece la institución. Sin embargo, el obvio
desconocimiento de esta matrícula, hace que en muchas oportunidades la
estimación de recursos no sea la óptima, pudiendo incurrir en situaciones
como falta de material de auto instrucción para determinadas materias,
insuficiencia del personal para atender las pruebas, o situaciones igualmente
graves como el gasto excesivo de recursos que no se llegan a utilizar,
incluyendo la obsolescencia o daño del material de auto instrucción por el
tiempo. Cabe igualmente destacar que la planificación debe hacerse por
Centro Local, ya que cada uno tiene sus características propias.
En particular, es posible lograr una estimación objetiva de las
matrículas de ciertas asignaturas, dado que dependen de variables
conocidas, como alumnos aprobados de las materias pre-requisito según la
oferta, alumnos reprobados de semestres anteriores, etc. Sin embargo, las
asignaturas que no tienen pre-requisitos de inscripción, las cuales pueden
ser inscritas por cualquier estudiante de la carrera que lo desee, requieren
otro tipo de tratamiento, debido a que su inscripción está supeditada sólo a
la decisión del estudiante, pudiendo interferir sobre ello una gran cantidad de
factores que objetivamente se tornan inmanejables.
Sobre esta variable matrícula (para cada asignatura) de las materias
sin pre-requisitos, los únicos datos certeros que posee la Universidad, son
las estadísticas de registros de semestres anteriores, aspecto sobre el cual
se basa este Trabajo de Grado, en la manipulación de esos datos para lograr
un pronóstico científico de la matrícula de las mencionadas asignaturas
haciendo uso del conocimiento que se tiene de su comportamiento pasado.
1.2 Formulación del problema
¿Cuál será la matrícula de las asignaturas sin pre-requisitos de todas
las carreras de la Universidad Nacional Abierta del Centro Local
Metropolitano para un
semestre dado, teniendo en consideración el
comportamiento pasado de dichas matrículas?
1.3 Objetivos
1.3.1 Objetivo General:
Pronosticar la matrícula de alumnos a inscribirse en un semestre
determinado en cada una de las materias de todas las carreras de la
Universidad Nacional Abierta del Centro Local Metropolitano que no tengan
ningún pre-requisito para su inscripción, mediante el desarrollo de modelos
matemáticos basados en series de tiempo.
1.3.2 Objetivos específicos
•
Recolectar y analizar los datos históricos de matrícula de la Universidad
en el Centro Local Metropolitano.
•
Determinar los modelos en series de tiempo en función del histórico de
cada asignatura.
•
Adaptar los modelos obtenidos al caso específico del Centro Local
Metropolitano.
•
Validar los modelos definitivos mediante reproducción del histórico.
•
Programar la aplicación computacional para correr los modelos
desarrollados.
1.4 Justificación de la Investigación
El presente Trabajo de Grado es conveniente para la Universidad
Nacional Abierta debido a que pone a disposición una herramienta confiable,
basada en una investigación científica, que le servirá de punto de partida
para la asignación de recursos destinados a la operatividad de sus
actividades para el próximo semestre, en las asignaturas sin pre-requisitos
de todas las carreras que ofrece como institución en el Centro Local
Metropolitano. La Investigación también es viable debido a que se cuenta con
todas las herramientas necesarias para llevarla a cabo.
1.5 Limitaciones
De acuerdo a las investigaciones preliminares realizadas sobre el
problema a tratar, las limitaciones que pueden influir en el resultado final de
este Trabajo de Grado o que pueden restringir su efectividad son las
siguientes:
•
La inconsistencia de los datos: Los datos han sido suministrados de dos
fuentes: la Unidad de Computación y el Área de Matemática, siendo que
entre ellos hay algunas diferencias leves. Se han tomado sólo los de la
Unidad de Computación por ser los más completos y se realizará el
trabajo partiendo de éstos.
•
Solamente se tomarán en cuenta los datos del Centro Local
Metropolitano.
CAPITULO II
MARCO TEÓRICO
2.1 Antecedentes de la Investigación
Para el Centro Local Metropolitano la estimación de la matrícula ha
sido un problema que ha venido atacándose con diversas herramientas que
van desde utilizar la matrícula del semestre inmediato anterior, el promedio
de los dos o seis últimos semestres, hasta el uso de herramientas basadas
en modelos de regresión, utilizadas actualmente en el Área de Matemática
del Centro Local.
Estudios similares de pronóstico de matrícula basados en series de
tiempo se han realizado en instituciones extranjeras como la Universidad de
la República (UDELAR) en Uruguay 1. En la literatura revisada no se
encontraron evidencias de casos concretos de uso de modelos para efectos
de pronóstico de matrícula, sin embargo, si se ha utilizado el modelo para
otros
fines
de
pronóstico,
tales
como
aplicaciones
hidrológicas,
meteorológicas y econométricas
El gobierno venezolano, en la actualidad, ha realizado su pronóstico
de matrícula de alumnos de la “Educación Bolivariana” (alumnos a todos los
niveles en las distintas instituciones públicas) para el período 2004-2005,
utilizando las estadísticas de matrícula de los años anteriores, tomando como
base el incremento interanual promedio 2. La siguiente tabla muestra la
estimación de la matrícula de alumnos de educación media calculada
mediante este método:
1
2
http://www.rau.edu.uy/sui/Publicaciones/algunosTopicos/doc_tr3.pdf
www.me.gob.ve/sistema_de_educacion_bolivariana
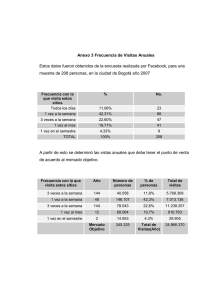
Estimado de la Matrícula estudiantil para el
período escolar 2004-2005 Fecha: 27-06-05
Entidad Federal
Estimado
Cargado
Diferencia
DTTO. CAPITAL
523831
390937
132894
AMAZONAS
42407
36471
5936
ANZOATEGUI
400547
317838
82709
APURE
150556
123711
26845
ARAGUA
453259
188894
264365
BARINAS
227663
189684
37979
BOLIVAR
420174
251648
168526
CARABOBO
588724
375788
212936
COJEDES
92126
70282
21844
DELTA AMACURO
48838
38822
10016
FALCON
272940
208639
64301
GUARICO
223042
63010
160032
LARA
486961
326407
160554
MERIDA
237550
171309
66241
MIRANDA
677166
372042
305124
MONAGAS
259009
160381
98628
NVA. ESPARTA
124520
97405
27115
PORTUGUESA
256061
154579
101482
SUCRE
278994
130215
148779
TACHIRA
321952
256687
65265
TRUJILLO
207541
162780
44761
YARACUY
178240
119128
59112
ZULIA
960376
580625
379751
VARGAS
87278
18141
69137
Total Cargado
7519753
4805423
2714330
TablaN° 1 Estimación de la matrícula de Educación Media Venezolana
Fuente: http://planteles.me.gob.ve/estimadoalumno2.php
2.2 Bases Teóricas
2.2.1. Definiciones Básicas
2.2.1.1 Proceso estocástico
Se llama Proceso estocástico al conjunto de variables aleatorias Xt
cuya distribución varía de acuerdo a un parámetro, generalmente el tiempo.
{Xt}, t= 0, 1..., ∞
La variable tiempo t toma valores en un subconjunto de los números
enteros positivos. Las variables aleatorias Xt toman valores en un conjunto
que se denomina espacio de estados, el cual esta compuesto por todos los
resultados posibles.
Existen algunos casos especiales de procesos estocásticos:
•
Proceso
estacionario:
Cumplen
con
las
condiciones
de
estacionariedad (ver definición mas adelante)
•
Proceso de Markov: Cuya evolución solo depende del estado actual,
sin tomar en cuenta los estados anteriores.
•
Proceso de Gauss: En el que toda combinación lineal de variables es
una variable de distribución normal.
•
Proceso de Poisson : Es un proceso donde el número de sucesos en
dos intervalos siempre es independiente, la probabilidad de que un
suceso ocurra en un intervalo es proporcional a la longitud del
intervalo y la probabilidad de que ocurra más de un suceso en un
intervalo muy pequeño es 0.
•
Proceso de Gauss-Markov: Son procesos que satisfacen al mismo
tiempo, las condiciones de los procesos de Gauss y de Markov.
•
Proceso de Bernoulli: Donde cada intento tiene sólo dos resultados
posibles. La probabilidad del resultado de cualquier intento permanece
fija en el tiempo. Los intentos son estadísticamente independientes.
2.2.1.2 Ruido Blanco
Se llama ruido blanco a una sucesión de variables aleatorias con
distribución
normal,
esperanza
nula,
varianza
constante
y
no
correlacionadas (Novales, 1991).
Para algunos autores, las variables no deben tener necesariamente
distribución normal, en cuyo caso las suponen independientes en el tiempo
(covarianza nula) en vez de no correlacionadas.
2.2.1.3 Variable aleatoria
Una variable aleatoria se define como el resultado numérico
de un experimento aleatorio. Matemáticamente, es una aplicación
que da un valor numérico a cada suceso en el espacio de los
resultados posibles del experimento.
2.2.1.4 Procesos estacionarios
Un proceso estocástico es estacionario si para todo entero m >0, los
conjuntos de variables aleatorias
{Yt1 , Yt2 , Yt3 ... Ytm } ;
Ytm = Observaciones de la serie en los momentos tm
tienen la misma distribución de probabilidad, independientemente del valor
del tiempo t (Novales, 1990).
Esto quiere decir, que un conjunto determinado de variables aleatorias
del proceso estocástico, tiene la misma distribución que cualquier otro
conjunto de m variables aleatorias extraídas del mismo proceso. Un ejemplo
de proceso estacionario es el ruido blanco, por ser una sucesión de variables
aleatorias de igual distribución e independientes a lo largo del tiempo.
La estacionariedad implica que la esperanza y la varianza son iguales
para todas las variables Ytm
Figura N° 1 Proceso estacionario de ruido blanco
Fuente: http://www.ccee.edu.uy
2.2.1.5 Series de tiempo estacionarias
Una serie se puede definir como estacionaria si cumple las siguientes
características:
•
La tendencia es lineal (la esperanza de todas las variables Ytm son
iguales). Algunos autores se refieren a estas series como “sin
tendencia”.
•
Es homocedástica, es decir, la variabilidad se mantiene constante a lo
largo de la serie.
Serie Homocedástica
15
10
5
0
1
2
3
4
5
6
7
8
9
10 11 12 13
Figura N° 2 Serie Homocedástica
Fuente: elaboración propia
Serie Heterodástica
25
20
15
10
5
0
1
2
3
4
5
6
7
8
9
10
11
12
13
Figura N° 3 Serie Heterocedástica
Fuente: elaboración propia
•
No tiene ciclos estacionales, lo cual implica que, si la serie no es
anual, no existen períodos de comportamientos típicos durante ciertas
épocas del año. Las series anuales normalmente no presentan ciclos
estacionales, sin embargo, podrían determinarse ciclos estacionales
cada cierto período de años. La serie homocedástica de la figura N° 2
no tiene ciclos estacionales, pero la siguiente, descrita en meses tiene
un claro ciclo de estacionalidad:
Figura N° 4 Temperatura en Madrid
Fuente: www.españahoy.com
•
La estructura de dependencia se mantiene constante, es decir si una
observación influye sobre la siguiente, esto siempre ocurre. Esta
condición es importante para modelar la serie, pues si el fenómeno
que genera la serie cambia, es imposible que podamos prever la
evolución de la serie.
•
La influencia de las observaciones de los valores de la serie sobre las
siguientes, disminuye con el tiempo.
