2.- Estudio Poblacional y Muestral Univariante
Anuncio

2.- Estudio Poblacional y Muestral Univariante
Población:
Colectivo de personas o elementos con una característica común, objeto de
estudio.
Imposibilidad de estudio de esta característica en toda la población
- Coste económico
- Destrucción
- Tamaño de la población
Muestra:
Subconjunto de la población
La muestra da un conocimiento parcial de la población y debe elegirse con
cuidado de forma que represente adecuadamente la población en estudio.
La Estadística Descriptiva tiene como principal objetivo resumir y presentar
de forma sencilla los resultados obtenidos en la muestra.
La presentación se hace mediante tablas numéricas y gráficos.
- Tamaño muestral: nº de individuos u objetos bajo observación.
- Censo: El tamaño muestral coincide con el poblacional
Variable:
Es la característica a estudiar.
- Variable cualitativa: Referente a atributos o categorías
o Puras
o Ordinales
o Procedentes de v. Numéricas
- Variable cuantitativa: Toma valores numéricos
o Discretas
o Continuas
1
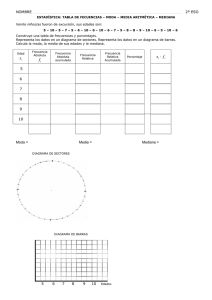
Tablas estadísticas
Tabla de distribución de frecuencias.
- n tamaño muestral o nº de observaciones
- Variables categóricas
o Frecuencia absoluta: ni nº de observaciones en la categoría i
Suma de frecuencias absolutas: n
o Frecuencia relativa: ni /n
Suma de frecuencias relativas: 1
Variable: Estudiaste estadística en Bachiller
Número de observaciones: 59
Número de categorias: 2
Tabla de distribución de Frecuencias
---------------------------------------------------------------Frecuencia Frecuencia Frecuencia
Clase Valor Frecuencia relativa
acumulada
relativa acum.
---------------------------------------------------------------1
no
56
0.9492
56
0.9492
2
si
3
0.0508
59
1.0000
----------------------------------------------------------------
Tabla de frecuencias de sexo por cómo _ vienes
filas
1
2
3
4
5
Total
-----------------------------------------------------------------h |
10 |
1 |
1 |
5 |
1 |18
|
16,95% |
1,69% |
1,69% |
8,47% |
1,69% |30,51%
|
55,56% |
5,56% |
5,56% |
27,78% |
5,56% |
|
27,03% |
100,00% |
25,00% |
33,33% |
50,00% |
-----------------------------------------------------------------m |
27 |
0 |
3 |
10 |
1 |41
|
45,76% |
0,00% |
5,08% |
16,95% |
1,69% |69,49%
|
65,85% |
0,00% |
7,32% |
24,39% |
2,44% |
|
72,97% |
0,00% |
75,00% |
66,67% |
50,00% |
-----------------------------------------------------------------Columnas
37
1
4
15
2
59
Total
62,71%
1,69%
6,78%
25,42%
3,39% 100,00%
2
- Variables cuantitativas discretas:
RX = {x1, x2,, xn} ordenados de menor a mayor
o Frecuencia absoluta: ni nº de veces que la variable toma el valor
xi
o Frecuencia absoluta acumulada: fi nº de veces que la variable
toma un valor ≤ xi
o Suma de frecuencias absolutas: n
o Frecuencia relativa: ni /n
o Frecuencia relativa acumulada: fi /n
o Suma de frecuencias relativas: 1
Variable: número de calzado
Número de observaciones: 59
Rango {35, 36,..., 48}
Tabla de distribución de Frecuencias
----------------------------------------------------------------Frecuencia
Frecuencia Frecuencia
Clase Valor Frecuencia relativa
acumulada relativa acum
----------------------------------------------------------------1
35
3
0.0508
3
0.0508
2
36
1
0.0169
4
0.0678
3
37
9
0.1525
13
0.2203
4
38
10
0.1695
23
0.3898
5
39
12
0.2034
35
0.5932
6
40
4
0.0678
39
0.6610
7
41
5
0.0847
44
0.7458
8
42
6
0.1017
50
0.8475
9
43
2
0.0339
52
0.8814
10
44
1
0.0169
53
0.8983
11
45
5
0.0847
58
0.9831
12
48
1
0.0169
59
1.0000
--------------------------------------------------------------------
3
- Variables cuantitativas continuas.
