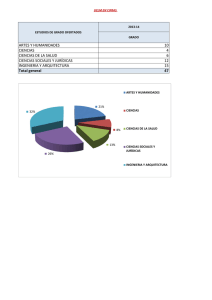
- Escuela Militar de Ingeniería
Anuncio

EQUIPO EDITORIAL: Director: Director vitalicio: Editor: Editor revista digital: Diagramación: Diseño de la portada: Tcnl. DIM. Julio Cesar Narváez Tamayo MSc. Fernando Yañez Romero Ing. Freddy Medina Miranda Tte. Com. Rolando Sánchez Montalvo TF.CGON. Wilson Charlie Seoane Sánchez Univ. Diego Feraudy Pinto Univ. Cesar Antonio Narváez Gutiérrez [email protected] [email protected] [email protected] [email protected] [email protected] [email protected] [email protected] EDICIÓN TECNICA: Escuela Militar de Ingeniería Unidad Académica La Paz Carrera de Ingeniería de Sistemas Irpavi, La Paz - Bolivia Tel. (0 591) 2775536 URL: www.emi.edu.bo E-mail: [email protected] Reservados todos los derechos de reproducción total o parcial del contenido de esta revista. Copyright © 2014 Ingeniería de Sistemas CONTENIDO REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 PAG. EDITORIAL 3 PRESENTACIÓN DEL RECTOR 4 PRESENTACIÓN DEL VICERRECTOR 5 PRESENTACIÓN DEL DIRECTOR DE LA UNIDAD ACADÉMICA LA PAZ 6 ARTÍCULOS DE DOCENTES 7 ARTÍCULOS DE ESTUDIANTES 50 ACTIVIDADES DE LA CARRERA 88 FOTOS DE ESTUDIANTES POR CURSO 92 1 Ingenieria de Sistemas Competencia General Competencia por Área El Ingeniero de Sistemas graduado de la EMI: “Determina el diseño, desarrollo, implementación, evaluación, mantenimiento, soporte y retiro de sistemas con enfoque sistémico y visión emprendedora, aplicando nuevas tecnología de información y comunicación realizando el modelado y automatización de sistemas, desarrollando sistemas de gestión empresarial y de producción orientados a la toma de decisiones que optimicen los procesos, con creatividad, liderazgo y pensamiento crítico en un entorno complejo conflictivo multidisciplinario”. √ √ √ √ Sistemas de Información y Conocimiento. Tecnologías de la Comunicación y Redes. Modelación y Automatización de Sistemas. Sistemas de Gestión Empresarial. EDITORIAL REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Tcnl. DIM. Julio César Narváez Tamayo JEFE DE LA CARRERA DE INGENIERÍA DE SISTEMAS La revista Paradigma, por el importante rol que cumple, de difundir las actividades de investigación y de interacción social de la comunidad universitaria de la Carrera de Ingeniería de Sistemas de la Escuela Militar de Ingeniería, a partir de la presente gestión se publicará semestralmente. La implantación gradual en la Carrera del nuevo diseño curricular por competencias, que se enfoca en dotar al estudiante de competencias del saber, saber hacer y saber ser, haciendo uso de métodos, técnicas y herramientas didácticas centradas en el aprendizaje del estudiante, el cual es fundamentalmente colaborativo y sustentado en la investigación y en la interacción social, tiene en la revista Paradigma un instrumento de apoyo para la publicación de los resultados de investigación y de los efectos de las tareas de interacción social. Asimismo, la elaboración del trabajo de Grado por estudiantes de quinto año, como requisito para la titulación, da lugar a la presentación de artículos con los resultados del proceso de investigación. La Jefatura de Carrera ha realizado importantes esfuerzos para la implementación del laboratorio de Redes, que se constituye en el más completo y actual del país y que, a partir de la presente gestión es utilizado por estudiantes de la Carrera, de otras Carreras y del postgrado de la EMI. Por otra parte, se está en proceso de adquisición de un moderno laboratorio de robótica y automatización, que apoyará el área competencial de Modelado y Automatización de Sistemas del nuevo Diseño Curricular. El ininterrumpido avance de la Ciencia y de la Tecnología, relacionada con la Ingeniería de Sistemas hace que la investigación y la interacción social sean una prioridad para los docentes, estudiantes y los profesionales egresados de la Carrera. La convergencia tecnológica, la computación en la nube, los métodos estadísticos multivariantes, la implementación de controles de seguridad de la información, la identificación de modelos borrosos usando clustering, la detección de patrones caóticos en fenómenos de contaminación y otras investigaciones presentadas en los artículos de la revista, requieren ser aplicados en nuestro medio, para generar ventajas competitivas y comparativas que contribuyan al desarrollo tecnológico del país. Finalmente, un grato homenaje al MSc. Fernando Yañez Romero, director vitalicio de la revista, quien, en fecha 6 de junio de 2014, ha sido reconocido por el Señor Rector Cnl. DAEN. Alvaro Rios Oliver, por los servicios prestados a la EMI. 3 PRESENTACIÓN REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 4 Cnl. DAEN. Álvaro Alfonzo Ríos Oliver RECTOR DE LA ESCUELA MILITAR DE INGENIERÍA En las diferentes etapas de mi desarrollo profesional, en la Escuela Militar de Ingeniería, he tenido la oportunidad de participar y/o ser testigo de la evolución de esta publicación que recoge el esfuerzo intelectual y de investigación de directivos, docentes y estudiantes de la Carrera de Ingeniería de Sistemas. La importancia de una publicación como la presente radica en la posibilidad de permitir que todo el trabajo desarrollado en la academia trascienda; trascienda el ámbito físico de los recintos universitarios y, tal vez con mayor preponderancia, trascienda a nuevas generaciones de profesionales, estudiantes e investigadores en general, que encuentren en estas páginas la inspiración para nuevos emprendimientos. A través de estas líneas hago llegar un saludo a las autoridades, docentes, estudiantes y personal administrativo de la Carrera de ingeniería de Sistemas, además mis congratulaciones al equipo de trabajo que ha hecho posible una nueva edición de la Revista Paradigma, esfuerzos de esta naturaleza contribuyen a mantener y dignificar la imagen de nuestra Casa de Estudios Superiores. VICERECTOR REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Cnl. DAEN. Francisco Rivero Villca VICERRECTOR ESCUELA MILITAR DE INGENIERÍA Los bolivianos hemos ingresado a una etapa de progresiva liberación de nuestras capacidades productivas, intelectuales e innovadoras, sobre la base de un modelo de desarrollo con inclusión social y nos encaminamos con paso firme al horizonte de la definitiva emancipación científico - tecnológico. La emancipación científico - tecnológica es una condición imprescindible para la sustentabilidad de cualquier estrategia de verdadero desarrollo en los campos social, humano y económico. Soberanía científico - tecnológica implica la potestad de un estado de elegir libremente y sin condicionamientos externos el rumbo al que prefiere orientar su desarrollo en los campos de la ciencia y tecnología sobre los cuales se basa su consolidación como nación con capacidad de responder a las demandas de su población y de insertarse en el contexto mundial en condiciones de igualdad. Considerando que el conocimiento ya no es una mercancía de acceso restringido, sino un bien público cuyo manejo y dominio determinará el poder de un Estado. El contenido de la presente revista sin duda alguna contribuye a la transmisión, difusión y divulgación del conocimiento, y representa un aporte importante en la búsqueda de la soberanía científico - tecnológica. 5 DIRECTOR REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 6 Cnl. DAEN. Roberto René Alarcón Loza DIRECTOR DE LA UNIDAD ACADÉMICA LA PAZ La Escuela Militar de Ingeniería y, en particular, la Unidad Académica La Paz, inmersa en el proceso de implementación del Diseño Curricular por Competencias, tiene el propósito de impulsar la investigación y la interacción social, para dotar a los estudiantes de una formación que responda al encargo social, con las competencias requeridas por el mercado profesional, orientadas a apoyar el desarrollo y la industrialización del país. La revista Paradigma contribuye a incentivar a los docentes y estudiantes de la Carrera de Ingeniería de Sistemas en la realización de trabajos de investigación, además de cumplir con el importante rol de difundir las actividades de interacción social. En este contexto, es una grata satisfacción para la Dirección de la Unidad Académica La Paz, presentar una nueva edición de la revista Paradigma, destacando el esfuerzo realizado en su elaboración por la Jefatura, docentes y estudiantes de la Carrera de Ingeniería de Sistemas. REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 “Rough sets” y su aplicación en la Ingeniería Kansei PAOLA CARRANZA BRAVO Departamento de Ingeniería de Sistemas - Escuela Militar de Ingeniería La Paz-Bolivia [email protected] RESUMEN El presente artículo trata de la teoría de conjuntos Rough, que es una aproximación matemática para el análisis y la modelización de problemas de clasificación y de decisión relacionados con la información vaga, imprecisa, incierta o incompleta, mostrando sus aplicaciones a la Ingeniería Kansei en la determinación de las características del diseño que producen las percepciones, sensaciones y gustos identificados del consumidor, concluyendo con la elaboración de la herramienta informática KES (Kansei Engineering System) ABSTRACT This article deals with the Rough Set theory, a mathematical approach to the analysis and modeling ofclassification problems and decisions relating to the vague, imprecise, uncertain or incomplete information, and show its application to Kansei Engineering in determination of design features that produce perceptions, feelings and tastes of consumers identified, concluding with the development of the software tool KES (Kansei Engineering System). INGENIERÍA KANSEI Es una tecnología que emplea desarrollos y métodos rigurosos que permiten manejar la información de las preferencias emocionales de los consumidores, aplicando técnicas estadísticas y analíticas de ingeniería, para comprenderlas profundamente y para actuar sobre los elementos del sistema (producto, servicio, publicidad, etc.) que percibe el cliente. elementos del sistema (producto, servicio, publicidad, etc.) que más inciden en las emociones percibidas por el usuario, como también, modificar los diseños en aquellos puntos que pueden facilitar la creación de nuevas emociones. ROUGH SET La técnica “Rough Set” se basa en la suposición de que con todo objeto X del universo U que está considerando se puede asociar alguna información (datos, conocimiento), expresado por medio de atributos que describen el objeto (Pawlak, 1982) que en general, no pueden ser caracterizados de manera precisa en términos de la información disponible. Figura 1. Kansei La Ingeniería Kansei permite medir las emociones a través de estudios de semántica diferencial, conocer los Figura 3. Rough Set LA TEORÍA DE LOS ROUGH SETS Aplicación de la Inteligencia Artificial Figura 2. Ingeniería Kanse La teoría de conjuntos Rough es una aproximación matemática se ocupa del análisis y la modelización de problemas de clasificación y de decisión relacionados con la información vaga, imprecisa, incierta o incompleta. Se han propuesto conjuntos aproximados para una 7 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 variedad de aplicaciones, incluyendo la inteligencia artificial y las ciencias cognitivas, especialmente la máquina de aprendizaje, descubrimiento de conocimiento, minería de datos, sistemas expertos, razonamiento aproximado, y reconocimiento de patrones. Analiza las decisiones pasadas (experiencia histórica) de un determinado decisor de manera cuantitativa, para, basándose en esas decisiones, explicitar reglas. Estas reglas constituyen la esencia de las decisiones pasadas y contribuyen a objetivarlas. Las reglas obtenidas pueden ayudar a tomar decisiones futuras. [Aplicando esta metodología se consigue]: • • Evaluar la importancia de los atributos de condición (los que describen los objetos del sistema de información); Eliminar los atributos y objetos redundantes en el sistema para obtener los denominados reductos (conjuntos mínimos de atributos que mantienen la misma clasificación que el conjunto inicial); una vez reducido el sistema, se obtiene el algoritmo consistente en un conjunto de reglas de decisión en forma de sentencias lógicas: (si <condiciones> entonces <clase de decisión>) FUNDAMENTOS DE LA TEORÍA ROUGH SET - RS La teoría Rough Set (Conjuntos aproximados) ha tenido un gran desarrollo y aplicación en diferentes campos del conocimiento. Esta teoría fue desarrollada a mediados de los años ochenta por el científico Polaco Pawlak. La teoría Rough Set fue desarrollada en un ámbito de inteligencia artificial para analizar datos donde existe alta ambigüedad, permitiendo su clasificación y toma de decisiones más racional. El propósito principal de la teoría RS es la transformación de datos en conocimiento, es decir, se trata de extraer información útil de las bases de datos (Greco et al. 2001;Pawlak 1982 y 1991). METODOLOGÍA ROUGH SETS (CONJUNTOS APROXIMADOS) 1. Modelo Rough Set Original (RSO) La teoría Rough Set permite establecer una metodología para la extracción de patrones dentro de un conjunto de datos y está basada en los conceptos de “discernibilidad y aproximación”. 1. Discernir significa “conseguir distinguir una cosa de otra, por medio de los sentidos o de la 8 razonamiento humano”, lo que busca es encontrar todos aquellos objetos que producen distinto tipo de información, es decir, aquellos objetos que son “discernibles” (Pawlak y Slowi_ski, 1994). 2. Aproximación se refiere a la existencia de vaguedad, imprecisión en la información de un conjunto de objetos, se puede conseguir una mayor información cuando se utiliza conjuntos aproximados. A partir de estos conceptos se construye toda la estructura matemática del Rough Set (Pawkak y Skowron, 2007). Esta consiste en buscar las aproximaciones superior e inferior basada en las reglas de decisión de los datos “Rough Kansei”. Un modelo apoyado en la técnica de inteligencia artificial “Rough set” para seleccionar el conjunto de amenazas críticas en las cuales se deben enfocar los gestores de proyectos de desarrollo de software, para mitigar los riesgos y dar cumplimiento a los requerimientos y necesidades demandados por el usuario en este tipo de proyectos. Esta teoría de “Rough Set” asume la representación del conocimiento de los objetos en forma de una tabla de información, que es un caso especial de un sistema de información. En las filas de la tabla se indican los objetos (acciones, alternativas, eventos, candidatos, pacientes, empresas, etc.), mientras que las columnas corresponden a los atributos (característica, variables, condiciones, indicadores, etc.). Las entradas en la tabla son los valores del atributo (Pawlak) Según O _Leary (1995), los sistemas inteligentes pueden construirse a través de dos enfoques: 1. Introduciendo en el ordenador el conocimiento que los expertos humanos han ido acumulando a lo largo de su vida, obteniéndose lo que se conoce como sistema experto, ó 2. Elaborando programas capaces de generar conocimiento a través de datos empíricos y, posteriormente, usar ese conocimiento para realizar inferencias sobre nuevos datos que transformará una base de datos en una base de conocimiento. Dentro de este enfoque podemos distinguir entre las técnicas que buscan el conocimiento a través de anticipar patrones en los datos, entre ellas las diversas redes neuronales, y las consistentes en inferir reglas de decisión a partir de los datos de la base. Entre ellas la teoría Rough Set. Mosqueda (2010), distingue tres categorías generales de imprecisión en el análisis científico. REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 1. La teoría Rough Set que es útil cuando las clases que se catalogan los objetos son imprecisas, pero, sin embargo, pueden aproximarse mediante conjuntos precisos. No se necesita ninguna información adicional acerca de los datos, tales como una distribución de probabilidad en estadística, o el grado o probabilidad de pertenencia en la teoría de lógica difusa. Es así que el modelo Rough Set se advierte como un método perteneciente a los Sistemas de Inducción de Reglas y Árboles de Decisión (o métodos de criterio múltiple), cuyo enfoque, a su vez, se encuadra dentro de las aplicaciones de la Inteligencia Artificial. equivalencia B*, es también referida como la clasificación y también es notada como U/IND(B). Los objetos que pertenecen a la misma clase de equivalencia Xi son indiscernibles, si están en distinta clase los objetos son discernibles con respecto al subconjunto de atributos B. Las clases de equivalencia Xi, i=1, 2, ..., r de la relación IND(B) son llamados los subconjuntos elementales en el sistema de información S. Un conjunto elemental de B se nota como [x]B y está definido así: [x]B = {y_U: xIND(B)y}. Un par ordenado AS=(U,IND(B)) es llamado un espacio de aproximación. Cualquier unión de conjuntos elementales en AS es llamado un conjunto compuesto en S. 1.1) SISTEMA DE INFORMACIÓN 1.3) Tablas de decisión La extracción de conocimiento es un proceso que tiene como referencia un sistema de información. Un sistema de información está compuesto por una cuádrupla S=U, A, V, f, donde: U el universo cerrado es un conjunto finito de N objetos {x1, x2, ... ,xN}; A es un conjunto no vacío de r atributos {a1, a2, ..., ar} que describe los objetos; V=a_AVa donde Va es el dominio del atributo a; y f:U_A_V es la función de decisión total llamada la función de información tal que f(x,a)_Va para todo a_A y x_U. Algunos sistemas de información pueden ser designados como tablas de decisión. El conjunto de atributos A se divide en dos subconjuntos disjuntos A=C_D, donde C es el conjunto de atributos condicionales y D es conjunto de atributos de decisión con C_D=_. Cualquier pareja (a,v) con a_A y v_V es llamado un descriptor en sistema de información S. El sistema de información puede ser representado por una tabla de información. 1.2) RELACIÓN DE INDISCERNIBILIDAD En un sistema de información para cada subconjunto de atributos del universo se puede definir una relación binaria que se denomina relación de indiscernibilidad. Sea S=<U, A, V, f> un sistema de información, y sean B_A un subconjunto de atributos y los objetos x, y_U, entonces a x e y se les dice indiscernibles para el conjunto de atributos B si y solo si f(x,a)=f(y,a) para todo a_B. La relación de indiscernibilidad en B se nota como IND(B). Donde: IND(B)={(x,y)_U_U:para todo a_B,f(x,a)=f(y,a)} Para cada pareja de objetos (x,y) que pertenece a la relación IND(B), ((x,y)_IND(B)), a los objetos x e y se dicen que son indiscernibles con respecto a B es decir, se puede distinguir los objetos x e y en términos de los atributos del conjunto B únicamente. La relación de indiscernibilidad IND(B) separa el universo U en una familia de clases de equivalencia {X1,X2, ... ,Xr}. La familia de clases de equivalencia {X1,X2, ... ,Xr} definida mediante la relación IND(B) en U, genera una partición de U y es notada como B*. La familia de clases de Del sistema de información S, se puede considerar una tabla de decisión denotada como DT=<U,C_D,V.f>, donde: C es un conjunto de atributos condicionales; D es un conjunto de atributos de decisión; V=_a_C_D Va con Va el conjunto de dominio del atributo a_A; y f:U_(C_D)_V es la función de decisión total llamada la función de información tal que f(x,a)_Va para todo a_A y x_U. Una tabla de decisión es notada por (U, C_D) o por DTC donde C nota el conjunto de atributos condicionales. El conjunto D en general puede contener muchos atributos de decisión, sin embargo, de cara a la aplicación a la Ingeniería Kansei este conjunto contiene un atributo de decisión denotando como un número dado de clases de categorías c{c1, c2, ... cl}. En general las tablas de decisión generadas en un estudio Kansei es no-deterministas debido a que las valoraciones son obtenidas de un conjunto de consumidores que dan valoraciones Kansei con algún grado de incertidumbre generando sistemas de información imprecisos. 1.4) ESPACIO DE APROXIMACIÓN Algunos subconjuntos de objetos en un sistema de información no pueden ser distinguidos en términos de los atributos disponibles. Ellos pueden ser definidos en forma aproximada. La idea de Rough Sets consiste de la aproximación de un conjunto mediante un par de conjuntos, llamados aproximación inferior_BX de X contiene todos los objetos que, basado en el conocimiento de atributos B, puede ser clasificado con certeza que pertenece al concepto X (basado en el conocimiento de B) y superior de este conjunto, B _X del conjunto X es 9 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 la unión de aquellos conjuntos elementales cada uno de los cuales tienen una intersección no-vacía con X. • • Figura 4. Espacio de aproximación 2) MÉTODO DE EXTRACCIÓN DE LAS REGLAS DE DECISIÓN DE LAS REGIONES APROXIMADAS La gran mayoría de las aplicaciones que tiene la teoría Rough Sets están fundamentadas en la toma de decisiones, por tanto una de las partes más importantes de su aplicación es la generación o extracción de reglas de decisión. Específicamente en la ingeniería Kansei, la extracción de reglas de decisión esta asociada a la combinación de categorías que debe tomar cada propiedad del producto que permita obtener la máxima valoración. Generación de un conjunto exhaustivo de reglas, buscando obtener todas las posibles reglas de una tabla de decisión. Generación de un conjunto “robusto” de reglas, que eventualmente podría se discriminante, pero cubriendo a muchos objetos de la tabla de decisión, es decir, no se llega a cubrir necesariamente a todos los objetos. En el contexto de la aplicación de Ingeniería Kansei, se proponen tres índices de evaluación de reglas de decisión usando las valoraciones de los productos y los efectos de los productos en la decisión . Las reglas extraídas pueden ser representadas en la forma de IF THEN . Para efectos prácticos se usa la siguiente notación IF condk THEN Dj con k=1, .... ,m. El índice de certidumbre notado como CER =cer(condk ;Dj ) es la razón entre el número de eventos que satisfacen la regla IF - THEN con respecto al número de eventos que satisfacen la parte condicional condk de la regla:_ _Donde |Cond_k_D_j | se refiere al número de eventos que cumplen la condk y d=j que son iguales a: es el número de eventos que cumplen la condk . Slowinski y Stefanowski (1989) establecen que dada una tabla de información S=<U, A, V, f> , donde A= C _D , se puede definir una tabla de decisión DT=<U,CD,V.f> donde C es un conjunto de atributos condicionales; D es un conjunto de atributos de decisión. Sea U/IND(C) la familia de clases de equivalencia definida por el conjunto de atributos C y designados por Xi con i 1,...,m , y sea también U/IND(D) la familia de clases de equivalencia definida por el conjunto de atributos D y designados por Yj con j= 1,...,n y llamados clases de decisión. Se quiere establecer una relación de dependencia entre los atributos de condición y decisión, así una tabla de decisión puede ser vista como un conjunto de reglas de decisión. Existen sentencias (implicaciones) lógicas del tipo “if..., then ...”, donde el antecedente (parte condicional) especifica valores asumidos por uno o mas atributos de condición y la consecuente (parte de decisión) especifica una asignación a uno o más clases de decisión. PROCEDIMIENTOS- ESTRATEGIAS QUE PERMITEN DERIVAR REGLAS DE DECISIÓN: • 10 Generación de un conjunto mínimo de reglas, cubriendo todos los objetos de una tabla de decisión. El índice de certidumbre muestra el grado de certeza para los cuales las condk _Dj se cumplen. El índice precisión o cobertura notado como PREC= cov(Condk ,Dj ) es la razón entre es la razón entre el número de eventos que satisfacen la regla de decisión con respecto al número de eventos que satisfacen a Dk. y esta definido como: El índice de calidad o de fuerza notado como CAL(Condk ,Dj), es la razón entre el número de eventos que satisfacen la regla de decisión con respecto al numero total de eventos. Mediante la Ingeniería Kansei se plasma en imágenes mentales, las percepciones, sensaciones y gustos del consumidor. Primero, mediante el uso de cuestionarios y de métodos tan curiosos como, por ejemplo, el análisis del movimiento inconsciente de los ojos al ver un producto nuevo, se obtienen las respuestas de en términos de Kansei. Posteriormente, mediante herramientas de regresión y análisis de datos, se identifican qué REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 características del diseño producen las respuestas anteriores. Por último, uniendo todo lo anterior, se elabora una herramienta informática denominada KES (Kansei Engineering System) y que consta de cuatro bases de datos: • • • Base de datos de palabras -> En esta base de datos se almacenan todas las palabras que el consumidor utiliza para describir el producto Base de datos de imágenes -> Se almacenan todas las relaciones entre los elementos de diseño y las palabras. Base de conocimientos -> A partir de datos anteriores, decide cuáles son los elementos de Estudiantes asistiendo a un seminario • diseño finales sugeridos para el producto. Base de datos de diseño y color -> Almacenamiento de detalles de diseño y colores, considerando su correlación con las palabras que utiliza el usuario En resumen, un diseñador que disponga de esta herramienta introduce en el sistema las palabras que describen todos los atributos que desea lograr con su producto o servicio. El sistema busca en la base de datos de palabras y utiliza las otras tres para indicar los elementos de diseño y de color que más se ajustan a los atributos buscados. 11 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 La Tecnología en Nuestros Días MSC ING. SERGIO ANTONIO TORO TEJADA Departamento de Ingeniería de Sistemas - Escuela Militar de Ingeniería La Paz-Bolivia RESUMEN El presente artículo trata de la convergencia tecnológica, sus pilares y los beneficios para los usuarios que puede traer su aplicación en nuestro país. ABSTRACT This article deals with the technological convergence, its pillars and benefits for users who can bring your application in our country. INTRODUCCIÓN Hoy en día estamos rodeados por un mundo multimedia, donde la tecnología se hace presente en nuestros días en forma convergente en muchos niveles. Con el presente artículo se propone realizar una revisión de las convergencias tecnológicas. Entonces podemos afirmar fehacientemente que en la actualidad la tecnología se encuentra en un constante avance, donde siempre se busca mejorar cada cosa que es inventada o descubierta, habiendo dejado atrás el privilegio que tenían los países desarrollados de ser los únicos propietarios del avance de la humanidad; hoy en día vemos con relativo asombro que países en vías de desarrollo son capaces, a través de sus individuos, de inventar o de al menos aportar con su conocimiento. Uno que los más grandes retos que nos debemos plantear quienes estamos inmersos en la educación y en la producción de científicos e intelectuales, que en un futuro no muy lejano serán quienes manejen el país, se debe centrar en ser soberanos en temas de ciencia y tecnología, y aprovechar esa convergencia tecnológica y esa presencia de la tecnología en prácticamente todo lo que nos rodea, siendo capaces de rescatar una identidad propia a partir de nuestros saberes y conocimientos ancestrales en beneficio de los bolivianos y de la humanidad. Es necesario saldar desde las universidades una deuda histórica, y ser capaces de generar conocimiento en un país como Bolivia que, en su visión republicana, siempre se vio a sí misma como incapaz de avanzar en el desarrollo del conocimiento científico-tecnológico, pues desde la colonia el primer mensaje que se recibió fue la sobrevaloración de lo foráneo y la desvaloración de lo nuestro. Siempre nos vimos como simples adoptantes y adaptadores de formas foráneas de hacer y de producir. 12 El desarrollo de la tecnología y la generación del conocimiento, lo pensábamos, estaba reservado para países del Norte Imperial o primer mundo, creencias profundas que son complementarias en una subjetividad marcada por el auto-sabotaje del ser nacional. Este bloqueo primordialmente mental del boliviano, resulta totalmente negativo en un siglo como el actual, donde los avances de la ciencia y la tecnología, son cada vez más vertiginosos e inclusivos pues están presentes en casi todas las actividades del quehacer de las personas, por lo que resultan determinantes dentro del futuro de cualquier sociedad. El intelectual Boliviano René Zavaleta Mercado, en su libro “Lo Nacional Popular en Bolivia” , afirma que la autonomía y soberanía de un país sólo podía ser posible en la medida en que éste se incorporara de manera positiva en las dinámicas económicas globales, y así dejar de ser tanto periféricos como funcionales y al mismo tiempo dependientes de las decisiones y direcciones de los países del Norte Imperial. De ahí la importancia de tomar en cuenta que el desarrollo tecnológico puede ser un factor gravitante para generar un desarrollo económico, social y cultural nacional. Pero esta vez, basados en ser autosuficientes y soberanos, capaces de generar conocimiento, revalorizando la identidad y rescatando los saberes que siempre han estado presentes, pero por esa obtusa visión se los ha ignorado o simplemente, no se los ha tomado en cuenta, convencidos de que sólo lo que llega de fuera es lo que vale. Debemos estar conscientes de que el hombre opta por unir varias tecnologías con un bien específico, lo cual mejora y facilita el trabajo. Como por ejemplo, la red los ordenadores o computadores, los cuales hoy en día poseen audio, por el cual se puede reproducir música u otros sonidos diferentes, el video por el medio del cual podemos reproducir imágenes y películas. Otro ejemplo de lo que ha hecho la convergencia tecnológica hoy en día es la creación de combos, o unión REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 de varios productos como es televisión por cable, internet de alta velocidad, telefonía móvil y telefonía fija. Originalmente, las redes públicas de telecomunicaciones fueron concebidas para prestar únicamente un servicio a través de ellas; por ejemplo, la red de telefonía fija únicamente transportaba voz, al igual que las redes de telefonía móvil, mientras que, la red utilizada para prestar servicios de televisión por cable, sólo permitían prestar el servicio de radiodifusión. FUNDAMENTOS La tecnología comenzó a desarrollarse desde que el hombre comenzó a utilizar su cerebro más allá de lo normal. Es decir, no quedarse en la monotonía de realizar siempre las mismas labores sino buscar más allá de lo que podía hacer. Explorar el terreno, entonces viene el desarrollo de herramientas, con un fin, facilitar la caza. La convergencia tecnológica de dos maneras: una hace referencia a la capacidad de diferentes plataformas de red para transportar servicios o señales similares; la otra se centra en la posibilidad de recibir diversos servicios a través de un mismo dispositivo como el teléfono, la televisión o el ordenador personal. En otras palabras, la convergencia tecnológica puede ser entendida como la posibilidad para el usuario de servicios de telecomunicaciones de recibir en un mismo dispositivo diversos servicios, como pueden ser, telefonía, internet, televisión, radio y, por otra parte, como la posibilidad de los proveedores, de soportar el envío por medio de sus redes, de diversos servicios. La base de la convergencia tecnológica tal y como se plantea, choca con una sociedad en la que prima el consumismo como una expresión fundamental del ser humano, especialmente en las ciudades o áreas urbanas. Por ello, y pese a que se pueda apreciar la conversión de dispositivos tecnológicos (celulares, smartphones, readers, tabletas y otros), su producción no se ha visto reducida, sino todo lo contrario, ya que responde a la premisa consumista imperante en la mente de cada individuo de ese mundo que hace pensar que tener lo último es “ser mejor”. Internet es quizás el ejemplo más extendido de la convergencia tecnológica. Prácticamente todas las tecnologías de entretenimiento - de la radio a la televisión, a los periódicos, a la prensa escrita, al vídeo a los libros a los juegos - se pueden ver y jugar en línea, a menudo con una mayor funcionalidad que la que tienen en la tecnología principal. Tecnologías de la comunicación, así, se puede utilizar, con la Internet para sustituir las máquinas de fax, teléfonos, videoteléfonos, y el servicio postal. En la convergencia tecnológica la podemos encontrar en algunos ámbitos, organizada de la siguiente manera, primero los servicios que nos ofrece, en segundo lugar están los equipos terminales, donde se reproducirá, más adelante están las redes o medios de transmisión y el mercado, como se va a publicar y como se venderá la convergencia tecnológica al público. Servicios: Se deben ofrecer variedad de servicios, una mejora, pes anteriormente cada uno de los servicios como internet, telefonía, televisión por cable, cada uno se vendía por aparte. La convergencia tecnológica los agrupa para venderlos como combotización. Equipos terminales: Son los medios donde finalmente llegarán los productos establecidos, como por ejemplo el internet llegara al ordenador que se encuentre en el sitio donde se concretó el servicio. De igual manera sucedería con el equipo de televisión y el servicio de televisión por cable o satelital. Redes o medios de transmisión: Se encuentran la diferentes plataformas por las que se transmiten los servicios, por ejemplo la televisión puede transmitirse por ondas satelitales con cables coaxiales que se encuentran en una red de infraestructura situada desde la casa hasta el sitio de transmisión del servicio. Mercado: Aquí se realizaran las tarifas y se promocionaran los paquetes con la variedad de servicios agrupados para vender al público. Entonces aquí puede haber tarifas planas, operaciones