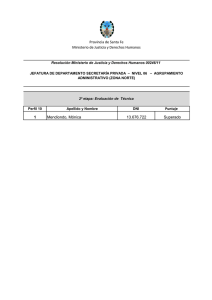
Agrupamiento de Datos utilizando técnicas MAM-SOM
Anuncio

Agrupamiento de Datos utilizando técnicas MAM-SOM
Carlos Eduardo Bedregal Lizárraga
Orientador: Prof. Mag. Juan Carlos Gutiérrez Cáceres
Tesis profesional presentada al Programa Profesional de
Ingeniería Informática como parte de los requisitos para
obtener el Título Profesional de Ingeniero Informático.
UCSP - Universidad Católica San Pablo
Julio de 2008
A mis padres y mi hermano.
Abreviaturas
MAM Métodos de Acceso Métrico
SAM Spatial Access Method
MAE Métodos de Acceso Espacial
NCD Número de Cálculos de Distancia
SOM Self-Organizing Maps
GSOM Growing Self-Organizing Maps
GHSOM Growing Hierarchical Self-Organizing Maps
GNG Growing Neural Gas
CHL Competitive Hebbian Learning
BMU Best Matching Unit
IGG Incremental Grid-Growing
RNA Redes Neuronales Artificiales
ART Adaptative Resonance Theory
MST Minimal Spanning Tree
SAT Spatial Approximation Tree
IGNG Incremental Growing Neural Gas
DBGNG Density Based Growing Neural Gas
NGCHL Neural Gas with Competitive Hebbian Learning
AESA Approximating and Eliminating Search Algorithm
3
Agradecimientos
En primer lugar deseo agradecer a Dios por haberme guiado a lo largo de mis años de estudio.
Agradezco a mi familia por el gran apoyo brindado para forjarme como un profesional.
Agradezco a la universidad por haberme brindado la formación que ahora me permitirá ayudar
a construir una mejor sociedad.
Agradezco de forma muy especial a Ernesto y a Juan Carlos por haberme guiado en esta tesis.
Muchas gracias también a todos los profesores con los que trabajé durante esos largos cinco
años, y al personal administrativo por la atención brindada y por su disposición a ayudar.
Resumen
Hoy en día la necesidad de procesar grandes volúmenes de datos es cada vez
más frecuente. Investigaciones recientes buscan proponer algoritmos eficientes para
problemas complejos como el agrupamiento de datos. Una de estas investigaciones
llevó al desarrollo de la familia de técnicas MAM-SOM y SAM-SOM, que propone
la combinación de Self-Organizing Maps (SOM) y Métodos de Acceso para una rápida recuperación de información por similitud. En esta investigación se presentan
resultados empíricos del uso de técnicas MAM-SOM empleando Métodos de Acceso recientes como Slim-Tree y Omni-Secuencial, aplicadas a tareas de agrupamiento
de datos; mostrando la mejora y propiedades de estas técnicas en contraste con una
de las técnicas tradicionales de agrupamiento: las redes SOM.
Abstract
Nowadays the need to process lots of complex multimedia databases is more
frequent. Recent investigations pursue to find efficient algorithms to solve complex
problems such as data clustering. One of these investigations led to the development of the MAM-SOM and SAM-SOM families, which propose the combination of Self-Organizing Maps (SOM) with Access Methods for a faster similarity
information retrieval. In this investigation we present experimental results of the
MAM-SOM techniques using recent Access Methods such as Slim-Tree and OmniSequential when performing clustering tasks, showing the improvement acquired
by these techniques and their properties in contrast with one traditional clustering
technique: the SOM networks.
Índice general
1. Introducción
14
1.1. Contexto y Motivación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
14
1.2. Definición del problema . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
16
1.3. Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
16
1.4. Organización de la tesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
16
2. Agrupamiento de datos
17
2.1. Consideraciones iniciales . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
17
2.2. Agrupamiento de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
18
2.2.1. Reducción de la dimensionalidad . . . . . . . . . . . . . . . . . . . .
19
2.2.2. Validez de un grupo . . . . . . . . . . . . . . . . . . . . . . . . . . .
19
2.2.3. Estimación de error . . . . . . . . . . . . . . . . . . . . . . . . . . . .
20
2.2.4. Conocimiento del dominio de datos . . . . . . . . . . . . . . . . . . .
20
2.2.5. Otras propiedades . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
20
2.3. Etapas del proceso de agrupamiento . . . . . . . . . . . . . . . . . . . . . . .
20
2.3.1. Representación del patrón . . . . . . . . . . . . . . . . . . . . . . . .
21
2.3.2. Definición de la medida de proximidad . . . . . . . . . . . . . . . . .
21
2.3.3. Agrupamiento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
22
2.3.4. Abstracción de datos . . . . . . . . . . . . . . . . . . . . . . . . . . .
22
2.3.5. Evaluación de resultados . . . . . . . . . . . . . . . . . . . . . . . . .
22
7
ÍNDICE GENERAL
2.4. Clasificación de las técnicas de agrupamiento . . . . . . . . . . . . . . . . . .
23
2.4.1. Agrupamiento jerárquico . . . . . . . . . . . . . . . . . . . . . . . . .
23
2.4.2. Agrupamiento particional . . . . . . . . . . . . . . . . . . . . . . . .
23
2.5. Técnicas comunes para agrupamiento de datos . . . . . . . . . . . . . . . . . .
24
2.5.1. Agrupamiento con vecinos más cercanos . . . . . . . . . . . . . . . .
24
2.5.2. Agrupamiento difuso . . . . . . . . . . . . . . . . . . . . . . . . . . .
24
2.5.3. Agrupamiento con RNA . . . . . . . . . . . . . . . . . . . . . . . . .
24
2.5.4. Agrupamiento con métodos evolutivos . . . . . . . . . . . . . . . . . .
24
2.6. Aplicaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
25
2.7. Consideraciones finales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
26
3. Redes Neuronales Artificiales
27
3.1. Consideraciones iniciales . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
27
3.2. Definiciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
27
3.2.1. Modelo de una neurona artificial . . . . . . . . . . . . . . . . . . . . .
28
3.2.2. Arquitectura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
28
3.2.3. Aprendizaje . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
29
3.3. Redes neuronales auto-organizables . . . . . . . . . . . . . . . . . . . . . . .
30
3.3.1. Entrenamiento de los mapas auto-organizables . . . . . . . . . . . . .
31
3.4. Redes SOM constructivas . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
32
3.4.1. Incremental Grid-Growing . . . . . . . . . . . . . . . . . . . . . . . .
33
3.4.2. Growing Self-Organizing Maps . . . . . . . . . . . . . . . . . . . . .
33
3.4.3. Growing Neural Gas . . . . . . . . . . . . . . . . . . . . . . . . . . .
33
3.4.4. Density Based Growing Neural Gas . . . . . . . . . . . . . . . . . . .
33
3.4.5. Aprendizaje Hebbiano Competitivo . . . . . . . . . . . . . . . . . . .
33
3.4.6. Gas Neuronal con Aprendizaje Hebbiano Competitivo . . . . . . . . .
34
3.5. Growing Neural Gas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
34
Ingeniería Informática - UCSP
8
ÍNDICE GENERAL
3.5.1. Algoritmo GNG . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
35
3.6. Consideraciones finales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
38
4. Métodos de Acceso Métrico
39
4.1. Consideraciones iniciales . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
39
4.2. Definiciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
39
4.2.1. Consultas de proximidad . . . . . . . . . . . . . . . . . . . . . . . . .
40
4.2.2. Consideraciones de eficiencia . . . . . . . . . . . . . . . . . . . . . .
41
4.3. Algoritmos de búsqueda . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
42
4.3.1. Burkhard-Keller Tree . . . . . . . . . . . . . . . . . . . . . . . . . . .
42
4.3.2. Vantage-Point Tree . . . . . . . . . . . . . . . . . . . . . . . . . . . .
43
4.3.3. M-Tree . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
43
4.3.4. Slim-Tree . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
44
4.3.5. Omni-Tree . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
44
4.3.6. DBM-Tree . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
44
4.4. Slim-Tree . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
45
4.4.1. Funcionamiento . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
45
4.5. Omni-Secuencial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
47
4.6. Consideraciones finales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
48
5. Técnica MAM-SOM para agrupamiento de datos
50
5.1. Consideraciones iniciales . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
50
5.2. Trabajos Previos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
50
5.3. Técnicas MAM-SOM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
52
5.3.1. MAM-SOM Híbrida . . . . . . . . . . . . . . . . . . . . . . . . . . .
52
5.3.2. MAM-SOM* . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
53
5.4. Propiedades de las técnicas MAM-SOM . . . . . . . . . . . . . . . . . . . . .
54
Ingeniería Informática - UCSP
9
ÍNDICE GENERAL
5.5. Estructuras propuestas para la técnica MAM-SOM . . . . . . . . . . . . . . .
55
5.6. Agrupamiento con MAM-SOM . . . . . . . . . . . . . . . . . . . . . . . . .
55
5.7. Consideraciones finales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
57
6. Experimentos
58
6.1. Consideraciones iniciales . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
58
6.2. Bases de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
58
6.3. Primer grupo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
59
6.3.1. Discusión en relación al número de agrupamientos . . . . . . . . . . .
59
6.3.2. Discusión en relación al número de patrones . . . . . . . . . . . . . .
61
6.4. Segundo grupo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
61
6.4.1. Discusión en relación al número de conexiones . . . . . . . . . . . . .
61
6.4.2. Discusión en relación al número de patrones . . . . . . . . . . . . . .
61
6.5. Tercer grupo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
64
6.6. Experimentos adicionales . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
67
6.6.1. Discusión con respecto a los agrupamientos . . . . . . . . . . . . . . .
67
6.6.2. Discusión con respecto al tiempo consumido . . . . . . . . . . . . . .
67
7. Conclusiones y Trabajos Futuros
70
7.1. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
70
7.2. Contribuciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
71
7.3. Problemas encontrados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
71
7.4. Recomendaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
71
7.5. Trabajo futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
71
Bibliografía
77
Ingeniería Informática - UCSP
10
Índice de cuadros
6.1. Comparación de resultados para la base de datos COVERT (54-d) . . . . . . .
64
6.2. Comparación de resultados para la base de datos IMAGES (1215-d) . . . . . .
67
6.3. Comparación de resultados para la base de datos NURSERY (8-d) . . . . . . .
67
11
Índice de figuras
2.1. Ejemplo de agrupamientos de diferentes formas. . . . . . . . . . . . . . . . . .
18
2.2. Etapas de la tarea de agrupamiento de datos. . . . . . . . . . . . . . . . . . . .
21
3.1. Neurona McCulloch-Pitts [Jain et al., 1996]. . . . . . . . . . . . . . . . . . . .
28
3.2. Taxonomía de la arquitectura de las RNA [Jain et al., 1996]. . . . . . . . . . .
29
3.3. Mapa auto-organizable de Kohonen [Jain et al., 1996]. . . . . . . . . . . . . .
31
3.4. La red GNG se adapta a la distribución de señales con áreas y dimensionalidades diferentes del espacio de entrada [Fritzke, 1995]. . . . . . . . . . . . . .
35
4.1. Tipos básicos de consultas por proximidad. . . . . . . . . . . . . . . . . . . .
41
4.2. Taxonomía de algoritmos en base a sus características [Chávez et al., 2001] . .
43
4.3. División de nodos con el algoritmo MST [Caetano Traina et al., 2000]. . . . . .
46
4.4. Funcionamiento del algoritmo Slim-down [Caetano Traina et al., 2000]. . . . .
47
4.5. Selección de los candidatos para una consulta de rango con diferentes cardinalidades de F [Filho et al., 2001]. . . . . . . . . . . . . . . . . . . . . . . . . .
48
5.1. Impacto del valor λ en la red GNG [Cuadros-Vargas and Romero, 2005]. . . . .
52
5.2. Ejemplo del proceso de poda de conexiones de las técnicas MAM-SOM* con
5000 patrones y N eighborhoodSize = 3 [Cuadros-Vargas and Romero, 2002].
54
6.1. Comparación del Número de Cálculos de Distancia acumulado de la red Growing Neural Gas y la técnica MAM-SOM GNG+Slim-Tree a lo largo del proceso
de entrenamiento de la red en relación al número de agrupamientos generados. .
60
12
ÍNDICE DE FIGURAS
6.2. Comparación del Número de Cálculos de Distancia acumulado de la red Growing Neural Gas y la técnica MAM-SOM GNG+Slim-Tree a lo largo del proceso
de entrenamiento de la red en relación al número de patrones presentados. . . .
62
6.3. Comparación del Número de Cálculos de Distancia acumulado de la red Growing Neural Gas y la técnica MAM-SOM* Slim-Tree en relación al número de
conexiones creadas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
63
6.4. Comparación del Número de Cálculos de Distancia acumulado de la red Growing Neural Gas y la técnica MAM-SOM* Slim-Tree en relación al número de
patrones presentados. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
65
6.5. Comparación del Número de Cálculos de Distancia acumulado por patrón presentado usando la base de datos COVERT (54-d) . . . . . . . . . . . . . . . .
66
6.6. Comparación del Número de Cálculos de Distancia acumulado por patrón presentado usando la base de datos IMAGES (1215-d) . . . . . . . . . . . . . . .
66
6.7. Comparación del Número de Cálculos de Distancia acumulado por patrón presentado usando la base de datos NURSERY (8-d) . . . . . . . . . . . . . . . .
66
6.8. Reducción gradual del parámetro τ para encontrar agrupamientos en un conjunto datos sintéticos de 1000 puntos en dos dimensiones. N eighborhoodSize = 3. 68
Ingeniería Informática - UCSP
13
Capítulo 1
Introducción
1.1. Contexto y Motivación
En el mundo actual la información se ha convertido en uno de los recursos más valiosos
dentro de cualquier actividad humana. Asimismo, la cantidad y complejidad de la información
disponible presenta un crecimiento explosivo a medida que la tecnología avanza, siendo cada
vez más frecuente el caso en que aplicaciones necesiten manejar grandes volúmenes de datos
con el fin de responder a determinados problemas.
La información cumple un rol muy importante en el desarrollo de personas, organizaciones y sociedades. La aparición de grandes conjuntos de datos es cada vez más frecuente
como consecuencia del acelerado desarrollo informático, en especial de la Internet (YouTube,
Wikis, Google, Yahoo, etc.). De igual manera, la complejidad de los datos se va incrementando: desde trabajar con datos simples como números o cadenas de texto hasta problemas que
involucran datos complejos como imágenes, vídeos o cadenas de ADN.
Proyectos como CLUTO 1 de la Universidad de Minnesota para tareas de agrupamiento
de datos, CYBER-T 2 de la Universidad de California para el análisis de ADN, IMEDIA 3 del
gobierno de Francia para la recuperación de información en bases de datos multimedia son solo
algunos ejemplos de la necesidad de técnicas cada vez más eficientes para procesar los datos,
detectar interrelaciones y agrupamientos entre ellos e incluso generar nuevo conocimiento.
El agrupamiento de datos es una tarea de análisis exploratorio que se refiere a la clasificación de patrones de una forma no supervisada, formando grupos en base a las relaciones
no perceptibles a simple vista, con el objetivo de poder descubrir una estructura subyacente
[Duda et al., 2000, Jain et al., 2000]. La utilidad en el análisis exploratorio de datos está fuertemente demostrada por su uso en diversos contextos y disciplinas como la recuperación de información, la minería de datos o la segmentación de imágenes entre muchas otras [Jain et al., 1999,
1
http://glaros.dtc.umn.edu/gkhome/views/cluto
http://cybert.microarray.ics.uci.edu/
3
http://www-rocq.inria.fr/imedia/
2
14
CAPÍTULO 1. Introducción
Jain and Dubes, 1988].
De las varias técnicas existentes para agrupamiento de datos, los Mapas Auto-organizables
de Kohonen [Kohonen, 1988], del inglés SOM, vienen siendo ampliamente utilizados en el
agrupamiento de grandes conjuntos de datos, debido principalmente a la poca dependencia
al dominio del conocimiento y a los eficientes algoritmos de aprendizaje disponibles. Estas
estructuras resaltan por su capacidad de generar mapas topológicos a través de una arquitectura paralela y distribuida. Estos mapas pueden ser vistos como una representación en bajas
dimensiones de los datos de entrada, preservando las propiedades topológicas de la distribución
[Kohonen, 1998].
Si bien los mapas auto-organizables son muy populares para tareas de agrupamiento
de grandes conjuntos de datos (siendo un caso muy popular WEBSOM [Lagus et al., 1999]),
poseen algunas debilidades como la búsqueda secuencial de la unidad ganadora utilizada en la
etapa de entrenamiento. Por cada patrón presentado a la red se hace una comparación de proximidad con todas las unidades (neuronas) existentes, haciendo pesado el entrenamiento de la
red [Cuadros-Vargas, 2004].
Otro punto importante a tocar en las redes SOM, y de la mayoría de Redes Neuronales
Artificiales (RNA), es el dilema Estabilidad-Plasticidad [Grossberg, 1972]. La estabilidad se refiere a la pertenencia de cada patrón a una sola categoría a lo largo del entrenamiento, es decir,
que no se activen diferentes unidades de salida en diferentes momentos, mientras que la plasticidad se refiere a la capacidad de adaptarse a nuevos datos, incorporando nuevo conocimiento sin
afectar el aprendido anteriormente. Elasticidad y plasticidad están inversamente relacionadas,
ya que la presencia de una afecta a la otra.
La topología estática del modelo original de Kohonen llevo al desarrollo de técnicas constructivas, que, incorporadas a las redes SOM, lograron abarcar el tema de la plasticidad, otorgando a las redes la capacidad de cambiar su arquitectura durante el entrenamiento. Entre algunas redes constructivas representativas tenemos Growing Neural Gas (GNG) [Fritzke, 1995],
Growing Self-Organizing Maps (GSOM) [Alahakoon et al., 1998], Growing Hierarchical SelfOrganizing Maps (GHSOM) [Dittenbach et al., 2000] e Incremental Grid-Growing (IGG)
[Blackmore and Miikkulainen, 1993].