2.2.1.6 Estacionariedad en sentido débil
La estacionariedad en sentido estricto es poco aplicable a las series
temporales ya que se tiene una sola observación de cada una de las
distribuciones de probabilidad que componen el proceso en cada período de
tiempo. En la práctica, se aplica más bien la estacionariedad en sentido débil
o de segundo orden como lo llaman algunos autores, lo que implica que
todos sus momentos de primer y segundo orden son independientes del
tiempo, es decir, Un proceso es estacionario en sentido débil (o de 2º orden)
si y solo si para todo t se cumple:
•
Media constante
•
Varianza constante
•
La covarianza entre dos observaciones Yt y Yt-k , COV(Yt ,Yt-k ) ,
depende solamente de la distancia k que haya entre ellas.
La siguiente es una serie estacionaria en media y varianza:
Figura N° 5 Consumo de Gasolina en España
Fuente: http://www.uam.es
2.2.1.7 Covarianza y correlación
Los conceptos de covarianza y correlación implican dos maneras de
medir la relación entre dos variables aleatorias. Sean X e Y variables
aleatorias (discretas o continuas), la covarianza entre X e Y, denotada
COV [ X , Y ] ó σ X Y , está dada por:
COV [ X , Y ] = E ⎡⎣( X − μ x ) (Y − μ y ) ⎤⎦ = E [ XY ] − μ x μ y
(1)
donde μ x es la media de X y μ y es la media de Y
Una covarianza alta implica un alto grado de dependencia entre X e Y
(sea negativa o positiva). Una covarianza cercana a cero implica poca
dependencia entre X e Y. El problema de la covarianza es que es sensible a
la escala de medición de las variables involucradas, por ejemplo, si una
variable se mide en millones de bolívares, la covarianza aumentaría en esa
misma
medida.
Luego,
es
posible
tener
covarianzas
altas
y
no
necesariamente una alta dependencia entre las variables. Al mismo tiempo
es posible tener una covarianza cero y las variables no ser independientes.
La correlación evita este problema ya que calcula la relación entre las
variables de acuerdo a un coeficiente expresado entre -1 y 1. Un coeficiente
de correlación nulo, significa que no hay correlación lineal entre las dos
variables. Se calcula según la siguiente ecuación:
r=
E [ XY ] − μ x μ y
Sx S y
(2)
Donde S x y S y son la desviación típica de las variables X e Y.
2.2.1.8 Autocorrelación
La Autocorrelación es la correlación consecutiva de series de tiempo
igualmente espaciadas entre sus miembros. Algunos autores utilizan los
términos
correlación
rezagada,
y
persistencia
para
referirse
a
la
autocorrelación. A diferencia de los datos estadísticos que son muestras
aleatorias que nos permiten realizar análisis estadísticos, las series de
tiempo
son
generalmente
autocorrelacionadas,
haciendo
posible
la
predicción y el pronóstico.
2.2.1.9 Función de Autocorrelación (FAC)
Es una función real que mide la correlación que existe entre los
valores de la serie temporal en distintos instantes de tiempo. Su objetivo es
determinar como se influyen las observaciones de la serie separadas un
numero de períodos determinados. De esta forma, la función de
autocorrelación será una sucesión de números denotados por:
ρ1 , ρ 2 , ρ3 ...ρ k ...
Por ejemplo,
si se quiere medir el factor de correlación de las
observaciones de la serie Y entre el instante t y el instante anterior t-1, es
decir, Yt y Yt-1 , se está hablando del coeficiente de autocorrelación de primer
orden y viene dado por:
ρ1 =
Cov(Yt ,Yt-1 )
Var(Yt )Var(Yt-1 )
(3)
Si se supone estacionariedad en la serie Var (Yt ) = Var (Yt −1 ) , luego
ρ1 =
Cov(Yt ,Yt-1 )
Var(Yt )
(4)
En general, para k períodos, se tiene
ρ1 =
Cov(Yt ,Yt-k )
Var(Yt )
(5)
Una FAC cercana a cero indica que no existe efecto de una
observación con otra separada k períodos. Una FAC cercana a 1 indica una
alta influencia de una observación sobre la otra.
2.2.1.10 Función de Autocorrelación Parcial (FACP)
Esta función responde a la misma idea que la FAC, pero a diferencia
de ésta, mide la correlación entre dos observaciones de la serie, ajustada por
el efecto de los períodos intermedios. Por ejemplo, parte de la correlación
que pueda detectarse entre dos valores de de la serie Y en los tiempos t y t-
2, ( Y t , Yt − 2 ) es debida a que ambas variables están correlacionadas con el
valor de la variable en t-1.
2.2.1.11 Hipótesis de los componentes subyacentes (HCS)
La HCS expone que una serie temporal Yt puede descomponerse en
todos o alguno de los siguientes elementos: tendencia (T), ciclo (C),
estacionalidad (E) e irregularidad (I), que estos elementos se estiman por
separado y luego se combinan de forma conveniente para modelar el
comportamiento de la serie.
2.2.1.12 Outlier
Es aquella observación que tiene un comportamiento muy diferente
con respecto al resto de los datos, frente al análisis que se desea realizar
sobre ellos. Esto implica, que dada una serie de datos, existen algunos que
se diferencian sustancialmente del resto y cuya ocurrencia puede deberse a
causas muy específicas, no normales en el comportamiento de la serie,
razón por la cual deben ser revisados con detenimiento. Por ejemplo,
teniendo una serie de datos que guarda la altura promedio de los niños en
edad preescolar, durante varios años, y los valores oscilan entre 0,75mt y 1
mt., conseguir un valor en la serie de 1,5mt puede ser considerado como
outlier y debe ser investigado para determinar si es correcta tal magnitud o si
se debe a un error.
2.2.1.13 Método de los mínimos cuadrados
Es el método de estimación mas usado comúnmente para ajustar una
serie de puntos de datos a ecuaciones de curvas conocidas. La sumatoria del
cuadrado de las distancias Dn entre la curva conocida y los datos originales,
es una medida de la bondad de ajuste de la curva, es decir, mientras mas
pequeño sea este valor, mejor es el ajuste de la curva.
“Una tal curva se dice que ajusta los datos en el sentido de mínimos
cuadrados y se llama curva de mínimos cuadrados. Así pues, una recta con
esa propiedad se llama recta de mínimos cuadrados, una parábola se llama
parábola de mínimos cuadrados, etc”.(Spiegel, 1990)
•
Recta de mínimos cuadrados
Por este método se ajusta un conjunto de puntos (X1 , Y1 ) , (X 2 , Y2 ) a una
recta cuya ecuación tiene la forma
Y = a0 + a1 X
(6)
a0 y a1 se calculan, resolviendo en forma simultánea las siguientes
ecuaciones:
∑Y = a N + a ∑ X
∑ XY = a ∑ X + a ∑ X
0
0
(7)
1
1
2
(8)
2.2.2 Series temporales
Los fenómenos sociales pueden ser estudiados estadísticamente
teniendo en cuenta su evolución en el tiempo. La cantidad de alumnos que
se inscriben semestralmente en cada materia del pénsun de estudios de
cualquier carrera en cualquier universidad puede ser concebida como uno de
estos fenómenos.
En el caso que nos compete, la Universidad Nacional Abierta, y
seguramente en todas las universidades, la matrícula de algunas materias
depende mayormente de factores que pueden medirse (pre-requisitos de
ingreso, repitencias, etc.) y por lo tanto pueden estimarse usando métodos
más concretos, sin embargo, para otras materias la matrícula depende de
muchos factores y situaciones complejas que sería muy difícil abarcar por
completo y aún cuando se pudiera, sería muy difícil medirlas. Este es el caso
de las asignaturas sin pre-requisitos (típicamente en los primeros semestres),
donde la matrícula no exhibe necesariamente un patrón determinado.
El siguiente, es un ejemplo de la matrícula de una asignatura en un
período de tiempo. Muestra la cantidad de alumnos inscritos por semestre.
Semestre
Matrícula
1995-1
1007
1995-2
1061
1996-1
1127
1996-2
1416
1997-1
1119
1998-1
1376
1998-2
487
1999-1
755
1999-2
1603
2000-1
1169
2000-2
1117
2001-1
1339
2001-2
1178
2002-1
909
2002-2
1126
2003-1
1154
2003-2
759
2004-1
1869
2004-2
1521
Tabla N°2: Matrícula de alumnos de la asignatura Lengua y Comunicación I.
Fuente: Unidad de Computación CLM.
La figura Nº 6 muestra la gráfica de los datos de la tabla Nº 2, donde
puede observarse el comportamiento de la serie entre 1995 y 2004.
Lengua y Comunicación I (102)
2000
1800
1600
1400
1200
1000
800
Serie1
600
400
20
04
-2
20
02
-2
20
03
-2
20
01
-2
20
00
-2
19
99
-2
19
98
-2
19
96
-1
19
97
-1
19
95
-1
200
0
Figura N° 6 Matrícula de la asignatura 102
Fuente: Elaboración propia
En estos casos, el estudio puede ser enfocado desde dos puntos de
vista: un punto de vista que estudia el comportamiento pasado de la variable
de estudio por ella misma (univariado) o un enfoque que utiliza una serie de
variables que permitan describir el mismo comportamiento (multivariado). El
primer enfoque puede ser incluido en el análisis estadístico que se denomina
Análisis de Series Temporales.
Una Serie Temporal está formada por un conjunto de valores
obtenidos de observaciones referentes al mismo fenómeno, realizadas en
una sucesión de momentos de tiempo, normalmente a intervalos iguales
(Sierra, 1994).
El análisis del comportamiento de una variable basado en Series de
Tiempo, es con frecuencia bastante práctico, dado que se enfoca en estudiar
la evolución de la variable en el tiempo, sin tomar en cuenta las causas que
la generaron ni los factores que influyeron en dicha evolución.
El estudio de series temporales ha sido un punto importante de estudio
en las ciencias econométricas, siendo muchos los autores que han trabajado
en ese sentido desde comienzos del siglo pasado.
El análisis clásico, o modelo de descomposición, ya utilizado en la
década de los treinta, sigue teniendo vigencia debido a su sencillez, aun
cuando han surgido muchos otros métodos que lo han complementado e
incluso intentado desplazar.
Los modelos conocidos como “macroeconométricos”, cuyo estudio
tuvo auge entre los años cincuenta-sesenta, se basaban en el uso de
ecuaciones simultáneas para la descripción y el pronóstico de ciertos
fenómenos tanto económicos como sociales. Estos modelos llegaron a tener
más de cien ecuaciones, lo cual fue posible de manipular gracias a la enorme
ayuda de la informática que les permitía hacer cálculos de forma más rápida.
Adicionalmente, y gracias a la estabilidad económica que existió durante ese
tiempo, los resultados hicieron pensar que se había conseguido el modelo
óptimo. Sin embargo, el surgimiento de la explosión petrolera, las crisis
inflacionarias, el desempleo y otras situaciones inesperadas mostraron la
incapacidad de estos modelos para representar la realidad del momento.
Un enfoque diferente para abordar las series de tiempo, lo introdujeron
en la década de los años 70, G.E.P. Box, profesor de estadística de la
Universidad de Wisconsin, y G.M. Jenkins, profesor de Ingeniería de
Sistemas de la Universidad de Lancaster, en sus trabajos sobre el
comportamiento de la contaminación en la bahía de San Francisco, que
resultaron en los modelos ARIMA 3, los cuales permitieron establecer mejores
mecanismos para el pronóstico de las series temporales, convirtiéndose
rápidamente en un clásico. También son conocidos como modelos BoxJenkins y su metodología fue de gran ayuda para simplificar los pronósticos
sobre series de tiempo, basándose en la estructura de correlaciones de la
propia serie.
Estos modelos lineales univariantes, con pocos parámetros a estimar,
proporcionaron
mejores
predicciones
que
los
complicados
modelos
macroeconométricos y pusieron en entredicho la utilidad de los mismos.
Varios estudios comparativos realizados para la fecha, confirmaron esa idea.
