memoria DeteccióndePolaridadcontweetsenEspañolVPostRevision
Anuncio

Procesamiento del Lenguaje Natural, Revista nº 47 septiembre de 2011
recibido 27-04-2011 aceptado 19-05-2011
Detección de la polaridad de tweets en español
Detecting polarity in Spanish tweets
Eugenio Martínez Cámara
Miguel Á. García Cumbreras
M. Teresa Martín Valdivia
L. Alfonso Ureña López
Departamento de Informática, Escuela Politécnica Superior de Jaén
Universidad de Jaén, E-23071 – Jaén
{emcamara, magc, maite, laurena}@ujaen.es
Resumen: En los últimos años las redes sociales se han convertido en recursos de compartición
de contenidos muy importante. Encontramos una gran cantidad de información en foros, blogs,
tiendas virtuales, sitios de noticias, etc. donde la gente expresa sus opiniones. Una de las tareas
comunes es la detección de la polaridad, esto es, identificar si la opinión expresada es positiva o
negativa. Por otro lado, cada día más, la gente utiliza las redes sociales para expresar sus
sentimientos y sensaciones sobre cualquier tema. Así, micro-bloggings como Twitter, están
empezando a utilizarse cada vez con mayor intensidad en España, y es a partir de 2010 cuando
empresas, políticos y gente en general se están dando cuenta del verdadero potencial de Twitter.
El propósito de este trabajo es la creación de un corpus de tweets en español y su posterior
aplicación para entrenar un clasificador automático capaz de detectar la polaridad de tweets. Se
han realizado múltiples experimentos, aplicando diferentes algoritmos de aprendizaje
automático y técnicas de procesado. Asimismo se ha filtrado la colección utilizada en base al
análisis de los anteriores resultados.
Palabras clave: Análisis de sentimientos, Minería de Opiniones, Redes Sociales, clasificación
de la polaridad, micro-blogging.
Abstract: In recent years, social media has become important for social networking and content
sharing. There are lots of forums, blogs, e-commerce sites, news sites, where people write their
opinions. One common task is the detection of the polarity, whether the opinion expressed is
positive or negative. Furthermore, every day a lot of people are using social networks to express
feelings about any subject. In 2010 businesses, politicians and people in general have begun to
realize the potential of Twitter. The purpose of this work is to collect a corpus of tweets in
Spanish, filtering it, and using to train a classifier that can automatically detect the polarity of
Twitter messages. We have accomplished several experiments using different learning
algorithms and processing techniques. The corpus used in the previous experiments has been
filtered based on the analysis of the results.
Keywords: Sentiment Analysis, Opinion Mining, Social Networks, detection of the polarity,
micro-blogging
1
Introducción
La Web ha cambiado sustancialmente desde su
nacimiento a principios de la década de los 90.
De hecho, estamos siendo testigos de la
revolución que está sufriendo la Web en los
últimos años. En la primera década del siglo
XXI Internet pasó de ser un contenedor estático
de información, en la que solo unos pocos
producían contenidos, a ser un elemento vivo
en el que cualquiera puede ser creador y
ISSN 1135-5948
consumidor de información, siendo esto la seña
de identidad de lo que se ha venido a llamar
“Web 2.0”. Esta eliminación de las barreras
entre productor y consumidor de información se
pone de manifiesto en la gran cantidad de blogs
que pueblan Internet, así como el continuo
crecimiento de todo tipo de redes sociales:
Facebook, Flickr, LinkedIn. En este contexto de
la “Web 2.0”, los usuarios de Internet no solo
crean contenidos a través de redes sociales,
blogs o wikis, sino que también comentan,
© 2011 Sociedad Española Para el Procesamiento del Lenguaje Natural
Eugenio Martínez Cámara, Miguel A. García Cumbreras, M. Teresa Martín Valdvia, L. Alfonso Ureña López
critican o dan su opinión sobre diferentes
temas, como cine, literatura, política, coches,
productos electrónicos, entre otros muchos. La
idea de procesar automáticamente esta gran
cantidad de comentarios ha atraído la atención
de muchos investigadores en el campo de la
minería de texto, con la intención de extraer
opiniones sobre un producto o tema a partir de
la gran cantidad de información desestructurada
que hay en Internet. Esta nueva tarea de
analizar o detectar la orientación de los textos
aparece con distintos nombres en la
bibliografía: Minería de opiniones (Opinion
Mining, OM), análisis de sentimientos
(Sentiment Analysis, SA), análisis de
subjetividad u orientación de sentimientos.
