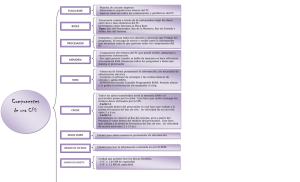
implementación de procesador con bus espía y guía pedagógica tg
Anuncio

IMPLEMENTACIÓN DE PROCESADOR CON BUS ESPÍA Y GUÍA PEDAGÓGICA T.G 1213 MÓNICA MARÍA VELÁSQUEZ TORRES NATALIA FRANCO ALFONSO PONTIFICIA UNIVERSIDAD JAVERIANA FACULTAD DE INGENIERÍA DEPARTAMENTO DE INGENIERÍA ELECTRÓNICA BOGOTÁ 2013 IMPLEMENTACIÓN DE PROCESADOR CON BUS ESPÍA Y GUÍA PEDAGÓGICA T.G 1213 MÓNICA MARÍA VELÁSQUEZ TORRES NATALIA FRANCO ALFONSO Informe final Trabajo de grado Director Ing. FRANCISCO VIVEROS MORENO Jefe Sección técnicas digitales PONTIFICIA UNIVERSIDAD JAVERIANA FACULTAD DE INGENIERÍA DEPARTAMENTO DE INGENIERÍA ELECTRÓNICA BOGOTA 2013 2 PONTIFICIA UNIVERSIDAD JAVERIANA FACULTAD DE INGENIERÍA DEPARTAMENTO DE INGENIERÍA ELECTRÓNICA RECTOR: DECANO ACADEMICO: DECANO MEDIO UNIVERSITARIO: DIRECTOR DE CARRERA: DIRECTOR DE PROYECTO: P. JOAQUÍN EMILIO SÁNCHEZ GARCÍA, S.J. LUIS DAVID PRIETO MARTÍNEZ P. SERGIO BERNAL RESTREPO, S.J. ING. JAIRO ALBERTO HURTADO LONDOÑO ING. FRANCISCO VIVEROS MORENO ARTÍCULO 23 DE LA RESOLUCIÓN No. 13 DE JUNIO DE 1946 “La Universidad no se hace responsable de los conceptos emitidos por sus alumnos en sus proyectos de grado. Sólo velará porque no se publique nada contrario al dogma y la moral católica y porque los trabajos no contengan ataques o polémicas puramente personales. Antes bien, que se vea en ellos el anhelo de buscar la verdad y la justicia”. 3 Dedicatoria: En la culminación de este proceso queremos dedicar la finalización del mismo a Dios, que nos ha brindado todo lo requerido para avanzar en el proceso, igualmente a nuestros padres y familiares quienes nos han acompañado a lo largo de la carrera. A nuestros profesores y en especial a los directores de este trabajo que nos han brindado su ayuda y comprensión. Y por último a nosotras que hoy podemos ver atrás un largo y arduo camino del que hemos aprendido grandes y valiosas lecciones. 4 AGRADECIMIENTOS Queremos agradecer a Dios y a todas y cada una de las personas que han sido parte de nuestro proceso de aprendizaje en la universidad, sin muchas de las personas que han estado presentes, la culminación de este gran proyecto no sería posible. Especiales agradecimientos para nuestros padres y hermanos que han sabido comprendernos y apoyarnos, a nuestros directores y profesores que han sido una guía invaluable en todo el proceso. Además un reconocimiento al personal del laboratorio del departamento de electrónica que ha sido un gran apoyo, gracias por su disposición y toda la colaboración brindada para llevar a cabo el trabajo de Grado, además de todos los proyectos desarrollados a lo largo de la carrera. 5 TABLA DE CONTENIDO LISTA DE FIGURAS .................................................................................................................................. 7 LISTA DE TABLAS .................................................................................................................................... 8 INTRODUCCIÓN........................................................................................................................................ 9 OBJETIVOS ................................................................................................................................................. 9 1. MARCO TEÓRICO .......................................................................................................................... 9 1.1 EL PROCESADOR .................................................................................................................... 9 1.2 AHPL:LEANGUAJE DE PROGRAMACIÓN EN HARDWARE .......................................... 9 1.3 VHDL ....................................................................................................................................... 10 2. ESPECIFICACIONES .................................................................................................................... 10 2.1 DIAGRAMA ENTRADA-SALIDA ........................................................................................ 10 2.2 DIAGRAMA DE BLOQUES DEL PROCESADOR .............................................................. 11 2.3 INTERRUPCIONES ................................................................................................................ 14 2.4 BUS ESPÍA .............................................................................................................................. 15 2.5 MAPA DE MEMORIA ............................................................................................................ 17 2.6 FORMATOS DE INSTRUCCIÓN .......................................................................................... 18 2.7 MODOS DE DIRECCIONAMIENTO .................................................................................... 19 2.7.1 INSTRUCCIONES DE 32 BITS ................................................................................. 19 2.7.2 INSTRUCCIONES DE 16 BITS ................................................................................. 20 2.8 CONJUNTO DE INSTRUCCIONES ...................................................................................... 21 3. DESARROLLO .............................................................................................................................. 24 3.1 AHPL ........................................................................................................................................ 24 3.2 PROGRAMAS PROPUESTOS ............................................................................................... 25 3.3 VHDL ....................................................................................................................................... 25 3.3.1 ENTIDADES ............................................................................................................... 25 3.3.2 TABLAS DE CONECTIVIDAD ................................................................................ 26 3.4 PROTOCOLO DE PRUEBAS ................................................................................................. 27 3.4.1 VHDL .......................................................................................................................... 27 3.4.2 HARDWARE .............................................................................................................. 28 3.5 TARJETA DE DESARROLLO ............................................................................................... 30 4. ANÁLISIS DE RESULTADOS ..................................................................................................... 31 4.1 ANÁLISIS PARA UN PROCESADOR .................................................................................. 32 4.1.1 ANÁLISIS DE RECURSOS ....................................................................................... 32 4.1.2 ANÁLISIS DE TIEMPOS........................................................................................... 34 4.1.2.1 CICLOS DE INSTRUCCIÓN PARA EL PROCESADOR ................................. 35 4.1.2.2 ANÁLISIS DE TIEMPOS UTILIZADO QUARTUS II 9.0 ............................... 35 4.1.3 ANÁLISIS DE POTENCIA ........................................................................................ 38 4.2 RESULTADOS EN SIMULACIÓN ........................................................................................ 40 4.2.1 JERARQUÍA FINAL .................................................................................................. 40 4.2.2 RTL.............................................................................................................................. 40 4.2.2.1 RTL GENERAL ................................................................................................... 40 4.2.2.2 RTL EXPANDIDO ............................................................................................... 41 4.3 RESULTADOS EN HARDWARE .......................................................................................... 42 5. CONCLUSIONES .......................................................................................................................... 43 6. BIBLIOGRAFÍA............................................................................................................................. 45 6 LISTA DE FIGURAS Figura 1. Diagrama general: Entrada – Salida Figura 2. Diagrama de Bloques general Figura 3. Formato de Instrucción 32 bits Figura 4. Formato de Instrucción 16 bits Figura 5. Direccionamiento Directo Figura 6. Direccionamiento Indirecto Figura 7. Direccionamiento Indexado Figura 8. Direccionamiento Indexado Indirecto Figura 9. Diagrama de Jerarquía para VHDL Figura 10. Bus Espía en Modo A Figura 11. Bus Espía en Modo B Figura 12. Bus Espía en Modo C Figura 13. Tarjeta de desarrollo TARDAC Figura 14. Reporte de compilación QUARTUS II Figura 15. Reporte de recursos utilizados Figura 16. Recursos por entidad Figura 17. Reporte de Tiempo de QUARTUS II. Figura 18. Reporte de Tiempo de QUARTUS II con Cyclone III. Figura 19. Reporte QUARTUS II Tiempo de Setup ( ) Figura 20. Reporte QUARTUS II Tiempo de Hold ( ) Figura 21. Reporte QUARTUS II Tiempo Clock to Output ( ) Figura 22. Reporte QUARTUS II Tiempo pin to pin ( ) Figura 23. Reporte de Potencia Figura 24. Core Dynamic Thermal Power Dissipation Figura 25. Thermal Power Dissipation por tipo bloque Figura 26. Thermal Power Dissipation por jerarquía Figura 27. Corriente consumida por la Fuente de Voltaje Figura 28. Jerarquía Final del Procesador PHERB. Figura 29. RTL general del procesador PHERB Figura 30. RTL expandido del procesador PHERB Figura 31. Parte I Programa Figura 32. Parte II Programa Figura 33. Parte III Programa Figura 34. Parte IV Programa 7 LISTA DE TABLAS Tabla 1. Codificación Modo Bus Espía Tabla 2. Codificación Registros para Modo B de Bus Espía Tabla 3. Modo C Bus espía Tabla 4. Mapa de Memoria Tabla 5. Codificación Registro Fuente Tabla 6. Codificación modo de direccionamiento Tabla 7. Codificación Registro del operando o dato Tabla 8. Instrucciones de 32 bits para manejo de datos Tabla 9. Instrucciones de 32 bits ALU Tabla 10. Instrucciones de 16 bits ALU Tabla 11. Instrucciones de Branch Tabla 12. Instrucciones de Rotación y Desplazamiento Tabla 13. Instrucciones Especiales Tabla 14. Instrucciones de Interrupciones Tabla 15. Instrucciones de Miscelánea Tabla 16. Programa Prueba Bus Espía Tabla 17. Número teórico de registros utilizados por el procesador Tabla 18. Tiempo de Duración de las instrucciones 8 INTRODUCCIÓN En el presente documento se encuentra la recopilación de todo el trabajo desarrollado, con el propósito de contribuir al proyecto PCSIM, este proyecto de larga trayectoria en la facultad de ingeniería, que empezó a desarrollarse en el año de 1999, con la idea de realizar un programa que permitiera a los estudiantes conocer y comprender la