integradas por fusiones y adquisiciones. LOS CUATRO PILARES DE LA CONVERGENCIA TECNOLOGICA Nanotecnología, es el estudio, diseño, creación, síntesis, manipulación, aplicación de materiales, aparatos y sistemas funcionales a través del control de la materia a nano escala, cuando se manipula la materia a la escala tan pequeña de átomos y moléculas demuestra fenómenos y propiedades totalmente nuevas, por lo tanto los científicos utilizan esta nanotecnología para la creación de materiales y aparatos y sistemas novedosos y económicos con propiedades únicas e increíbles. Biotecnología, es una rama de la tecnología que se basa en la aplicación práctica, orientada necesidades humanas de la biología y consiste en la manipulación de células vivas para la obtención y mejora de productos como medicamentos o alimentos, se utiliza en diferentes campos como en agricultura, farmacología ciencias forestales entre otras. Infotecnología es una cultura del trabajo, basada en un grupo de modernas herramientas informáticas para la navegación, la búsqueda, la revisión 13 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 y el procesamiento de la información en formato digital. Permite que profesionales e investigadores sean capaces de identificar las principales fuentes de información de frontera, seleccionar las herramientas más adecuadas de búsqueda, trabajar con bases de datos remotas, construir bibliotecas personales digitalizadas, realizar artículos y trabajos científicos en los formatos que exigen las principales revistas y editoriales del mundo. Cognotecnologia, es el estudio interdisciplinario de cono la información es representada y transformada en la mente, es el conjunto de disciplinas que surgen de la convergencia transdisciplinaria de investigaciones científicas y tecnológicas entorno a los fenómenos funcionales y emergentes dados a partir de las actividades neurofisiológicas del encéfalo y del sistema nervioso incorporados y que típicamente se les denomina como mente y comportamiento, la naturaleza de las investigaciones cognitivas es decir de naturaleza lingüística, la psicología cognitiva y la inteligencia artificial y la neurociencia y la antropología. Cognitiva. La neurística de las investigaciones cognitivas ha sido guiada por preocupaciones eminentemente filosóficas a partir de algunas de sus ramas como la lógica, gnoseología, la epistemología y la filosofía u ontología de la mente. BENEFICIOS DE LAS PROPUESTAS CONVERGENCIA TECNOLOGICA DE LA Una de las formas de aprovechar las diferentes propuestas de convergencia tecnológica es haciendo uso diario de ellas ya que hay gran variedad de estas tecnologías en nuestra sociedad de las cuales muchas veces no sabemos sus diferentes usos y no es aprovechado totalmente por lo que además de hacer uso de ellas deberíamos conocer un poco más a profundidad sus orígenes y propósitos específicos. Además de los beneficios que la convergencia genera en favor de los usuarios, derivados del incremento de la competencia en servicios de telecomunicaciones, la convergencia también permite maximizar el aprovechamiento de la capacidad de las redes, impulsando su pleno desarrollo y su ampliación hacia sectores que, todavía no cuentan con acceso a servicios digitales o éstos se ven muy limitados, ya que pueden emplearse indistintamente las redes de empresas de telefonía fija, móvil, de fibra óptica, e incluso de televisión satelital, para llevar todos los servicios a las comunidades a las que tengan acceso, multiplicando las posibilidades de cobertura sin la necesidad de desarrollar una red para cada tipo de servicio. Cabe señalar que este tipo de servicios, generalmente asociados al entretenimiento, 14 también son empleados en otros sectores fundamentales para el desarrollo actual de las comunidades, como pueden ser salud, educación, empleo y en general, para su crecimiento económico. Por ejemplo, al cierre del 2013 habrá en México unos 20 millones de nuevos teléfonos inteligentes y 4.5 millones de tabletas nuevas respecto al año pasado. Esto refleja un crecimiento exponencial en la adopción de las tecnologías móviles en el país pues, en total, existirán 41 millones de teléfonos inteligentes y 10.5 millones de tabletas en el país, de acuerdo con cálculos de la firma de análisis IDC. La adopción de estas tecnologías va en aumento. Una encuesta de IDC en Latinoamérica mostró que al 2013, el 46% de las empresas ya tenían al menos una solución que corre en la nube, desde el 3.5% del 2009. Pero el innovar también implica tomar riesgos, advirtió Jorge Zavala, cofundador y director de innovación Kinnevo, una empresa con sede en Silicon Valley que brinda asesoría y mentaría a emprendedores. Esta precisamente ha sido la clave para el éxito de las startups tecnológicas donde la velocidad de aprendizaje es la clave para el crecimiento. “Innovar implica riesgo, implica incertidumbres y uno puede ganar pero también puede perder. Si algo va a salir mal, procura que sea rápido para hacerlo mal. Fallar no es lo grave; no aprender es catastrófico y el nombre del juego es velocidad”, dijo. Los expertos advierten que hay dos factores que representan un reto para la innovación en las empresas: generación de talento y el costo de las innovaciones. “Cuanto a migrar hacia ese modelo de la nube tiene que ver con la parte de la gente y el talento, que es la principal barrera porque la parte tecnológica y operativa, derivado de gran cantidad de dispositivos, de datos y de aplicaciones, la que se terceariza; tenemos que desarrollar otro tipo de competencias para maximizar la tercerización y poder innovar”, dijo Edgar Fierro, de IDC . Por eso dijo que se debe estimular la comercialización a pequeñas y medianas empresas, a quienes los nuevos servicios tecnológicos y soluciones especializadas les permitirán incrementar su eficiencia en el negocio y satisfacer sus necesidades con respuestas específicas a cada una de ellas. CONCLUSIONES Es de vital importancia ser capaces de empezar a ver que el desarrollo tecnológico se lo puede ver desde REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 adentro, EN BOLIVIA SOMOS CAPACES, de subirnos a ese tren de los llamados adelantos tecnológicos. Empecemos a vernos a nosotros mismos como autosuficientes en un campo tan competitivo, y hagamos que desde las Universidades surjan los profesionales capaces de generar ciencia, de aportar conocimiento y de ser lo suficientemente innovadores, para generar riqueza a partir de nuestros saberes locales y conocimientos ancestrales, esa al parecer es una de las únicas fórmulas de hacerle frente a ese mundo cada vez Asistencia al desfile del 6 de agosto. más globalizado y poco solidario, en el que el fuerte irremediablemente empieza a comerse al más débil. Resulta de fundamental importancia que las autoridades que se encargan de regular las telecomunicaciones, impulsen y protejan los procesos de convergencia en las redes a favor de los usuarios de servicios, proceso que se encuentra estrechamente relacionado con la interconexión entre redes 15 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Construcción de Flujos de Caja GONZÁLEZ HERRERA JOHNNY. Departamento de Ingeniería de Sistemas - Escuela Militar de Ingeniería La Paz Bolivia [email protected] RESUMEN En el siguiente artículo se tratará sobre la importancia que tienen los flujos de caja en la evaluación de proyectos tanto privados como sociales, pues éstos constituyen uno de los elementos más importantes del estudio de un proyecto, ya que la evaluación del mismo se efectuará sobre los resultados que en ella se determinen. ABSTRACT In the next article will focus on the importance of the cash flows in the evaluation of projects both private and social, because they are one of the most important elements of the study of a project, because the evaluation of the same shall be made on the results that it determined. PALABRAS CLAVE Estudio de Mercado, Estudio Técnico, Estudio Organizacional, Depreciación, Amortización, Costos fijos, costos variables y Tasa de Descuento. INTRODUCCIÓN El presente artículo propone la evaluación financiera dentro de la metodología de evaluación de proyectos, consiste en expresar en términos monetarios todas las determinaciones hechas en los estudios de mercado, técnico y organizacional. Las decisiones que se hayan tomado en todos los estudios anteriormente citados en términos de cantidades del producto, bien o servicios que se piensa introducir al mercado, precios de dicho bien, materias primas, desechos del proceso, cantidad de personal, cantidad de mano de obra directa e indirecta, número y cantidad de equipo y maquinaria necesarios para el proceso determinado, ahora deberán aparecer en forma de inversiones y degasto. OBJETIVO Una vez que se hayan concluido los estudios de mercado, técnico y organizacional, se habrá dado cuenta de que existe un mercado potencial o bien una demanda insatisfecha por cubrir y que no existe impedimento tecnológico para llevar a cabo el proyecto. La parte del análisis del análisis financiero pretende determinar cual es el monto de los recursos económicos necesarios para la realización del proyecto, cual será el costo total de la operación de la planta si es un proyecto productivo, o cual será el costo total de los componentes del servicio, así como otra serie de indicadores que servirán como base para la parte final y definitiva del proyecto, que es la evaluación financiera. ANTECEDENTES 16 El problema más común asociado a la construcción de un flujo de caja es que existen diferentes flujos para diferentes fines: uno para medir la rentabilidad del proyecto, otro para medir la rentabilidad de los recursos propios y un tercero para medir la capacidad de pago frente a los préstamos que ayudarán a su financiación. También se producen diferencias cuando el proyecto es financiado con deuda o mediante leasing, factoring o warrant. El flujo de caja de cualquier proyecto se compone de cuatro elementos básicos: a) los egresos iniciales de fondos, b) los ingresos y egresos de operación, c) el momento en que ocurren estos ingresos y egresos, y d) el valor de desecho o salvamento del proyecto y la recuperación de capital. Los egresos iniciales corresponden al total de la inversión inicial requerida para la puesta en marcha del proyecto. El capital de trabajo, si bien no implicará un desembolso en su totalidad antes de iniciar la operación, se considerará también como un egreso en el año cero, ya que deberá quedar disponible para que el administrador del proyecto pueda utilizarlo en su gestión. La inversión en capital de trabajo puede producirse en varios periodos. Si tal fuese el caso, sólo aquella parte que efectivamente deberá estar disponible antes de la puesta en marcha se tendrá en cuenta dentro de los egresos iniciales. Los ingresos y los egresos de operación constituyen todos los flujos de entradas y salidas reales de caja. Es usual encontrar cálculos de ingresos y egresos basados en los flujos contables en estudios de proyectos, los cuales, por su carácter de causados o devengados, no necesariamente ocurren en forma simultanea con los flujos reales. Por ejemplo la contabilidad considera como ingreso el total de REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 la venta, sin reconocer la posible recepción diferida de los ingresos si ésta se hubiese efectuado a crédito. Igualmente concibe como egreso la totalidad del costo de ventas, que por definición corresponde al costo de los productos vendidos solamente, sin inclusión de aquellos costos en que se haya incurrido por concepto de elaboración de productos para existencias. La diferencia entre devengados o causados reales se hace necesaria, ya que el momento en que realmente se hacen efectivos los ingresos y egresos será determinante para la evaluación del proyecto. El flujo de caja se expresa en momentos. El momento cero reflejara todos los egresos previos a la puesta en marcha del proyecto. Si se proyecta reemplazar un activo durante el período de evaluación, se aplicara la convención de que en el momento de reemplazo se considerara tanto el ingreso por la venta del equipo antiguo como el egreso por la compra del nuevo. Con esto se evitaran las distorsiones ocasionadas por los supuestos de cuando se logra vender efectivamente un equipo usado o de las condiciones de crédito de un equipo que se adquiere. El horizonte de evaluación depende de las características de cada proyecto y de la realidad existente en cada país. Por ejemplo en Chile un buen horizonte de tiempo son diez años, en México se considera cinco años, en nuestro país yo sugeriría, dependiendo del monto de la inversión que se vaya efectuar, una variable importante es el tiempo en que la entidad financiadora otorgue el préstamo que vendría a ser el horizonte de tiempo del proyecto que en promedio son cuatro años. Los costos que componen el flujo de caja se derivan de los estudios de mercado, técnico y organizacional. Un egreso que no es proporcionado como información por otros estudios y que necesariamente tiene que incluirse en el flujo de caja del proyecto es el impuesto a las utilidades, teniendo la salvedad que si el proyecto es localizado en la ciudad de El Alto esta exento por una determinada cantidad de años de acuerdo a una ley de la República de Bolivia. Para su cálculo deben tomarse en cuenta algunos gastos contables que no constituyen movimientos de caja, pero que permiten reducir la utilidad contable sobre la cual deberá pagarse el impuesto correspondiente. Estos gastos conocidos como no desembolsables, están constituidos por las depreciaciones de los activos fijos como ser maquinaria, muebles, equipos, movilidades y todo aquel activo que tenga una vida útil; la amortización de activos intangibles como ser seguros, patentes, gastos de puesta en marcha y el valor libro o contable de los activos que se venden. Puesto que el desembolso se origina al adquirir un activo, los gastos por depreciación no implican un gasto en efectivo, sino uno contable para compensar, mediante una reducción en el pago de impuestos, la pérdida del valor del activo por su uso. Mientras mayor sea el gasto por depreciación el ingreso grabable disminuye y, por tanto, también el impuesto pagadero por las utilidades del negocio. Por eso que esta normado la vida útil de los activos y en nuestro caso la entidad que regula la vida útil es el Servicio de Impuestos Nacionales. Al depreciarse todo el activo por cualquier método se obtendrá el mismo ahorro tributario, diferenciándose solo el momento en que ocurre. Al ser tan marginal el efecto, se opta por el método de línea recta que además de ser más fácil de aplicar es el que entrega el escenario más conservador. Aunque lo que interesa al preparador y evaluador de proyectos es incorporar la totalidad de desembolsos, independientemente de cualquier ordenamiento o clasificación de costos que permita verificar su inclusión. Una clasificación usual de costos se agrupa, según el objeto del gasto, en costos de fabricación, gastos de operación, financieros y otros. Los costos de fabricación pueden ser fijos o variables (estos últimos conocidos como también gastos de fabricación). Los costos fijos los componen los materiales directos y la mano de obra directa, que debe incluir los salarios, la previsión social, las indemnizaciones, bonos y otros desembolsos relacionados con un salario o sueldo. Los costos variables por su parte, se componen de la mano obra indirecta (jefes de producción, choferes, personal de reparación y mantenimiento, personal de limpieza, guardias de seguridad); materiales indirectos (repuestos, combustibles y lubricantes, útiles de aseo), y los gastos indirectos, como energía (electricidad, agua, gas), comunicaciones (teléfono, fax, internet), seguros, alquileres depreciaciones, etc. Los gastos de operación pueden ser gastos de venta o gastos generales y de administración. Los gastos de venta están compuestos por los gastos laborales (como sueldos, bonos y otros), comisiones de venta y de cobranza, publicidad, empaques, transportes y almacenamiento. Los gastos generales y de administración los componen los gastos laborales (aguinaldos, vacaciones, aportes patronales a las AFP s, fondo solidario, seguro social médico, fondo de vivienda, beneficio social por año), gastos de representación, seguros alquileres, materiales y útiles de oficina, depreciación de edificios administrativos y equipos de oficina, impuestos y otros. 17 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Los gastos financieros que también están afectos a impuestos, salen de descomponer de la cuota que se paga al ente financiador. Cabe aclarar de que de la cuota se debe descomponer solo el interés y que la parte de la amortización de la deuda va después de impuestos. para la estimación del costo de capital o tasa de descuento relevante, el 14% utiliza modelos factoriales, el 10% utiliza tasas de descuento basadas en políticas corporativas 7y el 34% restante en lo que llaman “olfato”. CONCLUSIONES Otra de las variables que más influyen en el resultado de la evaluación de un proyecto es la tasa de descuento empleada en la actualización de sus flujos de caja. El costo de capital corresponde a aquella tasa que se utiliza para determinar el valor actual de los flujos futuros que genera un proyecto y representa la rentabilidad que se le debe exigir a la inversión por renunciar a un uso alternativo de los recursos en proyectos de riesgos similares. Toda empresa o inversionista espera ciertos retornos por la implementación de proyectos de inversión. Inicialmente se desarrollan diversos sistemas para determinar e incorporar el costo de capital, como las razones precio/utilidad, los dividendos esperados, los retornos esperados de la acción, los retornos sobre proyectos marginales, etcétera. Ninguno de estos métodos tradicionales incorpora el riesgo asociado con la inversión. Si los proyectos estuviesen libres de riesgo, no habría mayor dificultad en determinar el costo de capital, ya que bastaría usar como aproximación el retorno de los activos libres de riesgo. No obstante, la gran mayoría de los proyectos no están libres de riesgo, por lo que se debe exigir un premio sobre la tasa libre de riesgo, el que dependerá de cuan riesgoso sea el proyecto. La estimación del costo de capital es un punto de constante controversia entre los analistas. Un estudio realizado por McKinsey y la Escuela de Negocios de la Universidad de Chicago determino que el 42% de los analistas y académicos utilizan modelos lineales basados en el CAPM (Modelo de Valorización de Activos de Capital) 18 En conclusión se puede indicar que en la elaboración de un proyecto de factibilidad un factor muy importante es la correcta elaboración en la construcción de un flujo de caja. Ya que los datos que conlleva viene de los estudios de marcado, técnico y organizacional. Se tienen que considerar todas las erogaciones de dinero en las que se incurrirá o llamadas desembolsos de efectivo como también no se deben de olvidar los gastos no desembolsables que ayudan a aminorar el pago de impuestos. Existen dos tipos de beneficios que no debemos olvidar al final del periodo de evaluación que son el valor de desecho del proyecto como la recuperación del capital de trabajo ya que si obviamos dichos montos hará variar la tasa interna de retorno del proyecto y el valor actual neto. Por último otro factor importante es la tasa de descuento ya que si no es aplicada de la manera adecuada nos hará variar en la aceptación o rechazo del proyecto de inversión. REFERENCIAS BIBLIOGRAFICAS • • • • • Bolten, Steven, Administración Financiera. México; Limusa 1981 Brealey, R. y S.Myers, Principles of Corporate Finance. New York; Mc Graw Hill, 1998 Neveu, Raymond, Fundamentals of Managerial Finance. Cincinnati Ohio; South Western. 1981 Van Horne. Administración de Finanzas. México. Prentice Hall. 1998. REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Algunos de los errores más frecuentes en la implementación de controles de seguridad de la Información LIMBERG F. ILLANES MURILLO Departamento de Ingeniería de Sistemas - Escuela Militar de Ingeniería La Paz Bolivia RESUMEN Hablar de seguridad de la información, muchas veces se piensa que es hablar de criterios de confidencialidad, pero también comprende criterios de integridad y disponibilidad. Ahora, al momento de implementar controles de Seguridad de la Información que cumplan con estos criterios. Entre los errores más comunes está: la elección inadecuada del Líder del Proyecto de Seguridad de la Información, creer que únicamente con aplicaciones o sistemas se resuelven los problemas, hacer las cosas solo por cumplir, los proyectos no está alineados a los objetivos estratégicos del negocio y por último pensar que los consultores conocen más la Organización que uno mismo. El presente artículo explica de forma resumida cual la causa de estos errores frecuentes. ABSTRACT To talk about information security, often we thought to be only talk about confidentiality criteria, but also includes integrity and availability´s criterias. Now, when implemented Information Security controls that meet these criteria. Among the most common mistakes are: improper choice of the Information Security´s Project Leader, believing that only applications or systems solved the problems, do things just to meet, projects are not aligned to business objectives strategic and finally think that consultants know the Organization more than oneself. This article explains summarizes the cause of these common mistakes. INTRODUCCIÓN Existen diferentes situaciones que se presentan al momento de querer implementar controles de Seguridad de la Información que desnudan la madurez que tiene una Organización. Muchas veces esta madurez en Seguridad de la Información de una Organización tiene bases en la falta de comprensión o entendimiento de la Alta Gerencia, falta de concientización de los funcionarios, rechazo a los cambios, rechazo a los controles y sobre todo la falta de cultura en Seguridad de la Información. Pero lo descrito anteriormente ocurre muchas veces por los errores que cometen los responsables, líderes o auspiciadores de los diferentes proyectos de la empresa. Cabe aclarar que uno de los primeros errores que comenten las organizaciones es no realizar una Gestión de Riesgos de Seguridad de la Información, pero al ser éste un tema tan crítico y amplio lo mencionaremos en otro artículo. Ahora solo veremos algunos de los errores más comunes de la parte operativa de una organización así como de su área de Tecnología o Sistemas en temas de Seguridad de la Información. ERRORES MÁS FRECUENTES A continuación se describen algunos de esos errores: Elección inadecuada del Líder del Proyecto de Seguridad de la Información En muchos casos el líder de proyecto es muy técnico y debe llevar adelante tareas o actividades que van más allá de su cargo y responsabilidad, afectando la segregación de funciones. A raíz de esto, los requerimientos se traban, la información requerida se demora y ante la falta de apoyo, finalmente otro funcionario que desconoce el objetivo y alcance del proyecto decide sobre los temas desconociendo la problemática. Muchas veces los recursos humanos para encarar el proyecto no se asignan y si se hace, el proyecto se demora dado que hay que "poner en tema" al recurso asignado, ya que en gran parte tampoco tienen la jerarquía necesaria para tomar decisiones. Es un problema muy difícil de resolver si nuestro Líder de Proyecto no está en condiciones de obtener la información requerida, convocar a los referentes necesarios y/o tomar alguna decisión relevante en relación al proyecto. De presentarse esta situación estaríamos ante una Organización no muy comprometida con la implementación de controles de Seguridad de la Información. 19 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Creer que únicamente con aplicaciones o sistemas se resuelven los problemas Hay proyectos que se generan para generar una determinada aplicación o sistema, pero llegado el momento de la implementación comienzan a aparecer los problemas, que pueden ser que: • • • El producto no hace todo lo que queríamos, esto a raíz de que no se hizo el relevamiento adecuado o se comenzó el desarrollo sin tener claro el objetivo y alcance. Requiere información que aún no hemos podido recolectar Depende de procesos que la Organización aún no tiene implementados o con el nivel de madurez necesario. Por ejemplo es muy frecuente escuchar acerca de proyectos de Data Loss Prevention (DLP) en Organizaciones que aún no tienen un inventario centralizado de activos o no tienen establecido su Clasificación de la Información. Finalmente para "justificar" el proyecto, la herramienta se implementa con funcionalidades mínimas para luego volver a generar algún proyecto que regularice la situación (que muchas veces no lo hace). cumplir o para que los responsables de un determinado problema no asuman la responsabilidad de la falta de gestión. No está alineados a los objetivos estratégicos del negocio Si bien parece muy claro que el área de Tecnología o Sistemas debe brindar un servicio al negocio y acompañarlo para lograr el cumplimiento de los objetivos estratégicos, es frecuente encontrarse con proyectos que no tienen ninguna relación con el rumbo que tiene el negocio. Negocios que están pensando en ir hacia la nube (Cloud computing), en donde el área de Tecnología o Sistemas ejecuta proyectos de centralización de aplicaciones cliente/servidor o restricciones para el trabajo remoto, ambas cuestiones que muestran un camino completamente distinto entre el negocio y su área de Tecnología o Sistemas. Negocios que se despliegan sobre plataformas o redes sociales y canales de comunicación con sus clientes, frente a proyectos que buscan restringir el uso de redes sociales sin un análisis de riesgos previo para determinar que controles de Seguridad implementar. Hacer las cosas solo por cumplir No deja de ser un signo de problemas aún mayores, dado que generalmente en ese tipo de organizaciones, el área de Tecnología o Sistemas se considera dueña de los servidores y es frecuente que sea el usuario quien notifica los problemas dado que la "independencia" de gestión es absoluta y se prescinde o evita contar con una Gestión de Incidentes por temor a mostrar los problemas internos. Lamentablemente en reiteradas ocasiones se escucha que un determinado proyecto se hace: Pensar que los consultores conocen más la Organización que uno mismo En las organizaciones en las cuales se presenta esta situación, normalmente el área de Tecnología o Sistemas es la encargada de la mayoría de los temas referentes a Seguridad de la Información y las demás áreas no tienen ningún involucramiento al respecto. • • • • Por cumplir PCI DSS Porque me lo pide Auditoria Porque me lo exige mi ente Regulador Porque surgió de una reunión entre gente que desconoce los problemas (Comités de Riesgos, Reuniones de Directorio) y el auditor confundiendo su rol hace consultoría. Si el consultor toma decisiones que debe tomar la Organización, los controles de Seguridad de la Información presentan síntomas de fracaso. El valor agregado del consultor viene relacionado con la experiencia en otros proyectos, su formación, el hecho de mantenerse actualizado y de la dedicación a los temas relacionados con Seguridad de la Información. Por ende, el resultado es conocido, surge un proyecto de remediación de un problema que quizás no existe. Ahora bien, eso no lo convierte en la persona adecuada para tomar decisiones que le corresponden a los miembros de la Organización, dado que ellos conocen el valor de la información involucrada, los objetivos de negocio de corto, mediano y largo plazo, las idas y vueltas políticas, los intereses internos y todo aquello que es tan importante al momento de tomar decisiones. Más allá de que sería ideal que los proyectos surjan de necesidades reales de la Organización, que correspondan con un objetivo claro y medible, es poco frecuente encontrarse con tal escenario. A veces se hacen para 20 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 CONCLUSIONES En muchas oportunidades se menciona y repite la importancia del involucramiento de los máximos referentes de una Organización en temas relacionados con Seguridad de la Información. Es una responsabilidad de la Alta Gerencia y la Dirección el estado de seguridad de su negocio, definir el nivel de protección adecuado para sus activos y asignar los recursos necesarios para lograrlo. Si esto no se presenta, Frontis de la Unidad Académica La Paz - Irpavi. es muy probable que alguien asuma una responsabilidad que lo excede y por consiguiente el propio desconocimiento del negocio haga que la estrategia de seguridad sea errónea. El desafío para quienes deben gestionar la Seguridad de la Información es lograr el interés e involucramiento de los líderes, es allí en donde se debe invertir el mayor esfuerzo, para luego no dedicarle tanto tiempo y esfuerzo a reparar los errores producto de decisiones equivocadas, mal uso de los recursos y medidas desacertadas 21 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Generación de Sinergias, basada en actividades académicas para potenciar la investigación ALEJANDRO MIGUEL ZAMBRANA CAMBEROS Departamento Ingeniería de Sistemas - Escuela Militar de Ingeniería La Paz Bolivia [email protected] RESUMEN Este artículo explora la posibilidad de verificar competencias universitarias mediante la generación de sinergias positivas desencadenadas a raíz de actividades académicas que propicien un espacio que motive tanto a estudiantes como docentes a investigar. La actividad académica utilizada para tener un acercamiento es el concurso de programación que se realiza en la Carrera de Ingeniería de Sistemas de la Universidad. ABSTRACT This article explores the possibility of verifying college skills through the generation of positive synergies triggered as a result of academic activities to foster a space that motivates both students and teachers to investigate. The academic activity used to be a rapprochement is the programming contest that takes place in the career of Systems Engineering of the University. PALABRAS CLAVES: Competencias, Investigación, Programación, Concurso de Programación, Verificación. INTRODUCCION Las actividades académicas realizadas en la Universidad, normalmente son para lograr visibilidad en el entorno y fortalecer el proceso de enseñanza - aprendizaje, en el cual, el estudiante que se encuentra motivado por obtener un buen desempeño en la actividad y por lograr satisfacción personal, investiga, hace praxis y alcanza niveles verificables de competencias profesionales que pueden ser medidas por diversos medios. La Figura 1, muestra la metodología abordada en base a las sinergias entre los siguientes sistemas: • • • • • • • • Actividad académica. Habilidades de Estudiantes. Investigación de estudiantes. Exigencias a las materias afines. Investigación de Docentes. Aportes intelectuales. Generación de Proyectos de Investigación. Implementación de TIC´s La problemática radica, en ¿cómo lograr sinergias positivas para que a raíz de las actividades académicas, docentes y estudiantes investiguen y generen productos que puedan ayudar a verificar competencias desarrolladas en la Universidad? Para ello exploraremos el camino que puede trazarse a partir de la actividad denominada “Concurso de Programación” para la carrera de Ingeniería de Sistemas que tiene inicialmente el objetivo de mejorar las habilidades de programación de sistemas de información y TIC´s en los futuros profesionales de la carrera. CONTENIDO Iniciamos con la metodología para afrontar la problemática presentada, para luego evaluar los logros reales alcanzados y concluir con los retos que aún quedan para avanzar en la investigación planteada. 22 Básicamente se presenta la siguiente relación sinérgica en base al comportamiento deseado de los sistemas en consideración: REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 • • • • • • • El incremento de la realización de la actividad académica, genera un incremento de las habilidades en estudiantes para mejorar su rendimiento en la actividad académica. El incremento de habilidades de los estudiantes, genera incremento de la investigación estudiantil para resolver la actividad. El incremento de la investigación estudiantil, genera mayores exigencias de estos en las materias afines que nutren en conocimiento y practica. En paralelo, el incremento de la realización de la actividad académica y El incremento en la exigencia de los estudiantes, genera el incremento en la investigación en los Docentes para apoyar a los estudiantes. El incremento de investigación en los docentes, genera mayores Aportes Intelectuales (artículos, libros y otros) más el incremento de Proyectos de investigación. El incremento de Proyectos de investigación, generan incremento en implementación de TIC´s en la Universidad. El incremento de implementación de TIC´s en la universidad, generan evolución en la realización de la actividad académica, que desencadena nuevamente las relaciones sinérgicas ya explicadas. Realizado este análisis lo que queda es evaluar la metodología planteada en base modelo causa efecto planteado Luego revisar los indicadores en cada sistema involucrado. Los logros alcanzados pueden ser medidos en base a la verificación de los niveles alcanzados, al incremento de estudiantes involucrados y con el número de docentes generadores de investigaciones con base de actividades académicas. Otro aspecto importante, es considerar que el modelo, hasta el momento no asegura que se llegará a buen puerto con pocas realizaciones de la actividad académica en cuestión y que dependerá de las características específicas de la actividad que sea impulsada. La figura 2, muestra que el detonante es la realización de la actividad académica y que requiere del apoyo constante por parte de la Universidad. Sin embargo, los indicadores no podrán ser considerados como objetivos de gestión hasta que se identifiquen claramente las tareas necesarias para ajustar cada sistema y se logre el rendimiento esperado. Evaluemos ahora una actividad académica específica, realizada en la carrera de Ingeniería de Sistemas. “La Competencia de programación”, esta consiste en la resolución de problemas, de diversa complejidad, empleando un lenguaje de programación informática y tiene la finalidad de descubrir estudiantes con habilidades inherentes a la programación informática, trabajo en equipo en un entorno competitivo y empleando conocimientos de elaboración de algoritmos a niveles altos. Los estudiantes calificados en esta competencia pueden representar en varios niveles a la Universidad y su aprendizaje debe ser apoyado por los docentes, quienes se actualizan en las técnicas de programación empleadas por los mejores a nivel mundial. Los estudiantes participan en equipos de tres de acuerdo a reglas internacionales. Las Universidades que se tomaron en cuenta, fueron en las que el autor lideró esta actividad. Las Figuras 3 y 4, muestra el rendimiento obtenido de los equipos en las competencias locales, considerando las variables de: • • • • Número de problemas resueltos. Porcentaje de equipos con por lo menos un problema resuelto. Porcentaje de equipos con por lo menos 2 problemas resueltos. Porcentaje de equipos con por lo menos 3 problemas resueltos. Es necesario resaltar que los datos se extrajeron de los resultados de las competencias aceptadas por la ACMICPC sección Bolivia, realizadas en las Universidades de La Salle y la Escuela Militar de Ingeniería y que el mejor rendimiento de un equipo Boliviano es de 4 problemas resueltos de 11 planteados. 