Sesión 28 Tema: Ácidos nucleicos I. Objetivos de la sesión Que los
Anuncio
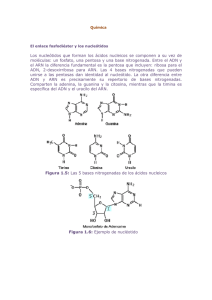
Sesión 28 Tema: Ácidos nucleicos I. Objetivos de la sesión Que los alumnos reconozcan la estructura y función de los ácidos nucleicos II. Temas Uno de los mayores triunfos de la moderna biología molecular fue el descubrimiento que los genes están compuestos de moléculas polímeros de largas cadenas llamadas ácido desoxirribonucleico (ADN), y que la información genética está contenida en una particular secuencia de nucleótidos (monómeros constituyentes) en la molécula de ADN. Así, la idea básica de la moderna genética molecular es que toda la información genética usable consiste de secuencias de nucleótidos en las moléculas de ADN. Pero esta es sólo parte de la historia. Los procesos viv ientes requieren que un gran número de moléculas de proteina específicas sean continuamente fabricadas en la célula en la cantidad necesaria, en el tiempo adecuado y en el lugar requerido. Como hemos visto, las proteinas son polímeros de grandes cadenas tridimensionales fabricados uniendo varios aminoácidos como monómeros. ¿Cómo se traslada la información genética contenida en la secuencia de nucleótidos en el ADN a secuencias de aminoácidos en las moléculas de proteinas? Esta es la cuestión fundamental del código genético. La síntesis de proteinas, usando ADN como patrón primario, involucra a otra importante clase de ácidos nucleicos, llamados ácidos ribonucleicos (ARN). Así, las moléculas clave de la vida parecen ser los ácidos nucleicos (ADN y ARN) y las proteinas. Para entender el papel de los ácidos nucleicos en la transmisión de la información genética, deberemos primero entender su estructura. Cada unidad de nucleótido en un ácido nucleico consiste de tres partes: un grupo fosfato, un grupo pentosa (azúcar de 5 átomos de carbono) y una base nitrogenada heterocíclica: Base Nitrogenada Fosfato Azúcar Representación simbólica de una unidad de nucleótido Las unidades simples de nucleótidos se unen unas a otras en una reacción química llamada condensación: se forma un enlace covalente entre el grupo azúcar de una unidad y el grupo fosfato de otra unidad. Las bases se proyectan desde esta columna vertebral azúcar-fosfato: Segmento de 4 nucleótidos de un polímero de un ácido nucleico A A A A El usuario solo podrá utilizar la información entregada para su uso personal y no comercial y, en consecuencia, le queda prohibido ceder, comercializar y/o utilizar la información para fines NO académicos. La Universidad conservará en el más amplio sentido la propiedad de la información contenida. Cualquier reproducción de parte o totalidad de la información, por cualquier medio, existirá la obligación de citar que su fuente es "Universidad Santo Tomás" con indicación La Universidad se reserva el derecho a cambiar estos términos y condiciones de la información en cualquier momento. Encontramos dos tipos de azúcar en unidades de nucleótidos: ribosa y desoxirribosa. El azúcar desoxyrribosa contiene un oxígeno menos que el azúcar ribosa. En el ARN la unidad de azúcar es la ribosa, como lo indica el nombre ácido ribonucleico. En el ADN la unidad de azúcar es la desoxirribosa, como lo implica el nombre ácido desoxirribonucleico. Encontramos dos clases de bases nitrogenadas heterocíclicas en el ADN y el ARN, las pirimidinas (un anillo simple) y las purinas (un doble anillo) Una unidad de nucleótido para el ADN se forma por dos enlaces covalentes: uno se forma entre una unidad fosfato (del ácido fosfórico) y el átomo de carbono número 5 de una unidad de azúcar desoxirribosa. El otro enlace covalente se forma entre el átomo de carbono número 1 del azúcar y un átomo de nitrógeno en el anillo de una de las cuatro bases nitrogenadas, adenina, timina, guanina o citosina. No encontramos El usuario solo podrá utilizar la información entregada para su uso personal y no comercial y, en consecuencia, le queda prohibido ceder, comercializar y/o utilizar la información para fines NO académicos. La Universidad conservará en el más amplio sentido la propiedad de la