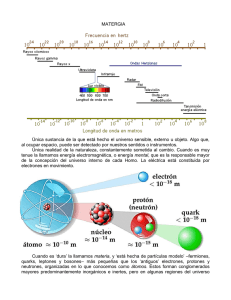
SPSS orientado a la gestión de Mercados
Anuncio

Esta obra esta bajo una licencia reconocimiento-no comercial 2.5 Colombia de creativecommons. Para ver una copia de esta licencia, visite http://creativecommons.org/licenses/by/2.5/co/ o envié una carta a creative commons, 171second street, suite 30 San Francisco, California 94105, USA SPSS ORIENTADO A LA GESTION DE MERCADOS Autores: MARTHA GUEVARA PEÑUELA HÉCTOR JAVIER CORTÉS SUÁREZ Director Unidad Informática: Henry Martínez Sarmiento Tutor Investigación: Maria Alejandra Enríquez Coordinadores: Maria Alejandra Enríquez Leydi Diana Rincón Rincón Coordinador Servicios Web: Daniel Alejandro Ardila Analista de Infraestructura y Comunicaciones: Adelaida Amaya Analista de Sistemas de Información: Álvaro Enrique Palacios Villamil Líder de Gestión de Recurso Humano: Islena del Pilar Gonzalez UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES BOGOTÁ D.C. ENERO DE 2006 SPSS ORIENTADO A LA GESTION DE MERCADOS Director Unidad Informática: Tutor Investigación: Henry Martínez Sarmiento María Alejandra Enríquez Auxiliares de Investigación: Adriana Lucia Castelblanco Alexis de Jesús Moros Andrés Ricardo Romero Brayan Ricardo Rojas Carlos Hernán Porras Catherin Cruz Pinzón Cristian Gerardo Gil Daniel Alejandro Melo Diana Patricia García Diego Fernando Rubio Edwin Montaño German David Riveros Guillermo Alberto Ariza Juan Felipe Rincón Leidy Viviana Avilés Leydy Johana Poveda Liliana Paola Rincón Luis Alfonso Nieto Luz Karina Ramos Maria Teresa Mayorga Miller Giovanny Franco Nubia Yolima Cucarian Rafael Leonardo Saavedra Sandra Liliana Barrios Sandra Milena Cárdenas Sandra Mónica Bautista Sonia Janeth Ramírez Yaneth Adriana Cañón Este trabajo es resultado del esfuerzo de todo el equipo perteneciente a la Unidad de Informática. Se prohíbe la reproducción parcial o total de este documento, por cualquier tipo de método fotomecánico y/o electrónico, sin previa autorización de la Universidad Nacional de Colombia. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES BOGOTÁ D.C. ENERO 2006 SPSS Aplicado a la Gestión de Mercados Tabla De Contenido Tabla De Contenido........................................................................................................................ 1 Tabla De Ilustraciones Y Tablas ................................................................................................... 5 Resumen ............................................................................................................................................ 9 Abstract ............................................................................................................................................. 9 Introducción .................................................................................................................................... 10 Objetivos ......................................................................................................................................... 11 OBJETIVO GENERAL .............................................................................................................. 11 OBJETIVOS ESPECIFICOS ...................................................................................................... 11 1. 2. Marco Teórico ...................................................................................................................... 12 1.1. SPSS................................................................................................................................. 12 1.2. Segmentación De Mercados ................................................................................... 13 1.2.1. Proceso de Segmentación de mercados................................................... 14 1.2.2. Tipos de Segmentación de mercados ....................................................... 14 1.2.3. Segmentación de mercados usando SPSS ................................................ 15 Árboles De Clasificación .................................................................................................. 16 2.1. Pasos ................................................................................................................................... 18 3. Análisis Cluster O Análisis De Conglomerados Para La Segmentación De Mercados ......................................................................................................................................... 19 3.1. Pasos para el análisis de Conglomerados ............................................................... 19 3.1.1. Formulación del Problema................................................................................ 20 3.1.2. Selección de una Medida de Similitud ............................................................ 20 3.1.3. Estandarización de Datos ................................................................................. 20 3.1.4. Supuestos del Análisis ........................................................................................ 20 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 1 SPSS Aplicado a la Gestión de Mercados 4. 3.1.5. Selección del Procedimiento de Agrupación ................................................ 20 3.1.6. Decisión del Número de Conglomerados.................................................... 21 3.1.7. Interpretación y Elaboración del Perfil de los Clusters ............................. 21 3.1.8. Validación de Conglomerados Obtenidos .................................................... 22 Análisis De Conglomerados En Dos Fases ..................................................................... 23 4.1. Pasos para el análisis de conglomerados en dos fases ........................................ 23 4.2. Medida de distancia ..................................................................................................... 24 4.3. Número de conglomerados: ..................................................................................... 24 4.4. Recuento de variables continuas .............................................................................. 25 4.5. Criterio de conglomeración: ..................................................................................... 25 4.6. Opciones ....................................................................................................................... 25 4.7. Asignación de memoria: ............................................................................................. 26 4.8. Tipificación de variables: ............................................................................................ 26 4.9. Opciones avanzadas .................................................................................................... 26 4.10. Gráficos:......................................................................................................................... 26 4.11. Resultados ..................................................................................................................... 27 4.12. Ejemplo .............................................................................................................................. 32 4.11.1. Conglomerados en dos fases ........................................................................... 33 4.11.2. Perfiles de los conglomerados ......................................................................... 35 4.11.3. Frecuencias........................................................................................................... 36 4.11.4. Importancia de los atributos ............................................................................ 36 4.11.5. Porcentaje Intra-conglomerado ...................................................................... 36 4.11.6. Variación Intra-conglomerado ......................................................................... 37 4.11.7. Importancia según agrupación ......................................................................... 40 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 2 SPSS Aplicado a la Gestión de Mercados 5. Análisis De Conglomerados Jerárquico ........................................................................... 44 5.1. Pasos para el análisis de conglomerados jerárquico ............................................ 45 5.2. Dendrograma:............................................................................................................... 45 5.3. Clases de métodos de Conglomeración ................................................................ 45 5.4. Medida ............................................................................................................................ 47 5.4.1. Medida de intervalo............................................................................................ 47 5.4.2. Medida de Frecuencias:........................................................................................ 48 5.4.3. Medida Binaria: .................................................................................................... 48 5.5. 6. 7. Ejemplo: ......................................................................................................................... 48 5.5.1. Gráficos................................................................................................................. 49 5.5.2. Método de conglomeración ............................................................................. 50 5.5.3. Conglomerados jerárquicos ............................................................................. 51 5.5.4. Vinculación de centroides................................................................................. 51 5.5.5. Dendrograma ...................................................................................................... 53 Conglomerados De K Medias ............................................................................................ 55 6.1. Preparando el análisis ................................................................................................. 56 6.2. Resultados del análisis ................................................................................................ 59 Análisis Factorial Para La Reducción De Datos ..................................................... 65 7.1. Que Buscar Cuando Se Realiza Un Analisis Factorial ......................................... 65 7.2. Principios ....................................................................................................................... 66 7.3. Análisis factorial en SPSS ............................................................................................ 66 7.4. Etapas en un análisis factorial. ................................................................................... 67 7.4.1. Extracción de factores....................................................................................... 68 7.4.2. Rotación De Factores........................................................................................ 70 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 3 SPSS Aplicado a la Gestión de Mercados 7.4.3. Descriptivos ......................................................................................................... 71 8. Conclusiones ......................................................................................................................... 81 9. Bibliografia .............................................................................................................................. 82 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 4 SPSS Aplicado a la Gestión de Mercados Tabla De Ilustraciones Y Tablas Ilustración 1. Ejemplo de árbol de Clasificación generado por SPSS 16 Ilustración 2. Conglomerados en dos Fases 24 Ilustración 3. Conglomerados en dos fases: Opciones 25 Ilustración 4. Conglomerados en dos fases: Gráficos 27 Ilustración 5. Conglomerados en dos fases: Resultados 27 Ilustración 6. Variación Intra- Conglomerado 30 Ilustración 7. Ajuste de Bonferroni aplicado 31 Ilustración 8. Ajuste de Bonferroni Aplicado2 32 Ilustración 9. Análisis de Conglomerados en dos Fases 33 Ilustración 10. Conglomerados en dos fases: Gráficos 33 Ilustración 11. Tamaño de los Conglomerados 36 Ilustración 12. Porcentaje dentro del Conglomerado de sexo 37 Ilustración 13. Variación Intra- Conglomerado 1 38 Ilustración 14.Variación Intra-Conglomerado 2 39 Ilustración 15. Variación Intra-Conglomerado 3 39 Ilustración 16.Variación Intra-Conglomerado 4 40 Ilustración 17. Ajuste de Bonferroni Aplicado-Sexo 41 Ilustración 18. Ajuste de Bonferroni Aplicado- Salario Actual 41 Ilustración 19. Ajuste de Bonferroni Aplicado: Salario Inicial 42 Ilustración 20. Ajuste de Bonferroni aplicado: Meses desde el contrato 42 Ilustración 21. AJuste de Bonferroni: Experiencia Previa en meses 43 Ilustración 22. Métodos de enlace para el Conglomerado 46 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 5 SPSS Aplicado a la Gestión de Mercados Ilustración 23. Métodos de Agrupación por Aglomeración 47 Ilustración 24. Menú: Análisis de Conglomerados Jerárquico 49 Ilustración 25.Análisis de Conglomerados Jerárquicos: Estadísticos 49 Ilustración 26. Análisis de Conglomerados Jerárquicos: Gráficos 50 Ilustración 27. Métodos de Conglomeración 50 Ilustración 28. Diagrama de témpanos Vertical 53 Ilustración 29. Dendograma 54 Ilustración 30. Diagrama de dispersión primer grupo 55 Ilustración 31. Diagrama de dispersión segundo grupo 56 Ilustración 32. Ruta conglomerados K medias 57 Ilustración 33. Cuadro de dialogo K medias 57 Ilustración 34. Iterar 58 Ilustración 35. Guardar 58 Ilustración 36. Opciones 59 Ilustración 37. Grafico de dispersión conglomerados finales primer grupo 63 Ilustración 38. Grafico de dispersión conglomerados finales segundo grupo 64 Ilustración 39. Análisis factorial 67 Ilustración 40. matriz de covarianza 67 Ilustración 41. Cuadro de dialogo análisis factorial 69 Ilustración 42. Cuadro de Dialogo Análisis factorial- Extracción 69 Ilustración 43. Cuadro de Dialogo Análisis factorial- Rotación. 71 Ilustración 44. Cuadro de Dialogo Análisis factorial- Descriptivos. 72 Ilustración 45. Detalle estadísticos. 74 Ilustración 46. Detalle matriz reproducida 76 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 6 SPSS Aplicado a la Gestión de Mercados Ilustración 47. Detalle varianza total 77 Ilustración 48. Grafico de sedimentación. 