- Ninguna Categoria
Universidad Tecnológica de Querétaro
Anuncio
Victor Hugo Ruiz Franco Universidad Tecnológica de Querétaro Firmado digitalmente por Universidad Tecnológica de Querétaro Nombre de reconocimiento (DN): cn=Universidad Tecnológica de Querétaro, o=Universidad Tecnológica de Querétaro, ou, [email protected], c=MX Fecha: 2011.05.19 11:16:26 -05'00' UNIVERSIDAD TECNOLÓGICA DE QUERÉTARO SERVIDOR WEB DTAI 2011 Servidor Web DTAI Memoria Que como parte de los requisitos para obtener el título de Ingeniero en Tecnologías de la Información y Comunicación Presenta Victor Hugo Ruiz Franco Asesor de la UTEQ M. en GTI. Jorge García Saldaña Asesor de la Empresa M. en C. José Felipe Aguilar Pereyra Santiago de Querétaro, Qro., Abril de 2011 1 2 RESUMEN El presente trabajo es una memoria de titulación que documenta la elaboración un servidor web para la Universidad Tecnológica de Querétaro, el cual permite a los alumnos de la universidad realizar prácticas para el desarrollo de sus habilidades. El documento está dividido por capítulos y secciones respectivamente, haciendo énfasis en los puntos más importantes esto para describir el desarrollo y funcionamiento en un punto de partida y cumplir en un lapso aceptable. El documento cuenta con capítulos los cuales van detallando los puntos clave del proyecto, los objetivos nos ayudan a establecer un punto de inicio y final del proyecto, el alcance muestra las tareas que el servidor realizará para conocimiento del cliente, el desarrollo es la fase donde se realiza el proceso se elaboración del proyecto, se toman los riesgos durante el proyecto y la estimación del tiempo que se tomará para realizar junto con las pruebas del proyecto lo cual nos permite tener una mejora continua en la elaboración del proyecto. Al definir cada uno de los capítulos nos permite llevar una mejor administración, elaboración del proyecto y no consume más tiempo del que se tiene planeado. El análisis del proyecto nos permite tener organización para realizar tareas eficazmente y agilizar la entrega del proyecto, y en dado momento de que el proyecto crezca ya se tiene los antecedentes para la modificación del proyecto. Con la realización de este proyecto se espera obtener un mayor aprovechamiento para los alumnos en su educación, para que cuenten con espacio propio para el incremento de sus conocimientos. 3 ABSTRACT Work is a certification report which records the installation of web server for the Technological University of Querétaro; this server will allow students to do internships to develop their skills. This report is divided into chapters and sections; the report emphasizes the most important in describing the development and operation to comply within a period acceptable. The report has chapters detailing the key points of the project and the objectives to help establish a starting point and end of the project, the scope shows what the webserver perform for the students, the development of the project face is where it performs project development process, risks are taken during the project and the estimated time it will take to perform. The tests with the project which allows us to have a better handle on the development of the project in defining each of the chapters allows us to bring better management, project and does not consume more time than is planned. The project analysis allows us to have organization to perform tasks efficiently and expedite project delivery, and given time the project grows and you have the background to the modification of the project. With the installation of this project is expected to make a greater use of technology for students in their education, to have their own space to increase their knowledge. 4 AGRADECIMIENTOS Le doy gracias a Jehová Dios por darme la oportunidad de terminar esta etapa de mi vida, también le agradezco por darme unos padres que siempre me apoyaron para lograr esta meta y que nunca tendré conque pagarles todo el esfuerzo que han hecho por mí. A mi hermana que siempre ha estado conmigo a pesar de las dificultades de la vida y que siempre nos apoyamos para salir adelante en cualquier situación que hay que superar. También agradezco a la familia Meza Ruiz que han sido un apoyo incondicional para lograr esta etapa de mi vida y que siempre me han brindado su apoyo en cualquier situación. Agradezco la labor de mis profesores por su entrega y profesionalismo que demostraron a lo largo de mi carrera y por el voto de confianza que depositaron en mí para culminar esta etapa. 5 ÍNDICE Página Resumen Abstract 3 Agradecimientos 4 Índice 5 I. INTRODUCCIÓN 7 II. ANTECEDENTES 8 III. JUSTIFICACIÓN 10 IV. OBJETIVOS 11 V. 12 ALCANCES VI. FUNDAMENTACIÓN TEÓRICA 13 VII. PLAN DE ACTIVIDADES 27 VIII. RECURSOS MATERIALES Y HUMANOS 28 IX. DESARROLLO DEL PROYECTO 29 X. RESULTADOS OBTENIDOS 122 XI. ANÁLISIS DE RIESGOS 123 XII. CONCLUSIONES 124 XIII. RECOMENDACIONES 125 XIV. REFERENCIAS BIBLIOGRÁFICAS 126 6 I. INTRODUCCIÓN En el presente trabajo se desarrolla la implementación y funcionamiento de un servidor web en la Universidad Tecnológica de Querétaro donde se busca brindar herramientas a los docentes para evaluar el desarrollo de sus alumnos y darle el seguimiento correspondiente para guiar su desarrollo aun nivel profesional y competitivo. El servidor web busca brindar un espacio para cada alumno en el cual le sirva para experimentar y desarrollar en las asignaturas de programación y base de datos principalmente entre otras y que el alumno tenga la mayor parte del tiempo esta herramienta disponible usando el internet sin la necesidad de instalar aplicaciones ya sea en su equipo o cualquier otro. La problemática actual es que la mayoría de los alumnos no cuentan con un equipo de cómputo propio y necesitan rentar uno o si cuentan con uno las aplicaciones que necesitan usar son difíciles de instalar o no compatibles, es por eso que se tiene la idea de centralizar en un servidor web todas las aplicaciones que el alumno necesita y que tenga acceso a ellas desde cualquier dispositivo con acceso a internet y que el docente pueda llevar un monitoreo del desarrollo de las prácticas o proyectos a entregar en cada una de las faces. 7 II. ANTECEDENTES La Universidad Tecnológica de Querétaro (UTEQ) a lo largo de 17 años de trayectoria en nuestra entidad, ésta se ha consolidado como una Institución Educativa de calidad que ofrece una formación profesional, cuyo distintivo es la estrecha relación con el sector productivo. La UTEQ comienza sus labores docentes en septiembre de 1994, iniciando la formación en las áreas de Administración, Comercialización, Mantenimiento Industrial y Procesos de Producción. Actualmente se imparten ocho carreras -a las cuatro primeras se sumaron las de Electrónica y Automatización, Telemática -actualmente Tecnologías de la Información y Comunicación-, Tecnología Ambiental y más recientemente Servicio Posventa: Área Automotriz, todas avaladas por la preparación profesional y curricular del cuerpo docente, en su mayoría con estudios de maestría y doctorado en áreas afines a las materias que imparten y en los atributos del modelo educativo, mismo que incluye actividades culturales y deportivas para la formación integral del estudiantado. En la carrera de Tecnologías de la Información y Comunicación se imparte clases a más de 500 alumnos tanto en el turno matutino como en el vespertino, de los cuales cada cuatrimestre necesita desarrollar sus habilidades en asignaturas tanto de programación como de base de datos, es por eso que el director de la carrera Ing. Rodrigo Mata Hernández propone implementar un servidor web donde los alumnos puedan interactuar con diferentes tecnologías para el desarrollo de su 8 aprendizaje, esto es con el fin de ayudar a los alumnos a que cuenten con un espacio en la red disponible las 24 horas del día en donde se accede ya sea por sus equipos o desde un cibercafé y sin la necesidad de instalar ninguna aplicación para el desarrollo de sus prácticas, así tener evidencias de sus logros y un mayor control de las calificaciones del alumno. 9 III. JUSTIFICACIÓN Se instalará un servidor web con la finalidad de tener un espacio para cada alumno para el desarrollo de prácticas para las asignaturas de programación y base de datos, por lo que el servidor les ayudará a que tengan este espacio disponible la mayor parte del tiempo desde cualquier lugar con acceso a internet, el alumno podrá subir, modificar, borrar, cualquier archivo que tengan en el espacio asignado. El proyecto busca brindar herramientas eficaces para que los maestros puedan utilizarlas para el beneficio de sus alumnos. 10 IV. OBJETIVOS Dentro de los principales objetivos del servidor web en la carrera de Tecnologías de la Información y Comunicación son: Proporcionar un medio activo y dinámico de proveer información sobre los aspectos docentes e investigadores. Publicar toda la información de asignaturas, cursos y dar ubicación a los recursos de programas elaborados en proyectos finales y de investigación. Desarrollo de habilidades en asignaturas de tecnologías de la información. 11 V. ALCANCES La instalación del servidor constará de 7 partes y en cada una se desglosará por subtemas donde contendrá los puntos principales para el desarrollo de cada parte, los temas a completar son los siguientes: Instalación de Ubuntu Server 10.4 Creando usuario SUDO Usuario limitado Actualización de SO Instalación de ia32-libs Instalación de JDK Instalación de Tomcat Iniciando Tomcat Instalación de XAMPP XAMPP para Linux Instalación de XAMPP en Ubuntu Iniciando XAMPP Configuración XAMPP Alta usuarios en sistema Rsync Cron 12 VI. JUSTIFICACION TEORICA Se instalará un servidor web con la finalidad de tener un espacio para cada alumno para el desarrollo de prácticas para las asignaturas de programación y base de datos. El proyecto busca brindar herramientas eficaces para que los maestros puedan utilizarlas para el beneficio de sus alumnos, las tecnologías que se utilizaran para realizar los proyectos son las siguientes: UBUNTU 10.10 Ubuntu es una distribución GNU/Linux basada en Debian GNU/Linux que proporciona un sistema operativo actualizado y estable para el usuario medio, con un fuerte enfoque en la facilidad de uso e instalación del sistema. Al igual que otras distribuciones se compone de múltiples paquetes de software normalmente distribuidos bajo una licencia libre o de código abierto. Estadísticas web sugieren que el porcentaje de mercado de Ubuntu dentro de las distribuciones Linux es de aproximadamente 50%, y con una tendencia a subir como servidor web. Está patrocinado por Canonical Ltd., una compañía británica propiedad del empresario sudafricano Mark Shuttleworth que en vez de vender la distribución con fines lucrativos, se financia por medio de servicios vinculados al sistema operativo y vendiendo soporte técnico. Además, al mantenerlo libre y gratuito, la empresa es capaz de aprovechar los desarrolladores de la comunidad en mejorar los 13 componentes de su sistema operativo. Canonical también apoya y proporciona soporte para cuatro derivaciones de Ubuntu: Kubuntu, Xubuntu, Edubuntu y la versión de Ubuntu orientada a servidores (Ubuntu Server Edition). Su eslogan es Linux for Human Beings (Linux para seres humanos) y su nombre proviene de la ideología sudafricana Ubuntu(«humanidad hacia otros»). Cada seis meses se publica una nueva versión de Ubuntu la cual recibe soporte por parte de Canonical, durante dieciocho meses, por medio de actualizaciones de seguridad, parches para bugs críticos y actualizaciones menores de programas. Las versiones LTS (Long Term Support), que se liberan cada dos años, reciben soporte durante tres años en los sistemas de escritorio y cinco para la edición orientada a servidores. Características En su última versión, Ubuntu soporta oficialmente dos arquitecturas de hardware en computadoras personales y servidores: x86 yAMD64 (x86-64); siendo la versión 6.10 la última que oficialmente soportó la arquitectura PowerPC, después de lo cual es solo soportada por la comunidad. Sin embargo, extraoficialmente, Ubuntu ha sido portado a tres arquitecturas más: SPARC, IA-64 yPlaystation 3. A partir de la versión 9.04 —lanzada en abril de 2009— se empezó a ofrecer soporte oficial para procesadores ARM, comúnmente usados en dispositivos móviles, PDA etc. 14 Al igual que la mayoría de las distribuciones basadas en GNU/Linux, Ubuntu es capaz de actualizar a la vez todas las aplicaciones instaladas en la máquina a través de repositorios. Esta distribución está siendo traducida a más de 130 idiomas, y cada usuario es capaz de colaborar voluntariamente a esta causa, a través de Internet. Software Incluido Posee una gran colección de aplicaciones para la configuración de todo el sistema, valiéndose principalmente escritorio predeterminado de Ubuntu de interfaces gráficas. es GNOME y se Elentorno sincroniza con de sus liberaciones. Existen otras dos versiones oficiales de la distribución, una con el entorno KDE, llamada Kubuntu, y otra con el entorno Xfce, llamada Xubuntu; existen otros escritoriosdisponibles, que pueden ser instalados en cualquier sistema Ubuntu independientemente del entorno de escritorio instalado por defecto. Aplicaciones de Ubuntu: Ubuntu es conocido por su facilidad de uso y las aplicaciones orientadas al usuario final. Las principales aplicaciones que trae Ubuntu son: navegador web Mozilla Firefox, cliente de mensajería instantánea Empathy, cliente de redes sociales Gwibber, cliente para enviar y recibir correo Evolution, reproductor multimedia Totem, reproductor de música Rhythmbox, editor de vídeos PiTiVi, gestor y editor de fotos Shotwell, cliente y gestor de torrents Transmission, grabador de discos Brasero, suite 15 ofimática OpenOffice.org, y el instalador central para buscar e instalar aplicaciones Centro de software de Ubuntu. Seguridad y accesibilidad: El sistema incluye funciones avanzadas de seguridad y entre sus políticas se encuentra el no activar, de forma predeterminada, procesos latentes al momento de instalarse. Por eso mismo, no hay un cortafuego predeterminado, ya que no existen servicios que puedan atentar a la seguridad del sistema. Para labores o tareas administrativas en la línea de comandos incluye una herramienta llamada sudo (de las siglas en inglés de SuperUser do), con la que se evita el uso del usuario administrador. Posee accesibilidad e internacionalización, de modo que el sistema esté disponible para tanta gente como sea posible. Desde la versión 5.04, se utiliza UTF-8 como codificación de caracteres predeterminado. No sólo se relaciona con Debian por el uso del mismo formato de paquetes .deb. También tiene