aplicación de técnicas de inducción de árboles de decisión a
Anuncio

APLICACIÓN DE TÉCNICAS DE INDUCCIÓN DE ÁRBOLES DE
DECISIÓN A PROBLEMAS DE CLASIFICACIÓN MEDIANTE EL USO
DE WEKA (WAIKATO ENVIRONMENT FOR KNOWLEDGE ANALYSIS).
FUNDACIÓN UNIVERSITARIA KONRAD LORENZ
FACULTAD DE INGENIERÍA DE SISTEMAS
BOGOTÁ
2008
APLICACIÓN DE TÉCNICAS DE INDUCCIÓN DE ÁRBOLES DE
DECISIÓN A PROBLEMAS DE CLASIFICACIÓN MEDIANTE EL USO
DE WEKA (WAIKATO ENVIRONMENT FOR KNOWLEDGE ANALYSIS).
PAULA ANDREA VIZCAINO GARZON
FUNDACIÓN UNIVERSITARIA KONRAD LORENZ
FACULTAD DE INGENIERÍA DE SISTEMAS
BOGOTÁ
2008
2
CONTENIDO
LISTA DE FIGURAS ........................................................................................................... 4
INTRODUCCION ................................................................................................................ 7
1.MINERÍA DE DATOS ....................................................................................................... 8
1.1.
CARACTERÍSTICAS Y OBJETIVOS DE LA MINERÍA DE DATOS ...................................... 8
2.ÁRBOLES DE DECISIÓN .............................................................................................. 11
2.1.
CICLO DE UN ÁRBOL DE DECISIÓN ....................................................................... 12
2.2.
CONSTRUCCIÓN DE ÁRBOLES DE DECISIÓN .......................................................... 13
2.3.
CLASIFICACIÓN DE ÁRBOLES DE DECISIÓN ........................................................... 14
2.3.1.
ADTree - Alternating Decision Tree [4] ................................................. 14
2.3.2.
Decision Stump o árbol de decisión de un nivel ..................................... 15
2.3.3.
ID3 ........................................................................................................... 16
2.3.4.
J48 o C4.5 ............................................................................................... 18
2.3.5.
LMT (Logistic Model Tree) ...................................................................... 20
2.3.6.
M5P (Árbol de regresión) ........................................................................ 21
2.3.7.
NBTree (Naive Bayes Tree) .................................................................... 21
2.3.8.
RandomForest ........................................................................................ 22
2.3.9.
RandomTree ........................................................................................... 23
2.3.10.
REPTree ................................................................................................. 24
2.3.11.
UserClassifier .......................................................................................... 24
3.WEKA – Waikato Environment for Knowledge Analysis................................................ 26
3.1.
3.2.
3.3.
INSTALACIÓN Y EJECUCIÓN ........................................................................ 27
FORMAS DE UTILIZAR WEKA ....................................................................... 28
FICHEROS .ARFF ........................................................................................... 31
4.SELECCIÓN Y SOLUCIÓN DEL PROBLEMA .............................................................. 34
4.1.
SELECCIÓN DE EJEMPLO............................................................................. 34
4.2.
EMPEZANDO CON WEKA .............................................................................. 37
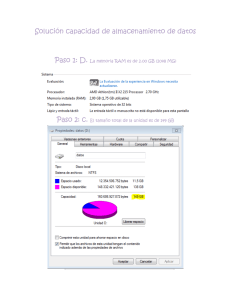
Paso 1 - Lanzar el interfaz Explorer. ........................................................................ 37
Paso 2 - Cargar la base de datos............................................................................. 37
Paso 3 - Generación de gráficos .............................................................................. 38
4.3.
ÁRBOLES DE DECISIÓN CON WEKA ........................................................... 43
4.4.
REVISANDO RESULTADOS .......................................................................... 68
5.BIBLIOGRAFÍA .............................................................................................................. 74
3
LISTA DE FIGURAS
Figura 1. Mapa Conceptual de Minería de Datos ............................................................... 9 Figura 2. Representación del conocimiento...................................................................... 11 Figura 3. Ejemplo de un árbol ADTree ............................................................................. 15 Figura 4. Ejemplo de un árbol ID3 .................................................................................... 17 Figura 5. Ejemplo aplicado de árbol de decisión adaptado para C4.5 ............................. 19 Figura 6. Ejemplo de un árbol de decisión generado por C4.5 ........................................ 19 Figura 7. Pseudo código para el algoritmo LMT ............................................................... 20 Figura 8. Esquema del algoritmo Random Forest ............................................................ 22 Figura 9. Proceso para construir un Random Tree .......................................................... 23 Figura 10. Ejemplo de UserClassifier básico .................................................................... 24 Figura 11. Ejemplo de UserClassifier final ........................................................................ 25 Figura 12. Imagen de una Weka ....................................................................................... 26 Figura 13. Ventana inicial de Weka .................................................................................. 29 Figura 14. Interfaz Simple CLI .......................................................................................... 29 Figura 15. Interfaz Explorer............................................................................................... 30 Figura 16. Interfaz Experimenter ...................................................................................... 30 Figura 17. Interfaz KnowledgeFlow .................................................................................. 31 Figura 18. Interfaz Explorer con archivo Empleados.arff.................................................. 37 Figura 19. Opción Visualice para Empleados.arff ............................................................ 38 Figura 20. Resultado de un nodo gráfico {Casado x Sueldo} ........................................... 39 Figura 21. Visualización de características atributo Sueldo ............................................. 39 Figura 22. Visualización de características atributo Casado ............................................ 40 Figura 23. Visualización de características atributo Coche .............................................. 40 Figura 24. Visualización de características atributo Hijos ................................................ 41 Figura 25. Visualización de características atributo Alq/Prop........................................... 41 Figura 26. Visualización de características atributo Sindicato.......................................... 42 Figura 27. Visualización de características atributo Bajas/Año ........................................ 42 Figura 28. Visualización de características atributo Antigüedad ...................................... 43 Figura 29. Visualización de características atributo Sexo ................................................ 43 Figura 30. Visualización de pantalla clasificación ADTree ............................................... 44 Figura 31. Visualización de pantalla al generar el árbol ADTree...................................... 44 Figura 32. Ventana Run information del árbol ADTree ..................................................... 45 Figura 33. Ventana Classifier model del árbol ADTree .................................................... 45 Figura 34. Ventana Stratified cross-validation del árbol ADTree ...................................... 46 Figura 35. Menú desplegable para visualización de árboles ............................................ 46 Figura 36. Ventana de visualización de árbol de decisión ADTree. ................................. 47 4
Figura 37. Visualización de pantalla clasificación DecisionStump. .................................. 47 Figura 38. Ventana al generar el árbol DecisionStump .................................................... 48 Figura 39. Ventana Run information del árbol DecisionStump ......................................... 48 Figura 40. Ventana Classifier model del árbol DecisionStump......................................... 49 Figura 41. Ventana Stratified cross-validation del árbol DecisionStump .......................... 49 Figura 42. Visualización de pantalla clasificación Id3....................................................... 50 Figura 43. Ventana al generar el árbol Id3. ...................................................................... 50 Figura 44. Visualización de pantalla clasificación J48. ..................................................... 51 Figura 45. Ventana al generar el árbol J48....................................................................... 51 Figura 46. Ventana Run information del árbol J48 ........................................................... 52 Figura 47. Ventana Classifier model del árbol J48 ........................................................... 52 Figura 48. Ventana Stratified cross-validation del árbol J48 ............................................ 52 Figura 49. Ventana de visualización de árbol de decisión J48. ........................................ 53 Figura 50. Visualización de pantalla clasificación LMT. ................................................... 53 Figura 51. Ventana al generar el árbol LMT. .................................................................... 54 Figura 52. Ventana Run information del árbol LMT .......................................................... 54 Figura 53. Ventana Classifier model del árbol LMT .......................................................... 55 Figura 54. Ventana Stratified cross-validation del árbol LMT ........................................... 55 Figura 55. Ventana de visualización de árbol de decisión LMT. ...................................... 56 Figura 56. Visualización de pantalla clasificación M5P. ................................................... 56 Figura 57. Ventana al generar el árbol M5P. .................................................................... 57 Figura 58. Visualización de pantalla clasificación NBTree. .............................................. 57 Figura 59. Ventana al generar el árbol NBTree. ............................................................... 58 Figura 60. Ventana Run information del árbol NBTree ..................................................... 58 Figura 61. Ventana Classifier model del árbol NBTree .................................................... 59 Figura 62. Ventana Stratified cross-validation del árbol NBTree ...................................... 59 Figura 63. Ventana de visualización de árbol de decisión NBTree. ................................. 60 Figura 64. Visualización de pantalla clasificación RandomForest. ................................... 60 Figura 65. Ventana al generar el árbol RandomForest. ................................................... 61 Figura 66. Ventana Run information del árbol RandomForest ......................................... 61 Figura 67. Ventana Classifier model del árbol RandomForest ......................................... 61 Figura 68. Ventana Stratified cross-validation del árbol RandomForest .......................... 62 Figura 69. Visualización de pantalla clasificación RandomTree....................................... 62 Figura 70. Ventana al generar el árbol RandomTree. ...................................................... 63 Figura 71. Ventana Run information del árbol RandomTree ............................................ 63 Figura 72. Ventana Classifier model del árbol RandomTree ............................................ 64 Figura 73. Ventana Stratified cross-validation del árbol RandomTree ............................. 64 Figura 74. Visualización de pantalla clasificación REPTree. ............................................ 65 5
Figura 75. Ventana al generar el árbol REPTree. ............................................................ 65 Figura 76. Ventana Run information del árbol REPTree .................................................. 66 Figura 77. Ventana Classifier model del árbol REPTree .................................................. 66 Figura 78. Ventana Stratified cross-validation del árbol REPTree ................................... 66 Figura 79. Visualización de árbol de decisión REPTree. .................................................. 67 Figura 80. Visualización de pantalla clasificación UserClassifier. .................................... 67 6
INTRODUCCION
Teniendo en cuenta el gran avance en los sistemas de minería de datos
desde el último siglo, las entidades educativas y empresariales han
buscado maneras de explotar al máximo la información existente en sus
sistemas de información, esto basándose en técnicas y software
especializados que permiten interpretación fácil y real de los resultados.
Es así como para dar apoyo en la toma de decisiones a niveles
administrativos o gerenciales, se crean metodologías especializadas y
técnicas de extracción adecuada de la información, haciendo que el
usuario final pueda ver los resultados en un solo clic o con pocos pasos,
por tanto y teniendo en cuenta lo anterior, se crea el presente manual de
usuario basado en la tecnología de información y software especializado
WEKA (Waikato Environment for Knowledge Analysis) de la universidad
de Waikato en Nueva Zelanda, este utiliza técnicas de minería de datos
basándose en diferentes reglas y tipos de clasificación de información
tales como árboles de decisión, reglas de clasificación, agrupamiento, etc.
Al ser un software especializado brindara apoyo suficiente para interpretar
resultados de manera matemática y estadística y por medio de
visualización de gráficos o árboles que agregarán valor a los resultados
obtenidos.
