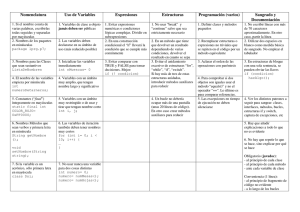
El ordenamiento por burbuja es el algoritmo más sencillo probablemente.
Ideal para empezar. Consiste en ciclar repetidamente a través de la lista,
comparando elementos adyacentes de dos en dos. Si un elemento es mayor
que el que está en la siguiente posición se intercambian. Es un algoritmo
estable. El inconveniente es que es muy lento.
static void burbuja_lims(int T[], int inicial, int final)
{
int i, j;
int aux;
for (i = inicial; i i; j--)
if (T[j] < T[j-1])
{
aux = T[j];
T[j] = T[j-1];
T[j-1] = aux;
}
}
El ordenamiento por inserción técnicamente es la forma mas lógica de ordenar
cualquier cosa para un humano, por ejemplo, una baraja de cartas. Requiere
O(n²).
Inicialmente se tiene un solo elemento, que obviamente es un conjunto ordenado.
Después, cuando hay k elementos ordenados de menor a mayor, se toma el
elemento k+1 y se compara con todos los elementos ya ordenados, deteniéndose
cuando se encuentra un elemento menor (todos los elementos mayores han sido
desplazados una posición a la derecha). En este punto se inserta el
elemento k+1 debiendo desplazarse los demás elementos.
static void insercion_lims(int T[], int inicial, int final)
{
int i, j;
int aux;
for (i = inicial + 1; i < final; i++) {
j = i;
while ((T[j] 0)) {
aux = T[j];
T[j] = T[j-1];
T[j-1] = aux;
j--;
};
};
}
Por último, el ordenamiento por selección: Al igual que el algoritmo de
inserción es muy trivial, puesto que recorre el vector o la lista, buscando el
elemento mas pequeño y colocandolo en la posición 0 del vector, y así
sucesivamente n-1 veces, tanto de grande como sea el vector. Al igual que los
algoritmos anteriores, requiere O(n²) .
static void seleccion_lims(int T[], int inicial, int final)
{
int i, j, indice_menor;
int menor, aux;
for (i = inicial; i < final - 1; i++) {
indice_menor = i;
menor = T[i];
for (j = i; j < final; j++)
if (T[j] < menor) {
indice_menor = j;
menor = T[j];
}
aux = T[i];
T[i] = T[indice_menor];
T[indice_menor] = aux;
};
}
Ahora vamos a hablar de los rápidos que son los mas interesantes:
1.
2.
3.
4.
Algoritmo mergesort ( ordenación por mezcla).
Algoritmo Quicksort (ordenación rápida).
Algoritmo Heapsort (ordenación por montículo).
Algoritmo Shellsort.
Todos estos muy interesantes en cuanto la implementación y a la idea de
organizar un vector, pero me voy a centrar en el algoritmo mergesort y en
el quicksort, que se basan en la técnica divide y vencerás, para quien lo sepa,
esta técnica es de las mas famosas en cuanto a multiplicación de matrices puesto
que la reduce de un n^3 a un n^2,78. Se basa en coger un problema P y dividirlo
en subproblemas y resolver estos sin solapamientos, y luego recursivamente
unirlos para formar la solución del problema original.
El algoritmo mergesort se basa en esta técnica, con lo cual si n=1, ya esta
ordenado, pero si n>1, partimos el vector de elementos en dos o mas
subcolecciones, ordenamos cada uno de ellaos y luego la unimos en un solo
vector ordenado, es de orden O(n log n) . Pero, ¿ cómo hacemos la partición?
1. Método 1: Primeros n-1 elementos en un conjunto A, y último en B, ordenar A
utilizando el esquema de división recursivamente, y B ya esta ordenado,
combinar A y B con un método inserta().
2. Método 2: Intentamos repartir los elementos de forma equitativa entre los dos
conjuntos, A toma n/k y B las sobrantes , ordenamos A y B recursivamente, y
por último combinamos A y B utilizando el proceso de mezcla que combina dos
listas en una.
static void mergesort_lims(int T[], int inicial, int final)
{
if (final - inicial < UMBRAL_MS)
{
insercion_lims(T, inicial, final);
} else {
int k = (final - inicial)/2;
int * U = new int [k - inicial + 1];
assert(U);
int l, l2;
for (l = 0, l2 = inicial; l < k; l++, l2++)
U[l] = T[l2];
U[l] = INT_MAX;
int * V = new int [final - k + 1];
assert(V);
for (l = 0, l2 = k; l < final - k; l++, l2++)
V[l] = T[l2];
V[l] = INT_MAX;
mergesort_lims(U, 0, k);
mergesort_lims(V, 0, final - k);
fusion(T, inicial, final, U, V);
delete [] U;
delete [] V;
};
}
El algoritmo quicksort ordena un vector V eligiendo entre sus elementos un
valor clave P que actúa como pivote, organiza tres secciones, izquierda-Pderecha, todos los elementos a la izquierda deberán ser menores a P, y los de la
derecha mayores, los ordena sin tener que hacer ningún tipo de mezcla para
combinarlos, ¿cómo elegimos el pivote?.
1. Método 1: Lo ideal sería que el pivote fuera la mediana del vector para que las
partes izquierda y derecha tuvieran el mismo tamaño.
2. Método 2: recorremos el vector con un indice i desde 0 a n-1, y otro
indice j inversamente y cuando se crucen, es decir, tenga el mismo valor, ese se
seleccionara como pivote.
static void quicksort_lims(int T[], int inicial, int final)
{
int k;
if (final - inicial < UMBRAL_QS) {
insercion_lims(T, inicial, final);
} else {
dividir_qs(T, inicial, final, k);
quicksort_lims(T, inicial, k);
quicksort_lims(T, k + 1, final);
};
}
 0
0