arquitectura de un procesador. Desde ese entonces, se han venido realizando algunas modificaciones al programa, es decir varias versiones del software, además se han realizado dos versiones implementadas en hardware, con bastante éxito. En este trabajo se presenta una versión más, que permite la evolución del proyecto enfocado a dos condiciones fundamentales para el aprendizaje de arquitectura de computadores, el manejo de las interrupciones y la idea del bus espía. Se considera que la modificación de las interrupciones se hace necesaria cuando los modos planteados en la versión anterior resultan con derivaciones no deseadas al momento de ponerlas a prueba. Replantear las especificaciones del bus espía proviene de la búsqueda de simplicidad y estructura de la idea original presentada como trabajo de grado en el departamento. Así todo el proyecto se desarrolla en torno a definir unas especificaciones que cumplan con las expectativas de las ideas en pro del aprendizaje de esta área del conocimiento. El proyecto se llevó a cabo sobre la versión anterior, presentada como Binaric que correspondió a un trabajo de grado realizado en el año 2007 por Bibiana Álvarez y Nathalie Pinilla, quienes realizaron la segunda versión implementada en hardware del proyecto inicial, y cabe mencionar que el procesador será implementado siguiendo la arquitectura y el conjunto de instrucciones de las versiones anteriores, para continuar con el proyecto de PCSIM y que sea coherente con todo el desarrollo y la trayectoria académica que éste ha tenido, por ende contribuir con el objetivo pedagógico de éste gran proyecto, exclusivo de la universidad Javeriana. OBJETIVOS Desarrollar e implementar la tercera versión en hardware de PCSIM - Diseñar e implementar un sistema de visualización del estado del procesador en tiempo real, denominado bus espía. Lograr concebir especificaciones de funcionamiento claras y sencillas para el trabajo del procesador con el medio, es decir el manejo de las interrupciones. Crear un manual demostrativo, que guie al usuario mediante programas sencillos, a través del manejo adecuado del procesador y por ende facilite el aprendizaje. Realizar una descripción adecuada y correctamente documentada del procesador en AHPL (A Hardware programming language). Contribuir a la evolución del proyecto denominado PCSIM, principalmente para que sea agradable al estudiante, el trabajo con el mismo. 1. MARCO TEÓRICO 1.1 El Procesador Una de las grandes preguntas que le surge al estudiante es ¿Qué es un procesador?, como primera respuesta que se obtiene es que un procesador es la parte fundamental de un computador o como se diría en la cotidianidad, el cerebro de un computador. Aunque cabe aclarar que en la actualidad no solo se encuentran en los computadores comúnmente conocidos, sino en un sinfín de artefactos que se usan a 9 diario. Es por esto, que es de vital importancia tener una definición precisa acerca del concepto de un procesador para así entender el diseño realizado en este proyecto. Aunque si bien es cierto, el procesador es una parte fundamental, una definición técnica sería: un procesador es un sistema digital complejo encargado de realizar la ejecución de diversas instrucciones, compuesto por un conjunto de registros que almacenan datos, una unidad aritmético-lógica (ALU), una unidad de control y las diferentes interconexiones entre ellas. A lo largo de los años, las arquitecturas de cada procesador han evolucionado para obtener mayor desempeño y velocidad, sin embargo, se ha mantenido la estructura básica descrita en el párrafo anterior. Hoy en día se diseñan procesadores con mejores especificaciones para que las instrucciones que se deben ejecutar tomen el menor tiempo posible; un ejemplo de estas mejoras corresponde al procesamiento paralelo donde se unen dos o más núcleos como los es el Intel Core I3 o I5, dando a lugar a la denominada tecnología de núcleos múltiples. Éste proyecto no pretende ser un procesador de mayor velocidad o con múltiples mejoras comerciales, el objetivo principal es desarrollar un procesador para que los estudiantes interesados en el área de técnicas digitales puedan tener un acercamiento más dinámico y profundo a una arquitectura, aunque sencilla, brinde la posibilidad de explorar y entender los conceptos básicos de éste tema de que es tan apasionante. 1.2 AHPL : Lenguaje de programación de Hardware El lenguaje AHPL (A Hardware Programming Language) fue creado por los ingenieros Frederick J. Hill y Gerald R. Peterson en los años 80s. Este lenguaje surge de la necesidad de realizar una descripción sencilla y clara de un sistema digital complejo. Este lenguaje de programación utiliza una descripción sencilla con convenciones lógicas para tener una descripción cercana al hardware, este se basa principalmente en un lenguaje de transferencia de registros. Para este proyecto se contaba con alguna parte del código en AHPL, proveniente del resultado del trabajo de grado denominado Binaric, por lo tanto se siguió la sintaxis y la distribución del uso de recursos. Cabe notar que resulta de gran importancia entender en detalle el funcionamiento del AHPL, ya que esta descripción corresponde a la unidad de control del procesador, que como su nombre lo indica controla las operaciones que debe realizar. 1.3 VHDL : Lenguaje de Descripción de Hardware Después de realizar una descripción en AHPL, el siguiente gran paso corresponde a la descripción en VHDL estas siglas son el resultado de la unión entre VHSIC (Very high speed integrated circuit) y HDL (Hardware description language). Este lenguaje es de vital importancia ya que corresponde a la descripción en hardware para su posterior implementación en un dispositivo de lógica programable FPGA. Este lenguaje permite modelar y simular sistemas digitales desde un nivel bajo hasta un nivel alto, llamado también un diseño jerárquico. Hay tres niveles de descripción, el primero siendo comportamental, el segundo estructural y finalmente un nivel de descripción de flujo de datos o RTL (siglas en ingles). 2. ESPECIFICACIONES 2.1 Diagrama Entrada – Salida En el siguiente diagrama general correspondiente a la Figura 1, se observan las entradas y salidas del procesador. 10 24 CLK ADBUS RESET READ SWAIT WRITE INT PRIN MODO_ESPIA BUS_ESPIAR DBUS IACK 3 PHERB IOREQ 2 CS_ROM 5 CS_RAM 32 40 BUS_ESPIA Figura 1. Diagrama general: Entrada - Salida Las señales de entrada son: CLK: señal de reloj con una frecuencia máxima de 4MHz. Cada uno de los bloques del procesador manejan borde de subida para la respectiva carga de datos, señales de control y operaciones. RESET: señal asíncrona que lleva al procesador a su estado inicial. SWAIT: señal activa en alto, es un bit que le indica al procesador que debe esperar antes de considerar válido el dato contenido en el bus de datos DBUS [0:31], evitando que el bus tome alta impedancia sin haber entregado el dato. Esta señal se utiliza para operaciones de lectura, escritura, importación y exportación de periféricos. INT: señal asíncrona, activa en alto de un bit que le informa al procesador que hay un periférico interrumpiendo y espera a ser atendido. El periférico debe mantener esta señal hasta que el procesador le informe que lo va a atender. PRIN: señal de tres bits que actúa en los modos B, C y D de interrupciones. En el modo B informa la prioridad de los 8 periféricos que pueden interrumpir. En los modos C y D cada periférico tiene su línea de interrupción que corresponde a cada bit de esta señal. MODOESPIA: señal de dos bits por la cual el usuario elige el modo en que el bus espía trabaje. BUS_ESPIAR: señal de cinco bits por la cual el usuario elige el registro a ver en el modo B del bus espía. DBUS: es un bus bidireccional de treinta y dos bits que contiene los datos para la respectiva interconexión entre la memoria, periféricos y el procesador. Las señales de salida son: ADBUS: es un bus de veinticuatro bits que contiene la dirección de memoria o del periférico a la cual se desea acceder 11 READ: es una señal de un bit, activa en bajo, la cual indica que el dato contenido en el bus de direcciones ADBUS [0:23] corresponde a la dirección efectiva. Esta señal se utiliza para operaciones de lectura desde memoria o importación desde un periférico. WRITE: es una señal de un bit, activa en bajo, la cual establece la operación de escritura en memoria o exportación de periférico. IACK: es una señal de un bit, que le indica al periférico que está interrumpiendo que va a ser atendido. IOREQ: es una señal de un bit; cuando se encuentra en cero indica que la instrucción que se está ejecutando interactúa con la memoria, de lo contrario interactúa con un periférico. CS_ROM: es una señal de un bit que controla el ciclo de lectura de la memoria ROM. CS_RAM: es una señal de un bit que controla el ciclo de escritura de la memoria RAM. BUS_ESPIA: es un bus de 40 bits, mediante el que se observa el contenido interno de los registros junto con el paso de control en el cual se encuentra el procesador. La organización de los bits de este bus variara de acuerdo al modo que el usuario elija. 2.2 Diagrama de bloques del procesadorLa arquitectura de PHERB se basa en una arquitectura RIC de tres buses, diseñado por Frederick J. Hill y Gerald R. Peterson. En el siguiente diagrama se presenta el diagrama de bloques del procesador. Figura 2. Diagrama de Bloques general Bloque Memorias: es un bloque externo al procesador que contiene memorias ROM (solo lectura) y RAM (lectura y escritura), estas almacenan los datos y las instrucciones a ejecutar. 