Econom´ıa y Gestión de la Salud Ejercicio práctico en ordenador
Anuncio

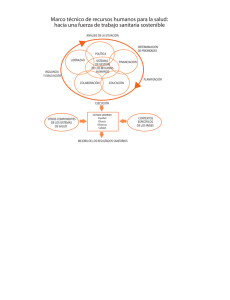
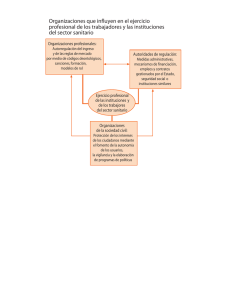
Economı́a y Gestión de la Salud Ejercicio práctico en ordenador usando STATA (Preparado por las Ayudantes Lucila Berniell y Dolores de la Mata) UC3M 26 de febrero, 2010 Se han realizado estimaciones con datos de 30 paı́ses de la OCDE sobre el impacto de distintas polı́ticas de salud sobre medidas alternativas del stock de salud, H (que en nuestro caso son: esperanza de vida al nacer 1997 (hombres), esperanza de vida al nacer 1997 (mujeres) o Mortalidad infantil 1997) de acuerdo al siguiente modelo: ln(H)i = βˆ0 + βˆ1 ln(pib)i + βˆ2 ln(gspub97)i + βˆ3 ln(gf 97)i + βˆ4 ln(alc97)i + ui (1) donde, pibi : PBI per cápita ajustado por PPP, 1997 gspub97i : gasto sanitario público (excluido fármacos) per cápita, 1997 gf 97i : gasto en fármacos, como porcentaje del gasto sanitario total, 1997 alc97i : consumo de alcohol per cápita en litros, 1997 En base a los resultados de las estimaciones comente: 1. ¿Cuál es el impacto de cada una de las polı́ticas de salud en las distintas medidas del stock de salud? Interprete el significado de cada uno de los coeficientes (recordar que las varibles están expresadas en logaritmos). (Tablas 1, 2 y 3). En función de los resultados anteriores, comente cuál serı́a la polı́tica más indicada en términos medios (recuerde que el objectivo del Banco Mundial es saber cuál es la mejor manera de invertir su ayuda, comparando los impactos del gasto en: 1) gastos médicos; 2) programas de educación sanitaria; 3) subsidios a fármacos.) 2. Comentar cuál de los imputs tiene un impacto significativamente distinto de cero en el output y el ajuste de la ecuación a los datos. 3. Interprete y comente los resultados para cada paı́s (Tabla 4) respecto al efecto marginal del input “gasto sanitario público per capita” sobre la mortalidad infantil. 4. Le parece esta muestra de paı́ses la mas adecuada para decidir el tipo de inversiones que deberı́a realizarse en el tercer mundo para mejorar el bienestar de esas poblaciones? Justifique. 1 1 Respuestas 1.1 Respuestas partes (1) y (2) Para poder responder a estas preguntas, primero debemos realizar las estimaciones correspondientes, para lo cual seguiremos una serie de pasos que se detallan a continuación. 1.1.1 Manejo de la base de datos en STATA Trabajaremos con la base de datos que está en el fichero “datos.dta”, el cual contiene las siguientes variables: Nombre de la variable pais evm evh morinf96 morinf97 gf96 gf97 pib gs96 gs97 gsp96 gsp97 tabaco alc96 alc97 Descripción paı́s esperanza de vida al nacer 1997, mujeres esperanza de vida al nacer 1997, hombres mortalidad infantil, 1996 mortalidad infantil, 1997 gasto en fármacos como % del total del gasto sanitario, 1996 gasto en fármacos como % del total del gasto sanitario, 1997 PIB per cápita, corregido por PPP, 1997 gasto sanitario (excepto fármacos) como % del PBI, 1996 gasto sanitario (excepto fármacos) como % del PBI, 1997 gasto sanitario público (excepto fármacos) como % del PBI, 1996 gasto sanitario público (excepto fármacos) como % del PBI, 1997 porcentaje de la población que fuma diariamente en 1997 consumo de alcohol en litros per cápita, 1996 consumo de alcohol en litros per cápita, 1997 ¿Cómo abro la base de datos en Stata?: Primero hay que asignar memoria al programa, para que pueda usarla al abrir la base de datos (mientras más grande sea la base, más memoria debemos asignar). En este caso le asignaremos 100 Mb, tipeando: set memory 100m Ahora sı́ podemos abrir la base de datos: usaremos el comando use, para el cual tenemos que indicar el “path” en el que está nuestro fichero “datos.dta” en nuestro ordenador use ‘‘C:\clase stata\datos.dta’’, clear Describir la base de datos y las variables que contiene: podemos usar los comandos describe, codebook, inspect, list, tabulate, summarize, table. describe describe pib tabulate pib tabulate pib if