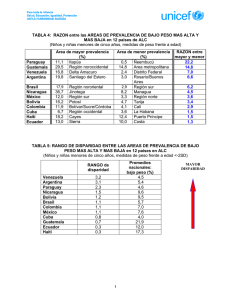
Vision Artificial - Percepcion de Profundidad
Anuncio

“Visión Artificial: Percepción de Profundidad” Opción I: Tesis Profesional Autor: Mario Gonzalo Chirinos Colunga Asesor: José Ramón Atoche Enseñat Departamento de Ingeniera Electrónica. Instituto Tecnológico de Mérida. Noviembre 2004 A la memoria de mi abuelo. Agradecimientos Este trabajo es la culminación de mis estudios de licenciatura, los cuales aproveche plenamente gracias a la formación que me dieron mis padres y a su empeño en que esta fuera más allá de lo aprendido en la escuela. Mi interés por la visión por computadora surgió gracias a mi profesor y asesor de tesis así como de otros proyectos José Ramón Atoche Enseñat, del cual he aprendido mucho. Los resultados de este trabajo mejoraron ampliamente gracias a los consejos de los doctores Luís Alberto Muñoz Ubando, Arturo Espinosa Romero y Ricardo Legarda Sáenz y a sus discusiones y platicas en las juntas de lunes dentro de la facultad de matemáticas. A mis tíos Dra. Patricia Colunga y Dr. Daniel Zizumbo, gracias por sus consejos sobre la forma de redactar textos científicos así como su paciencia para revisar y corregir parte de este documento. Y muchas gracias a toda mi familia por toda su confianza y apoyo. INDICE 1. Introducción. 1 1.1. Hipótesis. 5 1.2. Justificación. 5 2. Fundamento Teórico. 6 2.1. Formatos de Imagen. 6 2.2. Almacenamiento. 7 2.3. Filtros Lineales. 8 2.4. Tratamiento y Mejoramiento de Imagen. 9 2.4.1. Escala de Grises. 10 2.4.2. Contraste y Brillo. 10 2.4.3. Tolerancia Binaria. 11 2.4.4. Filtros Pasa Bajas (Eliminación de Ruido). 12 2.4.5. Filtros Pasa Altas (Detección de Contornos). 14 2.4.6. Filtro Pasa Bandas. 18 2.4.7. Histograma. 19 2.5. Percepción de Profundidad. 20 2.5.1. Geometría Epipolar. 23 2.5.2. Rectificación de Imágenes. 25 2.5.3. Algoritmos de Apareamiento Estereoscopio. 27 3. Procedimiento. 33 3.1. Introducción. 33 3.2. Algoritmo. 35 3.2.1. Apareamiento. 37 3.2.2. Mapa de Disparidad. 41 3.2.3. Mapa de Disparidad en Sub-pixel. 43 3.2.4. Filtro Iterativo de Mediana Condicional. 45 3.2.5. Oclusiones. 45 4. Resultados. 47 5. Conclusiones y Trabajos Futuros 52 6. Referencias. 53 Anexos. 56 Apéndice A. Algoritmos en C++. 56 Visión Artificial: Percepción de Profundidad Introducción 1. Introducción. El término “visión por computadora” dentro del campo de la Inteligencia Artificial puede considerarse como el conjunto de todas aquellas técnicas y modelos que nos permitan el procesamiento, análisis y explicación de cualquier tipo de información obtenida a través de imágenes digitales. Desde sus inicios, los desarrollos de la visión por computadora han estado inspirados en el estudio del sistema visual humano, el cual sugiere la existencia de diferentes tipos de tratamiento de la información visual dependiendo de metas u objetivos específicos, es decir, la información percibida es procesada en distintas formas con base en las características particulares de la tarea a realizar; así como en psicología se estudian y desarrollan teorías sobre la percepción visual, la visión por computadora propone varias técnicas y teorías que permiten obtener una representación del mundo a partir del análisis de imágenes obtenidas desde cámaras de video. Debido a que la información visual es una de las principales fuentes de datos del mundo real, resulta útil el proveer a una computadora digital del sentido de la vista, que junto con otros mecanismos como el aprendizaje hagan de esta una herramienta capaz de detectar y ubicar objetos en el espacio. La meta de la visión por computadora es modelar y automatizar el proceso de reconocimiento visual, esto es, “distinguir entre objetos con importantes diferencias entre ellos”, como diferenciar un automóvil y una bicicleta en una fotografía así como separar aves en vuelo del fondo en un video, o seguir la trayectoria de objetos en imágenes aéreas. El campo de la visión artificial esta aun en desarrollo, es una frontera intelectual. Como cualquier otra frontera del conocimiento es excitante y a la Instituto Tecnológico de Mérida 2004 1 Visión Artificial: Percepción de Profundidad Introducción vez desorganizada. Muchas veces no hay una autoridad en el campo a la cual se pueda acudir o hacer referencia, por lo que es necesario desarrollar métodos innovadores. Algunas ideas muy útiles, por su simpleza u obviedad carecen de sustento teórico y al mismo tiempo algunas teorías bien desarrolladas son imprácticas en muchos casos por el tiempo de procesamiento requerido, el cual impide que el análisis se haga en tiempo real. Este es uno de los principales problemas, pues el análisis de imágenes utiliza muchos recursos, por lo que cada vez se necesita de equipo más veloz para lograr analizar la imagen en el tiempo requerido, es decir, antes de que la siguiente imagen sea capturada, de forma que, dependiendo de la aplicación existirán sistemas en los cuales el tiempo de análisis no sea tan prioritario como en otros que necesiten procesar treinta imágenes por segundo, por ejemplo el tiempo en la identificación de una huella digital no requiere ser tan corto como el requerido para el análisis de imágenes en un sistema de rastreo de objetos en movimiento. La visión por computadora tiene una amplia variedad de aplicaciones, típicas como inspección industrial o inteligencia militar y nuevas como interacción humana, recuperación de imágenes de bibliotecas digitales, análisis de imágenes médicas y la generación de escenas en graficas por computadora, muy utilizadas en los videojuegos. El estudio de la visión por computadora así como el desarrollo de nuevos métodos y teorías no siempre requiere del uso de matemáticas profundas, pero si requiere de tener facilidad y estar abierto a una muy amplia variedad de ideas matemáticas. Uno de los tipos de información visual mas importante es la percepción de profundidad, la cual percibimos gracias a la visión estereoscópica; ella nos Instituto Tecnológico de Mérida 2004 2 Visión Artificial: Percepción de Profundidad Introducción permite interactuar en un mundo tridimensional al juzgar las dimensiones de los objetos que nos rodean. Por medio de la visión por computadora podemos procesar la información obtenida en un par de imágenes estereoscópicas, pues estas contienen una gran cantidad de información geométrica de la escena capturada, y con ella generar información útil para sistemas de navegación, robots, mapas topográficos, modelos tridimensionales etc. Auque existen otros métodos para obtener la profundidad de una escena, la visón estereoscópica es un proceso de captura rápido, y un método no invasivo pues a diferencia de los demás métodos no requiere de enviar una señal y analizar la señal de regreso, con esto se logra una invasión mínima en el ambiente que se desea recrear, el hardware involucrado es barato y fácil de utilizar ya que solo involucra al aparato estereoscópico formado por las dos cámaras para capturar la escena que se quiere reconstruir [1]. Alguno de los métodos utilizados para la obtención de profundidad son: Dispositivos ultrasónicos: El principal problema con estos dispositivos es que la medición obtenida es afectada por fenómenos extraños e impredecibles como reflexiones múltiples de las ondas ultrasónicas sobre varios objetos lo que lleva a una estimación errónea del tiempo de reflexión. Dispositivos láser: Son aplicados a la medición y reconstrucción de objetos relativamente pequeños y navegación autónoma. Estos sistemas son en extremo precisos pero sufren de los mismos problemas que los dispositivos ultrasónicos, son usados para un rango especifico de distancias y pueden ser caros y algunas veces peligrosos. Instituto Tecnológico de Mérida 2004 3 Visión Artificial: Percepción de Profundidad Introducción Luz estructurada. Es método activo que emplea cámaras para adquirir la imagen de un objeto iluminado por un patrón regular de luz, requiere de dispositivos auxiliares como un emisor láser o un proyector, para proyectar un patrón o patrones de luz en el objeto. Se utiliza para la medición precisa de superficies de objetos en un rango cercano y de poca textura. La necesidad de un proyector auxiliar hace que este método sea poco flexible, las mediciones obtenidas por dispositivos activos pueden ser afectadas por reflexiones inesperadas o interferencia y necesitan ser usadas con extremo cuidado. El utilizar un aparato estereoscópico formado por dos cámaras de video, nos permite obtener de una forma sencilla y no invasiva, la información necesaria para la recreación tridimensional de la escena sin necesidad de aditamentos externos que elevan el costo y reducen la flexibilidad del instrumento. Para recuperar la mayor cantidad posible de información en una escena estereoscópica se requiere de un método que logre generar un mapa de profundidad detallado y sin ruidos, el cual es el objetivo de este trabajo, pues los algoritmos que encuentran un mapa suave, sin errores que generen saltos bruscos de profundidad, tienden a perder detalle y aquellos que obtienen un mapa detallado tienden a ser ruidosos. Para el desarrollo de este trabajo fue necesario aprender sobre técnicas básicas en visión artificial. En el fundamento teórico se explican técnicas para la manipulación de imágenes, su almacenamiento en memoria y filtros lineales, y en al apéndice A se incluye su código fuente en C++. En la segunda parte del fundamento teórico se explican los principios de la visión estereoscópica y sus propiedades geométricas. En la parte final del fundamento teórico se describen las clases de algoritmos de apareamiento estereoscópico y los resultados Instituto Tecnológico de Mérida 2004 4 Visión Artificial: Percepción de Profundidad Introducción obtenidos mediante su implementación. EL resto del documento describe el método de apareamiento estereoscópico desarrollado, el cual genera mapas de disparidad detallados y sin ruido. Seguido de los resultados obtenidos para imágenes estereoscópicas reales y sintéticas. El método desarrollado permite generar mapas densos de disparidad detallados y sin ruido, mediante la modificación varias de técnicas como suma de diferencias al cuadrado, ventana de correlación adaptativa, filtros de mediana y obtención de disparidades en sub-píxel. La eficacia del algoritmo se demuestra por la calidad de los mapas de disparidad obtenidos. 1.1 Hipótesis. Por medio del perfeccionamiento de técnicas de apareamiento estereoscópico, como son la correlación con ventana adaptativa y el refinamiento de mapas de disparidad, se puede mejorar el detalle obtenido por los métodos actuales de apareamiento estereoscópico. 1.2 Justificación. Una de las principales motivaciones para la realización de este trabajo fue la necesidad de la comunidad de oceanógrafos de recrear el modelo del suelo marino y arrecifes para estudiarlo y obtener medidas precisas a partir de videos submarinos, sin embargo, esta no es la única aplicación, las técnicas de apareamiento estereoscópico son útiles para la generación de modelos tridimensionales, manipulación de objetos con robots, mapas topográficos, sistemas de navegación autónoma y otros. Instituto Tecnológico de Mérida 2004 5 Visión Artificial: Percepción de Profundidad Fundamento Teórico. 