23 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Con este análisis, observamos que las Universidades han logrado un proceso Docente - Estudiante para obtener logros y crecimiento, reflejados en el rendimiento de la actividad en las últimas gestiones. En la Escuela Militar de Ingeniería, el estado real muestra la presentación de proyectos orientados a respaldar un crecimiento mayor, que permita reducir la brecha con la región. Estos proyectos se han clasificado en dos categorías: Categoría Estudiantes: • La evolución del número de problemas resueltos respecto a los planeados es lenta, debido a la complejidad que representa su resolución. Otro dato importante es que en la región (Perú, Chile, Bolivia, Argentina y Colombia), la mayor cantidad de problemas resueltos también ha tenido una evolución lenta. • • • Proyecto 001: Capacitación para equipos para preparación a la competencia nacional, agosto 2011, propuesta por los estudiantes José Machicado y Miguel Machicado, aprobado por Consejo de Carrera de Ingeniería de Sistemas EMI. Proyecto 002: Desarrollo de juez virtual para la EMI, enero 2012, propuesta por los estudiantes José Machicado y Miguel Machicado, aprobado por Consejo de Carrera de Ingeniería de Sistemas EMI. Proyecto 003: Documentación para preparación de estudiantes para la competencia interna de programación EMI 2012, enero 2012, propuesta por los estudiantes José Machicado y Miguel Machicado, aprobado por Consejo de Carrera de Ingeniería de Sistemas EMI. Proyecto 004: Cursos de capacitación para equipos para la competencia interna EMI 2012, abril 2012, propuesta por los estudiantes José Machicado y Miguel Machicado, aprobado por Consejo de Carrera de Ingeniería de Sistemas EMI. Categoría Docentes: • La Figura 4, muestra esta evolución en los ejercicios resueltos en los últimos 5 años. Respecto al rendimiento interno, este análisis nos permite ser más exhaustivo, puesto que demuestra la interacción entre docentes y estudiantes en el apoyo para la resolución de estos problemas. Observamos que cada gestión, la cantidad de equipos que por lo menos resuelven un problema ha incrementado, eso denota mejorías considerables en los participantes y que adicionalmente, equipos lograron resolver por lo menos 3 problemas. Aunque todavía queda por avanzar, para alcanzar a los mejores de la región, la brecha puede ser disminuida empleando las sinergias planteadas en este artículo. 24 Proyecto 005: Implementación de Juez Virtual en la página Web de la EMI a cargo del equipo de trabajo de la competencia de programación, febrero 2012, aprobado por Consejo de Carrera de Ingeniería de Sistemas EMI. El análisis de los proyectos planteados y su efecto en la investigación, serán sujetos de un nuevo artículo que complementarán a éste, puesto que la rueda sigue girando y dependiendo de los logros, en aportes de estudiantes y docentes generados en esta gestión, permitirá obtener un parámetro más para evaluar Competencias trazadas por la Carrera de Ingeniería de Sistemas. Otro indicador interno, es el número de estudiantes involucrados en las investigaciones referidas a las exigencias de la competencia de programación. REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 a la formación de estudiantes, para mejorar el rendimiento en la competencia de programación, puede ser impulsada a partir de actividades académicas. También pueden evaluarse competencias académicas y de liderazgo relativas al proceso de investigación, considerando el avance en los logros obtenidos en las distintas instancias de la actividad. Se recomienda apoyar a iniciativas que permitan generar sinergias en base a actividades académicas. También se recomienda motivar a los docentes para que lideren actividades de investigación impulsadas por actividades académicas, de esta manera estos podrán presentar investigaciones sobre los métodos teóricos y prácticos empleados para mejorar continuamente. BIBLIOGRAFÍA El indicador mencionado en el anterior párrafo, muestra que en los seis últimos años, ha incrementado el interés de estudiantes involucrados, permitiendo que la competencia de programación presente no solo a competidores, sino también a líderes que son referentes para los estudiantes internos y externos a la universidad. El trabajo desarrollado para potenciar el liderazgo estudiantil, para incrementar los niveles de investigación de los estudiantes, ha permitido que estos líderes capaciten a sus compañeros desde una perspectiva entre pares. La labor docente entonces puede concentrarse en los nuevos retos, alcanzar niveles más altos de dominio y proporcionando herramientas mas complejas. CONCLUSIONES Y RECOMENDACIONES Referencias de libros: • Oscar Johanssen, Introducción a la Teoría General de Sistemas, Limusa, 1983. • Javier Aracil y Francisco Gordillo, Dinámica de Sistemas, Alianza editorial, 1997. • Benjamin Blanchard, Ingeniería de Sistemas, Isdefe, 1995. • Angel Sarabia, Teoria General de Sistemas, Isfede, 1995. • George Beal, Conducción y Acción Dinámica del Grupo, KAPELUSZ, 1964 • Noemi Paymal, Pedagogía 3000, Ox La-Hun,2008. Informes de actividades: • Informe Competencia de Programación, EMI, 2007, 2008, 2009, 2010 y 2011. • Informe Competencia de Programación, Universidad La Salle, 2009,2010 y 2011. Como se observó, la actividad de investigación relativa Unidad Académica Santa Cruz. 25 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Identificación de modelos borrosos utilizando la tecnicas de clustering ING. GERMAN JESÚS PEREIRA MUÑOZ Departamento Ingeniería de Sistemas - Escuela Militar de Ingeniería [email protected] RESUMEN La aplicación de las técnicas de clustering borroso para la identificación de modelos borrosos se está extendiendo cada vez más. Sin embargo, y dado que su origen es bien distinto a la ingeniería de control, aparecen numerosos problemas en su aplicación. En este trabajo se definen las características de un algoritmo de clustering ideal para su aplicación a la construcción de modelos locales de sistemas complejos no lineales para control. Posteriormente se desarrolla una nueva familia de algoritmos de clustering llamada AFCRC (Adaptive Fuzzy C-Regresssion models with Convex membership functions) que permite desarrollar modelos con esas características ideales, mejorando (respecto a algoritmos previamente existentes) la interpretabilidad de los modelos borrosos obtenidos y el descubrimiento de estructuras (hiper-)lineales en los mismos. Palabras Clave Clustering borrosas, identificación de sistemas complejos, sistemas borrosos INTRODUCCIÓN ALGORITMO DE CLUSTERING FUZZY C-MEANS Para tratar de modelar sistemas complejos se puede recurrir a su descomposición en un conjunto más o menos grande de submodelos con un rango de validez limitado, que denominamos modelos locales. El modelo global del sistema se puede obtener a través de la integración de los modelos locales utilizando, por ejemplo, una base de reglas borrosa que permite la selección de los modelos adecuados a la situación en que se encuentra el sistema [9]. Con este enfoque se dispone de una técnica simple e intuitiva para el modelado de procesos complejos, además de una herramienta muy útil para el diseño de sistemas de control. La mayoría de las técnicas analíticas de clustering borroso se basan en la optimización de la función objetivo cmeans [2] o alguna modificación de ésta. Los problemas que surgen a la hora de utilizar esta técnica son la selección del número de modelos locales que se deben emplear y la identificación de los distintos modelos locales utilizados. Una de las alternativas es la utilización de datos experimentales y extraer a partir de éstos la estructura del sistema de reglas borrosas (extracción de reglas) y los parámetros de los modelos locales (identificación paramétrica). Existen diversos métodos para resolver este problema y se basan en algoritmos genéticos, redes neuronales, plantillas o técnicas de agrupamiento (clustering)[1]. Los algoritmos de agrupamiento borroso son los más adecuados para la identificación borrosa ([12], [5], [1]). Los más utilizados en este tipo de aplicaciones son el método de Fuzzy CMeans (FCM) [2] y el método de Gustafson-Kessel (GK) [6]. Función objetivo c-means La función objetivo base de una gran familia de algoritmos de clustering borroso es la siguiente: Donde: son los datos que deben ser clasificados, (3) es una matriz partición borrosa de Z, (4) es el vector de centros (centroides, prototipos) a determinar, (5) es una norma, y (6) es un exponente que determina la "borrosidad" de los clusters resultantes. El valor de la función de coste (1) es una medida ponderada del error cuadrático que se comete al representar los c clusters por los prototipos ci. Algoritmo fuzzy c-means (FCM) La minimización de la función objetivo (1) es un problema de optimización no lineal que puede ser resuelto de muchas formas, pero la más habitual es la conocida como algoritmo fuzzy c-means. 26 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Los puntos estacionarios de la función objetivo (1) se encuentran añadiendo la condición de que la suma de las pertenencias de un punto a todos los clusters debe ser igual a uno a J mediante los multiplicadores de Lagrange [13]: aunque no tanto como el FCM, se usa bastante en la bibliografía para la obtención de modelos borrosos, dado que los clusters hiperlipsoidales que busca, detectan de forma bastante correcta los comportamientos quasi-lineales de los diversos regímenes de funcionamiento que pueden existir en un conjunto de datos. (7) ALGORITMO DE GUSTAFSON-KESSEL (GK) Igualando a cero las derivadas parciales de _ con respecto a U, C y _, las condiciones necesarias para que (1) alcance su mínimo son: Este algoritmo, al extender el algoritmo básico fuzzy cmeans eligiendo una norma diferente Bi para cada cluster, convierte (5) en [6]: (10) (8) (9) Estas matrices son ahora tomadas como posibles variables para la optimización de la función (1), con lo que se adaptará la norma a cada cluster según sus características. Sea B = {B1, B2, ..., Bc} el vector que contiene las c normas. La nueva función a minimizar será: (11) La ecuación (9) nos da un valor para ci como la media ponderada de los datos que pertenecen a un cluster, donde los pesos son las funciones de pertenencia. El problema más importante con el que nos enfrentamos al emplear el algoritmo FCM para la identificación de modelos borrosos, es que los clusters identificados tienen forma hiper-elipsoidal, cuando lo deseable para una posterior aplicación a control es que, como se ha dicho, dichos clusters tengan una estructura afín o lineal. Existen muchas extensiones y modificaciones al algoritmo básico c-means que se ha descrito. Estos nuevos métodos pueden ser clasificados en tres grandes grupos: • • • Algoritmos que utilizan una medida de la distancia adaptativa (una norma diferente para cada cluster). Esto posibilita la detección de clusters de datos con estructuras (tamaños y formas) diferentes. Algoritmos basados en prototipos lineales (norma constante y prototipos variables). Es una alternativa a la solución anterior de las restricciones de FCM. Algoritmos basados en prototipos no lineales. Este tipo de algoritmos no tienen aplicación al caso que nos ocupa (clusters huecos). De entre los algoritmos con distancia adaptativa, cabe destacar el de Gustafson-Kessel (GK), algoritmo que extiende el algoritmo básico fuzzy c-means eligiendo una norma diferente Bi para cada cluster. Este algoritmo, cumpliendo (3), (4) y (6). Para obtener una solución viable, Bi debe ser limitada de alguna forma. La forma más habitual es fijar el determinante de Bi, lo que es equivalente a optimizar la forma del cluster manteniendo su volumen constante: (12) con _i constante para cada cluster. La expresión que se obtiene mediante los multiplicadores de Lagrange es: (13) siendo Fi la matriz de covarianzas de cluster i definida por: (14) Una vez determinados los clusters hiperlipsoidales, si lo que se desea es conseguir un modelo borroso de TakagiSugeno, se deberán ajustar dichos clusters a estructuras lineales siguiendo la información proporcionada por el eje mayor de dicho cluster y mediante el uso de, por ejemplo, el algoritmo de mínimos cuadrados. El algoritmo GK es bastante adecuado para el propósito de la identificación, ya que tiene las siguientes 27 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 propiedades: • • • La dimensión de los clusters viene limitada por la medida de la distancia y por la definición del prototipo de los clusters como un punto. En comparación con otros algoritmos, GK es relativamente insensible a la inicialización de la matriz de partición. Como el algoritmo está basado en una norma adaptativa, no es sensible al escalado de los datos, con lo que se hace innecesaria la normalización previa de los mismos. El objetivo primordial de este trabajo es buscar técnicas de clustering que desarrollan clusters lineales o hiperplanos (consecuente deseado), manteniendo la interpretabilidad de las reglas (antecedente deseado) y todo ello con resultados de error de modelado al menos tan buenos como el algoritmo GK, de forma que se pueda facilitar el uso posterior de dichos modelos para el control del sistema que está siendo modelado. Como se verá, esto se consigue por medio de la implementación de lo que se ha llamado función de coste mixta. ALGORITMOS CON PROTOTIPOS LINEALES Por todas estas características es bastante empleado en la identificación de los sistemas que no ocupan. Sin embargo, también tiene sus desventajas: • • • • La carga computacional es bastante elevada, sobre todo en el caso de grandes cantidades de datos. El algoritmo GK puede detectar clusters de diferentes formas, no solo subespacios lineales que son los que en principio nos interesan (en realidad busca clusters hiperelipsoidales). Cuando el número de datos disponibles es pequeño, o cuando los datos son linealmente dependientes, pueden aparecer problemas numéricos ya que la matriz de covarianzas se hace casi singular. El algoritmo GK no podrá ser aplicado a problemas puramente lineales en el caso ideal de no existir ruido. Si no hay información al respecto, los volúmenes de los clusters se inicializan a valores todos iguales. De esta forma, no se podrán detectar clusters con grandes diferencias en tamaño. Por otra parte, es una característica común de la identificación de modelos borrosos por clustering olvidar el fin (el modelo borroso) en la etapa de agrupación de los datos. Siempre es un paso posterior derivar reglas en alguno de los tipos de modelo borroso existentes (Takagi-Sugeno en nuestro caso). Para ello, la solución más sencilla es proyectar la pertenencia a los clusters obtenidos en el espacio deseado, obteniendo así funciones de pertenencia que definirán conjuntos borrosos en los espacios que se proyecten. Otra opción en conservar en el espacio n-dimensional la función de pertenecía obtenida. Si no se realiza la proyección en el espacio de salida (modelo Mandami), se emplea un método alternativo de ajuste apropiado para la determinación del consecuente (mínimos cuadrados, algoritmos genéticos, ...). Además, se suele perder la interpretabilidad de las reglas a cambio de un bajo error de modelado. 28 Existen diferentes algoritmos que eliminan el problema de la limitación de forma y tamaño de los clusters impuesta por FCM manteniendo la norma constante pero definiendo prototipos r-dimensionales (0 ≤r ≤n-1), lineales o no lineales, en subespacios del espacio de datos. Esta opción es opuesta a la idea de GK de emplear normas variables, pero también obtiene buenos resultados. Los algoritmos de este tipo y que pueden ser de nuestro interés, referentes a espacios o subespacios lineales, son el algoritmo fuzzy c-varieties [2] (FCV) y el algoritmo fuzzy c-regression models [8] (FCRM). De entre todos estos algoritmos, el que en un principio parece más interesante es el FCRM, ya que ajusta los parámetros de la clasificación a un modelo de regresión genérico: (15) con las funciones fi parametrizadas por _i _R pi. El grado de pertenencia µik _U se interpreta en este caso como la cercanía existente entre el valor predicho por el modelo (15) e yk. El error de predicción suele calcularse como: (16) Las funciones objetivo a minimizar con el método que se presenta, son definidas por U _Mfc y (_1, ...,_c) _R p1x R p2 x ... x R pc para (17) Una posibilidad para minimizar (17) se presenta en [7] . A pesar de lo interesante que en un principio parece el algoritmo, tan solo Kim [10] sugiere emplearlo para el modelado borroso. Además, los resultados que obtiene no son muy prometedores, y se considera que solo debe ser empleado como una primera aproximación y el ajuste fino del modelo final se hará posteriormente, por ejemplo, con el método del gradiente. En cuanto al antecedente REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 de las reglas lo obtiene en un paso también posterior al clustering, mediante un ajuste de U a funciones exponenciales. El comportamiento de FCRM cuando en los datos no hay estrictamente clusters lineales, sino que lo que se pretende es obtener modelos lineales que aproximen a un sistema que no es lineal (ni siquiera a tramos) se puede comprobar buscando modelos lineales con alguna curva, por ejemplo, una parábola. Las soluciones que obtiene FCRM para este caso se muestran en la figura 1. Figura 1. FCRM en la detección de datos sin estructura lineal (azul: datos, verde: simulación, rojo: modelos lineales identificados). Una inicialización de la matriz de partición U más cercana al resultado deseado lleva a resultados como los mostrados es la figura 2a, pero nunca comparables a los que se obtienen con el algoritmo GK (figura 2.b). Por tanto, este algoritmo no consigue los objetivos deseados aunque su filosofía no sea desechable. Existe una familia de algoritmos que combina ventajas de uno y otro enfoque y que se presenta a continuación. Figura 2. a) FCRM en la detección de datos sin estructura lineal con U dada (azul: datos, verde: simulación, rojo: modelos lineales), b) GK en el mismo caso (azul: datos, rojo: simulación, verde: modelos lineales). A L G O R I T M O S C O N P R O TO T I P O S M I X TO S El problema del que adolece el algoritmo es que aunque el error entre los datos de salida y los del modelo se minimiza, los modelos lineales obtenidos no son nada parecidos a lo esperado (aproximar la función a modelar con modelos lineales en el entorno de un punto de funcionamiento), tal y como se muestra especialmente en la figura 1.b. Existe un tercer tipo de algoritmos (además de los que tienen norma adaptativa o los que emplean prototipos lineales) que intentan superar los problemas de los algoritmos con prototipos lineales mediante la combinación de éstos con los de norma adaptativa. Estos algoritmos son el algoritmo fuzzy celliptotypes [2] (FCE) y el algoritmo 29 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 adaptive fuzzy c-regression models [11] (AFCR), y a los que podríamos llamar algoritmos con prototipos mixtos. Con FCE se pretenden superar algunos de los problemas del FCV. Se toma un criterio genérico, (18) se fuerza a cada cluster a tener un centro de gravedad cdgi y se mide la distancia como combinación de las distancias de FCM (Dik) y FCV (Drik) (19) con _ _[0,1]. El problema en este algoritmo es la elección del _ correcto para cada cluster. El algoritmo AFCR (del que tan solo se han encontrado referencias en la literatura japonesa) intent proporcionar un tratamiento similar a FCRM del que hace FCE con FCV. En este caso el criterio queda: (20) y se toma la distancia como combinación de las distancias de FCRM (Eik) y FCM (Dik): Figura 3. AFCR en la detección de datos sin estructura lineal (azul: datos, verde: simulación, rojo: modelos lineales) para 3 clusters (a) y 5 clusters (b). (21) con _ _[0,1]. El primer término proporciona el mismo criterio que FCRM y el segundo incrementa la capacidad de partición en el espacio de las variables ya que tiene en cuenta la distancia de los datos al prototipo de los clusters. La elección del _ se hace de forma dinámica en este algoritmo y se acerca a 1 según la estructura descubierta en el cluster es más lineal. Su determinación se basa en (22) con _kl los autovalores de la matriz de covarianzas definida en (14) para GK. De este modo se conjuga en un solo algoritmo ventajas de FCRM, FCM y GK. El parámetro _ sirve de balance entre los términos cuando su tamaño medio es muy diferente y no hay ningún estudio respecto a su determinación. Los resultados que obtiene AFCR para el mismo ejemplo planteado en las figuras 1 y 2 se pueden observar en la figura 3 y se pueden comparar con el resultado obtenido por GK en la figura 4 y FCRM en la figura 3. 30 Figura 4.GK la detección de datos sin estructura lineal con U dada (azul: datos, rojo: simulación, verde: modelos lineales) para 3 clusters (a) y 5 clusters (b). REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Los resultados se corresponden con la mejora indicada en [11] respecto a FCRM, igualando resultados de algoritmos como el GK y obteniendo, al tiempo de realización del clustering, una serie de modelos locales lineales que se ajustan perfectamente a la función en estudio e incluyendo el error de modelado en la función de coste. Además, la capacidad de detección de estructuras lineales no se ha perdido en AFCR, obteniendo resultados idénticos a FCRM con diferentes conjuntos de datos en lo que éste funcionaba correctamente. A continuación, y dados los buenos resultados obtenidos, se estudió el campo en el que GK se comporta mejor y que es, por otra parte, el que más interesa: el mapeado de funciones estáticas y dinámicas, como nos vamos a encontrar en control. Para ello, se ha tomado en primer lugar una serie de datos reales de un biorreactor [3], ejemplo que se muestra en la figura 5. Figura 6. GK detectando estructuras lineales en datos reales (azul: datos, rojo: simulación, verde: modelos lineales). Este efecto (el de la pérdida de la interpretabilidad) se hace mucho más claro en sistemas más "complejos". Figura 5. AFCR (a) y FCRM (b) detectando estructuras lineales en datos reales (azul: datos, rojo: simulación, verde: modelos lineales). Claramente AFCR supera FCRM (figura 5) e iguala GK (figura 6). Cabe destacar que en ambos casos de resultado positivo (AFCR y GK) las funciones de pertenencia borrosas obtenidas pierden parte de su interpretabilidad (convexidad), como se muestra en la parte inferior de la figura 6. Figura 8. AFCR (a) y GK (b) en la detección de datos dinámicos. 31 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Los resultados mostrados en 8 no son demasiado buenos al fijarnos en las funciones de pertenencia y, aunque nuevas ejecuciones de AFCR (variando el valor de _) o GK dan clusters que aproximan mejor (localmente) la función en estudio, las funciones de pertenencia han perdido su interpretabiblidad a cambio de un bajo error de modelado. Una inspección de la matriz U definitiva a la que llevan AFCR o GK, nos indica que se minimiza el error no por cercanía del modelo obtenido, sino por la ponderación de varios modelos. Sin embargo, lo que nosotros pretendemos buscando modelos cuyo fin es un posterior control, son modelos locales lineales que se aproximen lo más posible al modelo del sistema: se pretende aproximar la función desconocida que representa al sistema con hiperplanos en el entorno del prototipo del cluster que representará un punto de funcionamiento. La idea que se persigue a partir de este momento es incluir en el proceso de clustering alguna condición que favorezca la pertenencia a clusters concretos: entradas de U (pertenencias) cercanas a 1 si estamos cerca del prototipo del cluster y cercanas a 0 si estamos lejos del prototipo. Se pretende, por tanto, conseguir la convexidad de las funciones de pertenencia borrosas suministradas en el proceso de identificación, pues es lo que se necesita para una posterior interpretación y validación y ni el algoritmo AFCR ni el GK lo consiguen. A pesar de esto, con los algoritmos propuestos hasta el momento, ya se puede decir que el funcionamiento de AFCR supera a GK, dado que para los mismos conjuntos de datos se obtienen resultados finales similares y siempre con la ventaja de que el consecuente afín de las reglas borrosas identificadas forma parte del propio proceso de clustering. (24) con _ _[0,1] siguiendo para su determinación el criterio (22). El parámetro _se mantiene para el balance entre los términos cuando su tamaño medio es muy diferente y se incluyen _1y _2con el mismo fin. Para determinar los valores de Dlejos iky Dcerca ik se identifica en (25) y (26), respectivamente, el criterio de distancia que es necesario incluir en un índice para expresar la penalización por alta pertenencia de puntos lejanos a un prototipo (25) y baja pertenencia de puntos cercanos al prototipo (26). Se ha utilizado una penalización exponencial en ambos casos, lo que llevará a una preferencia por la generación de funciones de pertenencia exponenciales, aunque dicho criterio puede ser modificado según el criterio que pueda interesar en cada caso. (25) (26) Este nuevo algoritmo, denominado AFCRC (adaptive fuzzy c-regression models with convex membership functions), ha sido programado y, aunque se pretende realizar en el futuro un estudio teórico para la determinación más adecuada de _1y _2, numerosas simulaciones se han llevado a cabo con resultados muy interesantes. Para el mismo conjunto de datos empleados en el ejemplo de la figura 8, el nuevo algoritmo se comporta para diferentes valores de _1(no se han incluido en este caso variaciones del término _2) como se observa en las figuras 9 a 11. ALGORITMOS QUE FAVORECEN LA CONVEXIDAD Aprovechando, como ya se ha comentado, la demostración de [2] en la que se indica que la única condición para la convergencia del índice J de los algoritmos de clustering es que la distancia sea siempre positiva, se van a añadir nuevos términos a la distancia (21) empleada en AFCR para mejorar la convexidad de las funciones de pertenencia y manteniendo lo positivo de este algoritmo. Para un criterio como el mostrado en (23) (23) se incluirá en DC ikun término para penalizar la alta pertenencia de los puntos lejanos a un prototipo (Dlejos ik) y otro para penalizar la baja pertenencia de puntos cercanos al prototipo (Dcerca ik), manteniendo también las distancias de FCRM (Eik) y FCM (Dik ). La nueva distancia global que se empleará será: 32 Figura 9. Clusters (a) y funciones de pertenencia (b) con AFCRC (_1= 10^5) REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 forma de las funciones de pertenencia y mejorar su convexidad con una correcta elección de parámetros, tal y como muestras las últimas figuras. El efecto de (26), aunque no tan espectacular, tampoco es despreciable. La combinación de ambos términos lleva a resultados como el de la figura 12, donde se ha tomado el mejor de los valores observados para _1en las simulaciones anteriores y se han probado distintos valores de _2 hasta obtener los resultados mostrados en la figura. Figura 10. Clusters (a) y funciones de pertenencia (b) con AFCRC (_1= 10^3 Figura 1 Clusters (a) y funciones de pertenencia (b) con AFCRC (_1= 10^3 y _2= 10^-2). Con este segundo término se aprecia una mejora en las pertenencias de los puntos centrales de los clusters, pero muy ligera. Por tanto, parece que ambos términos cumplen su cometido y ayudan a conseguir unas funciones de pertenencia más interpretables y unos clusters más ajustados a lo deseado. Figura 11. Clusters (a) y funciones de pertenencia (b) con AFCRC (_1= 10^2). El efecto del término generado en (25) en el proceso de clustering es muy claro en lo que respecta a modificar la Sin embargo, para el ejemplo anterior el ajuste de _1 y _2 se ha hecho de forma manual. Como ya se ha dicho, es un trabajo para el futuro determinar algún criterio para que fuese el propio proceso de clustering el que determinase el _ apropiado en cada caso. Una primera aproximación sencilla se ha determinado viendo que los términos sigma están situados en el denominador de un término exponencial, cuyo numerador es la distancia al cuadrado del punto que se está evaluando. Es por ello que se intuye una dependencia del _ adecuado con las distancias, el rango máximo de las variables (universo de discurso) y el número de clusters que se pretende emplear para explicar el sistema. Como regla sencilla se ha empleado en este artículo _1=DM/(clusters/2) y _2=Dm/(clusters/2). Los resultados con 33 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 esta estimación y permitiendo que los valores de DM (Distancia Máxima) y Dm (Distancia mínima) sean dinámicos (recalculados en cada iteración), se obtienen los resultados de la figura 13 para 4 y 6 clusters. Figura 13. Clusters y funciones de pertenencia con AFCRC y asignación automática de _. Los resultados en este caso son buenos para todo número de clusters y se puede comprobar una clara mejoría respecto al algoritmo GK en el caso concreto de tomar 6 clusters (figura 8.b). En el caso de volver a tomar los datos del biorreactor (como en las figuras 5 y 6) y aplicar AFCRC con este criterio, el algoritmo también llega a resultados correctos, tanto en modelado con funciones lineales (consecuentes de las reglas borrosas) como en la interpretabilidad de las funciones de pertenencia (antecedentes de las reglas borrosas). Los resultados de AFCRC se pueden observar en las figuras 14.a a 16.a y son fácilmente comparables con el algoritmo GK en las figuras 14.b a 16.b, siendo la mejora muy clara. 34 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Figura 15. Detección de 4 clusters y funciones de pertenencia con AFCRC de asignación automática de _(a) y GK (b). Figura 16. Detección de 5 clusters y funciones de pertenencia con AFCRC de asignación automática de _(a) y GK (b). En combinaciones de datos más sencillas, como el caso de la parábola empleada en las figuras 2 a 5, AFCRC no pierde sus capacidades. Esto queda claramente mostrado en la figura 17 para 2, 3, 4 y 8 clusters. Figura 17. Detección de diferentes números de clusters y sus funciones de pertenencia con AFCRC de asignación automática de _. CONCLUSIONES En el artículo se propone la definición e implementación de un nuevo algoritmo que mejora la interpretabilidad de las reglas borrosas, además de generar en el proceso de clustering los consecuentes afines de las reglas borrosas de tipo Takagi-Sugeno. Figura 14. Detección de 3 clusters y funciones de pertenencia con AFCRC de asignación automática de _(a) y GK (b). Este algoritmo de clustering (especialmente diseñado para identificar modelos borrosos para control) se espera que proporcione modelos que experimenten en su funcionamiento para simulación mejoras importantes, tanto por la facilidad de implementación de los antecedentes del modelo basado en reglas como distancias (ponderadas exponencialmente) al prototipo (gracias a la convexidad de las funciones de pertenencia), 35 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 como por la generación del consecuente en el proceso de clustering teniendo en cuenta el error de modelado en cada paso de la iteración. Igualmente se observa mejoría respecto al efecto del ruido en el proceso de identificación, pues la tendencia a la convexidad de las funciones de pertenencia hace disminuir la importancia de aquellos puntos que se salgan del comportamiento más común, no obligando al modelo a tener un error nulo en los mismos. • • • REFERENCIAS • • • • • 36 Babuska R. Fuzzy Modeling and Identification. PhD dissertation, Delft University of Technology, Delft, The Netherlands, 1996. Bezdek J. C. Pattern recognition with Fuzzy Objective Function Algorithms. Ed. Plenum Press, 1987. Carbonell P., Díez J. L., Navarro J. L. Aplicaciones de técnicas de modelos locales en sistemas complejos. Revista de la Asociación Española para la Inteligencia Artifical, nº 10, pp. 111-118, 2000. Díez J. L., Navarro J. L. Fuzzy Models of Complex Systems by means of Clustering Techniques. Proc. 2 Nd Intelligent Systems in Control and Measurement, pp.147-153,1999. Emami M. R., Türksen I. B., Goldenberg A. A. “Developement of a Systematic Methodology of Fuzzy Logic Modeling”, Transactions on Fuzzy Systems, vol. 6, nº3, pp. 346-36, 1998. • • • • Gustafson E. E., Kessel W. C. “Fuzzy Clustering with a Fuzzy Covariance Matrix”, IEEE CDC, San Diego, California, pp. 761-766. 