Finalmente al usuario final se deja el trabajo profundo de investigación de
teoremas o teorías si así lo desea para complementar sus
interpretaciones, pero se deja por parte del autor conceptos que facilitaran
la comprensión de funcionamiento de la herramienta para la generación
de resultados adecuados y continuar en la mejora constante de la misma.
7
1. MINERÍA DE DATOS
La Minería de Datos busca el procesamiento de información de forma
clara para el usuario o cliente, de tal forma que pueda clasificar la
información de acuerdo a parámetros inicialmente establecidos y de
acuerdo a las necesidades que se buscan, es decir por medio de la
minería de datos se dan acercamientos claros a resultados
estadísticamente factibles a entendimiento y razón de una persona.
Según Vallejos [1] varios autores describen la minería de datos como:
9 Reúne las ventajas de varias áreas como la Estadística, la
Inteligencia Artificial, la Computación Gráfica, las Bases de
Datos y el Procesamiento Masivo, principalmente usando como
materia prima las bases de datos.
9 Un proceso no trivial de identificación válida, novedosa,
potencialmente útil y entendible de patrones comprensibles que
se encuentran ocultos en los datos (Fayyad y otros, 1996)1.
9 La integración de un conjunto de áreas que tienen como
propósito la identificación de un conocimiento obtenido a partir
de las bases de datos que aporten un sesgo hacia la toma de
decisión (Molina y otros, 2001) 2.
1.1.
CARACTERÍSTICAS Y OBJETIVOS DE LA MINERÍA DE DATOS
o Explorar los datos que se encuentran en las profundidades de las
bases de datos.
o El entorno de la minería de datos suele tener una arquitectura
clientes-servidor.
o Las herramientas de la minería de datos ayudan a extraer el
mineral de la información enterrado en archivos corporativos o en
registros públicos, archivados
o El minero es, muchas veces un usuario final con poca o ninguna
habilidad de programación, facultado por barrenadoras de datos y
otras poderosas herramientas indagatorias para efectuar preguntas
adhoc y obtener rápidamente respuestas.
o Hurgar y sacudir a menudo implica el descubrimiento de resultados
valiosos e inesperados.
o Las herramientas de la minería de datos se combinan fácilmente y
pueden analizarse y procesarse rápidamente.
o Debido a la gran cantidad de datos, algunas veces resulta
necesario usar procesamiento en paralelo para la minería de datos.
1
Citado en S. Vallejos, “Trabajo de adscripción minería de datos”, Corrientes - Argentina,
2006, pp. 11.
2
Citado en S. Vallejos, “Trabajo de adscripción minería de datos”, Corrientes - Argentina,
2006, pp. 11.
8
o La minería de datos produce cinco tipos de información:
- Asociaciones.
- Secuencias.
- Clasificaciones.
- Agrupamientos.
- Pronósticos.
Como se puede observar en la Figura 1 la minería de datos clasifica la
información y la procesa para obtener un resultado, para esto se debe
pasar por ciertos procedimientos que se describen según [2] como:
1.
2.
3.
Limpieza de datos: Pre-procesar la data a fin de reducir el
ruido y los valores nulos.
Selección de característica: Eliminar los atributos
irrelevantes o redundantes.
Transformación de datos: Estandarizar, normalizar o
generalizar los datos.
Figura 1. Mapa Conceptual de Minería de Datos
Así mismo y según [2] lo que permite este modelo de minería de datos es
dar exactitud de la predicción (eficacia); velocidad y escalabilidad en
términos del tiempo para construir el modelo y el tiempo para usar el
modelo; robustez en cuanto a administración del ruido y de valores nulos;
9
escalabilidad para buscar eficiencia
disco; interpretabilidad para dar
proporcionados por el modelo; y por
cuanto a buscar tamaño de árbol de
de clasificación.
en bases de datos residentes en
entendimiento y descubrimientos
último dar bondad de las reglas en
decisión y compacidad de la reglas
10
2. ÁRBOLES DE DECISIÓN
Un árbol de decisión es un conjunto de condiciones o reglas organizadas
en una estructura jerárquica, de tal manera que la decisión final se puede
determinar siguiendo las condiciones que se cumplen desde la raíz hasta
alguna de sus hojas.
Un árbol de decisión tiene unas entradas las cuales pueden ser un objeto
o una situación descrita por medio de un conjunto de atributos y a partir
de esto devuelve una respuesta la cual en últimas es una decisión que es
tomada a partir de las entradas.
Los valores que pueden tomar las entradas y las salidas pueden ser
valores discretos o continuos. Se utilizan más los valores discretos por
simplicidad. Cuando se utilizan valores discretos en las funciones de una
aplicación se denomina clasificación y cuando se utilizan los continuos se
denomina regresión.
Un árbol de decisión lleva a cabo un test a medida que este se recorre
hacia las hojas para alcanzar así una decisión. El árbol de decisión suele
contener nodos internos, nodos de probabilidad, nodos hojas y arcos [3].
9 Un nodo interno contiene un test sobre algún valor de una de las
propiedades.
9 Un nodo de probabilidad indica que debe ocurrir un evento
aleatorio de acuerdo a la naturaleza del problema, este tipo de
nodos es redondo, los demás son cuadrados.
9 Un nodo hoja representa el valor que devolverá el árbol de
decisión.
9 Las ramas brindan los posibles caminos que se tienen de acuerdo
a la decisión tomada.
Y
0
1
X
X
0
1
0
1
0
Z
1
Z
0
1
0
1
0
1
0
1
Figura 2. Representación del conocimiento.
11
2.1.
CICLO DE UN ÁRBOL DE DECISIÓN
De acuerdo al ciclo que debe ser aplicado a un árbol de decisión, se tiene:
1. Aprendizaje:
2. Clasificación:
Un ejemplo para la compra de un computador se puede dar primero,
especificando las reglas o condiciones que se han recolectado de una
base de datos.
age
<=30
<=30
31…40
>40
>40
>40
31…40
<=30
<=30
>40
<=30
31…40
31…40
>40
income student
high
high
high
medium
low
low
low
medium
low
medium
medium
medium
high
medium
no
no
no
no
yes
yes
yes
no
yes
yes
yes
no
yes
no
credit
buys
rating
computer
fair
no
excellent
no
fair
yes
fair
yes
fair
yes
excellent
no
excellent
yes
fair
no
fair
yes
fair
yes
excellent
yes
excellent
yes
fair
yes
excellent
no
12
Seguidamente se construye el árbol de decisión de acuerdo a los
parámetros levantados en el punto anterior y se evalúan las posibilidades
ofrecidas dando así la respuesta más adecuada al usuario.
2.2.
CONSTRUCCIÓN DE ÁRBOLES DE DECISIÓN
Para la construcción de árboles de decisión se deben tener en cuenta
ciertas etapas, estas son:
1. Construir el árbol (Reglas de división)
9 Al inicio todos los ejemplos de entrenamiento están a la raíz.
9 Los atributos deben ser categóricos (si son continuos ellos
deben ser discretizados)
9 El árbol es construido recursivamente de arriba hacia abajo con
una visión de divide y conquista.
9 Los ejemplos son particionados en forma recursiva basado en
los atributos seleccionados
9 Los atributos son seleccionados basado en una medida
heurística o estadística (ganancia de información)
9 La ganancia de información se calcula desde el nivel de
entropía de los datos.
2. Detener la construcción (Reglas de parada): Se tienen en cuenta
las siguientes condiciones:
9 Todas las muestras para un nodo dado pertenecen a la misma
clase.
9 No existe ningunos atributos restantes para ser particionados
(el voto de la mayoría es empleada para clasificar la hoja).
13
9 No existe más ejemplos para la hoja.
3. Podar el árbol (Reglas de poda)
9 Identificar y eliminar ramas que reflejen ruido o valores atípicos.
2.3.
CLASIFICACIÓN DE ÁRBOLES DE DECISIÓN
Para este manual sólo se tendrá en cuenta los algoritmos y/o árboles de
decisión tomados en el software libre WEKA versión 3.4.
2.3.1. ADTree - Alternating Decision Tree [4]
Un Árbol de decisión alternativo es un método de clasificación proveniente
del aprendizaje automático conocido en inglés como Alternating Decision
Tree (ADTree). Las estructuras de datos y el algoritmo son una
generalización de los árboles de decisión. El ADTree fue introducido por
Yoav Freund y Llew Mason en 19993.
Los ADTree contienen nodos splitter y nodos de predicción. El primero es
un nodo que es asociado con una prueba, mientras que un nodo de
predicción es asociado con una regla. El nodo de la Figura 3, esta
compuesto por 4 nodos splitter y 9 nodos de predicción. Una instancia
define una serie de caminos en un ADTree. La clasificación es asociada
con una instancia que es el signo de la suma de las predicciones
cercanas al camino en el que es definido por esta instancia. Considere el
ADTree de la figura 3 y la instancia x = (color=red, year=1989, …), la
suma de predicciones es +0.2+0.2+0.6+0.4+0.6 = +2, así la clasificación
es +1 con alta confianza. Para la instancia x = (color=red, year=1999, …),
la suma de las predicciones es +0.4 y la clasificación es +1 con baja
confianza. Para la instancia x= (color=white, year=1999, …), la suma de
las predicciones es -0.7 y la clasificación es -1 con confianza media.
El ADTree puede ser visto como una consistencia de una raíz nodo de
dirección y cuatro unidades de tres nodos cada uno. Cada unidad es una
regla de decisión y esta compuesta por un nodo splitter y dos nodos de
predicción que son sus hijos [5].
3
Citado
en
Proz.”
Árbol
de
decisión
(óptima)”.
http://www.proz.com/kudoz/2311529 [citado en 28 de Febrero de 2008]
Disponible:
14
Figura 3. Ejemplo de un árbol ADTree
Las reglas en un ADTree son similares a las de árboles de decisión,
consecuentemente se puede aplicar métodos de empuje o aumento en el
orden para diseñar un algoritmo de aprendizaje ADTree. Una regla en un
ADTree define una partición de una instancia dentro de un espacio de tres
bloques definidos por C1 ∧ c2 , C1 ∧ ¬c2 y C1 . Básicamente, el algoritmo de
aprendizaje para construcción de un ADTree es una estrategia top-down.
Cada paso de aumento es seleccionado y adiciona una nueva regla o su
equivalente a una nueva unidad consistente de un nodo splitter y dos
nodos de predicción.
MULTI-LABEL ALTERNATING DECISION TREE [5]
Un árbol de decisión multi-label o multietiqueta es un ADTree con las
siguientes restricciones: cualquier nodo de predicción interior contiene un
0; esto es al menos un nodo splitter siguiendo cada nodo de predicción;
los nodos de predicción en una hoja contiene valores que pueden ser
interpretados como clases.
2.3.2. Decision Stump o árbol de decisión de un nivel
Como bien dice su nombre se trata de árboles de decisión de un solo
nivel.
15
Funcionan de forma aceptable en problemas de dos clases. No obstante,
para problemas de más de dos clases es muy difícil encontrar tasas de
error inferiores a 0.5 según [6].
Retomando los conceptos de [7], el propósito del algoritmo es construir un
modelo de cada caso que será clasificada, tomando únicamente un
subconjunto de casos de entrenamiento. Este subconjunto es escogido en
base a la distancia métrica entre las pruebas del caso y las pruebas de los
casos dentro del espacio. Por cada caso de prueba, se hace una
empaquetación conjunta de un árbol de un nivel clasificando así el
aprendizaje de los puntos de entrenamiento cerrando la prueba actual del
caso.