Para hacer la tabla de distribución de frecuencias deben elegirse las clases de
forma conveniente.
o Definir el recorrido o rango de la variable.
o Dividir el recorrido en clases o intervalos que no se solapen.
o El punto central de cada intervalo se denomina marca de clase.
o Se procede como en las variables discretas.
Variable: Altura
Rango:[156,191]
Tabla de distribución de frecuencias
-------------------------------------------------------------------Límite
Límite
Marca
Frec.
Frec.
Frec.
Frec.Rel.
Clase Inferior Superior clase
abs.
Relat. Abs.Acu
Acumu
-------------------------------------------------------------------<
155.0
0
0.0000
0
0.0000
1
155.0
160.0
157.5
7
0.1186
7
0.1186
2
160.0
165.0
162.5
15
0.2542
22
0.3729
3
165.0
170.0
167.5
14
0.2373
36
0.6102
4
170.0
175.0
172.5
8
0.1356
44
0.7458
5
175.0
180.0
177.5
9
0.1525
53
0.8983
6
180.0
185.0
182.5
4
0.0678
57
0.9661
7
185.0
190.0
187.5
1
0.0169
58
0.9831
8
190.0
195.0
192.5
1
0.0169
59
1.0000
≥
195.0
0
0.0000
59
1.0000
--------------------------------------------------------------------
4
Representaciones gráficas:
- Variables categóricas
o Diagrama de barras
Permite visualizar la distribución de frecuencias de una variable
cualitativa
d ia g r a m a d e b a r r a s . E s ta d ís tic a e n b a c h ille r
no
si
0
10
20
30
40
50
60
F re c u e n c ia
b
l
Barchart for como_vienes by sexo
percentage
50
sexo
h
m
40
30
20
10
0
1
2
3
4
5
como_vienes
Se dibuja sobre la clase correspondiente una barra o rectángulo de
altura proporcional a la frecuencia de la clase. Las barras horizontales o
verticales. Siempre:
El mismo ancho
Apoyadas sobre una línea común.
Longitud proporcional a las frecuencias.
5
o Diagrama de sectores:
diagrama de sectores
5.08%
Bach_Esta
no
si
94.92%
Un círculo en el que se representan sectores de áreas proporcionales a
la frecuencia de cada una de las clases.
- Variables cuantitativas discretas
o Diagrama de barras
diagrama de barras para n.calzado
12
frecuencia
10
8
6
4
2
0
35 36 37 38 39 40 41 42 43 44 45 48
6
Barchart for n_calzado by sexo
12
h
m
frecuencia
10
8
6
4
2
0
35
36 37 38
39 40 41
42 43 44 45 48
diagrama de barras según sexo
- Variables cuantitativas continuas.
o Histograma:
Histogram for altura
15
frecuencia
12
9
6
3
0
155
160
165
170
175
180
185
190
195
histograma
7
Histogram for altura
Histogram for altura
15
8
frecuencia
frecuencia
12
9
6
3
0
6
4
2
0
150
155
160
165
170
histograma
175
180
160
170
180
190
200
histograma
Los rectángulos se representan contiguos para dar idea de continuidad
Si la amplitud de las clases es la misma la altura de cada
rectángulo es proporcional a la frecuencia.
Si las clases no tienen la misma amplitud el área del
rectángulo es proporcional a la frecuencia.
h ≈ Frecuencia/long. de la clase.
El área total bajo el histograma es 1
La forma varia con la elección de las clases. No tenemos ninguna
información sí:
• Una sola clase. El histograma es un rectángulo.
• Cada clase tiene solo un dato
Hay que elegir con cuidado el número de clases.
o Polígono de frecuencias:
Esencialmente equivalente al histograma. Se obtiene uniendo
mediante poligonales los puntos medios de las bases superiores
de los rectángulos del histograma.
8
polígono de frecuencias
frecuencia
15
12
9
6
3
0
150
160
170
180
190
200
o Diagrama de tallo-hojas:
Permite obtener simultáneamente una distribución de frecuencias
de la variable y su representación gráfica.