1979. Hathaway R. J., Bezdek J. C. “Grouped Coordinate Minimization Using Newton's Method for Inexact Minimization in One Vector Coordinate”. Journal of Optimization Theory and Applications, vol. 71, nº 3, p. 503-516. 1991. Hathaway R. J., Bezdek J. C. “Switching Regression Models and Fuzzy Clustering”, Transactions on Fuzzy Systems, vol. 1, nº3, pp. 195-204, 1993. Johansen, T.A., Murray-Smith, R. “The operating regime approach to nonlinear modelling and control”, en Multiple Model Approaches to Modelling and Control. Ed. R. Murray-Smith and T.A. Johansen, London: Taylor & Francis, 1997. Kim E., Park M., Ji S., Park M. “A New Approach to Fuzzy Modeling”. Transactions on Fuzzy Systems, vol. 5, nº3, pp. 328-337, 1997. Ryoke M., Nakamori Y. “Simultaneous Analysis of Classification and Regression by Adaptive Fuzzy Clustering”. Japanese Journal of Fuzzy Theory and Systems, vol. 8, nº1, pp. 99-113, 1996. Sugeno M., Yasukawa T. “A Fuzzy-Logic-Based Approach to Qualitative Modeling”. Transactions on Fuzzy Systems, vol. 1, nº1, pp. 7-31, 1993. Vista Aérea Unidad Académica La Paz - Irpavi REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Detección de patrones caóticos en fenómenos de contaminación GIMMY NARDÓ SANJINÉS TUDELA Departamento Ingeniería de Sistemas - Escuela Militar de Ingeniería La Paz - Bolivia [email protected] RESUMEN En el presente trabajo se realiza una aplicación del método para la detección de caos. El trabajo empírico se realiza para la ciudad de Bogotá que según datos del Departamento Técnico Administrativo del Medio Ambiente (DAMA), en la primera década del presente siglo se superaron consecutivamente los niveles estándares de ozono y material particulado. Así, la concentración de partículas suspendidas (PM10) supera en varias estaciones en Bogotá la norma de 170 _g/m3. También las concentraciones máximas cada 8 horas de ozono llegan a superar los límites estándar establecidos, lo cual genera un ambiente de contaminación alto (DAMA, 2010). Es así que viendo la necesidad de estudios, donde se analicen las características dinámicas y de comportamiento no lineal o caótico de los datos, el presente trabajo muestra la aplicación de un método para la detección de caos. Creando de esta manera una herramienta para describir con características propias los fenómenos de contaminación ambiental. KEYWORDS Exponente de Lyapunov, Dimensión Fractal, Análisis Espectral, Teoría del Caos, Dinámica no Lineal, Dinámica de Sistemas Complejos. INTRODUCCIÓN La importancia de conservar el medio ambiente ha crecido considerablemente en la actualidad. Es así que se crearon metodologías y técnicas para poder explotar, asignar y conservar eficientemente los recursos naturales y ambientales. La prevención y mitigación de episodios de alta contaminación, por su parte, debe considerar medidas que sean efectivas, en cuanto a la disminución de concentración de contaminantes en el aire y también en términos de costos. Este tipo de estudios, es decir, sobre pronóstico de contaminación atmosférica, en la ciudad de Santa Fe de Bogotá, toma un papel importante a futuro, puesto que como sucede en países como Chile, este tipo de pronósticos son muy comunes y se aplican para realizar trabajos de prevención en cuadros de alta contaminación. Dada la importancia de conocer los patrones de comportamiento de los niveles de contaminación, la detección de caos muestra si las series de datos poseen características como la sensibilidad a condiciones iniciales, una dimensión fractal y si posee frecuencias complejas, Estos se describen con un cierto grado de confiabilidad, para determinar medios que ayuden determinar la ocurrencia de episodios críticos, con el fin de iniciar acciones que tiendan a prevenir, revertir o mitigar una situación de alta contaminación. El objetivo del presente trabajo es detectar caos en las series temporales de contaminación con la finalidad de permitir mostrar si las series poseen, enterradas en ruido, patrones de dinámica no lineal caótica. El método se muestra en la figura 1. Figura 1. Método para Detectar Caos en S.T. ANÁLISIS DE DATOS En la presente sección se inicia el estudio de las series temporales reales, en tal caso, las series temporales de partículas suspendidas serán del sector Nor-Occidental de la ciudad de Bogotá, en particular de la estación que se encuentra en "Carrefour", pues en dicha estación se superó en varias oportunidades los niveles permitidos. Las series temporales de Ozono serán tomadas de la estación de "SONY" ya que según información del DAMA, en esta estación se tienen los mayores niveles monitoreados de O3 en datos diarios. Así, se muestran las series en estudio de la siguiente manera; Ozono (Figura 3) y Partículas Suspendidas (Figura 4). Se prefieren los datos de estaciones que sobrepasaron los niveles establecidos, para buscar pronosticar los eventos extremos en el comportamiento de la serie, y así predecir niveles altos de contaminación, los cuales 37 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 son los que en realidad tienen efecto a corto plazo en las personas. La serie temporal de Ozono bajo la prueba de Dickey Figura 6, Desintegración logarítmica de PM10 Figura 3, Serie temporal 1000 datos de Ozono Estación “SONY” En la prueba de normalidad ambas series transformadas rechazan la hipótesis nula de normalidad mediante la prueba de Jarque-Bera a un nivel del 5%, esta característica se debe a la existencia de puntos atípicos en el comportamiento (outlier) los cuales responden a puntos de alta contaminación (puntos extremos). DETECCIÓN EMPÍRICA DE DINÁMICA NO LINEAL CAÓTICA Figura 4, Serie temporal 1200 datos de Partículas Suspendidas Estación "Carrefour" Fuller Ampliado (DFA) muestra estacionariedad, lo mismo sucede con la serie temporal de Partículas Suspendidas pues esta presenta la misma característica en los datos. Para buscar que la media sea cero, minimizar el efecto de puntos atípicos y conseguir normalidad en los datos se procede a encontrar la diferencia de logarítmica de los datos como se muestra en la ecuación 7, así esta es una transformación que es un caso particular de la transformación Box-Cox, Cromwell (1994). La noción de caos se puede abordar desde un punto de vista topológico, pero en el presente trabajo tendrá un enfoque distinto, puesto que se trabajaran con series temporales reales y de las cuales no tenemos el modelo caótico que lo genera, por lo tanto se hablará de caos en el contexto de cumplir requisitos que caracterizan la existencia de no linealidad y caos en las series temporales. Por otra parte cuando se analiza una serie temporal experimental no se conoce a priori si la serie es de tipo determinista o estocástica, por eso es fundamental aclarar que la aplicación de técnicas caóticas no implica que la serie sea de origen determinista a pesar que la teoría sea determinista. Así, el primer paso en la detección de caos es el modelado de las series temporales, mediante modelos lineales, como se muestra a continuación. Un modelo ARIMA(p,d,q) se define de la siguiente manera, (Judge & Hill, 1988): Sea entonces se tiene: Figura 5, Desintegración logarítmica de Ozono 38 con "L" el operador retrazo, Para el presente caso se estima el modelo mediante la metodología (Box & Jenkins, 1976), obteniendo para la serie temporal del Ozono el siguiente modelo ARMA(1,1) de la serie transformada con diferencia logarítmica. REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 dimensiones. Para cada una de las dimensiones de transformación m, se elige un épsilon , con cuyos datos la correlación integral está definida por: Tabla 1. Modelo Autoregresivo y de medias móviles para el ozono El presente modelo se diagnostica mediante la prueba de Ljung-Box, bajo diferentes cantidades de retrasos y a un nivel de significancia del 5% , con lo que se puede inferir de manera estadística la independencia lineal de los errores y con ello que el modelo a filtrado la componente lineal de la serie temporal. donde: Tm=T-m+1, t y s tienen rango de 1 a T-m+1 en la sumatoria y son restringidos tal que t`s. La función indicada en (11) es: El modelo estimado para partículas suspendidas se muestra en la tabla 2, el cual está conformado por un modelo ARMA(0,3)xSARMA(1,1), con rezago estacional de d = 7, esto significaría que el comportamiento de la contaminación se reproduce en cantidades similares en días iguales de cada semana, así también este tiene base en los datos resultado de diferencia logarítmica. En Cromwell, et al. (1994) se muestra que bajo la hipótesis nula de independencia, la presente prueba estará asintóticamente distribuida normal estándar. Se debe tomar en cuenta que en el estadístico se tienen dos variables no conocidas, la transformación o empotrado de dimensión m y el épsilon . Bajo la prueba de Brock, Dechert y Scheinkman se puede afirmar que la serie temporal correspondiente a los datos de partículas suspendidas y ozono, a un nivel de significancia del 5%, tiene comportamiento no lineal . Tabla 2. Parámetros del modelo para Partículas Suspendidas Bajo la prueba de Ljung-Box, a un nivel de significancia del 5% y diferentes cantidades de retrasos, se puede afirmar que los errores del modelo son linealmente independientes, por lo cual el modelo captura el componente lineal de la serie satisfactoriamente . Lo anteriormente descrito se ve respaldado por la propiedad de invertibilidad, ya que las raíces recíprocas reales son menores que uno, así también las raíces complejas se encuentran dentro del circulo de la unidad. Sin embargo, aunque se logró independencia en los datos, los errores no se comportan de manera normal, esto debido supuestamente a un comportamiento de dinámica no lineal, lo que se pasa a demostrar. Para lograr demostrar dinámica no lineal en la serie se aplica la prueba dada por Brock, Dechert y Scheinkman, el cual por su robustez es utilizado para detectar patrones de comportamientos no lineales y por ultimo caos, (Cromwell, et al. 1994). La dependencia de x(t) es examinada a través del concepto de correlación integral, una medida que examina las distancias entre puntos, estos mediante una transformación en una dimensión m dada, para diferentes Complementando, si bien los resultados de la presente sección muestran la existencia de dinámica no lineal en las series de tiempo en estudio, no se puede afirmar aun si este comportamiento no lineal responde a un proceso determinístico o estocástico. Para determinar si alguno de los procesos - estocástco o caótico - existen en las series temporales se procede a estimar y demostrar la existencia de una dimensión fractal, el exponente de Lyapunov y finamente la existencia de frecuencias dentro de las series. Estimación de la Dimensión Fractal. Una importante propiedad de los sistemas no lineales es que ellos generan procesos aleatorios aunque el sistema sea determinístico. Así aunque ambos procesos deterministicos y estocásticos generan comportamientos similares a los aleatorios, la dimensión de los procesos de estos modelos son diferentes. Los procesos generados por modelos determinísticos tienen dimensión finita mientras que los procesos estocásticos tienen dimensión infinita, esto en el contexto teórico. Este resultado es importante ya que esto forma parte de las bases para identificar si un sistema es determinístico o estocástico, (Creedy & Martin, 1994). Por un lado ya se ha visto que los atractores extraños poseen una dimensión fractal, en general no entera, 39 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 cuando se la define a través de la óptica de Haussdorf. En la presente sección se va hablar de la autosimilaridad como un concepto central cuantitativo de la fractalidad. Intuitivamente, la dimensión fractal de un objeto geométrico es relacionada con un valor entero, pero en este caso la dimensión es más abstracta pues esta es representada por un número real positivo. Luego podemos definir la dimensión de Hausdorff que H denotamos por D como: Donde Estimación del exponente de Lyapunov. Para lograr el fin de estimar el exponente de Lyapunov - que es otra característica a cumplir para diagnosticar caos - en el presente trabajo se utiliza el método dado por Roseintein, que se muestra en (Fernández, et al., 2000). Con base en lo anterior, se tiene un consistente y robusto estimador para estimar el máximo exponente de Lyapunov, el cual está dado por la siguiente expresión: el cuadrado usado sirve para propósitos de remplazar por hipercubos menores a _. Como se muestra en la figura 7 perteneciente a la serie temporal de Ozono, se puede observar que existe una zona entre 0.7 y 1.3 que si se estima una recta esta tiene una pendiente de 0, por lo cual se puede afirmar que la presente serie temporal tiene una dimensión fractal igual a: 2.275 ± 0.391. Cabe aclarar que cada curva graficada responde a una dimensión n de empotramiento. También se puede apreciar en la figura 8, perteneciente a la serie temporal de partículas suspendidas que esta no presenta ninguna "meseta" o lugar donde se pueda lograr una recta a partir del punto 1.3 del eje de las x, esto implica que en la serie analizada no se presenta una dimensión fractal. Si exhibe un incremento lineal con una pendiente constante positiva para todo tamaño de dimensión, m para un m0 adecuado y un razonable rango de _, entonces está pendiente que puede ser estimada por mínimos cuadrados, es el exponente máximo de Lyapunov (Schreiber & Schmitz,1999). En las figuras 9 y 10 se muestran los resultados de la estimación del exponente de Lyapunov. Estas fueron generadas con la aplicación de la metodología antes expuesta. Como se puede observar en la figura 9, se puede deducir la existencia de un exponente positivo el cual confirma la existencia de caos en la serie temporal de ozono. Figura 9. Exponente de Lyapunov, Ozono. Distancia de correlación Figura 7, Dimensión fractal de ozono - Sony Distancia de correlación Figura 8, Dimensión fractal de Partículas Suspendidas Estación "Carrefour" 40 Figura 10. Exponente de Lyapunov, PM10 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Así, en la figura 10, se puede deducir que no existe un exponente positivo o este es muy pequeño para ser considerado una serie caótica, esto porque, no se puede visualizar rectas con pendiente muy diferente a cero con lo que se puede deducir que la serie temporal no tiene características caóticas o estas son muy pequeñas. Las anteriores afirmaciones son corroboradas por el método estadístico por lo que con base en este análisis se puede afirmar que el exponente de Lyapunov para la serie temporal de ozono es, 0.05±0.01, con lo que podemos afirmar que existe caos en esta serie temporal. Para la serie temporal de partículas suspendidas se puede decir que el exponente de Lyapunov es muy pequeño, 0.03±0.02 cuyo valor mínimo es 0.01 que es muy cercano a cero por lo que el caos contenido en la serie puede considerarse muy pequeño. frecuencia, fn Figura 11, Transformada de Fourier Rápida de ozono, Estación "SONY" Análisis Espectral. El objetivo de una transformada de Fourier es el de encontrar frecuencias, expresadas en sus características, denominados armónicos, con lo que se puede re-construir la función original a partir de coeficientes numéricos multiplicados por funciones armónicas puras. En otras palabras, la Transformada de Fourier: es una descomposición del espacio temporal en componentes de frecuencias que la forman. Se trata de una curva en el espacio de frecuencias. En función del método descrito, el cual es aplicado con los datos en estudio, los que fueron muestreados en intervalo diario se puede apreciar que el ruido que distorsiona el patrón de comportamiento en las series temporales es muy grande. Los resultados obtenidos mediante la transformada de Fourier rápida, correspondiente a ozono, muestran que a un nivel de significancia del 95% se puede afirmar que no existen frecuencias en ninguna de las series en estudio, los resultados de este análisis se muestran en las figuras 11 y 12. Por lo que se diagnostica infrecuencia en las series temporales. También se puede decir que las series tienen gran incidencia de ruido, que se muestra en el análisis espectral y que se acompaña de que en estas no exhiben frecuencias significativas, por lo que ambas no cumplen la característica de existencia de frecuencia. Esta afirmación se realiza en el sentido de búsqueda de frecuencias de ciclos pertenecientes a señales senoidales, cosenoidales o cualquier combinación de estas. Pero dada la estructura de los resultados, que se muestran en las figuras anteriores, se presumen frecuencias complejas o caóticas. frecuencia, fn Figura 12, Transformada de Fourier de Partículas Suspendidas Estación "Carrefour" CONCLUSIONES Con base en los análisis realizados se puede afirmar que la serie temporal de ozono exhibe comportamiento de dinámica no lineal caótica. Esto se afirma porque cumple la prueba BDS, posee un exponente de Lyapunov y una dimensión fractal signigicativos. En contraste, en la serie perteneciente a partículas suspendidas se menciona que posee dinámica no lineal, empero, el exponente de Lyapunov y la dimensión fractal no son significativas. Entonces se asevera que la serie temporal de partículas suspendidas pertenece a la dinámica no lineal estocástica. BIBLIOGRAFÍA • Balacco et. al. (1998) Señal de caos en series temporales Financieras. Documento de trabajo. • Bermúdez, Fernández & Souto, (2002) Sistemas de Control suplementario de la Contaminación atmosférica. • Martinic et. al. (1995) Caos y meteorología. Documento de trabajo. • Montealegre, (1993) Afecciones respiratorias y contaminación del aire en Santafé de Bogotá una aplicación de la regresión Lave-Seskin 41 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Las Tics en la educación moderna Carlos Fernando Torrez Belmonte Dirección Nacional de Informática Escuela Militar de Ingeniería RESUMEN La nueva tecnología Wearable promete transformar el proceso de aprendizaje y enseñanza, en el que los estudiantes lidiarán con el conocimiento de una forma activa, auto-dirigida y constructiva. Una herramienta educativa con tecnología “wearable” puede ayudar a los estudiantes a ejercer su creatividad e innovación, para interactuar con su entorno al recibir información de una forma más rápida. ‘ANTECEDENTES La palabra Wearable tiene una raíz inglesa cuya traducción significa "llevable" o "vestible"; en el campo tecnológico hacemos referencia a computadoras corporales o llevables con el usuario. Bajo esta concepción el ordenador o PC deja de ser un dispositivo ajeno al usuario, el cual lo utilizaba en un espacio definido pasando a ser un elemento que se incorpora e interactúa continuamente, además de acompañarlo a todas partes. Por tanto la tecnología Wearable hace referencia a todos los productos que incorporan un microprocesador y que utilizamos diariamente formando parte de nosotros. Los Wearable son dispositivos electrónicos que se han miniaturizado lo suficiente como para poder emplearse como accesorios o complementos, con las comodidades que ello conlleva, ofreciéndonos funciones dignas de productos de un tamaño mucho mayor sin apenas darnos cuenta de que los llevamos encima. Dentro de estos dispositivos, podemos mencionar las gafas inteligentes (Google Glass), su funcionamiento es simple: hacer todo lo que imaginamos con nuestro smartphone sin tener que usar las manos ni sacarlo del bolsillo, todo ello gracias a una pantalla que veremos frente a nosotros. Los relojes inteligentes donde la idea principal reside nuevamente en la posibilidad de conectarnos y utilizar nuestro teléfono móvil sin necesidad de sacarlo del bolsillo, todo desde nuestra muñeca. Las pulseras inteligentes, con este pequeño dispositivo podremos monitorizar una gran cantidad de datos durante nuestras sesiones de ejercicio, que será sincronizada en todo momento en internet, para que podamos consultarla desde la comodidad del ordenador. Cada vez que existe un cambio tecnológico se produce una innovación social y finalmente una reforma representativa. Con Wearable Technologies nos acabaremos adaptando poco a poco hasta estar totalmente sumergidos en la nueva “tecnología puesta”. Aunque en nuestro medio Wearable Technologies no están siendo utilizadas al 100%, se puede observar que en las Universidades bolivianas su uso se está incrementado. Entonces es momento de preguntarnos, ¿Cómo afectará las nuevas TICs en la educación Superior? DESARROLLO Una nueva generación de dispositivos inteligentes: gafas, relojes, pulseras, anillos son ahora etiquetados como inteligentes y las personas pretenden aprovechar estas capacidades tanto en el trabajo como en la educación. Las llamamos “Wearable Technologies”, que en una traducción a nuestro idioma se refiere a las Tecnologías que se llevan puestas, como una prenda o un complemento. 42 Dentro de nuestro sistema educativo boliviano, contamos con una década de múltiples y ricas experiencias en materia de introducción de TICs en los procesos de enseñanza-aprendizaje. Muchas veces, los programas y proyectos vienen empujados por una fuerte presión social y económica para que se incluyan las nuevas tecnologías en la Educación Superior. Sobre todo si nos referimos a la enseñanza a distancia o semipresencial. Lastimosamente estas tecnologías requieren de nuevas competencias en docentes y alumnos, esto para que REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 dichas fórmulas resulten exitosas. Sin embargo, este método exige de los docentes nuevas competencias tanto en la preparación de la información y las guías de aprendizaje, como en el mantenimiento de una relación tutorial a través de la red Internet. Exige de los alumnos junto a la competencia técnica básica para el manejo de los dispositivos técnicos, la capacidad y actitudes para llevar a cabo un proceso de aprendizaje autónomo y para mantener una relación fluida con su tutor. Algunas de las ventajas que podemos apreciar en el uso de las nuevas tecnologías para la formación universitaria son: • • • • • • • • Acceso de los estudiantes a un abanico ilimitado de recursos educativos. Acceso rápido a una gran cantidad de información en tiempo real. Obtención rápida de resultados. Gran flexibilidad en los tiempos y espacios dedicados al aprendizaje. Adopción de métodos pedagógicos más innovadores, más interactivos y adaptados para diferentes tipos de estudiantes. Interactividad entre el docente, el alumno, la tecnología y los contenidos del proceso de enseñanzaaprendizaje. Mayor interacción entre estudiantes y docentes a través de las videoconferencias, el correo electrónico e Internet. Colaboración mayor entre estudiantes, favoreciendo la aparición de grupos de trabajo y de discusión. En cuanto a los inconvenientes, podemos citar los siguientes: • • • • • • Elevado coste de adquisición y mantenimiento de los equipos informáticos. Velocidad vertiginosa con la que avanzan los recursos técnicos, volviendo los equipos obsoletos en un plazo muy corto de tiempo. Dependencia de elementos técnicos para interactuar y poder utilizar los materiales. Se corre el riesgo de la desvinculación del estudiante del resto de agentes participantes (compañeros y docentes) por una falta de personalización en la enseñanza. La preparación de materiales implica necesariamente un esfuerzo y largo período de concepción. Es una forma totalmente distinta de organizar las enseñanzas, lo que puede generar rechazo en algunos docentes que no acepten el cambio. Integrar la tecnología en el aula va más allá del simple uso del laboratorio, la computadora y su software. Para que la integración sea efectiva, se necesita una investigación que muestre profundizar y mejorar el proceso de aprendizaje además apoyar cuatro conceptos claves de la enseñanza: 1. Participación activa por parte del estudiante, 2. Interacción de manera frecuente entre el docente y el estudiante, 3. Participación y colaboración en grupo y 4. Conexión con el mundo real. Es importante hacer notar que la educación a distancia es similar a la autoeducación, la cual depende mucho de la voluntad y la perseverancia de cada persona, la cual en muchos casos necesita un contexto para motivarse a sí misma, ya sea teniendo un horario predeterminado que es controlado por un docente o una actividad donde existe un compromiso con un grupo de trabajo. Una de las metas principales de las políticas educativas es: capacitar a todos los docentes para que puedan usar y aprovechar las TICs en todas las áreas curriculares, de manera cotidiana. En los términos del aprendizaje, creatividad y uso de las tecnologías también se ha planteado una dicotomía entre quienes ponen el énfasis en una formación dura y tradicional en el dominio del hardware y el uso del software, contrapuesto a una formación más “polivalente” que incorpore las disciplinas que trabajan con la afectividad, las emociones y que lleve a los alumnos a desarrollar destrezas expresivas y cognitivas que tienen en su base esta dimensión emocional. CONCLUSIONES Sin duda, todo indica que en un futuro próximo no podremos hablar de la educación sin hablar de la tecnología y de la personalización y flexibilidad que ésta proporcionará, aunque un aspecto preocupante, será el grado de dependencia de estos dispositivos. De momento parecen más un centro de notificaciones que un dispositivo independiente. 43 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Descripcion de los equipos del laboratorio de redes de la Escuela Militar de IngenierÍa Luis Alberto Ruiz Lara. Calle Litoral #1826 - Miraflores - La Paz e-mail: [email protected] Escuela Militar de Ingeniería Irpavi La Paz - Bolivia RESUMEN En el Artículo se presenta una breve descripción de los equipos del laboratorio de redes “Lic. Fernando Yañez Romero” ABSTRACT A brief description of the laboratory computers networks “Lic. Fernando Yañez Romero” is presented in this article. comunicaciones con tecnología 4G, etc. Es bueno recalcar que ninguna Universidad del ámbito Nacional cuenta con equipos de dichas características. El presente artículo tiene como finalidad dar una breve descripción de los equipos de laboratorio. DESARROLLO Routers Un router o encaminador es un dispositivo de red que permite la interconexión de redes al nivel de la capa de Red del Modelo de Referencia OSI. INTRODUCCIÓN En la gestión 2014 la carrera de Ingeniería de sistemas de la Escuela Militar de Ingeniería Campus La Paz, cuenta con un laboratorio Moderno de Redes y telecomunicaciones, un laboratorio que proporcione a los alumnos el “Now How” que demanda el Mercado Laboral, sin duda este logro que potencia nuestra carrera es gracias a las gestiones realizadas por nuestro jefe de carrera el Sr. Tcnl. Julio Cesar Narvaez Tamayo durante las gestiones académicas 2012 y 2013 Inquietud que surgió desde el análisis del mercado laboral y las necesidades de enseñanza aprendizaje que demanda la inclusión de las NTIC´s en el siglo 21, donde el despliegue de las redes y las comunicaciones se convierten en un factor diferenciador para la competitividad y porque no decir la integración. Los laboratorios cuentan con equipamiento del fabricante líder en el rubro como es CISCO, los equipos de laboratorio proporcionaran a nuestros estudiantes habilidades en IPV4, IPV6, Enrutamiento, Voz y Telefonía IP, Seguridad, Wireless, Wireless extendida, 44 Desde el punto de vista funcional, un router puede concebirse como una computadora de propósito específico, en contraposición a una computadora personal a la que suele caracterizarse como de “propósito general”. En efecto, en una computadora personal podemos ejecutar software tan variado como un procesador de texto, programas para el tratamiento de imágenes o de sonido, aplicaciones que accedan a bases de datos, programas de contabilidad e incluso juegos. En un router no es posible ejecutar este tipo de software; en particular, en un router de Cisco solo se ejecuta un software específicamente diseñado para el mismo. Se trata del sistema operativo IOS, Internetwork Operating System, que realiza todas las funciones lógicas del router como ser el encaminamiento de paquetes, registro de tráfico de datagramas, actualización de tablas de encaminamiento a otras redes, etc. Por este motivo, configurar un router significa establecer los valores de una serie de parámetros de funcionamiento de este sistema operativo tales como, por ejemplo, el nombre de host del router o las direcciones IP de sus REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 interfaces de red, habilitar la ejecución de ciertos procesos como, por ejemplo, el encaminamiento de datagramas IP mediante los protocolos de encaminamiento RIP o E IGRP, entre otros. Considerado el router, entonces, como una computadora especial, entre sus componentes de hardware principales se encuentran un procesador, encargado de la ejecución de tareas y procesos, una placa madre y distintos tipos de memorias, así como ranuras o “slots” de expansión y dispositivos para la entrada y salida de datos. Lo que no suele tener un router es monitor y teclado, ni unidades de almacenamiento secundarias de datos como lo son las unidades de disquetes y de discos duros. De los elementos de hardware que sí están presentes, vamos a analizar aquellos con los cuales el usuario responsable de la configuración del router interactúa más habitualmente. Memorias Un router de Cisco normalmente consta de cuatro tipos de memoria, cada uno destinado a almacenar, en forma temporal o permanente, diferentes tipos de información. Estos cuatro tipos de memoria se denominan: • • • • RAM ROM NVRAM FLASH En la memoria RAM se almacena, entre otros elementos, las tablas de encaminamiento del router, la caché del protocolo ARP, los datagramas entrantes y también las colas de datagramas salientes. Es, en esencia, la memoria de trabajo del router. En esta memoria también se encuentra un archivo con los parámetros de ejecución del router; este archivo se denomina RUNNING-CONFIG, el cual se va a tratar mas adelante. En la memoria RAM, por otra parte, es donde se carga el sistema operativo IOS para su ejecución, de modo similar a como ocurre con el sistema operativo de una computadora personal que se carga desde disco a la memoria RAM en el proceso de arranque. La memoria ROM contiene el código de arranque del router, encargado de realizar las tareas de inicialización y carga del sistema operativo IOS. También en esta memoria se encuentra una versión “reducida” del sistema operativo a la cual se accede en caso que se necesite realizar alguna tarea de mantenimiento del router o en caso en que no se encuentre la imagen “normal” del sistema operativo. En el capítulo 10 se tratará mas en detalle este punto. La memoria NVRAM es un tipo especial de memoria que tiene la particularidad de que su contenido no se borra cuando se apaga el router. NV significa Non-Volatile, es decir no volátil. En esta memoria se almacenan dos elementos muy importantes para la operativa del router: el archivo de configuración de arranque, denominado STARTUP-CONFIG y el registro de configuración, denominado CONFIG-REGISTER. Finalmente, en la memoria FLASH, que también es una memoria no volátil, se almacena la imagen del sistema operativo, pudiéndose almacenar más de una imagen si el tamaño de la memoria FLASH instalada resulta suficiente. Los routers de Cisco disponen principalmente de dos tipos de dispositivos para entrada y salida de datos: puertos e interfaces de red. Puertos A través de los puertos es que el Administrador accede al router para ver y modificar su configuración y también para ver sus estadísticas de funcionamiento. Todos los routers de Cisco disponen de un puerto denominado CONSOLA (CONSOLE) y la mayoría de ellos también disponen de un puerto denominado AUXILIAR (AUX). Ambos puertos suelen estar ubicados en el panel posterior del router. El puerto de CONSOLA proporciona una conexión serial asincrónica del tipo EIA/TIA-232 (anteriormente denominada RS-232). El tipo de conector depende del modelo del router; algunos tienen un conector del tipo DB25 y otros tienen un conector del tipo RJ-45. Puesto que un router no tiene ni teclado ni monitor, se debe utilizar una computadora personal para suplir esta ausencia. Mediante un cable especial se conecta la computadora a través de uno de sus puertos seriales (COM1, por ejemplo. El tipo de cable a utilizar depende del tipo de conector de consola que tenga el router. Si el conector es del tipo RJ-45, el cable a utilizar debe ser del tipo “rollover” y si el conector es DB25 se ha de utilizar un cable serial. El cable, cualquiera sea su tipo, es provisto por el fabricante junto con el router. El puerto AUXILIAR también proporciona una conexión serial asincrónica del tipo EIA/TIA-232. Este puerto se 45 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 utiliza principalmente para acceder al router en forma remota a través de un modem y su correspondiente línea telefónica. Esta forma de acceso es útil cuando no se tiene acceso físico directo al router. Este puerto también puede utilizarse como una interfaz de red, por ejemplo, para respaldo discado (“dial backup”) o discado bajo demanda (“dial on-demand”). Interfaces de red Las interfaces de red se utilizan para conectar físicamente el router a las redes que el router va a interconectar. Es a través de estas interfaces que los paquetes de datos entran y salen del router. Habitualmente los routers tienen una interface de tipo LAN y una o más interfaces del tipo WAN. La cantidad y tipos de interfaces de red dependerán del modelo de router de que se trate. Incluso, algunos modelos de Cisco tienen ranuras de expansión que permiten insertar módulos de hardware con interfaces LAN o WAN adicionales. Mediante una interfaz LAN se conecta el router a la red local y las interfaces WAN se utilizan para conectar el router a redes remotas. Este modelo dispone de un puerto de consola RJ-45 y USB, un puerto auxiliar del tipo RJ-45, y tres interfaces de red Ethernet de 10/100/1000 Mbps., también del tipo RJ-45. Asimismo, dispone de cuatro ranuras de expansión en las que pueden insertarse tarjetas de hardware con interfaces WAN (WIC, WAN Interface Card) o con interfaces para voz (VIC, Voice Interface Card). Las interfaces WAN permiten conectar el router a redes de área extensa basadas en las principales tecnologías de uso actual tales como Frame Relay, ISDN, DSL de banda ancha y enlaces dedicados punto a punto. Por su parte, las interfaces de voz permiten digitalizar el tráfico de voz para luego encapsularlo en paquetes de datos y priorizarlos sobre el tráfico de datos normal. En cuanto a las capacidades de memoria, el modelo base 2911 tiene 2 GB de memoria FLASH y 1 GB de memoria RAM. Entre las varias funcionalidades que brinda el modelo 2911 podemos destacar el soporte para VLANs (LANs virtuales) IEEE 802.1Q, soporte para la creación de VPNs (Virtual Private Network) y capacidades de firewall (mediante el paquete de IOS firewall), así como de administración basadas en el protocolo SNMP. Cisco ha definido una forma normalizada para identificar cada interfaz de un router; la forma general es TIPO #RANURA/#INTERFACE. TIPO hace referencia al tipo de interface, tal como Ethernet, FastEthernet, TokenRing, Serial, etc. y #RANURA/#INTERFACE hace referencia al número de identificación de una interface específica (#INTERFACE) del módulo de expansión inserto en la ranura #RANURA. La numeración de las ranuras de expansión y de las interfaces en cada ranura comienza en 0, es decir, la primera interface será la 0, la segunda la 1, etc. Por ejemplo, para hacer referencia a la primera interface LAN de tipo GigabitEthernet de la primera ranura se indica como GigabitEthernet 0/0 y la identificación de la primera interface serial de la segunda ranura es serial 1/0. 