Por otro lado, las redes SOM carecen de la capacidad para responder a búsquedas específicas como búsquedas por rango o búsquedas de los k-vecinos mas cercanos. En las comunidades de Base de Datos y Recuperación de Información el problema de búsquedas específicas por similitud es comúnmente abordado por los Métodos de Acceso Métrico (MAM)
[Chávez et al., 2001]. Algunas estructuras conocidas son BK-Tree [Burkhard and Keller, 1973],
M-Tree [Ciaccia et al., 1997], Slim-Tree [Caetano Traina et al., 2000] y más recientemente DBMTree [Marcos R. Viera and Traina, 2004], que permiten realizar consultas de proximidad eficientemente. La incorporación de Métodos de Acceso Métrico en las redes SOM, técnica conocida como MAM-SOM [Cuadros-Vargas, 2004], logra reducir el costo computacional de la
búsqueda de la unidad ganadora, acelerando drásticamente el proceso de agrupamiento.
Ingeniería Informática - UCSP
15
1.2. Definición del problema
1.2. Definición del problema
El problema en tareas de agrupamiento de datos es la complejidad algorítmica de procesamiento y clasificación. La dificultad de agrupar grandes conjuntos de datos complejos se debe
principalmente al alto número de cálculos de distancia entre elementos que los algoritmos SOM
realizan.
1.3. Objetivos
El objetivo principal de esta investigación es proponer un algoritmo de agrupamiento
MAM-SOM eficiente para su aplicación en grandes conjuntos de datos considerando una mínima complejidad algorítmica.
La presente investigación pretende además demostrar la eficiencia de las técnicas MAMSOM. Estas técnicas combinan mapas auto-organizables y métodos de acceso métrico para
agilizar el procesamiento de grandes conjuntos de datos.
Se busca demostrar la rapidez de las técnicas MAM-SOM comparándolas con otras redes
SOM en tareas de agrupamiento de datos, así como la mejora y beneficios ganados al introducir
Métodos de Acceso Métrico.
1.4. Organización de la tesis
La tesis está organizada como sigue:
En el capítulo 2 se desarrolla el tema de Agrupamiento de datos. Se describen sus definiciones, aplicaciones y etapas.
En el capítulo 3 se exponen las Redes Neuronales Artificiales, definiciones y su uso como técnicas de agrupamiento de datos, características de los mapas auto-organizables y la red
propuesta para los experimentos.
En el capitulo 4 se exponen los Métodos de Acceso Métrico: definiciones, propiedades y
consideraciones de eficiencia, así como las estructuras propuestas para este investigación.
En el capítulo 5 se presentan las técnicas MAM-SOM, la combinación de los métodos de
acceso y los mapas auto-organizables, y la técnica propuesta para las tareas de agrupamiento de
datos.
En el capítulo 6 se describirán y analizarán los experimentos realizados con diversas técnicas, y la comparación con las técnicas propuestas.
En el capítulo 7 se presentarán las conclusiones y consideraciones para trabajos futuros.
Ingeniería Informática - UCSP
16
Capítulo 2
Agrupamiento de datos
2.1. Consideraciones iniciales
El reconocimiento, descripción, clasificación y agrupamiento de patrones de forma automática son problemas importantes en varias disciplinas científicas como biología, psicología,
medicina, visión por computadora e inteligencia artificial. En [Watanabe, 1985] se define a patrón como lo opuesto al caos, una entidad vagamente definida que puede ser nombrada.
Dado un patrón, su reconocimiento/clasificación consiste en una de las siguientes dos
tareas [Jain et al., 2000]: 1) clasificación supervisada, en la que el patrón de entrada es identificado como miembro de una clase predefinida, o 2) clasificación no supervisada (agrupamiento
de datos o clustering), en la que el patrón es asignado a una clase aún no conocida.
El área de reconocimiento de patrones incluye aplicaciones de minería de datos (identificar una correlación entre millones de patrones multidimensionales), clasificación de documentos, predicciones financieras, organización y recuperación de bases de datos multimedia, y
biometría (identificación personal basada en atributos físicos), entre otras.
En [Jain et al., 2000] se especifican cuatro métodos para el reconocimiento de patrones:
1) templatematching, 2) clasificación estadística, 3) coincidencia sintáctica o estructural, y 4)
redes neuronales.
En los métodos estadísticos, cada patrón es representado en términos de d características
o medidas, y es visualizado como un punto en un espacio d-dimensional. El objetivo aquí es seleccionar las características que permitan a los vectores de patrones que pertenecen a diferentes
categorías ocupar regiones compactas y disjuntas en el espacio de características d-dimensional.
A pesar de los principios aparentemente diferentes, la mayoría de modelos de redes
neuronales son implícitamente equivalentes o similares a los métodos estadísticos clásicos de
reconocimiento de patrones [Jain et al., 2000]. Como veremos, las redes neuronales ofrecen
además varias ventajas.
17
2.2. Agrupamiento de datos
Figura 2.1: Ejemplo de agrupamientos de diferentes formas.
En muchas aplicaciones de reconocimiento de patrones, es en exceso costoso, difícil, o
incluso imposible, etiquetar manualmente cada un patrón con su categoría correcta. Por este motivo la clasificación no supervisada, conocida como agrupamiento de datos, provee una solución
a este tipo de problemas.
2.2. Agrupamiento de datos
En el área de reconocimiento de patrones, el reconocimiento o clasificación no supervisada (agrupamiento de datos), es el conjunto de procedimientos diseñados para encontrar grupos
naturales basados en las similitudes presentes en un conjunto de patrones; los patrones son representados como un vector de medidas o como un punto en un espacio multidimensional, para
luego ser agrupados en base a su similitud [Jain and Dubes, 1988, Jain et al., 1999].
En agrupamiento de datos, la clasificación de patrones se da de forma no supervisada, que
a diferencia de la clasificación supervisada en la que se tienen patrones previamente clasificados,
el objetivo radica en agrupar el conjunto de patrones no etiquetados en agrupamientos con algún
significado.
La clasificación no supervisada o agrupamiento es un problema complejo debido a que los
datos pueden originar grupos con diferentes formas y tamaños. En [Jain et al., 2000]se definen
las propiedades que deben cumplir los agrupamientos: 1) los patrones dentro de un grupo son
más similares entre sí que patrones que pertenecen a grupos diferentes, y 2) un grupo consiste
de una relativa alta densidad de puntos separados de otros grupos por una relativa baja densidad
de puntos.
El creciente uso de técnicas de agrupamiento en el campo de análisis exploratorio de paIngeniería Informática - UCSP
18
CAPÍTULO 2. Agrupamiento de datos
trones, agrupamiento, toma de decisiones y aprendizaje de máquina han demostrado su utilidad.
Aplicaciones como la minería datos [Hand et al., 2001, Vesanto and Alhoniemi, 2000], donde
se busca obtener información útil a partir de grandes cantidades de datos; el reconocimiento de objetos [Lowe, 2001], caracteres [Breuel, 2001], del habla [Waibel et al., 1990] e incluso
del hablante [Xu et al., 2006]; la recuperación de información [Tombros et al., 2002]; y la segmentación de imágenes [Rueda and Qin, 2005, Arifin and Asano, 2006] que permite una clasificación de los píxeles de una imagen para el reconocimiento de superficies o texturas (útil para
la medicina o la geología); son solo algunos ejemplos de su uso práctico en el mundo actual.
En varios de estos problemas existe poca información previa de los datos, por lo que las
técnicas de agrupamiento son apropiadas para la exploración de las interrelaciones existentes
entre los datos.
Entre los principales temas a considerar en las tareas de agrupamiento de datos tenemos la
dimensionalidad de los datos, la determinación de la validez de un grupo, la estimación de la tasa
de error del sistema de reconocimiento, el conocimiento previo que se tenga sobre el dominio de
datos y las propiedades del algoritmo de agrupamiento [Jain et al., 2000, Jain and Dubes, 1988,
Jain et al., 1999].
2.2.1. Reducción de la dimensionalidad
Hay dos razones principales para mantener la dimensionalidad de la representación de los
patrones lo más pequeña posible: costo de medición y precisión de la clasificación.
Un reducido conjunto de características simplifica tanto la representación del patrón como
los clasificadores que se construyen sobre la representación seleccionada. El clasificador resultante será más rápido y usará menos memoria, pero por otro lado la reducción del número de
características puede disminuir la exactitud del sistema al reducir el poder de discriminación.
Por lo tanto, la selección de características es muy importante, ya que es posible hacer dos
patrones similares arbitrariamente representándolos con características redundantes.
Para la reducción de la dimensionalidad se aplican algoritmos de selección y extracción de
características. La selección de características se refiere a algoritmos que seleccionan el mejor
subconjunto de características. Los algoritmos de extracción de características crean nuevas características en base a transformaciones o combinaciones del conjunto original de características.
2.2.2. Validez de un grupo
En general, se dice que un grupo es válido si es compacto y aislado. Entonces, se debe
determinar cuán compacto es un grupo midiendo la cohesión interna entre los elementos del
grupo; y cuán aislado es, midiendo la separación del grupo con otros patrones que no pertenecen
a él.
Ingeniería Informática - UCSP
19
2.3. Etapas del proceso de agrupamiento
2.2.3. Estimación de error
En la práctica, la tasa de error de un sistema de reconocimiento debe ser estimada a partir
de todas las muestras disponibles, divididas en conjuntos de entrenando y prueba. El clasificador
se construye usando las muestras de entrenamiento, y luego se evalúa en base a la clasificación
de las muestras del conjunto de prueba. El porcentaje de muestras de prueba que fueron mal
clasificadas se toma como una estimación de la tasa de error.
2.2.4. Conocimiento del dominio de datos
Debido a que la tarea de agrupamiento es subjetiva (i.e. los mismos datos pueden ser
particionados de diferentes formas para diferentes propósitos), esta subjetividad es incorporada en el criterio de agrupamiento al añadir conocimiento del dominio en una o más fases del
proceso de agrupamiento ya sea implícita o explícitamente. Este conocimiento influye en la
selección de la representación de los patrones, la selección de la medida de similitud y en la
selección del esquema de agrupamiento. En el caso de las Redes Neuronales Artificiales (RNA)
el conocimiento del domino se usa implícitamente al seleccionar los valores de los parámetros
de control o aprendizaje.
2.2.5. Otras propiedades
Algunas de las propiedades más comunes en los algoritmos de agrupamiento de datos
son:
Aglomerativo o divisivo. Una clasificación jerárquica aglomerativa coloca cada objeto en
un grupo propio y gradualmente une estos grupos en otros más grandes hasta que todos
los objetos están dentro del mismo grupo, mientras que una clasificación divisiva coloca
inicialmente a todos los objetos en un único grupo que es gradualmente dividido.
Serial o simultáneo. Los procesos seriales manejan a los patrones uno por uno, mientras
que los simultáneos trabajan con todo el conjunto de patrones al mismo tiempo.
Rígido o difuso. Un algoritmo rígido coloca cada patrón en un solo grupo. Un algoritmo
difuso asigna a cada patrón grados de pertenencia a varios grupos.
2.3. Etapas del proceso de agrupamiento
La Figura 2.2 muestra el proceso típico de agrupamiento de datos. Entonces, la actividad
de agrupamiento involucra los siguientes pasos [Jain et al., 1999]:
1. Representación del patrón (extracción y selección de características),
Ingeniería Informática - UCSP
20
CAPÍTULO 2. Agrupamiento de datos
Figura 2.2: Etapas de la tarea de agrupamiento de datos.
2. Definición de una medida de proximidad de patrones apropiada al dominio de datos,
3. Agrupamiento,
4. Abstracción de datos, y
5. Evaluación de resultados.
2.3.1. Representación del patrón
La representación de patrones hace referencia al número de clases, la cantidad de patrones
disponibles y en especial al número, tipo y escala de las características con las cuales el algoritmo de agrupamiento trabajará. Típicamente los patrones son representados como vectores
multidimensionales, donde cada dimensión es asociada a una característica. Las características
pueden ser cuantitativas (como el peso) o cualitativas (como el color).
Como se mencionó anteriormente, existen dos técnicas para determinar el grupo de características que representarán a los patrones: selección y extracción. En la selección de características se identifica el conjunto de características originales más efectivo para la tarea de
agrupamiento. En la extracción de características se aplican diversas transformaciones en las
características existentes para producir nuevas características. En ambos casos lo que se busca
es mejorar el rendimiento de la clasificación y/o la eficiencia computacional.
Una investigación cuidadosa sobre las características disponibles, y sus transformaciones,
puede mejorar significantemente los resultados del agrupamiento. Asimismo una buena representación de patrones facilitará el entendimiento del agrupamiento resultante.
2.3.2. Definición de la medida de proximidad
Debido a que la definición de similitud es una parte fundamental en la determinación de
agrupamientos, la métrica con la que se medirá la similitud entre patrones debe ser escogida
cuidadosamente. En lugar de medir la similitud entre dos patrones es más común medir la
disimilitud usando una métrica definida en el espacio de características. Esta disimilitud entre
patrones se mide por medio de una función de distancia (como la distancia Euclidiana) que
refleja la diferencia entre dos patrones.
Ingeniería Informática - UCSP
21
2.3. Etapas del proceso de agrupamiento
Estas y otras consideraciones sobre los espacios métricos se abordarán con más detalle en
el Capítulo 4.
2.3.3. Agrupamiento
La etapa de agrupamiento es donde se forman los grupos en sí. Este agrupamiento puede
darse de diferentes maneras dependiendo del algoritmo de agrupamiento seleccionado y de
sus propiedades. Los grupos de salida (clusters) pueden ser rígidos o difusos. Adicionalmente
pueden aplicarse otro tipo de técnicas para la etapa de agrupamiento, como métodos probabilísticos y de teoría de grafos.
2.3.4. Abstracción de datos
El proceso de abstracción de datos consiste en generar una representación simple del
conjunto de datos que sea fácil de comprender o procesar. En el contexto de agrupamiento
de datos, la abstracción de datos se refiere a una descripción compacta de cada grupo, por lo
general en términos de patrones representativos o prototipos.
Para grupos pequeños e isótropos se puede utilizar al “centroide” como representación.
En el caso de grupos grandes, es mejor trabajar con puntos localizados en la región externa del
grupo, requiriendo más puntos en proporción a la complejidad de la forma del grupo.
Al brindar una descripción simple e intuitiva de los grupos, la abstracción de datos es una
herramienta útil para el análisis exploratorio.
2.3.5. Evaluación de resultados
Así como se hace una evaluación previa de los datos de entrada para determinar si deben
ser procesados o no, en la etapa de evaluación de resultados se hace un análisis de validez de
los agrupamientos en base a un criterio específico de optimización (usualmente subjetivo). El
análisis de validez busca determinar si el agrupamiento obtenido es significativo.
Existen tres tipos de estudios para analizar la validez de los grupos formados: 1) una
evaluación externa que compara la estructura obtenida con una previa, 2) una evaluación interna
que determina si la estructura es intrínsecamente apropiada para los datos y, 3) una evaluación
relativa que compara dos estructuras y mide el mérito relativo de cada una [Dubes, 1993].
Ingeniería Informática - UCSP
22
CAPÍTULO 2. Agrupamiento de datos
2.4. Clasificación de las técnicas de agrupamiento
La gran variedad de técnicas para la representación de los datos, medición de similitud
entre elementos, y agrupamiento han producido una amplia gama de métodos de agrupamiento.
No existe una técnica de agrupamiento de datos que sea universalmente aplicable debido principalmente a las suposiciones implícitas de la forma del grupo o al criterio de agrupamiento que
posee cada algoritmo.
Considerando al agrupamiento de datos como una tarea de clasificación no supervisada, la gran mayoría de métodos pueden ser divididos en: 1) jerárquicos, que producen una
serie de particiones anidadas basadas en un criterio para unir o dividir grupos basados en su
similitud, y 2) particionales, que identifican la partición que optimiza un criterio agrupamiento
[Jain et al., 1999].
Según la forma de construcción del dendograma, los métodos jerárquicos pueden clasificarse a su vez en aglomerativos y particionales. Según el criterio de optimización, los métodos
particionales pueden clasificarse en error cuadrático, mixture resolving, mode seeking y teoría
de grafos.
2.4.1. Agrupamiento jerárquico
Los métodos jerárquicos pueden construirse de forma aglomerativa o divisiva. Los métodos aglomerativos construyen la jerarquía de abajo a arriba, creando un grupo por objeto para
luego unirlos gradualmente hasta que todos los objetos pertenezcan del mismo grupo. Los métodos divisivos construyen la jerarquía de arriba a abajo, creando inicialmente un único grupo al
que pertenecen todos los objetos para luego ser dividido gradualmente.
Los métodos particionales suelen tener ventaja sobre los jerárquicos en aplicaciones donde
se trabaja con grandes conjuntos de datos, debido principalmente al costo computacional de la
construcción del dendograma de los métodos jerárquicos.
2.4.2. Agrupamiento particional
El agrupamiento particional puede ser expresado como: dados n patrones en un espacio
métrico d-dimensional, determinar la partición de los patrones en K grupos, de modo que los
patrones en un grupo son más similares entre sí que con patrones de otros grupos. El valor
de K puede o no ser especificado, y debe adoptarse un criterio de optimización global o local
[Jain et al., 2000].
Un criterio global, como el de error cuadrático, representa cada grupo a través de un prototipo y asigna los patrones a los grupos de acuerdo a los prototipos más similares. Un criterio
local forma los grupos utilizando estructuras locales en los datos, por ejemplo, identificando
regiones de alta densidad en el espacio de patrones o asignando un patrón y sus k vecinos más
Ingeniería Informática - UCSP
23
2.5. Técnicas comunes para agrupamiento de datos
cercanos al mismo grupo.
Los criterios de error cuadrático y descomposición de mezcla (mixture decomposition)
son los más populares dentro de los métodos de agrupamiento particional [Jain et al., 2000],
siendo el error cuadrático la estrategia más usada. Aquí el objetivo es obtener la partición que,
para un determinado número de grupos, minimice el error cuadrático.
