Notas de Introducción a las Bases de Datos
Anuncio

Notas de
Introducción a las Bases de Datos
Enero de 2002
Desarrolladas por:
Dr. Felipe López Gamino
Adaptadas por:
Angel Kuri Morales
1 INTRODUCCION AL PROCESAMIENTO CON BASES
DE DATOS
1.1 CONCEPTOS DE BASES DE DATOS
1.1.1 SISTEMA DE BASE DE DATOS
Una base de datos es una colección de datos relacionados la cual tiene las siguientes propiedades
implícitas: representa algún aspecto del mundo real, llamado el minimundo o el Universo de Discurso
(UD). Cambios en el minimundo se reflejan en la base de datos; su colección de datos es lógicamente
coherente con un significado, inherente; esto es, un conjunto de datos al azar normalmente no
constituye una base de datos;
• su colección de datos es lógicamente coherente con un significado inherente; esto es, un conjunto
de datos al azar normalmente no constituye una base de datos;
• se diseña, se construye, y se llena con datos para un propósito especifico;
• puede ser usada desde múltiples aplicaciones por diversos grupos de usuarios;
• está sujeta a un conjunto de restricciones para garantizar la integridad de la información.
Un DBMS (DataBase Management System) (o SGBD- Sistema de Gestión de Bases de Datos) es una
colección de programas que permite a usuarios crear y mantener bases de datos. Es un software de
propósito general que facilita los procesos de:
- definición (especificación de estructuras, tipos de datos y restricciones),
- construcción (almacenamiento de los datos en algún medio) y
- manipulación (consultas y actualización) de bases de datos para diversas aplicaciones.
Un DBMS puede ser de propósito especial para manipular bases de datos que tienen un propósito
especifico.
Un lenguaje de 4a. generación (4GL) es un lenguaje de programación con un conjunto poderoso de
instrucciones el cual permite crear aplicaciones que manipulan bases de datos. Actualmente estos
lenguajes incluyen elementos para manejar en forma gráfica la información de una base de datos
(Visual Basic es un ejemplo). Con un 4GL se pueden definir aplicaciones constituidas por formas,
reportes, menúes, etc., que utilicen el contenido de una base de datos a fin de satisfacer las
necesidades de usuarios de la misma.
A la conjunción de base de datos con el software que la manipula le llamaremos Sistema o Aplicación
de Base de Datos.
1.1.2 CARACTERÍSTICAS DEL ENFOQUE DE BASE DE DATOS
Una serie de características distingue el enfoque de base de datos del enfoque tradicional de
programación con archivos.
En el procesamiento de archivos tradicional, cada usuario define e implementa los archivos necesitados
para una aplicación especifica. En este enfoque normalmente existe mucha redundancia en la
información y cambios en el minimundo son difíciles de implementar en la aplicación.
En el enfoque de base de datos, en un solo diccionario de datos se mantienen las estructuras de
las diversas bases de datos requeridas por los usuarios; éste se define una sola vez y después es usado
por diversas aplicaciones. Normalmente la redundancia es menor y los cambios son más fáciles de
hacer.
A continuación se detallan las principales diferencias entre ambos enfoques:
• Naturaleza auto-descriptiva de un sistema de base de datos
El sistema de base de datos contiene no sólo a la base de datos misma sino también una definición
completa de su estructura. La definición se almacena en el catálogo del sistema. Esta información se
conoce como meta-datos. El catálogo es usado por el DBMS para poder trabajar con cualquier base de
datos.
En un sistema con procesamiento de archivos la definición de los datos típicamente es parte de los
programas de aplicación mismos. De esta manera, estos programas están restringidos a trabajar con
una base de datos especifica: la declarada en ellos. Cambios en el UD son difíciles de reflejar en la
base.
• Aislamiento entre datos y programas
En el procesamiento de archivos, la estructura de los archivos de datos está embebida en los programas
que los usan, así cualquier cambio en la estructura de un archivo puede requerir cambiar todos los
programas que tienen acceso a él.
Por el contrario, los módulos del DBMS son independientes de cualesquier archivos específicos, ya que
la estructura, de éstos está almacenada en el catálogo del DBMS. Esta propiedad se conoce como
independencia entre programas y datos.
El DBMS proporciona a los usuarios una representación conceptual de los datos sin incluir muchos de
los detalles de cómo éstos son almacenados.
• Soporte de múltiples vistas de los datos
Una base de datos normalmente tiene muchos usuarios, cada uno de los cuales puede requerir
diferentes perspectivas o vistas de la base de datos. Una vista puede ser un subconjunto de la base de
datos o puede contener datos virtuales que son derivados de otros datos de la base.
• Compartimento de datos y procesamiento de transacciones multiusuario
El DBMS debe incluir software para control de la concurrencia a fin de asegurar que varios usuarios que
tratan de actualizar los mismos datos, lo hagan en una forma controlada de tal manera, que los
resultados sean correctos.
Ejemplo:
A este tipo de procesamiento se le conoce corno de transacciones multiusuario.
1.1.3 USUARIOS DE BASES DE DATOS
Para bases de datos personales, normalmente la misma persona define, construye y manipula la base
de datos. Para bases de datos multiusuario grandes, con varias decenas o cientos de usuarios, diverso
tipo de personal está involucrado:
• Administrador de la base de datos (DBA)
Es el responsable por la administración de los recursos tanto del DBMS como de las bases de datos que
tenga la organización. El DBA se encarga de autorizar el acceso a las bases de datos, coordinar y
supervisar su uso, adecuar el sistema para un uso eficiente, etc.
• Diseñadores de la base de datos (o Programadores de aplicaciones)
Son los responsables de identificar los datos a ser almacenados en una base de datos y de escoger las
estructuras apropiadas para representar y almacenar estos datos. Normalmente definen las vistas de los
diversos grupos de usuarios para al final integrar una base de datos con todas ellas.
• Usuarios finales
Son las personas que tienen acceso a la base de datos para hacer consultas y actualizaciones y generar
reportes. El rango es amplio y puede ir desde usuarios simples (capturistas) hasta usuarios
experimentados (analistas).
1.1.4 CAPACIDADES DESEABLES EN UN DBMS
• Control de la redundancia
Cuando se hace el diseño de una base de datos se debe almacenar una sola vez cada dato lógico, tal
como el nombre o fecha de nacimiento de una persona. Esto evita inconsistencias en la información y a
la vez ahorra espacio de almacenamiento. En algunos casos es deseable, o necesario, tener una
redundancia controlada para optimizar tiempos de respuesta en consultas o porque así lo exige el
modelo de datos empleado. El DBMS debe proporcionar este recurso.
• Restricciones de integridad
Esta característica se encuentra relacionada con la del punto anterior. Estas restricciones van desde
permitir que a la base sólo ingresen datos correctos, por ejemplo valores en un rango, hasta forzar que
un registro está relacionado con otros registros de una, cierta manera. Normalmente estas restricciones
se derivan del significado, o semántica de los datos del minimundo. La mayoría de las restricciones
pueden ser controladas por el DBMS; otras deben controlarse por medio, de módulos especializados
programados.
• Restricción a accesos no autorizados (Seguridad)
Normalmente el DBMS debe proporcionar un subsistema de seguridad y autorización que el DBA utiliza
para, asignar cuentas y privilegios (restricciones) a los usuarios de una base de datos. Con este
subsistema se puede definir el tipo de operaciones que un usuario puede efectuar y a qué partes de la
base puede tener acceso. El uso de vistas es otra forma de controlar el acceso.
• Múltiples interfaces de usuario
Debido a los diversos tipos de usuarios que usan una base de datos, el DBMS debe proporcionar una
variedad de interfaces para los mismos. Estas pueden incluir: lenguajes de consulta; lenguajes de
programación, con capacidades gráficas inclusive; interfaces basadas en menúes e interfaces de
lenguaje natural.
• Representación de vínculos complejos entre datos
El DBMS debe tener la capacidad de representar una gran variedad de vínculos complejos entre los
datos, así como poder recuperarlos y actualizarlos fácil y eficientemente.
• Respaldo (Backup) y Recuperación (Recovery)
El DBMS debe tener los recursos para, recuperarse de fallas de hardware y de software. El subsistema
de respaldo y recuperación es el responsable por esta tarea. Por ejemplo, si el sistema falla. a mitad de
una transacción, el DBMS debe poder restaurar la base de datos hasta el estado previo, que tenia antes
de la falla, y así asegurar que su contenido es válido.
1.1.5 IMPLICACIONES DEL ENFOQUE DE BASES DE DATOS
La utilización de bases de datos en las organizaciones presenta varias implicaciones las, cuales pueden
beneficiar a las funciones computacionales de las mismas.
• Potencial para establecer estándares
En una organización grande el enfoque de bases de datos permite al DBA establecer estándares entre
los usuarios de las mismas. Esto facilita la comunicación y la cooperación entre los departamentos,
proyectos y usuarios dentro de la organización. Los estándares pueden ser definidos para los nombres y
formatos de los datos, formatos de despliegue, estructuras de reportes, terminología, etc.
• Reducción del tiempo de desarrollo de aplicaciones
Una característica principal de las bases de datos es que el desarrollo de una nueva aplicación toma
poco tiempo. El diseñar e implementar una nueva base de datos a partir de cero puede llevar mucho
menos tiempo que escribir una sola aplicación con archivos especializados. Sin embargo, ya que la base
de datos está en funcionamiento, se requiere macho menos tiempo para crear nuevas aplicaciones
usando las facilidades del DBMS. Se estima un ahorro de un sexto a un cuarto de tiempo con respecto a
sistemas de archivos especializados.
Disponibilidad de información "al día"
Cuando una actualización a la base de datos es hecha por un usuario, todos los demás usuarios pueden
ver inmediatamente dicha actualización. Esta disponibilidad de información "al día" es esencial para
muchas transacciones, tales corno sistemas de reservaciones y bases de datos de bancos.
1.1.6 Ventajas y desventajas en el uso de bases de datos
Ventajas
- Al minimizar la redundancia, disminuye el margen de error.
- Independencia entre hardware y datos.
- Independencia entre datos y programas de aplicación.
- Los datos pueden compartirse (concurrencia).
- Disminución del tiempo de programación.
- Nuevas aplicaciones se pueden agregar más fácilmente.
- Mecanismos de seguridad superiores a los convencionales.
- Es más fácil recuperar información cuando ocurre una falla.
Desventajas
- Un sistema de bases de datos normalmente es menos eficiente (en tiempo y en espacio) que el mismo
sistema con procesamiento de archivos.
- El DBMS consume muchos recursos de hardware (memoria central y secundaria).
- Mayor costo (de adquisición y de mantenimiento).
- En bases de datos centralizadas el sistema es más vulnerable a catástrofes físicas.
1.2 TRES EJEMPLOS DE BASES DE DA TOS
En esta sección se describen tres ejemplos de bases de datos que muestran el espectro de aplicaciones
en las que éstas se pueden usar, así corno las características importantes de cada tipo de base de
datos.
Micro-empresa para pintar casas Es una micro-empresa, compuesta por dos personas de tiempo
completo y algunos trabajadores eventuales, que se dedica a pintar casas. Es una micro-empresa que
ya tiene varios años en el mercado, con una buena reputación, que consigue la mayor parte de sus
trabajos por recomendaciones de clientes y, ocasionalmente, por contratistas.
Cuentan con una cartera de varias docenas de clientes y emplean Una pequeña base de datos personal
para guardar información importante acerca de trabajos realizados anteriormente. Esto con el fin de
poder obtener datos relevantes cuando se va a efectuar un nuevo trabajo, ya sea para un cliente nuevo
(recomendado o no) o para un cliente anterior.
Enseguida se muestra un ejemplo de esta base de datos:
Las bases de datos personales, en general, no son grandes, contienen pocas tablas y almacenan poca
información.
• Agencia de venta de automóviles
Las bases de datos pueden ser mis complicadas que la del ejemplo anterior. Considérese ahora una
agencia de venta de autorn6viles en la cual laboran dos supervisores, cuatro agentes de ventas y un
administrador.
La base de datos contiene información sobre modelos en venta, clientes, ventas realizadas, etc. Esta
base de datos es compartida. por el personal de la agencia y está localizada en una red de área local
formada. por:
- un servidor de base de datos,
- dos PCs para los supervisores,
- una PC para el administrador, y
- cuatro PCs para. los agentes de ventas.
La base de datos requerida para gestionar la información de esta aplicación es más complicada que la
de la micro-empresa que pinta casas. Un ejemplo de las tablas que podría contener es el siguiente:
Obviamente, la información almacenada en esta base de datos es mucho mayor que en el primer caso.
Además, esta base de datos es multiusuario.
• Sistema de transacciones bancarias (cuentas de cheques)
Este es un ejemplo de un sistema de base de datos de mucho mayor complejidad que los dos
anteriores. El sistema debe poder:
- almacenar los datos generales de los clientes y de las cuentas que poseen, - registrar las
transacciones que se realizan y el lugar en que se efectúan,
- generar estados de cuenta,
- Ilevar a cabo consolidaciones, etc.