2. Fundamento Teórico Para lograr el objetivo de esta tesis es necesario tener conocimiento básico de las técnicas utilizadas en visión por computadora, como la forma de almacenar las imágenes para su posterior análisis, los filtros básicos para el tratamiento de imágenes y los métodos actuales de apareamiento estereoscópico. 2.1 Formatos de Imagen El estándar para imágenes de colores son palabras de 24 bits, tres palabras juntas de ocho bits cada una, las cuales representan los tres colores primarios [2], rojo verde y azul (RGB por sus siglas en ingles). De forma que para el negro se tiene la ausencia de color y se representa por: 0x00-0x00-0x00, el blanco contiene todas las frecuencias y se expresa: 0xFF-0xFF-0xFF, el color rojo puro es: 0xFF-0x00x00, y así para el verde y azul, la combinación de los tres colores puede formar una gama de 16,777,216 colores. Formalmente se define como el uso las longitudes primarias, 564.16nm para el rojo, 526.32nm para el verde y 444,44nm para el azul. Existe otro estándar de colores para imágenes digitales, HSL (Hue, Saturation & Light) [2] el cual indica el tono de color, su saturación y su brillantes, de igual manera son tres palabras cada una con valores del 0 al 255, pero no todos los filtros diseñados para estándar RGB responden de la misma manera para HSL. Instituto Tecnológico de Mérida 2004 6 Visión Artificial: Percepción de Profundidad Fundamento Teórico. RGB HSL Figura 2.1: Diferencia entre los canales de formato RGB y el HSL 2.2 Almacenamiento Para poder manipular una imagen es necesario almacenar los datos en la memoria de la computadora; una imagen digital es una matriz enorme en donde cada casilla representa un píxel en la imagen y su valor contiene el color del píxel correspondiente, por lo que la imagen se almacenara en forma de un arreglo bidimensional de las mismas dimensiones de la imagen. El primer código en el apéndice A genera un arreglo dinámico bidimensional en el cual se almacena la imagen en memoria, las direcciones del arreglo pueden ser accesadas de manera aleatoria. Instituto Tecnológico de Mérida 2004 7 Visión Artificial: Percepción de Profundidad Fundamento Teórico. 2.3 Filtros Lineales [2]. Los filtros para el tratamiento de imágenes digitales se basan en la convolución de la imagen con un patrón de píxeles llamado “Kernel”, máscara o ventana. Para los filtros lineales este proceso es un sistema lineal e invariante al desplazamiento. Invariante al desplazamiento por que el núcleo o máscara se desplaza a través de toda la imagen y el resultado de la convolución de la imagen con la máscara depende del patrón en la máscara y no de la posición de esta. Sistema lineal por que la convolución para la suma de dos imágenes, es la misma que la suma del resultado de aplicar la convolución a las dos imágenes independientemente. La mayoría de los sistemas lineales de imágenes cumplen tres importantes propiedades. Superposición: La respuesta a la suma de los estímulos es la suma de la respuesta individual de cada estimulo. R( f + g ) = R( f ) + R( g ) Escalamiento: La respuesta a un impulso nulo es cero. Con esto y la superposición, tenemos que la respuesta a un estimulo multiplicado por una constante es la respuesta del estimulo original multiplicada por la constante: R(kf ) = kR( f ) El tener la propiedad de superposición y la de escalamiento, lo hace un sistema lineal. Instituto Tecnológico de Mérida 2004 8 Visión Artificial: Percepción de Profundidad Fundamento Teórico. Invariante al desplazamiento: la respuesta a un estimulo desplazado es solo el traslado de la respuesta al estimulo. Esto significa que si por ejemplo, la vista de una pequeña luz apuntando al centro de la cámara, es un pequeño punto brillante, entonces si la luz es movida en la periferia, debemos de ver el mismo punto brillante solo desplazado. La respuesta de estos sistemas es obtenida por una convolución discreta en dos dimensiones y se expresa de la siguiente forma: R ( h)( x, y ) = ∑ ∑ g ( x − x ' , y − y ')h( x ' , y ') = ( g ⋅ ⋅h )( x, y ) x y Lo anterior representa la convolución de el núcleo o máscara (h(x,y), respuesta a un impulso unitario) y la imagen (estimulo), los dos son arreglos en dos dimensiones, que representan la estructura de los píxeles en la imagen. 2.4 Tratamiento y Mejoramiento de Imagen [3] Uno de los primeros pasos en las aplicaciones de visión artificial es mejorar la calidad de la imagen obtenida; en las imágenes con poca luz se observa generalmente un granulado o ruido que cubre toda la imagen, en algunas aplicaciones es útil el resaltar los bordes o las superficies uniformes de los objetos, algunas aplicaciones biométricas como el análisis de radiografías o de huellas digitales requieren de resaltar ciertas componentes de frecuencia y otras eliminar o resaltar colores específicos, también es útil mejorar la iluminación o el contraste de la imagen. Instituto Tecnológico de Mérida 2004 9 Visión Artificial: Percepción de Profundidad Fundamento Teórico. 2.4.1 Escala de Grises. En ciertas ocasiones es útil pasar una imagen a color (24 bits) a escala de grises (8 bits) ya sea solo por estética o por que se requiere trabajar con menos memoria utilizando palabras de solo ocho bits en vez de palabras de 24 bits, para agilizar el tiempo de procesamiento al realizar operaciones binarias mas cortas. Para lograr esto se requiere fusionar los tres canales de colores en uno solo que indique el tono de gris de la imagen. Esto se hace promediando los tres valores de cada píxel en la imagen original y poniendo el resultado en una imagen de 8 bits de un solo canal que indica el nivel de gris de la imagen. En el apéndice A se encuentra el código desarrollado para esta función. Figura 2.2: Imagen a color (izquierda). Imagen en escala de grises (Derecha) 2.4.2. Contraste y Brillo. Al modificar por igual el valor de cada canal de color en una imagen se aumenta o disminuye su luminosidad, al modificar el contraste se separan más los valores de colores en la imagen en base a un punto de balance, los valores por debajo del punto de balance se toman como obscuros, y los que están sobre el como claros, Instituto Tecnológico de Mérida 2004 10 Visión Artificial: Percepción de Profundidad Fundamento Teórico. el contraste hace que los tonos claros tengan mas brillo y las partes obscuras lo sean mas. El código para contraste y brillo en el apéndice A modifica el brillo y el contraste de una imagen de entrada en una imagen destino, con base al los paramentos de entrada, contraste, brillo y punto de balance. Se modifica el valor de cada píxel en cada canal de color, aumentando o disminuyendo la separación del color al punto de balance y aumentando o disminuyendo brillo. El parámetro de contraste se introduce en términos de porcentaje y el de brillo es un valor de –255 a +255 que determina el valor que se sumara por igual a cada canal de color. Figura 2.3: Modificar el brillo y contraste en una imagen es útil cuando se quiere separar del fondo los objetos que se encuentran en la imagen. 2.4.3 Tolerancia Binaria Este filtro convierte la imagen en una imagen binaria, se parte la imagen mediante un valor de tolerancia, cualquier valor por debajo del valor de tolerancia es tomado como 0 y cualquier por arriba de este es tomado como 255, en el caso de escala de grises como negro o blanco y en una imagen a color cada canal de color a cero o a 255. EL condigo en C++ para este filtro se encuentra en el apéndice A Instituto Tecnológico de Mérida 2004 11 Visión Artificial: Percepción de Profundidad Fundamento Teórico. Figura 2.4: Imagen en escala de grises e Imagen binaria resultante Figura 2.5: Imagen RGB e Imagen binarizada resultante en 8 colores. 2.4.4 Filtros Pasa Bajas (Difuminado - Eliminación de Ruido) Generalmente una imagen tiene la propiedad de que el valor de un píxel es similar el valor de sus vecinos, aunque la imagen sea afectada por el ruido podemos asumir que esta propiedad se mantiene. El ruido puede hacer que haya ocasionalmente píxeles faltantes o que un número aleatorio pueda ser añadido al valor de los píxeles, para corregir esto se puede sustituir el valor de este píxel por el valor promedio de sus píxeles vecinos. Para hacer esto se realiza la convolución de una máscara redonda de radio r con la imagen haciendo un promedio de los valores dentro del área de la máscara. Un mejor modelo para el difuminado, consiste en hacer que la importancia de los píxeles que conforman la máscara disminuya conforme se alejan de su centro. Instituto Tecnológico de Mérida 2004 12 Visión Artificial: Percepción de Profundidad Fundamento Teórico. Este filtro tiene una mejor respuesta, pues si bien un píxel es similar a sus vecinos esta similitud disminuye con la distancia. Si se le da a la máscara la forma de una campana gaussiana [2], la importancia de los píxeles vecinos para el promedio de valores tendrá la forma de esta y mientras mas cerca del centro de la máscara el efecto de difuminado será mayor pues el peso de los píxeles vecinos no caerá tan rápido con la distancia. El código de difuminado en el apéndice A es un filtro que difumina la imagen de entrada, mediante la convolución con una máscara de radio igual al parámetro de entrada “Kernel” en píxeles y el resultado lo almacena en una imagen destino. Al ir desplazando la máscara, se promedia el valor de todos los píxeles en ella y se remplaza el valor del píxel central con el promedio de los valores, entre mayor sea el radio de la máscara el difuminado será mas intenso, este filtro produce el efecto de que en apariencia la cámara esta desenfocada. Figura 2.6: Reducción de ruido gaussiano mediante un filtro de difuminado por promedio. Instituto Tecnológico de Mérida 2004 13 Visión Artificial: Percepción de Profundidad Fundamento Teórico. 2.4.5 Filtros Pasa Altas. (Detección de Contornos) En una imagen se puede utilizar un filtro de paso alto para resaltar sus bordes, pues estos son cambios bruscos de color y corresponden a altas frecuencias en la imagen, esto es un método basado en las primeras derivadas. En este método primero se miden los cambios de intensidad en todos los puntos de la imagen, haciendo uso de la primera derivada, después se seleccionan como puntos de bordes aquellos puntos en los que el cambio de intensidad rebasa algún umbral preestablecido. Una imagen puede representarse matemáticamente por una función f cuyo valor en el punto (x, y) representa la iluminación existente en ese punto, el cambio de iluminación de un punto en la imagen esta representado gráficamente por la pendiente que allí tiene la superficie que representa a f, y normalmente resulta diferente según sea la dirección considerada, la dirección en la que el cambio es más intenso esta dada por el vector gradiente en ese punto. El vector gradiente indica la dirección y magnitud del cambio máximo en la imagen y esta dado por la primera derivada: ⎡ ∂I ⎤ ⎢ ∂x ⎥ ⎡Gx ⎤ ∆I = ⎢ ⎥ = ⎢ ⎥ ⎣Gy ⎦ ⎢ ∂I ⎥ ⎢ ⎥ ⎣ ∂y ⎦ El cálculo del gradiente, por tanto, se basa en obtener las derivadas parciales para cada píxel. En la figura 2.7 se pueden ver los operadores de Roberts, Prewitt, Sobel y Frei-Chen para determinar las derivadas parciales. El requisito básico de un operador de derivación es que la suma de los coeficientes de la máscara sea Instituto Tecnológico de Mérida 2004 14 Visión Artificial: Percepción de Profundidad Fundamento Teórico. nula, para que la derivada de una zona uniforme de la imagen sea cero. Como en todos los métodos que utilizan máscaras, el procedimiento es realizar el producto de los elementos de la máscara por el valor