Práctica 2 Entorno de programación
Anuncio

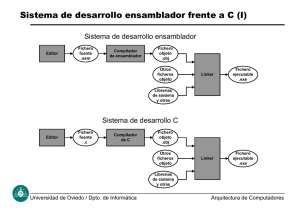
Práctica 2 Entorno de programación 1. Proceso de ensamblaje 2. Visual Studio .NET 1. Proceso de ensamblaje El proceso de ensamblado tiene el siguiente esquema: Listado Editor fuente 1 obj 1 Ensamblador fuente 2 obj 2 fuente 3 obj 3 Linker 1.1. Ensamblador A partir de los fuentes obtenidos de un editor, los fuentes se envían al Ensamblador el cual, traduce los nemotécnicos del lenguaje ensamblador al código objeto de la maquina. Y crea un fichero especial de listado de variables y procedimientos. Por último el Linker toma todos los ficheros objeto y con la información sobre las direcciones de memoria para las variables y procedimientos que contiene el fichero Listado, crea el fichero ejecutable final. Normalmente en el proceso de ensamblado bastan con 2 pasos para determinar todas las direcciones, por ejemplo: Jmp etiq … etiq: En este caso, cuando el ensamblador no puede determinar la dirección de etiq, ya que ésta está definida más adelante, con lo que debe dejar un espacio y dar una segunda pasada para determinar exactamente el dirección de memoria a la que debe saltar. Por lo tanto, en el 1er paso se utiliza una variable denominada “contador de posición” ($). A medida que se analiza el programa, se va incrementando dicha variable en función de los bytes que necesita cada sentencia. Por ejemplo: $ .CODE comi: mov ax, @data mov ds, ax mov cx, cont (3 bytes) (2 bytes) (5 bytes) 0 3 5 1 Práctica 1: Introducción a la programación en ensamblador repetir: dec cx … (1 byte) 9 10 Para cada segmento se inicializa el contador de posición. Ejemplo $ .DATA NUM db -29 VECTOR db 100 DUP (?) CONT dw 5 … 0 1 101 103 Para cada símbolo (variable, constante, etiqueta), se determina su $, su tipo, su nombre de segmento. Con esta información, ensamblador construye la TABLA DE SIMBOLOS en esta primera pasada. Luego sólo hay que buscar en esa tabla para determinar la dirección de cada etiqueta, constante o variable. El 2º paso comienza cuando se detecta END. Ayudado por las directivas y por los nemotécnicos de las instrucciones se comienza a general el código máquina. Ejemplo: MOV CX, CONT 1º comprobar si el tipo de fuente y destino coinciden 2º comprobar si CONT está en el segmento de datos 3º sustituir CONT por su desplazamiento, que en este caso es 101. No siempre es tan simple: - Pueden existir expresiones aritméticas (que se calculan en este segundo paso). Ejemplo: VAR1 EQU VAR2 + 10 En principio el ensamblador usa valores por defecto. Pero en todo caso, si 2 pasadas no fueran suficientes da un “Phase error”, Puede indicarle al ensamblador que de más pasadas. - Otra dificultad aparece con las llamas instrucciones “relocalizables”, por ejemplo: JMP ETIQ Con ETIQ en otro segmento. Estos valores son se sabe pues no tienen que ver el contador $ (que equivale a un desplazamiento) sino que hay que tener en cuenta es segmento en el que está. Por lo tanto no se conocerá el valor correcto hasta que el programa sea colocado en memoria. Para ello los ejecutables .EXE disponen de una cabecera con “información de relocalización” donde se indican las instrucciones relocalizables, y poder completar el código una vez situado el programa en memoria. 1.2. Linker El problema de la relozalización: suponer un procesador con memoria lineal. El ensamblador comienza siempre en 0, pero al cargar el programa en memoria no estará en la cero. En el 80x86, es fácil ya que lo único que hay que hacer es colocar el valor segmento correcto, y seguir los desplazamientos indicados de $. El problema de las llamadas “externas”: 2 Departamento de Arquitectura y Tecnología de Computadores: Universidad de Sevilla CALL proc MOV AX, SEGMENT JMP far ETIQ En todos estos casos se hacen referencias a otros módulos. El ensamblador trata cada modulo por separado y el linker soluciona estos problemas. El linker une todos los .obj de forma lineal, asumiendo un solo espacio de direcciones. Añade la cabecera de “relocalización” (en los ejecutable .exe). 