Los árboles de decisión de un nivel o decisión stump (DS) son árboles
que clasifican casos, basados en valores característicos. Cada nodo en
un árbol de decisión de un nivel representa una característica de un caso
para ser clasificado, y cada rama representa un valor que el nodo puede
tomar. Los casos son clasificados comenzando en el nodo raíz y se
cataloga basándose en sus valores característicos. En el peor de los
casos un árbol de decisión de un nivel puede reproducir el sentido más
común, y puede hacerse mejor si la selección característica es
particularmente informativa.
Generalmente, el conjunto propuesto consiste en los siguientes cuatro
pasos:
1. Determinar la distancia métrica conveniente.
2. Encontrar el k vecino más cercano usando la distancia
métrica seleccionada.
3. Aplicar la empaquetación de clasificación de los árboles de
decisión de un nivel como entrenamiento de los k casos.
4. La respuesta a la empaquetación de conjunto es la
predicción para los casos de prueba.
2.3.3. ID3
El ID3 es un algoritmo simple pero potente, cuya misión es la elaboración
de un árbol de decisión bajo las siguientes premisas [8]:
1. Cada nodo corresponde a un atributo y cada rama al valor posible
de ese atributo. Una hoja del árbol especifica el valor esperado de
la decisión de acuerdo con los ejemplos dados. La explicación de
una determinada decisión viene dada por la trayectoria desde la
raíz a la hoja representativa de esa decisión.
2. A cada nodo es asociado aquel atributo más informativo que aún
no haya sido considerado en la trayectoria desde la raíz.
16
3. Para medir cuánto de informativo es un atributo se emplea el
concepto de entropía. Cuanto menor sea el valor de la entropía,
menor será la incertidumbre y más útil será el atributo para la
clasificación.
El ID3 es capaz de tratar con atributos cuyos valores sean discretos o
continuos. En el primer caso, el árbol de decisión generado tendrá tantas
ramas como valores posibles tome el atributo. Si los valores del atributo
son continuos, el ID3 no clasifica correctamente los ejemplos dados. Por
ello, se propuso el C4.5, como extensión del ID3, que permite:
Otro concepto dado por [9] que se puede tomar es aquel donde se
describe que el ID3 es un algoritmo iterativo que elige al azar un
subconjunto de datos a partir del conjunto de datos de “entrenamiento” y
construye un árbol de decisión a partir de ello. El árbol debe clasificar de
forma correcta a todos los casos de entrenamiento. A continuación y
usando este árbol intenta clasificar a todos los demás casos en el
conjunto completo de datos de entrenamiento. Si el árbol consigue
clasificar el subconjunto, entonces será correcto para todo el conjunto de
datos, y el proceso termina. En caso contrario, se incorpora al
subconjunto una selección de los casos que no ha conseguido clasificar
correctamente, y se repite el proceso. De esta forma se puede hallar el
árbol correcto en unas pocas iteraciones, procesando un conjunto de
datos.
Figura 4. Ejemplo de un árbol ID3
17
2.3.4. J48 o C4.5
Es un algoritmo de inducción que genera una estructura de reglas o árbol
a partir de subconjuntos (ventanas) de casos extraídos del conjunto total
de datos de “entrenamiento”. En este sentido, su forma de procesar los
datos es parecido al de Id3. El algoritmo genera una estructura de reglas
y evalúa su “bondad” usando criterios que miden la precisión en la
clasificación de los casos. Emplea dos criterios principales para dirigir el
proceso dados por [10]:
1. Calcula el valor de la información proporcionada por una regla
candidata (o rama del árbol), con una rutina que se llama “info”.
2. Calcula la mejora global que proporciona una regla/rama usando
una rutina que se llama gain (beneficio).
Con estos dos criterios se puede calcular una especie de calor de
coste/beneficio en cada ciclo del proceso, que le sirve para decidir si
crear, por ejemplo, dos nuevas reglas, o si es mejor agrupar los casos de
una sola.
El algoritmo realiza el proceso de los datos en sucesivos ciclos. En cada
ciclo se incrementa el tamaño de la “ventana” de proceso en un
porcentaje determinado respecto al conjunto total. El objetivo es tener
reglas a partir de la ventana que clasifiquen correctamente a un número
cada vez mayor de casos en el conjunto total.
Cada ciclo de proceso emplea como punto de partida los resultados
conseguidos por el ciclo anterior.
En cada ciclo de proceso se ejecuta un submodelo contra los casos
restantes que no están incluidos en la ventana. De esta forma se calcula
la precisión del modelo respecto a la totalidad de datos.
Es importante notar que la variable de salida debe ser categórica.
Como se dice que el C4.5 es una mejora al Id3, se pueden describir
ciertas mejoras:
a) En vez de elegir los casos de entrenamiento de forma aleatoria
para formar la “ventana”, el árbol C4.5 sesga la selección para
conseguir una distribución más uniforme de la clase de la
ventana inicial.
b) En cuanto al límite de excepciones (casos clasificados
incorrectamente) C4.5 incluye como mínimo un 50% de las
excepciones en la próxima ventana. El resultado es una
convergencia más rápida hacia el árbol definitivo.
c) C4.5 termina la construcción del árbol sin tener que clasificar los
datos en todas las categorías (clases) posibles.
18
REPRESENTACIÓN TIPO ÁRBOL
La estructura del árbol esta compuesta por dos tipos de nodos:
una hoja (nodo terminal), que indica una clase;
un nodo de decisión, que especifica una comprobación a
realizar sobre el valor de una variable. Tiene una rama y un
subárbol para cada resultado posible de la comprobación.
Figura 5. Ejemplo aplicado de árbol de decisión adaptado para C4.5 [11]
C4.5 es una técnica de inducción que se basa en el método clásico de
“dividir y vencer” y forma parte de la familia de los TDIDT (Top Down
Induction Trees).
Figura 6. Ejemplo de un árbol de decisión generado por C4.5
19
2.3.5. LMT (Logistic Model Tree)
El LMT proporciona una descripción muy buena de los datos.
Un LMT consiste básicamente en una estructura de un árbol de decisión
con funciones de regresión logística en las hojas. Como en los árboles de
decisión ordinarios, una prueba sobre uno de los atributos es asociado
con cada nodo interno. Para enumerar los atributos con k valores, el nodo
tiene k nodos hijos, y los casos son clasificados en las k ramas
dependiendo del valor del atributo.
Para atributos numéricos, el nodo tienen dos nodos hijos y la prueba
consiste en comparar el valor del atributo con un umbral: un caso puede
ser clasificar los datos menores en la rama izquierda mientras que los
valores mayores en la rama derecha.
Formalmente [12] describe, un LMT consiste en una estructura de árbol
que esta compuesta por un juego N de nodos internos o no terminales y
un juego de T hojas o nodos terminales. La S denota el espacio,
atravesando por todos los atributos que están presentes en los datos.
Figura 7. Pseudo código para el algoritmo LMT
20
2.3.6. M5P (Árbol de regresión)
Miguel Ángel Fuentes y Pablo Galarza citan “es un método de aprendizaje
mediante árboles de decisión, utiliza el criterio estándar de poda M5” [13].
Es un árbol basado en árbol de decisión numérico tipo model tree.
Cita Raquel Bázquez, Fernando Delicado y M. Carmen Domínguez [14]
las características como:
•
•
•
Construcción de árbol mediante algoritmo inductivo de árbol de
decisión.
Decisiones de enrutado en nodos tomadas a partir de valores de
los atributos.
Cada hoja tiene asociada una clase que permite calcular el valor
estimado de la instancia mediante una regresión lineal.
2.3.7. NBTree (Naive Bayes Tree)
La referencia [15] muestra que es un algoritmo hibrido. Este genera un
tipo de árbol de decisión, pero las hojas contienen un clasificador Naive
Bayes construido a partir de los ejemplos que llegan al nodo.
Así mismo tomando conceptos de [16], es un eficiente y efectivo algoritmo
de aprendizaje, pero previo a los resultados muestra que su capacidad es
limitada ya que puede únicamente representar cierto grado de separación
entre las funciones binarias. Se le deben dar necesarias y suficientes
condiciones es el proceso en el dominio binario para ser aprendizaje
Naive Bayes bajo una representación uniforme. Se ve entonces que el
aprendizaje (y los datos de error) de Naive Bayes puede ser afectado
dramáticamente por distribuciones de muestreo. Los resultados ayudan a
dar un más profundo entendimiento de este de una manera más simple.
Se ha descrito que muestra datos de predicción tan eficientemente como
el algoritmo C4.5.
Los resultados ayudan a profundizar en el entendimiento de este
aparentemente simple algoritmo de aprendizaje. Naive Bayes aprende
capacidades que son determinadas no únicamente por las funciones
objetivo, sino también por muestreos de distribuciones, y de cómo el valor
de un atributo es representado.
21
2.3.8. RandomForest
Según cita Francisco José Soltero y Diego José Bodas en su artículo [17]
“Se basan en el desarrollo de muchos árboles de clasificación. Para
clasificar un objeto desde un vector de entrada, se pone dicho vector bajo
cada uno de los árboles del bosque. Cada árbol genera una clasificación,
el bosque escoge la clasificación teniendo en cuenta el árbol más votado
sobre todos los del bosque.
Cada árbol se desarrolla como sigue:
• Si el número de casos en el conjunto de entrenamiento es N,
prueba N casos aleatoriamente, pero con sustitución, de los datos
originales. Este será el conjunto de entrenamiento para el
desarrollo del árbol.
• Si hay M variables de entrada, un número m<<M es especificado
para cada nodo, m variables son seleccionadas aleatoriamente del
conjunto M y la mejor participación de este m es usada para dividir
el nodo. El valor de m se mantienen constante durante el
crecimiento del bosque.
• Cada árbol crece de la forma más extensa posible, sin ningún tipo
de poda”.
Figura 8. Esquema del algoritmo Random Forest [18]
CARACTERÍSTICAS DE RANDOM FOREST [19]
•
•
•
•
•
Corre eficientemente sobre grandes bases de datos
Puede manejar cientos de variables de entrada sin eliminación de
otras variables.
Esto da las estimaciones para saber que variables son importantes
en la clasificación.
Es un método eficaz para estimar datos perdidos y mantiene la
exactitud de cuándo una proporción grande de los datos falla.
Los árboles generados pueden ser salvados de un uso futuro sobre
otros datos.
22
•
•
Los prototipos son calculados ya que dan información acerca de la
relación entre las variables y las clasificaciones.
Ofrece un método experimental para detectar interacciones entre
variables.
2.3.9. RandomTree
Siguiendo los conceptos de [20] “Un RandomTree es un árbol dibujado al
azar de un juego de árboles posibles. En este contexto "al azar" significa
que cada árbol en el juego de árboles tiene una posibilidad igual de ser
probado. Otro modo de decir esto consiste en que la distribución de
árboles es "uniforme"”.
El proceso del RandomTree es un proceso que produce random trees de
permutaciones arbitrarias.