información contenida. Cualquier reproducción de parte o totalidad de la información, por cualquier medio, existirá la obligación de citar que su fuente es "Universidad Santo Tomás" con indicación La Universidad se reserva el derecho a cambiar estos términos y condiciones de la información en cualquier momento. uracilo en el ADN y no encontramos timina en el ARN. Así, las diferencias estructurales entre el ADN y el ARN están en la unidad de azúcar (desoxirribosa o ribosa respectivamente) y en las bases (timina en el ADN y uracilo en el ARN). Para conectar los nucleótidos en moléculas de largas cadenas de ADN o ARN, el grupo fosfato forma enlaces covalentes con el átomo de carbono número 5 del azúcar de un nucleótido y el átomo de carbono 3 del azúcar de otro nucleótido. Las unidades alternadas de azúcar y fosfato forman así una columna vertebral con las distintas bases nitrogenadas extendiéndose hacia fuera de la cadena: Adenina (A) Timina (T) Guanina (G) Citosina (C) Estructura detallada de una secuencia de cuatro nucleótidos de un polímero de ADN. El usuario solo podrá utilizar la información entregada para su uso personal y no comercial y, en consecuencia, le queda prohibido ceder, comercializar y/o utilizar la información para fines NO académicos. La Universidad conservará en el más amplio sentido la propiedad de la información contenida. Cualquier reproducción de parte o totalidad de la información, por cualquier medio, existirá la obligación de citar que su fuente es "Universidad Santo Tomás" con indicación La Universidad se reserva el derecho a cambiar estos términos y condiciones de la información en cualquier momento. Diferentes cadenas de ADN pueden contener de cientos a muchos miles de unidades de nucleótidos. Como veremos más adelante, la secuencia particular de bases nitrogenadas en una cadena de ADN porta la información del código genético. Estas unidades de bases se pueden ordenar de muchas diferentes maneras en la larga cadena. Un grupo de tres bases nitrogenadas, conocido como un codón, dirige la adición de una unidad base (un amino ácido) a la cadena proteica en crecimiento. El orden de las bases nitrogenadas en el codón determina qué amino ácido se agrega: Cadena de ADN Amino ácido 1 Amino ácido 2 Amino ácido 3 Amino ácido 4 Cada secuencia de tres bases nitrogenadas, llamada codón, contiene la información necesaria para unir un aminoácido específico en la cadena de proteina en crecimiento El ARN usualmente consiste de una cadena nucleótida simple. En 1953, Maurice Wilkins, James Watson y Francis Crick propusieron que el ADN normalmente aparecía en las células en la forma de una doble hélix, consistente en dos largas cadenas o hebras de ADN enrolladas una alrededor de la otra en una espiral o hélix: El usuario solo podrá utilizar la información entregada para su uso personal y no comercial y, en consecuencia, le queda prohibido ceder, comercializar y/o utilizar la información para fines NO académicos. La Universidad conservará en el más amplio sentido la propiedad de la información contenida. Cualquier reproducción de parte o totalidad de la información, por cualquier medio, existirá la obligación de citar que su fuente es "Universidad Santo Tomás" con indicación La Universidad se reserva el derecho a cambiar estos términos y condiciones de la información en cualquier momento. Columna vertebral de azúcarfosfato alternados (2 hebras) Bases: Timina T Guanina G Citosina C Adenina A El modelo de Watson-Crick del ADN como una hélix de dos hebras. Las dos hebras son mantenidas unidas por puentes de hidrógeno (líneas punteadas) entre bases nitrogenadas de las hebras opuestas. Esta estructura secundaria se puede visualizar como una escalera de espiral, en la cual las columnas vertebrales de ambas hebras representan las barandas, y los pares de bases (uno de cada hebra), unidos por los puentes de hidrógeno, representan los peldaños o escalones. Las moléculas de ADN varían en el número y secuencia de los pares de bases de los escalones, de los cuales pueden tener hasta 30.000. Watson y Crick analizaron datos de difracción de rayos