2. Visual Studio .NET La siguiente figura muestra un esquema simplificado de los principales elementos (programas y ficheros) que se manejan en el desarrollo de una aplicación, en este caso usando lenguaje C: Son necesarias una serie de operaciones para crear un programa ejecutable que funcione correctamente a partir de uno o varios ficheros fuente: • Editar los ficheros fuente con un programa editor. • Compilarlos. • Enlazarlos con el linker para conseguir el fichero ejecutable. • El ejecutable debe probarse con un programa depurador. Si encontramos errores repetiremos el ciclo anterior. Al conjunto de programas que realizan estas o cualquier otra operación destinada a generar y probar programas se le llama entorno de desarrollo. Tras cada operación se generan ficheros temporales para comunicar resultados al programa que ejecuta la siguiente operación, y mensajes para informar al programador del estado del proceso. Necesitamos al menos 4 programas distintos, cada uno de ellos con sus propios parámetros, ficheros de entrada y salida, y mensajes de error o información. Para facilitar el manejo de estos programas vamos a utilizar un entorno de desarrollo integrado (IDE: Integrated Development Environment). Un IDE no es más que un programa que integra el software necesario para el proceso de desarrollo. Como mínimo integra funciones del editor, compilador, linker, depurador y manejador de proyectos (project management). Un proyecto es un fichero o ficheros que contiene la 3 Práctica 1: Introducción a la programación en ensamblador información necesaria para generar un programa: los ficheros fuente que hay que compilar, las opciones de compilación/enlace, ficheros de salida, listado, etc. 2.1. El entorno de desarrollo Visual Studio .Net. Este entorno de desarrollo permite utilizar distintos lenguajes de programación para generar un programa. En TPBN usaremos solamente las características para programar en lenguaje C/C++ y ensamblador. Es lo que se conoce como Visual C++ .Net (Visual C++ ó VC++). Utilizaremos VC++ para crear y analizar programas que nos permitan conocer cómo interaccionan procesador y compilador. Crear un proyecto. Empezaremos creando un proyecto y el programa C que vamos a analizar. Con Visual C++ hay que seguir los siguientes pasos: X Ejecutar Visual Studio .Net. Aparecerá la ventana principal del programa, con este aspecto: Fig. 2. Pantalla principal de Visual C++. Puede haber pequeñas variaciones en el aspecto Debido al añadido o supresión de paneles durante la última sesión con el IDE. Se recomienda cerrar los paneles y ventanas que no se vayan a usar. X Crear un proyecto. • Pulsar Ctrl-Mayús-N (o seleccionar en el menú principal Archivo ÆNuevo Æ Proyecto). Aparece la ventana que permite seleccionar el tipo de fichero o proyecto que se quiere crear: 4 Departamento de Arquitectura y Tecnología de Computadores: Universidad de Sevilla • La siguiente ventana es la del asistente para aplicaciones, donde hay que activar la opción de Proyecto vacío y el tipo de aplicación: aplicación de consola. Fig. 4. Configuración de la aplicación. • Crear un fichero .c con el programa principal: Fig. 5. Aparecerá la ventana Agregar nuevo Elemento, donde se introduce el nombre del archivo fuente de nuestro programa: Principal.c. Esto crea el fichero Principal.c en disco y lo abre en la ventana de edición. ES MUY IMPORTANTE ASEGURARSE QUE LA EXTENSIÓN DE LOS FICHEROS C ES .c Y NO .cpp ó .C. • Escribir el código C. Compilar y depurar el proyecto. El programa se compila pulsando la tecla F7 (o seleccionando Generar Æ Generar Solución). La depuración de un programa se suele hacer colocando puntos de interrupción en las líneas de código que interese. Para activar un punto de interrupción (breakpoint), hay que pinchar con el ratón en el inicio de la línea del código fuente donde se quiere parar y pulsar F9 (o pulsar 5 Práctica 1: Introducción a la programación en ensamblador RATON_DERECHA Æ Insertar/Quitar punto de interrupción). El punto aparecerá marcada en la ventana de edición. Las teclas más útiles para usar el depurador (debugger) son1: X Ejecutar depurador (F5), terminar depuración (Mayúscula + F5) X Mostrar ventana de desensamblado (Alt + 8 ó Depurar Æ Ventanas Æ Desensamblador) X Mostrar ventana de registros (Alt + 5) X Mostrar ventana de memoria (Alt + 4) X Ejecutar paso a paso: Pinchar ventana de desensamblado y pulsar F11 Todas las ventanas del depurador se pueden organizar dentro de la ventana principal de la forma que resulte más cómoda. La siguiente figura muestra la ventana de desensamblado, que permite ver las direcciones donde están almacenados el código y la variable de nuestro programa. La ventana de registros también permite ver el valor del puntero de pila, ESP, que señala el final de la pila. Fig. 6. Ventanas de depuración. Como se ve, la dirección que señala el puntero de pila es menor que las direcciones donde se almacena código o datos, lo que nos indica que la pila está colocada en las posiciones más bajas de la memoria. 