PROCESO PARA CONSTRUIR UN RANDOM TREE
Siguiendo la conceptualización realizada por [21], primero se marcan los
vértices n por número 1 a través de de una manera aleatoria para cada
que cada vértice tenga la misma probabilidad (este vértice es la
permutación aleatoria).
Usando esta permutación, se comienza a construir un árbol sobre vértices
de n: inicialmente, se tiene vértices de n y ninguna marca. En el paso k-th
se intenta agregar el borde de k-th y ver si el gráfico resultante contiene
un ciclo. Si es así, se salta el borde o línea de marca, además se agrega
al gráfico y se repite para k+1. Durante este proceso el gráfico
almacenará un bosque.
Después de al menos
conectado).
pasos se obtendrá un árbol (un bosque
Las líneas punteadas representan las marcas o líneas que fueron
consideradas, pero omitidas o saltadas.
Figura 9. Proceso para construir un Random Tree
23
2.3.10. REPTree
Cita Aurora Agudo, Juan Carlos Alonso y Ruth Santana en [22] “Es un
método de aprendizaje rápido mediante árboles de decisión. Construye un
árbol de decisión usando la información de varianza y lo poda usando
como criterio la reducción del error. Solamente clasifica valores para
atributos numéricos una vez. Los valores que faltan se obtienen partiendo
las correspondientes instancias”.
Refiere Antonio Bellas [23] “Es un árbol de clasificación con modelo
comprensible (reglas if then else)”
Haciendo referencia de [24], construye un árbol de decisión usando la
ganancia de información y realiza una poda de error reducido. Solamente
ordena una vez los valores de los atributos numéricos. Los valores
ausentes se manejan dividiendo las instancias correspondientes en
segmentos.
2.3.11. UserClassifier
Su característica esencial es que permite al usuario construir su propio
árbol de decisión.
Figura 10. Ejemplo de UserClassifier básico
Citando conceptos de [25], los nodos en el árbol de decisión no son
prueba simple sobre los valores del atributo, pero son regiones que el
usuario selecciona. Si un caso miente dentro de la región este sigue una
rama del árbol, si este miente fuera de las regiones sigue por otra rama.
Por lo tanto cada nodo tiene sólo dos ramas que bajan de él.
24
Figura 11. Ejemplo de UserClassifier final [26]
25
3. WEKA – WAIKATO ENVIRONMENT FOR
KNOWLEDGE ANALYSIS
Diego García Morate cita en su manual [27] “Weka (Gallirallus australis)
es un ave endémica de Nueva Zelanda que da nombre a una extensa
colección de algoritmos de Máquinas de conocimiento desarrollados por
la universidad de Waikato (Nueva Zelanda) implementados en Java, útiles
para ser aplicados sobre datos mediante las interfaces que ofrece o para
embeberlos dentro de cualquier aplicación. Además Weka contiene las
herramientas necesarias para realizar transformaciones sobre los datos,
tareas de clasificación, regresión, clustering, asociación y visualización.
Weka está diseñado como una herramienta orientada a la extensibilidad
por lo que añadir nuevas funcionalidades es una tarea sencilla”.
Es un software que ha sido desarrollado bajo licencia GPL4 lo cual ha
impulsado que sea una de las suites más utilizadas en el área en los
últimos años [28]; así mismo si se toma a [29], es un software para el
aprendizaje automático o minería de datos.
Por ser GPL la licencia, este programa es de libre distribución y difusión,
además es independiente de la arquitectura, ya que funciona en cualquier
plataforma sobre la que haya una máquina virtual Java disponible [30].
Figura 12. Imagen de una Weka
Incluye las siguientes características dentro de la versión 3.4.10.:
• Diversas fuentes de datos (ASCII, JDBC).
• Interfaz visual basado en procesos/flujos de datos (rutas).
• Distintas herramientas de minería de datos: reglas de asociación (a
priori, Tertius, etc), agrupación/segmentación/conglomerado
(Cobweb, EM y k-medias), clasificación (redes neuronales, reglas y
4
Citado de GNU Public License. http://www.gnu.org/copyleft/gpl.html
26
•
•
•
•
árboles de decisión, aprendizaje Bayesiana) y regresión (Regresión
lineal, SVM...).
Manipulación de datos (pick & mix, muestreo, combinación y
separación).
Combinación de modelos (Bagging, Boosting, etc).
Visualización anterior (datos en múltiples gráficas) y posterior
(árboles, curvas ROC, curvas de coste, etc).
Entorno de experimentos, con la posibilidad de realizar pruebas
estadísticas (t-test).
Su uso esta entre investigación, educación y realización de aplicaciones
[29].
Las características que se pueden describir para Weka son:
1. Sistema integrado con herramientas de pre-procesado de datos,
algoritmos de aprendizaje y métodos de evaluación de algoritmos.
2. Posee interfaces graficas para comprensión y manejo del usuario.
3. Tiene un ambiente de comparación entre las herramientas de
aprendizaje.
3.1.
INSTALACIÓN Y EJECUCIÓN
Haciendo referencia a [27], para poder instalar el software, primero se
debe descargar el mismo de la página
http://www.cs.waikato.ac.nz/ml/weka, una vez descomprimido Weka y
teniendo apropiadamente instalada la máquina de virtual Java, para
ejecutar Weka simplemente se debe ordenar dentro del directorio de la
aplicación el mandato:
java -jar weka.jar
No obstante, si se esta utilizando la máquina virtual de Java de Sun (que
habitualmente es la más corriente), este modo de ejecución no es el más
apropiado, ya que, por defecto, asigna sólo 100 megas de memoria de
acceso aleatorio para la máquina virtual, que muchas veces será
insuficiente para realizar ciertas operaciones con Weka (y se obtendrá el
consecuente error de insuficiencia de memoria); por ello, es altamente
recomendable ordenarlo con el mandato:
java -Xms<memoria-mínima-asignada>M
-Xmx<memoria-máxima-asignada>M -jar weka.jar
Dónde el parámetro -Xms indica la memoria RAM mínima asignada para
la máquina virtual y -Xmx la máxima memoria a utilizar, ambos elementos
expresados en Megabytes si van acompañados al final del modificador
27
“M”. Una buena estrategia es asignar la mínima memoria a utilizar
alrededor de un 60% de la memoria disponible.
3.2.
FORMAS DE UTILIZAR WEKA
Según [30] WEKA se puede utilizar de 3 formas distintas:
A. Desde la línea de comandos: Cada uno de los algoritmos
incluidos en WEKA se pueden invocar desde la línea de
comandos de MS-DOS como programas individuales. Los
resultados se muestran únicamente en modo texto.
B. Desde una de las interfaces de usuario: WEKA dispone de 4
interfaces de usuario distintos, que se pueden elegir después de
lanzar la aplicación completa. Los interfaces son:
9 Simple CLI (Command Line Interface): Entorno consola
para invocar directamente con java a los paquetes de Weka.
9 Explorer: Interfaz gráfica básica, entorno visual que ofrece
una interfaz gráfica para el uso de los paquetes.
9 Experimenter: Interfaz gráfica con posibilidad de comparar
el funcionamiento de diversos algoritmos de aprendizaje.
Centrado en la automatización de tareas de manera que se
facilite la realización de experimentos a gran escala.
9 KnowledgeFlow: Interfaz gráfica que permite interconectar
distintos algoritmos de aprendizaje en cascada, creando una
red. Permite generar proyectos de minería de datos mediante la
generación de flujos de información.
C. Creando un programa Java: La tercera forma en la que se puede
utilizar el programa WEKA es mediante la creación de un
programa Java que llame a las funciones que se desee. El
código fuente de WEKA está disponible, con lo que se puede
utilizar para crear un programa propio.
Una vez que Weka esté en ejecución aparecerá una ventana denominada
selector de interfaces (Figura 13), que permite seleccionar la interfaz con
la que se desea comenzar a trabajar con Weka. Las posibles interfaces a
seleccionar son Simple Cli, Explorer, Experimenter y KnowledgeFlow.
28
Figura 13. Ventana inicial de Weka
Los botones de la parte inferior permiten elegir uno de los cuatro
interfaces. El aspecto de cada uno de ellos se muestra en las figuras
siguientes:
Figura 14. Interfaz Simple CLI
29
Figura 15. Interfaz Explorer
Figura 16. Interfaz Experimenter
30
Figura 17. Interfaz KnowledgeFlow
Para el enfoque del presente manual se hará énfasis en la interfaz
Explorer que permite un mejor manejo de la información y entendimiento
para el usuario, así como realizar operaciones sobre un solo archivo de
datos.
Cita José Hernández y César Ferri [28] “si se observa, se tienen 6 subentornos de ejecución:
1. Preprocess: Incluye las herramientas y filtros para cargar y
manipular los datos.
2. Classify: Acceso a las técnicas de clasificación y regresión.
3. Cluster: Integra varios métodos de agrupamiento.
4. Associate: Incluye unas pocas técnicas de reglas de asociación.
5. Select Attributes: Permite aplicar diversas técnicas para la
reducción del número de atributos.
6. Visualize: En este apartado se puede estudiar el comportamiento
de los datos mediante técnicas de visualización”.
3.3.
FICHEROS .ARFF
Para poder trabajar Weka utiliza un formato de archivo especial
denominado arff, acrónimo de Attribute-Relation File Format. Este formato
está compuesto por una estructura claramente diferenciada en tres partes
[27]:
31
1. Cabecera: Se define el nombre de la relación. Su formato es el
siguiente:
@relation <nombre-de-la-relación>
Donde <nombre-de-la-relación> es de tipo String (el ofrecido por
Java). Si dicho nombre contiene algún espacio será necesario
expresarlo entre comillas.
2. Declaraciones de atributos. En esta sección se declaran los
atributos que compondrán el archivo junto a su tipo. La sintaxis es
la siguiente:
@attribute <nombre-del-atributo> <tipo>
Donde <nombre-del-atributo> es de tipo String teniendo las mismas
restricciones que el caso anterior. Weka acepta diversos tipos,
estos son:
a) NUMERIC Expresa números reales.
b) INTEGER Expresa números enteros.
c) DATE Expresa fechas, para ello este tipo debe ir
precedido de una etiqueta de formato entre comillas. La
etiqueta de formato está compuesta por caracteres
separadores (guiones y/o espacios) y unidades de tiempo:
dd Día.
MM Mes.
yyyy Año.
HH Horas.
mm Minutos.
ss Segundos.
d) STRING Expresa cadenas de texto, con las restricciones
del tipo String comentadas anteriormente.
e) ENUMERADO El identificador de este tipo consiste en
expresar entre llaves y separados por comas los posibles
valores (caracteres o cadenas de caracteres) que puede
tomar el atributo. Por ejemplo:
@attribute tiempo {soleado, lluvioso, nublado}
3. Sección de datos. Se declaran los datos que componen la
relación separando entre comas los atributos y con saltos de línea
las relaciones.
@data
4,3.2
En el caso de que algún dato sea desconocido se expresará con un
símbolo de cerrar interrogación (“?").
32
Es posible añadir comentarios con el símbolo “%”, que indicará que
desde ese símbolo hasta el final de la línea es todo un comentario.
Los comentarios pueden situarse en cualquier lugar del fichero.
Un ejemplo de un archivo de prueba.
---------------------------------------------prueba.arff------------------------------------1 % Archivo de prueba para Weka.