Esto provocó una cierta división entre los económetras, por un lado, los
partidarios de los métodos de series temporales, acusaban a los modelos
multiecuacionales de no ser capaces de explicar la realidad económica, y
defendían la mayor simplicidad y eficacia de los modelos ARIMA, por otro
lado, los partidarios de los modelos econométricos, se defendían acusando a
los modelos uniecuacionales de series de tiempo de no suministrar
información de las causas de variación de la variable dependiente, lo que los
invalidaba para efectuar ciertos análisis económicos.
Ante las nuevas perspectivas de la econometría, iban a la par los
estudios de series temporales., además de la utilización de los modelos
ARIMA y la metodología Box-Jenkins, se añadieron los modelos estructurales
de series temporales,
los cuales son una especie de síntesis entre el
planteamiento tradicional de descomposición y la metodología de BoxJenkins, en el sentido de que cada componente se modela como un proceso
ARIMA.
3
Los modelos ARMA (autorregresivos y de media móvil), habían sido ya propuestos por Yule (1921, 1926) y Wold
(1938)
Actualmente nadie cuestiona la utilidad de la metodología ARIMA para
el modelaje econométrico, y se mantiene vigente el análisis clásico de
descomposición, con algunas variantes en la estimación de sus parámetros.
La vigencia de ambas metodologías queda reflejada en el hecho de que la
mayoría de los libros de texto de econometría, incluyen de preferencia sólo
estos métodos, sin embargo, una gran cantidad de metodologías han surgido
para complementar las existentes e incluso han surgido teorías que proponen
enfoques totalmente diferentes. En el resto del documento se analizaran las
más conocidas
2.2.2.1 Análisis Clásico de series temporales
El método clásico de análisis de series temporales, también llamado
por algunos autores método de descomposición o método de extracción de
señales, supone que la serie de tiempo está compuesta por cuatro
parámetros que pueden ser estimados individualmente para luego establecer
un modelo que permita pronosticar el comportamiento futuro de la serie, así
como explicar el comportamiento pasado.
El primer paso obligatorio para la descomposición de la serie es
establecer la consistencia de los datos. La serie debe cumplir con las
siguientes características:
•
Debe estar completa, es decir, no deben faltar valores en períodos
intermedios
•
Datos considerados como outliers, deben ser revisados para determinar si
se deben a condiciones atípicas cuya probabilidad de ocurrencia futura
sea muy baja
Una vez establecida la consistencia de los datos, y partiendo de la
gráfica de la serie, se pueden distinguir, de acuerdo a este método cuatro
componentes principales:
1. Un componente que se mantiene en el tiempo, cuyo comportamiento
es el mismo a lo largo de todos los valores de la serie. Esto significa
por ejemplo que a simple vista se puede observar que la gráfica de la
serie tiene tendencia a subir, bajar o mantenerse estable. Por ejemplo:
Figura N° 7: Indice de Actividad Económica
http://ciberconta.unizar.es/leccion/seriest/100.HTM
Este componente es denominado Tendencia ( T ) por casi todos los autores.
2. Un componente cíclico, cuyos valores están alrededor de la
Tendencia, generalmente de poca duración. Este componente es un
valor que se repite a lo largo de la serie y dependiendo del tamaño de
ésta (numero de observaciones) podría no ser tan fácil de observar, de
hecho es la componente más difícil de determinar, refleja movimientos
oscilatorios por encima y por debajo de la tendencia de la serie y se
debe principalmente a los periodos de prosperidad y de depresión. La
siguiente gráfica muestra una serie con un claro ciclo de crecimiento y
decrecimiento:
Figura N°8: Ciclos de operatividad debido a alteraciones de presión y temperatura
Fuente: www.aeportugal.pt.
3. Un componente estacional, que representa cortas variaciones que
pueden repetirse periódicamente cada cierto período de tiempo, lo
cual puede representar situaciones temporales tanto típicas como
atípicas de la estructura de los datos que se está observando. Estos
valores pueden ser notados a simple vista, por ejemplo picos de
incremento, disminución o variación aleatoria similar cada cierto
número de períodos. Las variaciones estacionales se refieren
normalmente a periodicidades anuales, con lo cual, si solo se tienen
datos anuales, estos valores son nulos. Sin embargo, pueden existir
variaciones estacionales, dependiendo de los datos,
intervalo de tiempo
Figura N° 9: Componente Estacional
http://ciberconta.unizar.es/leccion/seriest/100.HTM
a cualquier
4. Un componente irregular, formado por variaciones aleatorias que no
tienen una representación definida ni un patrón de ocurrencia. Este
valor puede representar las situaciones atípicas que suelen estar
presentes en todos los fenómenos sociales y que no pueden
predecirse ni medirse de ninguna forma determinista. Pueden deberse
a sucesos de azar tales como huelgas, inundaciones, elecciones, etc.
y aunque se supone que dichas variaciones pierden su influencia en el
tiempo, cabe la posibilidad de que sean tan intensos que den lugar a
nuevos movimientos cíclicos o de otro tipo.
Estos cuatro componentes tienen su correspondencia en los factores
que lógicamente podrían interesar del fenómeno en estudio y que aislándolos
podrían permitir tanto explicar el comportamiento del mismo, como
pronosticar su comportamiento futuro.
El análisis exige que la serie cronológica sea descompuesta en sus
cuatro componentes para que sean estudiados por separado y luego se
relacionen de acuerdo a un modelo determinado. Los modelos que se utilizan
generalmente son dos, el aditivo y el multiplicativo dependiendo de la
interacción entre los componentes de la serie, aunque existen autores que
promueven el uso de un tercer modelo llamado mixto que es una
combinación de los dos anteriores
Modelo Aditivo
En este modelo se supone que cualquier valor Y de la serie temporal
es la suma de los cuatro componentes y puede calcularse de la siguiente
forma:
Y= T+C+E+I
(9)
Los componentes de la serie se suponen no relacionados entre si,
esto significa que no hay dependencia de un componente con otro. La
dependencia existe si la variación de un componente implica la variación de
otro u otros componentes.
Algunos autores consideran que a menos que existan relaciones
claramente definidas, las series deben considerarse siempre aditivas, ya que
las relaciones que no están bien delimitadas pueden ser tomadas como
irrelevantes para el desarrollo del modelo.
Modelo Multiplicativo
En este modelo se supone que cualquier valor Y de la serie temporal
es el producto de los cuatro componentes y puede calcularse de la siguiente
forma:
Y= T*C*E*I
(10)
En
el
modelo
multiplicativo
los
componentes
tienen
alguna
dependencia entre ellos, lo cual hace que la variación de uno implique la
variación de los otros. Tiende a ser el más utilizado debido a que no siempre
se sencillo establecer esta independencia. Para algunos autores solo existe
el modelo multiplicativo, debido a que parten del hecho de que siempre existe
alguna relación dependiente entre los componentes de la serie de tiempo,
aun cuando no se muestre a simple vista, otros establecen que la relación
puede estar encubierta por la componente irregular.
Modelo Mixto
En este modelo se supone que cualquier valor Y de la serie temporal
es el producto de los tres componentes T, E y C pero la componente irregular
I es un componente independiente. Esto implica que el modelo a seguir es el
siguiente:
Y= T*C*E +I
(11)
En el cual se está asumiendo que existen relaciones de dependencia
entre 3 de los componentes de la serie excepto para el componente irregular.
Elección del modelo
Para elegir el mejor modelo no existe un método determinado, ya que
no se tiene información a priori que permita escogerlo, sin embargo, Arellano
(2001) recomienda el llamado método de los Coeficientes de Variación (CV),
que consiste en, una vez determinada la tendencia, calcular la tabla de
residuos para ambas series, eliminando la tendencia. Esto significa:
•
Si el modelo es aditivo, la serie con los efectos de tendencia removidos,
se representa con:
Rt = Yt − Tt ; t = 1, 2...n
(12)
•
Análogamente, si el modelo es mixto o multiplicativo, la siguiente
ecuación representa la serie, una vez removidos los efectos de tendencia
Y
Wt = t
Tt
(13)
Luego se deben ordenar las series de residuos por períodos, calcular
la media por cada período y elegir una estación determinada (la misma para
cada período en ambas series). El CV se calcula dividiendo el valor de la
estación determinada entre la media de cada período. Por ejemplo:
Período
Estación
1
2
K
1
W(1)
W(5)
W(4k-3)
2
W(2)
W(6)
W(4k-2)
Promedio
STD
Fila
Fila
S
1
W (1)
S2
W (2)
3
W(3)
W(7)
W(4k-1)
W (3)
S3
4
W(4)
W(8)
W(4k)
W (4)
S4
C.V.
Fila
S1
W (1)
S2
W ( 2)
S2
W ( 3)
Tabla N° 3: Residuos del modelo aditivo
Fuente: http://ciberconta.unizar.es/leccion/seriest/100.HTM
Período
Estación
1
2
K
1
R(1)
R(5)
R(4k-3)
2
R(2)
R(6)
R(4k-2)
3
R(3)
R(7)
4
R(4)
R(8)
Promedio
Fila
STD
Fila
C.V.
Fila
R (1)
S1
S1
R (2)
S2
S2
R(4k-1)
R (3)
S3
S2
R(4k)
R (4)
S4
R (1)
R ( 2)
R ( 3)
Tabla N° 4: Residuos del modelo Mixto/Multiplicativo
Fuente: http://ciberconta.unizar.es/leccion/seriest/100.HTM
El modelo a elegir, será aquel cuya variación sea menor en términos
de valor absoluto.
La elección entre el modelo mixto y el multiplicativo dependerá de la
experiencia del investigador, ya que puede suponer o no, de acuerdo al caso
que esté estudiando, que la componente irregular está correlacionada con el
resto de los valores de la serie.
Detección y corrección de outliers
Existen procedimientos específicos para detectar y corregir los
outliers. El método más usado para la detección de outliers se basa en fijar
intervalos o regiones tales que fuera de ellas, las observaciones sean
posiblemente outliers y consideradas como tales. Este método está basado
en la desigualdad de Tchebychev 4:
f {Xi : |Xi - Xj| < kS } ≥ 1 −
1
k2
(14)
Donde k es un valor decidido por el investigador y significa la mayor
distancia que la variable puede estar alejada de su media. Generalmente
toma valores enteros. S es la desviación típica. La elección de k significa
Se deduce que en el intervalo ( X - kS, X + kS) se encuentran al menos
el 100*(1 −
1
1
)% de las observaciones. Así si k es tal que 1 − 2
2
k
k
es próximo
a 1, observaciones fuera de ( X - kS, X + kS) pueden ser declaradas como
outliers. Por ejemplo, si k=3 , el intervalo ( X - 3S, X + 3S) contiene al menos
el 88.88% de las observaciones.
Para la corrección de outliers, el método mas usado en el caso de
series temporales es el de interpolación lineal entre el valor anterior y el
siguiente.
Existen otros mecanismos como el de recorte y reemplazamiento que
se emplean tanto para la detección como la corrección de outliers. En el
primero se eliminan de los datos los valores mas pequeños y los más
grandes luego de lo cual se calculan la media y la desviación típica
recortada, esto permite decidir cuales son datos outliers y cuales no. Con el
4
Pafnouti Lvovitch Tchebychev. Matemático ruso (1821-1894)
reemplazamiento se sustituyen los valores más pequeños por el menor valor
y los más grandes, por el mayor valor de la serie no considerados como
outliers.
Es de notar que para las series de tiempo, la eficacia de su análisis
depende en gran medida de la veracidad de sus datos, luego, esto debe ser
tomado en cuenta en el sentido de que una serie con muchos valores que
deben ser corregidos (en relación con la cantidad de datos), probablemente
no suministre un pronóstico adecuado.
