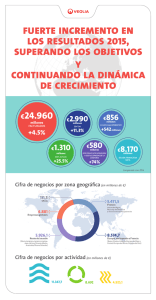
la ley de benford o el fenómeno del primer dígito
Anuncio

SIGMA
26
LA LEY DE BENFORD O EL FENÓMENO
DEL PRIMER DÍGITO
Ibon Martínez Arranz y Leire de la Torre Sebastián
“¡Sólo existe la estadística! El hombre racional es el hombre estadístico. ¿Será un niño guapo
o feo? ¿Sentirá amor por la música? Sobre todo esto decide un juego de dados. La estadística
está presente en el momento de nuestra concepción, es ella quien sortea los conglomerados
de genes que crean nuestros cuerpos, ella rifa nuestra muerte. De un encuentro con la mujer
que amaré, de mi longevidad, de todo decide la distribución estadística normal... La Historia,
a su vez, es el cumplimiento de unos movimientos brownianos, una danza estadística de fragmentos que no dejan de soñar en un mundo temporal diferente”
Stanislav Lem.
1. UN POCO DE HISTORIA
Estamos acostumbrados a vivir de las explicaciones estadísticas,
ellas nos dicen que la altura se distribuye de forma normal, que
los sucesos raros siguen una distribución de Poisson, y aceptamos
estos hechos usando técnicas de inferencia estadística, y con todo
esto la Ley de Benford es muy poco conocida a pesar de que describe de manera casi exacta fenómenos naturales.
Así como la distribución normal nació para explicar los errores
que se producían en las medidas astronómicas, la Ley de Benford
se estudió para explicar la frecuencia de la primera cifra significativa de datos estudiados. En 1881, Simon Newcomb (1835-1909),
físico y matemático, se percató de que su libro de tablas de logaSimon Newcomb
ritmos estaba más desgastado por las primeras páginas que por las
últimas, esto le llevó a concluir que en esos años en los que usó ese libro, trabajó más con
números cuyas primeras cifras significativas eran bajas(1). ¿Podía ser más probable encontrar en
la naturaleza un número que empezara por 1 o 2, que por 8 o 9?
No fue hasta 1938, que el físico Frank Benford estudió 20,229
números provenientes de distintas muestras(2), y a partir de las cuales postuló la llamada “Ley de los números anómalos de Benford”,
y comprobó que si estudiamos la primera cifra significativa de
números extraídos de datos producidos al azar, no sirve estudiar
la primera cifra significativa de las matrículas de los coches o el
primer dígito de un número de la lotería, se distribuían siguiendo
la siguiente distribución:
Frank Benford jr.
Mayo 2005 • 2005ko Maiatza
Es claro que es función de probabilidad, ya que:
131
Ibon Martínez Arranz y Leire de la Torre Sebastián
Lo que nos da la siguiente tabla de probabilidades para cada número
P(1)
P(2)
P(3)
P(4)
P(5)
P(6)
P(7)
P(8)
P(9)
0,301
0,176
0,125
0,097
0,079
0,067
0,058
0,051
0,046
Según esta ley, el 30% de las veces, la primera cifra significativa será un 1, mientras que sólo
un 5% de las veces será un 9.
2. ¿QUÉ SUCESOS SIGUEN ESTA LEY?
En su artículo, Benford estudió las cifras provenientes de la población de ciudades, longitudes
de ríos, alturas de montañas, números que aparecían en una revista, (es claro, que todas estas
cifras se producen por azar), seguían su distribución de manera asombrosa.