uniones muy fuertes con esa comunidad, contribuyendo con cualquier cambio directa e inmediatamente, y no sólo anunciándolos. Esto sucede en los tiempos de lanzamiento. Muchos de los desarrolladores de Ubuntu son también responsables de los paquetes importantes dentro de la distribución Debian. Para centrarse en solucionar rápidamente los bugs, conflictos de paquetes, etc. se decidió eliminar ciertos paquetes del componente main, ya que no son populares o simplemente se escogieron de forma arbitraria por gusto o sus bases de apoyo al software libre. Por tales motivos inicialmente KDE no se encontraba con más 16 soporte de lo que entregaban los mantenedores de Debian en sus repositorios, razón por la que se sumó la se liberan comunidad de KDE creando la distribución GNU/Linux Kubuntu Lanzamientos y Soporte Las versiones estables cada 6 meses y Canonical proporciona soporte técnico y actualizaciones de la seguridad para la mayoría de las versiones de Ubuntu durante 18 meses, excepto para las versiones LTS (Long term support) que ofrece 3 años para la versión escritorio y 5 años para la versión servidor, a partir de la fecha del lanzamiento. Existen planes para lanzar una rama de Ubuntu bajo el nombre en clave «Grumpy Groundhog», la cual solo estará disponible para desarrolladores. Soporte técnico extendido Cada 4 versiones de Ubuntu se libera una versión con soporte técnico extendido a la que se añade la terminación LTS. Esto significa que los lanzamientos LTS contarán con actualizaciones de seguridad de paquetes de software durante tres años en entorno de escritorio y cinco años en servidor por parte de Canonical, a diferencia de los otros lanzamientos de Ubuntu que sólo cuentan con 18 meses de soporte. La primera LTS fue la versión 6.06 de la cual se liberó una remasterización (la 6.06.1) para la edición de escritorio y dos remasterizaciones (6.06.1 y 6.06.2) para la 17 edición servidor, ambas incluían actualizaciones de seguridad y corrección de errores. La segunda LTS fue la versión 8.04 «Hardy Heron», de la cual ya va por la cuarta y última revisión de mantenimiento (la 8.04.4). La última versión LTS que ha sido lanzada es la 10.04, Lucid Lynx, fue liberada en abril de 2010, la versión de mantenimiento actual va por la 10.04.1. Estable y en desarrollo La última versión estable del sistema, Ubuntu 10.10 Maverick Meerkat, se lanzó el 10 de octubre de 2010. La versión para netbooks incluye el entorno Unity, el cual brinda una interfaz simple, ligera, y que proporciona un lanzador de aplicaciones al lado izquierdo de la pantalla. Unity fue creado especialmente para esta versión, siguiendo la misma línea de diseño que se utilizará en el futuro GNOME 3.0. En la versión para netbooks se incluye un menú de aplicaciones global en la barra superior, y los controles de ventana (cerrar, minimizar, maximizar) se integran en la barra superior. También se eliminan todos los notificadores de terceros de la barra superior, y son reemplazados por nuevos indicadores con menús desplegables. El instalador de Ubuntu fue casi completamente renovado, incluye la opción de instalar Adobe Flash Player, códecs como MP3,Xvid, DVD (MPEG-2), y Java (es necesaria una conexión a Internet), y en general es fácil de usar a la hora de instalar 18 el sistema. Las transparencias en ventanas y menús serán más consistentes con la interfaz de usuario gracias al soporte RGBA que vendrá por defecto. También se incluye una nueva fuente de texto, desarrollada por el equipo de Canonical. Los temas«Ambiance» y «Radiance» fueron modificados, recibiendo colores más claros (los tonos cafés ya no se utilizarán más), dando una interfaz más ligera en general. El menú de sonido ahora se integra con el reproductor de música Rhythmbox. El Centro de software de Ubuntu se actualiza a la versión 3.0, incluye un nuevo historial de sucesos diarios, las librerías y elementos extras se ocultan por defecto (hay un enlace inferior para verlas) y solo se muestran las aplicaciones, Canonical publicará nuevas aplicaciones post-lanzamiento en la versión estable, y permite comprar aplicaciones por medio de un sistema de logueo de usuario y sistema de compra. El editor de imágenes F-Spot es reemplazado por Shotwell, el cual es más rápido y simple de usar, y se pueden subir imágenes a Facebook, Flickr, y Picasa Web. Maverick Meerkat no incluye GNOME Shell por defecto, debido al retraso en el lanzamiento de GNOME 3.0 para 9 abril de 2011. Y en el aspecto más técnico, se utiliza el kernel Linux 2.6.35, el cual trae mejoras en drivers de video (ATI, nVidia), reconocimiento de hardware, y mejoras en el rendimiento del núcleo Linux.73 El escritorio GNOME se actualiza a la versión 2.32. Se agrega el soporte para el sistema de archivos Btrfs. La compilación de 19 arquitectura se optimiza para i686, siendo esta la que se utilizará por defecto, y se abandonará IA64, i386, e i486. En el área gráfica se actualiza X.Org Server a la versión 1.9. Se mejora aún más la velocidad de arranque del sistema, Upstart recibe optimizaciones a la hora de iniciar el sistema, y se otorga una interfaz gráfica más amigable a GRUB2. Soporte multitáctil para pantallas y dispositivos con estas prestaciones, y además los productos de Apple con capacidades multitouch tienen soporte por defecto. Requisitos Los requisitos mínimos «recomendados», teniendo en cuenta los efectos de escritorio, deberían permitir ejecutar una instalación de Ubuntu.103 Procesador x86 a 1 GHz. Memoria RAM: 512 MB. Disco Duro: 5 GB (swap incluida). Tarjeta gráfica VGA y monitor capaz de soportar una resolución de 1024x768. Lector de CD-ROM o puerto USB Conexión a Internet puede ser útil. Los efectos de escritorio, proporcionados por Compiz, se activan por defecto en las siguientes tarjetas gráficas:103 Intel (i915 o superior, excepto GMA 500, nombre en clave «Poulsbo») NVidia (con su controlador propietario) 20 ATI (a partir del modelo Radeon HD 2000 puede ser necesario el controlador propietario) Si se dispone de una computadora con un procesador de 64 bits (x86-64), y especialmente si dispone de más de 3 GB de RAM, se recomienda utilizar la versión de Ubuntu para sistemas de 64 bits. XAMPP XAMPP es un servidor independiente de plataforma, software libre, que consiste principalmente en la base de datos MySQL, el servidor web Apache y los intérpretes para lenguajes de script: PHP y Perl. El nombre proviene del acrónimo de X (para cualquiera de los diferentes sistemas operativos), Apache, MySQL, PHP, Perl. El programa está liberado bajo la licencia GNU y actúa como un servidor web libre, fácil de usar y capaz de interpretar páginas dinámicas. Actualmente XAMPP está disponible para Microsoft Windows, GNU/Linux, Solaris, y Mac. Características y Requerimientos XAMPP solamente requiere descargar y ejecutar un archivo zip, tar, o exe, con unas pequeñas configuraciones en alguno de sus componentes que el servidor Web necesitará. XAMPP se actualiza regularmente para incorporar las últimas versiones de Apache/MySQL/PHP y Perl. También incluye otros módulos como OpenSSL y phpMyAdmin. Para instalar XAMPP se requiere solamente una 21 pequeña fracción del tiempo necesario para descargar y configurar los programas por separado. TOMCAT Tomcat (también llamado Jakarta Tomcat o Apache Tomcat) funciona como un contenedor de servlets desarrollado bajo el proyecto Jakarta en la Apache Software Foundation. Tomcat implementa las especificaciones de los servlets y de JavaServer Pages (JSP) de Sun Microsystems. Estado de Desarrollo Tomcat es mantenido y desarrollado por miembros de la Apache Software Foundation y voluntarios independientes. Los usuarios disponen de libre acceso a su código fuente y a su forma binaria en los términos establecidos en la Apache Software Licence. Las primeras distribuciones de Tomcat fueron las versiones 3.0.x. Las versiones más recientes son las 7.x, que implementan las especificaciones de Servlet 3.0 y de JSP 2.2. A partir de la versión 4.0, Jakarta Tomcat utiliza el contenedor de servlets Catalina. Entorno Tomcat es un servidor web con soporte de servlets y JSPs. Tomcat no es un servidor de aplicaciones, como JBoss o JOnAS. Incluye el compilador Jasper, que compila JSPs convirtiéndolas en servlets. El motor de servlets de Tomcat a menudo se presenta en combinación con el servidor web Apache. 22 Tomcat puede funcionar como servidor web por sí mismo. En sus inicios existió la percepción de que el uso de Tomcat de forma autónoma era sólo recomendable para entornos de desarrollo y entornos con requisitos mínimos de velocidad y gestión de transacciones. Hoy en día ya no existe esa percepción y Tomcat es usado como servidor web autónomo en entornos con alto nivel de tráfico y alta disponibilidad. Dado que Tomcat fue escrito en Java, funciona en cualquier sistema operativo que disponga de la máquina virtual Java. (También se puede usar con xampp) Características del Producto Tomcat 4.x Implementado a partir de las especificaciones Servlet 2.3 y JSP 1.2 Contenedor de servlets rediseñado como Catalina Motor JSP rediseñado con Jasper Conector Coyote Java Management Extensions (JMX), JSP Y administración basada en Struts Tomcat 5.x Implementado a partir de las especificaciones Servlet 2.4 y JSP 2.0 Recolección de basura reducida Capa envolvente nativa para Windows y Unix para la integración de las plataformas 23 Análisis rápido JSP Tomcat 6.x Implementado de Servlet 2.5 y JSP 2.1 Soporte para Unified Expression Language 2.1 Diseñado para funcionar en Java SE 5.0 y posteriores Soporte para Comet a través de la interfaz CometProcessor Tomcat 7.x Implementado de Servlet 3.0 JSP 2.2 y EL 2.2 Mejoras para detectar y prevenir "fugas de memoria" en las aplicaciones web Limpieza interna de código Soporte para la inclusión de contenidos externos directamente en una aplicación web RSYNC r5 es una aplicación de software para sistemas de tipo Unix que ofrece transmisión eficiente de datos incrementales, que opera también con datos comprimidos y cifrados. Mediante una técnica de delta encoding, permite sincronizar archivos y directorios entre dos máquinas de una red o entre dos ubicaciones en una misma máquina, minimizando el volumen de datos transferidos. Una característica importante de rsync no encontrada en la mayoría de programas o protocolos es que la copia toma lugar con sólo una transmisión en cada dirección. rsync puede copiar o 24 mostrar directorios contenidos y copia de archivos, opcionalmente usando compresión y recursión. En modalidad de "Daemon" servidor, rsync escucha por defecto el puerto TCP 873, sirviendo archivos en el protocolo nativo rsync o via un terminal remoto como RSH o SSH. En el último caso, el ejecutable del cliente rsync debe ser instalado en el host local y remoto. Lanzado bajo la licencia GNU General Public License, rsync es software libre Características y Aplicaciones Mientras que el algoritmo rsync forma parte del núcleo de la aplicación rsync y esencialmente optimiza las transferencias entre dos computadoras sobre TCP/IP, la aplicación rsync provee otras funciones que asisten en la transferencia. Estas incluyen compresión y descompresión de los datos bloque por bloque, utilizando zlib al enviar y recibir, y soporte para protocolos de cifrado, tal como SSH, lo que permite transmisión cifrada y eficientemente diferenciada de datos comprimidos usando el algoritmo rsync. Adicionalmente puede utilizarse una aplicación de tunneling también para crear un túnel cifrado que asegure los datos transmitidos. Además de archivos, el algoritmo permite copiar directorios, aún recursivamente, así como vínculos, dispositivos, grupos y permisos. No requiere por defecto privilegios de root para su uso. 25 Rsync fue escrito como un reemplazo de rcp y SCP. Una de las primeras aplicaciones de rsync fue el espejado (mirroring) o respaldo de múltiples clientes Unix dentro de un servidor Unix central, usando rsync/ssh y cuentas estándares de Unix. Habitualmente se lo ejecuta mediante herramientas de scheduling como cron, para automatizar procesos de sincronización entre múltiples computadoras host y servidores centrales. 26 VII. PLAN DE ACTIVIDADES Figura 1.0 Diagrama general de Gantt 27 VIII. RECURSOS MATERIALES Y HUMANOS Los recursos a utilizar para la elaboración del proyecto son los siguientes: Recursos Hardware Cantidad 1 1 1 1 1 Recurso Servidor Dell Poweredge SC1430 Monitor VGA Teclado Mouse Laptop Recursos de Software Recursos Descripción Linux Ubuntu 10.10 64 bits Sistema operativo basado en Linux. XAMMP Versión 1.7.3ª Servidor independiente de plataforma y software libre. Instalación de JDK (Java Development Kit) Instalación Tomcat Múltiples herramientas para programación y desarrollo de aplicaciones. Servidor Web para Apache soporta Servlets y JSP para Java. Recursos Humanos 2 técnicos en soporte con las siguientes características: Conocimientos en sistema operativo Linux Conocimientos en redes Proactivos 28 IX. DESARROLLO DEL PROYECTO ANÁLISIS Y REQUERIMIENTOS Requerimientos del Hardware Se hiso una examinación exhaustiva para determinar cuáles son las necesidades requeridas para poder lograr nuestro objetivo en este caso en equipo físico, por lo tanto la Universidad Tecnológica de Querétaro adquirió un servidor que cumple con los requerimientos para el desarrollo de este proyecto, las especificaciones del servidor son las siguientes: Servidor PowerEdge 11G T410 Figura 1.1 Servidor Dell PowerEdge 29 Rendimiento de procesamiento, memoria y almacenamiento avanzados Compacto, flexible, silencioso y fácil de usar, el Dell PowerEdge T410 aprovecha las tecnologías de última generación de Dell para brindar un rendimiento confiable. El rendimiento avanzado de los procesadores de la serie Intel® Xeon®, la memoria DDR3 y hasta seis discos duros de 3,5" (o de 2,5" de manera opcional) satisfacen las necesidades de las diversas aplicaciones de una empresa en crecimiento. El Dell PowerEdge T410 cuenta con una acústica silenciosa, fuentes de alimentación redundantes disponibles y un medio de diagnóstico excelente a través de una LCD interactiva disponible. Diseño compacto inspirado en los clientes La profundidad del chasis de 24 pulgadas da una flexibilidad óptima para la implementación en empresas con restricciones de espacio. El Dell PowerEdge T410 cuenta con características comunes de sistema e imagen de primera clase y una facilidad de uso inspirada en los clientes. Tiene un 30 diseño lógico e impecable y la fuente de alimentación está ubicada de manera que la instalación se pueda realizar rápidamente y la reimplementación sea más simple. El Dell PowerEdge T410 también incluye un chasis de vanguardia, además de portadoras y ventiladores mejorados