2 @relation prueba
3
4 @attribute nombre STRING
5 @attribute ojo_izquierdo {Bien, mal}
6 @attribute dimension NUMERIC
7 @attribute fecha_analisis DATE "dd-MM-yyyy HH:mm"
8
9 @data
10 Antonio, bien,38.43,"12-04-2003 12:23"
11 ’Maria José’,?,34.53,"14-05-2003 13:45"
12 Juan, bien,43,"01-01-2004 08:04"
13 Maria,?,?,"03-04-2003 11:03"
33
4. SELECCIÓN Y SOLUCIÓN DEL PROBLEMA
4.1.
SELECCIÓN DE EJEMPLO
De acuerdo a las especificaciones dadas para la utilización de WEKA en
los capítulos anteriores y teniendo en cuenta el objetivo del presente
manual para dar explicación al funcionamiento de la herramienta se dará
la conceptualización de los procedimientos de escogencia del ejemplo
que será manejado a lo largo de los capítulos siguientes.
Como primer punto es importante dar claridad la cantidad de ejemplos
que se pueden encontrar a través de Internet, cada uno con objetivos
diferentes y dando respuesta a muchos temas, el lector podrá descargar
de diferentes páginas variedad de datasets, quedando así una invitación a
consultar dichas páginas.
Es importante hacer notar que se deben dar pautas que permitan la
escogencia de un ejemplo apropiado y entendible para el usuario, para
esto tenga en cuenta las siguientes características:
1.
2.
3.
4.
5.
Fácil de entender.
Existencia de datos suficientes dentro de la base de datos.
Los datos deben ser coherentes.
Debe tener un objetivo.
Las variables de resultado deben dar respuesta al problema.
De acuerdo a las características anteriores se evalúan varios ejemplos
que cumplen muchos los requisitos, entre los ejemplos revisados se
tienen en cuenta los que por defecto trae la herramienta incorporado
dentro de la carpeta data y algunos otros consultados de cursos y
manuales de WEKA5. Tales ejercicios son:
a) contact-lenses.arff: Muestra como recomendar lentes de contacto
teniendo en cuenta variables de: edad (3 valores), tipo de problema
visual (2 valores), existencia de astigmatismo (2 valores) y nivel de
producción de lágrimas (2 valores).
b) cpu.arff: Indica como se puede realizar la compra de un
computador de acuerdo a sus caracterìsticas de hardware, sólo
maneja variables de tipo numéricas.
5
Citado en My weka page.” Arff data files”. Disponible: http://www.hakank.org/weka/
[citado en 16 de Mayo de 2008]
34
c) cpu.with.vendor.arff: Describe la compra que se puede hacer de
un computador de acuerdo a la fábrica matriz que vende las partes,
maneja un dato nominal y 7 numéricos.
d) credit-g.arff: Ejemplo que describe las diferentes variables
existentes para la determinación de un crédito tales como estado
de cuenta, historia crediticia, propósito del crédito, empleos que ha
tenido, estado civil, edad, tipo de vivienda, existencia de otros
créditos, existencia de teléfono propio, entre otros.
e) Drug1n.arff: En este caso se trata de predecir el tipo de fármaco
que se debe administrar a un paciente afectado de rinitis alérgica
según distintos parámetros/variables. Las variables que se recogen
en los historiales clínicos de cada paciente son Edad, Sexo,
Tensión sanguínea, nivel de colesterol, Nivel de sodio en la sangre,
Nivel de potasio en la sangre. Hay cinco fármacos posibles: DrugA,
DrugB, DrugC, DrugX, DrugY.
f) Empleados.arff: La empresa de software para Internet “Memolum
Web” quiere extraer tipologías de empleados, con el objetivo de
hacer una política de personal más fundamentada y seleccionar a
qué grupos incentivar. Las variables que se recogen de las fichas
de los 15 empleados de la empresa son sueldo, casado, coche,
número de hijos, tipo de vivienda, pertenecer al sindicato
revolucionario de Internet, nº de bajas por año, antigüedad en la
empresa, sexo.
g) iris.arff: Ejemplo que permite definir el tipo de la planta Iris, setosa,
versicoulor o virginica, para esto se utilizan 4 atributos numéricos,
longitud y anchura de sepal, longitud y anchura de pétalo.
h) labor.arff: Describe como determinar de acuerdo a variables el tipo
de empleo o labor que puede tener una persona, para esto se tiene
en cuenta duración, horas de trabajo, pensión, vacaciones,
contribución a salud, contribución a servicio odontológicos, entre
otros.
i) segment-challenge.arff: Muestra como realizar un paisaje de
acuerdo a matices de colores, región de color, línea de densidad,
saturación ,etc.
j) segment-test.arff: Se busca que sea concordante los colores y
matices involucrados dentro de una imagen y s construcción.
k) soybean.arff: Describe los 19 tipos de enfermedades que puede
tener la planta de soja en función de 35 síntomas en un fichero con
50 ejemplos.
35
l) titanic.arff: Corresponde a las características de los 2.201
pasajeros del Titanic. Estos datos son reales y se han obtenido de:
"Report on the Loss of the ‘Titanic’ (S.S.)" (1990), British Board of
Trade Inquiry Report_ (reprint), Gloucester, UK: Allan Sutton
Publishing.
Para este ejemplo sólo se van a considerar cuatro variables clase
(0 = tripulación, 1 = primera, 2 = segunda, 3 = tercera), edad (1 =
adulto, 0 = niño), sexo (1 = hombre, 0 = mujer), sobrevivió (1 = sí, 0
= no).
m) train1.arff: Por medio de este ejemplo se podrá visualizar las
características que pueden tener los viajes en tren y así escoger
cuales son las mejores opciones de ocurrencia de un patrón.
n) Weather.arff: Describe un conjunto de factores meteorológicos de
un determinado día he indica si se puede jugar o no al tenis. Los
factores evaluados son humedad, temperatura, viento y si esta
soleado.
o) weather.nominal .arff: Se trata del problema que indica si una
cierta persona practicará deporte en función de las condiciones
atmosféricas. En este caso se utiliza la versión de la base de datos
en la que todos los atributos son discretos (nominales), aplica la
misma teoría del caso anterior.
De acuerdo a los ejemplos citados anteriormente y de acuerdo a las
características que especifican la posible elección de un ejercicio
(recuerdo que el lector puede escoger el ejercicio de acuerdo a su gusto)
se evalúan las características y se tiene como ejemplo a manejar para el
presente manual aquel con nombre “Empleados.arff”, se escoge primero
por los datos especificados dentro de la base de datos ya que son
concretos y de gran claridad, así mismo permiten mostrar al usuario más
fácilmente los resultados, de igual forma se escoge ya que muestra un
caso más cercano a la vida real y ante todo es desarrollado por personas
de habla castellana, contrario a los otros ejemplos evaluados que son
más complejos en su entendimiento y resultado y no son el caso para el
presente manual.
36
4.2.
EMPEZANDO CON WEKA
Teniendo en cuenta el documento de doctorado [30] se puede diferenciar
ciertos pasos para manejar WEKA, estos son:
Paso 1 - Lanzar el interfaz Explorer: Se lanzará esta interfaz de acuerdo
con lo indicado en la introducción del punto 3.2. ítem B.
Paso 2 - Cargar la base de datos: Para cargar la base de datos se
utilizará el botón OPEN FILE de la interfaz Explorer (pestaña Preprocess),
se seleccionará el directorio data y dentro de él, el fichero Empelados.arff,
este describe según [28] una empresa de software para Internet
“Memolum Web” que quiere extraer tipologías de empleados, con el
objetivo de hacer una política de personal más fundamentada y
seleccionar a qué grupos incentivar. La empresa para tal fin describe una
base de datos con 15 empleados.
El resultado de abrir la base de datos, será una pantalla como la que se
muestra en la figura:
Figura 18. Interfaz Explorer con archivo Empleados.arff
El ejemplo muestra 9 atributos empleados para el desarrollo del ejercicio,
estos se pueden ver en el cuadrante inferior izquierdo. Los atributos son:
1. Sueldo: Sueldo anual en euros.
2. Casado: Si está casado o no.
3. Coche: Si va en coche a trabajar (o al menos si lo parquea en el
estacionamiento de la empresa).
37
4.
5.
6.
7.
8.
9.
Hijos: Si tiene hijos.
Alq/Prop: Si vive en una casa alquilada o propia.
Sindic.: Si pertenece al sindicato revolucionario de Internet.
Bajas/Año: Media del nº de bajas por año
Antigüedad: Antigüedad en la empresa
Sexo: H: Hombre, M: Mujer.
Haciendo clic sobre cada uno de los atributos, se muestra información
sobre el mismo en la parte derecha de la ventana. En el caso de atributos
discretos se indica el número de instancias que toman cada uno de los
valores posibles; y en el caso de atributos reales se muestran los valores
máximo, mínimo, medio y la desviación estándar. Así mismo, se muestra
un gráfico en el que las distintas clases se representan con colores
distintos, en función de los valores del atributo elegido.
Paso 3 - Generación de gráficos: Para generar gráficos con los datos del
ejemplo, se seleccionará la pestaña Visualize. Por defecto, se muestran
gráficos para todas las combinaciones de atributos tomadas dos a dos, de
modo que se pueda estudiar la relación entre dos atributos cualesquiera.
El aspecto de la pantalla es el mostrado en la figura siguiente:
Figura 19. Opción Visualice para Empleados.arff
Si se desea mostrar un gráfico concreto, basta con hacer doble clic sobre
él. Por ejemplo, haciendo doble clic sobre el gráfico que relaciona el
aspecto de parejas casadas por sueldo (Casado / Sueldo) se muestra el
gráfico de la figura siguiente:
38
Figura 20. Resultado de un nodo gráfico {Casado x Sueldo}
Para manejar el presente problema, se describirá cada uno de los
atributos de acuerdo a lo estipulado para weka.
a. Sueldo: Su tipo de dato es Numérico, tiene un valor mínimo de 8000 y
un valor máximo de 50000, tiene una media de 21066.667 y una
desviación estándar de 12308.34. Si se observa en la figura 21, se
tienen 11 personas que están entre el valor máximo de 8000 y 4
personas entre el valor de 29000 y 50000.
Figura 21. Visualización de características atributo Sueldo
39
b. Casado: El tipo de dato es Nominal, tiene valores estándar de Si y No,
donde 7 personas están casadas y 8 personas no lo están.
Figura 22. Visualización de características atributo Casado
c. Coche: Donde el tipo de dato es Nominal y presenta valores estándar
de Si y No, donde 4 personas no tienen coche y 11 si lo tienen.
Figura 23. Visualización de características atributo Coche
d. Hijos: Es de tipo Numérico los datos ofrecidos, donde se muestra un
máximo de 0 y un mínimo de 3, presenta una media de 0.733 y una
desviación estándar de 1.033. Reconoce que se tienen 11 personas
entre el rango de 0 a 1.5 y 4 personas entre el rango de 1.6 a 3.
40
Figura 24. Visualización de características atributo Hijos
e. Alquiler/Propio: Es un atributo Nominal, donde 9 personas viven en
alquiler y 6 personas tienen vivienda propia.