Desde el punto de vista de la investigación,
la mayoría de los trabajos de OM estudian a
nivel de documento, la polaridad de las
opiniones vertidas en foros o sitios web como
Amazon o Epinion (Pang and Lee, 2008). Hay
que destacar el hecho de que las redes sociales
son una inmejorable fuente de datos para OM.
Concretamente, lo que actualmente se conoce
como micro-blogging, cuyo mejor y más
famoso ejemplo es Twitter, están siendo
utilizado para estudiar la intención de voto, la
opinión de consumidores y el estado de ánimo
de las personas. Debido principalmente a la
relativamente reciente aparición de Twitter, no
hay muchos trabajos de investigación de OM
que utilicen esta red social como fuente de
datos, aunque desde el año 2009 el interés
investigador en Twitter no ha parado de crecer.
Twitter es una web basada en microblogging que fue presentada en octubre de
2006. Los usuarios publican mensajes de 140
caracteres de longitud máxima que reciben el
nombre de tweets. Normalmente los tweets
expresan opiniones sobre productos y servicios,
o el punto de vista de los usuarios sobre religión
o política. El micro-blogging se ha convertido
en una herramienta verdaderamente útil para
expresar opiniones, difundir noticias, y
comunicarse con otras personas. Debido a esto,
investigadores, políticos, empresas y otros
sectores interesados en el estudio de opiniones,
se han dado cuenta de que Twitter es una fuente
muy valiosa para conocer la opinión de las
personas.
Los tweets tienen características que los
hacen diferentes de las opiniones y comentarios
que hay en foros y páginas web. Normalmente
los comentarios u opiniones que se escriben en
Internet suelen ser textos más o menos extensos
en los que los usuarios intentan resumir lo que
piensan sobre un determinado tema, pero los
tweets suelen estar escritos en un lenguaje
informal, y su extensión está limitada a 140
caracteres. Por otra parte, muchos tweets no
expresan opiniones sino situaciones que les
ocurren a los usuarios. Por último, los tweets
tienen que ser analizados a nivel de frase, y no a
nivel de documento.
Aunque la mayoría de los usuarios de
Twitter provienen de EE.UU., últimamente no
ha parado de crecer en el resto de países del
mundo, siendo España un ejemplo claro. Así
pues, debido a que la explosión de popularidad
de esta red social es relativamente reciente en
países de habla no inglesa, los hasta ahora
escasos trabajos de investigación publicados
relacionados con SA y Twitter son
prácticamente todos orientados al inglés.
El trabajo que presentamos ha consistido en
la creación de un corpus de tweets en español,
utilizados posteriormente para el entrenamiento
de un clasificador cuyo objetivo es la
determinación de la polaridad de los mensajes
en Twitter. El artículo tiene la siguiente
estructura: en la sección 2 se describen algunos
trabajos sobre SA y el uso de Twitter en este
área. En la sección 3 se describe cómo se ha
creado el corpus de tweets en español. Luego se
explican los algoritmos de clasificación que se
han utilizado. La sección 5 presenta la
experimentación realizada, así como los
resultados obtenidos. Por último, se ponen de
manifiesto las conclusiones a las que se ha
llegado y el trabajo futuro.
2
Trabajos relacionados
Aunque la minería de opiniones es un área de
investigación relativamente nueva, existen una
gran cantidad de trabajos relacionados con ella,
y más específicamente con la clasificación de la
polaridad. Se pueden distinguir dos formas de
tratar el problema. La primera se basa en
técnicas de aprendizaje automático, que utilizan
una colección de documentos con el fin de
entrenar un clasificador (Pang y otros, 2002), y
la segunda se fundamenta en el concepto de
orientación semántica, que no necesita el
entrenamiento de ningún algoritmo, pero sí
debe tener en cuenta la orientación de las
palabras (positiva o negativa) (Turney, 2002).