Hoy podemos estudiar esta ley con números de fenómenos más modernos, el tamaño en
bytes de los ficheros de texto que podemos encontrar en nuestro ordenador personal. Para ello
vamos a usar el programa de cálculo simbólico Mathematica(3). Los datos presentados son los
obtenidos en nuestro ordenador. Sigamos las siguientes instrucciones para Mathematica:
a = FileNames[{“*.dat”,”*.txt”},”c:”,Infinity];
Con este comando, encontramos todos los ficheros con extensión *.dat y *.txt, que tengamos
en el directorio raíz y sus subdirectorios.
datosreales = Table[IntegerDigits[FileByteCount[a[[i]]]][[1]],{i,1,Length[a]}];
Calculamos el tamaño en bytes de todos los ficheros con extensión *.dat y *.txt que tengamos,
y seleccionamos su primera cifra significativa.
datosreales = Table[Length[Select[datosreales,#==i &]],{i,1,9}]
{275,161,100,110,51,69,52,44,43}
Así, obtenemos el número de veces que aparece como primera cifra significativa cada número
de 1 a 9.
Y de la siguiente manera obtenemos la frecuencia de aparición de cada cifra.
datosreales = datosreales/Length[a]//N
{0.30021, 0.17576, 0.12008, 0.055676, 0.075327, 0.056768, 0.048034, 0.046943}
Según la Ley de Benford, estos valores son
leydebenford = Table[Log[10,1+1/k],{k,1,9}]//N
{0.30103, 0.17609, 0.12493, 0.09691, 0.07918, 0.06695, 0.057992, 0.05115, 0.04575}
¿No es asombroso?. Finalmente, dibujamos ambas frecuencias en un diagrama de barras.
132
SIGMA Nº 26 • SIGMA 26 zk.
La Ley de Benford o el Fenómeno del Primer Dígito
<< Graphics`Graphics`
BarChart[leydebenford,datosreales,ImageSize->600];
Figura 1. Diagrama de distribuciones de la primera cifra significativa del tamaño en byte
de los ficheros del ordenador
Es claro, que los ficheros de texto no se crean con la intención de que sea el 1, la cifra significativa más frecuente. También se verifica con las primeras cifras significativas de los términos de la sucesión de Fibonacci. Si seguimos usando Mathematica, tenemos una función,
Fibonacci[n], que devuelve el n-ésimo término de la sucesión de Fibonacci, así:
a = Table[IntegerDigits[Fibonacci[i]][[1]],{i,1,10000}];
De esta manera, guardamos en una lista las primeras cifras significativas de los términos 1 a
10000 de la serie de Fibonacci.
datosreales = Table[Length[Select[a,#==i &]],{i,1,9}]
{3011, 1762, 1250, 968, 792, 668, 580, 513, 456}
Hemos calculado el número de veces que es primera cifra significativa cada valor, y con el
siguiente comando, calculamos su frecuencia:
datosreales = Table[Length[Select[a,#==i &]]/Length[a],{i,1,9}]//N
{0.3011, 0.1762, 0.125, 0.0968, 0.0792, 0.0668, 0.058, 0.0513, 0.0456}
Y por último, una comprobación gráfica
BarChart[Table[Log[10,1+1/i],{i,1,9}],datosreales,ImageSize->600];
Figura 2. Diagrama de distribuciones de la primera cifra significativa
de los términos de la sucesión de Fibonacci
Mayo 2005 • 2005ko Maiatza
133
Ibon Martínez Arranz y Leire de la Torre Sebastián
3. ¿PODEMOS GENERALIZAR LA LEY DE BENFORD?
Esta pregunta surge de manera inmediata al estudiar si las dos primeras cifras significativas se
rigen de una manera similar, es decir, hemos visto que la cifra 1 es la más probable, ¿Podemos
pensar que la cifra 11 será más probable que, por ejemplo la cifra 19?
Es fácil pensar en una generalización, si observamos como está construida la Ley de Benford,
al probar que era función de probabilidad, hemos desarrollado y nos hemos encontrado una
suma telescópica, donde se anulaban todos los términos excepto el primer y el último término.