78 Ilustración 49. Analisis factorial- puntuaciones factoriales 80 Tabla 1. Agrupación Automática ................................................................................................ 28 Tabla 2. Distribución de los Conglomerados .......................................................................... 29 Tabla 3. Perfiles de los Conglomerados ................................................................................... 29 Tabla 4. Frecuencias de Conglomerados.................................................................................. 29 Tabla 5. Distribución de Conglomerados ................................................................................ 34 Tabla 6. Perfiles de los Conglomerados ................................................................................... 35 Tabla 7. Frecuencias de los Conglomerados ........................................................................... 36 Tabla 8. Resumen del procesamiento de los casos ................................................................ 50 Tabla 9. Matriz de Distancias ...................................................................................................... 51 Tabla 10. Historial de Conglomeración .................................................................................... 52 Tabla 11. Diagrama de témpanos Vertical ............................................................................... 52 Tabla 12. Cuadro conglomerados iniciales primer grupo..................................................... 59 Tabla 13. Cuadro conglomerados iniciales segundo grupo .................................................. 59 Tabla 14. Cuadro historial de iteraciones primer grupo ...................................................... 60 Tabla 15. Cuadro historial de iteraciones segundo grupo.................................................... 60 Tabla 16. Conglomerados finales primer grupo...................................................................... 61 Tabla 17. Conglomerados finales segundo grupo ................................................................... 61 Tabla 18. ANOVA ......................................................................................................................... 61 Tabla 19. Casos por conglomerado primer grupo ................................................................. 62 Tabla 20. Casos por conglomerado segundo grupo .............................................................. 62 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 7 SPSS Aplicado a la Gestión de Mercados Tabla 21. Estadísticos descriptivos ............................................................................................. 72 Tabla 22. Comunalidades iniciales .............................................................................................. 73 Tabla 23. Matriz reproducida ...................................................................................................... 75 Tabla 24.Prueba KMO .................................................................................................................. 77 Tabla 25. Varianza total explicada .............................................................................................. 77 Tabla 26. Matriz de componentes. ............................................................................................. 79 Tabla 27. Matriz de componentes rotados .............................................................................. 80 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 8 SPSS Aplicado a la Gestión de Mercados Resumen Esta investigación dedicada a varias herramientas útiles que incluye el programa estadístico SPSS para la realización de una investigación de mercados, en este caso para la realización de la segmentación de mercados. El documento empieza con un pequeño marco teórico dedicado a la segmentación y a explicar brevemente el programa, después se empieza a explicar concisamente un modulo llamado Árboles de clasificación, para luego entrar de lleno al estudio por conglomerados mediante una introducción a la forma en que se realizan generalmente, y se describen tres formas para realizarlos, análisis de dos fases, el conglomerado jerárquico y el sistema K medias. Para finalizar se explora el sistema de reducción de datos mediante análisis factorial. Abstract This investigation is dedicated to several useful tools of the statistical program SPSS for the accomplishment of an investigation of markets, in this case for the accomplishment of the segmentation of markets includes. The document begins with a little theoretical frame dedicated to the segmentation and to explain the program briefly, later begins to explain concisely the modulate call Answer Tree, soon to enter completely the cluster analysis by means of an introduction the form in which they are made generally, and three forms are described to make them, analysis of two phases, the hierarchic cluster and system K means. In order to finalize the system of reduction of data by factorial analysis is explored. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 9 SPSS Aplicado a la Gestión de Mercados Introducción SPSS es una potente herramienta para el análisis estadístico, la cual posee aplicaciones para gran variedad de ciencias y áreas del conocimiento. Teniendo en cuenta los módulos que esta herramienta presenta para el análisis y estudios de mercados, es necesario implementar una línea de investigación dedicada al estudio de las ventajas y aprovechamiento de los recursos ofrecidos. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 10 SPSS Aplicado a la Gestión de Mercados Objetivos OBJETIVO GENERAL Aprovechar en mayor medida la licencia adquirida de SPSS por la Universidad Nacional de Colombia a través del estudio de las herramientas de mercados que ofrece la aplicación adquirida y brindar soporte a la carrera de administración para que sea de amplia utilidad a la comunidad estudiantil. OBJETIVOS ESPECIFICOS Estudiar las diferentes funciones, módulos o herramientas específicas o aplicables al estudio de mercados que ofrece SPSS. Generar un manual completo referente a las herramientas para el análisis y gestión de mercados con la ayuda de SPSS. Crear un programa detallado para la gestión de un curso libre o capacitación para la Facultad de Ciencias Económicas. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 11 SPSS Aplicado a la Gestión de Mercados 1. Marco Teórico A nivel mundial la tendencia clave que afectará a la estrategia de mercadotecnia en el siglo XXI será el comercio global; porque no hay duda alguna de que el mundo se está convirtiendo en una economía global y en un mercado completamente abierto en todos los países; en los cuáles la competencia ya no solo se centra con las empresas productoras de la ciudad o del país sino con las empresas que están dedicadas a satisfacer las mismas necesidades a los clientes potenciales. Eso significa que la situación se va a volver más difícil. Cuando la competencia se desarrolle globalmente, todo el mundo intentará arrebatarle el negocio a todo el mundo. El siglo XXI hará que el siglo XX parezca una reunión para tomar el té. Se va a ver una serie de cambios masivos en respuesta a esos desarrollos globales. Aunque lo que debiera suceder es exactamente lo contrario. Conceptualmente, cuanto más grande es el mercado, más especializados debemos ser para poder tener éxito.1 Es aquí donde aparece la estrategia de mercados como una herramienta para que la empresa pueda definir más claramente su segmento de mercado y pueda dirigir con más eficiencia y eficacia sus esfuerzos para satisfacer a sus clientes de la mejor manera. Es clave que las empresas logren profundizar en el conocimiento de su mercado para que de esta forma pueda adaptar su oferta y su estrategia de mercado a los requerimientos de éste. Es en este punto donde la segmentación entra o tomar parte de todo proceso de planeación y toma como un factor primordial el reconocimiento de que el mercado es heterogéneo, y pretende dividirlo en grupos o segmentos homogéneos, que pueden ser elegidos como un mercado objetivo de la empresa. Así pues, la segmentación implica un proceso de diferenciación de las necesidades dentro de un mercado.2 1.1. SPSS El programa SPSS (Statistical Package for the Social Sciences) es un conjunto de paquetes y herramientas de tratamiento de datos y análisis estadístico. Al igual, que el resto de aplicaciones que utilizan como soporte el sistema operativo Windows y 1 Tomado de: http://www.coparmex.org.mx/contenidos/publicaciones/Entorno/2002/mar02/e.htm 2 REYES, Rafael. La Estrategia de Mercados en el Siglo XXI, Revista entorno No.163, Confederación Patronal de la República Mexicana, México, Marzo 2002. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 12 SPSS Aplicado a la Gestión de Mercados funcionan mediante menús desplegables y cuadros de dialogo que permiten hacer la mayor parte del trabajo simplemente utilizando el Mouse. SPSS es un paquete de software usado para conducir los análisis estadísticos, manipular datos, generar tablas y gráficos que resumen datos. Los análisis estadísticos se extienden desde estadística descriptiva básica, tales como promedios y frecuencias, a la estadística deductiva avanzada, tales como modelos de la regresión, análisis de variación y análisis factorial. 1.2. Segmentación De Mercados La segmentación de mercado es un proceso que consiste en dividir el mercado total de un bien o servicio en varios grupos más pequeños e internamente homogéneos. La esencia de la segmentación es conocer realmente a los consumidores. Uno de los elementos decisivos del éxito de una empresa es su capacidad de segmentar adecuadamente su mercado.3 La segmentación es también un esfuerzo por mejorar la precisión del mercadeo de una empresa. Es un proceso de incorporación: agrupar en un segmento de mercado a personas con necesidades semejantes. El comportamiento del consumidor suele ser demasiado complejo como para explicarlo con una o dos características, se deben tomar en cuenta varias dimensiones, partiendo de las necesidades de los consumidores. Las principales ayudas de la segmentación de mercados son:4 Permitir la identificación de las necesidades de los clientes específicamente dentro de un sub-mercado y así mismo lograr un diseño más eficaz de la mezcla de mercado para satisfacerlas de la mejor manera. Al tener claramente definido el segmento de mercado al que se quiere dirigir la oferta del producto se pueden establecer de una mejor manera el precio, la selección de los canales de distribución y además los medios publicitarios que serán usados. Cuando una empresa pequeña esta pensando en penetrar un mercado puede lograr una mejor posición si logra especializarse mas en la satisfacción de una necesidad más especifica. 3 STANTON, ET AL. “Fundamentos de Marketing”, McGrawHIl, México, 1999. 4 KOTLER, Phillip. “Dirección de Marketing. La edición del milenio” PrenticeHall, México., 2001. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 13 SPSS Aplicado a la Gestión de Mercados Al especificar el segmento se reducen el número de potenciales competidores. La segmentación permite la especialización lo que puede generar oportunidades de crecimiento y al mismo tiempo la creación de ventajas competitivas. 1.2.1. Proceso de Segmentación de mercados Para la segmentación se deben realizar los siguientes pasos: ESTUDIO: Se examina el mercado para determinar las necesidades específicas satisfechas por las ofertas actuales, las que no lo son y las que podrían ser reconocidas. Se llevan acabo una investigación exploratoria y se organizan sesiones de grupos para entender mejor las motivaciones, actitudes y conductas de los consumidores. Se reúnen datos sobre los atributos y la importancia que se les da, conciencia de marca y calificaciones de marcas, patrones de uso y actitudes hacia la categoría de los productos; así como, datos demográficos, psicográficos, etc. ANÁLISIS: Se interpretan los datos para eliminar las variables y agrupar o construir el segmento con los consumidores que comparten un requerimiento en particular y lo que los distingue de los demás segmentos del mercado con necesidades diferentes. PREPARACIÓN DE PERFILES: Se prepara un perfil de cada grupo en términos de actitudes distintivas, conductas, demografía, etc. Se nombra a cada segmento con base a su característica dominante. La segmentación debe repetirse periódicamente porque los segmentos cambian. También se investiga la jerarquía de atributos que los consumidores consideran al escoger una marca, este proceso se denomina partición de mercados. Esto puede revelar segmentos nuevos de mercado.5 1.2.2. Tipos de Segmentación de mercados6 Segmentación Geográfica: subdivisión de mercados con base en su ubicación. Posee características mensurables y accesibles. Segmentación Demográfica: se utiliza con mucha frecuencia y está muy relacionada con la demanda y es relativamente fácil de medir. Entre las características demográficas más conocidas están: la edad, el género, el ingreso y la escolaridad. Segmentación Psicográfica: Consiste en examinar atributos relacionados con pensamientos, sentimientos y conductas de una persona. Utilizando dimensiones de 5 Tomado de: http://www.monografias.com/trabajos13/segmenty/segmenty.shtml 6 STANTON, ob.cit. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 14 SPSS Aplicado a la Gestión de Mercados personalidad, características del estilo de vida y valores. Segmentación por comportamiento: se refiere al comportamiento relacionado con el producto, utiliza variables como los beneficios deseados de un producto y la tasa a la que el consumidor utiliza el producto. 1.2.3. Segmentación de mercados usando SPSS7 Para la realización de investigación de mercados se emplean las diferentes técnicas estadísticas que proporciona SPSS, como el análisis cluster, análisis factorial, segmentación de mercados con programas como CHAID y AnswerTree, análisis discriminante, el análisis conjunto (CONJOINT), modelado de ecuaciones estructurales con un programa denominado AMOS, y el diseño de redes neuronales con Neural Connection. 7 Market Segmentation Using SPSS®, SPSS Inc. Estados Unidos De America, 2003. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 15 SPSS Aplicado a la Gestión de Mercados 2. Árboles De Clasificación Los árboles de clasificación son un Nuevo modulo que ofrece SPSS el cual permite identificar grupos, descubrir relaciones entre los grupos y pronosticar eventos futuros. Los árboles de clasificación y decisión se pueden usar para la segmentación, estratificación, predicción, reducción de datos, examinar variables identificar interacciones, fundir categorías y categorizar variables. Los árboles pueden se usados para la creación de bases de datos para tomar decisiones en mercadeos ya que se puede elegir alguna variable respuesta para la segmentación, se pueden crear perfiles mediante cualquier atributo de las variables. Además el apoyo a la investigación de mercados debido a que permite al realizar encuestas de satisfacción la creación de variables en escala que midan dicha satisfacción, asimismo la creación de perfiles de niveles de satisfacción de acuerdo a las respuestas de distintas preguntas. Se pueden crear grupos de riesgos basados en la información que se posea de los clientes o trabajadores. Igualmente permite tener más seguridad en el establecimiento de objetivos ya que permite realizar pronósticos. Ilustración 1. Ejemplo de árbol de Clasificación generado por SPSS El procedimiento de Árbol de Clasificación crea a un modelo de la clasificación tipo árbol. Clasifica los casos en los grupos o predice valores de una pendiente (objetivo) la variable basada en los valores de la variable independiente (predictora). El procedimiento proporciona las herramientas para un análisis exploratorio y para la confirmación de la clasificación. El procedimiento puede usarse para: SEGMENTACIÓN: Identifica personas que probablemente pertenecen a un grupo en particular. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 16 SPSS Aplicado a la Gestión de Mercados ESTRATIFICACIÓN: Asigna varias categorías a los casos tales como alto, medio y bajo riesgo. PREDICCIÓN: Crea las reglas y las usa para predecir los eventos futuros, como la probabilidad que alguien solicite un préstamo o el valor de reventa potencial de un vehículo o casa. REDUCCION DE DATOS Y PROYECCION DE VARIABLES: Selecciona un subconjunto útil de predictoras de un juego grande de variables para lograr construir un modelo paramétrico formal. IDENTIFICACIÓN DE LA INTERACCIÓN: Identifica relaciones que sólo pertenecen subgrupos específicos y los especifica en un modelo paramétrico formal. A diferencia de otros métodos de clasificación como el Análisis Cluster, AnswerTree permite realizar clasificación de clientes en función de una variable criterio, así como realizar pronósticos con probabilidades conocidas, por tal motivo, se considera una herramienta con gran poder predictivo. Ofrece la posibilidad de usar cuatro potentes algoritmos de segmentación y una interfase intuitiva y fácil de manejar. Los resultados son sencillos de interpretar y entender dada su interfaz grafica o presentación de los resultados en forma de árbol. AnswerTree lee datos en distintos formatos a través de conexiones ODBC Standard y puede ser ejecutado como un programa independiente o integrado dentro de SPSS Base8. Crea modelos ágilmente gracias a su asistente de árbol. Además se pueden escoger entre tres distintos algoritmos predeterminado de clasificación: CHAID: Es un algoritmo estadístico multidireccional que explora datos rápida y eficientemente, también construye segmentos y perfiles en función de la variable respuesta establecida. CHAID exhaustivo: examina todas las particiones posibles de una variable predoctora. Árboles de clasificación y regresión (CRT): Produce subconjuntos de datos homogéneos y precisos. QUEST: Selecciona variables de manera insesgada y construye árboles binarios precisos de manera rápida y eficiente. 8 http://www.spss.com/la/apps/data-mining2.htm UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 17 SPSS Aplicado a la Gestión de Mercados 2.1. Pasos ¿Qué algoritmo seleccionar? ¿Cuál será la variable dependiente, target u objetivo? Seleccionar las variables independientes. Por ejemplo, edad, sexo, salario, categoría laboral, etc. que nos ayudarán a crear los perfiles. Después de lo anterior, AnswerTree generará el árbol respectivo; el cual puede ser aplicado a nuestra base de datos con el fin de generar listados de clientes que responder a determinadas características. Por ejemplo. Clientes dispuestos a adquirir determinado producto, satisfacción de los clientes, entre otras. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 18 SPSS Aplicado a la Gestión de Mercados 3. Análisis Cluster O Análisis De Conglomerados Para La Segmentación De Mercados El análisis de Conglomerados o análisis Cluster o es una técnica estadística exploratoria, multivariable, para el análisis de datos, diseñada para indicar las agrupaciones naturales dentro de un grupo de datos y como tal, realizar segmentación de mercados. Cluster sugiere varias maneras potencialmente útiles de agrupar a clientes. Se conoce también como análisis de clasificación o taxonomía numérica. Su origen se halla en la Biología y la botánica, por la necesidad de agrupar las especies en familias lo más homogéneamente posible El análisis cluster se ha desarrollado en diversos datos de marketing, como posición geográfica, comportamiento del consumidor, rangos de productos, información de uso, necesidades o ventajas. En este sentido, éste análisis contribuye a la identificación de grupos de consumidores con comportamientos semejantes, identificación de hábitos de compra, identificación de grupos de productos competitivos, oportunidades de mercado. Por ejemplo, el análisis cluster puede ser empleado para identificar ciudades o localidades para lanzar un nuevo producto. Se aplica el análisis a todo el mercado, de allí se determinan grupos que reúnen determinadas características y se analiza cual de ellos es el que más se acomoda al perfil de nuestro producto. Para comprender de una forma sencilla, el análisis cluster se basa en el concepto simple de repartir las observaciones de los datos en los grupos homogéneos basados en la proximidad o relación del uno al otro. Se pueden encontrar los siguientes tipos análisis cluster: Conglomerados en dos fases, análisis de k medias y análisis de conglomerados jerárquicos. Entonces, surge una pregunta, ¿En que difiere el análisis de conglomerados del análisis discriminante?, la respuesta es que el análisis de conglomerados como el discriminante se basa en la clasificación. No obstante, el análisis discriminante requiere del conocimiento previo de la participación en el grupo de cada caso analizado, con el fin de desarrollar la regla de clasificación. Por el contrario, en el análisis de conglomerados no hay información preliminar de la participación de los casos en los grupos. Esta participación se define cuando se realiza el análisis. Se debe decidir si se emplea un método de agrupación o un método de agregación. 3.1. Pasos para el análisis de Conglomerados Para realizar análisis de conglomerados se debe tener en cuenta los siguientes pasos: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 19 SPSS Aplicado a la Gestión de Mercados 3.1.1. Formulación del Problema Se debe tener claro en que variables se va a basar la agrupación. Si se incluyen variables irrelevantes se puede distorsionar la solución de agrupación y sus posteriores análisis. Un criterio para seleccionar las variables es la investigación previa y tener en cuenta las hipótesis que se prueban. 3.1.2. Selección de una Medida de Similitud Como el objeto del análisis de Conglomerados es agrupar dependiendo de la similitud, se necesitan medidas para evaluar las diferencias y similitudes entre los objetos. La medida de Similaridad permite realizar comparación entre objetos, donde los objetos con distancias reducidas tienen mayor parecido que aquellos que tienen distancias mayores, por lo tanto se agrupan dentro del mismo cluster. Para medir la similitud entre los objetos de un análisis cluster existen tres métodos. Medidas de Correlación Medidas de Distancia Medidas de Asociación Las medidas de correlación y las medidas de distancia requieren datos métricos, y las medidas de asociación requieren datos no métricos. 3.1.3. Estandarización de Datos Cuando se ha seleccionado la medida para cuantificar la similaridad entre objetos, se debe realizar una estandarización de los datos, ya que las variables con mayor desviación típica tienen un mayor impacto en el resultado final de similaridad. Por ejemplo, si se quiere hacer un análisis del consumidor y conocer que variables afectan de una manera significativa su decisión de compra y se tienen las variables edad, ingresos y gusto por el producto. Se puede notar que cada variable tiene una escala diferente, años, pesos, escala de 1 a 10; si se realizara un gráfico de distancias la variable más representativa seria sin duda los ingresos. En este orden de ideas, es necesario ser consciente del peso implícito de las varibles que hacen parte del estudio y realizar una estandarización de éstas. 3.1.4. Supuestos del Análisis Se debe tener en cuenta la representividad de la muestra y multicolinealidad. 3.1.5. Selección del Procedimiento de Agrupación UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 20 SPSS Aplicado a la Gestión de Mercados Se encuentran dos tipos de procedimientos los jerárquicos y los no jerárquicos. El análisis de conglomerado jerárquico se encarga de desarrollar una jerarquía o estructura en forma de árbol, tal es el caso de los dendogramas que arroja el análisis de conglomerado jerárquico en spss. Los métodos jerárquicos pueden ser por Aglomeración o por División. Para el método de conglomerados no jerárquico el caso de agrupación de k medias es el más representativo. Más adelante se explicará con más detalle. 3.1.6. Decisión del Número de Conglomerados Esta decisión es un poco subjetiva. Sin embargo, para el caso del análisis cluster jerárquico, las distancias entre los clusters pueden ser una guía útil o calcular varias soluciones de aglomeración para luego decidir cuál es la mejor. En el caso del análisis cluster no jerárquico, se puede realizar un gráfico para comparar el número de grupos con la relación entre la varianza total de los grupos y la varianza entre los grupos. En la parte del gráfico que presente una curva se estaría indicando el número idóneo de grupos. Si aparece un grupo de un solo miembro, se debe estudiar su representatividad. 3.1.7. Interpretación y Elaboración del Perfil de los Clusters En este paso se pretende examinar la variación de los clusters, donde se observan las características de cada uno y se analizan las variables que intervienen en su conformación. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 21 SPSS Aplicado a la Gestión de Mercados El análisis de perfiles se encarga de describir las características propias de cada cluster y no describe lo que determina la conformación de cada cluster. 3.1.8. Validación de Conglomerados Obtenidos Este paso hace referencia al hecho de asegurarse que los cluster resultantes sean representativos de la población, sean generalizables a otros objetos y estables con el transcurso del tiempo. Para realizar dicha validación se pueden realizar los siguientes pasos: Realizar el análisis con los mismos datos y utilizar distintas medidas de distancia y comparar los resultados Emplear distintos métodos de conglomerados y comparar resultados Realizar submuestras, hacer análisis por separado y comparar resultados y centroides arrojados. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 22 SPSS Aplicado a la Gestión de Mercados 4. Análisis De Conglomerados En Dos Fases Este procedimiento es una herramienta exploratoria que permite descubrir las agrupaciones o conglomerados de un conjunto de datos. Es útil cuando se tienen grandes archivos de datos. Realiza Tratamiento o conglomerados de variables categóricas y continuas, selección automática del número de conglomerados, construye un árbol de características de conglomerados (CF) que resume los registros. Este análisis es robusto, ya que tiene en cuenta la independencia y distribuciones de probabilidad. Emplea una medida de distancia de probabilidad que asume que las variables en el modelo de conglomerado son independientes. Además, se asume que cada variable continua tiene una distribución normal y cada variable categórica tiene distribución multinomial. Para determinar el número más conveniente de conglomerados se emplea el criterio Bayesiano de Schwarz's (BIC) o el criterio de información Akaike. 4.1. Pasos para el análisis de conglomerados en dos fases Se llega al análisis de conglomerados en dos fases mediante el Menú analizar, Clasificar, Conglomerado en dos fases. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 23 SPSS Aplicado a la Gestión de Mercados Ilustración 2. Conglomerados en dos Fases Como se puede notar hay dos cuadros para clasificar las variables categóricas y continuas a analizar. En este caso se colocó como variable categórica el sector y como variable continua los ingresos y la identificación del cliente. 4.2. Medida de distancia Determina cómo se calcula la similaridad entre dos conglomerados. Medida de Log-verosimilitud: Realiza una distribución de probabilidad entre las variables. Variables continuas => Distribución normal Variables categóricas => Multinomiales Medida Euclídea: Distancia según una "línea recta" entre dos conglomerados. Sólo se puede utilizar cuando todas las variables son continuas. 4.3. Número de conglomerados: Donde se especifica cómo se va a determinar el número de conglomerados Determinar automáticamente: Como su nombre lo indica, determina automáticamente el número "óptimo". Adicionalmente, se puede introducir un entero positivo para especificar el número máximo de conglomerados. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 24 SPSS Aplicado a la Gestión de Mercados Especificar número fijo: Permite establecer el número de conglomerados de la solución. 4.4. Recuento de variables continuas Realiza un resumen del cuadro de diálogo de opciones donde se especifica las variables para tipificar y asumidas como tipificadas. 4.5. Criterio de conglomeración: Existen dos opciones: El criterio de información bayesiano (BIC) y el criterio de información de Akaike (AIC). 