12 ALU: este bloque interno del procesador se encarga de realizar las operaciones aritméticas y lógicas según la instrucción, los datos se manejan en complemento a dos. De igual forma, este bloque se utiliza para incrementar o disminuir una dirección de memoria. ABUS: corresponde a un bus interno del procesador de treinta y dos bits [0:31]. Este bus interconecta la salida del registro de direcciones (MA), de instrucciones (IR) y de datos (MD) con una entrada de la unidad aritmético – lógica (ALU). BBUS: corresponde a un bus interno del procesador de treinta y dos bits [0:31]. Este bus interconecta la salida del registro acumulador (AC), contador de programa (PC), pila (SP), índice (IX), desplazamiento (SHC) y de propósito general (RPG) con la otra entrada de la unidad aritmética – lógica (ALU). OBUS: corresponde al bus de salida de la unidad aritmético – lógica (ALU), es un bus de treinta y dos bits. Por medio de este, sale el resultado de alguna operación ejecutada por la ALU. ] que recibe los datos desde el bus de datos Registro de Datos (MD): Es un registro de 32 bits [ ( ) (DBUS) o del bus de salida de la ALU , utilizado para almacenar los datos provenientes de memoria o de un periférico y los datos que van hacia memoria o hacia un periférico. Registro de Direcciones (MA): Es un registro de 24 bits [ ) y desde el bus de direcciones ( salida de la ALU ( efectiva de memoria o de periférico. ] que recibe los datos desde el bus de Registro de Instrucciones (IR): Es un registro de 32 bits [ ( ). salida de la ALU Durante el ciclo de fetch, carga el dato con la instrucción almacenado en el registro de datos para ser decodificada y luego proceder a su ejecución. ] que recibe los datos desde el bus de Contador de programa ( ) Es un registro de 24 bits [ ) que almacena e incrementa la dirección de la siguiente instrucción a salida de la ALU ( ejecutar. La dirección de arranque corresponde a . ] que recibe los datos desde el bus de Registro Acumulador (AC): Es un registro de 32 bits [ ). Por medio de este registro se realizan operaciones y se guardan de forma salida de la ALU ( temporal. Registros de Propósito general (RPG): Son seis registros , , , , y ; cada uno de 32 ]. Se utilizan para almacenar datos provenientes del bus de salida de la ALU ( ). bits [ ], recibe los datos desde el bus de Registro Puntero de pila (SP): Es un registro de 24 bits [ ( ). salida de la ALU Este se encarga de almacenar la dirección de memoria desde la cual se guardan las direcciones a las cuales se debe retornar después de una subrutina o de una interrupción, como también se almacenan los datos que el usuario desee. ] , recibe los datos desde el bus de salida de la Registro Índice (IX): Es un registro de 24 bits [ ( ). ALU Este registro contiene un dato que se suma con los 24 bits menos significativos del registro de instrucciones para la ejecución de una instrucción con direccionamiento indexado. Registro de Estados (SR): Es un registro de 10 bits [0:9] que contiene siete banderas, cada una de un bit; estas indican el estado y las operaciones del procesador, además tiene 3 bits que indican la 13 ] que recibe los datos desde el bus de ). Se utiliza para colocar la dirección prioridad de la interrupción que el procesador debe atender, esto se utiliza para los modos B, C y D. A continuación se presenta la organización de los bits en el registro: [ ] Indica si el resultado de una operación es cero. [ ] Indica si hubo acarreo. [ ] Indica si hubo desbordamiento en una operación de suma o resta. [ ] Indica si el número es negativo. [ ] Indica si la última instrucción ejecutada era de 16 bits. [ ] Indica si se habilitan las interrupciones. [ ] Indica la prioridad de la interrupción a ejecutar, utilizado en modo B, C y D. [ ] Indica ejecución normal de la instrucción. ] que recibe los datos Registro de Rotación y Desplazamiento (SHC): Es un registro de 5 bits [ ) e indica el número de movimientos que faltan por realizar en el del bus de salida de la ALU ( registro acumulador para que se termine de ejecutar la instrucción de rotación o desplazamiento. El máximo de movimientos permitido es de treinta y dos bits. ], recibe los datos desde el bus de salida Registro de Máscara (MR): Es un registro de dos bits [ ) y contiene el modo de interrupción el procesador debe ejecutar cuando un de la ALU ( periférico este interrumpiendo. Registro de Interrupciones (INTR): Es un registro de tres bits, utilizado para el modo D de interrupciones. Este registro cambia la prioridad dinámicamente. Registro Bus Espía (RBE): Es un registro de tres bits [0:2] utilizado para guardar el modo en que actúa el bus espía, de esta forma, de acuerdo al bit que se encuentre en uno activara los datos que se deban mostrar. 2.3 Interrupciones El módulo de entrada salida interrumpirá al procesador para solicitar su servicio cuando esté preparado para intercambiar datos con él. La serie de eventos en hardware cuando sucede una interrupción son: 1. El dispositivo envía una señal de interrupción al procesador. 2. El procesador termina la ejecución de la instrucción en curso antes de responder a la interrupción. 3. El procesador comprueba si hay interrupciones, determina que hay una y envía una señal de reconocimiento. La señal de reconocimiento hace que el dispositivo desactive su señal de interrupción. 4. El procesador se prepara para transferir el control a la rutina de interrupción. Debe guardar la información necesaria para continuar el programa en curso en el punto en el que se interrumpió. La información que se debe guardar es el estado del procesador es decir almacenar la información necesaria para que el procesador pueda continuar la ejecución previa a la interrupción, además dependerá del usuario y la posición de la siguiente instrucción a ejecutar. 5. El procesador carga el contador de programa con la posición de inicio del programa de gestión de la interrupción solicitada. Puede haber un solo programa, uno por cada tipo de interrupción, o uno por cada dispositivo y cada interrupción. Si hay más de una rutina el procesador debe determinar a qué programa llamar. 6. Se deben guardar los contenidos de los registros necesarios para el procesador, dado que estos registros pueden ser utilizados en la rutina de interrupción. 14 7. La rutina de interrupción puede continuar 8. Cuando el proceso de la interrupción ha terminado, los valores de los registros almacenados se recuperan de la pila. 9. Recuperar los valores del contador de programa. Después de un largo proceso de ideas acerca de los distintos modos de interrupciones que el procesador puede manejar, finalmente, se llegó a los siguientes cuatros modos A, B, C y D, descritos a continuación: Modo A Este modo consiste en una sola línea de interrupción, por la cual solo interrumpe un periférico a la vez, y es auto-vectorizado (La rutina requerida para la atención del periférico está contenida en memoria y esta previamente direccionada). En este modo el periférico envía la señal de requerimiento de atención (IRQ) por la línea INT, el procesador al recibir la señal, almacena la información requerida en la pila, para poder detenerse y luego le envía al periférico la señal de reconocimiento (IACK), en seguida éste es atendido con el salto a la subrutina correspondiente a este modo de interrupción, que se encuentra en la posición 000000h de memoria. Al finalizar la subrutina de atención, el procesador vuelve a la instrucción, en la que se encontraba antes de recibir la señal de interrupción, cargando la información de la pila nuevamente en los registros, para continuar con la ejecución del programa. Cabe aclarar que la primera instrucción del procesador no puede ser interrumpida. Modo B Este modo se compone de tres líneas de interrupción, una por cada periférico y este modo es vectorizado (La rutina de atención debe ser introducida a través del bus de datos). La prioridad se define mediante una tabla de prioridad utilizando los bits 6 a 8 del registro de estados, en este modo el periférico envía la señal de interrupción a través de su línea respectiva y un hardware interno procesa la interrupción, da la prioridad y envía la señal de reconocimiento, dependiendo de la cantidad de periféricos que lo requieran los atiende uno por uno, cada periférico entregara por el bus de datos la dirección de la rutina a ejecutar. El procedimiento que realiza el periférico por cada atención es igual al del modo A. Modo C Este modo consiste en tres líneas de interrupción, mediante las cuales pueden interrumpir distintos periféricos, la cantidad permitida por el número de bits de la máscara, en este caso la máscara tendrá tres bits, es decir podrán tener acceso 8 periféricos. El periférico enviara la señal de requerimiento a través de la línea INT y la máscara por otra línea PRIN, lo que permite decodificar la prioridad y el vector de las rutinas de interrupción que correspondan. La rutina de atención por parte del procesador será igual que en los modos descritos anteriormente. Modo D Este modo consiste en tres líneas de interrupción, una para cada periférico. Cada periférico envía su señal de interrupción por la línea INT y tendrá asignada una línea de PRIN para que el procesador tenga conocimiento de cual periférico debe atender primero. Este procesador cuenta con un registro INTR [0:2] de tres bits respectivamente que decide que periférico debe atender primero en caso de que haya más de uno interrumpiendo para después cambiar la prioridad de atención de una forma cíclica. El objetivo de este modo es que la prioridad cambie para que todos los periféricos tengan la posibilidad de ser atendidos. 15 100 010 010 100 001 001 El objetivo es recalcar que la atención a todos los periféricos es una de las actividades más relevantes en el uso de los procesadores, por ejemplo actualmente al comprar un computador se tiene una gran variedad de posibles periféricos y el procesador debe estar en la capacidad de atenderlos a todos y de cumplir las expectativas del usuario. Por ejemplo así como se creería que debe tener mayor prioridad el disco sobre la impresora, si el disco interrumpe todo el tiempo la impresora jamás podrá ser atendida y el usuario no tendrá la posibilidad de utilizar la impresora como periférico. Es por esta razón que se crea este modo de interrupción. 2.4 Bus Espía El bus espía es una función del procesador en la que el usuario dispone de un bus de 40 bits, que le permite revisar la secuencia de ejecución de las instrucciones. Ésta función permite visualizar un paso de control, y simultáneamente el contenido de un registro o ver la transferencia de los datos en cada registro de acuerdo a la instrucción que se va a ejecutar. Para elegir el modo del bus espía, el usuario cuenta con una entrada denominada MODOESPIA [0:1] codificada de la siguiente forma: MODO A B C D MODOESPIA[0] MODOESPIA[1] 0 1 1 0 1 1 0 0 Tabla 1. Codificación Modo Bus Espía A continuación se describe cada uno de los modos en que el bus espía puede trabajar: Modo A En este modo se pretende visualizar la secuencia de la máquina de control para que el usuario revise si el procesador está activando los pasos adecuados de cada instrucción. Para activar este modo, el usuario ingresara la codificación 01 por medio de un dip-switch. Al activarse este modo, el bus espía se mostrará de la siguiente forma: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Codificación paso de control En decimal Modo B El objetivo de éste modo es hacer posible la observación de la secuencia de la máquina de control y el contenido de algún registro. Para activar este modo, el usuario ingresara por medio MODO_ESPIA “10” e 16 ingresará por BUS_ESPIAR la codificación del registro que desea ver. En este modo se verá al mismo tiempo el paso de control y el contenido de un registro de tal forma, que el usuario solo podrá seleccionar un registro para su visualización. La organización de los bits en el bus espía se realiza de manera que en los ocho bits más significativos se cargue la codificación en binario del estado en el que se encuentra el procesador y en los treinta y dos bits restantes se cargará el contenido del registro seleccionado, así: 0 0 0 0 0 0 0 0 0 Contenido del Registro [8:39] Codificación