X en moléculas de ADN, y de estos y otros datos dedujeron que sólo determinadas bases podían aparearse. Adenina se aparea o forma dos enlaces de hidrógeno sólo con Timina (A-T o T-A), y Guanina se aparea o forma tres enlaces de hidrógeno sólo con Par de bases Citosina (G-C o C-G) El usuario solo podrá utilizar la información entregada para su uso personal y no comercial y, en consecuencia, le queda prohibido ceder, comercializar y/o utilizar la información para fines NO académicos. La Universidad conservará en el más amplio sentido la propiedad de la información contenida. Cualquier reproducción de parte o totalidad de la información, por cualquier medio, existirá la obligación de citar que su fuente es "Universidad Santo Tomás" con indicación La Universidad se reserva el derecho a cambiar estos términos y condiciones de la información en cualquier momento. 2 enla ces de hidrógeno Hebra 2 Timina (T) Adenina (A) Citosina (C) Hebra 1 Guanin a (G) 3 enla ces de hidrógeno Apareamiento de bases adenina y timina (A-T o T-A) y guanina y citosina (G-C o C-G) en dos hebras de ADN mediante enlaces de hidrógeno. Aunque estos enlaces de hidrógeno son débiles comparados con los enlaces covalentes que mantienen a los nucleótidos unidos a cada hebra, el gran número de enlaces formados le da a la doble hélix estabilidad en el rango de temperaturas encontradas en las células vivas. Los genes son segmentos de moléculas de ADN. Así, todos los genes consisten de ordenamientos de los cuatro posibles apareamientos de bases, pero difieren uno de otro en la secuencia de los pares de bases. Esta es la información genética que puede ser traspasada. Así la diferencia genética esencial entre nosotros y un caballo radica en la secuencia codificada de pares de bases en nuestras moléculas de ADN. Así como esta frase en castellano contiene información de acuerdo a la particular secuencia de las 26 posibles letras del alfabeto, la molécula de ADN traspasa información genética de acuerdo a la secuencia de los cuatro posibles pares de bases en el alfabeto genético. Una molécula de ADN puede contener muchos genes, o mensajes, igual como una frase puede contener muchas palabras. Este modelo del ADN como una doble hélix con pares de bases unidas por enlaces de hidrógeno fue un hito en el desarrollo y la historia de la bioquímica. En 1962, Watson, Crick y Wilkins recibieron el premio Nobel por su trabajo sobre la estructura del ADN. III. Actividad previa. Syllabus sesión 26 IV. Metodología de la sesión. Clase expositiva, de debate y con ejercicios prácticos El usuario solo podrá utilizar la información entregada para su uso personal y no comercial y, en consecuencia, le queda prohibido ceder, comercializar y/o utilizar la información para fines NO académicos. La Universidad conservará en el más amplio sentido la propiedad de la información contenida. Cualquier reproducción de parte o totalidad de la información, por cualquier medio, existirá la obligación de citar que su fuente es "Universidad Santo Tomás" con indicación La Universidad se reserva el derecho a cambiar estos términos y condiciones de la información en cualquier momento. V. Lectura post-sesión. Por definir El usuario solo podrá utilizar la información entregada para su uso personal y no comercial y, en consecuencia, le queda prohibido ceder, comercializar y/o utilizar la información para fines NO académicos. La Universidad conservará en el más amplio sentido la propiedad de la información contenida. Cualquier reproducción de parte o totalidad de la información, por cualquier medio, existirá la obligación de citar que su fuente es "Universidad Santo Tomás" con indicación La Universidad se reserva el derecho a cambiar estos términos y condiciones de la información en cualquier momento.
 0
0
Anuncio





Descargar
Anuncio
Añadir este documento a la recogida (s)
Puede agregar este documento a su colección de estudio (s)
Iniciar sesión Disponible sólo para usuarios autorizadosAñadir a este documento guardado
Puede agregar este documento a su lista guardada
Iniciar sesión Disponible sólo para usuarios autorizados