prob
Anuncio

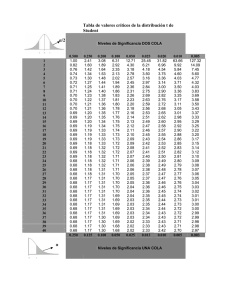
PROBABILIDAD Concepto clásico de probabilidad: Propiedades de la probabilidad: P(Ω)= 1 (Ω=suceso seguro) P(ø) = 0 (ø=suceso imposible) P(X)Є [0,1] P(A∪B) = P(A) + P(B) – P(A∩B) P( ) = 1 – P (A) ( es el suceso contrario de A) (Probabilidad de que ocurra el suceso A, sabiendo que ha ocurrido el suceso B) Distribución Normal: La distribución normal nos permite calcular probabilidades mediante una tabla: La tabla nos da valores para la N(0,1). Si no tenemos una normal así, la construimos: Para una N(0,1) (Distribución normal de media 0 y desviación típica 1). Si z es positivo: P(Z≤z) = F(z) P(Z≤-z) = 1 – F(z) P(Z≥z) = 1 – F(z) P(Z≥-z) = F(z) Siendo F(z) el valor obtenido en la tabla para z. P(z1≤Z≤z2) = F(z2) – F(z1) ESTIMACIÓN ESTADÍSTICA Estimación puntual de medias: Si tenemos una población con media μ y desviación σ desconocida, estimaremos la media de la población por la media de la muestra ( ): Estimación puntual de varianzas: Para estimar la varianza poblacionalσ2, se utiliza la varianza muestral (S2), la cuasivarianza muestral (S2c) o la cuasivarianza corregida por el tamaño N de la población (S2cN): Estimación puntual de proporciones: Para estimar una proporción p, de casos que poseen una determinada característica, se toma una muestra aleatoria y estimamos p por la proporción muestral: La variabilidad de p (Var(p)) se puede calcular de dos formas: ó , si la fracción de muestreo es conocida y no despreciable Donde = 1 – , y f = n/N. Despreciaremos la fracción de muestreo si f < 0,01. Intervalo de confianza para una media: Si la varianza de la población (σ 2) es conocida, nuestro intervalo de confianza para la media será: , donde el coeficiente z viene dado por: Grado de confianza 90% 95% 99% 99,9% Coeficiente z 1,645 1,96 2,576 3,291 Si la varianza de la población (σ 2) no es conocida, la estimaremos por la cuasivarianza muestral (Sc), y nuestro intervalo de confianza para la media será: , donde el coeficiente t lo iremos a buscar a la tabla de la distribución t de Student, con n – 1 grados de libertad (g). Si nuestra fracción de muestreo es conocida y no despreciable, utilizaremos otro intervalo de confianza: Intervalo de confianza para una proporción: Para construir el intervalo de confianza para una proporción, usaremos: ó Cálculo del tamaño de muestra: Si nos piden el tamaño de la muestra para un error concreto, lo calculamos Donde N es el tamaño de la población Si no conocemos p, utilizaremos (si no lo conocemos, nuestro tamaño el caso más desfavorable, es de la muestra será ) decir, p = q = 0,5 = 50% GRÁFICOS DE CONTROL Para construir un gráfico de control, primero hemos de construir las siguientes líneas: proporciones LSC Límite superior de Control LSA Límite superior de Alerta LC LIA Línea central Límite inferior de Alerta LIC p Racha: 8 o más puntos por encima o debajo de la línea central Límite inferior de Control Tendencia: 8 o más puntos en orden creciente o decreciente CONTRASTE DE HIPÓTESIS Comparación de una media con un valor dado: Calculamos el estadístico: , donde μ0 es el valor dado con el que compararemos la media. Buscamos en la tabla de la t de Student para n – 1 grados de libertad y el nivel de significación que nos digan (normalmente suele ser α = 0,05). Comparamos el valor del estadístico con el de la tabla (T c): - Si |T|<Tc: Aceptamos la hipótesis (la media es igual al valor dado) - Si |T|>Tc: Rechazamos la hipótesis (la media es distinta al valor dado) Comparación de dos medias: Si las varianzas son distintas, calculamos el estadístico: . Buscamos en la tabla de la t de Student para los grados de libertad g y el nivel de significación que nos digan (normalmente suele ser α = 0,05), con Si las varianzas son iguales, calculamos el estadístico , donde Buscamos en la tabla de la t de Student para n1+n2-2 grados de libertad y el nivel de significación que nos digan (normalmente suele ser α = 0,05). En ambos casos (varianza conocida o desconocida): - Si |T|<Tc: Aceptamos la hipótesis (las medias son iguales) - Si |T|>Tc: Rechazamos la hipótesis (las medias son distintas) REGRESIÓN LINEAL La recta de regresión es una recta que aproxima los datos de una muestra con dos variables: y=a+bx, donde: Se suma Se suma Se suma