Ejemplo práctico: Si tomamos la serie expresada en la tabla N°2:
Semestre
1995-1
1995-2
1996-1
1996-2
1997-1
1998-1
1998-2
1999-1
1999-2
2000-1
2000-2
2001-1
2001-2
2002-1
2002-2
2003-1
2003-2
2004-1
2004-2
Matrícula
1007
1061
1127
1416
1119
1376
487
755
1603
1169
1117
1339
1178
909
1126
1154
759
1869
1521
Podemos observar a simple vista que no existen datos para el
semestre 1997-2. Siendo una situación real, lo primero sería investigar si la
causa se debe a un error humano o realmente no existe el dato. En este
último caso, se procede a interpolar el mencionado dato por el método de
interpolación lineal:
Se toman los datos de la tabla donde se desea interpolar el valor
1997-1
1119
Y
X
1998-1
1376
El valor deseado es el semestre 1997-2, que en la tabla representa el
semestre 6, luego aplicando la fórmula (5), tenemos:
f (6) = 1119 +
1376 − 1119
*(6 − 5) = 1248
7−5
Con esto se completa la serie y se puede comenzar el análisis.
Y
X
1997-1
1119
1997-2
1248
1998-1
1376
Estimación de los componentes de la serie
La estimación de los diferentes componentes de la serie puede
hacerse de varias formas teniendo en cuenta parámetros como tamaño de la
serie, tipo de información almacenada en los datos, estructura, etc. El empleo
de alguna técnica en particular debe realizarse con base en estos parámetros
y tomando en cuanta también la experiencia, ya que no existe una forma
estándar de realizar la selección.
Estimación de la Tendencia
Para estimar la tendencia las técnicas más conocidas son las de los
semipromedios, la de los promedios móviles y la de los mínimos cuadrados.
•
Técnica de los semipromedios: Consiste en dividir la serie cronológica en
dos partes, de ser posible iguales, calcular la media aritmética de ambas
partes, situar los dos puntos hallados en el gráfico de la serie y unirlos
mediante una línea recta, que se supone la Tendencia buscada. Se aplica
cuando la tendencia es lineal o aproximadamente lineal.
Ejemplo práctico: Tomando en cuenta la serie de la tabla N°2 (después
del ajuste de outliers) primero se divide en dos partes la serie y se
calculan las medias aritméticas de cada una:
Semestre
Matrícula
Semestre
Matrícula
1995-1
1007
2000-1
1169
1995-2
1061
2000-2
1117
1996-1
1127
2001-1
1339
1996-2
1416
2001-2
1178
1997-1
1119
2002-1
909
1997-2
1248
2002-2
1126
1998-1
1376
2003-1
1154
1998-2
487
2003-2
759
1999-1
755
2004-1
1869
1999-2
1603
2004-2
1521
Media
1119.9
Media
1214, 1
Tabla N° 5: Matrícula de alumnos de la asignatura Lengua y Comunicación I.
Fuente: Unidad de Computación UNA
Mediante una grafica se pueden posicionar ambas medias en
cada punto central de la serie (en este caso se puede ubicar el centro
indistintamente entre los semestres 1997-1 y 19972 en la primera
parte y 2002-1 ó 2002-2 en la segunda parte) y trazar una línea recta
que permita establecer la tendencia, sin embargo, para efectos de
cálculo es mas preciso realizar un análisis como el que sigue:
En diez semestres (desde 1997-1, hasta 2002-1 se puede notar
que ha habido un incremento de 1214,1-119,9 = 94,2 alumnos, es
decir, un incremento de 94,2/10 = 9,42 semestral. Sabiendo esto,
podemos calcular los valores de tendencia para todos los semestres,
de la siguiente forma: El semestre 1996-2 (un período antes de la
media) viene dado por 1119,9 –9,42 = 1110,48, el anterior (1996-1)
será igual a 1119,9 –2*9.42= = 1101.06 y así sucesivamente. Los
semestres posteriores a la media serán 1119,9 + 9,42 (1997-2) 1119,9
+ 2 *9,42 (1998-1) . La gráfica de la siguiente figura muestra una
aproximación de lo anterior:
-1
04
20
20
03
-1
-1
02
20
20
01
-1
-1
00
20
19
99
-1
-1
98
19
97
-1
-1
19
96
19
19
95
-1
2000
1800
1600
1400
1200
1000
800
600
400
200
0
Figura N°.10 Aplicación del Método de los Semipromedios
Fuente: Elaboración propia
•
Técnica de los promedios móviles: Esta técnica permite seguir de cerca la
evolución de la serie, aunque se pierden los años del extremo superior e
inferior y en ocasiones no es posible ajustar a una curva conocida (Sierra,
1994).
Se determinan en la serie los períodos de tres o cinco años, según
convenga (se pueden combinar los períodos), luego se calculan los
totales móviles correspondientes. Para ello, se suman los totales del
período completo y el resultado se centra en el año intermedio del período
tomado (año 2 si es de 3 años o año 3 si es de 5 años), seguidamente se
descarta el primer año y se repite el procedimiento con los siguientes
años de acuerdo al periodo establecido, hasta el último valor. Por último,
cada total se divide por el número de años que comprenda el período,
obteniendo los promedios o medias móviles buscadas. El siguiente
gráfico muestra un promedio móvil a tres años de la serie de la Tabla N°2.
19
95
19 -1
95
19 -2
96
19 -1
96
19 -2
97
19 -1
97
19 -2
98
19 -1
98
19 -2
99
19 -1
99
20 -2
00
20 -1
00
20 -2
01
20 -1
01
20 -2
02
20 -1
02
20 -2
03
20 -1
03
20 -2
04
20 -1
04
-2
2000
1800
1600
1400
1200
1000
800
600
400
200
0
Figura N° 11 Aplicación del Método de los Promedios Móviles
Fuente: Elaboración propia
Técnica de los mínimos cuadrados: Consiste en buscar por el
procedimiento de los mínimos cuadrados, la ecuación de la recta,
curva parabólica, exponencial, logarítmica, etc. que mejor se ajuste al
conjunto de valores de la serie. Una vez hallada la ecuación, se
pueden determinar los valores de tendencia para cada momento.
(Sierra, 1994). La siguiente figura muestra un ejemplo del ajuste de
los datos de la tabla N°2 a una recta de mínimos cuadrados:
Título del gráfico
2000
1500
1000
500
20
04
-1
20
02
-1
20
03
-1
20
01
-1
20
00
-1
19
99
-1
19
98
-1
19
97
-1
19
96
-1
0
19
95
-1
•
Figura N°.12 Aplicación del Método de los Promedios Móviles
Fuente: Elaboración propia
Estimación de las variaciones estacionales
Las técnicas más usadas son la técnica del porcentaje promedio, la
técnica del porcentaje promedio móvil y la técnica del porcentaje de
tendencia.
•
Técnica del porcentaje promedio: Los valores de cada mes se
expresan como porcentajes de la media anual. Por lo tanto, la suma
de los porcentajes de todos los meses debe ser igual a 1200, en el
caso de que la serie tenga valores mensuales, 400 en caso de que
sean valores trimestrales y así sucesivamente. De nos ser así, deben
multiplicarse por la proporción adecuada para que se produzca ese
ajuste. Luego de obtenido el índice mensual de varios años, se forma
un índice común obteniendo su media. Siguiendo con el ejemplo de la
tabla N°2, lo primero es reordenar la serie en períodos anuales, para
luego calcular la media:
Año
Semestre 1 Semestre 2
Suma
1995
1007
1061
1034
1996
1127
1416
1271,5
1997
1119
1248
1183,5
1998
1376
487
931,5
1999
755
1603
1179
2000
1169
1117
1143
2001
1339
1178
1258,5
2002
909
1126
1017,5
2003
1154
759
956,5
2004
1869
1521
1695
Tabla N° 6: Datos reordenados por períodos
Fuente: Elaboración propia
Seguidamente, se expresan los valores de cada mes como
porcentajes de la media anual
Año
Semestre 1 Semestre 2
Suma
1995
97,39
102,61
200
1996
88,64
111,36
200
1997
94,55
105,45
200
1998
147,72
52,28
200
1999
64,04
135,96
200
2000
102,27
97,73
200
2001
106,40
93,60
200
2002
89,34
110,66
200
2003
120,65
79,35
200
2004
110,27
89,73
200
Tabla N° 7: Datos expresados como porcentajes de la media anual
Fuente: Elaboración propia
Afortunadamente, la suma de los porcentajes anuales es 200 (lo
deseado, dado que es una serie semestral), por lo tanto no es
necesario hacer ningún ajuste. En caso de que así fuera,
un
procedimiento como el siguiente serviría para lograrlo:
Si se tiene por ejemplo:
2004
110
87
197
Multiplicando 110 y 87 por 200/197 tenemos los nuevos valores
ajustados que ahora si suman 200:
2004
111.68
88.32
200
El último paso es calcular el índice común con la media de cada
semestre en todos los años:
Índices Estacionales
1
102,13
2
97,87
•
Técnica del porcentaje promedio móvil: Consiste en calcular primero el
promedio móvil de doce meses para los datos originales, y luego el
promedio móvil de dos meses para centrar los resultados en el centro
del mes a que se refieren y no entre dos meses. Luego los datos
originales se expresan como porcentajes del valor que corresponda al
promedio móvil centrado de doce meses. Esta técnica es la más
usada, por ser más satisfactoria matemáticamente. Para dar un mejor
ejemplo de este método se requiere una serie mensual mas que una
semestral como la que se ha venido ejemplificando. La siguiente serie
hipotética permitirá demostrar el método:
Mes
Vuelos
Mes
Vuelos
Enero
178
Julio
186
Febrero
175
Agosto
146
Marzo
120
Septiembre
161
Abril
165
Octubre
119
Mayo
132
Noviembre
170
Junio
135
Diciembre
185
Julio
145
Enero
168
Agosto
168
Febrero
133
Septiembre
196
Marzo
144
Octubre
137
Abril
179
Noviembre
155
Mayo
198
Diciembre
152
Junio
164
Enero
178
Julio
198
Febrero
163
Agosto
175
Marzo
172
Septiembre
129
Abril
165
Octubre
137
Mayo
139
Noviembre
163
Junio
195
Diciembre
169
Tabla N° 8: Tabla Hipotética con valores mensuales
Fuente: Elaboración propia
Calculando primero un promedio móvil de 12 meses y luego otro de 2
meses se tiene:
Mes
P. móvil
Mes
P. móvil
Enero
Julio
164,50
Febrero
Agosto
162,83
Marzo
Septiembre
160,42
Abril
Octubre
159,83
Mayo
Noviembre
162,88
Junio
Diciembre
164,04
Julio
154,83
Enero
163,25
Agosto
154,33
Febrero
164,96
Septiembre
156,00
Marzo
164,83
Octubre
158,17
Abril
164,25
Noviembre
158,46
Mayo
164,71
Diciembre
161,25
Junio
Enero
165,46
Julio
Febrero
166,25
Agosto
Marzo
163,88
Septiembre
Abril
161,67
Octubre
Mayo
161,54
Noviembre
Junio
163,54
Diciembre
Tabla N° 9: Promedio centrado a 12 meses
Fuente: Elaboración propia
Dividiendo cada valor real entre su correspondiente promedio móvil y
expresándolo en porcentajes:
Ene
Feb
Mar
Abr
May
Jun
Jul
93,65
107,58
98,05
112,78 102,91
104,96 102,06
86,05
80,63
108,98 120,21
87,36
119,24 113,07
Oct
Nov
Dic
108,86 125,64
Ago
Sep
86,62
97,82
94,26
89,66
74,45
104,37 164,04
100,36
Tabla N° 10: Técnica del Promedio Móvil
Fuente: Elaboración propia
Calculando el promedio y ajustando los valores se tienen finalmente
los índices estacionales para cada mes:
Ene
Feb
Mar
Abr
May
Jun
Jul
Ago
Sep
Oct
Nov
Dic
92,594 107,63 124,22 85,641 96,715 93,201
104,45 93,089
101,9
99,089
83,54
115,76 109,78 87,051
110,41 100,75 78,933 85,526 106,69 117,69
97,44
72,284 101,33 159,26
107,43 96,919 90,417 92,308 95,116 116,73 101,19
97,34
110,83 78,963 99,025 126,23
Tabla N° 11: Índices Estacionales
Fuente: Elaboración propia
•
Técnica del porcentaje de tendencia: En esta técnica se procede
eliminando de los datos el componente de la tendencia expresando los
resultados de cada mes como porcentajes de los valores de tendencia
mensuales. Se halla la media de las cantidades obtenidas para el
mismo mes dentro de cada año como porcentaje de los valores de
tendencia mensuales. Utilizando la serie de la tabla N°2, junto con el
cálculo de la tendencia ya realizado por el método de los mínimos
cuadrados, podemos reagrupar por semestre para tener lo siguiente
Año
Semestre 1
Semestre 2
Matrícula Tendencia Matrícula Tendencia
1995
1007
1082,22
1061
1091,64
1996
1127
1101,06
1416
1110,48
1997
1119
1119,9
1248
1129,32
1998
1376
1138,74
487
1148,16
1999
755
1157,58
1603
1167
2000
1169
1176,42
1117
1185,84
2001
1339
1195,26
1178
1214,1
2002
909
1223,52
1126
1232,94
2003
1154
1242,36
759
1251,78
2004
1869
1261,2
1521
1270,62
Tabla N° 12: Datos de Matrícula y Tendencia reagrupados por semestre
Fuente: Elaboración propia
Aquí se hallan los valores de cada mes expresados como porcentajes
de la tendencia (ver tabla N°13) Y luego se ajustan los valores
dependiendo de la suma por período, los resultados son mostrados en
la tabla N° 14.
