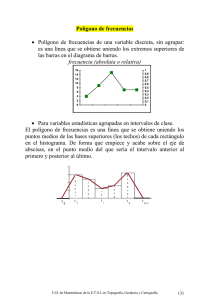
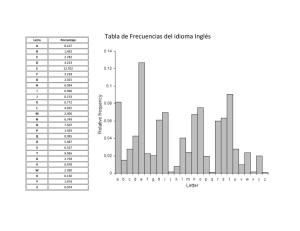
Estadística descriptiva Eduardo Moreno Barbosa FCFM BUAP ESTADISTICA DESCRIPTIVA Técnicas para organizar y procesar datos de tal manera que sea más fácil determinar que información contienen (es decir proporcionar una descripción de los datos ) Experimentos aleatorios (EA). • Un fenómeno o experimento es aleatorio si no puede predecirse cuál será su resultado. En caso contrario se dice que el fenómeno es determinista. • Los experimentos aleatorios se distinguen por los siguientes rasgos: • Los EA – Todos los posibles resultados son conocidos con anterioridad a su realización. – No se puede predecir el resultado de cada experimento particular. – El experimento puede repetirse en condiciones idénticas. • un experimento aleatorio simple, significa llevar a cabo solamente una vez dicho experimento. Cuando se repite un experimento aleatorio simple da lugar a un experimento aleatorio compuesto. Poblaciones y Muestras • Población: es el conjunto de todos los elementos que poseen una determinada característica. En general se asume que la población es muy grande. • Muestra: es un subconjunto de la población. • Muestreo: es el proceso mediante el cual se escoge una muestra de la población. La representatividad de la muestra depende de dos cosas: • – Del mecanismo de selección: que ha de garantizar que no hay un elemento de la población con más probabilidad que otro de entrar en la muestra. Si no, sería una muestra sesgada. – Del tamaño de la muestra: si el mecanismo de selección es correcto, cuanto más grande sea la muestra mayor será la probabilidad de que se parezca a la población. Tipos de muestreo • Muestreo aleatorio simple: todos los elementos de la población tienen la misma probabilidad de ser elegidos para formar parte de la muestra. • Muestreo aleatorio estratificado: la población se divide en grupos homogéneos que llamamos estratos. La proporción de cada estrato en la población se mantiene en la muestra. Cada uno de los estrato de la muestra se obtiene por muestreo aleatorio simple sobre el estrato correspondiente de la población. • Muestreo aleatorio sistemático: se selecciona al azar un elemento de la población y a partir de él se seleccionan de k en k los elementos siguientes. • Muestreo por conglomerados y áreas: se divide la población en distintas secciones o conglomerados. Se eligen al azar unas pocas de estas secciones y se toman todos los elementos de las secciones elegidas para formar la muestra. Tabla de frecuencias • Es una forma de organizar los datos, la cual se realiza a través de organizar los datos mediante grupos o categorías denominadas intervalos de clase (bin) o simplemente clases con sus respectivas frecuencias. • Rango: es la diferencia entre el valor máximo y mínimo del conjunto de datos. • Número de clases: – Propuestas por el problema o por quien realiza el estudio. – A través de la fórmula K=1+3.322log(n) con n el número de datos – Otra fórmula es – Ancho de clase= Rango/#clases=(dato mayor-dato menor)/#clases – Marca de clase: es el valor promedio entre el ínfimo y el supremo de dicho subintervalo. Tipo de representación • Frecuencia Absoluta: Es la frecuencia correspondiente en una determinada clase. • Frecuencias Relativa: Es la razón de la frecuencia correspondiente en una determinada clase dividida entre el numero total de datos (muestra o población). • Frecuencia Acumulada: Es la suma de las frecuencias absolutas de todos los valores inferiores o iguales al valor considerado. • Frecuencia Relativa Acumulada: Es la suma de las frecuencias absolutas de todos los valores inferiores o iguales al valor considerado dividida entre el total de datos. Se tiene una lista de las edades de 30 individuos que participaron en un estudio de la oxidación 18 24 27 38 47 51 20 25 29 41 48 55 22 25 31 42 49 57 23 25 33 42 50 61 23 26 35 45 50 63 • Al considerar clases de ancho 9, de 10 a 19 de 20 a 29 y así sucesivamente hasta 60 a 69. • Construyendo la tabla de clases con sus respectivas frecuencias se tiene lo siguiente: Clases Lim. Inf. Lim. Sup. Frecuencia Frec.Rel Frec.Acum Frec.Rel.Acum marca de clase 0 0 10 10 19 1 0.03 1 0.03 14.5 20 29 11 0.37 12 0.40 24.5 30 39 4 0.13 16 0.53 34.5 40 49 7 0.23 23 0.77 44.5 50 59 5 0.17 28 0.93 54.5 60 69 2 0.07 30 1.00 64.5 0 0 69 MÉTODOS GRÁFICOS • Histograma: Gráfica de columnas de clases contra frecuencia absoluta o frecuencia relativa. • Polígono de frecuencias: Gráfica poligonal de marcas de clase contra frecuencia absoluta o relativa agregando el límite inferior de la primera clase y el límite superior de la última clase. • Ojiva: Gráfica poligonal de límite superior contra frecuencia acumulada o frecuencia acumulada relativa. • Los gráficos correspondientes a la tabla de frecuencia del ejemplo anterior son: 12 Histograma de frecuencias 10 8 6 4 Histograma de frecuencias 2 0 Histograma de frecuencias relativas [10,19) [19,29) [29,39) [39,49) [49,59) [59,69) 0.40 0.30 0.20 0.10 Histograma de frecuencias relativas 0.00 [10,19) [19,29) [29,39) [39,49) [49,59) [59,69) Polígono de frecuencias absolutas Polígono de frecuencias relativas 12 0.4 10 0.35 0.3 8 0.25 Polígono de frecuencias absolutas 6 4 Polígono de frecuencias absolutas 0.2 0.15 0.1 0.05 2 0 10 14.5 24.5 34.5 44.5 54.5 64.5 69 0 10 14.5 24.5 34.5 44.5 54.5 64.5 69 Ojiva de frecuencias acumuladas Ojiva de Frecuencias Relativas Aumuladas 35 30 1.2 25 1 20 0.8 15 Ojiva de frecuencias 0.6 acumuladas Ojiva de Frecuencias Relativas Aumuladas 0.4 10 0.2 5 0 10 19 29 39 49 59 69 0 10 19 29 39 49 59 69 MEDIDAS DE TENDENCIA CENTRAL • son medidas estadísticas que pretenden resumir en un solo valor a un conjunto de valores – Media: es el promedio de los datos. – Mediana: es el valor que queda exactamente a la mitad de los datos ordenados en forma ascendente. – Moda: es el dato que se repite con la mayor frecuencia, puede no haber moda o más de una moda. Medidas de variabilidad Varianza: Muestral: Poblacional: Desviación estándar es la raiz cuadrada de la varianza A continuación se muestra la tabla resumen de estadística descriptiva que excel devuelve con el comando estadística descriptiva en el problema anterior Media Error típico Mediana Moda Desviación estándar Varianza de la muestra Curtosis Coeficiente de asimetría Rango Mínimo Máximo Suma Cuenta 37.5 2.4466 36.5 25 13.4 179.57 -1.2085 0.2809 45 18 63 1125 30