También se han realizado trabajos en los que se
intentan combinar ambas estrategias (Prabowo
y Thelwall, 2009). Una buena revisión
Detección de la polaridad de tweets en español
bibliográfica sobre el estado del arte en OM es
dada en (Pang and Lee, 2008).
La mayoría de los estudios en OM se han
llevado a cabo sobre textos en inglés, pero eso
no quiere decir que no se hayan publicado
algunos en otras lenguas. Por ejemplo,
(Denecke, 2008) trabaja sobre comentarios en
alemán recogidos de Amazon. Utiliza tres
corpora diferentes para comparar los resultados:
el corpus MPQA, opiniones en inglés de IMDb,
y opiniones en alemán recogidas de Amazon.
(Abbasi y otros, 2008) llevan a cabo un estudio
de análisis de sentimientos de contenido
inapropiado en inglés y árabe. Utilizan los
comentarios
de
un
importante
foro
estadounidense para el estudio en inglés, y para
el árabe los textos recogidos de un grupo
extremista de Oriente Medio. (Zhang y otros,
2009) aplican técnicas de SA en dos corpus de
textos en chino. El primero está formado por
comentarios sobre eutanasia recogidos de
diferentes sitios web, mientras que el segundo
está formado por opiniones sobre 6 categorías
diferentes de productos, recogidas de Amazon.
Siguieron una estrategia basada en aprendizaje
automático, utilizando los algoritmos SVM,
Naïve Bayes, y un árbol de decisión.
Como se puede ver la mayor parte de la
investigación en OM se ha realizado con textos
publicados en blogs, foros y sitios web,
caracterizándose todos por haber llevado a cabo
un estudio a nivel de documento. La
investigación sobre textos publicados en sitios
de micro-bloging es muy escasa, aunque hay
que destacar que desde 2009 este tipo de sitios,
y más concretamente Twitter, está atrayendo la
atención de la comunidad científica. Existen
algunos trabajos que utilizan Twitter a modo de
corpus. (Petrovic y otros, 2010) crean un gran
corpus con 97 millones de tweets. (Pak y
Paroubek, 2010) describen cómo generar de
forma automática un corpus de tweets positivos,
negativos y neutros. El corpus que crean lo
utilizan para entrenar un clasificador de
sentimientos. (Go y otros, 2009) usan técnicas
de aprendizaje automático para construir un
clasificador que les permita determinar la
polaridad de los tweets. Para el etiquetado del
corpus en tweets negativos y positivos siguen la
misma estrategia que se describe en (Read,
2005).
(Jansen et al., 2009) demuestran como los
sitios de micro-blogging son una herramienta
muy útil en marketing, e indica que los tweets
pueden considerarse como Electronic Word Of
Mouth (EWOM). Siguiendo esta línea de
utilizar Twitter como otra herramienta más en
marketing, en (Asur y Huberman, 2010) se
utiliza un corpus de tweets sobre un conjunto de
películas que se estrenaron a finales de 2009 y
principios de 2010, para demostrar la
correlación existente entre la cantidad de tweets
y su polaridad sobre una determinada película,
con la recaudación en taquilla que ha obtenido
en las dos primeras semanas desde su estreno.
(Bollen y otros, 2011) investigan la posible
correlación del estado de ánimo que se
manifiesta en Twitter con la variación de los
mercados de valores.
El estudio de la tendencia de la opinión
política también ha sido un tema que ha atraído
a la comunidad científica. (Tumasjan y otros,
2010) llevan a cabo un interesante estudio con
más de 100.000 tweets sobre las elecciones
federales al parlamento alemán que se
celebraron en 2009. Intentan medir la intención
de voto simplemente contando en número de
menciones que tiene cada partido. El resultado
es bastante sorprendente ya que el error
cometido no llega al 2%. (O’Connor y otros,
2010) analizan opiniones políticas y sobre
productos comerciales y comparan los
resultados usando Twitter y encuestas.
(Diakopoulos y Shamma, 2010) clasifican la
polaridad de los tweets durante el debate
presidencial en los Estados Unidos del año
2008 retransmitido por televisión y seguido por
muchas personas en Twitter.