2.5. Técnicas comunes para agrupamiento de datos
2.5.1. Agrupamiento con vecinos más cercanos
Debido a que la proximidad juega un papel importante en la noción de grupo, las distancias de los vecinos más cercanos sirven de base para procedimientos de agrupamiento. Un
patrón usualmente pertenece al mismo grupo que su vecino más cercano, y dos patrones son
considerados similares si comparten vecinos [Jain and Dubes, 1988].
2.5.2. Agrupamiento difuso
Los métodos tradicionales de agrupamiento de datos generan particiones, donde cada
patrón pertenece a un solo grupo, por lo que los grupos son disjuntos. El agrupamiento difuso
asocia cada patrón con todos los grupos usando una función de pertenencia. El diseño de esta
función de pertenencia es el punto más importante en el agrupamiento difuso.
2.5.3. Agrupamiento con RNA
Las Redes Neuronales Artificiales (RNA) han sido utilizadas extensamente en las últimas
décadas tanto para agrupamiento como para clasificación. Entre las principales características
tenemos la arquitectura de procesamiento paralela y distribuida, la capacidad de aprender relaciones no lineales complejas, el entrenamiento y la adaptación al dominio de datos. Las redes
neuronales competitivas son las más usadas para el agrupamiento de datos.
2.5.4. Agrupamiento con métodos evolutivos
Los métodos evolutivos hacen uso de operadores evolutivos y una población de soluciones
para obtener la partición de datos globalmente óptima. Las soluciones candidatas para el problema de agrupamiento son codificadas como cromosomas. Los operadores transforman uno o
más cromosomas de entrada en uno o más de salida, siendo los más populares: selección, combinación y mutación. Adicionalmente se aplica una función de evaluación a los cromosomas
para determinar la probabilidad de un cromosoma de pasar a la siguiente generación.
Ingeniería Informática - UCSP
24
CAPÍTULO 2. Agrupamiento de datos
Los métodos evolutivos destacan por ser técnicas de búsqueda global, a diferencia del
resto de métodos que realizan búsquedas locales.
2.6. Aplicaciones
Las técnicas de agrupamiento de datos fueron inicialmente desarrolladas en biología y
zoología para la construcción de taxonomías. La necesidad de varias disciplinas científicas de
organizar grandes cantidades de datos en grupos con significado ha hecho del agrupamiento
de datos una herramienta valiosa en el análisis de datos. Un sin número de entidades han sido objeto de aplicaciones de agrupamiento de datos: enfermedades, huellas digitales, estrellas,
consumidores e imágenes. En muchas aplicaciones no es primordial identificar el número exacto de grupos o la correcta pertenencia de cada patrón, basta con agrupar los objetos de una
forma eficaz para que el proceso físico, biológico o evolutivo subyacente pueda ser entendido o
aprendido [Jain and Dubes, 1988].
Entre las principales aplicaciones de agrupamiento de datos tenemos la segmentación de
imágenes, la minería de datos, la recuperación de información, el procesamiento del lenguaje
natural y el reconocimiento de objetos.
Segmentación de imágenes. Componente fundamental en muchas aplicaciones de visión computacional, consiste en el exhaustivo particionamiento de una imagen de entrada para la
identificación de regiones, cada una de las cuales es considerada homogénea con respecto a alguna propiedad de la imagen. Para cada píxel de la imagen se define un
vector de características compuesto por lo general de funciones de intensidad y ubicación del píxel. Esta idea ha sido satisfactoriamente usada para imágenes de intensidad (con o sin textura), imágenes de rango (profundidad) e imágenes multiespectrales
[Rueda and Qin, 2005, Arifin and Asano, 2006].
Reconocimiento de objetos. Cada objeto es representado en términos de un conjunto de imágenes del objeto obtenidas desde un punto de vista arbitrario. Debido a la infinidad de
vistas posibles de un objeto tridimensional se descartan las comparaciones de una vista
no conocida con las ya almacenadas. Entonces, a través de técnicas de agrupamiento es
posible seleccionar e identificar al conjunto de vistas de un objeto que sean cualitativamente similares [Lowe, 2001].
Procesamiento del lenguaje natural. Técnicas de agrupamiento son también utilizadas para
el reconocimiento de caracteres y del habla. Sistemas dependientes o independientes del
sujeto capaces de reconocer lexemas y morfemas para identificar caracteres escritos y
discursos hablados. A mayor número de sujetos con los que el sistema debe trabajar, más
difícil es discriminar entre clases debido a la superposición en el espacio de características
[Breuel, 2001, Waibel et al., 1990].
Minería de datos. Es necesario desarrollar algoritmos que puedan extraer información significante de la gran cantidad de datos disponibles. La generación de información útil, o
conocimiento, a partir de grandes cantidades de datos es conocida como minería de datos.
Ingeniería Informática - UCSP
25
2.7. Consideraciones finales
La minería de datos puede ser aplicada a bases de datos relacionales, transaccionales y
espaciales, así como en almacenes de datos no estructurados como la Internet. El agrupamiento de datos es a menudo un importante paso inicial de muchos procesos de minería
de datos, como segmentación de bases de datos, modelamiento predictivo, y visualización
[Hand et al., 2001, Vesanto and Alhoniemi, 2000].
2.7. Consideraciones finales
El análisis de agrupamientos es una técnica muy útil e importante. La velocidad, fiabilidad
y consistencia con las que un algoritmo de agrupamiento puede organizar grandes conjuntos de
datos constituyen las razones de su uso en aplicaciones de minería de datos, recuperación de
información entre otras. Los procedimientos de agrupamiento producen una descripción de los
datos en términos de grupos de datos que poseen fuertes similitudes internas [Duda et al., 2000].
Al aplicar un algoritmo de agrupamiento se debe considerar que: 1) antes de aplicar el algoritmo los datos deben sujetarse a pruebas para ver si existe alguna tendencia de agrupamiento,
2) no existe un “mejor.algoritmo de agrupamiento para los datos.
En [Jain et al., 1999] realizan una comparación de las diferentes técnicas de agrupamiento
de datos, donde se resalta que: la mayoría de métodos particionales utilizan la función criterio
de error cuadrado, pero las particiones generadas no son tan versátiles como las generadas por
algoritmos jerárquicos. Los grupos generados son en su mayoría de forma hiperesférica. Las
redes neuronales y los algoritmos genéticos pueden implementarse en hardware paralelo para
mejorar su velocidad, pero por otra parte, son sensibles a la selección de varios parámetros de
aprendizaje o control.
Los métodos evolutivos presentan un buen desempeño cuando el conjunto de datos es
pequeño y para datos de bajas dimensiones. Generalmente, al algoritmo de k-medias y su red
neuronal equivalente, la red de Kohonen, han sido aplicados en conjuntos de datos grandes.
Ingeniería Informática - UCSP
26
Capítulo 3
Redes Neuronales Artificiales
3.1. Consideraciones iniciales
Inspiradas en las redes neuronales biológicas, las Redes Neuronales Artificiales (RNA)
han sido satisfactoriamente utilizadas para resolver problemas de clasificación de patrones,
agrupamiento de datos, aproximación de funciones, predicción, optimización, recuperación por
el contenido, y control, convirtiéndose en herramientas populares para la resolución de este tipo
de problema.
En el área de reconocimiento de patrones, las RNA proveen arquitecturas que permiten
mapear algoritmos estadísticos de reconocimiento de patrones. La adaptabilidad de las RNA es
crucial para el diseño de sistemas de reconocimiento de patrones no sólo por su capacidad de
generalización, sino por su desempeño en ambientes dinámicos durante el entrenamiento.
Dentro de la tarea de agrupamiento de datos, las principales características de las redes
neuronales artificiales son [Jain et al., 1999]:
Procesamiento de vectores numéricos, por lo que los patrones deben representarse con
características cuantitativas.
Poseen una arquitectura de procesamiento distribuido y paralelo.
Pueden aprender los pesos de sus interconexiones adaptativamente, actuando como normalizadores de patrones y selectores de características.
3.2. Definiciones
Las redes neuronales pueden verse como sistemas de cómputo paralelos que consisten
en un gran número de procesadores simples con varias interconexiones. Los modelos de redes neuronales usan principios de organización como aprendizaje, generalización, adaptación,
27
3.2. Definiciones
Figura 3.1: Neurona McCulloch-Pitts [Jain et al., 1996].
tolerancia a fallos y procesamiento distribuido, en una red de grafos dirigidos, en la cual los
nodos son neuronas artificiales y las conexiones entre las salidas de las neuronas y sus entradas
son aristas dirigidas y con pesos. Entre sus principales características tenemos la habilidad de
aprender complejas relaciones no lineales de entrada-salida, usar entrenamiento secuencial y la
adaptación al dominio de datos [Jain et al., 1996, Haykin, 1994, Bishop, 1995].
3.2.1. Modelo de una neurona artificial
McCulloch y Pitts propusieron una unidad de umbral binario como modelo computacional
de una neurona. La Figura 3.1 muestra un diagrama esquemático de la neurona McCullochPitts, la cual calcula la suma de los pesos de sus n señales de entrada, xj , j = 1, 2, . . . , n, y
genera una salida “1” si la suma está por encima de un parámetro µ, o una salida “0” en el caso
contrario. McCulloch y Pitts probaron que con los pesos apropiados, un arreglo sincronizado de
las neuronas es capaz de una computación universal.
Comparando este modelo con la neurona biológica, las interconexiones modelan a los
axones, los pesos de conexión representan la sinapsis, y la función de activación aproxima la
actividad en el soma. Por otra parte las neuronas biológicas tiene grados de respuesta, producen
una secuencia de pulsos, y son actualizadas de forma asíncrona [Jain et al., 1996].
La neurona McCulloch-Pitts marcó una nueva era en el modelamiento computacional
de neuronas, siendo generalizado de muchas formas, principalmente remplazando la función
umbral de activación por otras como la sinodal o la Gaussiana.
3.2.2. Arquitectura
El agrupamiento de neuronas es llamado Redes Neuronales Artificiales (RNA), la que
puede ser vista como un grafo dirigido con pesos, donde los nodos son neuronas artificiales y
las aristas son las conexiones entre las neuronas [Haykin, 1994]. Como se observa en la Figura 3.2, según el patrón de conexión o arquitectura las RNA pueden clasificarse en: 1) redes
f eedf orward, en las que no existen ciclos en el grafo, y 2) redes f eedback en las que existen
ciclos debido a las conexiones de retroalimentación [Jain et al., 1996].
Las redes f eedf orward son llamadas estáticas porque producen un solo conjunto de salIngeniería Informática - UCSP
28
CAPÍTULO 3. Redes Neuronales Artificiales
Figura 3.2: Taxonomía de la arquitectura de las RNA [Jain et al., 1996].
idas, además, no poseen memoria ya que la respuesta a una entrada es independiente de los
estados previos de la red. Las redes f eedback o recurrentes son sistemas dinámicos donde un
nuevo estado de la red se genera por cada nueva entrada presentada, proceso que se repite hasta
llegar a un punto de convergencia.
3.2.3. Aprendizaje
La habilidad de aprender es una característica fundamental de la inteligencia. Un proceso
de aprendizaje, visto en el contexto de Redes Neuronales Artificiales, se refiere a la actualización de la arquitectura de la red y de los pesos de conexión. Algunos de los conceptos más
importantes en el aprendizaje de RNAs son el paradigma de aprendizaje, el algoritmo de aprendizaje y la teoría de aprendizaje [Haykin, 1994, Bishop, 1995, Jain et al., 1996].
El paradigma de aprendizaje se refieren al modelo de entrenamiento de la red (como la
información está disponible para la red). Los tres principales paradigmas son: 1) supervisado,
2) no supervisado, e 3) híbrido.
En el aprendizaje supervisado o aprendizaje con profesor, se le proporciona a la red la
respuesta correcta de cada patrón de entrenamiento. Opuestamente, en el aprendizaje no supervisado no se necesita la respuesta correcta de cada patrón, debido a que la red explora la
estructura subyacente de datos y la correlación de los mismos, organizándolos en categorías. El
aprendizaje híbrido combina el aprendizaje supervisado y el no supervisado.
La teoría de aprendizaje estudia la capacidad, complejidad de muestras, y complejidad
de tiempo de la red. La capacidad determina cuánto puede aprender la red de los ejemplos si
la solución óptima está contenida en las soluciones que da la red. La complejidad de muestras
determina el número de patrones de entrenamiento requeridos en la red para garantizar una generalización válida. Por último, la complejidad de tiempo investiga cuán rápido puede aprender
el sistema, es decir, la complejidad computacional del algoritmo para estimar una solución.
Ingeniería Informática - UCSP
29
3.3. Redes neuronales auto-organizables
El algoritmo de aprendizaje se refiere a la aplicación de las reglas de aprendizaje para
ajustar los pesos de la red. Los cuatro tipos básicos de aprendizaje son: 1) corrección de error,
2) Boltzmann, 3) Hebbiano, y 4) competitivo.
El algoritmo de corrección de error, aplicable al aprendizaje supervisado, utiliza la señal
de error (d − y), donde y es la salida actual y d la salida deseada, para modificar los pesos
de conexión y gradualmente reducir el error.
El aprendizaje Boltzmann es una regla de aprendizaje estocástico derivada de los principios de termodinámica y de teoría de información. El objetivo es ajustar los pesos de
las conexiones para que el estado de las unidades visibles satisfaga una distribución de
probabilidades deseada.
En el aprendizaje Hebbiano si dos neuronas son activadas simultanea y repetitivamente,
entonces la fuerza de la sinapsis es incrementada. Una propiedad importante es que el
aprendizaje se da localmente.
En el aprendizaje competitivo todas las unidades de salida compiten entre ellas para ser
activadas, resultando sólo una unidad de salida activada en un instante de tiempo.
Las redes más utilizadas en tareas de agrupamiento de datos son aquellas que hacen uso
del aprendizaje competitivo, donde patrones similares son agrupados automáticamente en base
a correlaciones de datos y representados por una neurona [Jain et al., 1999], siendo los mapas auto-organizables de Kohonen (SOM) [Kohonen, 1982] y las redes Adaptative Resonance
Theory (ART) [Carpenter and Grossberg, 1988] (y las derivaciones de ambos) los modelos más
difundidos.
Una característica común en ambos modelos es la simplicidad de sus arquitecturas ya que
poseen una sola capa. Los patrones son presentados en la entrada para luego ser asociados con
los nodos de salida. Los pesos entre los nodos de entrada y salida son iterativamente modificados
hasta satisfacer un criterio de parada.
3.3. Redes neuronales auto-organizables
Los mapas auto-organizables de Kohonen [Kohonen, 1982], del inglés Self-Organizing
Maps (SOM), trabajan bajo el paradigma no supervisado y emplean un aprendizaje competitivo
en el que se define una vecindad espacial para cada unidad de salida, pudiendo ser de forma
cuadrada, rectangular o circular. En este aprendizaje competitivo, se actualizan los vectores de
pesos asociados con la unidad ganadora y con sus vecinas.
Los mapas auto-organizables tienen la propiedad de preservar la topología, es decir, patrones de entrada cercanos activan unidades de salida cercanas en el mapa. La Figura 3.3 muestra la arquitectura básica de los SOM, pudiéndose describir como un arreglo de unidades cada
una conectada con todos los patrones de entrada.
Ingeniería Informática - UCSP
30
CAPÍTULO 3. Redes Neuronales Artificiales
Figura 3.3: Mapa auto-organizable de Kohonen [Jain et al., 1996].
3.3.1. Entrenamiento de los mapas auto-organizables
En el proceso de entrenamiento de los mapas auto-organizables, cada patrón o señal de
entrada es representado por un vector de tamaño n, x = {x1 , x2 , . . . , xn }, y cada unidad de
la red tiene asociado un vector de pesos w = {w1 , w2 , . . . , wn }, donde wi representa el peso
asociado al i-ésimo componente de la señal de entrada.
Inicialmente los pesos de las neuronas son establecidos aleatoriamente. Cuando se presenta un patrón x a la red se evalúan todas las salidas de la red, calculando la diferencia entre x
y los vectores de pesos w de cada neurona presente en la red de acuerdo con la Ecuación 3.1.
kx − wk
(3.1)
Luego se selecciona la unidad vencedora o Best Matching Unit (BMU) de acuerdo con la
Ecuación 3.2. Esta unidad presenta la menor diferencia con el patrón presentado.
kx − wc k = min{kx − wi k}∀i
(3.2)
Finalmente se actualizan el vector de pesos de la neurona vencedora y los vectores de
pesos de sus vecinos topológicos de acuerdo a la Ecuación 3.3, de manera que toda la vecindad
es aproximada hacia el patrón de entrada usando una tasa de aprendizaje α que va decreciendo
a través del entrenamiento.
w(t + 1) = w(t) + α[x(t) − w(t)]
(3.3)
Debido a que las redes SOM pueden generar una partición no óptima si los pesos iniciales
no son escogidos apropiadamente, se pueden aplicar políticas adicionales para la selección de
estos pesos.
La convergencia de la red es controlada por parámetros como la vecindad de la neurona
ganadora o la tasa de aprendizaje. Es aquí que surge el problema de la estabilidad, ya que
es posible que un mismo patrón de entrada active diferentes unidades de salida a lo largo del
Ingeniería Informática - UCSP
31
3.4. Redes SOM constructivas
entrenamiento. Entonces, se dice que un sistema es estable si ningún patrón cambia de categoría
durante la fase de entrenamiento. Este problema esta muy relacionado con la plasticidad o
habilidad de adaptarse a nuevos datos sin perder la información obtenida anteriormente. Para
salvaguardar la estabilidad la tasa de aprendizaje debe decrecer durante el proceso, pero la
plasticidad se ve aún afectada.
Con el modelo ART [Carpenter and Grossberg, 1988] se logró una red con estabilidad y
plasticidad pero se sacrificó la robustez de la misma al ser dependiente del orden en el que se
presentan los patrones, obteniendo así diferentes particiones del conjunto de datos para diferentes órdenes de presentación. Además, el tamaño y número de grupos generados por las redes
ART dependen del parámetro de vigilancia establecido.
También poseen un número fijo de nodos de salida, limitando el número de grupos que
pueden producir.