2.2. Cómo funcionan los depuradores. Un depurador es un programa capaz de parar la ejecución de otro cuando se dan determinadas circunstancias: X Se ha llegado a un punto determinado del código (punto de parada o breakpoint de código). X Se ha ejecutado una sola instrucción (ejecución paso a paso). X Se accede a datos o se intenta ejecutar código de zonas de memoria fuera de las asignadas al programa (detección de accesos ilegales a memoria). X Se intenta acceder a una variable determinada (breakpoint de datos). X etc. Cuando ocurre algo de esto, se produce una excepción, es decir, el procesador salva su estado (valor de los registros internos) y salta a una función del sistema operativo que debe manejar la 6 Departamento de Arquitectura y Tecnología de Computadores: Universidad de Sevilla excepción. El proceso es muy similar al de una interrupción hardware. La función del sistema operativo normalmente pasa el control al depurador, que informa al programador. Las circunstancias concretas tratables por un depurador dependen fundamentalmente del hardware de depuración del procesador. Hay grandes diferencias entre distintos procesadores. Algunos no disponen de ninguna facilidad, por lo que lo único que pueden hacer los depuradores son breackpoints de código y ejecución paso a paso4. Los procesadores con arquitectura IA32 (Pentium y sucesores) disponen de un hardware muy completo para depuración y análisis de prestaciones. Cuatro registros de depuración, DR0 a DR3 (Debug Registers), permiten especificar las direcciones a analizar, y con dos registros de control, DR6 y DR5, se indican cuáles son las condiciones que provocan la excepción de depuración: breackpoints de código o datos, ejecución paso a paso y muchas más. La variedad de condiciones que es capaz de detectar un procesador IA32 es realmente extensa, por lo que el hardware de depuración es complicado de manejar. De hecho, muchos depuradores no utilizan todas las condiciones. Una vez parada la ejecución del programa que se está depurando, la información a mostrar depende fundamentalmente del sofware del depurador. En el caso de VC++ la tenemos agrupada en ventanas: X Ventana de código. El código se puede mostrar en varios formatos: • Desensamblado. Es el más básico: siempre se puede utilizar, tenga o no información de depuración el ejecutable. • Desensamblado + fuente. Muestra el código ensamblador que corresponde a cada sentencia del código fuente. Para usarlo es necesario que el depurador disponga del fichero fuente y que el fichero ejecutable tenga información de depuración. • Sólo fuente. Fig. 9. Ventana de código con programa desensamblado y fuente. • Ventanas de memoria. Muestran el contenido de cualquier zona de la memoria virtual del programa en formato hexadecimal de 8 bits (byte), 16 (Short Hex) o 32 (Long hex). El programador puede modificar el contenido de la memoria que aparece en la ventana. Fig. 10 7 Práctica 1: Introducción a la programación en ensamblador • Ventana de registros. Contiene los registros que se pueden modificar desde una aplicación de usuario5. Fig. 11. Ventana con los registros enteros y los indicadores (flags). • Ventanas de inspección (watch). Permite seleccionar elementos puntuales para ver y modificar su contenido: registros, posiciones de memoria, variables, etc. Fig. 12 • Ventana de variables. Permite ver y modificar el valor de las variables locales. • Ventana de pila de llamadas. Muestra el árbol de llamadas de la instrucción de código donde nos hemos detenido por última vez. 2.3. Puntos a tener en cuenta. Las ventanas de la pantalla principal (Fig. 2). Las funciones de las ventanas más importantes son: X Ventanas de edición: Sirven para editar los ficheros con código fuente. X Ventana de proyectos. Permite manejar y organizar los ficheros fuente del proyecto. X Ventana de mensajes: es donde aparecen los mensajes de error o estado que se generan al ejecutar un elemento del entorno de desarrollo: compilador, linker, etc. Tipos de proyectos (Fig. 3). Cuando seleccionamos el tipo de proyecto estamos escogiendo unas opciones por defecto para el proceso de desarrollo: las opciones de compilación, las librerías y ficheros objeto con los que se enlazará, opciones de depuración, etc. Al seleccionar una aplicación de tipo consola le decimos a VC++ que active las opciones de compilación necesarias para que nuestra aplicación pueda usar las funciones de manejo de consola estándar de C: printf, getc, putc, etc. Extensiones de los archivos fuente (Fig. 5). La extensión del nombre de un fichero fuente determina las opciones por defecto de compilación/linkado. Algunas extensiones, como .c ó .cpp, ya tienen preasignadas estas opciones. Esto quiere decir que si llamamos a un programa Principal.c, se compilará de forma ligeramente distinta que si lo llamamos Principal.cpp. La mayor diferencia es que un fichero .c sólo puede usar las características de C, y no de C++. En principio, si un programa sólo usa C, podría tener cualquiera de las dos extensiones. Sin embargo, internamente se compilará de forma distinta, y algunas características del código generado también serán distintas. Por tanto, para evitar confusiones a la hora de analizar el código generado por el compilador, hay que procurar usar la extensión .c en todos los programas de prácticas. 