46 Los seis routers de laboratorio cuentan con un modulo HWIC, provista con dos interfaces seriales tal y como se ve en la figura: Las interfaces en serie de router permiten conectar varias redes LAN utilizando tecnologías WAN. Los protocolos REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 WAN transmiten datos a través de interfaces asíncronos y síncronos en serie (dentro del router), que están conectadas entre sí mediante líneas contratadas y otras tecnologías de conectividad suministradas por terceros. Las tecnologías WAN en la capa de enlace que más se utilizan en la actualidad son HDLC, X.25, Frame Relay, RDSI y PPP. Todos estos protocolos WAN se configuran en ciertas interfaces del router, como en una interfaz serie o una interfaz RDSI. La conexión física en serie de los routers Cisco es un puerto hembra de 60 pines, y soportan varios estándares de señalización como el V.35, X.21bis, y el EIA-530. Las interfaces en serie instaladas en routers no tienen direcciones MAC. dispositivos CSU/DSU pueden conectarse a un router utilizando un cable serial V.35). Otra posibilidad es que el router esté conectado directamente al equipo de conmutación de la compañía telefónica. Red Digital de Servicios Integrados (RDSI). Se trata de un protocolo WAN asíncrono que requiere que la red esté conectada a la línea telefónica a través de un equipo terminal comúnmente denominado modem RDSI. Sin embargo, también puede utilizarse routers de Cisco que integren una interfaz BRI, o conectar un puerto Serial del router a un modem RDSI. Cables Seriales inteligentes V35 Las comunicaciones síncronas en serie utilizan un dispositivo de sincronización que proporciona una sincronización exacta de los datos cuando éstos se transmiten del emisor al receptor a través de una conexión serie. Las comunicaciones asíncronas se sirven de los bits de inicio y de parada para garantizar que la interfaz de destino ha recibido todos los datos. HDLC. Es un protocolo de la capa de enlace que se encarga de encapsular los datos transferidos a través de enlaces síncronos. En un router, los puertos serie están conectados a un modem u otro tipo de dispositivo CSU/DSU a través de cables especiales. La implementación HDLC de Cisco es propietaria, por lo que no puede comunicarse con implementaciones HDLC de otros fabricantes. Protocolo Punto a Punto (PPP). Es otro protocolo de la capa de enlace que soporta los routers Cisco. No es propietario, por lo que puede utilizarse con dispositivos de otros fabricantes. PPP opera tanto en modo asíncrono como síncrono, y puede utilizarse para conectar redes IP, AppleTalk e IPX a través de conexiones WAN. PPP se configura en el puerto serie del router que proporciona la conexión a una línea dedicada u otro tipo de conexión WAN. X.25. Es un protocolo de conmutación de paquetes que se utiliza en las redes telefónicas públicas conmutadas, utilizando circuitos virtuales. Es muy lento, ya que efectua muchas comprobaciones de error, al estar desarrollado para funcionar sobre líneas antiguas. X.25 normalmente se implementa entre un dispositivo DTE y un dispositivo DCE. El DTE suele ser un router y el DCE el conmutador X.25 perteneciente a la red pública conmutada. Los cables que se utilizan para conectar los puertos serie de router a router, el cable que utilizaremos en los laboratorios son del tipo serial V.35, que es una norma originalmente desarrollada por el CCITT (ahora ITU) que hoy día se considera incluida dentro de la norma V.11. Es una norma de transmisión sincrónica de datos que especifica: • • • tipo de conector pin out niveles de tensión y corriente Las señales usadas en V35 son una combinación de las especificaciones V.11 (para clocks y data) y V.28 (para señales de control), utiliza señales balanceadas (niveles de tensión diferencial) para transportar datos y clock (alta velocidad). En una comunicación hay cuatro unidades básicas involucradas, un DTE y un DCE en un extremo y un DTE y un DCE en el otro. Un DTE genera los datos y los pasa a su DCE que los convierte a un formato apropiado y los introduce en la red. Cuando llega la señal al receptor, se efectúa el proceso inverso. Para entendernos un DTE podría ser un ordenador y un DCE un modem. EQUIPO TERMINAL DE DATOS (DTE): Incluye cualquier unidad que funcione como origen o destino para datos digitales binarios. Frame Relay. Es un protocolo de la capa de enlace de datos para la conmutación de paquetes que reemplaza X.25, y que también utiliza circuitos virtuales. En una conexión frame relay, un DTE como un router, está conectado a un DCE del tipo CSU/DSU (la mayoría de 47 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 EQUIPO TERMINAL DEL CIRCUITO DE DATOS (DCE): En cualquier dispositivo que transmite o recibe datos en forma de señal analógica o digital a través de una red. Telefonia Sin una centralita, el teléfono se conecta directamente al puerto FXS que brinda la empresa telefónica. Si tiene centralita, debe conectar las líneas que suministra la empresa telefónica a la centralita y luego los teléfonos a la centralita. Por lo tanto, la centralita debe tener puertos FXO (para conectarse a los puertos FXS que suministra la empresa telefónica) y puertos FXS (para conectar los dispositivos de teléfono o fax) Dos de los routers de los seis que componen el laboratorio de redes de la Escuela Militar de Ingenieria cuentan con dos modulos de telefonia, es decir con puertos FXS y FXO. Un modulo cuenta con 4 puertos FXO. FXS, FXO y VOIP Cuando decida adquirir equipos que le permitan conectar líneas telefónicas analógicas con una centralita telefónica VOIP, teléfonos analógicos con una centralita telefónica VOIP o las Centralitas tradicionales con un suministrador de servicios VOIP o unos a otros a través de Internet, se cruzará con los términos FXS y FXO. Pasarela FXO FXS y FXO son los nombres de los puertos usados por las líneas telefónicas analógicas (también denominados POTS - Servicio Telefónico Básico y Antiguo) FXS - La interfaz de abonado externo es el puerto que efectivamente envía la línea analógica al abonado. En otras palabras, es el “enchufe de la pared” que envía tono de marcado, corriente para la batería y tensión de llamada Para conectar líneas telefónicas analógicas con una centralita IP, se necesita una pasarela FXO. Ello le permitirá conectar el puerto FXS con el puerto FXO de la pasarela, que luego convierte la línea telefónica analógica en una llamada VOIP. FXO - Interfaz de central externa es el puerto que recibe la línea analógica. Es un enchufe del teléfono o aparato de fax, o el enchufe de su centralita telefónica analógica. Envía una indicación de colgado/descolgado (cierre de bucle). Como el puerto FXO está adjunto a un dispositivo, tal como un fax o teléfono, el dispositivo a menudo se denomina “dispositivo FXO”. Pasarela FXS FXO y FXS son siempre pares, es decir, similar a un enchufe macho/hembra. 48 La pasarela FXS se usa para conectar una o más líneas de una centralita tradicional con una centralita o REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 suministrador telefónico VOIP. Usted necesitará una pasarela FXS ya que usted desea conectar los puertos FXO (que normalmente se conectan a la empresa telefónica) a la Internet o centralita VOIP Licencias Los routers necesitan de un licenciamiento para operar correctamente, Las licencias se se dividen en: Licencias Technology Package que se trata de paquetes de grupos de características y servicios que se activan de forma independiente: • • • IPBASE: imagen por defecto. Añade BGP, OSPF, EIGRP, ISIS SECURITY: añade Firewall IOS, IPS, IPSEC, VPN y 3DES a las características de IPBase. UC: VoIP y Telefonía IP Adaptador FXS, también denominado adaptador ATA El adaptador FXS se usa para conectar un teléfono analógico o aparato de fax a un sistema telefónico VOIP o a un prestador VOIP. Usted lo necesitará para conectar el puerto FXO del teléfono/fax con el adaptador. Cuatro de los seis routers de laboratorio cuentan con los dos primeros paquetes de licencias y dos de los routers tienen licencias ademas de la IPBASE y SECURITY la de Comunicaciones Unificadas (UC), estos routers son los que cuentan con los modulos de voz y telefonia IP. CONCLUSIONES Se puede llegar a la conclusion que le Escuela Militar de Ingenieria, cuenta con un moderno laboraratorio de Redes y Comunicaciones, acorde a las necesidades de formacion de los estudiantes, dotado de caracteristicas tecnicas que posibilitara la enseñanza según las necesidades del mercado laboral, dotando al estudiante de competencias en el ambito de las redes, comunicaciones, telefonia Ip, wireless y seguridad. Unidad Académica La Paz - Irpavi. 49 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Reconocimiento de imágenes basado en redes neuronales para el diagnóstico de enfermedades cutáneo infecciosas FIDEL ALEJANDRO TAPIA QUEZADA Departamento de Ingeniería de Sistemas - Escuela Militar de Ingeniería [email protected] La Paz-Bolivia RESUMEN El presente artículo expone el desarrollo de un prototipo de reconocimiento de imágenes para el diagnóstico de enfermedades cutáneas de tipo infecciosas utilizando redes neuronales artificiales. El prototipo presentado se encuadra dentro de lo que se conoce comúnmente como reconocimiento de patrones basado en Redes Neuronales. El objetivo de este prototipo es realizar el reconocimiento de imágenes basado en redes neuronales, para proporcionar al médico general información necesaria en la toma de decisiones del diagnóstico de la enfermedad de tipo cutáneo infeccioso. ABSTRACT This article presents the development of images recognition prototype for the diagnosis of infectious diseases skin using artificial neural network. The prototype exposed into this article is known as pattern recognition on neural network. The objective of this prototype is perform the image recognition based on neural network to provide to the general doctor, necessary information, for take the best decision into the diagnosis of a disease infectious skin type. INTRODUCCIÓN Una forma de relacionar la medicina con un computador es a través de las redes neuronales, que es un campo muy amplio y que aun continua en evolución, en el cual se distinguen importantes áreas de aplicación como ser procesadores de lenguaje, reconocimiento de imágenes, reconocimiento de sonidos, y diagnósticos médicos. Con el presente trabajo se pretende contribuir a esta evolución, aplicando las redes neuronales como una herramienta que ayude al proceso de diagnóstico de enfermedades cutáneas infecciosas por medio de imágenes. Las redes neuronales artificiales son modelos matemáticos que pueden ser entrenados para aprender relaciones no lineales entre un conjunto de datos de entrada y un conjunto de datos de salida. En medicina la aplicación más común de estos modelos, es la clasificación de patrones con el propósito de apoyar al médico en el diagnóstico y tratamiento del paciente. los significativos, que en las enfermedades de la piel conlleva a imprecisiones en su diagnóstico. Al realizar el examen visual al paciente se nota la presencia de signos que corresponden a diferentes variantes de las enfermedades cutáneo infecciosas, lo que provoca confusiones al momento de brindar el diagnóstico. Tomando como referencia el anterior problema se inició el proceso de desarrollo reconocimiento de imágenes tomando como base las redes neuronales. RECONOCIMIENTO DE IMÁGENES El punto esencial del reconocimiento de patrones es la clasificación: se quiere clasificar una señal dependiendo de sus características. Un esquema que se muestra a continuación describe el proceso de reconocimiento. • Entrada de Datos (adquisición de la imagen) En esta etapa se realiza la obtención de la imagen por medio de una cámara digital, para posteriormente subirla al computador y cargarla al sistema para obtener el diagnóstico de la enfermedad. • Pre-procesamiento En esta etapa se lleva a cabo algunas operaciones para adaptar la información de una imagen y tener mejor análisis en pasos posteriores. De esta forma es necesario convertir la imagen a escala de grises PROBLEMÁTICA El reconocimiento de enfermedades cutáneo infecciosas que realiza el médico general al paciente, basado en un análisis visual y su experiencia, provoca dificultad en el diagnóstico, lo cual incide en la asignación de un correspondiente tratamiento inicial. También el problema radica en el poder diferenciar los hallazgos normales de los anormales y los triviales de 50 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 previamente ya que los métodos de segmentación son de carácter bidimensional. • • Segmentación La segmentación, es un proceso en el cual una imagen es subdividida en las regiones u objetos que la componen. La segmentación concluye cuando los objetos de interés han sido aislados. En nuestro caso, la segmentación deberá concluir cuando se delimite la región afectada separándola de la piel. Deteccion de objeto y clasificacion En esta etapa se realiza la determinación y clasificación de los objetos contenidos en la imagen. Para tal motivo se debe realizar una bancarización de la imagen. es lógico suponer una imagen en esas condiciones es mucho más fácil encontrar y distinguir características estructurales. • Análisis de la Imagen El análisis de la imagen consiste en obtener información de alto nivel acerca de lo que la imagen muestra. Para tal motivo se realizarán operaciones morfológicas sobre imágenes binarias basadas en formas. Las principales operaciones morfológicas son la dilatación y la erosión. REDES NEURONALES El modelo de red neuronal que se utilizó es la red neuronal Backpropagation, por sus características. La importancia de la red consiste en su capacidad de auto adaptar los pesos de las neuronas de las capas intermedias, para aprender la relación que existe entre un conjunto de patrones dados como ejemplo y sus salidas correspondientes. Después del entrenamiento, puede aplicar esta misma relación a nuevos vectores de entrada con ruido o incompletas, dando una salida activa si la nueva entrada es parecida a las presentadas durante el aprendizaje. Figura 1: Estructura de la Red Neuronal • Una imagen binaria es una imagen en la cual cada píxel puede tener solo uno de dos valores posibles 1 o 0. Como Capa de Entrada En esta etapa se ingresa la información, consistente en imágenes digitales, es decir, imágenes de infecciones cutáneas previamente procesadas. La misma será una matriz definida por 150 x 150, existiendo 22500 pixeles, donde cada pixel representa la intensidad de color, o la asociación de un grupo de binarios de manera que represente el tipo de infección cutánea. De esta matriz se extraerá una matriz de entrada 20 x 20, por lo tanto obtendremos una matriz de entrada de 400 neuronas. 51 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Este proceso de extracción y reducción en carga de neuronas y pixeles reduce la cantidad de información que representa a cada uno de los patrones obtenidos de esta forma. Obteniendo un vector con una dimensión más pequeña a la que se ha dado como entrada a la red neuronal, lo que tiene como beneficios: menor cantidad de pesos que deben hacer aprendidos, y al tener menos pesos, el tiempo de entrenamiento reduce. • Capas Ocultas Se utilizó tres capas ocultas, lo cual permite más conexiones, lo que significa almacenamiento de información. El número de neuronas de la capa oculta, se determinó mediante experimentación, entrenando a la red con imágenes de distintos tipos de infecciones cutáneas, llegando a tener como resultado 150 neuronas. HERRAMIENTAS La aplicación principal para el reconocimiento de imágenes se desarrolla con el software Matlab mientras que el módulo de gestión de usuarios y de pacientes se lo desarrolló en Microsoft Visual Studio C Sharp. Esto se debe a las capacidades de procesamiento que se necesita para el tratamiento de los datos, imágenes y el entrenamiento y simulación de la red neuronal son más efectivos con los programas mencionados previamente. METODOLOGÍA La metodología del presente trabajo de grado que consta de las cuatro fases siguientes: • • Capa de salida Los parámetros de aprendizaje se obtuvieron en función a experiencias basadas en estudio de los distintos casos de infecciones cutáneas, y luego la corrección y obtención del error mínimo, con 13 neuronas en la capa de salida indicando el tipo de infección cutánea que padece el paciente. Análisis de Datos Esta fase empieza con la identificación informal de todos los requisitos que deberían ser parte del sistema, para ello se empieza con la recolección de datos mediante la observación y principalmente utilizando la elaboración de entrevista programando citas con el experto dermatólogo. También en esta sección se realiza un análisis del caso de estudio del presente trabajo de grado en relación a la patología en estudio y el procedimiento que realiza el médico especialista dermatólogo y el médico general en el respectivo diagnóstico de las enfermedades cutáneo infecciosas. Para ello es necesario realizar una descripción de los procesos que son imprescindibles para el diagnóstico de las enfermedades cutáneo infecciosas, las cuales pueden ser tratadas por un médico general o un especialista dermatólogo. • Diseño del Prototipo Seguidamente se podrá realizar un diagrama de clases de alto nivel que muestre los objetos y todas sus relaciones, definido como modelo de dominio. Para seguir con la identificación de los procesos del sistema se procede a realizar los casos de uso expandido, además de la descripción detallada de todos los procesos mostrados en el caso de uso de alto nivel. Figura 2: Diagrama del funcionamiento de la red neuronal 52 Posteriormente se realiza el diagrama de robustez, para poder ilustrar gráficamente las interacciones entre los objetos participantes de un caso de uso. El análisis de robustez ayuda a saber si las especificaciones del sistema son razonables. REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Posteriormente se realiza el diagrama de secuencia, que representa la interacción entre objetos internos del sistema y las interacciones entre los mismos, es decir, interfaces graficas de usuario, procesos de control y entidades. Para ello se deben aplicar las siguientes reglas básicas: - • Actores solo pueden comunicarse con objetos interfaz. Los objetos entidad solo pueden comunicarse con controles. Los controles se comunican con interfaces, objetos identidad y con otros controles pero nunca con actores. Construcción de Prototipo A partir del análisis de las características, se determinan las variables que ingresaran al modelo para que la red neuronal pueda aprender. Mediante los diagramas de modelado mencionados anteriormente se puede describir el comportamiento del modelo a partir de la acciones de un usuario. Con respecto a la red neuronal se tendrá que determinar cuántas entradas y salidas tendrá la misma dependiendo de las entradas que se tengan. Además se tendrá que conocer el número de neuronas y como estas están distribuidas en capas e interconectadas entre sí. En esta fase también se determinan las funciones de transferencia que se usarán. • Prueba del Prototipo Una vez que se terminó el prototipo es necesario comprobar que realiza las tareas para las que ha sido diseñado y produce el resultado correcto y esperado. Para comprobar el funcionamiento del prototipo se realizaron pruebas con distintas imágenes que pertenecen al tipo de enfermedad de estudio, las cuales terminaron siendo positivos para los resultados esperados. La validación del software se consiguió mediante una serie de pruebas de caja negra que demuestran la conformidad con los requerimientos por parte del usuario. Este proceso de validación se llevó a cabo con un conjunto de treinta imágenes. El prototipo es validado en base a resultados reales bajo supervisión de médico dermatólogo, que es especialista en lesiones cutáneas. Tabla 1: Comparación Sistema - Experto Comprobación de la Hipótesis El cumplimiento del objetivo principal del proyecto debe ser comprobado a través de la prueba de hipótesis planteada, para lo cual se debe comprobar que el nivel de concordancia entre los resultados del sistema experto y el médico especialista sea de un grado aceptable, en correspondencia de la siguiente tabla de valoración del índice Kappa Tabla 2: Valoración de Índice Kappa Coeficiente kappa 0.00 0,01 - 0,20 0,21 - 0,40 0,41 - 0,60 0,61 - 0,80 0,81 - 1,00 Fuerza de concordancia Pobre Leve Aceptable Moderada Considerable Casi perfecta 53 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Las investigaciones realizadas para obtener datos e información requeridos fueron las siguientes: • • Entrevistas a expertos del área de Salud, específicamente dermatólogos, y observación de muestras de casos de infección. Investigación bibliográfica referente al marco teórico, mediante recopilación de información de libros, artículos, folletos, seminarios, todos los mencionados en el área de dermatología en las infecciones cutáneas. Inicialmente se realizó una recolección de resultados de diagnóstico que determinó el sistema experto y el médico especialista, el cual es representado en la tabla cruzada siguiente: Tabla 3: Frecuencias cruzadas de resultados de diagnóstico próximo del 0,60 - 0,80 y 0,81 - 1,00, logrando aceptar de manera estadística la hipótesis planteada, por lo tanto se deduce que las conclusiones de diagnóstico determinadas por el sistema experto tiene un grado significativo de importancia y confiabilidad que puede considerar el médico proseguir con el protocolo de atención médica a los pacientes. CONCLUSION Este artículo presenta las directrices generales para el desarrollo de un prototipo de reconocimiento de imágenes basado en redes neuronales. Los procedimientos por los cuales pasa el desarrollo son metodologías generales aplicadas a cubrir requerimientos de desarrollo de sistemas expertos. La capacidad de las redes neuronales como clasificadores ha sido demostrada teóricamente y con múltiples aplicaciones. Las redes neuronales introducen las ventajas de un examen cuantitativo en la práctica médica. Los registros médicos contienen información valiosa que puede ser utilizada para entrenar redes neuronales y crear sistemas expertos, estos enriquecen el diagnóstico del médico general y brindan una nueva perspectiva al médico especialista. Con el prototipo concluido y cada paso terminado, se puede concluir que cada objetivo propuesto ha sido cumplido a cabalidad. REFERENCIAS BIBLIOGRAFICAS ‘En relación a los datos de la Tabla 3 los resultados son los siguientes: Los resultados de diagnóstico tienen un grado del 90,00%, sin embargo si bien este valor es una estimación concreta del nivel de concordancia es necesario conocer su variabilidad, reflejado en su intervalo de confianza. Para determinar el intervalo de confianza se utilizó la siguiente ecuación, considerando un nivel de significación (_) del 5%. k=(k ) _± Z_(_/2)* √((Po(1-Po))/(N(1-Pe))) En relación a la valoración de la Tabla 2, el índice Kappa es casi perfecto debido a que se encuentra en un rango 54 • Arun Kumar M. (2012) Implementation of Neural Network Back Propagation Training Algorithm on FPGA • Berkow (1986) El manual Merck de Diagnóstico y Terapeuta 7ma edición en español • Duda (2001) Pattern Clasification 2da Edición • Erik Cuevas y Daniel Zaldivar (2008) Vision por Computador utilizando Matlab y el Toolbox de procesamiento Digital de Imágenes • M Hajek. (2005). Neural Networks • Pressman, R. (2005). Ingeniería del Software. McGraw-Hill. REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Implementación de sistema gráfico de cableado estructurado en función a Norma ISO 11801, enfocado a la construcción de edificios GUSTAVO ELÍAS ALCONZ EVIA Departamento de Ingeniería de Sistemas - Escuela Militar de Ingeniería La Paz - Bolivia [email protected] RESUMEN El artículo presenta el desarrollo de un sistema de grafico de cableado estructurado en función a la norma ISO 11801, de tal manera que se pueda realizar el trazado de planos de red y el diseño de nuevas redes dentro de infraestructuras cumpliendo los parámetros necesarios para cumplir los requerimientos mínimos de la norma. ABSTRACT The article presents the development of a system of graphic of structured cabling in function to the ISO 11801, so that they might be able to make the path of planes on network and the design of new networks within infrastructure fulfilling the necessary parameters to meet the minimum requirements of the standard. INTRODUCCIÓN Un Sistema Experto guía a los usuarios a través de los problemas y esto lo hace formulando un conjunto ordenado de preguntas sobre la situación y obteniendo conclusiones a partir de respuestas que ellos dan. La capacidad de solución de problemas se guía por un grupo de reglas programadas según el modelado de procesos de razonamiento de los expertos de la especialidad. Las redes de computadoras se desarrollan como consecuencia de aplicaciones comerciales diseñadas para computadoras ya que no existia otra manera de crecimiento en la calidad y el tamaño de las redes, estas fueron creciendo a medida que se introducían nuevas tecnologías de red. permita garantizar la correcta aplicación de normas internacionales, lo que da lugar a problemas y fallas en las redes al implementar y poner en funcionamiento las mismas. JUSTIFICACION El sistema propuesto se desarrolló en base a las técnicas y herramientas de Tecnologías de Comunicación y Redes, contribuyendo a la realización de las aplicaciones de Ingeniería de Software, así mismo la aplicación de Seguridad de sistemas para la utilización de normar internacionales. Por consiguiente el proposito del presente Trabajo de Grado es el de desarrollar una herramienta para apoyar a los expertos y/o tecnicos que deseen realizar el diseño fisico de una red LAN. Usando esta herramienta se podrá contar con un diseño fisico de una red que esté apoyado sobre las normas que se deseen aplicar con lo que se conseguira una red muy bien instalada y diseñada. Así mismo en la actualidad existen una serie de programas que pueden realizar el diseño de cableado estructurado, pero estas además de ser costosas no utilizan la norma ISO 11801 para el desarrollo de estas, entre la cuales podemos citar a la aplicación Fiber Runner de Panduit y Fiber Routing Layout Tool v1.0, que además de ser de un valor económico bastante elevado, requieren ejecutarse con Microsoft Visio 2002 en adelante lo que significa un costo adicional, y así mismo están son exclusivas para uso de fabricantes. PROBLEMÁTICA NORMA ISO 11801 En la actualidad el desarrollo de nuevas redes LAN es realizado de manera empírica y carece de procedimientos que apliquen normativas que garanticen el planteo de Redes en la construcción de nuevas infraestructuras, así mismo denota ausencia de una interfaz gráfica que ISO (Organización Internacional para la Normalización) es la organización internacional que tiene a su cargo una amplia gama de estándares, incluyendo aquellos referidos al networking. ISO desarrolló el modelo de referencia OSI, un modelo popular de referencia de networking. 55 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 La IS0/IEC estableció en julio de 1994 la norma ISO 11801 que define una instalación completa (componente y conexiones) y valida la utilización de los cable de 100 o mega o 120 o mega. También especifica cableado para uso comercial, el que puede abarcar uno o un conjunto de edificios dentro de un espacio físico limitado llamado campus. Figura 1: Longitud de los Latiguillos La ISO 11801 actualmente trabaja en conjunto para unificar criterios. La ventaja de la ISO es fundamental ya que facilita la detección de las fallas, para que al momento de producirse afecten solamente a la estación que depende de esta conexión, permite una mayor flexibilidad para la expansión, eliminación y cambio de usuario del sistema. Fuente: Estándares del Cableado Estructurado Los costos de instalación de UTP son superiores a los de coaxial, pero se evitan la pérdida económica producida por la caída del sistema por cuanto se afecte solamente un dispositivo. La ISO 11801 reitera la categoría EIA/TIA (Asociación de industria eléctricas y telecomunicaciones). Este define las clases de aplicación y es denominado estándar de cableado de telecomunicaciones para edificio comerciales. Distribuidor Debe existir un distribuidor por planta por cada 1.024 m2 de espacio o por cada planta. Debe haber como mínimo 2x4 pares por cada puesto de trabajo y al menos uno debe ser de categoría 5. Figura 2: Ubicación del Distribuidor La ISO 11801 en base a EIA/TIA toma con unos valores de impedancia, depurando la diafonía y de atenuación que son diferentes según el tipo de cables y a su vez define también las clases de aplicación. Las normas EIA/TIA fueron creadas como norma de industria en un país, pero se ha empleado como norma internacional por ser de las primeras en crearse. ISO/IEC 11801, es otra norma internacional. La norma ISO 11801 toma en cuenta los siguientes puntos: Máxima Longitud de los Latiguillos Los latiguillos son los cables que permiten conectar el panel de parcheo y los concentradores. También se les llama latiguillos a los cables que van a servir para conectar cada uno de los PCs de la red a sus correspondientes rosetas de conexión. Esta distancia debe considerar la longitud del cable de equipamiento, la distancia de un latiguillo A que una los puntos de correspondencia dentro de la consola y por último la distancia de un latiguillo B que vaya desde el punto de conexión al puesto de trabajo; en total la distancia no debe ser mayor a los 100 metros. Para comprender mejor lo anteriormente mencionado lo plasmaremos en la figura 1. 