Una desventaja del modelo original de Kohonen es la necesidad de definir el número de
grupos a priori, generando la necesidad de evaluar diferentes topologías para escoger de entre
todas la más óptima para la solución de un problema. Además, la distribución de datos puede
variar en el tiempo, y la red debe ser capaz de adaptarse adecuadamente a los cambios de la
distribución, creando unidades en caso de que el número de patrones aumente, o eliminando
unidades que dejen de ser útiles luego de la eliminación de patrones.
Entre algunos de los modelos constructivos que surgen para solucionar la topología estática del modelo original de Kohonen tenemos:
Growing Neural Gas [Fritzke, 1995]
Density Based Growing Neural Gas [Ocsa et al., 2007]
Growing Self-Organizing Maps [Alahakoon et al., 1998]
Growing Hierarchical Self-Organizing Maps [Dittenbach et al., 2000]
Incremental Grid-Growing [Blackmore and Miikkulainen, 1993]
3.4. Redes SOM constructivas
Las redes SOM constructivas incorporan técnicas para poder alterar su arquitectura a
través del proceso de entrenamiento. Como se muestra en [Cuadros-Vargas, 2004], un algoritmo
constructivo debe: 1) reconocer y corregir las neuronas que hayan sido generadas en posiciones
inapropiadas para la distribución de datos, o 2) corregir la topología existente para minimizar el
error.
Algunos de los algoritmos más representativos de redes SOM constructivas son:
Ingeniería Informática - UCSP
32
CAPÍTULO 3. Redes Neuronales Artificiales
3.4.1. Incremental Grid-Growing
El algoritmo de Incremental Grid-Growing (IGG) [Blackmore and Miikkulainen, 1993]
construye la red dinámicamente modificando la estructura de las conexiones de acuerdo con
los datos de entrada. El entrenamiento se inicia con cuatro neuronas conectadas formando un
cuadrado, y nuevas neuronas son creadas en los límites externos del mapa, cerca de las neuronas
con mayor error acumulado. Esto permite al algoritmo IGG mantener siempre una estructura de
dos dimensiones, incluso si los patrones son de dimensionalidad mayor.
3.4.2. Growing Self-Organizing Maps
El algoritmo Growing Self-Organizing Maps (GSOM) [Alahakoon et al., 1998] permite
el crecimiento de la red en forma dinámica, similar al algoritmo IGG, inicialmente se tienen
cuatro neuronas conectadas formando un rectángulo, y nuevas unidades son insertadas en base
a la unidad con mayor error acumulado. A diferencia de IGG, GSOM posee un método de
inicialización de pesos, lo que reduce la probabilidad de generar mapas inapropiados.
3.4.3. Growing Neural Gas
El algoritmo Growing Neural Gas (GNG) propuesto por Firtzke [Fritzke, 1995], permite
crear y eliminar unidades en el proceso de entrenamiento. El algoritmo GNG resulta de la
combinación de los métodos de Neural Gas [Martinetz and Schulten, 1994] y el Aprendizaje
Hebbiano Competitivo [White, 1992], siendo un importante representante de los modelos SOM
constructivos [Cuadros-Vargas, 2004]. La red GNG posee una arquitectura f eedback, y así como los Self-Organizing Maps, trabaja bajo el paradigma de aprendizaje no supervisado.
3.4.4. Density Based Growing Neural Gas
Density Based Growing Neural Gas (DBGNG) propuesto en [Ocsa et al., 2007], es una
red constructiva que introduce un criterio de densidad en el entrenamiento de la red, insertando
y eliminando unidades de en base a la relativa concentración de patrones en la región en la
que se ubique el patrón presentado. La región de evaluación es determinada por un radio de
forma similar al algoritmo Incremental Growing Neural Gas [Prudent and Ennaji, 2005], pero
a diferencia de éste, se generan una mejor representación del dominio de datos.
3.4.5. Aprendizaje Hebbiano Competitivo
La técnica de Aprendizaje Hebbiano Competitivo, o Competitive Hebbian Learning (CHL)
[White, 1992], permite crear conexiones dinámicamente durante el proceso de entrenamiento.
Ingeniería Informática - UCSP
33
3.5. Growing Neural Gas
A diferencia del modelo clásico de Kohonen, CHL verifica si existe una conexión entre las
unidades s1 y s2 más próximas al patrón ξ presentado, y la crea de no existir.
3.4.6. Gas Neuronal con Aprendizaje Hebbiano Competitivo
El algoritmo Gas Neuronal con Aprendizaje Hebbiano Competitivo, del inglés Neural
Gas with Competitive Hebbian Learning (NGCHL) [Martinetz and Schulten, 1994] elimina las
conexiones no útiles en la red incorporando un contador que controle la “edad” de las conexiones, contador que se incrementa cuando la neurona a la que pertenecen es elegida vencedora,
y que al alcanzar un parámetro máximo de edad elimina la conexión. La principal diferencia
con GNG es la necesidad de especificar el número de unidades de la red, además de trabajar
con parámetros no constantes en el tiempo.
Todos estos modelos proporcionan estructuras capaces de trabajar en ambientes dinámicos. De entre la gran variedad de modelos de redes constructivas, en esta investigación se utilizará la red GNG por ser una red representativa, por lo que será detallada con mayor profundidad a continuación.
3.5. Growing Neural Gas
Growing Neural Gas (GNG) es un algoritmo de agrupamiento incremental no supervisado resultante de la combinación de los métodos Neural Gas [Martinetz and Schulten, 1994] y
Aprendizaje Hebbiano Competitivo [White, 1992]. Dada una distribución de datos de entrada
en Rn , GNG crea incrementalmente un grafo, o red neuronal, donde cada nodo en el grafo tiene
una posición en Rn .
Este modelo surgió principalmente con el objetivo de mejorar algunas limitaciones del
modelo básico de Kohonen. En cuanto una red de Kohonen precisa de la iniciación de su
topología, Growing Neural Gas inicia su entrenamiento con una estructura mínima y nuevas
unidades son creadas gradualmente [Fritzke, 1995]. Por tanto el modelo GNG además de trabajar con el paradigma no supervisado, también es constructivo, siendo capaz de generar una
topología diferente para cada tipo de problema.
Otra diferencia con el modelo de Kohonen es la forma de conectar las unidades. En los
mapas de Kohonen las conexiones crean mallas rectangulares, mientras que en el modelo GNG,
una unidad puede tener más de cuatro vecinos [Fritzke, 1995], generando así diversas figuras
geométricas y una red con mayor capacidad de aprendizaje como se observa en la Figura 3.4.
Comenzando con dos nodos el algoritmo construye un grafo en el que los nodos son
considerados vecinos si están conectados entre sí por medio de una arista. La información de
vecindad se obtiene mediante CHL: para cada señal de entrada x se crea una arista entre los dos
nodos más cercanos a la señal medidos en una distancia Euclidiana [Fritzke, 1995].
El grafo generado por CHL, también llamado triangulación inducida de Delaunay, es un
Ingeniería Informática - UCSP
34
CAPÍTULO 3. Redes Neuronales Artificiales
Figura 3.4: La red GNG se adapta a la distribución de señales con áreas y dimensionalidades
diferentes del espacio de entrada [Fritzke, 1995].
sub-grafo de la triangulación de Delaunay correspondiente al grupo de nodos. La triangulación
inducida de Delaunay preserva óptimamente la topología en un sentido general. CHL es un
componente esencial del algoritmo GNG, ya que es usado para dirigir la adaptación local de los
nodos y la inserción de nuevos nodos. Además, Growing Neural Gas usa solamente parámetros
que son constantes en el tiempo.
3.5.1. Algoritmo GNG
El algoritmo GNG asume que cada nodo k consiste en:
kw - un vector de referencia en Rn , es decir, la posición de un nodo en el espacio de
entrada.
Errork - una variable local de error acumulado que representa la medida estadística que
se usa para determinar los puntos de inserción apropiados para nuevos nodos.
Un conjunto de aristas definen la topología de los vecinos del nodo k, donde cada arista
posee una variable de edad que se usa para decidir cuándo remover las aristas viejas con
el objetivo de mantener la topología actualizada.
Teniendo en cuenta lo anterior, el Algoritmo 1 muestra el proceso de entrenamiento de la
red GNG.
Ingeniería Informática - UCSP
35
3.5. Growing Neural Gas
Algoritmo 1: Algoritmo de entrenamiento de una red GNG
1: Inicializar la red A con dos unidades c1 e c2 :
A = {c1 , c2 }
(3.4)
Los pesos deben ser inicializados con valores aleatorios, generalmente en el intervalo [0,1].
Inicializar el conjunto de conexiones C, C ⊂ A x A:
C=∅
(3.5)
2: Presentar el patrón ξ 1 a la red de acuerdo con una distribución uniforme p(ξ).
3: Determinar las dos neuronas s1 y s2 más próximas a ξ de acuerdo con las ecuaciones (3.6)
y (3.7):
s1 = argminkξ − wc k ∀c ∈ A
(3.6)
s2 = argminkξ − wc k ∀c ∈ A − {s1 }
(3.7)
donde kξ−w~c k representa la función de distancia (en este caso euclidiana) entre los vectores
ξ e w~c .
4: Si no existe conexión entre s1 y s2 , entonces crearla.
C = C ∪ {s1 , s2 }
(3.8)
Inicializar la edad de esta nueva conexión en 0.
edad(s1 ,s2 ) = 0
(3.9)
5: Actualizar la variable de error local adicionando el cuadrado de la distancia entre la neurona
ganadora y el patrón presentado:
Es1 = Es1 + kξ − ws1 k2
(3.10)
6: Actualizar el vector de pesos de s1 y los vectores de pesos de sus vecinos de acuerdo con
las ecuaciones 3.11 y 3.12:
4w~s1 = µb (ξ − w~s1 )
(3.11)
4w
~ i = µn (ξ − w
~ i ) (∀i ∈ Ns1 )
(3.12)
donde Ns1 es el conjunto de vecinos topológicos de la unidad ganadora s1 , µb y µn son las
tasas de aprendizaje para la neurona ganadora y para sus vecinos respectivamente.
7: Incrementar la edad de todas las conexiones de s1 :
edad(si , i) = edad(si , i) + 1 ∀i ∈ Ns1 .
(3.13)
8: Remover las conexiones con edad mayor que amax 2 . Si después de este proceso existen
unidades sin conexiones, éstas deben ser removidas de la red.
1
2
ξ ∈ Rn , donde n es la dimensión de los patrones.
amax es el parámetro de entrenamiento que determina la edad máxima permitida para una conexión.
Ingeniería Informática - UCSP
36
CAPÍTULO 3. Redes Neuronales Artificiales
9: Si el número de patrones presentados hasta el momento es múltiplo del parámetro λ, una
nueva unidad debe ser insertada de la siguiente forma:
Determinar la unidad q con el mayor error acumulado de toda la red.
q = max{Ec , ∀c ∈ A}
(3.14)
Determinar, de entre los vecinos de q, la unidad f con el mayor error acumulado.
f = max{Ec } ∀c ∈ Nq
(3.15)
Agregar una nueva unidad r a la red e interpolar su vector de pesos a partir de q y f
de acuerdo con la Ecuación 3.17.
A=A∪r
w~r =
w~q + w~f
2
(3.16)
(3.17)
Conectar la nueva unidad r con q y f , y remover la conexión original entre q y f :
C = C ∪ {(r, q), (r, f )}
(3.18)
C = C − {(q, f )}
(3.19)
Disminuir las variables de error de las unidades q y f en una fracción α:
4Eq = −αEq , 4 Ef = −αEf
(3.20)
Interpolar la variable de error de r a partir de q e f :
Er =
Eq + Ef
2
(3.21)
10: Disminuir la variable de error de todas las unidades en base a la tasa de corrección de error
β:
4Ec = −βEc , ∀c ∈ A
(3.22)
11: Si el criterio de parada 3 no ha sido alcanzado, volver al paso 2.
Gracias al entrenamiento, GNG puede ser usado para encontrar estructuras topológicas
que reflejan la estructura de la distribución de entrada. Entonces, incluso si la distribución de
entrada cambia en el tiempo, GNG es capaz de adaptarse moviendo los nodos hasta cubrir la
nueva distribución.
No es necesario decidir a priori el número de nodos ya que los nodos son añadidos incrementalmente durante la ejecución. La inserción de nuevos nodos termina cuando se cumple un
criterio de desempeño definido por el usuario o si se llega a un tamaño máximo de la red.
3
Un criterio de parada puede ser un tamaño máximo de red, un determinado número de ciclos, o alguna otra
medida de desempeño.
Ingeniería Informática - UCSP
37
3.6. Consideraciones finales
3.6. Consideraciones finales
En este capítulo se presentaron las redes neuronales artificiales, algunas propiedades y
conceptos básicos así como los mapas auto-organizables o Self-Organizing Maps y algunas
de variaciones constructivas del modelo de Kohonen. La gran ventaja de las redes SOM es su
capacidad de aprendizaje y generalización.
Las redes SOM vienen siendo ampliamente usadas en aplicaciones de agrupamiento de
grandes conjuntos de datos (como WEBSOM [Lagus et al., 1999]) debido principalmente a que
estas redes son capaces de establecer nuevas relaciones entre los datos, organizando la información de entrada mediante un aprendizaje no supervisado.
Las redes SOM generan mapas topológico que mantiene las relaciones de vecindad en
base a criterios de similitud, y por lo tanto, crean de forma natural agrupamientos de patrones
con características similares, lo que sumado a sus otras características, ofrece una técnica de
agrupamiento de datos efectiva.
Una limitación importante de los mapas auto-organizables es la falta de una estructura
capaz de responder a consultas específicas como las de k-vecinos más cercanos o búsquedas
por rango, así como el alto costo computacional de su entrenamiento.
Ingeniería Informática - UCSP
38
Capítulo 4
Métodos de Acceso Métrico
4.1. Consideraciones iniciales
Los Métodos de Acceso Métrico (MAM) se enfocan en el problema de organización de
datos para que, en base a un criterio de similitud, facilitar la búsqueda del conjunto de elementos
que estén cerca de un elemento de consulta [Chávez et al., 2001]. Este problema está presente
en un sinfín de aplicaciones que van desde escenarios de la vida cotidiana hasta las ramas
de las ciencias de la computación, como el reconocimiento de patrones o la recuperación de
información.
Tradicionalmente, las estructuras de datos han aplicado operaciones de búsqueda, donde
se hace una coincidencia exacta. Por ejemplo, en las bases de datos donde se manejan registros,
cada registro es comparado con los demás por medio de una clave y las búsquedas retornan los
registros cuya clave coincida con la clave suministrada.
Tras la aparición de nuevos contextos, debido principalmente al desarrollo tecnológico,
vienen surgiendo nuevos algoritmos y métodos de acceso más eficientes y veloces.
En las búsquedas por similitud o proximidad, la similitud entre elementos es modelada
a través de una función de distancia que satisfaga la desigualdad triangular, y un conjunto de
objetos llamado espacio métrico.
4.2. Definiciones
Los Métodos de Acceso Métrico son estructuras ampliamente utilizadas en el campo de
Recuperación de Información. Un MAM debe organizar un conjunto de datos en base a un
criterio de similitud para responder eficientemente a consultas específicas de proximidad.
Los Métodos de Acceso Métrico puedes ser descritos como una herramienta de organización de datos. Los MAMs trabajan sobre espacios métricos definidos por un conjunto de
39
4.2. Definiciones
objetos y una función de distancia que mide la disimilitud entre los objetos del espacio métrico
[Chávez et al., 2001].
Consideremos un conjunto U que denota el universo de objetos válidos y la función
d : U × U −→ R que mide la distancia entre objetos. Se define como espacio métrico al
subconjunto S ⊆ U de tamaño n = |S| llamado diccionario o base de datos, que denota el conjunto de objetos de búsqueda, y a la función d() que mide la disimilitud entre objetos y satisface
las propiedades de:
1. ∀x, y ∈ U, d(x, y) ≥ 0, positividad;
2. ∀x, y ∈ U, d(x, y) = d(y, x), simetría;
3. ∀x ∈ U, d(x, x) = 0, reflexividad;
4. ∀x, y ∈ U, x 6= y ⇒ d(x, y) > 0, positividad estricta;
5. ∀x, y, z ∈ U, d(x, y) ≤ d(x, z) + d(z, y), desigualdad triangular.
La desigualdad triangular es la propiedad más importante porque establece los límites
de distancias que aún pueden no haberse calculado, generando algoritmos de búsqueda por
similitud significativamente más rápidos [Clarkson, 2006].
Para los espacios vectoriales (un caso particular de espacios métricos) donde cada objeto es descrito como un vector de características (x1 , x2 , x3 , . . . , xn ) varios Métodos de Acceso
Espacial (MAE) como Kd-Tree [Bentley, 1979] o R-Tree [Guttman, 1984] han sido propuestos
para indexar este tipo de objetos multidimensionales. El problema principal de los espacios vectoriales está relacionado con las altas dimensiones de los datos, la también conocida maldición
de la dimensionalidad [Chávez et al., 2001].
4.2.1. Consultas de proximidad
Dado un objeto de consulta q ∈ U, para poder recuperar los objetos similares a q, se
definen los siguientes tipos básicos de consulta:
Consultas de rango Rq(q, r). Recupera todos los elementos que se encuentran dentro de un
radio r de q. Esto es, {u ∈ U / d(q, u) ≤ r}.
Consulta de vecino más cercano N N (q). Recupera el elemento en U más cercano a q. Esto
es {u ∈ U / ∀v ∈ U, d(q, u) ≤ d(q, v)}. Adicionalmente se puede establecer un rango
máximo r.
Consulta de k-vecinos más cercanos N Nk (q). Recupera los k elementos en U más cercanos
a q. Esto es, {A ⊆ U / |A| = k ∧ ∀u ∈ A, v ∈ {U − A}, d(q, u) ≤ d(q, v)}.
Ingeniería Informática - UCSP
40
CAPÍTULO 4. Métodos de Acceso Métrico
(a) Ejemplo de búsqueda por rango (b) Ejemplo de búsqueda del veci- (c) Ejemplo de búsqueda de los kr en un conjunto de puntos.
no más cercano en un conjunto de vecinos más cercanos en un conjunpuntos.
to de puntos con k = 4.
Figura 4.1: Tipos básicos de consultas por proximidad.