Además, el sistema debe permitir acceso multiusuario ya que las diversas transacciones se pueden
efectuar:
- en ventanilla (en varias decenas de sucursales),
- a través de cajero automático (varias decenas),
- por teléfono, etc.
Esta base de datos tiene cientos de usuarios. Así, la base de datos es grande y compleja, pudiendo
constar de varias decenas de tablas, conteniendo cientos de miles de datos.
Comparación de las bases de datos
Estos tres ejemplos representan una muestra de los usos de la tecnología de las bases de datos. Cientos
de miles de ellas son corno la usada por la micro-empresa que pinta casas: bases de datos
monousuario, con una cantidad relativamente pequeña de datos. Las formas y reportes que generan
normalmente son simples y directos.
Otras son corno la usada por la agencia de autos; tienen más de un usuario pero generalmente menos
de veinte o treinta usuarios en total. Contienen una cantidad moderada de datos y las formas y reportes
deben ser de cierta complejidad para satisfacer la diferentes funciones de la organización.
Las bases de datos mis grandes son como la del sistema bancario que tiene cientos de usuarios y varios
gigabytes de datos. En general, muchas aplicaciones las usan, teniendo cada una sus propias formas y
reportes.
En la siguiente tabla se resumen las características importantes de cada una de estas clases de bases
de datos:
1.3 CONCEPTOS Y COMPONENTES DE UN SISTEMA DE BASE DE DATOS
1.3.1 MODELOS DE DATOS, ESQUEMAS E INSTANCIAS
Una característica fundamental del enfoque de base de datos es que proporciona un cierto nivel de
abstracción de los datos, ocultando detalles de su almacenamiento que no son necesarios para la mayor
parte de los usuarios de una base de datos. Un modelo de datos es la herramienta principal usada para
proporcionar esta abstracción.
Un modelo de datos:
- es un conjunto de conceptos usado para describir la estructura de una base de datos (el
t6imino estructura se refiere a la conjunción de tipos de datos, vínculos y restricciones que deben
observarse para los datos);
- en la mayoría de los casos, incluye un conjunto de operaciones básicas para especificar
recuperaciones y actualizaciones sobre la base de datos;
- puede incluir conceptos para especificar comportamiento, lo cual se refiere a especificar un
conjunto de operaciones definidas por el usuario permitidas sobre la base de datos. '
Muchos modelos de datos han sido propuestos. Se pueden definir tres categorías según el tipo de
conceptos que proporcionan:
- conceptuales (o de alto nivel): proporcionan conceptos que están más cercanos a la forma en
que los usuarios perciben los datos. Frecuentemente se auxilian en diagramas para plasmar un modelo
para. un caso especifico;
- físicos (o de bajo nivel): brindan conceptos que describen los detalles de la manera en que los
datos están almacenados en la computadora. En general, estos conceptos están dirigidos a especialistas
en Computación más que a usuarios finales típicos; de representación (o de implementación):
proporcionan conceptos que pueden ser entendidos por usuarios finales pero, que no están demasiado
lejos del modo, en que los datos están organizados dentro de la computadora. Estos modelos son los
usados en la mayoría. de los DBMS comerciales: de redes, jerárquico, relacional y de objetos.
Esquemas e instancias
En cualquier modelo de datos es importante distinguir entre la descripción de la base de datos y la base
de datos en si misma.
La descripción de la base de datos se conoce como esquema de la base de datos (o metadatos). Este
esquema se especifica durante el diseño de la base de datos y se espera que no cambie con frecuencia.
Un esquema dibujado se conoce como diagrama del esquema. Cada unidad en el esquema es un
elemento del esquema.
Ejemplo:
Un diagrama de esquema muestra sólo algunos aspectos del esquema, tal como el nombre de los
elementos y de los campos de datos; pero no muestra otros, como el tipo de los datos, los vínculos entre
ellos o restricciones sobre los mismos.
Los datos actuales en una base de datos pueden cambiar frecuentemente. Al conjunto de datos que está
en la base de datos en un momento particular del tiempo se le conoce corno estado de la base de datos
o conjunto de ocurrencias o instancias). En un estado dado, cada elemento del esquema tiene su propio
conjunto actual de instancias.
Cada vez que se actualiza la base de datos (inserción, modificación o eliminación de datos), ésta
cambia de un estado a otro.
Cuando se define una nueva base de datos, sólo se especifica su esquema al DBMS. Su estado
inicial es el "estado vacío". Cuando se cargan los primeros datos, éstos definen el "estado inicial" de la
base de datos. Después, cada actualización hace que la base de datos pase de un estado a otro.
En cualquier momento, un estado de la base de datos debe ser válido, esto es, el estado debe
satisfacer tanto la estructura como las restricciones especificadas para la base de datos.
El esquema es llamado algunas veces la intensión de la base de datos; al estado también se le conoce
como la extensión de la base de datos.
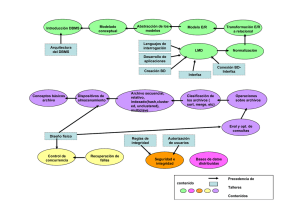
1.3.2 ARQUITECTURA DE UNA BASE DE DATOS
En esta parte se describirá una arquitectura de base de datos, llamada arquitectura de los tres
esquemas, cuyo propósito es, sobre todo, permitir el aislamiento entre datos y programas y múltiples
vistas de los datos. En esta arquitectura1, los esquemas pueden ser definidos en tres niveles:
(Véase la siguiente figura).
1 . El nivel interno tiene un esquema interno, el cual describe la estructura de almacenamiento físico de
la base de datos. El esquema interno usa un modelo de datos físico y describe los detalles completos
del almacenamiento de los datos y los caminos de acceso para la base de datos.
2. El nivel conceptual tiene un esquema conceptual, el cual describe la estructura de la base de datos
completa para una comunidad de usuarios. El esquema conceptual oculta los detalles de
almacenamiento físico y se concentra en describir entidades (datos), tipos de datos, vínculos,
operaciones del usuario y restricciones. Se puede usar un modelo de datos conceptual o uno de
implementación en este nivel. .
3. El nivel externo o de vistas comprende un conjunto de esquemas externos o vistas de usuario. Cada
esquema externo describe la parte de la base de datos que utiliza un grupo particular de usuarios y
oculta el resto de la base de datos. Se puede usar en este nivel un modelo de datos similar al del punto
anterior.
Hay que notar que los tres esquemas son sólo descripciones de datos; los únicos datos que actualmente
existen están en el nivel físico (base de datos almacenada).
1
Propuesta por la ANSI/SPARC (American National Standards Institute/Standard Planning and Requirements
Committee).
También hay que observar que se deben efectuar transformaciones entre los diferentes
esquemas para poder atender las solicitudes/resultados que se envían entre los diversos niveles. Dado
que este proceso puede consumir tiempo, no todos los DBMS se ajustan totalmente a esta arquitectura,
aunque varios de ellos sí la observan, hasta cierto punto.
Independencia de datos
La arquitectura de los tres esquemas puede ser usada para explicar el concepto de
independencia de datos, el cual puede ser definido como la capacidad para cambiar el esquema en un
nivel de la base de datos, sin tener que cambiar el esquema en el siguiente nivel superior.
Se pueden definir dos tipos de independencia de datos:
1 . Independencia de datos lógica, es la capacidad de cambiar el esquema conceptual sin tener que
cambiar los esquemas externos o programas de aplicación.
Cuando esto sucede, sólo las definiciones de las vistas y sus transformaciones correspondientes deben
ser cambiadas en un DBMS que soporta este concepto. Cambios a las restricciones en el nivel
conceptual tampoco deben afectar al nivel externo.
2. Independencia de datos física, es la capacidad para cambiar el esquema interno sin tener que
cambiar el esquema conceptual o los esquemas externos.
Debido a que la independencia física se refiere solamente al aislamiento de una aplicación
de las estructuras físicas de almacenamiento, es más fácil lograrla que la independencia
lógica.
1.3.3 LENGUAJES E INTERFACES
Lenguajes de un DBMS
A continuación se describen los diferentes lenguajes que un DBMS proporciona para poder
definir, construir (llenar) y manipular (consultar) una base de datos.
•
Lenguaje de definición de datos (DDL), es usado por el DBA y los diseñadores de bases de datos
para definir el esquema conceptual. Esta definición se compila y se guarda en el catálogo del
DBMS.
•
Lenguaje de definición del almacenamiento (SDL), es usado para especificar el esquema interno. No
es común encontrarlo en los DBMS, salvo en los de gran complejidad. Las transformaciones entre
los esquemas interno y conceptual se pueden especificar en este lenguaje o en el anterior.
•
Lenguaje de definición de vistas (VDL), especifica vistas de usuarios y sus transformaciones hacia el
esquema conceptual. En un DBMS que no observa estrictamente la arquitectura de los tres
esquemas, el DDL es usado con frecuencia para definir estas vistas.
•
Lenguaje de manipulación de datos (DML), permite manipular los datos de la base, lo cual incluye
recuperar, insertar, eliminar y modificar los datos.
En los DMBS actuales no es común encontrar separados a estos lenguajes, sino reunidos en uno solo.
Tal es el caso de SQL para manejadores relacionales.
Por otro lado, el DMI (en particular el de SQL) puede brindar instrucciones para ser usadas en forma
interactiva, a través de terminal o de PC comunicada con la base de datos, o embebidas en un lenguaje
de programación de propósito general. En este último caso, el lenguaje de programación se conoce
como lenguaje anfitrión (host) y al DML se le llama sublenguaje de datos. Al DMI, también se le conoce
como lenguaje de consulta (query language).
Interfaces
Son las diferentes interfaces que se pueden encontrar en un ambiente de bases de datos. Algunas
pueden ser proporcionadas por el DBMS; otras, programadas por medio de un lenguaje de 3a. o 4a.
generación.
•
•
•
•
•
•
Basadas en menúes, presentan al usuario listas de opciones que lo van guiando a través del
sistema. Los menús pueden presentarse por medio de caracteres, exclusivamente, o por medio de
un ambiente de ventanas.
Gráficas, típicamente despliegan al usuario un diagrama el cual éste va llenando con información.
Normalmente están combinadas con menús basados en ventanas.
Basadas en formas, presenta un forma al usuario para que éste edite datos; esto es, para que
inserte, elimine o modifique datos.
De lenguaje natural, las cuales aceptan solicitudes escritas en lenguaje natural (normalmente,
inglés). No son comunes y se puede decir que aún están en desarrollo.
Para usuarios paramétricos, que se emplean para presentar al usuario un conjunto reducido de
operaciones, muchas de ellas asignadas a teclas del teclado. Están destinadas a usuarios que
efectúan operaciones repetitivas, como los cajeros de bancos.
Para el DBA, que normalmente contienen instrucciones privilegiadas para ser usadas
exclusivamente por el DBA.
1.3.4 COMPONENTES DE UN DBMS
Un DBMS es un sistema de software grande y complejo. A continuación se describen brevemente las
partes importantes de un DBMS.
Catálogo del Sistema
Compilador DDL
Compilador DMI
Administrador de datos
Procesador Run-time
Subsistema de control de concurrencia
Subsistema de seguridad
Subsistema de respaldo/ recuperación
•
•
•
•
•
•
•
•
Catálogo del sistema, es una mini-base de datos almacenada en disco que puede estar separada
físicamente o no de las bases de datos controladas por el DBMS. Contiene información como
nombres de archivos, campos de datos, tipos de datos, detalles de almacenamiento, información de
transformación entre esquemas y restricciones. En su lugar puede usarse un diccionario de datos.
Compilador DDL, procesa las definiciones de los esquemas, especificadas con un DDL, y almacena
sus descripciones (meta-datos) en el catálogo.
Compilador DIVIL, analiza y traduce instrucciones del DML. Normalmente genera llamados al
procesador run-time para que éste las ejecute.
Administrador de datos, controla el acceso a la información almacenada en disco, ya sea que forme
parte de una base de datos o del catálogo. Usa servicios del sistema operativo para intercambiar
datos entre disco y memoria central.
Procesador run-time, recibe operaciones de recuperación y de actualización y las ejecuta sobre la
base de datos; para esto se apoya en el administrador de datos.
Subsistema de control de concurrencia, controla el acceso simultáneo a una base de datos realizado
por varios usuarios.
Subsistema de seguridad, restringe el acceso a la base de datos, tanto a usuarios no autorizados
como a partes de ésta que sólo determinado grupo de usuarios puede usar.
Subsistema de respaldo/recuperación, permite crear respaldos de las bases de datos en otro
dispositivo, ya sea disco o cinta magnética, para poder recuperar la información, posteriormente, en
caso de una falla catastrófica.