pib>100 summarize gs96 gs97 2 Modificar la base de datos: por ejemplo, es útil modificar la base agregando nuevas variables. Los comandos más útiles para generar variables son: generate, egen y replace. Notar que en STATA a veces podemos usar abreviaturas para ciertos comandos (por ejemplo, generate puede escribirse sólo gen). Para generar la variable “gasto sanitario per capita (excluido fármacos) 1997” (gspub97): generate gspub97=gsp97*pib Para “etiquetar” la variable (que significa agregar a la variable una explicación “en palabras” para entender de qué variable se trata) hacemos lo siguiente: label var gspub97 ‘‘gasto sanitario per capita (excluido fármacos) 1997’’ También tenemos que generar los logaritmos de las variables que usaremos para estimar el modelo de regresión que presentamos anteriormente. Para generar las variables en logaritmos de las distintas medidas de H que vamos a usar como variables independientes en nuestras regresiones: gen lnevh=ln(evh) label var lnevh ‘‘ln de la evh, 1997’’ gen lnevm=ln(evm) label var lnevm ‘‘ln de la evm, 1997’’ gen lnmorinf97=ln(morinf97) label var lnmorinf97 ‘‘ln de morinf97, 1997’’ Para las variables que usaremos como regresoras: gen lnpib=ln(pib) label var lnpib ‘‘ln de pib, 1997’’ gen lngsp97=ln(gspub97) label var lngsp97 ‘‘ln de gspub97, 1997’’ gen lngf97=ln(gf97) label var lngf97 ‘‘ln de gf97, 1997’’ gen lnalc97=ln(alc97) 3 label var lnalc97 ‘‘ln de alc97, 1997’’ Explorar relaciones entre variables: Podemos usar muchos comandos simples en STATA para explorar correlaciones entre algunas variables. Por ejemplo, con el comando scatter logramos un gráfico de dispersión entre dos variables scatter scatter scatter scatter evh evh evh evh pib gspub97 gf97 alc97 Para guardar un gráfico: scatter evh pib, saving(‘‘C:\clase stata\grafico1’’) 1.1.2 Hacer las regresiones en STATA Estimación por mı́nimos cuadrados ordinarios. Usaremos el comando regress. La sintaxis es la siguiente: Para los resultados que se muestran en la Tabla 1: regress lnevm lnpib lngsp97 lngst97 lnalc97 Para los resultados que se muestran en la Tabla 2: regress lnevh lnpib lngsp97 lngst97 lnalc97 Para los resultados que se muestran en la Tabla 3: regress lnmorinf97 lnpib lngsp97 lngst97 lnalc97 Table 1: Dep = ln esperanza de vida al nacer 1997, mujeres Variable Coefficient (Std. Err.) ln pib p.c. (97) 0.036 (0.023) ln gasto sanitario público p.c.(97) 0.009 (0.015) ln gasto en fármacos, % del gasto sanitario total (97) 0.008 (0.010) ln consumo de alcohol p.c. (97) -0.019 (0.012) Intercept 4.183∗∗ (0.056) N R2 F (4,18) Niveles de significación: 23 0.636 7.863** † : 10% ∗ : 5% ∗∗ : 1% 4 Table 2: Dep = ln esperanza de vida al nacer 1997, hombres Variable Coefficient (Std. Err.) ln pib p.c. (97) 0.068∗ (0.029) ln gasto sanitario público p.c.(97) 0.003 (0.018) ln gasto en fármacos, % del gasto sanitario total (97) 0.011 (0.013) ln consumo de alcohol p.c. (97) -0.045∗∗ (0.015) ∗∗ Intercept 4.046 (0.069) N R2 F (4,18) Niveles de significación: 23 0.727 11.98** † : 10% ∗ : 5% ∗∗ : 1% Table 3: Dep = ln mortalidad infantil, 1997 Variable Coefficient ln pib p.c. (97) 0.028 ln gasto sanitario público p.c.(97) -0.555∗ ln gasto en fármacos, % del gasto sanitario total (97) 0.011 ln consumo de alcohol p.c. (97) 0.012 Intercept 5.020∗∗ N R2 F (4,17) Niveles de significación: (Std. Err.) (0.297) (0.205) (0.103) (0.123) (0.558) 22 0.810 18.091** † : 10% ∗ : 5% ∗∗ : 1% 5 1.2 Respuesta parte (3) Recordar que el coeficiente estimado asociado a un input I es igual a: ∆H/H βˆI = ∆I/I (2) El incremento en un 1% del input impacta un βˆI % en la variable H y es igual para todos los paı́ses. Sin embargo, el efecto marginal de este input en la variable H es: ∆H H = βˆI × (3) ∆I I y por lo tanto tendrá un efecto diferencial en cada paı́s, dependiendo del valor de H e I en cada paı́s. Para crear este efecto marginal por paı́s, hacemos lo siguiente: gen marginal= -0.555*(morinf97/gspub97) Para listar los resultados (que se muestran en la Tabla 4): list pais morinf97 gspub97 marginal 1.3 Respuesta parte (4) Notar que la muestra de paı́ses incluye todos paı́ses desarrollados, por lo cual difı́cilmente se puedan extrapolar estos resultados para asesorar sobre polı́ticas sanitarias a aplicar en el tercer mundo. 