Se separa el último dígito de la derecha de cada dato (hoja) del
bloque de cifras restantes (tallo).
Procedimiento a seguir:
Redondear los datos a un número conveniente de cifras
significativas (dos o tres)
Colocarlas en una tabla con dos columnas separaradas por
una línea. Todas cifras menos la última a la izquierda de la
línea (tallo) y la última a la derecha (hoja)
Cada tallo define una clase y se escribe sólo una vez. El nº de
hojas representa la frecuencia de dicha clase.
9
Diagrama de tallo-hojas para número de calzado:
Unidad = 0.1
1|2 representa
Mujeres
3
35|000
4
36|0
13
37|000000000
(10)
38|0000000000
18
39|000000000000
6
40|000
3
41|000
1.2
Hombres
1
40|0
3
41|00
9
42|000000
9
43|00
7
44|0
6
45|00000
1
46|
1
47|
1
48|0
Diagrama de tallo-hojas para número de calzado:
Unidad = 0.1
1|2 representa 1.2
3
35|000
4
36|0
13
37|000000000
23
38|0000000000
(12)
39|000000000000
24
40|0000
20
41|00000
15
42|000000
9
43|00
7
44|0
6
45|00000
1
46|
1
47|
1
48|0
10
Diagrama de tallo-hojas para la variable altura:
2 15|68
17 16|000001222234444
29 16|555556888889
(13) 17|0000000222344
17 17|5566688
10 18|00001133
2 18|
2 19|01
1
2
8
13
(9)
19
18
15
9
5
2
2
Mujeres
15|6
15|8
16|000001
16|22223
16|444455555
16|6
16|888
17|000000
17|2223
17|445
17|
17|88
Hombres
3 16|889
4 17|0
4 17|
5 17|5
8 17|666
8 17|
(6) 18|000011
4 18|33
2 18|
2 18|
2 18|
2 19|0
HI|191.0
11
Medidas de localización.
- Variables cualitativas:
Frecuencia relativa de cada clase.
Moda o clase modal:
Clase con frecuencia mayor, puede no ser única
- Variables numéricas:
o Medidas de centralización:
Dan una idea del valor central en torno al cual se reparten los datos
Media muestral:
Dada una muestra de tamaño n X1, X2,..., Xn
X = 1/n∑Xi
Si no conocemos el conjunto original de datos, sino su distribución de
frecuencias
X = 1/n∑niXi si la variable es discreta
X = 1/n∑nici si la variable es continua
La media muestral equilibra las desviaciones positivas y negativas de
los datos respecto a su valor
∑(Xi- X ) = 0
Actúa como el centro geométrico o centro de gravedad.
Media poblacional
μ = E(X) = ∑ piXi si la variable es discreta
μ = E(X) = ∫ x f(x) dx si la variable es continua
Mediana muestral:
Dada una muestra de tamaño n X1, X2,..., Xn
Las ordenamos de menor a mayor X (1), X (2),..., X (n)
La mediana separa las observaciones en dos grupos. La mitad o más de
las observaciones son menores o iguales que la mediana y la mitad o
más de las observaciones son mayores o iguales que la mediana.
Si n es impar medX = X ((n+1)/2)
Si n es par la mediana es cualquier valor comprendido entre X(n/2)
y X((n/2)+1)
12
Datos agrupados:
Intervalo mediana: Es la clase en la que se encuentra la mediana.
Mediana poblacional:
Es un valor m tal que
P(X ≤ m) ≥ ½
P(X ≥ m) ≤ ½
Moda: Es el valor más frecuente en la muestra.
Moda, mediana y media aportan información complementaria sobre
los datos. La media utiliza todos los datos y es sensible a observaciones
atípicas, es preferible para datos homogéneos. La mediana sólo tiene en
cuenta el orden de los datos y no su magnitud. Cambia poco si se altera
alguna observación.
Conviene calcular las dos. Si son similares la distribución es simétrica (datos
homogéneos). Si son muy diferentes la distribución es asimétrica (datos
heterogéneos).
o Otras medidas de localización:
Media ponderada X = ∑wiXi/∑wi
Media geométrica: X = (ΠXi)1/n
Media armónica: X = (1/n∑Xi )-1
Percentiles: percentil p es aquel valor tal que el p% o más de las
observaciones son menores o iguales que el y el (1-p)% o más de
las observaciones son mayores o iguales que él.