4.2.2. Consideraciones de eficiencia
La eficiencia de los Métodos de Acceso Métrico está determinada por muchos factores.
Primero, como el conjunto inicial de datos es muy grande como para tenerlo en memoria principal, el número de accesos a disco requeridos para procesar una consulta o inserción es crucial. Segundo, el costo computacional de la función de distancia puede ser tan grande que el
número de cálculos de distancia tienen gran impacto en la eficiencia. Tercero, la capacidad
y uso del almacenamiento, no por el costo de almacenamiento sino por los accesos a disco
[Bozkaya and Ozsoyoglu, 1997].
El tiempo total para evaluar una consulta viene determinado por la Ecuación 4.1, donde
NCD representa el Número de Cálculos de Distancia, d() es la función de distancia, tiempo E/S
es el tiempo requerido para el acceso a memoria secundaria y tiempo CPU el tiempo consumido
por el procesador [Chávez et al., 2001].
T = NCD × complejidad de d() + tiempo CPU + tiempo E/S
(4.1)
En muchas aplicaciones evaluar la función d() puede ser tan costoso que los demás componentes son descartados. El Número de Cálculos de Distancia (NCD) se mide en base a la complejidad de los algoritmos. Se puede asumir un trabajo de CPU lineal siempre que el número
de cálculos de distancia sea bajo. La importancia del tiempo E/S depende de la cantidad de
memoria principal disponible y el costo relativo de calcular la función de distancia. Entonces,
para poder minimizar T es necesario reducir el NCD.
Es entonces necesario diseñar algoritmos de indexación eficientes que reduzcan el NCD.
En general, estas estructuras pueden resultar costosas de construir, pero el costo de construcción
es compensado por la reducción de cálculos de distancia en las consultas posteriores.
Ingeniería Informática - UCSP
41
4.3. Algoritmos de búsqueda
4.3. Algoritmos de búsqueda
Los Métodos de Acceso Métrico son estructuras que trabajan sobre espacios métricos,
organizando los datos para responder eficientemente a consultas por similitud. De acuerdo con
[Zezula et al., 2006], los MAMs pueden ser clasificados en:
Particionamiento de esferas: Fixed Queries Tree [Baeza-Yates et al., 1994], Vantage Point
Tree [Uhlmann, 1991].
Particionamiento de hiperplanos: Generalized Hyper-plane Tree [Uhlmann, 1991].
Distancias Precomputadas: Omni-Family [Filho et al., 2001], Approximating and Eliminating Search Algorithm [Ruiz, 1986].
Métodos híbridos: GNAT [Brin, 1995], Spatial Approximation Tree [Navarro, 2002], Multi Vantage Point Tree [Bozkaya and Ozsoyoglu, 1997].
Otros métodos: M-Tree [Ciaccia et al., 1997], Slim-Tree [Caetano Traina et al., 2000], DIndex [Dohnal et al., 2003].
La Figura 4.2 muestra otra clasificación de los Métodos de Acceso Métrico propuesta en
[Chávez et al., 2001], aquí se clasifican a los métodos de búsqueda en: basados en agrupamiento
y basados en pivotes. Los métodos basados en agrupamiento particionan el espacio en regiones
representadas por un centroide o centro de grupo, para luego poder descartar regiones completas
cuando se hace una búsqueda. Los métodos basados en pivotes seleccionan un conjunto de
elementos como pivotes, y construyen un índice en base a las distancias entre cada elemento y
los pivotes.
Se pueden encontrar buenas referencias sobre clasificación y definición de los MAMs
en [Chávez et al., 2001], [Hjaltason and Samet, 2003] y [Clarkson, 2006]. A continuación se
describen sólo algunos métodos de la gran variedad existente.
4.3.1. Burkhard-Keller Tree
La estructura Burkhard-Keller Tree (BKT) [Burkhard and Keller, 1973] inicialmente selecciona un elemento arbitrario p ∈ U como la raíz del árbol. Para cada distancia i > 0, se
define Ui = {u ∈ U, d(u, p) = i} como el conjunto de todos los elementos a distancia i de
la raíz p, y para cada Ui no vacío, se construye un hijo de p (etiquetado i) para luego recursivamente construir el BKT para Ui . Este método es conveniente para funciones de distancia
discreta.
Ingeniería Informática - UCSP
42
CAPÍTULO 4. Métodos de Acceso Métrico
Figura 4.2: Taxonomía de algoritmos en base a sus características [Chávez et al., 2001]
4.3.2. Vantage-Point Tree
El árbol Vantage-Point Tree (VPT) presentado por Uhlmann en [Uhlmann, 1991] fue diseñado para funciones de distancia continua. VPT construye recursivamente un árbol binario seleccionando también un elemento arbitrario p ∈ U como raíz y la mediana todas las distancias,
M = mediana{d(p, u)/u ∈ U }. Los elementos a distancia menor o igual a M son insertados
en el subárbol izquierdo, mientras que los mayores a M son insertados en el subárbol derecho.
4.3.3. M-Tree
La estructura de datos M-Tree [Ciaccia et al., 1997] provee capacidades dinámicas (construcción gradual) y un buen manejo de E/S además de un reducido número de cálculos de
distancia. Es un árbol donde se selecciona un conjunto de elementos representativos en cada
nodo y el elemento más cercano a cada representativo es organizado en el subárbol cuya raíz es
el elemento representativo. Cada representativo almacena su radio de cobertura.
Al hacer una consulta el elemento de consulta es comparado con todos los representativos
del nodo y el algoritmo de búsqueda entra recursivamente en los nodos no descartados usando
el criterio del radio de cobertura.
La principal diferencia en M-Tree con métodos anteriores es el algoritmo de inserción. Los
Ingeniería Informática - UCSP
43
4.3. Algoritmos de búsqueda
elementos son insertados en el “mejor” subárbol, definido como aquel subárbol que minimice
la expansión del radio de cobertura. El elemento es luego agregado al nodo hoja. En caso de
overf low se divide el nodo dos y se lleva un elemento del nodo a un nivel superior, obteniendo
una estructura de datos balanceada.
4.3.4. Slim-Tree
Slim-Tree propuesto por Traina en [Caetano Traina et al., 2000] es un MAM dinámico y
balanceado con una estructura básica similar al M-Tree donde los datos se almacenan en los
nodos hoja. Slim-Tree crece de abajo a arriba, de las hojas a la raíz, organizando los objetos en
un estructura jerárquica que usa un representativo como el centro de cada región que cubre los
objetos en el sub-árbol.
Las principales características son la introducción de un nuevo algoritmo de división e
inserción así como el algoritmo Slim-down [Caetano Traina et al., 2000] y una medida de sobreposición llamada Fat-factor par la construcción de árboles más rápidos. El algoritmo de
división está basado en el MST [Kruskal, 1956], desempeñándose más rápidamente que otros
algoritmos de división y sin sacrificar el rendimiento de las consultas. Además, el algoritmo
de inserción produce un considerable mayor uso de almacenamiento. El algoritmo Slim-down
es introducido para reducir el grado de sobreposición, haciendo al árbol más estrecho y por lo
tanto mejorando el desempeño de las consultas y de la construcción, trabajando con memoria
principal o secundaria.
4.3.5. Omni-Tree
La familia de métodos Omni [Filho et al., 2001] trabaja de forma similar a la estructura
LAESA [Micó L., 1994], pero a diferencia de ésta, Omni propone el algoritmo HF para la selección estratégica de un subconjunto de objetos del conjunto de datos para ser usados como
puntos de referencia globales u Omni-coordenadas, definidas como el conjunto de distancias de
un objeto a cada uno de los focos generalmente accesibles a través de una matriz con distancias
precalculadas. Una vez que las Omni-coordenadas son calculadas y almacenadas, pueden ser
utilizadas para reducir el número de cálculos de distancia.
4.3.6. DBM-Tree
Un método de acceso más reciente, DBM-Tree (del inglés Density Based Metric-Tree)
[Marcos R. Viera and Traina, 2004] presenta un funcionamiento similar a Slim-Tree, pero fue
el primero en proponer un relajo en la altura de las regiones del árbol con alta densidad de
datos para poder reducir aún más la sobreposición de nodos. Aunque generando árboles no
balanceados, esta aproximación logra reducir el número de cálculos de distancia sin afectar el
número de accesos a disco.
Ingeniería Informática - UCSP
44
CAPÍTULO 4. Métodos de Acceso Métrico
Actualmente existe una gran bibliografía sobre métodos de acceso, cada uno presentando
nuevas mejoras en la eficiencia de los algoritmos de búsqueda y construcción. Para la presente
investigación se han considerado las técnicas Slim-Tree y Omni-Secuencial, detalladas en las
siguientes secciones.
4.4. Slim-Tree
Slim-Tree [Caetano Traina et al., 2000] es un MAM dinámico. La estructura de datos básica de esta técnica es similar a la de otros árboles como el M-Tree [Ciaccia et al., 1997], donde
los datos son almacenados en las hojas y se construye una jerarquía de abajo hacia arriba.
Slim-Tree difiere de los demás Métodos de Acceso Métrico en los algoritmos de división e inserción que utiliza. El algoritmo de división es más rápido que otros algoritmos y sin sacrificar
el rendimiento de las consultas, además, el algoritmo de inserción hace un considerable mayor
uso del almacenamiento. El principal aporte es la introducción del algoritmo Slim-down, que
mantiene al árbol compacto y rápido en la etapa de post-procesamiento.
Slim-Tree es un árbol dinámico y balanceado que crece de las hojas a la raíz, organizando
los objetos en una estructura jerárquica y utilizando un nodo representativo como centro de cada
región que cubre a los objetos en un sub-árbol. Este árbol posee dos tipos de nodos: nodos dato
(hojas) y nodos índice, ambos con un tamaño de página predefinido que almacena un número
máximo de objetos.
4.4.1. Funcionamiento
En el algoritmo de construcción de Slim-Tree, cuando se agrega un nuevo objeto, primero
se busca al nodo que cubra a este objeto empezando desde la raíz. En caso de no encontrarse
un nodo que cumpla con esta condición, se selecciona un sub-árbol siguiendo uno de estos
tres métodos: 1) selección aleatoria de uno de los nodos, 2) selección del nodo cuyo centro
(también llamado centriode) posea la mínima distancia al objeto, o 3) selección del nodo que
tenga la mínima ocupación de entre los nodos calificados. Este proceso se aplica recursivamente
en todos los niveles del árbol.
Cuando un nodo se desborda se crea uno nuevo en el mismo nivel y se distribuyen los
objetos entre los nodos, insertándose en el nodo padre. Si el nodo raíz se divide se crea una
nueva raíz y el árbol crece un nivel.
Para la división de los nodos se proponen tres algoritmos:
Aleatorio , donde los dos nuevos centroides son seleccionados aleatoriamente y los objetos
existentes son distribuidos entre ellos, cada objeto es almacenado en el nuevo nodo cuyo
centro está más cerca.
minMax , donde se consideran todos los pares de objetos como representativos potenciales.
Ingeniería Informática - UCSP
45
4.4. Slim-Tree
(a) Nodo antes de la división.
(b) MST construido con los obje- (c) Nodos después de la división.
tos del nodo.
Figura 4.3: División de nodos con el algoritmo MST [Caetano Traina et al., 2000].
Para cada par, se asignan los objetos a un representativo por medio de un algoritmo lineal,
escogiendo el par que minimice el radio convergente.
Minimal Spanning Tree (MST) [Kruskal, 1956], donde se construye el MST de los objetos y se
desecha el arco más largo del árbol. Gracias al algoritmo de división basado en MST,
Slim-Tree logra una partición rápida de los nodos en dos grupos que posteriormente reducirán los tiempos de búsqueda.
El Algoritmo 2 [Caetano Traina et al., 2000] describe el funcionamiento de la división de
nodos usando MST. El algoritmo considera un grafo de C objetos y C(C − 1) aristas, donde
el peso de las aristas hacen referencia a la distancia entre los objetos conectados. La Figura 4.3
muestra de forma gráfica este proceso de división.
Algoritmo 2: Algoritmo de división MST
1: Construir el MST de los C objetos.
2: Eliminar la arista más larga.
3: Reportar los objetos conectados como dos grupos.
4: Escoger el objeto representativo de cada grupo, por ejemplo el objeto con la menor distancia
máxima a los demás objetos del grupo.
Adicionalmente, mediante la aplicación del algoritmo Slim-down, Slim-Tree logra producir árboles estrechos y con un reducido grado de sobreposición entre nodos (overlapping).
El Algoritmo 3 [Caetano Traina et al., 2000] describe el proceso del algoritmo Slim-down. La
Figura 4.4 muestra gráficamente el resultado obtenido por este algoritmo.
Algoritmo 3: Algoritmo Slim-down
1: Para cada nodo i en un nivel determinado del árbol, buscar el objeto c más lejano de
su centroide.
2: Buscar al nodo j hermano de i que también contenga al objeto c, si tal nodo existe,
quitar c del nodo i e insertarlo en el nodo j, corrigiendo los radios del nodo i.
Ingeniería Informática - UCSP
46
CAPÍTULO 4. Métodos de Acceso Métrico
(a) Nodos antes de aplicar el algo- (b) Nodos después de aplicar el
ritmo de Slim-down.
algoritmo de Slim-down.
Figura 4.4: Funcionamiento del algoritmo Slim-down [Caetano Traina et al., 2000].
3: Repetir los pasos 1 y 2 secuencialmente en todos los nodos de un nivel determinado
del árbol. Si en el proceso se produjo un movimiento de objetos de un nodo a otro,
repetir los pasos 1 y 2 de nuevo en todos los nodos del nivel.
Las regiones de los nodos pueden sobreponerse unas con otras, fenómenos conocido como
overlaping, incrementando el número de caminos a recorrer al realizar una consulta, y por
lo tanto incrementando el número de cálculos de distancia efectuados. Esta deficiencia se ve
claramente mejorada en el Slim-Tree.
4.5. Omni-Secuencial
La técnica Omni [Filho et al., 2001] hacen uso de un conjunto de puntos de referencia llamados “focos"para reducir el número de cálculos de distancia. Cada vez que se inserta un nuevo
elemento se calculan las distancias de este elemento hacia cada uno de los focos, información
que es luego utilizada en las consultas para reducir los cálculos de distancia haciendo uso de la
propiedad de la desigualdad triangular vista anteriormente.
Esta técnica introducen los conceptos de Omni-focos y Omni-coordenadas. Los Omnifocos son definidos como el conjunto F de distintos puntos que pertenecen al espacio métrico.
Las Omni-coordenadas son definidas como el conjunto de distancias calculadas entre cada punto del espacio métrico y cada elemento de F , por lo tanto la cardinalidad de la coordenada es
igual al número de focos. El costo adicional de calcular las Omni-coordenadas es compensado
por el ahorro obtenido en las consultas.
Uno de los puntos críticos en esta técnica es la selección del conjunto de focos F y su
cardinalidad. Con respecto a la cardinalidad, y como puede ser observado en la Figura 4.5, con
un mayor número de focos se puede reducir más el subconjunto de candidatos, acelerando el
proceso de búsqueda, pero se requiere mayor espacio y tiempo para procesarlos. Los autores
recomiendan una cardinalidad no mayor al doble de la dimensionalidad intrínseca de los datos
ya que a un mayor número de focos se obtiene un pequeño o ningún beneficio.
Ingeniería Informática - UCSP
47
4.6. Consideraciones finales
(a) Sin uso de focos (b) Usando un foco el (c) Subconjunto de
todo el conjunto de subconjunto de datos candidatos usando dos
datos es candidato.
candidatos (área som- focos.
breada) se reduce.
Figura 4.5: Selección de los candidatos para una consulta de rango con diferentes cardinalidades
de F [Filho et al., 2001].
Para la selección de los focos se recomienda seleccionar puntos lo más separado posible
y equidistantes. Se propone el algoritmo HF para esta tarea. Este algoritmo primero selecciona
un objeto aleatoriamente y luego selecciona como primer foco al objeto más alejado de este.
El segundo foco es el elemento más distante el primer foco. Por último se selecciona como
siguiente foco a aquel objeto con distancias más similares a los focos anteriores, este proceso
se repite hasta seleccionar todos los focos. El proceso completo está descrito en el Algoritmo 4
[Filho et al., 2001].
Algoritmo 4: Algoritmo HF
1: Seleccionar aleatoriamente un elemento s0 del conjunto de datos.
2: Encontrar el elemento f1 más lejano a s0 y seleccionarlo como foco.
3: Encontrar el elemento f2 más lejano a f1 y seleccionarlo como foco.
4: Encontrar el elemento f1 más lejano a si y seleccionarlo como foco.
5: Establecer edge = d(f1 , f2 ), variable usada para encontrar a los demás focos.
6: Mientras se necesiten encontrar más focos repetir los pasos 7 y 8.
7: Para cada punto si del conjunto de datos calcular:
P
errori = k k esf oco|edge − d(fk , si )|.
8: Seleccionar como foco al elemento si que posea el menor errori y que no haya sido seleccionado anteriormente como foco.
4.6. Consideraciones finales
Las búsquedas por similitud vienen siendo ampliamente usadas en muchas áreas de las
ciencias de la computación como minería de datos, bioinformática y compresión de vídeo para
citar sólo algunas. Los Métodos de Acceso Métrico han probado ser excelentes estructuras para
resolver este tipo de consultas específicas ya que han sido diseñados para trabajar sobre espacios
métricos reduciendo los costos de búsqueda.
Debido a que el cálculo de la función de distancia en sí puede tener un costo computaIngeniería Informática - UCSP
48
CAPÍTULO 4. Métodos de Acceso Métrico
cional alto, se asume que el desempeño de los MAMs depende principalmente del Número de
Cálculos de Distancia realizado durante los procesos de construcción y búsqueda. Trabajando
con grandes bases de datos, el número de accesos a disco es un factor que también debe ser
considerado.
La principal limitación de estos métodos es la falta de aprendizaje de las consultas anteriores [Cuadros-Vargas, 2004], es decir, no aprovechan el conocimiento generado por las consultas anteriores para reducir el tiempo de respuesta de consultas futuras.