paso de control En decimal La codificación para cada uno de los registros se da en la siguiente tabla: REGISTRO BUS_ESPIAR [0] BUS_ ESPIAR [1] BUS_ ESPIAR [2] BUS_ ESPIAR [3] BUS_ ESPIAR [4] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 0 0 1 1 1 1 0 0 0 0 1 1 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 REGISTRO DE DATOS(MD)[0:31] REGISTRO DE DIRECCIONES(MA)[0:23] CONTADOR PROGRAMA(PC)[0:23] REGISTRO ACUMULADOR(AC)[0:31] PUNTERO DE PILA(SP)[0:23] REGISTRO INDICE(IX)[0:23] REGISTRO DE ESTADOS(SR)[0:9] REGISTRO ROTAC Y DESPLA(SHC)[0:4] REGISTRO DE MASCARA(MR)[0:1] RA(RPG)[0..31] RB(RPG)[0..31] RC(RPG)[0..31] RD(RPG)[0..31] RE(RPG)[0..31] RF(RPG)[0..31] REGISTRO DE INSTRUCCIONES[0:32] Tabla 2. Codificación Registros para Modo B de Bus Espía Modo C La activación de este modo se hará ingresando “11” por medio de MODO_ESPIA. El usuario al elegir este modo podrá ver la transferencia de los datos entre los registros de acuerdo a la instrucción elegida, como también el paso de control en el que se encuentra. Se debe aclarar que en un paso en los que actúan dos o más registros se deberá introducir por medio de BUS_ESPIAR la codificación del registro que se desea ver, permitiendo así una mayor flexibilidad para el modo. La organización de los bits del bus espía se realiza de la misma forma que en el modo B. En la siguiente tabla se presenta los registros que se muestran en cada paso: PASO 1 2 3 4 5 6 7 REGISTRO MA ADBUS ADBUS MD PC - PASO 31 32 33 34 35 36 37 REGISTRO ADBUS ADBUS MD MD SR PC SP 17 PASO 61 62 63 64 65 66 67 REGISTRO DBUS DBUS SR SR MR SR PASO 91 92 93 94 95 96 97 REGISTRO MA ADBUS ADBUS MD - 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 MA MD IR MD MA ADBUS ADBUS MD MA ADBUS ADBUS MD AC PC IR AC ADBUS ADBUS 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 MD ADBUS ADBUS ADBUS PC MD Codificación SHC AC SHC PC IR IR ADBUS ADBUS MD AC AC Tabla 3. Modo C Bus espía 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 SP MD ADBUS ADBUS SP ADBUS ADBUS MD PC AC MA ADBUS MD PC SR SR ADBUS ADBUS MD 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 SP MA PC SP MA SR DBUS DBUS SP ADBUS ADBUS MD SR SP ADBUS ADBUS MD PC - MD Por ejemplo, si el usuario elige este modo ocurrirá lo siguiente: cuando el procesador llegue al paso número “10” mostrará el registro de direcciones (MA), luego al llegar al 13 mostrará el registro (MD), y así sucesivamente. De la Tabla 3, se observa que el paso “44” tiene el nombre “codificación” esto se debe a que precisamente en ese estado de control varios registros interactúan, de tal forma, que el usuario deberá ingresar por medio de BUS_ESPIAR el registro que desea ver para poder observar que sucede en el paso y en el registro, es decir ambas condiciones se deben cumplir. La codificación de este registro corresponde a la misma utilizada por el Modo B, Tabla 2 Codificación Registros para Modo B de Bus Espía. Modo D Si el usuario no desea utilizar el bus espía entonces deberá dejar MODO_ESPIA en “00” de tal forma, que el bus espía se encontrará inactivo hasta que el usuario ingrese por esta señal de dos bits el modo en que desea estar. 2.5 Mapa de Memoria El mapa de memoria corresponde a una tabla de datos que indica precisamente como está organizada la memoria; en la tabla se observa el tamaño total de la memoria al igual que se dan las posiciones asignadas para cada operación. En la siguiente tabla se observa el mapa de memoria para el procesador. DIRECCIÓN 000000H 000001H 000002H 000003H 000004H 000005H 000006H 000007H 000008H DESCRIPCIÓN Dirección de la rutina de Interrupción para la Máscara "000" Dirección de la rutina de Interrupción para la Máscara "001" Dirección de la rutina de Interrupción para la Máscara "010" Dirección de la rutina de Interrupción para la Máscara "011" Dirección de la rutina de Interrupción para la Máscara "100" Dirección de la rutina de Interrupción para la Máscara "101" Dirección de la rutina de Interrupción para la Máscara "110" Dirección de la rutina de Interrupción para la Máscara "111" Dirección de memoria de la primera instrucción a ejecutar 18 000009H a 0003FFH 000400H a 00043FH Direcciones para manejo del usuario Direcciones de los periféricos utilizados en Importar 000440H a 00047FH 000480H a 0004BFH 0004C0H a 0004FFH 000500H a FFFFFFH Direcciones de los periféricos utilizados en Exportar Direcciones para manejo del usuario Direcciones de las instrucciones después de realizar Reset por Software(RTS) Direcciones para manejo del usuario Tabla 4. Mapa de Memoria 2.6 Formatos de Instrucción Debido a que PHERB al igual que BINARIC manejan dos tipos de instrucciones, 32 y 16 bits respectivamente; a continuación se presenta el formato de instrucción para cada una. Instrucciones de 32 bits 0 1 2 Opcode 3 4 1 5 6 Dir [8………..31] Dirección 7 Figura 3. Formato de Instrucción 32 bits [0:3] Corresponde al código de operación de cada instrucción. [4] Este bit en uno significa que la instrucción es de 32 bits. [5:7] Estos bits corresponden a la codificación del modo de direccionamiento. [8:31]Corresponden a la dirección donde se encuentra el operando. Instrucciones de 16 bits 0 1 2 3 Opcode 4 0 5 6 7 8 9 10 11 12 13 14 1 AD1 MODE AD2 Figura 4. Formato de Instrucción 16 bits 15 [ ] Corresponde al código de operación de cada instrucción. [ ] Este bit en cero indica que la instrucción es de 16 bits. [ ] Bit utilizado para futura expansión [ ] Especifica la codificación del registro que se utiliza como destino para el resultado de una operación, como también se utiliza como el registro donde se encuentra el dato a ser utilizado para ciertas operaciones como la suma. [ ] Especifica el modo de direccionamiento sea registro fuente o dato inmediato. [ ] Especifica la codificación de un registro o un dato inmediato para ser operado. 2.7 Modos de direccionamiento 2.7.1 Instrucciones de 32 bits 19 Inmediato (100): El operando se da en los 24 bits menos significativos, es útil para inicializar los registros. Directo (000): Los 24 bits menos significativos de la instrucción contiene la dirección efectiva de memoria donde se encuentra el operando. Opcode Dirección Operando Figura 5. Direccionamiento Directo Indirecto (001): Los 24 bits menos significativos de la instrucción contiene la posición de memoria en donde se encuentra la dirección efectiva donde está el operando. Opcode Dirección Dirección Operando Figura 6. Direccionamiento Indirecto Indexado (010): Los 24 bits menos significativos de la instrucción se suman con el contenido del registro índice ( ), teniendo como resultado la dirección efectiva donde se encuentra el operando. Opcode Dirección + Operando IX Figura 7. Direccionamiento Indexado Indexado Indirecto (011): Los 24 bits menos significativos de la instrucción se suman con el contenido del registro índice ( ) dando como resultado la posición de memoria de la nueva instrucción de 32 bits, donde los 24 bits menos significativos de esta instrucción corresponden a la dirección efectiva en donde se encuentra el operando. Opcode Dirección + IX Dirección Operando Figura 8. Direccionamiento Indexado Indirecto 2.7.2 Instrucciones de 16 bits Las instrucciones de 16 bits manejan dos tipos de direccionamiento, inmediato y registro fuente. El primero indica en la instrucción el operando a utilizar, mientras que el segundo modo indica de cual registro se debe tomar el operando para realizar la instrucción. A continuación se presentan las codificaciones para cada registro: 20 [ ] Especifica la codificación del registro que se utiliza como destino para el resultado de una operación, como también se utiliza como el registro donde se encuentra el dato a ser utilizado para ciertas operaciones como la suma. Los registros a los que se puede hacer referencia con estos bits son: 0000 Registro Acumulador 1000 Registro Índice 1111 Registro puntero de pila 0001 Registro de propósito general 0010 Registro de propósito general 0011 Registro de propósito general 0100 Registro de propósito general 0101 Registro de propósito general 0110 Registro de propósito general Tabla 5. Codificación Registro Fuente [ ] Especifica el modo de direccionamiento sea registro fuente o dato inmediato. 00 Registro fuente 11 Dato Inmediato Tabla 6. Codificación modo de direccionamiento [ ] Especifica la codificación de un registro o un dato inmediato para ser operado. 0000 Registro Acumulador 1000 Registro Índice 1111 Registro puntero de pila 0001 Registro de propósito general 0010 Registro de propósito general 0011 Registro de propósito general 0100 Registro de propósito general 0101 Registro de propósito general 0111 Registro de propósito general Tabla 7. Codificación Registro del operando o dato Es importante tener en cuenta que si se desea realizar un programa con instrucciones de 16 y 32 bits simultáneamente, la instrucción de 16 bits para ser seguida por una de 32 bits debe tener en sus bits menos significativos una instrucción de NOP, a menos que sean dos de 16 bits en una misma dirección. 2.8 Conjunto de Instrucciones El procesador cuenta con las siguientes instrucciones: INSTRUCCIONES DE 32 BITS MANEJO DE DATOS 1 INSTRUCCIÓN DESCRIPCIÓN MVF Mover hacia memoria 2 INC Incremento 3 DEC Decremento MODO Directo Indirecto Indexado Indexado Indirecto CICLOS 13 18 13 18 BANDERAS - Directo Indirecto Indexado Indexado Indirecto Directo Indirecto Indexado Indexado Indirecto 15 19 15 19 15 19 15 19 - 21 4 JMP 5 JSR Directo Indirecto Indexado Indexado Indirecto Directo Salto a Indirecto subrutina Indexado Indexado Indirecto Tabla 8. Instrucciones de 32 bits para manejo de datos 18 22 18 22 12 16 12 16 - CICLOS 16 19 BANDERAS - Indexado Indexado Indirecto Inmediato Directo Indirecto Indexado Indexado Indirecto Inmediato Directo Indirecto Indexado Indexado Indirecto Inmediato Directo Indirecto Indexado Indexado Indirecto Inmediato Directo 15 19 12 16 19 15 19 12 16 19 15 19 12 16 19 15 19 12 16 Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Indirecto Indexado Indexado Indirecto Inmediato Directo Indirecto Indexado Indexado Indirecto Inmediato Directo Indirecto Indexado Indexado Indirecto Inmediato Directo Indirecto Indexado Indexado Indirecto Inmediato Directo Indirecto Indexado Indexado Indirecto Inmediato 19 15 19 12 16 19 15 19 12 16 19 15 19 12 16 19 15 19 12 16 19 15 19 12 Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Salto incondicional INSTRUCCIONES DE 32 BITS MANEJO DE DATOS INSTRUCCIÓN DESCRIPCIÓN MODO Directo Indirecto 6 MVT Mover desde memoria 7 CMP Comparación aritmética 8 SBC Resta con acarreo 9 SUB Resta 10 ADC Suma con acarreo 11 ADD Suma 12 ORA OR lógica 13 AND AND lógica 14 XOR XOR lógica 22 15 BIT 16 INSTRUCCIÓN MVT 17 CMP 18 SBC 19 SUB 20 ADC 21 ADD 22 ORA 23 AND 24 XOR 25 BIT Directo Indirecto AND Indexado comparación Indexado Indirecto Inmediato Tabla 9. Instrucciones de 32 bits ALU INSTRUCCIONES DE 16 BITS MANEJO DE DATOS DESCRIPCIÓN MODO