para los discos duros, que brindan una confiabilidad excepcional, operaciones silenciosas y fluidas y facilidad de uso. Procesadores Procesadores Intel® Xeon® serie 5500 y 5600 disponibles Intel® Xeon® X5560; 2,80 GHz/8 MB, 4 núcleos 95 W Intel® Xeon® E5540; 2,53 GHz/8 MB, 4 núcleos 80 W Intel® Xeon® E5530; 2,40 GHz/8 MB, 4 núcleos 80 W Intel® Xeon® E5520; 2,26 GHz/8 MB, 4 núcleos 80 W Intel® Xeon® E5506; 2,13 GHz/4 MB, 4 núcleos 80 W Intel® Xeon® E5504; 2,00 GHz/4 MB, 4 núcleos 80 W Intel® Xeon® E5502; 1,86 GHz/4 MB, 2 núcleos 80 W Chipset Chipset Intel® 5500 31 Memoria Hasta 128GB1 (8 ranuras DIMM2): 1 GB1/2 GB1/4 GB1/8 GB1/16 GB1 de memoria DDR3 de 800 MHz, 1066 MHz o 1333 MHz Sin búfer con ECC o con registros con ECC a 1333/1066/800 MHz Opciones: UDIMM/RDIMM de 1GB1 UDIMM/RDIMM de 2GB1 RDIMM de 4GB1 RDIMM de 8GB1 RDIMM de 16GB1 Sistemas operativos Microsoft® Windows® Small Business Server 2008 (en inglés) Microsoft® Windows® Essential Business Server 2008 (en inglés) Microsoft® Windows Server® 2008 SP2, x86/x64 (x64 inclut Hyper-VTM ) (en inglés) Microsoft® Windows Server® 2008 R2, x64 (includes Hyper-VTM v2) (en inglés) Novell® SUSE® Linux® Enterprise Server (en inglés) Red Hat® Enterprise Linux® (en inglés) Para obtener más información sobre las versiones y agregados específicos, visite www.dell.com/OSsupport (sólo en inglés). Almacenamiento 32 Opciones de disco duro SATA de 3,5" (7.200 RPM): 160GB1, 250 GB1, 500 GB1, 750 GB1, 1 TB1 SAS intermedio de 3,5" (7.200 RPM): 500GB1, 750 GB1, 1 TB1 3.5" 6Gps SAS (7.2K): 2 TB1 SAS de 3,5" (15.000 RPM): 146GB1, 300 GB1, 450 GB1 SAS de 3,5" (10.000 RPM): 600GB1 SAS de 2,5" (10.000 RPM): 73GB1, 146 GB1, 300 GB1 Unidad de estado sólido SATA de 2,5": 25 GB1, 50 GB1, 100 GB1 SAS Nearline de 2,5" (7.200): 1 TB Capacidad máxima de almacenamiento interno: 12 TBs1(6x 2TB SATA) 12 TBs1(6x 2TB NL-SAS) Dispositivos de respaldo RD1000 (interna y externa) DATA72 (interna y externa) LTO2-L (interna y externa) LTO3-060 (interna y externa) LTO3FH (externa) LTO4-120 de altura media (interna y externa) 33 LTO4-120 de altura completa (externa) PV114T (externa, 2U) Automatización de cintas TL2000/TL4000 ML6000 PV124T Software de respaldo y recuperación: CommVault Symantec Backup Exec incluido Backup Exec System Recovery Vizioncore Compartimientos para unidades Dos opciones básicas de disco duro: 6 HDD de 3,5" con cables O bien 6 HDD de 3,5" intercambiables en caliente O bien 6 HDD de 2,5" intercambiables en caliente SATA de 2,5" y 500 GB 34 Opciones de compartimiento para periféricos: 2 compartimientos para unidades de 5,25" con opción de DVD-ROM o DVD+/- RW, o TBU RANURAS 5 ranuras PCI Ranura 1: PCIe x8 (enrutamiento x4, Gen2), media longitud Ranura 2: PCIe x8 (enrutamiento x4, Gen2), longitud completa Ranura 3: PCIe x8 (enrutamiento x4, Gen1), longitud completa Ranura 4: PCIe x8 (enrutamiento x4, Gen2), media longitud Ranura 5: PCIe x16 (enrutamiento x8, Gen2), media longitud CONTROLADORAS RAID Internas: PERC H200 (6 Gb/s) PERC H700 (6 Gb/s) con 512 MB de memoria caché respaldada por batería; 512 MB, 1 G de memoria caché no volátil respaldada por la batería SAS 6/iR PERC 6/i con 256 MB de memoria caché respaldada por batería PERC S100 (basada en software, disponible para la configuración de 4 discos duros) PERC S300 (basada en software, disponible para las configuraciones de 4 y 8 discos duros) 35 Externas: PERC H800 (6 Gb/s) con 512 MB de memoria caché respaldada por batería; 512 MB, 1 G de memoria caché no volátil respaldada por la batería PERC 6/E con 256 MB o 512 MB de memoria caché respaldada por batería HBA externos (no RAID): HBA SAS de 6 Gbps HBA SAS 5/E HBA SCSI con PCIe LSI2032 Comunicaciones opcionales Intel PRO/1000PT; NIC GbE de cobre PCIe x1 Intel de un solo puerto Adaptador Intel® Gigabit ET de dos puertos para servidor Adaptador Intel® Gigabit ET de cuatro puertos para servidor NIC Intel® de 1 GbE y un puerto NIC Intel® de 1 GbE y dos puertos NIC Intel® de 1 GbE y cuatro puertos NIC GbE (basada en Xinan) PCIe Broadcom 5709 de cobre y dos puertos, TOE NIC GbE (basada en Xinan) PCIe Broadcom 5709 de cobre y dos puertos, TOE/Isoe NIC Broadcom® de 1 GbE y dos puertos NIC GbE PCIe x4 Intel de cobre y cuatro puertos, Intel PRO/1000VT 36 Brocade CNA Dual-port adapter HBA adicionales y opcionales: Brocade FC4 and 8 GB HBAs Alimentación No redundante, 525 W (80+) Redundante opcional, 580 W (80+ GOLD) Ajuste automático (100 V a 240 V) Sistema de alimentación ininterrumpida 500 W - 2700 W Módulo de batería de duración prolongada (EBM) Tarjeta de administración de red Disponibilidad Paquete de cuatro LED de diagnóstico / LCD con chasis para HDD intercambiable en caliente TCM Controladora integrada de red Controladora Ethernet Gigabit de dos puertos Gráficos Matrox G200eW con 8 MB 37 Chasis 444,9 x 217,9 x 616,8 (mm) (con cubierta, con pie para torre) 17,52 x 8,58 x 24,28 (pulgadas) Administración Dell OpenManage con Dell Management Console BMC, cumple con IPMI2.0 Opcional: iDRAC6 Express, iDRAC6 Enterprise y Vflash Microsoft® System Center Essential (SCE) 2010 v2 Requerimientos del Software Se examinaron varias alternativas para la instalación del software en el servidor, teniendo en cuenta que el proyecto se realiza en una institución pública y que los recursos son limitados se optó por utilizar tecnología de código libre, en este caso lo que se utiliza es lo siguiente: Linux Ubuntu 10.10 64 bits XAMMP Versión 1.7.3ª Instalación de JDK (Java Development Kit) Instalación Tomcat Cabe mencionar que cada una de los programas que se mencionaron no tienen ningún costo y se pueden descargar de internet desde la página del proveedor, 38 aunque sea software libre y sin costo cuenta con un soporte completo y las aplicaciones con robustas lo cual asegura la protección de nuestro servidor. Diseño de Plan de Trabajo El plan de trabajo fue diseñado para poder tener el proyecto realizado en el menor tiempo posible sin dejar el tiempo necesario en cada una de las etapas del proyecto, se estima que el tiempo a realizar el proyecto es de 50 días hábiles, el proyecto inicia en la fecha 10/01/11 y termina el día 17/03/11 con las siguientes etapas: Análisis y Requerimientos Instalación del Servidor Web Configuración y Altas de Usuarios Pruebas Entrega INSTALACIÓN DEL SERVIDOR WEB Instalación De Ubuntu Server 10.10 Para la Instalación de un servidor en Ubuntu 10.04 primero que todo descargamos una imagen iso del sistema operativo desde http://www.ubuntu.com/server/get-ubuntu/download escoges la versión de 32 o 64. 39 Al iniciar el cd dentro de nuestro equipo nos muestra la ventana donde escogeremos el idioma de instalación Figura 1.2 Ubuntu 10.10 idiomas. Luego seleccionamos la opción de instalar ubuntu server Figura 1.3 Ubuntu 10.10 pantalla de inicio 40 Escogemos el país de ubicación Figura 1.4 Ubuntu 10.10 Selección de lenguajes Ahora la distribución del teclado Figura 1.5 Ubuntu 10.10 Menú principal de instalación 41 Y comienzan a cargar los datos iniciales de instalación. Luego le damos el nombre a la máquina. Figura 1.6 Ubuntu 10.10 Configuración de Red Luego buscar la hora en un servidor y zona de horario correcta. Llegamos a la parte del particionado de los discos donde nos aparece la pantalla puedes asignarlas de forma automática configurando LVM o de forma manual. 42 Figura 1.7 Ubuntu 10.10 Partición de discos En este caso haremos las particiones de forma LVM automática, puesto que utilizaremos todo el espacio en disco duro. Anteriormente se administraba el sistema en varias particiones, esto era porque los discos duros eran solo de 1 o 2 gb a lo máximo, entonces pues teníamos varios discos y cada uno era de una partición o varios discos formaban una sola partición. El servidor cuenta con un disco duro de 2 T por lo que no nos preocuparemos por el espacio. Comienza la instalación del sistema y durante esta instalación nos pregunta: Nombre completo para nuevo usuario: Administrador DTAI Nombre de usuario para la cuenta: root Password: uteq2010.mx 43 Si deseas actualizar de forma manual o de forma automática. En esta parte es recomendable utilizar las actualizaciones automáticas, pero para tener un mejor control es mejor hacerlo de manera manual con: sudo apt-get update && sudo apt-get upgrade Luego de esto se cargan los paquetes a instalar y escogemos los servicios que vamos a usar dentro de la red LAN Figura 1.8 Ubuntu 10.10 Selección de programas Y se instalan todos los paquetes Adicional puedes instalar nmap para escanear los puertos de comunicación lo haces con el comando $ apt-get install nmap 44 Actualización de SO Una vez que terminamos de instalar el sistema operativo, debemos de actualizarlo para que podamos trabajar con los últimos paquetes. Para esto debemos de entrar al sistema con el usuario root o con el usuario uribe que tiene privilegios de root (lo acabamos de agregar al archivo sudoers). Una vez que entremos al sistema abrimos una sesión de consola y tecleamos lo siguiente si somos root: apt-get update && apt-get upgrade Si entramos como uribe entonces podemos hacer dos cosas: sudo apt-get update && sudo apt-get upgrade Nos pedirá de nuevo nuestro password y una vez que se lo demos ejecutará el comando. La otra forma es cambiarnos al perfil de root con el sudo: sudo su - (Así nos cambiamos al perfil de root) apt-get update && apt-get upgrade Cuando nosotros utilizamos #apt-get update, lo que en realidad estamos haciendo es actualizar los repositorios --ver si hay algo nuevo--, es decir actualizar la 45 lista de todos los paquetes, con la dirección de dónde obtenerlos para que a la hora de hacer la búsqueda y su posterior descarga, sea más rápida. En cambio, cuando utilizamos #apt-get upgrade, lo que hacemos es una actualización de nuestro sistema con todas las posibles actualizaciones que pudiera haber, es decir no sólo actualiza nuestro sistema operativo sino que también las aplicaciones que están contenidas en los repositorios. En resumen: el update lista los paquetes de los repositorios y el upgrade instala las actualizaciones. Figura 1.9 Actualización SO 46 Instalación de IA32-LIBS El servidor tiene un procesador de 64 bits, por lo que tendremos problemas ejecutando aplicaciones de 32 bits (que son la mayoría). Para aprovechar las mejoras de las extensiones de 64 bits de esta arquitectura con respecto a la arquitectura x86 (32 bits) es necesario tener instalado la versión AMD64 del sistema operativo. Ubuntu tiene una versión para 64 bits desde hace años. A pesar de las ventajas, ciertas aplicaciones no tienen una versión para 64 bits sino sólo para 32 bits. De todas formas, eso no significa que no puedan ser ejecutadas sobre un sistema operativo de 64 bits. Hay varias formas de hacer esto. La más sencilla es: apt-get install ia32-libs Cuando termine de instalar podremos ejecutar aplicaciones de 32 bits sin problemas. Nota: Hay que ejecutar el comando con permisos de root o con sudo. 47 Instalación de JDK (Java Development Kit) Java Development Kit (o simplemente, JDK) es un software que nos provee de excepcionales herramientas de desarrollo para programar y crear aplicaciones y programas en Java, mismo software que puede instalarse en un equipo local o en una unidad de Red. JDK es multiplataforma, y puede instalarse en entornos Linux, Windows, Solaris y Mac OS. Hoy vamos a aprender a instalarlo en Linux, concretamente en Debian y distribuciones basadas en ésta, tal es el caso de Ubuntu. Para llevar a cabo la instalación ejecutamos los siguientes comandos en una terminal como root o con sudo: sudo add-apt-repository "deb http://archive.canonical.com/ lucid partner" sudo apt-get install sun-java6-jdk La primera línea nos permite agregar un nuevo repositorio donde encontraremos los archivos de instalación de java. La segunda línea ejecuta la instalación de java. Cuando se inicie debemos de aceptar la licencia. 48 Figura 1.10 Configuración sun-java6-jre Ya que terminemos de instalar, verificamos la versión de java con el comando: java –version Para ejecutar los comandos ―java‖ y javac‖ desde cualquier ubicación hace falta editar el archivo .bashrc del superusuario (root) y de tu propio usuario. Para ello, debemos editar el archivo correspondiente para cada usuario con las siguientes líneas, mismas que se agregarán al final: export JAVA_HOME=/usr/java/jdk1.6.0_05 49 export PATH=$JAVA_HOME/bin:$PATH Para acceder a editar el archivo del usuario root: nano /root/.bashrc Para tu usuario: nano /home/tu_usuario/.bashrc Al terminar de añadir las líneas a ambos archivos, guardamos los cambios y cerramos la consola. JDK está instalado, con los permisos suficientes y listos para programar en Java. Instalación De Tomcat Tomcat es un servidor web desarrollado por la peña de Apache, que tiene soporte para servlets y JSP, bastante útil si quieres programar en Java. Un servlet es un programa escrito en java que se ejecuta en un servidor y que normalmente se utiliza para generar contenido html dinámico. JSP se parece más a php que un servlet, porque al igual que con php, podemos tener trozos de html y de JSP mezclados, el servidor tiene que interpretar JSP de la misma manera en la que interpreta PHP. Después de instalar el JDK nos descargamos el apache desde este enlace http://tomcat.apache.org/ 50 Después hay que descomprimirlo tar xvzf apache-tomcat-6.0.14.tar.gz Luego lo mandamos a este directorio sudo mv apache-tomcat-6.0.14 /usr/share/tomcat6 Iniciamos tomcat sudo /usr/share/tomcat6/bin/startup.sh Luego creamos un inicializador del apache para que cada vez que prendamos el servidor, se ejecute sudo nano /etc/init.d/tomcat # Tomcat auto-start # description: Auto-starts tomcat # processname: tomcat # Tomcat auto-start # description: Auto-starts tomcat # processname: tomcat # pidfile: /var/run/tomcat.pid export JAVA_HOME=/usr/lib/jvm/java-6-sun 51 case $1 in start) sh /usr/share/tomcat6/bin/startup.sh ;; stop) sh /usr/share/tomcat6/bin/shutdown.sh ;; restart) sh /usr/share/tomcat6/bin/shutdown.sh sh /usr/share/tomcat6/bin/startup.sh ;; esac exit 0 Luego dar permisos para ejecutar sudo chmod 755 /etc/init.d/tomcat Y por último, actualizamos 52 sudo update-rc.d tomcat defaults 99 Para probar que todo va bien, podemos ir a cualquier navegador web y escribir en la barra de direcciones: http://localhost:8080/manager/html Instalación De Xampp Muchos usuarios saben por experiencia propia que la instalación de un servidor web Apache no es fácil y que se complica aún más si se desea agregar MySQL, PHP y Perl. XAMPP es una forma fácil de instalar la distribución Apache que contiene MySQL, PHP y Perl. XAMPP es realmente simple de instalar y usar - basta descargarlo, extraerlo y comenzar. XAMPP es