En la literatura existente se pueden encontrar varios MAMs, pero Slim-Tree y los métodos
Omni presentan ciertas características que los destacan en relación a métodos anteriores.
Ingeniería Informática - UCSP
49
Capítulo 5
Técnica MAM-SOM para agrupamiento
de datos
5.1. Consideraciones iniciales
Como se vio en capítulos anteriores, el proceso de entrenamiento de los mapas autoorganizables se ve drásticamente perjudicado por a la búsqueda secuencial que realizan, siendo
esta una de las deficiencia más críticas al momento de trabajar con grandes conjuntos de datos.
Si adicionalmente consideramos la alta dimensionalidad de los datos y la complejidad de la
función de distancia, el uso de un entrenamiento secuencial en tareas de agrupamiento de datos
resultaría altamente costoso.
El creciente uso de grandes conjuntos de datos altamente complejos ha generado la necesidad de técnicas que optimicen considerablemente el procesamiento con redes neuronales. En
investigaciones recientes se han desarrollado la familia de técnicas MAM-SOM y SAM-SOM
[Cuadros-Vargas, 2004]. Estas técnicas proponen el uso de Métodos de Acceso Métrico (MAM)
y Métodos de Acceso Espacial (MAE), o en inglés Spatial Access Method (SAM), para mejorar el rendimiento de redes Self-Organizing Maps (SOM) [Bedregal and Cuadros-Vargas, 2006,
Ocsa et al., 2007].
La presente propuesta hará referencia a las técnicas MAM-SOM por el uso de Métodos de
Acceso Métrico, pero cabe destacar que la implementación y características permanecen iguales
a la familia SAM-SOM, es decir, usando Métodos de Acceso Espacial.
5.2. Trabajos Previos
El objetivo de utilizar métodos de acceso en el entrenamiento de las redes SOM es poder
remplazar la tradicional búsqueda secuencial de la neurona ganadora por una búsqueda más
rápida. Al reducir el número de comparaciones entre patrones presentados y neuronas en la
50
CAPÍTULO 5. Técnica MAM-SOM para agrupamiento de datos
red se obtiene, entre otras cosas, un entrenamiento menos costoso. Implementando una técnica
MAM-SOM es posible mejorar considerablemente la ejecución del proceso de entrenamiento
de la red y potenciar sus capacidades.
En el caso de las redes SOM, cada vez que un patrón es presentado, éste es comparado
con cada unidad en la red con el fin de determinar a la neurona cuyo vector de pesos sea el más
cercano al patrón. Considerando que este proceso se repite un determinado número de ciclos, el
total Número de Cálculos de Distancia (NCD) realizados durante el entrenamiento estaría dado
por la Ecuación 5.1, donde N U es el número de unidades, N P el número de patrones y N C el
número de ciclos de entrenamiento de la red.
N CD = N U × N P × N C
(5.1)
En el caso de SOMs constructivas el número de unidades de la red varía a través del
tiempo. En la mayoría de estas redes el crecimiento está determinado por medio del parámetro
λ o tasa de inserción. Este parámetro indica que, cada λ patrones presentados a la red, una nueva
unida será creada. Por ejemplo, si λ = 100 entonces cada vez que se presenten 100 patrones a
la red, se insertará una nueva neurona. El total de cálculos de distancia requeridos para construir
una red con n unidades está determinado por la Ecuación 5.2, donde N U0 es el número inicial
de unidades.
N DCCSOM = λ
n(n − 1) − N U0 (N U0 − 1)
2
(5.2)
Analicemos el caso específico de la red Growing Neural Gas (GNG) [Fritzke, 1995] utilizada en la propuesta. Esta red inicia su topología con dos unidades en posiciones aleatorias,
entonces, para el caso de λ = 1 el primer patrón será comparado con dos unidades, el segundo
con tres unidades, el tercero con cuatro y así sucesivamente de manera que, para encontrar la
unidad ganadora para el n-ésimo patrón, se realizarán n + 1 comparaciones. De acuerdo con
la Ecuación 5.2, el número total de cálculos de distancia para construir una red GNG con N
unidades estaría dado por la Ecuación 5.3 [Cuadros-Vargas, 2004].
N CDGN G
N2 − N − 2
=λ
2
(5.3)
De la Ecuación 5.3 se observa que el parámetro λ es un factor crítico para el número total
de comparaciones hechas por la red, entonces el caso que minimice la ecuación sería λ = 1.
Como fue señalado en el algoritmo de entrenamiento de GNG, cuando una nueva neurona es
creada, su vector de pesos y error local son interpolados a partir de las dos unidades con mayor
error acumulado. Por lo tanto, al trabajar con valores de λ pequeños la red no tiene el tiempo
suficiente para adaptar las nuevas unidades a la distribución de datos, y como es altamente
probable que estas unidades nunca resulten ganadoras, serían inútiles para la red, generando
redes deformadas como se observa en la Figura 5.1. Por otro lado, si se establece un valor muy
alto para λ el NCD se elevaría considerablemente y la red podría tardar demasiado en entrenar.
La Figura 5.1 muestra gráficamente el impacto de la variable λ en la red.
Ingeniería Informática - UCSP
51
5.3. Técnicas MAM-SOM
(a) 10000 patrones, λ = 500.
(b) 10000 patrones, λ = 100.
(c) 1000 patrones, λ = 10.
Figura 5.1: Impacto del valor λ en la red GNG [Cuadros-Vargas and Romero, 2005].
En agrupamiento de datos, donde se trabajan con grandes cantidades de datos multidimensionales, el tiempo de construcción de un clasificador de este tipo puede llegar a ser en exceso
lento. Con la finalidad de poder reducir el NCD realizados para el entrenamiento de redes SOM
se propone la técnica MAM-SOM descrita a continuación.
5.3. Técnicas MAM-SOM
Como se mencionó anteriormente, las técnicas MAM-SOM son producto de la incorporación de Métodos de Acceso Métrico (MAM) en redes SOM. El objetivo es aprovechar las
características de los métodos de acceso para optimizar la construcción de la red neuronal.
Además de la búsqueda secuencial de la neurona ganadora, otra limitación de las redes
SOM es la falta de capacidad para responder a consultas más precisas como la de k-vecinos
más cercanos o búsquedas por rango, consultas que resultarían costas de responder debido a
la constante modificación de las regiones descritas por la red [Cuadros-Vargas, 2004]. Por lo
tanto, al incorporar un Métodos de Acceso Métrico en la red, se provee de una estructura capaz
de responder eficientemente este tipo de consultas, facilitando de esta manera la recuperación
de información similar a un determinado patrón.
Dependiendo del grado de incorporación del método de acceso, dos familias de técnicas
MAM-SOM fueron propuestas por Cuadros-Vargas en [Cuadros-Vargas, 2004]: MAM-SOM
Híbrida y MAM-SOM*.
5.3.1. MAM-SOM Híbrida
La familia MAM-SOM Híbrida utiliza al MAM como una estructura independiente a la
red, remplazando la búsqueda secuencial de la unidad ganadora (propia de las redes SOM) por
una búsqueda más rápida y eficiente (proporcionada por el método de acceso). El MAM permite
Ingeniería Informática - UCSP
52
CAPÍTULO 5. Técnica MAM-SOM para agrupamiento de datos
además responder a consultas de proximidad con un menor costo.
Cada unidad es insertada o eliminada en la red y en el método de acceso para preservar
la correspondencia en ambas estructuras. La adaptación de pesos de las neuronas se realiza de
acuerdo al algoritmo de la red, actualizando adicionalmente las unidades correspondientes en
la estructura métrica para que cada unidad de la red sea exactamente reflejada en la estructura
métrica. Nótese que el costo adicional de construcción y actualización de datos en el método de
acceso es recuperado en la reducción en cálculos de distancia.
5.3.2. MAM-SOM*
En la familia MAM-SOM* el método de acceso ha sido incorporado completamente en la
red, generando una nueva familia de técnicas con interesantes propiedades. Para la construcción
de las técnicas MAM-SOM* se considera agregar una nueva unidad a la red por cada patrón que
sea presentado, conectándola además a un determinado número de vecinos como se muestra en
el Algoritmo 5. Debido a que el vector de pesos de la nueva unidad es igual al patrón presentado,
no existe proceso de actualización de pesos, entonces la auto-organización de la red se da en el
proceso de construcción, necesitándose sólo un ciclo de entrenamiento.
El dilema de estabilidad-plasticidad [Grossberg, 1972] es abordado por las técnicas MAMSOM*. La estabilidad se refiere a que ningún patrón presentado a la red cambie de categoría a
lo largo del proceso de entrenamiento de la red, es decir, que no active diferentes unidades de
salida en diferentes instantes de tiempo. La plasticidad por otro lado se refiere a la habilidad
de adaptarse a nuevos datos, incorporando nuevo conocimiento sin afectar el aprendido anteriormente. Para solucionar el problema de la estabilidad,cada patrón es asignado a una única
neurona, eliminando la necesidad de actualización de pesos sin sacrificar el rendimiento ni la
generalización.
El Algoritmo 5 fue propuesto en [Cuadros-Vargas and Romero, 2002] describe la construcción de la técnica MAM-SOM*. El algoritmo considera el parámetro N eighborhoodSize
(también representado por φ) que determina el número de vecinos más cercanos que serán
conectados con la nueva unidad.
Algoritmo 5: Algoritmo de entrenamiento MAM-SOM*
1: Inicializar la red vacía;
2: InvDistSum = 0;
3: Presentar el patrón ξi a la red;
4: Crear una nueva unidad para ξi y agregarla a la estructura métrica;
5: Para ξi , encontrar los φ-vecinos más cercanos (n1 , n2 , . . . , nφ ) usando la estructura métrica;
6: Conectar la unidad creada con ξi a nj , ∀j = 1, 2, . . . , φ;
1
7: InvDistSum+ = Distancia(ξ
;
i ,nφ )
i
8: T amanoRecomendado = InvDistSum ;
9: Si existen más patrones regresar al paso 3.
Ingeniería Informática - UCSP
53
5.4. Propiedades de las técnicas MAM-SOM
(a) Estructura antes del proceso de poda.
(b) Poda de conexiones con τ = 2,5.
Figura 5.2: Ejemplo del proceso de poda de conexiones de las técnicas MAM-SOM* con 5000
patrones y N eighborhoodSize = 3 [Cuadros-Vargas and Romero, 2002].
Debido a que inicialmente el método de acceso posee pocas unidades, es posible que en
esta etapa el Algoritmo 5 conecte unidades alejadas por ser consideradas vecinas. Es necesario
aplicar un proceso de poda para poder eliminar conexiones entre unidades muy distantes que no
aportan información valiosa a la estructura, ajustando así la red a la distribución de datos. En el
proceso de poda se eliminan las conexiones con longitud mayor a τ × T amanoRecomendado,
donde τ es un parámetro de refinamiento que permite controlar la longitud de las conexiones
que se podarán. El efecto de este proceso de poda puede apreciarse en la Figura 5.2.
Con el parámetro de control τ es posible encontrar agrupamientos dentro de la red. Esto
es, afinando el valor de τ se van podando las conexiones de la red para encontrar grupos de
unidades aisladas por similitud.
5.4. Propiedades de las técnicas MAM-SOM
La principal característica de las técnicas MAM-SOM Híbridas es la aceleración del proceso de selección de la unidad ganadora, brindando la posibilidad de trabajar con redes mucho
más grandes y bases de datos más complejas. Además, la recuperación de información por
consultas de similitud es soportada gracias al método de acceso.
Considerando el escenario de las técnicas MAM-SOM*, donde cada patrón es representado por una unidad, podemos observar las siguientes propiedades son [Cuadros-Vargas, 2004]:
Escalabilidad: mayor número de unidades pueden ser creadas en la red.
Menor costo computacional: incluso trabajando con más unidades, el costo computacional es considerablemente menor que las redes SOM.
Refleja la distribución de datos: el algoritmo genera unidades nuevas de acuerdo con la
distribución de datos y no por interpolación.
Mayor información de las conexiones: las conexiones pueden contener la información de
la distancia entre unidades.
Ingeniería Informática - UCSP
54
CAPÍTULO 5. Técnica MAM-SOM para agrupamiento de datos
Mayor información para detección de agrupamientos: considerando que la función de distancia representa la disimilitud entre elementos se podrían eliminar conexiones mayores,
generando dos grupos separados.
Mayor estabilidad-plasticidad: un patrón siempre es representado por la misma neurona,
además la inserción de nuevos patrones no provoca la pérdida del conocimiento adquirido.
Aprendizaje incremental: el modelo permite la inserción de nuevos elementos en cualquier
instante, sin la necesidad de reinicializar el proceso.
Independencia del orden: gracias al Métodos de Acceso Métrico la estructura generada
no depende del orden de inserción de datos.
5.5. Estructuras propuestas para la técnica MAM-SOM
Durante su entrenamiento, las redes SOM crean agrupamientos de patrones con características similares de forma natural. Para agrupamiento de datos con el modelo de Kohonen, el
establecer el número de grupos anticipadamente podría limitar la calidad de agrupamiento del
algoritmo, ya que, al ser una tarea de análisis exploratorio, no sabemos con precisión cuantos
grupos pueden contener los datos. Por lo tanto, se propone trabajar con la red neuronal constructiva Growing Neural Gas (GNG) [Fritzke, 1995] por ser una red constructiva representativa.
Por otra parte, en el campo de Métodos de Acceso Métrico, los algoritmos se enfocan
en reducir el número de cálculos de distancia (o por lo menos el tiempo de CPU), descartando
consideraciones de E/S [Chávez et al., 2001]. El MAM M-Tree [Ciaccia et al., 1997], destacó
por ser un árbol balanceado especialmente diseñado para trabajar en memoria secundaria. Una
mejora de M-Tree, Slim-Tree [Caetano Traina et al., 2000], introduce un algoritmo de división
de nodos más rápido, un nuevo algoritmo de inserción con mejor aprovechamiento del almacenamiento y el algoritmo Slim-down [Caetano Traina et al., 2000] que mantiene al árbol compacto; presentando un tiempo de consulta 35 % menor [Caetano Traina et al., 2000] que M-Tree.
La aplicación del Omni-concept [Filho et al., 2001] en los métodos de acceso de la familia Omni
[Filho et al., 2001] mejoraron hasta diez veces su desempeño en tiempo de respuesta y cálculos
de distancia, con una implementación simple. Se propone entonces trabajar con las técnicas
Slim-Tree y Omni-Secuencial.
El proceso de agrupamiento de datos utilizando las técnicas MAM-SOM Híbrida y MAMSOM* con las estructuras propuestas se detalla en la siguiente sección.
5.6. Agrupamiento con MAM-SOM
En la tarea de agrupamiento de datos se tiene un conjunto de elementos que desean ser
agrupados en base a la similitud existente entre ellos,
Ingeniería Informática - UCSP
55
5.6. Agrupamiento con MAM-SOM
Siguiendo el procedimiento descrito en la Figura 2.2 del Capítulo 2, inicialmente se tienen
un conjunto de datos a los que se aplican técnicas de extracción o selección de características
para encontrar la mejor forma de representar cada uno de los datos a través de un vector de características de tamaño n; este vector representa al objeto deseado en un espacio n-dimensional.
Los conjuntos de datos empleados en la investigación ya han pasado por este proceso de extracción de características.
Una vez obtenidos los vectores de características, es decir, el conjunto de patrones que
representan a los elementos, se debe seleccionar la métrica o medida de similitud que se utilizará
para la comparación de los patrones. El conocimiento que se tenga del dominio de datos es
un factor determinante en la selección de la métrica. En esta investigación se trabajará con la
Distancia Euclidiana para medir la disimilitud entre objetos.
Luego se entrena al clasificador con el conjunto de patrones obteniendo como salida un
los agrupamientos. Para esta investigación se utilizarán a las técnicas MAM-SOM como clasificadores del proceso de agrupamiento de datos. Para el caso específico de la técnica MAMSOM*, cada unidad de la red es asociada con un elemento de la estructura métrica, y el agrupamiento estará dado por la poda gradual de conexiones como se discutió en la Sección 5.3.2.
En el caso de la técnica MAM-SOM Híbrida usando la red Growing Neural Gas (GNG)
y la estructura métrica Slim-Tree, la clasificación es determinada por la red neuronal debido a
que el entrenamiento de la red sigue siendo el mismo. Para crear la relación entre el método
de acceso y la red neuronal se establece una correspondencia entre las neuronas de la red y
los datos almacenados en la estructura métrica. A medida que se va construyendo la red las
neuronas son indexadas y organizadas por el MAM, logrando que la búsqueda de la neurona
ganadora se haga a través de la estructura métrica y ya no de forma secuencial.
En el entrenamiento de la técnica MAM-SOM Híbrida, siguiendo el algoritmo de la red
GNG, cada vez que se presenta un patrón o señal de entrada, se buscan las dos unidades más cercanas al patrón efectuando una búsqueda de los 2-vecinos más cercanos a través de Slim-Tree.
Como inicialmente la red posee dos unidades, ambas son seleccionadas para la actualización.
Al actualizar los pesos de la neurona ganadora y de sus vecinas topológicas (las que posean una
conexión con la neurona ganadora), se debe reflejar también este movimiento de unidades en
el método de acceso, modificando o actualizando los elementos correspondientes dentro de la
estructura. A medida que se van presentando más señales de entrada se van insertando nuevas
unidades en base al parámetro λ debido a que GNG es una red constructiva. Adicionalmente esta inserción debe hacerse en Slim-Tree. Igualmente, la remoción de unidades de la red (aquellas
sin conexiones) debe realizarse en Slim-Tree para que durante todo el proceso de entrenamiento
las unidades de la red estén exactamente reflejadas en la estructura métrica. El proceso continúa
hasta que el criterio de parada establecido se haya satisfecho. El resultando es un agrupamiento
más rápido y, principalmente, escalable.