Figura 25. Visualización de características atributo Alq/Prop
f. Sindicato: Atributo de tipo nominal que clasifica si las personas
pertenecen o no al sindicato revolucionario de Internet. Este atributo
muestra que 8 personas no pertenecen al sindicato y 7 si lo hacen.
41
Figura 26. Visualización de características atributo Sindicato
g. Bajas/Año: Se muestra en este atributo de tipo numérico un valor
mínimo de 0, un valor máximo de 27, una media de 5.267 y una
desviación estándar de 7.106. Por tanto se puede observar que 13
personas se encuentran entre el rango de 0 hasta aproximadamente
10, y se encuentran 2 personas entre el rango de aproximadamente 11
a 27.
Figura 27. Visualización de características atributo Bajas/Año
h. Antigüedad: Atributo de tipo numérico que muestra un mínimo de 1,
máximo de 20, media de 8.2 y desviación estándar de 5.441. Describe
que se encuentran 11 personas entre el rango de antigüedad de 1 a
10.5 y 4 personas que se encuentran entre el rango de 10.6 a 20.
42
Figura 28. Visualización de características atributo Antigüedad
i.
Sexo: Atributo nominal que muestra 9 Hombres y 6 mujeres dentro de
la empresa.
Figura 29. Visualización de características atributo Sexo
4.3.
ÁRBOLES DE DECISIÓN CON WEKA
ADTREE
Para empezar a manejar WEKA con algoritmos de aprendizaje
automáticos, se debe seleccionar la pestaña Classify y se elegirá un
clasificador pulsando el botón Choose. Aparecerá una estructura de
directorios en la que se seleccionará el directorio trees y dentro del él el
43
algoritmo ADTRee. Se mantendrán las opciones por defecto del
clasificador (J48 –B 10 –E -3), tal y como muestra en la figura 30.
Figura 30. Visualización de pantalla clasificación ADTree
Se mantendrá el resto de valores por defecto tales como mantener
activada únicamente la opción de test de Cross-validation.
Para generar el árbol pulse Start y vera la pantalla de la figura 31.
Figura 31. Visualización de pantalla al generar el árbol ADTree
Analizando la información arrojada se destaca:
44
En primer lugar, se muestra información sobre el tipo de clasificador
utilizado (algoritmo ADTree), la base de datos sobre la que se trabaja
(empleados), el numero de instancias (15), el numero de atributos y su
nombre (9) y el tipo de test (cross validation).
Figura 32. Ventana Run information del árbol ADTree
Seguidamente se muestra el árbol que se ha generado y el número de
instancias que clasifica cada nodo:
Figura 33. Ventana Classifier model del árbol ADTree
Y por ultimo se muestran los resultados del test (indican la capacidad de
clasificación esperable para el árbol y la matriz de confusión):
45
Figura 34. Ventana Stratified cross-validation del árbol ADTree
Para visualizar mejor el árbol solo basta hacer clic con el botón derecho
en la ventana de resultados, sobre el resultado de la generación del árbol.
Aparecerá un menú desplegable:
Figura 35. Menú desplegable para visualización de árboles
Dentro de ese menú se debe seleccionar la opción ‘Visualize tree’
mostrándose en resultado siguiente:
46
Figura 36. Ventana de visualización de árbol de decisión ADTree.
DECISIONSTUMP
Seleccione la pestaña Classify y elija un clasificador pulsando el botón
Choose. De la estructura de directorios trees escoja el algoritmo
DecisionStump. Mantenga las opciones por defecto del clasificador tales
como:
•
Mantener activada únicamente la opción de test de Cross-validation.
Figura 37. Visualización de pantalla clasificación DecisionStump.
Para generar el árbol pulse Start y vera la pantalla de la figura 38.
47
Figura 38. Ventana al generar el árbol DecisionStump
La información describe:
Tipo de clasificador utilizado (DecisionStump), la base de datos sobre la
que se trabaja (empleados), numero de instancias (15), numero de
atributos y su nombre (9) y tipo de test (Cross-validation).
Figura 39. Ventana Run information del árbol DecisionStump
Luego se muestra el árbol que se ha generado y el número de instancias
que clasifica cada nodo:
48
Figura 40. Ventana Classifier model del árbol DecisionStump
Seguidamente se muestran los resultados del test:
Figura 41. Ventana Stratified cross-validation del árbol DecisionStump
Recuerde que para este tipo de algoritmo no se genera árbol de decisión.
ID3
Seleccione de la pestaña Classify el clasificador de la estructura de
directorios trees, escoja el algoritmo Id3. Mantenga las opciones por
defecto del clasificador de la opción test de Cross-validation.
49
Figura 42. Visualización de pantalla clasificación Id3.
Genere el árbol dando Start y vera la pantalla siguiente.
Figura 43. Ventana al generar el árbol Id3.
Lo anterior sucede ya que no se tienen en la base de datos Empleado.arff
valores nominales únicamente sino tanto valores numéricos como
nominales.
Es claro recordar entonces que para este algoritmo solo se pueden
evaluar valores que sean nominales.
50
J48
De la pestaña Classify, en el botón Choose escoja el algoritmo J48.
Mantenga las opciones por defecto del clasificador tales como:
•
Mantener activada únicamente la opción de test de Cross-validation.
Figura 44. Visualización de pantalla clasificación J48.
Genere el árbol pulsando Start.
Figura 45. Ventana al generar el árbol J48.
La información resultante describe el tipo de clasificador utilizado (J48), la
base de datos sobre la que se trabaja (empleados), numero de instancias
(15), numero de atributos y su nombre (9) y tipo de test (Cross-validation).
51
Figura 46. Ventana Run information del árbol J48
Seguidamente se muestra el árbol que se ha generado y el número de
instancias que clasifica cada nodo:
Figura 47. Ventana Classifier model del árbol J48
Por ultimo se muestran los resultados del test donde se indica la
capacidad de clasificación esperable para el árbol y la matriz de
confusión.
Figura 48. Ventana Stratified cross-validation del árbol J48
52
Podrá visualizar el árbol por medio del menú desplegable cuando hace
clic derecho sobre la ventana de resultados, seleccione la opción
Visualize tree.
Figura 49. Ventana de visualización de árbol de decisión J48.
LMT
Por medio de la pestaña Classify, escoja en el en el botón Choose el
algoritmo LMT. Para el algoritmo clasificador mantenga por defecto
señaladas las opciones que trae en la ventana de test como Crossvalidation y los datos por defecto LMT –I -1 –M 15.
Figura 50. Visualización de pantalla clasificación LMT.
53
Para generar el árbol de decisión de clic en el botón con nombre Start y
observara los siguientes resultados.
Figura 51. Ventana al generar el árbol LMT.
La información que resulta describe el tipo de clasificador utilizado (LMT –
I -1 –M 15), la base de datos sobre la que se trabaja (empleados), numero
de instancias (15), numero de atributos y su nombre (9) y tipo de test
(Cross-validation).
Figura 52. Ventana Run information del árbol LMT
Como segundo punto se muestran los datos del árbol generado y el
número de instancias que clasifica en cada nodo:
54
Figura 53. Ventana Classifier model del árbol LMT
Seguidamente se mostraran los resultados del test, donde se indicara la
capacidad de clasificación esperable para el árbol y la matriz de
confusión.
Figura 54. Ventana Stratified cross-validation del árbol LMT
Para visualizar el árbol diríjase a la lista de resultados que hace referencia
al árbol generado, haga clic derecho y del menú desplegable seleccione
la opción Visualize tree.
55
Figura 55. Ventana de visualización de árbol de decisión LMT.
M5P
En la pestaña Classify, escoja por medio del botón Choose el algoritmo
M5P. Mantenga las opciones por defecto tales como M5P –M 4.0 y Crossvalidation.
Figura 56. Visualización de pantalla clasificación M5P.
Genere el árbol de decisión dando clic en el botón Start y observe que se
genera los siguientes resultados.
56
Figura 57. Ventana al generar el árbol M5P.
Como se puede observar en la figura 57 este algoritmo solo debe ser
construido con valores de características numéricas y no nominales como
alguno de los valores que tiene la base de datos Empleados.arff.
NBTREE
Para la generación de este árbol primero debe dirigirse a la pestaña
Classify, escoja en el en el botón Choose el algoritmo NBTree.
Mantenga las opciones por defecto que son mostradas en la ventana de
test.
Figura 58. Visualización de pantalla clasificación NBTree.
Genere el árbol de decisión dando clic en el botón Start y observe.
57
Figura 59. Ventana al generar el árbol NBTree.
Entre la información arrojada se tiene la descripción del tipo de
clasificador utilizado (NBTree), la base de datos sobre la que se trabaja
(empleados), numero de instancias (15), numero de atributos y su nombre
(9) y tipo de test (Cross-validation).
Figura 60. Ventana Run information del árbol NBTree
Seguidamente se muestran los datos del árbol generado y el número de
instancias que clasifica en cada nodo:
58
Figura 61. Ventana Classifier model del árbol NBTree
Por último se muestran los resultados del test, donde se indica la
capacidad de clasificación esperable para el árbol y la matriz de
confusión.
Figura 62. Ventana Stratified cross-validation del árbol NBTree
59
Luego, si desea visualizar el árbol que ha sido generado, diríjase a la lista
de resultados que hace referencia al árbol NBTree, haga clic derecho y
del menú desplegable seleccione la opción Visualize tree.
Figura 63. Ventana de visualización de árbol de decisión NBTree.
RANDOMFOREST
Este árbol podrá generarlo por medio de la pestaña Classify, donde en el
botón Choose puede escoger el algoritmo RandomForest. Para el
presente algoritmo de árbol de decisión mantenga las opciones mostradas
por defecto tales como RandomForest –I 10 –K 0 –S 1
Figura 64. Visualización de pantalla clasificación RandomForest.
60
Para generar el árbol de decisión RandomForest de clic en el botón Start
y observara los resultados que aparecen en la Figura 65.
Figura 65. Ventana al generar el árbol RandomForest.
La información que se genera es, primero la descripción del tipo de
clasificador utilizado (RandomForest), la base de datos sobre la que se
trabaja (empleados), numero de instancias (15), numero de atributos y su
nombre (9) y tipo de test (Cross-validation).
Figura 66. Ventana Run information del árbol RandomForest
Luego se mostraran los datos del árbol generado y el número de
instancias que clasifica en cada nodo:
Figura 67. Ventana Classifier model del árbol RandomForest
61
Y por último se muestran los resultados del test, donde se indica la
capacidad de clasificación esperable para el árbol y la matriz de
confusión.
Figura 68. Ventana Stratified cross-validation del árbol RandomForest
Para este tipo de árbol de decisión no se muestra gráficamente le
resultado, es decir no se genera gráficamente el árbol de decisión.
RANDOMTREE
El RandomTree lo podrá generar por medio de la pestaña Classify, de
clic en botón Choose para escoger el algoritmo RandomTree. Maneje las
opciones que son mostradas por defecto tales como RandomTree –K 1 –
M 1.0 –S 1 y Cross-validation.
Figura 69. Visualización de pantalla clasificación RandomTree.
62
Genere el árbol de decisión dando clic en el botón Start.
Figura 70. Ventana al generar el árbol RandomTree.