4.6. Opciones En la parte de opciones se desprende el siguiente cuadro de diálogo, donde se le puede dar un Tratamiento a los valores atípicos durante la conglomeración. Ilustración 3. Conglomerados en dos fases: Opciones Si se selecciona la opción de realizar el tratamiento del ruido y el árbol CF se llena o no puede aceptar ningún caso más en un nodo hoja y no hay ningún nodo hoja que se pueda dividir se hará volver a desarrollar el árbol y los valores atípicos se colocan allí, de lo contrario se descartan dichos valores. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 25 SPSS Aplicado a la Gestión de Mercados 4.7. Asignación de memoria: Permite especificar la cantidad máxima de memoria en megabytes (MB) que puede utilizar el algoritmo de conglomeración. Si se supera este máximo, utilizará el disco para almacenar la información que no se pueda colocar en la memoria. 4.8. Tipificación de variables: El algoritmo de conglomeración trabaja con variables continuas tipificadas. Las variables continuas que no estén tipificadas deben colocarse en el espacio de variables "Para tipificar" y las variables que estén tipificadas se colocan como variables “Asumidas como tipificadas”. 4.9. Opciones avanzadas Se aplican al árbol de características de conglomerados (CF) Umbral del cambio en distancia inicial: Se emplea para incrementar la distancia inicial del árbol de conglomerados. Nº máximo de ramas (por nodo hoja): Número máximo de nodos que puede tener una hoja. Profundidad Máxima del árbol (Niveles): Número máximo de niveles que puede tener un árbol. Máximo número posible de nodos: Indica el número máximo de nodos del árbol CF que genera el procedimiento Cada nodo requiere como mínimo 16 Bytes. Actualización del modelo de conglomerados: Esta opción permite importar y actualizar modelos de conglomerados que se han generado en análisis anteriores. 4.10. Gráficos: Cuando se da click sobre la opción gráfico aparece el siguiente cuadro de diálogo: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 26 SPSS Aplicado a la Gestión de Mercados Ilustración 4. Conglomerados en dos fases: Gráficos En este caso se seleccionó la opción de grafico de prelación de importancia de las variables y un nivel de confianza de 95%. 4.11. Resultados Ilustración 5. Conglomerados en dos fases: Resultados En el grupo de estadísticas se seleccionó criterio de información AIC o BIC. Luego de determinar las variables, establecer las opciones, gráficos y resultados se da click en aceptar y me proporciona los resultados. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 27 SPSS Aplicado a la Gestión de Mercados En nuestro caso arrojo la siguiente tabla de agrupación automática: Número de conglomerados 1 Criterio bayesiano de Schwarz (BIC) 5373,494 Cambio en BIC(a) Razón de cambios en BIC(b) Razón de medidas de distancia(c) 2 3495,637 -1877,857 1,000 1,426 3 2191,641 -1303,996 ,694 5,795 4 2002,874 -188,767 ,101 1,128 5 1840,444 -162,430 ,086 1,115 6 1699,361 -141,083 ,075 1,360 7 1607,235 -92,126 ,049 1,217 8 1539,318 -67,917 ,036 1,025 9 1474,111 -65,207 ,035 1,423 10 1441,338 -32,773 ,017 1,000 11 1408,573 -32,765 ,017 1,203 12 1388,714 -19,859 ,011 1,013 13 1369,690 -19,024 ,010 1,352 14 1367,035 -2,656 ,001 1,103 15 1368,712 1,678 -,001 1,078 Tabla 1. Agrupación Automática a Los cambios proceden del número anterior de conglomerados de la tabla. b Las razones de los cambios están relacionadas con el cambio para la solución de los dos conglomerados. c Las razones de las medidas de la distancia se basan en el número actual de conglomerados frente al número de conglomerados anterior. Esta tabla resume el proceso por el cual se seleccionaron los conglomerados. El criterio de conglomeración (En este caso Criterio bayesiano de Schwarz (BIC)) es calculado para cada número potencial de conglomerados. Los valores más pequeños del Criterio bayesiano de Schwarz (BIC) indican la mejor solución de conglomerado. Sin embargo, se presentan problemas de conglomeración ya que el BIC disminuye cuando se incrementan los conglomerados. La siguiente tabla muestra la frecuencia de cada conglomerado, de los 100 datos fueron excluidos 12 del análisis por ser valores perdidos. Los 1488 casos restantes fueron distribuidos así: 476 para el primer conglomerado, 516 para el segundo conglomerado y 496 para el tercer conglomerado. 1 476 % de combinados 32,0% 2 516 34,7% 34,4% 3 496 33,3% 33,1% 1488 100,0% 99,2% N Conglomerado Combinados % del total 31,7% UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 28 SPSS Aplicado a la Gestión de Mercados Casos excluidos Total 12 ,8% 1500 100,0% Tabla 2. Distribución de los Conglomerados Beneficios Conglomerado Número ID del cliente 1 Media $2,545.64 Desv. típica $1,032.650 Media 786,21 Desv. típica 457,140 2 $2,481.21 $977.318 813,82 461,348 3 $2,525.49 $975.901 804,24 472,507 Combinados $2,516.58 $994.586 801,79 463,595 Tabla 3. Perfiles de los Conglomerados La tabla de perfiles de conglomerados presenta la media y desviación estándar de cada conglomerado. El sector en el conglomerado 1 tiene unos beneficios o ingresos medios de $2,545.64. Sector Administración Frecuencia Conglomerado 1 0 Comercio Porcentaje Frecuencia Universidad Porcentaje Frecuencia Porcentaje ,0% 0 ,0% 476 100,0% ,0% 2 0 ,0% 516 100,0% 0 3 496 100,0% 0 ,0% 0 ,0% Combinados 496 100,0% 516 100,0% 476 100,0% Tabla 4. Frecuencias de Conglomerados La tabla de frecuencia de conglomerados por Sector presenta con mayor claridad las propiedades de los conglomerados. El conglomerado tres comprende completamente el Sector de Administración, el conglomerado 2 esta compuesto por el Sector Comercio. Variación Intra-Conglomerado El siguiente grafico resume el comportamiento de las frecuencias por conglomerado y UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 29 SPSS Aplicado a la Gestión de Mercados la media para cada uno de ellos. Intervalos de confianza al 95% simultáneos para las medias 2700 2600 Beneficios 2500 2400 2300 N= 476 516 496 1 2 3 Conglomerado La línea de referencia es la media global = 2516,58 Ilustración 6. Variación Intra- Conglomerado Importancia Según Variable Continua Conglomerado 1 El siguiente grafico representa la importancia según variable continua. Las variables se ubican en el eje Y en orden descendente de acuerdo a la importancia. La línea vertical punteada indica los valores críticos para determinar la significancia de cada variable. Para considerar una variable significativa la t de student debe exceder la línea punteada en dirección positiva o negativa. Una t negativa indica que generalmente la variable toma valores más pequeños que sus valores medios dentro del conglomerado, mientras que una t positiva indica que la variable toma valores más grandes que los valores medios. En este conglomerado la variable beneficios tiene valores positivos. Desde que las medidas de importancia para todas las variables excedan el valor crítico en el gráfico, se puede concluir que todas las variables continuas contribuyen a la formación del conglomerado. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 30 SPSS Aplicado a la Gestión de Mercados Importancia Según Variable Continua Número de conglomerados en dos fases = 1 Ajuste de Bonferroni aplicado Número ID del client Beneficios Variable Valor crítico Estadístico de contr aste -3 -1 -2 1 0 3 2 t de Student Ilustración 7. Ajuste de Bonferroni aplicado Conglomerado 2 En este grafico se demuestra que las variables no son importantes para la formación del conglomerado porque no alcanzan a exceder el valor crítico. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 31 SPSS Aplicado a la Gestión de Mercados Número de conglomerados en dos fases = 2 Ajuste de Bonferroni aplicado Beneficios Número ID del client Variable Valor crítico Estadístico de contr aste -3 -1 -2 1 0 3 2 t de Student Ilustración 8. Ajuste de Bonferroni Aplicado2 Empleando el análisis de Conglomerados Jerárquico en dos fases se dividieron los sectores de acuerdo a los ingresos en tres grupos. Para obtener conglomerados más selectos es conveniente emplear más variables por ejemplo, estrato, experiencia, nivel de satisfacción, entre otras. 4.12. Ejemplo: Con el archivo de datos de empleados analizar y aplicar conglomerado en dos fases para las variables salario actual, salario inicial, meses desde el contrato y experiencia previa a partir de la variable categórica sexo. Se realizan los pasos que se mencionaron anteriormente, arroja el cuadro de diálogo y se seleccionan las variables. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 32 SPSS Aplicado a la Gestión de Mercados Ilustración 9. Análisis de Conglomerados en dos Fases Después se especifica que realice gráfico de porcentajes intra-conglomerado y gráfico de sectores de los conglomerados, que ordene las variables por conglomerado y arroje medida de distancia chi-cuadrado o prueba t de significancia. Ilustración 10. Conglomerados en dos fases: Gráficos Se oprime aceptar y arroja los siguientes resultados, que el investigador debe analizar. 4.11.1. Conglomerados en dos fases Del archivo de datos de empleados que tiene un total de 474 casos se realizó el UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 33 SPSS Aplicado a la Gestión de Mercados análisis de Conglomerados en dos fases. Como variable categórica se tomo el sexo y como variable continua el salario actual, salario inicial, meses de contrato y experiencia previa en meses. El siguiente cuadro de distribución de conglomerados muestra tres conglomerados Para el primer conglomerado hay 216 casos Para el segundo conglomerado hay 194 casos Para el tercer conglomerado hay 64 casos. No hay casos pedidos. 1 216 % de combinados 45,6% 2 194 40,9% 40,9% 3 64 13,5% 13,5% 474 100,0% 100,0% N Conglomerado Combinados Total 474 % del total 45,6% 100,0% Tabla 5. Distribución de Conglomerados UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 34 SPSS Aplicado a la Gestión de Mercados 4.11.2. Perfiles de los conglomerados Este cuadro representa la media y desviación estándar por cada variable continua de análisis. Por ejemplo,el conglomerado uno que representa un 45,6% del total tiene una media de salario actual de $26,031.92 y una Desviación típica de $ 7,558.021, teniendo en cuenta que si se saca la media del salario actual de todos los datos es de $34 419.57 y la desviación típica es de $17,075.661. Centroides Salario actual Conglomerado Salario inicial Meses desde el contrato Experiencia previa (meses) 1 Media $26,031.92 Desv. típica $7,558.021 Media $13,091.97 Desv. típica $2,935.599 Media 80,38 Desv. típica 9,676 Media 77,04 Desv. típica 95,012 2 $31,866.01 $6,761.617 $16,069.64 $2,660.667 81,80 10,327 121,35 117,674 3 $70,468.36 $16,514.008 $33,128.91 $9,731.349 81,48 10,503 82,13 74,085 Combinados $34,419.57 $17,075.661 $17,016.09 $7,870.638 81,11 10,061 95,86 104,586 Tabla 6. Perfiles de los Conglomerados UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 35 SPSS Aplicado a la Gestión de Mercados 4.11.3. Frecuencias El conglomerado 1 esta compuesto por 216 casos o 100% de las mujeres. El conglomerado 2 esta compuesto por 194 casos o 75,2% de los hombres El conglomerado 3 esta compuesto por 64 casos, es decir 24.8% de hombres. Sexo Hombre Frecuencia Conglomerado 1 2 3 Combinados Mujer Porcentaje Frecuencia Porcentaje 0 ,0% 216 100,0% 194 75,2% 0 ,0% 64 24,8% 0 ,0% 258 100,0% 216 100,0% Tabla 7. Frecuencias de los Conglomerados 4.11.4. Importancia de los atributos Este gráfico muestra el tamaño de cada conglomerado. El conglomerado 1 tiene el 46% de los casos, lo que equivale a 216 Tamaño de conglomerado 3 64 / 14% 1 216 / 46% 2 194 / 41% Ilustración 11. Tamaño de los Conglomerados 4.11.5. Porcentaje Intra-conglomerado En este grafico se muestra como la variable categorica sexo se distribuye entre los conglomerados. Así: El conglomerado 1 esta conformado en un 100% por mujeres, el conglomerado 2 esta conformado en 100% por hombres y el conglomerado 3 esta UNIVERSIDAD NACIONAL COLOMBIA 36 FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES SPSS Aplicado a la Gestión de Mercados conformado por el 100% de hombres. En el total de casos hay 43% de mujeres y 57% aprox. de hombres. Porcentaje dentro el Conglomerado de Sexo Ilustración 12. Porcentaje dentro del Conglomerado de sexo 4.11.6. Variación Intra-conglomerado A continuación se presentan los gráficos de variación al interior de cada conglomerado. Es decir, el comportamiento de frecuencias por conglomerado o medias de cada uno. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 37 SPSS Aplicado a la Gestión de Mercados Intervalos de confianza al 95% simultáneos para las medias 80000 70000 60000 Salario actual 50000 40000 30000 20000 N= 216 194 64 1 2 3 Conglomerado La línea de referencia es la media global = 34419,57 Ilustración 13. Variación Intra- Conglomerado 1 Este gráfico dice que en el primer conglomerado, compuesto por 216 personas, en su totalidad mujeres, el salario actual varia entre 23000 y 27000. En el conglomerado 2, compuesto por 194 hombres, el salario actual oscila entre $ 32000 y $34000 y en el conglomerado 3 compuesto por 64 hombres el salario actual varia entre 63000 y 75000 aprox. El salario promedio para todos los casos se encuentra en 34419,57. Aquí se puede notar la importancia de los conglomerados porque si se analizara de manera global el salario actual promedio sería $34419,57, sin tener en cuenta que las mujeres no ganan más de $28000 y que hay un grupo de hombres (64) que tienen un salario alto ($70000), que se aleja bastante del salario actual medio. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 38 SPSS Aplicado a la Gestión de Mercados Intervalos de confianza al 95% simultáneos para las medias 86 Meses desde el contrato 84 82 80 78 76 N= 216 194 64 1 2 3 Conglomerado La línea de referencia es la media global = 81,11 Ilustración 14.Variación Intra-Conglomerado 2 Intervalos de confianza al 95% simultáneos para las medias 40000 Salario inicial 30000 20000 10000 N= 216 194 64 1 2 3 Conglomerado La línea de referencia es la media global = 17016,09 Ilustración 15. Variación Intra-Conglomerado 3 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 39 SPSS Aplicado a la Gestión de Mercados Interval os de confi anza al 95% si mul táneos para l as medi as 160 140 120 100 80 60 40 N= 216 194 64 1 2 3 Conglomerado La línea de ref erencia es la media global = 95,86 Ilustración 16.Variación Intra-Conglomerado 4 El gráfico muestra que el conglomerado 1, compuesto por las mujeres, tiene 78 meses de experiencia. Y el conglomerado dos tiene 120 meses de experiencia y el conglomerado 3 tiene 81,5 meses de experiencia. El bajo salario de las mujeres se puede ver asociado a que tienen una experiencia menor. El salario del conglomerado 2 se asocia también a una mayor experiencia, pero en el caso del conglomerado tres no hay asociación entre el salario actual y la experiencia, ya que tienen el salario más alto pero su experiencia en meses es inferior a la del conglomerado dos. 4.11.7. Importancia según agrupación Los siguientes son los gráficos que se crearon por conglomerados. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 40 SPSS Aplicado a la Gestión de Mercados Sexo Ajuste de Bonferroni aplicado 1 Conglomerado 2 3 Valor crítico Estadístico de contr aste 0 100 200 300 Chi-cuadrado Ilustración 17. Ajuste de Bonferroni Aplicado-Sexo Salario actual Ajuste de Bonferroni aplicado 1 Conglomerado 3 2 Valor crítico Estadístico de contr aste -20 -10 0 10 20 t de Student Ilustración 18. Ajuste de Bonferroni Aplicado- Salario Actual El anterior grafico representa la importancia según Conglomerado. Como se puede notar los conglomerados se ubican en el eje Y dependiendo de su importancia. Debido a que la t de Student excede los valores críticos se puede considerar que los conglomerados 1, 2 y 3 son significativos, desde el punto de vista de la variable salario actual. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 41 SPSS Aplicado a la Gestión de Mercados En los conglomerados 1 y 2 se toman valores más pequeños que sus valores medios y en el conglomerado tres se toman valores más grandes que los valores medios. Salario inicial Ajuste de Bonferroni aplicado 1 Conglomerado 3 2 Valor crítico Estadístico de contr aste -30 -20 -10 0 10 20 t de Student Ilustración 19. Ajuste de Bonferroni Aplicado: Salario Inicial Para la variable salario inicial, los conglomerados son significativo Meses desde el contrato Ajuste de Bonferroni aplicado 1 Conglomerado 2 3 Valor crítico Estadístico de contr aste -3 -2 -1 0 1 2 3 t de Student Ilustración 20. Ajuste de Bonferroni aplicado: Meses desde el contrato Para la variable Meses de Contrato, ningún conglomerado es significativo UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 42 SPSS Aplicado a la Gestión de Mercados Experiencia previa (meses) Ajuste de Bonferroni aplicado 2 Conglomerado 1 3 Valor crítico Estadístico de contr aste -4 -3 -2 -1 0 1 2 3 4 t de Student Ilustración 21. AJuste de Bonferroni: Experiencia Previa en meses Para la variable Experiencia previa (meses), los conglomerados 1 y 2 son significativos, mientras que el conglomerado 3 no es significativo. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 43 SPSS Aplicado a la Gestión de Mercados 5. Análisis De Conglomerados Jerárquico Esta metodología trata de identificar grupos o segmentos relativamente homogéneos de casos (o de variables) basándose en las características propias de cada uno, mediante un algoritmo que comienza con cada caso o variable en particular y hace diferentes combinaciones hasta dejar un grupo uniforme. El calculo de la distancia o similaridad entre las variables o grupos se realiza mediante la técnica de Proximidades. Con el análisis de conglomerados jerárquico, se pueden agrupar los consumidores de un determinado producto en una ciudad para establecer estrategias de marketing. Adicionalmente, podría agrupar ciudades en diferentes grupos de acuerdo a sus características de consumo, cultura, labor de recompra, etc., para generar estrategias similares donde existen segmentos con comportamientos afines y así ser más eficientes en el momento de lanzar estrategias. El criterio base para cada conglomerado es la distancia. Las variables que se encuentran más cercanas a otras deben pertenecer al mismo conglomerado, y las variables que se encuentran más dispersas deben pertenecer a conglomerados diferentes. Este procedimiento es útil para encontrar agrupaciones naturales de casos o variables. Tiene mayor efectividad cuando el archivo de datos a analizar contiene un número pequeño de datos (Menos de 100 datos) para ser conglomerado. Para un conjunto de datos, los conglomerados que se construyen dependen de la especificación de los siguientes parámetros: Método de Conglomeración: Define los criterios para la formación de conglomerados. Por ejemplo, al calcular la distancia entre dos conglomerados, se pueden usar las variables más cercanas entre conglomerados o el par de variables más cercanas. Media: Define la formula para calcular la distancia. Por ejemplo, la medida de distancia Euclidea calcula la distancia como una "línea recta" entre dos conglomerados. La medida de intervalo asume que las variables son escalas, la medida de cuenta asume que hay números discretos; y la medida binaria asume que las variables toman únicamente dos valores. Estandarización: Permite igualar los resultados de variables medidas en diferentes escalas. Los fabricantes de automóviles necesitan poder estimar el mercado actual para determinar la competencia probable para sus vehículos. Si los automóviles se agrupan según los datos disponibles, esta tarea puede ser automática empleando el análisis cluster. Se busca información de varios fabricantes y modelos de vehículos en el archivo de spss. Empleando el análisis de conglomerados Jerárquico se pueden agrupar los automóviles de más altas ventas según sus precios y propiedades físicas. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 44 SPSS Aplicado a la Gestión de Mercados Primero es necesario definir que casos se van a analizar, para tal motivo se debe abrir el archivo que contiene los casos, luego acceder al menú Datos, Seleccionar Casos y de allí filtrar los datos mediante una muestra aleatoria de datos o si cumplen una serie de condiciones, luego se realiza al análisis de conglomerado Jerárquico como tal. 5.1. Pasos para el análisis de conglomerados jerárquico Se realiza mediante el menú Analizar, clasificar, Conglomerados jerárquicos. Para conglomerar casos se debe seleccionar como mínimo una variable numérica, para conglomerar variables, se deben seleccionar como por lo menos tres variables numéricas. En la opción de “etiquetar los datos mediante” se puede seleccionar una variable de identificación para etiquetar los datos, esta opción sólo se activa cuando se conglomeran variables. 5.2. Dendrograma: Representa paso por paso la solución de conglomeración Jerárquica, muestra los conglomerados que se combinan y los valores de los coeficientes de distancia. Las líneas verticales simbolizan combinación de casos. Son empleados para evaluar la cohesión de los conglomerados que se han creado y determinar el número adecuado de conglomerados que deben permanecer en el estudio. En la parte izquierda se muestran los casos. En el eje horizontal se muestra la distancia entre los conglomerados cuando se efectúa la unión, las líneas verticales representan los grupos que están unidos. La posición de la línea en la escala indica las distancias en las que se unieron los grupos. El árbol de clasificación para determinar el número de conglomerados es un proceso subjetivo. Generalmente se comienza buscando los intervalos entre las uniones a lo largo del eje horizontal. 5.3. Clases de métodos de Conglomeración En el link de Método de Conglomeración las opciones disponibles son: Vinculación Inter-grupos Vinculación intra-grupos Vecino más próximo, Vecino más lejano Agrupación de centroides Agrupación de medianas Método de Ward UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 45 SPSS Aplicado a la Gestión de Mercados Ilustración 22. Métodos de enlace para el Conglomerado 9 El método de enlace sencillo se basa en la distancia mínima o la regla del vecino más próximo, los primeros objetos conglomerados son aquellos que tienen una distancia mínima. Este método pierde efectividad cuando los conglomerados no están bien definidos El método del enlace completo se basa en la distancia máxima entre los objetos o el método del vecino más lejano. En el método del enlace promedio la distancia de los conglomerados se determina por el promedio de las distancias entre los dos pares de objetos Los Métodos de Varianza tratan generar conglomerados con el fin de reducir la varianza dentro de los grupos. El procedimiento Ward es empleado con frecuencia. Para cada uno de los conglomerados se calculan las medias de las variables. Luego, se calcula la distancia euclidiana cuadrada para las medias de los grupos. 9 Figura tomada de Artículos de estadística CRM, Data Mining, investigación mercados, satisfacciófghetn clientes__.htm UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 46 SPSS Aplicado a la Gestión de Mercados Ilustración 23. Métodos de Agrupación por Aglomeración 10 En el Método Centroide, la distancia entre dos grupos es la distancia entre sus centroides. 5.4. Medida Existen tres posibles casos de medida: Intervalo, Frecuencia, binaria. 5.4.1. Medida de intervalo Para los datos de intervalo existen las siguientes medidas: Distancia euclídea: La raíz cuadrada de la suma de los cuadrados de las diferencias entre los valores de los elementos. Ésta medida viene predeterminada para los datos de intervalo. Distancia euclídea al cuadrado: La suma de los cuadrados de las diferencias entre los valores de los elementos. Correlación de Pearson: La correlación producto-momento entre dos vectores de valores. Coseno: El coseno del ángulo entre dos vectores de valores. Chebychev: La diferencia absoluta máxima entre los valores de los elementos. Bloque: La suma de las diferencias absolutas entre los valores de los elementos. Se le conoce como la distancia de Manhattan. Minkowski: p-ésima raíz de la suma de las diferencias absolutas elevada a la potencia p-ésima entre los valores de los elementos. Personalizada: r-ésima raíz de la suma de las diferencias absolutas elevada a la potencia p-ésima entre los valores de los elementos. 10 Figura tomada de Artículos de estadística CRM, Data Mining, investigación mercados, satisfacciófghetn clientes__.htm UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 47 SPSS Aplicado a la Gestión de Mercados 5.4.2. Medida de Frecuencias: Las opciones disponibles son: Medida de chi-cuadrado: Esta medida se basa en la prueba de chi cuadrado de igualdad para dos conjuntos de frecuencias. Ésta medida viene por defecto. Medida de Phi-cuadrado: Esta medida es igual a la medida de chi-cuadrado normalizada por la raíz cuadrada de la frecuencia combinada. 5.4.3. Medida Binaria: Las opciones disponibles son: Distancia euclídea, Distancia euclídea al cuadrado, Diferencia de tamaño, Diferencia de configuración, Varianza, Dispersión, Forma, Concordancia simple, Correlación phi de 4 puntos, Lambda, D de Anderberg, Dice, Hamann, Jaccard, Kulczynski 1, Kulczynski 2, Lance y Williams, Ochiai, Rogers y Tanimoto, Russel y Rao, Sokal y Sneath 1, Sokal y Sneath 2, Sokal y Sneath 3, Sokal y Sneath 4, Sokal y Sneath 5, Y de Yule y Q de Yule. Si se desea, se puede cambiar los campos Presente y Ausente para especificar los valores que indican que una característica está presente o ausente. El procedimiento ignorará todos los demás valores. En el caso de que se desee saber si un cliente tiene un determinado servicio es conveniente elegir medidas binarias, por ejemplo Simple matching y Jaccard. 5.5. Ejemplo: Del una muestra del 10% del archivo Coches. Sav identificar las variables más homogéneas mediante el análisis de Conglomerados Jerárquico, con el fin de determinar las variables que tienen una mayor influencia para el comprador y la relación entre ellas en el momento de adquirir carro. Se accede al menú de Conglomerados Jerárquico, se pasan las variables a analizar al lado derecho y se selecciona la opción de conglomerar variables. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 48 SPSS Aplicado a la Gestión de Mercados Ilustración 24. Menú: Análisis de Conglomerados Jerárquico Luego se accede a la opción de estadísticos que arroja el siguiente cuadro de diálogo: Ilustración 25.Análisis de Conglomerados Jerárquicos: Estadísticos Si se desea se puede seleccionar la opción de Historial de Conglomeración y Matriz de distancias, para tener mayor claridad del origen de los resultados. 5.5.1. Gráficos Al acceder al link de Gráficos se activa la siguiente ventana, donde se puede seleccionar Dendograma y la cantidad de conglomerados que se desea obtener. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 49 SPSS Aplicado a la Gestión de Mercados Ilustración 26. Análisis de Conglomerados Jerárquicos: Gráficos 5.5.2. Método de conglomeración En la parte inferior del cuadro conglomerado Jerárquico se visualiza la opción de método, que al hacer clic aparece el siguiente cuadro de diálogo: Ilustración 27. Métodos de Conglomeración Para este ejemplo, se empleó como método de conglomeración agrupación de centroides y como medida de intervalo Distancia euclídea al cuadrado. Cuando se ejecuta el procedimiento presenta los siguientes resultados: Validos N Porcentaje 52 100,0% Casos Perdidos N Porcentaje 0 ,0% N Total Porcentaje 52 100,0% Tabla 8. Resumen del procesamiento de los casos UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 50 SPSS Aplicado a la Gestión de Mercados En esta tabla se resume la cantidad de datos analizados y los casos perdidos. 5.5.3. Conglomerados jerárquicos Caso Archivo matricial de entrada Aceleración 0 a 100 km/h Año del Peso total (kg) (segundos) modelo País de origen Número de cilindros Cilindrada en cc Potencia (CV) Cilindrada en cc ,000 591455574,000 335180113,000 Potencia (CV) 591455574,000 ,000 41450837,000 536234,140 156730,000 665212,000 619725,000 Peso total (kg) 335180113,000 41450837,000 ,000 50971884,740 45192481,000 52284171,00 0 51875656,000 626687223,940 536234,140 50971884,740 ,000 192437,740 9612,140 5809,140 607976848,000 156730,000 45192481,000 192437,740 ,000 285960,000 260343,000 630723266,000 665212,000 52284171,000 9612,140 285960,000 ,000 925,000 629228337,000 619725,000 51875656,000 5809,140 260343,000 925,000 ,000 Aceleración 0 a 100 km/h (segundos) Año del modelo País de origen Número de cilindros 626687223,940 607976848,000 630723266,0 00 629228337,000 Tabla 9. Matriz de Distancias En la matriz de distancias se mide, como su nombre lo indica, la distancia entre cada una de las variables, por este motivo la distancias entre las mismas variables es cero. Los valores representan la similaridad o disimilaridad entre cada par de variables. Los valores más grandes indican que las variables son muy diferentes, como es el caso de las variables Cilindrada en cc y Peso Total (kg) que presentan una alta disimilaridad con respecto a las demás variables. No obstante, se nota la alta similaridad entre las variables país de origen con la Aceleración 0 a 100 km/h (segundos) y con el Número de Cilindros y la variable Número de cilindros con la variable Aceleración 0 a 100 km/h (segundos). De estos resultados, se puede concluir que para el comprador es importante la aceleración y el número de cilindros de los autos y estas variables tienen una alta relación con el país de origen. 