1.3.5 APLICACIONES
Una aplicación para una base de datos consiste de formas, consultas, reportes, menús y módulos
especializados. El programa se elabora utilizando un lenguaje de programación y a través de una
interfaz se comunica con el DMBS para tener acceso a la base de datos. El lenguaje puede ser un:
•
•
Lenguaje de 3a. generación: son lenguajes de tipo algoítmico. basados en procedimientos, en los
cuales se insertan llamados a instrucciones del DBMS para realizar procesos con la base de datos.
Ejemplo de estos lenguajes son: C, Pascal. Cobol, Basic, etc. Actualmente no es común usarlos, ya
que es engorroso crear las aplicaciones y darles mantenimiento, salvo en aquellos casos en los que
se requiere una gran eficiencia, en tiempos de respuesta sobre todo.
Lenguaje asociado al DBMS: normalmente son lenguajes de 4a. generación, de caracteres o
ventanas, que son vendidos por la misma empresa propietaria del DBMS. Son bastante versátiles y
la comunicación con el DBMS es casi directa. Tienen como desventaja el que son especializados
para un DBMS particular.
•
•
Lenguaje de 4a. generación de terceros: son lenguajes basados en ventanas, en su gran mayoría,
producidos por empresas terceras y que no están ligados a DBMS particulares. Son bastante
poderosos y requieren siempre de una interfaz (ODBC) para comunicarse con algún DBMS
particular. Como ejemplos están: Visual Basic, Power Builder, Delphi, etc. La interfaz y las ventanas
pueden ocasionar tiempos de respuesta un poco lentos.
También se pueden usar lenguajes orientados a objetos (C++, SmallTalk, etc.) para crear programas
de aplicación, aunque en general éstos se asocian más a bases de datos 00 que a bases en otro
paradigma.
1.4 FASES EN EL DESARROLLO DE UNA BASE DE DATOS
En esta sección se describen a grandes rasgos las fases usuales seguidas durante el desarrollo de una
base de datos. En conjunción se comentan las actividades que normalmente se realizan para el
desarrollo de programas de aplicación asociados, bajo la perspectiva del análisis y diseño estructurados.
El diagrama anterior muestra las etapas del desarrollo, enmarcadas con rectángulo, y los productos que
se obtienen en cada etapa, sin enmarcar.
•
Recolección y análisis de requerimientos, es la etapa en la que se hacen entrevistas con los
usuarios potenciales de la base de datos con el fin de entender y documentar sus requerimientos de
datos. El resultado es un conjunto de requerimientos de usuario. Estos deberán ser especificados de
una manera tan detallada, completa y precisa como sea posible.
En paralelo se deben especificar los requerimientos funcionales de la aplicación. Estos consisten de
operaciones definidas por el usuario (o transacciones) que serán aplicadas a la base de datos, e
incluyen tanto recuperaciones como actualizaciones. Es común usar técnicas como los diagramas de
flujo de datos para especificar estos requerimientos.
•
•
•
•
Diseño conceptual de la base de datos, aquí se crea un modelo conceptual de la base de datos
usando para ello un modelo de datos de alto nivel. El modelo conceptual es una descripción concisa
de los requerimientos de datos de los usuarios y comprende descripciones de los tipos de datos,
vínculos y restricciones para los datos; expresados por medio de los elementos que proporciona el
modelo de datos de alto nivel. Dado que estos elementos no incluyen detalles de implementación,
pueden ser usados para comunicarse con usuarios no especializados a fin de asegurar que todos
sus requerimientos son cubiertos y que no hay contradicciones.
Después que el modelo conceptual ha sido elaborado, por medio de las operaciones básicas del
modelo de datos se deben especificar las transacciones de alto nivel correspondientes a las
operaciones del usuario identificadas durante el análisis funcional. Esto también sirve para confirmar
que el modelo conceptual satisface todos los requerimientos funcionales.
Diseño lógico de la base de datos, es la etapa en la cual se implementa la base de datos usando un
DBMS comercial. Aquí se transforma el modelo conceptual de la base de datos, obtenido en la fase
anterior, a una implementación usando el modelo de datos empleado por el DBMS: relacional,
objetual, de red o jerárquico (los dos últimos ya de poco uso). El resultado es un esquema lógico
(conceptual, según la arquitectura de los tres esquemas) de la base de datos.
Diseño físico de la base de datos, durante esta fase son especificadas las estructuras de
almacenamiento internas y las organizaciones de archivos para la base de datos. Normalmente el
DBMS controla estos aspectos y el diseñador tiene poca injerencia en los mismos.
En paralelo con estas actividades, los programas de aplicación son diseñados e implementados como
transacciones de la base de datos correspondientes a las especificaciones de las transacciones de alto
nivel.
2 MODELO DE ENTIDAD-VÍNCULO
El modelo de entidad-vínculo es un modelo de datos conceptual de uso muy extendido. Este modelo, y
sus variantes, se emplea frecuentemente para elaborar el esquema conceptual de una base de datos y
muchas herramientas existentes para tal fin utilizan sus conceptos.
El modelo fue creado por el Dr. Peter S. Chen con la finalidad de poder crear esquemas
conceptuales, independientes de la implementación física, que pudieran ser transformados
posteriormente a cualquiera de los modelos de DBMS comerciales existentes en ese entonces: de
redes, jerárquico y relacional.
En inglés recibe el nombre de: entity-relationship; en español también se conoce como: entidad-relación,
entidad-parentesco o modelo ER.
2.1 CONCEPTOS BASICOS
2.1.1 DEFINICIÓN DE ENTIDAD
Una entidad es un objeto (tangible o intangible) que puede distinguirse de los objetos de su misma
especie.
Ejemplo:
A las propiedades (características) que distinguen a las entidades entre sí se les conoce con el nombre
de atributos. La entidad persona anterior tiene 3 atributos: Nombre, Edad y Estado civil. Una entidad
particular tiene un valor para cada uno de sus atributos. Los valores para el ejemplo podrían ser: "Pablo
Sosa", "25", "soltero".
Tipos de atributos
Una entidad puede tener diferentes tipos de atributos:
•
•
Atómico, es un atributo indivisible, por ejemplo, un apellido, la edad de una persona, el nombre de
una calle. También se conoce como atributo simple.
Compuesto, es aquel que puede ser dividido en subpartes más pequeñas, las cuales representan
atributos más básicos con significado independiente entre sí. Un ejemplo es un domicilio compuesto
•
•
•
•
por calle, número, colonia y código postal. Las subpartes pueden ser atributos atómicos o también
compuestos.
Monovaluado, se usa este término cuando un atributo contiene un solo valor, que es el caso normal.
Por ejemplo, la edad de una persona es un atributo monovaluado.
Multivaluado, se tiene cuando el atributo puede contener varios valores. Por ejemplo, el atributo
Teléfono de una empresa puede ser multivaluado.
Almacenado, es un atributo cuyo valor físicamente existe para la entidad. Este atributo físicamente
existirá en la base de datos cuando ésta sea implementada. Ejemplo: la fecha de nacimiento de una
persona.
Derivado, es un atributo cuyo valor se deriva de otro(s) atributo(s) de la misma entidad o de una
entidad relacionada. Ejemplo: la edad de una persona la cual puede derivarse de la fecha actual y
de su fecha de nacimiento.
Obviamente un atributo es: atómico o compuesto, monovaluado o multivaluado y almacenado o
derivado. En algunos casos una entidad particular puede no tener valor para un atributo. En estos casos
se utiliza un valor especial: el valor nulo (null). Este valor significa que, para esa entidad. el valor del
atributo correspondiente no es aplicable o es desconocido. Si el valor es desconocido puede ser por dos
casos: porque el valor existe pero está perdido, por ejemplo la estatura de una persona; o porque no se
conoce si el valor existe, por ejemplo el teléfono de una persona.
Tipos de entidades, atributos clave y conjuntos de valores
Tipo de entidades, se aplica este término a un conjunto de entidades que tienen los mismos atributos.
Por ejemplo, el conjunto de empleados de una empresa podría formar el tipo de entidades ENIPLEADO;
o el conjunto de materias que ofrece un departamento académico podría formar el tipo MATERIA. Cada
tipo de entidades se representa por un nombre y la lista de los atributos de las entidades.
Atributos clave, es el conjunto de atributos de un tipo de entidades cuyos valores son distintos para cada
entidad individual. Por ejemplo, el RFC de un empleado en el tipo EMPLEADO. Hay una restricción para
estos atributos clave y es que dos entidades distintas no pueden tener los mismos valores para estos
atributos. Un tipo de entidades puede tener más de un conjunto de atributos clave.
Dominio de un atributo, es el conjunto de valores que puede ser asignado a un atributo simple de un tipo
de entidades. Por ejemplo, si el rango de edades permitido para un empleado va de 18 a 70 años,
entonces el dominio de ese atributo es el conjunto de números enteros entre 18 y 70.
2.1.2 DEFINICIÓN DE VÍNCULO
Definición matemática de relación binaria
Sean A y B dos conjuntos no vacíos. Una relación binaria R entre A y B es un subconjunto del producto
cartesiano A x B.
(Esta definición se puede generalizar a n conjuntos)
Un vínculo es una asociación entre entidades de diferentes tipos.
Un tipo de vínculos es una relación (en el sentido matemático) y representa a un conjunto de
asociaciones que existen entre entidades de tipos diferentes. Un vínculo específico asocia exactamente
a una entidad de cada tipo participante. Un vínculo específico representa una situación correspondiente
en el minimundo.
Ejemplo:
El grado de un tipo de vínculos está dado por el número de tipos de entidades participantes. Un tipo de
vínculos de grado dos es llamado binario y asocia a entidades de dos tipos. Uno de grado tres es
llamado temario y asocia entidades de tres tipos.
Un tipo de vínculos también puede tener atributos, en forma similar a los tipos de entidades.
2.1.3 DIAGRAMA DE ENTIDAD-VÍNCULO
Su función es la de representar en forma gráfica el esquema conceptual que se está elaborando para
una base de datos, empleando para ello los elementos que proporciona el modelo de entidad-vínculo.
En el diagrama, los tipos de entidades se representan con rectángulos, los tipos de vínculos con rombos,
etc.
2.1.4 CARDINALIDAD
La razón de cardinalidad (cardinalidad, para abreviar) es una restricción de un tipo de vínculos que nos
indica, en el caso de vínculos binarios, con cuántas entidades de un tipo está relacionada una entidad
del otro tipo y viceversa. Las cardinalidades comunes para los vínculos binarios son: 1 - 1, 1 -N y M-N.
En el caso del mini-sistema escolar, las cardinalidades de los tipos de vínculos son:
Si el modelo conceptual de la base de datos está bien diseñado, se deben poder contestar las siguientes
preguntas:
• Dado un profesor ¿qué materias imparte?
• Dado un profesor, ¿quiénes son los alumnos?
• Dada una materia, ¿qué profesor la imparte?
• Dada una materia, ¿qué alumnos la cursan?
• Dado un alumno, ¿qué materias cursa?
• Dado un alumno, ¿quiénes son sus profesores?
Ejemplo de entidades en el mini-sisterna escolar:
Ejemplo de vínculos:
Imparte:
El profesor P1 imparte las materias M1 y M2.
El profesor P5 imparte la materia M3.
Cursa:
El alumno A1 cursa las materias MI y M2.
El alumno A4 cursa la materia M2.
El alumno A5 cursa la materia M2.
¿Cómo están las asociaciones a nivel de entidades?
Otros modelos conceptuales del mini-sistema escolar
¿Cuál funciona?
¿Cuál es menos redundante?
¿Cuál es más sencillo?
¿Cuál es más eficiente en consulta?
¿Cuál es más eficiente en actualización?
2.2 CONCEPTOS AVANZADOS
2.2.1 GENERALIZACIÓN/ESPECIALIZACIÓN. VÍNCULO ISA
El concepto de Generalización/Especialización ocurre cuando se tienen varios tipos de entidades que
tienen atributos comunes entre sí, pero también tienen atributos que los diferencian.
En este caso se puede crear un nuevo tipo que agrupe a todos los atributos comunes de los tipos
originales. A este nuevo tipo se le [Luna tipo generalizado o supertipo.
Los tipos originales sólo conservarán aquellos atributos que los diferencian. A estos tipos se les conoce
como tipos especializados o subtipos.
Ejemplo:
Existe un conjunto de atributos en el supertipo que actúa como discriminante para determinar a que
subtipo pertenece una entidad especializada particular. En este ejemplo, el discriminante es el atributo
Tipo_e.
El conjunto de atributos de las entidades de un tipo especializado está constituido por los de ese tipo
más los del tipo generalizado.
El vínculo establecido entre un subtipo y su supertipo se conoce también como vínculo ISA (ES-UN o
ES-UNA), porque, según el ejemplo, un ASALARIADO ES-UN EMIPLEADO y uno de HONORARIOS
también ES-UN EMPLEADO.