Se genera la información de la descripción del tipo de clasificador utilizado
(RandomTree), la base de datos sobre la que se trabaja (empleados),
numero de instancias (15), numero de atributos y su nombre (9) y tipo de
test (Cross-validation).
Figura 71. Ventana Run information del árbol RandomTree
Seguidamente observara los datos del árbol generado y el número de
instancias que clasifica en cada nodo:
63
Figura 72. Ventana Classifier model del árbol RandomTree
Luego se mostrarán los resultados del test, donde se indica la capacidad
de clasificación esperable para el árbol y la matriz de confusión.
Figura 73. Ventana Stratified cross-validation del árbol RandomTree
Este tipo de algoritmo no genera visualmente un árbol de decisión.
REPTREE
Para generar el árbol de decisión diríjase a la pestaña Classify, luego de
clic en botón Choose para escoger el algoritmo REPTree. En este
64
algoritmo maneje las opciones que por defecto son mostradas tales como
REPTree –M 2 –V 0.0010 –N 3 –S 1 –L -1 y Cross-validation.
Figura 74. Visualización de pantalla clasificación REPTree.
Para generar el árbol de decisión de clic en el botón Start y podrá
visualizar la información de la Figura 75.
Figura 75. Ventana al generar el árbol REPTree.
La información generada se da primero describiendo el tipo de clasificador
utilizado (REPTree), la base de datos sobre la que se trabaja
(empleados), numero de instancias (15), numero de atributos y su nombre
(9) y tipo de test (Cross-validation).
65
Figura 76. Ventana Run information del árbol REPTree
Luego se podrán ver los datos del árbol generado y el número de
instancias que clasifica en cada nodo:
Figura 77. Ventana Classifier model del árbol REPTree
Seguidamente observará los resultados del test, donde se indica la
capacidad de clasificación esperable para el árbol y la matriz de
confusión.
Figura 78. Ventana Stratified cross-validation del árbol REPTree
Para visualizar el árbol de decisión generado, diríjase a la lista de
resultados y de clic derecho sobre el árbol REPTree, luego escoja
Visualize Tree.
66
Figura 79. Visualización de árbol de decisión REPTree.
USERCLASSIFIER
Genere el árbol de decisión ubicándose en la pestaña Classify, de clic en
el botón Choose y escoja el algoritmo UserClassifier. Maneje las opciones
que son mostradas por defecto como la selección de Cross-validation.
Figura 80. Visualización de pantalla clasificación UserClassifier.
Para generar el árbol de decisión de clic en el botón Start.
67
4.4.
REVISANDO RESULTADOS
De acuerdo al enunciado del punto 3.4.2. se podría entender y dar las
diferencias por cada árbol de decisión así:
Árbol
Precisión
ADTree
Decisión Stump
J48
LMT
NBTree
RandomForest
RandomTree
REPTree
66.6667%
80%
66.6667%
66.6667%
60%
73.3333%
66.6667%
46.6667%
Instancias
correctamente
clasificadas
10
12
10
10
9
11
10
7
Instancias
incorrectamente
clasificadas
5
3
5
5
6
4
5
8
Si observa los árboles conllevan al mismo porcentaje de precisión en las
15 instancias evaluadas.
Teniendo en cuenta esto, por ejemplo para el árbol de decisión ADTree
se muestran los resultados evaluados dependiendo de las condiciones
que se tienen para cada atributo teniendo en cuenta si el parámetro es
mayor o menor de cierto rango.
Por ejemplo, si se evalúan a las personas con un sueldo mayor o igual a
17500 se podrán evaluar las posibilidades de que haya hijos (menores o
mayores e iguales a 1 pero igualmente que hayan sido dados de baja en
el año estas personas.
Si por el contrario se observa el árbol generado por el algoritmo J48 se
notará que el árbol es mucho más pequeño que el anterior indicando que
dependiendo del sueldo de la persona se tendrán o no hijos, es decir con
un suelo menor e igual a 15000, las mujeres tienen al menos un hijo,
mientras que los hombres tienen mas de 1. Por el contrario sólo los
hombres tienen un sueldo mayor e igual a 15000 pero no tienen hijos.
En el caso del árbol de decisión LMT se tiene la generación de un solo
nodo, esto debido a que tanto a izquierda como a derecha existen los
mismos valores pero se anulan el uno con el otro por el signo a izquierda
que poseen.
En el árbol RandomTree se tiene que la dependencia inicial se da por el
tipo de vivienda que posea la persona (propia o alquilada), según los
resultados si se es casado se podrían tener o no hijos, mientras que si no
se es casado, la dependencia surge de pertenecer o no a un sindicato, si
esto es así se tendría en cuenta solo la posible tenencia de un automóvil,
68
por el contrario si no se pertenece al sindicato los rangos serian
determinados por la antigüedad de la persona dentro de la compañía.
En cambio si se hace referencia a que la vivienda es propia solo se
tendría relación por la antigüedad en la empresa y las posibles bajas que
se hayan tenido en el año.
Observe que para cada árbol de decisión generado se presentan ciertas
características importantes de recalcar y que permiten mejor
conceptualización y entendimiento de los resultados así:
1. Estadístico de Kappa o Kappa Statistics: Tomando el concepto
de [31] Kappa por su nombre griego es un índice que compara el
acierto o acercamiento entre lo que se debe esperar para realizar o
tener un cambio de acuerdo a ciertas características y parámetros
planteados. Puede ser pensado como un cambio correcto
proporcional al acercamiento que se desea, así mismo los posibles
valores van desde un rango de +1 (acuerdo u acercamiento
perfecto), 0 (ningún acuerdo por encima de lo esperado) y -1 (total
desacuerdo).
Para realizar el cálculo tenga en cuenta que:
Kappa=(Acierto observado–Cambio en lo esperado)/(1–cambio en lo esperado)
2. Mean absolute error o error medio absoluto: Siguiendo los
conceptos de [32], el MAE mide la magnitud media de los errores
en un conjunto de cálculos, sin tener en cuenta su dirección. Esto
da la medida de precisión para las variables continuas. En otras
palabras, el MAE es la media de la muestra de verificación de los
valores absolutos de las diferencias entre los cálculos y la
correspondiente observación. El MAE es un Resultado lineal, lo
que significa que todas las diferencias individuales se ponderan por
igual a la media.
La función esta dada por:
Donde fi es la predicción y yi es el valor verdadero.
3. Root Mean Squared Error o error cuadrático medio: El RMSE
dado por [33] es una regla que mide la magnitud media del error.
Esto es, la diferencia entre lo pronosticado y los correspondientes
valores observados al cuadrado para que luego sea promediado a
lo largo de la muestra. Por último, se toma la raíz cuadrada de la
media. Dado que los errores son al cuadrado antes de que se
promediaran, el RMSE da un peso relativamente alto a los grandes
errores. Esto significa que el RMSE es más útil cuando los grandes
errores son particularmente indeseables. Tenga en cuenta que el
69
RMSE será siempre mayor o igual a la MAE (error medio absoluto),
la gran diferencia entre ellos, es en los errores individuales de la
muestra. Si el RMSE = MAE, entonces todos los errores son de la
misma magnitud. Ambos pueden ir de 0 a ∞ y son orientados a que
los valores mas bajos son los mejores.
Donde P(ij) es el valor que se ha predicho individualmente para el
programa i del caso j, y Tj es el valor objetivo para el caso j.
Es asi que P(ij) = Tj y Ei son los rangos de los índices de 0 a infinito,
donde 0 corresponde al ideal [34].
4. Relative absolute error o error relativo absoluto: Dando como
concepto lo tomado por [34], es aquel que ayuda a predecir un
valor relativo, que no es más que la media de los valores reales.
Esto quiere decir, el error no es más que el total absoluto del error
más no es el total del error al cuadrado. Por lo tanto, el error
absoluto relativo toma el total y absoluto error que se normaliza
dividiendo por el total de error absoluto de la predicción simple.
Matemáticamente, el error relativo absoluto Ei de un individuo i es
evaluado por la siguiente ecuación:
Donde P(ij) es el valor que se ha esperado para el valor i del caso j
(fuera de los n casos simples); Tj es el valor objetivo para el caso j;
y T esta dado por la formula:
De mejor manera, el numerador es igual a 0 y a Ei=0. Por tanto el
indice Ei va desde 0 hasta infinito, donde 0 corresponde al ideal.
5. Root relative squared error o raíz cuadrada de error relativo:
Citando a [35], esta formula simple no es más que la media de los
valores reales. De este modo, la relativa de error al cuadrado toma
el total de errores al cuadrado y se normaliza dividiendo por el total
de errores simples al cuadrado. Al tomar la raíz cuadrada del valor
relativo, el error se reduce a las mismas dimensiones que la
cantidad prevista.
70
Matemáticamente, la raíz cuadrada de error relativo Ei de un
individuo i es evaluado por la siguiente ecuación:
Donde P(ij) es el valor que se ha esperado para el valor i del caso j
(fuera de los n casos simples); Tj es el valor objetivo para el caso j;
y T esta dado por la formula:
Para dar explicacion a los conceptos que siguen (6 a 11), se
tomara como base la siguiente matriz de confusion:
Citando a [36]:
6. TP Rate o True Positive Rate o Recall: Esta medida está definida
por el cociente entre el número de ejemplos que clasifican
correctamente para una clase y el número total de ejemplos para la
clase estudiada. Dicho de otra manera es la proporción de
elementos que están clasificados dentro de la clase Ci, de entre
todos los elementos que realmente son de la clase Ci. En la matriz
de confusión es el elemento diagonal dividido por la suma de todos
los elementos de la fila. Cuando las sensibilidades pertinentes para
cada ejemplo de clase tienda a 1, la matriz de confusión tenderá a
ser una matriz diagonal.
TP Rate = TP/ (TP + FN)
TP Rate (C1) = N11 / (N11 + N12 + … + N1z)
TP Rate (C2) = N22 / (N21 + N22 + … + N2z)
TP Rate (Cz) = Nzz / (Nz1 + Nz2 + … + Nzz)
7. FP Rate o False Positive Rate: Es la proporción de ejemplos que
han sido clasificados dentro de la clase Ci, pero pertenecen a una
clase diferente. En la matriz de confusión es la suma de la columna
71
de la clase Ci menos el elemento diagonal dividido la suma de las
filas del resto de las clases.
8. Precision: Proporción de ejemplos que realmente tienen clase Ci
de entre todos los elementos que se han clasificado dentro de la
clase Ci. En la matriz de confusión es el elemento diagonal dividido
por la suma de la columna en la que se esta.
Prec (Modelo) = (N11 + N22 +…+ Nzz) / Total_de_ejemplos
Prec (C1) = N11 / (N11 + N21 +…+ Nz1)
Prec (C2) = N22 / (N12 + N22 +…+ Nz2)
Prec (Cz) = Nzz / (N1z + N2z +…+ Nzz)
9. F-Measure: Es una medida que combina la Precisión con el Recall
o TPR para la clase Ci.
F-Measure = (2 * Precisión * Recall) / (Precisión + Recall)
10. False Negative Rate: Es la proporción de elementos que no
clasifican para la clase Ci, de entre todos los elementos que
realmente son de la clase Ci. En la matriz de confusión es la suma
de todos los elementos de la fila excluyéndole a la diagonal dividida
por la suma de todos los elementos de la fila.