Como se señala en el algoritmo de construcción de técnicas MAM-SOM* (Algoritmo 5),
para cada señal de entrada se crea una nueva unidad que representa a dicha señal igualándola al
vector de pesos de la unidad. Esta nueva unidad es insertada en Slim-Tree, y debido a que cada
unidad representa a un único patrón, no hay necesidad de actualización de pesos ni de ciclos de
entrenamiento adicionales. Seguidamente se conecta la unidad con sus φ-vecinos más cercanos
Ingeniería Informática - UCSP
56
CAPÍTULO 5. Técnica MAM-SOM para agrupamiento de datos
en base al parámetro N eighborhoodSize (los vecinos son encontrados mediante el método de
acceso). Estas conexiones almacenan la distancia entre las unidades que conectan, información
sumamente útil para realizar consultas posteriores.
Durante el proceso, la variable T amanoRecomendado se actualiza para almacenar una
medida recomendada para el tamaño máximo de las conexiones en base a las distancias de cada
unidad a su vecinos más cercano. Esta variable, junto al parámetro τ , permite la poda de aristas
con distancias muy grandes como se ve en la Figura 5.2.
Después de haber construido la estructura MAM-SOM*, la poda gradual de conexiones
modificando el valor de τ permite encontrar agrupamientos basados en similitud.
5.7. Consideraciones finales
Las técnicas MAM-SOM [Cuadros-Vargas, 2004] fueron propuestas para optimizar el uso
de redes SOM, técnicas muy populares para tareas de agrupamiento de datos. Es entonces posible construir un clasificador en base a las técnicas MAM-SOM que resultaría útil para agrupamiento de grandes conjuntos de datos ya que tienen un mejor desempeño en comparación de
las redes SOM en su forma original.
La técnica MAM-SOM híbrida ofrece un entrenamiento más rápido que las técnicas
SOM. Al introducir métodos de acceso métrico en la red, se remplaza la búsqueda secuencial de
la neurona ganadora por una búsqueda más eficiente, además de permitir consultas específicas
como de k-vecinos más cercanos y de rango.
La técnica MAM-SOM* ofrece una estructura enriquecida con conexiones que almacenan
distancias entre elementos que, sumado a sus características especiales, provee de información
altamente útil para la formación de grupos.
Ingeniería Informática - UCSP
57
Capítulo 6
Experimentos
6.1. Consideraciones iniciales
En base a las ideas presentadas en esta investigación se realizaron nuevos experimentos
utilizando recientes métodos de acceso. Los experimentos se realizaron en una PC de escritorio
con procesador Intel Celeron 1.8 GHz y 512 MB de memoria RAM.
Los experimentos fueron divididos en tres grupos principales:
Comparación entre la técnica MAM-SOM Híbrida y GNG,
Comparación entre la técnica MAM-SOM* y GNG, y
Comparación entre las técnicas MAM-SOM*, MAM-SOM Híbrida y GNG,
En todos los experimentos el desempeño de cada técnica fue medido en términos del
Número de Cálculos de Distancia (NCD) realizados en el proceso de construcción como fue
discutido en el capítulo anterior.
6.2. Bases de datos
Se consideraron seis bases de datos de áreas representativas de aprendizaje de máquina:
IRAS: La base de datos de InfraRed Astronomy Satellite contiene 531 instancias 103-dimensionales de espectros en baja resolución obtenidas de un satélite de astronomía.
DIGITS: Esta base de datos de dígitos manuscritos creada para el reconocimiento de dígitos
fue obtenida de 44 escritores. Contiene 7494 instancias 16-dimensionales.
58
CAPÍTULO 6. Experimentos
SPAM: Base de datos de datos para la detección de correos electrónicos masivos. Contiene
4601 instancias 57-dimensionales.
NURSERY: Esta base de datos contiene 12960 instancias 8-dimensionales derivadas de un
modelo de decisiones jerárquico desarrollado para calificar solicitudes a escuelas de enfermería.
COVERT: Esta base de datos contiene registros de las características de terreno en diferentes
bosques en América. Se trabajará con un subconjunto de 50000 instancias 54-dimensionales del conjunto original de 581012 vectores.
IMAGES: Esta base de datos contiene 6000 instancias 1215-dimensionales de la base original
de 80000 vectores obtenida de la extracción de características de imágenes del Proyecto
Informedia de la Universidad Carnegie Mellon.
Las bases de datos IRAS, DIGITS, SPAM, NURSERY y COVERT fueron obtenidas del
Repositorio de bases de datos para el aprendizaje de máquina y teorías de dominio de la Universidad de Californa - Irvine 1 .
6.3. Primer grupo
En el primer grupo de experimento se utilizaron las bases de datos IRAS, DIGITS y SPAM
para comparar las técnicas MAM-SOM Híbrida GNG+Slim-Tree y la red GNG. Se consideró
el NCD acumulado en dos escenarios: en relación al número de agrupamientos obtenido y
en relación al número de patrones presentados a las redes. Los parámetros utilizados para el
entrenamiento de la red en ambas técnicas fueron: λ = 600, α = 0,5, β = 0,0005, am = 300,
µb = 0,05 y µn = 0,006.
6.3.1. Discusión en relación al número de agrupamientos
La Figura 6.1 muestra resultados obtenidos de este primer grupo de experimentos considerando la eficiencia de las técnicas en relación al número de unidades creadas a lo largo del
proceso de construcción de las redes para las tres bases de datos. Debe notarse que a mayor
número de unidades en la red es posible trabajar con bases de datos más grandes, pudiéndose
además obtener agrupamientos más compactos. Se distingue claramente la ventaja que presenta la técnica GNG+Slim-Tree sobre su contraparte secuencial debido a que la búsqueda de la
neurona ganadora se hace mediante la estructura de datos y ya no secuencialmente.
1
ftp://ftp.ics.uci.edu/pub/machine-learning-databases/
Ingeniería Informática - UCSP
59
6.3. Primer grupo
Numero de calculos de distancia
1400000
1200000
GNG secuencial
GNG con Slim-Tree
1000000
800000
600000
400000
200000
8
16
24
Numero de unidades
32
40
(a) NCD por unidad en la red en el proceso de construcción utilizando la base de datos IRAS (103-d).
Numero de calculos de distancia
7000000
6000000
GNG secuencial
GNG con Slim-Tree
5000000
4000000
3000000
2000000
1000000
10
20
30 40 50 60 70
Numero de unidades
80
90
100
(b) NCD por unidad en la red en el proceso de construcción utilizando la base de datos DIGITS (16-d).
Numero de calculos de distancia
20000000
18000000
GNG secuencial
GNG con Slim-Tree
16000000
14000000
12000000
10000000
8000000
6000000
4000000
2000000
10
20
30 40 50 60 70
Numero de unidades
80
90 100
(c) NCD por unidad en la red en el proceso de construcción utilizando la base de datos SPAM (57-d).
Figura 6.1: Comparación del Número de Cálculos de Distancia acumulado de la red Growing
Neural Gas y la técnica MAM-SOM GNG+Slim-Tree a lo largo del proceso de entrenamiento
de la red en relación al número de agrupamientos generados.
Ingeniería Informática - UCSP
60
CAPÍTULO 6. Experimentos
6.3.2. Discusión en relación al número de patrones
Dentro del primer grupo de experimentos también se evaluó el desempeño de las dos
técnicas en relación al número de patrones presentados a las redes, registrando la variación del
Número de Cálculos de Distancia a lo largo del proceso de entrenamiento. Un bajo NCD indica
la capacidad de escalabilidad de la técnica, es decir, es posible aplicarla en bases de datos más
grandes y complejas. La Figura 6.2 muestra los resultados obtenidos en estos experimentos. Una
vez más la técnica propuesta presentó un desempeño notablemente mejor que al red neuronal
original al aplicarse en las tres bases de datos.
6.4. Segundo grupo
En el segundo grupo de experimentos se compara la red GNG esta vez con la técnica
MAM-SOM* Slim-Tree. Nuevamente se considera al NCD como medida de eficiencia en los
siguientes escenarios: considerando el número de patrones presentados a la red y considerando
el número de conexiones creadas por la técnica. En este grupo de experimentos no se hace una
comparación en relación al número de unidades creadas ya que ambas estructuras tendrán el
mismo tamaño: una unidad por patrón presentado.
Las bases de datos utilizadas en este grupo de experimentos fueron las mimas del grupo
anterior: COVERT, DIGITS y SPAM. Para GNG los parámetros de entrenamiento de la red
también permanecieron constantes, a excepción del parámetro λ que fue establecido en 1 para
obtener el mismo comportamiento en ambas técnicas, ya que en MAM-SOM* cada patrón es
asignado a una única neurona. Para MAM-SOM* se estableció N eighborhoodSize = 3.
6.4.1. Discusión en relación al número de conexiones
En la Figura 6.3 se observan los resultados obtenidos para el primer escenario propuesto:
NCD acumulado en relación al número de conexiones creadas por las redes. Se considerará
el número de conexiones creadas ya que éstas proporcionarán la información necesaria para
el descubrimiento de agrupamientos: a mayor número de conexiones, habrá más información
de distancias entre objetos y una mejor detección de agrupamientos y respuesta a consultas de
similitud. Entonces, es notable la mejora que representan las técnicas MAM-SOM* frente a los
modelos clásicos de redes neuronales.
6.4.2. Discusión en relación al número de patrones
Adicionalmente, y de manera similar al primer grupo de experimentos, se midió el desempeño de las dos técnicas en base al Número de Cálculos de Distancia acumulado en relación al
número de patrones presentados. Los resultados fueron los esperados: un drásticamente menor
Ingeniería Informática - UCSP
61
6.4. Segundo grupo
Numero de calculos de distancia
600000
GNG secuencial
GNG con Slim-Tree
500000
400000
300000
200000
100000
3000
6000
9000
12000
Numero de patrones presentados
15000
(a) NCD por patrón presentado en el proceso de construcción utilizando la base de datos IRAS (103-d).
Numero de calculos de distancia
5000000
GNG secuencial
GNG con Slim-Tree
4000000
3000000
2000000
1000000
10000
20000
30000
40000
Numero de patrones presentados
50000
(b) NCD por patrón presentado en el proceso de construcción utilizando la base de datos DIGITS (16-d).
Numero de calculos de distancia
10000000
GNG secuencial
GNG con Slim-Tree
8000000
6000000
4000000
2000000
20000
40000
60000
80000
Numero de patrones presentados
100000
(c) NCD por patrón presentado en el proceso de construcción utilizando la base de datos SPAM (57-d).
Figura 6.2: Comparación del Número de Cálculos de Distancia acumulado de la red Growing
Neural Gas y la técnica MAM-SOM GNG+Slim-Tree a lo largo del proceso de entrenamiento
de la red en relación al número de patrones presentados.
Ingeniería Informática - UCSP
62
CAPÍTULO 6. Experimentos
Numero de conexiones creadas
1200
GNG secuencial
MAM-SOM* Slim-Tree
1000
800
600
400
200
80
160
240
Numero de unidades
320
400
(a) NCD por conexión creada utilizando la base de datos
IRAS (103-d).
Numero de conexiones creadas
25000
GNG secuencial
MAM-SOM* Slim-Tree
20000
15000
10000
5000
1400
2800
4200
Numero de unidades
5600
7000
(b) NCD por conexión creada utilizando la base de datos
DIGITS (16-d).
Numero de conexiones creadas
18000
GNG secuencial
MAM-SOM* Slim-Tree
15000
12000
9000
6000
3000
800
1600
2400
Numero de unidades
3200
4000
(c) NCD por conexión creada utilizando la base de datos
SPAM (57-d).
Figura 6.3: Comparación del Número de Cálculos de Distancia acumulado de la red Growing
Neural Gas y la técnica MAM-SOM* Slim-Tree en relación al número de conexiones creadas.
Ingeniería Informática - UCSP
63
6.5. Tercer grupo
NCD de la técnica MAM-SOM* Slim-Tree, indicador no sólo de su eficiencia si no de la capacidad de ser aplicada a bases de datos mucho más grandes y complejas. La Figura 6.4 muestra los
resultados obtenidos en estos experimentos.
6.5. Tercer grupo
Por último, el tercer grupo de experimentos hace una comparación de la eficiencia de las
técnicas considerando el número de patrones presentados usando las bases de datos COVERT,
IMAGES y NURSERY. Las técnicas utilizadas son GNG, MAM-SOM Híbrida GNG+SlimTree, MAM-SOM* Slim-Tree y MAM-SOM* Omni-Secuencial.
Para obtener una comparación más precisa entre las técnicas se estableció el valor de λ
en 1 para GNG y MAM-SOM Híbrida. De este modo se obtiene el mismo comportamiento en
todas las técnicas, ya que en MAM-SOM* cada patrón es asignado a una única neurona.
Las Figuras 6.5, 6.6 y 6.7 muestran los resultados obtenidos en términos del NCD acumulado de cada técnica. Es posible notar que al inicio del proceso la técnica MAM-SOM*
implementada con Omni-Secuencial posee un alto NCD debido al costo de construcción de la
matriz de Omni-coordenadas. Como se puede observar, en todos los casos la red GNG obtuvo
el mayor número NCD.
El Cuadro 6.1 registra los resultados obtenidos en el conjunto de datos COVERT, mostrando la eficiencia de hasta 85,46 % obtenida por las técnicas MAM-SOM Híbrida y MAM-SOM*
en comparación a la implementación secuencial de GNG.
Cuadro 6.1: Comparación de resultados para la base de datos COVERT (54-d)
Técnica
GNG secuencial
GNG+Slim-Tree
MAM-SOM* Slim-Tree
MAM-SOM* Omni-Secuencial
NCD Acumulado
1600159995
298019806
232737830
653171081
% ganado
81,38 %
85,46 %
59,18 %
El Cuadro 6.2 muestra los resultados obtenidos en el conjunto de datos IMAGES. Nuevamente la técnica GNG obtuvo el NCD más elevado. También puede observarse que las técnicas
MAM-SOM* mostraron una gran ventaja sobre ambas implementaciones de GNG con una
eficiencia mayor al 50 % con respecto a GNG secuencial y mayor al 30 % con respecto a la
implementación con Slim-Tree. Puede entonces inferirse el buen rendimiento de estas técnicas
en altas dimensiones.
El cuadro 6.3 muestra los resultados obtenidos en el conjunto de datos NURSERY. La
eficiencia de las técnicas MAM-SOM es significativamente mejor que la técnica GNG, incluso
en bajas dimensiones.
Ingeniería Informática - UCSP
64
CAPÍTULO 6. Experimentos
Numero de calculos de distancia
180000
160000
GNG secuencial
MAM-SOM* Slim-Tree
140000
120000
100000
80000
60000
40000
20000
80
160
240
Numero de unidades
320
400
(a) NCD por patrón presentado utilizando la base de
datos IRAS (103-d).
Numero de calculos de distancia
50000000
45000000
GNG secuencial
MAM-SOM* Slim-Tree
40000000
35000000
30000000
25000000
20000000
15000000
10000000
5000000
1400
2800
4200
Numero de unidades
5600
7000
(b) NCD por patrón presentado utilizando la base de
datos DIGITS (16-d).
Numero de calculos de distancia
18000000
16000000
GNG secuencial
MAM-SOM* Slim-Tree
14000000
12000000
10000000
8000000
6000000
4000000
2000000
800
1600
2400
Numero de unidades
3200
4000
(c) NCD por patrón presentado utilizando la base de
datos SPAM (57-d).
Figura 6.4: Comparación del Número de Cálculos de Distancia acumulado de la red Growing
Neural Gas y la técnica MAM-SOM* Slim-Tree en relación al número de patrones presentados.
Ingeniería Informática - UCSP
65
6.5. Tercer grupo
Numero de calculos de distancia
500000000
400000000
GNG secuencial
GNG con Slim-Tree
MAM-SOM* Slim-Tree
MAM-SOM* Omni-Secuencial
300000000
200000000
100000000
10000
20000
30000
40000
Numero de patrones
50000
Figura 6.5: Comparación del Número de Cálculos de Distancia acumulado por patrón presentado usando la base de datos COVERT (54-d)
GNG secuencial
GNG con Slim-Tree
MAM-SOM* Slim-Tree
MAM-SOM* Omni-Secuencial
Numero de calculos de distancia
30000000
24000000
18000000
12000000
6000000
1000
2000
3000
4000
Numero de patrones
5000
6000
Figura 6.6: Comparación del Número de Cálculos de Distancia acumulado por patrón presentado usando la base de datos IMAGES (1215-d)
Numero de calculos de distancia
34000000
GNG secuencial
GNG con Slim-Tree
MAM-SOM* Slim-Tree
MAM-SOM* Omni-Secuencial
26000000
18000000
10000000
2000000
1500 3000 4500 6000 7500 9000 10500 12000
Numero de patrones
Figura 6.7: Comparación del Número de Cálculos de Distancia acumulado por patrón presentado usando la base de datos NURSERY (8-d)
En el tercer grupo de experimentos, el rendimiento de la técnica MAM-SOM* OmniSecuencial se ve afectada por el cálculo de las omni-coordenadas y principalmente por la cardiIngeniería Informática - UCSP
66
CAPÍTULO 6. Experimentos
Cuadro 6.2: Comparación de resultados para la base de datos IMAGES (1215-d)
Técnica
GNG secuencial
GNG+Slim-Tree
MAM-SOM* Slim-Tree
MAM-SOM* Omni-Secuencial
NCD Acumulado
36023995
26600212
14682611
17717785
% ganado
26,16 %
59,24 %
50,82 %
Cuadro 6.3: Comparación de resultados para la base de datos NURSERY (8-d)
Técnica
GNG secuencial
GNG+Slim-Tree
MAM-SOM* Slim-Tree
MAM-SOM* Omni-Secuencial
NCD Acumulado
144047995
15165159
22266439
72522291
% ganado
89,47 %
84,54 %
49,65 %
nalidad del conjunto de focos. Como se vio en el Capítulo 4, para optimizar el rendimiento de
esta técnica se debe seleccionar un número adecuado de focos en relación a la dimensionalidad
de los datos. En todos los experimentos se trabajo con una cardinalidad igual al doble de la
dimensión del espacio.
6.6. Experimentos adicionales
6.6.1. Discusión con respecto a los agrupamientos
La poda gradual de conexiones es el proceso propuesto para el hallazgo de agrupamientos
en las técnicas MAM-SOM*. Debido a que en estas técnicas las conexiones almacenan la distancia entre objetos, los agrupamientos encontrados estarán basados en un criterio de similitud,
formando agrupamientos compactos y aislados.