Debido al hecho de la diferencia en el inicio
del uso de Twitter en otros países, como es el
caso de España, no existen muchos artículos
que traten este problema en una lengua
diferente al inglés. Esta es la principal razón de
nuestro estudio. Queremos probar la potencia
de Twitter para entrenar un clasificador de
polaridad de opinión usando solamente tweets
en español.
3
Creación del corpus de datos
El análisis de la polaridad en micro-blogging es
una tarea muy reciente, por lo que, incluso en
inglés, el número de recursos es muy reducido.
Dado que en español no existe ningún corpus
de tweets, hemos tenido que crear uno para
poder llevar a cabo los experimentos. El
proceso de descarga de los tweets no es muy
complicado ya que Twitter ofrece dos tipos de
APIs para ello. Nosotros hemos utilizado la
Eugenio Martínez Cámara, Miguel A. García Cumbreras, M. Teresa Martín Valdvia, L. Alfonso Ureña López
conocida como API de búsqueda1, que nos
permite realizar una descarga programada de
tweets en base a una determinada consulta. La
API proporciona una opción para seleccionar el
idioma de los tweets, siendo el español el
idioma elegido para este trabajo.
Para un estudio supervisado de la polaridad
es necesario contar con un corpus etiquetado.
Según (Read, 2005), los emoticonos que los
usuarios utilizan en blogs, foros, o cualquier
otro tipo de medio electrónico, marcan
realmente su estado de ánimo. La principal
característica de Twitter es que la longitud de
los mensajes está limitada a 140 caracteres, por
lo que los usuarios de esta red social tienen que
expresar sus opiniones, pensamientos y estados
de ánimo como muy pocas palabras, siendo los
emoticonos un elemento común de muchos de
sus mensajes. Por esta razón, hemos
considerado como positivos los tweets que
contenían emoticonos positivos, mientras que
como negativos los que tenían emoticonos
negativos. Cuando al buscador de Twitter se le
realiza la consulta “:)” devuelve tweets que
contienen emoticonos positivos, y si se consulta
por “:(” devuelve mensajes con emoticonos
negativos, por lo que, al igual que (Go y otros,
2009) hemos utilizado estas consultas para
conseguir tweets negativos y positivos. El
corpus está formado por 34.634 tweets, de los
cuales 17.317 son positivos y 17.317 son
negativos, que fueron publicados entre el 3 y el
4 de marzo de 2011.
El lenguaje utilizado en Twitter tiene
algunas características propias que han sido
eliminadas porque no aportan ningún valor a los
experimentos. Estas características propias son:
1. Retweets: Es una forma de repetir un
mensaje publicado por otro usuario. Los
retweets se pueden realizar a través de la
interfaz web de Twitter o escribiendo RT y
el nombre del usuario cuyo tweet se
pretende replicar. Los retweets realizados
de la primera forma no son un problema
porque el tweet no es duplicado, pero los
que se han hecho siguiendo el segundo
método sí, ya que se generan tweets con el
mismo contenido pero que Twitter los
considera como distintos. Todos aquellos
tweets devueltos por la API que contienen
la expresión RT @[nombre_usuario] son
eliminados,
para
así
evitar
la
sobrevaloración de determinados tweets.
1
http://dev.twitter.com/doc/get/search
2. Menciones: Cuando un usuario quiere
referirse a otro introduce en su mensaje una
mención a dicho usuario. Toda mención
comienza con el símbolo @ al que le sigue
el nombre de un usuario. Al no aportar
ninguna
información relevante,
las
menciones son borradas del contenido de
los tweets.
3. Enlaces: Es muy normal que los tweets
incluyan enlaces a páginas web. En esta
experimentación
no
utilizamos
la
información de las web enlazadas, por lo
que al igual que las menciones también son
eliminados.
4. Hashtag: Un hashtag es el nombre de un
tema en Twitter, por lo que cuando un
usuario quiere referirse a un tema usa el
hashtag de dicho tema. Al no ser relevante
para esta experimentación, los hashtags
también son eliminados del contenido de
los tweets.
Los usuarios de Twitter suelen utilizar un
lenguaje muy informal, por lo que es necesario
limpiar el texto antes de construir el modelo de
clasificación. Para esta tarea se han aplicado los
siguientes filtros:
1. Retornos de carro: Todos los símbolos de
retorno de carro son eliminados.