Los tipos de entidades pueden participar en cualquier otro tipo de vínculos.
2.2.2 ENTIDAD DÉBIL
Este concepto surge cuando la existencia de una entidad en la base de datos depende de la existencia
de otra entidad asociada.
Por ejemplo, la existencia de una entidad HIJO, en una base de datos de empleados, depende
de la existencia de una entidad asociada EMPLEADO:
Esto es, si el empleado deja la empresa, ya no se registrarán sus hijos.
Al tipo de entidades del cual dependen las entidades débiles se le llama propietario o dueño.
2.2.3 VÍNCULO RECURSIVO
Un vínculo recursivo existe cuando entidades de un tipo están relacionadas con entidades del mismo
tipo. Por ejemplo, si se tiene el tipo de entidades EMPLEADO, un vínculo recursivo entre entidades de
este tipo podría ser SUPERVISA. La siguiente figura muestra este caso:
Cuando existe un vínculo recursivo las entidades participantes en él pueden jugar dos papeles.
Refiriéndonos al ejemplo anterior, una entidad particular puede participar en un caso como Supervisor y
en otro caso, como Supervisado. Algunos empleados sólo participarán como Supervisados (los que
están en el nivel más bajo de la jerarquía).
2.2.4 VÍNCULOS QUE SE USAN COMO ENTIDADES
En ocasiones es conveniente utilizar un vínculo como si se tratara de una entidad. Por ejemplo, en el
siguiente caso:
CURSA no se puede conectar ni a PROFESOR ni a CURSO porque se pierde información; se debe
conectar a INTARTE. La solución es tratar a MPARTE como si fuera un tipo de entidades.
El símbolo usado en este caso es un rectángulo conteniendo un rombo. Ejemplo:
2.2.5 VÍNCULO TERNARIO
Es un vínculo en el cual participan tres tipos de entidades; esto es. es un vínculo que relaciona a
entidades de tres tipos diferentes. Por ejemplo, si tenemos PROVEEDORes que abastecen
MATERIALes a diversos PROYECTOs entonces estos tres tipos de entidades podrían estar relacionados
por medio de un vínculo temario. La siguiente figura muestra este caso:
Las cardinalidades que se pueden presentar en los vínculos ternarios son: 1-1-1, 1-1-N, 1-M-N y L-M-N.
2.3 CONDICIONALIDAD
Hasta ahora sólo se ha considerado la cota superior de la cardinalidad. También se puede especificar la
cota inferior. Cuando la cota inferior es uno, la participación es total u obligatoria, es decir. todas las
entidades de los tipos involucrados participan en el vínculo. Cuando la cota inferior es cero, la
participación es parcial, o sea no todas las entidades de los tipos participan en el vínculo.
2.3.1 VÍNCULOS CONDICIONALES
Son vínculos en los cuales hay entidades de un tipo que no participan en el vínculo.
Uno a uno (1c-1)
Es similar al vínculo incondicional uno a uno, excepto que no todas las entidades de un tipo participan
en el mismo.
Ejemplo:
Uno a muchos (lado "uno" obligatorio) (1c-N)
Cada entidad de un tipo A (lado uno) está asociada a una o más de un tipo B (lado muchos). Cada
entidad de A participa en el vínculo. Una entidad de B está asociada con cero o una de A; o sea, no
todas las entidades de B participan en el vínculo.
Ejemplo:
Uno a muchos (lado "muchos" obligatorio) (1-Nc)
Cada entidad de un tipo A (lado uno) está asociada con cero o más de un tipo B (lado muchos); mientras
que cada entidad de B está asociada exactamente con una de A.
Ejemplo:
Muchos a muchos (M-Nc)
Es como la incondicional muchos a muchos, excepto que algunas de las entidades de un tipo pueden no
participar en el vínculo.
Ejemplo:
2.3.2 VÍNCULOS BICONDICIONALES
Son vínculos en los cuales hay entidades de ambos tipos que no participan en el vínculo.
Uno a uno (1c-1c)
Una entidad de un tipo A está asociada con cero o una de un tipo B y viceversa.
Ejemplo:
Uno a muchos (1c-Nc)
Es una variación del. vínculo uno a muchos; aquí puede haber entidades de ambos tipos qu e no
participen en el vínculo.
Ejemplo:
- puede haber oficinas vacías (por ej. en reparación)
- puede haber empleados sin oficina (por ej. mensajeros).
Muchos a Muchos (Mc-Nc)
Es como la incondicional M-N, pero puede haber entidades de ambos tipos que no participen en el
vínculo.
Ejemplo (sólo durante inscripciones):
2.4 Sugerencias para la elaboración de un modelo conceptual
1 . Cuando un tipo de entidades A tiene un solo atributo, este atributo puede pasarse a un tipo de
entidades relacionado y desaparecer a A.
2. Cuando un tipo de entidades tiene un conjunto de atributos cuyos valores se repiten para entidades
diferentes, entonces ese conjunto se puede quitar del tipo y con él crear un nuevo tipo de entidades.
Obviamente también surge un nuevo vínculo entre los dos tipos de entidades resultantes.
3. Cuando el dominio de un conjunto de atributos de un tipo de entidades A sea el mismo dominio que el
de los atributos clave de otro tipo de entidades B, entonces dicho conjunto de atributos de A debe
desaparecer y en su lugar establecer un vínculo entre A y B.
4. Los atributos de un tipo de vínculos binarios con cardinalidad 1-N, pueden pasarse al tipo de
entidades que está en el lado N. Cuando la cardinalidad es 1-1, los atributos pueden pasarse a
cualquiera de los tipos de entidades participantes.
5. Cuando por la naturaleza de los vínculos entre dos tipos de entidades se requiera que una entidad de
un tipo esté relacionada más de una vez con una misma entidad del otro tipo, entonces esos vínculos
deben representarse como un nuevo tipo de entidades en lugar de ser representados como vínculos.
Obviamente, se tendría que definir un conjunto de atributos clave para ese nuevo tipo de entidades.
3 MODELO RELACIONAL
3.1 ANTECEDENTES
•
•
•
•
•
•
•
El modelo de datos relacional fue introducido por E.F. Codd en 1970.
Está basado en una estructura de datos simple y uniforme: la relación.
Tiene un fundamento formal: teoría de conjuntos, álgebra y cálculo relacionales.
El acceso a la base de datos se realiza usando lenguajes basados en el álgebra relacional o en el
cálculo relacional.
Los conceptos de este modelo pueden ser usados para crear modelos lógicos de bases de datos,
hasta cierto punto independientes de un DBMS particular.
Es un modelo de datos firmemente establecido en el mundo de las aplicaciones de bases de datos,
sobre todo las orientadas a negocios.
Es la base de una gran cantidad de productos comerciales de DBMS.
3.2 CONCEPTOS
Toda la información de una base de datos (tanto de entidades como de vínculos) se representa por
medio de relaciones (también conocidas como tablas). Ejemplo: Mini-sistema escolar:
Cuando una relación es vista como una tabla de valores, cada fila en la tabla representa una colección
de datos relacionados. Estos valores pueden ser interpretados como hechos que describen una entidad
o un vínculo del minimundo.
A continuación se presentan los conceptos usados en este modelo:
Dominio
Es un conjunto de valores atómicos. Es el mismo concepto que en el caso del modelo de
entidad-vínculo. Ejemplos:
Teléfonos: conjunto de números telefónicos válidos de 10 dígitos;
Nombres: conjunto de cadenas de caracteres de nombres de personas. Para especificar un
dominio normalmente hay dar un nombre, un tipo de datos y un formato.
Esquema de relación (o esquema relacional)
Está formado por un nombre de relación R y una Esta de atributos Al, A2, ..., An; se denota como R(Al,
A2, ..., AJ
Ejemplo: Profs(Id_prof, Nom_prof, Categoría)
Cada atributo A¡ tiene un dominio D asignado y es denotado por dorn(Ai). Un esquema de relación es la
descripción de una relación.
Relación
Una relación r del esquema de relación R(A1, A2, ..., An), también denotada por r(R), es un conjunto de
tuplas r = {t1, t2, ..., tm}. Cada tupla t es una lista ordenada de n valores t = <v 1, v2, vn>, donde cada
valor vi es un elemento de dom(Ai) o es un valor nulo.
Ejemplo: r = {<1, "Laura", "tc">, <3, "Luis", "tc">}
Esta definición puede ser re-establecida como sigue:
Una relación r(R) es un subconjunto del producto cartesiano de los dominios que definen a R:
r(R) ⊆ ( dom(A1) x dom(A2) x ... x dorn(An))
De todas las posibles combinaciones del producto cartesiano, una relación refleja, en un momento dado,
sólo las tuplas válidas que representan un estado particular del minimundo.
En la terminología comercial, una relación comúnmente recibe el nombre de tabla, un atributo el de
columna o campo y una tupla el de fila o renglón. Gráficamente:
El grado de una relación es el número de atributos de su esquema.
Esquemas de bases de datos relacionales
Un esquema de base de datos relacional S es un conjunto de esquemas de relación S = {Rl, R2, ..., Rm}
y un conjunto de restricciones de integridad RI. Una instancia de base de datos relacional BD de S es un
conjunto de relaciones BD = {r1, r2, ..., rm} tal que cada ri es una relación de Ri y tal que las relaciones ri
satisfacen las restricciones de integridad especificadas en RI.
Ejemplo de esquema de base de datos relacional:
Mini-sistema escolar:
Profs(ld_prof Nom_prof, Categoría)
Curso(Clave, Nom_cu, Creds, Id_prof)
Alumno(Matri, Nonm_al, Carr, Prom)
Cursa(Matri, Clave, Calif)
Ejemplo de instancia de base de datos relacional:
La figura mostrada al inicio del capítulo para el mini-sistema escolar.
Las restricciones de integridad son especificadas sobre un esquema de base de datos y deben
respetarse para cada instancia de ese esquema..
3.3 RESTRICCIONES
En esta sección se analizan los diversos tipos de restricciones que pueden especificarse sobre un
esquema relacional de base de datos.
Restricción de dominio
Especifica que el valor de cada atributo A de una relación debe ser un valor atómico tomado del dominio
dom(a) de ese atributo.
Restricciones de clave
Dado que una relación está definida como un conjunto de claves, y por definición todos los elementos
de un conjunto son distintos, entonces todas las tuplas en una relación deben ser distintas. Esto significa
que ningún par de tuplas puede tener la misma combinación de valores para todos sus atributos.
Lo anterior da pie a la definición de clave de un esquema de relación:
Sea R(Al , A2 , ..., An) un esquema de relación. Se dice que un subconjunto X de los atributos
es clave de R si cumple con las siguientes dos propiedades:
i) cada valor de X identifica de manera única a cada tupla de la relación;
ii) no se puede remover algún atributo de X y seguir cumpliendo la propiedad (i).
La propiedad de clave debe cumplirse para cada instancia de un esquema de relación.
La clave de un esquema de relación es determinada en base al significado de sus atributos.
Un esquema de relación puede tener más de una clave, en cuyo caso cada una se conoce como clave
candidata. De éstas, una se escoge como clave primaria, cuyos valores se usarán para identificar a las
tuplas de la relación.
La clave primaria normalmente será la que tenga menos atributos.
Se sigue la convención de subrayar la clave primaria de un esquema de relación.
Ejemplo: Profs(id_prof, Nom prof, Categoría)
Integridad de la entidad e integridad referencial
La restricción de integridad de la entidad establece que ningún valor de la clave primaria puede ser
nulo. Esto se debe a que los valores de la clave primaria se usan para identificar tuplas individuales en
una relación; si hay valores nulos para la clave primaria no se podrían identificar algunas tuplas.
La restricción de integridad referencial (o integridad de referencia) se especifica entre dos relaciones y
es usada para mantener la consistencia entre las tuplas de esas dos relaciones.
Para definir formalmente este concepto, primero se definirá el concepto de clave externa:
Un conjunto de atributos FK en un esquema de relación RI es una clave externa (o clave foránea) de RI
si satisface las siguientes reglas:
i) Los atributos en FK tienen el mismo dominio que la clave primaria PK de otro esquema de relación
R2; se dice que los atributos FK hacen referencia a la relación R2 (R2 puede no ser otro esquema, sino
el mismo R1).
ii) El valor de FK en una tupla t1 de R1 ya sea es un valor de PK para alguna tupla t2 en R2 o es un
valor nulo. En el primer caso, se dice que la tupla t1 hace referencia a la tupla t2.
Las condiciones anteriores para una clave externa, especifican una restricción de integridad referencial
entre los dos esquemas de relación R1 y R2.
Ejemplo: El atributo Id_prof del esquema relacional Curso, es una clave externa que hace referencia a
Profs. Los atributos Matri y Clave del esquema relacional Cursa, son claves externas que hacen
referencia a los esquemas Alumno y Curso, respectivamente.
Un esquema de relación puede tener varias claves externas.