La Figura 6.8 explica claramente el proceso de agrupamiento para un conjunto de puntos
en 2 dimensiones. Como se puede observar, el decremento del parámetro τ permite encontrar
agrupamientos cada vez más pequeños y compactos.
6.6.2. Discusión con respecto al tiempo consumido
Para reforzar la hipótesis, se hicieron pruebas adicionales en relación al tiempo consumido
al aplicar las técnicas sobre el conjunto de datos SPAM. Los parámetros de la red permanecieron
constantes a excepción del parámetro λ y la edad máxima de conexión, que fueron cambiados a
Ingeniería Informática - UCSP
67
6.6. Experimentos adicionales
(a) Estructura inicial antes de aplicar la poda.
(b) Poda de conexiones con τ = 10.
(c) Poda de conexiones con τ = 5.
(d) Poda de conexiones con τ = 2,5.
Figura 6.8: Reducción gradual del parámetro τ para encontrar agrupamientos en un conjunto
datos sintéticos de 1000 puntos en dos dimensiones. N eighborhoodSize = 3.
Ingeniería Informática - UCSP
68
CAPÍTULO 6. Experimentos
1500 y 1600 respectivamente para comprobar el impacto del incremento del parámetro λ en el
proceso de construcción de la red como se discutió en la Sección 5.2 del capítulo anterior.
La técnica Growing Neural Gas tardó 325.8 segundos en construir una red con 100
unidades, lo cual es considerablemente más costos que la técnica GNG+Slim-tree que
demoró 205.6 segundos para la construcción de la misma red también con 100 unidades.
Entonces, la técnica MAM-SOM Híbrida realizó la misma tarea en un tiempo 37 % menor
que GNG.
Por otro lado, la técnica MAM-SOM* Slim-Tree aplicada en el mismo conjunto de datos
demoró sólo 95.2 segundos para la construcción de una estructura de 4601 unidades. El
tiempo requerido para obtener una estructura de las mismas dimensiones por una red
GNG con el parámetro λ = 1 fue 4.5 veces mayor.
Ingeniería Informática - UCSP
69
Capítulo 7
Conclusiones y Trabajos Futuros
7.1. Conclusiones
Las características de organización de datos propia de los métodos de acceso y las propiedades de generalización y aprendizaje de las redes neuronales, hacen de las familias MAMSOM técnicas altamente eficientes en tareas de clasificación y recuperación de información.
Para la familia de técnicas MAM-SOM híbridas existen varias combinaciones posibles de
redes neuronales del tipo Self-Organizing Maps y Métodos de Acceso Métrico. Por lo tanto, es
posible aprovechar las características propias de dos estructuras al mismo tiempo, haciendo de
esta familia una herramienta versátil por su aplicación en casi cualquier dominio de datos. El
resultado obtenido de estas técnicas en tareas de agrupamiento es cualitativamente igual al de
la red neuronal utilizada independientemente.
La familia MAM-SOM* provee de una representación exacta de los datos con un costo
computacional mucho menor a las redes neuronales SOM sin sacrificar rendimiento ni generalización. En este caso es posible trabajar con una gran variedad de métodos de acceso buscando
seleccionar al mejor método para el dominio de datos. Las características de los métodos de
acceso permanecen inmutables, pero gracias a la alta conectividad existente en estas técnicas,
se agregan más beneficios a los ya heredados.
Las tareas de agrupamiento de datos utilizando técnicas MAM-SOM* se dan estrictamente en base al concepto de similitud. Debido a que las conexiones almacenan las distancias
entre patrones, la información de similitud está siempre disponible, información útil tanto para
la detección de grupos como para la rápida recuperación de información en consultas de proximidad.
Las técnicas MAM-SOM ofrecen una estructura que acelera el proceso de entrenamiento
de las redes SOM, acelerando también la construcción del clasificador en tareas de agrupamiento y brindando una estructura con la capacidad de responder a consultas de similitud de forma
más eficiente.
70
CAPÍTULO 7. Conclusiones y Trabajos Futuros
Gracias a las técnicas MAM-SOM, es ahora posible trabajar con grandes conjuntos de
datos sin perjudicarse con altos tiempos y costos de procesamiento, incluso trabajando en altas
dimensiones.
7.2. Contribuciones
En esta investigación se propuso el uso de las técnicas MAM-SOM para tareas de agrupamiento de datos. Al demostrarse la eficiencia de estas técnicas, constituyen una excelente
herramienta para tareas de agrupamiento de grandes conjuntos de datos.
Debido a que las redes SOM vienen siendo ampliamente utilizadas en tareas de agrupamiento de datos, el uso de las técnicas MAM-SOM beneficiará a comunidades científicas
como las de inteligencia artificial, reconocimiento de patrones, minería de datos y recuperación
de información.
7.3. Problemas encontrados
Al trabajar con dos estructuras relacionadas (la red neuronal y el método de acceso), la
complejidad de la implementación es mayor a el uso independiente de las mismas, debiéndose
considerar en todo momento la correspondencia de datos existente entre ambas estructuras.
Se debe considerar que para la mayoría de técnicas existe un proceso de afinamiento
previo a la aplicación para optimizar su rendimiento.
7.4. Recomendaciones
El conocimiento que se tenga sobre el dominio de datos es un factor influyente tanto en la
determinación de la técnica de agrupamiento, como en la representación de patrones, selección
de métricas y en especial en la evaluación de resultados.
Es recomendable realizar un análisis previo a la aplicación del proceso de agrupamiento
para determinar la viabilidad y/o beneficios que se pueden obtener.
7.5. Trabajo futuro
Esta investigación puede servir como referencia para la creación de nuevas variantes de
las familias MAM-SOM para su aplicación en tareas de agrupamiento de grandes conjuntos de
datos.
Ingeniería Informática - UCSP
71
7.5. Trabajo futuro
Debido a los beneficios de las técnicas MAM-SOM*, se plantean aplicar nuevas políticas
para el hallazgo de agrupamientos, así como realizar una evaluación cualitativa de los resultados.
Para un trabajo futuro se planea aplicar técnicas MAM-SOM en un problema específico
de agrupamiento de datos.
Ingeniería Informática - UCSP
72
Bibliografía
[Alahakoon et al., 1998] Alahakoon, D., Halgamuge, S. K., and Srinivasan, B. (1998). A structure adapting feature map for optimal cluster representation. In International Conference on
Neural Information Processing ICONIP98, pages 809–812.
[Arifin and Asano, 2006] Arifin, A. Z. and Asano, A. (2006). Image segmentation by histogram
thresholding using hierarchical cluster analysis. Pattern Recognition Letters, 27(13):1515–
1521.
[Baeza-Yates et al., 1994] Baeza-Yates, R. A., Cunto, W., Manber, U., and Wu, S. (1994). Proximity matching using fixed-queries trees. In Crochemore, M. and Gusfield, D., editors, Proceedings of the 5th Annual Symposium on Combinatorial Pattern Matching, pages 198–212,
Asilomar, CA. Springer-Verlag, Berlin.
[Bedregal and Cuadros-Vargas, 2006] Bedregal, C. and Cuadros-Vargas, E. (2006). Using large
databases and self-organizing maps without tears. In Proceedings of the International Joint
Conference on Neural Networks (IJCNN06). IEEE.
[Bentley, 1979] Bentley, J. L. (1979). Multidimensional Binary Search Trees in Database Applications. IEEE Transactions on Software Engineering, 5(4):333–340.
[Bishop, 1995] Bishop, C. M. (1995). Neural networks for pattern recognition. Oxford.
[Blackmore and Miikkulainen, 1993] Blackmore, J. and Miikkulainen, R. (1993). Incremental
grid growing: Encoding high-dimensional structure into a two-dimensional feature map. In
Proceedings of the International Conference on Neural Networks ICNN93,, volume I, pages
450–455, Piscataway, NJ. IEEE Service Center.
[Bozkaya and Ozsoyoglu, 1997] Bozkaya, T. and Ozsoyoglu, M. (1997). Distance-based indexing for high-dimensional metric spaces. In SIGMOD ’97: Proceedings of the 1997 ACM
SIGMOD International Conference on Management of data, pages 357–368, New York, NY,
USA. ACM Press.
[Breuel, 2001] Breuel, T. M. (2001). Classification by probabilistic clustering. In ICASSP ’01:
Proceedings of the Acoustics, Speech, and Signal Processing, 200. on IEEE International
Conference, pages 1333–1336, Washington, DC, USA. IEEE Computer Society.
[Brin, 1995] Brin, S. (1995). Near neighbor search in large metric spaces. In The VLDB Journal, pages 574–584.
73
BIBLIOGRAFÍA
[Burkhard and Keller, 1973] Burkhard, W. A. and Keller, R. M. (1973). Some approaches to
best-match file searching. Commun. ACM, 16(4):230–236.
[Caetano Traina et al., 2000] Caetano Traina, J., Traina, A. J. M., Seeger, B., and Faloutsos,
C. (2000). Slim-trees: High performance metric trees minimizing overlap between nodes.
In Proceedings of the 7th International Conference on Extending Database Technology
EDBT00, pages 51–65, London, UK. Springer-Verlag.
[Carpenter and Grossberg, 1988] Carpenter, G. A. and Grossberg, S. (1988). The art of adaptive pattern recognition by a self-organizing neural network. Computer, 21(3):77–88.
[Chávez et al., 2001] Chávez, E., Navarro, G., Baeza-Yates, R., and Marroquín, J. (2001).
Proximity searching in metric spaces. ACM Computing Surveys, 33(3):273–321.
[Ciaccia et al., 1997] Ciaccia, P., Patella, M., and Zezula, P. (1997). M-tree: An efficient access
method for similarity search in metric spaces. In The VLDB Journal, pages 426–435.
[Clarkson, 2006] Clarkson, K. L. (2006). Nearest-neighbor searching and metric space dimensions. In Shakhnarovich, G., Darrell, T., and Indyk, P., editors, Nearest-Neighbor Methods
for Learning and Vision: Theory and Practice, pages 15–59. MIT Press.
[Cuadros-Vargas, 2004] Cuadros-Vargas, E. (2004). Recuperação de informação por similaridade utilizando técnicas inteligentes. PhD thesis, Department of Computer Science - University of Sao Paulo. in portuguese.
[Cuadros-Vargas and Romero, 2005] Cuadros-Vargas, E. and Romero, R. A. F. (2005). Introduction to the SAM-SOM* and MAM-SOM* families. In Proceedings of the International
Joint Conference on Neural Networks (IJCNN05). IEEE.
[Cuadros-Vargas and Romero, 2002] Cuadros-Vargas, E. and Romero, R. F. (2002). The SAMSOM Family: Incorporating Spatial Access Methods into Constructive Self-Organizing
Maps. In Proceedings of the International Joint Conference on Neural Networks IJCNN02,
pages 1172–1177, Hawaii, HI. IEEE Press.
[Dittenbach et al., 2000] Dittenbach, M., Merkl, D., and Rauber, A. (2000). The Growing Hierarchical Self-Organizing Map. In Amari, S., Giles, C. L., Gori, M., and Puri, V., editors,
Proc of the International Joint Conference on Neural Networks (IJCNN 2000), volume VI,
pages 15 – 19, Como, Italy. IEEE Computer Society.
[Dohnal et al., 2003] Dohnal, V., Gennaro, C., Savino, P., and Zezula, P. (2003). D-index: Distance searching index for metric data sets. Multimedia Tools Appl., 21(1):9–33.
[Dubes, 1993] Dubes, R. C. (1993). Cluster analysis and related issues. pages 3–32.
[Duda et al., 2000] Duda, R. O., Hart, P. E., and Stork, D. G. (2000). Pattern Classification.
Wiley-Interscience Publication.
[Filho et al., 2001] Filho, R. F. S., Traina, A. J. M., Jr., C. T., and Faloutsos, C. (2001). Similarity search without tears: The OMNI family of all-purpose access methods. In International
Conference on Data Engineering ICDE01, pages 623–630.
Ingeniería Informática - UCSP
74
BIBLIOGRAFÍA
[Fritzke, 1995] Fritzke, B. (1995). A growing neural gas network learns topologies. In Tesauro,
G., Touretzky, D. S., and Leen, T. K., editors, Advances in Neural Information Processing
Systems 7, pages 625–632. MIT Press, Cambridge MA.
[Grossberg, 1972] Grossberg, S. (1972). Neural expectation: Cerebellar and retinal analogs of
cells fired by learnable or unlearned pattern classes. kyb, 10:49–57.
[Guttman, 1984] Guttman, A. (1984). R-Trees: A dynamic index structure for spatial searching. In Yormark, B., editor, Proceedings of Annual Meeting, Boston, Massachusetts SIGMOD84, June 18-21, 1984, pages 47–57. ACM Press.
[Hand et al., 2001] Hand, D. J., Smyth, P., and Mannila, H. (2001). Principles of data mining.
MIT Press, Cambridge, MA, USA.
[Haykin, 1994] Haykin, S. (1994). Neural networks: a comprehensive foundation. Prentice
Hall.
[Hjaltason and Samet, 2003] Hjaltason, G. R. and Samet, H. (2003). Index-driven similarity
search in metric spaces. ACM Trans. Database Syst., 28(4):517–580.
[Jain and Dubes, 1988] Jain, A. K. and Dubes, R. C. (1988). Algorithms for clustering data.
Prentice-Hall, Inc., Upper Saddle River, NJ, USA.
[Jain et al., 2000] Jain, A. K., Duin, R. P. W., and Mao, J. (2000). Statistical pattern recognition:
A review. IEEE Trans. Pattern Anal. Mach. Intell., 22(1):4–37.
[Jain et al., 1996] Jain, A. K., Mao, J., and Mohiuddin, K. M. (1996). Artificial neural networks: A tutorial. IEEE Computer, 29(3):31–44.
[Jain et al., 1999] Jain, A. K., Murty, M.Ñ., and Flynn, P. J. (1999). Data clustering: a review.
ACM Computing Surveys, 31(3):264–323.
[Kohonen, 1982] Kohonen, T. (1982). Self-organized formation of topologically correct feature
maps. Biological Cybernetics, 43:59–69.
[Kohonen, 1988] Kohonen, T. (1988). Self-organized formation of topologically correct feature
maps. pages 509–521.
[Kohonen, 1998] Kohonen, T. (1998). Self-organization of very large document collections:
State of the art. In Niklasson, L., Bodén, M., and Ziemke, T., editors, ICANN, volume 1,
pages 65–74, London. Springer.
[Kruskal, 1956] Kruskal, J. B. (1956). On the shortest spanning subtree of a graph and the
traveling salesman problem. Proceedings of the American Mathematical Society, 7:48–50.
[Lagus et al., 1999] Lagus, K., Honkela, T., Kaski, S., and Kohonen, T. (1999). Websom for
textual data mining. Artificial Intelligence Rev., 13(5-6):345–364.
[Lowe, 2001] Lowe, D. (2001). Local feature view clustering for 3d object recognition.
Ingeniería Informática - UCSP
75
BIBLIOGRAFÍA
[Marcos R. Viera and Traina, 2004] Marcos R. Viera, Caetano Traina Fr., F. J. T. C. and Traina,
A. J. (2004). DBM-tree: A dynamic metric access method sensitive to local density data.
Brazilian Symposium on Databases.
[Martinetz and Schulten, 1994] Martinetz, T. and Schulten, K. (1994). Topology representing
networks. Neural Networks, 7(3):507–522.
[Micó L., 1994] Micó L., Oncina J., V. E. (1994). A new version of the nearest-neighbour
approximating and eliminating search algorithm (AESA) with linear preprocessing time and
memory requirements. Pattern Recognition Letters, 15:9–17.
[Navarro, 2002] Navarro, G. (2002). Searching in metric spaces by spatial approximation. The
VLDB Journal, 11(1):28–46.
[Ocsa et al., 2007] Ocsa, A., Bedregal, C., and Cuadros-Vargas, E. (2007). DB-GNG: A constructive self-organizing map based on density. In Proceedings of the International Joint
Conference on Neural Networks (IJCNN07). IEEE.
[Prudent and Ennaji, 2005] Prudent, Y. and Ennaji, A. (2005). A k nearest classifier design.
ELCVIA, 5(2):58–71.
[Rueda and Qin, 2005] Rueda, L. and Qin, L. (2005). An unsupervised learning scheme for
dna microarray image spot detection.
[Ruiz, 1986] Ruiz, E. V. (1986). An algorithm for finding nearest neighbours in (approximately) constant average time. Pattern Recognition Letters, 4(3):145–157.
[Tombros et al., 2002] Tombros, A., Villa, R., and Rijsbergen, C. J. V. (2002). The effectiveness of query-specific hierarchic clustering in information retrieval. Inf. Process. Manage.,
38(4):559–582.
[Uhlmann, 1991] Uhlmann, J. K. (1991). Satisfying general proximity/similarity queries with
metric trees. Inf. Process. Lett., 40(4):175–179.
[Vesanto and Alhoniemi, 2000] Vesanto, J. and Alhoniemi, E. (2000). Clustering of the selforganizing map. IEEE-NN, 11(3):586.
[Waibel et al., 1990] Waibel, A., Hanazawa, T., Hinton, G., Shikano, K., and Lang, K. J. (1990).
Phoneme recognition using time-delay neural networks. pages 393–404.
[Watanabe, 1985] Watanabe, S. (1985). Pattern recognition: human and mechanical. John
Wiley & Sons, Inc., New York, NY, USA.
[White, 1992] White, R. H. (1992). Competitive hebbian learning: algorithm and demonstrations. Neural Networks, 5(2):261–275.
[Xu et al., 2006] Xu, L., Qian, B., Cheng, W., and Tang, Z. (2006). Research on automatic
speaker recognition based on speech clustering. In ICICIC ’06: Proceedings of the First
International Conference on Innovative Computing, Information and Control, pages 105–
108, Washington, DC, USA. IEEE Computer Society.
Ingeniería Informática - UCSP
76
BIBLIOGRAFÍA
[Zezula et al., 2006] Zezula, P., Amato, G., Dohnal, V., and Batko, M. (2006). Similarity Search
- The Metric Space Approach, volume 32. Springer.
Ingeniería Informática - UCSP
77