2. Emoticonos opuestos: En ocasiones,
Twitter considera positivos o negativos
tweets en los que aparecen emoticonos con
sentidos opuestos. Por ejemplo:
@fragilejunkie Yo también
te
extraño
Marian!
:(
decime yaa un día de la
semana
que
viene
cuando
quieras que nos juntamos a
la tarde! :)
La API de búsqueda de Twitter devuelve
este tweet como negativo, pero como se
puede comprobar no puede considerarse
como tal, ya que claramente tiene dos
partes, una positiva y otra negativa. Todos
los tweets como este los eliminamos para
evitar ambigüedad en la colección.
3. Emoticonos con sentimiento no definido:
La API de búsqueda de Twitter considera
como emoticonos negativos: “:-P”, “:P”,
“:PP”, “\(”. Los usuarios de Twitter en
España no suelen utilizar estos emoticonos
para expresar sentimientos negativos, por lo
se decidió eliminar los tweets en los que
aparecían esos emoticonos.
Detección de la polaridad de tweets en español
4. Letras repetidas: Para enfatizar los
mensajes los usuarios suelen repetir letras.
cosaaaa hermosaaaa
te quiero mucho :)
Mantener estas palabras puede ser un
problema para el proceso de clasificación,
ya que la misma palabra con una o varias
letras que se repiten varias veces se
considerarían como una palabra distinta.
Para evitar esto, se reduce a dos el número
de ocurrencias de aquella letra que se
repita más de dos veces de forma seguida.
El ejemplo anterior quedaría como:
cosaa hermosaa
mucho :)
te
quiero
del sistema desarrollado es que se puedan
procesar los tweets en tiempo real, esto es, que
el procesamiento y la obtención de los
resultados no tenga una gran complejidad
temporal.
Los cuatro métodos para generar los
vectores de palabras han sido los siguientes:
Term
Frequency-Inverse
Document
Frequency (TFIDF).
Term Frequency (TF): la frecuencia relativa
de un término en un documento.
Term Occurrences (TO): es el número total
de ocurrencias de un término.
Binary Term Occurrences (BTO): cada
término recibe el valor 1 si aparece en un
documento, 0 en caso contrario.
5. Risa: No existe una única forma para que
los usuarios expresen risa, por lo que al
igual que con las letras repetidas también se
ha normalizado este aspecto. En la Tabla 1
se muestra cual ha sido la transformación.
Risa
Conversión
jajajajaja…
jaja
jejejejeje…
jeje
jijijijijiji…
jiji
jojojojojo…
jojo
jujujujuju…
juju
Lol
jaja
Juasjuasjuasjuas…
juas
muajajajaja
buajajajaja
Buaja
Tabla 1. Normalización de expresiones de risa
Por último, para el proceso de clasificación
se eliminaron todos los emoticonos, así como
todos los caracteres que no pertenecen al
alfabeto español para reducir al máximo posible
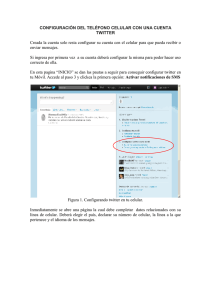
el ruido en los datos. La Figura 1 muestra el
proceso para generar el corpus.
Figura 1. Proceso de generación del corpus
Los algoritmos de aprendizaje automático
utilizados han sido Support Vector Machines
(SVM), Regresión Logística (LR) y Naïve
Bayes (NB).
Para la evaluación de los experimentos
realizados se han utilizado las medidas típicas
precisión (P), recall (R) y accuracy (Acc):
precision
4
(P)
Marco de trabajo
Además del uso de los dos conjuntos de
datos descritos en la sección anterior, se han
utilizado cuatro métodos para generar los
vectores de palabras y varios algoritmos de
aprendizaje automático para la detección de la
polaridad de cada tweet. Un objetivo importante
recall ( R )
accuracy
TP
TP FP
TP
TP FN
( Acc )
TP TN
TP FP FN TN
Eugenio Martínez Cámara, Miguel A. García Cumbreras, M. Teresa Martín Valdvia, L. Alfonso Ureña López
donde TP son los verdaderos positivos (valores
positivos acertados), FP son los falsos positivos
(valores positivos fallados), TN son los
verdaderos negativos (valores negativos
acertados) y FN son los falsos negativos
(valores negativos fallados). La precisión nos
indica la bondad del sistema en la asignación de
las etiquetas. El recall nos indica la cobertura
de nuestro sistema. El accuracy combina ambas
medidas, calculando la proporción de resultados
acertados.