Mover desde Registro Fuente memoria Inmediato Comparación Registro Fuente aritmética Inmediato Resta con Registro Fuente acarreo Inmediato Resta Registro Fuente Inmediato Suma con Registro Fuente acarreo Inmediato Suma Registro Fuente Inmediato OR lógica Registro Fuente Inmediato AND lógica Registro Fuente Inmediato XOR lógica Registro Fuente Inmediato AND Registro Fuente comparación Inmediato Tabla 10. Instrucciones de 16 bits ALU 16 19 15 19 12 Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N CICLOS 14 14 14 14 14 14 14 14 14 14 14 14 14 14 14 14 14 14 14 14 BANDERAS Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N Z,C,V,N INSTRUCCIONES DE BRANCH 26 27 28 29 30 31 32 33 34 35 36 37 38 39 INSTRUCCIÓN BEQ BNE BPL BMI BCS BCC BVS BVC BSR BRA BLT BLE BGE BGT 40 41 42 43 44 45 46 INSTRUCCIÓN LSR ASR SHL ROR RRC ROL RLC DESCRIPCIÓN Bandera de cero activa, en uno Bandera de cero inactiva, en cero Bandera de negativo inactiva, en cero Bandera de negativo activa, en uno Bandera de acarreo activa, en uno Bandera de acarreo inactiva, en cero Bandera de desbordamiento activa, en uno Bandera de desbordamiento inactiva, en cero Salto a subrutina Salto incondicional Salto condicional Salto si XOR entre Nff y Vff es cero Salto si XOR entre Nff y Vff es cero Salto si XOR entre Nff y Vff es uno Tabla 11. Instrucciones de Branch CICLOS 13 13 13 13 13 13 13 13 18 13 13 13 13 13 BANDERAS - INSTRUCCIONES ROTACIÓN Y DESPLAZAMIENTO DESCRIPCIÓN Desplazamiento a la derecha lógico Desplazamiento a la derecha aritmético Desplazamiento a la izquierda Rotación a la derecha Rotación a la derecha con carry Rotación a la izquierda Rotación a la izquierda con carry Tabla 12. Instrucciones de Rotación y Desplazamiento 23 CICLOS 15 15 15 15 15 15 15 BANDERAS C C C C 47 48 49 INSTRUCCIÓN NOP HLT RST INSTRUCCIONES ESPECIALES DESCRIPCIÓN No Haga ninguna instrucción Detiene el procesador Acceso a 63 direcciones distintas Tabla 13. Instrucciones Especiales CICLOS 14 14 14 BANDERAS - 50 51 52 53 54 55 56 57 58 INSTRUCCIÓN CIE SIE RTI IMP EXP IM-A IM-B IM-C IM-D INSTRUCCIONES DE INTERRUPCIONES DESCRIPCIÓN Desactivar bandera interrupción Activar interrupción Retorno de interrupción Importar periférico Exportar periférico Modo A interrupciones Modo B interrupciones Modo C interrupciones Modo D interrupciones Tabla 14. Instrucciones de Interrupciones CICLOS 14 14 19 18 17 14 14 14 14 BANDERAS - 59 60 61 62 63 64 INSTRUCCIÓN CLC SEC PSH POP RTS MSI INSTRUCCIONES DE MISCELÁNEA DESCRIPCIÓN Poner en cero bandera de acarreo Poner en uno bandera de acarreo Poner en pila Sacar de pila Retorno de subrutina Mover bits más significativos Tabla 15. Instrucciones de Miscelánea CICLOS 14 14 17 18 18 14 BANDERAS - 3. DESARROLLO 3.1 AHPL Como se explicó anteriormente, el AHPL describe la sección de control y de datos de un procesador, es por esto, que fue de gran importancia este paso para el diseño satisfactorio de PHERB. El punto de partida de la descripción en hardware consistió en la asignación de los valores iniciales de cada una de las señales descritas en la sección 2.1, estas corresponden a los pasos uno a seis del AHPL; en éstos, se carga la dirección de la rutina de principal como los valores iniciales de los bits del registro de estados (SR). A continuación se presenta el inicio del procesador en AHPL: Inicio del AHPL 1. [( ) (̅̅̅̅̅̅̅̅̅ )] Señales de Salida Señales de salida Inicio del procesador Carga el contador de programa 2. 3. Se carga la dirección de la rutina principal Señales de Salida Señales de Salida Se carga la dirección de la rutina principal 4. Se carga la dirección de la rutina principal [( ) (̅̅̅̅̅̅̅̅̅ )] Espera validez del dato contenido en el DB 24 5. [ Se carga la dirección de la rutina principal Dirección efectiva de la rutina principal Se carga el registro de estados Señal de lectura Se carga el contador de programa Señales de Salida Señales de Salida ] [ 6. ] Cabe aclarar que el punto de partida del AHPL fue tomada de BINARIC ya que debe haber una correspondencia en ambos proyectos como también con el software PCSIM. Al estudiar el AHPL de BINARIC se encontraron algunas falencias que fueron corregidas utilizando el AHPL dado por Fredrick J. Hill y Gerald R. Peterson en el libro “Digital Systems: Hardware Organization and Design”, así como también, se realizaron las modificaciones adecuadas en los temas principales que se manejaron, las interrupciones y el bus espía. El AHPL completo contiene 118 pasos de control. El documento se encuentra en el Anexo A: AHPL PHERB. 3.2 Programas Propuestos Se realizaron algunos programas teniendo en cuenta que este proyecto tiene un fin altamente académico de enseñanza, donde se probaron todas las instrucciones del procesador encontrando un buen funcionamiento. 3.3 VHDL Después de realizar la descripción en AHPL y teniendo una claridad en la estructura del procesador, se inició la descripción en VHDL (Very High-Level Design Hardware), este lenguaje de descripción permite el acceso a la herramienta de simulación de sistemas digitales Quartus II de ALTERA, la cual permite simular el funcionamiento del procesador por medio de diagramas de tiempos, realizando así una primera comprobación del sistema. De igual forma, para este proyecto se tuvo acceso a la programación en VHDL de BINARIC, sin embargo, al realizar un estudio, se encontró que es una programación más avanzada ya que principalmente se basó en sentencias concurrentes como when, else, if, case entre otras. Debido a este tipo de programación y teniendo en cuenta que uno de los principales objetivos de este proyecto es la enseñanza de la materia, se decidió realizar una nueva descripción en VHDL más organizada y sencilla, buscando dar facilidad al estudiante. En la siguiente figura se encuentra la jerarquía utilizada para el desarrollo en VHDL. PHERB UNIDAD_DATOS UNIDAD_CONTROL SALIDA DBUS ALU REGISTRO 2 INC AND REGISTRO 3 DEC BIT REGISTRO 5 RESTA XOR REGISTRO 10 SUMA OR REGISTROS MUX_ABUS MUX_BBUS SALIDA ADBUS CONTROL FULL_ADDER REGISTRO 24 ROT_DES REGISTRO 32 Figura 9. Diagrama de Jerarquía para VHDL 25 SIGNALS UNIDAD_ESPIA RBE REGISTROS BE ESTADOS En el Anexo B: VHDL PHERB se encuentra documentado entidad por entidad. 3.3.1 Entidades PHERB Esta entidad corresponde a la unidad principal de implementación en el lenguaje VHDL, es decir corresponde a la entidad de mayor jerarquía, de tal forma que contiene las entradas y salidas del procesador ya definidas en la sección 2.3 de este documento. UNIDAD_DATOS La unidad de datos corresponde a la entidad que recibe los datos para realizar operaciones de almacenamiento, operaciones aritméticas o lógicas y donde posteriormente serán guardados los resultados de cada una de estas. De acuerdo a esta descripción se concluye que esta entidad se encarga de distribuir todos los datos hacia los registros y hacia la unidad aritmético-lógica (ALU). Como se puede observar en la Figura 9, esta unidad se compone de los siguientes bloques: Registros: como su nombre lo indica se refiere a los registros donde se almacenan las operaciones y donde se distribuyen los datos de acuerdo a las instrucción que se va a ejecutar, como también el estado de control indicado. Este bloque está compuesto por registros de 2, 3, 5, 10, 24 y 32 bits respectivamente. Mux_ABUS: corresponde a un multiplexor que recibe las salidas de los registros de direcciones, datos e instrucciones, de tal forma que dependiendo de la instrucción y del paso de control, se cargará el dato en el BUS A de la ALU. Mux_BBUS: corresponde a un multiplexor que recibe las salidas de los registros acumulador, índice, pila, contador de programa, propósito general, rotación y desplazamiento y máscara, de tal forma que dependiendo de la instrucción y del paso de control, se cargará el dato en el BUS B de la ALU. Salida_ADBUS: este bloque corresponde a la lógica de salida de acuerdo al estado de control para que el bus de direcciones tome el contenido del registro de direcciones; en AHPL, esta operación se evidencia de la siguiente forma: ADBUS=MA. Salida_DBUS: este bloque corresponde a la lógica de salida de acuerdo al estado de control para que el bus de datos tome el contenido del registro de datos; en AHPL, esta operación se evidencia de la siguiente forma: DBUS=MD. ALU: es la unidad que se encarga de ejecutar operaciones aritméticas o lógicas, como se observa en la Figura 2, la ALU recibe los datos que provienen de los buses A y B. Se compone de los siguientes sub-bloques: AND, BIT, OR, XOR, Incremento, Decremento, Rot_Des, Resta y Sumador. 26 UNIDAD_CONTROL Esta unidad corresponde a la máquina de estado, se encarga de decodificar las instrucciones, así como también envía las señales necesarias para efectuar cada una de las instrucciones en la unidad de datos. Se compone de los siguientes sub-bloques: control, signals y RBE. UNIDAD_ESPIA Este bloque corresponde al manejo del bus espía, a él entran todas las salidas de cada uno de los registros, de tal forma, que dependiendo del modo que el usuario elija se cargara en el bus los datos correspondientes. Se compone de las sub-unidades Registros_BE y Estados. 3.3.2 Tablas de conectividad Una de las ayudas fundamentales a la hora de hacer una descripción hardware en VHDL son las tablas de conectividad, éstas son una herramienta que conecta las entidades e instancias, es decir conectan las señales de entrada y salida de cada bloque. Son de gran utilidad ya que los nombres dados a cada entidad difieren entre ellas, resulta útil utilizar estas tablas para mayor claridad en la conexión de cada uno de los bloques como también a la hora de depurar errores. Estas tablas se presentan en el Anexo C: Tablas de Conectividad. 