correspondiente a los píxeles de la imagen encerrados por la máscara. Figura2.7 Operadores de derivación. Otro metodo para encontrar los contornos en una imagen es el SUSAN (“Smallest Univalue Segment Assimilating Nucleus”) [4], del cual se presenta un desarrollo mas a fondo por ser el que genera mejores resultados. En este modelo se hace la convolución R(r0) entre la imagen y una máscara circular para asegurar una respuesta isotropica, la máscara se centra en cada píxel de la imagen. En cada caso se compra cuantos del los píxeles dentro del área de la máscara tiene un valor similar, con una tolerancia t, al del píxel central c(r,r0), cada píxel similar se marca con un 1 y los otros con un 0. Si el total de píxeles similares al píxeles central n(r0) (área USAN) es aproximadamente del 50% (g tolerancia geométrica), del área total de la máscara entonces el píxel central se encuentra en un borde R(r0), y el píxel central se marca como borde en una nueva imagen, la respuesta a Instituto Tecnológico de Mérida 2004 15 Visión Artificial: Percepción de Profundidad Fundamento Teórico. los bordes será mayor si el área USAN es pequeña, este es el principio del algoritmo SUSAN: ⎧⎪1 si I (r ) − I (r0 ) ≤ t ⎧ g − n(r0 ) si n(r0 ) < g c(r , r0 ) = ⎨ , n(r0 ) = ∑ c(r , r0 ) , R(r0 ) = ⎨ ⎪⎩0 si I (r ) − I (r0 ) > t r ⎩0 otro Figura 2.8:Si el píxel central de la mascar esta en un borde, el área USAN será de alrededor del 50%. Un valor de 25 en la tolerancia t, es adecuado para la mayoría de las imágenes reales, para la supresión de ruido es conveniente hacer que la tolerancia geométrica g, sea mayor del 50% del área total, un valor de ¾ es adecuado para este propósito, se puede encontrar esquinas en lugar de bordes reduciendo el área USAN a un 25%. El algoritmo SUSAN para la detección de contornos se pude resumir en los siguientes pasos [5]: 1. Use una máscara circular centrada en cada píxel de la imagen. 2. Cuente el número de píxeles con intensidad similar al píxel del núcleo. 3. Reste el área USAN de la tolerancia geométrica para detectar bordes. Instituto Tecnológico de Mérida 2004 16 Visión Artificial: Percepción de Profundidad Fundamento Teórico. 4. Calcule el momento del área USAN para determinar la dirección del los bordes. La dirección de el contorno se encuentra con la perpendicular a la línea entre el centro de gravedad del área USAN y el núcleo de la máscara. Figura 2.9: Imagen obtenida después de pasar un filtro SUSAN para la detección bordes. El algoritmo SUSAN para la detección de esquinas se pude resumir en los siguientes pasos: 1. Use una máscara circular centrada en cada píxel de la imagen. 2. Cuente el número de píxeles con intensidad similar al píxel del núcleo. 3. Reste el área USAN de la tolerancia geométrica para detectar esquinas. 4. Buscar los falsos positivos calculando cada centroide USAN y sus contiguos. Instituto Tecnológico de Mérida 2004 17 Visión Artificial: Percepción de Profundidad Fundamento Teórico. 2.4.6. Filtros Pasa Bandas. Los filtros pasa bandas se utilizan para resaltar características en la imagen que estén en determinado rango de frecuencias. Una de sus aplicaciones es el mejoramiento de imágenes de huellas dactilares, en las imágenes de abajo se muestra el mejoramiento de una huella digital por medio de un filtro pasa bandas Grabor, este filtro permite resaltar los surcos de la huella introduciendo como parámetros del filtro pasa bandas, la orientación y frecuencia de estos [6]. Figura 2.10: La imagen de una huella digital puede ser mejorada mediante un filtro Grabor con la orientación y frecuencia de los surcos. Figura 2.11: Imagen original de círculos concéntricos (izquierda), Ruido añadido a la imagen original (Centro). Imagen recuperada mediante el filtro Grabor (Derecha). Instituto Tecnológico de Mérida 2004 18 Visión Artificial: Percepción de Profundidad Fundamento Teórico. 2.4.7 Histograma El histograma proporciona información acerca de la distribución de los canales de color en la imagen (rojo, verde y azul). El eje horizontal representa la luminosidad de la imagen de negro a blanco (0 a 255) para una imagen en escala de gris y la intensidad de cada canal para una imagen a color, el eje vertical indica el numero de píxeles en la imagen que contienen el tondo de color indicado en el eje horizontal. Cuando hay un muchos píxeles con la misma intensidad, aparecerá un pico en la grafica en el valor correspondiente, donde hay pocos píxeles con la misma intensidad la grafica estará cercana al eje horizontal. En imágenes obscuras, la mayoría de los píxeles están agrupados del lado izquierdo, si la imagen es muy clara los píxeles se agrupan a la derecha. Esta información es útil para determinar los valores de entrada de los filtros, de esta manera los filtros pueden determinar sus valores de entrada de manera autónoma. El algoritmo para obtener el histograma es fácil de implementar, solo se requiere explorar toda la imagen e incrementar la aparición de cada intensidad de color en una variable que contenga 3 vectores, uno por cada canal de color y 255 casillas para cada una de las tonalidades en cada canal. Figura 2.12: En el histograma (derecha) se observan que los picos corresponden a los colores característicos de la imagen (izquierda). Instituto Tecnológico de Mérida 2004 19 Visión Artificial: Percepción de Profundidad Fundamento Teórico. 2.5 Percepción de Profundidad A través de la visión binocular, somos capaces de interactuar en un mundo tridimensional al apreciar las distancias y volúmenes en el entorno que nos rodea. Nuestros ojos, debido a su separación, obtienen dos imágenes con pequeñas diferencias entre ellas, a lo que denominamos disparidad. Nuestro cerebro procesa las diferencias entre ambas imágenes y las interpreta de forma que percibimos la sensación de profundidad, lejanía o cercanía de los objetos que nos rodean. Este proceso se denomina estereopsis. La distancia interpupilar más habitual es de 65 mm, pero puede variar desde los 45 a los 75 mm [7]. En la estereopsis intervienen diversos mecanismos. Cuando observamos objetos muy lejanos, los ejes ópticos de nuestros ojos son paralelos. Cuando observamos un objeto cercano, nuestros ojos giran para que los ejes ópticos estén alineados sobre él, es decir, converjan. A su vez se produce la acomodación o enfoque para ver nítidamente el objeto. Este proceso conjunto se llama fusión. No todo el mundo tiene la misma capacidad de fusionar un par de imágenes en una sola tridimensional. Alrededor de un 5% de la población tiene problemas de fusión. La agudeza estereoscópica es la capacidad de discernir, mediante la estereopsis, detalles situados en planos diferentes y a una distancia mínima. Hay una distancia límite a partir de la cual no somos capaces de apreciar la separación de planos, y que varía de unas persona a otras. Así, la distancia límite a la que dejamos de percibir la sensación estereoscópica puede variar desde unos 60 metros hasta cientos de metros. La figura 2.13 ilustra una situación simplificada en dos dimensiones. Instituto Tecnológico de Mérida 2004 20 Visión Artificial: Percepción de Profundidad Fundamento Teórico. Figura 2.13: El punto mas cercano es enfocado por los ojos, y se proyecta en el centro de sus retinas, sin disparidad, .Las dos imágenes del punto lejano se desvían de la posición central en diferente cantidad. Si l y r denotan el ángulo (en sentido antihorario) entre los planos de simetría vertical de los dos ojos y los dos rayos pasando a través de el mismo punto en la escena, entonces denotamos sus disparidades correspondientes como d = r - l y por lo tanto como se puede demostrar por trigonometría d = D - F, donde D es el ángulo entre estos rayos y F es el ángulo entre los rayos que pasan por el punto de enfoque. Los puntos con disparidad cero caen en el círculo Vieth-Muller que pasa por el punto enfocado y los centros focales de los ojos. Los puntos que se encuentran adentro del círculo tienen una disparidad positiva (o convergente), los que están fuera del circulo tienen una disparidad negativa (o divergente), y la posición de todos los puntos que tienen una disparidad dada d, forman, d como variable, un circulo que pasa a través de los dos centros focales. Esta propiedad es claramente suficiente para ordenar por orden de disparidad los puntos que están cerca del punto de enfoque, Instituto Tecnológico de Mérida 2004 21 Visión Artificial: Percepción de Profundidad Fundamento Teórico. Sin embargo también es claro que los ángulos entre el plano medio vertical de simetría de la cabeza y los dos rayos de enfoque se deben conocer para poder reconstruí la posición absoluta de los puntos en la escena. El caso tridimensional es un poco mas complicado, la posición para los puntos de disparidad cero se convierte en una superficie, horopter, pero la conclusión general es la misma, una posición absoluta requiere de los ángulos. Como fue demostrado por A Wundt y Helmholtz [8] hay evidencia clara de que estos ángulos no pueden ser evaluados con precisión por nuestro sistema nervioso. Por lo tanto se puede argumentar razonablemente que la salida del esteropsis humana consiste en un mapa de profundidad relativa. Transmitiendo un orden parcial de profundidad ente los puntos [9]. En este contexto el papel principal de el movimiento de los ojos en la estereopsis es poder traer las imágenes dentro del área de fusión, un disco pequeño en el centro de la retina donde la fusion puede ocurrir [9] (se pueden percibir puntos para disparidades mucho mas grandes pero aparecerán como imágenes dobles, un fenómeno conocido como diplopía). Un factor que interviene directamente en la estereopsis es la separación interocular. A mayor separación entre los ojos, mayor es la distancia a la que apreciamos el efecto de relieve. Esto se aplica por ejemplo en los prismáticos, en los que, mediante prismas, se consigue una separación interocular efectiva mayor que la normal, con lo que se consigue apreciar en relieve objetos distantes que en condiciones normales no seríamos capaces de separar del entorno. También se aplica en la fotografía aérea, en la que se obtienen pares estereoscópicos con separaciones de cientos de metros y en los que es posible apreciar claramente el Instituto Tecnológico de Mérida 2004 22 Visión Artificial: Percepción de Profundidad Fundamento Teórico. relieve del terreno, lo que con la visión normal y desde gran altura sería imposible. El efecto obtenido con una separación interocular mayor que la habitual es el de que los objetos parecen más pequeños de lo normal (liliputismo), y la técnica se denomina hiperestereoscopia. El efecto contrario se consigue con la hipoestereoscopia, es decir, con la reducción de la distancia interocular, imprescindible para obtener imágenes estereoscópicas de pequeños objetos (macrofotografías), o incluso obtenidas por medio de microscopios 2.5.1 Geometría epipolar [2] La geometría epipolar describe las relaciones geométricas de las imágenes formadas en dos o más cámaras enfocadas en un mismo punto o polo. Los elementos más importantes de este sistema geométrico (figura 2.14) son: El plano epipolar, formado por el polo (P) y los dos centros ópticos (O y O’) de dos cámaras. Los epipolos (e y e’) que son la imagen virtual del centro óptico (O’ y O) de una cámara en otra. La línea base, la cual une los dos centros ópticos. Y las líneas epipolares (l y l’), formadas por las intersecciónes del plano epipolar con los planos de las imagenes (Π y Π’), esta une el epipolo con la imagen del punto observado (p, p’). La línea epipolar es fundamental en la visión estereoscópica, pues una de las partes mas difíciles en el análisis estereoscópico es establecer la correspondencia entre dos imágenes, apareamiento estero, decidiendo que punto en la imagen derecha corresponde a cual en la izquierda. Instituto Tecnológico de Mérida 2004 23 Visión Artificial: Percepción de Profundidad Fundamento Teórico. La restricción epipolar :(figura 2.15) “Si p y p’ son imágenes del mismo punto P, entonces p’ debe encontrarse en la línea epipolar l’ asociada con p”, nos permite reducir la búsqueda de la correspondencia estereoscópica, de dos dimensiones (toda la imagen) a una búsqueda en una dimensión sobre la línea epipolar. Figura 2.14. Geometría epipolar, el punto P, los centros ópticos O y O’, las dos imágenes p y p’ de P, todos se encuentran sobre el mismo plano [2]. Figura 2.15. Restricción epipolar: el conjunto de posibles apareamientos para el punto p se restringe a estar sobre la línea epipolar l’ [2]. Instituto Tecnológico de Mérida 2004 24 Visión Artificial: Percepción de Profundidad Fundamento Teórico. 