Año
Semestre 1 Semestre 2
Suma
1995
93,05
97,19
190,24
1996
102,36
127,51
229,87
1997
99,92
110,51
210,43
1998
120,84
42,42
163,25
1999
65,22
137,36
202,58
2000
99,37
94,19
193,56
2001
112,03
97,03
209,05
2002
74,29
91,33
165,62
2003
92,89
60,63
153,52
2004
148,19
119,71
267,90
Tabla N° 13: Valores como porcentaje de Tendencia
Fuente: Elaboración propia
Año
Semestre 1 Semestre 2
Suma
1995
97,82
102,18
200,00
1996
89,06
110,94
200,00
1997
94,97
105,03
200,00
1998
148,04
51,96
200,00
1999
64,39
135,61
200,00
2000
102,67
97,33
200,00
2001
107,17
92,83
200,00
2002
89,72
110,28
200,00
2003
121,01
78,99
200,00
2004
110,63
89,37
200,00
Tabla N° 14: Datos ajustados del porcentaje de Tendencia
Fuente: Elaboración propia
Sólo resta promediar cada período para conseguir los índices
estacionales:
Indices Estacionales
1
69,81
2
70,19
Estimación de las variaciones cíclicas e irregulares
Aquí hay que hacer una distinción entre si se usan valores anuales o
mensuales. En el primer caso, los datos generalmente no contienen
variaciones estacionales y por lo tanto se deben dividir o restar los datos
entre los valores de tendencia, de acuerdo al modelo elegido.
Modelo aditivo: Y − T = C + I
Modelo Multiplicativo/Mixto: Y / T = C * I
En el segundo caso se deben dividir o restar los datos de las
estimaciones de tendencia y estacional, esto da como resultado el producto
C*I, procurando eliminar luego la componente irregular utilizando un
promedio móvil. Los resultados se dan en porcentajes.
El componente cíclico y el regular, en la práctica tienden a ser
inspeccionados primero para determinar su influencia real en la serie, de esta
forma, si el producto C*I, expresado en porcentajes no supera un cierto
criterio establecido (por ejemplo 5%, entonces puede asumirse como 1 y
eliminarse de la serie, de esta forma la serie puede ser expresada como
Modelo aditivo: Y = T + E
Modelo Multiplicativo/Mixto: Y = T * E
Si la contribución de estos componentes (cíclicos e irregulares) es
considerable,
entonces
el
procedimiento
consiste
en
eliminar
los
componentes de tendencia y estacional, luego suavizar la serie con un
promedio móvil, con lo cual el resultado sería el componente cíclico. Este
componente debe ser estudiado en detalle para luego construir índices de la
misma forma que los índices estacionales.
La estimación del componente irregular, se hace ajustando los valores
originales según los valores de tendencia, estacionales y cíclicos
encontrados. Esto se hace dividiendo o restando sucesivamente de los datos
originales, los valores de T, E y C.
Un ejemplo práctico de aplicación lo tenemos determinando los
componentes cíclicos e irregulares de los datos de la tabla N°2, a quienes ya
le fueron calculados los componentes de tendencia en párrafos anteriores.
Recopilando nuevamente los datos tenemos:
Datos
T
E
Originales
1995-1
1007
1082,22
102,13
1995-2
1061
1091,64
97,87
1996-1
1127
1101,06
102,13
1996-2
1416
1110,48
97,87
1997-1
1119
1119,9
102,13
1997-2
1248
1129,32
97,87
1998-1
1376
1138,74
102,13
1998-2
487
1148,16
97,87
1999-1
755
1157,58
102,13
1999-2
1603
1167
97,87
2000-1
1169
1176,42
102,13
2000-2
1117
1185,84
97,87
2001-1
1339
1195,26
102,13
2001-2
1178
1214,1
97,87
2002-1
909
1223,52
102,13
2002-2
1126
1232,94
97,87
2003-1
1154
1242,36
102,13
2003-2
759
1251,78
97,87
2004-1
1869
1261,2
102,13
2004-2
1521
1270,62
97,87
Tabla N° 15: Componentes de Tendencia y Estacional
Fuente: Elaboración propia
Donde T fue hallada por el método de los semipromedios y E por el
método del porcentaje promedio.
Asumiendo un modelo multiplicativo, los indices C*I puden verse
calculados en la tabla N° 16.
Graficando el componente C*I podemos observar que si existen
variaciones cíclicas e irregulares considerables (Ver figura N° 13), por lo cual,
haciendo un promedio móvil de 3 semestres podemos suavizar las
variaciones irregulares y quedarnos con el componente cíclico únicamente
(pueden seguir existiendo variaciones irregulares, aunque en menos escala).
Datos
T
E
Y/T
Y/TS=C*I
Originales
1995-1
1007
1082,22
102,13
93,05
91,11
1995-2
1061
1091,64
97,87
97,19
99,30
1996-1
1127
1101,06
102,13
102,36
100,23
1996-2
1416
1110,48
97,87
127,51
130,28
1997-1
1119
1119,9
102,13
99,92
97,84
1997-2
1248
1129,32
97,87
110,51
112,91
1998-1
1376
1138,74
102,13
120,84
118,32
1998-2
487
1148,16
97,87
42,42
43,34
1999-1
755
1157,58
102,13
65,22
63,87
1999-2
1603
1167
97,87
137,36
140,34
2000-1
1169
1176,42
102,13
99,37
97,30
2000-2
1117
1185,84
97,87
94,19
96,24
2001-1
1339
1195,26
102,13
112,03
109,69
2001-2
1178
1214,1
97,87
97,03
99,13
2002-1
909
1223,52
102,13
74,29
72,75
2002-2
1126
1232,94
97,87
91,33
93,31
2003-1
1154
1242,36
102,13
92,89
90,95
2003-2
759
1251,78
97,87
60,63
61,95
2004-1
1869
1261,2
102,13
148,19
145,11
2004-2
1521
1270,62
97,87
119,71
122,30
Tabla N° 16: Componentes de Tendencia, Estacional y Ciclico-Irregulares
Fuente: Elaboración propia
La Grafica de la figura N° 15 muestra la serie suavizada donde se
puede observar un ciclo de aproximadamente 10 semestres. Un ciclo
completo puede observarse desde el semestre 1988-2 hasta el 2003-1. Con
esta información procedemos a calcular los índices cíclicos de manera similar
a como se calcularon los índices estacionales.
160,00
140,00
120,00
100,00
80,00
60,00
40,00
20,00
2004-2
2004-1
2003-2
2003-1
2002-2
2002-1
2001-2
2001-1
2000-2
2000-1
1999-2
1999-1
1998-2
1998-1
1997-2
1997-1
1996-2
1996-1
1995-2
1995-1
0,00
Figura N°.13 Variaciones cíclicas e irregulares
Fuente: Elaboración propia
120
100
80
60
40
20
41
20
0
31
20
0
21
20
0
11
20
0
01
20
0
91
19
9
81
19
9
71
19
9
61
19
9
19
9
51
0
Figura N°.14 Variaciones cíclicas
Fuente: Elaboración propia
Luego, retomando los datos originales, ordenándolos de acuerdo a los
ciclos encontrados, se tiene entonces la información de la tabla N° 17. Es de
notar que una vez establecidos los ciclos, pueden colocarse en el orden
deseado, siempre y cuando se respete el número de períodos que lo
componen.
Sem1 Sem2 Sem3 Sem4 Sem5 Sem6 Sem7 Sem8 Sem9 Sem10
487
755 1603 1169 1117 1339 1178
909 1126
1154
1007 1061 1127 1416 1119 1248
1376
759 1869 1521
Tabla N° 17: Datos reorganizados de acuerdo al ciclo
Fuente: Elaboración propia
Media
1083,70
1193,43
1383,00
Los datos ajustados, junto con el índice cíclico se muestran en la tabla N° 18.
Sem1
44,94
0
54,88
49,91
Sem2 Sem3 Sem4 Sem5 Sem6 Sem7 Sem8 Sem9 Sem10
69,67 147,9 107,9 103,1 123,6 108,7 83,88 103,9 106,49
0
0
84,38 88,9 94,43 118,6 93,76 104,6 115,30
135,1 110
0
0
0
0
0
0
0,00
102,4 128,9 96,12 95,99 109 113,7 88,82 104,2 110,89
Tabla N° 18: Datos ajustados e índices cíclicos
Fuente: Elaboración propia
Suma
1000
700
300
Los datos de los componentes T, E y C se pueden resumir en la tabla
N° 19.
Finalmente, teniendo tres de los cuatro componentes, se pueden
calcular las variaciones irregulares, ajustando la serie con los valores de T, E
y C. Esto implica dividir los valores originales de la serie por T, E y C.
Normalmente estos valores, aunque se expresen en porcentajes, suelen ser
bastante pequeños. Los datos completos pueden verse en la tabla N° 20.
Es fácilmente observable que multiplicando los valores calculados de
T, E, C e I podemos reproducir los datos originales. Por ende, la elección de
los métodos para estimar las componentes, es notoriamente importante a la
hora de descomponer cualquier serie.
Datos
T
E
C
Originales
1995-1
1007
1082,22
102,13
49,91
1995-2
1061
1091,64
97,87
102,40
1996-1
1127
1101,06
102,13
128,95
1996-2
1416
1110,48
97,87
96,12
1997-1
1119
1119,9
102,13
95,99
1997-2
1248
1129,32
97,87
109,00
1998-1
1376
1138,74
102,13
113,68
1998-2
487
1148,16
97,87
49,91
1999-1
755
1157,58
102,13
102,40
1999-2
1603
1167
97,87
128,95
2000-1
1169
1176,42
102,13
96,12
2000-2
1117
1185,84
97,87
95,99
2001-1
1339
1195,26
102,13
109,00
2001-2
1178
1214,1
97,87
113,68
2002-1
909
1223,52
102,13
88,82
2002-2
1126
1232,94
97,87
104,24
2003-1
1154
1242,36
102,13
110,89
2003-2
759
1251,78
97,87
49,91
2004-1
1869
1261,2
102,13
102,40
2004-2
1521
1270,62
97,87
128,95
Tabla N° 19: Componentes de Tendencia, Estacional y Cíclico
Fuente: Elaboración propia
Pronóstico de la serie.