2 ¿Cómo crear ficheros .do y .log y para qué sirven? Todos los comandos que fuimos utilizando pueden guardarse en un sólo fichero, que denominamos “fichero de comandos”, y que es un fichero de texto con extensión “.do”. Estos ficheros son útiles porque nos permiten repetir la secuencia de comandos que utilizamos para crear variables y para hacer estimaciones cuantas veces queramos. Los ficheros “.log” son ficheros que guardan todos los resultados (por eso los llamamos “archivo de registro”) que salen de los comandos que hemos utilizado. Es útil crear este fichero porque ası́ no necesitamos correr todos los comandos nuevamente cuando queramos volver a ver los resultados. Para crear ficheros “.do” y “.log” seguimos los siguientes pasos: • Pinchamos en la barra de menú de STATA sobre el ı́cono que parece un sobre, y se abrirá el editor de texto de STATA en el que crearemos nuestro fichero .do. • Copiamos el siguiente encabezamiento: ]delimit ; clear all; set more off; capture log close; use ‘‘C:\......\datos.dta’’, clear; log using ‘‘C:\......\resultados.log’’, clear; 6 Table 4: Efecto marginal del gasto público sanitario per cápita pais Australia Austria Belgium Canada Czech-Republic Denmark Finland France Germany Greece Hungary Iceland Ireland Italy Japan Korea Luxembourg Mexico Netherlands New-Zealand Norway Poland Portugal Slovakia Spain Sweden Switzerland Turkey UK USA morinf97 5.3 4.7 6.1 5.5 5.9 5.2 3.9 4.7 4.8 6.4 9.9 5.5 6.2 5.6 3.7 . 4.2 16.4 5 6.8 4.1 10.2 6.4 8.7 5 3.6 4.8 40 5.9 7.2 gspub97 609.9 638.4 683.2 737.1 403 822.8 560 710 864 316.8 263.2 790.6 551.2 576.8 708 130.2 968 82.8 678 507.4 871 158.4 375 253.8 544 782.8 387 173.6 607.7 . marginal -0.0048 -0.0041 -0.0050 -0.0041 -0.0081 -0.0035 -0.0039 -0.0037 -0.0031 -0.0112 -0.0209 -0.0039 -0.0062 -0.0054 -0.0029 . -0.0024 -0.1099 -0.0041 -0.0074 -0.0026 -0.0357 -0.0095 -0.0190 -0.0051 -0.0026 -0.0069 -0.1279 -0.0054 . • A continuación pegamos la lista de comandos (los asteriscos son para comentar el renglón): * Generamos la variable “gasto sanitario per capita (excluido fármacos) 1997”; generate gspub97=gsp97*pib; label var gspub97 ‘‘gasto sanitario per capita (excluido fármacos) 1997’’; * Generamos las variables independientes en nuestras regresiones; gen lnevh=ln(evh); label var lnevh ‘‘ln de la evh, 1997’’; gen lnevm=ln(evm); 7 label var lnevm ‘‘ln de la evm, 1997’’; gen lnmorinf97=ln(morinf97); label var lnmorinf97 ‘‘ln de morinf97, 1997’’; * Generamos las variables regresoras de nuestras regresiones; gen lnpib=ln(pib); label var lnpib ‘‘ln de pib, 1997’’; gen lngsp97=ln(gspub97); label var lngsp97 ‘‘ln de gspub97, 1997’’; gen lngf97=ln(gf97); label var lngf97 ‘‘ln de gf97, 1997’’; gen lnalc97=ln(alc97); label var lnalc97 ‘‘ln de alc97, 1997’’; *Estimación por mı́nimos cuadrados ordinarios. *Para los resultados que se muestran en la Tabla 1; regress lnevm lnpib lngsp97 lngf97 lnalc97; *Para los resultados que se muestran en la Tabla 2; regress lnevh lnpib lngsp97 lngf97 lnalc97; *Para los resultados que se muestran en la Tabla 3; regress lnmorinf97 lnpib lngsp97 lngf97 lnalc97; *Para calcular los efectos marginales por paı́s; gen marginal=-0.555*(morinf97/gspub97); list pais morinf97 gspub97 marginal; • Finalmente, escribimos lo siguiente (para cerrar el fichero de registro en el que estamos guardando los resultados): log close; • Guardamos el archivo como ”ejerciciosalud.do”. • Tipeamos en la ventana de comandos de STATA: do "C:\......\ejerciciosalud.do" y automáticamente todas las acciones anteriores serán repetidas y los resultados mostrados en la ventana de output (ventana negra). Además, en el fichero resultados.log se han guardado todos los resultados. 8