56 Fuente: Estándares del Cableado Estructurado Administración Etiquetado: Cada cable, distribuidor y punto de terminación debe tener un identificador único. Documentación Esquema del cableado desde el armario hasta los puestos de trabajo. APLICACIÓN DE LA NORMA ISO 11801 Para la aplicación de la Norma ISO 11801 se tomó en cuenta aspectos requeridos por la ECE, y así mismo aspectos que puedan ser aplicados dentro de nuestro país, para entender mejor la norma se muestra a continuación parte de esta norma: Dentro de las instalaciones que el cliente realiza en una infraestructura, la importancia del cableado de red es similar a los otros servicios de construcción REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 ser implementado con material de fuentes simples y múltiples, y se relaciona con: fundamentales como la calefacción, el alumbrado y la red eléctrica, y al igual que con los otros servicios, las interrupciones en una red pueden tener un grave impacto y esto se debe a la mala calidad del debido a la falta de previsión en el diseño, el uso de componentes inapropiados, instalación incorrecta, mala administración o soporte inadecuado que puede poner en peligro la eficacia de la organización. Históricamente, el cableado dentro de las instalaciones comprende tanto la aplicación específica y multipropósito redes. La edición original de esta norma permitió una migración controlada de datos genéricos y la reducción en el uso de cableado específico de la aplicación. • • • • El crecimiento posterior de cableado genérico diseñado de acuerdo con ISO / IEC 11801 tiene: Contribución a la economía y el crecimiento de la Tecnología de Información y Comunicaciones (TIC). El apoyo al desarrollo de aplicaciones de alta velocidad de datos basado en un cableado definido modelo. Inició el desarrollo del cableado con un rendimiento alto superando las clases de potencia especificados en la norma ISO / IEC 11801:1995 e ISO / IEC 11801 Ed1.2: 2000. La Norma ISO / IEC 11801, edición 1.2 consiste en la mejora de la edición 1.0 (1995) y sus enmiendas 1 (1999) y 2 (1999). Esta segunda edición de la norma ISO / IEC 11801 ha sido desarrollada para reflejar este aumento de demandas y oportunidades. • - - - - Esta Norma Internacional proporciona: Usuarios con un sistema de cableado genérico independiente de la aplicación son capaces de soportar una amplia gama de aplicaciones. Usuarios con un sistema de cableado flexible, de manera que las modificaciones son a la vez fácil y económica. Profesionales de la construcción (por ejemplo, los arquitectos) con orientación permitirán el alojamiento de cableado antes de que se conocen los requisitos específicos, es decir, en la planificación inicial, ya sea para construcción o rehabilitación. La industria y aplicaciones de los organismos de normalización con un sistema de cableado que soporta productos actuales y proporciona una base para el desarrollo de futuros productos. - - - - Requisitos de la capa física para las aplicaciones enumeradas en la norma y se han analizado para determinar su compatibilidad con el cableado de las clases especificadas en esta norma. Estas aplicaciones requisitos, junto con estadísticas sobre la topología de los locales y el modelo se describen en la norma y se han utilizado para desarrollar los requisitos para las clases A a D y los sistemas de cableado de clase ópticos. Nuevas clases E y F se han desarrollado en previsión de futuras tecnologías de red. • Como resultado, cableado genérico define dentro de esta Norma Internacional específica una estructura de cableado de apoyo a una amplia variedad de aplicaciones. - Especifica las clases de canal y enlace A, B, C, D y E de reuniones con los requisitos de aplicaciones estandarizadas. Especifica canal y enlace de las clases E y F basado en componentes de mayor rendimiento a apoyar el desarrollo e implementación de aplicaciones futuras. Especifica las clases de canal óptico y el enlace OF-300, DE-500, y la Reunión de 2000-el requisitos de las aplicaciones estandarizadas y capacidades de componentes para facilitar la explotación de la ejecución de aplicaciones desarrolladas en el futuro. Invoca requisitos de los componentes y especifica las cableadas implementaciones que garanticen rendimiento de los vínculos permanentes y de - - • Esta Norma Internacional especifica un sistema de múltiples proveedores de cableado que puede Las normas internacionales de cableado componentes desarrollados por los comités de la IEC, por ejemplo cables de cobre y conectores, así como cables de fibra óptica y los conectores. Las normas para la instalación y el funcionamiento de tecnología de la información de cableado, así como para los la prueba de cableado instalado. Las aplicaciones desarrolladas por los comités técnicos de la IEC, por subcomités ISO / IEC JTC 1 y de las Comisiones de Estudio del UITT, por ejemplo, para redes LAN y RDSI. La planificación y las guías de instalación que tengan en cuenta las necesidades de aplicaciones específicas para la configuración y el uso de sistemas de cableado en las instalaciones del cliente (ISO / IEC 14709 series). 57 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 - canales que cumplen o superan los requisitos de cableado de las clases. Se dirige a, pero no limitado a, el medio ambiente de oficina en general. Esta Norma Internacional especifica un sistema de cableado genérico que se prevé que tenga una vida útil de más de 10 años. CONCLUSIONES Este articulo presenta las directrices generales para el desarrollo de un sistema gráfico de cableado estructurado en función a la Norma ISO 11801. Las metodologías de desarrollo son generales, aplicadas a cubrir requerimientos de la aplicabilidad de la Norma; sin embargo, para que estos requerimientos sean tomados en cuenta, no deben basarse en opiniones propias sino en estándares analizados previamente. 58 Es por eso que el presente trabajo está enfocado sobre la norma ISO 11801 y estándares EIA/TIA 570, ANSI/TIA/EIA-568-A, ANSI/TIA/EIA-569-AANSI/TIA/EIA606, ElA/TIA 607 que se usaron como directrices para el desarrollo del proyecto REFERENCIAS BIBLIOGRAFICAS • La Norma ISO / IEC 11801, edición 1.2 • LOZA, Sistema experto de apoyo al diseño de redes de área local LAN en base a la norma ISO 11801, TESIS de licenciatura en Ing. de Sistemas. • HARMON, KING. Sistemas Expertos Aplicaciones de la Inteligencia Artificial en la actividad empresarial. Ediciones Díaz de Santos S.A., Madrid 1988. • TANENBAUM. Redes de Computadoras, 4ª Edición, Pearson Prentice Hall, México 2003. Unidad Académica La Paz - Alto Irpavi REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Sistema basado en Tecnología Web Móvil y Datamart para la administración del Historial Clínico Caso: Clínica del Deporte CHRISTIAN GABRIEL CUEVAS CARRILLO Departamento de Ingeniería de Sistemas - Escuela Militar de Ingeniería La Paz - Bolivia e-mail: [email protected] RESUMEN En el presente artículo se presenta el desarrollo de un sistema para la clínica del Deporte, basado en tecnología web móvil para mejorar la disponibilidad y acceso a la información médica de los pacientes, y un Datamart para la administración de historias clínicas y elaboración de informes, de esta manera se evitarán pérdidas de historiales médicos así como su deterioro. La clínica del deporte actualmente realiza todo este proceso de forma manual, las búsquedas de estos archivos tienen a demorar varios minutos y a ralentizar la atención a los pacientes. ABSTRACT In the present article presents the development of a system for the medical clinic of the sport, based on mobile web technology to improve the availability and access to medical information for patients, and a Datamart for the administration of medical histories and the preparation of reports, this will prevent loss of medical records as well as their deterioration. The clinic of the sport currently does all this process manually, searches for these files have to take several minutes to slow down and the attention to the patients. INTRODUCCIÓN Actualmente los sistemas basados en tecnologías de la información representan una herramienta de apoyo muy importante en grandes áreas de las actividades humanas, proporcionando grandes ventajas sobre los métodos antiguos de almacenamiento y manejo de información. Así también las bases de datos, Datamart's y Data Warehouse son herramientas que permiten generar reportes e informes que permiten a las gerencias y directivos tomar decisiones, buscar patrones de datos de salud y realizar actividades en pro de los mismos. El presente trabajo muestra la forma de implementar un sistema para la administración del historial clínico, mismo que estará basado en tecnología web móvil para aumentar la disponibilidad de la información; y Datamart para la generación de informes para controlar la actividad de la Clínica Deporte. a 20 minutos, en algunos casos estos archivos son extraviados o se encuentran incompletos. Tomando como referencia el anterior problema se inicio el proceso de desarrollo del sistema web y datamart tomando como base los archivos usados en la clínica, además del proceso que lleva adquirir la ficha médica deportiva. DESARROLLO DEL SISTEMA PROPUESTO La metodología empleada para el diseño y desarrollo del sistema fue la metodología XP, esta metodología se caracteriza por enfocarse en la programación ágil, siendo ideal para el desarrollo de sistemas grandes que llevan tiempo. Para la elaboración del DataMart se aplicó la metodología "Rapid Warehousing Methodology" es una metodología ágil y se adecua a la XP, se tomaron los puntos más importantes de cada una de estas metodologías para un correcto desarrollo del sistema propuesto. PROBLEMÁTICA • Actualmente la Clínica del Deporte trabaja con formularios que corresponden a tres tipos de exámenes: examen físico, examen odontológico y el examen de laboratorio. Estos se llenan de forma manual y luego archivados en el file del paciente, cada año los pacientes deben realizarse este examen para obtener la ficha médica, para ello se debe buscar el historial clínico del anterior año; y este proceso de búsqueda demora aproximadamente de 15 Análisis de requerimientos Antes de iniciar con el desarrollo del sistema, se identificaron los requerimientos que se tienen para el sistema, estos fueron identificados en 3 categorías: - Requerimientos funcionales Requerimientos no funcionales Requerimientos del sistema 59 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Una vez definidos estos se procedió con la etapa de análisis. • • Una vez diseñada la base de datos se procedió a su construcción en el SGBD, en este caso MySQL para finalmente obtener las tablas: Análisis Dentro esta etapa es necesario identificar el funcionamiento los actores q tendrá el sistema, sus funciones, en esta etapa se realizaron las historias de los usuarios además de realizar el modelado del negocio. Diseño En la etapa de diseño se elaboran los diagramas formales para que el programador pueda identificar los roles de los usuarios, para ello se hizo uso de algunos diagramas UML, dentro del diseño se realizaron los diagramas de casos de uso. Nombre Tablas Consulta_medica Doctor Ficha_labo Ficha_medica Ficha_nedicina Ficha_odonto Paciente Recepcionista Nro. Columnas 6 10 19 5 32 27 9 7 Tabla 1. Base de datos transaccional Una vez creada la base de datos es posible crear el OLAP (On-line analytical processing). Las bases de datos OLAP se suelen alimentar de información procedente de los sistemas operacionales existentes, mediante un proceso de extracción, transformación y carga (ETL). En este caso nuestro OLAP se alimenta de la información procedente de la Base de datos Transaccional, para este procedimiento se hizo uso de la herramienta Pentaho. También se realizaron los diagramas de secuencias, diagrama de clases y de despliegue. Primero se realizo la conexión con la herramienta Pentaho, una vez importado la base de datos se eligen las tabas y se seleccionan los campos de datos que se desean copiar al OLAP, de esta manera se van armando los cubos de información y finalmente se crea la base de datos OLAP desde la cual se extrae información para la creación de informes. • • Imagen 1. Caso de uso de alto nivel Diseño y modelización del Datamart A partir del análisis de la clínica, se realizo la identificación de los datos que pasaran a formar parte de la base de datos transaccional para ello también se realizo el diagrama Entidad - Relación donde se muestra la realicen de las tablas. Implementación del sistema Una vez creado el Datamart, se procedió a la construcción de la interfaz de usuario, mismo que debe ser desarrollado para una plataforma web móvil, además de cumplir con los requisitos definidos por el usuario al inicio de la construcción del sistema. Las pantallas de los usuarios fueron construidos a partir de la herramienta Dreamweaver, además se hizo uso de código PHP y Java Script. Hecha la conexión con el datamart se hizo su implementación en un servidor local para que pueda ser finalmente revisado por el usuario y realizar las respectivas pruebas del sistema. Cada pantalla tiene una interfaz amigable e intuitiva, las principales pantallas para el registro de historias clínicas conservan el formato utilizado por la clínica del deporte, de esta manera no confundir al usuario con su trabajo. Imagen 2. Diagrama entidad-relacion 60 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 • Pruebas del sistema En esta etapa se realizaron las respectivas pruebas al sistema, con el fin de identificar errores o requerimientos no cumplidos. • Pruebas de validación Se realizaron las pruebas de validación para verificar que el sistema se ajusta a los requerimientos de usuario final ya definidos. • Pruebas de validación de requerimientos funcionales Se desea verificar el cumplimiento satisfactorio de los requerimientos funcionales. Como se mostró en la etapa de diseño y elaboración del DataMart se puede verificar todo el proceso de construcción del DataMart para la clínica del deporte así como el proceso ETL que permite presentar datos que son de importancia para la clínica del deporte. Se realizó la consulta al sistema para poder visualizar el historial clínico de un paciente en una fecha cualquiera, el sistema mostro primero la pantalla del examen físico general. Los datos que alimentan todo el DataMart son consecuencia de un proceso de estandarización de información proveniente de los formularios antiguamente usados en la clínica del deporte. • Pruebas de seguridad Se desea verificar la existencia de un nivel de seguridad apropiado en el sistema, lo cual incluye que solo usuarios autorizados puedan acceder al mismo y que estos estén restringidos solo a funciones específicas. CONCLUSIONES Imagen 3. Historial clinico, examen fisico A partir de esta pantalla es posible visualizar los otros dos exámenes que corresponden al examen odontológico y el examen de laboratorio. Además en la interfaz del usuario "Director general" es posible visualizar algunos informes introduciendo las fechas de las cuales se desea consultar. El presente artículo presenta las directrices del desarrollo de un sistema web móvil y datamart como herramienta para ayudar en la organización registro y búsqueda de las historias clínicas para la clínica del deporte. Los procedimientos por los cuales pasa el desarrollo son metodologías generales aplicadas al desarrollo de sistemas complejos y la correcta elaboración del datamart REFERENCIAS BIBLIOGRAFICAS • Miguel Rodríguez Sanz “Análisis Y Diseño De Un Datamart Para El Seguimiento Académico De Alumnos En Unentorno Universitario”, 22 Julio, 2010 • William H. Inmon: "Building the Data Warehouse" Technical Publishing Group, 1992 • SAS Institute, Inc. SAS Rapid Warehousing Methodology, SAS Institute White Paper, 2001 • José Joskowicz, "Reglas y Prácticas en eXtreme Programming", 2008 Imagen 4. Informe de consultas medicas Se puede apreciar que el sistema permite visualizar los datos y ordenados según la especialidad y deporte. 61 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Sistema experto para el diagnóstico de problemas de aprendizaje en niños de 6 a 8 años en el área de matemática Caso: U.E.P. Boliviano Holandes de la Ciudad de El Alto CLAUDIA INES GUTIERREZ VILLEGAS Departamento de Ingeniería de Sistemas - Escuela Militar de Ingeniería La Paz - Bolivia e-mail: [email protected] RESUMEN En el presente artículo se expone el desarrollo de un sistema experto basado en lógica difusa para diagnosticar problemas de aprendizaje en el área de matemática en niños de 6 a 8 años de la U.E.P. Boliviano Holandés de la ciudad de El Alto. ABSTRACT In this paper the development of an expert system based on fuzzy logic to diagnose learning disabilities in the area of mathematics in children 6-8 years of UEP exposed Dutch Bolivian city of El Alto. INTRODUCCIÓN JUSTIFICACION Desde el punto de vista educativo, es importante conocer cuáles son las habilidades matemáticas básicas que los niños deben aprender para poder así determinar donde se sitúan las dificultades y planificar su enseñanza y desde el punto de vista psicológico. Cuanto más temprana sea la detección, se traducirá en mayores posibilidades de acción. El desarrollo de un Sistema Experto para el diagnóstico de problemas de aprendizaje se justifica de acuerdo a los criterios siguientes: • Entre las dificultades que se presentan con frecuencia en matemática se tiene la discalculia o dificultades en el aprendizaje de las matemáticas es una dificultad de aprendizaje específica en matemática. La discalculia puede ser causada por un déficit de percepción visual o problemas en cuanto a la orientación secuencial. El término discalculia se refiere específicamente a la incapacidad de realizar operaciones de matemática o aritméticas. Es una discapacidad relativamente poco conocida. De hecho, se considera una variación de la dislexia. Quien padece discalculia por lo general tiene un cociente intelectual normal o superior, pero manifiesta problemas con la matemática, señas o direcciones, etc. De forma técnica, ya que proporciona una herramienta que apoya a un diagnóstico efectivo dentro de los problemas que puede presentar un niño en el aprendizaje en Matemática. El manejo de Sistemas Expertos tendrá la capacidad de diagnosticar la discalculia, utilizando como herramienta la computadora y las reglas que permiten representar el conocimiento humano de manera formal y precisa. • Socialmente, en el sentido que es de gran importancia para los padres de familia contar con un instrumento que apoye con un diagnóstico acertado de la discalculia. Ya que la discalculia escolar termina frustrando no solo al estudiante, sino también al maestro si no está pedagógicamente apto para tratar con el problema. PROBLEMÁTICA • Económicamente por que ayudará al Psicopedagogo y al estudiante a recibir un diagnóstico oportuno lo que a su vez influirá en una reducción de costos para los padres ya que el diagnóstico a destiempo, es decir, en la adolescencia es más costoso y difícil de llevar a cabo. Los procedimientos empleados por el profesor y/o psicólogo no permiten detectar oportunamente las dificultades de aprendizaje de matemáticas en estudiantes de 6 a 8 años lo cual incide significativamente en el rendimiento escolar, la vida diaria, desarrollo cognitivo y formación académica de los mismos. 62 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 DESARROLLO DEL SISTEMA EXPERTO Las etapas para el diseño e implementación del Sistema Experto (SE) son: Planteamiento del Problema, Encontrar expertos humanos, Diseño del SE, Elegir herramienta de desarrollo, Construir el Prototipo que al conjuncionarse con la metodología ICONIX se identifican 4 etapas: Análisis del Sistema, Diseño del Sistema, Construcción del Sistema, Validación y Prueba del prototipo. Análisis del Sistema Es aquí donde se realizó el análisis del Sistema Experto y de igual manera del Producto Software. Pero antes se pretende definir la problemática que se busca resolver además de su análisis de la situación actual, Para luego obtener y conceptualizar el conocimiento con el fin de obtener los datos necesarios para la construcción del SE. entonces existen posibles deficiencias de discalculia. • Elección de Variables Lingüísticas Difusas y Conjuntos Difusos De acuerdo con la opinión de los expertos se tomaron en cuenta 3 conjuntos difusos para las variables de entrada al primero de estos se le asignó la etiqueta lingüística LEVE, al segundo MODERADO, y al tercero SEVERO, ya que las variables de entrada (Antecedentes, síntomas, etc.) que se tomaran en cuenta pueden presentarse en estas tres formas. • Conjunto difuso LEVE Se estableció como función de pertenencia de la función L, que tiene que tiene a forma que se muestra en la FIGURA: • Conjunto difuso MODERADO Se seleccionó la función de pertenencia trapezoidal, como se muestra en la FIGURA: • Conjunto difuso SEVERO Se determinó como función de pertenencia a la función Gamma cuya forma se muestra en la FIGURA: Diseño del Sistema El desarrollo del Sistema Experto comprende al diseño y construcción del mismo, para esta fase se realizaron los siguientes pasos: • Diseño del Sistema Experto difuso que comprende la formalización del conocimiento, elección de variables lingüísticas difusas y conjuntos difusos, construcción de las reglas de producción. Formalización del Conocimiento La formalización del conocimiento es el diseño de las estructuras para organizar el conocimiento: Una forma correcta para representar el conocimiento es utilizando reglas y premisas lógicas, análogamente al análisis del Sistema Experto, se propone una relación: Síntomas-Diagnóstico: IF <Hechos. Premisas> THEN <decisión - conclusión> Donde: IF Premisas Hechos observados en la realización del test, captura de síntomas. <Datos provistos a través de cada pregunta> THEN CONCLUSIONES • Posibles problemas de Discalculia En cada pregunta se debe tener en cuenta la formalización siguiente: IF X THEN Y Si la pregunta X se respondió con una notoria deficiencia demostrando síntomas específicos, 63 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Variables de Entrada Se identifican 10 variables de entrada para cada una de ellas se definen las funciones de pertenencia, la representación gráfica de cada variable de entrada es de la siguiente manera: La Función de Pertenecía de los conjuntos difuso se expresa: La Función de Pertenecía de los conjuntos difusos se expresa Variables de Salida El diagnóstico es la variable de salida del proyecto y se toman en cuenta 6 conjuntos difusos con funciones de pertenencia TRIANGULAR, éstos fueron construidos como variables lingüísticas correspondientes: 64 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Construcción de las reglas de producción Para la construcción de reglas se utilizo la herramienta FIS de MatLab • • Variable Dependiente: Diagnóstico oportuno y confiable de dificultades en el aprendizaje en el área de matemática. Variable Moderante: Niños de 6 a 8 años de la U.E.P. Boliviano Holandés de la ciudad de El Alto. Como se puede observar, la hipótesis planteada pretende demostrar que el sistema experto brinda información confiable sobre el diagnóstico del estudiante; por lo tanto la confiabilidad del sistema experto será comprobada con técnicas estadísticas como se demuestra a continuación. Para la construcción de la Base de Conocimiento se establecen las reglas de producción La confiabilidad del sistema experto es evaluada de acuerdo a las afirmaciones de diagnóstico que determina el mismo y la relación con las afirmaciones de la psicopedagoga, debido a que debe comprobarse la relación coherente entre ambos diagnósticos. Para comprobar la confiabilidad del sistema experto se utiliza el coeficiente de concordancia de Cohen, es decir el Índice Kappa, debido a que esta prueba estadística relaciona la concordancia de resultados entre dos observadores en relación a “n” categorías de los posibles resultados. De acuerdo a la hipótesis planteada, la hipótesis nula y alterna son las siguientes: Prueba de la Hipótesis El cumplimiento del objetivo principal del proyecto debe ser comprobado a través de la prueba de hipótesis planteada, que para el presente trabajo de grado es el siguiente: • Hipótesis Nula (H0): No existe concordancia entre los resultados del sistema experto difuso y los resultados de la Psicopedagoga. • Hipótesis Alterna (H1): Existe concordancia entre los resultados del sistema experto difuso y los resultados de la Psicopedagoga. Para demostrar la Hipótesis Alterna (H1) se debe comprobar que el nivel de concordancia entre los resultados del sistema experto y la psicopedagoga sea de un grado aceptable, en correspondencia de la siguiente tabla de valoración del índice Kappa: La ecuación del índice de Kappa (k) es el siguiente: “El Sistema Experto propuesto permitirá el diagnóstico oportuno y confiable de las dificultades en el aprendizaje de la matemática en niños de 6 a 8 años, estudiantes de la U.E.P. Boliviano Holandés de la ciudad de El Alto” De acuerdo a la hipótesis planteada, se pueden identificar las siguientes variables: • Variable Independiente: El Sistema Experto Propuesto. Dónde: P0= Proporción de concordancia observada Pe= Proporción de concordancia esperada por puro azar 65 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 La ecuación para calcular P0 es el siguiente: El valor en tablas de distribución normal estándar (z) a un nivel de confianza del 95% y significancia de 0.05 el valor de Z para ±/2 es de 1.96 por lo tanto el intervalo de confianza es: Dónde: aii= Frecuencia cruzada para cada diagnostico N= Muestra de diagnósticos realizados La ecuación para calcular Pe es la siguiente: Para el inicio del cálculo del índice Kappa, se tiene el cuadro cruzado de resultados del análisis del diagnóstico del sistema experto vs el médico especialista, el cual podemos ver en la TABLA: En relación a los datos de la TABLA los valores del índice Kappa son los siguientes: Por lo tanto el intervalo de confianza del índice Kappa al 95% es k(0.767, 0.915), de acuerdo a la Tabla 4.46, el índice Kappa es casi perfecta debido a que se encuentra en el rango de 0.80 - 1.00 logrando aceptar de manera estadística la hipótesis alterna (H1) planteada con anterioridad por lo cual se determina que el diagnostico determinado por el sistema experto tiene un grado de significativo de confiabilidad que puede considerar la psicopedagoga al momento de la utilización del sistema experto en diagnóstico de la discalculia. Para demostrar la oportunidad planteada en la hipótesis del sistema experto se demuestra la oportunidad ya que el sistema tarda en dar un diagnostico una hora como máximo, a diferencia cuando se realiza un diagnostico en base a la forma manual que realiza la psicopedagoga el tiempo utilizado es de 2 días aproximadamente. REFERENCIAS BIBLIOGRAFICAS • • Finalmente el índice Kappa (k) para la prueba de hipótesis es el siguiente: • • Se determina que el valor de la concordancia entre los resultados de diagnósticos tiene un grado de 84.1%, ahora la variabilidad de este valor en su intervalo de confianza se determinara con un nivel de significancia (±) de 0.05 en la siguiente ecuación: • • Dónde: = Índice Kappa estimado (k) Z= Abscisa de la curva normal tipificada ±= Nivel de significancia 66 • Working memory and children's mental addition John W. Adams y Graham J. Hitch 1997 Persistent arithmetic, reading or arithmetic and reading disability. Annals of Dyslexia, Badian, N. (1999). Pág. 49, 45-69 VII Congresso Iberoamericano de Informática Educativa 2007 Lcdo. Alex Espinoza Cárdenas Ing. Viera Elistratova de Barriga Escuela Superior Politécnica del Litoral - ESPOL Forns I Santacana, M. “Evaluación psicológica infantil”. Ed.Barcanova S.A. 2003. GÁMEZ José; PUERTA José. Sistemas Expertos Probabilísticos 1ra. Edición. Ediciones de la Universidad de Castilla - La Mancha, 1998, España. La mente no escolarizada cómo piensan los niños y cómo deberían enseñar las escuelas 2000 Howard Gardner. Discalculia escolar: Dificultades en el aprendizaje de las matemáticas. Luis Héctor Giordano Ediciones I.A.R, 2000 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Algoritmo de Encriptación basado en escalas musicales ISRAEL QUISBERT ANTI Departamento de Ingeniería de Sistemas - Escuela Militar de Ingeniería La Paz - Bolivia e-mail: [email protected] RESUMEN En éste artículo se presenta el desarrollo de un algoritmo de encriptación basado en escalas musicales, de tal manera que pueda asegurarse la seguridad de este en términos de confidencialidad e integridad donde vaya a aplicarse. ABSTRACT This article presents the development of an encryption algorithm based on musical scales, in such a way as to ensure the safety of this in terms of confidentiality and integrity where is going to be applied. INTRODUCCIÓN El presente trabajo tiene por motivación diseñar un algoritmo de encriptación basado en escalas musicales, de tal manera que pueda asegurarse los términos de integridad de determinados archivos debido a que los hurtos del contenido intelectual musical son bastante común en estos tiempos. Impulsando esta investigación se tienen ciertas referencias que apuntan a que existe una gran relación entre la música y las matemáticas por las cuales será posible realizar el algoritmo de encriptación de manera satisfactoria. PROBLEMÁTICA El envío y recepción actual de mensajes por el Correo Electrónico Institucional dentro del Ejército de Bolivia presenta vulnerabilidades de seguridad tanto en confidencialidad e integridad en la transrecepción de mensajes privados ocasionando que existan ataques de seguridad sobre el sistema gestor de correo actual. Tomando como referencia el anterior problema se inicio el proceso de desarrollo del algoritmo tomando como base las matemáticas discretas; y más específicamente la aritmética modular. • Económicamente por el ahorro de tiempo y optimización de procesos actuales que brinda la solución relativo al problema. DESARROLLO DEL ALGORITMO La metodología la cual dirige el proyecto es la de desarrollo de algoritmos, debido a que el proyecto se enfoca a la realizacion de un algoritmo de encriptación, sin embargo cada uno de los pasos de esta metodología necesita o trabaja en conjunción con otras metodologías, las cuales en este caso son el Análisis de Riesgos y desarrollo de Software. Por lo tanto, las 4 fases desarrolladas de la solución empiezan con la comprensión del problema para finalizar con la Evaluación de la solución. Comprensión del Problema El enfoque del cual se partió para el avance responde al sistémico, debido a que el modo de abordar los elementos del presente trabajo no puede ser aislado, sino que tienen que verse como parte de un todo. No es la suma de elementos, sino un conjunto de éstos que se encuentran en interacción, de forma integral, que produce nuevas cualidades con características diferentes, cuyo resultado es superior al de los componentes que lo forman y provocan un salto de calidad. JUSTIFICACION • Si bien existen muchos modelos de encriptación actuales (RSA, AES, etc.) las razones para elegir un algoritmo nuevo se justifican de acuerdo a los criterios siguientes: • Tecnológicamente, porque una herramienta nueva de cifrado brinda un nivel de seguridad más adecuado a la institución debido a que inicialmente solo el encargado de la institución conoce el funcionamiento del algoritmo. Primera Fase: La primera fase del proyecto es la implementación de la Metodología de Diseño de Algoritmos Paralelos, la cual sigue los pasos de: Analizar los Algoritmos Actuales que para el presente proyecto llegaría a ser Análisis de Algoritmos de Encriptación Actuales, Descomposición en Tareas que para el presente proyecto llegaría a ser la Descomposición de los Procesos del Algoritmo, para finalmente llegar a la conjunción de los procesos del algoritmo. 67 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 • entrar a la tercera fase que es el desarrollo del módulo a través de la metodología XP. Tercera Fase: La última fase comprende el desarrollo del módulo ya mencionado, pasando por los pasos de la metodología XP: Planificación, Diseño del Módulo, la Codificación con el Algoritmo y finalmente las pruebas; el objetivo de esta fase es coadyuvar en los últimos productos de la metodología de desarrollo de algoritmos para completar el presente trabajo. Planteamiento de la Lógica Para esta fase se realizaron los siguientes pasos:’ • • Se eligió al Diagrama de Flujo como representación del algoritmo en su totalidad. Para la representación matemática se tomaron en cuenta la aritmética Proceso de Generación de Claves En la primera parte del presente algoritmo se observa la declaración de variables las cuales tienen el siguiente significado: - nd = número a descomponer f[100] = vector donde se almacenaran los números primos de nd Una vez declaradas las variables se procede a la descomposición del 'nd', pasada la descomposición se obtiene el ultimo numero primo generado y se lo almacena en 'p' y al penúltimo numero primo se lo almacena en 'q' para realizar una operación y de esa forma obtener 'z', una vez obtenida 'z' se calcula el valor de n, se halla la prima relativa de 'z' almacenándola en 'k', y realizando la última operación se obtienen la llave publica compuesta por 'k' y 'n', y la llave privada compuesta por 'j' y 'n' Proceso de Cifrado de Información • 68 Segunda Fase: La segunda fase del proyecto comprende la realización del algoritmo como tal la cual está dirigida por la metodología de desarrollo de algoritmos, comprendiendo 4 pasos: el primero recolecta los procesos obtenidos en la primera fase para posteriormente realizar la abstracción del algoritmo en base a la matemática relacionada y finalmente pasando a la codificación y evaluación del algoritmo; para estos dos últimos se necesita REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Al principio del Algoritmo de Encriptación se tiene la declaración de variables, donde: K es el número generado por las escalas musicales N es la constante de afinación musical T es el texto a ser encriptado E es el resultado de la encriptación • • • Fase 1 - Planeación: Donde se obtuvieron las especificaciones generales del Módulo: Historias de usuario y el contexto de desarrollo. Fase 2 - Diseño: Desarrollo de los prototipos de las interfaces usando como referencia a las historias de usuario. Fase 3 - Codificación: Aquí se unieron las metodologías para generar el código en C# del algoritmo e introducirlo en las interfaces. Evaluación y ejecución de la Solución Para comprobar que el algoritmo realiza las tareas para las que ha sido diseñado y produce el resultado correcto y esperado se realizaron pruebas con archivos de diferente índole generados por herramientas que se encargan de evaluar la consistencia del algoritmo, los cuales fueron positivos para los resultados esperados. CONCLUSIONES Este articulo presenta las directrices generales para el desarrollo de un algoritmo de encriptación basado en un modelo asimétrico que sea capaz de responder a las necesidades de la institución donde se aplica. Proceso de descifrado de Información Al principio del Algoritmo se tiene la declaración de variables donde: Los procedimientos por los cuales pasa el desarrollo son metodologías generales aplicadas a cubrir requerimientos de Seguridad de la Información. REFERENCIAS BIBLIOGRAFICAS J es el número relativa a K generado por las escalas musicales N es la constante de afinación musical E es el texto a ser desencriptado D es el resultado de la desencriptación Codificación del Problema En esta etapa se procedió al paso de la lógica representada en el Diagrama de Flujo a un lenguaje máquina, en este caso a C#. Esta etapa trabaja con la metodología de desarrollo de Software XP, dividido en las siguientes fases: • • • • • Gallardo Mario, “Modelos Criptográficos”, Maestría en TICs, Universidad Politécnica de Pachuca, 2000. Pheby J.,” Methodology and Economics”, Ed. MacMillan Press LTD, Londres., 1988. Andrews, George, “Number Theory”, Dover, 1994 Massachusetts Institute of Technology “La Criptografía: Escritura Oculta”, Articulo del 24 de Octubre del 2010. Galende, Juan Carlos, “Historia de la escritura Cifrada”, Ed. Complutense, 1ª Edición, Madrid, España, 1995. 