Para especificar las restricciones de integridad referencial se debe tener un claro entendimiento del
significado que cada conjunto de atributos tiene en los esquemas relacionales de una base de datos.
Estas restricciones surgen por los vínculos existentes entre las entidades representadas por los
esquemas de relación.
Normalmente la parte DDL de un DBMS relacional brinda los elementos necesarios para especificar los
diferentes tipos de restricciones comentadas, a fin de mantener la consistencia (validez) de los datos
almacenados en una base de datos.
3.4 TRANSFORMACIÓN ENTIDAD-VÍNCULO A RELACIONAL
En esta sección se describen las reglas que se siguen para transformar un modelo conceptual de una
base de datos, del modelo de entidad-vínculo al modelo relacional, a fin de obtener el modelo lógico de
ésta, como paso previo a su implementación con un DBMS.
Entidades
Los tipos de entidades simplemente se representan como esquemas de relación (o tablas base).
Ejemplo del mini-sisterna escolar:
Profs(ld_prof, Nom_prof, Categoría)
Alumno(Matri, Nom. al, Carr, Prom)
Cuando un tipo de entidades tiene un atributo compuesto, en el esquema relacional sólo aparecerán los
atributos simples de dicho atributo.
Para atributos multivaluados será necesario crear un nuevo esquema relacional por cada atributo, el
cual tendrá como clave primaria a los atributos clave del tipo de entidades más el atributo multivaluado.
Vínculos
Se puede crear un esquema de relación por cada tipo de vínculos existente entre varios tipos de
entidades. La clave primaria de cada esquema estará formada por la conjunción de los atributos clave
de los tipos de entidades participantes en el vínculo.
Ejemplo del mini-sistema escolar:
Cursa(Matri, Clave, Calif)
Hay que observar que en los esquemas relacionales que representan vínculos se aplica la restricción de
integridad referencial.
Cuando un tipo de vínculos tiene atributos compuestos o multivaluados, se aplican las mismas reglas
que en el caso de las entidades.
Cuando la cardinalidad de un tipo de vínculos binarios es 1-1 o 1-N, normalmente no se crea un nuevo
esquema de relación sino que al esquema de uno de los tipos de entidades participantes se le agrega
una clave externa, según se observa en las siguientes figuras:
Vínculo ISA
Todos los tipos de entidades, tanto el generalizado como los especializados, generan un esquema
relacional por tipo. La clave primaria de todos ellos está formada por la clave primaria del supertipo:
A(A1, Atribs. comunes)
B(A1(FK), Atribs. diferentes)
...
Y(A1(FK), Atribs. diferentes)
Entidad débil
Cada tipo de entidades se traduce como un esquema de relación. La clave primaria de la entidad débil
estará formada por sus propios atributos clave más los atributos de la clave primaria de la entidad
identificadora:
A(A1,A2)
B(A1(FK), B1, B2)
Vínculos recursivos
En los tres casos, el dominio de A1’ es el mismo dominio que el de A1.
Vínculo-entidad
Sin importar la cardinalidad de R1, conviene crear un esquema relacional para el mismo. Después el
vínculo con C, a través de R2, ya puede tratarse de acuerdo a la cardinalidad de R2.
Vínculos ternarios
Con cualquier cardinalidad de R, siempre se debe generar un esquema relacional para cada tipo de
entidades:
A(A1,A2)
B(B1, B2)
C(C1, C2)
R genera otro esquema; dependiendo de su cardinalidad se escogerá la clave primaria:
a) 1 - 1 - 1
R(A1(FK), B1(FK), C1(FK)) o R(A1(FK), B1(FK), C1(FK)) o
R(A1(FK), B1(FK), C1(FK))
b) 1 – N - 1
R(A1(FK), B1(FK), C1(FK)) o R(A1(FK), B1(FK), C1(FK))
c) 1 – M - N
R(A1(FK), B1(FK), C1(FK))
d) L – M - N
R(A1(FK), B1(FK), C1(FK))
Condicionalidad
Vínculo 1-1-c
La clave primaria del lado 1 se coloca como clave externa en el lado 1c. No se permiten nulos para ésta.
Vínculo 1c-N
La clave primaria del lado 1c se coloca como clave externa en el lado N. Se permiten valores nulos para
ésta. Si son muchos nulos en la clave externa, es mejor crear un nuevo esquema relacional que
represente al vínculo.
Vínculo 1-Nc
La clave primaria del lado 1 se agrega como clave externa en el lado N. No se permiten nulos para ésta.
Vínculo M-Nc
Se crea un nuevo esquema relacional para el vínculo.
Vinculo 1c-1c
Se coloca la clave primaria de un tipo como clave externa en el otro. Se permiten nulos. Si hay mucho
nulos, crear una nueva relación con las entidades participantes en el vínculo.
Vínculo 1c-Nc
Ídem 1c-N.
Vínculo Mc-Nc
Ídem M-Nc.
4 ALGEBRA RELACIONAL
4.1 INTRODUCCION
El álgebra relacional es un conjunto de operaciones sobre relaciones. Cada operación toma una o más
relaciones como su(s) operando(s) y produce otra relación como resultado; por lo tanto las expresiones
del álgebra relacional pueden anidarse a cualquier profundidad.
Codd definió originalmente un conjunto de operaciones del álgebra relacional y demostró que cualquier
resultado del álgebra relacional puede obtenerse a partir de dichas operaciones. Matemáticamente se
dice que este conjunto es completo y correcto. Este conjunto está formado por las operaciones:
selección, proyección, producto cartesiano, unión y diferencia.
Existe otro conjunto de operaciones que pueden derivarse a partir de las operaciones básicas. Se
incluyen como parte del álgebra relacional con el fin de simplificar las consultas que se hacen a una
base de datos. Este conjunto está compuesto por las operaciones: intersección, junta, junta natural y
división.
El conjunto de operaciones del álgebra relacional define un lenguaje que sirve para hacer consultas a
una base de datos. Sin embargo, en la práctica comercial este lenguaje no se usa por la dificultad que
presenta para la especificación de sus operaciones.
Entonces, se estudia con el propósito de presentar los aspectos teóricos formales relacionados con el
lenguaje de manipulación de datos del modelo relacional, lo cual sirve de base para el estudio posterior
de SQL (Structured Query Language) que es el lenguaje utilizado en el mundo comercial para la
explotación de bases de datos relacionales.
4.2 OPERACIONES BÁSICAS
OPERACIÓN DE SELECCIÓN (σ )
Esta operación produce un subconjunto "horizontal" de una relación dada; es decir, el subconjunto de
tuplas (t), tal que cada tupla t satisface una condición de selección (o sea, t hace que la condición sea
verdadera). La operación se representa como:
σ <condición de selección> (Relación)
Ejemplo:
σ
Nombre_Prof
= "Luisa" (Cursos)
La relación resultante tiene los mismos atributos que la relación original. La <condición de selección>
está compuesta por expresiones de comparación de la forma:
<nombre atributo> <op_comp> <constante> , o
<nombre atributo><op_comp><nombre atributo> donde <op_comp> es cualquier
operador de comparación {=, <, etc.}. Estas expresiones de comparación pueden estar
conectadas arbitrariamente por los operadores lógicos AND, OR y NOT.
Características y propiedades de σ
•
•
•
•
el operador es unario; por lo tanto no se pueden seleccionar tuplas de más de una relación
la operación se aplica individualmente a cada tupla de la relación
el conjunto de tuplas seleccionado se conoce como la selectividad de la condición de selección
la operación es conmutativa, es decir:
σ <cond1> (σ <cond2> (R))=σ <cond2> (σ cond1> (R))
•
operaciones Select en cascada se pueden sustituir por una condición de selección conjuntiva:
σ <cond1> (σ <cond2> ( ... (σ <condn> (R)) ... ))=
σ <cond1> AND <cond2> AND ... AND <condn> (R)
OPERACIÓN DE PROYECCIÓN ( ð )
La operación de proyección produce un subconjunto "vertical" de una relación dada, es decir, el
subconjunto obtenido al tomar los atributos especificados, de izquierda a derecha, y eliminando luego
las tuplas duplicadas en los atributos seleccionados. La operación se representa como:
ð
<lista de atributos>
(Relación)
Ejemplo:
Cursos
ð
Nombre-Prof
(Cursos)
Características y propiedades de ð
•
La expresión
ð <lista1> ( ð <lista2> (R))= ð <lista1>(R)
es válida, si <lista2> contiene a los atributos que están en <lista1>. En caso, contrario, no se sostiene.
•
La operación no es conmutativa.
OPERACIONES DE CONJUNTOS
PRODUCTO CARTESIANO (X)
El producto cartesiano de dos relaciones, R(A1 , A2 , . . .,An) X S(B 1 , B2 , .,Bm), es una relación Q(A1
, A2 , . . .,An, BI , B2 , . . .,Bm), en ese orden. La relación resultante Q tiene una tupla por cada
combinación de tuplas: una de R y una de S. De esta manera, si R tiene nR tuplas y S tiene nS tuplas,
entonces R X S tendrá nR*nS tuplas.
Ejemplo:
UNION (U)
La unión de dos relaciones R y S (compatibles con la unión), es el conjunto de todas las tuplas (t), tal
que cada tupla t pertenece a R o pertenece a S.
Ejemplo:
DIFERENCIA (-)
La diferencia entre dos relaciones R y S (compatibles con la unión), en este orden R-S, es el conjunto de
todas las tuplas (t), tal que cada tupla t pertenece a R y no pertenece a S.
Ejemplo:
Características y propiedades de las operaciones de conjuntos
•
•
•
•
•
•
Dos relaciones R(A1 , A2 , . . .,An) y S(B1 , B2 , ...,Bn) son compatibles con la unión si tienen el
mismo grado n, y si Dom(Ai) = Dom(Bi), para 1 ≤ i ≤ n
Se adopta la convención de que la relación resultante tiene los mismos nombres de atributos que la
primera relación especificada con el operador
En la unión, los duplicados se eliminan
La unión es conmutativa:
R ∪ S=S ∪ R
La unión puede aplicarse a cualquier número de relaciones. También, es una operación asociativa:
R ∪ (S ∪ T) = (R ∪ S) ∪ T
La operación de diferencia no es conmutativa; esto es:
R-S ≠ S-R
4.3 OPERACIONES DERIVADAS
INTERSECCIÓN ( ∩ )
La intersección entre dos relaciones R y S (compatibles con la unión), es el conjunto de todas las tuplas
(t), tal que cada tupla t pertenece tanto a R como a S.
Ejemplo:
Características y propiedades de la intersección
•
La operación de intersección R ∩ S es equivalente a R-(R-S)
•
•
•
La intersección es conmutativa:
R ∩ S=S ∩ R
La intersección puede aplicarse a cualquier número de relaciones.
También es una operación asociativa:
R ∩ (S ∩ T) = (R ∩ S) ∩ T
OPERACIÓN DE JUNTA (REUNION 0 JOIN)
, es usada para combinar tuplas relacionadas de dos relaciones.
La operación de junta, denotada por
Esta operación es muy importante para cualquier base de datos relacional ya que nos permite procesar
vínculos entre relaciones.
La forma general de la operación de junta sobre dos relaciones R(Al , A2 .,An) y S(BI B2,...,Bm) es
R <cond-junta> S
El resultado de la junta es una relación Q con n+m atributos Q(A1, A2 ,...,An, B1, B2, ...,Bm) en ese
orden. Q tiene una tupla por cada combinación de tuplas -una de R y una de S- que satisface la
condición de junta.
La condición de junta es de la forma:
<cond> AND <cond> AND ... AND <cond>
donde cada cond es de la forma A¡ è Bj con A¡ como atributo de R, Bj atributo de S y è un operador de
comparación. Una operación de junta con tal condición general también se conoce como è -junta.
La operación de junta es una abreviación para σ <cond-junta> (R X S).
Ejemplo:
entonces:
R(A,B,C)={<1,2>, <4,5,6>, <7,8,9>} y S(D,E)={<3,1>, <6,2>}.
R B<D S(A,B,C,D,E)= {<1,2,3,3,1>, <1,2,3,6,2>, <4,5,6,6,2>}.
Tuplas cuyos atributos de junta son nulos no aparecen en el resultado.
Una operación de junta donde sólo aparece el operador = en la condición, se conoce como equijunta
(equijoin).
OPERACIÓN DE JUNTA NATURAL
Es una operación de equijunta la cual se denota por
o por *. La definición estándar de junta natural
requiere que los dos atributos de junta (o cada par de atributos de junta) tengan el mismo nombre. La
junta natural se ejecuta igualando todos los pares de atributos que tienen el mismo nombre en ambas
relaciones, desechando los atributos repetidos de la segunda relación.
Ejemplo:
entonces:
R(A,B,C)= {< 1,2>, <4,5,6>, <7,8,9>} y S(C,E)= {<3, 1 >, <6,2>}
R * S (A,B,C,E)= {<1,2,3,1>, <4,5,6,2>}.