De acuerdo a como se haya decidido el modelo, el pronóstico de un
valor de la serie para un momento determinado estará determinado por éste.
De esta forma, si se eligió el modelo aditivo, una vez establecidos los
parámetros de composición de la serie, y estimada la tendencia para el
período n+1, se escoge el índice estacional y el índice cíclico calculados de
los períodos correspondientes, y para el caso del componente irregular, se
puede tomar un valor promedio del obtenido en la serie de datos. Se pueden
pronosticar varios períodos si se desea.
Retomando nuevamente el ejemplo de la tabla N°2, se puede
pronosticar el semestre 2005-1 mediante el siguiente cálculo:
•
Se estima la Tendencia para el semestre 2005-1, la cual resulta de
sumar 9,42 (el crecimiento intersemestral) al último valor de Tendencia
calculada, siendo el resultado 1280, 04.
•
Dado que es el semestre 1, el índice estacional correspondiente es
102,13.
•
El componente cíclico correspondiente es 96.12
•
El componente irregular promedio es 0,01
•
Aplicando el método multiplicativo, se obtiene como resultado
1256,58, equivalente a 1257 estudiantes a inscribirse en el semestre
2005-1 en la asignatura Lengua y Comunicación I.
Datos
T
E
Originales
1995-1
1007
1082,22
102,13
1995-2
1061
1091,64
97,87
1996-1
1127
1101,06
102,13
1996-2
1416
1110,48
97,87
1997-1
1119
1119,9
102,13
1997-2
1248
1129,32
97,87
1998-1
1376
1138,74
102,13
1998-2
487
1148,16
97,87
1999-1
755
1157,58
102,13
1999-2
1603
1167
97,87
2000-1
1169
1176,42
102,13
2000-2
1117
1185,84
97,87
2001-1
1339
1195,26
102,13
2001-2
1178
1214,1
97,87
2002-1
909
1223,52
102,13
2002-2
1126
1232,94
97,87
2003-1
1154
1242,36
102,13
2003-2
759
1251,78
97,87
2004-1
1869
1261,2
102,13
2004-2
1521
1270,62
97,87
Tabla N° 20: Componentes de Tendencia, Estacional,
Fuente: Elaboración propia
C
I
49,91
0,02
102,40
0,01
128,95
0,01
96,12
0,01
95,99
0,01
109,00
0,01
113,68
0,01
49,91
0,01
102,40
0,01
128,95
0,01
96,12
0,01
95,99
0,01
109,00
0,01
113,68
0,01
88,82
0,01
104,24
0,01
110,89
0,01
49,91
0,01
102,40
0,01
128,95
0,01
Cíclico e Irregular
2.2.2.2 Procesos de Box-Jenkins
El análisis de series temporales basado en el trabajo de Box y Jenkins
propone una metodología de trabajo rigurosa para tratar las series a través
de modelos dinámicos que se conoce como metodología Box-Jenkins o
metodología ARIMA.
Los modelos ARIMA, Modelos Autorregresivos Integrados de Medias
Móviles de orden p, d, q, o abreviadamente ARIMA (p,d,q), están basados
en estudios anteriores, realizados por Yule (1921, 1926) y aseveradas por
Wold (1938), no es más que un modelo ARMA (p,q) aplicado a una serie
integrada de orden d, I (d), es decir, a la que ha sido necesario diferenciar d
veces para eliminar la tendencia.
Tipos de Procesos de Series Temporales- Ecuaciones de Yule-Wold
Si se tiene una Serie Temporal, es interesante descubrir si existe
algún patrón de comportamiento de la serie, de manera de poder hacer
predicciones.
Cuando se habla de procesos, se está suponiendo que es una forma
de generar series de números. La idea es conseguir el proceso que mejor
genere nuestra serie de datos, teniendo en cuenta que también podría estar
generada por varios procesos. Los tipos de procesos a revisar
siguientes:
•
Procesos Autoregresivos (AR)
•
Procesos de Medias Móviles (MA)
•
Modelos Autoregresivos y de Medias Móviles (ARMA)
son los
Procesos Autoregresivos (AR)
Se puede definir un modelo AR de orden p, también escrito AR(p),
como
Yt = φ1Yt −1 + φ2Yt − 2 + φ 3Yt −3 + ...φ pYt − p + ε t
(15)
Es decir, se escribe Yt (valor de la serie en el momento t), en función
de valores pasados de la propia serie y se incluye en la ecuación un término
de perturbación o error ε t que se supone se comporta como ruido blanco.
Ejemplo: Si se intenta explicar la evolución de las ventas de la
empresa SSC Sistemas, mediante un proceso autorregresivo, se podría
expresar como sigue:
Las ventas de la empresa este año (Ventast) dependen directamente
de las ventas de los dos últimos años según la relación de ventas:
Ventast = 0.8*Ventast −1 + 0.5*Ventast − 2
En este caso puede decirse que la serie de ventas sigue un proceso
autoregresivo de orden 2, cuyos coeficientes son
φ1 = 0.8;φ2 = 0.5; ε t = 0
Con ayuda de una hoja de cálculo, se puede generar, a partir de los
dos primeros datos aleatorios, una columna de números que sigan un
proceso AR(2). El resultado se da en el siguiente cuadro:
Año
Ventas
2003
Bs 763.192,92
2004
Bs 219.993,06
2005
Bs 557.590,91
2006
Bs 556.069,26
2007
Bs 723.650,86
2008
Bs 856.955,32
2009
Bs 1.047.389,69
2010
Bs 1.266.389,41
2011
Bs 1.536.806,37
2012
Bs 1.862.639,80
2013
Bs 2.258.515,03
2014
Bs 2.738.131,92
2015
Bs 3.319.763,05
Tabla N° 21 : Pronóstico de ventas de la empresa SSC Sistemas C.A
Fuente: SSC Sistemas y Suministros
Graficando esta tabla, tenemos:
7000000
6000000
5000000
4000000
Ventas
3000000
Año
2000000
1000000
0
1
2
3
4
5
6
7
8
9 10 11 12 13
Figura N° 15 Pronóstico de ventas de la empresa SSC Sistemas C.A
Fuente:SSC Sistemas y Suministros C.A.
Obviamente, esto sería el resultado final de una investigación donde
se ha determinado, primero que estamos ante un proceso AR(2) y luego, se
han estimado los parámetros φ1 , φ2 , ε t . El reconocimiento de este tipo de
procesos se hace con base en su FAC y FACP.
En la práctica, estos procesos, se hallan de orden 1 ó 2. A medida que
el orden del proceso (p) es mas grande, la estimación de los parámetros se
complica porque involucra muchos mas datos de los observados por la
variable.
Procesos de Medias Móviles (MA)
Un modelo de los denominados de medias móviles es aquel que
explica el valor de una determinada variable en un período t en función de un
término independiente y una sucesión de errores correspondientes a
períodos precedentes, ponderados convenientemente. Estos modelos se
denotan normalmente con las siglas MA, seguidos, como en el caso de los
modelos autorregresivos, del orden entre paréntesis. Así, un modelo con q
términos de error MA(q) respondería a la siguiente expresión:
Yt = μ + ε t + ϕ1ε t −1 + ϕ2ε t − 2 + ϕ3ε t −3 + ... + ϕqε t − q
(16)
Donde ε t es ruido blanco
Un modelo de medias móviles puede obtenerse a partir de un modelo
autorregresivo sin más que realizar sucesivas sustituciones.
Suponiendo que se desea modelar el precio de un producto agrícola
en un contexto no inflacionario y se dispone de una serie cuya periodicidadad
corresponde al ciclo de cultivo del producto. Un ejemplo del modelo que
podría describir este producto es:
Yt = 10 + ε t + 0.8ε t −1
Obviamente ya se ha determinado la media del proceso μ , el
coeficiente ϕ1 y la distribución del ruido blanco.
Procesos Autoregresivos y de Medias Móviles (ARMA)
En el análisis empírico de series temporales, es frecuente encontrar
representaciones
que
tienen
una
componente
autoregresiva
y
una
componente de medias móviles, estos modelos se denotan como
ARMA(p,q), donde p y q denotan los componentes autorregresivos y de
medias móviles respectivamente.
Normalmente estos modelos no se encuentran en órdenes superiores
a los que usualmente se hallan en modelos AR y MA.
La formulación general del un proceso ARMA, denotada por
ARMA(p,q) viene dada por:
Yt = φ1Yt −1 + φ2Yt − 2 + φ 3Yt −3 + ...φ pYt − p + ε t + ϕ1ε t −1 + ϕ 2ε t − 2 + ϕ3ε t −3 + ... + ϕ qε t − q
(17)
Su FAC y su FACP serán combinación de ambos procesos y tendrán la
siguiente estructura:
•
FAC: Los primeros q coeficientes de la FAC vendrán establecidos por
la parte MA. A partir del momento q se producirá un decrecimiento de
los coeficientes vendrá dado por la estructura AR.
•
FACP: Los primeros coeficientes de la FACP vendrán establecidos
por la parte AR. A partir del momento p se producirá un decrecimiento
de los coeficientes que vendrá dado por la estructura MA.
Modelos ARIMA
En los puntos anteriores (modelos AR, MA, y ARMA) hemos supuesto
que se satisfacen las características para que el proceso sea estacionario,
sin embargo, encontramos en muchas situaciones, series que no lo son,
como es el caso de las series de datos económicos, que
suelen
caracterizarse por ser claramente no estacionarias, en cuyo caso no es
posible utilizar dichos modelos en forma inmediata.
Para estos casos, existen procedimientos que permiten, tomando las
primeras o segundas diferencias de la serie, obtener series que son
estacionarias o simplemente no son no estacionarias en forma obvia.
Los modelos ARIMA, son modelos realizados para este tipo de series,
en los cuales se transforma la serie original para formar otra serie que si
satisfaga las condiciones para aplicar los procedimientos de los procesos
estudiados anteriormente, luego de lo cual , se recuperan las predicciones
para la serie original, con base en las predicciones elaboradas con la serie
transformada.
2.2.2.3 Modelo Espectral
Se demuestra que cualquier proceso periódico se puede modelar, con
la precisión deseada, mediante series de términos de funciones senoidales
(seno y coseno), lo que se conoce como series de Fourier, y se denomina
espectro a la representación de las amplitudes, en el eje de las Y, que
constituyen los diferentes términos de la serie para toda la gama de
frecuencias (eje de las X).
La idea básica del análisis espectral es que un proceso estacionario
Yt puede ser descrito como la suma de movimientos de seno y coseno de
diferente frecuencia y amplitud. La meta es determinar cuales son los ciclos
de diferentes frecuencias importantes para describir el comportamiento de
Yt . Estos ciclos pueden ser de corto o largo plazo, por lo que no se realiza
una descomposición de la serie en la forma usual de tendencia, ciclo,
estacionalidad y componente irregular, sino que en su lugar se descompone
la serie en la totalidad de frecuencias existentes.
Además, es importante resaltar el hecho de que el análisis espectral
no depende de un modelo para generar resultados. Este analiza la serie en
forma puramente matemática y no está basado en ninguna teoría acerca de
los procesos que definen las series. Por esto se requiere una gran cantidad
de datos para utilizar esta técnica (se recomienda al menos 100
observaciones).
En la siguiente figura se muestra una imagen típica del espectro de
frecuencias de una serie, en el que se representa en el eje de las Y la
amplitud y en el de las X la frecuencia, y partiendo de la estimación directa
del espectro a partir de los datos (esquina superior izquierda), se va
refinando mediante procedimientos de alisado y nos permite en este caso
detectar la presencia de un factor de periodicidad para la frecuencia en torno
del valor 1.
Figura N° 16: Modelo Espectral
Fuente: http://www.bccr.fi.cr/ndie/Documentos/COMPENDIO%20N%B01.PDF
Las principales ventajas que posee esta técnica son:
•
No es necesario eliminar los componentes irregular y estacional de
las series para estudiar su comportamiento.