un servidor independiente de plataforma, software libre, que consiste principalmente en la base de datos MySQL, el servidor Web Apache y los intérpretes para lenguajes de script: PHP y Perl. El nombre proviene del acrónimo de X (para cualquiera de los diferentes sistemas operativos), Apache, MySQL, PHP, Perl. El programa está liberado bajo la licencia GNU y actúa como un servidor Web libre, fácil de usar y capaz de interpretar páginas dinámicas. Actualmente XAMPP está disponible para Microsoft Windows, GNU/Linux, Solaris, y MacOS X. 53 XAMPP solamente requiere descargar y ejecutar un archivo zip, tar, o exe, con unas pequeñas configuraciones en alguno de sus componentes que el servidor Web necesitará. XAMPP se actualiza regularmente para incorporar las últimas versiones de Apache/MySQL/PHP y Perl. También incluye otros módulos como OpenSSL y phpMyAdmin. Para instalar XAMPP se requiere solamente una pequeña fracción del tiempo necesario para descargar y configurar los programas por separado. XAMPP para Linux La versión para sistemas Linux (testeado para SuSE, RedHat, Mandrake y Debian)contiene: Apache, MySQL, PHP & PEAR, Perl, ProFTPD, phpMyAdmin, OpenSSL, GD, Freetype2, libjpeg, libpng, gdbm, zlib, expat, Sablotron, libxml, Ming, Webalizer, pdf class, ncurses, mod_perl, FreeTDS, gettext, mcrypt, mhash, eAccelerator, SQLite e IMAP C-Client. Instalando Xampp En Ubuntu El proceso es sencillísimo. Nos descargamos la última versión: Descarga XAMPP http://www.apachefriends.org/en/xampp-linux.html Actualmente la 1.7.3 Una vez descargado, abrimos una terminal y nos vamos al directorio donde lo descargamos y ejecutamos el comando: 54 sudo tar xvfz xampp-linux-1.7.3.tar.gz -C /opt Nos pide nuestra contraseña, la ponemos. Si somos root: tar xvfz xampp-linux-1.7.3.tar.gz -C /opt Y ya tenemos instalado XAMPP en /opt/lampp. Iniciando XAMPP Para iniciar XAMPP abrimos una terminal, y escribimos: /opt/lampp/lampp start Si todo ha ido bien, debemos ver esto Starting XAMPP for Linux 1.7.3... XAMPP: Starting Apache with SSL (and PHP5)... XAMPP: Starting MySQL... XAMPP: Starting ProFTPD... XAMPP for Linux started. Pues nada, ya tenemos XAMPP iniciado. ¿Cómo se puede comprobar que todo funciona de verdad? Sólo tienes que escribir en la siguiente URL en su navegador web favorito: http://localhost 55 Figura 1.11 Pantalla de inicio XAMPP Ahora deberías ver la página de inicio de XAMPP conteniendo algunos enlaces para comprobar el estado del software instalado y algunos ejemplos de programación pequeños. Parámetros de Stop y Start Parámetro Descripción start Inicia XAMPP. stop Detiene XAMPP. restart Detiene e inicia XAMPP. 56 startapache Inicia sólo el Apache. startssl Inicia el soporte Apache SSL. Este comando activa el soporte SSL permanentemente, por ejemplo, si se reinicia XAMPP en el futuro SSL permanecerá activado. startmysql Inicia sólo la base de datos MySQL. startftp Inicia el servidor ProFTPD. A través de FTP se pueden subir archivos de su servidor web (el usuario "nobody", password "lampp"). Este comando activa el ProFTPD permanentemente, por ejemplo, si se reinicia XAMPP en el futuro FTP permanecerá activado. stopapache Detiene el Apache. stopssl Detiene el soporte Apache SSL. Este comando desactiva el soporte SSL permanentemente, por ejemplo, si se reinicia XAMPP en el futuro SSL se quedará desactivada. stopmysql 57 Detiene la base de datos MySQL. stopftp Detiene el servidor ProFTPD. Este comando desactiva el ProFTPD permanentemente, por ejemplo, si se reinicia XAMPP en el futuro FTP permanecerá desactivado. Configurando XAMPP httpd.conf Lo primero que debemos de hacer es editar el archivo httpd.conf que es el archivo de configuración de apache del servidor web. Y está localizado en /opt/lampp/etc Ahí podemos modificar en puerto en que aparecerán las páginas web, por ejemplo podemos seleccionar que todas las páginas por defecto se abran en el puerto 8080 Para esto buscamos el atributo Listen y lo modificamos Listen 8080 También podemos cambiar el usuario y el grupo que ejecutaran las páginas web User nobody 58 Group nogroup Algo que si es muy importante para este proyecto, es que apache ligue un directorio de nuestros usuarios (www) con el nombre de usuario en el dominio. Es decir, que al teclear www.dtai.uteq.edu.mx/uribe, nos muestre el contenido de lo que el usuario uribe tiene en su directorio /home/uribe/www/ y para esto debemos de activar un módulo en el archivo httpd.cof llamado mod_userdir, por default ya está activado, pero debemos de activar el archivo de configuración: # User home directories #Include etc/extra/httpd-userdir.conf En el archivo httpd.conf si tenemos un # es que esta comentado así que debemos de desconectarlo para que se active: Include etc/extra/httpd-userdir.conf Guardamos y ahora vamos a editar un archivo que esta /opt/lampp/etc/extra y se llama httpd-userdir.conf En él está la ruta del directorio del usuario al que queremos acceder. Vamos a poner la siguiente línea: UserDir ~/www 59 Con esta ruta le indicamos con el ~ que es cualquier usuario y que muestre el contenido de la carpeta www que está dentro de su home. Ahora guardamos los cambios. Para que XAMPP tome la configuración, vamos a reiniciar SOLO apache: /opt/lampp/./lampp reloadapache Se reinicia el servidor apache y ahora debemos de ligar el directorio www con el usuario uribe para que se vea en nuestro servidor web. Y esto lo hacemos de la siguiente manera ln –s /home/uribe/www /opt/lampp/htdocs/uribe Lo que hacemos es crear un linksoft para que apache lo vea y nos muestre el contenido de www con el alias de uribe. Ahora sí, si tecleamos www.dtai.uteq.edu.mx/uribe podremos ver el contenido. proftpd.conf Proftp es un servidor de ftp, por default ya se activa cuando iniciamos XAMPP, pero tenemos que configurar que los usuarios queden encasillados en su home, de tal manera que no puedan accesar por ftp a otros directorios que estén por encima de su home. Para hacer esto es muy fácil, editamos el archivo proftpd.conf que está en /opt/lampp/etc 60 Y lo que haremos es añadir la siguiente línea: DefaultRoot ~ De esta manera hacemos que la raíz para todos los usuarios sea su home. Seguridad XAMPP El comando security nos revisa la seguridad del sitio, principalmente si el password de root de MySQL esta en blanco, los permisos, etc. Es muy importante ejecutarlo para modificar los parámetros adecuados como el password de root de MySQL. MySQL Server XAMPP cuenta con un servidor de bases de datos MySQL versión 5.1.41 Lo primero que debemos de hacer es cambiar los permisos del usuario root (usuario de la base de datos) si es que no se hizo cuando se corrió el script para mejorar la seguridad del servidor MySQL. Lo que debemos de hacer es ir a http://localhost o a la dirección ip del servidor o al nombre del dominio del servidor y entrar a phpAdmin. Ahora nos vamos privilegios y editamos el usuario root. Nos vamos a la sección Cambiar la información de la cuenta. Ahí cambiamos el password de la cuenta de root. 61 Usuarios en MySQL PhpMyAdmin es un programa de libre distribución en PHP, creado por una comunidad sin ánimo de lucro. Es una herramienta muy completa que permite acceder a todas las funciones típicas de la base de datos MySQL a través de una interfaz web muy intuitiva. La aplicación en si no es más que un conjunto de archivos escritos en PHP que podemos copiar en un directorio de nuestro servidor web, de modo que, cuando accedemos a esos archivos, nos muestran unas páginas donde podemos encontrar las bases de datos a las que tenemos acceso en nuestro servidor de bases de datos y todas sus tablas. La herramienta nos permite crear tablas, insertar datos en las tablas existentes, navegar por los registros de las tablas, editarlos y borrarlos, borrar tablas y un largo etcétera, incluso ejecutar sentencias SQL y hacer un backup de la base de datos. Para dar de alta en MySQL un usuario, debemos de ir al phpMyAdmin y entrar a la pestaña de privilegios y le damos clic en Agregar un nuevo usuario. 62 Figura 1.12 Pantalla de inicio phpMyAdmin Nos aparecerán varios campos para llenar. Empezamos por el nombre de usuario, hay que recordar que si se diferencian las mayúsculas de las minúsculas. Así que debemos de agregar usuarios en minúsculas para que no tengamos problemas. Figura 1.13 phpMyAdmin 63 Es importante que agreguemos un password bien definido o si lo deseamos, XAMPP no puede generar password. Para seleccionar el servidor, phpMyAdmin nos permite seleccionar si deseamos conectarnos a la base de datos local o si queremos a cualquier servidor ya sea local o remoto con el comodín % Para que no haya problemas seleccionaremos que el usuario tenga el comodín % que es Cualquier Servidor. La siguiente parte debemos de indicar que al crear el usuario debemos de crear una base de datos con el mismo nombre de usuario. Figura 1.14 phpMyAdmin agregar un nuevo usuario 64 La siguiente parte es donde le damos privilegios globales al usuario, pero si seleccionamos esto tendrá privilegios sobre todas las bases de datos. Una vez que terminemos, le damos continuar y listo, ya tenemos un usuario con acceso a una base de datos con su mismo nombre y con privilegios sobre esa base de datos. No podrá ver las demás bases de datos que existan en el servidor. Figura 1.15 Privilegios de Usuarios 65 CONFIGURACION Y ALTA DE USUARIOS EN SISTEMA Creando Usuarios Sudo Cuando se instala el sistema, nos pide un usuario adicional al de root, el cual no tiene ningún privilegio. Recordemos que en Linux podemos tener varios niveles de usuarios, pero básicamente se manejan 3: Root Sudos Users Root es el usuario principal del sistema, es el que tienen el mayor nivel de privilegios en el sistema. Los usuarios sudos son usuarios que se crean de manera normal, pero se le dan ciertos permisos que pueden llegar casi al de root, estos permisos se configuran en un archivo llamado: sudoers. Users son los usuarios comunes que también tienen ciertos privilegios dependiendo del Shell que se les asigne como bash, zshell, cshell o nologin. 66 Una vez que hayamos creado el usuario normal en Linux y queremos darle permisos de tipo sudo, debemos de ir a /etc/ y con el comando nano editamos el archivo sudoers. sudo /etc/sudoers Una vez dentro del archivo sudoers, podemos establecer varias cosas, como crear grupos los cuales tendrán permisos a ciertos comandos, o que tengan permisos para ejecutar cualquier cosa. Vemos los dos casos. Usuario Limitado Lo primero que debemos de hacer es crear un alias. Un alias se refiere a un usuario, un comando o a un equipo. El alias engloba bajo un solo nombre (nombre del alias) una serie de elementos que después en la parte de definición de reglas serán referidos aplicados bajos cierto criterio. La forma para crear un alias es la siguiente: tipo_alias NOMBRE_DEL_ALIAS = elemento1, elemento2, elemento3, ... elementoN tipo_alias NOMBRE1 = elemento1, elemento2 : NOMBRE2 = elemento1, elemento2 El tipo_alias define los elementos, es decir, dependiendo del tipo de alias serán sus elementos. Los tipo de alias son cuatro y son los siguientes: Cmnd_Alias - define alias de comandos. 67 User_Alias - define alias de usuarios normales. Runas_Alias - define alias de usuarios administradores o con privilegios. Host_Alias - define alias de hosts o equipos. Cmnd_Alias Definen uno o más comandos y otros alias de comandos que podrán ser utilizados después en alias de usuarios. Ejemplos: Cmnd_Alias WEB = /usr/sbin/apachectl, /usr/sbin/httpd, sudoedit /etc/httpd/ Indica que a quien se le aplique el alias WEB podrá ejecutar los comandos apachectl, httpd y editar todo lo que este debajo del directorio /etc/httpd/, nótese que debe de terminar con '/' cuando se indican directorios. También, la ruta completa a los comandos debe ser indicada. Cmnd_Alias APAGAR = /usr/bin/shutdown -h 23\:00 Al usuario que se le asigne el alias APAGAR podrá hacer uso del comando 'shutdown' exactamente con los parámetros como están indicados, es decir apagar h (halt) el equipo a las 23:00 horas. Nótese que es necesario escapar el signo ':', así como los símbolos ' : , = \ Cmnd_Alias NET_ADMIN = /sbin/ifconfig, /sbin/iptables, WEB 68 NET_ADMIN es un alias con los comandos de configuración de interfaces de red ifconfig y de firewall iptables, pero además le agregamos un alias previamente definido que es WEB, así que a quien se le asigne este alias podrá hacer uso de los comandos del alias WEB. Cmnd_Alias TODO_BIN = /usr/bin/, !/usr/bin/rpm A quien se le asigne este alias podrá ejecutar todos los comandos que estén dentro del directorio /usr/bin/ menos el comando 'rpm' ubicado en el mismo directorio. NOTA IMPORTANTE: este tipo de alias con un permiso muy amplios menos '!' algo, generalmente no son una buena idea, ya que comandos nuevos que se añadan después a ese directorio también podrán ser ejecutados, es mejor siempre definir específicamente lo que se requiera. User_Alias Definen a uno o más usuarios, grupos del sistema (indicados con %), grupos de red (netgroups indicados con +) u otros alias de usuarios. Ejemplos: User_Alias MYSQL_USERS = andy, marce, juan, %mysql Indica que al alias MYSQL_USERS pertenecen los usuarios indicados individualmente más los usuarios que formen parte del grupo 'mysql'. User_Alias ADMIN = sergio, ana 'sergio' y 'ana' pertenecen al alias ADMIN. 