2.5.2 Rectificación de Imágenes. Una forma de simplificar aun más los cálculos asociados con los algoritmos estereoscópicos es rectificar las imágenes, esto consiste en remplazar las imágenes por sus proyecciones equivalentes sobre un plano común paralelo a la línea base (Figura 2.16). Se proyecta la imagen, eligiendo un apropiado sistema de coordenadas, las líneas epipolares rectificadas son paralelas a la línea base y se convierten en una sola línea de exploración. Existen dos grados de libertad involucrados en la selección del plano de rectificación [10]: (1) La distancia entre el plano y la línea base, este es irrelevante pues al modificarlo solo se cambia la escala de las imágenes rectificadas, su efecto se balancea fácilmente haciendo un escalamiento inverso. (2) La dirección del plano rectificado normal en el plano perpendicular a la línea base, la elección natural incluye escoger un plano paralelo a la línea donde las dos retinas originales se intersectan y minimizar la distorsión asociada con el proceso de proyección Para el caso de las imágenes rectificadas (figura 2.17) dados dos puntos p y p’ localizados en la misma línea de exploración de la imagen izquierda y derecha, con coordenadas (u, v) y (u’, v’), la disparidad es dada como la diferencia d = u’-u. Si B es la distancia entre los centros ópticos, también llamada línea base, es fácil demostrar que la profundidad de P es z = − B / d [2]. Instituto Tecnológico de Mérida 2004 25 Visión Artificial: Percepción de Profundidad Fundamento Teórico. Figura 2.16: Un Par de imágenes rectificadas: los dos planos de la imagen Π y Π’ son proyectados en un plano común Π = Π ' paralelo a la línea base. Las líneas epipolares l y l’ asociadas con los puntos p y p’ en las dos imágenes tiene la línea epipolar común l = l ' también paralela a la línea base y pasa a través de los puntos p y p ' [2]. Figura 2.17: Triangulación para imágenes rectificadas: los rayos asociados con dos puntos p y p’ en la misma línea de exploración se intersectan en el punto P. La profundidad de P relativa al sistema de coordenadas de la cámara izquierda es inversamente proporcional a la disparidad d = u-u’ [2]. Instituto Tecnológico de Mérida 2004 26 Visión Artificial: Percepción de Profundidad Fundamento Teórico. 2.6 Algoritmos de Apareamiento Estereoscopio. Los algoritmos de apareamiento estereoscópico reproducen el proceso de estereopsis humana para que una maquina pueda percibir la profundidad de cada punto en la escena observada y así poder manipular objetos, evitarlos o recrear modelos tridimensionales. Para un par de imágenes estereoscópicas la meta principal de estos algoritmos es encontrar para cada píxel en una imagen su correspondiente en la otra imagen (apareamiento) con el fin de obtener un mapa de disparidad que contienga la diferencia de posición para cada píxel entre las dos imágenes la cual es proporcional a la profundidad. Para conocer la profundidad real de la escena es necesario conocer la geometría de sistema estereoscópico en el cual feron tomadas las imágenes, para obtener un mapa de profundidad métrico Principalmente existen dos tipos de algoritmo de apareamiento estereoscópico: Basados en características: Encuentran los apareamientos solo de las principales características en la imagen como contornos de los objetos. Requieren mucho menos tiempo de proceso pues al solo utilizar algunas características de la imagen la información de entrada es menor. Tienen la desventaja de que no pueden encontrar las profundidades que cambian suavemente y producen mapas de disparidad dispersos. Por correlación: Producen mapas densos de disparidad, en los cuales se encuentra la disparidad para cada píxel en la imagen. Como aparear un solo píxel es casi imposible, cada píxel es representado por una pequeña región que lo contiene, llamada ventana de correlación, Instituto Tecnológico de Mérida 2004 27 Visión Artificial: Percepción de Profundidad Fundamento Teórico. realizando asi la correlación entre la ventana de una imagen y de otra utilizando el color de los píxeles dentro de ellas. Uno de los métodos basados en contornos titulado: “Stereo by intra and InterSacanline Search Using Dinamic Programing” [11] fue el primero analizado e implementado para la realización de este trabajo de investigación En el se presenta un algoritmo de apareamiento estereoscópico usando la técnica de programación dinámica. La búsqueda de correspondencia que se realiza dentro de líneas de exploración “intra-scanline” es tratada como el problema de encontrar un camino de apareo en un espacio de búsqueda de dos dimensiones, cuyos ejes son las líneas de exploración derecha e izquierda, los contornos conectados verticalmente en la imagen proveen la restricción de consistencia a través de los planos de búsqueda. La búsqueda entre líneas de exploración “Inter-scanline” en un espacio tridimensional (el cual es una pila de todos los planos de búsqueda) es necesaria para utilizar esta restricción. El algoritmo usa intervalos delimitados por contornos como los elementos a ser apareados, y utiliza las dos búsquedas antes mencionadas: una es entre líneas de exploración “Inter-scanline” para posibles correspondencias entre contornos conectados en la imagen derecha e izquierda y la otra dentro de la línea de exploración “intra-scanline” para correspondencias de intervalos delimitados por contornos en cada par de líneas de exploración. Se utiliza la programación dinámica para ambas búsquedas, las cuales proceden simultáneamente: la primera provee la restricción de consistencia para la siguiente mientras esta provee el puntaje de apareamiento para la inicial. Una medición de similitud entre los intervalos es usada para obtener el puntaje. Instituto Tecnológico de Mérida 2004 28 Visión Artificial: Percepción de Profundidad Fundamento Teórico. El método genera un mapa de disparidad disperso y obtiene la información faltante interpolando la profundidad de los contornos encontrados. Es muy susceptible al ruido en la imagen y el mapa obtenido presenta muchos saltos que aparecen como líneas horizontales de disparidad continua. El resultado para un par de imágenes sintéticas mediante la implementación del algoritmo de programación dinámica se muestra a continuación. Figura 2.18: Mapa de disparidad (derecha) resultado de la implementación del algoritmo [11], para un par de imágenes estereoscópicas sintéticas (izquierda). Otro método Analizado “Maximum Likelihood Stereo Algorithm” [12] también basado en programación dinámica genera un mapa de disparidad denso mediante el mismo principio realizando la comprobación para cada píxel en lugar de para cada segmento entre contornos [12], sin embargo aunque obtiene un mejor resultado que el anterior basado en contornos al poder encontrar las disparidades que cambian suavemente entre los contornos de un objeto, genera los mismos errores en forma de líneas horizontales de disparidad continua. Instituto Tecnológico de Mérida 2004 29 Visión Artificial: Percepción de Profundidad Fundamento Teórico. Figura 2.19: Mapa de disparidad obtenido para el par de imágenes estereoscópicas del pentágono mediante “Maximum Likelihood Stereo Algorithm” [12] Figura 2.20: Mapa de disparidad obtenido mediante “A Cooperative Algorithm For Stereo, Matching And Occlusion Detection” [13](izquierda). Mapa de disparidad obtenido por “Fast Stereo Vision for Mobile Robots by Global Minima of Cost Functions” [14] (drecha) Algunos métodos basados en correlación utilizan un paso complementario de refinamiento para todos los valores obtenidos por las correlaciones evaluadas, para reducir el tiempo de proceso utilizan una ventana de comparación pequeña y después mejoran el resultado [13] [14]. La figura 2.19 y 2.20 muestra los resultados obtenidos para el par de imágenes estereoscópicas del pentágono las cuales son muy utilizadas para comparar resultados entre los métodos de apareamiento estereoscópico. La imagen de la figura 2.20 izquierda presenta el resultado obtenido por Kanade en [13] mediante un algoritmo para obtener mapas Instituto Tecnológico de Mérida 2004 30 Visión Artificial: Percepción de Profundidad Fundamento Teórico. de disparidad con las oclusiones detectadas explícitamente. Para producir un mapa suave y detallado, Kanade adopta dos supuestos propuestos originalmente por Marr y Poggio: unicidad y continuidad. Esto es, el mapa de disparidad tiene un valor único para cada píxel y es continuo casi en cualquier lado. Estos supuestos se cumplen dentro de un arreglo tridimensional de valores de apareo en el espacio de disparidad. Cada valor de disparidad corresponde a un píxel en una imagen y su disparidad relativa a la otra imagen. Un algoritmo iterativo actualiza los valores de apareamiento con una cobertura difusa entre los valores vecinos e inhibiendo otros a través de líneas de vista similares. Aplicando este supuesto de unicidad, las regiones ocluidas pueden ser identificadas explícitamente. Para demostrar la eficiencia del algoritmo, Kanade presenta los resultados del procesamiento para pares de imágenes sintéticas y reales. EL mapa de disparidad de la figura 2.20 izquierda se obtiene después de una gran cantidad de iteraciones del algoritmo, en cada una de las cuales se pierden detalles de la imagen para obtener un mapa de disparidad suave y con las oclusiones marcadas. De manera similar el mapa de disparidad (Figura 2.20 derecha) obtenido por: “Fast Stereo Vision for Mobile Robots by Global Minima of Cost Functions” [14] obtiene un mapa de disparidad suave pero sin detalle mediante un algoritmo para computar mapas de disparidad de un par de imágenes minimizando la función de costo global. El método consiste de dos pasos: primero se realiza una correlación tradicional basada en la medición de similitud. Entonces el segundo paso toma lugar para eliminar posibles ambigüedades, este es descrito como un método de optimización de costos, tomando en cuenta la restricción de continuidad Instituto Tecnológico de Mérida 2004 31 Visión Artificial: Percepción de Profundidad Fundamento Teórico. estereoscópica y las consideraciones de similitud del píxel. La descripción garantiza la existencia de un mínimo único de la función de costos el cual puede ser encontrado fácil y rápidamente por procedimientos comunes. La dificultad en los métodos por correlación esta en la selección del tamaño de la ventan, pues esta debe ser lo suficientemente grande para contener la cantidad suficiente de variación de intensidad y los suficientemente pequeña para evitar los efectos de la distorsión proyectiva [15]. El mapa de disparidad obtenido por un algoritmo estereoscópico debe ser detallado y sin errores, aunque esto es difícil de lograr pues los que logran evitar los errores tienden perder detalle y aquellos que conservan detalle tienden a ser ruidosos. Instituto Tecnológico de Mérida 2004 32 Visión Artificial: Percepción de Profundidad Procedimiento 3. Procedimiento: Algoritmo de Apareamiento Estereoscópico En esta sección se describe los pasos del método de apareamiento estereoscopio desarrollado, el cual obtiene un mapa de disparidad denso y detallado en sub-píxel a partir de un par de imágenes rectificadas. 