8 Departamento de Arquitectura y Tecnología de Computadores: Universidad de Sevilla 2.4. Compilación externa en Visual C++. Algunos entornos de desarrollo pueden compilar ficheros de un proyecto con compiladores externos. El mecanismo concreto para hacerlo dependerá del entorno de desarrollo. Supongamos, por ejemplo, que inicialmente todos los ficheros fuente del proyecto son programas C que se compilan con el compilador interno de Visual Studio. El proyecto tendría la siguiente estructura: Cuando genera el ejecutable, Visual Studio procesa automáticamente los ficheros fuente que componen el proyecto. Para los que tengan extensión conocida por Visual Studio (.h, .c, .cpp, ...), el IDE ejecuta el compilador interno que tiene asociada la extensión3. Una vez obtenido todos los ficheros objeto, el IDE lanza el linker interno para generar el ejecutable. Para las extensiones conocidas por Visual Studio el IDE sabe qué compilador utilizar, cómo usarlo (con qué opciones) y cuál es el resultado de la compilación (el fichero objeto). Para compilar algún fichero fuente con un compilador “externo” a Visual Studio hay que indicar al IDE cómo tiene que tratarlo. Esto implica que: X El fichero fuente debe tener una extensión no conocida para el IDE. En caso contrario, usará la compilación por defecto para esa extensión. X Hay que indicarle al IDE que debe hacer una compilación a medida (Custom Build) para ese fichero. Vamos a modificar el proyecto, para que uno de los ficheros se compile usando un ensamblador externo. La estructura del proyecto quedaría: 9 Práctica 1: Introducción a la programación en ensamblador Para ello se tendría que borrar el fichero Combina3.c y crear uno nuevo llamado Combina3.asm. Como el IDE no sabe cómo manejarlos, no hace ninguna operación sobre ficheros .asm a menos se lo indiquemos explícitamente activando la compilación personalizada (Custom Build). La forma de hacerlo es: X Seleccionamos el fichero en la ventana Explorador de soluciones y pulsamos el botón de la derecha del ratón. • Seleccionar Propiedades en el menú que aparezca. X El IDE mostrará la ventana de propiedades asociadas al fichero. Seleccionando la entrada Paso de generación personalizada (Fig. 3) podremos ajustar los tres campos necesarios para integrar el compilador externo: • Línea de comandos: Es la línea de comandos que ejecutará el IDE para procesar el fichero. • Descripción: Es el mensaje que mostrará el IDE cuando procese el fichero fuente. • Resultado: Es el resultado de la compilación externa. Le indica al linker (vinculador o enlazador) interno el fichero que tiene que usar. 10 Departamento de Arquitectura y Tecnología de Computadores: Universidad de Sevilla Fig. 3. Ventana Paso de generación personalizada. En nuestro ejemplo, la compilación de combina3.asm tendrá los siguientes parámetros: X Línea de comandos: \masm32\bin\ml.exe /Zi /Zd /Cp /c /coff /Gd "$(InputPath)". Hay que asegurarse que el ensamblador o compilador externo esté previamente instalado y que tiene el path y las opciones correctas en las líneas de comandos. X Descripción: Ensamblando "$(InputPath)". El IDE sustituye la cadena $(InputPath) por el nombre completo del fichero de entrada, incluyendo su path. X Resultado: "$(InputName).obj". El IDE sustituye la cadena $(InputName) por el nombre completo del fichero, incluyendo path, pero excluyendo la extensión. Las distintas cadenas de sustitución que pueden utilizarse en los campos de la ventana Paso de generación personalizada se insertan con el botón Macro de la ventana que aparece cuando se pulsa “…”. Ya estaría integrado el fichero ensamblador en el proceso de construcción del ejecutable. El IDE lanza automáticamente el ensamblador cada vez que se necesite, mostrando los mensajes de error o estado en la ventana de Resultados: 11 Práctica 1: Introducción a la programación en ensamblador 3. Primer programa en Ensamblador El siguiente código corresponde a un programa escrito en ensamblador que suma dos vectores de enteros almacenando el resultado en un tercero. .386 .model flat,stdcall option casemap:none include \masm32\include\windows.inc include \masm32\include\kernel32.inc include \masm32\include\user32.inc .data vect1 DD 10 dup (1,2,3,4,5,6,7,8,9,10) vect2 DD 10 dup (10,9,8,7,6,5,4,3,2,1) vectres DD 10 DUP (?) .code start: mov ecx, 10 xor edx,edx inibucle: mov eax, vect1[edx] add eax ,vect2[edx] mov vectres[edx] , eax add edx,4 loop inibucle call ExitProcess end start 12