•
Analiza relaciones económicas con más detalle de lo que los
métodos tradicionales de construcción de modelos econométricos
son capaces. Describe las fluctuaciones de los ciclos económicos
de una serie de tiempo en forma más correcta, por cuanto
considera todo el comportamiento histórico de la serie en estudio y
no sólo sus picos y valles. Es un método matemáticamente más
riguroso y general que los modelos ARIMA,
•
Puede utilizarse para series con cualquier tipo de periodicidad.
Las desventajas son:
•
Las series de tiempo deben ser estacionarias. Transformar una
serie puede alterar el espectro de la serie básica.
•
Utiliza únicamente las frecuencias de Fourier, que son aquellas
que contienen un número completo de ciclos desde la primera
hasta la última observación. Por ello, las frecuencias particulares
utilizadas dependen de la extensión de las series y es enteramente
posible que un ciclo importante en los datos no sea tomado en el
análisis. Si se conoce la existencia de la periodicidad de la serie y
se quiere mostrar claramente, entonces la extensión de la serie
debe ser un múltiplo de esa periodicidad
•
El método espectral requiere más datos (sobre 100 observaciones)
que otros técnicas, debido a que no utiliza la muestra en forma
eficiente.
•
Es un modelo no teórico, en el sentido de que no responde a
alguna teoría económica.
2.2.2.4 Modelo UCARIMA
La metodología UCARIMA (“unobserved components ARIMA”) asume
que tanto la serie observada como los componentes inobservables
responden a modelos ARIMA, cómo veremos la estimación de los mismos no
consiste más que en la aplicación de filtros de características adecuadas. La
ventaja que aporta este método está ligada a la estimación-especificación
previa de un modelo a la serie observada lo que resuelve los problemas de
adecuación del filtrado a la naturaleza de las series. De manera adicional,
este método permite la obtención de medidas estadísticas de confianza
sobre la estimación, así como efectuar predicciones sobre los componentes.
El modelo UCARIMA coincide en que las series temporales pueden
ser descompuestas de acuerdo con las especificaciones de la Hipótesis de
los componentes subyacentes (HCS) basada en modelo ARIMA. Según la
HCS una serie temporal Y , puede descomponerse en cuatro elementos:
Tendencia (T), Ciclo (C) , Estacionalidad (E) e Irregularidad (I) según un
esquema aditivo o multiplicativo.
2.2.2.5 Modelo ARCHI
Desarrollado por Robert F. Ingle (premio Nobel compartido 2003)
permite analizar series de tiempo con volatilidad temporal. Es usado
intensivamente en el campo de las finanzas para replicar la volatilidad del
precio de los activos en el tiempo. El modelo plantea que la varianza de las
series de precios evoluciona de acuerdo a un proceso autorregresivo,
generalmente lineal. La aplicación de este método es común en la evaluación
del riesgo de activos financieros. Está basado en la metodología de BoxJenkins.
2.2.2.6 Modelo de Cointegración
Clive W.J. Granger ( premio Nobel compartido 2003), desarrolló el
método
para
analizar
series
de
tiempo
con
tendencias
comunes
(cointegración). Este método explora las series de tiempo para detectar
relaciones de largo plazo que encierran sentido económico. Con frecuencia
se encuentran relaciones estadísticas entre variables económicas no
estacionarias
2.2.2.7 Modelo AFRIMA
Propuestos por Granger, Joyeux (1980) y Hosking (1981). Los
modelos ARFIMA permiten modelizar procesos con dependencias a largo
plazo. Para ello aprovechan el concepto de procesos fraccionarios
introducidos por Mandelbrot y Van Ness (1968). Existen múltiples estudios
sobre modelización ARFIMA de mercados financieros.
2.2.2.8 Modelo del Caos
Un planteamiento distinto al de los procesos estocásticos es el que
presenta a las series temporales no como originadas por un proceso
estocástico, sino como un proceso determinista. El desarrollo de la teoría del
caos propiciado en los años 70, gracias a las contribuciones de autores como
Ruelle, Takens, Lorenz, Li, Yorke, May, Feigenbaum y Mandelbrot,
proporciona una explicación teórica alternativa para la existencia de sistemas
dinámicos con comportamientos irregulares sin necesidad de recurrir a las
variables aleatorias.
El paso definitivo de los sistemas dinámicos caóticos teóricos al
análisis de series temporales fue propuesto por Packard, Crutchfield, Farmer
y Shaw en 1980. La idea de estos físicos era que todo el sistema dinámico
podría estudiarse a través de una sola variable, pues la historia de ésta
guardaría información sobre el resto del sistema. Una versión formalizada
matemáticamente de dicho concepto se conoce como el teorema de Takens,
desarrollado por este en 1981, sobre el que está construido el análisis
caótico de las series temporales.
En los años 80 se desarrollan dentro de la física toda una serie de
herramientas para diferenciar series temporales aleatorias de series
temporales caóticas. Estas herramientas han tenido éxito para detectar
comportamientos caóticos en campos tan dispares como la física, la química
o la medicina.
2.3. Formulación del Modelo
Del análisis realizado, surgen muchas expectativas sobre cual
metodología se debe usar para tratar las series de datos que le competen a
este trabajo, sin embargo, dada la estructura de la información que se tiene,
es posible ver con claridad muchas ventajas que representa el método
clásico sobre los otros métodos.
•
La sencillez de uso del método.
•
El hecho de que el fenómeno estudiado es un fenómeno social más
que económico. Los métodos como el de Box-Jenkins, y todos los que
se basan en él, son recomendados para situaciones principalmente
económicas, pero aunque pueden usarse para otros casos tanto
sociales como físicos, químicos, ambientales, etc., su verdadera
fortaleza está en las series económicas. El método clásico es un
método que hace bastante abstracción del origen de los datos.
•
No se tiene una gran cantidad de períodos en los datos de las series
para justificar el uso de algunos modelos como el espectral, por
ejemplo, que requiere una gran cantidad de datos.
•
Facilidad de programación.
Para tomar la decisión sobre la mejor estimación de los parámetros de
la serie, el primer paso dependerá de la gráfica de todas las series que se
tienen.
Para efectos de estimación de la tendencia se debe elegir entre los
tres métodos existentes: el método de los promedios móviles, el método de
los semipromedios y el método de los mínimos cuadrados, de acuerdo al que
represente mejor la tendencia aplicando el método de la bondad de ajuste, el
cual consiste en buscar la curva cuya suma del cuadrado de las desviaciones
Dn entre la curva original ya la curva estimada sea menor.
Para estimar la estacionalidad se empleará el método del porcentaje
promedio, debido a que es el que mejor se ajusta. El porcentaje promedio
móvil no se usará debido a que mayormente es útil para series con valores
mensuales y en nuestro caso, las series solo tienen valores semestrales. El
método del porcentaje de tendencia se descartó también debido a que si
existen variaciones grandes, los índices estacionales pueden contener
variaciones cíclicas e irregulares
Con respecto a la estimación del ciclo, será necesario la determinación
del modelo a a ser usado (el aditivo, el multiplicativo o el mixto). La mejor
forma es aplicar el método de variación de los coeficientes (CV) a los datos
obtenidos y luego determinando el mejor modelo entre el aditivo y el
multiplicativo o mixto.
Si resultase mejor el método multiplicativo ó mixto se debe usar el
multiplicativo por dos razones primordiales:
•
Es más fácil de manipular.
•
No existe certeza real de que la componente irregular de las series
sea un parámetro absolutamente desligado del resto de los
parámetros de la serie.
Una vez determinado el modelo que va a ser empleado, deben
dividirse o restarse los valores de la serie de los componentes Tendencia y
Estacional para lograr un residuo C*I ó C+I según convenga. Estos residuos
serán evaluados para determinar su incidencia sobre la serie. Si el valor de
esta incidencia no supera el 5% se pueden obviar estos componentes.
De no haber incidencia de los residuos sobre la serie, se debe asumir
este valor como uno para el caso del modelo multiplicativo, con lo cual la
serie quedará descrita por el producto T * E ó se tendrá por nulo (valor 0)
para el caso del modelo aditivo, siendo entonces la serie descrita por la suma
T+E.
Si existe incidencia de los residuos sobre la serie, se suaviza la con
una media móvil corta de 3 períodos para eliminar la componente irregular,
con lo que se tendrá entonces la componente cíclica pura. Esta componente
debe ser evaluada para determinar si existen ciclos, aunque sea aproximado,
luego de lo cual se determinarán de la misma forma que el componente
estacional.
Determinado el componente cíclico, se ajustan los datos originales de
la serie por los valores calculados de T, S y C para aislar la componente
irregular.
Teniendo ya descrita completamente la serie, se puede hacer la
predicción del período n+1, de acuerdo al siguiente procedimiento:
•
Siguiendo el mismo esquema de la Tendencia calculada, se estima el
valor de ésta para el período n+1, dependiendo del método utilizado.
•
Se ubica el índice estacional calculado para ese período (semestre 1 o
semestre 2) de acuerdo al período a predecir.
•
De acuerdo a la evaluación que se haya hecho sobre la incidencia de
los residuos cíclico-irregulares se determina si el modelo va a incluir o
no estos componentes.
•
En caso afirmativo se puede emplear directamente el componente
cíclico-irregular C*I ó C+I.
•
Teniendo a mano todos los componentes de la serie, pronosticar el
período n+1 no es más que aplicar las ecuaciones 7 u 8 dependiendo
del modelo más conveniente.
•
Pronosticar períodos superiores a n+1, es decir n+2, n+3 etc. es
posible tomando en cuenta que se incluirían en la serie, los valores
pronosticados y se reutilizaran para calcular de nuevo el pronóstico.
La validación del modelo se realizará una vez que se tengan los valores
reales, semestre a semestre, el algoritmo se irá recalculando para arrojar,
aparte del valor pronosticado, la desviación con respecto al valor real. Con
esto, se podrá evaluar fácilmente la funcionalidad del modelo.
CAPITULO III
MARCO METODOLÓGICO
En esta parte del documento, se mostrará información detallada acerca de
cómo se aplicaron los conceptos desarrollados en el marco teórico para la
ejecución de la investigación, así como también ubicar la investigación en el
marco de estudio que le corresponde.
3.1 Nivel de Investigación:
Esta investigación es de tipo explicativa, dado que pretende establecer
el comportamiento de las variables matrícula de alumnos ubicada en el
contexto específico del Centro Local Metropolitano de la Universidad
Nacional Abierta.
3.2 Diseño de la investigación:
Dado que los datos provienen directamente de la realidad donde
ocurren,
es decir, son datos primarios que no han sido manipulados ni
controlados, se puede decir que estamos en presencia de una investigación
de campo.
Es intensiva, dado que se está estudiando un caso particular cuyo
marco se encuentra centrado en el Centro Local Metropolitano de la
Universidad Nacional Abierta, lo cual imposibilita su generalización a
universidades u otros ámbitos similares.
El diseño de campo utilizado es el post-facto ya que se utilizan datos
ya ocurridos sin posibilidad de manipular las variables independientes.
Adicionalmente, la investigación también es documental, porque
involucró
la
el
análisis
e
interpretación
de
información
obtenida
primordialmente de fuentes bibliográficas documentales tanto impresas como
electrónicas. Adicionalmente, también se tomaron en cuenta los trabajos
realizados con anterioridad con respecto al tema en el Centro Local
Metropolitano.
3.3 Población y Muestra:
La Población en estudio serán todos aquellos estudiantes inscritos con
anterioridad en las asignaturas sin prerrequisitos del Centro Local
Metropolitano de la Universidad Nacional Abierta. En este caso la muestra es
igual a la población.