OPERACIÓN DE DIVISIÓN
La operación de división es útil para una clase especial de consultas que algunas veces ocurren en
aplicaciones de bases de datos. Un ejemplo seria: 'Obtener los nombres de los alumnos que llevan
todas las materias que lleva Rebeca'.
En general, la operación de división se aplica a dos relaciones R(Z) ÷ S(X), donde X ⊆ Z. Sea Y = Z-X;
esto es, sea Y el conjunto de atributos de R que no son atributos de S. El resultado de la división es una
relación T(Y) tal que para cada tupla t que aparezca en ésta, los valores de t deben aparecer en R en
combinación con cada tupla de S.
La operación de división puede ser expresada como una secuencia de operaciones ð , x, -, de la
siguiente manera:
T1 ← ð Y(R)
T2 ← ð Y ((S x T1) – R)
T ← T1 - T2
4.4 EXTENSIóN DEL ÁLGEBRA RELACIONAL
FUNCIONES DE TOTALES (0 DE AGREGADOS 0 DE ESTADÍSTICAS)
El primer tipo de solicitud que no puede ser expresado en el álgebra relacional es el de especificar
funciones de totales sobre colecciones de valores de la base de datos. Un ejemplo podría ser calcular
promedios o sumatorias.
Otro tipo de solicitud que no se puede hacer es el de agrupar las tuplas de una relación por el valor de
alguno de sus atributos y aplicarles alguna de estas funciones.
Para manejar este tipo de solicitudes se extiende el álgebra relacional incluyendo una operación
especial para poder especificar estas funciones. La operación Función se usará para tal fin y se denotará
con el símbolo , aunque la notación no es estándar. Esta extensión se toma en cuenta debido a que la
mayoría de los lenguajes relaciones de consulta comerciales incluyen recursos para ejecutar este tipo de
solicitudes.
La sintaxis de esta operación es:
<atribs. de agrupación>
<lista de funciones>
(<nombre de relación>)
donde:
<atribs. de agrupación> es una lista de atributos de <nombre de relación>.
<lista de funciones>
es una lista de pares (<función> <atributo>), siendo <función> una de
las funciones permitidas, como: SUM, AVG, MAX, MIN, COUNT; y <atributo> uno de los atributos de
<nombre de relación>.
La relación resultante tiene a los atributos de agrupación más un atributo por cada elemento en la lista
de funciones.
Si no se especifican atributos de agrupación, las funciones se aplican a los atributos de todas las tuplas
en la relación, tal que la relación resultante tiene una sola tupla.
Hay que enfatizar que el resultado de aplicar una función de totales es una relación, no un escalar
aunque el resultado sea un solo valor.
5 SQL - Un lenguaje de bases de datos
relacionales
5.1 Introducción
El SQL (Structured Query Language) es un lenguaje estándar que se utiliza para definir y usar bases de
datos relacionales. Originalmente se desarrolló en IBM's San Jose Research Laboratory a finales de los
70 y desde entonces ha sido adoptado y adaptado por muchos sistemas administradores de bases de
datos relacionales. Ha sido aprobado como el lenguaje relacional oficial por el American National
Standards Institute (ANSI) y la International Standards Organization (ISO).
Este lenguaje se utiliza no sólo para hacer consultas a una base de datos, esto es para recuperar datos;
sino también para definir la base de datos y los objetos que la componen, agregar, eliminar y/o modificar
datos, así como para realizar otras funciones relacionadas con la manipulación de una base de datos
(por ejemplo, cambiar su estructura).
El SQL no permite elaborar formas de edición de datos, reportes, menús de opciones, etc.; ya que éstas
son funciones que corresponden a un lenguaje de 4a. generación. Entonces, el desarrollo normal de una
aplicación completa que incluya la utilización de un DBMS de esta naturaleza implicaría, primeramente,
el desarrollo de la base de datos usando este software y luego, la elaboración de las interfaces de
entrada/salida (por ejemplo, formas y reportes) con un lenguaje de 4a. generación que se pueda acoplar
a este DBMS (por ejemplo, Visual Basic o Access). Naturalmente, este tipo de aplicaciones está
relacionado con problemas que requieren de manejar volúmenes muy grandes de informacion; para
cantidades pequeflas, basta con DBMS's para micros o estaciones de trabajo.
En las siguientes páginas se describirán las características principales del SQL estándar y se
comentarán algunas extensiones que se manejan en el SQL de Sybase.
5.2 Expresiones condicionales
Una expresión condicional es una expresión lógica que SQL evalúa a falso, verdadero o desconocido.
Estas expresiones se utilizan en ciertas frases de SQL para expresar condiciones que se deben cumplir
y que normalmente se relacionan con la manipulación de tuplas en relaciones. Las condiciones que se
pueden expresar con estas expresiones son los siguientes.
Condición de comparación
Sirve para comparar dos expresiones utilizando un operador de comparación:
expresión operador_comparación expresión
donde expresión puede ser: constante, nombre de columna, función, subconsulta, o cualquier
combinación de ellos conectados por operadores aritméticos; y operador_comparación es uno de los
operadores:
=, <>, <, <=, >=, !=, !>, !<
Condición between
Da un valor verdadero si expresión] es mayor o igual que expresión2 y menor o igual que expresión3:
expresión] [not] between expresión2 and expresión3
Condición in
Da uir valor verdadero si expresión] es igual a alguna de las expresiones que están en la lista
especificada después de in (incluyendo subconsultas):
expresión] [not] in lexpresión2 1 ({expresión3 1 subconsultal}
[,{expresión4 1 subconsulta2fl ... )}
Condición like
Da un valor verdadero si el patrón especificado es encontrado en una subcadena de la primera
expresión. En el patrón se pueden usar los caracteres especiales:
%
para indicar cualquier cadena de cero o más caracteres
para indicar cualquier carácter
expresión [not] like patrón
Condición null
Da un valor,verdadero si expresión produce un valor nulo: expresión is [not] null
Condición lógica
Sirve para conectar lógicamente a varias expresiones condicionales. Los operadores lógicos son los
habituales: and, or y not. Su precedencia de evaluación, cuando aparecen en la misma expresión, es:
not, and y or. Se pueden usar paréntesis para dar otro orden de evaluación:
[not] [(] expre_cond [)] [{ and | or } [not] [(] expre_cond [(] ...
Condición exists
Da un valor verdadero si la tabla de resultados de una subconsulta no está vacía (esto es, contiene por
lo menos una tupla):
[not] exists (subconsulta)
Condición de cuantificación (operadores: all, any)
El operador all da un valor verdadero si expresión operador_comparación es cierto para todas las tuplas
de la tabla de resultados de la subconsulta o si la tabla está vacía. El predicado any da un valor
verdadero si expresión operador_comparación es cierto para al menos una tupla de la tabla de
resultados de la subconsulta:
expresión operador_comparacion { all | any } (subconsulta)
5.3 Definición del esquema lógico (conceptual) de una base de datos
5.3.1 Instrucción create table
Esta instrucción es la que se utiliza para definir las tablas del esquema conceptual de una base de datos
relacional. Su sintaxis es la siguiente:
create table nom_tabla
(columna_1 (tipo_de_datos | dominio} [DEFAULT {literal | NULL) ]
PRIMARY KEY
NOT NULL |
UNIQUE |
REFERENCES nom_tabla_n [(atributo_i)] |
CHECK (expre_cond)
[,columna_2 .... . .... ] )
donde:
tipo_de_datos:
CHAR(n)
TINYINT, SMALLINT, INTEGER
REAL, DOUBLE PRECISION
SMALLDATETIME, DATETIME
literal:
numéricas:
cadenas:
fecha hora:
123, 34.9, 6.023E23, -0.25
'ejemplo', "otro ejemplo"
'Aug 29 1995 10:20'
5.3.2 Definición de la base de datos Mini-sistema escolar
--
ESQUEMA RELACIONAL DE LA BASE DE DATOS:
-profs(id_prof, nom_prof, categoria)
-cursos(clave, nom_cu, creds, id_prof (FK))
-alums(matri, nom,_al, carr, prom)
-cursa(matri (FK), clave (FK), califs)
--DEFINICIÓN DE DOMINIOS:
sp__,addtype noms, "char(20)"
--
DEFINICIÓN DE TABLAS
create table profs
(id_prof
nom_prof
categoria
tinyint
noms,
char(2)
primary key,
create table cursos
(clave
nom cu
creds
id_prof
smallint
noms,
tinyint
tinyint
primary key,
create table alums
(matri
nom-al
carr
smallint
noms,
char(3)
prom
create table cursa
real
check (categoria in ('tc’,'mt’,’tp’)))
check (creds between 2 and 12),
references profs)
primary key,
check (carr in ('adm','com',’eco’)
or carr is null),
check (prom is null
or prom between 6 and 10))
(matri
clave
smallint
smallint
califs
tinyint
references alums,
references cursos,
primary key (matri,clave),
check (califs between 5 and 10))
5.4 Instrucciones para actualizar la base de datos
5.4.1 Instrucción insert
Esta instrucción se utiliza para agregar tuplas a una tabla. Su sintaxis (básica) es:
insert into nom - tabla [(Iista_de_columnas)]
values (lista_de_valores)
donde:
lista - de columnas: representa a las columnas de la tabla (separadas por coma).
lista_de_valores: representa los valores de la tupla a insertar.
Ejemplos:
insert into cursos (clave, nom_cu)
values (900, “Estadistica I”)
insert into cursos
values (902, “Estadistica III” 9, null)
5.4.2 Instrucción update
Sirve para modificar los valores de las columnas de una tabla. Su sintaxis (básica) es:
update nom_tabla
set columna - 1 = valor_1 [, columna_2 = valor_2, ...]
[where expre_cond]
donde:
columna_1, columna_2, son las columnas a modificar.
Ejemplos:
update cursos set id_prof = 5
where clave = 816
update cursos set id_prof = 1, creds = 9
5.4.3 Instrucción delete
Se emplea para eliminar tuplas de una tabla. Su sintaxis (básica) es:
delete from nom tabla [where expre_cond]
Ejemplos:
delete from cursos where clave = 620
delete from cursa
5.5 Instrucción select
SQL tiene una instrucción básica para recuperar información de una base de datos: la instrucción select.
Esta instrucción genera una tabla de resultados que contiene las tuplas que produce la consulta. La
instrucción presenta diversas opciones las cuales se analizarán gradualmente a continuación.
La sintaxis general de la instrucción select es:
select [all | distinct] lista_de_columnas_s
from lista_de_tablas
[where expre_cond]
[group by lista_de_columnas_g]
[havíng expre_cond]
[order by columna [asc | descl [, columna [asc | desc]] ... ]
donde:
lista_de_columnas-s: es un lista de columnas (separadas con coma) cuyos valores van a ser
recuperados por la consulta. Una columna puede ser:
[{nombre_de_tabla | alias}.]nombre_de_columna,
[{nombre_de_tabla | alias}.]* o expresion
lista_de_tablas: es una lista de tablas (separadas con coma) requeridas para procesar la
consulta
expre_cond: es una de las expresiones condicionales que pueden especificarse en SQL
lista_de_columnas_g: es una lista de columnas (separadas con corna); para cada columna sólo
se puede usar la sintaxis:
[Inombre_de_tabla | alias}.]nombre_de_columna,
columna: es de la forma: [{nombre_de_tabla | alias}.Inombre_de_columna
Cada una de las distintas cláusulas de la instrucción select genera una tabla intermedia que es usada
para evaluar la cláusula siguiente.
La cláusula select especifica las columnas cuyos valores se van a tomar para generar la tabla de
resultados.
La cláusula from especifica las tablas (relaciones) de donde se van a tomar las columnas indicadas en
la cláusula select.
La cláusula where sirve para especificar una condición que deben cumplir las tuplas que se seleccionen
de las tablas indicadas en from.
La cláusula group by sirve para formar grupos con las tuplas que aparecen en la tabla intermedia
producida por where o por from.
La cláusula having se emplea para aplicar alguna condición a los grupos formados con group by.
Finalmente, la cláusula order by sirve para ordenar las tuplas de la tabla de resultados.
SQL evalúa las cláusulas en la instrucción select en el siguiente orden: from, where, group by,
having, lista_de_columnas_s, order by. Como se mencionó anteriormente, después de hacer una
evaluación dada, SQL produce una tabla intermedia la cual es usada para realizar la siguiente
evaluación.
Opcionalmente se puede usar la cláusula union para producir una sola tabla uniendo el resultado de
varias instrucciones select. La sintaxis es la siguiente:
select_1
union [all]
select 2 [union [all]...]
[order by resto_del_order_by]
Por default, el resultado de union elimina tuplas duplicadas. Para conservar todas las tuplas resultantes
de la unión se debe usar all.
Cuando se usa union las instrucciones select_1, select_2, ... no deben contener order by.