3.1. Introducción: Mediante un algoritmo de apareamiento estereoscopio se determina el conjunto de correspondencias correctas entre al menos dos imágenes estereoscópicas con el fin de encontrar la profundidad de la escena en base a las diferencias de posición entre un conjunto de correspondencias. La geometría epipolar del sistema estereoscópico limita la búsqueda de correspondencia a solo una dimensión. Mediante la restricción epipolar la correspondencia para un píxel en una imagen se encontrara sobre la línea epipolar de la otra imagen, esta búsqueda se simplifica aun más si se rectifican las imágenes, transformando así la línea epipolar en una línea de exploración horizontal común a las dos imágenes. La comparación para cada píxel de una imagen se realiza utilizando todos los píxeles alrededor de este que estén dentro de una ventana de correlación mediante alguna función de similitud como la suma de diferencias al cuadrado SSD, la correlación cruzada NCC o la suma de las diferencias absolutas SAD. En el presente algoritmo el diámetro de la ventana de comparación es variable, crece hasta contener la suficiente variación de textura con la cual la comparación pueda encontrar una buena correspondencia, esto otorga un balance entre detalle y Instituto Tecnológico de Mérida 2004 33 Visión Artificial: Percepción de Profundidad Procedimiento error, el cual es uno de los problemas principales en los mapas de disparidad densos, pues los algoritmos que encuentran un mapa suave, sin errores que generen saltos bruscos de disparidad, tienden a perder detalle y aquellos que obtienen un mapa detallado tienden a ser ruidosos. La búsqueda de correspondencia se realiza sobre la línea de exploración dentro de un rango de disparidad establecido, como las imágenes se encuentran rectificadas esta es una línea horizontal común a las dos imágenes. El mejor valor obtenido por la función de similitud determina a que distancia o disparidad horizontal, se encuentra el píxel analizado, respecto a la posición de su correspondiente en la otra imagen. Con cada apareamiento se crea un mapa de disparidad el cual indica para cada píxel la diferencia de posición a la que se encuentra su correspondencia en la otra imagen. En cada imagen existirán detalles que no se encuentran en la otra pues se encuentran ocluidos. Las oclusiones se determinan mediante un umbral en los costos de oclusión obtenidos por la función de similitud. El valor de disparidad de cada píxel se mejora encontrando le valor mínimo de la función de segundo grado descrita por los valores de apareo cercanos al valor mínimo encontrado, así se obtiene un mapa de disparidad en sub-píxel, donde existe una gama mas amplia de disparidades utilizando fracciones de píxel. Para encontrar la profundidad real de la escena es necesario conocer las propiedades geométricas del sistema y así transformar las disparidades en unidades de longitud. Instituto Tecnológico de Mérida 2004 34 Visión Artificial: Percepción de Profundidad Procedimiento 3.2. Algoritmo La entrada del algoritmo estereoscopio son dos imágenes rectificadas, derecha e izquierda (Figura 3.1), las cuales se comparan una a otra para obtener un arreglo tridimensional (volumen de disparidad) el cual almacena el costo de apareamiento para cada disparidad en cada píxel respecto a una imagen. Con los valores mínimos de apareamiento se obtienen un mapa de disparidad denso, en base al cual se encuentran las disparidades en sub-pixel mediante la función de segundo grado descrita por los costos almacenados en el volumen de disparidad, y final mente los errores en el mapa de disparidad en sub-pixel se eliminan utilizando un filtro de mediana condicional. Los pasos del algoritmo son los siguientes: 1) Cálculo de costos de apareamiento. Para cada píxel de la imagen: a. Selección del tamaño de ventana. b. Para cada valor en el rango de disparidad, se obtiene el costo de apareamiento. c. Cada costo calculado se almacena en el volumen de disparidad 2) Obtención del mapa de disparidad a. A cada elemento (x, y) del mapa de disparidad se le asigna el valor d del volumen de disparidad para el cual el costo de apareamiento en (x, y, d) es mínimo. 3) Determinación de oclusiones. Para cada valor (x, y) del mapa de disparidad: a. Si el valor de costo de oclusión (x, y, d) en el volumen de disparidad es mayor a un umbral marcar elemento como ocluido. Instituto Tecnológico de Mérida 2004 35 Visión Artificial: Percepción de Profundidad Procedimiento b. Generar mapa de oclusiones 4) Refinamiento a sub-píxel. Para cada elemento del mapa de disparidad se encuentra su valor en sub-píxel: a. Obtener los coeficientes de la función de segundo grado descrita por los valores próximos a la disparidad mínima d, (x, y, d-n) a (x, y, d+n) b. Obtener el valor mínimo de la función de segundo grado. c. Actualizar el mapa de disparidad. 5) Eliminación de errores por filtro de mediana condicional. Para cada elemento (x, y) del mapa de disparidad: a. Aplicar una mascara de N x N centrada en el elemento actual del mapa de disparidad. b. Obtener la mediana de las disparidades dentro de la mascara. c. Si la diferencia del valor mediano y el valor de la disparidad original (x, y) es mayor a un umbral, remplazar el valor con el valor mediano, si no conservar el valor (x, y). Figura 3.1: Par de imágenes estereoscópicas rectificadas. Instituto Tecnológico de Mérida 2004 36 Visión Artificial: Percepción de Profundidad Procedimiento 3.2.1 Apareamiento La diferencia de posición de cada característica en una imagen respecto a la otra es proporcional a su profundidad. La meta del algoritmo es encontrar para cada píxel de una imagen su correspondiente en la otra imagen, ya que las imágenes de entrada se encuentran rectificadas, esto es son coplanares, el punto correspondiente a (x, y) se encontrara sobre la misma línea y a una distancia o disparidad horizontal d en el punto (x+d, y) de la otra imagen [2]. Para encontrar la correspondencia de una imagen respecto a la otra, utilizamos una ventana circular de área Φ píxeles, centrada en la imagen de interés en (x, y) [16] y otra de igual área en la segunda imagen cuyo centro será desplazado sobre la línea de exploración, línea que comparten las dos imágenes sobre la cual se busca la correspondencia, dentro de un rango de disparidad (x-D, y) a (x+D, y) (Figura 3.2). Para determinar cual punto dentro del rango de disparidad es el apareamiento correcto se utiliza la sumatoria de las diferencias al cuadrado SSD [12, 13, 15, 17,18] como función de similitud para comparar las dos ventanas, pues a diferencia de la sumatoria de diferencias absolutas SAD, otorga un mayor costo a los errores grandes. Cada píxel de la primera ventana se sustrae de su correspondiente en la otra y la diferencia se eleva al cuadrado, la suma de todos estos valores determina la similitud o costo de apareamiento entre las dos ventanas, o que tan parecida es la característica de interés en una imagen con la evaluada en la segunda imagen, entre menor sea el valor SSD mayor será la similitud entre las dos ventanas. Instituto Tecnológico de Mérida 2004 37 Visión Artificial: Percepción de Profundidad SSD = Procedimiento ∑ (I (x , y ) − I (x + d , y )) 2 ( x , y )∈ Φ 1 2 El área de la venta Φ, la cual es el numero de píxeles dentro de ella, deberá contener la suficiente información para realizar un buen apareamiento [14, 17], si la ventana es pequeña, no contendrá la suficiente información en áreas de baja textura, pues no existirá referencia para la comparación, y si es muy grande se perderán los detalles debido a que el numero de píxeles correspondientes a el detalle analizado será mucho menor que el resto que se encuentran dentro de la ventana y su valor se prendera dentro de la sumatoria. Por lo que el tamaño de la ventana deberá variar en proporción a la cantidad local de textura, variación en el tono de color, (Figura 3.2). Por lo tanto antes de realizar la comparación entre las dos ventanas se deberá ajustar el tamaño de estas. Φ ∝σ = 1 (I ( x, y ) − m )2 ∑ Φ ( x , y )∈Φ El radio de la ventana se incrementara en un píxel hasta que la desviación estándar de las tonalidades en los píxeles dentro de esta sea mayor a un umbral ThΦ, el cual es establecido experimentalmente. En la Figura 3.4 la tonalidad indica el radio de la ventana utilizado para cada píxel, en donde los tonos obscuros corresponden a ventanas pequeñas y los claros a ventanas grandes. Instituto Tecnológico de Mérida 2004 38 Visión Artificial: Percepción de Profundidad Procedimiento Figura 3.2: Dos imágenes estereoscópicas, derecha e izquierda, son comparadas por medio de dos ventanas, la primera centrada en el punto de interés de la primera imagen y la segunda se desplaza dentro de un rango de disparidad sobre la línea de exploración de la segunda imagen obteniendo el valor de la comparación SSD dentro de las dos ventanas para cada valor del rango de disparidad. El diámetro de la ventana de correlación varia dependiendo de la cantidad de textura local contenida en ella. Como el tamaño de cada ventana es diferente para cada píxel, en ventanas de diferente área los valores SSD encontrados no estarán en la misma escala, por lo que utilizaremos el promedio de las diferencias al cuadrado como función de similitud para que independientemente del tamaño de la ventana, el costo obtenido este en la misma escala para todos los posibles diámetros. ∑ (I (x , y ) − I (x + d , y )) 2 Simil = SSD = Φ ( x , y )∈ Φ 1 2 Φ Para mejorar el resultado, la contribución de cada píxel a la sumatoria variará de forma gaussiana al alejarse del centro de la ventana, de manera que al alejarse Instituto Tecnológico de Mérida 2004 39 Visión Artificial: Percepción de Profundidad Procedimiento del centro el píxel perderá importancia en la sumatoria, pues no tendrá tanta similitud con el centro de la mascara. Peso = 2 πσ ⋅ e − x2 + y2 2σ 2 De manera que nuestra función de similitud es la siguiente: Simil = ∑ (Peso (x , y ) ⋅ (I (x , y ) − ( x , y )∈ Φ 1 ∑ I 2 ( x + d , y )) 2 ) Peso ( x , y ) ( x , y )∈ Φ El costo de apareamiento para cada píxel (x, y) con otro a una disparidad d en la segunda imagen (x+d, y), se almacena en un arreglo tridimensional de dimensiones [X, Y, D] en la posición [x, y, d], donde X es el ancho de la imagen, Y su altura y D el rango de disparidad. Costo[x, y, d ] ⇐ Simil ( x, y, d ) Cada valor del arreglo tridimensional (x, y, d) indica el costo de