3.4 Técnicas e Instrumentos de Recolección de Datos:
Los datos fueron generados por la Unidad de Computación del Centro
Local Metropolitano de la Universidad Nacional Abierta, quienes son los
responsables de mantener y controlar este tipo de información para uso
interno de la Universidad. Fueron entregados en formato digital, en archivos
con formato
texto (extensión .txt), donde se incluyen por semestre los
alumnos inscritos, los regulares y los repitientes en cada asignatura.
La figura N° 16 muestra el detalle de uno de los archivos obtenidos
para el semestre 1997-1 con la relación estadística por asignaturas emitida
por la Unidad de Computación. La información contenida en estos archivos
debe ser depurada para dejar solamente lo necesario y no recargar el
sistema de información que debe manipularlos con datos que no van a ser
necesarios.
Figura N° 24: Archivo con datos de la matrícula semestral por asignatura
Fuente: Centro Local Metropolitano U.N.A
3.5 Técnicas de procesamiento de Datos
Los archivos obtenidos en formato texto, fueron depurados para
mantener sólo los datos necesarios. Para ello se realizó el siguiente
procedimiento:
•
Se borró el encabezado de los archivos para dejar solamente información
de la matrícula. La figura N° 17 muestra un ejemplo del archivo sin
encabezado, solamente con los datos necesarios para continuar su
exportación hacia la aplicación Microsoft Excel.
•
Se abrieron los archivos con la aplicación Microsoft Excel y se ajustaron
las columnas para lograr la tabulación exacta de los datos
Figura N°:17 Archivos sin encabezado
Fuente: Elaboración propia
Figura N° 18: Paso1 del Asistente de importación de Excel
Fuente: Elaboración propia
Figura N° 19: Paso2 del Asistente de importación de Excel
Fuente: Elaboración propia
•
Los archivos importados en Microsoft Excel fueron consolidados en uno
solo, teniendo en cuenta las siguientes consideraciones:
o Algunas asignaturas, como Matemática I (código 100) fueron
reemplazadas por otras, con lo cual los datos aparecen nulos a partir
de un semestre determinado.
o Nuevas asignaturas fueron creadas para reemplazar algunas otras.
Por ejemplo la asignatura Matemática I, código 177, luego, no tiene
valores para semestres anteriores a su creación.
o Algunas asignaturas, como Procesos Estocásticos, código 322, fueron
ofertadas solo en algunos semestres, por ende no aparece en todos
los archivos suministrados. Fue necesario ajustar el espacio necesario
en el archivo consolidado para mantener la integridad de los datos.
•
El archivo consolidado en Excel fue guardado como consolidado.txt bajo
el formato archivo separado por tabulador, con lo cual se facilita su
exportación hacia la herramienta de gestión de Base de Datos My SQL.
•
Luego para importarlo desde My SQL, se utiliza la sentencia
•
“LOAD
DATA
INFILE
'C:/Archivos
de
programa/EasyPHP1-
8\\tmp\\php94.tmp' INTO TABLE `dataoriginal` FIELDS TERMINATED
BY'”
Figura Nº 20 Importación de Datos a MySQL desde MySQL Front.
Fuente: Elaboración propia. 2005
•
Adicionalmente, se filtraron las asignaturas sin pre-requisitos, para tener
solamente la información importante para el estudio. Este procedimiento
se realizó manualmente con base en la oferta académica de todas las
carreras.
3.6 Análisis de los Datos
El análisis de los datos para desarrollar los modelos de series de
tiempo adaptados a los datos de la matrícula que nos compete, parte de la
gráfica de todas las series cronológicas. No se tomaron en cuenta las
asignaturas que ya no estaban vigentes y las que fueron creadas a posteriori
se analizaron solamente con los datos que se tienen.
Es de notar que los datos indican la falta de información en un
semestre (1997-2) para todas las asignaturas,
el cual no se realizó por
razones que no debido a que es requisito indispensable que las series estén
completas para poder comenzar su análisis.
Estos valores nulos o inexistentes, conocidos como outliers, se
reemplazaron en todas las series por el valor resultante de la interpolación
entre el valor del semestre 1997-1 y el semestre 1998-1. No se realizaron
detecciones adicionales de outliers en el resto de los datos, partiendo de la
confiabilidad de los mismos dado su origen y su forma de manipulación,
amén de la poca cantidad de datos que se tienen lo cual minimiza la
ocurrencia de errores.
Muchas asignaturas tienen valores cero en algunos semestres lo cual
indica que no hubo estudiantes inscritos en ese momento. Estos valores se
asumieron como nulos partiendo del hecho de las múltiples ocurrencias
Ahora bien, una vez superado el tema de los outliers y graficadas las
series, se comenzó el análisis de los componentes de cada una de ellas.
La estimación de la tendencia, se realizó utilizando los tres métodos
existentes: el método de los promedios móviles, el método de los
semipromedios y el método de los mínimos cuadrados, luego de lo cual se
estableció cual representaba mejor la tendencia aplicando el método de la
bondad de ajuste.
Se estimó la estacionalidad con la técnica del porcentaje promedio.
El siguiente paso consistió en determinar, mediante el método de los
Coeficientes de Variación, cuál es el modelo más conveniente. Una vez
determinado el modelo a ser empleado, se ajustaron los valores de la serie
de los componentes Tendencia y Estacional para lograr un residuo C*I ó C+I,
los cuales fueron evaluados para determinar su incidencia sobre la serie. Se
tomaron en cuenta sólo si esta incidencia superaba el 5%.
En los casos donde no hubo incidencia de este parámetro, se tomaron
sólo los parámetros T y E. En caso contrario, se calcularon los índices
cíclicos y luego el componente irregular para completar el estudio.
Con todos los componentes calculados de la serie,
se validó el
modelo obtenido reproduciendo el pasado de la serie. En virtud de que ya se
validó la estimación de la tendencia de acuerdo a la bondad de ajuste de la
curva y se tienen dos métodos para calcular la componente Estacional, se
comprobó la bondad de ajuste de las dos series calculadas con los dos
métodos para determinar cual se ajustaba mejor a la serie original y se eligió
aquella cuya bondad de ajuste fuera mejor.
Teniendo ahora establecidos los cuatro parámetros, se realizó el
pronóstico de los períodos necesarios para cada serie de acuerdo al
siguiente procedimiento:
1. Estimación la tendencia para el período solicitado.
2. Ubicación del índice estacional calculado para ese período (semestre
1 o semestre 2) de acuerdo al período a predecir.
3. Determinación del índice cíclico, si existe.
4. Promedio del valor de la componente irregular
5. Validación del modelo de acuerdo al histórico.
6. Cálculo del valor pronosticado de la serie para el período deseado
7. Cálculo de la desviación aproximada del pronóstico.
8. Repetición de los pasos del 1 al 6 para los siguientes períodos, si
fuera el caso.
Pronósticos deseados para períodos superiores a n+1, requiere que
se utilice el método sucesivamente para lograr estimaciones sobre la base de
estimaciones anteriores.
La aplicación desarrollada para calcular los modelos, denominada
Promatric V1.0, le dio solución de forma automática a todas las series
permitiendo generar un archivo de pronóstico con todas las asignaturas sin
pre-requisitos indicando adicionalmente la desviación que podría tener.
Promatric V1.0 fue diseñada en el lenguaje de programación PHP
soportado por el motor de base de datos MySQL Server. La elección de
estas
herramientas
estuvo
condicionada
por
el
reciente
decreto
gubernamental (ver anexo G: Decreto 3390 uso del Software Libre) en el
cual se establece el uso de Software Libre para las instituciones del estado.
Otros aspectos como la sencillez de programación, la transportabilidad y el
bajo uso de recursos en cuanto a espacio de memoria, también incidieron en
la elección de las mismas. Por último, el hecho de ser una aplicación Web,
abre muchos caminos de utilización futura como integración en portales,
posibilidad de uso remoto, alimentación de otras aplicaciones similares, etc.
CAPITULO 4
RESULTADOS
En este capítulo, se pueden observar los resultados de la aplicación
del modelo formulado en la parte final del capitulo dos, aplicando la
metodología y el análisis descrito en el capítulo tres, dándole finalmente
solución al problema planteado en el primer capítulo.
Debido al tamaño de los datos originales, las gráficas de las
asignaturas se encuentran en el anexo A al final del documento.
4.1 Software desarrollado
La aplicación desarrollada,
Promatric V1.0 realiza los cálculos
necesarios para pronosticar la matrícula de las asignaturas sin pre-requisitos
de todas las carreras del Centro Local Metropolitano de la Universidad
Nacional Abierta, mediante la aplicación de un algoritmo basado en series de
tiempo aplicado a los datos históricos de matrícula de las mencionadas
asignaturas, guardados desde 1995 hasta el 2004.
La aplicación Promatric V1.0 consta de los siguientes módulos:
•
Consulta de histórico: Aquí se pueden observar los datos
cargados como históricos que le sirven de base a la aplicación.
Los datos no son modificables. Permite además ver la gráfica
del comportamiento de la matrícula, por asignatura
•
Nuevos datos: Permite cargar los datos del nuevo semestre una
vez realizadas las inscripciones para poder realizar los nuevos
pronósticos basados en datos reales.
•
Cálculo de pronóstico. Arroja el pronóstico de la matrícula de
las asignaturas sin pre-requisitos.
•
Mantenimiento de tablas: Permite manipular las tablas de
carreras, materias, centros locales y prerrequisitos.
4.1 Datos de entrada
Los datos de entrada suministrados por la Unidad de Computación
del Centro Local Metropolitano, inicialmente en formato texto (.txt) fueron
formateados de acuerdo a la estructura siguiente, para estandarizar los datos
de acuerdo a lo establecido en los parámetros del sistema. El archivo de
materias sin pre-requisitos tiene los siguientes campos:
•
Código de asignatura: 3 dígitos numéricos, por ejemplo: 102.
•
Descripción de la asignatura: 20 dígitos alfanuméricos, por ejemplo:
Lengua y Comunicación I.
•
Inscritos regulares: 4 dígitos numéricos.
•
Inscritos repitientes: 4 dígitos numéricos.
•
Total inscritos: 4 dígitos numéricos.
Figura N° 21 Formato de los datos de entrada
Fuente: Elaboración propia
Los datos son ingresados al sistema a través del módulo nuevos
datos, una vez estandarizados en el formato establecido.
Figura N° 22 Pantalla de importación de datos
Fuente: Elaboración propia
4.1 Salida de la simulación
Para comenzar la simulación es necesario acceder al módulo de
pronóstico y elegir la opción de materias sin pre-requisitos. Es importante
recordar que este Trabajo de Grado está complementado por otro de
condiciones similares cuya función es determinar el pronóstico de las
asignaturas con pre-requisitos de la carrera Ingeniería de Sistemas del
Centro Local Metropolitano y se decidió elaborar una sola aplicación que
permitiera recuperar el pronóstico de ambos grupos de materias. Por esta
razón, para iniciar la simulación, es necesario elegir a que grupo se referirá el
pronóstico. La figura N° 23 muestra la pantalla donde se inicia la simulación.
Figura N° 23 Pantalla de Pronóstico de Materias
Fuente: Elaboración propia
Eligiendo convenientemente el rango de asignaturas deseadas, el
semestre a pronosticar y el grupo sin pre-requisitos, se comienza el
pronóstico presionando la tecla Aceptar.
La simulación produce una pantalla con los valores arrojados luego de
los cálculos de pronóstico. La figura N° 24 muestra el detalle del reporte de
pronóstico. El campo Desviación, estará en blanco para este primer
pronóstico, sin embargo, a medida que se vayan incluyendo los datos reales
esta columna se recalculará para indicar la desviación promedio del
pronóstico con respecto a la realidad. Esto permitirá la revisión del modelo
para su optimización en el tiempo. Desde esta pantalla se podrá imprimir el
reporte de pronóstico.
Figura N° 24 Reporte de Pronóstico de Materias
Fuente: Elaboración propia