Así, si queremos estudiar como se distribuyen k cifras, podemos definir:
Evidentemente, sigue siendo función de probabilidad, y aún podemos generalizarla más, añadiendo otro parámetro, quedando de la siguiente manera:
Es claro, que si tomamos m=1 y k=9, obtenemos la Ley de Benford. Ahora estamos en disposición de estudiar, de la misma manera que hemos hecho para los nueve primeros dígitos, si
existe otra relación parecida para los noventa primeros dígitos (10, 11, 12, …, 97, 98 y 99).
Observamos, que tomamos, m tal que m*k+1=10, así, para noventa dígitos, tomamos m = 0,1.
Volvemos a seleccionar los dos primeros dígitos del tamaño en bytes de los ficheros de nuestro
ordenador para comprobarlo empíricamente. Así:
a = FileNames[{“*.*”},”c:”,Infinity];
datosreales = Table[{IntegerDigits[FileByteCount[a[[i]]]][[1]],IntegerDigits[FileByteCount[a[
[i]]]][[2]]},{i,1,Length[a]}];
concatenar2[lista_]:=lista[[1]]*10+lista[[2]]
datosreales = Table[concatenar2[datosreales[[i]]],{i,1,Length[a]}];
datosreales = Table[Length[Select[datosreales,#==i &]]/Length[a],{i,10,99}];//N
<< Graphics`Graphics`
BarChart[datosreales,ImageSize->600,DefaultFont->{“Helvetica”,8},BarSpacing->0,
BarGroupSpacing->0];
Figura 3. Diagrama de distribuciones de las dos primeras cifras significativas del tamaño en byte de los
ficheros del ordenador
134
SIGMA Nº 26 • SIGMA 26 zk.
La Ley de Benford o el Fenómeno del Primer Dígito
Realizamos el siguiente comando con el Mathematica
m=0.1;
k=90;
Y con la siguiente sintaxis, comprobamos que, efectivamente, es función de probabilidad.
Sum[Log[k*m+1,((1+m)+m*(i-1))/(1+m*(i-1))],{i,1,k}]//N
1. Realizamos la consiguiente comprobación gráfica,
BarChart[Table[Log[k*m+1,((1+m)+m*(i-1))/(1+m*(i-1))],{i,1,k}],datosreales,ImageSize->600];
Figura 4. Distribución conjunta de los datos obtenidos y los dados
por la generalización de la Ley de Benford
Observamos, que con no sólo existe el fenómeno del primer dígito, también tiene importancia, el segundo dígito, y es más probable que encontrar 10 que 19. Se puede comprobar para
las tres primeras cifras significativas, y saldría algo parecido.
Para todos los datos hemos tomado como base del logaritmo 10. Esto es porque la base de los
números con los que trabajábamos era diez. Si estuviéramos estudiando como se distribuyen
unos datos recogidos en otras bases, entonces la base del logaritmo sería esa base.
4. UTILIZACIÓN DE LA LEY DE BENFORD
La Ley de Benford, auque poco conocida, es usada para encontrar fraudes en declaraciones (5).
Otro de sus posibles usos, es la búsqueda de datos en un ordenador, hemos comprobado, que
la primera cifra significativa del tamaño en byte de los ficheros sigue la Ley de Benford, así,
que si tenemos los ficheros ordenados por su primera cifra (que no por tamaño), tendremos
cerca de un 30% de posibilidades de encontrarlo entre aquellos ficheros cuya primera cifra
significativa sea 1.
5. NOTAS
(1) S. Newcomb, Note on the frecuency of use of the diferent digits in natural numbers, Amer. J. Math. 4 (1881) 39-40.
(2) F. Benford, The law of anomaolus numbers, Proc. Amer. Phil. Soc. 78 (1938) 551-572.
(3) The Mathematica, Fourth Edition, Wolfram Media, Cambrige University Press.
(4) Quadrature, Magazine de mathématiques pures et épicées, Avril-Juin 2003.
(5) http//:www.nigrini.com/benford’s_law.htm
Mayo 2005 • 2005ko Maiatza
135