apareamiento del píxel (x, y) en la imagen de referencia con el píxel (x+d, y) de la segunda imagen. (Figura 3.3). Instituto Tecnológico de Mérida 2004 40 Visión Artificial: Percepción de Profundidad Procedimiento Figura 3.3:.El valor de coso de apareamiento obtenido por la función de similitud para la comparación de la ventana centrada en cada píxel (x, y) de la primera imagen con cada píxel (x+d, y) de la segunda imagen, dentro de el rango de disparidad D, es almacenado en un arreglo tridimensional de dimensiones [X, Y, D] en la posición [x, y, d]. Donde X es el ancho de la imagen, Y su altura, D el rango de disparidad y la escala de colores indica el costo de apareamiento 3.2.2 Mapa de Disparidad Un mapa de disparidad es un arreglo bidimensional con las mismas dimensiones que la imagen de referencia, en donde cada localidad indica la distancia horizontal en píxeles a la cual se encuentra el mejor apareamiento encontrado en la otra imagen para la comparación estereoscópica. Se representa mediante una imagen donde la intensidad de tono en cada píxel indica a que distancia horizontal se encuentra el píxel correspondiente de una imagen en la otra [2] (Figura 3.7). A cada píxel (x, y) en el mapa de disparidad se le asigna el valor de disparidad d, del volumen de costos de apareamiento, para el cual el costo de apareo es mínimo en la coordenada (x, y, d). De esta manera el mapa de disparidad contendrá el valor de disparidad para cada píxel en la cual se encontró el mejor apareamiento. Instituto Tecnológico de Mérida 2004 41 Visión Artificial: Percepción de Profundidad Figura 3.4. El tono de gris en cada píxel de la imagen indica el tamaño utilizado para la ventana de comparación (imagen ecualizada). Procedimiento Figura 3.5. Mapa de costos de oclusión correspondientes a cada apareamiento utilizado para el mapa de disparidad. En la figura 3.6 y 3.7 los niveles de disparidad se indican en escala de grises de 256 tonos, la disparidad cero esta indicada por el tono medio, d0 = 227, los valores por debajo de este corresponden a disparidades negativas y las disparidades positivas se indican con tonos mayores a 227. DisMap[ x, y ] ⇐ d + 127 Donde d es la disparidad en el punto (x, y) para la cual el costo de apareamiento es mínimo. Figura 3.6: Mapa de disparidad obtenido con una mascar de diámetro fijo de 7 píxeles Figura 3.7: Mapa de disparidad en exactitud de píxel obtenido con mascara de diámetro variable. Instituto Tecnológico de Mérida 2004 42 Visión Artificial: Percepción de Profundidad Procedimiento 3.2.3 Mapa de Disparidad en Sub-píxel En el mapa de disparidad anterior los niveles de disparidad se encuentran limitados a valores enteros, lo que ocasiona que los cambios en disparidad no sean suaves, se obtenga un mapa tosco y no se aprecien los detalles cuya profundidad esta en disparidades intermedias. Como se observa en la figura 3.2 y 3.3 los valores de los costos de oclusión próximos al valor mínimo describen una parábola, el valor mínimo real para esta parábola puede ser encontrado aproximando estos valores a una función de segundo grado [19, 20] por medio del método de mínimos cuadrados, y hallar los coeficientes del polinomio de segundo grado: Simil = Ad 2 + Bd + C De esta manera se obtienen disparidades fraccionarias (sub-píxel). El método de mínimos cuadrados es el procedimiento más conveniente para determinar la mejor aproximación de un grupo de muestras a un polinomio, minimizando el error dado por la suma de los cuadrados de las diferencias entre los valores de la curva de aproximación y los valores de los datos. El método de mínimos cuadrados proporciona sustancialmente mas peso a un punto que se encuentre fuera de la tendencia del resto de los datos, pero no permitirá que tal punto domine por completo la aproximación [21]. Los términos de la ecuación de segundo grado se encuentran resolviendo el siguiente sistema de ecuaciones. Instituto Tecnológico de Mérida 2004 43 Visión Artificial: Percepción de Profundidad m m Procedimiento m C ∑ d i + B ∑ d i + A∑ d i = 0 i =1 m 1 i =1 m 2 i =1 m C ∑ d i + B ∑ d i + A∑ d i = 1 i =1 m 2 i =1 m 3 i =1 m C ∑ d i + B ∑ d i + A∑ d i = i =1 2 3 i =1 i =1 4 m ∑ Simil d i =1 0 i i m ∑ Simil d i =1 i 1 i m ∑ Simil d i =1 i 2 i El costo mínimo se encuentra igualando la derivada de la función de costos a cero. ∂Simil = 0 ⇒ 2 Ad + B = 0; ∂d d min = − B 2A En el mapa en sub-pixel (Figura 3.8) se puede observar como se redujeron los apareamientos erróneos y aparecieron detalles que no eran observables en el mapa anterior (Figura 3.7) pues tienen valores de disparidad fraccionaria. Figura 3.8: Mapa de disparidad en sub-píxel. Figura 3.9: Mapa de disparidad en sub-píxel, obtenido después del filtrado por mediana condicional. Instituto Tecnológico de Mérida 2004 44 Visión Artificial: Percepción de Profundidad Procedimiento 3.2.4 Filtro Iterativo de Mediana Condicional. Si bien el mapa obtenido por el procedimiento anterior contiene los detalles que se encuentran en disparidades fraccionarias (sub-píxel), aun contiene apareamientos erróneos los cuales son áreas pequeñas que presentan saltos bruscos de disparidad, estos son causados por varios factores, como ruido, oclusiones o patrones periódicos. Estos saltos erróneos se eliminan utilizando un filtro no lineal sobre el mapa de disparidad, el cual encuentra la mediana [22] de todos los valores de disparidad dentro de una mascara centrada en el píxel de interés y remplaza su valor por el valor mediano si la diferencia entre este y el valor original es mayor a uno. De esta manera se eliminan los saltos indeseados de disparidad y se conservan los detalles en sub-pixel. El filtro es aplicado cíclicamente hasta que no encuentre valor alguno de disparidad que modificar. El mapa de disparidad resultante se muestra en la figura 3.9. 3.2.5 Oclusiones En un par de imágenes estereoscópicas existen detalles que se encuentran en una imagen pero no en la otra, pues se encuentran ocluidos por objetos cercanos debido a la diferencia de perspectiva entre ellas y a los cambios en profundidad. El costo de aparear una característica será muy alto si esta se encuentra ocluida en la otra imagen, pues no existirá similitud entre ninguno de los apareamientos dentro del rango de disparidad D. Para determinar las oclusiones se toman todos los puntos del mapa de disparidad cuyo costo de colusión sea mayor a un umbral tho [15, 22] y se les marca como ocluidos (Figura 3.10 y 3.11). Instituto Tecnológico de Mérida 2004 45 Visión Artificial: Percepción de Profundidad Procedimiento Figura 3.10: Los costos de apareamiento que son mayores a un umbral tho se marcan como oclusiones en el mapa de disparidad. Figura 3.11: Mapa de disparidad en sub-píxel con oclusiones marcadas en negro. Instituto Tecnológico de Mérida 2004 46 Visión Artificial: Percepción de Profundidad Resultados 4. Resultados Los resultados para la imagen del pentágono, en el primer mapa de disparidad (Figura 3.6) muestra la desventaja de utilizar una mascara de diámetro fijo, pues si su tamaño es pequeño no podrá encontrar en áreas de baja textura un buen apareamiento, produciendo errores en el mapa de disparidad y si su tamaño es grande se perderán los detalles cuyo tamaño sea menor que el área de la ventana. En el mapa de disparidad de la figura 3.7 se observa el detalle obtenido y la reducción de errores al usar una ventana redonda de tamaño variable en proporción a la cantidad de textura local, en comparación con la ventana de tamaño fijo. Con el Refinamiento en sub-píxel (Figura 3.8) el detalle se incrementa considerablemente, dejando ver pequeñas variaciones de profundidad que no aparecen en el mapa de disparidad anterior. Aunque se obtiene un mapa de disparidad detallado existen aun errores indeseables en la imagen ocasionados por oclusiones y malos apareamientos. Para eliminarlos se aplica repetidamente el filtro de mediana condicional hasta que el filtro no pueda modificar ningún valor, eliminando así la mayoría de los errores (Figura 3.9). Las oclusiones se determinan por medio de un umbral sobre los costos de oclusión de las disparidades utilizadas para el apareamiento correcto (Figura 3.10) el cual fue ajustado a un valor de 255, los apareamientos con un costo mayor son declarados como ocluidos y se marcan en negro en el mapa de disparidad (Figura 3.11) En la tabla 4.1 se muestra el tiempo proceso requerido para las tres etapas principales del algoritmo para las imágenes de prueba: 1) Apareamiento, Instituto Tecnológico de Mérida 2004 47 Visión Artificial: Percepción de Profundidad Resultados almacenamiento en el volumen de disparidad y obtención del mapa de disparidad. 2) obtención y generación del mapa de disparidad en sub-píxel. 3) Filtro de iterativo de mediana condicional. El algoritmo fue implementado en C++ Builder, sobre Windows XP, en una computadora Pentium 4 a 2.8 GHz y 512Mb en RAM. En la tabla 4.2 se muestran los resultados para cada una de las imágenes sobre las cuales fue probado el algoritmo. Se indica el tamaño de la imagen, el rango de disparidad utilizado para la búsqueda de apareamientos, el tamaño mínimo, máximo, promedio y mediano de la ventana de comparación utilizada, la cual varia en cada píxel de la imagen dependiendo de la cantidad de textura existente; El rango de costos de los apareamientos utilizados para el mapa de disparidad, el numero de niveles mostrados en el mapa de disparidad en exactitud de píxel contra el numero del mapa en sub-pixel, el numero de veces que fue aplicado el filtro de mediana al mapa de disparidad y finalmente la disparidad máxima y mínima mostradas en la imagen. Las figuras 4.2 a 4.6 muestran las imágenes utilizadas y los mapas de disparidad en píxel y en sub-píxel resultantes junto con la escala de colores utilizada, en la cual el blanco corresponde la menor profundidad y el negro a lo que se encuentra mas alejado. En el caso de la imagen “Tsukuba”, se muestra el mapa en sub-pixel y el mapa de profundidad verdadera proporcionado. Para estas pruebas el umbral de textura fue fijado en 20, el de oclusiones en 255, el diámetro menor utilizado para la ventana de comparación en 7 pixeles, el tamaño de la ventana para el filtro de mediana en 5x5 píxeles y la cantidad de de valores tomados para el método de mínimos cuadrados al generar el mapa de Instituto Tecnológico de Mérida 2004 48 Visión Artificial: Percepción de Profundidad Resultados disparad en sub-píxel fue de 5 valores de disparidad dos a la izquierda y dos a la derecha de la disparidad de apareamiento. Estos valores fueron calculados experimentalmente. Sub-pixe (seg) Filtro iterativo de mediana Condicional (seg) Total (seg) Imagen Tamaño Volumen y Mapa de disparidad (seg) Pentágono 512x512 1050.561 4.837 775.065 1830.463 Random Dot 250x250 12.147 1.152 14.060 27.359 Coal Mine 240x256 193.268 1.102 22.642 197.012 CMU Shurub 512x480 6017.333 4.596 562.569 6584.498 House of 512x512 578.993 4.827 449.667 1033.487 Tsukuba 384x288 527.759 2.123 237.611 767.493 Tabla 4.1 Diámetro de ventana Mínimo/Máximo/ Promedio/Media na Costo de apareamiento Mínimo/Máxim o/Mediana Niveles de disparidad Píxel/Subpixel Numero de Iteracion es Filtro 5x5 Disparidad Mínima/Má xima Imagen Tamaño Rango de disparid ad Pentágono 512x512 -20/+20 7 / 251 / 19 / 11 0 / 2047 / 38 41 / 831 81 -18/+12 Random Dot 250x250 - 20/+20 7/ 7/ 7 / 7 0 / 6655 41 / 1003 38 -17/+16 Coal Mine 240x256 0/+55 7/ 77 / 21 / 19 0 / 