5.5.4. Vinculación de centroides Etapa en la que el conglomerado aparece por primera vez Conglomerado que se combina Etapa 1 2 3 Conglome rado 1 6 4 2 Conglome rado 2 7 6 5 Coeficientes 925,000 7479,390 156730,000 Conglome rado 1 0 0 0 Conglome rado 2 0 1 0 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES Próxima etapa 2 4 4 51 SPSS Aplicado a la Gestión de Mercados 4 5 6 2 4 2 3 1 2 385653,227 48245686,42 2 563416670,9 37 3 2 5 4 0 6 0 5 0 Tabla 10. Historial de Conglomeración Esta tabla es un resumen numérico de la solución del conglomerado que muestra como se juntan los casos por conglomerados en cada fase del análisis. En la etapa 1 se combina el caso 6 con el caso 7 porque tienen las distancias más pequeñas. La próxima etapa hace referencia a la siguiente etapa en la que aparecerá el conglomerado. En la etapa 4 se unen los conglomerados creados en la etapa 3 y 2, esto se puede observar en las filas que especifican la etapa en la que el conglomerado aparece por primera vez (En la tabla se encuentran de color rojo). El conglomerado resultante aparece nuevamente en la fase 5. Dependiendo de los casos la anterior tabla se va haciendo más larga, sin embargo es importante y más fácil observar la columna de coeficientes que observar los intervalos en el dendrograma. Una buena solución de conglomerado arroja saltos repentinos o inesperados en el coeficiente de distancia. X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X Cilindrada en cc Potencia (CV) Año del modelo Aceleración 0 a 100 km/h (segundos) Número de cilindros País de origen Número de conglomerados 1 2 3 4 5 6 Peso total (kg) Caso X X X X X X X X X X X X X X X X X Tabla 11. Diagrama de témpanos Vertical En esta tabla se da una representación de cómo los casos se unen en cada fase del análisis. No obstante, antes de hacer el análisis es conveniente ir al menú edición, opciones, procesos y activar la opción de permitir el Autoprocesamiento y Cluster_Table_Icicle_Create para que arroje el Diagrama de témpanos en forma de gráfico y sea mucho más fácil de analizar. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 52 SPSS Aplicado a la Gestión de Mercados Diagrama de témpanos verti cal Cilindrada en cc Potencia (CV) Año del modelo Aceler ación 0 a 100 km/h (segundos) País de origen Número de conglomerados Número de cilindros Peso total (kg) Caso 1 2 3 4 5 6 Ilustración 28. Diagrama de témpanos Vertical En cada fase se unen dos conglomerados y cada barra blanca representa el límite entre conglomerados. En este caso, las variables peso total y número de cilindros hacen presencia en el conglomerado 1 y 2, las variables número de cilindros y país de origen se encuentran en todos los conglomerados, la variable país de origen y Aceleración 0 a 100 km/h (segundos) se encuentran en 5 conglomerados, las variables potencia y cilindrada en cc se encuentran sólo en el primer conglomerado. Dentro de las filas cada parte negra indica que los casos son agrupados como un conglomerado. En el conglomerado 1 se encuentran todas las variables, en el conglomerado 2 se encuentran el conglomerado de la variable cilindrada y el otro conglomerado agrupa las demás variables. En el conglomerado tres se pueden distinguir tres grupos de variables, Peso Cilindrada Nro de cilindros, país de origen, aceleración, año del modelo, y potencia. Y así sucesivamente en el conglomerado 4, 5 y 6. 5.5.5. Dendrograma * * * * * * H I E R A R C H I C A L C L U S T E R * * * * * A N A L Y S I S * Dendrogram using Centroid Method Rescaled Distance Cluster Combine C A S E 0 5 10 15 20 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 25 53 SPSS Aplicado a la Gestión de Mercados Label Num +---------+---------+---------+---------+---------+ ORIGEN 6 CILINDR 7 ACEL 4 CV 2 AÑO 5 PESO 3 MOTOR 1 Ilustración 29. Dendograma Este dendograma o diagrama de árbol representa los pasos para llegar a la solución de conglomerados jerárquicos, muestra la combinación de las variables, se puede notar que las variables origen, cilindrada, aceleración, potencia y año presentan similaridad, mientras que las variables aceleración, peso y motor presentan disimilaridad, ya que la distancia a la que se unieron estas variables es alta. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 54 SPSS Aplicado a la Gestión de Mercados 6. Conglomerados De K Medias Esta herramienta trata de identificar grupos de casos relativamente homogéneos basándose en las características seleccionadas y empleando algoritmos, para lo cual es indispensable introducir el número de conglomerados que se desea obtener. Este método de agrupación que se basa en la distancia que existe entre un grupo de casos y un caso específico central denominado “centroide”, Este tipo de clasificación es útil cuando se posee un gran número de casos y se puede utilizar de manera exploratoria para comenzar a identificar grupos de casos. Para realizar un ejemplo, se tiene la base de datos de Ruspini 11. Lo primero que se debe hacer para tener una idea acerca de cuantos conglomerados se puedan obtener de los datos que se tiene es la realización de un diagrama de dispersión, este se realiza en la herramienta gráficos interactivos Gráficos de dispersión, en este caso se contrastan las variables 2 y 3: 10 0 75 V2 50 25 0 0 50 10 0 15 0 V3 Ilustración 30. Diagrama de dispersión primer grupo 11 Datos simulados por Ruspini Ruspini, E.H. (1970), "Numerical Methods for Fuzzy Clustering," Information Science, 2, 319-350. Representan 75 datos bidimensionales simulados de cuatro distribuciones distintas UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 55 SPSS Aplicado a la Gestión de Mercados Se puede observar claramente que los casos se agrupan en cuatro conjuntos, esta información es importante para elegir el número de conglomerados que se desea realizar. Al contrastar las variables V1 y V2 se obtiene el siguiente grafico: 75 50 V1 25 0 0 25 50 75 10 0 V2 Ilustración 31. Diagrama de dispersión segundo grupo En este caso no son tan claros los grupos que se desean realizar pero si se observa muy bien existen espacios entre algunos datos que pueden ayudar a la realización del conglomerado en este caso 3 6.1. Preparando el análisis De esta forma procedemos a realizar la clasificación de conglomerados mediante el sistema K medias; para utilizar este procedimiento se va al menú analizar clasificar conglomerado de k medias. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 56 SPSS Aplicado a la Gestión de Mercados Ilustración 32. Ruta conglomerados K medias Ya en el cuadro de dialogo se eligen las variables con las que se quieren realizar los conglomerados y se trasladan a las listas de variables, las variables de cadena sólo pueden utilizarse para etiquetar datos. Ilustración 33. Cuadro de dialogo K medias En la opción de Nº de Conglomerados se encuentra por defecto 2, si se desea un número mayor de conglomerados se puede introducir el nuevo número, para las primeras variables se realizaran 4 conglomerados y para el segundo grupo 3. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 57 SPSS Aplicado a la Gestión de Mercados Este tipo de clasificación tiene dos métodos para realizar la aglomeración: Iterar y clasificar: Esta técnica exploratoria no se queda solo con el primer centro que encuentra sino que sigue buscando dentro de la base para buscar el mas conveniente se pueden realizar varias iteraciones, están predeterminadas 10; se pueden utilizar mas pero de todos modos el proceso de iteración se detendrá cuando el cambio entre los centros llegue a cero, aunque esta opción también se puede cambiar a gusto del investigador, en la opción iterar. Clasificar: Esta opciones conforma con los centros obtenidos inicialmente al activa esta opción se desactiva Iterar en el cuadro de dialogo. Iterar: En este link se especifica el número máximo de iteraciones y criterio de convergencia, además se puede seleccionar la opción de usar medias actualizadas. Ilustración 34. Iterar Guardar: Permite guardar el conglomerado de pertenencia (el conglomerado al cual pertenece cada caso) y la distancia de este desde centro del conglomerado. Esta es información es de gran ayuda para la construcción de diagramas de dispersión por conglomerados. Para este ejemplo se seleccionan las dos opciones para ver más claramente los conglomerados en un futuro diagrama de dispersión. Ilustración 35. Guardar Opciones: En la parte de estadísticos se puede escoger si se quiere tener en la respuesta los centros que obtuvo inicialmente, si se quiere obtener una tabla de resumen del análisis de varianza de los casos para la realización de un análisis descriptivo. La información del conglomerado muestra los casos utilizados para la aglomeración y su conglomerado asignado. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 58 SPSS Aplicado a la Gestión de Mercados Ilustración 36. Opciones Luego se comienza a realizar el conglomerado de k medias como tal, donde se especifica un número de conglomerados igual a 4 y en opciones que realice la tabla anova. 6.2. Resultados del análisis Después de preparar el análisis se pueden obtener los siguientes resultados: Centros i ni ciales de los conglomerados Conglomerado 2 3 63 126 5 111 1 V3 V2 21 83 4 155 55 Tabla 12. Cuadro conglomerados iniciales primer grupo Centros i niciales de los conglomerados 1 V1 V2 Conglomerado 2 1 68 4 58 3 60 117 Tabla 13. Cuadro conglomerados iniciales segundo grupo La anterior tabla muestra los centros de conglomerados iniciales y muestra los valores centrales para cada una de las variables en sus distintos conglomerados El historial de iteraciones muestra el progreso del proceso de conglomeración en cada etapa. En las primeras interacciones el centro de conglomerado cambia en grandes proporciones, mientras que en las últimas interacciones se presentan ajustes menores hasta llegar a cero a la convergencia que se haya seleccionado en las opciones de iteración. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 59 SPSS Aplicado a la Gestión de Mercados a Historial de iteraci ones It erac ión 1 2 Cambio en los centros de los conglomerados 1 2 3 4 14, 157 15, 275 16, 972 14, 253 ,000 ,000 ,000 ,000 a. Se ha logrado la conv ergencia debido a que los centros de los conglomerados no present an ningún cambio o éste es pequeño. El cambio máximo de coordenadas abs olutas para cualquier c entro es de ,000. La it eración actual es 2. La distancia mínima ent re los c entros iniciales es de 63,063. Tabla 14. Cuadro historial de iteraciones primer grupo a Historial de iteraci ones It erac ión 1 2 3 4 5 Cambio en los centros de los conglomerados 1 2 3 25, 574 15, 641 16, 264 2, 283 2, 344 2, 293 ,755 1, 083 ,000 ,752 1, 115 ,000 ,000 ,000 ,000 a. Se ha logrado la c onv ergencia debido a que los centros de los conglomerados no presentan ningún cambio o éste es pequeño. El cambio máx imo de coordenadas absolutas para cualquier cent ro es de ,000. La it eración actual es 5. La distancia mínima ent re los c entros iniciales es de 59,540. Tabla 15. Cuadro historial de iteraciones segundo grupo En el segundo grupo de variables es más notorio el proceso de iteración, y para ambos grupos se puede observar en la información que ofrece el programa el cambio máximo absoluto para cualquier centro y la distancia mínima que existe entre los centros que se plantaron al inicio. Posteriormente de las iteraciones se puede observar los centros de conglomerados finales para el estudio: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 60 SPSS Aplicado a la Gestión de Mercados Centros de los conglomerados finales Conglomerado 2 3 65 115 20 98 1 V3 V2 19 69 4 146 44 Tabla 16. Conglomerados finales primer grupo Centros de los conglomerados finales 1 V1 V2 Conglomerado 2 18 57 28 64 3 53 100 Tabla 17. Conglomerados finales segundo grupo Como en las opciones se eligió que mostrara la tabla Anova, esta aparece en el resultado final e indica que variables contribuyen en mayor medida a la solución del conglomerado, teniendo muy en cuenta la explicación que el mismo programa da sobre su interpretación: ANOVA V3 V2 Conglomerado Media cuadrát ica gl 56590,892 20573,380 Error 3 3 Media cuadrát ica 81, 004 100,419 gl 71 71 F 698,620 204,874 Sig. ,000 ,000 Las pruebas F sólo se deben ut ilizar con una f inalidad descriptiv a puesto que los conglomerados han s ido elegidos para maximizar las dif erencias ent re los casos en dif erentes conglomerados. Los niv eles crít icos no s on c orregidos , por lo que no pueden interpretars e como pruebas de la hipótesis de que los c entros de los conglomerados s on iguales. Tabla 18. ANOVA Finalmente muestra que cantidad de casos han sido asignados a los diferentes conglomerados que se han creado UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 61 SPSS Aplicado a la Gestión de Mercados Número de casos en cada conglomerado Conglomerado 1 2 3 4 Válidos Perdidos 15, 000 20, 000 17, 000 23, 000 75, 000 ,000 Tabla 19. Casos por conglomerado primer grupo En este caso se puede ver que al primer conglomerado se le asignaron 15 casos de los 75 incluidos en la base de datos, al segundo 20, al tercer conglomerado 17 y por ultimo 23 casos al cuarto conglomerado, del mismo modo se puede observar el numero de casos que se no se utilizaron por ser valores perdidos. Número de casos en cada conglomerado Conglomerado Válidos Perdidos 1 2 3 35, 000 24, 000 16, 000 75, 000 ,000 Tabla 20. Casos por conglomerado segundo grupo En este grupo de variables se interpretan de igual manera los casos por conglomerado Para terminar el análisis es muy aclaratorio observar gráficamente como quedaron los diferentes conglomerados, para esto fue que se guardaron los conglomerados de pertenencia los cuales generaron una nueva variable llamada qcl_1 y cuya etiqueta es Numero inicial de casos; con esta nueva variable como leyenda se diseña un nuevo grafico de dispersión: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 62 SPSS Aplicado a la Gestión de Mercados Núme ro inicial de casos 10 0 75 V2 1 2 3 4 50 25 0 0 50 10 0 15 0 V3 Ilustración 37. Grafico de dispersión conglomerados finales primer grupo De esta forma se puede observar muy claramente los cuatro conglomerados que se crearon los cuales por ejemplo podrían definir los clientes de una empresa comercial en los que la variable V2 podría representar las cantidades compradas y la variable V3 el precio, de esta forma la empresa tendría de la muestra seleccionada 4 grupos distintos de clientes: 1. 