69 User_Alias TODOS = ALL, !samuel, !david Aquí encontramos algo nuevo, definimos el alias de usuario TODOS que al poner como elemento la palabra reservada 'ALL' abarcaría a todos los usuarios del sistema, pero no deseamos a dos de ellos, así que negamos con '!', que serían los usuarios 'samuel' y 'david'. Es decir, todos los usuarios menos esos dos. NOTA IMPORTANTE: este tipo de alias con un permiso muy amplios menos '!' algo, generalmente no son una buena idea, ya que usuarios nuevos que se añadan después al sistema también serán considerados como ALL, es mejor siempre definir específicamente a los usuarios que se requieran. ALL es válido en todos los tipos de alias. User_Alias OPERADORES = ADMIN, uribe Los del alias ADMIN más el usuario 'uribe'. Runas_Alias Funciona exactamente igual que User_Alias, la única diferencia es que es posible usar el ID del usuario UID con el caracter '#'. Runas_Alias OPERADORES = #501, uribe Al alias OPERADORES pertenecen el usuario con UID 501 y el usuario 'uribe' Host_Alias 70 Definen uno o más equipos u otros alias de host. Los equipos pueden indicarse por su nombre (si se encuentra en /etc/hosts) por nombre de dominio, si existe un DNS de dominios, por dirección IP, por dirección IP con máscara de red. Ejemplos: Host_Alias LANS = 192.168.0.0/24, 192.168.0.1/255.255.255.0 El alias LANS define todos los equipos de las redes locales. Host_Alias WEBSERVERS = 172.16.0.21, web1: DBSERVERS = 192.168.100.10, dataserver Se define dos alias en el mismo renglón: WEBSERVERS y DBSERVERS con sus respectivas listas de elementos, el separador ':' es válido en cualquier definición de tipo de alias. Reglas de acceso Aunque no es obligatorio declarar alias, ni opciones (defaults), y de hecho tampoco reglas de acceso, pues el archivo /etc/sudoers no tendría ninguna razón de ser si no se crean reglas de acceso. De hecho podríamos concretarnos a crear solamente reglas de acceso, sin opciones ni alias y podría funcionar todo muy bien. Las reglas de acceso definen que usuarios ejecutan que comandos bajo que usuario y en que equipos. La mejor y (según yo, única manera) de entender y aprender a configurar sudoers es con ejemplos, así que directo al grano: 71 usuario host = comando1, comando2, ... comandoN Sintaxis básica, 'usuario' puede ser un usuario, un alias de usuario o un grupo (indicado por %), 'host' puede ser ALL cualquier equipo, un solo equipo, un alias de equipo, una dirección IP o una definición de red IP/máscara, 'comandox' es cualquier comando indicado con su ruta completa. Si se termina en '/' como en /etc/http/ entonces indica todos los archivos dentro de ese directorio. uribe ALL = /sbin/iptables Usuario 'uribe' en cualquier host o equipo puede utilizar iptables. ADMIN ALL = ALL Los usuarios definidos en el alias 'ADMIN' desde cualquier host pueden ejecutar cualquier comando. Para nuestro caso, solo agregaremos nuestro usuario al sudoers con todos los privilegios que pueda tener. Para esto buscamos una línea que dice así: root ALL=(ALL) ALL Y debajo de esta ponemos uribe ALL=(ALL) ALL 72 De esta manera el usuario uribe tendrá los privilegios de root, solo nos queda guardar el archivo y listo. Para dar de alta un usuario en sistema podemos hacerlo de dos formas: Con el comando adduser Con el script llamado userman La diferencia es que con el adduser agregamos un solo usuario y con el userman, podemos generar un archivo txt que tenga una lista de usuarios y passwords y lo tomara para crear de una sola vez todas las cuentas que se necesiten. Adduser La sintaxis de adduser es la siguiente: useradd [D binddn] [P-ruta] [c comentario] [-d directorio home] [ -e expire ] [ -f inactive ] [ -G group,... ] [ -g gid ] [-E expirará] [-f inactivo] [G-grupo, ...] [-g gid] [ -m [ -k skeldir ]] [ -o ] [ -p password ] [ -u uid] [M [-k skeldir]] [-o] [-p contraseña] [-u uid] [ -r ] [ -s shell ] [ --service service ] [ --help ] [-R] [-s shell] [- Servicio] [- help] [ -usage ] [ -v ] account [- Uso] [-v] cuenta useradd --show-defaults useradd - se presenta por defecto useradd --save-defaults [ -d homedir ] [ -e expire ] [ -f inactive ] useradd - guardar-por defecto [-d directorio home] [-e expirará] [-f inactivo] [ -g gid ] [ -G group,... ] [ -k skeldir ] [ -s shell ] [-G gid] [-G grupo, ...] [k skeldir] [shell-s] useradd 73 creates a new user account using the default values from /etc/default/useradd and the specified on the useradd crea una nueva cuenta de usuario utilizando los valores por defecto de / etc / default / useradd y el especificado en el command line. de línea de comandos. Depending on the command line options the new account will be added to the system files or LDAP Dependiendo de las opciones de línea de comandos de la nueva cuenta se agregará a los archivos del sistema o LDAP database, the home directory will be created and the initial default files and directories will be copied. base de datos, el directorio se creará y los archivos y directorios por defecto inicial se copiarán. The account name must begin with an alphabetic character and the rest of the string should be from the POSIXEl nombre de cuenta debe comenzar con un carácter alfabético y el resto de la cadena debe ser de la POSIX portable character class ([A-Za-z_][A-Za-z0-9_-.]*[A-Za-z0-9_-.$]). clase de caracteres móviles ([A-Zaz_] [A-Za-z0-9_-.] * [A-Za-z0-9_-.$]). Opciones -C, - comentario Comentario Esta opción especifica la información de los usuarios de los dedos. -D, - homedir casa Esta opción especifica el directorio home del usuario. Si no se especifica, por defecto de / etc / default / useradd se utiliza. 74 -E, - expirarán expirará Con esta opción, podemos modificar la fecha en que estará vencida y se podrá cambiar. EXPIREDATE tiene que ser especificado como el número de días desde el 01 de enero 1970. La fecha también puede expresarse en el formato AAAA-MM-DD. Si no se especifica, el valor por defecto de / etc / default / useradd se utiliza. -F, - inactivos inactivos Esta opción se utiliza para establecer el número de días de inactividad después de una contraseña ha caducado antes de la cuenta está bloqueada. Un usuario cuya cuenta está bloqueada debe comunicarse con el administrador del sistema antes de poder para utilizar la cuenta de nuevo. Un valor de -1 desactiva esta función. Si no se especifica, el valor predeterminado de / Etc / default / useradd se utiliza. -G, - grupo de grupos,.. Con esta opción puede ser una lista de grupos suplementarios especificados, que el usuario debe ser miembro de cada grupo se separa de la siguiente sólo por una coma, sin espacios en blanco. Si no se especifica, el por defecto de / etc / default / useradd se utiliza. -G, - gid gid 75 El nombre del grupo o el número de grupo principal del usuario. El nombre del grupo o el número debe hacer referencia a una ya existentes grupo. Si no se especifica, por defecto de / etc / default / useradd se utiliza. -K, - skeldir skel Especifique un directorio skel alternativa. Esta opción sólo es válida, si el directorio de inicio para el nuevo usuario se debe crear, también. Si no se especifica, por defecto de / etc / default / useradd o / etc / skel se utiliza. -M, - crear el hogar Crear directorio para la nueva cuenta de usuario. -O, - no único Permita que duplicado (no únicos) ID de usuario. -P, - password contraseña Contraseña cifrada devuelta por la cripta (3) para la nueva cuenta. El valor por defecto es desactivar la cuenta. -U, - uid uid 76 Fuerza el ID de usuario nuevo sea el número dado. Este valor debe ser positivo y único. El valor por defecto es usar la primera identificación libre después de la más grande que se utiliza. La gama de la cual se elige el ID de usuario se puede especificar el archivo / etc / login.defs. -R, - sistema de Crear una cuenta de sistema. Una cuenta de sistema es un usuario con un UID entre SYSTEM_UID_MIN y SYSTEM_UID_MAX tal como se define en / etc / login.defs, si no se especifica UID. La entrada GRUPOS en / etc / default / useradd también se ignora. -S, - shell shell Shell de login del usuario Indique la. El valor por defecto para las cuentas de usuario normal es tomado de / etc / default / useradd /, por defecto para las cuentas del sistema es / bin / false. -D, - binddn binddn Utilice el binddn nombre completo para enlazar con el directorio LDAP. El usuario se le solicitará una contraseña para la autenticación simple. -P, - ruta ruta 77 La sombra de los archivos passwd y se encuentran por debajo de la ruta del directorio especificado. Useradd utilizará estos archivos, no / etc / passwd y / etc / shadow. - Help Muestra una lista de opciones válidas con una breve descripción. - Use Imprimir una lista de opciones válidas. -V, Versión Imprimir el número de versión y salir. Para usar el script userman seguimos la siguiente sintaxis. UserMan USERMAN es un simple script de perl-que ayuda a la gestión de cuentas de usuario. It can completely handle /etc/passwd, /etc/shadow, /etc/group and /etc/gshadow. Se puede manejar por completo el archivo / etc / passwd, / etc / shadow, / etc / group y / etc / gshadow. To use userman you need the following: Para utilizar USERMAN necesita lo siguiente: 78 - Perl 5 (or above) - Perl 5 (o superior) - Shadowed Passwords (saving passwords to /etc/shadow instead to /etc/passwd) – Las contraseñas Sombrío (contraseñas de ahorro a / etc / shadow en vez de / etc / passwd) Opciones Basta con añadir un usuario con todos los valores predeterminados Agregar: userman -A user Agregar un usuario con 'foobar' password userman -A user -p foobar Agregar un usuario con la contraseña 'foobar', donde '/ tmp', concha '/ bin / false "y nombre real "foo bar" userman -A user -p foobar -H /tmp -s /bin/false -R "foo bar" Borrar: Borrar usuario userman -D user Elimina un usuario y quita su home y su cola de correo 79 userman -D user -r o userman -rD user Modificar: Cambiar una contraseña a los usuarios 'foobar' userman -M user -p foobar Cambio de Home a los usuarios '/ tmp', pero deja intacta el antiguo Home userman -M user -H /tmp Cambio de Home a los usuarios '/ tmp' y mover el viejo Home al nuevo userman -M user -H /tmp -r or userman -M user -rH /tmp USERMAN-M también puede construir un nuevo usuario completo, utilizando uno ya existente, cambiar un nombre de usuario 'dummy', mueve su Home para "/ home / dummy ', pone la contraseña a 'dummyuser' y cambia su nombre real de "usuario simulado" userman -M user -U dummy -rH /home/dummy -p dummyuser -R "dummy user" 80 Eliminar un usuario de 'bin' de los grupos y 'root' y lo pone en "juegos". userman -M user -E games -e bin,root GROUPHANDLING: Agregar un grupo al sistema userman -GA group Agregar un grupo con 'foobar' password userman -GA group -p foobar Eliminar un grupo userman -GD group Cambiar el grupo-contraseña para 'foobar' userman -GM group -p foobar Añadir el usuario 'dummy' a un grupo userman -GM group -E dummy Eliminar los usuarios 'dummy' y «dau» de un grupo userman -GM group -e dummy,dau Cambiar el nombre de grupo de 'foobar', quita el usuario 'dummy', añade 'dau' usuarios y 'foo' y desactivar el grupo-contraseña. 81 userman -GM group -U foobar -e dummy -E dau,foo -J Control: Comprobar la SystemFiles de los errores comunes userman -C Comprobar la SystemFiles de los errores comunes y repararlos userman -C -r or userman -rC Usar el modo BATCH-MODE: galileo:~# cat > foo user1 password1 user2 password2 user3 password3 galileo:~# userman -B foo galileo:~# grep "^user" /etc/passwd user1:x:500:100:user1:/home/user1:/bin/false 82 user2:x:501:100:user2:/home/user2:/bin/false user3:x:502:100:user3:/home/user3:/bin/false galileo:~# Rsync Rsync es una aplicación de software para sistemas de tipo Unix que ofrece transmisión eficiente de datos incrementales, que opera también con datos comprimidos y cifrados. Mediante una técnica de delta encoding, permite sincronizar archivos y directorios entre dos máquinas de una red o entre dos ubicaciones en una misma máquina, minimizando el volumen de datos transferidos. Una característica importante de rsync no encontrada en la mayoría de programas o protocolos es que la copia toma lugar con sólo una transmisión en cada dirección. rsync puede copiar o mostrar directorios contenidos y copia de archivos, opcionalmente usando compresión y recursión. En modalidad de "Daemon" servidor, rsync escucha por defecto el puerto TCP 873, sirviendo archivos en el protocolo nativo rsync o via un terminal remoto como RSH o SSH. En el último caso, el ejecutable del cliente rsync debe ser instalado en el host local y remoto. 83 Características y aplicaciones Mientras que el algoritmo rsync forma parte del núcleo de la aplicación rsync y esencialmente optimiza las transferencias entre dos computadoras sobre TCP/IP, la aplicación rsync provee otras funciones que asisten en la transferencia. Estas incluyen compresión y descompresión de los datos bloque por bloque, utilizando zlib al enviar y recibir, y soporte para protocolos de cifrado, tal como SSH, lo que permite transmisión cifrada y eficientemente diferenciada de datos comprimidos usando el algoritmo rsync. Adicionalmente puede utilizarse una aplicación de tunneling también para crear un túnel cifrado que asegure los datos transmitidos. Además de archivos, el algoritmo permite copiar directorios, aun recursivamente, así como vínculos, dispositivos, grupos y permisos. No requiere por defecto privilegios de root para su uso. Rsync fue escrito como un reemplazo de rcp y SCP. Una de las primeras aplicaciones de rsync fue el espejado (mirroring) o respaldo de múltiples clientes Unix dentro de un servidor Unix central, usando rsync/ssh y cuentas estándares de Unix. Habitualmente se lo ejecuta mediante herramientas de scheduling como cron, para automatizar procesos de sincronización entre múltiples computadoras host y servidores centrales. 84 Uso de la aplicación La invocación más simple de la aplicación a través de línea de comandos tiene la siguiente forma: rsync [OPTION]... SRC [SRC]... DEST La simplicidad de la aplicación se puede ver en el siguiente ejemplo (se utilizan opciones largas para facilitar su explicación, pero también se pueden utilizar opciones abreviadas): rsync --verbose --compress --rsh=/usr/local/bin/ssh --recursive \ --times --perms --links --delete --exclude "*bak" --exclude "*~" \ /www/* webserver:/www Este comando ejecuta rsync en modo verboso (muestra mensajes de estado por la salida estándar), con compresión, a través de ssh, en forma recursiva para los subdirectorios, preservando fechas y permisos del archivo origen, incluyendo vínculos, borrando archivos que fueron borrados en el directorio origen, excluyendo backups y archivos temporales (*bak, *~); el origen es el contenido del directorio /www y el destino el directorio /www en el host webserver. Adicionalmente es necesario configurar uno de los puntos hosts como servidor rsync, ejecutando rsync en modo daemon: rsync –-daemon 85 Y configurando el archivo /etc/rsyncd.conf. Una vez configurado un servidor, cualquier máquina con rsync instalado puede sincronizar archivos hacia o desde éste. Backups Rsync es una poderosa implementación de un pequeño y maravilloso algoritmo. Su principal poder es la habilidad de replicar eficientemente un sistema de archivos. Usando rsync, es fácil configurar un sistema que mantendrá una copia actualizada de un sistema de archivos usando un arreglo flexible de protocolos de red, tales como NFS, SMB o SSH. La segunda gran característica que consigue este sistema de copias de seguridad es la capacidad de archivar viejas copias de archivos que han sido modificadas o eliminadas. Hay muchas más características de rsync a considerar. En resumen, este sistema usa una máquina Linux barata con muchos discos baratos y con un pequeño script que llama a rsync. [Fig 1] Cuando se hace una copia de seguridad, le decimos a rsync que cree un directorio llamado ‗YY-DD-MM‘ como lugar para almacenar los cambios incrementales. Seguidamente, rsync examina los servidores de los que hacemos copias de seguridad de los cambios. Si un archivo ha cambiado, se copia la versión vieja al directorio incremental, y luego sobrescribe el archivo en el directorio principal de copias de seguridad. [Fig 2] 86 Figura 1.16 Estructura de Rsync En general, los cambios de un día tienden a ser solamente un pequeño porcentaje del total del sistema de archivos. Encuentro que el tamaño medio está entre el 0.5% y 1%. De todas formas, con un conjunto de discos de copias de seguridad que es dos veces el tamaño de nuestros servidores de archivos, puede mantener 50-100 días de copias de seguridad incrementales en el disco duro. Cuando el disco se llene, sólo cambio a un nuevo conjunto de discos, y muevo los viejos. En la práctica, es posible mantener cerca de seis meses de respaldos incrementales en el disco. De hecho, si puede encontrar espacio en cualquier lugar, puede copiar sus incrementales a otro servidor antes de rotar los discos. De este modo, puede mantener un número arbitrariamente grande de incrementales en disco. 