69 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Sistema experto basado en lógica difusa para la detección temprana de Enfermedades Hepaticas SAÚL MEYER TERRAZAS ROLLANO Departamento de Ingeniería de Sistemas - Escuela Militar de Ingeniería La Paz - Bolivia e-mail: [email protected] RESUMEN Este artículo presenta el desarrollo de un Sistema Experto para la detección de enfermedades hepáticas a través de la utilización de la lógica difusa, de tal manera que este pueda ayudar en la toma de decisiones a los médicos especialistas de la institución donde vaya a aplicarse, ya que la detección y el diagnóstico de este tipo de enfermedades debe ser confiable y oportuno para que el paciente de la institución de salud no sufra complicaciones. ABSTRACT This article presents the development of an expert system for the detection of liver disease through the use of fuzzy logic, so it can help in the decision-making to medical specialists of the institution where you go to apply, as the detection and diagnosis of diseases of this kind must be reliable and timely for the patient in the institution of health does not suffer complications. INTRODUCCIÓN rápido y eficiente, que permitirá optimizar la detección temprana de enfermedades hepáticas. Los Sistemas Expertos son una técnica de la inteligencia artificial que tiene aplicación en las diversas áreas de la ciencia y tecnología. Estos sistemas se encargan de capturar la experiencia y conocimiento de una persona experta en una respectiva área del saber, donde la persona no experta llamado usuario pueda hacer uso de este sistema aprovechando así la información contenida. El sistema propuesto aplicará en el diseño, modelado y construcción de herramientas teóricas y científicas, como ser el estudio y la investigación mediante el método científico y el desarrollo mediantes teorías de sistemas expertos. La Lógica Difusa se aplica a los procesos en los que existe incertidumbre, esta lógica es aplicada en la toma de valores que van desde la existencia de veracidad absoluta hasta la existencia de la falsedad total. Los sistemas basados en lógica difusa a diferencia de los basados en lógica clásica, tienen capacidad de reproducir de forma aceptable modos usuales de razonamiento, aplicando sus características más relevantes de la lógica difusa como ser su flexibilidad y tolerancia de impresión. Tecnológicamente el sistema propuesto aportará una herramienta de consulta e información, y podrá ser utilizada por los médicos especialistas para reforzar su conocimiento, para así obtener mejores resultados y con respaldo tecnológico. La herramienta también podrá servir de apoyo a la toma de decisiones a especialistas con poca experiencia de las enfermedades hepáticas dentro el establecimiento. Por otra parte, traerá beneficios a los pacientes, debido a que el diagnostico será rápido, preciso y con menor probabilidad de inicializar un tratamiento deficiente. El trabajo de grado tuvo como objetivo desarrollar un Sistema Experto basado en lógica difusa que contribuya a la toma de decisiones para la detección temprana y confiable de enfermedades hepáticas del paciente de COSSMIL. PROBLEMÁTICA La información incompleta que emplea el médico especialista da lugar a la detección no oportuna de enfermedades hepáticas del paciente de COSSMIL. JUSTIFICACION El presente trabajo, servirá como instrumento alternativo, 70 Económicamente, porque el sistema experto ayudará al especialista a reducir el tiempo de atención al paciente realizando un diagnóstico confiable, evitando en algunos casos la realización de exámenes complementarios innecesarios; influyendo en una reducción de costos en la atención al paciente. DISEÑO DEL SISTEMA EXPERTO La metodología empleada es la de desarrollo de Buchanan y la de diseño para Sistemas expertos basados en lógica difusa, sin embargo cada uno de los pasos trabaja en conjunción con la metodología Iconix. Por lo tanto, las REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 fases desarrolladas de la solución empiezan con la Identificación para finalizar con la Validación. que cada característica del paciente se le asocia un valor mínimo no pudiendo representar con 0 % al conjunto difuso. Identificación Aquí se hizo el análisis de la situación actual para comprender el desenvolvimiento del proceso actual, además que se obtuvo información de los diagnósticos realizados por el especialista en hepatologías del hígado. Conceptualización Para esta fase se siguieron los siguientes pasos: • • Se realizó la elección de las variables de relevancia obtenidas de las fuentes de conocimiento y mostrando la formalización de algunas de ellas Se realizó la conversión de variables a variables lingüísticas, expresando de manera formal la asignación de valores de una variable a palabras tomadas del lenguaje natural. Se puede definir la variable lingüística como: - Para el conjunto difuso Normal/Probable se estableció la función de pertenencia Trapezoidal puesto que como se indicó anteriormente presentar valores mínimos y máximos. - Para el conjunto difuso Alto/Muy Probable se estableció la función L ya que cada característica del paciente si se presenta no podría pertenecer con 0 % al conjunto difuso Alto/Muy probable y este se incrementará en cuanto más se aleje. • Una vez transformadas las variables a variables lingüísticas y asignado su valor de pertenecía, se representa el conocimiento adquirido en una red semántica para luego comenzar con la construcción de la base de conocimientos estableciendo las reglas e producción con la sintaxis de Mandami: Variable Lingüística =(A, T(A), U, G, M) Donde: A Nombre de variable T(A) Conjuntos de términos que nombran los valores x que pueden tomar A, valores que son conjuntos difusos. U Universo del discurso de la variable x G Sintáctica para la generación de los nombres de los valores x M Regla semántica para asociar un significado a cada valor de los componentes Por otra parte, cuando se trabaja con conjuntos difusos es necesario constituir funciones de pertenencia de los elementos a los diferentes conjuntos, lo cual permite determinar, a partir del valor de un elemento su grado de pertenencia al conjunto, siendo este un valor real normalizado entre 0 (no pertenece en absoluto) y 1 (pertenece al 100%), este se denota como µ(x), siendo x el valor del elemento. Para el proyecto se tomaron en cuenta 3 conjuntos difusos con sus respectivas etiquetas lingüísticas como ser el primero Bajo, el segundo Normal y el tercero Alto para los exámenes complementarios se eligieron a partir del conocimiento del experto, además de las variables de entrada que se representar bajo la función de pertenencia trapezoidal puesto que cada característica del paciente puede presentar valores mínimos y máximos. También se tomaron las etiquetas lingüísticas Poco probable, Probable y Muy probable para los antecedentes presentados por el paciente. - Para el conjunto difuso Bajo/Poco Probable se estableció la función de pertenencia Gamma ya R. IF [Premisa1][AND][OR][Premisa2]…..then Conclusion Formalización Aquí se realizó la determinación de las interfaces de Fuzzificacion y Defuzzificacion, donde la interfaz de Fuzzificacion recibe como entrada los valores numéricos 71 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 y lingüísticos procedentes del módulo de recepción de datos. La salida del módulo son las variables fuzzyficadas, en un intervalo que engloba un número reducido de valores lingüísticos por ejemplo. {Bajo, Normal, Alto}, la interfaz de Defuzzificacion traduce el resultado lingüístico en valor real que represente el valor actual corriente de la variable de control. Existen varios métodos de defuzzificacion, el método empleado en el presente proyecto es el del Centroide, en el cual este método combina cada una de las reglas inferidas. Ya que el sistema debe devolver una salida precisa, la interfaz de defuzzificación debe agregar la información aportada por cada uno de los conjuntos individuales y transformarla en un valor preciso. Implementación En este punto se realizó el diseño del software a través del modelado de casos de uso, prototipos de interfaz gráfica, como el modelamiento del comportamiento del sistema. Todo esto basado en la Metodología de desarrollo Iconix. Una vez que se terminó el diseño es necesario comprobar que realiza las tareas para las que ha sido diseñado y produce el resultado correcto y esperado. CONCLUSIONES Este artículo presenta las directrices generales para el desarrollo de un Sistema experto basado en lógica difusa para la detección temprana de enfermedades hepáticas que sea un apoyo a la toma de decisiones por parte del médico especialista. Los procedimientos por los cuales pasa el desarrollo son metodologías aplicadas a cubrir requerimientos del médico especialista. Así mismo, para el desarrollo de futuras herramientas para el apoyo en la toma de decisión, se pueden tomar como referencia éste, ya que las directrices vertidas en el desarrollo de este sistema experto pueden ser aplicadas a otros tipos de enfermedad no considerados por el sistema. REFERENCIAS BIBLIOGRAFICAS • • • • Para comprobar el funcionamiento se realizaron pruebas con historiales médicos para determinar la confiabilidad del diagnóstico brindado por el sistema experto en relación con el brindado por médico especialista, las cuales terminaron siendo positivos para los resultados esperados. 72 Menchen A.J. La lógica y los conjuntos borrosos. Aplicaciones en Inteligencia Artificial, control de procesos e ingeniería, 2001. Pedrycz W. Fuzzy equalization in the construction of fuzzy sets and Systems, 2001. MARK H. BEERS, M.D., y ROBERT BERKOW, M.D., D., Manual Merck de diagnóstico y tratamiento, Harcourt edición Española, 1999 Pressman, Roger, Ingeniería de Software un enfoque práctico, Sexta Edición, España, Editorial McGraw-Hill, 2008 Unidad Académica Riberalta REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Auditoría de sistemas de tecnologías de la información basados en el estándar internacional cobit Caso: Dirección Nacional de Informática sistema de calificaciones JHONNY GABRIEL LOZA QUENTA Departamento de Ingeniería de Sistemas - Escuela Militar de Ingeniería La Paz-Bolivia [email protected] RESUMEN El presente artículo expone el desarrollo de una auditoria de sistemas basada en el estándar internacional COBIT, la cual se encarga de verificar las amenazas y vulnerabilidades que existen en el sistema de calificaciones de la Escuela Militar de Ingeniería y dar una solución a las mismas mediante un plan de acción. El objetivo principal es Realizar una auditoría de sistemas basada en el estándar internacional COBIT para sugerir la implantación de gestión de tecnologías de la información que reduzcan las vulnerabilidades identificadas en el sistema de calificaciones de la Dirección Nacional de Informática. ABSTRACT This paper presents the development of a systems audit based on international standard COBIT, which is responsible for verifying the threats and vulnerabilities that exist in the grading system of the Military Engineering School and provide a solution to them by a action plan. The main objective is to Conduct an audit of systems based on international standard COBIT to suggest the implementation of management information technologies that reduce the vulnerabilities identified in the grading system of the National Informatics Directorate. INTRODUCCIÓN La información es el activo más importante dentro de cualquier empresa o institución, por lo cual la pérdida, robo, intromisión de la misma, resultaría un perjuicio y también un alto costo por la amenaza de que dicha información sea revelada. Para proteger tal información se hace uso de la seguridad de sistemas, la cual toma en cuenta tres aspectos fundamentales: la Integridad de la información, que nos garantiza que la información es verídica; la Confidencialidad de la información, que nos garantiza que solo personas autorizadas tengan acceso a la información y la Disponibilidad de la Información, que se refiere a que la información debe estar disponible en el momento en que sea requerida. De la misma forma la Auditoría constituye una herramienta de control y supervisión que contribuye a la creación de una cultura de la disciplina de la institución y permite descubrir fallas en las estructuras o vulnerabilidades existentes. COBIT es precisamente un modelo para auditar la gestión y control de los sistemas de tecnologías de la información, orientado a todos los sectores de una institución, es decir administradores de Tecnologías de la Información, usuarios y los auditores involucrados en el proceso. La estructura del modelo COBIT propone un marco de acción donde se evalúan los criterios de información, como la seguridad y calidad, se auditan los recursos que comprenden la tecnología de información, por ejemplo el recurso humano, instalaciones, sistemas entre otros y finalmente se realiza una evaluación sobre los procesos involucrados en la institución. La misión de COBIT es "investigar, desarrollar, publicar y promocionar un conjunto de objetivos de control generalmente aceptados para las tecnologías de la información que sean autorizados (dados por alguien con autoridad), actualizados, e internacionales para el uso del día a día de los gestores de negocios (también directivos) y auditores". Gestores, auditores, y usuarios se benefician del desarrollo de COBIT porque les ayuda a entender sus Sistemas de Información (o tecnologías de la información) y decidir el nivel de seguridad y control que es necesario para proteger los activos de sus compañías mediante el desarrollo de un modelo de administración de las tecnologías de la información. 73 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 PROBLEMÁTICA La carencia de auditoria de sistemas y objetivos de control documentados en la Dirección Nacional de Informática en el Sistema Académico de Calificaciones provoca vulnerabilidades en el proceso de gestión de tecnologías de la información. • • • Se evidencia la falta de procedimientos de control normalizados bajo gestión de tecnologías de información en el control del sistema académico de calificaciones. Los procesos de tecnologías de la información de la Dirección Nacional de Informática son insuficientes en métodos y procedimientos especializados para el sistema académico de calificaciones. El sistema académico de calificaciones no posee registros de auditoría actualmente dada la discontinuidad y la falta de aplicación de herramientas que apoyan el o los criterios del auditor y usuarios. AUDITORIA DE SISTEMAS La auditoría de sistemas es el conjunto de técnicas, actividades y procedimientos, destinados a analizar, evaluar, verificar y recomendar en asuntos relativos a la planificación, control, eficacia, seguridad y adecuación de los sistemas de información de la empresa. Figura 1. Dominios de COBIT Para satisfacer los objetivos del negocio, la información necesita adaptarse a ciertos criterios de control, los cuales son referidos en COBIT como requerimientos de información del negocio. Con base en los requerimientos más amplios de calidad, fiduciarios y de seguridad, se definieron los siguientes siete principios: • • • • COBIT 4.1 COBIT, es un marco de Gobierno de las Tecnologías de la información que permite a la dirección de una organización conectar los requerimientos de negocio y de control con los aspectos técnicos, controlando los riesgos y optimizando los recursos. Está basado en procesos y se enfoca fuertemente en el control y menos en la ejecución, es decir, indica qué se debe conseguir sin focalizarse en el cómo. La primera impresión es que ISACA ha orientado definitivamente COBIT hacia el Gobierno de las TI. La misión de COBIT es: “Investigar, desarrollar, hacer público y promover un marco de control de TI autorizado, actualizado, aceptado internacionalmente para la adopción por parte de las empresas y el uso diario por parte de gerentes de negocio, profesionales de TI y profesionales de aseguramiento””. COBIT define las actividades de TI en un modelo de 34 procesos genéricos agrupados en 4 dominios como se muestra en la Figura. 74 • • • La efectividad, tiene que ver con que la información sea relevante y pertinente a los procesos del negocio, y se proporcione de una manera oportuna, correcta, consistente y utilizable. La eficiencia, consiste en que la información sea generada con el óptimo (Más productivo y económico) uso de los recursos. La confidencialidad, se refiere a la protección de información sensitiva contra revelación no autorizada. La integridad, está relacionada con la precisión y completitud de la información, así como con su validez de acuerdo a los valores y expectativas del negocio. La disponibilidad, se refiere a que la información esté disponible cuando sea requerida por los procesos del negocio en cualquier momento. También concierne a la protección de los recursos y las capacidades necesarias asociadas. El cumplimiento, tiene que ver con acatar aquellas leyes, reglamentos y acuerdos contractuales a los cuales está sujeto el proceso de negocios, es decir, criterios de negocios impuestos externamente, así como políticas internas. La confiabilidad, se refiere a proporcionar la información apropiada para que la gerencia administre la entidad y ejerza sus responsabilidades fiduciarias y de gobierno. ANALISIS DE RIESGOS El análisis de riesgos es una herramienta que permite identificar, clasificar y valorar los eventos que pueden amenazar la consecución de los objetivos de la Organización y establecer las medidas oportunas para reducir el impacto esperable hasta un nivel tolerable. REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Planear y Organizar Adquirir e Implementar Entregar y Dar Soporte Monitorear y Evaluar 20% NO CUMPLE 80% BUENA 60% REGULAR 40% MINIMO 100% EXCELENTE SRM es un proceso que ayuda en la evaluación del contexto operativo de las organizaciones no gubernamentales y evalúa el nivel de riesgo de reacciones adversas que puedan afectar al personal, los activos y operaciones. Proporciona orientación sobre la aplicación de soluciones en forma de medidas de mitigación específica, dirigida a la reducción de los niveles de riesgo mediante la reducción del impacto y la probabilidad de un suceso indeseable. Auditoria de Sistemas bajo el estándar internacional COBIT Se procede a realizar la Auditoria de Sistemas bajo la verificación de COBIT en la cual se pudieron obtener los siguientes resultados: DOMINIO DEL ESTANDAR INTERNACIONAL COBIT La metodología SRM es usada para el Diseño e Implementación de un Modelo de Gestión y Análisis de Riesgos en todo lo que tenga que ver con tecnologías de información. X X X X Tabla 1. Cumplimiento del Estándar COBIT Cumplimiento del Estándar Internacional COBIT en el Sistema Académico de Calificaciones El cumplimiento promedio esta dado, sumando todos los cumplimientos parciales y dividiéndolos entre la cantidad de dominios evaluados: =(60%+57,14%+69,23%+50%) 4 Cumplimiento Promedio=59,09% Lo que nos indica que el cumplimiento es REGULAR, inferior a lo requerido y deseado. Figura 2. Metodología SRM. Cumplimiento de los Criterios de Calificación del Estándar Internacional COBIT en el Sistema Académico de Calificaciones HERRAMIENTAS La aplicación se desarrolla con el software PHP levantando el servidor Apache y Mysql. Esto se debe a que el software de auditoria de sistemas basado en COBIT tiene una base de datos madre en la cual debe basarse la auditoria. Además de que cumple con las condiciones de un modelo cliente servidor. El cliente es el usuario que manda la información que genera la auditoria al servidor que se encuentra en la institución con la cual se intercambiará información confidencial. El cumplimiento promedio esta dado, sumando todos los cumplimientos parciales y dividiéndolos entre la cantidad de dominios evaluados: = (0%+0%+7.69%+0%) 4 Cumplimiento Promedio=1.92% Lo que nos indica que NO CUMPLE con los criterios de información según COBIT, muy inferior a lo requerido y deseado. METODOLOGÍA Análisis de Riesgos A continuación se presenta la metodología del presente trabajo de grado, que consta de tres fases: Auditoria de Sistemas bajo el estándar internacional COBIT, Análisis de Riesgos, Tratamiento de Procesos y Objetivos de Control. Se procede a identificar las amenazas y vulnerabilidades para luego someterlos a un análisis de probabilidad en el cual podemos determinar el nivel de riesgo de cada amenaza. 75 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Agrupando los riesgos de un nivel más alto se obtiene la siguiente Figura. Para concluir con el tratamiento de los procesos y objetivos de control se procede a plantear el Plan de Acción de gestión de tecnologías de la información con sugerencias, para los objetivos de control identificados en un nivel medio y alto en el análisis. COMPROBACIÓN DE LA HIPOTESIS Hipótesis “Las implantación de la gestión de tecnologías de la información basados en el estándar internacional COBIT permitirá la realización de la auditoria de sistemas mejorando la seguridad de la información en el sistema de calificaciones.” Confiabilidad Cumplimiento Disponibilidad Situación Inicial 2.7 2.7 2.7 2.7 2.7 2.7 2.7 Situación Actual 2.95 2.95 2.95 2.95 2.95 2.95 2.95 Situación Posterior 4 4 4 4 4 4 4 Tabla 3. Resultados de COBIT Y KOSOVO Para la demostración estadística, nos basamos en las situaciones propuestas anteriormente, para cada criterio de información, se deberá realizar la respectiva comprobación estadística y como se trata de la hipótesis nula, esta afirma que con la implantación de gestión de tecnologías de la información basados en el estándar internacional COBIT es totalmente igual al panorama actual. Por otro lado la hipótesis alterna significa que existe un cambio del antes y después de la implantación de gestión de tecnologías de la información basados en el estándar internacional COBIT. Tabla 2. Priorizar Riesgos 76 Integridad Objetivos de Alto + Control Evaluados Medio PO1. Definir un Plan Estratégico de TI. 1 1 PO2. Definir la Arquitectura de la Información. 3 2 PO4. Definir los Procesos, Organización y Relaciones de TI. 7 1 PO5. Administrar la Inversión en TI. 2 0 PO6. Comunicar las Aspiraciones y la Dirección de la Gerencia. 2 0 PO7. Administrar los Recursos Humanos de TI. 2 1 PO8. Administrar la Calidad. 1 1 PO9. Evaluar y Administrar los Riesgos de TI. 4 2 AI1. Identificar Soluciones Automatizadas 1 0 AI2. Adquirir y Mantener Software Aplicativo 6 0 AI3. Adquirir y Mantener Infraestructura Tecnológica 2 0 AI5. Adquirir Recursos de TI 1 0 DS2. Administrar los Servicios de Terceros 1 0 DS3. Administrar el Desempeño y la Capacidad 1 0 DS5. Garantizar la Seguridad de los Sistemas 11 11 DS7. Educar y Entrenar a los Usuarios 1 1 DS10. Administración de Problemas 1 1 DS11. Administración de Datos 2 2 TOTAL 49 23 Posteriormente se obtiene la situación actual mediante métricas evaluadas a la auditoria de sistemas ya realizada. Finalmente obtenemos una situación posterior mediante los modelos de madurez obtenidos en la auditoria, todo lo mencionado puede observarse en la siguiente Tabla. Confidencialidad Procesos Prueba de Hipótesis Se puede realizar una demostración lógica mediante la obtención de datos basados en entrevistas con la cual obtenemos una situación inicial del sistema. Eficiencia Tratamiento de Procesos y Objetivos de Control Una vez identificados los riegos se procede a discriminarlos mediante una evaluación de riesgos identificados. Realizada esta evaluación, se obtiene la siguiente Tabla con los riesgos medios y altos a ser tratados por el Plan de Acción. Efectividad Figura 3. Agrupación del Nivel de Riesgo REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Efectividad Eficiencia Confidencialidad Integridad Disponibilidad Cumplimiento Confiabilidad tp > 1.796 se rechaza Ho 5.99 6.21 4.79 5.36 5.48 5.65 4.79 Tabla 4. Comprobación Estadística REFERENCIAS BIBLIOGRAFICAS • • • • CONCLUSIONES Se pudo proponer un dictamen con objetivos de control basados en el estandar COBIT, coadyuvando asi a la correcta gestion de tecnologias de la infromacion. • Gómez Vieites, Álvaro (2007). ENCICLOPEDIA DE LA SEGURIDAD INFORMÁTICA. PIATTINI, 1998, Auditoria Informática: Un enfoque práctico. PIATTINI, Mario. Editorial Alfa omega 1998 España. ISACA, 2012, COBIT 4.1 Disponible e n http://www.isaca.org COSO, 2004, COSO (Committee of Sponsoring Organization of the Treadway commission). Enterprise Risk Management - Integrates Framework, 2004. CANSLER, 2003, Auditoria en contextos computarizados CANSLER Leopoldo, Editoriales Cooperativas Se aplicaron metodos y procedimientos especializados a fin de evaluar el estado de los procesos del sistema academico de calificaciones plasmados en un Plan de Accion, el cual nos brindará informacion relevante de mitigacion de riesgos y utilizacion de procesos y objetivos de control mediante COBIT para mejorar las deficiencias. Estudiantes en el Laboratorio de Informática 77 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Implementación de un Data Mart para apoyar la toma de decisiones operativas y administrativas JOSÉ IGNACIO MAMANI MURGA Departamento de Ingeniería de Sistemas - Escuela Militar de Ingeniería La Paz - Bolivia e-mail: [email protected] RESUMEN Este artículo se presenta la Implementación de un Data Mart para apoyar la toma de decisiones operativas y administrativas en la Dirección General de Asuntos Administrativos del Ministerio de Justicia a través de la centralización de las bases de datos de los sistemas transaccionales existentes, con el incremento en la capacidad de generar sus propios reportes detallados e históricos y los niveles de seguridad que respeten la normativa legal e integral de la información amparada por la Constitución Política del Estado para así evitar vulneraciones, ataques y contingencias a la seguridad de la información del personal que desempeñan sus funciones en las distintas áreas de la institución. ABSTRACT This article presents the implementation of a Data Mart to support operational decision-making and administrative in the Directorate General of Administrative Affairs at the Ministry of Justice, through the centralization of the databases of the existing transactional systems, with the increase in the capacity to generate their own reports and detailed historical and levels of security to respect the legal regulations and integral of the information covered by the Constitution of the State so as to avoid violations, attacks and contingencies to the safety of the personnel information which they perform their functions in the different areas of the institution. INTRODUCCION A nivel mundial la empresa líder de tecnología de comunicación japonesa Fujitsu que ofrece una gama completa de productos de tecnología, soluciones y servicios. El personal de Fujitsu da soporte a los clientes en más de 100 países de todo el mundo. En los últimos años la empresa Fujitsu ha logrado un nuevo resultado record en el benchmark de aplicaciones estándares de Business Intelligence - Data Mart utilizado por las empresas para analizar de forma eficaz y optimizar el rendimiento del sistema en entornos de Data Warehouse. Este test proporciona indicaciones reales del rendimiento de la base de datos corporativa a través de la medición del rendimiento del sistema para manejar grandes volúmenes de peticiones a la base de datos del sistema de almacenamiento de negocio. A nivel regional considerando todo lo que es el continente sudamericano la empresa Chilena Data Mart Web actualmente entrega servicios de inteligencia de negocios y visualización multidimensional de información para la toma de decisiones de una empresa. Los profesionales de Data Mart Web han sido consultores para diversos organismos internacionales. También se desarrolló la implementación de esta tecnología en Aguas Andinas, en base a la necesidad de realizar gestión sobre la información que rutinariamente se enviaba a organismos reguladores, para validarla y así cumplir con los estándares 78 de calidad exigidos por la Compañía, hecho que llevo a buscar una herramienta que permitiese de forma amigable visualizar la información y mejorar su calidad para enviar a los organismos externos. A nivel local aproximadamente siete años atrás se comenzó con la implementación de tecnología de Business Intelligence las empresas Entel La Paz en el año 2006, implementó la Inteligencia de Negocios destinado a la identificación de áreas que no perciben los recursos económicos que deberían percibir según objetivos planteados, logrando actualmente distribuir sus recursos humanos y económicos a las áreas potencialmente menos explotadas, Banco Los Andes de Santa Cruz en el año 2007, implemento BI en las áreas de servicios y seguimiento a oficiales de crédito, mejorando el tiempo en la toma de decisiones y brindando una mejor atención a sus clientes al reducir los tiempos de respuesta en el análisis de casos individuales de créditos y Nuevatel en el año 2008, implementó BI en las áreas de marketing, minería de datos para servicios en general, todavía no se han percibido los cambios internos en el área de marketing, sin embargo es notable exteriormente en las promociones de esta empresa de telecomunicaciones. En nuestro país un número muy reducido de empresas, cuentan con tecnología para el manejo y administración de la información centralizada, algunas de estas empresas son Nuevatel, Entel, Tigo, la Superintendencia de Bancos, ATC (Administradora de Tarjetas de Crédito) entre otras. REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 El trabajo desarrollado tuvo como objetivo Implementar un Data Mart que brinde información oportuna y confiable almacenada en una base de datos centralizada, que apoye la toma de decisiones operativas y administrativas en la Dirección General de Asuntos Administrativos del Ministerio de Justicia para reducir el tiempo de los procesos operativos y administrativos dentro de las distintas áreas a cargo del personal que desempeña sus funciones en la institución. Mart. Se realizó un análisis de la situación actual en la Dirección General de Asuntos Administrativos del Ministerio de Justicia y se establecieron los recursos necesarios para el Trabajo de Grado. Estructura del Sistema Actual PROBLEMÁTICA La información que fluye en la Dirección General de Asuntos Administrativos es inoportuna, está dispersa y contenida en base de datos descentralizados, lo que impide realizar la toma de decisiones operativas y administrativas, provocando demora en los procesos operativos y administrativos dentro de las distintas áreas a cargo del personal de la institución. JUSTIFICACION Asignación de Recursos de Hardware, Software, Recursos Humanos y de Información Para el desarrollo del Data Mart se empleó la Metodología de Kimball o Data Marting: - - - Requiere documentación, está enfocado en procesos, genera resultados más rápidos, el cliente interviene constantemente, el tiempo de desarrollo es relativamente corto y el tamaño del equipo es reducido. Proporciona un enfoque de menor a mayor, es muy versátil, y tiene una serie de herramientas prácticas que ayudan a la implementación del Data Mart. Está asociado con esfuerzos departamentales en este caso la Dirección General de Asuntos Administrativos y no así corporativos. Para el desarrollo de la Aplicación de Usuario Final se empleara la Metodología de Prototipado Rápido MPR: - - - Requiere documentación, está más enfocado en personas, se genera resultados rápidos, el cliente interviene constantemente. El tiempo de desarrollo es relativamente corto, permite desarrollar prototipos ante una alta complejidad de un problema y el tamaño del equipo es reducido. Está orientado al desarrollo de prototipos y fuertemente apoyada en tecnología de Bases de Datos que es el Data Mart construido, se concentra en la involucración del usuario. DESARROLLO DEL DATAMART Planificación En la Etapa de Planificación, se llevaron a cabo de varias actividades primordiales para un óptimo diseño del Data ANALISIS En esta etapa a través de las fases del Diseño de la Arquitectura Técnica y el Modelo Dimensional de los datos, se definió la estructura que soporta la integración de todas las tecnologías empleadas y la información que se almacena en el Data Mart. Diseño de la Arquitectura Técnica Se determinó la organización y comunicación de todos los elementos que componen la estructura que soporta al Data Mart. El sistema se implementa bajo una arquitectura cliente/servidor de dos capas, en la cual las herramientas de usuario final, es decir las aplicaciones de consulta y reporte se ejecutan en la capa cliente y el Data Mart reside en la capa servidor. 