FN Rate = 1 – TPR = 1 – [TP / (TP + FN)] = FN / (FN + TP)
FN Rate (C1) = [(N11 + …+ N1z) - N11] / (N11 + N12 + …+N1z)
FN Rate (C2) = [(N21 + … + N2z) - N22] / (N21 + N22 + …+ N2z)
FN Rate (Cz) = [(Nz1 + … + Nzz) - Nzz] / (Nz1 + Nz2 + … + Nzz)
11. True Negative Rate o Especificidad: Es la proporción de
ejemplos que han sido clasificados dentro de las otras clases
diferente a la clase Ci. En la matriz de confusión es la suma de las
diagonales menos el elemento de la clase Ci dividido la suma de
las filas del resto de las clases.
Tenga en cuenta igualmente la definición dada para una matriz de
confusión o también llamada tabla de contingencia según [37]. Es de
tamaño n*n, siendo n el número de clases. El número de instancias
clasificadas correctamente es la suma de los números en la diagonal de la
matriz; los demás están clasificados incorrectamente.
72
Siendo esto así podrá verificar los resultados obtenidos de acuerdo a los
árboles de decisión tomados para la resolución del ejemplo manejado en
el presente manual, observe que loa matriz de confusión confirma la
información presentada en el ítem Sumario de los resultados generados
para cada árbol de decisión.
73
5. BIBLIOGRAFÍA
[1] S. Vallejos, “Trabajo de adscripción minería de datos”, Corrientes Argentina, 2006, pp. 11 – 14.
[2] Cursos, investigación y recursos en inteligencia artificial. “Introducción
a
técnicas
de
Minería
de
Datos”.
Disponible:
http://www.wiphala.net/courses/KDD_DM/20070/class/02_dt_for_classification/class_61_decision_trees.ppt [citado en 23
de Febrero de 2008]
[3]
IEspaña.
“Árboles
y
reglas
de
decisión”.
Disponible:
http://supervisadaextraccionrecuperacioninformacion.iespana.es/arboles.h
tml [citado en 23 de Febrero de 2008]
[4]
Proz.”
Árbol
de
decisión
(óptima)”.
Disponible:
http://www.proz.com/kudoz/2311529 [citado en 28 de Febrero de 2008]
[5] Google. “Machine learning and data mining in pattern recognition: third”
Disponible:
http://books.google.com.co/books?id=oaepxemimbmc&pg=pa49&dq=llew
+mason+%2b+alternating+decision+tree&lr=lang_es&sig=oexir3dg6nsmjx
f4aj4nrr2cnnu#ppa48,m1 [citado en 28 de febrero de 2008]
[6] Universidad Carlos III de Madrid. “Minería de datos” Disponible:
http://www.it.uc3m.es/jvillena/irc/practicas/03-04/13.mem.pdf [citado en 3
de Marzo de 2008]
[7]
Google.
”Innovations
in
applied
artificial
intelligence”
Disponible:
http://books.google.com.co/books?id=4uu_kxxbmboc&pg=ra3pa407&dq=decision+stump&lr=lang_es&sig=u3vqepmlkfgpuly2rs2z4lyekg#pra3-pa414,m1 [citado en 3 de marzo de 2008]
[8] Ciberconta. ”Sistemas de inducción de árboles de decisión: utilidad en
el
análisis
de
crisis
bancarias”
Disponible:
http://ciberconta.unizar.es/Biblioteca/0007/arboles.html [citado en 4 de
Marzo de 2008]
[9] The university of Arizona. “Expert prediction, symbolic learning, and
neural networks: an experiment on greyhound racing” Disponible:
http://ai.arizona.edu/papers/dog93/figs [citado en 4 de Marzo de 2008]
[10] Google. “Técnicas para el análisis de datos clínicos”. Disponible:
http://books.google.com.co/books?id=QqfuCWT3h8cC&pg=PA315&dq=id
3+%2B+%C3%A1rboles+de+decisi%C3%B3n&sig=jwd5cvqqVx47dxalFH
UvG6gY16U#PPA136,M1 [citado en 4 de Marzo de 2008]
74
[11] Instituto tecnológico de nuevo Laredo. “Algoritmo C4.5”. Disponible:
http://www.itnuevolaredo.edu.mx/takeyas/Apuntes/Inteligencia%20Artificial
/Apuntes/tareas_alumnos/C4.5/C4.5(2005-II-B).pdf [citado en 4 de Marzo
de 2008]
[12]
Google.
“Machine
learning:
ecml
2003”.
Disponible:
http://books.google.com.co/books?id=l4h2a2vf2puc&pg=pa245&dq=lmt+
%2b+logistic+model+tree&sig=xgu-lihrxmgctkc2ub5gqvdfxfw#ppr14,m1
[citado en 4 de marzo de 2008]
[13] Universidad Carlos III de Madrid. “Predicción Meteorológica”.
Disponible:
http://www.it.uc3m.es/jvillena/irc/practicas/05-06/13mem.pdf
[citado en 4 de Marzo de 2008]
[14] Universidad Carlos III de Madrid. “Aprendizaje y minería de datos”.
Disponible:
http://www.it.uc3m.es/jvillena/irc/practicas/03-04/8.pres.pdf
[citado en 4 de Marzo de 2008]
[15] Google. “Tasks and methods in applied artificial intelligence”.
Disponible:
http://books.google.com.co/books?id=edu4cqyz0mc&pg=pa274&dq=naive+bayes+tree&lr=&sig=hq1czrqjhp55ujz
vke-tkns4kjw#ppa256,m1 [citado en 4 de marzo de 2008]
[16]
Google.
“Advances
in
artificial
intelligence”.
Disponible:
http://books.google.com.co/books?id=aayvv5i1kzic&pg=pa432&dq=naive+
bayes+tree&lr=&sig=19qxtse7rnps-enwcrkxi6utl3e#ppt1,m1 [citado en 4 de
marzo de 2008]
[17] El profesional de la información. “Clasificadores inductivos para el
posicionamiento
web”.
Disponible:
http://www.elprofesionaldelainformacion.com/contenidos/2005/enero/1.pdf
[citado en 12 de Marzo de 2008]
[18] Intel. “Performance and scalability analysis of tree-based models in
large-scale
data-mining
problems”.
Disponible:
http://www.intel.com/technology/itj/2005/volume09issue02/art05_treebased_models/p05_workload.htm [citado en 12 de Marzo de 2008]
[19] University of California. “Random Forests” Disponible:
http://www.stat.berkeley.edu/users/breiman/RandomForests/cc_home.htm
[citado en 12 de Marzo de 2008]
[20]
Gla.ac.
“Page
Lab”
http://taxonomy.zoology.gla.ac.uk/rod/cplite/ch6.pdf [citado
Marzo de 2008]
Disponible:
en 12 de
75
[21]
Dimacs.
“The
Random
Tree
Process”.
Disponible:
http://dimax.rutgers.edu/~alexak/tree_process.html [citado en 12 de Marzo
de 2008]
[22] Universidad Carlos III de Madrid. “Evaluación de Modelos para
predicción
meteorológica”.
Disponible:
http://www.it.uc3m.es/jvillena/irc/practicas/04-05/21mem.pdf [citado en 14
de Marzo de 2008]
[23] Departament de sistemes informàtics i computació. “Detección de
intrusos mediante técnicas de minería de datos DIMIDA”. Disponible:
http://www.dsic.upv.es/~abella/papers/DIMIDA.pdf [citado en 14 de Marzo
de 2008]
[24]
Informática
en
salud
2007.
Disponible:
http://www.informatica2007.sld.cu/.../2006-11-15.5808751092/download
[citado en 14 de Marzo de 2008]
[25] The university of waikato. “WEKA - Data Mining, Building Decision
Trees”.
Disponible:
http://www.cs.waikato.ac.nz/~gs23/Pubs/WICworkshop.pdf [citado en 14
de Marzo de 2008]
[26] Java italian portal. “Tecniche di classificazione di data mining tramite
la
piattaforma
WEKA”.
Disponible:
http://www.javaportal.it/rw/33801/editorial.html [citado en 14 de Marzo de
2008]
[27] D. García. “Manual de WEKA”. pp. 2-5
[28] J. Hernandez. and C. Ferri. “Practica de Minería de Datos,
Introducción al WEKA, Curso de Doctorado Extracción Automática de
Conocimiento en Bases de Datos e Ingeniería de Software”, Universidad
de Valencia, 2006, pp. 2-15
[29] E. Frank. “Machine Learning with WEKA”. Department of computer
science; University of Waikato, New Zeland. pp.1
[30] “Programa de Doctorado Tecnologías Industriales. Aplicaciones de la
inteligencia robótica. Practica 1: Entorno de WEKA de aprendizaje
automático y data mining”, pp. 6-9
[31] J. Chiang. “Agreement between categorical measurements: Kappa
Statistics”
Disponible:
http://www.dmi.columbia.edu/homepages/chuangj/kappa/ [citado en 28 de
Mayo de 2008]
76
[32] “Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE)”
Disponible:http://www.eumetcal.org.uk/eumetcal/verification/www/english/
msg/ver_cont_var/uos3/uos3_ko1.htm [citado en 28 de Mayo de 2008]
[33] gepsot. “Analyzing APS Models Statistically. Root mean squared
error”.Disponible:http://www.gepsoft.com/Gepsoft/APS3KB/Chapter09/Sec
tion3/SS04.htm [citado en 28 de Mayo de 2008]
[34] gepsot. “Analyzing APS Models Statistically. Relative Absolute Error”.
Disponible:http://www.gepsoft.com/gxpt4kb/Chapter10/Section1/SS08.htm
[citado en 30 de Mayo de 2008]
[35] gepsot. “Analyzing APS Models Statistically. Relative Absolute Error”.
Disponible:http://www.gepsoft.com/gxpt4kb/Chapter10/Section1/SS07.htm
[citado en 30 de Mayo de 2008]
[36] W. Inchaustti. “[Wekalist] 3-clases False Negative, False Positive,
True
Positive,
True
Negative”.
2005.
Disponible:
http://209.85.215.104/search?q=cache:D9aZ2QIafO0J:https://list.scms.wai
kato.ac.nz/pipermail/wekalist/2005December/005634.html+tp+rate+%2B+weka&hl=es&ct=clnk&cd=6&gl=co
&lr=lang_es [citado en 30 de Mayo de 2008]
[37] J. Escribano. ”Minería de datos, análisis de datos mediante WEKA”.
pp. 2
[38] Instituto colombiano de normas técnicas y certificación.
“Documentación: Citas y notas de pie de página”. 2nd ed. Bogotá: Icontec,
1995, pp. 7, (NTC 1487)
[39] Instituto colombiano de normas técnicas y certificación. “Presentación
de tesis, trabajos de grado y otros trabajos de investigación”. 5 ed.
Bogotá: Icontec, 2002, pp. 34. (NTC 1486)
[40] Instituto colombiano de normas técnicas y certificación. “Referencias
documentales para fuentes de información electrónicas”. Bogotá: Icontec,
1998, pp. 23 (NTC 4490)
[41] Fundación universitaria Konrad Lorenz. “Reglamento académico para
programas de pregrado”. Bogotá, 2002, pp. 39
77