87 Figura 1.17 Respaldo usando Rsync Las ventajas: La recuperación de desastres y la restauración de archivos se hace más fácil. Vuelva a la conversación imaginaria de arriba. Ahora, en vez de un incómodo sistema basado en cintas, imagine tener seis meses de copias de seguridad incrementales esperándole en su máquina Linux. Usando su combinación favorita de locate/find/grep, puede encontrar todas las ocurrencias de archivos que posee nuestro usuario imaginario, que contengan una ‗e‘ y que su fecha sea un jueves en Febrero o Abril, y volcarlos dentro de un directorio en el directorio principal del usuario. El problema de averiguar qué versión es la correcta se ha convertido en mi tipo de problema favorito: ¿el de alguien más? Seguidamente, imagine nuestro escenario favorito: fallo completo. Digamos que tiene un gran servidor NSF/SMB que ha perdido. Bueno, si ha hecho copia de seguridad de sus configuraciones, puede levantar su servidor de copia de seguridad como un sustituto solo-lectura en minutos. Intente esto con las cintas. 88 Porque el uso de rsync para copias de seguridad de disco duro tiene ventaja frente a las cintas Cinta de copia de Rsync seguridad Coste Muy alto Bajo Rápido Rápido Rápido Rápido Copia de seguridad completa Copia de seguridad incremental Muy lento, Restauración Rápido -está todo en probablemente completa discomúltiples cintas Muy rápido -está Lento, quizás Restauración múltiples cintas, a de archivo todo en disco y tiene todo el poder de las menudo difícil de herramientas de encontrar la búsqueda de UNIX 89 versión correcta como find, grep o locate- Se puede establecer La única opción es Fallo como un servidor de la restauración archivos en un completo completa momento Tabla 1.1 Ventajas de Rsync Las herramientas Hay muchas formas para ponerlos en funcionamiento. Todas estas herramientas son de Código Abierto, incluidas en las distribuciones estándar, y muy flexibles. Aquí, describimos una posible configuración, pero no es la única manera. El servidor: Utilizo Red Hat Linux. Cualquier distribución puede funcionar, al igual que cualquier UNIX. (Incluso lo he configurado con Mac OS X). Una advertencia: mucha RAM ayuda. Disco:. La manera más fácil que hemos encontrado de construir un gran conjunto barato de discos es una tarjeta PCI Firewire conectada a un puñado de 90 discos IDE baratos en cajas Firewire externas. Configurar Linux para usarlos como una gran partición RAID es cosa sencilla. El software: rsync en una gran herramienta. Es un tipo de herramienta multiuso de replicación de sistemas de archivos. Si no sabe sobre él, compruébelo en rsync.samba.org. Conectando a los servidores de archivos: rsync es muy flexible. Usamos NFS y smbfs. También puede usar el protocolo de red propio de rsync ejecutando un demonio rsync en el servidor de archivos. También puede decirle a rsync que use SSH para hacer copias de seguridad seguras de sitios remotos. En los recursos de abajo existe información sobre cómo configurar estas conexiones. Haciendo un script Veamos la sintaxis del comando Rsync NOMBRE rsync - una forma rápida, versátil, a distancia (y local) la herramienta de copia de archivos SYNOPSIS Local: rsync [OPTION...] SRC... Local: rsync [OPCIÓN ...] SRC ... [DEST] [DEST] Access via remote shell: Acceso a través de shell remoto: 91 Pull: rsync [OPTION...] [USER@]HOST:SRC... Tire: rsync [OPCIÓN ...] [user @ host]: SRC ... [DEST] [DEST] Push: rsync [OPTION...] SRC... Push: rsync [OPCIÓN ...] SRC ... [USER@]HOST:DEST [User @ host]: DEST Access via rsync daemon: Acceso a través de demonio rsync: Pull: rsync [OPTION...] [USER@]HOST::SRC... Tire: rsync [OPCIÓN ...] [user @ host]:: SRC ... [DEST] [DEST] rsync [OPTION...] rsync://[USER@]HOST[:PORT]/SRC... rsync [OPCIÓN ...] rsync: / / [user @ host] [: puerto] / SRC ... [DEST] [DEST] Push: rsync [OPTION...] SRC... Push: rsync [OPCIÓN ...] SRC ... [USER@]HOST::DEST [User @ host]:: DEST rsync [OPTION...] SRC... rsync [OPCIÓN ...] SRC ... rsync://[USER@]HOST[:PORT]/DEST rsync: / / [user @ host] [: puerto] / DEST Usos con un solo argumento SRC y no arg DEST listará los archivos de origen en lugar de copiar. Aquí está un breve resumen de las opciones disponibles en rsync. Por favor, descripción detallada a continuación para una descripción completa. - v --verbose -V, - verbose Incrementa la verbosidad 92 - q --quiet -Q, - quiet no elimine los mensajes de error - no - motd - No-motd suprimir MOTD demonio-mode (ver advertencia) - c - checksum skip based on checksum, not mod-time & size -C, - suma de comprobación saltar sobre la base de suma de comprobación no, mod en tiempo y tamaño - a - archive - el modo de archivo de archivo, es igual-rlptgoD (sin H, A,-X) - no - OPTION - desactivar una opción implícita (por ejemplo - no-D) - r - recursive -R, - recursive recursiva en directorios - R - relative - los nombres relativos uso relativo ruta - no - implied - dirs - no envía dirs implícita - en relación - b - backup copia de seguridad hacer copias de seguridad (ver - y el sufijo - backupdir) - backup - dir - DIR hacer copias de seguridad en la jerarquía basada en DIR - suffix = SUFIJO sufijo de respaldo (por defecto ~ W / O - backup-dir) - u - update omitir archivos que son más recientes en el receptor - inplace update - archivos de destino actualización en contexto - append - añade los datos en archivos de menor 93 - append - verify - append w / datos antiguos en el archivo de control - d - dirs - directorios directorios transferencia sin recursivamente - l - links - copia de enlaces enlaces simbólicos como enlaces simbólicos - L - copia de los enlaces transformar enlace simbólico en el archivo referente / dir - copy – unsafe - links - Seguro de copia de enlaces sólo "inseguros" enlaces simbólicos se transforman - safe - links - Caja-enlaces ignorar enlaces simbólicos que apuntan fuera del árbol - k – copy - dirlinks - copia dirlinks transformar enlace simbólico al directorio en el directorio referente - K – keep - dirlinks - tratar dir un enlace simbólico en el receptor como dir - H – hard - links - enlaces duros preservaba enlaces duros - p - perms - preservar los permisos permanentes - E - executability - ejecutabilidad preservar ejecutabilidad - chmod = CHMOD afectan a archivos y / o directorio permisos - A - ACL preservar ACL (implica-p) - X - xattrs preservar los atributos extendidos - o - propietario de conservar sus (súper-usuario solamente) 94 - g - grupo de preservar grupo - devices - Dispositivos de preservar los archivos de dispositivos (super-usuario solamente) - specials - Especiales preservar archivos especiales - t - tiempos de preservar hora de modificación - O - omitir-dir veces omiten directorios - de los tiempos - super - Receptor súper intentos de las actividades de super-usuario - fake-super - La tienda del falso-super / recuperar attrs privilegiada con xattrs - S, - escasa manejar archivos dispersos de manera eficiente - N – dry - run realizar un ensayo sin cambios realizados - W, - archivos de copia de archivos de todo el conjunto (w / algoritmo o delta-xfer) - X, - un sistema de archivos no cruzan las fronteras del sistema de archivos - B, - block-size = TAMAÑO vigor una suma de comprobación del bloque de tamaño fijo - E - rsh = COMANDO especificar el shell remoto para utilizar Rsync - path = PROGRAMA especificar el rsync para ejecutar en la máquina remota -existing - Existentes saltar la creación de nuevos archivos en el receptor 95 - ignore-existing - omitir archivos de actualización que existen en el receptor - remove-source-files - Remitente extraer los archivos de código elimina archivos sincronizados (no dir) - delete - Eliminar archivos superfluos de dest directorios -delete - Antes de eliminar borra el receptor antes de la transferencia (por defecto) - delete-delay - Eliminar el retardo encontrar supresiones durante, después de eliminar - delete - after -después elimina el receptor después de la transferencia, no antes - delete - excluded - eliminar archivos excluidos de dest directorios -ignore – errors - eliminar errores, incluso si hay errores E / S - max – delete = NUM no eliminar más de archivos NUM - Max-size = TAMAÑO no transferir cualquier archivo de más de TAMAÑO - Min-size = TAMAÑO no transferir cualquier archivo más pequeño que talla - partial - Parcial mantener parcialmente los archivos transferidos - Parcial-dir = DIR poner un fichero parcialmente transferido a DIR - Delay-actualizaciones de poner todos los archivos actualizados en su lugar al final 96 - M, - ciruela-vacío-dirs podar las cadenas vacías directorio desde el archivo de la lista - Numeric-ids no se asignan uid / gid valores por el usuario / nombre de grupo - Timeout = SEGUNDOS conjunto de E / S de tiempo de espera en segundos - Contimeout = SEGUNDOS demonio de fijar el tiempo de conexión en segundos - I - ignore-veces no se salte los archivos que coinciden con el tamaño y el tiempo - size - only - Tamaño de sólo omitir archivos que coinciden en el tamaño - Modificar la ventana = NUM comparar mod veces con menor precisión -T - dir = temp-DIR crear archivos temporales en el directorio DIR -Y, - difusa encontrar el archivo de base similares si dest no hay ningún archivo Compare - dest = DIR también comparar los archivos recibidos en relación con DIR - Copy-dest = DIR ... and include copies of unchanged files e incluir copias de los archivos no modificados - Enlace dest = DIR enlaces duros a los archivos en DIR cuando sin cambios - Z, - compress comprimir los datos de archivos durante la transferencia - Comprimir nivel = NUM establece explícitamente el nivel de compresión - Skip-comprimir = Ignorar la lista de compresión de archivos con el sufijo en la 97 LISTA - C: - CV / exclusión automática ignorar archivos en el CVS misma manera se - filter = REGLA añadir una regla de filtrado de archivos - F lo mismo que - filter = "dir-fusión / rsync-filtro. - Exclude = PATRÓN excluye archivos que coinciden con PATRÓN - Exclude-from = ARCHIVO leer excluir a los patrones de ARCHIVO - Include-from = ARCHIVO leer, como los patrones de ARCHIVO - Los archivos-from = ARCHIVO leer la lista de nombres de archivo de origen, desde ARCHIVO - 0 - From0 todos desde / filtrar archivos están delimitados por 0s -S, - proteger-args ningún espacio-división; caracteres comodín sólo - Address = DIRECCIÓN DE unen para toma de salida a demonio - Port = PUERTO especificar dos puntos el número de puerto alternativo - Sockopts OPCIONES = especificar opciones personalizadas TCP - stats - Estadísticas de dar algunas estadísticas de transferencia de archivos - H, - número de salida legible en un formato legible para el usuario - progress - muestra el progreso durante la transferencia 98 -I - la producción detallan los cambios de un cambio-resumen de todas las actualizaciones - Fuera format = FORMATO actualizaciones de salida utilizando el formato especificado - Log - file = archivo de registro de lo que estamos haciendo en el archivo especificado - Log - file - format = actualizaciones FMT registro utilizando la FMT especificado - Password - file = ARCHIVO leer demonio de acceso a la contraseña del ARCHIVO - only - write - batch = FILE like --write-batch but w/o updating dest - Sólo-escritura como proceso por lotes = ARCHIVO - escritura de lotes, pero w / o actualización de dest - read – batch = FILE read a batched update from FILE - Lectura lote = ARCHIVO leer una actualización por lotes de ARCHIVO - protocol = NUM force an older protocol version to be used - Protocol = NUM vigor una versión del protocolo más para ser utilizado - iconv = CONVERT_SPEC request charset conversion of filenames - Iconv = solicitud CONVERT_SPEC juego de caracteres de conversión de nombres de archivo 99 - checksum – seed =NUM set block/file checksum seed (advanced) - Suma de control de semillas = bloque NUM sistema / semillas de suma de comprobación de archivos (avanzado) - 4, --ipv4 prefer IPv4 -4 - Ipv4 prefieren IPv4 - 6, --ipv6 prefer IPv6 -6 - Ipv6 prefieren IPv6 - version print version number - Versión para imprimir el número de versión (-h) --help show this help (see below for -h comment) (H) - help muestra esta ayuda (ver más abajo comentario para-h) Rsync también se puede ejecutar como un demonio, en cuyo caso las siguientes opciones are accepted: Se aceptan: -daemon run as an rsync daemon - Demonio se ejecute como un demonio rsync - address = ADDRESS bind to the specified address - Address = DIRECCIÓN se une a la dirección especificada - bwlimit=KBPS limit I/O bandwidth; KBytes per second - Bwlimit = límite KBPS de E / S de ancho de banda; Kbytes por segundo - config = FILE specify alternate rsyncd.conf file - Config = FILE especifica archivo rsyncd.conf alternativo - no - detach do not detach from the parent - No separar-no separarse de los padres 100 - port = PORT listen on alternate port number - Port = PUERTO escuchar en el número de puerto alternativo - log – file = FILE override the "log file" setting - Log-file = ARCHIVO reemplazar el "archivo de registro de" ajuste - log – file – format = FMT override the "log format" setting - Log-archivo-formato FMT = reemplazar el "formato de registro" ajuste - sockopts = OPTIONS specify custom TCP options - Sockopts OPCIONES = especificar opciones personalizadas TCP - v, --verbose increase verbosity -V, - verbose Incrementa la verbosidad - 4, --ipv4 prefer IPv4 -4 - Ipv4 prefieren IPv4 - 6, --ipv6 prefer IPv6 -6 - Ipv6 prefieren IPv6 - h, --help show this help (if used after --daemon) -H, - help muestra esta ayuda (si se utilizan después - demonio) Con las opciones que hemos visto, ahora crearemos un script. La forma básica de hacer un respaldo es de esta forma /usr/bin/rsync -avzrpog --delete /home/Origen /home/Destino Lo que hacemos es respaldar lo que está en el directorio /home/Origen a /home/Destino pero además hacemos lo siguiente: 101 Con a le decimos que copie archivo por archivo, con v incrementamos la verbosidad o cantidad de palabras, z que los comprima cuando los esté transfiriendo, r que sea recursivo, p conserva los permisos de los archivos, o conserva el propietario y g conserva el grupo. Pero ahora ¿qué hacemos? Bien, editamos un archivo llamado backup con el comando nano, vi o pico y creamos el script #!