79 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 el Data Mart se tuvo como objetivo la información deseada en los reportes. Se construyó la matriz bus del Data Mart, en base a la definición de requerimientos. Esta herramienta permitió especificar los procesos de la institución, que en nuestro caso corresponden a las actividades de la Dirección General de Asuntos Administrativos, así como las distintas facetas de análisis (dimensiones) para cada uno. Estructura Grafica de los elementos que componen la estructura que soporta el Data Mart Estructura Grafica de los cuatro módulos que componen la Arquitectura Técnica del Data Mart. En esta estructura se disponen a su vez de cuatro modulos bien diferenciados: Las fuentes de datos, los Procesos ETL, El Data Mart y las herramientas de acceso, los tres primeros forman el back-end del sistema, y el último corresponde al front-end. Arquitectura del Data Mart Propuesto Modelamiento Dimensional Para iniciar el modelamiento dimensional, se tomó en cuenta que el principal objetivo de un almacén de datos o Data Mart es el análisis de la información, el cual es realizado por medio de reportes, por lo tanto al modelar 80 Matriz bus del Data Mart DISEÑO En el diseño del Data Mart se procedió a convertir los modelos lógicos desarrollados en la etapa anterior a modelos físicos, los cuales permitieron determinar los aspectos técnicos necesarios para la posterior construcción del Data Mart. Diseño de los Procesos de Extracción, Transformación y Carga del Data Mart CONSTRUCCIÓN En la etapa de construcción se procedió a implementar REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 los diseños físicos de la etapa anterior, haciendo uso de las herramientas que se especificaron también en dicha etapa. La Construcción física del Data Mart es similar a la creación de una base de datos relacional común, salvando las diferencias en cuanto a orientación o aplicabilidad. Creación de los Paquetes de Extracción, Transformación y Carga para la implementación de la estrategia ETL definida para el Data Mart, se utiliza el componente Business Intelligence Development Studio de SQL Server 2008 Enterprise Edition, para la creación de un proyecto de Microsoft Integration Services. Ejecución del Paquete ETL para las Dimensiones de un Sistema Transaccional Desarrollo de la Aplicación de Usuario Final Como último paso para la construcción del sistema, se procedió con la implementación de las aplicaciones de usuario final, en base a las especificaciones realizadas en la etapa de diseño. Para esto se creó un proyecto en Visual Studio 2010 Asp.Net C#. Reporte de un Proceso del Data Mart Ejecución del Paquete ETL para las Tablas de Hechos de un Sistema Transaccional CONCLUSIONES oEn base a la exploración y evaluación de los sistemas origen, se logró realizar una selección minuciosa de datos útiles para el análisis en el proceso de toma de decisiones, descartando a la vez una gran cantidad de información irrelevante. Posteriormente se efectuó un análisis profundo de las fuentes de datos que alimentarían al Data Mart logrando el diseño de los procesos ETL, seguido del diseño mismo del repositorio en base al modelamiento dimensional de los datos acorde a la definición de requerimientos, continuando con su descripción física y posterior construcción e implementación en el motor de bases de datos de SQL Server, en Integration Services, BI-Lite Cube it Zero Professional 6.1.1.9 y Microsoft Visual Studio 2010, consiguiendo de esta manera la reducción notable de los tiempos de obtención de datos. 81 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 oEn función a la determinación de requerimientos se pudo definir, diseñar y construir en Microsoft Visual Studio 2010 los reportes al detalle correspondientes a las consultas hechas con mayor frecuencia, logrando así una implementación de una aplicación web en ASP.Net con sus diferentes complementos como ser el Dev Express Universal, la cual ofrece una forma sencilla y rápida de generar y visualizar una innumerable cantidad de combinaciones de los datos permitiendo así explotar al máximo el modelo creado y se logró también establecer un acceso directo e inmediato a la información de la Dirección General de Asuntos Administrativos de la institución, sin solicitudes a terceros ni la manipulación de los datos por parte del personal de otras áreas para la elaboración de reportes. cantidad de combinaciones de los datos permitiendo así explotar al máximo el modelo creado y se logró también establecer un acceso directo e inmediato a la información de la Dirección General de Asuntos Administrativos de la institución, sin solicitudes a terceros ni la manipulación de los datos por parte del personal de otras áreas para la elaboración de reportes. REFERENCIAS BIBLIOGRÁFICAS • • • oEn función a la determinación de requerimientos se pudo definir, diseñar y construir en Microsoft Visual Studio 2010 los reportes históricos correspondientes a las consultas hechas con mayor frecuencia, logrando así una implementación de una aplicación web en ASP.Net con sus diferentes complementos como ser el Dev Express ASP Subscription 2012 vol 2.6, la cual ofrece una forma sencilla y rápida de generar y visualizar una innumerable 82 • • • [BOZA, 2004] "Data Warehouse para la gestión por procesos en el sistema productivo", Boza García Andrés Cancún, México, 2004 pág. 9. [CANO, 2008] Business Intelligence: Competir con Información, Fundación Banesto 2008. [DAN PRATTE, 2001] Inteligencia de Negocios Dan Pratte 2001. [INMON, 2003] Inmon Bill. Building the Data Warehouse. 2003. [INMON, 2005] Building the Data Warehouse - W. H. Inmon 2005 [KIMBAL, 2004] The DataWarehouse ETL Toolkit - Ralph Kimball 2004. Parte en la iza de la bandera Unidad Académica La Paz - Irpavi REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Sistema web de planeación de recursos empresariales con soporte para dispositivos móviles que apoye en la toma de decisiones MIGUEL ANGEL LOZA MAMANI Departamento de Ingeniería de Sistemas - Escuela Militar de Ingeniería La Paz - Bolivia e-mail: [email protected] RESUMEN En el presente artículo se expone el desarrollo de un sistema ERP (Planeación de Recursos empresariales) de manera que el mismo al brindar información centralizada y oportuna apoye a la toma de decisiones mediante la presentación principalmente de reportes con la información más relevante además que se pueda visualizar dicha información a través de dispositivos móviles. ABSTRACT In the present article describes the development of an ERP system (Enterprise Resource Planning) so that the same by providing centralized information and timely support to the decision-making through the presentation of reports mainly with the most relevant information in addition that you can view this information through mobile device. INTRODUCCIÓN En los últimos tiempos, la mayoría de las empresas es soportada, automatizada y gestionada por sistemas informáticos, así como los sistemas de información apoyan la actividad gerencial y la toma de decisiones, incluso muchas veces, es la propia información y el acceso a la misma, el producto / servicio que se intercambia como el resultado de una medida defensiva para preservar los activos del negocio, ya que muchas veces, es un activo en sí mismo, una condición para operar y/o competir en el sector. El Sistema de Planeación de Recursos Empresariales (ERP) es un sistema de la empresa multifuncional impulsado por un conjunto integrado de módulos de software que soporta los procesos de negocio internos básicos de una empresa y con ayuda de el mismo se puede realizar la toma de decisiones de acuerdo a los datos obtenidos. algunos procesos y en la elaboración de reportes debido a que se debe recopilar información de distintos archivos Excel, además cuando se necesita información esta no se obtiene de manera inmediata, por lo tanto el flujo de la información es deficiente. Así, problema principal es que la información disponible en la empresa “Tick Tech BOLIVIA” se encuentra dispersa y no está disponible para el personal, lo que dificulta el procesamiento y obtención inmediata de la información que apoye a la toma de decisiones. OBJETIVO En base a la anterior problemática se tiene que como objetivo principal para dar solución a este problema es desarrollar un sistema web de Planeación de Recursos Empresariales con soporte para dispositivos móviles que apoye a la toma de decisiones en la empresa “Tick TECH BOLIVIA” para obtener información requerida en tiempo real. INGENIERÍA DE SOFTWARE El presente trabajo de grado tuvo como objetivo el desarrollo de un sistema de planeación de recursos empresariales con soporte para dispositivos móviles confidencialidad e integridad en el envío y recepción de mensajes privados. PROBLEMÁTICA El sistema actual que posee la empresa apoya tanto al funcionamiento como a la toma de decisiones de manera regular, ya que existe demora en la realización de Esta ingeniería trata con áreas muy diversas de la informática y de las ciencias de la computación, tales como construcción de compiladores, sistemas operativos, o desarrollos Intranet/Internet, abordando todas las fases del ciclo de vida del desarrollo de cualquier tipo de sistemas de información y aplicables a afinidad de áreas: negocios, investigación científica, medicina, producción, logística, banca, control de tráfico, meteorología, derecho, Internet, intranet, etc. 83 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 COMPUTACIÓN MÓVIL Los sistemas de computación móvil son sistemas de computación que deben trasladarse físicamente con facilidad y cuyas capacidades de cómputo deben emplearse mientras éste se mueve. Algunos ejemplos son: laptops, PDAs, tablets y teléfonos móviles. A partir de la distinción de los sistemas de computación móvil de cualquier otro tipo de sistema de computación es posible identificar las diferencias en las tareas que estos deben desempeñar, la forma en que deben diseñarse y la manera en que son operados. Los requerimientos a especificar tienen que ser tanto para el sistema ERP como para la aplicación móvil, en el caso del ERP se tiene un documento externo denominado FRD o Documento de Requisitos Funcionales. ANÁLISIS DEL SISTEMA PROPUESTO En esta etapa lo que se hace es definir en primer lugar de que módulos contara el Sistema ERP y aclarando que se hará en cada uno de ellos, en la Figura 1 podemos observar el diagrama de contexto del Sistema ERP. PLANEACIÓN DE RECURSOS EMPRESARIALES Un sistema ERP es un paquete de software comercial que integra toda la información que fluye a través de la compañía: información financiera y contable, información de recursos humanos, información de la cadena de abastecimiento e información de clientes. Un ERP automatiza las actividades corporativas nucleares, tales como: manufactura, recursos humanos, finanzas y gestión de la cadena de abastecimiento, incorporando las mejores prácticas para facilitar la toma de decisiones rápida, la reducción de costes y el mayor control directivo. DESARROLLO DEL SISTEMA ERP Para desarrollar el proyecto se hizo uso de la metodología XP combinada con la metodología SureStep de Microsoft Systems y Mobile-D para el desarrollo de la aplicación móvil, tomando en cuenta las siguientes etapas: ANÁLISIS DE LA SITUACION ACTUAL En esta etapa se identificó que problemas presenta la empresa, un análisis FODA, la identificación de los actores y finalmente un análisis de los procesos actuales que realiza la empresa. Además como primer documento para sustentar el ERP se tiene el PAD que es el documento de Pre-Análisis. ANÁLISIS DE REQUERIMIENTOS En esta etapa lo que se busca es especificar los requerimientos que tiene la empresa de manera que satisfaga sus necesidades y en base a los mismos realizar el diseño y desarrollo del sistema, en base a los requerimientos se puede realizar los casos de uso correspondientes. 84 Figura 1. Diagrama de Contexto Luego de eso se procede a realizar el modelado de procesos con ayuda de diagramas de secuencias DISEÑO Y DESARROLLO DEL SISTEMA En esta etapa, primero se realiza los diagramas de actividades, para representar los flujos de trabajo. Un punto importante a considerar es el diseño de la base de datos ya que este debe realizarse de manera que toda la base de datos sea centralizada y no distribuida y para ello se diseña el diagrama E/R y de clases de la base de datos. También se debe realizar el diseño de la interfaces tanto del Sistema ERP, la aplicación móvil y de los reportes u otros documentos necesarios de manera que se estandarice su elaboración o generación, además que los reportes son la principal fuente que dará apoyo a la toma de decisiones en la empresa. Realizado el diseño en general se procede a la construcción o desarrollo del sistema en donde comenzamos por la base de datos y se realiza el modelo relacional que se puede observar en la Figura 2, así como el diccionario de datos de cada una de las tablas que comprende la base de datos. Lógicamente lo siguiente es la construcción de las interfaces tanto del sistema principal como de la aplicación móvil. REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 CONCLUSIONES Este artículo presenta las directrices generales para el desarrollo de un Sistema ERP el mismo que responde a las necesidades de la empresa en la que se aplica. El Sistema Web ERP permite reducir el tiempo requerido en la recolección de información relevante que ayuda a la toma de decisiones oportunas y confiables en la empresa. Con la implementación del Sistema Web ERP se logró centralizar información de varias bases de datos de considerables dimensiones lo que facilito la identificación acceso y manejo de los datos que son presentados en dispositivos móviles. El procesamiento de la información por medios automáticos facilita la obtención de esta, su manipulación, preparación y presentación de informes, obviando la participación de recursos humanos que en muchos casos se convertían en cuellos de botella y en fuentes de retraso. Figura 2. Modelo Relacional HERRAMIENTAS Las herramientas utilizadas para el desarrollo del presente proyecto son: Los procesos de presentación de la Información se la realiza en tiempo real lo que facilita la implementación de sistemas para la toma de decisiones con datos en línea y acordes a la realidad del momento. REFERENCIAS BIBLIOGRÁFICAS • • • • • • PHP y HTML5 para el desarrollo del sistema ERP ya que HTML5 es un lenguaje que permite publicar hipertexto en la gran red y PHP Es un lenguaje multiplataforma para el desarrollo de aplicaciones de tipo web que se ejecuta desde el servidor. Javascript que es un lenguaje basado en objetos, que se interpreta en el lado del cliente. Se incluye en los documentos HTML para ejecutar operaciones, sin acceso a las funciones del servidor. jQueryMobile para la parte de la aplicación móvil ya que este facilita el desarrollo de los mismos al estar desarrollado en base a HTML5 es una librería que se puede utilizar sin complicaciones. MySQL para la parte de base de ya que MySQL es un sistema de gestión de bases de datos relacional y con ayuda del lenguaje SQL se pueden realizar consultas a la base de datos. FusionCHART que es una librería hecha en PHP que permite realizar gráficos de varios tipos para poder mostrar la información de la base de datos de una manera gráfica que permita tener un mejor entendimiento y con ayuda de un gráfico y reportes se apoye a la toma de decisiones. • • • • PRESSMAN, Roger S., “Ingeniería de Software: Un Enfoque Práctico”, Sexta Edición, México, McGraw Hill, 2005. VALENZUELA Adriana, RODRIGUEZ Nelson. Computación móvil, experiencia en el desarrollo y dictado de cursos. San Juan - Argentina. 2012. A Critical Success Factors Model For ERP Implementation. IEEE Softw. 1999. MICROSOFT DYNAMICS, Methodology Sure Step, 2012. ROSSI Gustavo, Pastor Oscar, Schwabe Daniel y Olsina Luis. Ingeniería Web. Modelado e implementación de aplicaciones web. 2008. 85 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Algoritmo de encriptación simétrico basado en seguridad wireless aplicando XOR y serie FIBONACCI DIEGO CARLOS FERAUDY PINTO Departamento de Ingeniería de Sistemas - Escuela Militar de Ingeniería La Paz - Bolivia [email protected] RESUMEN En el presente artículo se expone una nueva operación para poder cifrar claves tipo wep de 64 y 128 bits de 10 a 26 dígitos, tomando en cuenta que la seguridad de la configuración de puntos de acceso y routers es muy importante, evidentemente se van generando nuevos diccionarios de des encriptación y nuevas herramientas para encontrar claves de acceso a redes wi fi. ABSTRACT In this paper a new operation to encrypt wep key type 64 and 128 bits 10 to 26 digits is exposed, taking into consideration the security settings of access points and routers is very important, obviously are generating new dictionaries des encryption and key tools to find new network access wi fi. INTRODUCCIÓN WEP acrónimo de Wired Equivalent Privacy o Privacidad Equivalente a Cableado, es el sistema de cifrado incluido en el estándar IEEE 802.11 como protocolo para redes Wireless que permite cifrar la información que se transmite. Proporciona un cifrado a nivel 2, basado en el algoritmo de cifrado RC4 que utiliza claves de 64 bits (40 bits más 24 bits del vector de iniciación IV) o de 128 bits (104 bits más 24 bits del IV). Los mensajes de difusión de las redes inalámbricas se transmiten por ondas de radio, lo que los hace más susceptibles, frente a las redes cableadas, de ser captados con relativa facilidad. Presentado en 1999, el sistema WEP fue pensado para proporcionar una confidencialidad comparable a la de una red tradicional cableada. Podemos definir de forma muy rápida y creíble, que el tipo ASCII corresponde a los botones de un teclado. Y el tipo hexadecimal como un nivel de agrupación de bits (0/1) entendida por todos los componentes electrónicos. Cuando se invento la seguridad wireless con encriptación WEP en las redes inalámbricas, en principio pensaron es usar una clave estática con una longitud de 64 bits, esta clave se genera de forma pseudoaleatoria, pero el acabado final corresponde teóricamente a 10 dígitos hexadecimales (0-1-2-3-4-5-6-7-8-9-A-B-C-D-E-F), luego pensaros que era mejor subir el nivel a una de 128 bits, y se aumento el valor de 10 dígitos a 26 dígitos hexadecimales. DESCRIBIENDO LA OPERACIÓN La operación consiste en realizar una simple operación XOR a los números a cual corresponden los caracteres 86 de la clave, es decir el valor a cual corresponde al valor hexadecimal de cada uno de los caracteres y el que corresponda a la posición en la serie Fibonacci, el valor obtenido generara un resultado que corresponda a el valor cifrado en código ASCII. REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 DIAGRAMA DE FLUJO DEL ALGORITMO EJEMPLO DE LOS RESULTADOS DE UN CIFRADO Cifrar la palabra “seguridad”: s e g u r i d a d 73 65 67 75 72 69 64 61 64 R = [RS » U Z › DC3 EOT ‰ 6] => cadena de resultados con operación XOR entre cadenas C y F Y SE calcula el mod 255 si sobre pasa el valor de 255. Resultado del cifrado: RS»UZ›DC3EOT‰6 CONCLUSIONES Se toma en cuenta que todos los caracteres difieres si están escritos en minúsculas y en mayúsculas. C = [73 65 67 75 72 69 64 61 64] => cadena de valores hexadecimales, Valores equivalentes a decimal ASCII => D = [115 101 103 117 114 105 100 97 100] => cadena de valores decimales Valores en serie Fibonacci => 115 = 483162952612010163284885 mod 255 = 200 101 = 573147844013817084101 mod 255 = 251 103 = 1500520536206896083277 mod 255 = 22 117 = 1264937032042997393488322 mod 255 = 17 114 = 298611126818977066918552 mod 255 = 127 105 = 3928413764606871165730 mod 255 = 70 100 = 354224848179261915075 mod 255 = 30 97 = 83621143489848422977 mod 255 = 157 100 = 354224848179261915075 mod 255 = 30 F = [200 251 22 17 127 70 30 157 30] => cadena de valores Fibonacci. Unidad Académica Cochabamba Existe una gran variedad de dificultades en la conbinacion de estos números ASCII ya que se tomara en cuenta los caracteres menores de 33 es decir los primero 33 caracteres tomaran como valor las siglas cual correspondan el valor equivalente a la simbología y los caracteres en mayúsculas. REFERENCIAS BIBLIOGRAFICAS • • • • • http://www.hsc.fr/ressources/articles/hakin9_wifi/ hakin9_wifi_ES.pdf https://support.google.com/dfp_premium/answer /165721?hl=es http://bibliotecadigital.ilce.edu.mx/sites/ciencia/ volumen3/ciencia3/150/htm/sec_14.htm http://www.maths.surrey.ac.uk/hostedsites/R.Knott/Fibonacci/fibtable.html http://www.seguridadwireless.net/php/conversoruniversal-wireless.php 87 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Actividades de la Carrera ING. FREDDY MEDINA MIRANDA Departamento de Ingeniería de Sistemas - Escuela Militar de Ingeniería La Paz - Bolivia [email protected] RESUMEN A continuación se presentan las actividades más destacadas de la Carrera en el semestre I/2014, complementarias al proceso de enseñanza aprendizaje, las cuales son la Competencia de Programación ACM-ICPC-EMI 2014, la implementación del diseño curricular por competencias y la conferencia Internet of things. VIII Competencia de Programación ACM - ICPC - EMI 2014 Departamento de Ingeniería de Sistemas - Escuela Militar de Ingeniería RESUMEN En este artículo se presentan los antecedentes y el desarrollo de la VIII competencia de Programación ACM ICPC organizada por la Carrera de Ingeniería de Sistemas de la EMI UALP, correspondiente a la gestión 2014 ANTECEDENTES La Primera Competencia Internacional de Programación de la ACM - ICPC (International Collegiate Programming Contest) fue realizada en Texas A&M en 1970, organizada por el Capítulo Alfa de la Sociedad de Honor en Ciencias de la Computación UPE. ACM - ICPC Bolivia realiza la competencia nacional, clasificatoria a la sudamericana. La carrera de Ingeniería de Sistemas de la EMI UALP organiza anualmente, desde el año 2008, la competencia para seleccionar tres equipos, habiendo tenido destacada participación en los eventos nacionales. MODALIDAD DE LA COMPETENCIA Actualmente, sobre todo desde que IBM se convirtió en el auspiciador oficial en 1997, la competencia se ha expandido a una red global de universidades que organizan competencias regionales para clasificar equipos a la Competencia Final, participando más de diez mil de los mejores estudiantes en diferentes áreas de las ciencias de la computación de más de 1800 universidades de más de 80 países de los 6 continentes. Esta es la mayor y más prestigiosa competencia de programación del mundo. El evento anual comprende tres niveles de competencias: • • • 88 Competencias Locales. Las Universidades seleccionan hasta tres equipos como representantes en el siguiente nivel de la competencia. Competencias Regionales. Los equipos inscritos de las diferentes universidades participan en la Competencia Regional de Programación ACMICPC. Final Mundial. Participan los 88 clasificados de las competencias regionales en una sede, compitiendo por premios monetarios, becas y otros beneficios. Estos equipos representan lo mejor de las mejores universidades en los seis continentes. Se evalúa a equipos de 3 estudiantes de la EMI UALP o egresados del 2013, con 8 o más problemas de programación en un tiempo máximo de 5 horas, equipados con una computadora. Los integrantes de cada equipo trabajan colaborativamente determinando requerimientos, diseñando casos de prueba y construyendo el software que resuelve el problema. La prueba es controlada por jueces presenciales y virtuales. Los estudiantes solo acceden al enunciado del problema y un ejemplo de datos de prueba. Cada solución incorrecta es sancionada con 5 minutos de penalidad El equipo que resuelve más problemas en el menor tiempo acumulado es declarado ganador. Una solución es incorrecta si: • • • • • El programa no compila correctamente. El tiempo de ejecución excede el máximo. Ocurre un error en tiempo de ejecución. El programa proporciona una respuesta incorrecta. El formato de salida es diferente al establecido en la hoja de problemas. El tiempo de resolución de los problemas es considerado REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 desde que inicia la competencia hasta la aceptación del último problema resuelto. Los lenguajes de programación habilitados son C, C++ y JAVA. réplica de esta en la EMI para identificar estudiantes con buen perfil académico. Los participantes pueden usar recursos impresos como libros, manuales y listas de programas. Es prohibido emplear información almacenada magnéticamente o cualquier tipo de software. OBJETIVOS DE LA COMPETENCIA • • • • Clasificar tres equipos a la competencia Nacional. Incentivar e impulsar las actividades de programación en la Escuela Militar de Ingeniería. Generar proyectos de interacción social con la participación de docentes y estudiantes de la EMI. Generar proyectos de investigación sobre las Líneas de Investigación de la Carrera. Figura 1. Participantes en el programa de Capacitación PROGRAMA DE CAPACITACIÓN La capacitación en la elaboración de estrategias para la resolución de problemas de competencias internacionales la realizó el grupo ACM ICPC EMI, a partir del 19 de abril los días sábados, de 9:00 a 12:00. Los miembros del grupo ICPC ACM EMI se están cursando en la empresa auspiciadora Code Road para convertirse en instructores del nivel inicial de la Olimpiada Boliviana de Informática OBI. El objetivo es generar una ORGANIZACIÓN Se designaron comisiones de organización, de jurados y de auspicio y premios. Los integrantes del comité responsable de la capacitación y del Juez Virtual ICPC son: Est. Ana Castillo, Tte. Charlie Seoane, Est. Ximena Cangri, Est. Eyvind Tiñini e Ing. Christian Conde Copa REALIZACION DE LA COMPETENCIA Figura 2- Inauguración del evento, a cargo del Tcnl. DIM. Julio César Narváez Tamayo, Jefe de Carrera 89 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Figura 3. Participantes resolviendo problemas Figura 4. Refrigerio, bajo la supervisión del Ing. Alejandro Zambrana responsable de la comisión de organización. EQUIPOS GANADORES Figura 5. Primer lugar: Eyvind Emilio Tiñini Coaquira, Ted Carrasco Carrasco y Ximena Cangri Toro Figura 6. Segundo lugar: Carlos Jesús Gutiérrez, José Ignacio Calvo Llanos y Diego Jauregui Salvatierra Figura 7. Tercer lugar: José Junior Paricagua Siñani, Lizeth Dayana Dávila Tapia y Yuri Iver Ortuño Calvo CONCLUSIONES Se alcanzaron los objetivos propuestos, seleccionando tres equipos calificados para representar a la EMI en la competencia nacional. 90 REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 Internet de las cosas RESUMEN El presente artículo destaca la importancia de la Conferencia “Internet de las cosas” organizada por la Carrera de Ingeniería de Sistemas de la EMI UALP, en el mes de abril de 2014. ANTECEDENTES La Red ha pasado del concepto de Internet de las Personas (que permitía el acceso a portales, servicios y aplicaciones) al de Internet de las Cosas (donde todo tipo de objeto o cosa está conectado a Internet: electrodomésticos, etc. y puede enviar información a un smartphone, tableta o computadora). • fue que la última de las 4.000 millones de direcciones IP se asignó en 2011. Por eso, en 2012 el mundo online comenzó la migración a un nuevo protocolo de Internet, IPv6, con 340 trillones de trillones de direcciones IP. En 2013 se crearon chips eficientes y baratos, que permiten que cualquier cosa pueda conectarse a Internet vía Wi-Fi o a un celular mediante el estándar Bluetooth Low Energy. CONFERENCIA Figura 1. Lic. Gabriel Rivera, disertante El Internet de las Cosas se basa en sensores, en redes de comunicaciones y en una inteligencia que maneja todo el proceso y los datos que se generan. Sus campos de aplicación son: salud, sectores de energía, transporte, telecomunicaciones, servicios de información y financieros, fábricas inteligentes, marketing, educación, vehículos y entretenimiento. Como parte de los eventos programados a nivel nacional para celebrar 2014 como el año del Internet de las cosas, la Carrera de Ingeniería de Sistemas de la EMI UALP, realizó la Conferencia “Internet of the things”, a cargo del Lic. Gabriel Rivera, de CodeRoad, empresa de desarrollo de software. 2014 AÑO DE INTERNET DE LAS COSAS Según un estudio de General Electric en 2012, en los siguientes 20 años, el Internet de las cosas añadiría US$ 15 billones al PIB global, estimándose que 25.000 millones de dispositivos estarán conectados a Internet para fines de 2014. 2014 es el año del Internet de las cosas debido a dos cambios tecnológicos: • Para que cualquier objeto pueda conectarse a internet, necesita una dirección IP. El problema Figura 2- Participantes en la conferencia 91 3ER. SEMESTRE ARNOL FRANCISCO ROBLES TINTAYA, JORGE LUIS KAMA COPA, EDDY ALVARO MONTECINOS AGUILERA, FABRICIO GABRIEL TORRICO BARAHONA, JHOSELYN CRUZ MAMANI, WILSON CHARLIE SEOANE SANCHEZ, DEYSI MARIBEL CHURA COYO, PAOLA MARCIA TARQUI ATAHUICHI, JESUS KEVIN CHAMBI MAMANI, MARCOS MAURICIO LANDIVAR FERNANDEZ REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 92 4TO. SEMESTRE BRANDON FELIPE MERLO LOZA, BEHIMAR MOISES ALVARADO ARANDA, SANTOS MANOLO ALARCON ALARCON, YVORY SAAVEDRA DAZA, IRIS NARELLA LUNA MAIDANA, LIA ALEXI MARIN QUISPE, FRANCIS ANGEL ROJAS LOPEZ, WILLIAM CASTRO AYAVIRI, WILSON REAS ALANOCA, HENRY IVAN QUISPE ACARAPI REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 93 5TO. SEMESTRE JOSÉ JUNIOR PARICAGUA SIÑANI, DANY MILTON LIMACHI HERRERA, JUDY ADRIANA QUISPE GERÓNIMO, YURY YVER ORTUÑO CALVO, LIZETH DAYANA DÁVILA TAPIA, WALTER FERNANDO MAMANI QUISPE, ERICK ROLANDO PALENQUE RÍOS, JOSELINE GABRIELA ABENDAÑO, JOSÉ IGNACIO CALVO LLANOS, KATHERINE GEOVANA VILLCA NINA, FREDDY BERNARDO MAMANI GUTIÉRREZ, DIEGO YESSID JÁUREGUI SALVATIERRA REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 94 6TO. SEMESTRE ERIK ABRAHAM BLANCO PAUCARA, EYVIND EMILIO TIÑINI COAQUIRA, MAYA ISABEL SÁNCHEZ GAMBOA, GRECIA JORGELINDA MACHACA YAPURA, ALEJANDRA STEFANY ÁLVAREZ CHURA, WILLIAM CESAR MENDOZA ALARCÓN, CARLOS JESÚS GUTIÉRREZ GUARACHI REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 95 7MO. SEMESTRE GIOVANA EDITH YUJRA NINA, AIDA VANESSA MAMANI CASTAÑETA, RITA CANAVIRI CAMA, ROLANDO SÁNCHEZ MONTALVO, DIEGO LUIS MARIÑO PERALTA, MAURICIO JOSE FELIPE SOTO TALAVERA REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 96 8VO. SEMESTRE DAYSI PATTY RAMIREZ, SERGIO ALEJANDRO MORALES ZUBIETA, MISCHELL SONIA HUCHANI HUCHANI, RUDY ALANOCA SOLOZANO, JESSICA REINA TANCARA ZABALA, ERLAND DANIEL CHURQUI MORALES, ROSARIO CRISTAL CANAVIRI CALLISAYA, CESAR ANTONIO NARVAEZ GUTIERREZ, GABRIELA MARISOL ESPINOZA MONTES, YERI ANTONIO REVOLLO ENDARA, DANITZA HELEN VALLEJOS QUIÑONES, DIEGO CARLOS FERAUDY PINTO, SOLEDAD SILVIA GUTIERREZ PARRA, RAUL MARCO ANTONIO COLQUE GARCIA REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 97 9NO. SEMESTRE MARIO RUBÉN ONTIVEROS DAZA, CARLOS ALEXANDRO POMARES NINA, PEDRO DAMIÁN VÁSQUEZ CALLE, OBRAYAN KEVIN HUANCA MARQUEZ, BRIAN ERLAND DEREK MARISCAL RODRÍGUEZ, XIMENA LISETT CANGRI TORO, ARIEL SANJINÉS CASTRO, ANA LAURA CASTILLO ALFARO, PEDRO ARIEL CASTILLO MOLLINEDO, MELISA TICONA MUJICA, VLADIMIR VARGAS ÁLVAREZ, WARA VANESA SIÑANI LOPEZ, RICARDO ALEJANDRO TRUJILLO CASTAÑETA, ADEMIR FERNANDO NINA MIRANDA, JORGE HERNANDO CANDIA MENACHO, RAÚL GILMAR CORTEZ LAURA REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 98 10 MO. SEMESTRE DOUGLAS LEONARD DEL VILLAR VASQUEZ, SAÚL MEYER TERRAZAS ROLLANO, JUAN JESÚS YAMPASI ESPEJO, JORGE CRISTÓBAL CORTEZ CALLE, JAVIER RONALD ESCOBAR CRUZ, FIDEL ALEJANDRO TAPIA QUEZADA, CLAUDIA INES GUTIERREZ VILLEGAS, GUSTAVO ELÍAS ALCONZ EVIA, DHEMELZA PAOLA ALIAGA NISTTAHUZ, ROMER YUJRA TUCUPA, JOSÉ IGNACIO MAMANI MURGA, MARCELO RILMAR HUALLARTE HUALLARTE, ISRAEL QUISBERT ANTI, DIEGO BRUNO FLORES SALAZAR, RAUL RUBEN PACHECO SANDOVAL, JHONNY GABRIEL LOZA QUENTA, RENE ANDRÉS RIVERO RUIZ, MIGUEL ÁNGEL LOZA MAMANI, EDWIN SANTOS TINTA GÓMEZ REVISTA INGENIERIA DE SISTEMAS PARADIGMA GESTION 2014 99 Ingenieria de Sistemas Competencia General Competencia por Área El Ingeniero de Sistemas graduado de la EMI: “Determina el diseño, desarrollo, implementación, evaluación, mantenimiento, soporte y retiro de sistemas con enfoque sistémico y visión emprendedora, aplicando nuevas tecnología de información y comunicación realizando el modelado y automatización de sistemas, desarrollando sistemas de gestión empresarial y de producción orientados a la toma de decisiones que optimicen los procesos, con creatividad, liderazgo y pensamiento crítico en un entorno complejo conflictivo multidisciplinario”. √ √ √ √ Sistemas de Información y Conocimiento. Tecnologías de la Comunicación y Redes. Modelación y Automatización de Sistemas. Sistemas de Gestión Empresarial. Programa Académico Ingeniería de Sistemas PRIMER SEMESTRE Algebra Algoritmos Calculo I Dibujo Para Ingeniería Física I SEGUNDO SEMESTRE Algebra Lineal y Teoría Matricial Cálculo II Estadística y Probabilidades Física II Química General TERCER SEMESTRE Diseño y Programación de Sistemas Basados en Microprocesadores I Ecuaciones Diferenciales Electrónica Aplicada Estadística y Probabilidades Ii Programación Orientada a Objetos Sistemas Administrativos y Contables CUARTO SEMESTRE Diseño y Programación de Sistemas Basados en Microprocesadores II Estructura de Datos Investigación Operativa I Metodología de la Investigación Métodos Numéricos Sistemas Económicos Teoría General de Sistemas QUINTO SEMESTRE Análisis y Diseño de Sistemas I Gestión de Bases de Datos I Investigación Operativa Ii Planeación y Procesos de Sistemas Sistemas de Control y Automatización Tecnología de Comunicaciones y Redes I SEXTO SEMESTRE Administración de Sistemas Operativos y Servidores Análisis Y Diseño de Sistemas II Gestión de Bases de Datos II Investigación Operativa III Modelación de Sistemas Tecnología de Comunicaciones y Redes II SÉPTIMO SEMESTRE Ingeniería de Software Inteligencia Artificial I Programación Avanzada Robótica Simulación de Sistemas Tecnología de Comunicaciones y Redes III OCTAVO SEMESTRE Auditoria de Sistemas Ingeniería Web Inteligencia Artificial II Preparación y Evaluación de Proyectos Seguridad de Sistemas Sistemas Distribuidos Sistemas De Mercadeo NOVENO SEMESTRE Gestión de Proyectos Sistémicos Ingeniería Legal y Derecho Informático Trabajo de Grado I Tópicos Avanzados de Modelación y Automatización De Sistemas DÉCIMO SEMESTRE Trabajo de Grado II Tópicos Avanzados de Sistemas de Información y de Conocimiento Tópicos Avanzados de Tecnologías de Comunicación y Redes