Consultas que involucran una sola relación
1) Obtener el nombre de cada materia y sus créditos.
2)
Obtener todos los datos de los Profesores.
3) Obtener el nombre y el promedio de los alumnos de la carrera de computación con promedio mayor
a 9.
4)
Obtener el nombre de las carreras registradas.
5)
Obtener el nombre de las carreras registradas sin duplicados.
6) Obtener el nombre de los alumnos, sus carreras y sus promedios, ordenados ascendentemente por
carrera y descendentemente por promedio.
7) Obtener el nombre de los cursos de 8 o de 9 créditos, ordenando descendentemente por créditos y
ascendentemente por nombre del curso.
Consultas que involucran varias relaciones
8) Para cada profesor obtener el nombre de los cursos que imparte. Ordenar por nombre del profesor.
9) Obtener el nombre de los alumnos inscritos en cada curso.
10) Para cada profesor, obtener su nombre, el nombre de los cursos que imparte y el nombre de sus
alumnos. Ordenar ascendentemente por nombre del profesor y descendentemente por nombre del
curso.
Subconsultas
11) Obtener el nombre y la carrera de todos los alumnos que actualmente cursan alguna materia.
12) Obtener el nombre y el promedio de todos los alumnos que actualmente no cursan materia alguna.
Notas- Cualquier subconsulta sólo puede generar como resultado una tabla con una sola columna (la
cual, por supuesto, puede contener varios valores). Cuando se tienen varias subconsultas anidadas, el
orden de evaluación es de la más interna hacia la más externa.
Funciones de totales (o estadísticas o de agregados)
SUM, AVG, MAX, MIN, COUNT
13) Obtener el promedio general de todos los alumnos de administración.
14) Contar todas las materias registradas.
Uso de group by y having
15) Obtener para cada curso el promedio de las calificaciones aprobatorias.
16) Obtener el nombre de los profesores y la cantidad de cursos que cada uno está dictando.
17) Obtener el nombre de las carreras en donde el promedio general (de los alumnos de dicha carrera)
sea inferior a 9.
18) Obtener el nombre de las materias donde existen más de dos alumnos inscritos.
19) Obtener el nombre de las materias donde aparece más de un alumno de computación.
20) Obtener para cada curso cuyo promedio general (de las calificaciones aprobatorias) sea mayor que
7, el nombre y dicho promedio general.
Varios
21) Obtener la matrícula de aquellos alumnos que cursan la carrera de computación o que cursan la
materia Matemáticas 1 (o ambas cosas).
22) Obtener el nombre del alumno con el máximo promedio.
23) Obtener la matrícula de los alumnos que cursan a la vez las materias con claves 300 y 800.
24) Obtener la matrícula de los alumnos que cursan a la vez las materias Computación I y Matemáticas
I.
25) Escribir el nombre de las materias de 9 créditos en las cuales no se inscribieron alumnos. Ordenar
alfabéticarnente.
26) Contar, por carrera y por materia, la cantidad de alumnos inscritos en las materias de 7 u 8 créditos.
Escribir nombre de la carrera, nombre de la materia y la cuenta.
27) Escribir el nombre de las materias en las cuales se inscribieron máximo 3 alumnos. Escribir también
el nombre de dichos alumnos.
28) Obtener el nombre y la categoría de los profesores que imparten todas las materias.
Condición de cuantificación (operadores: all, any)
Comparan un valor contra una colección de valores.
Si se usa el operador all, SQL evalúa la condición como verdadera si:
- la comparación es verdadera para cada tupla de la tabla de resultados producida por la
subconsulta especificada, o
dicha tabla de resultados no tiene tuplas.
29) Encontrar el nombre de los alumnos con el menor y el mayor promedios, junto con su carrera.
select nom_al, prom, carr
from alums where prom <-- all (select prom from alums)
or prom >= all (select prom from alums)
30) Obtener el nombre y el promedio de los alumnos que superen el promedio global de todos los
alumnos.
Si se usa any, SQL evalúa la condición como verdadera si la comparación es verdadera para al menos
una de las tuplas de la tabla de resultados producida por la subconsulta especificada.
31) Encontrar el nombre de los alumnos que están llevando por lo menos una materia.
select nom_al
from alums
where matri = any (select matri from cursa)
32) La siguiente consulta, ¿encuentra a los alumnos que no están cursando materia alguna?
select nom_al
from alums
where matri <> any (select matri from cursa)
Condición exists
Prueba si la tabla de resultados producida por la subconsulta especificada está vacía (false) o no (true).
33) Encontrar el nombre de los alumnos que están llevando por lo menos una materia.
select nom_al
from alums a
where exists
(select * from cursa c where a.matri = c.matri)
34) Obtener el nombre de los alumnos que no están llevando materia alguna.
select nom_al
from alums a
where not exists
(select * from cursa c where a.matri = c.matri)
35) Obtener el nombre de los alumnos que están llevando todas las materias.
Este operador es el unico que permite especificar * dentro de la subconsulta.
Observaciones
• Cláusula where
El DBMS evalúa la expresión condicional dada en where para cada tupla de la tabla intermedia creada
por from.
Las columnas especificadas en la expresión condicional de where deben:
- ser columnas de la tabla intermedia creada por from, o
- ser una referencia externa (una referencia externa es una referencia dentro de una subconsulta a
una tabla declarada en la cláusula from de una (sub)consulta externa que engloba a dicha
subconsulta). Por ejemplo, en la siguiente consulta
select nom_al
from alums
where not exists
(select * from cursa where alums.matri = cursa.matri)
alums, dentro de la subconsulta, es una referencia externa con respecto a dicha subconsulta, ya
la tabla está declarada en la consulta externa.
• Cláusula group by
Especifica columnas que el DBMS usa para formar grupos con la tabla intermedia creada por where, si
existe, o por from.
Se pueden especificar varias columnas consecutivas, con lo cual se van formando subgrupos dentro- de
los grupos. Ejemplo:
select carr, clave, count(*)
from cursa c, alums a
where c.matri = a.matri group by carr, clave
En este ejemplo se forman grupos por cada carrera de los alumnos que toman cursos y, para cada una,
se forman subgrupos con las claves de los cursos tomados.
Todos los valores nulos para una columna dada son agrupados juntos.
Cuando se usa esta cláusula, columnas que aparecen en lista_de_columnas_s, no
especificadas en group by, deben colocarse siempre dentro de una función. En caso
contrario, no pueden aparecer en dicha lista. Por ejemplo, la siguiente consulta es
incorrecta
select carr, nom_al, count(*)
from alums
group by carr
debido a que nom_al es una columna que no aparece dentro de group by, ni dentro de una función.
• Cláusula having
El DBMS aplica la expresión condicional de having a cada grupo de la tabla intermedia creada por la
cláusula precedente (que en general es group by).
La cláusula having afecta grupos de la misma forma que where afecta tuplas individuales.
Si having no es precedida por group by, el DBMS aplica la expresión condicional a todas las tuplas de
la tabla intermedia creada por where o por from, como si se tratará de un solo grupo.
Las columnas especificadas en having deben:
- estar también en group by,
- ser especificadas dentro de una función, o
- ser una referencia externa.
Restricciones de uso
•
En general, el predicado en where no puede contener una función. La única excepción a esta
restricción es cuando la función en where tiene como argumento una referencia externa.
Si no se usa group by, la lista_de_columnas_s debe:
- ser unicamente una lista de funciones, o
- no contener función alguna.
El siguiente ejemplo es incorrecto:
select carr, avg(prom)
from alums
• Si se usa group by o having, las columnas en la lista_de_columnas_s deben:
- estar también en group by, o
- ser especificadas dentro de una función.
5.6 Definición de índices
Los índices son utilizados por el DBMS para acelerar el proceso de recuperación de datos. Su manejo es
transparente para el usuario ya que el DBMS decide cuando usarlos o no al ejecutar una consulta. SQL
sólo proporciona instrucciones para crear o eliminar índices sobre tablas. La sintaxis usada para crear
índices es la siguiente:
create [unique] index nombre_índice
on nombre_tabla (columna_1 [, columna_2] ... )
En el caso de Sybase, y de muchos otros manejadores como Access, cada que se define una tabla se
crea automáticamente un índice sin duplicados para los campos que constituyen la clave primaria de la
misma. Se pueden definir más índices, con o sin duplicados, para los otros campos de una tabla, por
ejemplo, para las claves externas.
Ejemplo:
--- Creación de índices
-create index ind_cs_profs on cursos(id_prof)
5.7 Eliminación de objetos de una base de datos
Para eliminar algún objeto (tabla o índice) de una base de datos se utiliza la instrucción drop. Cuando
se elimina una tabla desaparecen, además de su estructura, los datos que almacena así como los
índices y permisos que tiene asociados. La sintaxis de la instrucción para cada caso es:
Para tablas:
drop table nombre_tabla [, nombre_tabla] ...
Para índices:
drop index nombre_tabla.nombre_indice
[nombre_tabla.nombre_índice] ...
Para triggers:
drop trigger nombre_trigger [, nombre_trigger] ...
5.8 DefInición de disparadores (Triggers)
Un disparador (trigger) es una clase especial de procedimiento almacenado el cual se activa cuando se
insertan, eliminan o modifican datos en una tabla específica. Los triggers pueden ayudar a conservar la
integridad referencial de los datos manteniendo la consistencia entre datos lógicamente relacionados
que estén en tablas diferentes. Los triggers son automáticos: se disparan cuando ocurre una
actualización de datos en una tabla, ya sea causada por un usuario o por una aplicación. La sintaxis de
definición de un trigger es la siguiente:
create trigger nombre_ trigger
on nombre_tabla
for {insert, update, delete)
as instrucciones_SQL
donde:
nombre_tabla: es la tabla que al actualizarse va a ocasionar que se dispare el trigger
for {insert, update, delete}: sirve para indicar con qué operaciones de actualización se activará
el
trigger
instrucciones_SQL: son instrucciones SQL (normalmente insert, update o delete) que se
ejecutarán al activarse el trigger.
Ejemplos:
Definición de triggers
•
El siguiente trigger borrará tuplas relacionadas en la tabla cursa cuando se elimine algún alumno de
la tabla alums.
create trigger BorraAlumsCursa
on alums for delete
as delete cursa from cursa, deleted where cursa.matri = deleted.matri
•
Este trigger borrará tuplas relacionadas en la tabla cursa cuando se elimine algún curso de la tabla
cursos.
create trigger BorraCursosCursa
on cursos for delete
as delete cursa from cursa c, deleted d where c.clave = d.clave
Este trigger coloca un valor nulo en la columna id_prof, de la tabla cursos, para aquellas tuplas que
estén relacionadas con algún profesor que se elimine de la tabla profs.
create trigger QuitaProfCursos
on profs for delete
as update cursos set cursos.id_prof = null from cursos cs, deleted d where cs.id_prof = d.id_prof
5.9 Lenguaje de programación y procedimientos almacenados
Un lote (batch, en inglés) es simplemente un conjunto de instrucciones SQL que Sybase puede
ejecutar ya sea interactivamente o desde un archivo. Un lote siempre es terminado por una marca de
fin-de-lote que sirve para indicarle a Sybase que ejecute al conjunto de instrucciones que están en el
lote. El default para isql es la palabra reservada "go". Ejemplo:
select * from alums
select * from profs
go
select * from cursos
go
Sybase proporciona además un conjunto de instrucciones muy similares a las típicas que se tienen en
un lenguaje de programación de 3a generación (como C). Esto permite efectuar un tipo de programación
que combina a estas instrucciones con las frases que pertenecen a SQL, con el fin de poder expresar
soluciones para aquellos problemas que no pueden resolverse directamente con SQL (por ejemplo:
Obtener el nombre de los alumnos que tienen los tres promedios más altos).
5.9.1 Lenguaje de programación
Como ya se comentó, está constituido por un conjunto de instrucciones muy similares a las de un
lenguaje de 3a generación, aunque dicho conjunto es bastante reducido con respecto al que se
proporciona en uno de estos lenguajes. Estas instrucciones pueden usarse en los lotes, en los
procedimientos almacenados y en los disparadores. A continuación se presentan las instrucciones más
importantes de este lenguaje proporcionado por Sybase.
if ... else
Es la típica instrucción para ejecutar condicionalmente otras instrucciones. Su sintaxis es:
if exp_cond
instrucción
[else
instrucción
]
donde:
exp_cond: es una expresión lógica, la cual puede incluir también un nombre de columna,
una
constante,
cualquier combinación de éstos conectados con operadores
aritméticos
o
una
subconsulta
(siempre y cuando la subconsulta regrese un solo valor; si ésta se usa, debe escribirse
entre
paréntesis).
instrucción: es cualquier instrucción del lenguaje de programación de Sybase o de SQL.