3.4 Protocolo de pruebas 3.4.1 VHDL En esta sección se muestran las distintas pruebas que se realizaron para la verificación del funcionamiento del procesador PHERB. Las pruebas en VHDL se realizaron con la ayuda de la implementación de memoria ROM y RAM para verificar tanto la lectura de datos como la escritura. Teniendo en cuenta el diagrama de jerarquía dado en la Figura 9, se realizaron las pruebas en VHDL en el siguiente orden. a. Registros: se probó cada uno de los registros por separado para verificar la carga de los datos, como se dijo anteriormente, cada uno de los registros se carga con los datos cuando hay borde de subida. b. ALU: Sumador: el sumador se realizó con lógica combinatoria utilizando un full adder hecho con compuertas XOR. Aunque es un sumador lento debido a la propagación del carry a lo largo de todos los bits, se considera que es adecuado para la enseñanza de la materia, se realizaron diferentes sumas con este bloque comprobando su funcionamiento. Sin embargo, si el estudiante desea profundizar más puede optar por realizar simulaciones utilizando la carpeta IEEE.std_logic_unsigned.all y el sumador “+”. Resta: este bloque utiliza un sumador de 32 bits, teniendo en cuenta que un operando se encuentra en complemento base dos. Al igual que el sumador, se realizaron diferentes operaciones para comprobar su funcionamiento. XOR, OR, AND, BIT: se realizaron las pruebas con distintos operandos para verificar el buen funcionamiento. Incremento: utiliza un sumador de 32 bits donde un operando equivale a un “1” (decimal). Al igual que los demás bloques se realizaron diversas operaciones. Decremento: utiliza un sumador en complemento base dos donde un operando equivale a 27 un “1” (decimal). Al igual que los demás bloques se realizaron diversas operaciones. Rot_Des: corresponde a la unidad de rotación y desplazamiento, se comprobó satisfactoriamente su funcionamiento. c. Máquina de control: la realización de la máquina de control se basó en una máquina one-hot (un solo paso a la vez) de 118 pasos que cambia de estado en cada borde de subida. Primero, se probaron las instrucciones donde se aprecia que cada una de ellas siguiera la secuencia adecuada de acuerdo al AHPL, y se verificó que las señales de control se activaran en los pasos adecuados; estas señales corresponden a los bloques Signals y RBE, donde el primero, contiene las señales de lectura, escritura, entre otras, y el último corresponde a un registro de tres bits que guarda el modo de bus espía que el usuario eligió. Con estas pruebas se verificó el funcionamiento de las señales de control para las memorias. En el Anexo D: Pruebas Máquina Control, se encuentran los programas realizados. d. Registros_BE y Estados: Registros_BE corresponde a la lógica combinatoria del bus espía, esto se refiere al contenido del registro que se debe cargar en el bus espía de cuarenta (40) bits. Esta carga se realiza de acuerdo al paso de control y la codificación según sea el modo. Estados corresponde a la codificación en binario de cada estado de control, de tal forma que si el procesador se encuentra en el paso número dos, el bus espía en sus ocho bits más significativos mostrará “00000010”. Se probó cada uno de los modos del bus espía con diferentes codificaciones. A continuación se presenta una simulación para cada modo del bus espía mediante la realización de un programa pequeño. El programa consiste en mover desde memoria el número “10” al registro acumulador, este dato transferirlo al registro de propósito general RF, realizar la operación SUB (resta) inmediata entre ambos registros y finalmente, congelar el procesador. Nombre del Archivo: PruebaControl1.vwf Nombre del Archivo Memoria: PruebaBE1.mif INSTRUCCIÓN MVT Inmediato MVT RF,AC SUB AC,RF HLT REGISTRO Acumulador AC Registro PG RA Datos MD BINARIO HEXADECIMAL 00101100000000000000000000001010 2C00000A 0010010110000000 0001010000000110 25801406 110001000100 C4400000 BINARIO HEXADECIMAL 00011 03 01001 09 00000 00 Tabla 16. Programa Prueba Bus Espía En el Modo A del bus espía solo se muestra los estados de control que se activan. 28 EXECUTE 16,25 43,44,52,53 43,44,52 48,50 MVT inm, AH MVT RF, AC; SUB AC, RF HLT Figura 10. Bus Espía en Modo A En la Figura 10 se observa que el procesador está ejecutando los pasos adecuados para la instrucción, así como también solo está mostrando los estados de control ya que en el vector “Registro_BE” no muestra nada así el “BUS_ESPIAR” este activo. A continuación se muestra el Modo B de bus espía donde se puede observar el contenido interno del registro que el usuario elige. MVT inm, AH MVT RF, AC SUB AC,RF HLT Figura 11. Bus Espía en Modo B Para este modo, ya se observa el contenido de los registros, en este caso RF y AC; en 4.16 [µs] el estado “25” se encuentra activo y por el vector “Registro_BE” se observa el contenido del registro acumulador ya que por “BUS_ESPIAR” se ingresó la codificación para observarlo, efectivamente este registro toma el número “10”, luego el procesador regresa a “fetch” para leer la nueva instrucción, cuando llega al estado “13” el registro de datos MD toma la instrucción como se observa en 6.08 [µs]; el procesador detecta que es una instrucción de 16 bits y va al paso “43” y en el paso “44” se transfiere el dato al registro RF como 29 se observa en 7 [µs], luego se debe leer la segunda mitad de la instrucción que corresponde a la operación de SUB inmediata entre ambos registros; el procesador regresa al estado “44” donde se realiza la operación y muestra por el vector “Registro_BE” el resultado que corresponde al número “0” en 8.32 [µs], finalmente, el procesador vuelve a “fetch” para leer una nueva instrucción que corresponde a HLT para congelar el procesador como se observa en 11.2 [µs] paso “50”. De igual forma, se observan todas las transiciones de “0” al contenido adecuado. El Modo C del bus espía corresponde a mostrar el paso de control y el contenido de un registro para poder visualizar el proceso de forma “paralela”, se debe tener en cuenta que para instrucción de 16 bits se debe ingresar por “BUS_ESPIAR” la codificación del registro que se desea ver, esto se realizó de esta forma debido a que en el paso de control “44” el usuario puede interactuar con varios registros, de tal forma que debe haber claridad en cuál de ellos se desea ver; para este programa de prueba evidentemente se desea ver el contenido del registro acumulador ya que hay es donde se guarda el resultado final. En este modo no se observan todos los pasos de control, solamente los que interactúan con registros, por ejemplo, la instrucción HLT no interactúa con ninguno de tal forma que se debe observar un “0” en todo el bus espía. MVT RF, AC SUB AC, RF HLT Figura 12. Bus Espía en Modo C De la Tabla 3, se observa que cuando el procesador llegue al paso “25” se mostrará el registro acumulador AC, de acuerdo a la instrucción este registro debe tomar el número “10”; en 3.92 [µs] se observa que el registro acumulador finalmente tiene el dato de memoria, cabe destacar que hay un lapso de tiempo en este estado, mientras que el registro toma el dato como se observa claramente la transición entre “0” a “10”. Cuando el procesador vuelve a “fetch” toma la nueva instrucción de memoria por medio del bus de datos y el registro de datos la toma en el paso “13” para su ejecución como se muestra en 5.44 [µs], como es instrucción de 16 bits, el procesador debe ir al paso “43” donde según la tabla se muestra el registro de datos con el número “10”, esto concuerda con el AHPL, ya que las operaciones de la ALU se realizan con este registro, en el paso “44” se muestra el registro RF ya que por “BUS_ESPIAR” se ingresó la codificación para observar este registro, evidentemente en 6.48 [µs] el registro de propósito general toma el dato; a continuación se lee la segunda mitad de la instrucción correspondiente a la operación lógica SUB; en 7.76 [µs] se observa claramente la transición entre el dato que contiene el acumulador al nuevo dato que corresponde al resultado de la operación. De esta forma, se puede concluir que los modos de uso para bus espía se encuentran funcionando de acuerdo a lo planteado anteriormente. En el Anexo E: Pruebas Bus Espía se encuentran las simulaciones hechas en Quartus II 9.0 con diferentes programas que incluyen la mayoría de instrucciones. 30 e. Lógicas de Entrada: Esta prueba corresponde a los bloques Mux_ABUS, Mux_BBUS, Salida_ADBUS, Salida_DBUS. Se probó cada uno de los bloques para comprobar que la lógica combinatoria funcionara adecuadamente. Después de probar cada bloque por separado, se realizaron las conexiones entre cada entidad para así tener el procesador PHERB ya terminado. Cabe destacar que una de las mayores ayudas que se tuvo a la hora de probar el procesador fue el bus espía, ya que permitía ver la transferencia de los datos en los registros y de esta forma, comprobar el funcionamiento adecuado del procesador de una forma rápida y eficiente. f. Pruebas de todo el procesador conectado: Se realizaron diferentes programas teniendo en cuenta que abarcaran todo el conjunto de instrucciones para así comprobar el adecuado funcionamiento de todo el procesador; al mismo tiempo se comprobaron cada uno de los modos de bus espía que el procesador puede manejar. Estas pruebas se encuentran explicadas en el Anexo F: Pruebas Procesador PHERB con sus respectivas simulaciones. Después de realizar las simulaciones y comprobar el funcionamiento del procesador, se implementó en la tarjeta de desarrollo TARDAC que será explicada en la sección 3.5. g. Pruebas de Interrupciones: Se simularon cada uno de los modos de interrupciones ya descritos, observando que se cumpliera la secuencia de pasos de control de acuerdo al AHPL. Estas pruebas también se encuentran en el Anexo F: Pruebas Procesador PHERB. 3.4.2 Hardware Las pruebas en hardware consistieron en varias partes para verificar el adecuado funcionamiento. a. b. c. d. e. f. Revisión del montaje Conexión del analizador lógico con puntas de prueba Programación de las memorias Conexión tarjeta Verificación inicio del procesador Verificación lectura de memorias 3.5 Tarjeta de desarrollo Siguiendo la continuidad del proyecto de grado BINARIC, el procesador PHERB se implementó sobre el hardware ya hecho para este procesador. La tarjeta de desarrollo utilizada fue la TARDAC que contiene un dispositivo de lógica programable FPGA de ALTERA con referencia ACEX EP1K100QC208-3. Este dispositivo contiene 208 terminales de salida, 100.000 compuertas típicas, 49152 bits de memoria RAM, consumo bajo de potencia, entre otras características. La tarjeta de desarrollo TARDAC se muestra a continuación: 31 Figura 13. Tarjeta de desarrollo TARDAC Además de contar con el dispositivo FPGA, esta tarjeta cuenta con lo siguiente: Memoria EPC2LC20: Es una memoria no volátil que se comunica con el dispositivo EP1K100QC2083 por medio de un protocolo JTAG. Conector de voltaje: adaptador de 5 , 1.5ª. Regulador de 3.3 y 2.5 Cable de programación y configuración: Cable para la comunicación de puerto JTAG con el puerto paralelo del computador. Circuito Oscilador: Circuito de reloj de 8MHz. Puentes de configurar JP1 y JP2. Regletas de 40 terminales para la conexión externa. Cintas de 40 hilos. 4. ANÁLISIS DE RESULTADOS 4.1 Análisis para un procesador Para la realización del análisis de recursos, tiempos y de potencia se utilizó la herramienta de simulación QUARTUS II 9.1 de Altera. Los ajustes realizados para obtener los distintos análisis fueron los siguientes: 4.1.1 Dispositivo: EP1K100QC208-3 Early timing mode: Realistic Physical Synthesis: Normal(optimize during fitting) VHDL 1993 Fitter settings: Standard Fit(Highest effort). Classic Timing Analyzer con frecuencia máxima de 4MHz. Power Up Análisis corresponde al análisis de potencia se realizó sobre el dispositivo FPGA Cyclone III EP3C25F324 ya que esta herramienta solo es soportada para ciertas familias de dispositivos de lógica programable. Análisis de Recursos En la siguiente Figura se aprecia la cantidad de recursos utilizados por la FPGA en la programación del procesador. Este reporte corresponde al primer informe que la herramienta QUARTUS II entrega al programador. 