2. 3. 4. Los que compran mucho a un bajo precio Los que compran poco cuando el precio se acerca o supera 50 Los que compran mucho cuando el precio supera los cien Los que compran relativamente poco cuando el precio es mayor a cien. De esta forma se puede ver que para la empresa es rentable tener precios mayores a 50 ya que en este rango de precios se encuentra su mayoría de clientes, además el conglomerado tres que es el de mayor compra de productos supera el precio de 100 (de esto se deduce que la empresa vende un giffen12). 12 BIEN GIFFEN. Bien inferior en el que al aumentar su precio aumenta su demanda. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 63 SPSS Aplicado a la Gestión de Mercados Para el segundo grupo de datos el grafico de dispersión da de la siguiente manera: 75 50 Núme ro inicial de casos V1 25 0 0 25 50 75 1 2 3 10 0 V2 Ilustración 38. Grafico de dispersión conglomerados finales segundo grupo En este caso los conglomerados como ya se dijo no son tan claros como en el primer grupo de variables, se puede observar como un caso en especial del conglomerado 3 parece que hace mas parte del conglomerado dos y como algunos del conglomerado 1 también parece que hacen mas parte del conglomerado 2; Pero como se puede recordar al principio se aclaro que este tipo de clasificación era una manera de explorar los datos. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 64 SPSS Aplicado a la Gestión de Mercados 7. Análisis Factorial Para La Reducción De Datos En el área de la segmentación de mercados, el análisis factorial sirve especialmente para ayudar a reducir las muchas variables disponibles a una base de las variables compuestas (factores) con el propósito de realizar una segmentación tipo cluster, análisis discriminante o una regresión logística. Mediante este método se toma un gran número de variables y se investiga para ver si tiene un pequeño número de factores en común que expliquen su ínter correlación y que cada grupo sea independiente entre si. 7.1. Que Buscar Cuando Se Realiza Un Análisis Factorial Según Malhotra (1997)13 el Análisis Factorial puede aplicarse en diferentes campos del marketing como: Segmentación de Mercados: Para identificar las variables subyacentes en las cuales se deben agrupar los clientes. Así, por ejemplo, los compradores de automóviles nuevos pueden agruparse sobre la base de la importancia que dan a la economía, la comodidad, el desempeño, el lujo, el servicio postventa, etc. Investigación de Productos: Para identificar los atributos de las marcas que influyen en la elección del consumidor. La elección de un jabón de tocador se puede determinar por la frescura, protección que proporciona, suavidad, marca, entre otras. Publicidad: Para comprender los hábitos de consumo del mercado meta. Los consumidores de comida rápida pueden tener una audiencia específica de programas de televisión, escuchar determinado tipo de música, tener gustos similares que nos permiten clasificar nuestro grupo de interés. Estudios sobre Precios: Para identificar las características de los consumidores sensibles al precio. Estos consumidores pueden ser de clase media, preocupados por la economía, caseros, vivir en un lugar determinado, etc. Hay dos preguntas principales que se deben tener en cuenta cuando se realiza un análisis factorial: ¿cuántos (si existen) factores hay? y que representan? Estas preguntas están muy relacionadas porque en la práctica del estudio de mercados raramente se conservaran los factores que no se puedan identificar y nombrar. Al realizar el análisis se tiene muy en cuenta la interpretación del analista ya que el 13 Malhotra, Naresh K.. Investigación de mercados un enfoque práctico Naresh K. Malhotra ; tr. Verania de Parres Cárdenas. 2a. ed..-- México: Prentice Hall: Pearson Educación: Addison Wesley 1997. Pág. 120 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 65 SPSS Aplicado a la Gestión de Mercados tendrá los criterios para decidir que factores se mantienen o se dejan. 7.2. Principios La primera parte del análisis se basa en la matriz de correlaciones, la que muestra los coeficientes de correlación (su variabilidad) entre cada par de variables. El análisis factorial funciona mediante la matriz de correlaciones que relaciona las variables que se descompondrán en factores. El argumento básico es que las variables están correlacionadas porque comparten unos o más componentes comunes, y si no fuera así no habría necesidad de realizar análisis factorial. Un modelo del uno-factor para tres variables puede ser representado matemáticamente como sigue (Vs son las variables, Fs son los factores, Es representan la variación que es única a cada uno variable (sin correlación con el componente de E de los otros)): Cada variable se compone del factor común (F1) multiplicado por un coeficiente (L1, L2, L3 , los lambdas) más un componente único o aleatorio. Si el factor fuera medible (que no es) esta ecuación sería una regresión simple. 7.3. Análisis factorial en SPSS El análisis factorial intenta identificar variables subyacentes, o factores, que expliquen la configuración de las correlaciones dentro de un conjunto de variables observadas. El análisis factorial se suele utilizar en la reducción de los datos para identificar un pequeño número de factores que explique la mayoría de la varianza observada en un número mayor de variables manifiestas. También puede utilizarse para generar hipótesis relacionadas con los mecanismos causales o para inspeccionar las variables para análisis subsiguientes (por ejemplo, para identificar la colinealidad antes de realizar un análisis de regresión lineal). UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 66 SPSS Aplicado a la Gestión de Mercados Ilustración 39. Análisis factorial El procedimiento de análisis factorial ofrece un alto grado de flexibilidad: Existen siete métodos de extracción factorial disponibles. Existen cinco métodos de rotación disponibles. Existen tres métodos disponibles para calcular las puntuaciones factoriales; y las puntuaciones pueden guardarse como variables para análisis adicionales. 7.4. Etapas en un análisis factorial. El método es desarrollado principalmente en cuatro pasos: 1. La matriz de correlación o de covarianza es calculada. En el caso de que una variable muestre bajos coeficientes de correlación con las otras variables, esta puede ser eliminada y, por lo tanto, obtener la nueva matriz de correlación. Sin embargo, es necesario que observe los valores de su comunidad y las cargas factoriales. Ilustración 40. Matriz de covarianza UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 67 SPSS Aplicado a la Gestión de Mercados 2. Las cargas factoriales son estimadas. En este parte, es necesario establecer el método empleado para la extracción de los factores ya sea por componentes principales u otro método de extracción. 3. Las cargas factoriales son rotadas a fin de obtener cargas más fácilmente interpretables. Los métodos de rotación genera cargas para cada factor ya sea grandes o pequeñas, pero no de valores intermedios. Esta rotación permite reducir el número de factores a la estructura más simple que describe los datos, esto es, encontrar una solución final. 4. Para cada caso, los puntajes pueden ser calculados para cada factor y almacenados para usarlos como variables de entrada en otros procedimientos. 7.4.1. Extracción de factores. Para este caso se utilizara la base de datos mundo 95 que trae SPSS, es un estudio realizado en 109 países acerca de datos demográficos. Utilizamos las variables: Esperanza de vida femenina Mortalidad infantil (muertes por 1000 nacimientos vivos) Personas Alfabetizadas (%) Tasa de natalidad (por 1.000 habitantes) Tasa de mortalidad (por 1.000 habitantes) Fertilidad: número promedio de hijos Habitantes en ciudades (%) Log(10) de PIB_CAP Aumento de la población (% anual) Tasa Nacimientos/Defunciones Log(10) de Población UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 68 SPSS Aplicado a la Gestión de Mercados Ilustración 41. Cuadro de dialogo análisis factorial Son muchos los métodos que pueden emplearse para extraer los factores iniciales de la matriz de correlación. En general, estos métodos son complejos numéricamente. El SPSS proporciona de siete métodos de extracción, sin embargo, el más ampliamente usado en la práctica es el método de extracción por componentes principales. Ilustración 42. Cuadro de Dialogo Análisis factorial- Extracción 1. Análisis de componentes principales. Método de extracción de factores utilizado para formar combinaciones lineales no correlacionadas de las variables observadas. La primera componente tiene la varianza máxima. Las componentes sucesivas explican progresivamente proporciones menores de la varianza y no están correlacionadas las unas con las otras. El análisis de componentes principales se utiliza para obtener la solución factorial inicial. Puede utilizarse cuando una matriz de correlaciones es singular. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 69 SPSS Aplicado a la Gestión de Mercados 2. Método de mínimos cuadrados no ponderados. Método de extracción factorial que minimiza la suma de los cuadrados de las diferencias entre las matrices de correlaciones observada y reproducida, ignorando las diagonales. 3. Método de mínimos cuadrados generalizados. Método de extracción de factores que minimiza la suma de los cuadrados de las diferencias entre las matrices de correlación observada y reproducida. Las correlaciones se ponderan por el inverso de su unicidad, de manera que las variables que tengan un valor alto de unicidad reciban un peso menor que las que tengan un valor bajo de unicidad. 4. Método de máxima verosimilitud. Método de extracción factorial que proporciona las estimaciones de los parámetros que con mayor probabilidad han producido la matriz de correlaciones observada, si la muestra procede de una distribución normal multivariada. Las correlaciones se ponderan por el inverso de la unicidad de las variables y se emplea un algoritmo iterativo. 5. Factorización de ejes principales. Método de extracción de factores que parte de la matriz de correlaciones original con los cuadrados de los coeficientes de correlación múltiple insertados en la diagonal principal como estimaciones iniciales de las comunalidades. Las saturaciones factoriales resultantes se utilizan para estimar de nuevo las comunalidades y reemplazan a las estimaciones previas en la diagonal de la matriz. Las iteraciones continúan hasta que los cambios en las comunalidades, de una iteración a la siguiente, satisfagan el criterio de convergencia para la extracción. 6. Alfa. Método de extracción factorial que considera a las variables incluidas en el análisis como una muestra del universo de las variables posibles. Este método maximiza el Alfa de Cronbach para los factores. 7. Factorización imagen. Método de extracción de factores, desarrollado por Guttman y basado en la teoría de las imágenes. La parte común de una variable, llamada la imagen parcial, se define como su regresión lineal sobre las restantes variables, en lugar de ser una función de los factores hipotéticos. 7.4.2. Rotación De Factores Con frecuencia es muy difícil interpretar los factores iniciales. Por consiguiente la solución inicial se rota con el propósito de generar una solución que permita la interpretación. Existen dos amplios tipos de rotación: (1) rotación ortogonal, que mantiene a los factores no correlacionados entre sí y (2) rotación oblicua, la cual permite que los factores se correlacionen entre sí, la idea básica de la rotación es generar factores que tengan algunas variables muy correlacionadas y otras poco correlacionadas. Esto evita tener el problema de factores con todas las variables que presentan correlaciones de medio rango y, por tanto, permite una interpretación más fácil. El SPSS dispone de cinco métodos de rotación. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 70 SPSS Aplicado a la Gestión de Mercados Ilustración 43. Cuadro de Dialogo Análisis factorial- Rotación. 1. Método varimax. Método de rotación ortogonal que minimiza el número de variables que tienen saturaciones altas en cada factor. Simplifica la interpretación de los factores. 2. Criterio Oblimin directo. Método para la rotación oblicua (no ortogonal. Cuando delta es igual a cero (el valor por defecto) las soluciones son las más oblicuas. A medida que delta se va haciendo más negativo, los factores son menos oblicuos. Para anular el valor por defecto 0 para delta, introduzca un número menor o igual que 0,8. 3. Método quartimax. Método de rotación que minimiza el número de factores necesarios para explicar cada variable. Simplifica la interpretación de las variables observadas. 4. Método equamax. Método de rotación que es combinación del método varimax, que simplifica los factores, y el método quartimax, que simplifica las variables. Se minimiza tanto el número de variables que saturan alto en un factor como el número de factores necesarios para explicar una variable. 5. Rotación promax. Rotación oblicua que permite que los factores estén correlacionados. Puede calcularse más rápidamente que una rotación oblimin directa, por lo que es útil para conjuntos de datos grandes. 7.4.3. Descriptivos Esta opción permite obtener estadísticos descriptivos de las variables que usamos para el análisis factorial además de varias opciones estadísticas y matriciales para un mejor estudio de la matriz de correlaciones. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 71 SPSS Aplicado a la Gestión de Mercados Ilustración 44. Cuadro de Dialogo Análisis factorial- Descriptivos. Descriptivos univariados: muestra para cada variable, número de casos validos, la desviación estándar y la media. Estadí sticos descri ptivos Des v iac ión tí pica N del análisis 69, 94 10, 695 105 43, 317 38, 3699 105 78, 14 23, 056 105 26, 124 12, 3582 105 9, 62 4, 277 105 3, 551 1, 8909 105 57, 02 24, 010 105 3, 4086 ,62725 105 1, 696 1, 1929 105 3, 1868 2, 09158 105 4, 1252 ,65961 105 Media Esperanza de v ida f emenina Mortalidad inf antil (muertes por 1000 nac imientos v iv os) Pers onas Alf abetizadas (%) Tas a de natalidad (por 1. 000 habitant es) Tas a de mort alidad (por 1. 000 habit antes) Fert ilidad: número promedio de hijos Habitant es en c iudades (%) Log(10) de PIB_CAP Aumento de la población (% anual) Tas a Nac imient os/ Def unc iones Log(10) de Poblac ión Tabla 21. Estadísticos descriptivos Como se puede observar son los estadísticos para cada variable que interviene en el estudio. Solución inicial: con esta opción se obtienen las comunalidades iniciales, los UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 72 SPSS Aplicado a la Gestión de Mercados autovalores de la matriz analizada y los porcentajes de varianza que esta relacionada a cada factor que ha sido extraído; las comunalidades son la proporción de la varianza que puede ser explicada por el modelo factorial en cada variable, en este caso se puede observar que son altos los niveles que posee cada variable que fue utilizada para la extracción de los factores en este caso. Comunali dades Inic ial Esperanza de v ida f em enina Mortalidad inf ant il (m uertes por 1000 nac imient os v iv os) Personas Alf abetizadas (%) Tas a de nat alidad (por 1. 000 habitant es) Tas a de m ortalidad (por 1. 000 habitantes ) Fert ilidad: núm ero promedio de hijos Habit ant es en ciudades (%) Log(10) de PIB_CAP Aumento de la población (% anual) Tas a Nac im ient os/D ef unciones Log(10) de Población Extracción 1, 000 ,965 1, 000 ,944 1, 000 ,857 1, 000 ,965 1, 000 ,911 1, 000 ,927 1, 000 ,719 1, 000 ,813 1, 000 ,958 1, 000 ,951 1, 000 ,939 Mét odo de extracción: Análisis de C omponent es principales. Tabla 22. Comunalidades iniciales Dentro de los estadísticos que ofrece la matriz de correlaciones tenemos: Coeficientes: Muestra los coeficientes de correlación de cada variable. Determinante: Añade a la matriz de correlaciones su determinante, el cual sirve para analizar la pertinencia del análisis ya que si este es muy cercano a cero indica que las variables utilizadas están linealmente relacionadas, pero si este es cero indica dependencia lineal entre ellas lo cual no sirve para la realización del análisis. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 73 SPSS Aplicado a la Gestión de Mercados Coeficientes variable de cada Determinante Ilustración 45. Detalle estadísticos. Para el caso se puede observar que el determinante es muy cercano a cero 1.506 x10-8 lo que indica que este estudio factorial es muy indicado para este caso. Reproducida: La matriz reproducida es la matriz de correlaciones que se obtiene de la solución factorial, en la diagonal de esta matriz se encuentran la comunalidades finales inmediatamente debajo se muestra la matriz de correlacione residuales que tiene la diferencia de de las correlaciones observadas y las reproducidas, si el modelo es bueno los factores con residuos altos debe ser pequeño, Si el modelo es bueno y el numero de factores el adecuado esta la matriz de correlaciones debe poderse reproducir. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 74 SPSS Aplicado a la Gestión de Mercados Correlaci ones reproducidas Esperanza de v ida f emenina Personas Alf abetizadas (%) Mortalidad inf ant il (muertes por 1000 nac imient os v iv os ) ,703 ,800 ,703 -, 790 ,563 -, 676 ,800 ,975 ,878 -, 958 ,656 -, 867 Habit ant es en ciudades (%) Correlac ión reproducida Res iduala Habit ant es en ciudades (%) Esperanza de v ida f emenina Personas Alf abetizadas (%) Mortalidad inf ant il (muertes por 1000 nac imient os v iv os) Producto interior brut o per-capita Tas a de nat alidad (por 1. 000 habitant es) Tas a de mortalidad (por 1. 000 habitantes ) Tas a Nac imient os/D ef unciones Fert ilidad: número promedio de hijos Log(10) de Población Esperanza de v ida masculina Habit ant es en ciudades (%) Esperanza de v ida f emenina Personas Alf abetizadas (%) Mortalidad inf ant il (muertes por 1000 nac imient os v iv os) Producto interior brut o per-capita Tas a de nat alidad (por 1. 000 habitant es) Tas a de mortalidad (por 1. 000 habitantes ) Tas a Nac imient os/D ef unciones Fert ilidad: número promedio de hijos Log(10) de Población Esperanza de v ida masculina b b b Producto interior bruto per-capita Tas a de nat alidad (por 1.000 habitant es) Tas a de mortalidad (por 1.000 habitant es) Tas a Nac imient os/ Def unciones Fert ilidad: número promedio de hijos Log(10) de Población -, 570 ,000 -, 658 -, 270 ,790 -, 703 -, 070 -, 856 -, 077 ,959 Esperanza de v ida masculina ,703 ,878 ,838 -, 874 ,671 -, 873 -, 502 -, 274 -, 856 -, 011 ,847 -, 790 -, 958 -, 874 ,946 -, 672 ,872 ,652 ,119 ,858 ,096 -, 939 ,563 ,656 ,671 -, 672 ,646 -, 735 -, 183 -, 423 -, 700 -, 202 ,614 -, 676 -, 867 -, 873 ,872 -, 735 ,951 ,374 ,469 ,927 -, 055 -, 821 -, 570 -, 703 -, 502 ,652 -, 183 ,374 ,937 -, 551 ,403 -, 034 -, 741 ,000 -, 070 -, 274 ,119 -, 423 ,469 -, 551 ,939 ,428 -, 162 ,006 -, 099 -, 814 b b b b b b -, 658 -, 856 -, 856 ,858 -, 700 ,927 ,403 ,428 ,907 -, 270 -, 077 -, 011 ,096 -, 202 -, 055 -, 034 -, 162 -, 099 ,790 ,959 ,847 -, 939 ,614 -, 821 -, 741 ,006 -, 814 -, 034 -, 049 ,046 ,056 ,041 ,048 ,004 -, 012 -, 004 -, 008 ,001 ,000 -, 011 -, 028 -, 117 ,004 ,017 ,025 -, 003 -, 016 ,067 -, 034 ,935b -, 081 b -, 081 ,950 ,050 ,097 -, 036 ,009 -, 008 ,023 ,003 -, 010 -, 039 -, 039 -, 005 -, 014 ,010 ,002 ,014 ,069 ,105 ,118 ,030 ,011 -, 003 ,049 ,036 ,012 ,041 ,021 ,031 -, 002 ,002 ,027 -, 012 ,055 ,020 -, 049 -, 012 ,046 -, 004 -, 028 ,056 -, 008 -, 117 ,025 ,041 ,001 ,004 -, 003 ,067 ,048 ,000 ,017 -, 016 ,014 ,011 ,004 -, 011 ,003 -, 005 ,069 -, 003 ,041 ,050 ,009 -, 010 -, 014 ,105 ,049 ,021 ,002 ,097 -, 008 -, 039 ,010 ,118 ,036 ,031 ,027 ,055 -, 036 ,023 -, 039 ,002 ,030 ,012 -, 002 -, 012 ,020 ,002 ,002 Mét odo de extracción: Análisis de Componentes principales. a. Los residuos se calculan entre las correlaciones observ adas y reproduc idas. Hay 9 (16,0%) residuales no redundantes con v alores absolut os may ores que 0,05. b. Comunalidades reproducidas Tabla 23. Matriz reproducida UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 75 SPSS Aplicado a la Gestión de Mercados Diagonal de Comunalidades Residuos Ilustración 46. Detalle matriz reproducida KMO y Prueba de esfericidad de Bartlett: Kaiser-Meyer-Olkin (KMO) es la medida de adecuación maestral este toma valores entre 0 y 1; los datos menores a 0.5 dan al investigador la noción de que no es muy buena idea realizar el análisis factorial con los datos que se tienen. La prueba de esfericidad es el estadístico de prueba para la hipótesis nula de que la matriz de correlaciones es una matriz identidad, lo que querría decir que no existen correlaciones significativas entre las variables lo que supone que la realización de análisis factorial no seria adecuado. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 76 SPSS Aplicado a la Gestión de Mercados KMO y prueba de Bartl ett Medida de adecuac ión muest ral de Kaiser-Mey er-Olkin. Prueba de esf ericidad de Bartlet t ,862 Chi-cuadrado aproximado gl 1785,571 55 Sig. ,000 Tabla 24.Prueba KMO Después del cuadro de varianza total explicada la cual nos permite ver cuales factores son los mas apropiados para el estudio, aquellos cuyos autovalores sean mayores que 1y que preferiblemente al realizar la suma de las saturaciones y la rotación de factores sigan siendo mayores que 1 y logren explicar en gran cantidad la varianza total de las variables. Varianza total expl icada Componente 1 2 3 4 5 6 7 8 9 10 11 Autov alores iniciales % de la Tot al v arianza % acumulado 6, 887 62, 610 62, 610 1, 790 16, 275 78, 885 1, 049 9, 539 88, 425 ,567 5, 151 93, 576 ,292 2, 654 96, 230 ,171 1, 553 97, 783 ,106 ,961 98, 744 ,074 ,676 99, 420 ,038 ,349 99, 770 ,016 ,150 99, 920 ,009 ,080 100,000 Sumas de las sat urac iones al c uadrado de la extracción % de la Tot al v arianza % acumulado 6, 887 62, 610 62, 610 1, 790 16, 275 78, 885 1, 049 9, 539 88, 425 Suma de las saturaciones al cuadrado de la rotac ión % de la Tot al v arianza % acumulado 6, 874 62, 488 62, 488 1, 773 16, 118 78, 606 1, 080 9, 819 88, 425 Mét odo de extracción: Anális is de Componentes principales. Tabla 25. Varianza total explicada Ilustración 47. Detalle varianza total UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 77 SPSS Aplicado a la Gestión de Mercados Para este ejemplo podemos ver como el primer factor explica gran cantidad de la varianza y que además se cuenta con otros dos factores que sirven para el modelo ya que el total supera 1 y además entre los tres logran explicar el 88.42% de la varianza total de las variables del modelo. Este cuadro se puede ver de una manera grafica mediante el grafico de sedimentación: Gráfico de sedimentación 7 6 Autovalor 5 4 3 2 1 0 1 2 3 4 5 6 7 8 9 10 11 Número de componente Ilustración 48. Grafico de sedimentación. Este es el grafico de los autovalores generados por el análisis y al verlo ya se puede hacer una idea de los factores que más explicarían el modelo, ya que cuando la grafica se torna muy plana estos son componentes residuales que no son importantes para el análisis. Una de las partes más importantes del análisis es la matriz de componentes o estructura factorial ya que su nombre cambia dependiendo el método de extracción utilizado ya que esta nos permite ver las correlaciones o saturaciones que mas explica cada factor y de esta manera ver que variables están mas relacionadas con cada factor y de esta manera podemos nombrar cada factor para su estudio. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 78 SPSS Aplicado a la Gestión de Mercados a Matri z de componentes 1 Esperanza de v ida f emenina Mortalidad inf ant il (muertes por 1000 nac imientos v iv os) Esperanza de v ida masculina Tas a de natalidad (por 1. 000 habitant es) Personas Alf abetizadas (%) Fert ilidad: número promedio de hijos Habit ant es en ciudades (%) Producto interior brut o per-capita Tas a Nac imient os/ Def unciones Tas a de mort alidad (por 1. 000 habit antes) Log(10) de Población Componente 2 3 ,978 ,134 ,024 -, 969 -, 082 ,009 ,952 ,207 ,037 -, 926 ,301 -, 055 ,910 -, 096 ,034 -, 909 ,264 -, 109 ,798 ,179 -, 184 ,716 -, 283 -, 232 -, 202 ,947 ,045 -, 616 -, 701 -, 256 -, 071 -, 231 ,936 Mét odo de extracción: Anális is de componentes principales. a. 3 componentes ext raí dos Tabla 26. Matriz de componentes. En esta tabla podemos observar que las esperanzas de vida masculina y femenina, personas alfabetizadas, habitantes en ciudades y producto interno bruto saturan positivamente el primer factor y como la mortalidad infantil y la tasa de natalidad lo hacen negativamente en este caso podríamos denominar el factor como calidad de vida y esperanza de vida. El segundo factor es saturado por la tasa de nacimientos/defunciones y por la tasa de mortalidad, este factor se podría denominar simplemente tasa de nacimientos/defunciones y el tercer factor solamente es saturado por el log 10 de la población; como se puede ver todos los factores son independientes entre ellos lo que comprueba que el análisis es apropiado para este caso. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 79 SPSS Aplicado a la Gestión de Mercados Y además es importante tener en cuenta la matriz ya rotada: a Matri z de componentes rotados 1 Esperanza de v ida f emenina Mortalidad inf ant il (muertes por 1000 nac imientos v iv os) Esperanza de v ida masculina Tas a de natalidad (por 1. 000 habitant es) Fert ilidad: número promedio de hijos Personas Alf abetizadas (%) Habit ant es en ciudades (%) Producto interior brut o per-capita Tas a Nac imient os/ Def unciones Tas a de mort alidad (por 1. 000 habit antes) Log(10) de Población Componente 2 3 ,970 ,179 -, 026 -, 964 -, 121 ,049 ,941 ,253 -, 028 -, 940 ,243 -, 088 -, 922 ,197 -, 134 ,914 -, 048 ,029 ,786 ,176 -, 235 ,725 -, 290 -, 191 -, 247 ,928 -, 132 -, 586 -, 764 -, 101 -, 044 -, 050 ,964 Mét odo de extracción: Anális is de componentes principales. Mét odo de rotación: Normalización Varimax con Kaiser. a. La rot ación ha conv ergido en 4 iteraciones. Tabla 27. Matriz de componentes rotados En este caso las saturaciones no cambian mucho lo que permite seguir con los factores que ya se habían elegido. Para finalizar el análisis entre las opciones que ofrece la reducción factorial esta el cálculo de las puntuaciones que servirán para la realización de la regresión lineal con los nuevos factores que se obtuvieron Ilustración 49. Analisis factorial- puntuaciones factoriales UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 80 SPSS Aplicado a la Gestión de Mercados 8. Conclusiones El análisis de conglomerados jerárquicos y el análisis de conglomerados de k medias son métodos de análisis de tipo aglomerativo, ya que parten de casos individuales y van agrupando casos hasta llegar a grupos o conglomerados homogéneos. Si se tiene un gran número de casos para conglomerar es conveniente emplear el método de conglomerado jerárquico en dos fases. Si se tiene un gran número de casos para conglomerar y todas las variables son escalares se puede emplear el análisis de Análisis de Conglomerados de K Medias. Si se desea examinar la estructura de las variables y son variables escalares, se puede realizar mediante el análisis factorial. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 81 SPSS Aplicado a la Gestión de Mercados 9. Bibliografia REYES, Rafael. La Estrategia de Mercados en el Siglo XXI, Revista entorno No.163, Confederación Patronal de la República Mexicana, México, Marzo 2002. STANTON, ET AL. “Fundamentos de Marketing”, McGrawHIl, México, 1999. KOTLER, Phillip. “Dirección de Marketing. La edición del milenio” PrenticeHall, México., 2001 Market Segmentation Using SPSS®, SPSS Inc. Estados Unidos De America, 2003. Malhotra, Naresh K.. Investigación de mercados un enfoque práctico Naresh K. Malhotra ; tr. Verania de Parres Cárdenas. 2a. ed..-- México : Prentice Hall : Pearson Educación : Addison Wesley 1997. http://www.spss.com/la/apps/data-mining2.htm http://www.estadistico.com/arts.html?20001023 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 82