/bin/bash /usr/bin/rsync -avzrpog --delete /home/Origen /home/Destino Lo guardamos y le damos los permisos correspondientes. Ahora, si queremos que el script se ejecute a cierta hora y día o lo queremos que se ejecute cada cierto tiempo, debemos de agregarlo al cron del sistema. Veamos cómo funciona el crontab. Cron El nombre cron viene del griego chronos que significa "tiempo". En el sistema operativo Unix, cron es un administrador regular de procesos en segundo plano (demonio) que ejecuta procesos o guiones a intervalos regulares (por ejemplo, cada minuto, día, semana o mes). Los procesos que deben ejecutarse y la hora en la que deben hacerlo se especifican en el fichero crontab. 102 Cron se podría definir como el "equivalente" a Tareas Programadas de Windows. Cron es impulsado por un cron, un archivo de configuración que especifica comando shell para ejecutarse periódicamente a una hora específica. Los archivos crontab son almacenados en donde permanecen las listas de trabajos y otras instrucciones para el demonio cron. Los usuarios habilitados para crear su fichero crontab se especifican en el fichero cron.allow. De manera análoga, los que no lo tienen permitido figuran en /etc/cron.d/cron.deny, o /etc/cron.deny, dependiendo de la versión de Unix. Cada línea de un archivo crontab representa un trabajo y es compuesto por una expresión CRON, seguida por un comando shell para ejecutarse. Formato del fichero crontab Fichero crontab de ejemplo: SHELL=/bin/bash PATH=/sbin:/bin:/usr/sbin:/usr/bin MAILTO=root HOME=/ # run-parts 103 01 * * * * root nice -n 19 run-parts /etc/cron.hourly 50 0 * * * root nice -n 19 run-parts /etc/cron.daily 22 4 * * 0 root nice -n 19 run-parts /etc/cron.weekly 42 4 1 * * root nice -n 19 run-parts /etc/cron.monthly Sintaxis El formato de configuración de cron es muy sencillo. El símbolo # es un comentario, todo lo que se encuentre después de ese carácter no será ejecutado por cron. El momento de ejecución se especifica de acuerdo con la siguiente tabla: 1. Minutos: (0-59) 2. Horas: (0-23) 3. Días: (1-31) 4. Mes: (1-12) 5. Día de la semana: (0-6), siendo 1=lunes, 2=martes,... 6=sábado y 0=domingo (a veces también 7=domingo). 104 Figura 1.18 Script de respaldo Bien ahora que tenemos esto podremos configurar que nuestro script se ejecute cuando lo deseemos. Ejemplo, vamos a configurar el cron para que ejecute nuestro script los viernes a las 11:30 pm de todas las semanas. En el cron quedaría así: 30 23 * * 5 root /usr/local/sbin/backup.sh Pero si queremos que se ejecute todos los días cada 30 minutos: 30 * * * * root /usr/local/sbin/backup.sh 105 PRUEBAS Simulación De Ataque Introducción al análisis de puertos Nmap comenzó como un analizador de puertos eficiente, aunque ha aumentado su funcionalidad a través de los años, aquella sigue siendo su función primaria. La sencilla orden nmap objetivo analiza más de 1660 puertos TCP del equipo objetivo. Aunque muchos analizadores de puertos han agrupado tradicionalmente los puertos en dos estados: abierto o cerrado, Nmap es mucho más descriptivo. Se dividen a los puertos en seis estados distintos: abierto, cerrado, filtrado, no filtrado, abierto |filtrado, o cerrado| filtrado. Estos estados no son propiedades intrínsecas del puerto en sí, pero describen como los ve Nmap. Por ejemplo, un análisis con Nmap desde la misma red en la que se encuentra el objetivo puede mostrar el puerto 135/tcp como abierto, mientras que un análisis realizado al mismo tiempo y con las mismas opciones, pero desde Internet, puede presentarlo como filtrado. Los seis estados de un puerto, según Nmap abierto Una aplicación acepta conexiones TCP o paquetes UDP en este puerto. El encontrar esta clase de puertos es generalmente el objetivo primario de realizar un sondeo de puertos. Las personas orientadas a la seguridad saben que cada puerto abierto es un vector de ataque. Los atacantes y las personas que 106 realizan pruebas de intrusión intentan aprovechar puertos abiertos, por lo que los administradores intentan cerrarlos, o protegerlos con cortafuegos, pero sin que los usuarios legítimos pierdan acceso al servicio. Los puertos abiertos también son interesantes en sondeos que no están relacionados con la seguridad porque indican qué servicios están disponibles para ser utilizados en una red. Cerrado Un puerto cerrado es accesible: recibe y responde a las sondas de Nmap, pero no tiene una aplicación escuchando en él. Pueden ser útiles para determinar si un equipo está activo en cierta dirección IP (mediante descubrimiento de sistemas, o sondeo ping), y es parte del proceso de detección de sistema operativo. Como los puertos cerrados son alcanzables, o sea, no se encuentran filtrados, puede merecerla pena analizarlos pasado un tiempo, en caso de que alguno se abra. Los administradores pueden querer considerar bloquear estos puertos con un cortafuegos. Si se bloquean aparecerían filtrados, como se discute a continuación. Filtrado Nmap no puede determinar si el puerto se encuentra abierto porque un filtrado de paquetes previene que sus sondas alcancen el puerto. El filtrado puede provenir dedicado, de las reglas de un enrutador, de o instalada en el propio equipo. 107 por un dispositivo una de cortafuegos aplicación de cortafuegos Estos puertos suelen frustrara los atacantes, porque proporcionan muy poca información. A veces responden con mensajes de error ICMP del tipo 3, código 13 (destino inalcanzable: comunicación prohibida por administradores), pero los filtros que sencillamente descartan las sondas sin responder son mucho más comunes. Esto fuerza a Nmap a reintentar varias veces, considerando que la sonda pueda haberse descartado por congestión en la red en vez de haberse filtrado. Esto ralentiza drásticamente los sondeos. No Filtrado Este estado indica que el puerto es accesible, pero que Nmap no puede determinar si se encuentra abierto o cerrado. Solamente el sondeo ACK, utilizado para determinar las reglas de un cortafuego, clasifica a los puertos según este estado. El analizar puertos no filtrados con otros tipos de análisis, como el sondeo Windows, SYN o FIN, pueden ayudar a determinar si el puerto se encuentra abierto. Abierto | Filtrado Nmap marca a los puertos en este estado cuando no puede determinar si el puerto se encuentra abierto o filtrado. Esto ocurre para tipos de análisis donde no responden los puertos abiertos. La ausencia de respuesta puede también significar que un filtro de paquetes ha descartado la sonda, o que se elimina cualquier respuesta asociada. De esta forma, Nmap no puede saber con certeza si el puerto 108 se encuentra abierto o filtrado. Los sondeos UDP, protocolo IP, FIN, Null y X más clasifican a los puertos de esta manera. Cerrado | Filtrado Este estado se utiliza cuando Nmap no puede determinar si un puerto se encuentra cerrado o filtrado, y puede aparecer sólo durante un sondeo IPID pasivo. Técnicas De Sondeo De Puertos Cuando intento pasarme horas realizar un arreglo intentando utilizar mis de mi coche, siendo novato, puedo herramientas rudimentarias (martillo, cinta aislante, llave inglesa, etc.). Cuando fallo miserablemente y llevo mi coche antiguo en grúa al taller a un mecánico de verdad siempre pasa lo mismo: busca en su gran cajón de herramientas hasta que saca una herramienta que hace que la tarea se haga sin esfuerzo. El arte de sondear puertos es parecido. Los expertos conocen docenas de técnicas de sondeo y eligen la más apropiada (o una combinación de éstas) para la tarea que están realizando. Los usuarios sin experiencia y los "script kiddies", sin embargo, intentan resolver cada problema con el sondeo SYN por omisión. Dado que Nmap es libre, la única barrera que existe para ser un experto en el sondeo de puertos es el conocimiento. Esto es mucho mejor que el mundo del automóvil, donde puedes llegar a saber que necesitas un compresor de tuerca, pero tendrás que pagar mil dólares por él. La mayoría de los distintos tipos de sondeo disponibles sólo los puede llevar a cabo un usuario privilegiado. Esto 109 es debido a que envían y reciben paquetes en crudo, lo que hace necesario tener acceso como administrador (root) en la mayoría de los sistemas UNIX. En los entornos de administrador, Windows es recomendable aunque Nmap algunas utilizar una cuenta veces funciona para usuarios no privilegiados en aquellas plataformas donde ya se haya instalado WinPcap. La necesidad de privilegios como usuario administrador era una limitación importante cuando se empezó a distribuir Nmap en 1997, ya que muchos usuarios sólo tenían acceso a cuentas compartidas en sistemas como usuarios normales. Ahora, las cosas son muy distintas. Los ordenadores son más baratos, hay más personas que tienen acceso permanente a Internet, y los sistemas UNIX (incluyendo Linux y MAC OS X) son más comunes. También se dispone de una versión para Windows de Nmap, lo que permite que se ejecute en más escritorios. Por todas estas razones, cada vez es menos necesario ejecutar Nmap utilizando cuentas de sistema compartidas. Esto es bueno, porque las opciones que requieren de más privilegios hacen que Nmap sea más potente y flexible. Aunque Nmap intenta generar resultados precisos, hay que tener en cuenta que estos resultados se basan en los paquetes que devuelve el sistema objetivo (o los cortafuegos que están delante de éstos). Estos sistemas pueden no ser fiables y sea confundir a Nmap. enviar respuestas cuyo Son aún más comunes los sistemas que 110 objetivo no cumplen con los estándares RFC, que no responden como deberían a las sondas de Nmap. Son especialmente susceptibles a este problema los sondeos FIN, Null y Xmas. Hay algunos problemas específicos a algunos tipos de sondeos que se discuten en las entradas dedicadas a sondeos concretos. Esta sección documenta las aproximadamente doce técnicas de sondeos de puertos que soporta Nmap. Sólo puede utilizarse un método en un momento concreto, salvo por el sondeo UDP (-sU) que puede combinarse con cualquiera de los sondeos TCP. Para que sea fácil de recordar, las opciones de los sondeos de puertos son del estilo -sC, donde Ces una letra característica del nombre del sondeo, habitualmente la primera. La única excepción a esta regla es la opción obsoleta de sondeo FTP rebotado (-b). Nmap hace un sondeo SYN por omisión, aunque lo cambia a un sondeo Connect() si el usuario no tiene los suficientes privilegios para enviar paquetes en crudo (requiere acceso de administrador en UNIX) o si se especificaron objetivos IPv6. De los sondeos que se listan en esta sección los usuarios sin privilegios sólo pueden ejecutar los sondeos Connect() o de rebote FTP. -r (No aleatorizar los puertos) Nmap ordena de forma aleatoria los puertos a sondear por omisión (aunque algunos puertos comúnmente accesibles se ponen al principio por razones de eficiencia). 111 Esta aleatorización generalmente es deseable, pero si lo desea puede especificar la opción-r para analizar de forma secuencial los puertos. Detección de servicios y de versiones Si le indica a Nmap que mire un sistema remoto le podrá decir que tiene abiertos los puertos 25/tcp, 80/tcp y 53/udp. Informará que esos puertos se corresponden habitualmente con un servidor de correo (SMTP), servidor de web (HTTP) o servidor de nombres (DNS), respectivamente, si utilizas su base de datos nmap-services con más de2.200 puertos conocidos. Generalmente este informe es correo dado que la gran mayoría de demonios que escuchan en el puerto 25 TCP son, en realidad, servidores de correo. Pero no debe confiar su seguridad en este hecho! La gente ejecuta a veces servicios distintos en puertos inesperados Aún en el caso de que Nmap tenga razón y el servidor de ejemplo indicado arriba está ejecutando servidores de SMTP, HTTP y DNS esto no dice mucho. Cuando haga un análisis de vulnerabilidades (o tan sólo un inventario de red) en su propia empresa o en su cliente lo que habitualmente también quiere saber es qué versión se está utilizando del servidor de correcto y de DNS. Puede ayudar mucho a la hora de determinar qué ataques pueden afectar a un servidor el saber el número de versión exacto de éste. La detección de versiones le ayuda a obtener esta información. La detección de versiones pregunta para obtener más información de lo que realmente se está ejecutando una vez se han detectado los puertos TCP y/o UDP 112 con alguno de los probes contiene métodos de sondeo. La base sondas para tratar distintas respuestas en base de datos nmap-service- consultar distintos servicios y a una serie de expresiones. reconocer y Nmap intenta determinar el protocolo del servicio (p. ej. ftp, ssh, telnet óhttp), el nombre de la aplicación (p. ej. Bind de ISC, http de Apache, telnet de Solaris), un número de versión, un tipo de dispositivo (p. ej. impresora o router), la familia de sistema operativo (p. ej. Windows o Linux) y algunas veces algunos detalles misceláneos como por ejemplo, si un servidor X acepta cualquier conexión externa, la versión de protocolo SSH o el nombre de usuario Kazaa). Por supuesto, la mayoría de los servicios no ofrecen Nmap con soporte toda OpenSSL esta se información. conectará también a Si se ha compilado servidores SSL para determinar qué servicio escucha detrás de la capa descifrado. Se utiliza la herramienta de pruebas RPC de Nmap (-sR) de forma automática para determinar el programa RPC y el número de versión si se descubren servicios RPC .Algunos puertos UDP se quedan en estado open|filtered (N. del T., 'abierto|filtrado') si un barrido de puertos UDP no puede determinar si el puerto está abierto o filtrado. La detección de versiones intentará obtener una respuesta de estos puertos (igual que hace con puertos abiertos) y cambiará el estado a abierto si lo consigue. Los puertos TCP en estado open|filtered se tratan de forma similar. Tenga en cuenta que detección de versiones entre la opción -A otras cosas. 