Además, se ha realizado validación cruzada.
Se trata de un método estadístico para evaluar y
comparar los resultados obtenidos por varios
algoritmos de aprendizaje. El conjunto de datos
se divide en dos partes: una parte para entrenar
el modelo y la otra parte para evaluarlo. En
nuestros experimentos hemos utilizado la
denominada “10-fold cross-validation”. Esta
validación consiste en crear diez subconjuntos
de datos y se realizan diez iteraciones. En cada
iteración se toman nueve partes para
entrenamiento y se evalúa con la otra parte
restante. Los resultados se calculan como la
media de las evaluaciones de todas las
iteraciones.
5
MLA
SVM
LR
NB
WVM
TFIDF
TF
TO
BTO
TFIDF
TF
TO
BTO
TFIDF
TF
TO
BTO
Precision
0,7342
0,7396
0,7356
0,7368
0,6628
0,6688
0,6514
0,6540
0,6601
0,6422
0,6270
0,6292
Recall
0,7324
0,7388
0,7321
0,7320
0,6365
0,6352
0,5916
0,5962
0,6544
0,6299
0,6072
0,6093
Accuracy
0,7324
0,7388
0,7321
0,7320
0,6365
0,6352
0,5916
0,5962
0,6544
0,6299
0,6072
0,6093
Tabla 2. Resultados base
En un segundo conjunto de experimentos
nuestro objetivo fue comprobar la aportación de
métodos básicos de procesamiento de texto,
eliminación de palabras vacías (stopping) y
extracción de raíces (stemming). La lista de
palabras vacías utilizada es la clásica para
español, y hemos utilizado el stemmer de Porter
para la extracción de raíces.
En la Tabla 3 se muestran los resultados
obtenidos con el algoritmo de aprendizaje
automático SVM y la aplicación varios métodos
para generar los vectores de palabras, stopping
y stemming.
Experimentos y resultados
En los primeros experimentos realizados con la
colección de 34.634 tweets hemos combinado
los cuatro métodos utilizados para generar los
vectores de palabras y los tres algoritmos de
aprendizaje automático. En todos los casos se
ha utilizado la validación cruzada descrita
anteriormente.
En la Tabla 2 se muestran estos primeros
resultados base. Como se puede observar en
estos experimentos base, el algoritmo de
aprendizaje automático que mejores resultados
ha obtenido es SVM, obteniendo LR y NB
valores muy parecidos (accuracy entre 0,6 y
0,66). Con todos los algoritmos de aprendizaje
automático el mejor resultado se ha obtenido
con el método TF para generar los vectores de
palabras.
WVM
TF
IDF
TF
TO
BTO
Stop
No
Sí
No
Sí
No
Sí
No
Sí
No
Sí
No
Sí
No
Sí
No
Sí
Stem
No
No
Sí
Sí
No
No
Sí
Sí
No
No
Sí
Sí
No
No
Sí
Sí
Precision
0,7342
0,7169
0,7356
0,7188
0,7396
0,7225
0,7429
0,7261
0,7356
0,7244
0,7420
0,7274
0,7368
0,7257
0,7416
0,7289
Recall
0,7324
0,7168
0,7343
0,7186
0,7388
0,7224
0,7427
0,7260
0,7321
0,7243
0,7394
0,7273
0,7320
0,7255
0,7382
0,7289
Acc
0,7324
0,7168
0,7343
0,7186
0,7388
0,7224
0,7427
0,7260
0,7321
0,7243
0,7394
0,7273
0,7320
0,7255
0,7382
0,7289
Tabla 3. Aplicación de stopper y stemmer con
SVM y los distintos métodos WVM
Como se puede observar todos los resultados
son comparables, con unas diferencias mínimas.