5887 / 5 54 / 743 9 +29/+41 CMU Shurub 512x480 -20/+20 7 / 231 / 45 / 23 0 / 1023 / 9 41 / 692 88 -14/+13 House of 512x512 -15/+40 7 / 127 / 13 / 9 0 / 5631 / 42 46/917 70 -13/+27 Tsukuba 384x288 -5/+30 7 / 127 / 25 / 15 0 / 65535 36 / 939 58 -2/+27 Tabla 4.2 Instituto Tecnológico de Mérida 2004 49 Visión Artificial: Percepción de Profundidad Resultados Figura 4.1: Representación tridimensional del mapa de disparidad. Instituto Tecnológico de Mérida 2004 50 Visión Artificial: Percepción de Profundidad Resultados Figura 4.2 Random Dot 250x250. Figura 4.3 Coal Mine CMU 240x256. Figura 4.4 CMU Shurub 512x480. Figura 4.5 House Of 512x512. Figura 4.6 Tsukuba 384X288. Instituto Tecnológico de Mérida 2004 51 Visión Artificial: Percepción de Profundidad Conclusiones 5. Conclusiones y Trabajos Futuros Como se puede observar en los mapas de disparidad resultantes, por medio de este tipo de técnicas de apareamiento estereoscópico se pueden obtener mapas de disparidad muy detallados y sin ruido. Si bien la obtención de un mapa de disparidad denso, mediante este método incrementa el tiempo de procesamiento, debido principalmente a que la variación de tamaño en la ventana permite diámetros de tamaño considerable, el tiempo de proceso se pede reducir limitando el tamaño máximo de la ventana de comparación o utilizando un método piramidal en el cual se encuentre las disparidades iniciales en una menor resolución de la imagen original y realizar las siguientes búsquedas en una resolución mayor y dentro de un rango de disparidad limitado por las encontradas en el paso anterior, hasta llegar a la resolución original de la imagen. El tiempo del algoritmo también puede reducirse mediante la paralelización del algoritmo utilizando lenguajes de descripción hardware para implementarlo sobre hardware configurable, utilizando múltiples mascaras que exploren las imágenes paralelamente o utilizando tarjetas aceleradoras graficas GPU (Graphics Processing Units) las cuales permiten operaciones con matrices de gran tamaño [23, 24] en menor tiempo que el CPU. El tiempo total de proceso se puede reducir dividiendo el proceso entre el CPU y el GPU o bien entre un conjunto de procesadores gráficos trabajando en forma simultanea. Instituto Tecnológico de Mérida 2004 52 Visión Artificial: Percepción de Profundidad Referencias 6. Referencias [1] Antonio Criminisi. “Accurate Visual Metrology from Single and Multiple Uncalibrated Images”. Robotics Research Group Department of Engineering Science University of Oxford. Michaelmas Term, 1999 [2] David A. Forsyth, Jean Ponce “Computer Vision: A Modern Approach”. Prentice Hall. [3] Rafael C. González y Richard E. Woods, “Digital Image Processing”. Addison-Wesley, 1992. [4] Stephen M. Smith, J. Michael Brady. “SUSAN – A New Approach to Low Level Image Processing”. Department of Engineering Science, Oxford University, Oxford, UK. Technical Report, FMRIB, 1995. [5] Miguel Arias-Estrada, César Torres-Huitzil. “A Real-time FPGA Architecture for Computer Vision”. National Institute for Astrophysics, Optics and Electronics, Computer Science Department. Puebla. Pue., México. [6] Raymond Thai. “Fingerprint Image Enhancement and Minutiae Extraction”. The University of Western Australia, 2003. [7] K. N. Ogle, W.B. “Binocular Vision”. Saunders Co., Philadelphia, 1950. [8] H. von Helmholtz. ”Physiological optics”. Dover, 1909. 1962 edition of the English translation of the 1909 German original, first published by the Optical Society of America in 1924. [9] B. Julesz. “Foundations of Cyclopean Perception”. The University of Chicago Press, London, 1971. [10]. O.D. Faugeras. “Three-dimensional computer vision: a geometric viewpoint”. MIT Press, 1993. [11] Ohta and T. Kanade. –“Stereo by intra-an d inter-scanline search”. EEE Transaction on Pattern Analysis Machine. Intelligence Vol. PAMI -7 No. 2, March1985. [12] Ingemar J. Cox, Sunita L. Hingorani, And Satish B. Rao.“A Maximum Likelihood Stereo Algorithm”. NEC Research Institute, Princeton, New Jersey 08540. And Bruce M. Maggsi, School of Computer Science, Carnegie Mellon University, Pittsburgh, Pennsylvania 15213. Computer Vision And Image Understanding, Vol. 63, No. 3, May, pp. 542–567, 1996 Instituto Tecnológico de Mérida 2004 53 Visión Artificial: Percepción de Profundidad Referencias [13] C. Lawrence Zitnick And Takeo Kanade. “A Cooperative Algorithm For Stereo, Matching And Occlusion Detection”. Fellow, IEEE, IEEE Transactions On Pattern Analysis And Machine Intelligence, Vol. 22, No. 7, July 2000. [14] Roland Brockers, Marcus Hund, Barbel Mertsching. “Fast Stereo Vision for Mobile Robots by Global Minima of Cost Functions”. GET Lab, University of Paderborn, Pohlweg 47-49, 33098 Paderborn, Germany. 0-7803-83877/04/$20.00 © 2004 IEEE. [15] Kanade, T. Okutomi, M. “A stereo matching algorithm with an adaptive window: theory and experiment”. Sch. of Comput. Sci., Carnegie Mellon Univ., Pittsburgh, PA. IEEE International Conference on robotics and automation. Sacramento California – April 1991. [16] Etienne Vincent and Robert Lagani`ere. “Matching Feature Points in Stereo Pairs: A Comparative Study of Some Matching Strategies”. School of Information Technology and Engineering, University of Ottawa. [17] L. Di Stefano, M. Marchionni, S. Mattoccia, G. Neri. “A Fast Area-Based Stereo Matching Algorithm” (2002). [18] Takeo Kanade, Hiroshi Kano, Shigeru Kimura, Atsushi Yoshida, Kazuo Oda. “Development of a Video-Rate Stereo Machine”. Robotics Institute, Carnegie Mellon University, 5000 Forbes Ave., Pittsburgh PA 15213. Proceedings of International Robotics and, Systems Conference (IROS’95), August 5-9, 1995, Pittsburgh PA. [19] Richard Szeliski and Daniel “Scharstein.Symmetric Sub-Pixel Stereo Matching”. In Seventh European Conference on Computer Vision (ECCV 2002), volume 2, pages 525–540, Copenhagen, Denmark, May 2002. [20] Maarten Vergauwen, Marc Pollefeys, and Luc Van Gool. “A Stereo Vision System for Support of Planetary Surface Exploration”. [21] Richard L.Burden, J. Douglas Faires. “Análisis Numérico”. Grupo Editorial Iberoamericana. ISBN 970-625-063-8. [22] Karsten Muhlmann, Dennis Maier, Jurgen Hesser, Reinhard Manner. “Calculating Dense Disparity Maps from Color Stereo Images, an Efcient Implementation”. Lehrstuhl fur Informatik V, Universitat Mannheim, B6, 2329, C, D-68131 Mannheim, Germany [23] Ádám Moravánszky “Dense Matrix Algebra on the GPU”. NovodeX AG. [email protected]. 2004 Instituto Tecnológico de Mérida 2004 54 Visión Artificial: Percepción de Profundidad [24] Referencias K. Fatahalian, J. Sugerman, and P. Hanrahan. “Understanding the Efficiency of GPU Algorithms for Matrix-Matrix Multiplication”. Stanford University. Graphics Hardware (2004) T. Akenine-Möller, M. McCool (Editors). Instituto Tecnológico de Mérida 2004 55 Visión Artificial: Percepción de Profundidad Apéndice A Algoritmos en C++ //------------------------------------------------------Asignar dimensiones de la Imagen--------------------------------------------------------------DynamicArray < DynamicArray <RGBTRIPLE> > SetTableDim(int Width, int Height) { DynamicArray < DynamicArray <RGBTRIPLE> > Buffer; Buffer.Length = 0; Buffer.Length = Height; for (int i=0; i < Height; i++) { Buffer[i].Length = Width; for (int j=0; j<Width; j++) { Buffer[i][j].rgbtRed = 0; Buffer[i][j].rgbtGreen = 0; Buffer[i][j].rgbtBlue = 0; } } return Buffer; } //--------------------------------------------------------Almacena BMP en Memoria -------------------------------------------------------------------DynamicArray < DynamicArray <RGBTRIPLE> > LoadImage(Graphics::TBitmap *Imagen) { DynamicArray < DynamicArray <RGBTRIPLE> > Buffer; Int Height= Imagen->Height; Int Width= Imagen->Width; Buffer = SetTableDim(Width, Height); RGBTRIPLE * ptr; for(int y = 0; y < Height; y++) { ptr = (RGBTRIPLE*) Imagen->ScanLine[y]; for(int x = 0; x < Width; x++) { Buffer[y][x].rgbtRed = ptr[x].rgbtRed; Buffer[y][x].rgbtGreen = ptr[x].rgbtGreen; Buffer[y][x].rgbtBlue = ptr[x].rgbtBlue; } } return Buffer; } //------------------------------------------------------------------------------------------------------------------------------------------------------------------//--------------------------------------------------------------Escala de Grises -----------------------------------------------------------------------------void RGBtoGray(DynamicArray < DynamicArray <RGBTRIPLE> > &Imagen) { int Height = Imagen.Length; int Width = Imagen [0].Length; for(int y = 0; y < Height; y++) { for(int x = 0; x < Width; x++) { byte promedio = (Imagen [y][x].rgbtRed+ Imagen [y][x].rgbtGreen + Imagen [y][x].rgbtBlue) / 3; Imagen [y][x].rgbtRed = promedio; Imagen [y][x].rgbtGreen = promedio; Imagen [y][x].rgbtBlue = promedio; } } } //------------------------------------------------------------------------------------------------------------------------------------------------------------------- Instituto Tecnológico de Mérida 2004 56 Visión Artificial: Percepción de Profundidad Apéndice A //------------------------------------------------------------Brillo y Contraste ------------------------------------------------------------------------------void BrightContast(RandomAccessIterator &Imagen, RandomAccessIterator &Destino, int C, int Brillo, int Balance) { int Height = Imagen.Length; int Width = Imagen [0].Length; float Contraste = C/100; for(int y = 0; y < Height; y++) { for(int x = 0; x < Width; x++) { short valR =((Contraste * (Imagen [y][x].rgbtRed - Balance)) + Balance + Brillo); short valG =((Contraste * (Imagen [y][x].rgbtGreen - Balance))+ Balance + Brillo); short valB =((Contraste * (Imagen [y][x].rgbtBlue - Balance))+ Balance + Brillo); Destino[y][x].rgbtRed = (Byte)(valR > 255 ? 255 : (valR < 0 ? 0 : valR)); Destino[y][x].rgbtGreen = (Byte)(valG > 255 ? 255 : (valG < 0 ? 0 : valG)); Destino[y][x].rgbtBlue = (Byte)(valB > 255 ? 255 : (valB < 0 ? 0 : valB)); } } } //------------------------------------------------------------------------------------------------------------------------------------------------------------------//------------------------------------------------------------------Tolerancia Binaria-------------------------------------------------------------------------void BinImage(RandomAccessIterator &Imagen, RandomAccessIterator &Destino, int Balance) { Height = Imagen.Length; Width = Imagen [0].Length; for(int y = 0; y < Height; y++) { for(int x = 0; x < Width; x++) { Destino[y][x].rgbtRed = (Byte)( Imagen [y][x].rgbtRed > Balance ? 255 : (Buffer[y][x].rgbtRed < Balance ? 0 : 0)); Destino[y][x].rgbtGreen = (Byte)( Imagen [y][x].rgbtGreen > Balance ? 255 : (Buffer[y][x].rgbtGreen < Balance ? 0 : 0)); Destino[y][x].rgbtBlue = (Byte)( Imagen [y][x].rgbtBlue > Balance ? 255 : (Buffer[y][x].rgbtBlue < Balance ? 