Ejemplos:
1) if exists (select clave from cursos where creds=2)
print "Sí hay materias de dos créditos"
2) if (select max(prom) from alums) < 9.7
print "No hay alumnos con promedio mínimo de 9.7"
else
select nom-al, carr, prom from alums
where prom >= 9.7
begin ... end
Se usan para enmarcar a un conjunto de instrucciones para que sean tratadas como si fueran una
unidad. A tal conjunto normalmente se le conoce como bloque de instrucciones. Su sintaxis es:
begin
bloque_instrucciones
end
Ejemplo:
if (select avg(precio) from. titulo) < 60
begin
update titulo set precio = precio * 1.2
select nom_t, precio
from titulo
where precio > 60 end
while y break, continue
while es usada para establecer una condición con el fin de ejecutar repetidamente una instrucción. La
instrucción es ejecutada mientras la condición especificada sea verdadera. Su sintaxis es:
while exp_cond
instrucción
Ejemplo:
while (select avg(precio) from titulo) < 90
begin
select nom_t, precio
from titulo
where precio > 50
update titulo
set precio = precio * 1.2
end
break y continue controlan la ejecución de las instrucciones dentro de un ciclo while. La instrucción
break causa que se abandone de inmediato el ciclo (si hay dos o más ciclos anidados, break ocasiona
que el control se pase al siguiente ciclo externo). La instrucción continue causa que el ciclo se reinicie,
saltando todas las instrucciones que le siguen pero que están dentro del mismo ciclo.
Ejemplo:
while (select avg(precio) from titulo) > 50
begin
update titulo
set precio = precio/1.2
if (select max(precio) from titulo) < 40
break
else
if (select avg(precio) from titulo) < 50
continue
print 'Trecio promedio aún superior a $50"
end
select nom_t, precio
from titulo
where precio < 50
print 'Libros no demasiado caros"
declare (variables locales)
Es una frase que se utiliza para declarar variables locales en un lote o en un procedimiento almacenado.
Estas variables se declaran y se nombran por medio de esta frase asignándoles, posteriormente, un
valor por medio de la instrucción select. Sólo pueden usarse dentro del lote o procedimiento
almacenado en el cual se declaran.
El nombre de estas variables debe comenzar con "@" y pueden ser de cualquier tipo de datos, salvo
text, image o sysname. Su sintaxis de declaración es:
declare @NomVar TipoDatos
[, @NomVar TipoDatos] ...
Cuando se declara la variable, por default tiene el valor null. Valores concretos se asignan a las
variables locales con select, por medio de la siguiente sintaxis:
select @NornVar = {exp | (instr_select)}
[, @NomVar = {exp | (instr_select)} ...
[cláusula from] [cláusula wherel [cláusula group by]
[cláusula having] [cláusula order by] [cláusula compute]
donde:
exp:
instr_select:
es una expresión que debe producir un solo valor.
es una subconsulta que debe regresar un solo valor.
Ejemplos:
1) declare @muyalto money
select @muyalto = max(precio) from titulo
if @muyalto > 500
print 'Trecio máximo demasiado alto"
else
print 'Precio máximo razonable"
2) declare @cant J alums int, @cant-mats int
select @cant_alums = (select count(*) from alums),
@cant_mats = (select count(*) from cursos)
select @cant_alums Total-alumnos, @cant-mats Total-materias
(el último select muestra en pantalla el valor de las variables)
Si exp o instr_select producen más de una valor, se asigna a la variable el último valor que se produce.
3) declare @m money
select @m = anticipo from titulo
select @m Anticipo
Variables globales
Son variables predefinidas proporcionadas por el sistema. Su nombre comienza con dos "@" para
distinguirlas de las variables locales. Existe todo un conjunto de este tipo de variables que se utiliza para
diversos fines; por su importancia, aquí sólo se destacan dos de ellas:
Variable
@@error
@@rowcount
Contenido
Contiene 0 si la última transacción tuvo éxito; en caso contrario,
contiene el número del último error generado por el sistema.
Contiene el número de filas afectadas por la última consulta.
@@rowcount es puesta a cero por cualquier instrucción que no
regresa filas, tal como un if.
return
Esta instrucción causa la terminación incondicional de un lote o de un procedimiento. Su sintaxis es:
return [exp_ent] donde:
exp_ent:
es una expresión que produce un valor entero que se pueda usar para enviar
un código explicando la causa de la terminación.
Ejemplo:
select * from profs
if @@error!= 0
return
/* Termina el proceso si hubo un error en el select */
(La última línea muestra otra forma de escribir un comentario en Sybase. El comentario se puede
extender en varias líneas.)
print
Sirve para desplegar en la pantalla un mensaje, el contenido de una variable local o el de una global. Su
sintaxis es:
print {cadena_cars | @VarLocal | @@VarGIobal)
El contenido de una variable local o global sólo puede imprimirse directamente con print si es de tipo
cadena de caracteres; si no es así, hay que hacer algo similar a lo que se muestra en el ejemplo 2
siguiente.
Ejemplos:
1) declare @t1 char(30)
select @t1 = "Muy bien"
if (select avg(prom) from alums) < 8.5
print "Promover la dedicación al estudio"
else
print @t1
2) declare @m money, @c char(20)
select @m = anticipo from titulo
select @c = convert(char(20),@m)
print @c
El segundo select de este último ejemplo muestra el uso de la función convert(.,.) la cual sirve para
convertir el tipo de datos del valor de una expresión en otro tipo de datos diferente. Su sintaxis es:
convert (NuevoTipoDatos, expresión)
5.9.2 Procedimientos almacenados
Los procedimientos almacenados son colecciones de instrucciones de SQL y del lenguaje de
programación. Estos procedimientos pueden:
- tomar parárnetros
- llamar a otros procedimientos
- regresar un valor de status al procedimiento o lote que llamó, para indicar éxito o falla y la razón
en este último caso
- regresar valores al procedimiento o lote que llamó
- ser ejecutado en servidores SQL remotos
Los procedimientos almacenados normalmente son compilados por Sybase, de tal manera que su
rendimiento es muy alto por lo que normalmente su ejecución es bastante rápida. Esto sugiere que
cuando se tienen tareas muy bien definidas para la explotación de una base de datos, conviene
implementarlas por medio de estos procedimientos para tener un procesamiento muy eficiente de las
mismas.
La sintaxis seguida para crear un procedimiento almacenado es la siguiente:
create procedure NomProc
[[(] @NomPar TipoDatos [= default] [output]
@NomPar TipoDatos [= default] [output]] ...[)]]
as instrs
donde:
@,NomPar:
nombre de un parárnetro
default:
valor que el parámetro tomará en caso de que no se le asigne explícitamente
uno cuando se
llama al procedimiento
Output:
palabra reservada que indica que el parámetro es de "salida"
instrs:
conjunto de instrucciones de SQL, o del lenguaje de programación, que definen
al procedimiento
La sintaxis para llamar a ejecución al procedimiento es:
[execute] [@VarStatus = ] NomProc
[ [@NomPar ] valor |
[@NomPar = @NomVar [output]
[, [@NomPar ] valor |
[@NomPar = @NomVar [output] ... ]]
donde:
@ VarStatus: es una variable local donde se puede guardar un valor de status,
indicando éxito o falla, que el procedimiento puede regresar
valor:
valor que se asignará al parámetro correspondiente en el procedimiento
@Nom Var:
una variable que debe darse en el caso de parámetros de salida
output:
palabra reservada para indicar que el contenido de @,NomVar se escriba
de inmediato en la pantalla
Ejemplos:
1) Definición:
create procedure procl as
select * from alums
select * from cursos
2) Ejecución:
execute proc1
o
exec proc1
o
proc1
/* En este caso, el llamado debe ser la única (o la 1a) instr. en un lote*/
Se puede usar el procedimiento almacenado (del sistema) sp_helptext para ver la definición de
cualquier otro procedimiento. Por ejemplo:
sp_helptext proc1
También se puede usar el procedimiento (del sistema) sp_help para ver datos generales de otro
procedimiento. Por ejemplo:
sp_he1p proc1
5.9.2.1 Parámetros con valores por default
El siguiente ejemplo muestra como se define un procedimiento con un parámetro que toma un valor por
default. Ejemplo: obtener el nombre de los alumnos que toman una materia cuyo nombre se da como
parámetro (default: Economia V):
create proc pardef (@nom char(20) = "Economía V") as
select nom_cu, nom_al
from cursos cs, cursa c, alums a
where nom_cu like @nom
and cs.clave=c.clave and c.matri=a.matri
Si el procedimiento se ejecuta de la siguiente manera, listaría los alumnos que lleven cualquier materia
cuyo nombre comience con "Comp":
exec pardef "Comp%"
Si se ejecuta sin dar parámetro, listaría a los alumnos que están llevando "Economia V":
exec pardef
5.9.2.2 Información de salida de un procedimiento
Un procedimiento almacenado puede dar un "status de terminación" que indica si se completó
exitosamente o si terminó con fallas. Este valor puede almacenarse en una variable para que
posteriormente pueda ser usado por otras instrucciones (p. ej., un if). Sybase utiliza el valor 0 para
indicar que el procedimiento se ejecutó bien; emplea los valores -1 a -99 para indicar que ocurrió una
falla. Ejemplo:
declare @status int
exec @status = pardef
if @status = 0
print "El procedimiento se ejecutó exitosamente"
else
print "Ocurrió un error en la ejecución del procedimiento"
5.9.2.3 Parámetros de salida en un procedimiento
Un procedimiento puede ser definido con parámetros formales de salida para regresar valores, por
medio de ellos, al lote o procedimiento que lo llamó. Si un procedimiento se define así, en el llamado al
mismo deben especificarse variables en los parámetros actuales correspondientes a dichos parámetros
de salida. Ejemplo: dado el nombre de una materia como parámetro (deflault: Economia V), calcular y
regresal el promedio que llevan los alumnos que la están cursando:
Definición:
create proc parsal (@nom char(20) = "Economia V', @prom real out) as
select @prom = avg(convert(real,califs))
from cursos cs, cursa c
where nom_cu = @nom and cs.clave=c.clave
group by cs.clave
Llamado:
declare @mat varchar(20), @prom real, @m varchar(60)
select @mat = "Computacion I"
exec parsal @mat, @prom out
if @prom!= null
select @m="En "+@mat+ " se lleva promedio de: "+ convert(varchar(10),@prom)
else
select @m=”La materia "+@mat+ " no se está dictando" print
@m
5.9.2.4 Eliminación de un procedimiento
Para eliminar un procedimiento de una base de datos basta con ejecutar la instrucción drop proc, cuya
sintaxis es la siguiente:
drop proc NomProc [, NomProc] ...
5.9.3 Cursores
Un cursor es un nombre simbólico asociado con una instrucción select. Consiste de las siguientes
partes:
•
conjunto resultado del cursor - es el conjunto (tabla) de tuplas resultante de la ejecución de la
consulta asociada al cursor
•
posición del cursor - un apuntador (conceptual) a una tupla de dicho conjunto
Declaración del cursor
Se utiliza la siguiente sintaxis para declarar un cursor:
declare NomCursor cursor
for instr_select
[ for {read only I update [of ListaNomCols] } ]
Apertura del cursor
Todo cursor debe abrirse antes de ser utilizado. Esto significa que se instruye al DBMS para que ejecute
el select asociado al cursor con el fin de producir la tabla de resultados respectiva. La frase utilizada
para esto es open, cuya sintaxis es:
open NomCursor
Cuando se hace la apertura el cursor queda apuntando antes de la 1a tupla.
Lectura de tuplas
Una vez abierto el cursor, ya se pueden leer las tuplas de la tabla de resultados. Para hacer esto se
emplea la instrucción fetch, cuya sintaxis es:
fetch NomCursor [into ListaVars]
Con cada lectura el cursor queda apuntando a la última tupla leída. La lectura de las tuplas es
secuencial; si se quieren volver a leer las tuplas, hay que cerrar el cursor y volverlo a abrir.
Obtención de múltiples tuplas
La instrucción fetch lee tupla por tupla de la tabla de resultados. Si se quiere leer una cantidad más
grande tuplas, se debe usar la instrucción set para tal fin. La sintaxis para esta instrucción es:
set cursor rows NumTuplas for NomCursor
Verificación del status del cursor
Se puede utilizar la variable global @@sqlstatus para conocer cuál fue el resultado del último fetch
realizado con un cursor. Los posibles valores que puede tener la variable son los siguientes:
0 - ejecución exítosa
1 - se produjo un error
2 - no hay más datos en la tabla de resultados. Normalmente ocurre cuando el cursor ya apunta a la
última tupla y se hace un fetch adicional.
Cierre y liberación del cursor
Para cerrar un cursor se emplea la instrucción close, cuya sintaxis es:
close NomCursor
Una vez cerrado un cursor puede volver a abrirse si así se desea.
Para liberar los recursos usados por un cursor se utiliza la instrucción deallocate, cuya sintaxis es:
deallocate cursor NomCursor
El cursor ya no se puede usar una vez que ha sido ejecutada esta instrucción.