En todos los casos la aplicación del stopper
empeora los resultados, mientras que la
aplicación del stemmer mejora ligeramente los
resultados base. Este resultado es bastante
Detección de la polaridad de tweets en español
lógico teniendo en cuenta que en los tweets
raramente se introducen palabras vacías dada la
limitación del número de caracteres del tweet.
Una vez analizados los mejores resultados
obtenidos se hizo un estudio del valor de
predicción obtenido por los tweets acertados y
por los fallados por el algoritmo de aprendizaje
automático SVM. Se obtuvieron conclusiones
interesantes dado que un porcentaje alto de los
tweets que se fallaron tenían un valor de
predicción cercano a 0,5, y los tweets acertados
tenían un valor casi siempre superior a 0,5.
El tercer conjunto de experimentos tenía
como objetivo la mejora de la colección base.
Teniendo en cuenta que el clasificador
automático devuelve un valor de predicción
positiva y negativa entre 0 y 1 se crearon cinco
subconjuntos partiendo de los tweets bien
clasificados en el mejor experimento anterior,
con las siguientes características:
Set1: se incluyeron todos los tweets
acertados.
Set2: se incluyeron los tweets acertados con
valor de predicción superior a 0,55.
Set3: se incluyeron los tweets acertados con
valor de predicción superior a 0,6.
Set4: se incluyeron los tweets acertados con
valor de predicción superior a 0,65.
Set5: se incluyeron los tweets acertados con
valor de predicción superior a 0,7.
En estos subconjuntos de datos, la
proporción de valores positivos y negativos se
mantuvo en torno al 50% en los primeros
filtros,
aunque
los
más
restrictivos
desbalanceaban la colección, como se puede
observar en la Tabla 4.
Corpus
Base
Set1
Set2
Set3
Set4
Set5
Positivos
17.317
(50%)
13.293
(52%)
11.355
(53%)
8.966
(55%)
6.767
(60%)
4.653
(66%)
Negativos
17.317
(50%)
12.295
(48%)
9.945
(47%)
7.317
(45%)
4.601
(40%)
2.364
(34%)
Totales
34.634
25.588
21.300
16.283
11.368
7.017
Tabla 4. Resumen subcolecciones filtradas
Una
vez
filtradas
estas
cuatro
subcolecciones se lanzó el mismo experimento
base que mejor resultado había obtenido
(TF+SVM con stemmer), aplicando de nuevo
validación cruzada. En la Tabla 5 se muestran
los resultados obtenidos.
Corpus
Base
Set1
Set2
Set3
Set4
Set5
Precisión
0,7429
0,8841
0,9086
0,9201
0,9156
0,9147
Recall
0,7427
0,8686
0,8902
0,8966
0,865
0,8215
Accuracy
0,7427
0,872
0,8958
0,9055
0,8891
0,8774
Tabla 5. Resultados obtenidos con el conjunto
de datos filtrada
Los resultados obtenidos con estas
subcolecciones filtradas en todos los casos
mejoran el mejor resultado base. Cabe destacar
el resultado obtenido con el subconjunto 3, con
una mejora de accuracy del 22%, filtrando las
predicciones correctas con un valor de
predicción superior a 0,6.
6
Conclusiones y trabajo futuro
En este artículo presentamos los experimentos
realizados sobre un corpus que hemos generado
de tweets en español, considerando los
emoticonos que aparecen en los tweets para
etiquetarlos como positivos o negativos. Hemos
realizado varios experimentos con el fin de
detectar de forma automática la polaridad de
estos tweets, utilizando diversos métodos para
generar los vectores de palabras y tres
algoritmos de aprendizaje automático. Una vez
obtenidos los experimentos base hemos
realizado un filtrado de la colección original
teniendo en cuenta el valor de predicción de los
primeros
experimentos.
Los
resultados
obtenidos muestran un muy buen rendimiento
del sistema, superior al 90% de accuracy en el
mejor de los casos.
Como trabajo futuro quedan pendientes
muchas alternativas, como la resolución del
propio vocabulario utilizado en los tweets
(Twitter slang), el uso de recursos externos
como SentiWordNet, y la creación de
colecciones de datos generales con más datos, y
también colecciones de temáticas específicas.