0 : 0)); } } } //------------------------------------------------------------------------------------------------------------------------------------------------------------------//---------------------------------------------------------------- Difuminado ---------------------------------------------------------------------------------void Smooth(RandomAccessIterator &Imagen, RandomAccessIterator &Destino, int Kernel) { Int ColresultR, ColresultG, ColresultB; int Height = Imagen.Length; int Width = Imagen [0].Length; for (int y = 0; y < Height; y++) { for (int x = 0; x < Width; x++) { ColresultR=0; ColresultG=0;ColresultB=0; Int n=0; for (int nYMatrix = -Kernel; nYMatrix <= Kernel; nYMatrix++) { for (int nXMatrix = -Kernel; nXMatrix <= Kernel; nXMatrix++) { if ( 0 < Y + nYMatrix && Y + nYMatrix < Height && 0 < X + nXMatrix && X + nXMatrix < Width) { ColresultR = Imagen [y + nYMatrix][x + nXMatrix].rgbtRed + ColresultR; ColresultG = Imagen [y + nYMatrix][x + nXMatrix].rgbtGreen+ ColresultG; ColresultB = Imagen [y + nYMatrix][x + nXMatrix].rgbtBlue + ColresultB; n++; } } } ColresultR = ColresultR/n; ColresultG=ColresultG/n; ColresultB=ColresultB/n; Destino[y][x].rgbtRed = ColresultR; Destino[y][x].rgbtGreen = ColresultG; Destino[y][x].rgbtBlue = ColresultB; } } } //------------------------------------------------------------------------------------------------------------------------------------------------------------------- Instituto Tecnológico de Mérida 2004 57 Visión Artificial: Percepción de Profundidad Apéndice A //------------------------------------------------------------Detección de contornos ---------------------------------------------------------------------void SUSAN_RGB(RandomAccessIterator &Buffer, RandomAccessIterator &Destino, int Kernel, int Tolerancia) { int n, ContR, ContG, ContB, YmasnYMatrix, XmasnXMatrix, y, x, nYMatrix, nXMatrix, F, G; int Height = Buffer.Length; int Width = Buffer[0].Length; RGBTRIPLE PixC, DiferenciaColor; for ( y = 0; y < Height; y++) { for ( x = 0; x < Width; x++) { ContR = ContG = ContB = n =0; PixC.rgbtRed = Buffer[y][x].rgbtRed; PixC.rgbtGreen = Buffer[y][x].rgbtGreen; C.rgbtBlue = Buffer[y][x].rgbtBlue; for ( nYMatrix =(y-Kernel>=0 ? -Kernel : -y) ; nYMatrix <= Kernel && y + nYMatrix< Height; nYMatrix++) { F=sqrt((Kernel+.5)*(Kernel+.5)-nYMatrix*nYMatrix); for ( nXMatrix = (x-F>=0 ? -F : -x); nXMatrix <= F && x + nXMatrix < Width; nXMatrix++) { YmasnYMatrix = y + nYMatrix; XmasnXMatrix = x + nXMatrix; DiferenciaColor.rgbtRed = (Byte) abs ( (Buffer[YmasnYMatrix][XmasnXMatrix].rgbtRed) - PixC.rgbtRed ); DiferenciaColor.rgbtGreen =(Byte)abs ( (Buffer[YmasnYMatrix][XmasnXMatrix].rgbtGreen) - PixC.rgbtGreen ); DiferenciaColor.rgbtBlue = (Byte)abs ( (Buffer[YmasnYMatrix][XmasnXMatrix].rgbtBlue) - PixC.rgbtBlue ); n++; if (DiferenciaColor.rgbtRed <= Tolerancia) ContR++; if (DiferenciaColor.rgbtGreen <= Tolerancia) ContG++; if (DiferenciaColor.rgbtBlue <= Tolerancia) ContB++; } } G=3*n/4; Destino[y][x].rgbtRed = (Byte)(ContR <= G ? 255-255*ContR/G: 0);//(3*n/4) - ContR : 255); Destino[y][x].rgbtGreen = (Byte)(ContG <= G ? 255-255*ContG/G: 0);//(3*n/4) - ContG : 255); Destino[y][x].rgbtBlue = (Byte)(ContB <= G ? 255-255*ContB/G: 0);//(3*n/4) - ContB : 255); } } } //------------------------------------------------------------------------------------------------------------------------------------------------------------------- Instituto Tecnológico de Mérida 2004 58 Visión Artificial: Percepción de Profundidad Apéndice A //------------------------------------------------------- Creación de volumen de disparidad -------------------------------------------------------void Set3Ddim(DynamicArray < DynamicArray < DynamicArray <float> > > &Dis3D, int Width, int Height, int dis) { Dis3D.Length = 0; Dis3D.Length = dis; for(int d=0; d<dis; d++) { Dis3D[d].Length = Height; for(int i=0; i < Height; i++) { Dis3D[d][i].Length = Width; for(int j=0; j < Width; j++) { Dis3D[d][i][j]=0xFFFFFFFF; } } } } //------------------------------------------------------ Inicialización del arreglo bidimensional ----------------------------------------------------template <class RandomAccessIterator> void InitMap(RandomAccessIterator &Buffer, int Width, int Height, int K) { Buffer.Length = 0; Buffer.Length = Height; for (int i=0; i < Height; i++) { Buffer[i].Length = Width; for (int j=0; j < Width; j++) { Buffer[i][j]=K; } } } //------------------------------------------------------------ Obtención de la Desviación Media ------------------------------------------------------float DesviacionM(RandomAccessIteratore &Left, int x, int y, int Kernel) { int Height = Left.Length; int Width = Left[0].Length; int n=0, Sum=0, SumS=0; int YmasnYMatrix, XmasnXMatrix; float W; for (int nYMatrix = -Kernel; nYMatrix <= Kernel; nYMatrix++) { for (int nXMatrix = -Kernel; nXMatrix <= Kernel; nXMatrix++) { YmasnYMatrix = y + nYMatrix; XmasnXMatrix = x + nXMatrix; if ( (0 <= YmasnYMatrix) && (YmasnYMatrix < Height) && (0 <= XmasnXMatrix) && (XmasnXMatrix < Width) && ( (Kernel+.5)*(Kernel+.5) ) >= (nXMatrix*nXMatrix + nYMatrix*nYMatrix)) { W=Left[YmasnYMatrix][XmasnXMatrix].rgbtRed; Sum+=W; SumS+=W*W; n++; } } } W=Sum/n; return sqrt(SumS/n - W*W); } Instituto Tecnológico de Mérida 2004 59 Visión Artificial: Percepción de Profundidad Apéndice A //-------------------------------------------------------------- Function de Similitud ----------------------------------------------------------------------float Simil(RandomAccessIterator &Left, RandomAccessIterator &Right, int x, int y, int d, int Kernel) { float Peso, n=0, dif=0, Sum=0; int YmasnYMatrix, XmasnXMatrix, XmasnXMatrixD; int Height = Left.Length; int Width = Left[0].Length; for (int nYMatrix = -Kernel; nYMatrix <= Kernel; nYMatrix++) { for (int nXMatrix = -Kernel; nXMatrix <= Kernel; nXMatrix++) { YmasnYMatrix = y + nYMatrix; XmasnXMatrix = x + nXMatrix; XmasnXMatrixD = nXMatrix+x+d; if ( (0 <= YmasnYMatrix) && (YmasnYMatrix < Height) && (0 <= XmasnXMatrix) && (XmasnXMatrix < Width) && (0 <= XmasnXMatrixD) && (XmasnXMatrixD < Width) && ( (Kernel+.5)*(Kernel+.5) ) >= (nXMatrix*nXMatrix + nYMatrix*nYMatrix)) { Peso=1/(1+(nXMatrix*nXMatrix+nYMatrix*nYMatrix)/(Kernel+.5)); dif=Peso*(Left[YmasnYMatrix][XmasnXMatrix].rgbtRedRight[YmasnYMatrix][XmasnXMatrix+d].rgbtRed); Sum+=dif*dif; n+=Peso; } } } Sum/=n; return Sum; } //------------------------------------------------------ Obtención de Disparidad en Sub-píxel -------------------------------------------------------float SubPixel(int x , int y, int dis, int K, RandomAccessIterator &Dis3D) { int m = 2*K+1; DynamicArray < DynamicArray <float> > Data = SetMatrix(m, 2); for(int i=0; i<m; i++) { Data[i][0]=(dis-(K-i)); Data[i][1]==Dis3D[dis-(K-i)][y][x]; } DynamicArray < DynamicArray <float> > Temp = LeastSqrtMatrix(Data, 2); DynamicArray <float> Soluciones = LinearSysSolve(Temp); return (-Soluciones[1]/(2*Soluciones[2])); } Instituto Tecnológico de Mérida 2004 60 Visión Artificial: Percepción de Profundidad Apéndice A //-------------------------------------------- Filtro De Mediana Condicional --------------------------------------------------template <class RandomAccessIterator> DynamicArray < DynamicArray <float> > MedianaIFth2D(RandomAccessIterator &Buffer, int Kernel, bool &Change, int dismin, int dismax) { int Height = Buffer.Length; int Width = Buffer[0].Length; int YmasnYMatrix, XmasnXMatrix; DynamicArray < DynamicArray <float> > Temp; InitMap(Temp, Width, Height, 0); vector<float> Lista; float Sum; Change=false; for(int y=0; y<Height; y++) { for(int x=-dismin; x<Width-dismax; x++) { Sum=0; Lista.clear(); for (int nYMatrix = -Kernel; nYMatrix <= Kernel; nYMatrix++) { for (int nXMatrix = -Kernel; nXMatrix <= Kernel; nXMatrix++) { YmasnYMatrix = y + nYMatrix; XmasnXMatrix = x + nXMatrix; if ( (0 <= YmasnYMatrix) && (YmasnYMatrix < Height) && (0-dismin <= XmasnXMatrix) && (XmasnXMatrix < Width-dismax)) { Lista.push_back(Buffer[YmasnYMatrix][XmasnXMatrix]); Sum+=Buffer[YmasnYMatrix][XmasnXMatrix]; } } } list <float> lista; lista.clear(); for (int i = 0; i < Lista.size(); i++) { lista.push_back(Lista[i]); }; lista.sort(); Lista.clear(); int n2=lista.size(); for (int i=0; i< n2; i++) { Lista.push_back(lista.front()); lista.pop_front(); } float Mediana = Lista[Lista.size()/2]; if(abs(Buffer[y][x]-Lista[Lista.size()/2])>1.5) { Temp[y][x]=Mediana;//(Sum-Buffer[y][x]+Lista[Lista.size()/2])/Lista.size(); Change=true; } else { Temp[y][x]=Buffer[y][x]; } } } return Temp; } Instituto Tecnológico de Mérida 2004 61 Visión Artificial: Percepción de Profundidad Apéndice A //------------------------------------------------------------ Apareamiento Estereoscópico -----------------------------------------------------------DynamicArray < DynamicArray <float> > SteroMatch(RandomAccessIterator &Left, RandomAccessIterator &Right, int dismin, int dismax, int K) { float S=0; int Width, Height, Kt=0; Height = Left.Length; Width = Left[0].Length; DynamicArray < DynamicArray < DynamicArray <float> > > Dis3D; DynamicArray < DynamicArray <int> > DisMap; DynamicArray < DynamicArray <float> > SubDisMap; int Th_s=20; Set3Ddim(Dis3D, Width, Height, 1+dismax-dismin); InitMap(DisMap, Width, Height, 0); InitMap(SubDisMap, Width, Height, 0); for(int y=0; y<Height; y++) { for(int x=0; x<Width; x++) { Kt=K; do { S=DesviacionM(Left, x, y, Kt); if (S <Th_s) Kt++; }while (S< Th_s); for(int d=dismin; d<=dismax; d++) { if(x+d>=0 && x+d<Width) { Dis3D[d-dismin][y][x]=Simil(Left, Right, x,y,d,Kt); if( (Dis3D[d-dismin][y][x]<Dis3D[DisMap[y][x]-dismin][y][x]) || (Dis3D[ddismin][y][x]==Dis3D[DisMap[y][x]-dismin][y][x])&& abs(d)<abs(DisMap[y][x])) DisMap[y][x]=d; } } } } //------------Sub-Pixel--------------------------------------float SP; for(int y=0; y<Height; y++) { for(int x=0; x<Width; x++) { int DIS = DisMap[y][x]; if(DIS-2 > dismin && DIS+2 < dismax) { SP = SubPixel(x , y, DIS-dismin, 2, Dis3D, SubCostMap[y][x]); SubDisMap[y][x]= SP; } else { SubDisMap[y][x]= DIS; } } } //------------Filtro iterativo de mediana condicional---------bool Cambio; DynamicArray < DynamicArray <float> > SubDisMapF=MedianaIFth2D(SubDisMap,1, Cambio, dismin, dismax); int n=0; do { SubDisMapF = MedianaIFth2D(SubDisMapF,2, Cambio, dismin, dismax); n++; }while(Cambio); return SubDisMapF } //-------------------------------------------------------------------------------------------------------------------------------------------------------------------- Instituto Tecnológico de Mérida 2004 62 Visión Artificial: Percepción de Profundidad Apéndice A //--------------------------------- Minimos Cuadrados-----------------------------------------template <class RandomAccessIterator> DynamicArray < DynamicArray <float> > LeastSqrtMatrix(RandomAccessIterator Data, int n) {DynamicArray < DynamicArray <float> > Temp = SetMatrix(n+1, n+2); float sum; int m = Data.Length; for(int i=0; i<=2*n; i++) { sum=0; for(int j=0; j<m; j++) { sum+=pow(Data[j][0],i); } for(int j=i; j>=0; j--) { if(j<=n && (i-j)<=n) { Temp[j][i-j]=sum; } } } for(int i=0; i<=n; i++) { sum=0; for(int j=0; j<m; j++) { sum+=Data[j][1]*pow(Data[j][0],i); } Temp[i][n+1]=sum; } return Temp; } //-----------------------------------Solución de sistema lineal de n ecuaciones y n incógnitas---------------------------------------DynamicArray <float> LinearSysSolve(DynamicArray < DynamicArray <float> > Matrix) {DynamicArray <float> Temp; int Height= Matrix.Length; int Width= Matrix[0].Length; Temp.Length = Height; float p, sum; for(int i=0; i<Width-1; i++) { p=0; for(int j=i; j<Height; j++) { p=j; if(Matrix[p][i]!=0) break; } if(p!=i) { swap(Matrix[p], Matrix[i]); } for(int j=i+1; j<Height; j++) { int m = Matrix[j][i]/Matrix[i][i]; for(int n=0; n<Width; n++) { Matrix[j][n]=Matrix[j][n]-m*Matrix[i][n]; } } } Temp[Height-1]=Matrix[Height-1][Width-1]/Matrix[Height-1][Width-2]; for(int i=Height-2; i>=0; i--) { sum=0; for(int j=i+1; j<=Height-1; j++) { sum+=Matrix[i][j]*Temp[j]; } Temp[i]=(Matrix[i][Width-1]-sum)/Matrix[i][i]; } return Temp; } Instituto Tecnológico de Mérida 2004 63