Cuartiles: Dividen a la población en cuatro partes
Primer cuartil Q1: percentil 25
Segundo cuartil Q2: la mediana o percentil 50
Tercer cuartil Q3: el percentil 75.
Rango intercuartílico: RI = Q3-Q1
13
Summary Statistics for altura
Total
Count
59
Average
170.03
Median
170.0
Mode
170.0
Variance
63.65
Standard deviation
7.978
Minimum
156.0
Maximum
191.0
Range
35.0
Lower quartile
164.0
Upper quartile
176.0
Interquartile range
12.0
Skewness
0.5572
Kurtosis
-0.161
Percentiles for altura
Total
1.0%
156.0
5.0%
160.0
10.0%
160.0
25.0%
164.0
50.0%
170.0
75.0%
176.0
90.0%
181.0
95.0%
183.0
99.0%
191.0
Mujeres Hombres
41
18
166.46
178.16
165.0
180.0
170.0
180.0
30.40
44.85
5.514
6.697
156.0
168.0
178.0
191.0
22.0
23.0
162.0
175.0
170.0
181.0
8.0
6.0
0.2941
0.1294
-0.6802 -0.2358
Mujeres
156.0
160.0
160.0
162.0
65.0
170.0
174.0
175.0
178.0
Hombres
168.0
168.0
168.0
175.0
180.0
181.0
190.0
191.0
191.0
14
Summary Statistics for n_calzado
Total
Count
59
Average
39.69
Median
39.0
Mode
39.0
Variance
8.112
Standard deviation
2.848
Minimum
35.0
Maximum
48.0
Range
13.0
Lower quartile
38.0
Upper quartile
42.0
Interquartile range
4.0
Skewness
0.7463
Kurtosis
0.2343
Percentiles for n_calzado
Total
1.0%
35.0
5.0%
35.0
10.0%
37.0
25.0%
38.0
50.0%
39.0
75.0%
42.0
90.0%
45.0
95.0%
45.0
99.0%
48.0
Mujeres
35.0
35.0
37.0
37.0
38.0
39.0
40.0
41.0
41.0
Hombres Mujeres
18
41
43.166
38.17
42.5
38.0
42.0
39.0
4.0294
2.2451
2.0073
1.4983
40.0
35.0
48.0
41.0
8.0
6.0
42.0
37.0
45.0
39.0
3.0
2.0
0.6763
-0.212
0.3032
0.0681
Hombres
40.0
40.0
41.0
42.0
42.5
45.0
45.0
48.0
48.0
15
Representaciones gráficas
- Diagrama de cajas
Es una representación semigráfica donde se muestran características
importantes de la población estudiada y se señalan posibles datos atípicos. Su
construcción está basada en los cuartiles.
o Se ordenan los datos de la muestra de menor a mayor y se obtiene
máximo, mínimo, Q1, Q2 y Q3.
o Se dibuja un rectángulo con extremos Q1 y Q3 y se señala la mediana
Q2 mediante una línea recta.
o Se calculan los límites superior e inferior admisibles.
LS = Q3 +1.5 RI
LI = Q1 – 1.5 RI
Si LI < mínimo entonces LI = mínimo
Si LS > máximo entonces LS = máximo
o Se dibuja una línea de cada extremo del rectángulo hasta LI y LS
o Se identifican todos los datos fuera del intervalo (LI, LS)
mostrándolos como atípicos.
o Los datos atípicos son de gran interés ya que pueden ser debidos a
errores o pueden suministrar una información relevante sobre el
comportamiento de la población.
