Se llama big data al análisis de gigantescas bases de datos para
Anuncio

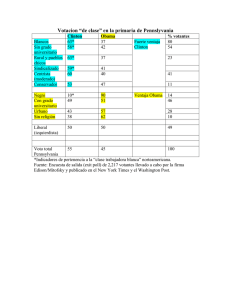
Cuando el tamaño definitivamente importa Por Esteban Magnani Una diferencia determinante entre nuestra vida virtual y la material es que la primera puede pasarse fácilmente a una base de datos. Pero cuando esta información se lleva a cierta escala también puede usarse para prever el comportamiento de la sociedad, controlar a las personas o vender productos. A esta enorme cantidad de material en permanente movimiento se la llama big data y sabe más sobre nosotros que la madre que nos parió. ¿Qué es lo que determina el éxito de una banda de rock? La respuesta podría llevar entrevistas enteras de grandes productores cazatalentos que explican cómo funciona su intuición. Es que cuando la cantidad de variables que intervienen en un fenómeno es demasiado grande, sólo cierta capacidad inexplicable puede dar algún tipo de respuesta. Pero algo está cambiando: los ríos de terabytes que circulan por la red, el aumento brutal en la capacidad de recolección y procesamiento de datos, sumados a programadores cada vez más entrenados en este campo, ahora hacen posible obtener algunas respuestas de una realidad hasta hace poco inconmensurable. De eso se trata big data: de grandes cantidades de información cargada por millones y millones de personas a través de las redes sociales, al usar sus tarjetas de crédito, sus celulares o realizar cualquier otra actividad digital. El espionaje masivo de los servicios de inteligencia de los EE.UU. es sólo un ejemplo del poder de los datos que hace unos años habrían resultado inmanejables. Cuando se habla de big data suele pensarse en enormes cantidades de información, tan grandes que no pueden funcionar en una sola computadora sino que requiere “clusters”: es decir, redes de computadoras funcionando simultáneamente. A este requisito conocido y que le da el nombre hay que sumarle la velocidad, porque las redes sociales no 1 descansan y es necesario recopilar, por ejemplo, los millones de tweets, que se lanzan a cada segundo, además de interpretarlos. Y por último se debe tener en cuenta la necesidad de estructurar esa información en bases de datos para así poder darle sentido. Cantidad, velocidad y estructura, más capacidad tecnológica y el software adecuado, permiten encontrar las respuestas que se estaban buscando. La herramienta es muy poderosa y ya se usa en las áreas más disímiles. Una de ellas es la política. En EE.UU. no sólo es optativo votar, sino que quien quiera hacerlo primero debe realizar los trámites necesarios y cumplir con los requisitos exigidos –varían según los diferentes estados–. Esto en parte explica los bajos niveles de participación en las elecciones de este país y las estrategias de campaña de los candidatos. Para atraer nuevos votantes el equipo de Barack Obama clasificó a los usuarios de las redes sociales de acuerdo con las posiciones políticas de sus amigos. Así los especialistas reconocieron a 3,5 millones de potenciales votantes a Obama no empadronados y luego se dedicaron a conocer sus intereses específicos sistematizando las publicaciones que hacían en las redes sociales. Ese perfil permitió dirigirles sólo aquellas propuestas del candidato que podían persuadirlos: leyes de género para las feministas, propuestas verdes para los ecologistas, etcétera. El nivel de precisión de esta campaña fue muy superior al de afiches con candidatos sonrientes que no pueden decir nada por el riesgo de espantar a quien piense distinto. Finalmente el equipo de Obama logró que al menos un millón de personas a las que apuntaron se registrara para votar. Obama ganó por menos de cinco millones de votos en todo el país, y en estados como Florida, clave para la victoria, la diferencia con su oponente fue de menos de setenta mil. La misma lógica puede aplicarse para diseccionar otros campos y encontrar las variables que expliquen fenómenos complejos, siempre y cuando existan los datos. Lo que antes requería focus groups y hordas de estudiantes munidos de encuestas trajinando las calles, ahora requiere un puñado de programadores desmontando la información que proveen las redes sociales. Google, por ejemplo, utiliza esta capacidad para, en la “intimidad” de nuestro correo electrónico, colocar publicidad que se corresponde con el tema del e-mail “privado” que estamos por 2 mandar a un amigo. El sistema funciona interpretando nuestros correos en tiempo real y permite a las empresas facturar en publicidad cuando usamos sus servicios. La información es poder y en el caso de Google, Facebook o Twitter, entre otros, simplemente toman lo que sus usuarios les brindan gentilmente para hacer con ella cosas por demás novedosas. Otro ejemplo: Google presentó recientemente una herramienta para prever éxitos de taquilla. Según pudieron establecer estadísticamente, cada persona consulta la película que le interesa unas trece veces en internet antes de ir a verla. O sea que si el buscador encuentra cierto número de visitas a trailers, críticas y demás puede estimar la futura recaudación del film. Es como si tuviera una especie de bola de cristal digital capaz de adivinar el futuro. PERSPECTIVAS ATEMORIZANTES Por supuesto que estos ejemplos más o menos ingenuos tienen una contracara bastante más oscura. No hace falta insistir en las recientes revelaciones sobre el control que EE.UU. hace sobre las llamadas y el uso de internet de ciudadanos de todo el mundo. Ese país se encuentra en un lugar privilegiado porque la columna vertebral global de las telecomunicaciones pasa por allí. La distopía orwelliana 1984, con el Gran Hermano vigilando a través de su ojo omnisciente a cada uno de los ciudadanos, resulta ingenua al lado de la capacidad de empresas y Estados para generar bases de datos que prevean comportamientos gracias a la fuerza de las estadísticas. Ya no es ciencia ficción la posibilidad de cruzar los videos tomados por las cámaras de seguridad con sistemas de reconocimiento facial para identificar el recorrido y las actividades de cualquier individuo. Las perspectivas resultan atemorizantes. El futuro no tan lejano lo es. Pero también big data tiene, aunque bastante más pequeño, su costado luminoso: la cantidad de información disponible en la red permite a las organizaciones desnudar vínculos de poder o formas más sutiles de corrupción. Es que los poderosos siempre tuvieron herramientas para someter y controlar, pero lo novedoso de nuestra era digital es lo contrario: que herramientas similares quedan más cerca para quienes intentan balancear ese poder. Un ejemplo es la tarea que viene haciéndose desde el periodismo de datos, donde confluyen programadores con la capacidad técnica y 3 periodistas con el criterio necesario para encontrar historias en la maraña de información que ofrece internet. Con esa lógica, una organización como ProPublica.org recogió de la web datos que luego cruzan para saber cuánto pagan los laboratorios a cada médico o quiénes financian las fundaciones que, a su vez, donan para las campañas de los distintos candidatos políticos de los EE.UU. La información estaba en la web, escondida dentro de cientos de declaraciones obligatorias que nadie podía revisar individualmente. Gracias al esfuerzo de periodistas y programadores se pudo recoger la parte relevante en bases de datos que hicieran visible lo que estaba oculto. Quien tenga una base de datos suficientemente amplia y capacidad para procesarla de forma adecuada podrá saber más sobre la sociedad que lo que nunca se supo. Hasta qué punto se la usará para liberarla o para dirigirla es algo que aún falta determinar, pero lo más probable es que la tensión entre ambas posibilidades continúe su ya largo recorrido histórico. *http://www.estebanmagnani.com.ar/wpcontent/uploads/2013/09/bigdata.pdf 4