32 Figura 14. Reporte de compilación QUARTUS II PHERB De la Figura se observa la cantidad de elementos lógicos utilizados correspondiente a 2,323 de 4,992 equivalentes a un 47% de la FPGA. Se observa que queda un 53% restante para futuras modificaciones, sin embargo, se aclara que este procesador puede ser programado en un dispositivo como Cyclone o Stratix que contienen alrededor de 24,624 elementos lógicos, lo cual daría la posibilidad de realizar otras actualizaciones del procesador más grandes, además la posibilidad de utilizar memorias embebidas y hacer el montaje mucho más sencillo. De igual forma, se observa la cantidad de pines utilizados que corresponden a 124, un 84% del chip. Aunque este dispositivo no tiene tantos pines de salida en comparación con una Cyclone, la diferencia de la utilización de esta FPGA se centra en la tarjeta de desarrollo. Uno de los requisitos a tener en cuenta, es la posibilidad de poder visualizar en el analizador de estados lógicos absolutamente todas las señales de salida descritas en la Sección 2.1, como también el bus espía, es por esto, que la única tarjeta de desarrollo que permitió esto fue la TARDAC ya que permite utilizar todos los pines de salida de la FPGA. Así mismo, se realizó una breve comparación con el reporte de compilación de BINARIC, que dio como resultado un total de 2,609 elementos lógicos, de esta forma, se evidenció una breve optimización en la descripción de VHDL del 3%. En el siguiente reporte se muestra la cantidad de elementos lógicos, como se observa en la Figura hay un total de 2,323 elementos lógicos que se encuentran repartidos en los registros, en las lógicas combinatorias utilizadas para la carga de datos y las operaciones que realiza la ALU (Unidad Aritmético Lógica). Para esta FPGA el elemento lógico corresponde a la unidad más pequeña de la arquitectura que permite un uso eficiente de la lógica. Cada elemento lógico contiene una tabla de búsqueda (LUT) de 4 entradas que realiza rápidamente cualquier función de cuatro variables. Figura 15. Reporte de recursos utilizados 33 De la Figura 15 se observa el máximo fan-out, este es uno de los parámetros más importantes ya que corresponde a la máxima cantidad de puertas básicas que se pueden conectar a la salida de una sola compuerta lógica; del reporte se observa que éste corresponde a 566, que a su vez es la cantidad de registros del procesador, de igual forma, se analiza que el nodo con el máximo fan-out es el reloj, lo cual es coherente porque es una señal que marca el ritmo de carga de los datos, por lo tanto, se encuentra conectada a cada uno de los registros utilizados. También se observa la cantidad de funciones lógicas utilizadas, donde 1410 corresponden a funciones de 4 entradas, al ser de esta categoría se afirma que los elementos lógicos están operando en forma normal, este modo es perfecto para aplicaciones de lógica combinatoria, para las funciones de 3 entradas se puede decir que están operando en función aritmética, la cual es perfecta para la implementación de sumadores. Del reporte se extrae también la cantidad de registros utilizados por el procesador correspondiente a 566, este dato debe tener una exacta correspondencia con la cantidad calcula teóricamente dada a continuación: NOMBRE DEL REGISTRO CANTIDAD 118 MÁQUINA DE CONTROL 2 REGISTRO MÁSCARA 3 REGISTRO BUS ESPÍA 3 REGISTRO INTERRUPCIONES 5 REGISTRO CORRIMIENTO 10 REGISTRO DE ESTADOS 24 CONTADOR DE PROGRAMA 24 REGISTRO PUNTERO PILA 24 REGISTRO DE DIRECCIONES 24 REGISTRO ÍNDICE 32 REGISTRO DE DATOS 32 REGISTRO DE INSTRUCCIONES 32 REGISTRO ACUMULADOR 192 REGISTROS PROPÓSITO GNA TOTAL 525 Tabla 17. Número teórico de registros utilizados por el procesador Del reporte, se observa que hay 41 registros que hacen falta en el dato teórico. 32 de estos corresponden al manejo del bidireccional necesario para la lectura y escritura de datos. Los 9 restantes corresponde al bloque Signals para la sincronización de las señales de lectura y escritura en memoria. A continuación se presenta el análisis de recursos por entidad, donde se indica la cantidad de registros que cada una utiliza, así como también la cantidad de celdas lógicas; una celda lógica es un bloque que tiene la capacidad de resolver una función combinatoria o secuencial de hasta 5 entradas. De la Figura se evidencia una total correspondencia entre lo teórico y lo programado: 34 Figura 16. Recursos por Entidad 4.1.2 Análisis de Tiempos 4.1.2.1 Ciclos de Instrucción para el procesador Un primer análisis de tiempo se centra en la contabilización de la cantidad de ciclos de reloj que cada instrucción utiliza; para esto nos referimos a la tablas 6 a 13 como también se tiene en cuenta la frecuencia máxima de trabajo que corresponde a 4MHz teniendo como periodo de reloj 250ns. En la siguiente tabla se presentan el tiempo que cada instrucción toma para ejecutarse de acuerdo a los ciclos de reloj: CICLOS DE RELOJ TIEMPO 3 µs 12 3,25 µs 13 3,5 µs 14 3,75 µs 15 4 µs 16 4,5 µs 18 4,75 µs 19 5,5 µs 22 Tabla 18. Tiempo de Duración de las instrucciones. 4.1.2.2 Análisis de tiempos utilizando QUARTUS II 9.0 En la primera compilación del procesador, la herramienta QUARTUS nos entrega un reporte mostrando los tiempos críticos, es decir los peores casos donde los tiempos dejarían de ser válidos produciendo un mal funcionamiento del procesador. En la siguiente figura se muestra el primer reporte extraído: 35 Figura 17. Reporte de Tiempo de QUARTUS II. De la Figura se observa un valor de gran importancia, la máxima frecuencia de trabajo correspondiente a 4.21MHz, que corresponde al trayecto entre el paso número 10 de la máquina de control al bit número 2 del registro de estados; en caso de que se trabaje con una frecuencia mayor a esta, el funcionamiento del procesador no sería el adecuado debido a que varios caminos entre las señales no trabajarían correctamente. Sin embargo, para obtener una mayor velocidad se sugiere utilizar una FPGA con mejores características. Teniendo en cuenta el deseo de utilizar una Cyclone III, se decidió realizar una compilación para determinar la máxima frecuencia de trabajo que el procesador puede tener, de tal forma que se obtuvo una frecuencia máxima de 25.45 MHz, esto se observa en la siguiente figura: Figura 18. Reporte de Tiempo de QUARTUS II con Cyclone III. De igual forma, se observan los valores para los tiempos de setup ( pin to pin ( ) que serán explicados uno a uno posteriormente. a. Tiempo de Setup ( ), hold ( ), clock to output ( )y ) El tiempo de Setup o también llamado tiempo de asentamiento se refiere al intervalo tiempo en que la entrada debe ser válida, es decir no debe cambiar antes de un flanco de reloj. Este parámetro puede tener un valor negativo el cual representa el intervalo más corto para el cual el sistema funciona correctamente. Del reporte de QUARTUS II se tomaron los valores máximos y mínimos para este tiempo, se observan en la siguiente figura: 36 Figura 19. Reporte QUARTUS II Tiempo de Setup ( ) Del reporte extraído, se encuentra que el tiempo de setup es de 14.800 [ns], este ocurre cuando la señal de interrupción PRIN llega al Registro de direcciones (MR), de igual forma, el mejor tiempo se da cuando la señal SWAIT pasa al estado número 30 de la máquina de control. b. Tiempo de Hold ( ) El tiempo de hold o tiempo de mantenimiento se refiere al tiempo mínimo después de un flanco de reloj, en la cual las entradas no pueden cambiar de valor. A continuación se muestra el peor y mejor tiempo para este sistema. Figura 20. Reporte QUARTUS II Tiempo de Hold ( ) De la Figura, se concluye que el mejor tiempo corresponde a -0.400 [ns] que ocurre del paso de la señal SWAIT al estado número 88 de la máquina de control; de igual forma, el peor caso para este tiempo, ocurre del paso de la señal PRIN[1] al flip - flop número 22 del registro de direcciones (MA) con un valor de -13.200 [ns]. 37 c. Tiempo Clock to Output ( ) Este tiempo se refiere al tiempo mínimo para obtener una salida válida en un pin de salida después de un flanco de reloj. Como en los casos anteriores, se presentan los valores más críticos del diseño. Figura 21. Reporte QUARTUS II Tiempo Clock to Output ( ) Del análisis dado por la herramienta QUARTUS II, se determina que el mejor tiempo para una salida válida en el bus espía es de 39.600 [ns], se considera que es un tiempo muy largo, sin embargo, esto se debe a la extensión de la lógica combinatoria utilizada en el diseño. El peor caso corresponde a 50.200[ns] que corresponde a la conexión entre la unidad de control y el bus espía. d. Tiempo pin to pin ( ) Este tiempo se refiere al tiempo de propagación punto a punto desde un pin de entrada a uno de salida. El mayor tiempo se encontró desde la entrada BUS_ESPIAR[0] a la salida BUS_ESPIA[39] con un valor de 49.700 [ns], la primera corresponde a un bit de entrada por el cual el usuario escoge el registro que desea ver por medio del bus espía; de igual forma, el menor valor es de 24.800 [ns] correspondiente al camino entre BUS_ESPIAR[0] a BUS_ESPIA[5]. En la siguiente figura se observan estos resultados: Figura 22. Reporte QUARTUS II Tiempo pin to pin ( 38 ) 4.1.3 Análisis de Potencia Para realizar el análisis en potencia se debió simular el procesador utilizando un dispositivo FPGA Cyclone III con referencia EP3C25F324 ya que para el dispositivo ACEX la herramienta PowerPlay no se encuentra habilitada. El primer reporte que entrega QUARTUS II, corresponde a un resumen, este se da en la siguiente figura: Figura 23. Reporte de potencia Se observa que el procesador disipará un total de 105.98 [mW] dentro del dispositivo. Dentro de este total de potencia se encuentra la potencia dinámica del núcleo, la cual corresponde a la conmutación interna del dispositivo, es decir, la carga y descarga de capacitancias en los nodos internos. El total de esta potencia es de 1.50 [mW] como se muestra a continuación: Figura 24. Core Dynamic Thermal Power Dissipation Otro de los componentes importantes acerca de la potencia, se refiere a la potencia térmica disipada, esta se refiere al total disipado por el dispositivo, de otra manera, se refiere a la habilidad de la FPGA para transferir calor y así, mantener las junturas en condiciones de operación normales. En la siguiente figura se observa el total por cada bloque, donde el bloque de entradas y salidas es el que más consume con un total de 13.80 [mW]: Figura 25. Thermal Power Dissipation por tipo de bloque Otro de los reportes entregado por QUARTUS II, se refiere al consumo de potencia total de cada jerarquía; este total se divide en potencia térmica dinámica, térmica estática y térmica de enrutamiento. En la siguiente figura se observan los valores obtenidos de cada una de ellas por jerarquía: 39 Figura 26. Thermal Power Dissipation por jerarquía De la anterior figura, se observa que la entidad PHERB consume 15.28 [mW] esto se debe a que ella contiene las entradas y salidas del procesador, el mayor consume se da en la potencia térmica estática que hace referencia a la potencia consumida por los transistores. Al seguir observando, el segundo valor más alto corresponde a la Unidad de Datos, esto se debe a que esta esta jerarquía contiene toda la lógica de carga, al igual, que realiza todas las operaciones aritméticas y lógicas; de tal forma, entre más lógica combinatoria el diseño tenga el consumo será mayor, es decir a mayor elementos lógicos mayor potencia. Figura 27. Corriente consumida por la Fuente de Voltaje En la Figura se observa la corriente consumida por cada una de las fuentes. La fuente VCCINT corresponde al voltaje para la lógica interna, esta consume un total de 13.23 [mA] donde el mayor porcentaje de consumo se encuentra en la corriente estática correspondiente a los transistores del dispositivo. Observando la figura, se observa que la fuente VCCA correspondiente a un regulador PLL es el que más consume corriente, esto es lógico ya que se trata de un dispositivo análogo basado en un lazo enganchado en fase comúnmente llamado PLL (ingles). A partir de estos resultado y observando la Figura se encuentra una gran coherencia en el consumo de potencia de los transistores, siendo esta la de mayor valor con 81.33 [mW]. 