Box-and-Whisker Plot
h
m
150
160
170
180
190
200
altura
16
Box-and-Whisker Plot
150
160
170
180
190
200
47
50
altura
Box-and-Whisker Plot
35
38
41
44
n_calzado
Box-and-Whisker Plot
h
m
35
38
41
44
47
50
n_calzado
17
Medidas de Dispersión:
n
- Varianza muestral:
S X2 =
∑(X
i =1
i
− X )2
n
n
- Desviación típica muestral:
∑(X
SX =
i =1
i
− X )2
n
- Varianza Poblacional: σ X2 = E{( X − μ ) 2}
- Desviación típica poblacional: σ X = E{( X − μ )2}
La varianza es la media de las desviaciones de las observaciones a la media
elevadas al cuadrado y mide la concentración de los datos en torno a la
media.
n
Para datos agrupados
SX =
∑ (c − X ) n
i =1
2
i
i
n
- Regla de Chebychev:
El porcentaje de observaciones que distan de la media menos de k
desviaciones típicas es mayor o igual que (1 – 1/k2).100
- Desigualdad de Chebychev:
P(|X-μ|≤kσ)≥ 1- 1/k2
P(μ - kσ ≤ X ≤ μ - kσ) ≥ 1- 1/k2
- Meda:
Mide la variación de las observaciones respecto de la mediana. Es la
mediana de las desviaciones absolutas de los datos respecto de la mediana.
Si las observaciones son X1, X2, ... , Xn
Definimos Yi = |Xi – MedX|
MedaX = MedY
Los valores extremos influyen menos en la meda que en la varianza
Medidas de forma:
- Coeficiente de variación: CVX = SX/|X|
Sirve para comparar la dispersión de variables que aparecen en unidades
distintas
18
n
- Coeficiente de asimetría:
CAX =
∑(X
i =1
i
− X )3
nS X3
Distribución simétrica: CAX = 0
Distribución asimétrica a la derecha: CAX > 0
Distribución asimétrica a la izquierda: CAX < 0
n
- Coeficiente de apuntamiento o curtosis:
CAPX =
∑(X
i =1
i
− X )4
nS X4
Describe lo picuda o plana que es una distribución
Para datos agrupados
n
∑ (c
CAX =
i
i =1
n
− X )3 ni
nS
CAPX =
3
X
∑ (c
i =1
i
− X ) 4 ni
nS X4
Las medidas poblacionales se definen
CVX = σX/|μ|
E ( X − μ )3
CAX =
CAPX =
σ X3
E ( X − μ )4
σ X4
Otras medidas:
- Momento de orden k respecto al origen
n
mk =
∑X
i =1
k
i
mk = E(Xk)
n
- Momento de orden k respecto a la media
n
μk =
∑(X
i =1
i
− X )k
n
μk = E(X-μ)k
19
Posición relativa de media y mediana según simetría de la
distribución
0,4
0,3
0,2
0,1
0
-4
-3
-2
-1
0
1
2
3
4
x
Distribución simétrica: media, mediana y moda iguales
0,1
0,08
0,06
0,04
0,02
0
0
10
20
30
40
x
Distribución asimétrica a la dcha: moda<mediana<media
4
3
2
1
0
0
0,2
0,4
0,6
0,8
1
x
Distribución asimétrica a la izqda: media<mediana<moda
20
Transformaciones de los datos:
Los datos se transforman para
- Obtener mejores propiedades de la distribución (simetría)
- Comparar valores correspondientes a distribuciones distintas
- Transformaciones lineales: Cambio de localización y escala
Y = aX + b
Propiedades:
o μY = aμX + b
o σY = |a|σX
o med(Y) = a med(X) + b
o Meda(Y) = |a|meda(X)
o RIY = |a| RIX
o Los coeficientes de asimetría y curtosis no cambian
- Variable tipificada
Y=
X − μX
σ
μY = 0 σY = 1
Las transformaciones lineales no corrigen la asimetría de la distribución
- Transformación inversa Y = 1/X
- Transformación logarítmica Y = log X
- Transformación radical Y = X
- Transformación potencia Y = X2
Las tres primeras comprimen los valores altos y expanden los bajos, son
adecuadas para corregir asimetría a la derecha.
21
0,1
0,08
0,06
0,04
0,02
0
0
10
20
30
40
x
La última actúa en sentido contrario, comprime los valores pequeños y
expande los altos, es adecuada para corregir datos con asimetría a la
izquierda
4
3
2
1
0
0
0,2
0,4
0,6
0,8
1
x
En todos los casos el efecto de la transformación depende del rango de los
datos.
22