Agradecimientos
Esta investigación ha sido parcialmente
financiada por el Fondo Europeo de Desarrollo
Regional (FEDER), proyecto TEXT-COOL 2.0
(TIN2009-13391-C04-02)
del
Gobierno
Eugenio Martínez Cámara, Miguel A. García Cumbreras, M. Teresa Martín Valdvia, L. Alfonso Ureña López
Español, por la Junta de Andalucía, proyecto
GeOasis (P08-TIC-41999), por el Instituto de
Estudios Giennenses, proyecto RFC/IEG2010,
y por la Universidad de Jaén, proyecto
UJA2009/12/14.
Bibliografía
Asur, Sitaram, Huberman, Bernardo A.,
"Predicting the Future with Social Media,"
wi-iat,
vol.
1,
pp.492-499,
2010
IEEE/WIC/ACM International Conference
on Web Intelligence and Intelligent Agent
Technology, 2010.
Abbasi, A., Chen, H., & Salem, A. (2008).
Sentiment analysis in multiple languages:
Feature selection for opinion classification
in Web forums. ACM Trans. Inf. Syst. 26
(3).
Bollen, J. Mao, H., Zeng, X. Twitter mood
predicts the stock market, Journal of
Computational Science, Volume 2, Issue 1,
March 2011, Pages 1-8.
Resources and Evaluation (LREC’10),
European Language Resources Association
(ELRA), Valletta, Malta, pp. 19–21.
Pang, B., Lee, L., & Vaithyanathan, S. (2002).
Thumbs up? Sentiment classification using
machine learning techniques. Proceedings of
the Conference on Empirical Methods in
Natural Language Processing (EMNLP).
Association for Computational Linguistics.
pp. 79–86.
Pang, B., & Lee, L. (2008). Opinion mining and
sentiment analysis. Foundations and Trends
in Information Retrieval 2. pp. 1-135.
Prabowo, R., & Thelwall, M. (2009). Sentiment
analysis: A combined approach. J.
Informetrics, 3(2), 143–157.
Petrovic, S., Osborne, M., Lavrenko, V. (2010).
The Edinburgh Twitter corpus. In:
SocialMedia Workshop: Computational
Linguistics in a World of Social Media, pp.
25–26
Denecke, K. (2008). Using SentiWordNet for
multilingual sentiment analysis. ICDE
Workshops (pp. 507–512). IEEE Computer
Society.
Read, J. (2005). Using emoticons to reduce
dependency in machine learning techniques
for sentiment classification. In: Proceedings
of the ACL Student Research Workshop, pp.
43–48
Diakopoulos, N. A. and D. A. Shamma (2010).
Characterizing debate performance via
aggregated twitter sentiment. In CHI ’10:
Proc. of the 28th International Conf. on
Human Factors in Computing ystems, pages
1195–1198, New York, NY, USA. ACM.
Tumasjan, A., T. O. Sprenger, P. G. Sandner,
and I. M. Welpe (2010). Predicting elections
with Twitter: What 140 characters reveal
about political sentiment. In International
AAAI Conference on Weblogs and Social
Media, Washington, D.C.
Go, A., R. Bhayani, and L. Huang. 2009.
Twitter sentiment classification using distant
supervision. Technical report, Stanford
Digital Library Technologies Project
Turney, P. D. (2002). Thumbs up or thumbs
down?: semantic orientation applied to
unsupervised classification of reviews.
Proceedings of the 40th Annual Meeting on
Association for Computational Linguistics
(ACL). ACL. Morristown, NJ, USA. pp.
417–424
Jansen, B., M. Zhang, K. Sobel, and A.
Chowdury (2009). Twitter power:tweets as
electronic word of mouth. Journal of the
American Society for Information Science
and Technology.
O’Connor, B., R. Balasubramanyan, B. R.
Routledge, and N. A. Smith (2010). From
Tweets to polls: Linking text sentiment to
public opinion time series. In International
AAAI Conference on Weblogs and Social
Media, Washington, D.C.
Pak, A., P. Paroubek (2010). Twitter as a
corpus for sentiment analysis and opinion
mining, in: Proceedings of the Seventh
conference on International Language
Zhang, C., Zeng, D., Li, J., Wang, F.-Y., and
Zuo, W. 2009. Sentiment analysis of chinese
documents: From sentence to document
level. JASIST, 60(12):2474–2487.