4.2 Resultados en simulación 4.2.1 Jerarquía Final 4.2.2 RTL Figura 28. Jerarquía Final del Procesador PHERB. El visor RTL (Register Transfer Level) corresponde al esquema o diagrama de flujo equivalente de las descripciones hechas en VHDL; es decir, corresponde al sistema digital después del análisis. El uso de esta herramienta se basa en la comprobación de que no existan componentes alternos no pertenecientes al 40 sistema como también que las conexiones hechas en la descripción sean apropiadas y conecten a los bloques adecuadamente. Sin embargo, muchas veces no resulta útil ya que no hay el conocimiento suficiente de las diferentes formas que QUARTUS realiza el componente, esto se tiene en cuenta al utilizar sentencias como case, when, switch, entre otras. 4.2.2.1 RTL general Figura 29. RTL general del sistema En la figura anterior se puede observar el diagrama general del procesador PHERB; este diagrama obtenido por QUARTUS II corresponde totalmente al diagrama principal de entrada/salida visto en la sección 2.1 Figura 1. 4.2.2.2 RTL expandido Figura 30. RTL expandido del sistema. Después de observar el RTL obtenido general, al hacer un “click” sobre ese bloque, se obtiene un diagrama general expandido como se ve en la Figura; de ella, se aprecia tres grandes entidades correspondientes a la Unidad de Datos, Unidad de Control y Unidad Espía, esto concuerda con lo planeado anteriormente a la hora del diseño del procesador. 41 4.3 Resultados en hardware Mediante el analizador de estados lógicos Tektronix TLA5202B se realizó la comprobación del funcionamiento del procesador con las instrucciones, para de esta forma comparar los resultados simulados con los implementados. Sin embargo, a continuación se presenta un pequeño programa con modo de bus espía C activo: Figura 31. Parte I programa. En la Figura 32 se observa que el bus espía está mostrando el registro MA el cual contiene la posición de memoria donde se encuentra la primera instrucción a ejecutar. Figura 32. Parte II programa La primera instrucción consiste en traer de memoria un dato de forma directa; el dato corresponde a un “10”. En la Figura 33 se observa que el registro de direcciones toma está dirección y cuando el procesador llega al paso de control número “33” toma el dato, de la figura se puede observar la transición que ocurre en el registro de datos de tener la instrucción a obtener solo el número; Luego el procesador 42 llega al siguiente estado donde ocurre el incremento, en la Figura se observa que el registro cambia de 0AH a 0BH que en decimal corresponde un incremento de “1”. Figura 33. Parte III programa En la Figura 34 se puede visualizar la siguiente instrucción que corresponde a traer de memoria un dato de forma indirecta, en el estado “17” se puede observar la transición de una posición de memoria a otra, ya que en este modo de bus espía el registro de direcciones se muestra cuando el procesador se encuentra en este estado. Siguiendo el procedimiento cuando el procesador llega al estado “21” hay otra transición de posición de memoria, al igual que en el estado “17” en este también se muestra el registro de direcciones. Figura 34. Parte IV programa Esta figura muestra que el procesador lee de memoria el número “0” y lo realiza un decremento en el paso “34” respectivamente. 43 Figura 35. Parte V programa Finalmente, el procesador regresa a “fetch” donde lee de nuevo una instrucción, esta última corresponde a un salto incondicional para volver a empezar todo el programa planteado. 5. CONCLUSIONES La metodología de diseño digital que se utiliza en la Sección de Técnicas digitales para el diseño e implementación de sistemas digitales sencillos y complejos permite al estudiante una mayor claridad en cuanto al funcionamiento de cada sistema diseñado, ya que a partir de una descripción en AHPL, tablas de conectividad, diagrama de bloques y descripción en VHDL se logra una conceptualización adecuada acerca del diseño de sistemas digitales. Las modificaciones hechas a los modos de bus espía permitieron realizar un seguimiento paso a paso del sistema para cubrir en su totalidad la prueba de instrucciones, ya que permitió observar la unidad de control y unidad de datos al mismo tiempo y de esta forma, verificar el buen funcionamiento de una forma sencilla y eficiente. Unas de las características para posibles mejoras, corresponden a la velocidad y a el montaje aparatoso, juntas van ligadas con el dispositivo FPGA utilizado, aunque la universidad cuenta con dispositivos de desarrollo adecuados, ninguna tarjeta proporciona la cantidad de pines disponibles para uso del usuario, lo que hace imposible la conexión del bus espía, junto con la conexión externa de las memorias. Esta tercera implementación en hardware de PCSIM es más sencilla y clara que las versiones anteriores ya que se realizaron documentaciones detalladas acerca de cada proceso realizado, como también un manual de usuario más adecuado para el aprendizaje del estudiante. Una de las grandes modificaciones en hardware constituye el manejo de interrupciones definiendo modos sencillos y diferentes para que el estudiante logre una mayor compresión acerca de este tema de gran importancia en un computador. Entre más compleja sea la lógica de entrada a una compuerta, la capacitancia del dispositivo FPGA (Field Programmable Array) aumentara causando que haya más conmutaciones entre estados lógicos, lo cual lleva a un consumo de potencia mayor. 44 La simulación de periféricos en QUARTUS II 9.1 resulta difícil de realizar para los modos vectorizados, ya que no hay un periférico implementado que envíe por el bus de datos la rutina a ejecutar. La implementación en QUARTUS II 9.1 de un memoria RAM resulta confusa, aunque se realizó siguiendo los lineamientos que la ayuda de Altera proporcionó, resulta difícil entender cómo funciona al interior, de tal forma, que sería una excelente práctica en la sección de técnicas digitales. La implementación del “bus espía” fue de gran ayuda ya que el uso del mismo permitió la depuración de errores del procesador, específicamente cuando se perdían datos al realizar las cargas en los registros. Una de las ideas que se deja para proyectos futuros corresponde al diseño de una tarjeta de desarrollo con una FPGA como la Cyclone III que tenga la mayor cantidad de pines libres, esto con el fin de tener un procesador con mayor velocidad y la posibilidad de tener memorias embebidas; como se observó en los análisis hechos, la Cyclone III permite una frecuencia máxima de 32MHz, de tal forma que el procesador tendría una mayor rapidez en la ejecución de las instrucciones. Se realizó satisfactoriamente una descripción en VHDL más sencilla y entendible para el estudiante, ya que ésta se realizó en su totalidad de forma concurrente, es decir sin sentencias como when, case, if, else; se implementó de esta forma debido a que este proyecto tiene como finalidad su uso pedagógico y estas sentencias suponen el conocimiento por parte del estudiante de la cantidad de elementos lógicos utilizados y su forma adecuada de utilización. Se realizaron algunas modificaciones en relación a las especificaciones de la propuesta inicial en pro de facilitar el manejo del procesador. Nosotras como usuario principal del procesador pudimos observar con bastante claridad los resultados obtenidos; como usuario consideramos que las especificaciones serian de agrado al estudiante. La elaboración del manual permitirá a los estudiantes de sistemas digitales acercarse a la arquitectura de procesador de una manera más clara ya que acompaña al estudiante en todo el proceso de diseño e implementación. Los tres modos de bus espía nos permitieron depurar errores y comprobar de una forma didáctica el funcionamiento del procesador. Seguir la metodología de diseño aprendida durante las asignaturas del área de técnicas digitales, hizo posible la implementación exitosa del proyecto. En el resultado se observa, que al trabajar de manera disciplinada, se obtienen los resultados deseados en el tiempo asignado para cumplir los objetivos. Es de resaltar que no existe ninguna referencia bibliográfica externa a la universidad Javeriana, para el concepto de bus espía, o alguna especificación similar, que permita visualizar la dinámica interna del funcionamiento de un procesador. Todos los objetivos propuestos fueron cumplidos de manera exitosa, y esperamos que se cumpla su fin pedagógico. 45 6. BIBLIOGRAFÍA [1] ALVAREZ RIVERA, Bibiana Andrea, PINILLA PICO, Lady Nathalie. “Implementación de un procesador digital BINARIC”. Trabajo de Grado, Carrera de Ingeniera Electrónica, Pontificia Universidad Javeriana, 2007. [2] BELTRÁN VELEZ, Diego Hernán, HERRERA BUITRAGO, Moisés Fernando, MAYOLO OBREGÓN, Marco Antonio. “Implementación del procesador ALTERIC”. Trabajo de Grado, Carrera de Ingeniera Electrónica, Pontificia Universidad Javeriana, 2004. [3] HILL, Frederick J, PETERSON, Gerald R. "Digital Systems, Hardware organization and design". Tercera edición. Singapore. John Wiley & Sons. 1987. [4] PEDRONI, Volnei A. “Circuit Design with VHDL”. Massachussets Institute of Technology. United States .2004 [5] STALLINGS, William. “Organización y Arquitectura de Computadores”. Séptima Edición. Pearson Education, 2006. [6] HENNESSY, John L. PATTERSON, David A. “Computer Architecture A Quantitative Approach”. Second Edition.1996. [7] WAKERLY, John F. “Diseño Digital : Principios y Prácticas”. Tercera Edición. Prentice Hall. 2001. 46