113 de Nmap actualiza la Puede encontrar un documento describiendo el funcionamiento, modo de uso, y particularización de la detección de versiones en http: //ww w.insecure.org/nmap /v s c an /. Cuando Nmap obtiene una respuesta de un servicio pero no encuentra una definición coincidente en la base de datos se imprimirá una firma especial y un URL para que la envíe si sabe lo que está ejecutándose detrás de ese puerto. Por favor, tómese unos minutos para enviar esta información para ayudar a todo el mundo. Gracias a estos envíos Nmap tiene ahora alrededor de 3.000 patrones para más de 350 protocolos distintos como smtp, ftp, http, etc. La detección de versiones se activa y controla con las siguientes opciones: -sV (Detección de versiones) Activa la detección de versiones como se ha descrito previamente. Puede utilizar la opción -A en su lugar para activar tanto la detección de versiones como la detección de sistema operativo. --allports (No excluir ningún puerto de la detección de versiones) La detección de versiones de Nmap omite el puerto TCP 9100 por omisión porque algunas impresoras imprimen cualquier cosa que reciben en este puerto, lo que da lugar a la impresión de múltiples páginas con solicitudes HTTP get, intentos de conexión de SSL, etc. modificando o eliminando la Este directiva 114 comportamiento Exclude puede cambiarse en nmap-service-probes, o especificando –allports para sondear todos los puertos independientemente de lo definido en la directiva Exclude. --version-intensity <intensidad> (Fijar la intensidad de la detección de versiones) Nmap envía una serie de sondas cuando se activa la detección de versiones (-sV) con un nivel de rareza pre asignado y variable de 1 a 9. Las sondas con un número bajo son efectivas contra un amplio número de servicios comunes, mientras que las de números más altos se utilizan rara vez. El nivel de intensidad indica que sondas sea el número, mayor las probabilidades de deberían utilizarse. Cuanto más alto identificar el servicio. Sin embargo, los sondeos de alta intensidad tardan más tiempo. El valor de intensidad puede variar de 0 a 9. El valor por omisión es 7. Se probará una sonda independientemente del nivel de intensidad cuando ésta se registra para el puerto objetivo a través de la directiva nmap-service-probes ports. De esta forma se asegura que las sondas de DNS se probarán contra cualquier puerto abierto 53, las sondas SSL contra el puerto 443, etc. --version-light (Activar modo ligero) Éste es un alias conveniente para --version-intensity 2. Este modo ligero hace que la detección de versiones sea más rápida, pero sea menos probable identificar algunos servicios. --version-all (Utilizar todas las sondas) 115 también hace que Éste es un alias para --version-intensity 9, hace que se utilicen todas las sondas contra cada puerto. --version-trace (Trazar actividad de sondeo de versiones) Esta opción hace que Nmap imprima información de depuración detallada explicando lo que está haciendo el sondeo de versiones. Es un conjunto de lo que obtendría si utilizara la opción --packet-trace. -sR (Sondeo RPC) Este método funciona conjuntamente con los distintos métodos de sondeo de puertos de Nmap. Toma todos los puertos TCP/UDP que se han encontrado y los inunda con órdenes de programa NULL SunRPC con el objetivo de determinar si son puertos RPC y, si es así, los programas y número de versión que están detrás. Así, puede obtener de una forma efectiva la misma información que rpcinfo -p aunque el mapeador de puertos («portmapper», N. del T.) está detrás de un cortafuegos (o protegido por TCP wrappers). Los señuelos no funcionan con el sondeo RPC actualmente. Esta opción se activa automáticamente como parte de la detección de versiones (-sV) si la ha seleccionado. Rara vez se utiliza la opción -sR dado que la detección de versiones lo incluye y es más completa. Detección de sistema operativo 116 Uno de los aspectos más conocidos de Nmap es la detección del sistema operativo (SO) en base a la comprobación de huellas TCP/IP. Nmap envía una serie de paquetes TCP y UDP al sistema remoto y analiza prácticamente todos los bits de las respuestas. Nmap compara los resultados de una docena de pruebas como puedan ser el análisis de ISN deTCP, el soporte de opciones TCP y su orden, el análisis de IPID y las comprobaciones de tamaño inicial de ventana, con su base de datos nmap-os-fingerprints. Esta base de datos consta de más de 1500 huellas de sistema operativo y cuando existe una coincidencia se presentan los detalles del sistema operativo. Cada huella contiene una descripción en texto libre del sistema operativo, una clasificación que indica el nombre del proveedor (por ejemplo, Sun), el sistema operativo subyacente (por ejemplo, Solaris), la versión del SO (por ejemplo, 10) y el tipo de dispositivo (propósito general, en caminador, conmutador ,consola de videojuegos, etc.). Nmap le indicará una URL donde puede enviar las huellas si conoce (con seguridad) el sistema operativo que utiliza el equipo si no puede adivinar el sistema operativo de éste y las condiciones son óptimas (encontró al menos un puerto abierto y otro cerrado). Si envía esta información contribuirá al conjunto de sistemas operativos que Nmap conoce y la herramienta será así más exacta para todo el mundo. La detección de sistema operativo activa, en cualquier caso, una serie de pruebas que hacen uso de la información que ésta recoge. Una de estas pruebas 117 es la medición de tiempo de actividad, que utiliza la opción de marca de tiempo TCP (RFC 1323) para adivinar cuánto hace que un equipo fue reiniciado. Esta prueba sólo funciona en sistemas que ofrecen esta información. Otra prueba que se realiza es la clasificación de predicción de número de secuencia TCP. Esta prueba mide de forma aproximada cuánto de difícil es crear una conexión TCP falsa contra el sistema remoto. Se utiliza cuando se quiere hacer uso de relaciones de confianza basadas en la dirección IP origen (como es el caso de login, filtros de cortafuegos, etc.) para ocultar la fuente de un ataque. Ya no se hace habitualmente este tipo de malversación pero aún existen muchos equipos que son vulnerables a ésta. Generalmente es mejor utilizar la clasificación en inglés como: ―worthychallenge‖ («desafío difícil», N. del T.) o ―trivial joke‖ («broma fácil», N. del T.). Esta información sólo se ofrece en la salida normal en el modo detallado (-v). También se informa de la generación de números de secuencia IPID cuando se activa el modo detallado conjuntamente con la opción -O. La mayoría de los equipos estarán en la clase ―incremental‖, lo que significa que incrementan el campo ID en la cabecera IP para cada paquete que envían. Esto hace que sean vulnerables a algunos ataques avanzados de obtención de información y de falseo de dirección. Puede encontrar un trabajo traducido a una docena de idiomas que detalla el modo de funcionamiento, utilización y ajuste de la detección de versiones en http://www.insecure.org/nmap/osdetect/. 118 La detección de sistema operativo se activa y controla con las siguientes opciones: -O (Activa la detección de sistema operativo) Tal y como se operativo. También se indica previamente, activa puede utilizar la la opción -A detección de sistema para activar la detección de sistema operativo y de versiones. --osscan-limit (Limitar la detección de sistema operativo a mejor si se los objetivos prometedores) La detección de sistema operativo funcionará dispone de un puerto TCP abierto y otro cerrado. Defina esta opción si no quiere que Nmap intente siquiera la detección de sistema operativo contra sistemas que no cumplan este criterio. Esta opción puede ahorrar mucho tiempo, sobre todo si está realizando sondeos -P0 sobre muchos sistemas. Sólo es de aplicación cuando se ha solicitado la detección de sistema operativo con la opción -O o -A. --osscan-guess; --fuzzy (Aproximar los resultados de la detección de sistema operativo) Cuando Nmap no puede perfectamente a detectar un sistema veces ofrecerá posibilidades operativo que se que encaje aproximen lo suficiente. Las opciones tienen que aproximarse mucho al detectado para que 119 Nmap haga esto por omisión .Cualquiera de estas dos opciones (equivalentes) harán que Nmap intente aproximarlos resultados de una forma más agresiva. Pruebas de Acceso Al tener todas las configuraciones necesarias en el servidor se hace una prueba de acceso con las cuentas agregadas de todos los usuarios, se eligen a lazar 5 cuentas de usuarios y se hacen los accesos desde computadoras en otra ubicación, esto es con la finalidad de probar el comportamiento del servidor y su configuración. ENTREGA Capacitación En esta última etapa se le da una capacitación al encargado de administrar el servidor web, la capacitación constará de que el administrador tenga las habilidades para altas, bajas y cambios de usuarios, en dado caso que sea necesario instalar el servidor desde cero el administrador contara con un manual que lo guiara paso a paso en la instalación del servidor web. Manual Se le entregara al administrador del servidor web un manual enfocado en la instalación del servidor web desde el sistema operativo Ubuntu 10.10, el servidor XAMPP, la librería JAVA, la aplicación TOMCAT, agregar usuarios tanto en el 120 servidor como en la base de datos y realizar las pruebas tanto de seguridad y acceso. 121 X. RESULTADOS OBTENIDOS Los principales resultados obtenidos de este proyecto son los siguientes: Instalación de Ubuntu 10.10 64bits. Se instaló este sistema operativo por su estabilidad y seguridad, está basado en Unix por lo cual hasta el momento no tiene virus que lo dañen, su instalación fue rápida y sencilla, el sistema operativo se actualiza constantemente, aunque es diferente a Windows es muy amigable y fácil de entender para el administrador, al momento de instalar no se detectó algún problema y al finalizar tampoco se tuvo problemas con los drivers para el uso del hardware del servidor. Instalación de XAMPP. Apache es uno de los servidores web más utilizados, esto es debido a que su instalación es muy sencilla y rápida, es un servidor configurable y de diseño agradable con la capacidad de extender su funcionalidad y la calidad de sus servicios, trabaja en conjunto con gran cantidad de lenguajes de programación lo que lo hace un servidor web completo. Aplicación Rsync. Esta aplicación es solo para sistemas Unix el cual no tuvo problemas de instalación con Ubuntu 10.10, esta aplicación nos permite tener una copia de seguridad de archivos en el servidor ya sea en red o en la misma máquina. 122 XI. ANALISIS DE RIESGOS Clasificación de Riesgos Riesgos – Consecuencias Riesgo…….Bajo Retraso en fecha de entrega Riesgo……Medio Caída del Servidor por energía Riesgo….…Alto Accesos no autorizados por configuraciones erróneas Riesgo……Medio Contraseñas débiles de los usuarios Riesgo…….Bajo Riesgo de pérdida de datos Riesgo…….Bajo Mal entendidos con el alcance del proyecto Fecha de identificación de riesgo Responsable 10/01/11 14/01/11 17/01/11 17/01/11 07/02/11 11/01/11 Acciones de Mitigación Fecha limite mitigación Team Leader Cumplir con los tiempos establecidos 14/01/11 Soporte Técnico Asegurar la energía del servidor o en caso de no es posible respaldar la información 17/01/11 Realizar pruebas de acceso y de seguridad en el servidor incluso simulando ataques. 31/02/11 Manejar un estándar en las contraseñas de los usuarios para que sean robustas 21/02/11 Uso de la tecnología Rsync para el respaldo de la información 21/02/11 Mantener al tanto de los avances del servidor aclarando los puntos ya cubiertos 14/01/11 Team Leader Team Leader Team Leader Team Leader Tabla 1.2 Análisis de Riesgos 123 XII. CONCLUSIONES En conclusión el servidor web se terminó en tiempo y forma, a pesar de haber tenido problemas con la configuración ya que al principio se planeó usar Centos una versión de Linux más enfocada a servidores, pero no cumplió con los requerimientos lo cual se optó por Ubuntu que es la versión más popular de Linux y con muy buen soporte, otro problema que se tuvo en el transcurso de la configuración fueron la alta de los usuarios ya que el script que utilizamos para dar de alta todos los usuarios estaba teniendo problemas de implementación por la sintaxis que se utilizaba. Sin embargo todas las dificultades fueron superadas y resueltas el servidor se encuentra funcionando en la carrera de Tecnologías de la Información y Comunicación dando servicio a la comunidad estudiantil de esta carrera. 124 XIII. RECOMENDACIONES El proyecto cuenta con posibilidades de crecimiento ya que en el futuro se puede implementar un servidor de correo para los alumnos, claro que el crecimiento de aplicaciones en el servidor y de servicios llevará a estructurar los servicios en el mismo e incluso pensar en dividir servicios como por ejemplo tener en un servidor la base de datos y en otro el servidor web para una mayor distribución de los recursos y manejo de los mismos, incluso ayudará para que en un momento que se tenga problemas se puede separar la falla dependiendo del error que se tenga. Más que una recomendación es un punto importante en el funcionamiento del servidor web que es mantener siempre los respaldos de la información, ya que de eso depende la calificación y el buen aprendizaje que los profesores les impartan a los alumnos con respecto a sus trabajos. Tener esta nueva herramienta habla bien de la carrera y es por eso que es muy importarte darle el uso apropiado para sacar el mayor provecho posible de ambas partes. 125 XIV. REFERENCIAS BIBLIOGRAFICAS Servidor Web Dell PowerEdge T410 Manual PDF http://www.dell.com/downloads/global/products/pedge/pedge_t410_spe csheet_new.pdf Ubuntu Server Guide 2010 Manual en PDF Copyright 2010 Canonical Ltd. http://help.ubuntu.com/10.10/serverguide/C/serverguide.pdf XAMPP Install Guide 2007 A3webtech 2007 XAMPP http://www.a3webtech.com/index.php/xampp.html http://www.a3webtech.com/index.php/xampp-2.html Apache y Tomcat en Linux http://www.mundogeek.net/archivos/2006/04/03/apache-y-tomcat-enlinux/ Rsync Tutorial http://www.fredshack.com/docs/rync.html Cron Tutorial http://www.ebitacora.com/tutorial-de-cron.html American Psychological Association. (2001). Publication Manual of the American Psychological Association (5th ed.). Washington, DC: The Author. (R 808.066 P976 2001). Version en Ingles. 126
 0
0
Anuncio
Documentos relacionados
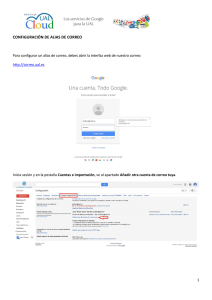






![([SOLOINTERNET] Manual 07.Cómo crear una alias de dominio)](http://s2.studylib.es/store/data/004495242_1-83ba831829883a378408284a750c0b01-300x300.png)
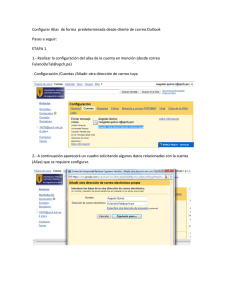

Descargar
Anuncio
Añadir este documento a la recogida (s)
Puede agregar este documento a su colección de estudio (s)
Iniciar sesión Disponible sólo para usuarios autorizadosAñadir a este documento guardado
Puede agregar este documento a su lista guardada
Iniciar sesión Disponible sólo para usuarios autorizados